Occurrence of disordered patterns and homorepeats in eukaryotic and bacterial proteomes†‡
M. Yu.
Lobanov
and
O. V.
Galzitskaya
*
Institute of Protein Research, Russian Academy of Sciences, Institutskaya str., 4 Pushchino, Moscow Region, 142290, Russia. E-mail: ogalzit@vega.protres.ru
First published on 18th October 2011
Abstract
Combining the motif discovery and disorder protein segment identification in PDB allows us to create the first and largest library of disordered patterns. At present the library includes 109 disordered patterns. Here we offer a comprehensive analysis of the occurrence of selected disordered patterns and 20 homorepeats of 6 residues long in 123 proteomes. 27 disordered patterns occur sparsely in all considered proteomes, but the patterns of low-complexity—homorepeats—appear more often in eukaryotic than in bacterial proteomes. A comparative analysis of the number of proteins containing homorepeats of 6 residues long and the disordered selected patterns in these proteomes has been performed. The matrices of correlation coefficients between numbers of proteins where at least once a homorepeat of six residues long for each of 20 types of amino acid residues and 109 disordered patterns from the library appears in 9 kingdoms of eukaryota and 5 phyla of bacteria have been calculated. As a rule, the correlation coefficients are higher inside the considered kingdom than between them. The largest fraction of homorepeats of 6 residues belongs to Amoebozoa proteomes (D. discoideum), 46%. Moreover, the longest uninterrupted repeats belong to S306 from D. discoideum (Amoebozoa). Homorepeats of some amino acids occur more frequently than others and the type of homorepeats varies across different proteomes, http://antares.protres.ru/fp/. For example, E6 appears most frequent for all considered proteomes for Chordata, Q6 for Arthropoda, S6 for Nematoda. The averaged occurrence of multiple long runs of 6 amino acids in a decreasing order for 97 eukaryotic proteomes is as follows: Q6, S6, A6, G6, N6, E6, P6, T6, D6, K6, L6, H6, R6, F6, V6, I6, Y6, C6, M6, W6, and for 26 bacterial proteomes it is A6, G6, P6, and the others occur seldom. This suggests that such short similar motifs are responsible for common functions for nonhomologous, unrelated proteins from different organisms.
Introduction
Prediction of protein structure and function is one of the general directions in structural genomics. The identification of essential features within protein domains can greatly facilitate their functional description. There are well established databases on protein motifs or domain information, such as PROSITE, InterPro and Pfam.1–3 Of special interest is the prediction of the so-called disordered regions of protein chains (regions without fixed spatial structure in the native state). Such disordered regions often play an important functional role.4–9 It can be suggested that if one and the same pattern corresponds to disordered regions in the protein structures then it is highly probable that such a pattern will be disordered in other proteins. Search for disordered patterns is an important task for prediction of disordered regions and search for the functioning of the considered motifs.Prediction methods are aimed at identifying disordered regions through an analysis of amino acid sequences using mainly the physico-chemical properties of amino acids10–19 or evolutionary conservation.20–23
Combining the motif discovery and disordered protein segment identification in PDB allows us to create a library of disordered patterns.24 At present the library includes 109 disordered patterns. Such an approach is novel and promising for further studies and understanding of the functional role of the obtained patterns in different proteomes. With the library of disordered patterns taken into account, it would be easier to improve the accuracy of prediction of structured/unstructured residues inside the given region.
The patterns occur more often as short fragments. Patterns of six residues long occur more frequently (75 from 109) among the disordered patterns of the library.24 It should be noted that six residue patches affect the folding/aggregation features of proteins, and they are important “words” for the understanding of protein dynamics.25 Moreover, nucleation sites are constrained by patches of approximately six residues.26,27 There is some evidence that the minimum length necessary for a peptide to elicit an allergenic response and molecular mimicry (a patch of a protein eliciting an immune response equivalent to the entire protein) is about six.28 All these facts suggest the existence of a fragment of biologically meaningful information located along approximately six residues.25
It is of interest that among 109 disordered patterns, homorepeats of low-complexity appear in the human, fly, and worm proteomes more often than others.24 Poly H fragments at the termini of protein chains are artificial parts of proteins in the PDB which have been added for better purification of proteins, but in the eukaryotic proteomes (HHHHHH is practically absent from the bacterial proteomes at all) such a repeat is likely to have a biological function. Recently, it has been demonstrated that an increased number of perfect tandem repeats correlates with their stronger tendency to be unstructured.29 Moreover, a strong association between homorepeats and unstructured regions has been shown elsewhere.30
The current study is focused on the occurrence of 109 disordered patterns in 97 eukaryotic proteomes, since eukaryotic proteomes include more disordered regions than other proteomes,20,31,32 and for comparison, in 26 bacterial proteomes. Separately, we analyzed the occurrence of homorepeats of six residues long for each of 20 types of amino acid residues. Very short runs occur randomly and have no statistical significance. The minimum length used for genome analyses is 5–7 residues.33–35 In accordance with the Online Mendelian Inheritance in Man (OMIM) annotation,36 more than 40% of proteins containing multiple runs of homorepeats are associated with different human diseases.35 There are two known examples for homorepeats: expansion of poly-A in polyadenine-binding protein 2 is associated with oculopharyngeal muscular dystrophy,37 and expansion of poly-H (larger than 36 residues long) in the gene called Huntingtin results in Huntington's disease. A growing number of studies suggest that homorepeats may play a more important role in human diseases than it was previously recognized.38
We came to some general conclusions after analysis of 123 proteomes. The disordered patterns of low-complexity—homorepeats—appear more often in eukaryotic than in bacterial proteomes. A comparative analysis of the number of proteins containing homorepeats of 6 residues long and the 109 disordered selected patterns in these proteomes has been performed. Homorepeats of some amino acids occur more frequently than others and the type of homorepeats vary across different proteomes. This suggests that such short similar motifs are responsible for common functions of nonhomologous, unrelated proteins from different organisms.
Results and discussion
Occurrence of disordered patterns in 97 eukaryotic and 26 bacterial proteomes
After creating the library of disordered patterns24 taken from PDB, a question arises as to how often these patterns could occur in some proteomes. Since eukaryotic proteomes include more disordered regions than other proteomes,20,31,32 we compared 97 eukaryotic proteomes and 26 bacterial ones (see Table 1, S1, ESI‡, and Methods).| Eukaryota | Eukaryota (Fungi) | Bacteriac | ||
|---|---|---|---|---|
| a Category without rank is given. b The name of order is given because the highest ranks are missing in the taxonomic description. c The superkingdom of bacteria is divided in phyla rather than kingdoms. | ||||
| Metazoa | 25.H_sapiens | 34310.A_capsulata_ATCC_26029 | Acidobacteria | 25797.S_usitatus |
| 22974.B_taurus | 34967.A_capsulata_H143 | Actinobacteria | 37022.A_mediterranei | |
| 59.M_musculus | 34495.A_dermatitidis_SLH14081 | 33926.C_acidiphila | ||
| 122.R_norvegicus | 34498.A_dermatitidis_ER-3 | 35278.Frankia_sp_EuI1c | ||
| 21457.G_gallus | 35919.A_benhamiae | 35534.F_sp | ||
| 20721.D_rerio | 29154.A_clavatus | 74443.K_setae | ||
| 22388.T_nigroviridis | 33020.A_flavus | 33113.R_opacus | ||
| 17.D_melanogaster | 22118.A_fumigatus_FGSC_A1100 | 25456.Rhodococcus_sp | ||
| 25396.D_pseudoobscura | 31018.A_fumigatus_CEA10 | 131.S_avermitilis | ||
| 31436.A_aegypti | 29130.A_niger | 36666.S_bingchenggensis | ||
| 78607.A_darlingi | 23077.A_oryzae | 84.S_coelicolor | ||
| 22426.A_gambiae | 28239.A_terreus | 34910.S_scabies | ||
| 21633.C_briggsae | 30100.B_fuckeliana | 35554.S_sp_ACT-1 | ||
| 9.C_elegans | 22024.C_albicans_SC5314 | 58962.S_violaceusniger | ||
| 64800.L_loa | 32738.C_dubliniensis | 34011.S_roseum | ||
| 79720.T_spiralis | 19665.C_glabrata | Proteobacteria | 112.B_japonicum | |
| 30565.N_vectensis | 34491.C_tropicalis | 22343.Burkholderia_sp_ATCC_17760 | ||
| Viridiplantae | 23214.O_sativa | 25585.C_globosum_IFO_6347 | 25388.B_xenovorans | |
| 3.A_thaliana | 34493.C_lusitaniae | 33223.H_ochraceum | ||
| 33157.Micromonas_sp | 34218.C_posadasii | 23351.M_xanthus | ||
| 29351.O_lucimarinus | 79902.C_graminicola | 32044.P_pacifica | ||
| 25972.O_tauri | 20018.D_hansenii | 30295.S_cellulosum | ||
| Stramenopilesa | 35109.E_siliculosus | 34482.L_thermotolerans | 33616.S_aurantiaca | |
| Choanoflagellidab | 30562.M_brevicollis | 29447.L_elongisporus | Bacteroidetes | 33930.C_pinensis |
| Euglenozoaa | 83400.L_braziliensis | 22028.M_oryzae | 32144.M_marina | |
| 83363.L_infantum | 34471.N_otae | Chloroflexi | 36622.K_racemifer | |
| 71330.T_brucei | 34970.N_haematococca | |||
| 33602.T_cruzi | 29157.N_fischeri | |||
| Alveolataa | 32114.P_berghei | 22025.N_crassa | ||
| 31998.P_chabaudi | 34307.P_brasiliensis_Pb03 | |||
| 493.P_falciparum | 34389.P_brasiliensis_Pb18 | |||
| 31342.P_knowlesi | 34392.P_brasiliensis_ATCC_MYA-826 | |||
| 31632.P_vivax | 31898.P_chrysogenum | |||
| 21631.P_yoelii | 32999.P_marneffei | |||
| Amoebozoaa | 21395.D_discoideum | 25591.P_nodorum | ||
| 35301.P_pallidum | 29448.P_guilliermondii | |||
| Diplomonadidaa | 33600.G_intestinalis_ATCC_50803 | 28727.P_stipitis | ||
| 35295.G_intestinalis_ATCC_50581 | 79908.P_graminis | |||
| 65115.G_intestinalis | 79905.P_teres | |||
| 30091.S_cerevisiae_YJM789 | ||||
| 31651.S_cerevisiae_RM11-1a | ||||
| 34506.S_cerevisiae_JAY291 | ||||
| 35062.S_cerevisiae_Lalvin_EC1118 | ||||
| 71242.S_cerevisiae | ||||
| 30103.S_sclerotiorum | ||||
| 35280.S_macrospora | ||||
| 33056.T_stipitatus | ||||
| 35921.T_verrucosum | ||||
| 34386.U_reesii | ||||
| 30097.V_polyspora | ||||
| 35359.V_albo-atrum | ||||
| 20011.Y_lipolytica | ||||
| 31020.C_cinerea | ||||
| 20846.C_neoformans_JEC21 | ||||
| 21380.C_neoformans_B-3501A | ||||
| 31023.L_bicolor | ||||
| 33031.P_placenta | ||||
| 22029.U_maydis | ||||
We considered two cases for coincidence. In the first case, we calculated the number of proteins where the patterns match a fragment of the polypeptide chain with a precise coincidence. In the other case we analyzed the coincidence according to the following definition:24 pattern A matches chain P at position s if
(1) two residues from each end coincide:
| A[1] = P[s + 1], A[2] = P[s + 2], A[L − 1] = P[s + L − 1], A[L] = P[s + L]. |
(2) there are at most L/5 positions r in the middle of the pattern in which
| A[r] ≠ P[s + r]. |
This means that for patterns with a length of L ≤ 5 no change may occur, for 5 < L ≤ 10 only 1 change may take place, for 10 < L ≤ 15 2 changes, etc.
Among 109 disordered patterns 27 occur only in PDB but are very sparse in 123 proteomes (see S2, ESI‡). Such patterns as ASMTGGQQMGR, AHHHHHHMGTLEAQTQGPGSM, HHHHSSGLVPRGSHM, HHHHHHSSGVDLGTENLYFQSM, HHHHSSGVDLGTENLYFQSNAM, SMTGGQQMGRGS, PTTENLYFQGAM, SHHHHHHSQDP, and KLAAALEHHHHH do not appear in the analyzed 123 proteomes even in the two cases (exact coincidence and precise coincidence of two terminal residues and no coincidence in the L/5 positions). This suggests that such patterns are an artificial addition to proteins from PDB for their better purification.
From Table 2 it is evident that the disordered patterns with the most frequent occurrence in the eukaryotic and even in bacterial proteomes are homorepeats Q6, G6 (GGKGGG), E6 (EEEDEE), P6, K6 (KKKGKK). Previous studies suggest24 that these patterns will be disordered in most cases. It is notable that low-complexity regions can additionally include ordered structural proteins or proteins with strong structural propensity, like collagens, coiled-coils or fibrous proteins.39 Recently, it has been demonstrated that the increasing number of perfect tandem repeats correlates with a stronger tendency to be unstructured.29 Moreover, a strong association between homorepeats and unstructured regions was shown elsewhere.30 Such patterns as GSSGSS, DEEAEE, EDEDEE, APAPAP, GGGGGSG, DDEDED, and DEEEED also occur frequently in the considered 97 eukaryotic proteomes. Such a pattern as APAPAP often occurs in 26 bacterial proteomes as well (see Table 2).
| Eukaryotic proteomes (97) | Bacterial proteomes (26) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metazoa (17) | Viridiplantae (5) | Heterokontophyta (1) | Choanoflagellida (1) | Euglenozoa (4) | Alveolata (6) | Amoebozoa (2) | Diplomonadida (3) | Fungi (58) | Acidobacteria (1) | Actinobacteria (14) | Proteobacteria (8) | Bacteroidetes (2) | Chloroflexi (1) | |
| QQQQQQ | 534.1 | 192.6 | 472.0 | 201.0 | 317.0 | 19.0 | 1918.5 | 24.0 | 198.9 | 9.0 | 7.9 | 6.0 | 8.5 | 16.0 |
| GGKGGG | 466.2 | 1038.0 | 2601.0 | 98.0 | 248.8 | 62.7 | 383.5 | 13.0 | 149.0 | 104.0 | 89.1 | 93.0 | 23.5 | 33.0 |
| EEEDEE | 499.5 | 434.8 | 744.0 | 148.0 | 290.0 | 212.5 | 518.0 | 22.3 | 190.2 | 7.0 | 6.9 | 10.0 | 12.0 | 25.0 |
| PPPPPP | 528.5 | 672.2 | 575.0 | 139.0 | 280.8 | 16.8 | 231.5 | 21.3 | 181.4 | 45.0 | 44.5 | 84.1 | 9.0 | 23.0 |
| KKKGKK | 249.0 | 185.0 | 139.0 | 85.0 | 67.8 | 669.8 | 242.5 | 12.7 | 86.8 | 13.0 | 2.9 | 6.5 | 36.0 | 42.0 |
| GSSGSS | 271.3 | 195.2 | 399.0 | 71.0 | 151.5 | 40.8 | 305.0 | 41.0 | 93.4 | 9.0 | 22.4 | 20.5 | 12.0 | 14.0 |
| DEEAEE | 225.5 | 203.0 | 284.0 | 102.0 | 139.0 | 109.2 | 218.0 | 17.0 | 102.7 | 5.0 | 9.9 | 8.3 | 5.5 | 13.0 |
| EDEDEE | 219.9 | 187.6 | 192.0 | 106.0 | 94.3 | 108.3 | 210.0 | 10.3 | 109.9 | 3.0 | 5.9 | 8.6 | 8.5 | 12.0 |
| DDEDED | 145.1 | 171.8 | 154.0 | 148.0 | 62.3 | 81.8 | 249.0 | 10.3 | 103.2 | 1.0 | 5.6 | 11.6 | 4.0 | 6.0 |
| APAPAP | 164.8 | 228.6 | 263.0 | 170.0 | 84.0 | 4.8 | 31.0 | 19.3 | 81.5 | 73.0 | 126.1 | 142.3 | 6.5 | 26.0 |
| DEEEED | 137.7 | 142.0 | 109.0 | 80.0 | 68.0 | 71.7 | 181.5 | 9.7 | 81.0 | 0.0 | 3.9 | 7.0 | 4.0 | 3.0 |
| GGGGGSG | 150.3 | 147.4 | 752.0 | 23.0 | 53.5 | 30.3 | 144.5 | 5.3 | 31.8 | 11.0 | 28.6 | 29.1 | 3.5 | 8.0 |
| KKGEKK | 113.2 | 77.2 | 64.0 | 26.0 | 35.5 | 237.8 | 106.0 | 9.7 | 39.3 | 2.0 | 1.1 | 2.6 | 22.5 | 7.0 |
| QPPPPP | 137.2 | 114.0 | 95.0 | 39.0 | 53.3 | 7.5 | 86.0 | 7.7 | 50.7 | 12.0 | 13.8 | 16.4 | 0.5 | 12.0 |
| SGGGSGG | 129.4 | 170.4 | 791.0 | 30.0 | 57.8 | 28.2 | 153.5 | 1.0 | 31.5 | 13.0 | 20.0 | 18.5 | 3.5 | 6.0 |
| PPPPPK | 112.2 | 87.0 | 53.0 | 47.0 | 28.8 | 3.8 | 46.5 | 5.3 | 48.5 | 17.0 | 4.6 | 13.8 | 5.0 | 13.0 |
| KKRKRK | 99.4 | 93.6 | 51.0 | 13.0 | 22.5 | 144.3 | 55.0 | 9.0 | 36.5 | 3.0 | 1.2 | 3.8 | 9.0 | 28.0 |
| GGSGSGG | 111.6 | 112.0 | 639.0 | 18.0 | 49.0 | 22.8 | 115.0 | 2.3 | 24.9 | 6.0 | 21.6 | 23.5 | 3.0 | 9.0 |
| HHHHHH | 143.8 | 65.6 | 46.0 | 25.0 | 23.3 | 10.2 | 168.0 | 0.3 | 29.9 | 0.0 | 1.1 | 2.1 | 0.0 | 2.0 |
| PGGMGG | 108.8 | 106.6 | 295.0 | 28.0 | 29.3 | 10.0 | 15.5 | 4.7 | 27.2 | 26.0 | 40.2 | 24.6 | 9.0 | 14.0 |
| APAPSA | 64.7 | 89.6 | 116.0 | 115.0 | 78.3 | 2.3 | 15.5 | 15.7 | 36.0 | 26.0 | 58.8 | 61.1 | 4.5 | 19.0 |
| PPEPPK | 86.7 | 55.8 | 35.0 | 32.0 | 22.8 | 4.2 | 36.0 | 7.7 | 35.0 | 10.0 | 4.4 | 11.0 | 3.0 | 8.0 |
| GSAMAS | 44.4 | 45.0 | 83.0 | 44.0 | 56.0 | 7.0 | 14.0 | 10.3 | 28.5 | 13.0 | 18.8 | 21.8 | 8.0 | 14.0 |
| PGSSGG | 62.8 | 51.8 | 120.0 | 11.0 | 33.3 | 5.0 | 16.5 | 3.3 | 17.9 | 17.0 | 32.6 | 23.1 | 9.0 | 16.0 |
| SGGGGSG | 53.2 | 40.8 | 182.0 | 9.0 | 26.8 | 18.0 | 65.5 | 3.0 | 13.2 | 8.0 | 12.8 | 12.3 | 3.0 | 1.0 |
Poly H fragments are artificial parts of proteins in PDB which have been added for better purification of proteins, but in eukaryotic proteomes such a repeat is likely to have a biological function. It should be added that H6 occurs often in eukaryotic proteomes and very seldom in bacterial ones. For some cases, molecular functions of the proteins including the H6 pattern are as follows: growth factor activity; methyltransferase activity; protein binding; transcription factor activity; calcium-dependent cysteine-type endopeptide; zinc ion binding; sequence-specific DNA binding, etc. (see GO annotation for proteins where patterns and homorepeats occur in different proteomes at the site http://antares.protres.ru/fp/).
Occurrence of homorepeats for each of 20 types of amino acid residues in 97 eukaryotic and 26 bacterial proteomes
We calculated the occurrence of homorepeats of 6 residues long for each of the 20 types of amino acid residues in 123 proteomes (see Table 3, Fig. 1, and S3, ESI‡). The runs of hydrophobic and sulfur containing residues (C6, M6, F6, I6, L6, V6, W6, and Y6) occur sparsely in all considered proteomes, with exception of L6 which occurs more often in 123 proteomes. As reported,40 in eukaryotes, the most common homorepeats (in order of decreasing frequency) are poly-P, poly-G, poly-S, poly-A, poly-N, and poly-Q. The averaged occurrence of multiple long runs of 6 amino acids in a decreasing order for 97 eukaryotic proteomes is as follows: Q6, S6, A6, G6, N6, E6, P6, T6, D6, K6, L6, H6, R6, F6, V6, I6, Y6, C6, M6, and W6, and for 26 bacterial proteomes it is A6, G6, and P6, and the others occur seldom.| Eukaryotic proteomes (97) | Bacterial proteomes (26) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metazoa (17) | Viridiplantae (5) | Heterokontophyta (1) | Choanoflagellida (1) | Euglenozoa (4) | Alveolata (6) | Amoebozoa (2) | Diplomonadida (3) | Fungi (58) | Acidobacteria (1) | Actinobacteria (14) | Proteobacteria (8) | Bacteroidetes (2) | Chloroflexi (1) | |
| Q6 | 388.1 | 128.4 | 339.0 | 137.0 | 209.8 | 9.3 | 1590.0 | 14.3 | 138.5 | 3.0 | 2.1 | 2.4 | 1.0 | 6.0 |
| S6 | 325.4 | 436.8 | 424.0 | 76.0 | 152.3 | 39.0 | 1122.5 | 15.3 | 126.5 | 0.0 | 5.6 | 9.0 | 3.0 | 9.0 |
| A6 | 315.5 | 648.8 | 1760.0 | 155.0 | 257.3 | 6.3 | 67.0 | 5.7 | 79.1 | 26.0 | 60.8 | 41.8 | 3.5 | 8.0 |
| G6 | 271.6 | 653.8 | 1953.0 | 43.0 | 123.3 | 14.7 | 222.5 | 1.7 | 63.0 | 35.0 | 26.8 | 34.6 | 7.0 | 8.0 |
| N6 | 71.2 | 36.2 | 31.0 | 17.0 | 50.5 | 348.8 | 3161.5 | 1.3 | 49.1 | 1.0 | 0.4 | 0.4 | 6.0 | 0.0 |
| E6 | 257.5 | 233.8 | 534.0 | 63.0 | 139.0 | 91.5 | 327.0 | 4.7 | 85.1 | 3.0 | 0.7 | 3.4 | 2.0 | 7.0 |
| P6 | 256.2 | 351.8 | 339.0 | 70.0 | 139.3 | 8.7 | 141.0 | 7.3 | 84.4 | 25.0 | 11.1 | 28.8 | 6.5 | 10.0 |
| T6 | 131.9 | 91.8 | 50.0 | 133.0 | 200.5 | 8.3 | 1497.5 | 2.7 | 58.2 | 1.0 | 4.2 | 2.6 | 1.5 | 2.0 |
| D6 | 106.9 | 231.6 | 210.0 | 127.0 | 72.8 | 66.3 | 304.5 | 4.7 | 77.5 | 0.0 | 1.0 | 8.5 | 3.5 | 4.0 |
| K6 | 99.2 | 64.4 | 62.0 | 46.0 | 18.5 | 403.0 | 87.0 | 0.0 | 29.5 | 0.0 | 0.1 | 1.4 | 7.0 | 1.0 |
| L6 | 134.6 | 78.4 | 23.0 | 54.0 | 144.3 | 9.8 | 18.0 | 8.3 | 8.6 | 9.0 | 3.7 | 3.8 | 15.0 | 27.0 |
| H6 | 97.1 | 42.8 | 28.0 | 13.0 | 11.5 | 4.7 | 117.0 | 0.3 | 18.2 | 0.0 | 0.1 | 0.4 | 0.0 | 2.0 |
| R6 | 31.1 | 164.0 | 112.0 | 19.0 | 16.3 | 5.2 | 2.0 | 2.0 | 11.3 | 0.0 | 7.1 | 7.9 | 0.5 | 0.0 |
| F6 | 6.7 | 10.8 | 0.0 | 8.0 | 33.3 | 28.0 | 35.5 | 0.0 | 3.5 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 |
| V6 | 11.4 | 22.2 | 11.0 | 7.0 | 7.5 | 0.3 | 5.0 | 1.0 | 4.4 | 0.0 | 1.5 | 0.6 | 0.5 | 0.0 |
| I6 | 11.1 | 1.8 | 0.0 | 3.0 | 10.0 | 4.3 | 16.5 | 0.0 | 1.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Y6 | 5.1 | 1.6 | 0.0 | 3.0 | 7.5 | 3.5 | 3.0 | 0.0 | 0.7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| C6 | 5.4 | 2.0 | 0.0 | 1.0 | 3.8 | 0.3 | 1.0 | 0.0 | 0.5 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 |
| M6 | 2.5 | 1.6 | 1.0 | 3.0 | 1.3 | 0.5 | 0.5 | 0.0 | 0.6 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| W6 | 0.3 | 0.6 | 2.0 | 0.0 | 0.8 | 0.0 | 0.0 | 0.0 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
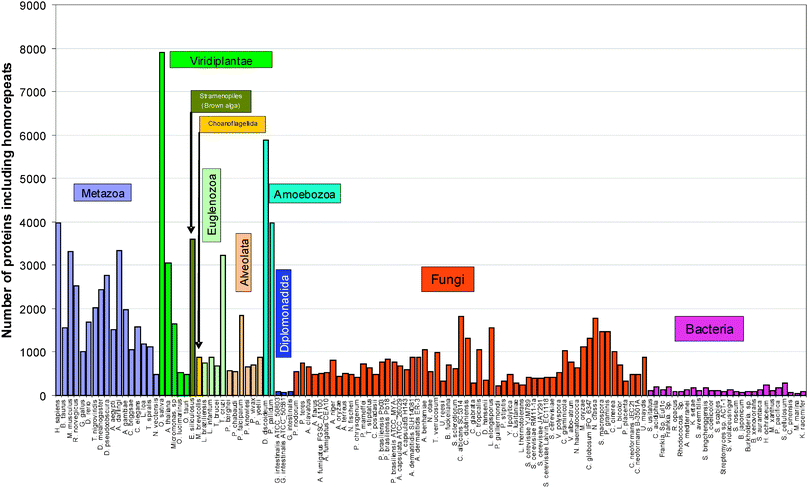 | ||
| Fig. 1 Occurrence of 20 homorepeats of 6 residues long in 123 proteomes. | ||
We assume that only those homorepeats which are included in the library of disordered patterns will be disordered. Such homorepeats are six: H6, P6, Q6, K6 (KKKGKK), G6 (GGKGGG), and E6 (EEEDEE). We are sure about the disordered state of the above-mentioned six homorepeats, and previous studies suggest11,24 that S6, D6, N6, and R6 should be also disordered because these amino acids are disordered with a higher probability than the others in statistics obtained from the protein data bank. For other homorepeats we cannot make reliable predictions.
We calculated the frequencies of occurrence for all 20 amino acid residues in the considered 123 proteomes. It should be noted that practically in all cases we revealed a correlation between all pairs of 115 proteomes that is higher than 75%. Only for two kingdoms (Alveolata and Amoebozoa) including 8 proteomes the correlation coefficients are even negative.
The averaged frequencies of occurrence for amino acids in 6 kingdoms including 6 Alveolata and 2 Amoebozoa proteomes are presented in Fig. 2. In Alveolata proteomes, high frequencies of occurrence are observed for such amino acids as N, K, I, and Y. Moreover, N6 and K6 homorepeats occur more often in Alveolata proteomes than in other eukaryotic organisms. K6 (KKKGKK) falls into the library of disordered patterns, but N6 or disordered patterns enriched with N are absent from the library. On the other hand, such proline-rich disordered patterns (P6, APAPAP, PPPPPK, QPPPPP) and G6 (GGKGGG) occur infrequently in the Alveolata proteome.
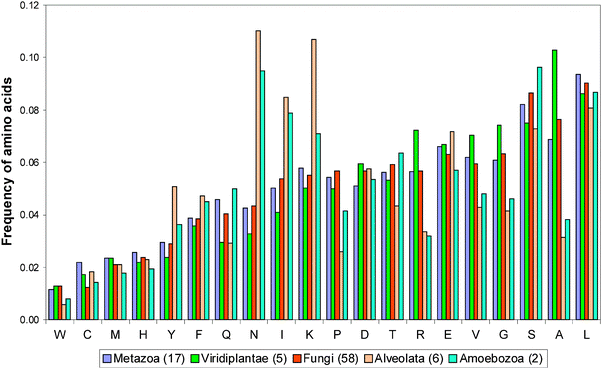 | ||
| Fig. 2 Averaged frequencies of occurrences of amino acids in 6 kingdoms including 6 Alveolata and 2 Amoebozoa proteomes. | ||
A similar regularity takes place in the Amoebozoa proteomes. Homorepeats occur in this kingdom more often than in other eukaryotic kingdoms. N6, Q6, S6, and T6 occur very often, but K6 occurs with usual frequency. Among disordered patterns Q6 is most frequent.
For each proteome we calculated a set of 20 values reflecting the number of proteins containing at least one homorepeat of 6 residues long for each of the 20 types of amino acid residues. Then considering all possible pairs of proteomes, the correlation coefficients between the 20 values have been calculated resulting in the matrix of correlation coefficients (see Table 4). As a rule, the correlation coefficients are higher inside the studied kingdom than between them. A similar conclusion follows from considering proteins with at least one disordered pattern.
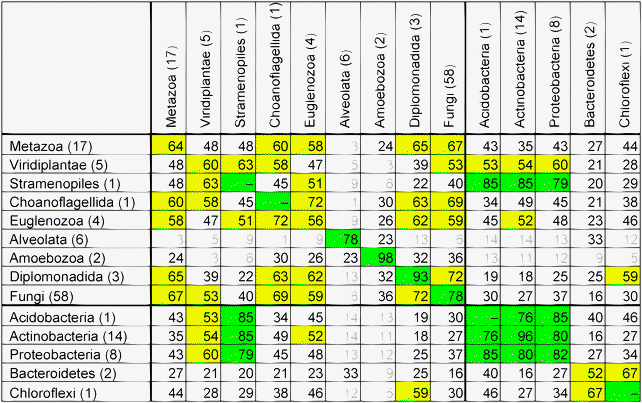
|
Comparison of the matrices of correlation coefficients for the frequencies of occurrence of amino acid residues and the number of proteins containing homorepeats in the studied proteomes shows that the former correlation coefficients are higher.
We averaged correlation coefficients over all proteomes from the studied kingdoms. The averaged correlation coefficient is low inside such a kingdom as Metazoa. We decided to analyze in more detail the proteomes from the Metazoa kingdom.
The averaged pattern of occurrence of multiple long runs of 6 amino acids in a decreasing order for 17 animal proteomes is as follows: Q6, S6, A6, G6, E6, P6, L6, T6, D6, K6, H6, N6, R6, V6, I6, F6, C6, Y6, M6, and W6. Runs of hydrophobic and sulfur containing residues (I6, F6, V6, W6, M6, and C6) occur sparsely with exception of L6 which occurs more often in mammalian proteomes. Another exception is the L. loa proteome (Nematoda phylum) where large hydrophobic residues occur often, especially I6, V6, Y6, and M6, in comparison with other proteomes considered here.
The most frequent amino acid runs in the human proteome occur for E6, P6, A6, L6, S6, G6, Q6, and K6 (in decreasing order). The acidic runs (E6 and D6) exceed the basic runs (K6 and R6) by a factor of 3 in the human proteome. In chordates, homorepeats of amino acids Asn (N) and Thr (T) are rare. N6 occurs only in 3 proteins in the human proteome.
The most frequent amino acid runs in D. melanogaster occur for Q6, A6, G6, S6, P6, T6, and N6. The percentage of amino acid runs in 6 residues is larger for fruit flies than for the human proteome. For African malaria mosquitoes, the most frequent amino acid runs are Q6, G6, A6, S6, T6, H6, P6, and E6 (see S3, ESI‡). The largest fraction of homorepeats for 6 residues belongs to the mosquito proteome, Anopheles darlingi, 29% (percentage of proteins containing at least one homorepeat for 20 amino acids from the whole proteome). At the same time, another representative of the genus Anopheles has only about a half, 16%.
We calculated the statistical significance of the observed runs over the length of 6 residues using eqn (4) (see Methods). The average length of proteins in eukaryotic proteomes is larger (400 residues) than the average protein length given in the PDB database (260 residues). Practically all homorepeats are statistically significant with exception of homorepeats with very sparse occurrences, that is, for hydrophobic residues and sulfur containing residues (C6 and M6). E6 is most frequent among all considered proteomes for Chordata, Q6 for Arthropoda, S6 for Nematoda (Q6 only for T. spiralis proteome), and P6 for Cnidaria (see S3, ESI‡).
From Table 5 four clusters can be selected with a high correlation between the numbers of proteins where homorepeats of 6 residues long appear at least once for each of the 20 types of amino acid residues. The first cluster corresponds to the phylum Chordata (7 proteomes), the second corresponds to Arthropoda (5 proteomes), the third to Nematoda (4 proteomes), and the fourth to Cnidaria (only 1 proteome). Green color in Table 5 is used to show a correlation higher than 75%, and yellow the correlation from 50% to 75%. As a rule, the correlation coefficients are higher inside the considered phylum than between them.
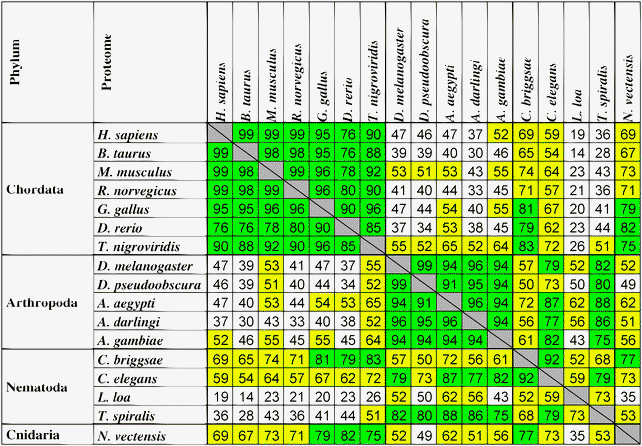
|
It should be noted that each proteome has specific multiple long runs. We found the maximal possible uninterrupted runs for each amino acid among 123 considered proteomes (see Table 6). The most frequent is L. loa (phylum Nematoda, class Chromadorea) which includes six longest repeats: I130, L115, V84, Y132, A34, and N128. The longest uninterrupted repeats belong to S306 from D. discoideum (Amoebozoa). The occurrence of maximal uninterrupted runs is not connected with taxonomy. For example, for nearest relatives of L. loa (class Chromadorea) C. briggsae and C. elegans, the maximal length of runs for I, L, V, Y, A, and N is less than 20 residues.
| Kingdom | Proteome | Runs | Kingdom | Proteome | Runs |
|---|---|---|---|---|---|
| Fungi | C. albicans | C 19 | Choanoflagellida | M. brevicollis | T 101 |
| Metazoa | N. vectensis | M 20 | Amoebozoa | D. discoideum | S 306 |
| Fungi | S. sclerotiorum | F 28 | Metazoa | N. vectensis | Q 163 |
| Metazoa | L. loa | I 130 | Metazoa | L. loa | N 128 |
| Metazoa | L. loa | L 115 | Viridiplantae | A. thaliana | E 118 |
| Metazoa | L. loa | V 84 | Metazoa | D. rerio | D 200 |
| Fungi | A. dermatitidis | W 10 | Metazoa | T. nigroviridis | H 66 |
| Metazoa | L. loa | Y 132 | Fungi | B. fuckeliana | R 31 |
| Metazoa | L. loa | A 34 | Viridiplantae | A. thaliana | K 240 |
| Metazoa | C. briggsae | G 89 | Metazoa | A. gambiae | P 71 |
The longest uninterrupted runs in the human proteome are of 58 residues for serine, 74 for glutamine, 58 for aspartic acid, and 53 for lysine, threonine in D. melanogaster (49 residues long), serine in C. elegans (27 residues long), 163 for glutamine in N. vectensis (see Fig. 3). The determined longest runs for each amino acid inside each proteome and calculated correlations between different proteomes give low correlation coefficients which do not depend on the systematics.
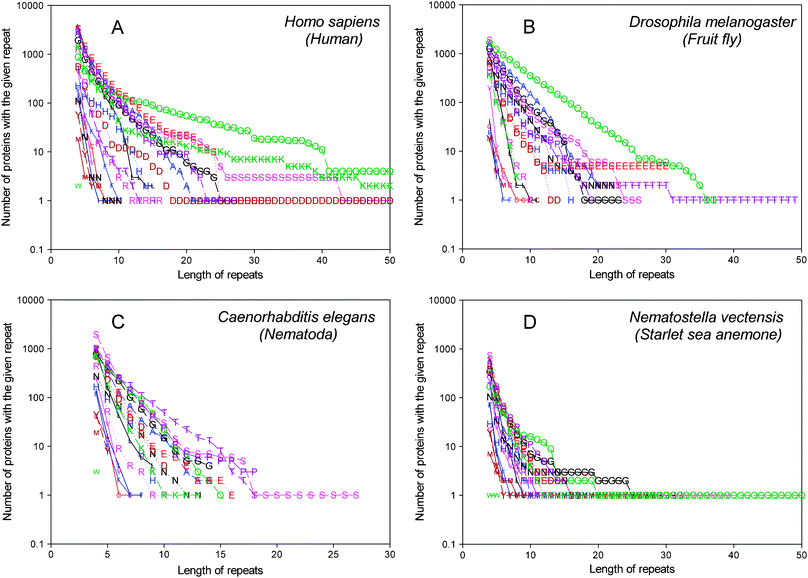 | ||
| Fig. 3 Dependence of the number of proteins that contain homorepeats of different lengths for 20 amino acids in the human proteome (A), in D. melanogaster (B), in C. elegans (C), and in N. vectensis (D). | ||
The analysis of occurrence of disordered patterns in 123 proteomes allowed a conclusion as to which of them are more important than the others. 27 disordered patterns occur sparsely in all considered proteomes. It turned out that such disordered homorepeats as H6, P6, Q6, K6 (KKKGKK), G6 (GGKGGG) and E6 (EEEDEE) are more important than other more complex disordered patterns. Some homorepeats and disordered patterns appear more often in eukaryotic proteomes than in some bacterial proteomes. This is in agreement with the fact that the disorder content increases with increasing organism complexity, with about one third of all eukaryotic proteins predicted to be disordered.20,31,32 It has been demonstrated that among 126 known unstructured sequences the percentage of proteins with tandemly repeated short segments is much higher (39%) than earlier reported for all Swiss-Prot (14%).41 The study42 using only five proteomes suggests that X4 repeats (repeated motifs of four members) decreased in number with increasing phylogenetic distance. In our case, X6 repeats (in similar terms) showed no such behavior in 123 proteomes. Even bacterial proteomes (Actinobacteria, Proteobacteria) include a larger number of proteins with X6 repeats (A6, G6, P6) than some eukaryotic proteomes (Alveolata, Diplomonadida). The authors42 used the program RONN to state that this repeat will be disordered. In our case, the disordered homorepeats X6 included in the library are shown as disordered in the majority of structures from the Protein Data Bank.
Disorder in a protein may facilitate binding to multiple partners. Disordered regions are mostly involved in cell signaling or transcriptional and translational regulation.43 Moreover, it has been demonstrated that they are able to adapt quickly to changes in the environment. Recently, a significantly higher degree of positive Darwinian selection has been shown in intrinsically disordered regions of proteins as compared to regions of the alpha helix, beta sheet or tertiary structure.44
We can conclude that the occurrence of disordered patterns and homorepeats is more monotonous within the same kingdom than between kingdoms. Homorepeats of some amino acids occur more frequently than those of others, and the type of a homorepeat varies from proteome to proteome. The set of homorepeats is not a reliable characteristic of evolutionary similarity. Nevertheless, it may be suggested that such short similar motifs are responsible for common functions of nonhomologous, unrelated proteins from different organisms.
It should be stressed that expansion of homorepeats is a molecular basis for at least 18 human neurological diseases. Therefore, an understanding of the functional role of these patterns, homorepeats in particular, in the human proteome is a formidable challenge.
Methods
Database of proteomes
We considered 3279 proteomes from the EBI site (ftp://ftp.ebi.ac.uk/pub/databases/SPproteomes/uniprot/proteomes/). A preliminary analysis showed that the number of proteins with at least one occurrence of homorepeats of 6 residues long is less than 500 for proteomes with an overall number of residues below 2![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 500000. Even so, only 22 proteomes out of 3156 have more than 100 proteins with at least one occurrence of 6-residue homorepeats. These data gave grounds for our research involving only proteomes with an overall number of residues exceeding 2500000.
500000. Even so, only 22 proteomes out of 3156 have more than 100 proteins with at least one occurrence of 6-residue homorepeats. These data gave grounds for our research involving only proteomes with an overall number of residues exceeding 2500000.
We obtained 123 proteomes taking into account the length of proteomes representing 9 kingdoms of eukaryotes and 5 phyla of bacteria (see Table 1 and S1, ESI‡). Unfortunately, only three kingdoms of eukaryotes (Metazoa, Viridiplantae, and Fungi) are given at http://www.ncbi.nlm.nih.gov/Taxonomy/. In other cases, the rank of kingdom is missing. In such situations, we chose the highest taxonomic category following from the subkingdom of eukaryotes instead of the kingdom. We chose 97 out of 120 eukaryotic proteomes, and a small number of bacterial proteomes. The smallest eukaryotic proteome belongs to Hemiselmis andersenii, class Cryptophyta. It is evident that 498 proteins with an overall number of 167452 of amino acid residues are not sufficient for reliable statistics. Historically, the superkingdom of bacteria is divided into phyla but not kingdoms. We preferred to consider such phyla separately.
Among 97 eukaryotic proteomes, 17 belong to the kingdom of Metazoa or animals: Homo sapiens (51778 protein sequences), Bos taurus (18405), Mus musculus (42120), Rattus norvegicus (28166), Gallus gallus (12954), Danio rerio (21576), and Tetraodon nigroviridis (27836) belong to Chordata phylum, Drosophila melanogaster (15101), Drosophila pseudoobscura (16000), Aedes aegypti (16042), Anopheles darlingi (11437), and Anopheles gambiae (12455) to arthropods, and Caenorhabditis briggsae (18531), Caenorhabditis elegans (23817), Loa loa (16271), and Trichinella spiralis (16040) belong to nematodes, Nematostella vectensis (24435) belongs to cnidaria phylum.
Statistical significance of the observed number of occurrences of homorepeat X
In a protein of length N fragment X with 6 residues in it occurs N − 5 times. If the fragments are assumed to be independent, the probability to find a six-residue homorepeat n times is calculated using an equation of binomial distribution: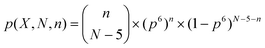 | (1) |
For our analysis we neglect that fragments may occur two or more times, i.e., we ignore the third term 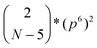 and the others. To evaluate the statistical significance of the observed number of occurrences of homorepeat X, we calculated the probability p(X, N, 1) that pattern X of six residues long occurs in a sequence of length N. Here N is an average length of a protein in the considered proteome. When n = 1 the binomial distribution is a Bernoulli distribution. In our case we have
and the others. To evaluate the statistical significance of the observed number of occurrences of homorepeat X, we calculated the probability p(X, N, 1) that pattern X of six residues long occurs in a sequence of length N. Here N is an average length of a protein in the considered proteome. When n = 1 the binomial distribution is a Bernoulli distribution. In our case we have
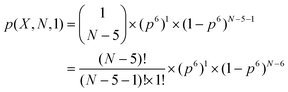 | (2) |
| p(X, N, 1) ≅ p(x)6 × (N − 5), | (3) |
Let S be the number of sequences containing at least one homorepeat X. R is the number of proteins in the considered proteome. If the expected number of proteinsSexpect ≪ R then in this case the binomial distribution is very well described by the Poisson distribution. At the same time if Sexpect is close to 0 then the normal distribution is not good for description of the real situation. We calculated the Poisson distribution for each proteome: the probability to find the given number of proteins with homorepeats. To do so, it is necessary to find an expected averaged number of proteins in a proteome:
| Sexpect = p(X, N, 1) × R. | (4) |
This is a single parameter of the Poisson distribution. From the statistics of proteomes we obtained an observed number of proteins with the given homorepeat Sreal. Having these values we can calculate the probability Y(X) that we will observe Sreal or a larger number of proteins with the given homorepeat X.
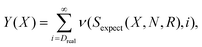 | (5) |
The correlation coefficient (r) was calculated using the equation
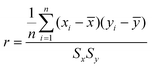 | (6) |
For 20 homorepeats the standard error of correlation coefficient is less than 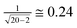 (the standard error of correlation coefficient is
(the standard error of correlation coefficient is 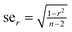 where n is the number of points, see http://www.sjsu.edu/faculty/gerstman/StatPrimer/correlation.pdf) and for 109 disordered patterns it is less than
where n is the number of points, see http://www.sjsu.edu/faculty/gerstman/StatPrimer/correlation.pdf) and for 109 disordered patterns it is less than 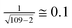 . Therefore, in Tables 4 and 5 the correlation coefficients range as follows: less than 0.5, from 0.5 to 0.75, and larger than 0.75.
. Therefore, in Tables 4 and 5 the correlation coefficients range as follows: less than 0.5, from 0.5 to 0.75, and larger than 0.75.
Acknowledgements
This study is supported in part by the Russian Foundation for Basic Research (grant No 11-04-00763), Russian Academy of Sciences (programs “Molecular and Cell Biology” (01200959110) and “Fundamental Sciences to Medicine”), as well as by a grant from the Federal Agency for Science and Innovations (No 16.512.11.2204).References
- R. D. Finn, J. Mistry, J. Tate, P. Coggill, A. Heger, J. E. Pollington, O. L. Gavin, P. Gunasekaran, G. Ceric, K. Forslund, L. Holm, E. L. Sonnhammer, S. R. Eddy and A. Bateman, Nucleic Acids Res., 2010, 38, D211–D222 CrossRef CAS.
- S. Hunter, R. Apweiler, T. K. Attwood, A. Bairoch, A. Bateman, D. Binns, P. Bork, U. Das, L. Daugherty, L. Duquenne, R. D. Finn, J. Gough, D. Haft, N. Hulo, D. Kahn, E. Kelly, A. Laugraud, I. Letunic, D. Lonsdale, R. Lopez, M. Madera, J. Maslen, C. McAnulla, J. McDowall, J. Mistry, A. Mitchell, N. Mulder, D. Natale, C. Orengo, A. F. Quinn, J. D. Selengut, C. J. Sigrist, M. Thimma, P. D. Thomas, F. Valentin, D. Wilson, C. H. Wu and C. Yeats, Nucleic Acids Res., 2009, 37, D211–D215 CrossRef CAS.
- C. J. Sigrist, L. Cerutti, E. de Castro, P. S. Langendijk-Genevaux, V. Bulliard, A. Bairoch and N. Hulo, Nucleic Acids Res., 2010, 38, D161–D166 CrossRef CAS.
- P. Tompa, Trends Biochem. Sci., 2002, 27, 527–533 CrossRef CAS.
- P. E. Wright and H. J. Dyson, J. Mol. Biol., 1999, 293, 321–331 CrossRef CAS.
- H. J. Dyson and P. E. Wright, Nat. Rev. Mol. Cell Biol., 2005, 6, 197–208 CrossRef CAS.
- C. A. Galea, Y. Wang, S. G. Sivakolundu and R. W. Kriwacki, Biochemistry, 2008, 47, 7598–7609 CrossRef CAS.
- M. Fuxreiter, P. Tompa, I. Simon, V. N. Uversky, J. C. Hansen and F. J. Asturias, Nat. Chem. Biol., 2008, 4, 728–737 CrossRef CAS.
- H. Xie, H. Vucetic, L. M. Iakoucheva, C. J. Oldfield, A. K. Dunker, V. N. Uversky and Z. Obradovic, J. Proteome Res., 2007, 6, 1882–1898 CrossRef CAS.
- R. Linding, R. B. Russell, V. Neduva and T. J. Gibson, Nucleic Acids Res., 2003, 31, 3701–3708 CrossRef CAS.
- M. Yu. Lobanov and O. V. Galzitskaya, Phys. Biol., 2011, 8, 035004 Search PubMed.
- Z. Dosztanyi, V. Csizmok, P. Tompa and I. Simon, Bioinformatics, 2005, 21, 3433–3434 CrossRef CAS.
- K. Coeytaux and A. Poupon, Bioinformatics, 2005, 21, 1891–1900 CrossRef CAS.
- O. V. Galzitskaya, S. O. Garbuzynskiy and M. Y. Lobanov, Bioinformatics, 2006, 22, 2948–2949 CrossRef CAS.
- O. V. Galzitskaya, S. O. Garbuzynskiy and M. Y. Lobanov, PLoS Comput. Biol., 2006, 2, e177 CrossRef.
- A. Schlessinger, M. Punta and B. Rost, Bioinformatics, 2007, 23, 2376–2384 CrossRef CAS.
- K. Peng, P. Radivojac, S. Vucetic, A. K. Dunker and Z. Obradovic, BMC Bioinf., 2006, 7, 208 CrossRef.
- Z. Obradovic, K. Peng, S. Vucetic, P. Radivojac and A. K. Dunker, Proteins, 2005, 61(Suppl. 7), 176–182 Search PubMed.
- Z. Obradovic, K. Peng, S. Vucetic, P. Radivojac, C. J. Brown and A. K. Dunker, Proteins, 2003, 53(Suppl. 6), 566–572 CrossRef CAS.
- J. J. Ward, J. S. Sodhi, L. J. McGuffin, B. F. Buxton and D. T. Jones, J. Mol. Biol., 2004, 337, 635–645 CrossRef CAS.
- J. Hecker, J. Y. Yang and J. Cheng, BMC Genomics, 2008, 9(Suppl. 1), S9 CrossRef.
- C. T. Su, C. Y. Chen and Y. Y. Ou, BMC Bioinf., 2006, 7, 319 CrossRef.
- Z. R. Yang, R. Thomson, P. McNeil and R. M. Esnouf, Bioinformatics, 2005, 21, 3369–3376 CrossRef CAS.
- M. Y. Lobanov, E. I. Furletova, N. S. Bogatyreva, M. A. Roytberg and O. V. Galzitskaya, PLoS Comput. Biol., 2010, 6, e1000958 CrossRef.
- J. P. Zbilut, G. H. Chua, A. Krishnan, C. Bossa, M. Colafranceschi and A. Giuliani, FEBS Lett., 2006, 580, 4861–4864 CrossRef CAS.
- O. V. Galzitskaya, J. Bioinf. Comput. Biol., 2008, 6, 681–691 Search PubMed.
- G. V. Nikiforovich and C. Frieden, Proc. Natl. Acad. Sci. U. S. A., 2002, 99, 10388–10393 CrossRef CAS.
- B. Hemmer, T. Kondo, B. Gran, C. Pinilla, I. Cortese, J. Pascal, A. Tzou, H. F. McFarland, R. Houghten and R. Martin, Int. Immunol., 2000, 12, 375–383 CrossRef CAS.
- J. Jorda, B. Xue, V. N. Uversky and A. V. Kajava, FEBS J., 2010, 277, 2673–2682 CrossRef CAS.
- M. Simon and J. M. Hancock, Genome Biol., 2009, 10, R59.1–R59.16.
- N. S. Bogatyreva, A. V. Finkelstein and O. V. Galzitskaya, J. Bioinf. Comput. Biol., 2006, 4, 597–608 Search PubMed.
- A. K. Dunker, Z. Obradovic, P. Romero, E. C. Garner and C. J. Brown, Genome Inform. Ser. Workshop Genome Inform., 2000, 11, 161–171 Search PubMed.
- S. Karlin, Curr. Opin. Struct. Biol., 1995, 5, 360–371 CrossRef CAS.
- M. V. Katti, P. K. Ranjekar and V. S. Gupta, Mol. Biol. Evol., 2001, 18, 1161–1167 CAS.
- S. Karlin, L. Brocchieri, A. Bergman and J. Mrazek, Proc. Natl. Acad. Sci. U. S. A., 2002, 99, 333–338 CrossRef CAS.
- A. Hamosh, A. F. Scott, J. Amberger, C. Bocchini, D. Valle and V. A. McKusick, Nucleic Acids Res., 2002, 30, 52–55 CrossRef CAS.
- B. Brais, J. P. Bouchard, Y. G. Xie, D. L. Rochefort, N. Chretien, F. M. Tome, R. G. Lafrenière, J. M. Rommens, E. Uyama, O. Nohira, S. Blumen, A. D. Korczyn, P. Heutink, J. Mathieu, A. Duranceau, F. Codère, M. Fardeau and G. A. Rouleau, Nat. Genet., 1998, 18, 164–167 CrossRef CAS.
- P. Siwach and S. Ganesh, Front Biosci., 2008, 13, 4467–4484 CrossRef CAS.
- Z. Dosztányi, B. Mészáros and I. Simon, Briefings Bioinf., 2010, 11, 225–243 Search PubMed.
- J. Jorda and A. Kayava, Adv. Protein Chem. Struct. Biol., 2010, 79, 59–88 Search PubMed.
- P. Tompa, Bioessays, 2003, 25, 847–855 CrossRef CAS.
- M. Simon and J. M. Hancock, Genome Biol., 2009, 10, R59 CrossRef.
- A. K. Dunker, C. J. Brown, J. D. Lawson, L. M. Iakoucheva and Z. Obradovic, Biochemistry, 2002, 41, 6573–6582 CrossRef CAS.
- J. Nilsson, M. Grahn and A. P. H. Wright, Genome Biol., 2011, 12, R65 CrossRef CAS.
Footnotes |
| † Published as part of a Molecular BioSystems themed issue on Intrinsically Disordered Proteins: Guest Editor M. Madan Babu. |
| ‡ Electronic supplementary information (ESI) available. See DOI: 10.1039/c1mb05318c |
| This journal is © The Royal Society of Chemistry 2012 |