Self-explaining effect in general chemistry instruction: eliciting overt categorical behaviours by design†
Adrian
Villalta-Cerdas
and
Santiago
Sandi-Urena
*
Department of Chemistry CHE205, University of South Florida, Tampa, Florida 33620, USA. E-mail: ssandi@usf.edu
First published on 9th April 2014
Abstract
Self-explaining refers to the generation of inferences about causal connections between objects and events. In science, this may be summarised as making sense of how and why actual or hypothetical phenomena take place. Research findings in educational psychology show that implementing activities that elicit self-explaining improves learning in general and specifically enhances authentic learning in the sciences. Research also suggests that self-explaining influences many aspects of cognition, including acquisition of problem-solving skills and conceptual understanding. Although the evidence that links self-explaining and learning is substantial, most of the research has been conducted in experimental settings. There remains a need for research conducted in the context of real college science learning environments. Working to address that need, the larger project in which this work is embedded studied the following: (a) the effect of different self-explaining tasks on self-explaining behaviour and (b) the effect of engaging in different levels of self-explaining on learning chemistry concepts. The present study used a multi-condition, mixed-method approach to categorise student self-explaining behaviours in response to learning tasks. Students were randomly assigned to conditions that included the following: explaining correct and incorrect answers, explaining agreement with another's answer, and explaining one's own answer for others to use. Textual, individual data was gathered in the classroom ecology of a university, large-enrolment general chemistry course. Findings support an association between the self-explaining tasks and students' self-explaining behaviours. Thoughtful design of learning tasks can effectively elicit engagement in sophisticated self-explaining in natural, large-enrolment college chemistry classroom environments.
Introduction
Regardless of correctness, generation of authentic explanations is a core characteristic of scientific behaviour and central to scientific and technological development (Deutsch, 2011). This centrality is reflected by the US Next Generation Science Standards (National Research Council, 2013) that posit the construction of explanations as one of eight practices of science essential for all students to learn. Furthermore, A Science Framework for K-12 Science Education (National Research Council, 2012) asserts that when students demonstrate their understanding of the implications of a scientific idea by developing their own explanations of phenomena, they take part in an essential activity by which conceptual change can occur. That is, in addition to being a desirable learning outcome in itself, the ability to generate one's own explanations supports conceptual learning. The process of generating scientific explanations requires analysis and reflection of current models and theories, thereby influencing conceptual understanding. In the process of formulating explanations, the generation of inferences relies on the application of skills associated with scientific behaviour (e.g., analytical reasoning and critical thinking). In this study we explore student engagement in the process of generating authentic explanations, by and for themselves, through a General Chemistry in-class activity that prompts them to self-explain.Self-explaining is a domain-independent learning strategy whose effect has been widely replicated, and it refers to student's generation of inferences of causality (Siegler and Lin, 2009). Its effectiveness compared to other learning activities is explained by the passive–active-constructive-interactive, ICAP, theoretical framework first introduced by Chi (2009) and to which we ascribe in our work. In the ICAP framework, a learning activity is characterized by observable, overt actions undertaken by the learner. These overt actions are assumed to be an adequate proxy for the covert cognitive processes that support the manifested behaviours. Although, understandably specific overt behaviours are not a requisite for the learners to resort to specific cognitive processes, Chi (2009) argues that learners are more likely to engage in certain cognitive processes when they display certain overt actions. These actions (and their products) are in turn manipulable by the instructor or researcher and allow their use as evidence of learning, that is, they can be assessed, coded, and analysed (Fonseca and Chi, 2010). It is this quality what renders possible the classification of learning activities from the learner's perspective. Passive, active, constructive, and interactive refer to and are defined by what the learner does when in contact with the learning materials, the overt behaviours. A passive learning activity is characterised by lack of actions on the learner's part. For example, listening to a lecture or reading a text without engaging in any additional activity such as note taking or underlining. In an active learning activity, the learner does something physical in support of learning. Highlighting while reading falls under the active category as does repeating rules that describe periodic trends to increase retention. The production of “some additional output that contains information beyond that provided in the original material” (Fonseca and Chi, 2010, p. 301) is the hallmark of constructive learning activities. Constructing a concept map and comparing and contrasting chemical reactivity are two examples. An interactive learning activity is one in which the learner establishes a dialogue with a peer, expert, or intelligent system that includes substantive contributions from all parts and where no part's contribution is ignored. Therefore, if one interlocutor dominates the interaction or participants simply take turns speaking and ignore each other's contributions, the activity is not considered interactive. Thorough analysis of published research has contributed evidence supporting the hypothesis that learning activities produce greater learning outcomes when they are interactive compared to constructive (Chi, 2009). Likewise, constructive activities are more efficient than active and active than passive.
Self-explaining is a constructive learning activity. It requires the learner to elaborate upon the presented information by relating it to prior knowledge and integrating with other pieces of information to generate inferences beyond the learning materials. Therefore, individuals build new knowledge as they uniquely appraise their own mental model during the process of solving a given task and elaborate their self-explanations—the outcomes of self-explaining (Chi, 2000).
Despite the prolific research literature on self-explaining in specialised journals, very little research has appeared in publications that are typically within the scope of chemistry educators (Villalta-Cerdas and Sandi-Urena, 2013). This single fact may account for the widespread absence of self-explaining in chemistry instruction in contrast with the prevalence of approaches that teach chemistry as a collection of facts, which Schwab (1962) referred to as rhetoric of conclusions. Evidently, this disconnect is not exclusive to self-explaining or chemistry education. It is part of a bigger picture where “the research communities that study and enact change are largely isolated from one another” (Henderson et al., 2011).
We identified such a void in domain-specific research pertaining to chemical education (Villalta-Cerdas and Sandi-Urena, 2013): only two articles have explored self-explaining in chemistry and both addressed computer-assisted learning (Crippen and Earl, 2004; Crippen and Earl, 2007). In addition, even when focused on STEM knowledge domains, research has rarely focused on STEM majors (Villalta-Cerdas and Sandi-Urena, 2013). To date, the research has been largely theoretical in nature and not applied, and it has been conducted in educational research laboratory settings (e.g., Chi et al., 1989; Bielaczyc et al., 1995; Schworm and Renkl, 2006; Gadgil et al., 2012; Villalta-Cerdas and Sandi-Urena, 2013). In this sense, a laboratory is a space where individuals are abstracted from their natural learning environment and function as study participants, not necessarily as students. Although this trend is changing (Villalta-Cerdas and Sandi-Urena, 2013), the need for applied research in naturalistic classroom environments persists in order to gather ecological evidence to support novel pedagogical strategies.
The 2013 National Survey of Student Engagement (NSSE) report showed that half of the respondents who majored in physical sciences, math, and computer science, never or only sometimes “prepared for exams discussing or working through course material with other students” (NSSE, 2013). Likewise, preliminary results of study habits at our own institution suggest that only a small segment of General Chemistry 1 students engage in group study outside the classroom. In the fall of 2013 only 13% reported to study in a group for up to one quarter of their study time. For the remaining students nearly all of their unsupervised learning occurred individually. Although we strongly support interactive learning in its multiple expressions, it seems reasonable to think that students do not have the opportunities to maximise use of collaborative skills they may learn in the classroom. On the other hand, in-class constructive learning activities can reinforce learning strategies students can eventually use spontaneously while studying individually. Added to the robust research evidence that supports the self-explaining effect (Chi et al., 1989; Villalta-Cerdas and Sandi-Urena, 2013), our interest in this particular constructive learning activity stems from its being an essential and desirable scientific competence (National Research Council, 2013).
In our research group, we endeavour to develop studies that address the void in domain-specific, self-explaining research pertaining to chemical education. As an initial approach, we are investigating whether framing of learning tasks may modify student self-explaining behaviour in large-enrolment General Chemistry courses. Ultimately, we are interested in assessing the impact that modifying self-explaining practices may have on conceptual learning in chemistry.
Research goals
This study is embedded in a larger research program that focuses on the following: (a) ways to promote self-explaining during chemistry instruction and (b) the assessment of how different levels of self-explaining influence learning of specific chemistry content. This investigation of the self-explaining effect is different from other work in the field in the following regards: (a) participants take part in this study in their normal student function; therefore we refer to them exclusively as students to differentiate from laboratory approaches; (b) we use a real problem situation that resembles the process of doing science to evoke self-explaining; (c) prompting to self-explain occurs at various demand levels instead of relying on spontaneous production of self-explanations; (d) we focus on conceptual understanding of chemistry (as assessed by a transfer task) rather than learning declarative or procedural knowledge (e.g., using worked-out examples, reviewing an expert explanation); (e) data collection happens within the undisturbed ecology of a college level large-enrolment chemistry classroom.Herein we report the findings from a study within this research program that specifically addressed the following research question:
Do tasks that require different levels of self-explaining effectively induce observable, categorical differences in self-explaining behaviour in the context of a General Chemistry classroom?
Our stance is that an association between self-explaining tasks and overt self-explaining behaviour strongly suggests that appropriate instruction in the naturalistic classroom setting can effectively modify self-explaining practices.
Methodology
We developed the materials specifically for use in this study (Appendix S1, ESI†). The domain includes entropy and the Second Law of Thermodynamics, which we treat as individual knowledge components (VanLehn, 2006) for the purpose of this work.
The naturalistic classroom setting we chose to use carried the intricate complexities of a live learning environment that, in chemical terms, we liken to a complex matrix. We argue this complexity translates into enhanced ecological validity (Brewer, 2000). The complex matrix presents a series of challenges in the design, data collection and analysis, and condition comparisons. For instance, a simple comparison between self-explaining and non-self-explaining conditions was not warranted in this setting. Much like use of standard additions in the chemical analysis lab counteracts the effects of a complex matrix, we believe our approach isolates the effect of self-explaining in the complexity of the study setting. We created four conditions (Table 1), each calibrated to promote different levels of self-explaining engagement. We adhere to Chi's (2011) conceptualization of engagement as that what learners do with learning materials. We understand self-explaining engagement as the level of purposeful allocation of cognitive resources and strategies, time, and effort to generate explanations by and for oneself to address a particular phenomenon. We gradually increased the self-explaining demand for the conditions by modifying the prompts describing the task. We based the calibration of the conditions on literature reports (Fonseca and Chi, 2010), especially multi-condition comparison studies (Siegler and Lin, 2009) and tested them through cognitive interviews as described below. The fundamental assumption was that since the matrix was the same for all conditions, variations in the outcome or dependent variable—self-explaining behaviour—would be associated with condition membership.
| SE-Task | Description |
|---|---|
| SEA | Explaining own answer. |
| EADA | Considering others' answers and explaining one's agreement/disagreement. |
| SEO | Explaining answer for others to use in their studying. |
| SEIA | Explaining others' incorrect answer. |
The learning event consisted of a textbook passage with a general description of the Second Law of Thermodynamics and common to all the participants. A self-explaining task, SE-Task, followed this passage. There were four different SE-Tasks, each defining one of the study conditions described in Table 1. Students completed the learning event within fifteen minutes.
Unlike most of the research in the field, this learning task does not focus on advancing procedural knowledge through self-explanation of examples (complete or incomplete worked-out problems‡) (e.g.Atkinson et al., 2003; Schworm and Renkl, 2006) or conceptual understanding through self-explanation of expository text, such as explaining the logic underlying statements in textbooks (e.g., Chi et al., 1994; Ainsworth and Loizou, 2003; Butcher, 2006; Ainsworth and Burcham, 2007). Neither did we utilise a conventional training study design to show or demonstrate a skill or strategy that students would perform at a later stage (e.g., Bielaczyc et al., 1995; Schworm and Renkl, 2007). Our purpose was to create an experience that was closer to doing science than to the procedural aspects of solving exercises or learning about science (Talanquer and Pollard, 2010; Chamizo, 2012).
We presented an otherwise familiar phenomenon to the students (water freezes spontaneously below 0 °C) and a fact that would potentially induce cognitive imbalance (the change in entropy for the system in this process is negative) to prompt them to self-explain. Although not instructed to do so, we anticipated that students would be prone to use the concept introduced in the same document—Second Law of Thermodynamics—in their self-explanations. We intended to affect the engagement in self-explaining by creating different levels of encouragement to explain (Table 1) (Siegler, 2002). For this purpose, we combined two mechanisms: the effect of social engagement (e.g. explaining for others) and the depth of explaining (i.e. to explain answers that are described as correct or incorrect; Siegler, 2002).
It is reasonable to consider that the cognitive processes associated with self-explaining may take place covertly. However, our premise is that students are more likely to engage in self-explaining when an overt behaviour is required (Fonseca and Chi, 2010). Therefore, we collected written responses from students as indicators of their self-explaining behaviour. Although informative, think-aloud protocols were not an option given our desire to use large cohorts and to gather data in the most naturalistic environment possible.
We reviewed the materials after the pilot study (Table 2) and no major changes resulted from this process. We also conducted cognitive interview checks to assess interpretability of the materials. The protocol for the cognitive interviews is included in Appendix S2 (ESI†). Our interviewees were two second-year chemistry students who had taken General Chemistry 2 within the past year. They were recruited from a pool of chemistry undergraduate researchers, and they received no compensation for their interviews. Interviews lasted around 35 minutes, in which students completed the tasks and then discussed them in depth with the interviewer. This procedure provided evidence that supported interpretability and face validity in general. In addition, we consulted and held separate meetings with three doctoral candidates in chemical education and two experienced general chemistry instructors at the authors' home institution, who offered general advice and completed assessment rubrics to evaluate content validity of the materials. Finally, two chemical education researchers, who were external to the authors' institution and not associated with the research study, assessed the content and construct validity of the materials independently and provided feedback. No modifications were necessary upon the assessment by experts.
| Study phase | Sample size (n) | Dataset |
|---|---|---|
| Pilot study | 103 | Fall 2011 |
| Main study | 134 | Fall 2012 |
![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 000 undergraduate students. Diverse ethnic minority students make up 39% of the undergraduate student body. Typically majors in General Chemistry 2 are distributed as follows: pre-professional (pre-Medicine, pre-Pharmacy and Health Sciences), 61%; Chemistry, 6%; other sciences (Physics, Biology, Geology, etc.) or Math, 23%; Engineering, 8%. The remaining students are non-science/non-engineering majors. The tasks in this study were embedded within the normal requirements of the course; therefore they were simply part of normal assignments from the students' perspectives. The activity was conducted before students were formally introduced to the chemistry concepts (i.e., entropy and the Second Law of Thermodynamics). Grading guidelines for this activity were the same as those for similar assignments throughout the semester. Credit was received for the satisfactory completion of the activity and not based on performance. This study only used data from students who had previously granted informed consent. The gender distribution in the main study was representative of the university demographics (42% males, 58% females).
000 undergraduate students. Diverse ethnic minority students make up 39% of the undergraduate student body. Typically majors in General Chemistry 2 are distributed as follows: pre-professional (pre-Medicine, pre-Pharmacy and Health Sciences), 61%; Chemistry, 6%; other sciences (Physics, Biology, Geology, etc.) or Math, 23%; Engineering, 8%. The remaining students are non-science/non-engineering majors. The tasks in this study were embedded within the normal requirements of the course; therefore they were simply part of normal assignments from the students' perspectives. The activity was conducted before students were formally introduced to the chemistry concepts (i.e., entropy and the Second Law of Thermodynamics). Grading guidelines for this activity were the same as those for similar assignments throughout the semester. Credit was received for the satisfactory completion of the activity and not based on performance. This study only used data from students who had previously granted informed consent. The gender distribution in the main study was representative of the university demographics (42% males, 58% females).
Materials were printed, used individually without student interactions, administered during regular class schedule, and timed. Written explanations were collected, photocopied, assigned an alphanumeric code (student identifiers were removed from the photocopied materials), and later transcribed to electronic support. File names used the alphanumeric code. Drawings, diagrams, and equations were scanned and integrated to the corresponding electronic files.
The Hawthorne effect describes how in behavioural studies participants may behave in ways different from the normality if they realise they are being observed (Franke and Kaul, 1978; Jones, 1992). Therefore, we took measures to minimise any potential risk of evoking such behaviours. This included following procedures such as distribution of materials and delivery of instructions that were not different from procedures typically used for other in-class assignments. We assumed familiarity with these procedures prevented predisposition of any kind.
Textual analysis of learning event data. The learning event produced written explanations, which we refer to as responses. In preparation for textual analysis, the prompts were removed so that coders had access to the responses only. Unavoidably, in many cases the structure of the response could be associated with a specific prompt.
We used the sentences as constructed by the students as unit of response segmentation. For this purpose, independently of their syntactic accuracy, the use of a period indicated the closing of a sentence. Although the systematic analysis required segmentation, it is important to underscore that we did not intend to de-contextualise the analysis: we considered each unit of response segmentation in the light of the entire response, i.e., explanation. For the pilot study, a single researcher coded the textual data (103 responses) using a sequence of coding schemes reported in the literature (Durst, 1987; McNamara, 2004; Best, et al., 2005; McNamara and Magliano, 2009; Ford and Wargo, 2012). This preliminary analysis allowed us to ascertain the feasibility of the study; however, as an analytical tool, it was too involved and impractical. For the main study, we streamlined coding to a single scheme that was more robust and easier to apply to large cohorts. This scheme preserved fundamental codes from the literature (McNamara, 2004; McNamara and Magliano, 2009) that we modified slightly in consideration of emergent categories and subcategories and refined it through consensus coding of a subset of 50 responses by three coders. Table 3 shows the final coding scheme and a brief description of each code type. Codes BI, DI, E, and P in Table 3 derived from research reports (McNamara, 2004; McNamara and Magliano, 2009). During coding we identified two types of paraphrasing: repetition of information from the learning materials and repetition of information already in the response itself. From the total database, only three sentences were unclassifiable, U, and given the small count we dropped them from further analysis as we did with the statements deemed non-relevant, NR, since they did not provide information regarding the sophistication of the explanations (e.g., “They are on the right track but just need to pushed [sic] in the right direction”).
| Code type | Description | Example from responses |
|---|---|---|
| BI-bridging inference | Relational inference linking the problem (i.e., water freezing below 0 °C) with entropy change, and/or Second Law of Thermodynamics. | Even though ΔS_sys < 0, the ΔS_univ is still positive because when the water freezes the surroundings have a sharp increase in entropy (ΔS_surr > 0). |
| DI-deductive inference | Inference that uses specific content knowledge (i.e., water freezing below 0 °C, entropy, or Second Law of Thermodynamics), but does not link to other information. | Just because the ΔS_system is negative doesn't mean that the process must all be negative. |
| E-elaboration | Use of information not provided in the materials | When water begins to freeze at 0 °C, water (unlike other liquid) expands which make this less dense than when water is above 0 °C. |
| P-paraphrasing |
(Pa) Recount of entropy concept, or Second Law of Thermodynamics.
(Pb) Repetition of previously used information within response. |
If the process is indeed spontaneous, that means the ΔS_univ must be positive. |
| U-unclassifiable | Statement of concepts without drawing relational inference. | Plus, although the change in entropy of the surrounding may change some in a resulting reaction that leaves ΔS_univ negative, there is still H2O(g) in the air (Earth's atmosphere). (R48, F12) |
| NR-non-relevant | Comments and observations unrelated to the task. | He did not look at the big picture. |
Once we had established the coding scheme, the same coders analysed 50 responses separately. Subsequently, these coded responses were team reviewed and disagreements were discussed and resolved. One researcher coded the remaining responses; the other two coders verified a different subset (42 responses each) and solved any discrepancies with the main coder. We assigned an individual code to each sentence and then tallied the codes by response. The ratio of frequency of a given code type count (n) to the total sentences in the response (N)—hereafter the code-ratio (n/N)—became the observed variable for the subsequent Latent Profile Analysis (described below). From the main study dataset we eliminated six responses that where unintelligible and 128 remained. Once the main study data was coded, we re-coded the dataset from the pilot study to investigate other potential changes to the coding scheme. Two coders worked independently on a subset of the dataset and later discussed the coding. All discrepancies were resolved, and no changes were made to the coding system. Fig. 1 shows the coding of an example response.
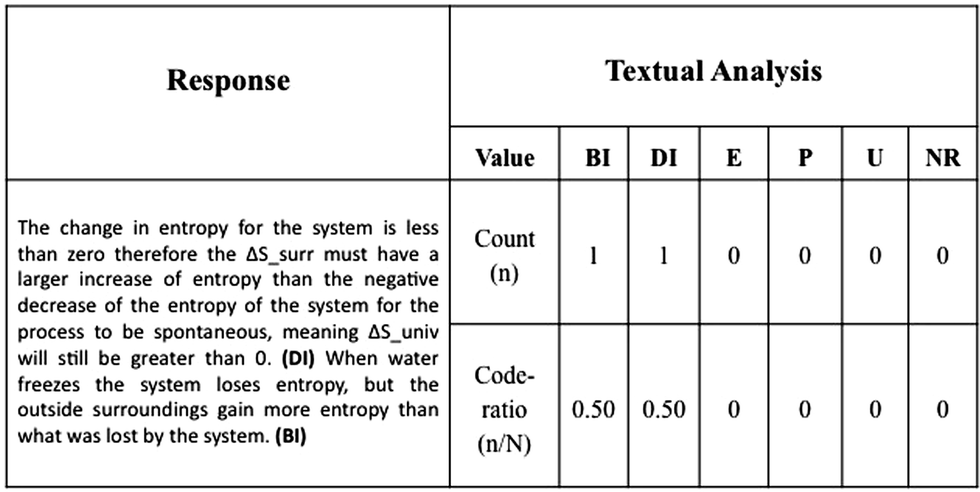 | ||
| Fig. 1 Coding example. | ||
Latent profile analysis, LPA. LPA is a model-based statistical technique to find profile classes in continuous data (Pastor et al., 2007). It is a latent variable model, where non-observable latent constructs are inferred through mathematical modelling using observed variables (Collins and Lanza, 2010). LPA assumes that different profiles can be explained by the existence of frequency patterns in the observed variables (Pastor et al., 2007; Marsh et al., 2009). During the analysis, several profile-model solutions are generated and compared. The comparison is evaluated to select the best fitting model for the data. A number of techniques have been devised to guide selection of the best model fit (e.g., Model based hypothesis tests, Log likelihood, Akaike Information Criterion, Bayesian Information Criterion, sample-size adjusted Bayesian Information Criterion, Entropy value; Pastor et al., 2007; Marsh et al., 2009; Collins and Lanza, 2010).§
Although manual inspection of data could result in the identification of patterns of response, the process would be limited to small datasets and be tedious, time-consuming and seemingly prone to researcher bias. Moreover, traits could be overlooked easily, and the process would be inherently unreliable. In our study, we used LPA to elicit otherwise undetectable trends and to minimise bias in the categorisation of student responses in explanatory behaviours. We performed LPA using the code-ratios from the textual analysis as the observed variables (i.e., four observed variables). The output of LPA was the categorisation of students into distinct profiles based on the nature of their explanations, the self-explaining profiles (SE-Profiles). LPA was performed using MPlus Version 6 (Muthén and Muthén, 2010). Fig. 1 shows a coded response along with the corresponding code ratios used as observed variables in the latent profile analysis.
Analysis of the association between self-explaining tasks and self-explaining profiles. We used Chi-square tests to determine the association between self-explaining profile membership, SE-Profile, and self-explaining task, SE-Task. For the interpretation of the Chi-square test results we selected a 95% confidence level. We used IBM SPSS Statistics (Version 21.0.0.0) for the Chi-square tests.
Results and discussion
Pilot study
The purpose of the pilot study in the initial stage of this project was to test the study design and instruments and to identify potential methodological gaps. In summary, the pilot test results suggested that tasks of different self-explaining demand elicited different self-explaining behaviours (Villalta-Cerdas, 2014). Although this evidence supports the association between the SE-Profiles and SE-Tasks, the statistical analysis was not conclusive. The pilot test supported the appropriateness of the study design, materials, and analysis procedures; it did not reveal deficiencies that required modifications prior to the implementation of the main study. Nonetheless, to enhance the design we decided to utilise true randomisation for the main study instead of pseudo-randomisation.Main study
| Code Type | Total count | SE-Task | |||
|---|---|---|---|---|---|
| %SEA | %SEIA | %EADA | %SEO | ||
| χ 2 (9, N = 357) = 22.50, p < 0.05, codes U and NR excluded. | |||||
| BI | 47 | 43 | 21 | 9 | 28 |
| DI | 122 | 19 | 33 | 23 | 25 |
| E | 88 | 22 | 27 | 32 | 19 |
| P | 100 | 23 | 19 | 28 | 30 |
| U | 3 | 33 | 33 | 0 | 33 |
| NR | 28 | 7 | 21 | 64 | 7 |
In the case of the codes for elaboration, E, and paraphrasing, P, their abundance in the students' responses may reflect what Taber (2000) described as a social imperative to produce an answer in acknowledgement to a question, in this case, the SE-Task prompt. These two codes, E and P, are associated with less sophisticated explanatory behaviours as they reflect recounting of information rather than generation of causal inferences. Moreover, when students are continually exposed to instruction as rhetoric of conclusions (Schwab, 1962), one could imagine that paraphrasing may become a habitual substitute for explaining. Therefore, in the case of paraphrasing, it might be that students intended to explain but lacked the ability to construct responses beyond re-statement of information. Undeniably, some students may default to paraphrasing even when prompted otherwise.
For our research purposes, the codes unclassifiable, U, and non-relevant, NR, did not contribute valuable insight to elucidate the explanatory behaviour of the students. Therefore, we did not consider them in subsequent analyses.
In a first analysis, we studied the association between the code type (e.g. bridging inference, BI, deductive inference, DI, etc.) and the self-explaining task, SE-Task (Table 4). The Chi-square test showed a statistically significant association between the code type and the SE-Task at a 95% confidence level, χ2 (9, N = 357) = 22.50, p < 0.05. The values in bold (Table 4) indicate the highest occurrence for each code type and the overall trend in the association. In the case of the bridging inference code, BI, the highest percentage of occurrences originated from the self-explaining-own-answer task, SEA, which effectively prompted students to connect chemistry concepts (i.e., entropy and the Second Law of Thermodynamics) in their effort to make sense of the phenomenon. For deductive inference, DI, the predominant source was the self-explaining-incorrect-answer task, SEIA. Encouraging students to explain the possible reasoning that led their peers to incorrect solutions generated more deductive inferences. The EADA (self-explain-agreement/disagreement) and SEO (self-explain-for-others) tasks had moderately high percentages for the DI code, thus students in these conditions engaged in the generation of deductive inferences as well. In the case of the elaboration code, E, the results showed the highest percentage in the self-explain-agreement/disagreement task, EADA. This SE-Task seemed to favour a more summative approach to self-explaining where participants brought in external information that was not provided in the materials. Despite their elaborative effort, students did not use the external information to draw deductions or bridge with other concepts; instead, they essentially recounted it in their responses. Lastly, the paraphrasing code, P, showed similar high percentages for two of the SE-Tasks: EADA and SEO. Again, we maintain this behaviour reflected the social imperative to answer a question as described by Taber (2000) even when students operated under the illusion of producing an explanation.
The code type distribution addressed the research question guiding this work: Do tasks of different self-explaining demand induce observable, categorical differences in self-explaining behaviour? Evidence supports an association between the code types in the student responses and the SE-task prompts assigned to them. This association suggests that the prompts, which we designed with differential self-explaining demand, effectively produced an observable effect on the students' behaviour as they composed their written responses. The variance of code types across SE-Tasks is indicative of the effect of individuals' characteristics. That is, students within a SE-Task still produced explanations of different sophistication. This variability is congruent with reports that have associated quantity and quality of explanations with intrinsic properties of students (Roy and Chi, 2005). This occurrence underscores the significance of randomisation of students in the conditions since otherwise the effect of task membership may be obscured by this natural variability.
To better contrast these approaches it is noteworthy to mention that the simpler association described above assumes the occurrence of all codes as independent when single students might have contributed more than one code (actually, 79% did). In addition, those who contributed more than one code did not necessarily contribute the same codes; in other words, multiple patterns of response were possible. The analysis at the person-oriented level takes these considerations into account and focuses on each individual's behaviour by integrating the number and type of codes into the categorisation of patterns. This transformative analysis allowed us to investigate whether the behaviours, and not only the codes, were linked to the SE-tasks.
Using Latent Profile Analysis (LPA) we identified patterns in code-ratios (i.e., number of code type divided by total codes in response) in student responses. These analyses required the selection of the best model for the data. We include the selection procedure and other pertinent data handling in Appendix S3 (ESI†). The analysis and interpretation of the models led us to select the seven-profile model solution for the main study data.
Table 5 shows the profiles in the seven-profile model solution along the number of students in each profile and the respective mean values for the four code-ratios. In the case of Profiles 1–3 and 5–7, the mean code-ratios within profiles showed a single predominant value (values in bold). Therefore, self-explaining within each of these six profiles was strongly characterised by the single class predominant code; that is, the pattern of behaviour of members within each of these profiles was homogeneous. Profile separation refers to the uniqueness of each profile; in our case that implies comparison of predominant mean code-ratio between profiles. Ideally, all profiles would have a maximum mean code-ratio for different codes; however, in the case at hand, there were more profiles than mean code-ratios (or code-types), which unavoidably led to profiles sharing a maximum code-ratio. In turn, this led to the merging of profiles.
| Profiles | n | Mean code-ratio | SE-Profile descriptor | |||
|---|---|---|---|---|---|---|
| BI | DI | E | P | |||
| a p < 0.05. | ||||||
| Profile 1 | 6 | 1.00 | 0.00a | 0.00a | 0.00a | Bridging inferential |
| Profile 2 | 4 | 0.70 | 0.17a | 0.05 | 0.08 | |
| Profile 3 | 15 | 0.50 | 0.22 | 0.13a | 0.15a | |
| Profile 4 | 12 | 0.29 | 0.27 | 0.19 | 0.25 | Mixed-behaviour |
| Profile 5 | 20 | 0.00a | 0.95 | 0.03 | 0.02 | Deductive inferential |
| Profile 6 | 24 | 0.00a | 0.23 | 0.73 | 0.05a | Elaborative |
| Profile 7 | 47 | 0.00a | 0.35 | 0.12a | 0.53 | Summative |
Although profiles 1–3 have each a single most prevalent code-ratio (Table 5), it is not unique to each profile but the same for all three of them; the separation is not strong. Hence we combined these profiles into a single self-explaining profile (SE-Profile). Members of this merged profile (n = 25) are characterised by responses composed mainly of bridging inference codes, BI, (>50% of response); consequently, we described this SE-Profile as bridging inferential.
Profile 4 is non-homogenous: there is no single code type that characterises membership in this profile. Quite the contrary, it is the multiplicity in the nature of their behaviour that identifies members in this group; we described this SE-Profile as mixed behaviour. Although not homogenous, this group is clearly separated from the others. Emergence of this profile is an example of the power of statistical tools such as LPA. An analysis based solely on the number of codes would have masked the behaviour of students in this SE-Profile who used all four explanatory codes in similar proportions.
Profiles 5, 6, and 7 have a single and unique predominant code-ratio and are homogenous and well separated from all other profiles. We assigned labels to these profiles in accordance with the code that predominates in each case. Therefore, Profile 5 became deductive inferential, Profile 6 became elaborative, and Profile 7 became summative (Table 5).
| SE-Profile | n | SE-Task | |||
|---|---|---|---|---|---|
| %SEA | %SEO | %SEIA | %EADA | ||
| χ 2 (12, N = 128) = 22.75, p < 0.05. | |||||
| Bridging inferential | 25 | 36 | 32 | 20 | 12 |
| Mixed-behaviour | 12 | 50 | 25 | 25 | — |
| Deductive inferential | 20 | 10 | 35 | 40 | 15 |
| Elaborative | 24 | 17 | 12 | 29 | 42 |
| Summative | 47 | 17 | 30 | 21 | 32 |
In the trend in Table 6, the SEA task—self-explain-own-answer—has the highest percentage of students in the SE-Profiles associated with the more analytic self-explaining behaviours (i.e., bridging inferential and mixed-behaviour). Thus, more students in this SE-Task engaged in generating inferences and connecting ideas via more complex explanatory behaviours. Conversely, SEIA and EADA (explain-incorrect-answer and explain-agreement/disagreement with others, respectively) showed a higher percentage of students in the less analytical self-explaining behaviours (i.e., elaborative and summative).
We hypothesise that in the case of SEIA and EADA the constraint set for the students might have acted as an inhibitor of self-explaining. When presented with the solution, those participants in agreement may default to restating the solution while those in disagreement may simply rephrase it in opposite sense. We propose that by constraining students to agreeing/disagreeing we induced knowledge-telling episodes (i.e., unelaborated summaries and paraphrases) over knowledge-building episodes (integration of concepts and generation of inferences; Chi, 2009). Our original assumption was that considering solutions different from the student's own answer could engage students in a deeper reflection and a stronger commitment to self-explain. The nature of the task and the dichotomous nature of the answer (one thing or the other) might have obscured the original intended effect for this particular General Chemistry 2 sample.
In the case of SEA (self-explain-own-answer) and SEO (self-explain-for-others) tasks, we kept the task unconstrained for students. The fact that self-explaining directed to others was not more conducive to sophisticated behaviours is not entirely surprising. Roscoe and Chi (2008) compared self-explaining and other-directed explaining with students interacting with a tutor and found that the former was better, even when the tutor was virtual (i.e., computer generated). One possible explanation is that explaining to oneself focuses on repairing what one does not understand, without the distraction of focusing on others (Chi, 2009). However, it must be stressed that one cannot rely on a general description of an activity to judge its quality and outcomes as a learning experience (Chi, 2009). Otherwise neglected aspects may prove to be fundamental warrants for caution when generalising findings. For instance, Siegler (2002) observed that creating a social dimension by telling students to explain for others acted as an incentive to explain. This may seem sufficiently similar to our conditions as to try to extend their findings to ours, however, in that study, researchers utilised a think-aloud protocol in a laboratory setting where children interacted with an adult researcher. In our case, an ecologically natural learning environment at college level, the other was an anonymous peer.
Regardless of the SE-Task a number of students defaulted to paraphrasing which is evidenced by the distribution of students in the summative SE-Profile across all SE-Tasks (Table 6). We contend that this behaviour may be more attributable to long periods of conditioning supported by prior class norms (e.g. the classroom game; Lemke, 1990) than indicative of task effectiveness or lack thereof. Kohn (2004) has pointed out that students may become accustomed to and comfortable with learning environments in which they are not expected to actively engage with intellectual challenges. It may take some effort to persuade students to act differently. Far from discouraging, we deem understanding of this occurrence informative and constructive. Students are not blank slates; they bring their personal history, prior knowledge, attitudes, skills and strategies, etc. to the classroom, and naturalistic approaches to research intend to explore behaviour in the complex ecology of classroom learning. This finding highlights that students, in addition to not spontaneously engaging in explaining, may resist explaining when prompted. That is, student behaviour is not determined by the prompt provided—a stance that would evoke a behavioural approach to learning. It is not surprising that the same instructional activity may trigger varying self-explaining responses in different individuals. This individual-task interaction is consistent with the “subtle interaction between a task and the individual struggling to find an appropriate answer or solution” that Bodner and Herron (2003) identified in problem solving research. Acknowledging the effect of these individual differences and their interactions with the nature of the prompts is an important step in advancing instructional design.
There are no quick fixes in education, and the resistance or activation barrier associated with self-explaining will not be resolved with a single instantiation. Our emphasis is on the fact that a considerable proportion of students did engage in self-explaining upon prompting and that the sophistication of this engagement was, to some extent, tuneable by the design of the task.
Limitations
Some limitations of this study are worth mentioning and findings must be interpreted within these limitations. First and foremost, although we randomised condition assignment within our sample, this was a convenience sample. Students in this study were enrolled in the General Chemistry 2 section taught by one of the authors. Although basic demographic indicators are not significantly different from the rest of the General Chemistry cohort, we have no way to elucidate whether latent factors might have influenced students' choice of this particular section (e.g. instructor reputation, schedule convenience).We removed prompts from the responses for the textual analysis; however, coders could infer the corresponding self-explaining condition from the structure of the responses. This limitation creates the potential for coder bias where coders may be prone to make code assignments based on the condition and not strictly on the analysis of the responses. Although not very practical, one may choose to assign the coding process to individuals who are not involved with the research study.
Despite the clear value of research in naturalistic environments, there are concomitant limitations. Understandably, unlike the case of tightly controlled experimental studies, in a natural setting control of exogenous variables is not possible and their effects unpredictable. Our randomisation within the sample contributed to minimize this limitation. Another possible concern related to the study design may be participants' impulse to behave as socially desirable or to adjust their behaviour some other way when they are under the impression of being observed. To minimize this effect, for this study we used procedures consistent with in-class assignment norms. Our assumption is that the sense of familiarity with the procedures prevented predisposition of any kind. From the students' perspective, this learning event was not different from other learning experiences in class, that is, there were no cues to interpret it as research. There were no unfamiliar individuals in the lecture hall while data gathering. Use of a convenience sample actually allowed us to frame the learning event in such a natural way.
Conclusions and implications
The ability to generate explanations of scientific phenomena is an essential learning outcome for all students (National Research Council, 2013). This study intended to gather evidence to establish whether tasks of different self-explaining demand induce observable, categorical differences in self-explaining behaviour. Students' self-explaining behaviours were categorised via analysis of textual data of their responses, followed by data transformation and modelling using Latent Profile Analysis. Data was reduced to five self-explanatory behaviours that proved to be associated with the tasks we created as study conditions.Independently of the rationale one may generate to explain the behaviour of this particular cohort of students, results in this study reveal an association between the way the tasks are framed for students and their engagement in producing self-explanations of different sophistication levels. Caution is warranted in that we do not intend to be prescriptive and describe the type of prompts that should be used in chemistry classrooms to engage students in effective self-explaining. Such a goal would imply an over-simplistic, reductive view of the complexity of learning environments. Those involved in instructional design should understand this complexity and the effect of contextual and other situational factors. As cited by O'Donnell (2008), Berman and McLaughlin observed: “The bridge between a promising idea and the impact on students is implementation, but innovations are seldom implemented as intended.”
We hypothesised that an association between self-explaining tasks and overt self-explaining behaviour would strongly suggest that instruction in the naturalistic classroom setting can effectively modify self-explaining practices. In other words the qualities of student responses could be modulated through the design of learning experiences in tune with the instructor's goals (Chi, 2009). Considering the different responses from students, a varied array of prompts may be more effective than searching for a single, one-size-fits-all type of prompt. Chemistry educators may use this and other supporting evidence to decide whether to integrate self-explaining activities to the repertoire of their instructional design. Identifying the evidence-based active ingredients that promote learning in natural learning environments may lower the activation barrier associated with undertaking innovations. This is especially true for novice instructors, who may find integrating such strategies into their instructional design less intimidating and invasive than relinquishing control to a pre-packaged pedagogical model.
Our work did not use strategy training or direct-instruction, that is, we did not teach students to self-explain to later test their adherence to a particular behaviour that may vanish once the stimulus is removed. Self-explaining behaviour was effectively elicited by the learning event. Thus, we put forth cultivating constructive learning strategies such as self-explaining as components of well-designed instruction. Deeper engagement in self-explaining may become habitual upon practice and hopefully develop into the new norm in students' relationship with chemistry knowledge. This stance is consistent with related research in the field that suggests “meaningful learning may help students progress from a stage in which re-description and functional explanations are dominant, to a phase in which connections between parts are emphasised, to a point in which cause-effect relationships are frequently used as the basis for explanations” (Talanquer, 2010).
Several future lines of work arise from findings in this study. Whereas in this study we focused on learning strategies as the learning outcome of interest, currently we are engaged in the assessment of how different levels of self-explaining influence learning of specific chemistry content. In this work we observed variability in the sophistication of student responses to the same self-explaining task. Investigating what individual characteristics may be associated with this differential behaviour is another potential line of work. Likewise, we are interested in the investigation of change in self-explaining behaviour by using latent variable models on longitudinal data collected across multiple learning activities.
Notes and references
- Ainsworth S. and Burcham S., (2007), The impact of text coherence on learning by self-explanation, Learn. Instruct., 17(3), 286–303.
- Ainsworth S. and Loizou A. T., (2003), The effects of self-explaining when learning with text or diagrams, Cognitive Sci., 27(4), 669–681.
- Atkinson R. K., Renkl A. and Merrill M. M., (2003), Transitioning from studying examples to solving problems: effects of self-explanation prompts and fading worked-out steps, J. Educ. Psychol., 95(4), 774–783.
- Best R. M., Rowe M., Ozuru Y. and McNamara D. S., (2005), Deep-level comprehension of science texts: the role of the reader and the text, Top. Lang. Disord., 25(1), 65–83.
- Bielaczyc K., Pirolli P. L. and Brown A. L., (1995), Training in self-explanation and self-regulation strategies: investigating the effects of knowledge acquisition activities on problem solving, Cogn. Instr., 13(2), 221–252.
- Bodner G. and Herron J., (2003), in Gilbert J., Jong O., Justi R., Treagust D. and Driel J. (ed.), Problem-solving in chemistry, Netherlands: Springer.
- Brewer M. B., (2000), Research design and issues of validity. Handbook of research methods in social and personality psychology, pp. 3–16.
- Butcher K. R., (2006), Learning from text with diagrams: promoting mental model development and inference generation, J. Educ. Psychol., 98(1), 182–197.
- Chamizo J. A., (2012), Heuristic diagrams as a tool to teach history of science, Sci. Educ., 21(5), 745–762.
- Chi M. T. H., (2000), Self-explaining expository texts: the dual processes of generating inferences and repairing mental models, Advances in Instructional Psychology, 5, 161–238.
- Chi M. T. H., (2009), Active-constructive-interactive: a conceptual framework for differentiating learning activities, Top. Cogn. Sci., 1(1), 73–105.
- Chi M., (2011), Differentiating four levels of engagement with learning materials: the ICAP hypothesis. Presentation at the 19th International Conference on Computers in Education, Chiang Mai, Thailand.
- Chi M. T., Bassok M., Lewis M. W., Reimann P. and Glaser R., (1989), Self-explanations: how students study and use examples in learning to solve problems, Cognitive Sci., 13(2), 145–182.
- Chi M. T. H., De Leeuw N., Chiu M. H. and LaVancher C., (1994), Eliciting self-explanations improves understanding, Cognitive Sci., 18(3), 439–477.
- Collins L. M. and Lanza S. T., (2010), Latent class and latent transition analysis: with applications in the social, behavioral, and health sciences, Wiley, vol. 718.
- Crippen K. J. and Earl B. L., (2004), Considering the efficacy of web-based worked examples in introductory chemistry, J. Comp. Math. Sci. Teach., 23(2), 151–167.
- Crippen K. J. and Earl B. L., (2007), The impact of web-based worked examples and self-explanation on performance, problem solving, and self-efficacy, Comput. Educ., 49(3), 809–821.
- Deutsch D., (2011), The Beginning of Infinity: Explanations that Transform the World, UK: Penguin.
- Durst R. K., (1987), Cognitive and linguistic demands of analytic writing, Res. Teach. Engl., 347–376.
- Fonseca B. A. and Chi M. T. H., (2010), Instruction based on self-explanation, in Mayer R. E. and Alexander P. A. (ed.), The Handbook of Research on Learning and Instruction, New York: Routledge, pp. 296–321.
- Ford M. J. and Wargo B. M., (2012), Dialogic framing of scientific content for conceptual and epistemic understanding, Sci. Educ., 96(3), 369–391.
- Franke R. H. and Kaul J. D., (1978), The Hawthorne experiments: first statistical interpretation, Am. Sociol. Rev., 623–643.
- Gadgil S., Nokes-Malach T. J. and Chi M. T. H., (2012), Effectiveness of holistic mental model confrontation in driving conceptual change, Learn. Instruct., 22(1), 47–61.
- Henderson C., Beach A. and Finkelstein N., (2011), Facilitating change in undergraduate STEM instructional practices: an analytic review of the literature, J. Res. Sci. Teach., 48(8), 952–984.
- IBM Corp., Released 2012, IBM SPSS Statistics for Windows, Version 21.0. Armonk, NY: IBM Corp.
- Jones S. R., (1992), Was there a Hawthorne effect? Am. J. Sociol., 451–468.
- Kohn A., (2004), Challenging students-and how to have more of them, Phi Delta Kappan, 86, 184–194, available online http://www.alfiekohn.org/teaching/challenging.htm, accessed 17th December 2013.
- Lemke J. L., (1990), Talking science: language, learning, and values, 355 Chestnut Street, Norwood, NJ 07648: Ablex Publishing Corporation (hardback: ISBN-0-89391-565-3; paperback: ISBN-0-89391-566-1).
- Magidson J. and Vermunt J. K., (2004), Latent class models. The Sage handbook of quantitative methodology for the social sciences, pp. 175–198.
- Marsh H. W., Lüdtke O., Trautwein U. and Morin A. J., (2009), Classical latent profile analysis of academic self-concept dimensions: synergy of person-and variable-centered approaches to theoretical models of self-concept, Struct. Equ. Modeling, 16(2), 191–225.
- McNamara D. S., (2004), SERT: self-explanation reading training, Discourse Processes, 38(1), 1–30.
- McNamara D. S., Magliano J. P., (2009), 5 Self-Explanation and Metacognition, in Hacker D. J., Dunlosky J. and Graesser A. C. (ed.), Handbook of metacognition in education, Hoboken: Routledge, pp. 60–81.
- Microsoft, (2010), Microsoft Excel [computer software], Redmond, Washington: Microsoft.
- Muthén L. K. and Muthén B. O., (1998–2010), Mplus User's Guide, 6th edn, Los Angeles, CA: Muthén and Muthén.
- National Research Council, (2012), A Framework for K-12 Science Education: Practices, Crosscutting Concepts, and Core Ideas, Washington, DC: The National Academies Press.
- National Research Council, (2013), Next Generation Science Standards: For States, By States. Washington, DC: The National Academies Press.
- National Survey Student Engagement, NSSE., (2013), http://nsse.iub.edu/html/summary_tables.cfm, accessed 17th February 2014.
- O'Donnell C. L., (2008), Defining, conceptualizing, and measuring fidelity of implementation and its relationship to outcomes in K–12 curriculum intervention research, Rev. Educ. Res., 78(1), 33–84.
- Pastor D. A., Barron K. E., Miller B. J. and Davis S. L., (2007), A latent profile analysis of college students' achievement goal orientation, Contemp. Educ. Psychol., 32(1), 8–47.
- Ravid R., (2010), Practical statistics for educators, Rowman & Littlefield Publishers.
- Roscoe R. D. and Chi M. T. H., (2008), Tutor learning: the role of explaining and responding to questions, Instruct. Sci., 36(4), 321–350.
- Ross K. N., (2005), Educational Research: Some Basic concepts and Terminology, International Institute for Educational Planning, UNESCO, available http://www.unesco.org/iiep.
- Roy M. and Chi M. T., (2005), The self-explanation principle in multimedia learning, in Mayer R. E. (ed.), The Cambridge handbook of multimedia learning, Cambridge, England: Cambridge University Press, pp. 271–286.
- Ruscio J. and Ruscio J., (2008), Advancing psychological science through the study of latent structure, Curr. Dir. Psychol. Sci., 17(3), 203–207.
- Schwab J. J., (1962), The teaching of science as inquiry, in P. F. Branwein (ed.), The teaching of science, Cambridge, MA: Harvard University Press, pp. 3–103.
- Schworm S. and Renkl A., (2006), Computer-supported example-based learning: when instructional explanations reduce self-explanations. Computers and Education, 46(4), 426–445.
- Schworm S. and Renkl A., (2007), Learning argumentation skills through the use of prompts for self-explaining examples, J. Educ. Psychol., 99(2), 285–296.
- Siegler R. S., (2002), Microgenetic studies of self-explanation, in N. Granott and J. Parziale (ed.), Microdevelopment: Transition Processes in Development and Learning, Cambridge, England: Cambridge University Press, pp. 31–58.
- Siegler R. and Lin X., (2009), Self-explanations promote children's learning, in Waters H. S. and Schneider W. (ed.), Metacognition, strategy use, and instruction, Guilford Press, pp. 85–112.
- Shadish W. R., Cook T. D. and Campbell D. T., (2002), Experimental and quasi-experimental designs for generalized causal inference, Boston: Houghton-Mifflin.
- Taber K. S., (2000), Chemistry lessons for universities?: a review of constructivist ideas, Univ. Chem. Educ., 4(2), 63–72.
- Talanquer V., (2010), Exploring dominant types of explanations built by general chemistry students, Int. J. Sci. Educ., 32(18), 2393–2412.
- Talanquer V. and Pollard J., (2010), Let's teach how we think instead of what we know, Chem. Educ. Res. Pract., 11(2), 74–83.
- van Teijlingen E. and Hundley V., (2001), The importance of pilot studies, Social Research Update, Issue 35, pp. 1–4.
- Vanlehn K., (2006), The behavior of tutoring systems, Int. J. Artif. Intell. Educ., 16(3), 227–265.
- Villalta-Cerdas A., (2014), Development and Assessment of Self-Explaining Skills in College Chemistry Instruction, Unpublished doctoral dissertation, University of South Florida, Florida, USA.
- Villalta-Cerdas A. and Sandi-Urena S., (2013), Self-explaining and its Use in College Chemistry Instruction, Educ. Quím., 24(4), 431–438.
- Wheatley G. H., (1984), Problem solving in school mathematics, MEPS Technical Report, 84.01, School Mathematics and Science Center, Purdue University, West Lafayette, IN.
- Woloshyn V. and Gallagher T., (2009), Self-Explanation, available online: http://www.education.com/reference/article/self-explanation, accessed 11th June 2013.
Footnotes |
| † Electronic supplementary information (ESI) available: Research instruments, interview protocol, and supplemental data analysis and results. See DOI: 10.1039/c3rp00172e |
| ‡ Hereafter we reserve the use of the term problem to novel situations for which one does not have a set of rules or a procedure to produce an answer (Wheatley, 1984). |
| § A detailed description of Latent Profile Analysis is outside the scope of this report. For detailed descriptions and exemplar applications see the following: Magidson and Vermunt (2004), Pastor et al. (2007), Marsh et al. (2009), Collins and Lanza (2010) and Muthén and Muthén (2010). |
| This journal is © The Royal Society of Chemistry 2014 |