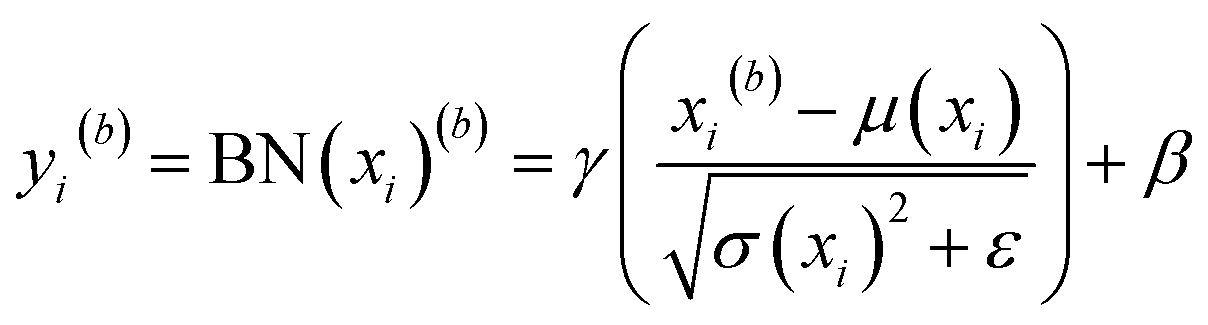DOI:
10.1039/D5RA00933B
(Paper)
RSC Adv., 2025,
15, 19431-19442
Water chemical oxygen demand prediction based on a one-dimensional multi-scale feature fusion convolutional neural network and ultraviolet-visible spectroscopy
Received
8th February 2025
, Accepted 4th June 2025
First published on 9th June 2025
Abstract
Chemical oxygen demand (COD) is an important indicator of organic pollution in water. It plays a crucial role in assessing water quality and protecting the environment. The rapid and accurate detection of COD is essential for continuous water quality monitoring. Traditional methods are often time-consuming and require chemical reagents. To address these challenges, a novel approach based on a one-dimensional convolutional neural network (1D-CNN) combined with UV-vis spectroscopy is proposed. This method is efficient, fast, and reagent-free, offering significant advantages over conventional techniques. The proposed 1D-CNN method incorporates one-dimensional multi-scale feature fusion to enhance the accuracy of COD detection. The method improves spectral feature extraction by fusing features extracted from three parallel sub-convolutional and pooling layers within the same channel. Experimental results show that the fusion network performs well in COD detection. The proposed method demonstrates superior performance compared to traditional and deep learning methods such as partial least squares regression (PLSR), support vector machines (SVM), artificial neural network (ANN), and 1D-CNNs. It significantly improves the accuracy of UV-vis spectroscopy for COD detection, achieving higher precision in real-time water quality monitoring.
1. Introduction
Water quality is essential for human health, life, and ecological security. It directly impacts the well-being of individuals and the stability of ecosystems. However, rapid urbanization and industrialization have significantly worsened water pollution. Industrial wastewater discharge, along with the widespread use of pesticides and fertilizers, are major contributors to this issue. As a result, water eutrophication is becoming an increasingly severe problem. Eutrophication causes a decline in dissolved oxygen levels, disrupting the distribution of species within the ecosystem. This imbalance in species distribution, coupled with the drop in oxygen levels, presents major challenges for water resource conservation.1 To address these issues, real-time monitoring of water pollution is critical. Rapid detection of polluted areas, along with effective prevention measures, is essential for protecting water resources and ensuring their sustainable use.
Chemical oxygen demand (COD) is a key indicator employed to assess the degree of water pollution. It represents the mass concentration of oxygen consumed by dissolved substances and suspended matter in water when exposed to strong oxidants like potassium dichromate and potassium permanganate.2 A higher COD value signifies a higher concentration of reducing substances, indicating more severe water pollution. At present, the mainstream methods for determining COD are chemical and physical methods.3 Chemical methods, such as titrimetric and electrochemical analysis, are often complex, slow, and require reagents.4 These limitations hinder real-time detection. Physical methods, like molecular spectroscopy, offer a different approach by identifying and quantifying substances through their emission or absorption spectra.5 Among these, UV-vis spectroscopy has gained widespread use in water quality monitoring due to its fast measurement, convenience, low cost, and high sensitivity. This method is not only environmentally friendly but also highly efficient for real-time monitoring.6 The advantages of UV-vis spectroscopy significantly improve monitoring efficiency, enabling governments to track pollution distribution more effectively and timely.
After obtaining spectral data, it is essential to establish an accurate mapping relationship between UV-vis spectroscopy and COD. Traditional methods mainly focus on preprocessing spectral data to enhance spectral quality and extract relevant spectral features. These preprocessing steps are necessary to reduce interference and improve model performance. After extracting features, statistical or machine learning algorithms are commonly applied to construct COD analysis models. These models aim to establish a quantitative relationship between spectral data and COD concentration.7–9 Fogelman et al.10 proposed a novel approach for the rapid estimation of COD in wastewater samples. This method integrates the mathematical processing of spectral absorbance profiles with artificial neural networks (ANNs). It was necessary to reduce the dimensionality of the input data to optimize the performance of the spectroscopic analysis and improve computational efficiency. Specifically, reducing the size of the input vector was essential for accelerating the training process of the ANN and minimizing storage requirements for the trained model. Key features were systematically extracted from the raw spectral data to achieve this reduction. As a result, the dimensionality of the ANN input vector was significantly decreased from 160 to 10 features, while preserving the relevant information necessary for accurate COD estimation. The reduced-input ANN model was rigorously evaluated against the full-input model. The results demonstrated that COD values predicted using the selected features closely matched those derived from the complete spectral profile. Cao et al.11 investigated a rapid and efficient method for determining COD in aquaculture wastewater using ultraviolet (UV) spectroscopic analysis. The study aimed to enhance the speed and accuracy of COD estimation through advanced modeling and data processing techniques. Four calibration methods were employed and compared to establish an effective prediction model. These included multiple linear regression (MLR), partial least squares (PLS), least squares support vector machine (LS-SVM), and ANN. A variable selection strategy was implemented to reduce the influence of redundant and irrelevant spectral data. The successive projections algorithm (SPA) was adopted to identify efficient wavelengths (EWs) that contribute significantly to the COD prediction. Furthermore, six spectral pretreatment methods were evaluated to improve the quality and consistency of the input data. Among the various modeling and preprocessing combinations, the best performance was observed with the ANN model. This model utilized 11 EWs selected by SPA, in conjunction with the standard normal variate (SNV) pretreatment method, which proved to be the most effective. Liu et al.12 conducted a comprehensive investigation focused on the rapid determination of COD in aquaculture water. A total of 135 absorbance spectra were collected from aquaculture water samples to serve as the basis for spectral analysis. To minimize the influence of absolute noise present in the raw spectral data, three preprocessing methods were applied: Savitzky–Golay (SG) smoothing, empirical mode decomposition (EMD), and wavelet transform (WT). Following preprocessing, latent variables (LVs) were extracted from the spectral data using PLS, which served to reduce the dimensionality and highlight relevant spectral features. Multiple modeling strategies were explored based on these LVs. PLS was first used to construct models utilizing the full spectral dataset. In parallel, ANN and LS-SVM models were developed using the extracted LVs. A comparative analysis of the modeling results revealed that both ANN and LS-SVM models exhibited superior predictive performance compared to the PLS models. Among all configurations, the LS-SVM model built using LVs derived from WT-preprocessed spectra achieved the most accurate results. Lepot et al.13 conducted a comprehensive comparative study to evaluate the performance of various modeling methods for estimating key water quality parameters. The primary objective was to determine the accuracy and robustness of different predictive approaches across a range of environmental scenarios. Four modeling techniques were explicitly assessed, including linear regression (LR), support vector machine (SVM), evolutionary algorithm (EVO), and PLS. These models were applied to diverse datasets obtained from different aquatic environments, including sewers, rivers, and wastewater treatment plants (WWTPs). The study also considered varying meteorological conditions, such as dry, wet, and all-weather situations, to enhance the generalizability of the results. The target water quality parameters included COD and others. The results indicated that PLS and SVM methods consistently provided the most accurate predictions, as reflected by their lower RMSE values. Li et al.14 proposed a practical and efficient method for COD detection based on UV-vis spectroscopy. The COD estimation model was globally calibrated using effluent samples collected from rural sewage treatment facilities. The performance of PLS, SVM, and ANN methods was compared to identify the most effective modeling technique. Among them, PLS achieved superior performance and was validated as the most suitable algorithm for global model construction. A wavelength selection strategy was implemented to reduce computational complexity and improve model simplicity. Instead of utilizing the full spectral range, the model employed absorbance values at specific wavelengths selected via interval partial least squares regression (iPLSR) and synergy interval partial least squares regression (siPLSR). The simplified model was based on three key wavelengths: 251 nm, 356 nm, and 363 nm. It demonstrated stable and reliable predictive capability. There has been some progress in COD detection by traditional methods. However, these methods often suffer from limitations, such as poor accuracy or the need for extensive preprocessing. Traditional statistical learning or machine learning models require more preprocessing of the spectra, which involves extracting COD-related features in advance. This step is crucial because the quality of feature extraction during spectral preprocessing has a significant impact on the model's accuracy. Without proper feature extraction, the model may struggle to make accurate predictions, thereby reducing its overall effectiveness.15
A general and efficient method is needed to automatically extract spectral features without manual intervention. The success of deep learning in image and language processing has encouraged researchers to investigate it in spectral feature extraction and modeling.16–18 Among deep learning models, convolutional neural networks (CNNs) are widely used for feature extraction. CNNs extract high-dimensional features through multi-level convolutional operations and reduce feature dimensions with a pooling layer. Compared to traditional prediction models, CNNs provide superior self-learning and adaptive capabilities. They can automatically extract features and handle nonlinear relationships more effectively.19 Due to their strong feature extraction and nonlinear mapping capabilities, CNNs can achieve high prediction accuracy even without spectral preprocessing. This advantage makes CNNs a promising alternative to traditional methods in COD detection.20 Jia et al.21 developed a COD prediction model based on CNNs and UV-vis spectroscopy. In this model, spectral data features were automatically extracted through the CNN framework, eliminating the need for complex preprocessing. Experimental results showed that the CNN model exhibited strong predictive ability, high accuracy, and excellent regression fitting. Compared to other models, the CNN-based approach achieved the smallest root mean square error of prediction (RMSEP) and mean absolute error (MAE). Additionally, it obtained the highest coefficient of determination (R2), indicating the best-fitting performance among all the evaluated models. These results highlight the effectiveness of CNNs in improving COD prediction accuracy. Xia et al.22 proposed a novel spectrometric quantification method based on a double-channel 1D CNN to quantify nitrate and COD concentrations in water combined with long UV-vis absorption spectra. To improve model robustness, a new dataset augmentation method was introduced, enhancing the model's ability to resist turbidity disturbances. The absorption spectra of nitrate and COD under different turbidity conditions were successfully simulated, allowing the model to adapt to varying water qualities. A comparison with the PLSR model demonstrated a significant improvement in regression accuracy. The CNN model increased nitrate solution accuracy from 56% to 93% and COD solution accuracy from 68% to 91%. These results highlight the CNN model's superior performance in nitrate and COD quantification compared to traditional spectroscopic modeling approaches. Ye et al.23 proposed a COD prediction model that combines UV-vis spectroscopy with CNNs. Unlike traditional COD prediction models, this approach utilizes the absorbance of all ultraviolet and visible wavelengths. It avoids information loss that occurs when only specific wavelengths are selected by considering the full spectrum. The model leverages CNN's strong feature extraction capability, reducing dependence on preprocessing methods. This enhances the utilization of spectral information, improving COD prediction accuracy. Experimental results showed that the CNN-based model achieved better fitting performance and higher accuracy compared to traditional COD prediction models. It outperformed methods such as principal component analysis (PCA), PLSR, and BP-ANN, demonstrating its effectiveness for COD detection. Compared to traditional methods, CNN-based approaches have greatly improved spectral feature extraction and COD modeling. These models can automatically learn complex relationships from UV-vis spectra, reducing the need for extensive preprocessing. They also enhance the accuracy and robustness of COD prediction. However, despite these advancements, challenges remain. There is still significant room for improvement in further enhancing the accuracy of COD detection. Future research should focus on optimizing CNN architectures and improving automatic feature extraction capability to achieve more accurate COD predictions.
This paper focuses on enhancing the accuracy of COD detection in water by UV-vis spectroscopy. Traditional methods for COD detection have several limitations, including complexity, slow analysis times, and the need for reagents. These challenges hinder real-time monitoring and the accuracy of results. To address these issues, the paper draws inspiration from the success of two-dimensional convolutional neural networks in image processing. It proposes a novel approach based on a one-dimensional multi-scale feature fusion convolutional neural network (1D-MSFF-CNN) for UV-vis spectral modeling tasks. Spectral features at various scales are extracted by the model, which employs three parallel sub-convolutional neural networks with different convolution kernel sizes. A multi-scale feature fusion algorithm is proposed to provide a more comprehensive and accurate representation of the UV-vis spectrum. Experimental results demonstrate that the proposed method effectively predicts COD with high accuracy, surpassing the performance of traditional and deep learning methods. The comparison with other COD prediction techniques shows a smaller prediction error, indicating the superior performance of the proposed method. It offers a more effective solution for improving the accuracy of COD detection based on UV-vis spectroscopy, paving the way for more reliable water quality monitoring.
2. Materials and methods
2.1 Hardware setup
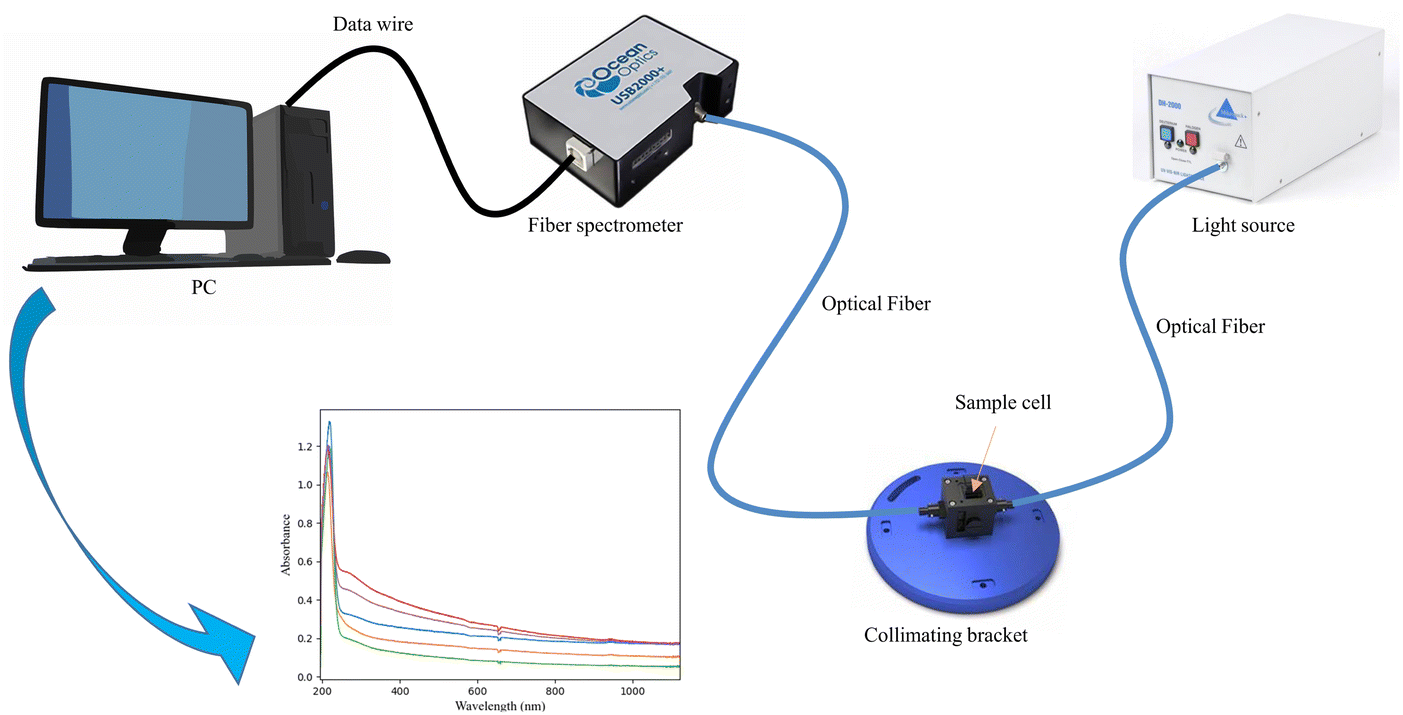
The COD detection method is based on a UV-vis spectroscopy acquisition system, as shown in Fig. 1. This system includes several key components: a light source, a sample cell, a spectrometer, and a personal computer (PC) for data processing. The sample cell has a width of 10 mm, ensuring the proper path length for light absorption measurements. The light source employed is a DH-2000 deuterium-halogen light source, which emits light across a broad wavelength range from 190 to 2500 nm (Ocean Optics, USA). The spectrometer employed in the system is the USB2000+, which captures spectra within the wavelength range of 193.91 to 1121.69 nm (Ocean Optics, USA). Data collected by the spectrometer is stored and processed on the PC, where models are built by appropriate algorithms and software to analyze the spectra. The COD standard value for samples is determined by the rapid digestion spectrophotometric method (HJ/T 399-2007). This method involves the use of the DRB200 digester device and the DR3900 visible spectrophotometer (Hach, USA), which aid in the digestion and spectrophotometric measurement of COD, as shown in Fig. 2.
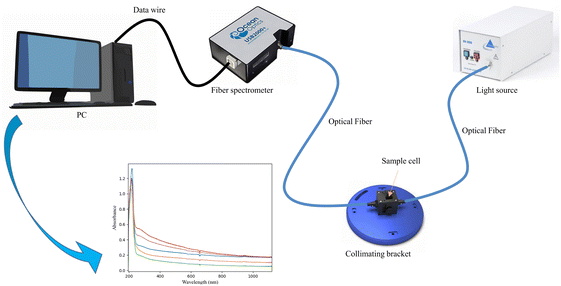 |
| | Fig. 1 UV-vis spectroscopy acquisition system. | |
 |
| | Fig. 2 COD standard value collection equipment. (a) DRB200 digester device; (b) DR3900 visible spectrophotometer. | |
2.2 Convolutional neural networks
CNNs are a widely used deep learning network.24 They are known for their ability to automatically extract features from data, which allows them to map complex data relationships effectively. These characteristics make CNNs suitable for applications in various artificial intelligence fields, such as computer vision25,26 and natural language processing.27,28 Compared to traditional deep learning algorithms, CNNs excel in feature extraction, making them more powerful in identifying relevant relationships from data. The key components of CNNs include the convolutional layer and the pooling layer. The convolutional layer extracts local features by sliding filters on a two-dimensional grid of input data based on convolutional operations. Although CNNs are commonly associated with image processing, they also offer significant advantages in handling one-dimensional data,29,30 such as sequences,31 signals,32 text,33 and spectra.34 In this study, a one-dimensional CNN is applied to predict COD by training the network with one-dimensional UV-vis spectral data of water as input and the corresponding COD concentration as output. This approach leverages the power of CNNs to automatically extract features and predict COD more accurately from the UV-vis spectra, enhancing water quality monitoring.
2.3 The proposed method
2.3.1 One-dimensional multi-scale feature fusion convolutional neural network (1D-MSFF-CNN). CNNs are highly effective in feature extraction and fitting, which makes them well-suited for COD determination. Their ability to automatically extract relevant features from raw data allows for improved accuracy in COD prediction tasks. CNNs are capable of performing end-to-end analysis, where raw UV-vis spectral data can be directly inputted, eliminating the need for extensive preprocessing and simplifying the COD detection process. In this paper, we propose a one-dimensional CNN (1D-CNN) method for COD modeling, which is based on multi-scale feature fusion to enhance the representation of spectral data. The proposed model structure is shown in Fig. 3. This approach leverages the powerful capabilities of CNNs to provide accurate and efficient COD detection.
 |
| | Fig. 3 One-dimensional convolutional neural network COD prediction model based on multi-scale feature fusion. | |
The 1D-MSFF-CNN consists of three parallel sub 1D-CNN, each made up of convolutional and pooling layers. One of the convolutional and pooling layers is named the conv-pooling layer. The three sub networks employ different convolution kernel sizes (1, 3, and 5) to capture spectral features at different scales. Each sub 1D-CNN is structured with three one-dimensional conv-pooling layers, with 32, 64, and 128 units in each layer, respectively. Features are extracted by multiplying the input with a filter, and the operation only moves in one direction along the spectral vector. The rectified linear unit (ReLU) activation function is used in each convolutional layer due to its simplicity and efficiency in computation. A max pooling layer follows each convolutional layer to extract features, reduce the number of parameters, and improve model training efficiency. The pooling operation focuses on retaining the most “important” local features, ensuring more accurate feature extraction. After the max pooling step, a multi-scale feature fusion layer combines the features extracted from the three sub 1D-CNN at different scales by element-wise addition. The outputs from the three sub conv-pooling layers are then merged into a single layer with the same number of channels. A batch normalization (BN) layer is added after the feature fusion to normalize the data, helping to solve issues like gradient vanishing and improving training speed. This batch normalization also regularizes the data, enhancing both the training efficiency and overall model performance. The entire multi-scale feature fusion process is shown in Fig. 4.
 |
| | Fig. 4 Multi-scale feature fusion process. | |
The feature fusion layer calculation process is divided into two steps. These steps are crucial for effectively combining the features extracted from three sub networks. The first step involves combining the features extracted from the three sub 1D-CNN at different scales by element-wise addition. The second step is to add a BN layer after the feature fusion to normalize the data. The equations for these calculations are provided in eqn (1) and (2).
| |
 | (1) |
| |
 | (2) |
where
xk represents the element-wise addition for the feature map of the
k-th channel of the three sub 1D-CNN.
fki (
i = 1, 2, 3) represents the output of the three sub conv-pooling layers.
K represents the number of channels for the feature map, which is 32, 64, or 128.
xi(b) represents the value of the
i-th input node of this layer when the
b-th sample of the current batch is input.
xi represents a row vector [
xi1,
xi2,
xi3, …,
xim] with a batch size of
m.
μ and
σ represent the mean and standard deviation.
∈ represents a minimum quantity (negligible) introduced to prevent division by 0.
β and
γ represent shift and scale parameters.
After the feature fusion layer, a fully connected layer (flatten) is added to convert the output into a single vector. This step helps to simplify the output and prepares it for further processing. Two additional fully connected layers, with 128 and 32 units, are then introduced to map the learned feature distribution to the label space. These layers enable the network to capture more complex relationships within the data. At the end, a fully connected output layer (Dense 1) is added to provide the final COD prediction results. The network extracts spectral features at different scales, performs feature fusion, and predicts the COD concentration through the fully connected layers. In comparison to traditional CNNs, the multi-scale feature fusion CNN is more effective in obtaining valuable spectral information and providing a more comprehensive description of sample features. The detailed parameters of the proposed 1D-MSFF-CNN architecture are provided in Table 1.
Table 1 The parameters of the proposed 1D-MSFF-CNN architecture
| Layer |
Input shape |
Output shape |
Kernel number |
Kernel size |
Padding |
Stride |
Activation |
| Convolution 0_1 |
(1,2048,1) |
(1,2048,32) |
32 |
1 × 1 |
0 |
1 |
ReLU |
| Convolution 1_1 |
(1,2048,1) |
(1,2048,32) |
32 |
1 × 3 |
1 |
1 |
ReLU |
| Convolution 2_1 |
(1,2048,1) |
(1,1024,32) |
32 |
1 × 5 |
2 |
1 |
ReLU |
| Max pooling 0_1 |
(1,2048,32) |
(1,1024,32) |
None |
1 × 2 |
None |
2 |
None |
| Max pooling 1_1 |
(1,2048,32) |
(1,1024,32) |
None |
1 × 2 |
None |
2 |
None |
| Max pooling 2_1 |
(1,2048,32) |
(1,1024,32) |
None |
1 × 2 |
None |
2 |
None |
| Fusion |
(1,1024,32) |
(1,1024,32) |
None |
None |
None |
None |
None |
| Convolution 0_2 |
(1,1024,32) |
(1,1024,64) |
64 |
1 × 1 |
0 |
1 |
ReLU |
| Convolution 1_2 |
(1,1024,32) |
(1,1024,64) |
64 |
1 × 3 |
1 |
1 |
ReLU |
| Convolution 2_2 |
(1,1024,32) |
(1,1024,64) |
64 |
1 × 5 |
2 |
1 |
ReLU |
| Max pooling 0_2 |
(1,1024,64) |
(1,512,64) |
None |
1 × 2 |
None |
2 |
None |
| Max pooling 1_2 |
(1,1024,64) |
(1,512,64) |
None |
1 × 2 |
None |
2 |
None |
| Max pooling 2_2 |
(1,1024,64) |
(1,512,64) |
None |
1 × 2 |
None |
2 |
None |
| Fusion |
(1,512,64) |
(1,512,64) |
None |
None |
None |
None |
None |
| Convolution 0_3 |
(1,512,64) |
(1,512,128) |
128 |
1 × 1 |
0 |
1 |
ReLU |
| Convolution 1_3 |
(1,512,64) |
(1,512,128) |
128 |
1 × 3 |
1 |
1 |
ReLU |
| Convolution 2_3 |
(1,512,64) |
(1,512,128) |
128 |
1 × 5 |
2 |
1 |
ReLU |
| Max pooling 0_3 |
(1,512,128) |
(1,256,128) |
None |
1 × 2 |
None |
2 |
None |
| Max pooling 1_3 |
(1,512,128) |
(1,256,128) |
None |
1 × 2 |
None |
2 |
None |
| Max pooling 2_3 |
(1,512,128) |
(1,256,128) |
None |
1 × 2 |
None |
2 |
None |
| Fusion |
(1,256,128) |
(1,256,128) |
None |
None |
None |
None |
None |
| Flatten |
(1,256,128) |
(1,256*128) |
None |
None |
None |
None |
None |
| FC |
(1,256*128) |
(1,128) |
None |
None |
None |
None |
ReLU |
| FC |
(1,128) |
(1,32) |
None |
None |
None |
None |
ReLU |
| FC (output) |
(1,32) |
(1,1) |
None |
None |
None |
None |
None |
2.3.2 Model training. The Adam optimization algorithm is employed for model training, ensuring efficient and adaptive learning. The learning rate is set to 0.0001, which controls the size of the steps taken during optimization. The number of training epochs is determined by observing the evolution curve of the loss value during training, ensuring that the model converges effectively. The CNN's training and optimization rely on a loss function that calculates the error between the prediction and standard values. In this study, MSE is used as the loss function, as it provides a clear measure of prediction accuracy. The equation for MSE is provided in eqn (3).| |
 | (3) |
where yi represents the measured value according to the standard method. ŷi represents the prediction value of the model. n is the number of samples.
2.4 COD prediction process of the proposed method
The process for COD prediction based on the 1D-MSFF-CNN and UV-vis spectroscopy is shown in Fig. 5. This method achieves accurate COD value prediction by developing a one-dimensional multi-scale feature fusion CNN model specifically designed for UV-vis spectroscopy data. One of the key advantages of the 1D-MSFF-CNN model is its ability to perform automatic feature extraction, eliminating the need for complex and time-consuming spectral preprocessing. This significantly simplifies the COD prediction process. The model demonstrates superior generalization ability and exhibits good adaptive performance in predicting COD concentrations. The COD prediction process involves five key steps, ensuring a structured and efficient approach to obtaining reliable results.
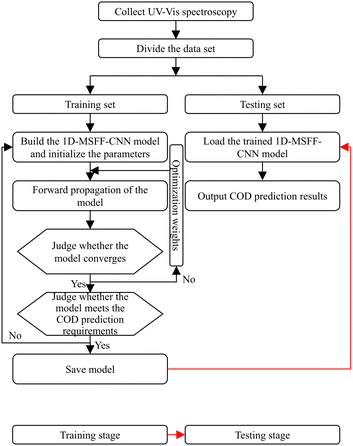 |
| | Fig. 5 COD prediction process of the proposed method. | |
Step 1: the UV-vis spectroscopy data for the water samples are obtained to perform the COD prediction. The data is collected by the spectroscopy acquisition system, as shown in Fig. 1.
Step 2: the samples are randomly divided into two sets: a training set and a testing set. The training set is used as input during the model training stage, allowing the model to learn mapping relationships within the data. The testing set, on the other hand, is reserved for the testing stage of the model. It is used to evaluate the performance of the trained model on unseen data.
Step 3: the 1D-MSFF-CNN model is designed for COD detection. The hyperparameters and weights of the model are initialized to set up the training process. The training set is then input into the model, allowing it to learn from the data. During the training process, forward propagation is applied to calculate the error between the model's predicted results and the standard values.
Step 4: the model is regularly checked for convergence to ensure it meets a certain criterion. If the model satisfies the convergence criterion, it proceeds to step 5. However, if the model does not meet the criterion, it requires further optimization. In this case, the weights are adjusted layer by layer through backpropagation.
Step 5: the model's performance is evaluated to determine whether it meets the criteria for accurate COD prediction. If the model satisfies the performance requirements, the testing set is input into the trained model, and the final prediction results are generated. However, if the model does not meet the performance criteria, it proceeds to step 3 for further adjustments. In this case, the hyperparameters are re-designed to improve the model's performance.
2.5 Performance indices
Various models for COD prediction each have their own advantages and disadvantages, so it is important to select the most suitable model based on the specific task. To effectively compare the performance of different models, standardized evaluation indices are essential. Two commonly used performance evaluation indices are the coefficient of determination (R2) and the root mean square error (RMSE). R2 is used to evaluate the fitting ability of the model, with larger values indicating a better fit. RMSE assesses the accuracy of the model, with smaller values indicating higher accuracy. Interpreting these performance metrics is straightforward: larger R2 values and smaller RMSE values signify better model performance, while smaller R2 values and larger RMSE values suggest poorer performance. The equations for calculating R2 and RMSE are provided in eqn (4)–(6). These equations allow for a detailed and quantitative comparison of model performance.| |
 | (4) |
| |
 | (5) |
| |
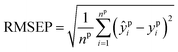 | (6) |
where yi represents the measured value based on the standard method. ȳ represents the average value of yi. ŷi represents the prediction value of the model. n represents the number of samples in the calibration/prediction set. yci represents the measured value of the calibration set based on the standard method. ŷci represents the prediction value of the calibration set based on the model. nc represents the number of samples in the calibration set. ypi represents the measured value of the prediction set based on the standard method. ŷpi represents the prediction value of the prediction set based on the model. np represents the number of samples in the prediction set.
3. Experiments and results analysis
3.1 Dataset
All water samples were collected from Slender West Lake in Yangzhou, a historic site with a history spanning hundreds of years. However, the water quality in the lake faces significant challenges due to increasing wastewater discharge from urban development and industrial activities. These factors have negatively impacted the growth of animals and plants in the area. Therefore, effective water quality testing and real-time monitoring are crucial for the local ecosystem. The UV-vis spectra shown in Fig. 6 were acquired by the UV-vis spectroscopy acquisition system shown in Fig. 1. A total of 600 water samples were collected from different regions of the lake, along with their corresponding UV-vis spectra. These samples were randomly divided into training/calibration and testing/prediction sets, with a 5![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :1 ratio. The training set contains 500 samples, while the testing set consists of 100 samples. The COD standard values of the collected water samples were determined by the equipment shown in Fig. 2.
:1 ratio. The training set contains 500 samples, while the testing set consists of 100 samples. The COD standard values of the collected water samples were determined by the equipment shown in Fig. 2.
 |
| | Fig. 6 UV-vis spectra of the water samples. (a) UV-vis spectra of training set; (b) UV-vis spectra of testing set. | |
3.2 Experimental environment
All experiments were conducted by PyTorch GPU 2.5.1 with dual Geforce RTX 4090 graphics cards from Nvidia Corporation. The environment was set up with CUDA 11.8 to leverage GPU acceleration for faster computations. The hardware employed for the experiments consisted of a small server computer equipped with a 2.9 GHz Intel® Xeon® Silver 4310 CPU and 32 GB of RAM. The system ran the Windows 10 operating system and Python 3.9.6. For development, PyCharm and Anaconda were employed, providing an efficient environment for coding and package management. During model training, the Adam optimization algorithm was employed to optimize the network. The learning rate was set to 0.0001 to ensure stable convergence. For optimal performance, a batch size of 20 was chosen, and the model was trained for 1000 epochs to ensure adequate training and model convergence.
3.3 Training procedure
The 1D-MSFF-CNN model was trained on the data described in Section 3.1. For model evaluation, MSE was employed as the loss function, serving as an indicator of the model's error. The R2 was employed to measure the model's fitting effectiveness. At the end of each training epoch, the best model was saved for use during the testing stage. Fig. 7 illustrates the evolution of the loss and R2 during the training process. In the first 10 epochs, the loss value rapidly decreased, and R2 rapidly increased, indicating fast initial learning. After this initial stage, both loss and R2 exhibited slower changes over several hundred epochs. Throughout the training, the loss consistently decreased, and R2 consistently increased, demonstrating good consistency in their progress. The model approached convergence as both values stabilized by the 850th epoch. After 1000 epochs, the loss stabilized at approximately 50, while R2 stabilized around 0.94. The minimum loss value decreased to about 25, and the maximum R2 value increased to about 0.97. However, the final model performance showed that the loss reached around 50 instead of 0, and R2 increased to around 0.94 instead of 1, due to interference from factors such as temperature, noise, and turbidity in the data.
 |
| | Fig. 7 Changes of loss value and R2 during the training process of 1D-MSFF-CNN model. (a) changes of loss; (b) changes of R2. | |
3.4 Model performance analysis
After the training process, the model with the lowest loss value is saved as the final COD prediction model. This model is then evaluated by inputting 100 testing/prediction samples to predict the corresponding COD values. The predicted COD values are compared with the standard COD values to evaluate the model's performance. A summary of the model's performance is provided in Table 2. The goodness of fit, represented by the R2 value, is 0.9705/0.9693, which indicates the model's excellent feature extraction and mapping capabilities. Additionally, the RMSE is calculated as 5.1219/5.2250, showing the model's high accuracy in predicting COD values. Both the R2 and RMSE values demonstrate that the model possesses strong fitting ability and accuracy, confirming its effectiveness in COD prediction.
Table 2 The performance of the 1D-MSFF-CNN model
| Method |
Calibration set |
Prediction set |
| R2 |
RMSEC |
R2 |
RMSEP |
| 1D-MSFF-CNN |
0.9705 |
5.1219 |
0.9693 |
5.2250 |
To further quantify the prediction performance of the model, a comparison was made between the predicted COD values and the standard COD values. The comparison curve presents the relationship between the COD prediction values from the 1D-MSFF-CNN model and the standard values in the testing set, as shown in Fig. 8. The higher the accuracy of the model, the closer the predicted values are to the standard values, and the closer the scatter points are to or on the blue straight line, indicating good consistency. The scattering of points near the blue line also suggests that the model has strong robustness and adaptability, providing accurate COD predictions. Notably, the error does not increase with higher COD concentrations, indicating that the error distribution remains uniform. The model achieves high accuracy within the COD concentration range of 20 to 120 mg L−1, ensuring reliable performance for lake water. These results demonstrate that the method effectively extracts UV-vis spectroscopy features, leading to accurate and consistent COD detection.
 |
| | Fig. 8 Comparison curve between the prediction and standard COD values. | |
3.5 Comparison with other methods
The effectiveness of the proposed method is evaluated by comparing it with several common traditional methods and deep learning methods. Traditional methods include PLSR,35 SVM,36 and ANN.37 Deep learning methods included three 1D-CNNs.21–23 The datasets employed for comparison are consistent with those described in previous sections, ensuring a fair evaluation. The prediction results of the three traditional methods (PLSR, SVM, and ANN), three deep learning methods and the proposed method (1D-MSFF-CNN) are presented in Table 3 and Fig. 9. The error bars based on standard deviation are also plotted in Fig. 9. This comparison provides a clear assessment of the relative performance of the proposed model in COD prediction.
Table 3 Comparison of the proposed method with other methods
| Method |
Calibration set |
Prediction set |
| R2 |
RMSEC |
R2 |
RMSEP |
| PLSR |
0.9096 |
8.976 |
0.8941 |
9.7167 |
| SVM |
0.9179 |
8.5531 |
0.9032 |
9.2869 |
| ANN |
0.9471 |
6.8629 |
0.9436 |
7.0854 |
| 1D-CNN21 |
0.9577 |
6.1351 |
0.9532 |
6.4564 |
| 1D-CNN22 |
0.9683 |
5.3100 |
0.9642 |
5.6462 |
| 1D-CNN23 |
0.9594 |
6.0127 |
0.9565 |
6.2246 |
| 1D-MSFF-CNN |
0.9705 |
5.1219 |
0.9693 |
5.2250 |
 |
| | Fig. 9 Comparison of the proposed method with other methods. (a) R2; (b) RMSE. Here, Jia 2020 represents 1D-CNN,21 Xia 2023 represents 1D-CNN,22 Ye 2022 represents 1D-CNN.23 | |
The comparison presented in Table 3 and Fig. 9 comprehensively evaluates the performance of traditional methods, deep learning methods, and the proposed method for predicting COD based on our spectral data. This comparative analysis reveals significant performance differences among these approaches. Among traditional methods, the ANN achieves the best results. It achieves R2 values of 0.9471 for the calibration set and 0.9436 for the prediction set. The corresponding RMSEC and RMSEP values are 6.8629 and 7.0854, respectively. Although ANN outperforms other traditional methods, it still lacks the capacity to fully capture the nonlinear and complex relationship between spectral features and COD concentrations. PLSR and SVM models perform even less effectively. Both exhibit higher RMSEC and RMSEP values, indicating reduced predictive accuracy and limited modeling capability. In contrast, deep learning methods show overall improvements in fitting performance. The 1D-CNN, as reported in previous studies (ref. 22), emerges as the strongest among the three deep learning methods. It achieves R2 values of 0.9683 and 0.9642 for the calibration set and prediction set, along with RMSEC and RMSEP values of 5.3100 and 5.6462, respectively. However, the remaining two deep learning models under evaluation fail to match the performance of the 1D-CNN (ref. 22). These two models demonstrate a weaker capacity to model the nonlinear spectral–COD relationship, reflecting inefficiencies in feature extraction and prediction accuracy. The proposed method clearly surpasses all the traditional and deep learning methods. It achieves the highest R2 values, reaching 0.9705 for the calibration set and 0.9693 for the prediction set. Furthermore, it obtains the lowest RMSEC and RMSEP values of 5.1219 and 5.2250, respectively. These results indicate its superior capability in accurately modeling the nonlinear relationship between spectral data and COD. The method's excellent fit and low prediction error reflect its enhanced ability to extract and utilize spectral features. Overall, the proposed method delivers highly reliable and precise COD predictions, outperforming all other evaluated methods and providing a promising solution for spectral-based water quality assessment.
Further comparisons were made between the proposed method and the three traditional methods and deep learning methods, as shown in Fig. 8 and 10. A scatter plot was applied to visualize the predicted COD values against the standard values from the testing set. The closer the prediction points are to the blue line in the plot, the higher the prediction accuracy. The accuracy of the models was evaluated by analyzing the distance between the scatter points and the blue line. Two red lines were added as reference lines in the scatter plots. These red lines maintained the same position and width across all subplots. The distance of the points from the red lines helped assess the accuracy of the models. The points in Fig. 10(a)–(c) are clearly farther from the blue line compared to those in Fig. 10(d)–(f) and 8. More points in Fig. 10(a)–(c) exceeded the red line area or were at the boundary, indicating relatively low prediction accuracy for PLSR, SVM, and ANN. In contrast, Fig. 10(d)–(f) show that no points exceeded the red line area, only one point of each subplot at the boundary, indicating that the prediction accuracy of the three deep learning methods is better. Finally, all points in Fig. 8 are within the red line area, and there are no points at the boundary, indicating that the proposed model has the best prediction accuracy. Overall, the proposed 1D-MSFF-CNN method showed the best COD prediction accuracy and stability compared to other methods.
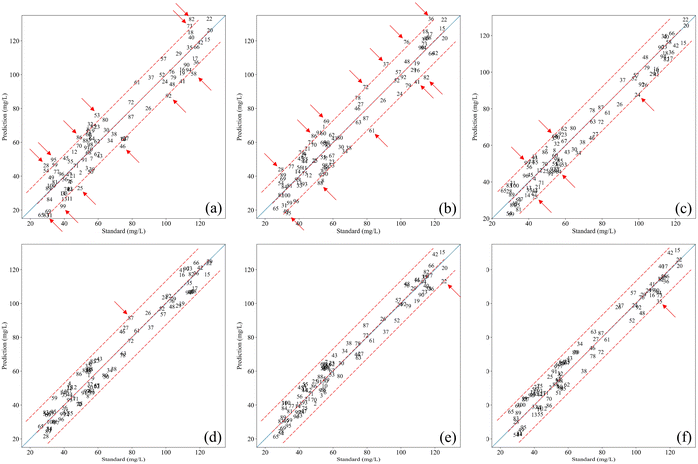 |
| | Fig. 10 Comparison curve between the prediction and standard COD values of 1D-MSFF-CNN and other methods. (a) PLSR; (b) SVM; (c) ANN; (d) 1D-CNN;21 (e) 1D-CNN;22 (f) 1D-CNN.23 | |
4. Conclusion
The method aims to address the issue of insufficient accuracy in COD detection based on spectroscopy. A UV-vis spectroscopy modeling method based on multi-scale feature fusion, called 1D-MSFF-CNN, is proposed to improve the accuracy of COD detection. This method builds on the structure of a 1D-CNN with several network improvements. The model incorporates a conv-pooling layer, which directly extracts UV-vis spectroscopy features from different scales. A multi-scale feature fusion layer is added to maximize the value of these features. This layer fully applied the features extracted from different scales, allowing for a more comprehensive representation of the spectral data. The features from the three sub conv-pooling layers are fused through element-wise addition on the same channel. This fusion method improves the description of the spectral features, leading to better prediction accuracy. The experimental results demonstrate that the 1D-MSFF-CNN model achieves higher COD prediction accuracy compared to traditional and deep learning methods. Therefore, the proposed method provides a more efficient and accurate solution for fast COD detection.
Data availability
The data supporting this study's findings are available from the corresponding author upon reasonable request.
Conflicts of interest
There are no confilicts to declare.
References
- S. Pandey, E. Makhado, S. Kim and M. Kang, Recent developments of polysaccharide based superabsorbent nanocomposite for organic dye contamination removal from wastewater-A review, Environ. Res., 2023, 217, 114909 CrossRef CAS.
- M. G. Uddin, S. Nash, A. Rahman and A. I. Olbert, A comprehensive method for improvement of water quality index (WQI) models for coastal water quality assessment, Water Res., 2022, 219, 118532 CrossRef CAS.
- X. Xu, J. Wang, J. Li, A. Fan, Y. Zhang, C. Xu, H. Qin, F. Mu and T. Xu, Research on COD measurement method based on UV-Vis absorption spectra of transmissive and reflective detection systems, Front. Environ. Sci., 2023, 11, 1–12 CAS.
- Y. Liang, F. Ding, L. Liu, F. Yin, M. Hao, T. Kang, C. Zhao, Z. Wang and D. Jiang, Monitoring water quality parameters in urban rivers using multi-source data and machine learning approach, J. Hydrol., 2025, 648, 1–15 CrossRef.
- S. Penzel, T. Mayer, T. Goblirsch, H. Borsdorf, M. Rudolph and O. Kanoun, A novel turbidity compensation method for water measurements by UV/Vis and fluorescence spectroscopy, Measurement, 2025, 239, 1–10 CrossRef.
- X. Cui, D. P. Webb and S. Rahimifard, Capability evaluation of real-time inline COD detection technique for dynamic water footprint management in the beverage manufacturing industry, Water Resour. Ind., 2023, 30, 1–18 Search PubMed.
- Y. Lyu, W. Zhao, T. Kinouchi, T. Nagano and S. Tanaka, Development of statistical regression and artificial neural network models for estimating nitrogen, phosphorus, COD, and suspended solid concentrations in eutrophic rivers using UV-Vis spectroscopy, Environ. Monit. Assess., 2023, 195, 1–16 CrossRef.
- Li. Chun, X. Ma, Y. Teng, S. Li, Y. Jin, J. Du and L. Jiang, Quantitative Analysis of Forest Water COD Value Based on UV–vis and FLU Spectral Information Fusion, Forests, 2023, 14, 1–12 Search PubMed.
- K. Zhou, Z. Liu, M. Cong and S. Man, Detection of chemical oxygen demand in water based on UV absorption spectroscopy and PSO-LSSVM algorithm, Optoelectron. Lett., 2022, 18, 251–256 CrossRef.
- S. Fogelman, M. Blumenstein and H. Zhao, Estimation of chemical oxygen demand by ultraviolet spectroscopic profiling and artificial neural networks, Neural Comput. Appl., 2006, 15, 197–203 CrossRef.
- H. Cao, W. Qu and X. Yang, A rapid determination method for chemical oxygen demand in aquaculture wastewater using the ultraviolet absorbance spectrum and chemometrics, Anal. Methods, 2014, 6, 3799–3803 RSC.
- X. Liu and H. Zhang, Rapid Determination of COD in Aquaculture Water Based on LS-SVM with Ultraviolet/Visible Spectroscopy, Spectrosc. Spectr. Anal., 2014, 34, 2804–2807 CAS.
- M. Lepot, A. Torres, T. Hofer, N. Caradot, G. Gruber, J. B. Aubin and J. L. Bertrand-Krajewski, Calibration of UV/Vis spectrophotometers: A review and comparison of different methods to estimate TSS and total and dissolved COD concentrations in sewers, WWTPs and rivers, Water Res., 2016, 101, 519–534 CrossRef CAS.
- P. Li, J. Qu, Y. He, Z. Bo and M. Pei, Global calibration model of UV-Vis spectroscopy for COD estimation in the effluent of rural sewage treatment facilities, RSC Adv., 2020, 10, 20691–20700 RSC.
- J. Qiu, H. Guo, Y. Xue, Q. Liu, Z. Xu and L. He, Rapid detection of chemical oxygen demand, pH value, total nitrogen, total phosphorus, and ammonia nitrogen in biogas slurry by near infrared spectroscopy, Anal. Methods, 2023, 15, 3902–3914 RSC.
- L. Guan, Y. Zhou and S. Yang, An improved prediction model for COD measurements using UV-Vis spectroscopy, RSC Adv., 2024, 14, 193–205 RSC.
- X. Chen, S. Wang, H. Chen and R. Fan, Improved boosting and self-attention RBF networks for COD prediction based on UV-vis, Anal. Methods, 2024, 16, 6383–6391 RSC.
- Y. Hu, B. Dai, Y. Yang, D. Zhao and H. Ren, Sample Generation Method Based on Variational Modal Decomposition and Generative Adversarial Network (VMD-GAN) for Chemical Oxygen Demand (COD) Detection Using Ultraviolet Visible Spectroscopy, Appl. Spectrosc., 2023, 77, 1173–1180 CrossRef CAS.
- M. Xia, R. Yang, N. Zhao, X. Chen, M. Dong and J. Chen, A Method of Water COD Retrieval Based on 1D CNN and 2D Gabor Transform for Absorption-Fluorescence Spectra, Micromachines, 2023, 14, 1–24 Search PubMed.
- Y. Huang, Y. Pan, C. Liu, L. Zhou, L. Tang, H. Wei, K. Fan, A. Wang and Y. Tang, Rapid and Non-Destructive Geographical Origin Identification of Chuanxiong Slices Using Near-Infrared Spectroscopy and Convolutional Neural Networks, Agriculture, 2024, 14, 1–15 Search PubMed.
- W. Jia, H. Zhang, J. Ma, G. Liang, J. Wang and X. Liu, Study on the Predication Modeling of COD for Water Based on UV-VIS Spectroscopy and CNN Algorithm of Deep Learning, Spectrosc. Spectr. Anal., 2020, 40, 2981–2988 CAS.
- M. Xia, R. Yang, G. Yin, X. Chen, J. Chen and N. Zhao, A method based on a one-dimensional convolutional neural network for UV-vis spectrometric quantification of nitrate and COD in water under random turbidity disturbance scenario, RSC Adv., 2023, 13, 516–526 RSC.
- B. Ye, X. Cao, H. Liu, Y. Wang, B. Tang, C. Chen and Q. Chen, Water chemical oxygen demand prediction model based on the CNN and ultraviolet-visible spectroscopy, Front. Environ. Sci., 2022, 10, 1–9 Search PubMed.
- A. Homborg, A. Mol and T. Tinga, Corrosion classification through deep learning of electrochemical noise time-frequency transient information, Eng. Appl. Artif. Intell., 2024, 133, 1–9 CrossRef.
- I. A. Choudhry, S. Iqbal, M. Alhussein, K. Aurangzeb, A. N. Qureshi and A. Hussain, A Novel Interpretable Graph Convolutional Neural Network for Multimodal Brain Tumor Segmentation, Cogn. Comput., 2025, 17, 1–25 CrossRef.
- Z. Xian, R. Huang, D. Towey and C. Yue, Convolutional Neural Network Image Classification Based on Different Color Spaces, Tsinghua Sci. Technol., 2025, 30, 402–417 Search PubMed.
- H. Guo, T. Wang, J. Yun and J. Zhao, Multilingual natural scene text detection via global feature fusion, Appl. Intell., 2025, 55, 1–16 CrossRef.
- M. A. Islam, F. Rabbi and N. U. I. Hossain, Performance evaluation of NLP and CNN models for disaster detection using social media data, Soc. Netw. Anal. Min., 2024, 14, 1–17 CAS.
- Q. Li, B. Li and L. Wen, An Intrusion Detection Model Based on Feature Selection and Improved One-Dimensional Convolutional Neural Network, Int. J. Distrib. Sens. Netw., 2023, 1–12 Search PubMed.
- Y. Zhou, H. Shi, Y. Zhao, W. Ding, J. Han, H. Sun, X. Zhang, C. Tang and W. Zhang, Identification of encrypted and malicious network traffic based on one-dimensional convolutional neural network, J. Cloud. Comp., 2023, 12, 1–10 CrossRef.
- W. Lin and Y. Yeh, Efficient Malware Classification by Binary Sequences with One-Dimensional Convolutional Neural Networks, Mathematics, 2022, 10, 1–14 Search PubMed.
- L. Fan, H. Hu, X. Zhang, H. Wang and C. Kang, Magnetic Anomaly Detection Using One-Dimensional Convolutional Neural Network With Multi-Feature Fusion, IEEE Sens. J., 2022, 22, 11637–11643 Search PubMed.
- S. Soni, S. S. Chouhan and S. S. Rathore, TextConvoNet: a convolutional
neural network based architecture for text classification, Appl. Intell., 2023, 53, 14249–14268 CrossRef.
- I. A. Potărniche, C. Saroşi, R. M. Terebeş, L. Szolga and R. Gălătuş, Classification of Food Additives Using UV Spectroscopy and One-Dimensional Convolutional Neural Network, Sensors, 2023, 23, 1–29 Search PubMed.
- H. Wang, H. Xiang, T. Xiong, J. Feng, J. Zhang and X. Li, A straightforward approach utilizing an exponential model to compensate for turbidity in chemical oxygen demand measurements using UV-vis spectrometry, Front. Microbiol., 2023, 14, 1–8 Search PubMed.
- S. Hossain, C. W. K. Chow, G. A. Hewa, D. Cook and H. Martin, Spectrophotometric Online Detection of Drinking Water Disinfectant: A Machine Learning Approach, Sensors, 2020, 20, 1–29 Search PubMed.
- E. M. Alves, R. J. Rodrigues, C. D. S. Corrêa, T. Fidemann, J. C. Rocha, J. L. L. Buzzo, P. D. O. Neto and E. G. F. Nunez, Use of ultraviolet–visible spectrophotometry associated with artificial neural networks as an alternative for determining the water quality index, Environ. Monit. Assess., 2018, 190, 1–15 CrossRef.
|
| This journal is © The Royal Society of Chemistry 2025 |
Click here to see how this site uses Cookies. View our privacy policy here. 
 Open Access Article
Open Access Article This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported Licence
This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported Licence *,
Jia Liu,
Iqbal Muhammad Tauqeer and
Zhiyu Shao
*,
Jia Liu,
Iqbal Muhammad Tauqeer and
Zhiyu Shao