
Describing the public perception of chemistry on twitter†
Manuel
Guerris
 *,
Jordi
Cuadros
*,
Lucinio
González-Sabaté
and
Vanessa
Serrano
*,
Jordi
Cuadros
*,
Lucinio
González-Sabaté
and
Vanessa
Serrano
IQS Univ. Ramon Llull, Via Augusta 390, 08017 Barcelona, Spain. E-mail: manuel.guerris@iqs.url.edu; jordi.cuadros@iqs.url.edu; Tel: +34 932672000
First published on 14th May 2020
Abstract
The public image of chemistry is a relevant issue for chemical stakeholders. It has been studied throughout history by means of document analysis and more recently through surveys. Twitter, a worldwide online social network, is based on spontaneous opinions. We tried to identify the public perception of chemistry on Twitter, what it explains, and which sentiments are perceived. We gathered 256![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 833 tweets between 1st January 2015 and 30th June 2015 containing the words “chemistry”, “chemical” or “chem”. We cleaned and filtered them down to 50725 tweets with textual information in English and clustered them using spherical k-means. The resulting clusters were categorised according to six topics by 18 chemistry experts. The prevailing topics were the learning environment topic, related to activities and tasks in chemistry courses, and the human activity topic, referring to facts and news about the chemical industry. The scientific knowledge topic, concerning communication of chemistry knowledge, only accounted for a small percentage of the tweets. We classified the tweets of most relevant topics based on their sentiment values and obtained more positive than negative perceptions. Nevertheless, the analysis of the unigrams and bigrams word clouds revealed a significant presence of chemophobia-related terms in the human activity topic, both in positive and negative classified tweets. It also revealed specific elements of chemistry courses negatively perceived in the learning environment topic.
833 tweets between 1st January 2015 and 30th June 2015 containing the words “chemistry”, “chemical” or “chem”. We cleaned and filtered them down to 50725 tweets with textual information in English and clustered them using spherical k-means. The resulting clusters were categorised according to six topics by 18 chemistry experts. The prevailing topics were the learning environment topic, related to activities and tasks in chemistry courses, and the human activity topic, referring to facts and news about the chemical industry. The scientific knowledge topic, concerning communication of chemistry knowledge, only accounted for a small percentage of the tweets. We classified the tweets of most relevant topics based on their sentiment values and obtained more positive than negative perceptions. Nevertheless, the analysis of the unigrams and bigrams word clouds revealed a significant presence of chemophobia-related terms in the human activity topic, both in positive and negative classified tweets. It also revealed specific elements of chemistry courses negatively perceived in the learning environment topic.
Introduction
We are literally surrounded by chemistry. Its role in modern society cannot be underestimated. Chemistry and its applications affect and improve almost all aspects of people's lives. Human health, the environment, products and production processes are but a few areas in which chemistry plays a major part. The general public perceives its effects as positive or negative. Some people's perception of chemistry is so negative they may develop an irrational fear of chemical products (Duffus et al., 2007) or “chemophobia”, a term defined by the International Union of Pure and Applied Chemistry (IUPAC).These perceptions are related to how chemistry communicates itself. Science communication helps citizenship to acquire the knowledge about science to participate actively and responsibly in, with and for society (Hazelkorn, 2015), plays a significant role in awakening vocations (Stekolschik et al., 2010) and promoting scientific careers (Hayden et al., 2011). A lack of vocation can cause an insufficient supply of graduates from upper-secondary and higher education to meet increasing demand across the EU, and a shortage of STEM (science, technology, engineering and mathematics) professionals (Cedefop, 2016). Additionally, the role of chemistry is not well understood by policymakers, funders and the chemistry community itself (Palermo, 2018). Therefore, the knowledge of chemistry's public image and its understanding in terms of its contents and sentiments perceived by the public matters to all chemistry stakeholders. It is critical to understand what is communicated and how it is perceived to define better policies to reduce this shortage.
There is scientific literature that investigates this public image at academic and social levels. At the academic level, studies reveal that the view perceived by students of chemistry (Yager and Penick, 1983; Furió Más, 2006) and of science (Schibeci, 1986) is generally negative because of a lack of clarity on its communication and a distorted perception of students (Nicolas, 2006; Penagos and Lozano, 2009; Chamizo, 2011; Lacolla et al., 2013). Academic contents far from students motivation (Piñeros and Parga, 2014), the lack of historical and social perspectives in the curricula (Jiménez and Criado García-Legaz, 2005; Nicolas, 2006; Muñoz and Nardi, 2011; Linthorst, 2012) and the absence of science, technology and society relationships in the teaching of science (Solbes and Vilches, 1992; Ribelles et al., 1995; Malaver et al., 2004; Furió Más, 2006) are aspects that contribute to giving a poor image of chemistry far away from the real world impacting students in a negative way.
At the social level, the public image of chemistry seems to have inherited a negative perception due to its negative historical associations (Schummer and Spector, 2007; Schummer et al., 2007) and a lack of efficient communication on behalf of chemists (Hartings and Fahy, 2011). For instance, sensationalist propaganda in global media used to associate the chemical industry and chemistry with pollution and environmental degradation (Trozzolo, 1975; Penagos and Lozano, 2009). Despite this negative perception, efforts to improve the image of chemistry have been implemented such as “Chemical for All” (Hill and Kumar, 2013), a global strategy to convince the public that chemistry provides health, comfort, and well-being.
It seems the public image of chemistry has always been negative, although some of the recent studies reviewed suggest a positive change. In 2004, IUPAC (Mahaffy et al., 2008) found a negative public image of chemistry related to the misunderstanding of chemistry, chemists, chemicals and the chemical industry. In 2010, the European Chemical Industry Council (Hadhri, 2010) measured the public perception of the chemical industry in relation to several industries in the European Union. It suggested that chemistry had a favourable image approximately at the same level as it was in 2008 and has improved since the late 90s. The Royal Society of Chemistry analysed chemists’ internal perceptions and the society's perception of chemists and chemical products in the UK (The Royal Society of Chemistry and TNS BMRB, 2015) and refuted the negative image. The results of the study showed a neutral or even positive image with 51% of the respondents being neutral and 19% happy, and 59% of the respondents answering that the benefits of chemistry were higher than its harmful effects. They mostly perceived chemistry as a solution to major global challenges such as oil dependence, food shortages, pollution and access to drinking water as well feeling a positive impact on well-being. Additionally, 21% of the general public associated chemistry to school or teachers with negative memories related to it but with mixed feelings about the chemistry that they learnt at school. 48% either agreed or were neutral that school had put them off chemistry, 45% disagreed that chemistry learnt at school had been useful in everyday life, and 52% agreed that they did not feel confident enough to talk about chemistry, with negative described perceptions of chemistry in comparison with science.
Several authors have proposed educational activities to improve this perception (Pratt and Yezierski, 2018; Ratamun and Osman, 2018; Molina and Carriazo, 2019; Tortorella et al., 2019).
All the methods used to study the public image of chemistry were based on surveys and document analysis. They are not designed and are not able to capture spontaneous opinions. Social networks, on the other hand, collect ideas that are expressed spontaneously. Twitter with its 204 million monthly active users in the second quarter of 2015 (Clement, 2019), and 23% of total adult internet users (Duggan, 2015) demonstrates to be a relevant and significant online social network. Moreover, it is used by citizens to read news (Pew Research Center, 2019) and it is one of the leading social media platforms used by business-to-business (B2B) and business-to-consumer (B2C) marketers worldwide (Statista, 2019). On Twitter, users can communicate by exchanging short messages or tweets of up to 140 characters in real-time during the time span of this research, and can follow other users without any relationship between them. Public tweets can be freely gathered using Twitter Search API and analysed to get their sentiments (Sailunaz and Alhajj, 2019).
Tweets overcome survey challenges (Choi and Pak, 2005; Tourangeau and Yan, 2007; Krumpal, 2013) and document analysis challenges (Casadevall and Fang, 2009; Antilla, 2010) because tweets are part of conversations between Twitter users (Boyd et al., 2010; Huang et al., 2010; Smith et al., 2014). These conversations give Twitter users the ability to express their thoughts, opinions (Kanavos et al., 2014) and emotions (Tago and Jin, 2018) which are included in human social behaviour (Aarts et al., 2012; Ye and Wu, 2013).
Therefore, Twitter seems an appropriate social network for this analysis because of its high number of users, the spontaneous contents written by its users, its use in different sectors and the ability to gather public users’ messages and to analyse their sentiments. Consequently, it will complement existing literature about the public image of chemistry.
The objectives of this research are the following:
• Which topics related to chemistry can be found on Twitter?
• To what extent do Twitter messages portray positive and negative sentiments towards chemistry?
• What do users tweet about chemistry?
Experimental section
The methodology we used combines text mining with sentiment analysis techniques (Fig. 1) and is explained with specific details in the coming sections.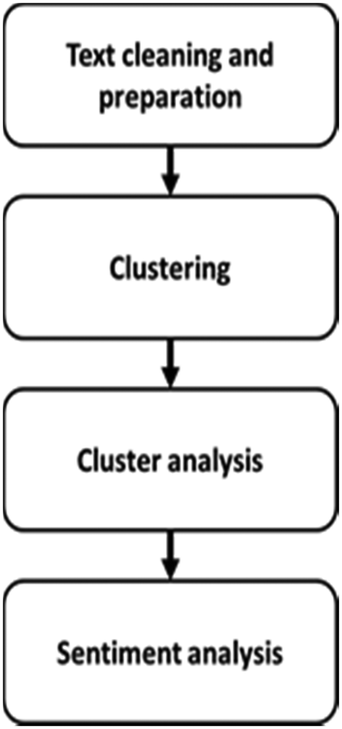 | ||
| Fig. 1 Methodology used in the research. | ||
Just as an outline of the methods used, text mining enables deriving information extracted from written resources through computation (Gupta and Lehal, 2009) and includes techniques and processes reported in the literature (Hearst, 1999; Hotho et al., 2005; Berry, 2007; Feldman and Sanger, 2007; Delen and Crossland, 2008; Gupta and Lehal, 2009; Irfan et al., 2015) to clean and obtain relevant information and to cluster those data according to topics. Clustering consists in grouping a set of objects based on their similarity and is useful with new or unlabelled objects (Jain et al., 1999). There are different groups of clustering techniques (Fahad et al., 2014), the partitioning-based methods such as the k-means algorithm (Jain, 2010) being the most popular and the most used.
We gathered twitter data during a period of time, cleaned and filtered them to eliminate non-relevant information and clustered them using a partitioning-based technique suitable to be applied to documents. Chemistry experts classified the clusters obtained into topics based on their contents. We did not opt for automatic classification methods which need text documents already classified into those topics (Hotho et al., 2005) to classify new documents.
Sentiment analysis techniques (Yadollahi et al., 2017) allow us to evaluate sentiments from terms, sentences, and documents. We classified the tweets related to the topics in the literature based on their sentiment value using a lexicon-based approach and analysed them by applying statistical and visual methods.
Text cleaning and preparation
To gather unbiased tweets about chemistry, we opted to limit our search to the terms “chemistry”, “chemical” and “chem” admitting that, doing so, some other chemistry-related tweets could be missed. Public tweets containing these words were gathered between 1st January 2015 and 30th June 2015 using the twitteR package in R (Gentry, 2015).Retweets, tweets written by a user and forwarded by another one, were discarded to avoid them possibly hiding in the clusters other tweets with a lower number and related to other contents. Expressions that did not add any meaning such as HTML tags, Unicode codes, Twitter account names, emails, URL addresses, non-letter symbols, and one and two-letter words were removed. Hashtags were kept because they could contain meaningful information.
English language tweets were selected with the textcat package in R (Hornik et al., 2013). Stop words, commonly used words that do not add meaning to a document and provided by the tm package in R (Feinerer et al., 2008), were removed. Based on previous tests, the terms “just”, “now”, “got”, “will”, “get”, “much”, “can” and “no”, which did not contribute to the clustering process, as well as empty and duplicated tweets were also eliminated.
A bigram is a set of two consecutive words in a tweet. A bigram TDM (term-document matrix) is a matrix where each column corresponds to a tweet, a row to a bigram and each cell ij contains the number of times bigram i appears in tweet j. We built bigram TDM with cleaned tweets. We used bigrams instead of unigrams (single words) because there is no clear advantage in using unigrams in text categorization (Bekkerman and Allan, 2004) and bigrams are more accurate during cluster analysis. We did not want to lose information using n-grams, a sequence of n consecutive words from a given document being n an integer over three as their appearance in TDM could decrease.
We reduced the dimensionality of bigram TDM removing those bigrams with a low frequency to keep the most relevant ones and avoid those which might add noise to the information hampering the clustering process.
Clustering
Partitioning-based clustering techniques divide a set of objects into several partitions or clusters in such a manner that the objects in the same group are more similar to each other than to those in other clusters. We opted for a spherical k-means partitioning-based technique, a version of the k-means technique, because of its efficiency and effectiveness in text clustering (Dhillon and Modha, 2001; Zhong, 2005). We used an implementation of the skmeans package in R (Hornik et al., 2012) to cluster the tweets automatically based on their similarity. Following Salton and Buckley (1988), we established a common baseline for the cosine similarity measure used in skmeans using term frequency-inverse document frequency (tf-idf).We selected the number of clusters in skmeans based on two commonly used clustering validity indices, the elbow method (Madhulatha, 2012; Kodinariya and Makwana, 2013) and the silhouette method (Rousseeuw, 1987). Both methods are heuristic and used to determine the number of clusters visually. Then we quantitatively calculated it using the L-method algorithm (Salvador and Chan, 2004) and the curvature of a graph (Zhang et al., 2017).
The different results obtained allowed us to choose a specific number of clusters trying to find a balance between the chemistry experts’ capacity to manually classify the clusters and the closeness to the best solutions. With this number of clusters, we ran the skmeans clustering technique almost 10000 times because of its stochastic behaviour, and we obtained the best solution. This optimal was the one in which the minimum value was calculated by the sum of the distance of each tweet to its respective prototype assigned to a cluster.
Cluster analysis
A word cloud is a graphical representation of the most important terms in a document where the size of a term is proportional to its frequency. We represented two word clouds per cluster, one with the 100 most frequent unigrams of tweets associated with the cluster and the other with the 100 most frequent bigrams. Our previous tests bigrams showed it is more useful for a cluster to be categorized by a chemistry expert. Still, we also decided to use unigrams word clouds to obtain more comprehensive information and to help the experts with their analysis.The word clouds generated were visually interpreted by a group of chemistry experts. The topics obtained from our previous tests were the following:
• Human activity (HA): most terms are related to the presence of chemistry within the human activity such as production or the chemical industry.
• Scientific knowledge (SK): most terms are related to chemical concepts and abstract entities.
• Learning environment (LE): most terms are related to chemistry as a subject or course taught in class as well as student activities or exercises.
• Entertainment (E): most terms are related to cultural and media performances such as songs, musical groups, movies or TV series.
• Human relationships (HR): most terms are related to feelings between two or more people or emotions in general.
• Undefined (U): most terms either belong to several previous topics in which none of the terms predominate over others, or they belong to topics not defined in the list.
We defined a balanced incomplete block design (BIBD) (Fleiss, 1981) to assign clusters to be classified by chemistry experts. The experts were randomly divided into three groups where every expert was randomly assigned to one of the cluster groups defined in the BIBD. The order of the clusters analysed by every expert was randomized too. Each cluster was represented by its unigram and bigram word clouds.
We calculated the percentage of clusters and tweets assigned to each topic summing all the votes that a cluster received in each topic. The cluster was assigned to the topic with the highest number of votes. If several topics had the same number of votes, then the cluster was assigned to the U topic. Tweets belonging to the cluster inherited their cluster assignation.
We statistically analysed the results obtained using Fleiss’ kappa (Fleiss, 1971). Fleiss’ kappa and its significance level were calculated for every topic and the whole experiment (Fleiss et al., 2003). The closer the value of kappa to one, the better the agreement. If the value was zero or below zero, the agreement was weaker than expected by chance. We used a common benchmark scale (Landis and Koch, 1977) to evaluate HA and LE Fleiss’ kappa value results in addition to their statistical representativeness.
Sentiment analysis
We classified tweets from HA and LE topics, which were the most frequent ones, using a lexicon-based sentiment analysis method. A word sentiment is found using a lexicon and is measured by its polarity. A tweet polarity and thus its sentiment value is calculated adding its words polarities (Sun et al., 2017). A polarity higher than zero means a positive sentiment, lower than zero a negative sentiment and equal to zero is considered neutral. We used bar charts to visualize the distribution of Twitter sentiment polarity.The lexicon we used was based on SentiWordNet 3.0 lexicon (Baccianella et al., 2010), which is commonly referenced in the literature (Medhat et al., 2014; Mohey and Hussein, 2018; Sun et al., 2017; Yadollahi et al., 2017; Mäntylä et al., 2018). This lexicon contains repeated words with different contexts and similar or different words which share polarity value because of similar contexts. We separated different words that shared a polarity value, assigned one polarity value per word and calculated an average polarity value for identical words. The result was a new list of single words with a single polarity value for each word.
A comparison word cloud is a graphical representation of terms from different documents represented in the same word cloud and differentiated by colour. The common terms are assigned to the document where the term has its maximum deviation calculated by its frequency in that document minus the average frequency in all the documents (Fellows, 2018). We built comparison word clouds of unigrams and bigrams with positive and negative tweets for the HA and LE topics and used them to interpret their main contents visually.
We selected representative samples of the tweets corresponding to some of the most frequent positive learning environment terms to understand their content better. Samples sizes were calculated using sample size for a proportion formula with a 0.95 confidence interval, 0.05 margin of error and 0.5 (worst case) expected sample proportion. We visually analysed the contents of the tweets samples and classified them into ironies or non-ironies and positive, negative and neutral sentiment.
Results
Text cleaning and preparation
We gathered a total of 256833 tweets that ended up being 76242 after text cleaning and preparation processes. Retweets and English language filtering were the operations that most affected them, reducing them to 89663 (35% of the initial number of tweets).
We built the two bigram TDMs with their main characteristics described in Table 1. The selection of bigrams with a frequency over 29 caused the number to be reduced from 302637 to 864 and the non-empty tweets from 76242 to 50725.
| TDM | Tweets number | Bigrams number | Frequency | ||||
|---|---|---|---|---|---|---|---|
| Min | Q1 | Median | Q3 | Max | |||
| Bigrams | 76242 |
302637 |
1 | 1 | 1 | 1 | 3990 |
| Bigrams with frequency over 29 | 50725 |
864 | 30 | 36 | 48 | 81 | 3990 |
This reduction was due to the low frequency of most bigrams in tweets. At least 75% appeared once in all of them (Q3 = 1). We show an example of the processing of three tweets and part of the bigram TDM (Table 2).
| Original tweets | Tweet 1: “im dreading going back to college… especially bc that monday i have an 8am chem lab” | |||
| Tweet 2: “baking cookies for chem lab and accidentally used self rising flour OMG” | ||||
| Tweet 3: “2 kumbe 1 chem journal… Copying time” | ||||
| Cleaned tweets | Tweet 1: “dreading going back college especially monday chem lab” | |||
| Tweet 2: “baking cookies chem lab accidentally used self rising flour omg” | ||||
| Tweet 3: “kumbe chem journal copying time” | ||||
| Bigrams obtained from cleaned Tweet 1 | “dreading going”, “going back”, “back college”, “college especially”, “especially monday”, “monday chem”, “chem lab” | |||
| Bigram term document matrix | Tweet 1 | Tweet 2 | Tweet 3 | |
| “college especially” | 1 | 0 | 0 | |
| “especially monday” | 1 | 0 | 0 | |
| “monday chem” | 1 | 0 | 0 | |
| “chem lab” | 1 | 1 | 0 | |
Clustering
We calculated the tf-idf value instead of bigram frequencies in TDM. For each number of clusters between 2 and 285, we repeated the skmeans method 50 times and we selected the best solution from each one of the 50 repetitions. We calculated and graphically represented the clustering validity indexes of these best solutions for the elbow method and the silhouette method (Fig. 2A and B).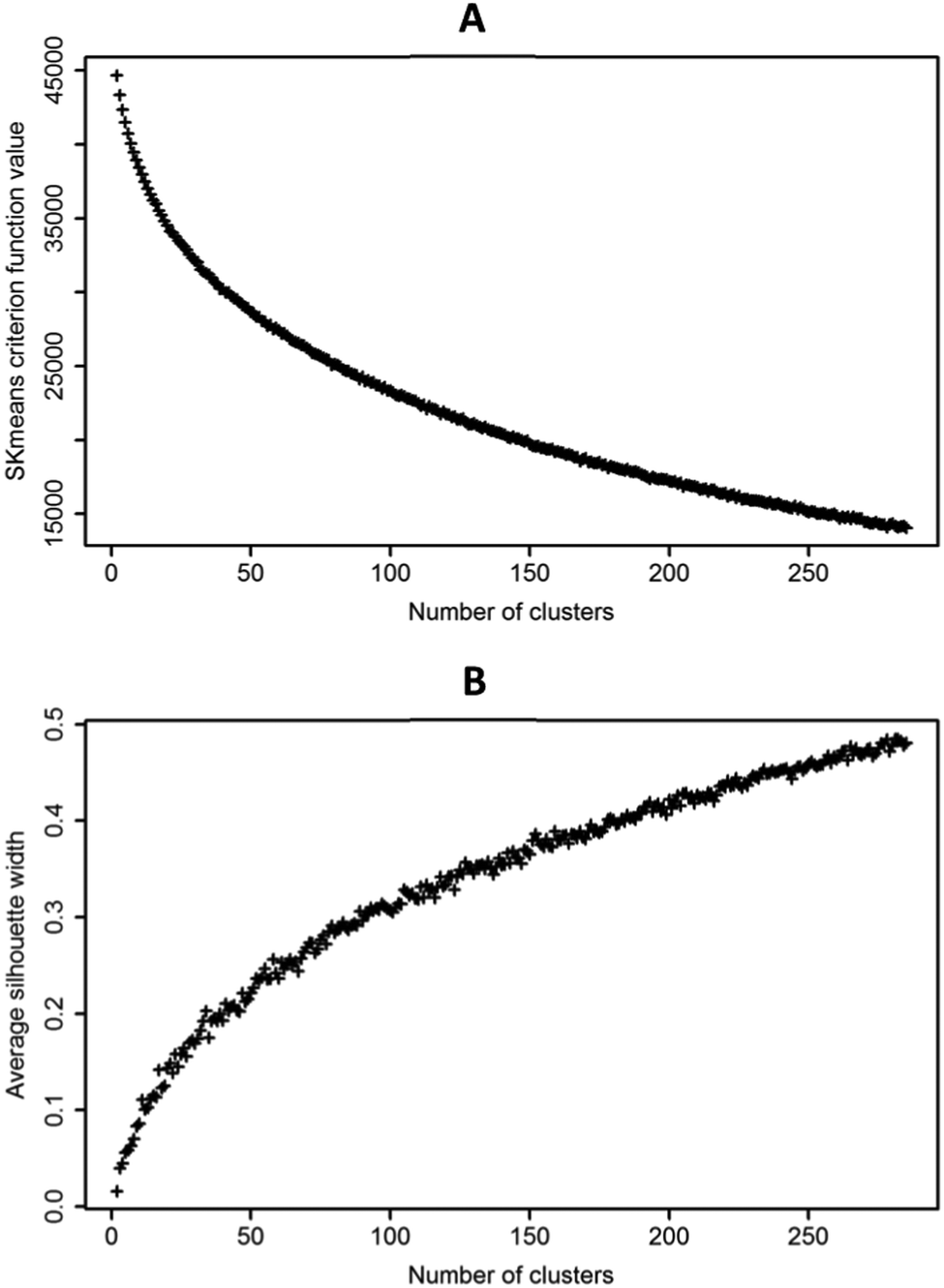 | ||
| Fig. 2 Graphs to calculate the different methods for calculating the best number of clusters (A) elbow method graph. Skmeans criterion function value vs. number of clusters (B) silhouette method graph. Average silhouette width vs. number of clusters. | ||
We observed that there was no clear elbow in the elbow method graph and no sharp change in the slope of the silhouette method graph, which did not let us visually determine the best number of clusters. We used the L-method and the curvature method to select the number of clusters numerically. The cluster corresponding to the minimum value in the L-method and the one corresponding to the maximum in the curvature method were considered to be the best ones. These results are included in ESI 1 (ESI†).
The elbow graph suggested using 78 and 193 clusters and the silhouette graph, 78 and 98. As there was no clear and exact solution for the number of clusters, we decided to round it off to 100 clusters. It is large enough to minimize mixed topic clusters and small enough to be classified by a chemistry expert.
We tried to run the skmeans implementation technique for 100 clusters 10000 times, but we could only get 9723 due to technical issues. We selected the best solution with the best skmeans criterion value. In that solution, the minimum tweets per cluster were 95, the maximum 3476, the median 383 and Q1 and Q3 were 251 and 647 respectively.
Cluster analysis
Eighteen chemistry experts classified and assigned each cluster to a single topic. These experts were chemistry professors, all of them with a chemistry or chemical engineering university degree and holding a PhD in chemistry. They were selected based on their educational background, having more than ten years of professional experience and on the diversity of their expertise. To validate the classification, we designed a BIBD composed by six chemistry experts, 50 clusters per expert, six experts per cluster and 100 clusters.With a total of 18 different experts, we replicated this design in each of the three groups with six experts per group, so each cluster was categorized by nine different experts. An example of one cluster with its graphical representation is shown in Fig. 3. The representations of all the clusters are included in ESI 2 (ESI†). These representations were used to classify the clusters obtaining the results shown in Table 3. The table with the specific cluster number assigned to each expert and the detailed classification results per expert are included in ESI 3 (ESI†).
 | ||
| Fig. 3 Unigram and bigram word clouds of cluster number 8. This cluster was classified by experts 1, 2, 6, 8, 10, 11, 16, 17 and 18. Expert 4 classified it as human activity (HA) topic, experts 1, 8, 18 as human relationship (HR) and the rest as learning environment (LE). Based on the number of votes this cluster was classified in the LE topic. | ||
| Topic | Percentage classified | |
|---|---|---|
| Clusters (%) | Tweets (%) | |
| Human activity (HA) | 20 | 18 |
| Scientific knowledge (SK) | 6 | 5 |
| Learning environment (LE) | 45 | 39 |
| Entertainment (E) | 5 | 13 |
| Human relationship (HR) | 10 | 7 |
| Undefined (U) | 14 | 18 |
It was possible to classify most clusters and tweets and only 14% of the clusters and 18% of the tweets were considered as undefined. LE and HA were the topics that obtained the largest numbers of clusters and tweets. LE represented 45% of the clusters and 39% of the tweets and HA 20% of the clusters and 18% of the tweets classified, whereas SK and E obtained the lowest ones. The SK topic, which concerns spreading scientific knowledge, only attained 6% of the clusters and 5% of the tweets classified.
We calculated Fleiss’ kappa for each topic and the whole experiment. These values were statistically representative because of their very low p-values (less than 1 × 10−6). We compared the Fleiss’ kappa values for HA and LE (0.388 and 0.517 respectively) with Landis and Koch (1977) Kappa's benchmark scale. The obtained values show fair and moderate inter-rater reliabilities respectively.
Sentiment analysis
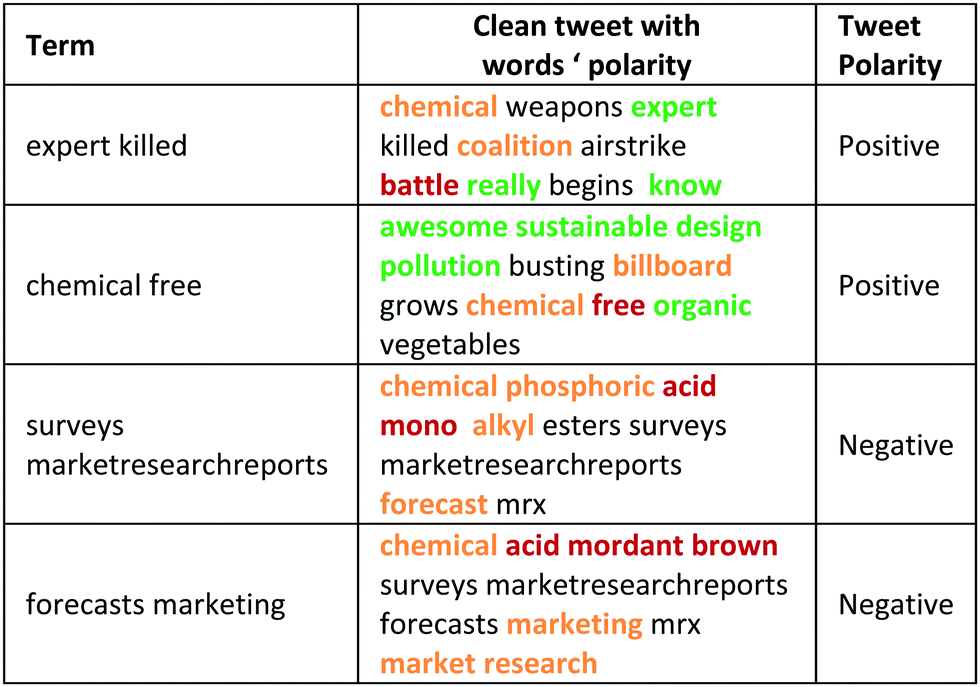
As it is explained in sentiment analysis of the experimental section, we modified the 117659 polarities of SentiWordNet 3.0 to obtain a list of 146842 and associated each one to a single word. We classified the HA and LE tweets into positive, neutral and negative tweets based on their polarity (Fig. 4). A higher percentage of positive than negative tweets was obtained. 72% and 75% of the total number of words from HA and LE tweets, respectively, were detected by the lexicon. The highest polarity tweets in the HA topic included “expert killed”, “chemical free”, “surveys marketresearchreports” and “forecasts marketing” bigrams. Their respective polarity classifications, as an example, are shown in Table 4.
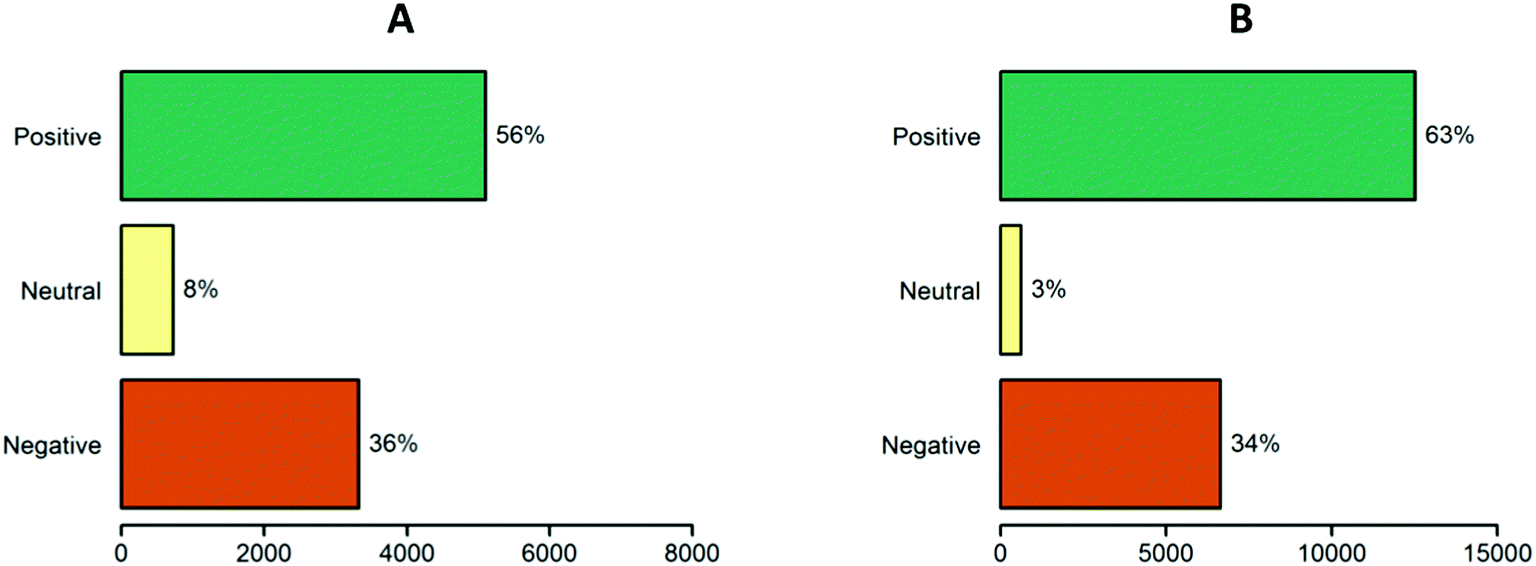 | ||
| Fig. 4 Tweets classified by their polarity (A) human activity (HA) tweets (total number = 9159) (B) learning environment (LE) tweets (total number = 19804). | ||
|
It is worth noting how, for instance, the terms “free” and “acid” were valued as negative. Their polarity values depend on the different contexts provided by the lexicon, the polarity value of each context and the average polarity value calculated with all polarity values of a term. As an example, the different contexts of “acid” in the lexicon were “water-soluble compounds being able to damage water”, “having the characteristics of an acid”, “an acid reaction” and “being sour to the taste”. Each context had a polarity value which was used to calculate the average polarity value of “acid”.
Finally, we compared the positive and negative tweets of the HA and LE categories through comparative unigram and bigram word clouds (Fig. 5).
 | ||
| Fig. 5 Comparative word clouds of positive (green) and negative (red) tweets (A) human activity (HA) unigrams (B) human activity (HA) bigrams (C) learning environment (LE) unigrams (D) learning environment (LE) bigrams. | ||
The visual analysis of HA comparison word clouds suggests that tweets classified as negative containing terms such as “attack”, “syria”, “chemical attack”,”syrian opposition” and “chemical warfare” and “toxic”, “toxic chemical”, “chemical fire” and “chemical leak” predominate over other negative tweet contents capable of fuelling chemophobia attitudes. The existence of terms such as “chemical free” and “used chemical” in tweets classified as positive might reinforce this effect. The term “chemical”, seemingly understood as industry products, is considered mostly in negative tweets whereas “chemistry”, apparently related as a physical science, appears in positive tweets.
The visual analysis of LE comparison word clouds indicates the difficulty of chemistry as a subject. Terms in tweets classified as negative related to academic activities such as “final”, “exam”, “chem final”, “final tomorrow”, “quiz tomorrow”, “lab”, “lecture”, “chem lab”, and “chem lecture” and terms related to feelings such as “hate”, “hard”, “crying“, “need help”, “never understand” and “chemistry hard” are predominant. This difficulty of learning chemistry is reinforced by the presence of terms in positive tweets such as “someone help” and “help chemistry”, which can be due to several factors described in the literature.
Despite these negative feelings about chemistry, terms such as “test”, “chem test”, “chemistry test”, “test tomorrow”, “teacher”, “chem teacher” and “chemistry teacher” also appear in tweets classified as positive. We created two statistically representative samples of the tweets corresponding to the terms “test” and “teacher” to analyse them and understand their content. These terms included the rest of the most frequent positive terms. Sample sizes were 344 and 292 tweets from 3203 and 1208 corresponding to “test” and “teacher” terms respectively. We randomly selected these tweets and analysed and classified their contents as it was described in the experimental section part. Results obtained are included in ESI 4 (ESI†).
We found that many tweets in both samples seem to transmit either a neutral or a negative sentiment. There were also many ironies within negative classified tweets such as “First organic chemistry test tonight… Will someone start digging my grave now?” or “My Chem teacher looks like she could be a character on Phineas and Ferb”. Despite been classified as positive by the sentiment lexicon used, these terms seem to reinforce the negative ones and thus increasing negative sentiment.
Discussion
Our findings based on the analysed data suggest that Twitter provides another, much broader side of the public image of chemistry which has not been studied so far. It is built upon spontaneous opinions in contrast to surveys and document analysis, which are limited to a few topics.Chemistry-related public tweets containing the words “chemistry”, “chemical” or “chem” reveal a strong presence of learning environment (LE) and human activities (HA) topics, but a limited one as far as transmitting chemistry knowledge is concerned.
The sentiment analysis results of HA tweets with a higher percentage of positive tweets than negative ones seem to follow the trend of the most recent studies (Hadhri, 2010; The Royal Society of Chemistry and TNS BMRB, 2015). The existence of both positive and negative tweets also seems to be in line with the contraposition between the positive and negative effects of chemistry described in The Royal Society of Chemistry and TNS BMRB (2015). There, 59% of the respondents answered that the benefits of chemistry were higher than its harmful effects and 51% perceived a neutral feeling. This contraposition seems to be highlighted by the terms “chemical”, understood as industry products, and “chemistry”, considered as a physical science, with a negative and positive connotations respectively. These results are in common with The Royal Society of Chemistry and TNS BMRB (2015). Chemophobia attitudes seem to be suggested by terms that appear in both negative and positive tweets related to HA. Many of these terms seem to be related to chemical war, chemical toxicity and chemical disasters. At the same time, these terms might create or reinforce chemophobia perceptions on Twitter users.
The sentiment analysis results of LE tweets also results in a higher percentage of positive tweets than negative ones. LE positive tweets, however, should be analysed deeper to review their sentiment values because of the context of the terms used in the sentiment lexicon. The contraposition between the positive and negative effects of chemistry is also present in this topic.
In LE, chemistry image seems to be based on specific elements of chemistry education such as evaluation methods and teachers rather than chemistry communication topics in academia and their influence (Nicolas, 2006; Penagos and Lozano, 2009; Chamizo, 2011; Lacolla et al., 2013) and curricula contents (Jiménez and Criado García-Legaz, 2005; Nicolas, 2006; Muñoz and Nardi, 2011; Linthorst, 2012; Piñeros and Parga, 2014) being a new contribution on this topic. Similar to our research, this image has so far always been considered negative in the view perceived by students of chemistry (Yager and Penick, 1983; Furió Más, 2006).
Additionally, LE messages seem to contain words related to classroom elements such as lectures and exams, perceived negatively as well as expressing the difficulty of learning. These negative feelings about chemistry learning might favour the association between chemistry and negative memories, in agreement with the conclusions of The Royal Society of Chemistry and TNS BMRB (2015) study.
Conclusions
The collection of 256833 tweets containing the words “chemistry”, “chemical” or “chem” has allowed us to explore and analyse the public perception of chemistry on Twitter.
Text cleaning and preparation techniques reduced to 50725 useful tweets. These were classified into six different topics. The two more frequent topics were activities and tasks related to chemistry courses (the learning environment topic, 39%) and facts and news related to the chemical industry and industry products (the human activity topic, 18%). Only a small percentage of tweets related to the transmission and communication of chemistry knowledge (the scientific knowledge topic, 5%) was found. The remaining tweets are either unclassified or belonging to categories less relevant to chemistry and chemistry education.
Sentiment analysis techniques helped us to observe many terms in the human activity topic suggesting chemophobia, whereas chemistry is perceived as difficult by Twitter users in the learning environment topic. These terms seem to relate to war, toxicity and disasters in the human activity topic. In the learning environment, most frequent terms seem to relate to classroom activities and students’ sentiments about the chemistry subject.
These two topics contained both positive and negative sentiments aligned with the latest accepted vision of the public image of chemistry with chemophobia still present in the human activity topic. This observation and the negative feelings found in the learning environment topic suggest that there is still room for improvement in current practices in chemistry education, both in the formal and informal settings. These improvements may lead to better scientific communication and knowledge, enhancing and improving citizenship participation in science.
Limitations and further work
The main limitations of this study are the number of tweets, the text cleaning and preparation methods used, and the sentiment classification method. Contents and topics could differ depending on the period of time during which the tweets were gathered. Enhancing the time span and thus the number of tweets would provide more generalizable results while monitoring the evolution of positive and negative attitudes. At the same time, we could analyse special chemistry events and how attitudes differ between and after the events. Advanced natural language techniques to stem words, to interpret abbreviations, emojis and emoticons, once they become more accessible, could affect the number of different bigrams and might result in a better classification. The lexicon-based approach used in this research did not take into account the context of a word and was dependent on the lexicon words. A tweet's polarity, therefore, depended on the polarity value assigned to each word and the words found in the lexicon. This approach is not able, for instance, to evaluate ironies properly. Additionally, a small number of tweets might undergo a change in their sense because of some stop words removal, such as negative adverbs. The construction of a lexicon specifically focused on chemistry, combining several lexicons and the use of advanced sentiment techniques to evaluate words in their context might also help to obtain better generalizable results.Further studies should focus on improving the main limitations described above as well as on monitoring the evolution of the public perception of chemistry on Twitter during a longer period. Thus, scientists and practitioners could obtain a wider view of this perception on Twitter as well as to be able to detect new topics and associated contents. This new knowledge will be helpful to chemistry stakeholders for improving the public image of chemistry.
Statement of ethics
All research has been conducted according to the ethics research guidelines in place at Univ. Ramon Llull.Conflicts of interest
The authors declare no conflict of interest.Acknowledgements
We acknowledge the help provided by all the chemistry experts who participated in this research.References
- Aarts O., Van Maanen P. P., Ouboter T. and Schraagen J. M., (2012), Online social behavior in twitter: a literature review, Proceedings – 12th IEEE International Conference on Data Mining Workshops, ICDMW 2012, pp. 739–746 DOI:10.1109/ICDMW.2012.139.
- Antilla L., (2010), Self-censorship and science: a geographical review of media coverage of climate tipping points, Public Understand. Sci., 19(2), 240–256 DOI:10.1177/0963662508094099.
- Baccianella S., Esuli A. and Sebastiani F., (2010), SentiWordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining SentiWordNet, Analysis, 1–12 DOI:10.1.1.61.7217.
- Bekkerman R. and Allan J., (2004), Using Bigrams in Text Categorization, Technical Report IR-408, Center of Intelligent Information Retrieval, UMass Amherst, pp. 1–10.
- Berry M. W., (2007), Survey of text mining: clustering, Classification, and Retrieval, ed. M. W. Berry and M. Castellanos, Springer, 2nd edn DOI:10.1007/978-1-84800-046-9.
- Boyd D., Golder S. and Lotan G., (2010), Tweet, tweet, retweet: conversational aspects of retweeting on twitter’, Proceedings of the Annual Hawaii International Conference on System Sciences DOI:10.1109/HICSS.2010.412.
- Casadevall A. and Fang F. C., (2009), Is peer review censorship?, Infect. Immun., 77(4), 1273–1274 DOI:10.1128/IAI.00018-09.
- Cedefop, (2016), Skill shortage and surplus occupations in Europe, pp. 1–4 DOI:10.2801/05116.
- Chamizo J. A., (2011), La imagen pública de la química, Educ. Quim., 22(4), 320–331.
- Choi B. C. K. and Pak A. W. P., (2005), A catalog of biases in questionnaires, Prev. Chronic Dis., 2(1), 1–13.
- Clement J., (2019), Number of monthly active Twitter users worldwide from 1st quarter 2010 to 1st quarter 2019, Statista. Available at: https://www.statista.com/statistics/282087/number-of-monthly-active-twitter-users/, accessed: 28 January 2020.
- Delen D. and Crossland M. D., (2008), Seeding the survey and analysis of research literature with text mining, Expert Syst. Appl., 34(3), 1707–1720 DOI:10.1016/j.eswa.2007.01.035.
- Dhillon I. S. and Modha D. S., (2001), Concept decompositions for large sparse text data using clustering, Mach. Learn., 42(1–2), 143–175 DOI:10.1023/A:1007612920971.
- Duffus J. H., Nordberg M. and Templeton D. M., (2007), Glossary of terms used in toxicology, 2nd edition (IUPAC Recommendations 2007)’, Pure Appl. Chem., 79(7), 1153–1344 DOI:10.1351/pac200779071153.
- Duggan M., (2015), The Demographics of Social Media Users, Pew Research Center. Available at: https://www.pewresearch.org/internet/2015/08/19/the-demographics-of-social-media-users/, accessed: 28 January 2020.
- Fahad A., Alshatri N., Tari Z., Alamri A., Khalil I., Zomaya A. Y., Foufou S. and Bouras A., (2014), A survey of clustering algorithms for big data: Taxonomy and empirical analysis, IEEE Trans. Emerg. Top. Comput., 2(3), 267–279 DOI:10.1109/TETC.2014.2330519.
- Feinerer I., Hornik K. and Meyer D., (2008), Text Mining Infrastructure in R, J. Stat. Softw., 25(5), 1–54 DOI:citeulike-article-id:2842334.
- Feldman R. and Sanger J., (2007), The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, Cambridge University Press DOI:10.1017/CBO9780511546914.
- Fellows I., (2018), wordcloud: Word Clouds’, R package version 2.6, https://CRAN.R-project.org/package=wordcloud.
- Fleiss J. L., (1971), Measuring nominal scale agreement among many raters, Psychol. Bull., 76(5), 378–382 DOI:10.1037/h0031619.
- Fleiss J. L., (1981), Balanced Incomplete Block Designs for Inter-Rater Reliability Studies, Appl. Psychol. Meas., 5(1), 105–112 DOI:10.1177/014662168100500115.
- Fleiss J. L., Levin B. and Paik M. C., (2003), Statistical Methods for Rates and Proportions, 3rd edn, Hoboken: John Wiley & Sons, Inc.
- Furió Más C., (2006), La motivación de los estudiantes y la enseñanza de la Química. Una cuestión controvertida, Educ. Quim., 17(IV Jornadas Internacionales), 222–227.
- Gentry J., (2015), twitteR: R Based Twitter Client, R package version 1.1.9, https://CRAN.R-project.org/package=twitteR.
- Gupta V. and Lehal G. S., (2009), A survey of text mining techniques and applications, J. Emerg. Technol. Web Intell., 1(1), 60–76 DOI:10.4304/jetwi.1.1.60-76.
- Hadhri M., (2010), CEFIC Facts and Figures 2010. The European Chemical Industry in a worldwide perspective. CEFIC. Available at: https://es.scribd.com/document/44470516/Facts-and-Figures-2010-Report.
- Hartings M. R. and Fahy D., (2011), Communicating chemistry for public engagement, Nat. Chem., 3(9), 674–7 DOI:10.1038/nchem.1094.
- Hayden K., Ouyang Y., Scinski L., Olszewski B. and Bielefeldt T., (2011) Increasing Student Interest and Attitudes in STEM: Professional Development and Activities to Engage and Inspire Learners, Contemp. Issues Technol. Sci. Teach. Educ., 11(1), 47–69.
- Hazelkorn E., (2015), Science education for responsible citizenship: report to the European Commission of the Expert Group on Science Education, Publications Office of the European Union, p. 88 DOI:10.2777/12626.
- Hearst M. A., (1999), Untangling text data mining, Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics, pp. 3–10 DOI:10.3115/1034678.1034679.
- Hill J. and Kumar D. D., (2013), Challenges for Chemical Education: Implementing the ‘Chemistry for All’ Vision, J. Am. Inst. Chem., 86(2), 27–32.
- Hornik K., Feinerer I., Kober M. and Buchta C., (2012), Spherical k-Means Clustering, J. Stat. Softw., 50(10), 1–22.
- Hornik K., Mair P., Rauch J., Geiger W., Buchta C. and Feinerer I., (2013), The textcat Package for n-Gram Based Text Categorization in R, J. Stat. Softw., 52(6), 1–17 DOI:10.18637/jss.v052.i06.
- Hotho A., Nürnberger A. and Paaß G., (2005), A Brief Survey of Text Mining, J. Comput. Linguis. Lang. Technol., 20, 19–62 DOI:10.1111/j.1365-2621.1978.tb09773.x.
- Huang J., Thornton K. M. and Efthimiadis E. N., (2010), Conversational tagging in Twitter, HT’10 – Proceedings of the 21st ACM Conference on Hypertext and Hypermedia, pp. 173–177 DOI:10.1145/1810617.1810647.
- Irfan R., King C. K., Grages D., Ewen S., Khan S. U., Madani S. A., Kolodziej J., Wang L., Chen D., Rayes A., Tziritas N., Xu C. Z., Zomaya A. Y., Alzahrani A. S. and Li H., (2015), A survey on text mining in social networks, Knowl. Eng. Rev., 30(2), 157–170 DOI:10.1017/S0269888914000277.
- Jain A. K., (2010), Data clustering: 50 years beyond K-means, Pattern Recogn. Lett., 31(8), 651–666 DOI:10.1016/j.patrec.2009.09.011.
- Jain A. K., Murty M. N. and Flynn P. J., (1999), Data clustering: a review, ACM Comput. Surv., 31(3), 264–323 DOI:10.1145/331499.331504.
- Jiménez J. B. and Criado García-Legaz A., (2005), Análisis de las actividades sobre la historia de la química en los libros de física y química del segundo ciclo de la eso, Enseñanza De Las Ciencias, 2000, 1–6.
- Kanavos A., Perikos I., Vikatos P., Hatzilygeroudis I., Makris C. and Tsakalidis A., (2014), Conversation Emotional Modeling in Social Networks, Proceedings – International Conference on Tools with Artificial Intelligence, ICTAI, 2014-Decem, pp. 478–484 DOI:10.1109/ICTAI.2014.78.
- Kodinariya T. M. and Makwana P. R., (2013), Review on determining number of Cluster in K-Means Clustering, Int. J. Adv. Res. Comput. Sci. Manage. Stud., 1(6), 90–95.
- Krumpal I., (2013), Determinants of social desirability bias in sensitive surveys: a literature review, Qual. Quan., 47(4), 2025–2047 DOI:10.1007/s11135-011-9640-9.
- Lacolla L., Meneses Villagrá J. A. and Valeiras N., (2013) Las representaciones sociales y las reacciones químicas: Desde las explosiones hasta Fukushima, Educ. Quim., 24(3), 309–315.
- Landis J. R. and Koch G. G., (1977), The Measurement of Observer Agreement for Categorical Data, Biometrics, 33(1), 159–174 DOI:10.2307/2529310.
- Linthorst J. A., (2012), The image of chemistry and curriculum changes, Educ. Quim., 23(2), 240–242 DOI:10.1016/S0187-893X(17)30115-5.
- Madhulatha T. S., (2012), An overview on clustering methods, IOSR J. Eng., 02(04), 719–725 DOI:10.9790/3021-0204719725.
- Mahaffy P., Ashmore A., Bucat B., Do C. and Rosborough M., (2008), Chemists and “the public”: IUPAC's role in achieving mutual understanding (IUPAC Technical Report), Pure Appl. Chem., 80(1), 161–174 DOI:10.1351/pac200880010161.
- Malaver M., Pujol R. and D’Alessandro Martínez A., (2004), Los Estilos De Prosa Y El Enfoque Ciencia-Tecnología-Sociedad En Textos Universitarios De Química General, Educ. Quim., 22(3), 441–453.
- Mäntylä M. V., Graziotin D. and Kuutila M., (2018), The evolution of sentiment analysis—A review of research topics, venues, and top cited papers, Comput. Sci. Rev., 27, 16–32 DOI:10.1016/j.cosrev.2017.10.002.
- Medhat W., Hassan A. and Korashy H., (2014), Sentiment analysis algorithms and applications: A survey, Ain Shams Eng. J., 5(4), 1093–1113 DOI:10.1016/j.asej.2014.04.011.
- Mohey D. and Hussein E. M., (2018), A survey on sentiment analysis challenges, J. King Saud Univ. Sci., 30(4), 330–338, DOI:10.1016/j.jksues.2016.04.002.
- Molina M. F. and Carriazo J. G., (2019), Awakening Interest in Science and Improving Attitudes toward Chemistry by Hosting an ACS Chemistry FeSTiVAl in Bogotá, Colombia, J. Chem. Educ., 96(5), 944–950 DOI:10.1021/acs.jchemed.8b00670.
- Muñoz L. and Nardi R., (2011), Las representaciones científicas en la formación inicial de profesores de química, Encontro Nacional de Pesquisa em Educação em Ciências, 8.
- Nicolas E., (2006), Aula y Laboratorio de Química La Química vista por 840 estudiantes de bachillerato, Anal. Quim., 102(4), 64–67.
- Palermo A., (2018), The future of the Chemical Sciences. Preparing for an Uncertain Future, Chem. World, 6 DOI:10.1021/ed020p304.
- Penagos W. M. M. and Lozano D. L. P., (2009), La imagen pública de la química y su relación con la generación de actitudes hacia la química y su aprendizaje, Tecné, Episteme y Didaxis: TED, vol. 27, pp. 67–93.
- Pew Research Center, (2019), News Use Across Social Media Platforms 2018, available at: http://www.journalism.org/2018/09/10/news-use-across-social-media-platforms-2018/, accessed: 19 February 2019.
- Piñeros Y. and Parga D., (2014), Caracterización de los contenidos curriculares contextualizados para la enseñanza de la química, Revista Tecné, Episteme y Didaxis: TED.
- Pratt J. M. and Yezierski E. J., (2018), A novel qualitative method to improve access, elicitation, and sample diversification for enhanced transferability applied to studying chemistry outreach, Chem. Educ. Res. Pract., 19(2), 410–430 10.1039/c7rp00200a.
- Ratamun M. M. and Osman K., (2018), The Effectiveness Comparison of Virtual Laboratory and Physical Laboratory in Nurturing Students’ Attitude towards Chemistry, Creat. Educ., 9(9), 1411–1425 DOI:10.4236/ce.2018.99105.
- Ribelles R., Solbes J. and Vilches A., (1995), Las interacciones C.T.S. en la enseñanza de las ciencias, Análisis comparativo de la situación para la Física y Química y la Biología y Geología, Comunicación, Lenguaje y Educación, pp. 135–143.
- Rousseeuw P. J., (1987), Silhouettes: A graphical aid to the interpretation and validation of cluster analysis, J. Comput. Appl. Math., 20(C), 53–65 DOI:10.1016/0377-0427(87)90125-7.
- Sailunaz K. and Alhajj R., (2019), Emotion and sentiment analysis from Twitter text, J. Comput. Sci., 36, 101003 DOI:10.1016/j.jocs.2019.05.009.
- Salton G. and Buckley C., (1988), Term-weighting approaches in automatic text retrieval, Inform. Process. Manage., 24(5), 513–523.
- Salvador S. and Chan P., (2004), Determining the Number of Clusters/Segments in Hierarchical Clustering/Segmentation Algorithms’, 16th IEEE international conference on tools with artificial intelligence, pp. 576–584 DOI:10.1109/ICTAI.2004.50.
- Schibeci R. A., (1986), Images of science and scientists and science education, Sci. Educ., 70(2), 139–149 DOI:10.1002/sce.3730700208.
- Schummer J., Bensaude-Vincent B. and Van Tiggelen B., (2007), The Public Image of Chemistry, World Scientific Publishing DOI:10.1142/9789812775856.
- Schummer J. and Spector T. I., (2007), The visual image of chemistry: Perspectives from the history of art and science, Int. J. Philos. Chem., 13(1), 1–40.
- Smith M. A., Rainie L., Shneiderman B. and Himelboim I., (2014), Mapping Twitter Topic Networks: From Polarized Crowds to Community Clusters, Pew Research Center, vol. 20, pp. 1–56.
- Solbes J. and Vilches A., (1992), El modelo constructivista y las relaciones ciencia/técnica/sociedad, Enseñanza de las Ciencias, 10(2), 181–186.
- Statista, (2019) Leading social media platforms used by B2B and B2C marketers worldwide as of January 2018, Available at: https://www.statista.com/statistics/259382/social-media-platforms-used-by-b2b-and-b2c-marketers-worldwide/, accessed: 19 February 2019.
- Stekolschik G., Draghi C., Adaszko D. and Gallardo S., (2010), Does the public communication of science influence scientific vocation? results of a national survey, Public Underst. Sci., 19(5), 625–637 DOI:10.1177/0963662509335458.
- Sun S., Luo C. and Chen J., (2017), A review of natural language processing techniques for opinion mining systems, Inform. Fusion, 36, 10–25 DOI:10.1016/j.inffus.2016.10.004.
- Tago K. and Jin Q., (2018), Influence analysis of emotional behaviors and user relationships based on Twitter data, Tsinghua Sci. Technol., 23(1), 104–113 DOI:10.26599/TST.2018.9010012.
- The Royal Society of Chemistry and TNS BMRB, (2015), Public attitudes to chemistry’, Research report, https://www.rsc.org/campaigning-outreach/campaigning/public-attitudes-chemistry/, pp. 1–78.
- Tortorella S., Zanelli A. and Domenici V., (2019), Chemistry Beyond the Book: Open Learning and Activities in Non-Formal Environments to Inspire Passion and Curiosity, Substantia, 3, 39–47 DOI:10.13128/Substantia-587.
- Tourangeau R. and Yan T., (2007), Sensitive Questions in Surveys, Psychol. Bull., 133(5), 859–883 DOI:10.1037/0033-2909.133.5.859.
- Trozzolo A. M., (1975), The image of chemistry. Conference, https://www3.nd.edu/~atrozzol/Image-2.pdf, pp. 1–7.
- Yadollahi A., Shahraki A. G. and Zaiane O. R., (2017), Current State of Text Sentiment Analysis from Opinion to Emotion Mining, ACM Comput. Surv., 50(2), 1–33 DOI:10.1145/3057270.
- Yager R. E. and Penick J. E., (1983), Analysis of Current Problems in the US.pdf, Eur. J. Sci. Educ., 5(4), 463–469.
- Ye S. and Wu F., (2013), Measuring message propagation and social influence on Twitter.com, Int. J. Commun. Netw. Distri. Syst., 11(1), 59–76 DOI:10.1504/IJCNDS.2013.054835.
- Zhang Y., Mańdziuk J., Quek C. H. and Goh B. W., (2017), Curvature-based method for determining the number of clusters, Inform. Sci., 415–416, 414–428 DOI:10.1016/j.ins.2017.05.024.
- Zhong S., (2005), Efficient Online Spherical K-Means Clustering, IEEE Int. Joint Conf. Neural Netw., 5, 3180–3185 DOI:10.1109/IJCNN.2005.1556436.
Footnote |
| † Electronic supplementary information (ESI) available: Additional analysis results and figures. See DOI: 10.1039/c9rp00282k |
| This journal is © The Royal Society of Chemistry 2020 |