
 Open Access Article
Open Access Article This Open Access Article is licensed under a
This Open Access Article is licensed under a Creative Commons Attribution 3.0 Unported Licence
Computationally predicting the performance of gas sensor arrays for anomaly detection†
Paul
Morris
 * and
Cory M.
Simon
*
* and
Cory M.
Simon
*
School of Chemical, Biological, and Environmental Engineering, Oregon State University, Corvallis, OR, USA. E-mail: morripau@oregonstate.edu; Cory.Simon@oregonstate.edu
First published on 19th August 2024
Abstract
In many gas sensing tasks, we simply wish to become aware of gas compositions that deviate from normal, “business-as-usual” conditions. We provide a methodology, illustrated by example, to computationally predict the performance of a gas sensor array design for detecting anomalous gas compositions. Specifically, we consider a sensor array of two zeolitic imidazolate frameworks (ZIFs) as gravimetric sensing elements for detecting anomalous gas compositions in a fruit ripening room. First, we define the probability distribution of the concentrations of the key gas species (CO2, C2H4, H2O) we expect to encounter under normal conditions. Next, we construct a thermodynamic model to predict gas adsorption in the ZIF sensing elements in response to these gas compositions. Then, we generate a synthetic training data set of sensor array responses to “normal” gas compositions. Finally, we train a support vector data description to flag anomalous sensor array responses and test its false alarm and missed-anomaly rates under conceived anomalies. We find the performance of the anomaly detector diminishes with (i) greater variance in humidity, which can mask CO2 and C2H4 anomalies or cause false alarms, (ii) higher levels of noise emanating from the transducers, and (iii) smaller training data sets. Our exploratory study is a step towards computational design of gas sensor arrays for anomaly detection.
1 Introduction
1.1 Gas sensor arrays
Gas sensors are used in the chemical industry for controlling processes1,2 and detecting threats to human health and safety by harmful gases/volatile compounds.3–5 Applications of gas sensors are emerging and expanding for monitoring crops,6,7 air quality,8,9 food freshness,10 and human health.11 The development of more sensitive and robust gas sensors—paired with advanced algorithms to parse their response—could accelerate and widen the adoption of sensors for these myriad applications.A promising route to realizing a robust electronic nose is via a sensor array, comprised of multiple sensors, each harboring a distinct, [usually] cross-sensitive recognition element.12 Mimicking the mammalian olfactory system,13 a sensor array with diverse recognition elements produces a high-dimensional response vector containing information to distinguish many different gas compositions14,15 (the sensor array response vector stacks features of the response of each sensor belonging to the array). Typically, a supervised machine learning model is trained—using labeled data, i.e., example gas compositions paired with the sensor response vectors they produce—to predict the composition of the gas from the response vector of the sensor array.16,17
1.2 Anomaly detection
In many gas sensing tasks, we simply wish to become aware of gas compositions that deviate from normal conditions in the environment.18–23 More, there may be numerous diverse and unforeseen mechanisms (malfunctions of equipment, leaking pipes, exogenous introduction of vapors, etc.) that lead to such deviations. Consequently, collecting the response of a sensor array to anomalous gas compositions for training a supervised classifier (normal vs. anomalous) is difficult.Semi-supervised anomaly detection algorithms24 can learn a classifier of sensor array response vectors as “normal” or “anomalous” using only a data set of “normal” responses. Following the definition in ref. 25, an anomalous sensor array response deviates so much from the distribution of observed responses under “normal” conditions that it arouses a suspicion of some underlying problem (e.g., equipment malfunction, a leak in a pipe, etc.)—warranting further investigation. A high-performing anomaly detector avoids (i) false alarms, normal conditions mislabeled as anomalous, and (ii) false negatives, anomalous conditions mislabeled as normal.
Clustering algorithms could also identify anomalous gas compositions in an un- or partially-labeled data set of sensor array responses.27,28
1.3 Design of an electronic nose for anomaly detection
For the design and deployment of a gas sensor array for anomaly detection in a specific environment, key questions are:
 How many and what sensing elements should constitute the array?
How many and what sensing elements should constitute the array?
For example, tunable, nanoporous materials such as metal–organic frameworks (MOFs)29 can serve as sensitive and selective sensing elements.30 For constructing a MOF-based sensor array,31,32 we may choose among a large menu of MOFs with different pore sizes and geometries and internal surface chemistries.
Generally, the performance of a sensor array tends to increase with the number of sensing elements, as each additional sensor provides additional information about the gas,33,34 albeit with diminishing marginal returns.33 If the number of sensors is fewer than the number of components in the gas phase, multiple distinct gas compositions produce an identical sensor array response and hence are indistinguishable by the array.34,35 Deciding the number of sensors to comprise the array likely involves a tradeoff between performance, cost, and complexity.
A lofty goal is to computationally design a gas sensor array, i.e., curate the optimal sensing elements, for a specific gas sensing task. Several methods have been developed to computationally design gas sensor arrays of nanoporous materials for quantitative sensing,33,34,36–40 but not anomaly detection.
 Which anomaly detection algorithm should we employ?
Which anomaly detection algorithm should we employ?
Several anomaly detection algorithms are available,24 including the SVDD,26 isolation forests,41 elliptic envelope with robust statistics,42 and the local outlier factor.43 Each algorithm makes different assumptions about (i) the defining aspects of an anomaly, (ii) the underlying distribution of the anomalies, and (iii) if the training data set (consisting of [labeled] “normal” vectors) is polluted by [mislabeled] “anomalous” vectors.
 How much data is needed to train the anomaly detector?
How much data is needed to train the anomaly detector?
Typically, the learning curve (performance of an anomaly detector as a function of the size of the data set used for training it) increases rapidly at small data sizes, then reaches diminishing returns and saturates as more data is used for training. The amount of training data needed to reach diminishing returns for an anomaly detector for gas sensor arrays, likely, depends on the sensor array, sensing task, and distribution of gas compositions encountered.
 How robust is the performance of the anomaly detector to variation in the concentrations of interfering [non-analyte] gas species in the “background”?
How robust is the performance of the anomaly detector to variation in the concentrations of interfering [non-analyte] gas species in the “background”?
Often, the gas species by definition causing anomalies of interest do not include water, yet humidity varies dramatically. Depending on both the variance in the humidity and the degree to which humidity contributes to the response of the sensors, the performance of the electronic nose operating in anomaly detection mode may suffer. Generally, humidity interference is an imposing problem for gas sensor arrays.44
1.4 Our contribution
Herein, we create a blueprint for computationally predicting the performance of a given sensor array for anomaly detection. By computationally screening combinations of sensing elements for the array, then, we can computationally design electronic noses for anomaly detection.We consider a two-sensor array, employing nanoporous materials (zeolitic imidazolate frameworks, ZIFs) as gravimetric recognition elements, for detecting anomalous ternary gas compositions in a fruit ripening room. The chief analytes in a ripening room (near room temperature) are carbon dioxide (CO2), released from fruit respiration, and ethylene (C2H4), the fruit ripening hormone, and humidity (H2O), to prevent moisture loss in the fruit.
We computationally predict the performance of the sensor array for anomaly detection in the fruit ripening room by:
 Defining the sensing task. We specify the probability distribution of C2H4, CO2, and H2O concentrations we expect to encounter in a fruit ripening room under both normal and anomalous conditions.
Defining the sensing task. We specify the probability distribution of C2H4, CO2, and H2O concentrations we expect to encounter in a fruit ripening room under both normal and anomalous conditions.
 Modeling the response of the sensing elements to each gas composition. We invoke Henry's law of gas adsorption to predict the equilibrium, gravimetric response of—i.e., the mass of gas adsorbed in—each ZIF sensing element in response to any concentration of CO2, C2H4, and H2O in the gas phase. We identify the Henry coefficients from experimental adsorption measurements. Importantly, we model noise in the observed response to account for imperfect devices/transducers such as a quartz crystal microbalances45–47 that relay to us, via an electrical signal, the mass of gas adsorbed in the ZIF sensing elements.
Modeling the response of the sensing elements to each gas composition. We invoke Henry's law of gas adsorption to predict the equilibrium, gravimetric response of—i.e., the mass of gas adsorbed in—each ZIF sensing element in response to any concentration of CO2, C2H4, and H2O in the gas phase. We identify the Henry coefficients from experimental adsorption measurements. Importantly, we model noise in the observed response to account for imperfect devices/transducers such as a quartz crystal microbalances45–47 that relay to us, via an electrical signal, the mass of gas adsorbed in the ZIF sensing elements.
 Training an anomaly detector. We train an SVDD on the simulated sensor array response vectors under normal conditions. To gain intuition about the inner-workings of the SVDD, we visualize its decision boundary in the 2D sensor response space, used to discriminate between normal and anomalous response vectors.
Training an anomaly detector. We train an SVDD on the simulated sensor array response vectors under normal conditions. To gain intuition about the inner-workings of the SVDD, we visualize its decision boundary in the 2D sensor response space, used to discriminate between normal and anomalous response vectors.
 Testing the performance of the electronic nose for detecting anomalies. Next, we test the performance of the proposed electronic nose design—constituting (i) the choice of the sensing elements, (ii) the precision with which the transducer/device measures the response of the sensing elements, and (iii) the trained anomaly detector—for detecting anomalous gas compositions in the ripening room. We quantify the false alarm and false negative rates, broken down by class of anomaly.
Testing the performance of the electronic nose for detecting anomalies. Next, we test the performance of the proposed electronic nose design—constituting (i) the choice of the sensing elements, (ii) the precision with which the transducer/device measures the response of the sensing elements, and (iii) the trained anomaly detector—for detecting anomalous gas compositions in the ripening room. We quantify the false alarm and false negative rates, broken down by class of anomaly.
 Qualitatively, we highlight three salient factors that deteriorate the performance of a gas sensor array for anomaly detection:
Qualitatively, we highlight three salient factors that deteriorate the performance of a gas sensor array for anomaly detection:
■ Imprecision in the transducer used to measure the response of the sensing elements.
■ Variance in background e.g. humidity levels that interfere with the response of the sensors to the chief analytes defining anomalies.
■ Insufficiently large data sets for training the anomaly detector.
For readers unfamiliar with QCM–ZIFs, fruit ripening rooms, and the SVDD, we provide optional explanations in Box 1, Box 2, and Box 3, respectively.
2 Results
2.1 Proposed sensor array design
Suppose the hardware of our proposed electronic nose is an array of two QCM–ZIF sensors as depicted Fig. 1. Box 1 explains QCM–ZIF sensors and their working principle (gravimetry). We chose ZIF-8 and ZIF-71 as the recognition elements for their hydrophobicity and stability48,49 and for the availability of their experimentally-measured C2H4, CO2, and H2O adsorption isotherms near room temperature. Generally, the sensitivity and selectivity of each ZIF sensing element to/for various gases depends on the structure of the ZIF, including pore shape and size, topology, and internal surface chemistry. We describe the structures of the ZIFs below and show a cage of each ZIF in Fig. 1. | ||
| Fig. 1 Sensor array design. Our proposed gas sensor array design is comprised of two distinct QCM–ZIF sensors, one employing a ZIF-8 sensing film, the other ZIF-71. The sensor array response vector is m = [mZIF-8, mZIF-71] where mZIF-i is the total mass of gas adsorbed in ZIF-i film per mass of ZIF, at thermodynamic equilibrium. | ||
Box 1 A QCM–ZIF sensorA QCM–ZIF sensor48,54 employs a thin film of zeolitic imidazolate framework (ZIF, the sensing element) attached to a quartz crystal microbalance (QCM, the transducer).55ZIFs56,57 are a category of metal–organic frameworks made up of metal ions [e.g., Zn(II), Co(II), Fe(II), Cu(II)] tetrahedrally-coordinated to imidazolate-based ligands to form an extended network, giving a crystal with nano-sized cavities capable of adsorbing gas. ZIFs exhibit zeolite-like topologies owing to the similarity between their metal–imidazolate–metal angles and the Si–O–Si angles in zeolites. ZIFs are sensitive recognition elements due to their high internal surface areas onto which gases adsorb. More, the topology, pore size, and internal surface chemistry (e.g., the metal and the functional groups on the imidazolate ligand) of ZIFs can be tuned to arrive at a diverse set of structures for a gas sensor array. As a result of different adsorptive selectivities for various species in the gas phase among the ZIFs in a sensor array, a QCM–ZIF sensor array will produce a response that contains much information about the gas composition.56 ZIFs also tend to be chemically and thermally stable.58 A QCM45 is a quartz crystal between two gold electrodes. Applying an alternating voltage across the piezoelectric crystal induces vibrations. When gas ad-/de-sorbs into/out of the thin film of ZIF attached to the top of the QCM, increasing/decreasing its mass, the frequency of the vibrations of the QCM decreases/increases. Using the Sauerbrey equation, we can convert the change in vibration frequency of the QCM to a change in the mass of the thin film of ZIF due to the ad-/de-sorption of gas. The working principle of a QCM–ZIF sensor is gravimetry: when the composition of the gas phase changes, the amount of gas adsorbed in the thin film of ZIF changes, which the QCM relays to us via an electrical signal.48,54,55 Recently, a QCM-MOF array based on UiO-66 has been demonstrated for ethylene sensing for fruit ripening.59 |
2.2 Gas compositions encountered in a ripening room
A fruit ripening room experiences variations in the concentration of three chief gas species that will strongly adsorb in the ZIF sensing elements: ethylene (C2H4), carbon dioxide (CO2), and water (H2O). Under normal conditions, these variations are caused by the introduction of exogenous C2H4 and H2O, production of C2H4 and CO2 by the fruit's metabolism during ripening, and periodic ventilation to control accumulation of CO2. See Box 2. Under anomalous conditions, we anticipate failures of (i) the ventilation system and (ii) the equipment that introduces exogenous C2H4 and H2O, to cause aberrations in the concentrations of C2H4, CO2, and H2O in the ripening room.
Box 2 Fruit ripening roomsClimacteric fruit, such as tomatoes, avocados, apples, pears, and bananas, can ripen after they are harvested and, during ripening, increase their rate of respiration and produce ethylene gas.60 More, ripening in climacteric fruit is triggered by exposure to exogenous ethylene gas, which acts as a plant hormone.62–65To allow for longer transport times, reduce the risk of damage during packing and transport, and enable longer storage in warehouses, many climacteric fruits are harvested before they begin to ripen. E.g., tomatoes, bananas, and pears are typically harvested when they are mature but unripened—when they are hard and green.66 Fruit ripening is inhibited during transport and storage by preventing67,68 (a) exposure to biologically active concentrations of ethylene via e.g. ventilation or ethylene capture by adsorbents or (b) perception of the ethylene by the fruit via maintaining low temperatures and/or introducing gaseous, competitive inhibitors, such as 1-methyl cyclopropene,69 into the storage atmosphere. To promote ripening before sale, the unripe fruit is placed in an ethylene ripening room for 2–3 days, wherein the air is typically controlled by:
Research is devoted to developing ethylene sensors for fruit storage and ripening.59,71–76 |




We precisely define “normal” and various “anomalous” gas compositions we expect to encounter in a ripening room by modeling the (assumed, independent) probability distributions of the C2H4, CO2, and H2O concentrations in the air under each condition. Fig. 2 displays the distributions, listed below.
 | ||
| Fig. 2 Gas compositions we expect to encounter in a fruit ripening room. The probability distributions of the C2H4, CO2, and H2O concentrations (columns) in the air of a fruit ripening room under normal and various anomalous conditions (rows). RH = relative humidity. σH2O = 0.01 RH. | ||
Throughout, we assume the ripening room is at constant [room] temperature.
Specifically, we model the partial pressures (random variables) under normal conditions as:
PC2H4 ∼ ![[scr N, script letter N]](https://www.rsc.org/images/entities/char_e52d.gif) (150 ppm, 400 ppm2) (150 ppm, 400 ppm2) | (1) |
PCO2 ∼ ![[scr U, script letter U]](https://www.rsc.org/images/entities/char_e534.gif) (400 ppm, 5000 ppm) (400 ppm, 5000 ppm) | (2) |
 | (3) |
(μ, σ2) denoting a Gaussian distribution with mean μ and variance σ2 and (a, b) denoting a uniform distribution over the interval [a, b]. We do not yet specify the variance of the water distribution,  , because we will vary it and study its effect on the performance of our anomaly detector.
, because we will vary it and study its effect on the performance of our anomaly detector.
■ CO2↑. CO2 accumulates in the room due to the failure of the ventilation system—slowing the fruit ripening process60 and posing a human health hazard. To simulate this, we modify eqn (2) to follow PCO2 ∼ (7500 ppm, 2000 ppm).
■ C2H4↑. C2H4 accumulates in the room due to rapid metabolism of the fruit and/or a malfunction in the process introducing exogenous C2H4, such as a pipe rupture. To simulate this, we modify eqn (1) to follow to follow PC2H4 ∼ (300 ppm, 2000 ppm).
■ C2H4off. The exogenous C2H4 source is incidentally shut off, resulting in a deficit of C2H4 in the air. However, some C2H4 is still naturally produced by the fruit ripening, hence some ethylene is still present.60 To simulate this, we modify eqn (1) to follow PC2H4 ∼ (0 ppm, 10 ppm).
■ CO2& C2H4↑. This anomalous scenario combines the modifications in the CO2↑ and C2H4↑ scenarios.
■ H2O↓. The system that introduces exogenous humidity fails, detrimentally causing the fruit to lose moisture.61 To simulate this, we modify eqn (3) to follow PH2O ∼ (0.5 RH, 0.8 RH).
2.3 Adsorption model governing the response of the sensor array
Here, we construct a model to predict the [equilibrium] response of the [QCM–ZIF-8, QCM–ZIF-71] sensor array to [small] concentrations of C2H4, CO2, and H2O in the gas phase near room temperature. Fundamentally, the model is a mixed-gas adsorption model in the ZIF sensing elements. We will exploit this surrogate model to simulate laboratory experiments whereby we would expose the sensor array to a known gas composition and observe its response. i.e., we will use the model to generate synthetic training and test data for our anomaly detector (note, in practice, such an adsorption model is not needed/used for developing an anomaly detector, as bona fide gas exposure experiments are used to generate the training and test data).We assume Henry's law governs the [additive] mass of each gas species adsorbed in each ZIF at room temperature and thermodynamic equilibrium. Henry's law maps (a) a gas composition vector p ∈ ![[Doublestruck R]](https://www.rsc.org/images/entities/i_char_e175.gif) 3 [bar], stacking the partial pressures of C2H4, CO2, and H2O in the gas phase, to (b) the [equilibrium] sensor array response vector m ∈ 2 [g gas/g ZIF] stacking the total mass of gas adsorbed in the ZIF-8 and ZIF-71 sensing films:
3 [bar], stacking the partial pressures of C2H4, CO2, and H2O in the gas phase, to (b) the [equilibrium] sensor array response vector m ∈ 2 [g gas/g ZIF] stacking the total mass of gas adsorbed in the ZIF-8 and ZIF-71 sensing films:
| m = Hp + εσm, | (4) |
2×3 [g gas/(g ZIF·bar)] is a matrix containing the Henry coefficients of the gases in the ZIFs. The additive, independent white noise vector εσm ∈ 2 models measurement noise originating from QCM transducer, sampled from a zero-mean Gaussian with standard deviation σm. We write eqn (4) in expanded form: | (5) |
 | ||
Fig. 3 Modeling gas adsorption in the ZIF sensing elements. We use Henry's law as the equilibrium gas adsorption model governing the response of the [QCM–ZIF-8, QCM–ZIF-71] sensor array to small concentrations of C2H4, CO2, and H2O in the gas phase near room temperature. (a and b) Experimentally measured, equilibrium, pure-component gas adsorption isotherms (points) of C2H4![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 53,77 (293 K), CO2 (303 K, 298 K),78,79 and H2O80,81 (298 K, 308 K) in (a) ZIF-8 and (b) ZIF-71. Solid/hollow points: used/not used for identifying the Henry coefficient. The Henry model for adsorption of each gas in ZIF-8 and ZIF-71 (valid only at small partial pressures) is shown with lines. (c) A comparison of the identified Henry coefficients of each gas in each ZIF. (d) The approximate binary, dilute adsorptive selectivity of each ZIF near 298 K. Horizontal dashed line marks a selectivity of one. 53,77 (293 K), CO2 (303 K, 298 K),78,79 and H2O80,81 (298 K, 308 K) in (a) ZIF-8 and (b) ZIF-71. Solid/hollow points: used/not used for identifying the Henry coefficient. The Henry model for adsorption of each gas in ZIF-8 and ZIF-71 (valid only at small partial pressures) is shown with lines. (c) A comparison of the identified Henry coefficients of each gas in each ZIF. (d) The approximate binary, dilute adsorptive selectivity of each ZIF near 298 K. Horizontal dashed line marks a selectivity of one. | ||
Fig. 3d shows that ZIF-8 and ZIF-71 exhibit different dilute binary adsorptive selectivities for C2H4, CO2, and H2O near room temperature (ratio of Henry coefficients). This suggests ZIF-8 and ZIF-71 are diverse materials for a sensor array aiming to discriminate among different compositions p in a fruit ripening room. Note, both ZIFs are most selective towards water; ZIF-71 is more selective for C2H4 over CO2 than ZIF-8.
. While this non-injectivity could be resolved by adding an additional sensor, we elected to consider non-injectivity as a source of undetected anomalies.
2.4 Training the SVDD anomaly detector
 Our objective is to train a support vector data description (SVDD) anomaly detector that takes, as input, the response vector m of the sensor array in Fig. 1 and outputs a label, “normal” or “anomalous”, on the gas composition in the fruit ripening room.
Our objective is to train a support vector data description (SVDD) anomaly detector that takes, as input, the response vector m of the sensor array in Fig. 1 and outputs a label, “normal” or “anomalous”, on the gas composition in the fruit ripening room.
An instance of a training data set for σm = 10−5 g gas/g ZIF and σH2O = 0.01 RH is shown in Fig. 4, as sensor array response vectors scattered in response space. Note the responses of the two QCM–ZIF sensors are strongly correlated, largely owing to their high selectivity to water.
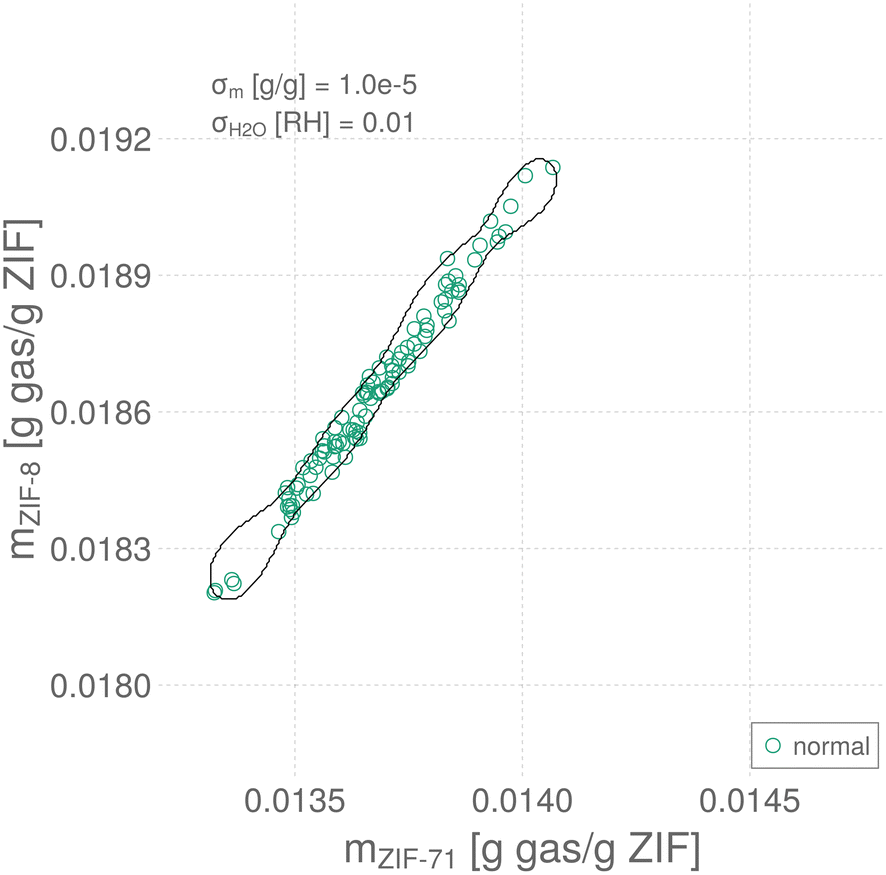 | ||
| Fig. 4 Training an SVDD anomaly detector. A synthetic data set {(mi, normal)} of sensor array response vectors collected under normal conditions in the ripening room and the decision boundary of the SVDD trained on it (optimal ν = 0.012, γ = 0.540). | ||
Box 3 The support vector data description (SVDD)The support vector data description (SVDD)26 is a versatile anomaly detection algorithm. During training, the SVDD employs an optimization algorithm to draw the smallest sphere in a mapped feature space that contains most of the normal response vectors within it. The intention is to tightly circumscribe the bulk of the support of the underlying distribution that generated the normal sensor response vectors. During inference, given a new response vector of the sensor array to an unknown gas composition, the SVDD anomaly detector acts as a binary classifier for which the sphere serves as a decision boundary: if the new response, when mapped to the feature space, falls within the sphere, it is labeled as “normal” (negative); if it falls outside the sphere, it is labeled as “anomalous” (positive). The SVDD is a sparse kernel method; thus, (i) via a menu of kernel functions, we can create flexibly-shaped decision boundaries, not just spheres, in the original response space and (ii) it is memory- and computation-efficient.The feature map and associated kernel function. First, we employ kernel functions to implicitly map our original response vectors into a high-dimensional space, wherein the SVDD operates, enabling us to draw complicated decision boundaries in the original response space with a simple sphere in the mapped feature space.26 Let ϕγ: A kernel function kγ:
Known as the “kernel trick”, explicitly evaluating kγ(m, m′) implicitly (i) maps the two sensor response vectors to the Hilbert space For our problem, we employ the radial basis function (RBF) kernel:84
where γ is a length-scale and corresponds with the feature map
The decision boundary. Ultimately, the decision boundary of an SVDD is a sphere in the mapped feature space
Training. Training the SVDD constitutes finding the center c and radius R of the sphere from the n training data {(mi, normal)}ni=1e.g. in Fig. 4. To do so, we pose and solve the optimization problem:
The objective in eqn (10) is to minimize, by tuning c, R, and slack variables in ξ, the squared radius of the sphere R2 plus the mean of the slack variables weighted by hyperparameter ν−1 > 0. The former term seeks a minimum-size sphere; the latter term penalizes constraint violations. Each response vector mi is associated with a non-negative (imposed by constraint in eqn (12)) slack variable ξi ≥ 0. eqn (11) expresses a soft constraint that each response vector mi falls inside the hypersphere; a nonzero slack variable ξi > 0 allows mi to fall outside the hypersphere, but this is penalized by the second term in the objective function. The hyperparameter ν controls how much to penalize such nonzero slack variables. In words, the optimization problem is to find the smallest sphere that contains most of the response vectors. If ϕγ maps vectors into an infinite-dimensional space, the optimization problem 10–12 is computationally infeasible. Consequentially, we (well, scikit-learn85) computationally solve the dual optimization problem, formulated by using the method of Lagrange multipliers and setting partial derivatives with respect to R, c, and ξ to zero. The dual is an optimization problem over the n Lagrange multipliers α involving only the dot product ϕγ(m)·ϕγ(m′) between mapped feature vectors, which we replace with the kernel kγ(m, m′) that we can compute:
Hyperparameters. Our SVDD has two hyperparameters: ν and γ. The hyperparameter ν in the objective controls the penalty for slack granted to the constraints and makes a trade-off between the minimization of the radius of the hypersphere and the number of training errors ([normal] training vectors outside the hypersphere) allowed.26 A larger ν will allow more training errors and give a smaller hypersphere. A smaller ν forces more of the training vectors to lie inside the hypersphere but results in a larger hypersphere. The hyperparameter γ belongs to the kernel function. For the RBF kernel in eqn (7), γ is a length-scale. A large γ yields an optimal hypersphere in kernel space that translates to a smooth decision boundary in original sensor response space while a small γ produces a more wiggly decision boundary. A larger γ and larger ν may help prevent overfitting to the training data. See Fig. S2.† Making predictions with the SVDD. Given a new sensor array response vector m, a trained and hyperparameter-tuned SVDD uses the decision rule in eqn (16) to categorically label it as an anomalous or normal response. While we do not use it here, the continuous anomaly score ‖ϕγ(m) − c‖2 − R2 loosely quantifies uncertainty (e.g., if large and positive, the observed vector m is far outside the hypersphere and thus highly likely to be anomalous). Application of a non-zero threshold to this anomaly score adjusts the classification rule to balance false positives and false negatives. |
![[Doublestruck H]](https://www.rsc.org/images/entities/i_char_e16b.gif)

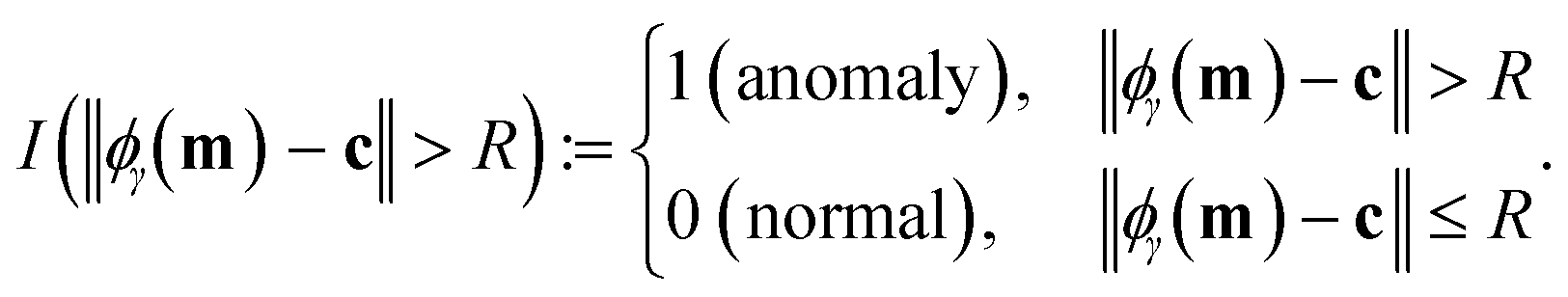

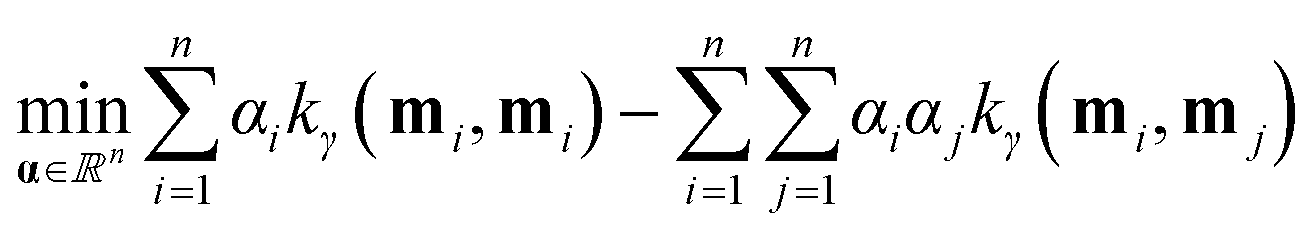




The decision boundary of the trained and hyperparameter-tuned SVDD in sensor array response space is shown as the closed, black curve in Fig. 4—on top of the instance of data used to train it. Response vectors falling inside the boundary are classified by the SVDD as normal; those falling outside are classified as anomalous. Of the 100 normal data used to train the SVDD, four are located outside the boundary and thus misclassified as anomalies.
2.5 Testing the electronic nose for detecting anomalies
 We now wish to evaluate the performance of our hypothetical electronic nose—the sensor array in Fig. 1 paired with the trained anomaly detector whose decision boundary is displayed in Fig. 4—to assess its performance for detecting anomalous gas compositions in the ripening room and avoiding false alarms.
We now wish to evaluate the performance of our hypothetical electronic nose—the sensor array in Fig. 1 paired with the trained anomaly detector whose decision boundary is displayed in Fig. 4—to assess its performance for detecting anomalous gas compositions in the ripening room and avoiding false alarms.
![[small script l]](https://www.rsc.org/images/entities/i_char_e146.gif) i) pairs (100 normal, 10× each anomalous condition‡), where mi is the response vector of the sensor array to a gas composition under a condition i ∈ {normal, CO2↑, C2H4↑, C2H4 off, CO2 & C2H4↑, H2O↓} in the fruit ripening room. Each data point represents a snapshot of the equilibrium response of the sensor array inside the room at one point in time during testing. Again, we sample a gas composition from the probability distribution in Fig. 2 according to the label, then invoke the adsorption model in eqn (4) to sample the associated response vector of the sensor array with sensor noise standard deviation σm = 10−5 g gas/g ZIF and relative humidity standard deviation σH2O = 0.01 [RH].
i) pairs (100 normal, 10× each anomalous condition‡), where mi is the response vector of the sensor array to a gas composition under a condition i ∈ {normal, CO2↑, C2H4↑, C2H4 off, CO2 & C2H4↑, H2O↓} in the fruit ripening room. Each data point represents a snapshot of the equilibrium response of the sensor array inside the room at one point in time during testing. Again, we sample a gas composition from the probability distribution in Fig. 2 according to the label, then invoke the adsorption model in eqn (4) to sample the associated response vector of the sensor array with sensor noise standard deviation σm = 10−5 g gas/g ZIF and relative humidity standard deviation σH2O = 0.01 [RH].
Fig. 5a shows a realization of a test data set, as sensor response vectors scattered in sensor response space and colored according to the true condition in the fruit ripening room (normal or various anomalies) that produced the response. Compare the test response vectors with the SVDD decision boundary in Fig. 5a. Many responses to anomalous conditions lie outside of the SVDD decision boundary, thus are correctly recalled as anomalies. But, some responses to anomalous conditions (particularly, responses to C2H4 off anomalies) lie inside the decision boundary and go undetected. Further, we observe some false alarms—responses to normal conditions falling [slightly] outside the SVDD decision boundary.
 | ||
| Fig. 5 Testing the SVDD anomaly detector. (a) To judge the performance of the SVDD, the test data {(mi, i)} are shown, along with the decision boundary of the trained SVDD (closed, black curve). The inset zooms out. (b) The confusion matrix benchmarks the performance of the trained SVDD for discriminating normal from anomalous conditions, based on the test data. Green squares represent correctly predictions, red squares mis-classifications. | ||
The SVDD appears to be good at detecting some categories of anomalies and poor at detecting others. For example, the SVDD correctly labels all all responses to CO2 build-up (CO2↑) as anomalous; all fall outside of the decision boundary. On the other hand, the SVDD detects none of the anomalies where the C2H4 supply is shut off (C2H4 off); all fall inside the decision boundary, with the majority of the normal responses. Noteworthy is the humidity anomaly. The high water Henry coefficient in the ZIFs makes the QCM–ZIF sensors sensitive to humidity. Consequently, the responses to water anomalies are far outside the decision boundary and thus easy to detect (see inset in Fig. 5a).
2.6 Factors that deteriorate performance of the anomaly detection
We hypothesize that we can attribute errors and the failure to detect some classes of anomalies in our case study to three principal factors:■ The limited-size training data set, as, generally, machine learning models tend to improve with more experience.
■ The level of measurement noise, emanating from the transducer device, dictated by σm, that contaminates the sensor array response vectors. Measurement noise can “push” the true sensor response, on the correct side of the decision boundary, across the boundary, causing it to be mis-classified.
■ The non-injectivity of the sensor array operating in this gaseous environment. Fundamentally, it is impossible to distinguish between certain sets of ternary gas compositions from the response of a two-sensor array. Treating C2H6 and CO2 as the chief analytes and focusing on the non-humidity anomalies, we measure the effect of non-injectivity through the variance in the background humidity concentration, σH2O, which interferes with the response to changes in C2H6 and CO2 we wish to detect.
We investigate each of these factors next. Here, we omit the humidity anomalies and focus on anomalies with respect to C2H4 and CO2 because (i) humidity anomalies are easy for the SVDD to reliably detect owing to the sensitivity of the QCM–ZIF sensors to water and (ii) we wish to view humidity as a “background” interferent that varies in concentration as in many gas sensing tasks.
Given the small size of our synthetic data sets, the performance of the anomaly detector will vary from sample-to-sample. To address this, we generate 100 synthetic data sets and report median performance.
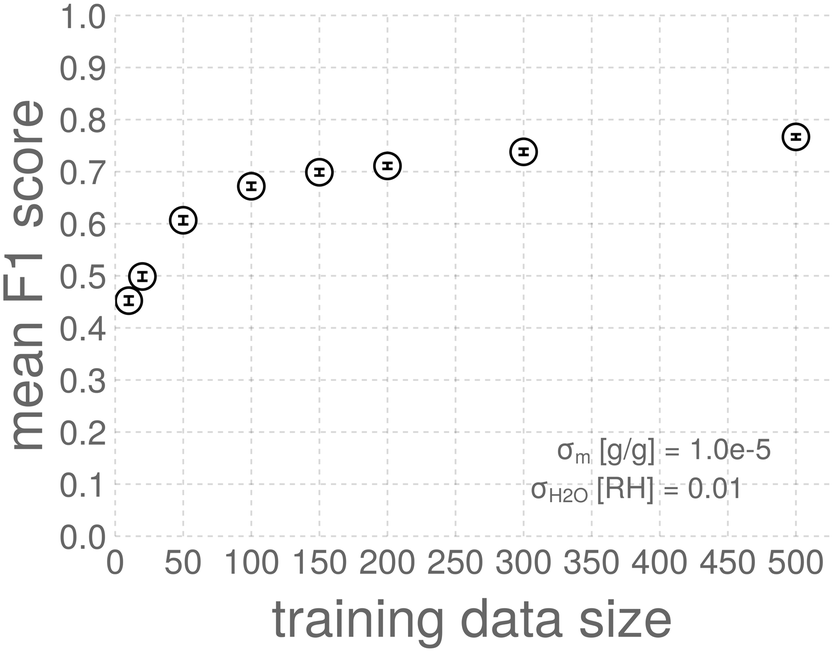 | ||
| Fig. 6 The learning curve. The average test-set F1 score of SVDDs trained using different-sized training data sets. The error bars show standard error. The variance in the mean F1-score comes from (i) measurement noise added to the response of the sensors and (ii) variance in the gas compositions drawn from the probability distributions in Fig. 2. | ||
 | ||
| Fig. 7 SVDD performance over different levels of humidity variance σH2O and measurement noise σm. The heat map shows the average F1-score performance metric on test data over 100 instances of SVDDs trained and tested on different realizations of synthetic data. The 3 × 3 grid below displays a typical (giving median F1 score) instance of the SVDD decision boundary, test data set, and confusion matrix under a particular pairing of measurement noise and humidity variance. For perspective, the dashed bounding box depicts the same region in all nine plots. | ||
For nine parings of variances in the measurement noise and humidity, Fig. 7 also shows a typical instance (the one giving the median F1 score among the 100 instances) of the SVDD decision boundary, test data, and confusion matrix. The pseudo-elliptical regions over which the sensor response vectors are scattered (i) elongate as σH2O increases, as water adsorbs strongly and variance in its concentration tends to dominate the variance in the responses, and (ii) spread isotropically as σm increases. At the largest values of σH2O and σm, many responses to normal conditions fall outside of the decision boundary (false positives), and many responses to anomalous conditions fall inside of the decision boundary (false negatives).
 , the performance of the SVDD will diminish. The SVDD may need to be retrained when transferring it to new environments.
, the performance of the SVDD will diminish. The SVDD may need to be retrained when transferring it to new environments.
![[m with combining macron]](https://www.rsc.org/images/entities/b_char_006d_0304.gif) and covariance matrix ∑ and (2) the [unlabeled] training data are mostly normal response vectors but perhaps contaminated with some anomalous vectors. From the training data, EE estimates and ∑ in a way that is robust to the presence of anomalous vectors contaminating the training data.89 During the inference phase, the trained EE classifies a new sensor response vector m as anomalous if its Mahalanobis distance from the distribution of normal response vectors
and covariance matrix ∑ and (2) the [unlabeled] training data are mostly normal response vectors but perhaps contaminated with some anomalous vectors. From the training data, EE estimates and ∑ in a way that is robust to the presence of anomalous vectors contaminating the training data.89 During the inference phase, the trained EE classifies a new sensor response vector m as anomalous if its Mahalanobis distance from the distribution of normal response vectors | (17) |
We use the EE implementation EllipticEnvelope in scikit-learn85 and tune the contamination hyperparameter using the same procedure we use to tune γ and ν for our SVDD (see Section 4.1.2).
We find that the EE outperforms the SVDD in both computational cost and F1-score for anomaly detection on test data (average [over σH2O and σm values and runs] F1-score improvement of 0.04; see Fig. S3†). This result is unsurprising because our normal sensor response vectors closely resemble a Gaussian distribution, owing to the underlying Gaussian and uniform distributions of gas compositions and linear gas adsorption model. In practice, the Gaussian assumption limits the practical application of EE for anomaly detection in favor of the more flexible SVDD that is capable of drawing non-elliptical decision boundaries that may even enclose disjoint regions.
3 Discussion and conclusions
By example, we laid out a methodology to computationally predict the performance of an electronic nose for anomaly detection. The example constituted (i, hardware) a two-sensor array using nanoporous materials ZIF-8 and ZIF-71 as gravimetric recognition elements paired with a (ii, software) the SVDD algorithm for detecting anomalous concentrations of C2H4 and CO2 in a fruit ripening room with varying humidity. Our methodology is: (1) specify the probability distribution of normal and anomalous gas compositions, (2) construct a model governing the response of each sensing element to any of these gas compositions, (3) use the model to generate synthetic training and testing data sets, (4) train an anomaly detector and evaluate its ability to detect anomalies in the test data set. Looping over proposed sensor array designs and anomaly detection algorithms, we may cheaply apply this methodology to rank electronic nose designs—especially if the response model of the sensing elements comes from molecular simulation.33,36,40We found trends likely to generalize to other sensing tasks: (i) some categories of anomalies are better detected than others, and (ii) the performance of the anomaly detector diminishes when (a) the size of the training data set decreases, (b) the precision of the transducer decreases, and (c) the variance of concentrations of interfering gas species (e.g., humidity) increases.
For didactic purposes, we considered a two-sensor array—particularly, to visualize the scatter of the response vectors and the decision boundary of the anomaly detector on the page. Instead of using a [fancy] SVDD, we could have manually constructed a good anomaly detector by hand-drawing a tight decision boundary containing most of the normal response vectors in Fig. 4—a luxury of a 2D response space. However, drawing a manual decision boundary is infeasible for a sensor array with >3 sensors. By contrast, the SVDD is capable of drawing a good decision boundary in such a higher-dimensional response space. Generally, we expect our methodology to be useful and necessary for computationally screening size-n > 3 combinations of sensing elements for anomaly detection of complex gas mixtures containing many species.
Weaknesses of our methodology for computational prediction of sensor array performance for anomaly detection are that it relies on (i) an accurate model governing the response of the sensor array to any gas composition, which generally is difficult to obtain without manufacturing the array and conducting gas exposure experiments, and (ii) explicit stipulation of the anomalous gas compositions expected to be encountered, despite that anomalies are typically difficult to conceive of and ill-defined.
Note, an anomaly detector can also detect drift and malfunctions in gas sensors constituting an electronic nose.90,91
Future work to extend our exploratory study includes: (i) search for optimal combinations of sensing elements constituting a sensor array for anomaly detection, (ii) account for variance in temperature, which can affect the response of the sensor, and (iii) test the SVDD for anomaly detection using data from a bona fide sensor array in a real environment.
4 Methods
4.1 Training and evaluating the anomaly detector
Following ref. 92, we define an objective function ∧(ν, γ) that expresses the quality of the hyperparameters ν and γ using only normal response vectors. This objective function expresses two qualities we wish the SVDD to have:
1. A decision boundary in response space that encapsulates a small region, hugging our training data as tightly as possible, to avoid anomalies going undetected.
2. A small number of support vectors, some of which are mis-classifications as they fall outside of the SVDD hypersphere, to avoid false alarms.
These two wishes are competing; the first (second) seeks a decision boundary that encapsulates a small (large) region.
To measure the region contained in the decision boundary, we employ a Monte Carlo (MC) procedure, where we (1) generate 5000 uniform-randomly distributed response vectors within a sphere centered at the center of the training data and with radius extending to the outermost training vector then (2) count the fraction of these responses that fall inside the decision boundary (and, hence, are classified as normal). A smaller fraction indicates the area within the decision boundary is small. Fig. S1† illustrates.
Our objective function ∧(ν, γ) is then:
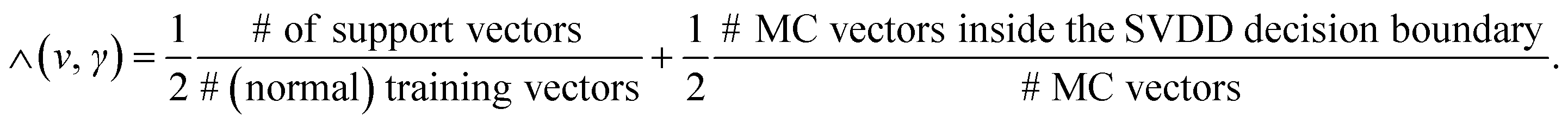 | (18) |
Fig. S1† shows the sequence of hyperparameter pairs (νi, γi) queried by BO as the search for the optimal pair (νopt, γopt) proceeds, colored by the evaluated objective ∧(νi, γi). As designed, BO automatically concentrates its samples of (ν, γ) in the region of hyperparameter space where the objective ∧(ν, γ) is the smallest.
 | (19) |
 | (20) |
 | (21) |
Data availability
All data and Julia code to reproduce our results is available on Github, at https://github.com/SimonEnsemble/anomaly_detection_gas_sensor_arrays.Conflicts of interest
There are no conflicts to declare.Acknowledgements
P. M. and C. M. S. acknowledge support from the US Department of Homeland Security Countering Weapons of Mass Destruction under CWMD Academic Research Initiative Cooperative Agreement 21CWDARI00043. This support does not constitute an expressed or implied endorsement on the part of the Government. We also thank Edward Celarier, Luther Mahoney, and Elliot Parrish for feedback on our work.References
- Q. Li, W. Zeng and Y. Li, Sens. Actuators, B, 2022, 131579 CrossRef CAS.
- S. Capone, A. Forleo, L. Francioso, R. Rella, P. Siciliano, J. Spadavecchia, D. Presicce and A. Taurino, J. Optoelectron. Adv. Mater., 2003, 5, 1335–1348 CAS.
- J. Yinon, TrAC, Trends Anal. Chem., 2002, 21, 292–301 CrossRef CAS.
- M. Burnworth, S. J. Rowan and C. Weder, Chem. – Eur. J., 2007, 13, 7828–7836 CrossRef CAS PubMed.
- A. Francis, S. Li, C. Griffiths and J. Sienz, J. Field Robot., 2022, 39, 1341–1373 CrossRef.
- J. Laothawornkitkul, J. P. Moore, J. E. Taylor, M. Possell, T. D. Gibson, C. N. Hewitt and N. D. Paul, Environ. Sci. Technol., 2008, 42, 8433–8439 CrossRef CAS.
- S. Li, A. Simonian and B. A. Chin, Electrochem. Soc. Interface, 2010, 19, 41 CrossRef CAS.
- E. G. Snyder, T. H. Watkins, P. A. Solomon, E. D. Thoma, R. W. Williams, G. S. W. Hagler, D. Shelow, D. A. Hindin, V. J. Kilaru and P. W. Preuss, Environ. Sci. Technol., 2013, 47, 11369–11377 CrossRef CAS PubMed.
- J. S. Apte, K. P. Messier, S. Gani, M. Brauer, T. W. Kirchstetter, M. M. Lunden, J. D. Marshall, C. J. Portier, R. C. Vermeulen and S. P. Hamburg, Environ. Sci. Technol., 2017, 51, 6999–7008 CrossRef CAS PubMed.
- H. Yousefi, H.-M. Su, S. M. Imani, K. Alkhaldi, C. D. M. Filipe and T. F. Didar, ACS Sens., 2019, 4, 808–821 CrossRef CAS PubMed.
- G. Konvalina and H. Haick, Acc. Chem. Res., 2014, 47, 66–76 CrossRef CAS PubMed.
- K. J. Albert, N. S. Lewis, C. L. Schauer, G. A. Sotzing, S. E. Stitzel, T. P. Vaid and D. R. Walt, Chem. Rev., 2000, 100, 2595–2626 CrossRef CAS PubMed.
- B. Malnic, J. Hirono, T. Sato and L. B. Buck, Cell, 1999, 96, 713–723 CrossRef CAS.
- V. Schroeder, E. D. Evans, Y.-C. M. Wu, C.-C. A. Voll, B. R. McDonald, S. Savagatrup and T. M. Swager, ACS Sens., 2019, 4, 2101–2108 CrossRef CAS PubMed.
- T. Aishima, J. Agric. Food Chem., 1991, 39, 752–756 CrossRef CAS.
- U. Yaqoob and M. I. Younis, Sensors, 2021, 21, 2877 CrossRef CAS PubMed.
- P. C. Jurs, G. A. Bakken and H. E. McClelland, Chem. Rev., 2000, 100, 2649–2678 CrossRef CAS PubMed.
- P.-F. Qi, M. Zeng, Z.-H. Li, B. Sun and Q.-H. Meng, Rev. Sci. Instrum., 2017, 88, 095001 CrossRef PubMed.
- V. Van Zoest, A. Stein and G. Hoek, Water, Air, Soil Pollut., 2018, 229, 1–13 CrossRef CAS PubMed.
- E. Phaisangittisagul, 2009 6th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, 2009, pp. 748–751 Search PubMed.
- L. Zhang and P. Deng, IEEE Trans. Syst. Man. Cybern., 2017, 49, 1922–1932 Search PubMed.
- J. Qiao, Y. Lv, Y. Feng, C. Liu, Y. Zhang, J. Li, S. Liu and X. Weng, Agronomy, 2024, 14, 766 CrossRef CAS.
- S. Prudenza, A. Panzitta, C. Bax and L. Capelli, Chem. Eng. Trans., 2022, 95, 169–174 Search PubMed.
- V. Chandola, A. Banerjee and V. Kumar, ACM Comput. Surv., 2009, 41, 1–58 CrossRef.
- D. M. Hawkins, Identification of outliers, Springer, 1980, vol. 11 Search PubMed.
- D. M. Tax and R. P. Duin, Mach. Learn., 2004, 54, 45–66 CrossRef.
- H. Fan, V. H. Bennetts, E. Schaffernicht and A. J. Lilienthal, IEEE Sens. J., 2016, 2016, 1–3 Search PubMed.
- Y. Yu, R. Gutierrez-Osuna and Y. Choe, Pattern Recognit. Lett., 2014, 37, 85–93 CrossRef.
- H. Furukawa, K. E. Cordova, M. OKeeffe and O. M. Yaghi, Science, 2013, 341, 1230444 CrossRef PubMed.
- L. E. Kreno, K. Leong, O. K. Farha, M. Allendorf, R. P. Van Duyne and J. T. Hupp, Chem. Rev., 2012, 112, 1105–1125 CrossRef CAS.
- P. Qin, B. A. Day, S. Okur, C. Li, A. Chandresh, C. E. Wilmer and L. Heinke, ACS Sens., 2022, 7, 1666–1675 CrossRef CAS.
- M. G. Campbell, S. F. Liu, T. M. Swager and M. Dinca, J. Am. Chem. Soc., 2015, 137, 13780–13783 CrossRef CAS PubMed.
- J. A. Gustafson and C. E. Wilmer, J. Phys. Chem. C, 2017, 121, 6033–6038 CrossRef CAS.
- A. Sturluson, R. Sousa, Y. Zhang, M. T. Huynh, C. Laird, A. H. York, C. Silsby, C.-H. Chang and C. M. Simon, ACS Appl. Mater. Interfaces, 2020, 12, 6546–6564 CrossRef CAS PubMed.
- N. Gantzler, E. A. Henle, P. K. Thallapally, X. Z. Fern and C. M. Simon, J. Phys.: Condens. Matter, 2021, 33, 464003 CrossRef CAS PubMed.
- J. A. Gustafson and C. E. Wilmer, Sens. Actuators, B, 2018, 267, 483–493 CrossRef CAS.
- B. A. Day and C. E. Wilmer, ACS Sens., 2021, 6, 4425–4434 CrossRef CAS PubMed.
- R. Sousa and C. M. Simon, ACS Sens., 2020, 5, 4035–4047 CrossRef CAS.
- A. K. Rajagopalan and C. Petit, ACS Sens., 2021, 6, 3808–3821 CrossRef CAS PubMed.
- J. Gonzalez, K. Mukherjee and Y. J. Colon, J. Chem. Eng. Data, 2022, 68, 291–302 CrossRef.
- F. T. Liu, K. M. Ting and Z.-H. Zhou, 2008 eighth IEEE international conference on data mining, 2008, pp. 413–422 Search PubMed.
- P. J. Rousseeuw and M. Hubert, Wiley Interdiscip. Rev.: Data Min. Knowl. Discov., 2018, 8, e1236 Search PubMed.
- M. M. Breunig, H.-P. Kriegel, R. T. Ng and J. Sander, Proceedings of the 2000 ACM SIGMOD international conference on Management of data, 2000, pp. 93–104 Search PubMed.
- Z. Li and K. S. Suslick, Acc. Chem. Res., 2020, 54, 950–960 CrossRef PubMed.
- S. K. Vashist and P. Vashist, J. Sens., 2011, 571405 Search PubMed.
- C. Osullivan and G. Guilbault, Biosens. Bioelectron., 1999, 14, 663–670 CrossRef CAS.
- I. Stassen, N. Burtch, A. Talin, P. Falcaro, M. Allendorf and R. Ameloot, Chem. Soc. Rev., 2017, 46, 3185–3241 RSC.
- M. Tu, S. Wannapaiboon, K. Khaletskaya and R. A. Fischer, Adv. Funct. Mater., 2015, 25, 4470–4479 CrossRef CAS.
- N. C. Burtch, H. Jasuja and K. S. Walton, Chem. Rev., 2014, 114, 10575–10612 CrossRef CAS PubMed.
- I. Khay, G. Chaplais, H. Nouali, G. Ortiz, C. Marichal and J. Patarin, Dalton Trans., 2016, 45, 4392–4400 RSC.
- O. Karagiaridi, M. B. Lalonde, W. Bury, A. A. Sarjeant, O. K. Farha and J. T. Hupp, J. Am. Chem. Soc., 2012, 134, 18790–18796 CrossRef CAS PubMed.
- L. Sarkisov, R. Bueno-Perez, M. Sutharson and D. Fairen-Jimenez, Chem. Mater., 2020, 32, 9849–9867 CrossRef CAS.
- S. Bendt, M. Hovestadt, U. Böhme, C. Paula, M. Döpken, M. Hartmann and F. J. Keil, Eur. J. Inorg. Chem., 2016, 2016, 4440–4449 CrossRef CAS.
- J. Devkota, K.-J. Kim, P. R. Ohodnicki, J. T. Culp, D. W. Greve and J. W. Lekse, Nanoscale, 2018, 10, 8075–8087 RSC.
- L. Wang, Sens. Actuators, A, 2020, 307, 111984 CrossRef CAS.
- B. Chen, Z. Yang, Y. Zhu and Y. Xia, J. Mater. Chem. A, 2014, 2, 16811–16831 RSC.
- A. Phan, C. J. Doonan, F. J. Uribe-Romo, C. B. Knobler, M. Okeeffe and O. M. Yaghi, Acc. Chem. Res., 2010, 43(1), 58–67 CrossRef CAS PubMed.
- K. S. Park, Z. Ni, A. P. Côté, J. Y. Choi, R. Huang, F. J. Uribe-Romo, H. K. Chae, M. OKeeffe and O. M. Yaghi, Proc. Natl. Acad. Sci. U. S. A., 2006, 103, 10186–10191 CrossRef CAS.
- P. Sun, H. Han, X.-C. Xia, J.-Y. Dai, K.-Q. Xu, W.-H. Zhang, X.-L. Yang and M.-H. Xie, Talanta, 2024, 269, 125484 CrossRef CAS PubMed.
- J.-C. Pech, M. Bouzayen and A. Latché, Plant Sci., 2008, 175, 114–120 CrossRef CAS.
- S. Ahmad, Z. A. Chatha, M. A. Nasir, A. Aziz and M. Mohson, J. Agric. Soc. Sci., 2006, 2, 54–56 Search PubMed.
- C. Brady, Annu. Rev. Plant Physiol., 1987, 38, 155–178 CrossRef CAS.
- Z. Lin, S. Zhong and D. Grierson, J. Exp. Bot., 2009, 60, 3311–3336 CrossRef CAS PubMed.
- M. E. Saltveit, Postharvest Biol. Technol., 1999, 15, 279–292 CrossRef CAS.
- S. Brizzolara, G. A. Manganaris, V. Fotopoulos, C. B. Watkins and P. Tonutti, Front. Plant Sci., 2020, 11, 80 CrossRef.
- K. Moirangthem and G. Tucker, Front. Young Minds, 2018, 6, 16 CrossRef.
- K. C. Gross, C. Y. Wang and M. Saltveit, The Commercial Storage of Fruits, Vegetables, and Florist and Nursery Stocks, U.S. Department of Agriculture, 2016 Search PubMed.
- N. Keller, M.-N. Ducamp, D. Robert and V. Keller, Chem. Rev., 2013, 113, 5029–5070 CrossRef CAS PubMed.
- S. M. Blankenship and J. M. Dole, Postharvest Biol. Technol., 2003, 28, 1–25 CrossRef CAS.
- R. Porat, Tree For. Sci. Biotech., 2008, 2, 71–76 Search PubMed.
- F. Caprioli and L. Quercia, Sens. Actuators, B, 2014, 203, 187–196 CrossRef CAS.
- S.-Y. Jeong, Y. K. Moon, T.-H. Kim, S.-W. Park, K. B. Kim, Y. C. Kang and J.-H. Lee, Adv. Sci., 2020, 7, 1903093 CrossRef CAS PubMed.
- B. Li, M. Li, F. Meng and J. Liu, Sens. Actuators, B, 2019, 290, 396–405 CrossRef CAS.
- P. Ivanov, E. Llobet, A. Vergara, M. Stankova, X. Vilanova, J. Hubalek, I. Gracia, C. Cané and X. Correig, Sens. Actuators, B, 2005, 111–112, 63–70 CrossRef CAS.
- Z. Li and K. S. Suslick, Anal. Chem., 2018, 91, 797–802 CrossRef PubMed.
- M. A. Zevenbergen, D. Wouters, V.-A. T. Dam, S. H. Brongersma and M. Crego-Calama, Anal. Chem., 2011, 83, 6300–6307 CrossRef CAS PubMed.
- U. Bohme, B. Barth, C. Paula, A. Kuhnt, W. Schwieger, A. Mundstock, J. Caro and M. Hartmann, Langmuir, 2013, 29, 8592–8600 CrossRef PubMed.
- W. Morris, B. Leung, H. Furukawa, O. K. Yaghi, N. He, H. Hayashi, Y. Houndonougbo, M. Asta, B. B. Laird and O. M. Yaghi, J. Am. Chem. Soc., 2010, 132, 11006–11008 CrossRef CAS PubMed.
- S. Aguado, G. Bergeret, M. P. Titus, V. Moizan, C. Nieto-Draghi, N. Bats and D. Farrusseng, New J. Chem., 2011, 35, 546–550 RSC.
- R. P. Lively, M. E. Dose, J. A. Thompson, B. A. McCool, R. R. Chance and W. J. Koros, Chem. Commun., 2011, 47, 8667–8669 RSC.
- J. Canivet, J. Bonnefoy, C. Daniel, A. Legrand, B. Coasne and D. Farrusseng, New J. Chem., 2014, 38, 3102–3111 RSC.
- R. Gutierrez-Osuna and H. T. Nagle, IEEE Trans. Syst. Man Cybern., B Cybern., 1999, 29, 626–632 CrossRef CAS PubMed.
- L. Heinke, Z. Gu and C. Wöll, Nat. Commun., 2014, 5, 4562 CrossRef CAS PubMed.
- M. Ring and B. M. Eskofier, Pattern Recognit. Lett., 2016, 84, 107–113 CrossRef.
- F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot and E. Duchesnay, J. Mach. Learn. Res., 2011, 12, 2825–2830 Search PubMed.
- B. Schölkopf, R. C. Williamson, A. Smola, J. Shawe-Taylor and J. Platt, Advances in Neural Information Processing Systems, 1999, vol. 12 Search PubMed.
- J. Quinonero-Candela, M. Sugiyama, A. Schwaighofer and N. D. Lawrence, Dataset shift in machine learning, Mit Press, 2008 Search PubMed.
- M. R. Carbone, MRS Bull., 2022, 47, 968–974 CrossRef.
- P. J. Rousseeuw and K. van Driessen, Technometrics, 1999, 41, 212223 CrossRef.
- D. P. Purbawa, R. Sarno, M. S. H. Ardani, S. I. Sabilla, K. R. Sungkono, C. Fatichah, D. Sunaryono, I. S. Parimba and A. Bakhtiar, et al. , Sens. Bio-Sens. Res., 2022, 36, 100492 CrossRef.
- P. Verma, M. Sinha and S. Panda, IEEE Sens. J., 2020, 21, 1975–1981 Search PubMed.
- D. M. Tax and R. P. Duin, J. Mach. Learn. Res., 2001, 2, 155–173 Search PubMed.
- S. Han, C. Qubo and H. Meng, World Automation Congress 2012, 2012, pp. 1–4 Search PubMed.
- A. Agnihotri and N. Batra, Distill, 2020, 5, e26 Search PubMed.
Footnotes |
| † Electronic supplementary information (ESI) available. See DOI: https://doi.org/10.1039/d4sd00121d |
| ‡ We elect to use only ten test cases for each anomaly to (i) reflect the, in reality, typically-high cost of collecting anomalous data and (ii) give un-crowded visualizations of our sensor response vectors for our illustration/demonstration herein; in reality, the number of anomalous conditions to test must strike a trade-off between cost and confidence in the performance statistics. |
| This journal is © The Royal Society of Chemistry 2024 |