
 Open Access Article
Open Access Article This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported Licence
This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported LicenceCreating de novo peptide-based bioactivities: from assembly to origami
Yuxing Ma†
abc,
Xiaofang Li†
abd,
Ruoyang Zhao†
ab,
Enqi Wuc,
Qiqige Duab,
Jun Guo
de,
Liping Wang
*ab and
Feng Zhang
 *abde
*abde
aWenzhou Institute, University of Chinese Academy of Sciences, Wenzhou 325001, China. E-mail: lpwang-wiucas@ucas.ac.cn
bOujiang Laboratory, Wenzhou, Zhejiang 325000, P. R. China
cInner Mongolia Key Laboratory of Tick-Borne Zoonotic Infectious Disease, Department of Medicine, Hetao College, Bayannur, 015000, China
dKey Laboratory of Optical Technology and Instrument for Medicine, Ministry of Education, University of Shanghai for Science and Technology, Shanghai, 200093, P. R. China. E-mail: fengzhang1978@hotmail.com; fzhang@usst.edu.cn
eState Key Laboratory of Respiratory Disease, Guangzhou Institute of Oral Disease, Stomatology Hospital, School of Biomedical Engineering, Guangzhou Medical University, Guangzhou 511436, China
First published on 12th September 2022
Abstract
DNA origami has created complex structures of various spatial dimensions. However, their versatility in terms of function is limited due to the lower number of the intrinsic building blocks, i.e. nucleotides, compared with the number of amino acids. Therefore, protein origami has been proposed and demonstrated to precisely fabricate artificial functional nanostructures. Despite their hierarchical folded structures, chain-like peptides and DNA share obvious similarities in both structures and properties, especially in terms of chain hybridization; therefore, replacing DNA with peptides to create bioactivities not only has high theoretical feasibility but also provides a new bottom-up synthetic strategy. However, designing functionalities with tens to hundreds of peptide chains using the similar principle of DNA origami has not been reported, although the origami strategy holds great potential to generate more complex bioactivities. In this perspective review, we have reviewed the recent progress in and highlighted the advantages of peptide assembly and origami on the orientation of artificially created bioactivities. With the great potential of peptide origami, we appeal to develop user-friendly softwares in combination with artificial intelligence.
 Yuxing Ma | Yuxing Ma received her Master degree at Inner Mongolia Agricultural University. Then worked as a research fellow at Hetao College and a research assistant in Wenzhou Institute, University of Chinese Academy of Sciences. Her research interests focused on the biomaterials and biomedical application. |
 Xiaofang Li | Xiaofang Li is currently pursuing a PhD degree under the supervision of Professor Feng Zhang in Inner Mongolia Agricultural University, and meantime working as a research assistant in Wenzhou Institute, University of Chinese Academy of Sciences and University of Shanghai for Science and Technolgoy. Xiaofang Li received her Master of Engineering degree from Tianjin Polytechnic University in 2012, and now her research interests focus on computational biology and its applications in biological medicine. |
 Ruoyang Zhao | Ruoyang Zhao received her PhD degree from Inner Mongolia Agricultural University. She is now working as a postdoctoral fellow in Professor Feng Zhang's group, Wenzhou Institute, UCAS. Her research interests in self-assembly of peptides and its applications in biological medicine. |
 Jun Guo | Jun Guo received his PhD degree from Inner Mongolia Agricultural University. He worked as a postdoctoral fellow in Professor Feng Zhang and Professor Bo Song's groups, University of Shanghai for Science and Technology. His research interests include the design of biomimetic materials from self-assembling peptides. |
 Liping Wang | Liping Wang received her PhD degree at East China Normal University, and finished her postdoctoral training and worked as a research fellow at Shanghai Jiao Tong University. She has been working as an associated professor at Wenzhou Institute, University of Chinese Academy of Sciences since 2021. Her research interests focused on the drug delivery, bioactive materials and biomedical application. |
 Feng Zhang | Feng Zhang is a Professor at University of Shanghai for Science and Technology. He received his PhD degree from Shanghai Institute of Applied Physics, Chinese Academy of Sciences. After two PostD trainings in Germany and USA, he started his independent career. His research interests are focused on the nanofabrication of bioactivities through peptide assembly (especially peptide origami) and the development of new quantum biological methodologies for analytical and biomedical applications. |
In cells, peptides form versatile nanostructures with different bioactivities through self-assembly and co-assembly. Proteins such as collagen,1 actin2 and the peptides/proteins that are associated with amyloid diseases3 can self-assemble into fibrous structures. Helicase4 and nuclease5 are naturally ring-shaped structures. TMV capsid protein,6 α-hemolysin,7 and the Bacillus anthracis protective antigen8 are tubular structures. Citrate synthase,9 lysyl oxidase,10 RecR proteins,11 ribonucleotide reductase I,12 and hydrolase CS2
![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 13 can self-assemble into the lariat structures. Transferrin,14 vault protein,15 clathrin,16 chaperonin,17 and the capsids of viruses18 can form cage structures. These ordered nanostructures formed by the peptide assembly play essential roles in life.
13 can self-assemble into the lariat structures. Transferrin,14 vault protein,15 clathrin,16 chaperonin,17 and the capsids of viruses18 can form cage structures. These ordered nanostructures formed by the peptide assembly play essential roles in life.
One of the ultimate goals of synthetic biology is to create artificial cells, and assembly is an important approach. DNA origami has been used to create versatile nanostructures since its origin19 and proof-of-concept reports20 published by Seeman and coworkers. The nanostructures from DNA origami can act as scaffolds to synthesize inorganic particles or units to conduct multi-component and multi-functional assembly. Recently, de novo designed proteins have been investigated in various fields such as catalysis,21 energy (i.e., light harvesting22), medicine (i.e., vaccine R&D,23 gene and drug delivery24), and environmental science (i.e., water treatment25). Related review papers have been published by Guang et al.26 and Yan et al.27 However, the current artificial protein design is normally folded from one to a few long single-peptide chains (as the subunits of tertiary/quaternary structures), and designing complex artificial nanostructures with tens to hundreds of peptide chains using the similar principle of DNA origami (Fig. 1) has not been reported yet.
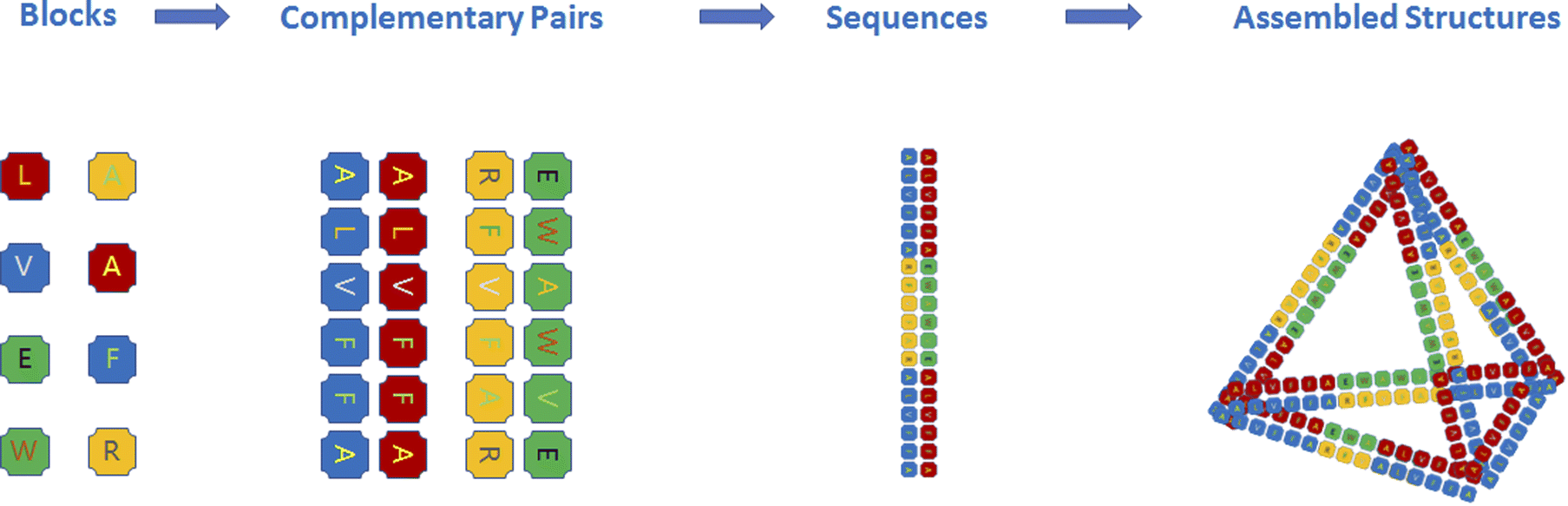 | ||
Fig. 1 Peptide assembly with the principle of DNA origami. All amino acids are blocks for peptide assembly, and short peptide sequences can be designed as complementary pairs similar to base pairs (A![[double bond, length as m-dash]](https://www.rsc.org/images/entities/char_e001.gif) T, G T, G![[triple bond, length as m-dash]](https://www.rsc.org/images/entities/char_e002.gif) C) for peptide origami. Peptide sequences containing such complementary pairs can further assemble into nanostructures. C) for peptide origami. Peptide sequences containing such complementary pairs can further assemble into nanostructures. | ||
Origami: a special type of assembly
The concept of protein origami was proposed by Jerala et al.28 Similar to DNA origami, protein origami employs the complementary pairing capability of coiled-coil secondary structures; for example, the first artificial tetrahedron was fabricated using six pairs of coiled-coil sequences, which were all set in a single chain. Significantly, unlike DNA origami, the current so-called protein origami has not employed stapling sequences, which are very short sequences normally over ten in number used in DNA origami. In this regard, current protein origami is more like protein folding from an artificial peptide chain using the complementary pairing capability of coiled-coil sequences. Single peptide chains, termed as the primary sequence of proteins, not only contain all the information for intramolecular folding and intermolecular self-assembly29 but also determine the final chemical properties and bioactivities of proteins. Generally, peptides are defined as either protein fragments or the amino acid sequence of proteins before folding, while proteins are the 3-D structures after the intramolecular folding and intermolecular self-assembly of peptides. In order to include most current techniques to create desirable bioactivities, especially for peptide/protein origami, self-assembly and co-assembly with more than a single peptide chain, hereafter we suggest calling them a peptide assembly (Fig. 1).Despite advances in protein design and engineering, precisely fabricating multiprotein architectures with both structural and functional sophistication is still challenging. Considering the combination number of the basic building blocks, the huge difference between the twenty kinds of amino acids and four types of bases undoubtedly endows the peptide assembly with a great advantage. Similar to antibodies produced by B cells, the enormous number of peptide sequence or amino acid combinations can create numerous bioactivities. Because two amino acid residues cannot form a robust conjugation like that of base pairs, the origami-like strategy of peptide assembly is hard to design due to the orthogonal issue. In addition, both synergistic effects and long-distance interactions among amino acids make it more difficult than DNA origami.
The success of DNA origami is mainly ascribed to the two AT and GC pairings. However, the limitation of both the permutation and combination number and chemical activities of these DNA bases significantly restrict their potential to produce enough bioactivities, which might be the reason for life to use DNA as a conserved genetic material and use peptides to create bio-functionalities. Therefore, to employ the origami strategy for peptide assembly, the most important requirement is to realize orthogonal complementary pairing between short peptide motifs. Here, we introduce a new idea of using short peptide sequences or motifs instead of single amino acids to form conjugations with both specificity and affinity. Fortunately, leucine zipper sequences or so-called coiled-coils (a short α-helix peptide sequence consisting of ∼35 amino acids) can perfectly realize this idea,30–32 which has been successfully demonstrated by Jerala et al.33,34 If one could consider these special peptide sequences similar to DNA base pairs, the principle of origami can naturally extend from DNA to peptides. Regarding the regulation capabilities of both specificity and affinity, peptide motifs show more advantages than DNA sequences due to the various interactions among amino acids. Moreover, such orthogonal motifs could be derived from some natural proteins, i.e., prions,35 α-synuclein,36,37 insulin,38 A-β,39 the core sequence of natural silk proteins40 and the artificially designed ionic-complementary peptides,41 which could be a giant bank for developing orthogonal pairs for peptide assembly.
The increasing protein data bank can also provide a resource pool for orthogonal pairs. For example, motifs like β-sheets and coiled-coils coexist in proteins, and normally form natural orthogonal pairs. Simply with coiled-coils, scientists have already designed complex nanostructures such as cages for diverse applications in biomedicine.42 Secondly, short peptides with less than 100 amino acid residues can be easily synthesized in the solid phase, while longer peptides can be obtained through genetic engineering, i.e., fused protein expression. Thirdly, the rapid development of molecular dynamics simulation makes the theoretical prediction of peptide spatial structures increasingly accurate.43 There are already several powerful software such as Gromacs, NAMD, RoseTTAfold and α-Fold that not only allow scientists to understand the dynamic process of peptide assembly but also help perfect the design of peptide sequences. Prof. Susan Lindquist from MIT wrote, “Humans have been domesticating plants and animals about 10000 years ago, and now it's time to domesticate molecules”. Now it is time to develop peptide origami.
Woolfson and co-workers constructed a single-layered protein grid using two coiled-coil orthogonal complementary pairs, which further self-assembled into hollow balls with a diameter of 100 nm.44 Jerala and co-workers designed an artificial peptide containing six coiled-coil orthogonal complementary pairs (Fig. 2a), which was produced by the genetic engineering method and can fold into a tetrahedral structure with a 10 nm length.45 Ryadnov and co-workers constructed the smallest artificial viruses using coiled-coil orthogonal complementary pairs.46 Baker and co-workers successfully constructed 2-D47 and 3-D nanostructures48 using a theoretical calculation that has been published online.49,50 Recently, they also precisely controlled the β-sheet curvature of proteins at the nanoscale.51 Ryoichi et al. constructed versatile nanostructures with one dimer of WA20 and one trimer of foldon conjugated peptides52 (Fig. 2b). These results indicate that peptide origami is already comparable to DNA origami, and has ushered a new era for creating novel nanostructures and bioactivities.
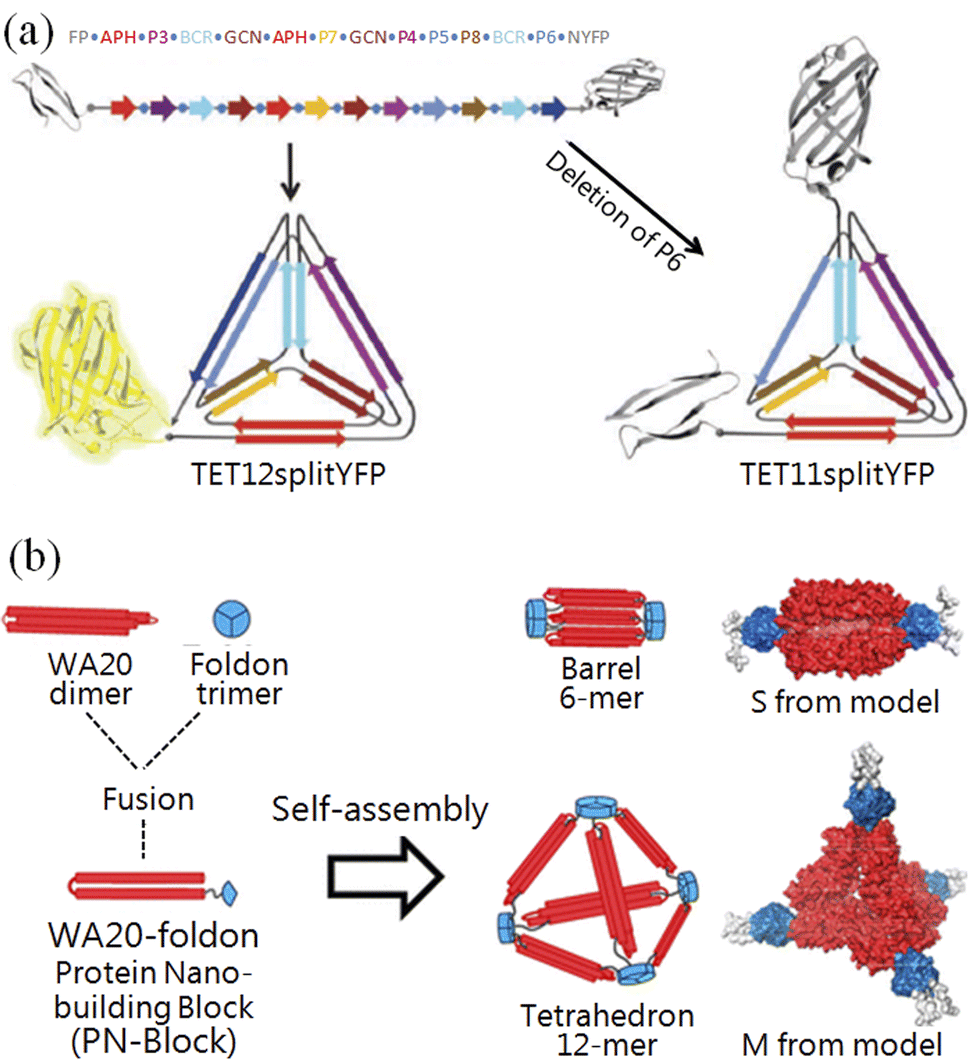 | ||
| Fig. 2 Creating pre-designed nanostructures with peptide origami. (a) A tetrahedron was folded by a single peptide chain, which was fused with a fluorescent protein.45 (b) Constructing nanostructures with genetically fused peptide WA20–foldons.52 | ||
Superiority of peptide origami
In living systems, efficient functions are normally achieved by nanostructures that are subtly arranged with complex molecules, such as molecular machines (2016 Nobel Prize in Chemistry) and light-harvesting complexes, both of which were listed as the top ten research hotspots in biology. In contrast, DNA origami involves covalently conjugating functional groups to complementary DNA sequences in advance to realize pre-designed functionalities.53 There are a few approaches to realize site-specific conjugation to proteins, such as the unnatural amino acid-based conjugation invented by Schultz and co-workers,54 but these are highly skilled. Due to the orthogonality of the complementary pairs, coiled-coil motifs could produce more complex nanostructures than β-tails. The development of new vaccines requires the following effects: long-term, highly effective immune-stimulating enhancement with minimal or complete elimination of adjuvant additions. With both protein fusion and peptide assembly/origami, high-efficiency polyvalent vaccines or combined vaccines of multiple diseases can be achieved by displaying different types and quantities of epidemic antigens on the surface of predesigned nanostructures such as nanofibers55 (Fig. 3a). In this way, catalytic performance can also be enhanced by clustering proteinases or antigens on the surface of fibrils.56 With the same principle, Collier and co-workers constructed fibrils using β-tail-fused fluorescent proteins, which not only retain the structure's fluorescence but can also emit different fluorescence by mixing fluorescent proteins in different ratios56 (Fig. 3b).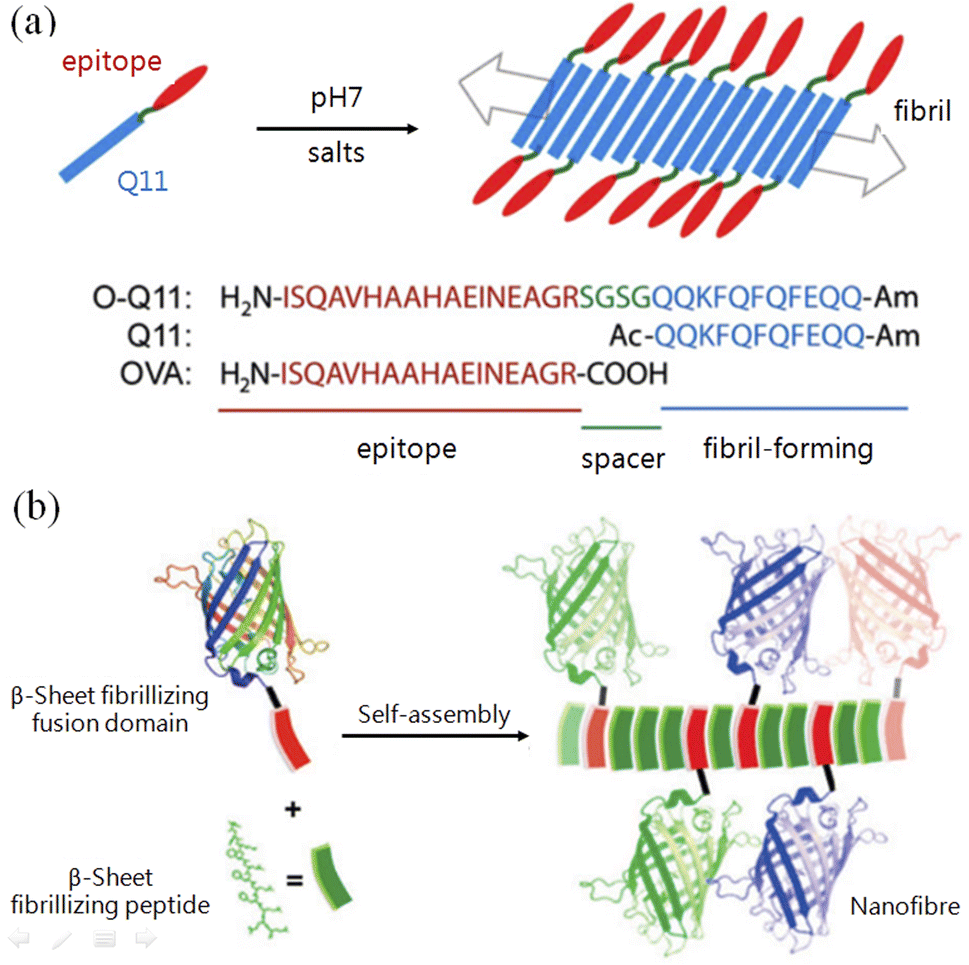 | ||
| Fig. 3 Application demonstrations of peptide origami with β-tails. (a) Immune stimulating action was enhanced by conjugating antigen epitopes with fibril-forming β-tail peptides.55 (b) Replacing the antigen epitope with fluorescent proteins (of different colors) to construct nanofibrils with β-tail-based peptide origami.56 | ||
Compared with DNA origami, the central dogma endows more advantages to peptide origami, i.e., bioactivities created by peptide origami hold the potential to be replicated in vivo. Although DNA self-replicates, DNA origami requires temperature ramping to finish the annealing process, which is hard to achieve in vivo. Peptides can be excreted from cells after being produced from the protein synthesizing machinery, which inspires us to yield bioactivities en masse using cells. Yeates and co-workers reported a fusion protein including two orthogonal complementary pair subunits, and this protein can further self-assemble into protein cages with a diameter of 16 nm.57 Afterwards, they created another kind of porous cube with a pore diameter of 130 nm using the same peptide origami approach.58 Our group overcame the shortcomings of the poor photostability and complex synthetic process of organic molecular probes and used the natural tripeptide GYK (G, glycine, Y, tyrosine, K, lysine) to generate fluorescence.59 The red shift of about 100 nm in the fluorescence of GYK assemblies already overcame the obstacle of natural amino acids.60 Such peptide assemblies hold great promise for developing novel fluorescent probes for cell labeling and imaging.61
Due to the intrinsic chemical complexity based on amino acid sequences, peptides can be screened out or designed to specifically respond to metal ions62 or recognize inorganic materials with relatively high affinity (Fig. 4). Liu and co-workers constructed protein-based nanorings and nanorods using the recognition between metal ions and proteins, and demonstrated their application value in artificial light-harvesting systems (Fig. 4a).63 In combination lab experiments with theoretical simulations, Zhou and co-workers conducted a systematic study on controlling GAV peptide origami on a liquid–solid interface.64 In general, thiol group-modified DNA can form robust conjugation with some materials (such as gold and silver), while such functional groups are naturally contained in peptides. Fan and co-workers reported an interesting method wherein polyA has strong affinity to gold nanoparticles, whereby gold–DNA hybrid nanostructures were constructed by DNA origami.65 Systematic evolution of ligands by exponential enrichment (SELEX) could screen out DNA aptamers binding to different molecules and materials,66 but so far these aptamers cannot be compared to antibodies in terms of affinity. However, peptide aptamers have a higher affinity than DNA aptamers and can be selected using a bio-evolution system. For example, Belcher and co-workers successfully applied the phage display technique to screen out peptides with high affinity to semiconductors (Fig. 4b).67 Hence, regarding their diversity and affinity, we believe that there is plenty of room at the bottom of peptide origami.
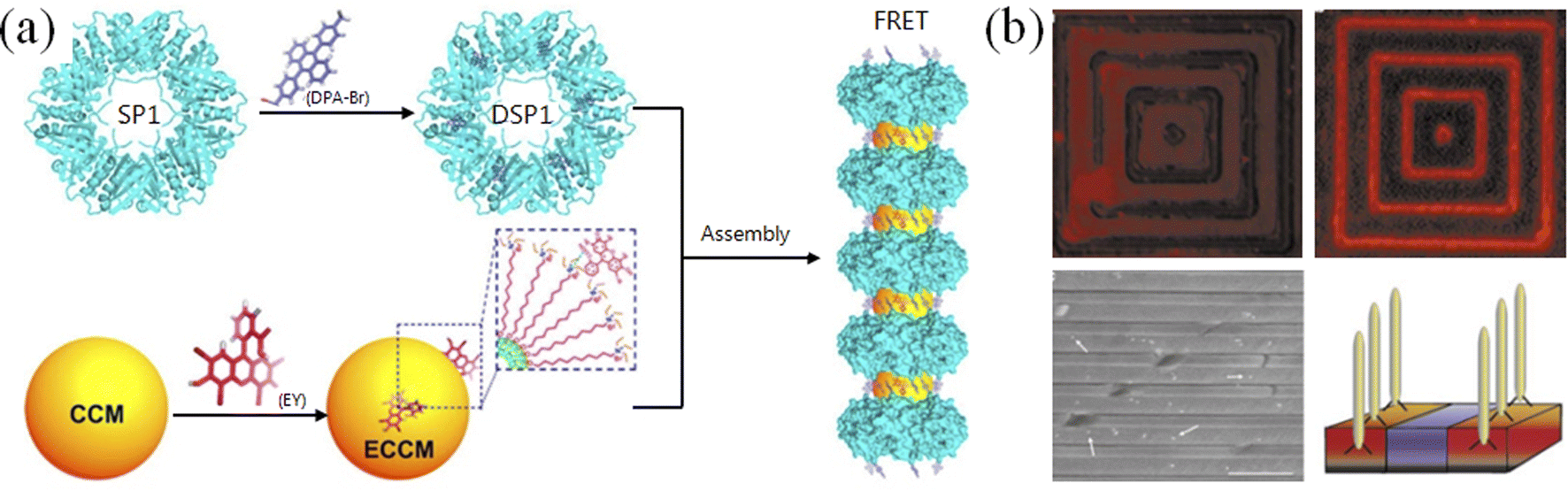 | ||
| Fig. 4 Peptide–inorganic hybrid functional nanomaterials. (a) Artificial light-harvesting hybrid nanostructures by co-assembling proteins and nanoparticles.63 Stable protein one (SP1) forms ring-like nanostructures, DSP1, which were modified by a thiol-reactive chromophore 9-[4-(bromomethyl)phenyl]-10-(4-methylphenyl)anthracene (DPA-Br, as the donor chromophore). EY (eosin Y, as the acceptor chromophore)-modified CCMs (core-cross-linked micelles), ECCMs, can co-assemble with DSP1 into antenna-like hybrid nanostructures for FRET (Förster resonance energy transfer). (b) Screening out semiconductor-recognizing peptides using the phage display technique. GaAs, but not SiO2, was specifically recognized by phages that were fluorescently labeled with tetramethyl rhodamine (TMR), which was verified by scanning electron microscopy.67 | ||
Outlook
Although the current nanostructures created by peptide origami are less complex than those made by DNA origami, and the computational assisted programs are also limited to a few peptide chains that are much less than the chain number used in current DNA origami, peptide origami has already demonstrated its feasibility and superiority, and holds great potential to combine other material blocks for fabricating hybrid origami structures, i.e., DNA–peptide hybrid origami structures.68Our group previously discovered strong physical adsorption between serum albumin and amphiphilic polymer-encapsulated nanoparticles,69 and proposed a “mortise–tenon joint” mechanism.70 This mortise–tenon joint is independent of the properties of the material encapsulated inside the polymer, and with this advantage, nanostructures with a discrete number of ligands (i.e., peptides) can be obtained by gel electrophoresis.71 Such peptide/protein–nanoparticle72 hybrid building blocks hold great potential for bottom-up origami-like nanofabrication, with which Parak and co-workers demonstrated the significant differences of nanoparticles conjugated with a different number of antibodies in tumor-targeting therapy.73 Artificial light-harvesting complexes have been a hot spot to use “infinite” light energy due to the depleting fossil fuels such as coal, oil and natural gas. However, improving the current light energy conversion rate is still challenging, and the delicate design of photosynthetic nanostructures is key; therefore, peptide origami could be the most effective way to solve this problem.
Consent for publication
All authors agree to be published.Author contributions
Feng Zhang and Liping Wang conceived the concept and supervised the writing of the manuscript. Feng Zhang, Liping Wang, Yuxing Ma, Ruoyang Zhao, and Xiaofang Li collected the literature, prepared the figures and drafted the manuscript. Feng Zhang, Liping Wang, Yuxing Ma, Ruoyang Zhao, Xiaofang Li, Enqi Wu, Qiqige Du, and Jun Guo read and approved the final manuscript.Conflicts of interest
The authors declare that they have no competing interests.Acknowledgements
This work was supported by the National Key Research and Development Program of China (No. 2021YFA1200402), the National Natural Science Foundation of China (No. T2241002, U1832125 and 51763019), the start-up funding from Wenzhou Institute, University of Chinese Academy of Sciences (No. WIUCASQD2021003 and WIUCASQD2021011), the Program Funded by the University for Fostering Distinguished Young Scholars, the Grassland Talents Program of Inner Mongolia Autonomous Region, the Distinguished Young Scholars Foundation of Inner Mongolia Autonomous Region, and the Young Leading Talents of Science and Technology Program of Inner Mongolia Autonomous Region.References
- D. M. Darvish, Mater. Today Bio, 2022, 15, 100322 CrossRef CAS PubMed.
- Q. Du, W. Li, M. Yuan, P. Gong, Y. Zhang and F. Zhang, Luminescence, 2017, 32, 618–624 CrossRef CAS PubMed.
- D. Li and C. Liu, Biochemistry, 2020, 59, 639–646 CrossRef CAS.
- K. Li, J. Zheng, M. Wirawan, N. M. Trinh, O. Fedorova, P. R. Griffin, A. M. Pyle and D. Luo, Nucleic Acids Res., 2021, 49, 9978–9991 CrossRef CAS.
- S. A. McMahon, W. Zhu, S. Graham, R. Rambo, M. F. White and T. M. Gloster, Nat. Commun., 2020, 11, 500 CrossRef CAS PubMed.
- J. Zhang, X. Wang, K. Zhou, G. Chen and Q. Wang, ACS Nano, 2018, 12, 1673–1679 CrossRef CAS PubMed.
- L. Fiaschi, B. Di Palo, M. Scarselli, C. Pozzi, K. Tomaszewski, B. Galletti, V. Nardi-Dei, L. Arcidiacono, R. P. Mishra, E. Mori, M. Pallaoro, F. Falugi, A. Torre, M. R. Fontana, M. Soriani, J. Bubeck Wardenburg, G. Grandi, R. Rappuoli, I. Ferlenghi and F. Bagnoli, Clin. Vaccine Immunol., 2016, 23, 442–450 CrossRef CAS PubMed.
- D. Das and B. A. Krantz, J. Mol. Biol., 2017, 429, 753–762 CrossRef CAS PubMed.
- S. H. Lee and K. J. Kim, Biochem. Biophys. Res. Commun., 2019, 509, 722–727 CrossRef CAS PubMed.
- S. D. Vallet, M. Gueroult, N. Belloy, M. Dauchez and S. Ricard-Blum, ACS Omega, 2019, 4, 8495–8505 CrossRef CAS PubMed.
- Q. Tang, Y. P. Liu, X. X. Yan and D. C. Liang, DNA Repair, 2014, 24, 10–14 CrossRef CAS.
- Y. Kwak, W. Jiang, L. M. Dassama, K. Park, C. B. Bell 3rd, L. V. Liu, S. D. Wong, M. Saito, Y. Kobayashi, S. Kitao, M. Seto, Y. Yoda, E. E. Alp, J. Zhao, J. M. Bollinger Jr, C. Krebs and E. I. Solomon, J. Am. Chem. Soc., 2013, 135, 17573–17584 CrossRef CAS PubMed.
- J. C.-Y. Wang, A. Zlotnick and J. Mecinovi, Chem. Commun., 2014, 50, 10281–10283 RSC.
- Y. Jin, J. He, K. Fan and X. Yan, Nanoscale, 2019, 11, 12449–12459 RSC.
- K. Kato, H. Tanaka, T. Sumizawa, M. Yoshimura, E. Yamashita, K. Iwasaki and T. Tsukihara, Acta Crystallogr., Sect. D: Biol. Crystallogr., 2008, 64, 525–531 CrossRef CAS.
- M. Halebian, K. Morris and C. Smith, Subcell. Biochem., 2017, 83, 551–567 CAS.
- A. Bracher, S. S. Paul, H. Wang, N. Wischnewski, F. U. Hartl and M. Hayer-Hartl, PLoS One, 2020, 15, e0230090 CrossRef CAS.
- A. Liu, M. V. de Ruiter, S. J. Maassen and J. Cornelissen, Methods Mol. Biol., 2018, 1798, 1–9 CrossRef CAS PubMed.
- N. C. Seeman, J. Theor. Biol., 1982, 99, 237–247 CrossRef CAS.
- J. H. Chen and N. C. Seeman, Nature, 1991, 350, 631–633 CrossRef CAS PubMed.
- R. Song, X. Wu, B. Xue, Y. Yang, W. Huang, G. Zeng, J. Wang, W. Li, Y. Cao, W. Wang, J. Lu and H. Dong, J. Am. Chem. Soc., 2019, 141, 223–231 CrossRef CAS.
- Y. Bai, Q. Luo and J. Liu, Chem. Soc. Rev., 2016, 45, 2756–2767 RSC.
- A. W. Purcell, J. McCluskey and J. Rossjohn, Nat. Rev. Drug Discovery, 2007, 6, 404–414 CrossRef CAS PubMed.
- B. Dai, D. Li, W. Xi, F. Luo, X. Zhang, M. Zou, M. Cao, J. Hu, W. Wang, G. Wei, Y. Zhang and C. Liu, Proc. Natl. Acad. Sci. U. S. A., 2015, 112, 2996–3001 CrossRef CAS.
- S. Bolisetty and R. Mezzenga, Nat. Nanotechnol., 2016, 11, 365–371 CrossRef CAS PubMed.
- G. Wei, W. Xi, R. Nussinov and B. Ma, Chem. Rev., 2016, 116, 6516–6551 CrossRef CAS PubMed.
- J. Wang, K. Liu, R. Xing and X. Yan, Chem. Soc. Rev., 2016, 45, 5589–5604 RSC.
- A. Ljubetic, F. Lapenta, H. Gradisar, I. Drobnak, J. Aupic, Z. Strmsek, D. Lainscek, I. Hafner-Bratkovic, A. Majerle, N. Krivec, M. Bencina, T. Pisanski, T. C. Velickovic, A. Round, J. M. Carazo, R. Melero and R. Jerala, Nat. Biotechnol., 2017, 35, 1094–1101 CrossRef CAS.
- K. B. Joshi and S. Verma, J. Pept. Sci., 2008, 14, 118–126 CrossRef CAS PubMed.
- C. C. Huang, S. Ravindran, Z. Yin and A. George, Biomaterials, 2014, 35, 5316–5326 CrossRef CAS PubMed.
- M. Zhou, D. Bentley and I. Ghosh, J. Am. Chem. Soc., 2004, 126, 734–735 CrossRef CAS PubMed.
- W. Shen, R. G. H. Lammertink, J. K. Sakata, J. A. Kornfield and D. A. Tirrell, Macromolecules, 2005, 38, 3909–3916 CrossRef CAS.
- A. Majerle, S. Hadzi, J. Aupic, T. Satler, F. Lapenta, Z. Strmsek, J. Lah, R. Loris and R. Jerala, Proc. Natl. Acad. Sci. U. S. A., 2021, 118, e2021899118 CrossRef CAS PubMed.
- S. Bozic Abram, H. Gradisar, J. Aupic, A. R. Round and R. Jerala, ACS Chem. Biol., 2021, 16, 310–315 CrossRef CAS PubMed.
- R. Honda, Angew. Chem., Int. Ed. Engl., 2018, 57, 6086–6089 CrossRef CAS PubMed.
- F. Zhang, X. J. Lin, L. N. Ji, H. N. Du, L. Tang, J. H. He, J. Hu and H. Y. Hu, Biochem. Biophys. Res. Commun., 2008, 368, 388–394 CrossRef CAS PubMed.
- F. Zhang, L. N. Ji, L. Tang, J. Hu, H. Y. Hui, H. J. Xu and J. H. He, Acta Biochim. Biophys. Sin., 2005, 37, 113–118 CrossRef CAS PubMed.
- X. Zhou, Y. Zhang, F. Zhang, S. Pillai, J. Liu, R. Li, B. Dai, B. Li and Y. Zhang, Nanoscale, 2013, 5, 4816–4822 RSC.
- H. Li, F. Zhang, Y. Zhang, M. Ye, B. Zhou, Y. Z. Tang, H. J. Yang, M. Y. Xie, S. F. Chen, J. H. He, H. P. Fang and J. Hu, J. Phys. Chem. B, 2009, 113, 8795–8799 CrossRef CAS PubMed.
- M. Humenik and T. Scheibel, ACS Nano, 2014, 8, 1342–1349 CrossRef CAS PubMed.
- S. G. Zhang, D. M. Marini, W. Hwang and S. Santoso, Curr. Opin. Chem. Biol., 2002, 6, 865–871 CrossRef CAS.
- F. Lapenta, J. Aupic, Z. Strmsek and R. Jerala, Chem. Soc. Rev., 2018, 47, 3530–3542 RSC.
- S. Ovchinnikov, H. Park, N. Varghese, P. S. Huang, G. A. Pavlopoulos, D. E. Kim, H. Kamisetty, N. C. Kyrpides and D. Baker, Science, 2017, 355, 294–298 CrossRef CAS PubMed.
- J. M. Fletcher, R. L. Harniman, F. R. Barnes, A. L. Boyle, A. Collins, J. Mantell, T. H. Sharp, M. Antognozzi, P. J. Booth, N. Linden, M. J. Miles, R. B. Sessions, P. Verkade and D. N. Woolfson, Science, 2013, 340, 595–599 CrossRef CAS PubMed.
- H. Gradisar, S. Bozic, T. Doles, D. Vengust, I. Hafner-Bratkovic, A. Mertelj, B. Webb, A. Sali, S. Klavzar and R. Jerala, Nat. Chem. Biol., 2013, 9, 362–366 CrossRef CAS PubMed.
- J. E. Noble, E. De Santis, J. Ravi, B. Lamarre, V. Castelletto, J. Mantell, S. Ray and M. G. Ryadnov, J. Am. Chem. Soc., 2016, 138, 12202–12210 CrossRef CAS PubMed.
- S. Gonen, F. DiMaio, T. Gonen and D. Baker, Science, 2015, 348, 1365–1368 CrossRef CAS PubMed.
- N. P. King, W. Sheffler, M. R. Sawaya, B. S. Vollmar, J. P. Sumida, I. Andre, T. Gonen, T. O. Yeates and D. Baker, Science, 2012, 336, 1171–1174 CrossRef CAS PubMed.
- N. Koga, R. Tatsumi-Koga, G. Liu, R. Xiao, T. B. Acton, G. T. Montelione and D. Baker, Nature, 2012, 491, 222–227 CrossRef CAS PubMed.
- N. P. King, J. B. Bale, W. Sheffler, D. E. McNamara, S. Gonen, T. Gonen, T. O. Yeates and D. Baker, Nature, 2014, 510, 103–108 CrossRef CAS.
- E. Marcos, B. Basanta, T. M. Chidyausiku, Y. Tang, G. Oberdorfer, G. Liu, G. V. Swapna, R. Guan, D. A. Silva, J. Dou, J. H. Pereira, R. Xiao, B. Sankaran, P. H. Zwart, G. T. Montelione and D. Baker, Science, 2017, 355, 201–206 CrossRef CAS.
- N. Kobayashi, K. Yanase, T. Sato, S. Unzai, M. H. Hecht and R. Arai, J. Am. Chem. Soc., 2015, 137, 11285–11293 CrossRef CAS.
- M. J. Urban, P. K. Dutta, P. Wang, X. Duan, X. Shen, B. Ding, Y. Ke and N. Liu, J. Am. Chem. Soc., 2016, 138, 5495–5498 CrossRef CAS PubMed.
- J. W. Chin, A. B. Martin, D. S. King, L. Wang and P. G. Schultz, Proc. Natl. Acad. Sci. U. S. A., 2002, 99, 11020–11024 CrossRef CAS.
- J. S. Rudra, Y. F. Tian, J. P. Jung and J. H. Collier, Proc. Natl. Acad. Sci. U. S. A., 2010, 107, 622–627 CrossRef CAS.
- G. A. Hudalla, T. Sun, J. Z. Gasiorowski, H. Han, Y. F. Tian, A. S. Chong and J. H. Collier, Nat. Mater., 2014, 13, 829–836 CrossRef CAS.
- Y. T. Lai, D. Cascio and T. O. Yeates, Science, 2012, 336, 1129 CrossRef CAS.
- Y. T. Lai, E. Reading, G. L. Hura, K. L. Tsai, A. Laganowsky, F. J. Asturias, J. A. Tainer, C. V. Robinson and T. O. Yeates, Nat. Chem., 2014, 6, 1065–1071 CrossRef CAS PubMed.
- J. Guo, S. Ramachandran, R. Zhong, R. Lal and F. Zhang, Chembiochem, 2019, 20, 2324–2330 CrossRef CAS PubMed.
- J. Guo, X. Li, J. Lian, F. Gao, R. Zhao, B. Song and F. Zhang, ACS Macro Lett., 2021, 10, 825–830 CrossRef CAS PubMed.
- J. Guo, R. Zhao, F. Gao, X. Li, L. Wang and F. Zhang, ACS Macro Lett., 2022, 11, 875–881 CrossRef CAS.
- N. Singh, R. Singh, K. B. Joshi and S. Verma, ChemPlusChem, 2020, 85, 2001–2009 CrossRef CAS PubMed.
- H. Sun, X. Zhang, L. Miao, L. Zhao, Q. Luo, J. Xu and J. Liu, ACS Nano, 2016, 10, 421–428 CrossRef CAS.
- S. G. Kang, T. Huynh, Z. Xia, Y. Zhang, H. Fang, G. Wei and R. Zhou, J. Am. Chem. Soc., 2013, 135, 3150–3157 CrossRef CAS PubMed.
- G. B. Yao, H. Pei, J. Li, Y. Zhao, D. Zhu, Y. N. Zhang, Y. F. Lin, Q. Huang and C. H. Fan, NPG Asia Mater., 2015, 7, e159 CrossRef.
- X. Fang and W. Tan, Acc. Chem. Res., 2010, 43, 48–57 CrossRef CAS PubMed.
- S. R. Whaley, D. S. English, E. L. Hu, P. F. Barbara and A. M. Belcher, Nature, 2000, 405, 665–668 CrossRef CAS.
- A. Udomprasert, M. N. Bongiovanni, R. Sha, W. B. Sherman, T. Wang, P. S. Arora, J. W. Canary, S. L. Gras and N. C. Seeman, Nat. Nanotechnol., 2014, 9, 537–541 CrossRef CAS PubMed.
- R. Zhong, Y. Liu, P. Zhang, J. Liu, G. Zhao and F. Zhang, ACS Appl. Mater. Interfaces, 2014, 6, 19465–19470 CrossRef CAS.
- Y. Liu, R. Zhong, P. Zhang, Y. Ma, X. Yun, P. Gong, J. Wei, X. Zhao and F. Zhang, ACS Appl. Mater. Interfaces, 2016, 8, 2478–2485 CrossRef CAS PubMed.
- J. Guo, R. B. Zhong, W. R. Li, Y. S. Liu, Z. J. Bai, J. Yin, J. R. Liu, P. Gong, X. M. Zhao and F. Zhang, Appl. Surf. Sci., 2015, 359, 82–88 CrossRef CAS.
- S. K. Tripathi, K. Kesharwani, G. Kaul, A. Akhir, D. Saxena, R. Singh, N. K. Mishra, A. Pandey, S. Chopra and K. B. Joshi, ChemMedChem, 2022, 17, e202200251 CrossRef CAS PubMed.
- M. Colombo, L. Fiandra, G. Alessio, S. Mazzucchelli, M. Nebuloni, C. De Palma, K. Kantner, B. Pelaz, R. Rotem, F. Corsi, W. J. Parak and D. Prosperi, Nat. Commun., 2016, 7, 13818 CrossRef CAS PubMed.
Footnote |
| † These authors contribute equally. |
| This journal is © The Royal Society of Chemistry 2022 |