
Rational design of protein–protein interaction inhibitors
Didier
Rognan
Laboratory for Therapeutical Innovation, UMR7200 CNRS-Université de Strasbourg, MEDALIS Drug Discovery Center, 67400 Illkirch, France. E-mail: rognan@unistra.fr
First published on 23rd September 2014
Abstract
Protein–protein interactions are at the heart of most physiopathological processes. As such, they have attracted considerable attention for designing drugs of the future. Although initially considered as high-value but difficult to identify, low molecular weight compounds able to selectively and potently modulate protein–protein interactions have recently reached clinical trials. Along with high-throughput screening of compound libraries, combining structural and computational approaches has boosted this formerly minor area of research into a currently tremendously active field. This review highlights the very recent developments in the rational design of protein–protein interaction inhibitors.
 Didier Rognan | Didier Rognan heads the Laboratory of Structural Chemogenomics at the Faculty of Pharmacy of Strasbourg (France). He studied Pharmacy at the University of Rennes (France) and did a Ph.D. in Medicinal Chemistry in Strasbourg (France) under the supervision of Prof. C.G. Wermuth. After a post-doctoral fellowship at the University of Tübingen (Germany), he moved as an Assistant Professor to the Swiss Federal Institute of Technology (ETH) until October 2000. He was then appointed Research Director at the CNRS to build a new group in Strasbourg. He is mainly interested in all aspects (method development and applications) of structure-based drug design, notably on G protein-coupled receptor ligands and protein–protein interaction inhibitors. |
Introduction
Drug discovery is a long, costly, multi-step endeavour which aims at reducing all possible risks to deliver a novel therapeutic solution to previously unmet clinical needs. To reduce chemical risks, empirical rules are used to filter the chemical space and retain drug-like low molecular weight compounds. Reduction of the biological risk is addressed by considering privileged target families (e.g., G protein-coupled receptors and kinases) whose activation/inhibition by drug-like compounds is likely to correct or reverse pathological states. Until recently, mostly single macromolecules (proteins and nucleic acids) have been considered as potential drug targets. Out of 68![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 000 proteins currently annotated in UniProt for the human proteome,1 only about 300 targets2 have been addressed by current drugs, and the large majority of single targets is still awaiting first-in class drugs.
000 proteins currently annotated in UniProt for the human proteome,1 only about 300 targets2 have been addressed by current drugs, and the large majority of single targets is still awaiting first-in class drugs.
Besides single targets, large scale genomics and proteomics3 have identified complex networks of targets and pathways regulating physiopathological processes in a coordinated manner. The current human protein–protein interactome has been estimated between 130000 (ref. 4) and 650000 (ref. 5) complexes, out of which only a tiny amount is known, and only a very few6–8 have been the object of a drug discovery initiative. Protein–protein interactions (PPIs) therefore describe a totally new biological space that attracts more and more attention, with 26PPI inhibitors9,10 already under clinical development, notably in the oncology field.11 Despite PPIs may adopt quite different sizes, shapes and electrostatics,12 identifying high-affinity PPI inhibitors is a considerable challenge for many reasons: (i) in contrast to conventional targets, a medicinal chemist cannot start inhibitor design from the structure of endogenous ligands, (i) PPIs often involve flat surfaces delocalized over multiple epitopes, usually lack well-defined buried cavities13 typical of conventional targets, and are significantly larger (ca. 1000–3000 Å2) than enzyme/receptor pockets (300–1000 Å2), (iii) high-throughput screening of traditional compound libraries often returns no viable hits14 for the main reason that PPI inhibitor chemical space is quite different from that described by traditional drug-like compounds.10 Nonetheless, thanks to bioinformatics and proteomics-guided prioritization of therapeutically relevant protein–protein complexes, more and more PPI inhibitors are currently reported. Several excellent reviews6,7,9,11,15–18 have already been published on experimental methods (high throughput screening, biochemical and cellular assays, and fragment-based approaches) suitable to discover PPI inhibitors. The present report will only cover computer-aided approaches, with a major emphasis on structure-based methods and recent discoveries (2012–2014).
Databases
Preliminary access to experimentally validated data is key to launch a drug discovery program on PPI modulators. A multitude of databases storing genomics, proteomics and structural data are currently available to help the medicinal chemist. We will here briefly review these archives, focusing mostly on easily interpretable structural data.PPI databases
Many experimental methods with different throughputs (from low to high) have been developed to characterize binary interactomes in various species, among which the most prominent has been the yeast two-hybrid (Y2H) assays, and mass-spectrometry (MS) coupled with co-immunoprecipitation or co-affinity purification.19 These experimental data are stored in many primary databases (Table 1) that are difficult to mine due to their large heterogeneity. Metadatabases have been derived thereof to facilitate their analysis, among which the most popular are APID and PRIMOS (Table 1). These metadatabases cover a wide range of organisms and notably offer the possibility to mine experimental PPI data according to disease relevance or inter-organism crosstalk, and provide graphic tools to visualize complex networks of interacting proteins and identifying important protein nodes (hubs).| Database | Interactions | Website | References |
|---|---|---|---|
| BIND | 32211 |
http://bond.unleashedinformatics.com | 20 |
| DIP | 78191 |
http://dip.doe-mbi.ucla.edu/dip/Main.cgi | 21 |
| HPRD | 41327 |
http://www.hprd.org/ | 22 |
| IntAct | 448986 |
http://www.ebi.ac.uk/intact/ | 17 |
| MIPS | 9835 | http://mips.helmholtz-muenchen.de/proj/ppi/ | 23 |
| APID | 196700 |
http://bioinfow.dep.usal.es/apid/index.htm | 24 |
| PRIMOS | 384127 |
http://primos.fh-hagenberg.at/ | 19 |
It is however very difficult, from this large amount of data, to clearly prioritize PPIs for a drug discovery program. Attempts to classify the PPIs by structural druggability25 (although ligandability26 is probably a better term) are worth mentioning but should be taken with care due to the still insufficient number of existing PPI three-dimensional (3D) structures.
Ligand databases
Initially limited to a limited subset of inhibitors able to disrupt few PPIs (e.g. p53/MDM2, Bcl-Xl/Bak, and IL-2/IL-2Rα),7,27 the repertoire of PPI inhibitors rises constantly thanks to exciting developments in biophysical fragment screening.15,28Three publicly available databases storing information on PPIs and their inhibitors (Table 2) may be used to better describe the structural properties of druggable PPIs and the chemical space associated with their disruptors.
The 2P2Idb database12 is a hand-curated repository of protein–protein complexes of known X-ray structures (X-ray diffraction and nuclear magnetic resonance spectroscopy) for which at least one low molecular weight orthosteric inhibitor has been co-crystallized with one of the two protein partners. It currently describes 71 inhibitors for 14 PPIs, clustered in two groups (Fig. 1) with respect to the nature of the interface (protein–peptide and protein–protein). Companion tools (2P2I inspector,30 2P2I score,30 and 2P2I hunter31) are provided to analyse PPIs at a structural level, predict their structural druggability and design PPI focussed libraries, respectively.
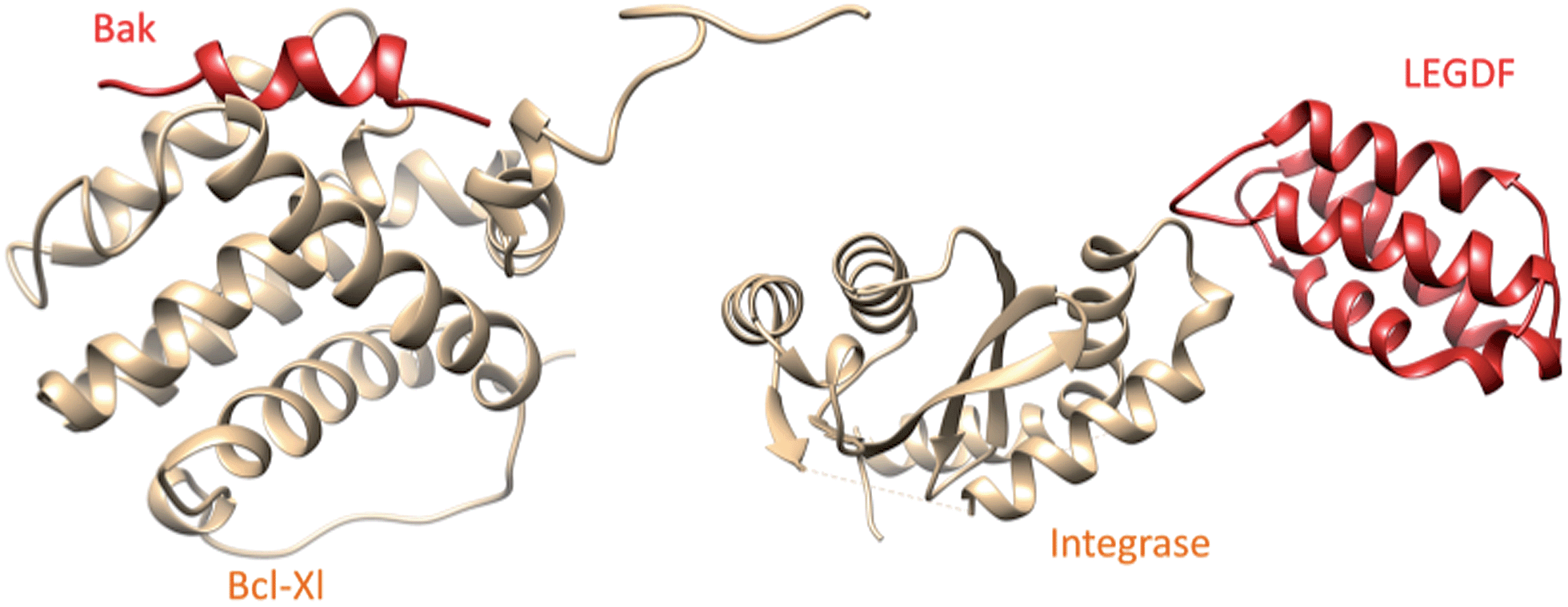 | ||
| Fig. 1 Prototypical examples of class I (left panel) and class II PPIs (right panel), exemplified by the Bcl-Xl/Bak (PDB id 1BXL) and integrase/LEDGF (PDB id 2B4J) complexes, respectively. Class I PPIs involve the interaction of a globular protein with a peptide or a single secondary structure (α-helix and β-strand) of a second protein partner. Class II PPIs are characterized by the interaction of two globular proteins. | ||
The iPPI-DB10 is another manually curated database from world patents and the medicinal chemistry literature, focussing on low molecular weight orthosteric inhibitors, disease-related protein–protein interfaces and a clear biochemical readout (e.g. fluorescence polarisation and enzyme-linked immunosorbent assay). The database archives 1650 PPI inhibitors targeting 13 families of homologous PPI targets mainly involved in cancer, immune disorders and infectious diseases.
Finally, the TIMBAL database29 reports ca. 7000 inhibitors for 50 known PPIs. In contrast to the two other databases, TIMBAL is maintained through a predefined list of PPIs and automated searches in ChEMBL32 and the Protein Data Bank.33 In contrast to the other databases, TIMBAL also registers short peptides with an upper molecular weight limit of 1200 Da. It should be pointed that most of the 15000 uncurated biological data present in TIMBAL arise from a single target family (integrins) and should be considered with care.
Analysing the content of these databases enables a first comparison of PPI inhibitors versus drugs, as well as PPIs amenable to disruption versus standard heterodimers. PPI surfaces disrupted by inhibitors tend to be smaller, more hydrophobic and accessible than standard heterodimers.12 As a consequence, low molecular weight PPI inhibitors tend to be larger, more hydrophobic and more aromatic-rich than standard drugs. Interestingly, many of them (ca. 60%) still comply with Lipinski's rule-of-five,10 revealing some hopes in the developability of such compounds.
However, it should be stated that the set of empirical rules designed to discriminate druggable from non-druggable PPIs, as well as to distinguish PPI inhibitors from conventional drug-like compounds still rely on a very limited set of highly homologous data (PPIs, inhibitors), and should therefore be regarded with caution. Increasing coverage of the PPI repertoire by future experimental screens will undoubtedly lead to a better definition of PPI biological and chemical spaces. We therefore expect in the future the above-mentioned rules to be refined and be more descriptive of the true world of PPI inhibitors, notably with respect to rational design of PPI focussed libraries.
Rational design of PPI modulators
Sequence-based approaches
Whatever the nature of the PPI (type I or type II, see the definition above), PPI interfaces are often characterized by the presence of hotspots,34 in other words anchor residues that contribute the most to the binding free energy of the protein–protein complex. The interaction of a single modified amino acid with a single anchor residue might be sufficient to disrupt a PPI as elegantly demonstrated by Lin et al. in a recent study.35 Capitalizing on the presence of a reactive cysteine (C246) at the interface of the complex between caspase-7 (CASP7) and the X-linked inhibitor of apoptosis protein (XIAP), they designed the N-iodoacetyl-lysine amino acid derivative 1 (Fig. 2) that covalently traps C246 and further disrupts the XIAP–CASP7 complex, therefore triggering CASP7-dependent apoptosis and killing MCF-7 breast cancer cells (EC50 = 0.64 μM) previously resistant to chemotherapy.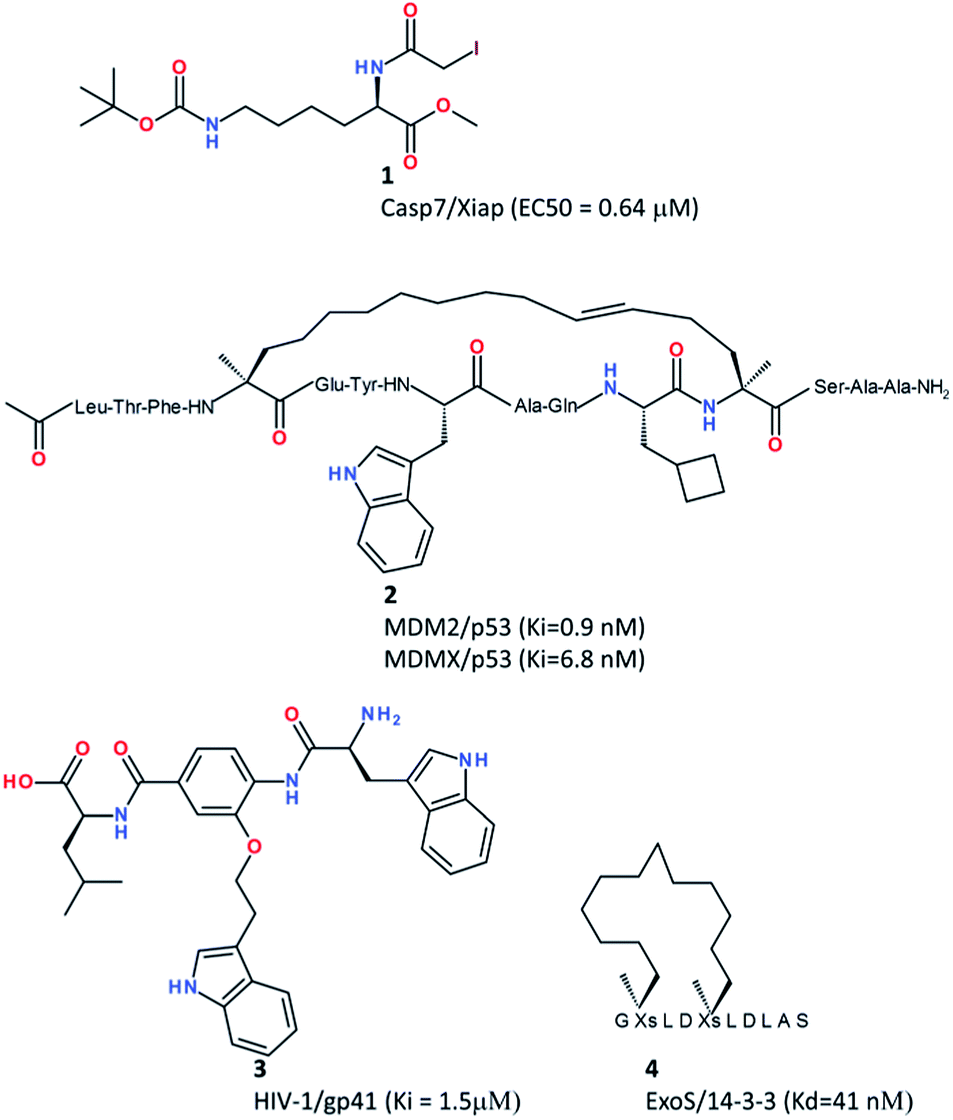 | ||
| Fig. 2 Peptidomimetics as PPI disruptors. | ||
The easiest way to inhibit a PPI is to start with the amino acid sequence of one interacting epitope, notably if the latter is part of regular secondary structures (α-helix, β-strand, and β-turn). For example, α-helical peptides mimicking the sequence of protein transmembrane domains may disrupt PPIs quite efficiently.36,37
Due to poor pharmacokinetic profiles, linear peptides are good in vitro tools but usually not efficient clinical candidates. Chemical modifications are required to stabilize their secondary structures in physiological media and prevent early degradation. Among the most exciting developments in this area38,39 is the design of stapled peptides.40,41 Stapled peptides are synthetic analogues of α-helical protein epitopes involved in a PPI, and in which a covalent hydrocarbon linkage connects adjacent turns of the helix. Stapling is known to significantly increase the in vivo half-life of the natural peptide (increasing proteolytic stability), decrease the entropic cost of binding, and even enable cellular uptake.42 Many stapled peptides with potent in vivo activities have already been reported.39 One of these stapled peptides (ATSP-7041, compound 2, Fig. 2) just entered clinical development as a dual nM MDM2/MDMX inhibitor for p53-dependent cancer therapy.43
Heterocyclic scaffolds mimicking secondary structures can also be obtained by solution-phase synthesis to afford peptidomimetic libraries amenable to PPI inhibition. Whitby et al. notably reported the design of 8000 member 4-acetamido-3-alkoxy-benzamide focused library featuring weak p53/MDM2 inhibitors and potent HIV-1/gp41 inhibition (compound 3, Fig. 2).44 When the peptide epitope is not structured, developing macrocyclic analogues is more difficult but still feasible as recently demonstrated by Glas et al.38 who successfully improved 14-3-3 binding of a 11-mer peptide from a bacterial ExoS virulence factor by cross-linking binding amino acids with polymethylene linkers, up to an in vitro 40 nM disruptor of the ExoS/14-3-3 interaction (compound 4, Fig. 2). Interestingly, the cross-linker was not only chosen to rigidify the natural ExoS peptide structure but also to directly provide additional hydrophobic interactions to the 14-3-3 binding site.38
Only in exceptional cases the natural unmodified peptide is directly usable as a PPI inhibitor. One recent example is the 28 amino acid cell-penetrating peptide (p28) from a bacterial azurin redox protein, that binds to the DNA-binding domain of the p53 tumor suppressor and inhibits p53 degradation by interfering with the Cop1-mediated ubiquitination,45 thereby enhancing p53 levels in cancer cells and exhibiting antitumoral efficacy in patients with advanced solid tumors.46
Pharmacophore-based approaches
As defined by the IUPAC,47 a pharmacophore is “an ensemble of steric and electronic features that are necessary to ensure the optimal supramolecular interactions with a specific biological target and to trigger (or block) its biological response.” Although pharmacophores are mainly used to align and compare ligands sharing the same target,48 the same concept can be easily transferred to PPIs in which one partner is the “receptor” and the second one the “ligand”. Pharmacophore features (hydrophobic, aromatic, H-bond donor and H-bond acceptor, positively and negatively ionisable) can therefore be manually or automatically mapped to atoms of the ligand in direct interactions with the receptor. The resulting pharmacophore can then be used to identify a compound library for hits fulfilling the defined query. Several tools (e.g. LigandScout,49 Discovery Studio,50 and Pocket Query51) can be directly used to map PPI pharmacophores onto protein–protein X-ray structures (Fig. 3).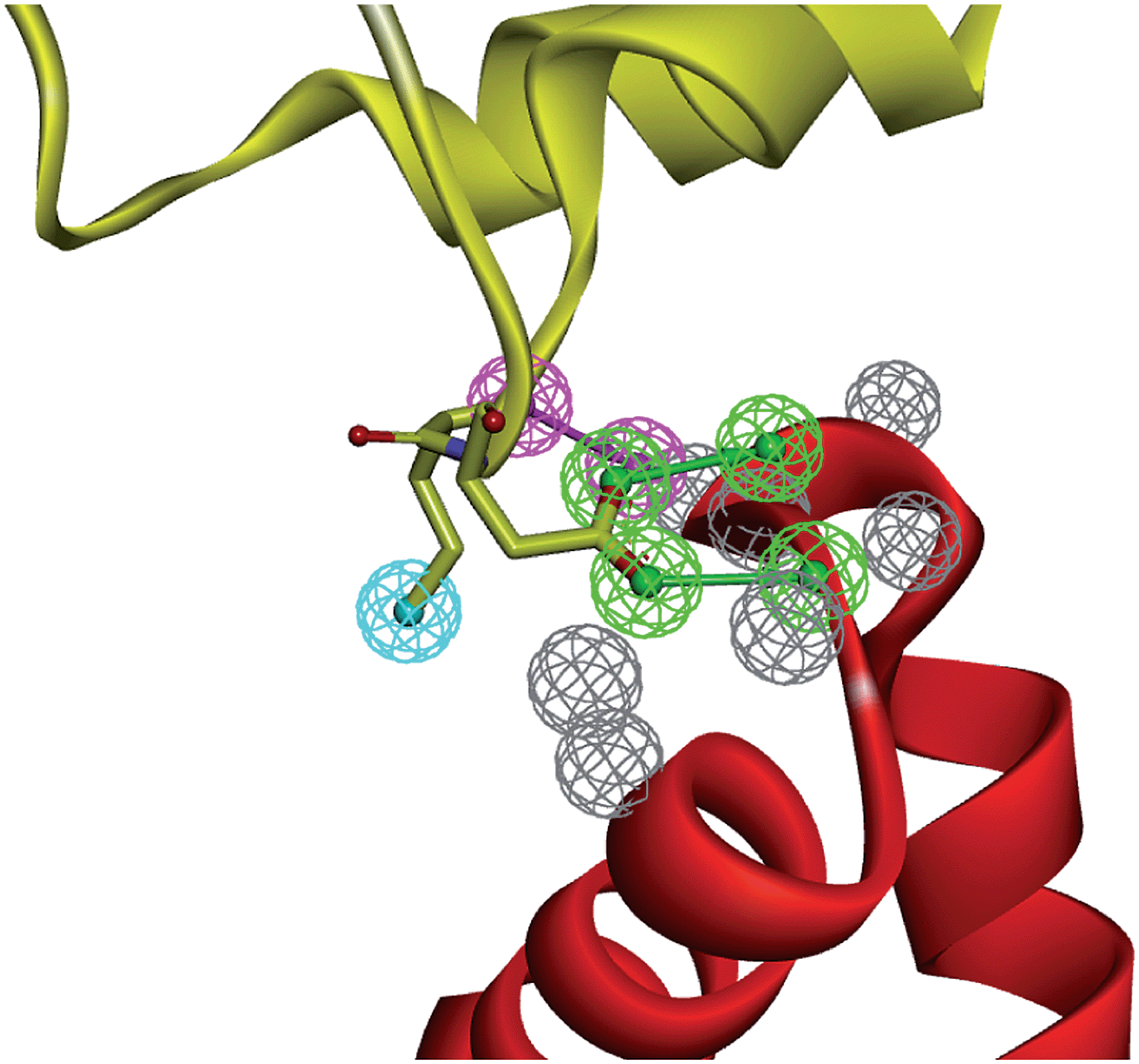 | ||
| Fig. 3 Example of a PPI pharmacophore mapped onto interacting atoms of human LEDGF (yellow ribbons) bound to HIV-1 integrase (red ribbons, PDB ID 2B4J). The PPI pharmacophore is composed of 2 H-bond donors (magenta balls), two H-bond acceptors (green balls), one hydrophobic feature (cyan ball) and 6 exclusion volumes (gray balls). | ||
Using a manual PPI pharmacophore defined from the X-ray structure of the Annexin A2/S100A10 complex, a pro-angiogenic complex, Reddy et al.52 derived a simple pharmacophore (2 hydrophobes, 2 H-bond donors, and 2 H-bond acceptors) using the Unity program,53 and screened a library of 700000 compounds to select 586 hits which were further docked to the Annexin A2 binding site to retain only 190 candidates with both a good docking and pharmacophore fitness score (Table 3). Out of 190 tested compounds, 7 hits blocked the interaction between S100A10 and the Annexin A2 N-terminus in a competitive fluorescent binding assay, with the most potent PPI inhibitor (compound 5, Fig. 4) exhibiting an IC50 of 24 μM.52
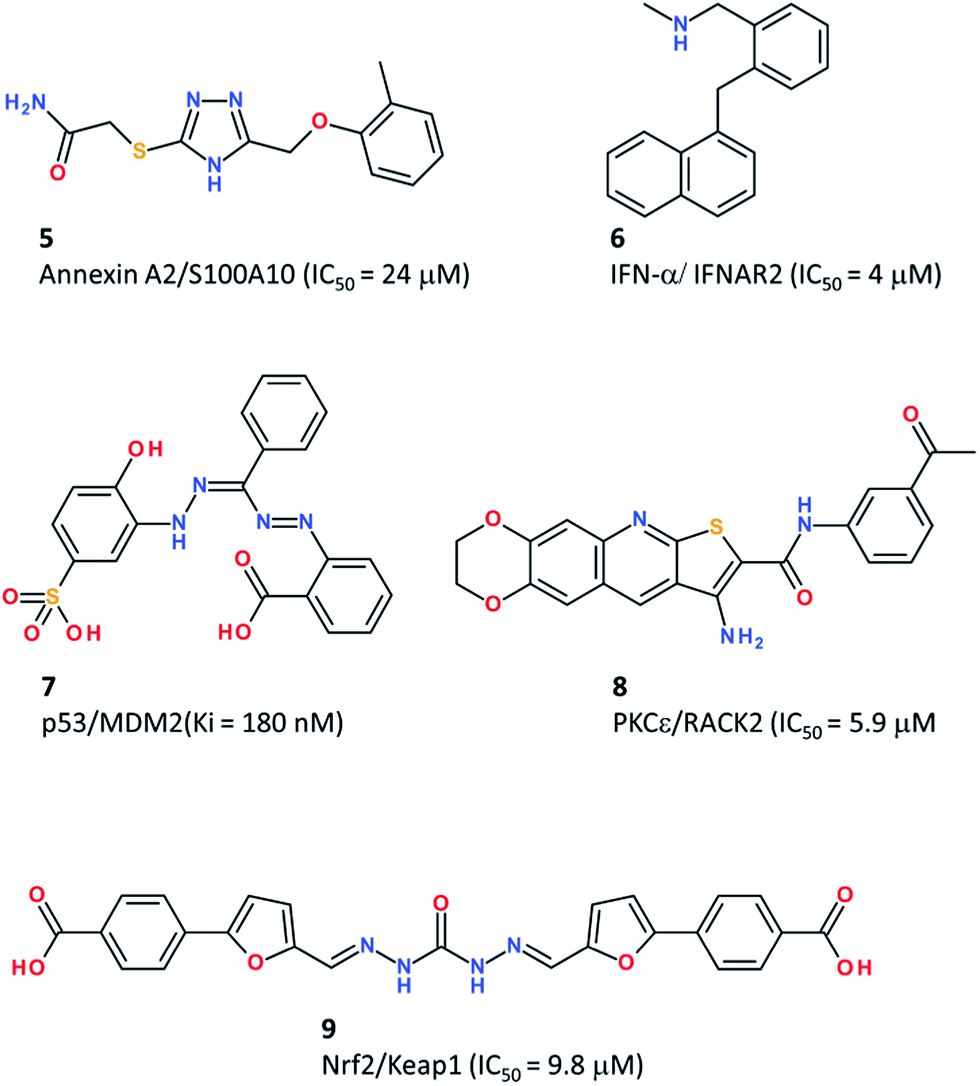 | ||
| Fig. 4 PPI inhibitors identified by pharmacophore-based virtual screening. | ||
Geppert et al.54 reported the rational discovery of a low molecular weight inhibitor of the complex between interferon-α (IFN-α) and its receptor (IFNAR2). Fortunately, the PPI interface was small enough (ca. 800 Å2) to be targeted by a small heterocyclic compound. After identifying major hotspots at the IFN-α surface, a fuzzy receptor-based pharmacophore was determined using the VirtualLigand approach,55 which assigns pharmacophoric features to Gaussian densities. Screening a collection of 556000 commercially available compounds retained six virtual hits, out of which two were weak IFN-α inhibitors, but one (compound 6, Fig. 4) was confirmed by NMR and surface plasmon resonance (SPR) to bind to IFN-α with a dissociation constant (Kd) of 4 μM and to inhibit IFN-α responses in various cell assays. The novel inhibitor may be useful to reduce IFN-α titers in autoimmune disorders.
Due to the inherent complexity of PPI pharmacophores (many features covering a large surface), combining several pharmacophores into a consensus model may help to retrieve essential features and simplify pharmacophore queries. Xue et al. applied this approach to the identification of p53–MDM2 inhibitors.56 The p53–MDM2 complex has become a prototypical PPI for its biological background (this interaction plays an important role in regulating the transcriptional activity of tumour cells) and many high affinity low molecular-weight inhibitors of this PPI identified by various screening approaches.59 Starting from a set of 15 MDM2-peptide X-ray structures, a common feature structure-based pharmacophore (2 H-bond donors, one H-bond acceptor, 2 aromatic rings, and one hydrophobe) was first identified. In addition, a receptor-ligand pharmacophore (five hydrophobes, one aromatic, and one H-bond donor) was generated from a separate set of 10 MDM2-non peptide complexes. Merging both pharmacophores and retaining the most common features led to an ensemble pharmacophore definition (two aromatic rings, two hydrophobes, and one H-bond donor) taking into account both peptide and non-peptide binding. This pharmacophore was used to screen a collection of 21287 commercially available compounds, and led to a hit list of 15 compounds out of which 6 were confirmed as p53–MDM2 inhibitors using an in vitro fluorescence polarization assay.56 The most potent inhibitor (compound 7, Fig. 4) is a 180 nM MDM2 inhibitor. Despite a good selectivity in a MTT tumour cell proliferation assay (p53+/+vs. p53−/− cells), compound 7 was a weak inhibitor (IC50 = 85 μM) of tumour cell growth, because of poor pharmacokinetic properties.
Along the same lines, two X-ray structures were used to derive inhibitors of the PPI between Keap1 and Nrf2, a complex involved in the response to oxidative stress.57 The two PPI pharmacophores were merged into a single query consisting of one H-bond donor, two H-bond acceptors and three negative ionisable centers. To afford some fuzziness in the search, up to two features were allowed to be missed by virtual hits. Since the Keap1-binding epitope of Nrf2 is composed of several acidic residues, only compounds bearing a negative charge were searched among a full commercial library of 251774 compounds. The remaining 21199 hit list was matched to the pharmacophore, and led after confirmation with docking and MM-PBSA scoring, to a list of 17 potential hits which were tested for Keap1–Nrf2 inhibition using an in vitro fluorescence polarization assay. A single compound (compound 9, Fig. 3) was confirmed in vitro as a moderately potent Keap1–Nrf2 inhibitor with an EC50 of 9.8 μM.57 Interestingly, the inhibitor activated the Nrf2 transcriptional activity.
When both protein partners involved in the PPI have not been co-crystallized, it is still possible to rationally discover PPI inhibitors, starting from the sole X-ray structure of one of the two proteins. This approach was followed by Rechfeld et al. in the discovery of PKCε–RACK2 inhibitors.58 Starting from the X-ray structure of the PKCε octameric epitope binding to RACK2 (a receptor for activated protein kinase C), a simple peptide-based pharmacophore model (3 H-bond donor/acceptor, one hydrophobe) was defined and used to screen a collection of 330000 compounds. Out of 19 virtual hits, a thienoquinoline was found to disrupt the PPI in vitro and served as a query for a secondary screen for chemically similar analogues, which led to compound 8 (Fig. 4) as a micromolar potent PKCε-RACK2 inhibitor (IC50 = 5.9 μM) which also inhibited PKCε downstream signalling, HeLa cancer cell migration and invasion.58
Finally, pharmacophore searches may be used to prioritize privileged scaffolds for synthesizing PPI-focused libraries. For example, Fry et al. reported a rational approach to PPI library design targeting α-helical binding epitopes.60 Starting from the known X-ray structure of an α-helical p53 epitope binding to MDM2, a three point pharmacophore, featuring the three important hydrophobic side chains (Phe19, Trp23, and Leu26) of the p53 peptide, was designed and used to find heterocyclic scaffolds among the CSD database61 of small molecule X-ray structures. Several small-sized libraries (ca. 100 members) were synthesized from each hit and tested for general inhibition of PPIs involving an α-helical epitope (e.g. MDM2, BCL2, BCL-XL, and MCL1). Although no potent hit could be discovered, the average hit rate was far superior (4%) to what should be expected from a random screen. Moreover, many starting hits exhibited good ligand efficiencies,60 and are therefore interesting starting points for hit leading optimization.
Despite its apparent simplicity, PPI-based pharmacophore search is a fast, cost-effective and simple in silico approach to discover the very first inhibitors of a particular PPI. Of course, all successful examples mentioned above imply that the PPI is of manageable size and does not involve a too large and complex binding epitope. Beside the existence of a X-ray or NMR structure of the protein–protein (peptide) complex, it is therefore equally important to properly select PPIs amenable to pharmacophore-based searches, notably with respect to the complexity of the query (5–6 features) and its hydrophobic/hydrophilic balance.
Docking-based approaches
At the first sight, protein–ligand docking should be considered as the most intuitive and logical computational tool to predict likely ligands of any target of known 3D structures.62 Unfortunately, severe drawbacks associated with the scoring of protein–ligand interactions render that tool usually suitable for positioning a ligand into a binding site, but rarely to predict binding free energies or to precisely rank ligands by decreasing affinity.63 Moreover, the ability of docking algorithms to anchor ligands to flat PPI surfaces has long remained elusive. In a benchmark study, Krüger et al. used two popular docking tools (AutoDock and Glide) to reproduce the known X-ray structure of PPI inhibitors to their target.64 Surprisingly, the performance of these standard docking programs with respect to the positioning of the ligand (rmsd to the X-ray structure) was only moderately affected by switching from conventional targets to PPIs. Although PPI inhibitors with more than 10 rotatable bonds were found more difficult to properly dock, a good pose was generated in ca. 54% of the 80 PPI inhibitors considered. Docking to PPIs providing at least one charge residue was favoured over those purely hydrophobic.64 There are therefore no particular reasons to discard docking-based approaches from rational PPI inhibitor discovery scenarios. Many of the following success stories support this assumption.We will not here review the many recent reports describing docking as a mean to predict the binding mode of a PPI inhibitor discovered by an experimental screening method.59,65–68 The next section will only focus on inhibitors discovered by a docking-based virtual screening campaign (Table 4).
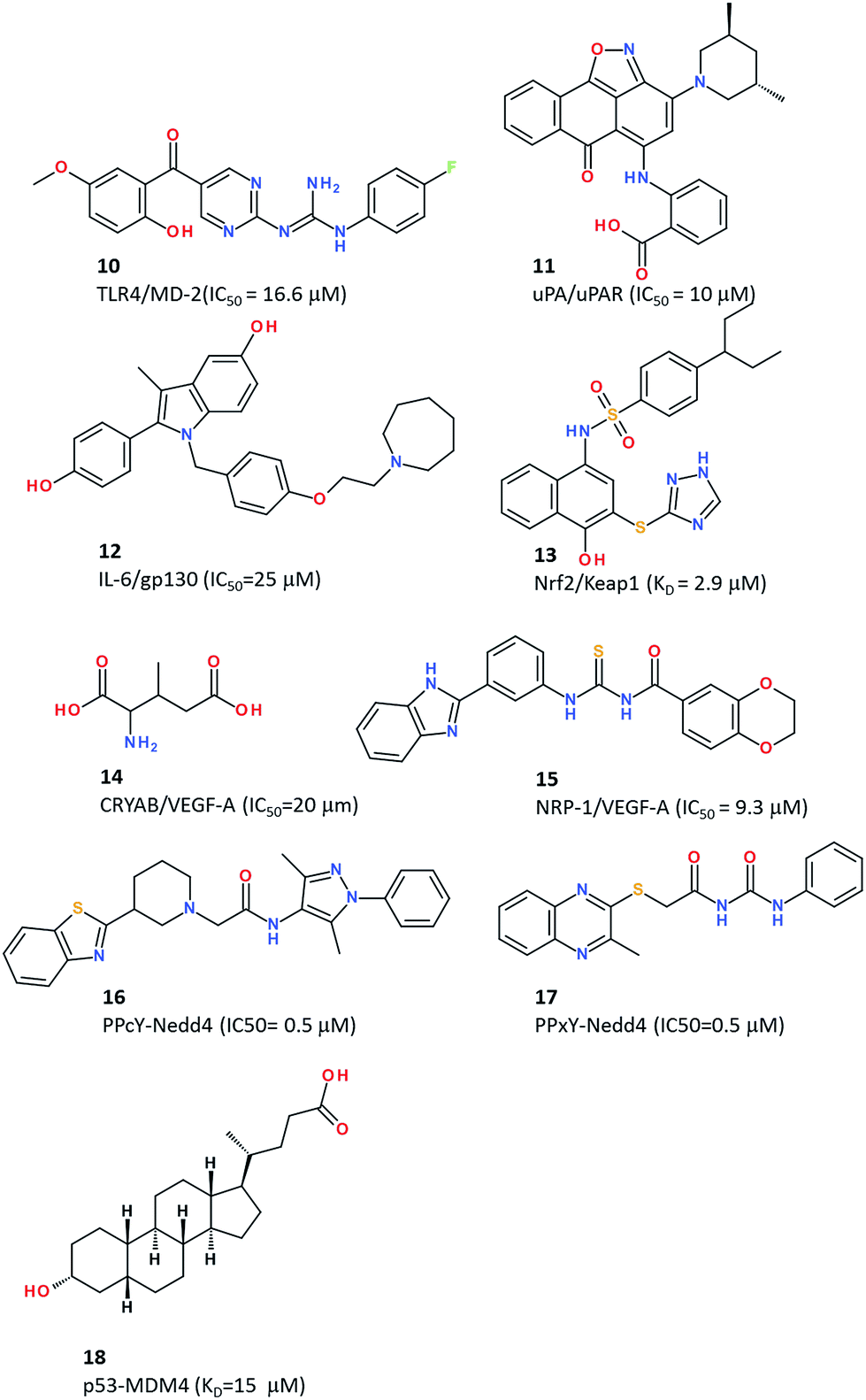
Despite an apparent unsuitable large and concave cavity, the MD-2-binding site at the surface of the toll-like receptor 4 (TLR4) was selected for pharmacophore-constrained FlexX77 docking of a library of 49600 compounds pre-filtered for 3D shape similarity to an existing TLR4 antagonist.69 40 virtual hits were selected for in vitro TLR4 binding and functional antagonism, and 3 of them could be confirmed experimentally. The most potent antagonist (compound 10, Fig. 5) blocked TLR4 in a gene receptor assay with an IC50 of 16.6 μM and inhibited pro-inflammatory cytokine release (e.g. TNF-α) from human peripheral blood mononuclear cells upon LPS activation. Due to unfavourable aqueous solubility, the compound could not be tested in vivo but represent a good starting hit for developing small molecule TLR4 antagonists for the treatment of neuropathic pain and sepsis.
 | ||
| Fig. 5 PPI inhibitors identified by docking-based virtual screening. | ||
To account for the conformational flexibility of proteins, Khanna et al. reported a cascade docking-based virtual screening for discovering inhibitors of the interaction between the urokinase-type plasminogen activator (uPA) and the urokinase receptor (uPAR).70 Two X-ray structures of the uPAR were first used for docking a collection of 5 million commercially available compounds using AutoDock4.78 10000 top-ranked virtual hits were further docked, still with AutoDock, to 50 molecular dynamics snapshots of the uPAR structure, leading to 500 top-ranked compounds which, in a third step, were docked using a different program (Glide) on the 50 receptor conformers. After clustering the top 250 compounds by chemical similarity, the highest scoring compounds from each of the top 50 clusters were finally selected, purchased and evaluated in vitro in a fluorescence polarization assay. Among the three validated hits, the most potent inhibitor (compound 11, Fig. 5) binds to uPRA with a submicromolar affinity (Kd = 310 nM) and inhibits the uPA–uPAR interaction with an IC50 of 10 μM.70 The hit blocked invasion of breast cancer cells but not their migration or adhesion. A close analogue of compound 11 was recently shown to be efficient in an in vivo breast cancer metastasis assay.79
Docking is not limited to the study of single protein–ligand interactions. In an elegant study, Li et al. reports a computational method enabling the simultaneous docking of multiple fragments to a single binding site, by analogy to experimental fragment screening.71 When applied to the PPI between IL-6 and gp130, simultaneous docking of two fragment pools (6 and 3 fragments, respectively) targeting two different hotspots at the PPI, two theoretical ligands could be reconstructed after tethering the best fragments at each hotspot. Searching for known drugs80 which are chemically similar to the two virtual hits suggested than two estrogen receptor modulators (raloxifene and bazedoxifene) may bind to the gp130/IL-6 PPI. Effective binding of both drugs to gp130 was confirmed experimentally, as well as inhibition of IL-6 induced STAT3 phosphorylation in various cancer cell lines defective in estrogen receptor expression. Bazedoxifene (compound 12, Fig. 5) was the most efficient (IC50 = 25 μM) in inhibiting the ER-independent IL6-induced breast cancer cell proliferation, thereby offering some repositioning potential in the treatment of IL-6/gp130/STAT3 dependent tumours.71
The Nrf2–Keap1 complex, previously investigated using a pharmacophore-based approach (see the previous section), was also used for docking 300000 commercially available compounds with the program Glide. Among the chemically diverse 65 top-ranking hits, 9 compounds were confirmed to be PPI inhibitors, the most potent disruptor (compound 13, Fig. 5) exhibiting a Kd of 2.9 μM in a fluorescence anisotropy-based assay.
A major hurdle in PPI inhibitor development is the frequently objected high molecular weight and unfavourable pharmacokinetic properties. Chen et al. strikingly contradicted this dogma by reporting a very low molecular weight inhibitor of the αB-crystallin (CRYAB)/VEGF-A interaction.73 CRYAB is a protein overexpressed in triple-negative breast cancer cells that acts as a chaperone to several proteins including the pro-angiogenic vascular endothelial growth factor (VEGF). Disrupting the interaction between CRYAB and VEGF-A is therefore a potential approach to cancer cell proliferation and invasion. The VEGF-binding site on the surface of the CRYAB X-ray structure was therefore targeted by docking 140000 compounds from the NCI database using the Dock6.5 program (UCSF). Despite a very modest molecular weight (161.16 Da), one compound (compound 14, Fig. 5) was identified as an in vitro disruptor of the CRYAB/VEGF-A interface with an IC50 of ca. 20 μM. Intraperitoneal injection of compound 14 (200 mg kg−1) remarkably suppresses tumour growth in vivo in human breast cancer xenograft models. VEGF-A is an important angiogenic factor that interacts with many other partners, notably the family of neuropilin receptors (NRP-1, NRP-2) whose inhibition leads to cancer cell apoptosis. The PPI between the C-terminal end of VEGF-A165 and the tandem b1 and b2 domains of NRP-1 was targeted for docking 430000 molecules with a consensus docking approach relying on two docking programs (Surflex-Dock81 and ICM82). A consensus list of 1317 top-scoring compounds was retained for their in vitro anti-proliferative activity and binding to NRP-1 using a chemiluminescent assay.74 56 molecules (hit rate of 4.2%) antagonized the NRP-1/VEGF-A interaction by at least 30% at the concentration of 10 μM. The best hit (compound 15, Fig. 5) is the first non-peptide NRP-1/VEGF-A antagonist (IC50 = 34 μM) and displays remarkable anti-proliferative effects (IC50 = 0.2 μM) on breast cancer cells. Administered at the dose of 50 mg kg−1 in NOG-xenografted mice, compound 15 strongly inhibits tumour growth inhibition by inducing cell apoptosis, without any effect on pro-angiogenic kinases.
Although most of the above reported therapeutical indications remain in the oncology field, PPI inhibitors have clear potential in other areas, notably infectious diseases as recently demonstrated by Han et al.75 who reported the structure-based discovery of antiviral compounds inhibiting viral–host interactions. The PPI target is the complex between the conserved L-domain PPxY sequence of several viral matrix proteins (e.g. Ebola, Marburg, Lassa fever, and VSV) and the ubiquitin ligase Nedd4 protein. Docking ca. 5 million compounds (ZINC database)83 on the Nedd4 X-ray structure with the AutoDock4 program, yielded to the evaluation of 20 compounds, out of which one molecule was confirmed as a true inhibitor of the PPI in a cellular assay. Acquiring close analogs of the initial hit led to two more potent inhibitors (compounds 16 and 17, Fig. 5) as submicromolar inhibitors of the PPxY–Nedd4 interaction in vitro.75 Both compounds exhibit antibudding activity against Ebola, Lassa fever, Marburg and VSV viruses, thereby decreasing viral titers, without apparent cytotoxicity on HEK293T cells.
Natural compounds are also a major source of potentially interesting PPI inhibitors. By docking a library of commercially available compounds to the p53 binding site, Vogel et al. recently reported lithocholic acid (compound 18, Fig. 5), a secondary bile acid, as a weak binder (Kd of 15 μM) to MDM4 and MDM2 proteins with a slight preference for MDM4.76 The natural compound was further shown to inhibit p53–MDM4 interactions and promote apoptosis in a p53-dependent manner by inducting caspase3/7.
Conclusions
We should acknowledge that peptides usually remain a good starting point to derive PPI inhibitors. Given the increasing number of high resolution X-ray structures of biologically relevant protein–protein complexes, the number of potentially increasing PPIs is likely to significantly rise in the next years. Provided that molecular rules exist to prioritize the most interesting anchoring residues at the interface, continuous protein epitopes can be easily converted into linear peptides for quick experimental validation. Recent progress in peptide stabilisation by chemical stapling next opens an immense field for deriving either pharmacological tools or drug candidates. Numerous successes in identifying non-peptide PPI inhibitors also exist. The present review has only considered inhibitors mostly discovered by a rational structure-based virtual screening approach. Despite the few cases described herein (15 in total), examples are pretty much indicative of results than can be reasonably achieved. Comparing the properties of PPIs (Fig. 6A and B) and their inhibitors (Fig. 6C) with previously reported larger PPI data,64 some trends could be verified. Considering success as the availability of low micromolar non-peptide inhibitors, successfully targeted PPIs present a higher proportion of charged residues with respect to conventional targets (sc-PDB data).84 Unsurprisingly, PPI inhibitors bind to smaller cavities (200–350 Å3) than that presented by conventional targets (450–800 Å3 range). Consequently, PPI inhibitors present a high proportion of aromatic rings, amide moieties and charged groups (Fig. 4 and 5) that hamper their druggability potential, as estimated here by the QED metric85 (Fig. 6C). We notice a significant proportion of negatively charged compounds, suggesting that a strong electrostatic interaction with the target is often mandatory to reach detectable affinity to PPI-participating cavities.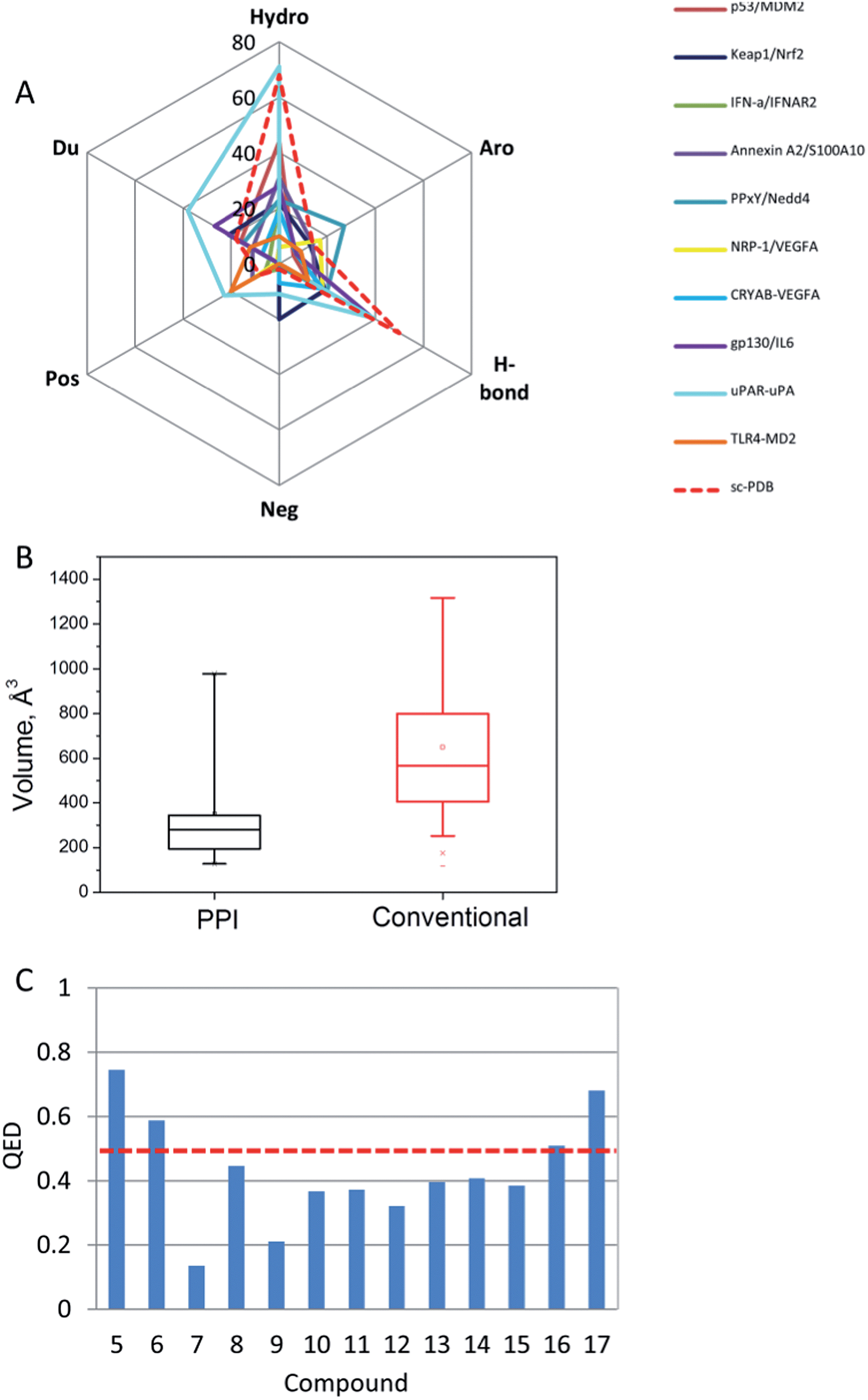 | ||
| Fig. 6 Properties of PPIs and their inhibitors: (A) cavity properties expressed in percentage according to the cavity detection VolSite program86 (Hydro, hydrophobic; Aro, aromatic; H-bond, H-bond accepting/donating properties; Neg: negatively charged; Pos, positively charged, Du: fully accessible); (B) cavity volumes targeted by PPI inhibitors (this review) and conventional ligands (sc-PDB data84). The box delimits the 25th and 75th percentiles, and the whiskers delimit the 5th and 95th percentiles. The median and mean values are indicated by a horizontal line and an empty square in the box; (C) quantitative estimate of druggability (QED)85 of the inhibitors. QED values for true drug-like compounds should be over 0.5 (red broken line). | ||
However, the current survey also indicates that there is no absolute dogma with respect to PPI inhibitor identification. Very low molecular weight compounds (compounds 1, 6 and 14) have been successfully identified as PPI disruptors.
Beside interfacial inhibitors, there exist promising alternative ways of inhibiting PPIs. For example, PPI stabilizers87,88 (e.g. paclitaxel, rapmycine, and forskolin) bind to rim exposed pockets at or very close to the interface, and also lead to the functional inactivation of the protein–protein complex. Such stabilizers are frequent in the nature, and this area still has not been fully exploited until now. Likewise, the allosteric inhibition of PPIs, at pockets remote from the interface, clearly deserves some consideration. Such pockets have been shown to be frequent at the close vicinity of two protein chains in close interaction,89 and represent, at least for some of them, more ligandable pockets than those presented by PPIs.
Although dominated by a continent of flat and featureless interfaces, the PPI world is also populated by very different islands in terms of shape and electrostatics that should not been discarded. Many factors are likely to increase our knowledge of PPIs and their inhibitors among which: (i) the increasing number of biologically relevant and crystallized protein–protein complexes, (ii) the development of label-free experimental screening techniques, and (iii) the significant contribution of molecular simulations to detect transient interfaces. Medicinal chemistry will be a key factor to transform moderately potent PPI inhibitor hits into clinical candidates with desired pharmacokinetic properties.
References
- http://www.uniprot.org/uniprot/?query=organism%3A9606+AND+keyword:%22Complete+proteome+[KW-0181]%22, (accessed 17/07/2014).
- J. P. Overington, B. Al-Lazikani and A. L. Hopkins, Nat. Rev. Drug Discovery, 2006, 5, 993–996 CrossRef CAS PubMed.
- P. Legrain and J. C. Rain, J. Proteomics, 2014, 107, 93–97 CrossRef CAS PubMed.
- K. Venkatesan, J. F. Rual, A. Vazquez, U. Stelzl, I. Lemmens, T. Hirozane-Kishikawa, T. Hao, M. Zenkner, X. Xin, K. I. Goh, M. A. Yildirim, N. Simonis, K. Heinzmann, F. Gebreab, J. M. Sahalie, S. Cevik, C. Simon, A. S. de Smet, E. Dann, A. Smolyar, A. Vinayagam, H. Yu, D. Szeto, H. Borick, A. Dricot, N. Klitgord, R. R. Murray, C. Lin, M. Lalowski, J. Timm, K. Rau, C. Boone, P. Braun, M. E. Cusick, F. P. Roth, D. E. Hill, J. Tavernier, E. E. Wanker, A. L. Barabasi and M. Vidal, Nat. Methods, 2009, 6, 83–90 CrossRef CAS PubMed.
- M. P. Stumpf, T. Thorne, E. de Silva, R. Stewart, H. J. An, M. Lappe and C. Wiuf, Proc. Natl. Acad. Sci. U. S. A., 2008, 105, 6959–6964 CrossRef CAS PubMed.
- A. Whitty and G. Kumaravel, Nat. Chem. Biol., 2006, 2, 112–118 CrossRef CAS PubMed.
- J. A. Wells and C. L. McClendon, Nature, 2007, 450, 1001–1009 CrossRef CAS PubMed.
- A. G. Cochran, Chem. Biol., 2000, 7, R85–R94 CrossRef CAS.
- A. Mullard, Nat. Rev. Drug Discovery, 2012, 11, 173–175 CrossRef CAS PubMed.
- C. M. Labbe, G. Laconde, M. A. Kuenemann, B. O. Villoutreix and O. Sperandio, Drug Discovery Today, 2013, 18, 958–968 CrossRef CAS PubMed.
- A. A. Ivanov, F. R. Khuri and H. Fu, Trends Pharmacol. Sci., 2013, 34, 393–400 CrossRef CAS PubMed.
- R. Bourgeas, M. J. Basse, X. Morelli and P. Roche, PLoS One, 2010, 5, e9598 Search PubMed.
- M. R. Arkin, M. Randal, W. L. DeLano, J. Hyde, T. N. Luong, J. D. Oslob, D. R. Raphael, L. Taylor, J. Wang, R. S. McDowell, J. A. Wells and A. C. Braisted, Proc. Natl. Acad. Sci. U. S. A., 2003, 100, 1603–1608 CrossRef CAS PubMed.
- M. R. Arkin and J. A. Wells, Nat. Rev. Drug Discovery, 2004, 3, 301–317 CrossRef CAS PubMed.
- A. P. Higueruelo, A. Schreyer, G. R. Bickerton, W. R. Pitt, C. R. Groom and T. L. Blundell, Chem. Biol. Drug Des., 2009, 74, 457–467 CAS.
- X. Morelli, R. Bourgeas and P. Roche, Curr. Opin. Chem. Biol., 2011, 15, 475–481 CrossRef CAS PubMed.
- S. Orchard, M. Ammari, B. Aranda, L. Breuza, L. Briganti, F. Broackes-Carter, N. H. Campbell, G. Chavali, C. Chen, N. del-Toro, M. Duesbury, M. Dumousseau, E. Galeota, U. Hinz, M. Iannuccelli, S. Jagannathan, R. Jimenez, J. Khadake, A. Lagreid, L. Licata, R. C. Lovering, B. Meldal, A. N. Melidoni, M. Milagros, D. Peluso, L. Perfetto, P. Porras, A. Raghunath, S. Ricard-Blum, B. Roechert, A. Stutz, M. Tognolli, K. van Roey, G. Cesareni and H. Hermjakob, Nucleic Acids Res., 2014, 42, D358–D363 CrossRef CAS PubMed.
- B. O. Villoutreix, M. A. Kuenemann, J.-L. Poyet, H. Bruzzoni-Giovanelli, C. Labbé, D. Lagorce, O. Sperandio and M. A. Miteva, Mol. Inf., 2014, 33, 414–437 CrossRef CAS PubMed.
- R. Rid, W. Strasser, D. Siegl, C. Frech, M. Kommenda, T. Kern, H. Hintner, J. W. Bauer and K. Onder, Assay Drug Dev. Technol., 2013, 11, 333–346 CrossRef CAS PubMed.
- C. Alfarano, C. E. Andrade, K. Anthony, N. Bahroos, M. Bajec, K. Bantoft, D. Betel, B. Bobechko, K. Boutilier, E. Burgess, K. Buzadzija, R. Cavero, C. D'Abreo, I. Donaldson, D. Dorairajoo, M. J. Dumontier, M. R. Dumontier, V. Earles, R. Farrall, H. Feldman, E. Garderman, Y. Gong, R. Gonzaga, V. Grytsan, E. Gryz, V. Gu, E. Haldorsen, A. Halupa, R. Haw, A. Hrvojic, L. Hurrell, R. Isserlin, F. Jack, F. Juma, A. Khan, T. Kon, S. Konopinsky, V. Le, E. Lee, S. Ling, M. Magidin, J. Moniakis, J. Montojo, S. Moore, B. Muskat, I. Ng, J. P. Paraiso, B. Parker, G. Pintilie, R. Pirone, J. J. Salama, S. Sgro, T. Shan, Y. Shu, J. Siew, D. Skinner, K. Snyder, R. Stasiuk, D. Strumpf, B. Tuekam, S. Tao, Z. Wang, M. White, R. Willis, C. Wolting, S. Wong, A. Wrong, C. Xin, R. Yao, B. Yates, S. Zhang, K. Zheng, T. Pawson, B. F. Ouellette and C. W. Hogue, Nucleic Acids Res., 2005, 33, D418–D424 CrossRef CAS PubMed.
- L. Salwinski, C. S. Miller, A. J. Smith, F. K. Pettit, J. U. Bowie and D. Eisenberg, Nucleic Acids Res., 2004, 32, D449–D451 CrossRef CAS PubMed.
- T. S. Keshava Prasad, R. Goel, K. Kandasamy, S. Keerthikumar, S. Kumar, S. Mathivanan, D. Telikicherla, R. Raju, B. Shafreen, A. Venugopal, L. Balakrishnan, A. Marimuthu, S. Banerjee, D. S. Somanathan, A. Sebastian, S. Rani, S. Ray, C. J. Harrys Kishore, S. Kanth, M. Ahmed, M. K. Kashyap, R. Mohmood, Y. L. Ramachandra, V. Krishna, B. A. Rahiman, S. Mohan, P. Ranganathan, S. Ramabadran, R. Chaerkady and A. Pandey, Nucleic Acids Res., 2009, 37, D767–D772 CrossRef CAS PubMed.
- P. Pagel, S. Kovac, M. Oesterheld, B. Brauner, I. Dunger-Kaltenbach, G. Frishman, C. Montrone, P. Mark, V. Stumpflen, H. W. Mewes, A. Ruepp and D. Frishman, Bioinformatics, 2005, 21, 832–834 CrossRef CAS PubMed.
- C. Prieto and J. De Las Rivas, Nucleic Acids Res., 2006, 34, W298–W302 CrossRef CAS PubMed.
- N. Sugaya, S. Kanai and T. Furuya, Database, 2012, 2012, bas034 CrossRef PubMed.
- F. N. Edfeldt, R. H. Folmer and A. L. Breeze, Drug Discovery Today, 2011, 16, 284–287 CrossRef CAS PubMed.
- D. C. Fry, Curr. Protein Pept. Sci., 2008, 9, 240–247 CrossRef CAS.
- D. Joseph-McCarthy, A. J. Campbell, G. Kern and D. Moustakas, J. Chem. Inf. Model., 2014, 54, 693–704 CrossRef CAS PubMed.
- A. P. Higueruelo, H. Jubb and T. L. Blundell, Database, 2013, 2013, bat039 CrossRef PubMed.
- M. J. Basse, S. Betzi, R. Bourgeas, S. Bouzidi, B. Chetrit, V. Hamon, X. Morelli and P. Roche, Nucleic Acids Res., 2013, 41, D824–D827 CrossRef CAS PubMed.
- V. Hamon, R. Bourgeas, P. Ducrot, I. Theret, L. Xuereb, M. J. Basse, J. M. Brunel, S. Combes, X. Morelli and P. Roche, J. R. Soc., Interface, 2014, 11, 20130860 CrossRef PubMed.
- A. Gaulton, L. J. Bellis, A. P. Bento, J. Chambers, M. Davies, A. Hersey, Y. Light, S. McGlinchey, D. Michalovich, B. Al-Lazikani and J. P. Overington, Nucleic Acids Res., 2012, 40, D1100–D1107 CrossRef CAS PubMed.
- H. M. Berman, J. Westbrook, Z. Feng, G. Gilliland, T. N. Bhat, H. Weissig, I. N. Shindyalov and P. E. Bourne, Nucleic Acids Res., 2000, 28, 235–242 CrossRef CAS PubMed.
- T. Clackson and J. A. Wells, Science, 1995, 267, 383–386 CrossRef CAS.
- Y. F. Lin, T. C. Lai, C. K. Chang, C. L. Chen, M. S. Huang, C. J. Yang, H. G. Liu, J. J. Dong, Y. A. Chou, K. H. Teng, S. H. Chen, W. T. Tian, Y. H. Jan, M. Hsiao and P. H. Liang, J. Clin. Invest., 2013, 123, 3861–3875 CAS.
- M. A. Bonache, B. Balsera, B. Lopez-Mendez, O. Millet, D. Brancaccio, I. Gomez-Monterrey, A. Carotenuto, L. M. Pavone, M. Reille-Seroussi, N. Gagey-Eilstein, M. Vidal, R. de la Torre-Martinez, A. Fernandez-Carvajal, A. Ferrer-Montiel, M. T. Garcia-Lopez, M. Martin-Martinez, M. J. de Vega and R. Gonzalez-Muniz, ACS Comb. Sci., 2014, 16, 250–258 CrossRef CAS PubMed.
- Z. Mi, X. Wang, Y. He, X. Li, J. Ding, H. Liu, J. Zhou and S. Cen, Biopolymers, 2014, 102, 280–287 CrossRef CAS PubMed.
- A. Glas, D. Bier, G. Hahne, C. Rademacher, C. Ottmann and T. N. Grossmann, Angew. Chem., Int. Ed., 2014, 53, 2489–2493 CrossRef CAS PubMed.
- V. Azzarito, K. Long, N. S. Murphy and A. J. Wilson, Nat. Chem., 2013, 5, 161–173 CrossRef CAS PubMed.
- L. D. Walensky, A. L. Kung, I. Escher, T. J. Malia, S. Barbuto, R. D. Wright, G. Wagner, G. L. Verdine and S. J. Korsmeyer, Science, 2004, 305, 1466–1470 CrossRef CAS PubMed.
- C. J. Brown, S. T. Quah, J. Jong, A. M. Goh, P. C. Chiam, K. H. Khoo, M. L. Choong, M. A. Lee, L. Yurlova, K. Zolghadr, T. L. Joseph, C. S. Verma and D. P. Lane, ACS Chem. Biol., 2013, 8, 506–512 CrossRef CAS PubMed.
- F. Bernal, A. F. Tyler, S. J. Korsmeyer, L. D. Walensky and G. L. Verdine, J. Am. Chem. Soc., 2007, 129, 2456–2457 CrossRef CAS PubMed.
- Y. S. Chang, B. Graves, V. Guerlavais, C. Tovar, K. Packman, K. H. To, K. A. Olson, K. Kesavan, P. Gangurde, A. Mukherjee, T. Baker, K. Darlak, C. Elkin, Z. Filipovic, F. Z. Qureshi, H. Cai, P. Berry, E. Feyfant, X. E. Shi, J. Horstick, D. A. Annis, A. M. Manning, N. Fotouhi, H. Nash, L. T. Vassilev and T. K. Sawyer, Proc. Natl. Acad. Sci. U. S. A., 2013, 110, E3445–E3454 CrossRef CAS PubMed.
- L. R. Whitby and D. L. Boger, Acc. Chem. Res., 2012, 45, 1698–1709 CrossRef CAS PubMed.
- T. Yamada, K. Christov, A. Shilkaitis, L. Bratescu, A. Green, S. Santini, A. R. Bizzarri, S. Cannistraro, T. K. Gupta and C. W. Beattie, Br. J. Cancer, 2013, 108, 2495–2504 CrossRef CAS PubMed.
- M. A. Warso, J. M. Richards, D. Mehta, K. Christov, C. Schaeffer, L. Rae Bressler, T. Yamada, D. Majumdar, S. A. Kennedy, C. W. Beattie and T. K. Das Gupta, Br. J. Cancer, 2013, 108, 1061–1070 CrossRef CAS PubMed.
- C. G. Wermuth, C. R. Ganellin, P. Lindberg and L. A. Mitscher, Pure Appl. Chem., 1998, 70, 1129–1143 CrossRef CAS.
- A. R. Leach, V. J. Gillet, R. A. Lewis and R. Taylor, J. Med. Chem., 2010, 53, 539–558 CrossRef CAS PubMed.
- G. Wolber and T. Langer, J. Chem. Inf. Model., 2005, 45, 160–169 CrossRef CAS PubMed.
- J. Meslamani, J. Li, J. Sutter, A. Stevens, H. O. Bertrand and D. Rognan, J. Chem. Inf. Model., 2012, 52, 943–955 CrossRef CAS PubMed.
- D. R. Koes and C. J. Camacho, Nucleic Acids Res., 2012, 40, W387–W392 CrossRef CAS PubMed.
- T. R. Reddy, C. Li, P. M. Fischer and L. V. Dekker, ChemMedChem, 2012, 7, 1435–1446 CrossRef CAS PubMed.
- TRIPOS: St-Louis, MO 63144-2319, USA.
- T. Geppert, S. Bauer, J. A. Hiss, E. Conrad, M. Reutlinger, P. Schneider, M. Weisel, B. Pfeiffer, K. H. Altmann, Z. Waibler and G. Schneider, Angew. Chem., Int. Ed., 2012, 51, 258–261 CrossRef CAS PubMed.
- M. Lower, T. Geppert, P. Schneider, B. Hoy, S. Wessler and G. Schneider, PLoS One, 2011, 6, e17986 Search PubMed.
- X. Xue, J. L. Wei, L. L. Xu, M. Y. Xi, X. L. Xu, F. Liu, X. K. Guo, L. Wang, X. J. Zhang, M. Y. Zhang, M. C. Lu, H. P. Sun and Q. D. You, J. Chem. Inf. Model., 2013, 53, 2715–2729 CrossRef CAS PubMed.
- H. P. Sun, Z. Y. Jiang, M. Y. Zhang, M. C. Lu, T. T. Yang, Y. Pan, H. Z. Huang, X. J. Zhang and Q. D. You, MedChemComm, 2014, 5, 93–98 RSC.
- F. Rechfeld, P. Gruber, J. Kirchmair, M. Boehler, N. Hauser, G. Hechenberger, D. Garczarczyk, G. B. Lapa, M. N. Preobrazhenskaya, P. Goekjian, T. Langer and J. Hofmann, J. Med. Chem., 2014, 57, 3235–3246 CrossRef CAS PubMed.
- Z. Y. Jiang, M. C. Lu, L. L. Xu, T. T. Yang, M. Y. Xi, X. L. Xu, X. K. Guo, X. J. Zhang, Q. D. You and H. P. Sun, J. Med. Chem., 2014, 57, 2736–2745 CrossRef CAS PubMed.
- D. Fry, K. S. Huang, P. Di Lello, P. Mohr, K. Muller, S. S. So, T. Harada, M. Stahl, B. Vu and H. Mauser, ChemMedChem, 2013, 8, 726–732 CrossRef CAS PubMed.
- F. H. Allen, Acta Crystallogr., Sect. B: Struct. Sci., 2002, 58, 380–388 CrossRef PubMed.
- N. Moitessier, P. Englebienne, D. Lee, J. Lawandi and C. R. Corbeil, Br. J. Pharmacol., 2008, 153(suppl. 1), S7–S26 CAS.
- K. L. Damm-Ganamet, R. D. Smith, J. B. Dunbar, Jr, J. A. Stuckey and H. A. Carlson, J. Chem. Inf. Model., 2013, 53, 1853–1870 CrossRef CAS PubMed.
- D. M. Krüger, G. Jessen and H. Gohlke, J. Chem. Inf. Model., 2012, 52, 2807–2811 CrossRef PubMed.
- J. R. Courter, N. Madani, J. Sodroski, A. Schon, E. Freire, P. D. Kwong, W. A. Hendrickson, I. M. Chaiken, J. M. LaLonde and A. B. Smith, 3rd, Acc. Chem. Res., 2014, 47, 1228–1237 CrossRef CAS PubMed.
- S. He, T. J. Senter, J. Pollock, C. Han, S. K. Upadhyay, T. Purohit, R. D. Gogliotti, C. W. Lindsley, T. Cierpicki, S. R. Stauffer and J. Grembecka, J. Med. Chem., 2014, 57, 1543–1556 CrossRef CAS PubMed.
- M. Mori, G. Vignaroli, Y. Cau, J. Dinic, R. Hill, M. Rossi, D. Colecchia, M. Pesic, W. Link, M. Chiariello, C. Ottmann and M. Botta, ChemMedChem, 2014, 9, 973–983 CrossRef CAS PubMed.
- F. A. Abulwerdi, C. Liao, A. S. Mady, J. Gavin, C. Shen, T. Cierpicki, J. A. Stuckey, H. D. Showalter and Z. Nikolovska-Coleska, J. Med. Chem., 2014, 57, 4111–4133 CrossRef CAS PubMed.
- U. Svajger, B. Brus, S. Turk, M. Sova, V. Hodnik, G. Anderluh and S. Gobec, Eur. J. Med. Chem., 2013, 70, 393–399 CrossRef CAS PubMed.
- M. Khanna, F. Wang, I. Jo, W. E. Knabe, S. M. Wilson, L. Li, K. Bum-Erdene, J. Li, G. W. Sledge, R. Khanna and S. O. Meroueh, ACS Chem. Biol., 2011, 6, 1232–1243 CrossRef CAS PubMed.
- H. Li, H. Xiao, L. Lin, D. Jou, V. Kumari, J. Lin and C. Li, J. Med. Chem., 2014, 57, 632–641 CrossRef CAS PubMed.
- C. Zhuang, S. Narayanapillai, W. Zhang, Y. Y. Sham and C. Xing, J. Med. Chem., 2014, 57, 1121–1126 CrossRef CAS PubMed.
- Z. Chen, Q. Ruan, S. Han, L. Xi, W. Jiang, H. Jiang, D. A. Ostrov and J. Cai, Breast Cancer Res. Treat., 2014, 145, 45–59 CrossRef CAS PubMed.
- L. Borriello, M. Montes, Y. Lepelletier, B. Leforban, W. Q. Liu, L. Demange, B. Delhomme, S. Pavoni, R. Jarray, J. L. Boucher, S. Dufour, O. Hermine, C. Garbay, R. Hadj-Slimane and F. Raynaud, Cancer Lett., 2014, 349, 120–127 CrossRef CAS PubMed.
- Z. Han, J. Lu, Y. Liu, B. Davis, M. S. Lee, M. A. Olson, G. Ruthel, B. D. Freedman, M. J. Schnell, J. E. Wrobel, A. B. Reitz and R. N. Harty, J. Virol., 2014, 88, 7294–7306 CrossRef CAS PubMed.
- S. M. Vogel, M. R. Bauer, A. C. Joerger, R. Wilcken, T. Brandt, D. B. Veprintsev, T. J. Rutherford, A. R. Fersht and F. M. Boeckler, Proc. Natl. Acad. Sci. U. S. A., 2012, 109, 16906–16910 CrossRef CAS PubMed.
- M. Rarey, B. Kramer, T. Lengauer and G. Klebe, J. Mol. Biol., 1996, 261, 470–489 CrossRef CAS PubMed.
- G. M. Morris, D. S. Goodsell, R. S. Halliday, R. Huey, W. E. Hart, R. K. Belew and A. J. Olson, J. Comput. Chem., 1998, 19, 1639–1662 CrossRef CAS.
- T. Mani, F. Wang, W. E. Knabe, A. L. Sinn, M. Khanna, I. Jo, G. E. Sandusky, G. W. Sledge, Jr., D. R. Jones, R. Khanna, K. E. Pollok and S. O. Meroueh, Bioorg. Med. Chem., 2013, 21, 2145–2155 CrossRef CAS PubMed.
- C. Knox, V. Law, T. Jewison, P. Liu, S. Ly, A. Frolkis, A. Pon, K. Banco, C. Mak, V. Neveu, Y. Djoumbou, R. Eisner, A. C. Guo and D. S. Wishart, Nucleic Acids Res., 2011, 39, D1035–D1041 CrossRef CAS PubMed.
- A. N. Jain, J. Comput.-Aided Mol. Des., 2007, 21, 281–306 CrossRef CAS PubMed.
- M. A. Neves, M. Totrov and R. Abagyan, J. Comput.-Aided Mol. Des., 2012, 26, 675–686 CrossRef CAS PubMed.
- J. J. Irwin and B. K. Shoichet, J. Chem. Inf. Model., 2005, 45, 177–182 CrossRef CAS PubMed.
- J. Meslamani, D. Rognan and E. Kellenberger, Bioinformatics, 2011, 27, 1324–1326 CrossRef CAS PubMed.
- G. R. Bickerton, G. V. Paolini, J. Besnard, S. Muresan and A. L. Hopkins, Nat. Chem., 2012, 4, 90–98 CrossRef CAS PubMed.
- J. Desaphy, K. Azdimousa, E. Kellenberger and D. Rognan, J. Chem. Inf. Model., 2012, 52, 2287–2299 CrossRef CAS PubMed.
- P. Thiel, M. Kaiser and C. Ottmann, Angew. Chem., Int. Ed., 2012, 51, 2012–2018 CrossRef CAS PubMed.
- P. Block, N. Weskamp, A. Wolf and G. Klebe, Proteins, 2007, 68, 170–186 CrossRef CAS PubMed.
- M. Gao and J. Skolnick, Proc. Natl. Acad. Sci. U. S. A., 2012, 109, 3784–3789 CrossRef CAS PubMed.
| This journal is © The Royal Society of Chemistry 2015 |