Assessing confidence in predictions made by knowledge-based systems
Philip N.
Judson
*a,
Susanne A.
Stalford
b and
Jonathan
Vessey
b
aHeather Lea, Bland Hill, Norwood, Harrogate HG3 1TE, UK. E-mail: philip.judson@blubberhouses.net; Fax: +44 (0)194 388 0241; Tel: +44 (0)194 388 0241
bLhasa Limited, 22-23 Blenheim Terrace, Woodhouse Lane, Leeds LS2 9HD, UK. E-mail: susanne.stalford@lhasalimited.org; jonathan.vessey@lhasalimited.org; Fax: +44 (0)113 394 6099; Tel: +44 (0)113 394 6020
First published on 26th September 2012
Abstract
A new metric, “veracity”, is proposed for assessing the performance of qualitative, reasoning-based prediction systems that takes into account the ability of these systems to express levels of confidence in their predictions. Veracity is shown to be compatible with concordance and it is hoped that it will provide a useful alternative to concordance and other Cooper statistics for the assessment of reasoning-based systems and for comparing them with other types of prediction system. A few datasets for four end points covered by the program, Derek for Windows, have been used to illustrate calculations of veracity. The levels of confidence expressed by Derek for Windows in these examples are shown to carry meaningful information. The approach provides a way of judging how well open predictions (“nothing to report” in Derek for Windows) can support qualified predictions of inactivity.
Introduction
The performance of statistically-based toxicity-prediction programs is usually reported in terms of classification performance, for example using the three Cooper statistics, sensitivity, selectivity, and concordance – the proportion of active compounds predicted to be active, the proportion of inactive compounds predicted to be inactive, and the proportion of compounds in the dataset for which activity is predicted correctly – or using Receiver Operating Characteristic (ROC) curves.1–3 Perhaps partly for reasons of history, partly for consistency, and partly for lack of a suitable alternative, the same measures have been used to assess the performance of knowledge-based systems.4–6 Performance of models that use multiple classification has been assessed by, for example, creating a set of ROC curves for different classification criteria.3 However, knowledge-based predictions may be qualified in terms of likelihood of, or confidence in, the classification of a query, which these methods of assessment cannot take into account. The limitation applies to all systems that report on confidence in their predictions, although this paper concentrates on knowledge-based systems. The paper proposes a new measure of performance, “veracity”, based on positive predictivity (the proportion of compounds predicted to be active which are found to be active) and compatible with concordance.Predictions made by Derek for Windows7 were used for the work described. The measures of confidence are called “likelihood” in Derek for Windows but the term “confidence” is preferred in this paper. “Confidence” is perhaps the better term to use in relation to human judgement, while “likelihood” implies more an assessment of physical probability. This paper is about the former. The definition of “plausible” in Derek for Windows, for example, is that on balance the arguments in favour outweigh the arguments against. Strictly, that kind of evidence indicates not the probability of an event but how confident one might be about expecting it.
Although these preliminary results appear to show that Derek for Windows makes satisfactory assessments of confidence, that is not the purpose of this paper: its purpose is only to illustrate the calculation and use of veracity values. It is hoped that the paper will encourage similar, more wide-ranging evaluations of Derek for Windows and of other prediction systems and comparisons between them, perhaps using proprietary as well as published data.
Limitations of conventional methods of assessment of performance
The three Cooper statistics, sensitivity, selectivity, and concordance are widely used to assess the reliability of binary predictions, such as “active” versus “inactive” in the case of toxicity prediction. There is a difficulty with programs that express a measure of confidence in their prediction. Derek for Windows, for example, uses the terms certain, probable, plausible, equivocal, doubted, improbable, and impossible. So to apply the statistical tests it is necessary to make an arbitrary decision about what should constitute a positive prediction. In the case of Derek for Windows, should predictions that are at least plausible be classed as positive or only predictions that are at least probable? If a prediction is equivocal, then activity surely cannot be ruled out, but is it appropriate to categorise the prediction as positive?A further difficulty is that where there is uncertainty, a lack of evidence in favour of something does not imply evidence against it. In Derek for Windows, the terms doubted, improbable, and impossible are explicit predictions of inactivity. The absence of evidence either way is termed “open” within the reasoning model but reported to the user as “nothing to report”. The usual performance statistics require that compounds be predicted either active or inactive and so evaluations have depended on the assumption that “not predicted active” is the same as “predicted inactive”; i.e. “nothing to report” has been interpreted as a negative prediction. This may be reasonable in practice, especially for an end point such as mutagenicity, for which Derek for Windows is believed to have good coverage of the sub-structural chemical features, “alerts”, that are responsible for activity: if no alerts are found then inactivity might be expected. However, a way of measuring the reliability of such assumptions is needed.
Finally, assessing performance in terms of binary output perhaps misses the point of using a reasoning-based approach, which aims to answer the question “how concerned should I be that this compound might be active?” rather than “is this compound active or not?” Veracity, as described in this paper, provides a way of judging how meaningful the assessments of confidence made by a prediction system are.
Assessing confidence in reasoning-based predictions
The formal definitions of “certain” and “impossible” in Derek for Windows are “proven to be true” and “proven to be false”, although, as noted later, the proofs may not be absolute in practice. The programs define “probable” as meaning “there is at least one strong argument that the proposition is true and there are no arguments against it” and define “plausible” as meaning “the weight of evidence supports the proposition”. In qualitative terms, “probable” is associated with greater confidence than “plausible”. “Equivocal” is defined as meaning that there is an equal weight of evidence for and against a proposition, and this is distinct from “open” which means that there is no evidence in support of or against a proposition. “Contradicted”, a third kind of neutrality, means that there is proof both that a proposition is true and that it is false. With regard to arguments against a proposition (i.e. arguing that the proposition is false – in the case of the toxicity of a compound, that it is inactive) “activity improbable” is the stronger and “activity doubted” the weaker term, defined analogously to “probable” and “plausible”.8In qualitative terms, it might thus be expected that the success of prediction by Derek for Windows would be graded from certain to impossible, with 100% of compounds classed as certain to be active being active and 0% of compounds with activity classed as impossible being active (see Fig. 1). Although Fig. 1 shows a neat gradation of steps across the range, this need not be the case, since the assessments are qualitative. What should be expected is the correct trend from certain to impossible, even if the steps are uneven.
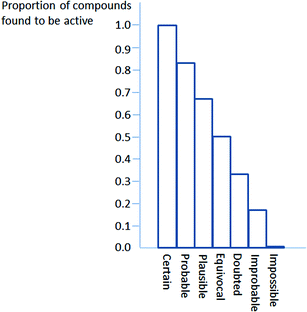 | ||
| Fig. 1 An idealised chart of predictive success against confidence levels. | ||
In practice, “certain” and “impossible” may not imply absolute proof for and against activity in Derek for Windows.8 Activity is reported to be certain if reliable experimental results showing the exact query compound to be active are available in an associated database (and there are no contradictory results) and to be impossible if the physiological apparatus required for toxicity to occur is absent from the test species (e.g. bacteria have no skin and are therefore not susceptible to skin sensitisation). The datasets used in the work described in this paper did not include compounds for which the Derek for Windows database contained exact answers to test queries. So the terms “certain” and “impossible” do not feature in the results and following discussion. Similarly, “contradicted” is not discussed further.
Data sets used for the study
Seven datasets were used in this study and a eighth one was derived from them. Datasets 1 to 7 contained predictions from the version of Derek for Windows packaged with Lhasa LPS 13 using knowledge base version 2011 D beta. Also recorded in the datasets were the observed results for toxicological activity. In some datasets results were recorded as “active” and “inactive” while in others they were recorded as “positive” and “negative”, or “1” and “0”. For consistency, all results are reported in this paper as “active” and “inactive”.Equivocal experimental results (as distinct from equivocal levels of confidence in predictions) were not included in the calculations (vide infra). As commented earlier, the datasets did not include compounds for which the Derek for Windows database contained exact answers. Confidence levels of “certain” or “impossible” were thus excluded.
The datasets were as follows:
Results and discussion
Relevant data from datasets 1 to 8, including the fraction of compounds found to be active (the positive predictivity) at each confidence level, are listed in Tables 2–9 and presented graphically in Fig. 2. The results in all cases for probable, plausible, and equivocal are consistent with the relative levels of confidence they represent: the proportion of compounds for which activity is assessed to be probable and which are found to be active is high; the proportion of compounds for which activity is assessed to be plausible and which are found to be active is lower but still well above 50%; the proportion of compounds for which activity is assessed to be equivocal is generally close to 50%.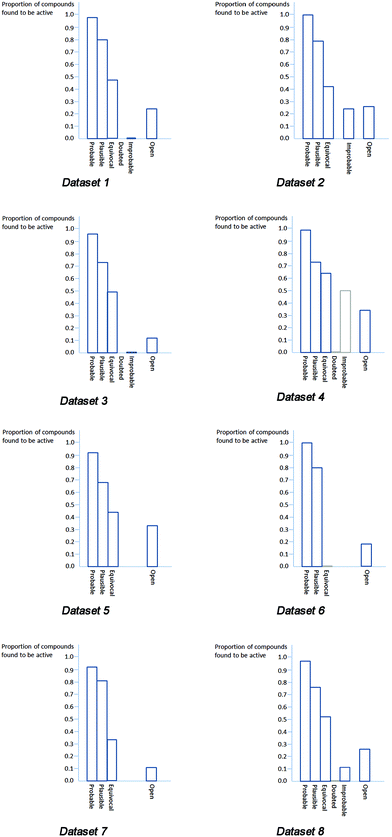 | ||
| Fig. 2 Charts of predictive success for Datasets 1 to 8. | ||
| Confidence level | Proportion active |
|---|---|
| 1 | 1.00 |
| 2 | 0.83 |
| 3 | 0.67 |
| 4 | 0.5 |
| 5 | 0.33 |
| 6 | 0.17 |
| 7 | 0.00 |
| Derek prediction | Active | Inactive | Equivocal | Fraction active (ignoring equivocal) |
|---|---|---|---|---|
| Probable | 103 | 2 | 0 | 0.98 |
| Plausible | 3042 | 753 | 0 | 0.80 |
| Equivocal | 82 | 85 | 0 | 0.49 |
| Doubted | 0 | 0 | 0 | — |
| Improbable | 0 | 7 | 0 | 0.00 |
| Subtotals | 3227 | 847 | 0 | 0.79 |
| Open | 1073 | 3268 | 6 | 0.25 |
| Totals | 4300 | 4115 | 6 | 0.51 |
| Derek prediction | Active | Inactive | Equivocal | Fraction active (ignoring equivocal) |
|---|---|---|---|---|
| Probable | 83 | 0 | 0 | 1.00 |
| Plausible | 2556 | 672 | 0 | 0.79 |
| Equivocal | 54 | 76 | 0 | 0.42 |
| Doubted | 0 | 0 | 0 | — |
| Improbable | 1 | 3 | 0 | 0.25 |
| Subtotals | 2694 | 751 | 0 | 0.78 |
| Open | 809 | 2258 | 0 | 0.26 |
| Totals | 3503 | 3009 | 0 | 0.54 |
| Derek prediction | Active | Inactive | Equivocal | Fraction active (ignoring equivocal) |
|---|---|---|---|---|
| Probable | 48 | 2 | 1 | 0.96 |
| Plausible | 380 | 140 | 48 | 0.73 |
| Equivocal | 22 | 23 | 6 | 0.49 |
| Doubted | 0 | 0 | 0 | — |
| Improbable | 0 | 5 | 0 | 0.00 |
| Subtotals | 450 | 170 | 55 | 0.73 |
| Open | 141 | 1064 | 120 | 0.12 |
| Totals | 591 | 1234 | 175 | 0.32 |
| Derek prediction | Active | Inactive | Equivocal | Fraction active (ignoring equivocal) |
|---|---|---|---|---|
| Probable | 109 | 1 | 3 | 0.99 |
| Plausible | 295 | 110 | 15 | 0.73 |
| Equivocal | 90 | 50 | 8 | 0.64 |
| Doubted | 0 | 1 | 0 | 0.00 |
| Improbable | 1 | 1 | 0 | 0.50 |
| Subtotals | 495 | 163 | 28 | 0.75 |
| Open | 488 | 942 | 58 | 0.34 |
| Totals | 983 | 1105 | 84 | 0.47 |
| Derek prediction | Active | Inactive | Equivocal | Fraction active (ignoring equivocal) |
|---|---|---|---|---|
| Probable | 72 | 6 | 0.92 | |
| Plausible | 488 | 228 | 1 | 0.68 |
| Equivocal | 7 | 9 | 0 | 0.44 |
| Doubted | 0 | 0 | 0 | — |
| Improbable | 0 | 0 | 0 | — |
| Subtotals | 567 | 243 | 1 | 0.70 |
| Open | 232 | 463 | 2 | 0.33 |
| Totals | 799 | 706 | 3 | 0.53 |
| Derek prediction | Active | Inactive | Equivocal | Fraction active (ignoring equivocal) |
|---|---|---|---|---|
| Probable | 36 | 0 | 7 | 1.00 |
| Plausible | 60 | 15 | 47 | 0.80 |
| Equivocal | 0 | 0 | 2 | — |
| Doubted | 0 | 0 | 0 | — |
| Improbable | 0 | 0 | 0 | — |
| Subtotals | 96 | 15 | 56 | 0.86 |
| Open | 6 | 27 | 10 | 0.18 |
| Totals | 102 | 42 | 66 | 0.71 |
| Derek prediction | Active | Inactive | Equivocal | Fraction active (ignoring equivocal) |
|---|---|---|---|---|
| Probable | 37 | 3 | 0 | 0.92 |
| Plausible | 52 | 12 | 15 | 0.81 |
| Equivocal | 1 | 2 | 1 | 0.33 |
| Doubted | 0 | 0 | 0 | — |
| Improbable | 0 | 0 | 0 | — |
| Subtotals | 90 | 17 | 16 | 0.84 |
| Open | 7 | 59 | 25 | 0.11 |
| Totals | 97 | 76 | 41 | 0.56 |
| Derek prediction | Active | Inactive | Equivocal | Fraction active (ignoring equivocal) |
|---|---|---|---|---|
| Probable | 488 | 14 | 11 | 0.97 |
| Plausible | 6873 | 1930 | 126 | 0.78 |
| Equivocal | 256 | 245 | 17 | 0.51 |
| Doubted | 0 | 1 | 0 | 0.00 |
| Improbable | 2 | 16 | 0 | 0.11 |
| Subtotals | 7619 | 2206 | 154 | 0.78 |
| Open | 2756 | 8081 | 221 | 0.25 |
| Totals | 10![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 375 375 |
10287 |
375 | 0.49 |
Exceptions or borderline cases are Datasets 3, 4 and 7. The proportion of compounds with equivocal predictions in Dataset 4 that are active is rather high, at 0.64, although this value still ranks equivocal appropriately relative to the other levels of confidence. The high value suggests that the rules and alerts relating to chromosome damage might be made more sensitive provided that sufficient knowledge could be found to support making changes. There were no clear results available for compounds with equivocal predictions in Dataset 6. There were only three compounds with equivocal predictions in Dataset 7, making a calculated value closer than 0.33 to 0.5 mathematically impossible, and three is too small a number for a statistically-meaningful assessment.
There were few predictions of doubted or improbable in any of the datasets. In Dataset 4 a confidence of doubted was assigned to only one compound and a confidence of improbable to only two. The results have been included in Table 5 and Fig. 2 for completeness but cannot be considered statistically significant. The statistical support for assessing improbable predictions in Datasets 1, 2 and 3 is weak, being based on seven, four and five compounds, respectively.
Datasets 1 to 7 cover several end points. Bringing together the findings from all of them gives some indication of the overall effectiveness of using reasoning-based levels of confidence in Derek for Windows. In Dataset 8 and Table 9 all the predictions from Datasets 1 to 7 at each level of confidence and the counts of active and inactive compounds have been combined. Unfortunately, the fraction calculated for doubted remains meaningless as there was only one such prediction in the dataset, and the fraction calculated for improbable is of limited significance as there were only eighteen instances of improbable predictions.
The proportion of compounds with a confidence level of probable which actually were active was high, being over 0.95 in all cases. The most usual reason for a prediction to be assigned the level of probable in Derek for Windows is that the query compound is present in the database and has been observed to be active but not in the specific strain or species for which the prediction is being made. For example, suppose a user asks about activity in mammals and the database contains data from a study in mice. The program cannot be certain about activity in mammals generally and the level of confidence is therefore probable, not certain. A similar situation applies if a user asks about bacterial mutagenicity and the database contains only data for Salmonella Typhimurium, since that might or might not be the bacterium of interest to the user. It is not surprising that a high proportion of such predictions turn out to be correct. Fig. 3 perhaps represents how confidence levels are actually distributed in Derek for Windows. It is derived from the graph for Dataset 8 in Fig. 2 by shifting the columns so that their heights lie on a straight line. To reach a trustworthy conclusion about the distribution of levels of confidence would require more and bigger datasets and it is outside the scope of this paper. Some further comments on this are made in the following section.
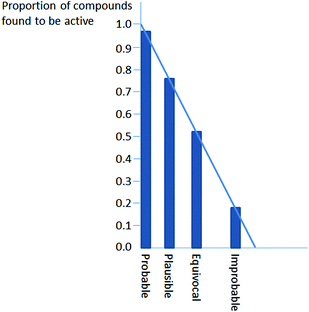 | ||
| Fig. 3 Chart of predictive success for dataset 8 with columns shifted to the relative positions of levels of confidence in Derek for Windows implied by the proportions of active compounds. | ||
Comparing the performance of models
Given the definition of equivocal, it must always be the case that 50% of compounds assigned equivocal confidence ought to be active. 100% of those assigned to confidence level certain and 0% of those assigned to confidence level impossible should be active, but as explained earlier the two levels are not included in the analyses conducted in this study. There is no theoretical reason why other confidence levels should be evenly distributed but the special case in which they are (i.e. the case that conforms to Fig. 1) might be thought of as ideal, in the sense that it is neat and readily understandable rather than in the sense of being fundamental. A well-defined yardstick is needed against which to judge performance and this one is proposed as the preferred choice. If there is formal guidance about how levels are actually distributed for a given application or model, evaluation might be done against that distribution as well as, or instead of, the ideal one. In such cases it would be necessary to show that the particular distribution of levels was justified and that the resultant reports on confidence in predictions could be easily understood by users. As commented earlier, there are reasons why the level for “probable”, for example, in Derek for Windows is not where it would be found in an evenly-distributed set of levels. Statistical evidence independent of the current study on which to base an uneven distribution of levels was not available. In any case, it is of interest to know how Derek for Windows performs relative to the intuitively-straightforward ideal distribution and so comparison with that distribution was used for the work described in the rest of this paper.Table 10 shows how the performance of Derek for Windows at each level of confidence compares with what would be expected for seven, evenly-distributed levels of confidence (i.e. in comparison with Table 1).
| Model | Dataset | Probable | Plausible | Equivocala | Doubteda | Improbableb |
|---|---|---|---|---|---|---|
| a The figure for “doubted” is included for completeness but it is not statistically meaningful because confidence was classed as “doubted” for only one compound in the dataset. b The figures for “improbable” are unreliable because confidence was classed as “improbable” for very few compounds in the datasets. | ||||||
| Ames mutagenicity | 1 | 0.14 | 0.11 | 0.01 | — | 0.05 |
| 2 | 0.17 | 0.12 | 0.08 | — | 0.08 | |
| 3 | 0.13 | 0.06 | 0.01 | — | 0.00 | |
| Chromosome damage | 4 | 0.16 | 0.06 | 0.14 | 0.00 | 0.00 |
| Carcinogenicity | 5 | 0.12 | 0.01 | 0.06 | — | — |
| Skin sensitisation | 6 | 0.17 | 0.13 | — | — | — |
| 7 | 0.07 | 0.27 | — | — | — | |
The deviation, d, from ideal for a given confidence level is given by
| d = |R − a/n| |
The values for veracity shown in Table 11 are calculated as follows:
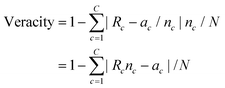
| Model | Ames mutagenicity | Chrom. damage | Carc. | Skin sensitisation | |||
|---|---|---|---|---|---|---|---|
| Dataset | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| a The figure for “doubted” is included for completeness but it is not statistically significant because confidence was classed as “doubted” for only one compound in the dataset. Including or excluding it makes no difference to the value for aggregate deviation unless it is calculated to at least three significant figures (five decimal places), which would itself be speciously precise. b The figures for “improbable” are unreliable because confidence was classed as “improbable” for very few compounds in the datasets. Including or excluding them makes no difference to the values for aggregate deviation rounded to two decimal places. | |||||||
| |Rn − a| | |||||||
| Probable | 14.1 | 14.1 | 6.5 | 17.7 | 7.3 | 6.1 | 3.8 |
| Plausible | 393.2 | 393.2 | 31.6 | 23.6 | 8.3 | 9.8 | 9.1 |
| Equivocal | 11.0 | 11.0 | 0.5 | 20.0 | 1.0 | — | 0.5 |
| Doubteda | — | — | — | 0.33 | — | — | — |
| Improbableb | 0.3 | 0.3 | 0.8 | 0.66 | — | — | — |
| Number of predictions | 3445 | 3445 | 620 | 658 | 810 | 111 | 107 |
| Aggregate deviation | 0.12 | 0.12 | 0.06 | 0.09 | 0.02 | 0.14 | 0.11 |
| Veracity | 0.87 | 0.88 | 0.94 | 0.91 | 0.98 | 0.86 | 0.89 |
As measures of performance for each individual level of confidence, only the deviations for probable, plausible, and equivocal in Table 10 can be considered significant, because the numbers of examples of predictions with confidence levels equal to doubted and improbable are too low. However, the fact that the number of compounds, n, for these levels is so small relative to the total number in the dataset, N, means that they have a negligible effect on the calculated veracity values in Table 11. If there are no predictions at a given level, it is not possible to calculate a value for deviation from the ideal for that level, ac, and the entry has been left blank in the tables (since nc is zero in these cases, the non-availability of a value for ac is irrelevant to the calculation of veracity).
Models reporting confidence as a probability value
The foregoing equations are easily adapted for the assessment of confidence expressed in terms of the probability that a compound will be active. As shown earlier, for a given level of confidence:| d = |R − a/n| |
For numerical probabilities, by definition, the ideal proportion of active compounds for a given prediction R, is the probability reported for the prediction, P. So for a given confidence level, defined as the subset of compounds assigned to probabilities within a specified range:
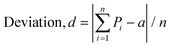
Hence, for a set of probability ranges in a model:
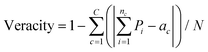
Influence of number of levels of confidence on veracity
The method of calculation of veracity might at first sight appear to penalise systems that have large numbers of levels of confidence. However, the veracity of a system with a high number of levels all of which are well assessed will match the veracity of one with fewer levels that are also well assessed, because the arithmetic dictates that deviations from ideal for the first system will be smaller than those for the second. The veracity of a system that has more levels than the evidence can support will be lower than that of a system with an appropriate, smaller number of levels. A system with many well-supported levels will outperform one with fewer, less well-supported levels. A corollary to the preceding two sentences is that veracity might be used by a model developer as an aid to deciding on the appropriate number of levels.The most extreme example might be a model that reports numerical probability values with high precision. It may, in consequence, have as many levels as the number of predictions it makes. Veracity can only equal 1 if the probability for all positive predictions is 1 and the probability for all negative predictions is 0. But it must be re-emphasised that veracity is a measure of confidence. If the probability of activity is interpreted as a measure of confidence in whether a compound will be active, over-precise probability values do imply false confidence. If the probability for one prediction is 0.75558 and the probability for another is 0.75557 and each is a unique prediction, what is the evidence-based confidence in those values? If the model were restructured to class together, say, all predictions with probabilities between 0.7 and 0.8, these predictions would be reported as equally probable at 0.75 ± 0.05. The deviation for the group would be low, provided it were true that three quarters of the compounds in the group were active. Confidence in the, albeit vaguer, prediction would rightly be higher.
As commented earlier, calculating veracity by comparison with an even distribution of levels of confidence will penalise models if the levels are not evenly distributed in those models. If statistical guidance is available about the actual distribution of the levels, it is appropriate to calculate veracity against those. If no such guidance is available, perhaps it is appropriate that a model with an uneven distribution of levels should be penalised, since the lack of a statement to the contrary at least implies that the distribution is even.
The relationship between veracity and concordance
In the context of this paper, a conventional binary prediction is a model with two levels of confidence, for true and false (or positive and negative). For such a model, veracity is equal to concordance, as the following shows.| Let: | x be the number of correct positive predictions; |
| y be the number of correct negative predictions; | |
| X be the number compounds predicted negative that were actually positive; | |
| N be the total number of items in the dataset; | |
| Z be the number of positive predictions; | |
| Y be the number of negative predictions; | |
| R 1 be the ideal ratio for true; | |
| R 2 be the ideal ratio for false; | |
| v be the veracity. |
| R1 = 1 |
| R2 = 0 |
| v = 1 − [(|R1X − x| + |R2Y − z|)/N] |
| = 1 − [(|(X − x)| + | − z|)/N] |
Since x ≤ X and | − z| = z:
| v = 1 − [(X − x + z)/N] |
| = 1 − [(X − x + Y − y)/N] |
| = 1 − [(X + Y − (x + y))/N] |
Since X + Y = N:
| v = 1 − [(N − (x + y))/N] |
| = (x + y)/N |
| But concordance = (x + y)/N |
| ∴Veracity = Concordance |
An optional final step in comparing the performance of models
What has been described so far allows comparison of the performance of models for the cases where they make predictions. A metric may sometimes be useful that also takes into account the proportion of compounds in a dataset for which predictions are made. The following metric, utility, is suggested for this purpose:| Utility, Uds = V N M−1 |
It is important to note that utility may be of limited application. It is entirely context-dependent, as implied by the use of Uds in the above equation. For example, the utility of a statistical QSAR model for a set of compounds all inside its applicability domain should be high. Its utility for a set of compounds all outside its applicability domain should be zero (since the value of N should be zero).
Context in which the term equivocal is used
The equivocal experimental results listed in the tables were not used in the calculations to generate the entries in the columns headed “Fraction Active”. Being equivocal about whether a compound will be found to be active or inactive is not the same as observing equivocal results for the compound in a study. So equivocal confidence and equivocal experimental results are not inherently correlated. The possibility was considered that they might be linked if the criteria used to define rules in the knowledge base and to classify results as equivocal were linked in some way. However, a consideration of the equivocal experimental results in the tables suggests that if there is a link, it is a weak one. For example, in Table 9, 5% of compounds for which predictions were equivocal gave equivocal experimental results but so did 2.5% of compounds for which predictions were plausible, 2.5% for which predictions were probable, and 3% of compounds for which predictions remained open.To reiterate, equivocal confidence in a prediction means that it is unclear whether a query compound will or will not be active, and not that the results of tests on it are likely to be equivocal.
Making better use of open predictions
As mentioned earlier, cases where there is no evidence for or against activity are classed as “open” and for these Derek for Windows delivers the message “nothing to report”. If a program were able to recognise every possible reason for a given kind of toxicological activity then it would be logical to argue that if no reason were found for a query to be active then that query must be inactive. In reality, no knowledge-based program can recognise every possible reason for activity – at best it might be able to recognise all known reasons for activity. However, at some level of knowledge it becomes acceptable to argue that the absence in a query of any feature known to cause activity at least throws doubt on there being activity. As mentioned earlier, researchers assessing the performance of Derek for Windows using methods such as Cooper statistics have made this assumption. Indeed, for the purposes of the statistical analyses they have assumed that an open prediction is equivalent to a categorical prediction of inactivity. Anecdotally, researchers using Derek for Windows (as distinct from evaluating the program) also interpret open predictions as equivalent to negative ones for end points for which they believe that the program has good coverage.It would be possible to formalise this approach by adding rules of the form “If no alerts for <end point> are found then <end point> is doubted” to the program knowledge bases. As with all rules in Derek for Windows, the firing of the rule would be reported to the user and a supporting explanation would be available. The user would thus know the grounds on which this negative prediction had been made. Note that, in this context, “doubted” means that the evidence points towards inactivity, as distinct from being a categorical prediction of inactivity. Note also that it is a prediction about inactivity, not low-confidence prediction of activity. The work described in this paper provides for the first time a way of assessing the performance of rules of this kind and thus might allow them to be implemented, subject to the availability of mechanistic or other justification.
The fractions of active compounds generating an open prediction for Ames mutagenicity are 0.25, 0.26, and 0.12 (see Tables 2–4). The ideal value for the “improbable” level of confidence is 0.17 and for the “doubted” level of confidence it is 0.33 (see Fig. 1). So erring on the side of caution, this evidence at least supports the case for a rule in the Derek knowledge bases of the following form:
“If no alerts fire for mutagenicity then mutagenicity is doubted.”
In the current absence of such a rule, the evidence suggests that users may be justified in taking “nothing to report” for mutagenicity as reason to doubt that a query will be mutagenic (which, of course, is not the same as saying that the query will not be mutagenic). The advantages of using rules for the conversion from “nothing to report” to, say, “activity doubted”, rather than leaving the user to make the assumption, are that the conversion is explicit and automatically documented and that whether the conversion is made – and, if so, to what level of confidence – can take account of factors such as the breadth and quality of supporting knowledge.
Similarly, the results for chromosome damage and carcinogenicity (see Tables 5 and 6) would justify the following rules:
“If no alerts fire for chromosome damage then chromosome damage is doubted.”
“If no alerts fire for carcinogenicity then carcinogenicity is doubted.”
The fractions for skin sensitisation, 0.19 and 0.09 (see Tables 7 and 8) might justify the rule:
“If no alerts fire for skin sensitisation then skin sensitisation is improbable.”
However, the data sets are small and the fact that the figure in one of the datasets for mutagenicity would have suggested “improbable” while the figures in the other two suggest “doubted” illustrates that there can be significant variation. The following, more cautious rule might therefore be more appropriate in this case too:
“If no alerts fire for skin sensitisation then skin sensitisation is doubted.”
A rule predicting inactivity in the absence of alerts would not be trustworthy for a query outside the applicability domain covered by the knowledge in the knowledge base. This will need to be taken into account if rules such as those above are implemented – e.g. by having rules about the level of confidence that a query is inside the applicability domain – but further discussion is outside the scope of this paper.
Notes of caution
The datasets used in this work are likely to contain structures that informed the researchers compiling the knowledge bases for Derek for Windows. In some cases, the datasets may have been used as test sets to support refinement of the knowledge bases. It is thus not clear whether the work in this paper assesses how well the programs report confidence in human understanding of existing data, or how well the programs report confidence in their own predictions. As stated earlier, the paper is not an assessment of the performance of Derek for Windows – the program is used here only for illustrative purposes.A second point of caution is that there are not enough examples of veracity in this paper to judge how it relates to quality of performance in practice. It indicates whether one model performs better than another but assumptions should not be made about how much better until more experience has been gained through its use.
Conclusions
In this paper, a new measure of performance, veracity, has been described which is suitable for qualitative, reasoning-based prediction systems as well as others such as those reporting probability of activity. Instead of asking the question “how good is this system at getting predictions right?” it asks the question “how good is this system at assessing how confident it is about each prediction?” In the context of uncertainty, and especially for qualitative prediction, the second question would seem to be the more useful criterion.Just a few datasets for four end points covered by Derek for Windows have been used to show how the approach is applied. Within the strict limitations of these datasets and end points, the study suggests that the levels of confidence expressed by Derek for Windows carry meaningful information which should not be ignored, either during the use of the program or when assessing its performance. Although only Derek for Windows was used for this work, it is hoped that the approach will be useful for researchers working on or assessing and comparing other prediction systems.
Acknowledgements
The authors thank Lhasa Limited for allowing access to the datasets used in this work.Notes and references
- N. L. Kruhlak, R. D. Benz, H. Zhou and T. J. Colatsky, (Q)SAR modelling and safety assessment in regulatory review, Clin. Pharmacol. Ther., 2012, 91(3), 529–534 CrossRef CAS.
- J. A. Cooper 2nd., R. Saracci and P. Cole, Describing the validity of carcinogenic screening tests, Br. J. Cancer, 1979, 39, 87–89 CrossRef CAS.
- Classification Models (CM) in OECD Environmental Health and Safety Publication Series on Testing and Assessment No. 69: Guidance Document on the Validation of (Quantitative) Structure–Activity Relationships [(Q)SAR], ENV/JV/MONO(2007)2, pp. 48.
- E. R. Bentzien, E. R. Hickey, R. E. Kemper, M. L. Brewer, J. D. Dyekjær, S. P. East and M. Whittaker, An in silico method for predicting Ames activities of primary aromatic amines by calculating the stabilities of nitrenium ions, J. Chem. Inf. Model., 2010, 50(2), 274–297 CrossRef.
- N. Greene, L. Fisk, R. T. Naven, R. R. Note, M. L. Patel and D. J. Pelletier, Developing structure–activity relationships for the prediction of hepatotoxicity, Chem. Res. Toxicol., 2010, 23(7), 1215–1222 CrossRef CAS.
- A. C. White, R. A. Mueller, R. H. Gallavan, S. Aaron and A. G. E. Wilson, A multiple in silico program approach for the prediction of mutagenicity from chemical structure, Mutat. Res., Genet. Toxicol. Environ. Mutagen., 2003, 539(1–2), 77–89 CrossRef CAS.
- (a) C. A. Marchant, K. A. Briggs and A. Long, In silico tools for sharing data and knowledge on toxicity and metabolism: Derek for Windows, Meteor and Vitic, Toxicol. Mech. Methods, 2008, 18(2–3), 177–187 CrossRef CAS; (b) http://www.lhasalimited.org/derek_nexus/ (accessed on 26th March 2012).
- P. N. Judson, C. A. Marchant and J. D. Vessey, Using argumentation for absolute reasoning about the potential toxicity of chemicals, J. Chem. Inf. Comput. Sci., 2003, 43, 1364–1370 CrossRef CAS.
- Collections of test data derived from the FDA/CFSAN/OFAS knowledge base and made available under a Co-operative Research And Development Agreement (CRADA).
- K. Hansen, S. Mika, T. Schroeter, A. Sutter, A. ter Laak, T. Steger-Hartmann, N. Heinrich and K. R. Müller, Benchmark dataset for in silico prediction of Ames mutagenicity, J. Chem. Inf. Model., 2009, 49(9), 2077–2081 CrossRef CAS.
- Mutagenicity data extracted from the Lhasa Vitic database, originally loaded from the DSSTox file of mutagenicity data from the National Toxicology Program (NTP) – NTPGTZ: National Toxicology Program Gene-Tox Database. DSSTox files can be downloaded from the website, http://www.epa.gov/ncct/dsstox/FTPDownload.html (accessed on 16th April 2012).
- (a) http://www.epa.gov/NCCT/dsstox/sdf_cpdbas.html ; (b) L. S. Gold, T. H. Slone, B. N. Ames, N. B. Manley, G. B. Garfinkel and L. Rohrbach, Carcinogenic potency database, in Handbook of Carcinogenic Potency and Genotoxicity Databases, ed. L. S. Gold and E. Zeiger, CRC Press, Boca Raton, FL, 1997, pp. 1–605 Search PubMed; (c) L. S. Gold, N. B. Manley, T. H. Slone and J. M. Ward, Compendium of chemical carcinogens by target organ: results of chronic bioassays in rats, mice, hamsters, dogs and monkeys, Toxicol. Pathol., 2001, 29, 639–652 CrossRef CAS; (d) L. S. Gold, N. B. Manley, T. H. Slone, L. Rohrbach and G. B. Garfinkel, Supplement to the carcinogenic potency database (CPDB): results of animal bioassays published in the general literature through 1997 and by the national toxicology program in 1997 and 1998, Toxicol. Sci., 2005, 85, 747–800 CrossRef CAS.
- G. F. Gerberick, C. A. Ryan, P. S. Kern, H. Schlatter, R. J. Dearman, I. Kimber, G. Y. Patlewicz and D. A. Basketter, Compilation of historical local lymph node data for evaluation of skin sensitization alternative methods, Dermatitis, 2005, 16, 157–202 CrossRef . Downloadable from http://www.inchemicotox.org/results/.
- M. T. Cronin and D. A. Basketter, Multivariate QSAR analysis of a skin sensitization database, SAR QSAR Environ. Res., 1994, 2, 159–179 CrossRef CAS.
| This journal is © The Royal Society of Chemistry 2013 |