Increased structural disorder of proteins encoded on human sex chromosomes†‡
Hedi
Hegyi
*a and
Peter
Tompa
ab
aInstitute of Enzymology, Biological Research Center, Hungarian Academy of Sciences, Budapest, Hungary. E-mail: hegyi@enzim.hu
bVIB Department of Structural Biology, Vrije Universiteit Brussel, Pleinlaan 2, 1050 Brussels, Belgium
First published on 22nd November 2011
Abstract
Intrinsic protein disorder has been studied with respect to the chromosomal location of each protein in the human proteome and also in other fully sequenced organisms. We found that in all studied mammalian species the sex chromosome-coded proteins were significantly more disordered than the autosome-coded ones, the strongest discrepancy being observed in humans. In explaining this phenomenon we analyzed local chromosomal features and found that (1) the autosomes have a stronger correlation between the GC content of the transcripts and the structural disorder of the coded proteins than the sex chromosomes; (2) the neighbors' protein disorder correlates the strongest on the sex chromosomes; (3) the GO functions on chromosome X are somewhat biased towards functions with higher disorder but do not account for the entire phenomenon; (4) the protein–protein interactions show a non-random chromosomal distribution, the Y chromosome-coded proteins having the lowest overall frequency for interactions but the largest bias towards intra-chromosomal interactions. Tissue-specific distributions showed the most protein disorder for sex-chromosome coded proteins expressed in the testis and the ovary. We raise the possibility that the high disorder of X- and Y-encoded proteins facilitates the fast evolution of testis- and cancer-specific antigenic protein clusters on these chromosomes, in relation to their immunogenic properties and likely contribution to speciation.
Introduction
Intrinsic protein disorder has been the subject of growing interest in the past decade, both in experimental biology and bioinformatics. There is significant evidence1 that some proteins function despite an inherent lack of a stable conformation—we call a paradigm expansion as previously all proteins were thought to require it (i.e. a stable conformation) to carry out their functions. Many studies looked at the phenomenon from a global perspective, predicting disorder for each protein in an organism, and found that different organisms have significantly different average protein disorder.2,3 It has been suggested that disorder also correlates with the complexity of an organism,4 can be attributed to the environment of a species,5,6 and plays important roles in signal transduction pathways.7 It has been shown that disorder is also associated with disease states8 possibly because intrinsically disordered proteins have a high flexibility/tolerance to large structural changes caused by alternative splicing9 and chromosomal translocations10 without compromising the survival of the protein. This is particularly pronounced for oncogenes, which are very often fusion proteins that arise by chromosomal translocations, with a very high level of intrinsic disorder.10However, protein disorder has so far been studied only from a proteomic perspective, without regard to the chromosomal location of the genes coding for these disordered proteins. This paper is the first to our knowledge that attempts to look at this phenomenon from a genomic/chromosomal perspective. We found that human proteins coded on the X, Y sex chromosomes have a significantly higher average disorder than the ones on the 22 autosomes. To see if there is any systematic difference between the two types of chromosomes that could account for this difference, we studied several aspects of the chromosomes and the local environment such as the GC content, average gene density and the disorder of neighboring genes on all chromosomes. In accordance with others,5 we found a correlation between the GC content of the transcripts and intrinsic disorder of the corresponding proteins, including the sex chromosomes.
We also analyzed the relationship between gene density and protein disorder. Intriguingly, we found that except for the two most gene-packed chromosomes, 1 and 19, there is little correlation between gene density and protein disorder. However, we found that for most chromosomes both the GC content and the disorder of neighboring genes correlate, and for the latter we could actually see different tendencies for the sex chromosomes setting them apart from the autosomes.
We also studied the functional aspects of the sex chromosomes and the autosomes to see if these can account for the differences in disorder between the two types of chromosomes. We used the GO classification system and confirmed the high occurrence of transcription-related genes on the X chromosome. We also analyzed the number of interacting protein partners for the sex-chromosome- and autosome-coded proteins to see if the higher disorder of X and Y-coded proteins also entails a greater number of interacting partners. We found that the opposite is actually true for the sex chromosomes, and in general the number of interacting proteins correlate with the size of the chromosome, or more precisely, with the number of genes coded on a chromosome. This is particularly true of the Y chromosome, the genes of which tend to interact with one another much more often than it would be expected based on a random chromosomal distribution of interacting partners.
We also looked at the tissue specific expression of the sex chromosome-coded genes and compared them to the autosome-coded genes to see if there is a significant bias in the tissue types each gene is expressed in (e.g. as expected, if the sex chromosome-coded genes are more often expressed in sex organs and related tissues) and if these biases can account for the higher disorder of the proteins coded on the sex chromosomes. We did find significant differences between the different tissues and also between the sex chromosomes and the autosomes. We did not find a universally high disorder in all reproductive organs; it was highest in testis and ovary.
Results
Local structural effects
Fig. 1 shows the median and mean predicted %disorder for human proteins coded on the 22 autosomes and the sex chromosomes, X and Y. The mean percentage disorder for the autosomes was 23.6% (with standard deviation, SD, of 2.1%) whereas for the sex chromosomes it was 35.1%, the difference measured in the z-value being 5.5 (corresponding to p-value < 0.0001). Similar results were obtained for the median values (14.6% for the autosomes, 23.6% for the sex chromosomes, with standard deviation, SD, of 2.6%) the difference between the autosomes and the sex chromosomes also proving highly significant (p-value < 0.0001). To explain this anomaly, we wanted to see if the disorder of a protein depends on any other attribute of the chromosome, either structural such as local GC content, gene density or proximity to other disordered genes or functional, such as the unequal distribution of certain GO functions, interaction with proteins of certain functions or if there is any reproductive advantage associated with them, considering that higher disorder was found on both sex chromosomes. | ||
| Fig. 1 Median and mean %disorder (indicated as %IU) of proteins on the 24 human chromosomes, as determined by IUPred.32 | ||
To that effect, at first we calculated the GC content and the percentage disorder for each gene and each chromosome (using cDNAs and proteins of ENSEMBL)11 as it has been shown previously, albeit for bacterial genomes, that the two features correlate.5 Next, we calculated the r Pearson correlation coefficient for each chromosome separately, and also globally, for the whole human genome/proteome. (Table S1 (ESI‡) shows the average GC content of the transcripts of human genes in the Ensembl database and the average %disorder of the coded proteins for each chromosome.) Fig. 2 shows various correlation values between the GC content of the transcripts and the percentage disorder (%IU) value of the corresponding proteins and also the correlation of both between neighbors for each of the 24 human chromosomes. For most chromosomes the correlation between %GC content and %IU values is small but statistically significant positive value, with the exception of chromosomes 21 and Y where no statistical significance could be shown either between the two actual values or between the moving averages (Fig. 2A). The highest correlation was observed for chromosome 19 (Pearson correlation = 0.348), which also has the 2nd highest GC content (GC content = 0.570) of all the chromosomes (for p-values of the correlations in Fig. 2A and B see Table S1, ESI‡). After calculating the moving averages of 10 for both the %IU values and the GC content we found that the correlations between these two values further increase for most chromosomes except for the sex chromosomes and chromosome 22 where the correlations between the moving averages are smaller values than for the original numbers.
 | ||
| Fig. 2 Various correlations. (A) Pearson correlation values between %disorder (indicated as %IU) of proteins and GC content of their transcripts and the moving averages of 10 consecutive values for the 24 human chromosomes. (B) Pearson correlations of neighboring proteins and Pearson correlations of GC content of neighboring transcripts for the human chromosomes. | ||
We also calculated the r Pearson correlation values between the percentage disorder (%IU) of neighboring genes for each chromosome (Fig. 2B) and found the values varying between 0.01 (for chromosome 22, the smallest autosome) and 0.368 (for the Y chromosome), with X chromosome having the 2nd largest correlation value (0.279). The GC content correlation of neighboring genes is also shown for each chromosome in Fig. 2B. It is clear that while the neighbors' %IU values correlate the most on the sex chromosomes, they do not have particularly high values for the GC content correlation. The latter is again highest on chromosome 19, which has the highest gene density as discussed above.
GO functional analysis
To see if there are any functional differences between the sex chromosomes and the autosomes that would account for the higher protein disorder of the sex-chromosome coded proteins we studied the distribution of GO terms12 on the sex chromosomes and also on chromosomes 10, 9, 5 and 16 which have the closest numbers of annotated genes to that of chromosome X.The results are shown in Fig. 3. Only the 30 most abundant GO categories are shown. Those categories that were the highest for chromosome X (when compared to the four autosomes) are boxed whereas those categories that had the smallest values for chromosome X of the five studied here are underlined. The GO categories that were most enriched on the X chromosome among the 30 most abundant categories were: nucleus, intracellular, regulation of transcription, nucleic acid binding, metabolic process and transport. On the other hand, ATP binding, DNA binding, extracellular region and binding occurred the least frequently on chromosome X of the five chromosomes (Fig. 3A). The median disorder of human proteins on the selected autosomes (5, 9, 10 and 16) and the X and combined X and Y sex chromosomes associated with each of the 30 categories are shown in Fig. 3B. The total median disorder of all proteins in the 30 categories for the selected and all autosomes were 13.08% and 12.57%, respectively, whereas for chromosomes X, Y they were 21.58% and 24.40%, respectively. To see if the higher disorder of proteins on the sex chromosomes is due to the enrichment of transcription-related proteins on X and Y, we grouped the proteins into these two categories (transcription-related or not) and calculated the median disorder for each group, shown in Table 2. The sex chromosomes-coded proteins are always more disordered, whether we take into consideration only the 30 most abundant GO categories or all of them (data not shown) and both in the transcription-related and -unrelated groups.
 | ||
| Fig. 3 The 30 most abundant Gene Ontology (GO) categories in proteins on the X chromosome and chromosomes 5, 9, 10 and 16, with the closest number of genes to that of X. (A) Categories with highest occurrence (out of these 5 chromosomes) on X are boxed, those with the smallest numbers are underlined. (B) The combined average %disorder values with proteins in those categories on the selected autosomes (open circle, chromosomes 5, 9, 10 and 16), on chromosome X (open triangle), combined values for X and Y (filled triangle). | ||
We also calculated the median disorder for all proteins with a GO annotation, also shown in Table 2. The median disorder of all autosome-coded proteins was 11.7% whereas for X and Y the combined value was 21.1%. When we took into account only those proteins with no GO function associated yet (altogether 2890 proteins), the median disorder for all such autosome-coded proteins increased to 25.2% whereas for the X and Y chromosomes this value was 49.5%. These values are significantly higher both for the autosomes and the sex chromosomes than for proteins with existing GO categories.
Protein–protein interactions in STRING
We also studied the distributions of pairwise protein–protein interactions (PPIs) as recorded in the STRING database.13–15Fig. 4 shows the average number of protein–protein interactions for each chromosome. The sex chromosomes have the smallest average numbers of PPIs (mean numbers for chromosomes X and Y were 129.1 and 62.9, the standard deviations, SDs, were 5.1 and 9.9, respectively) whereas for the autosomes the average number of PPIs was 147.8. Statistical analysis shows that both the X- (p-value = 0.0003) and Y-coded (p-value < 0.0001) proteins have significantly less pairwise interactions than the autosome-coded ones. This effectively eliminates the possibility that higher protein disorder on X and Y might be caused by a higher number of interacting proteins. We also found that proteins both on the X and especially on the Y chromosome have significantly more intra- than interchromosomal interactions (Fig. S1, ESI‡) | ||
| Fig. 4 Average number of protein–protein interactions (PPI) per protein for the 24 human chromosomes. Only proteins with at least one recorded PPI in STRING were taken into consideration. | ||
Tissue and disorder distribution of human Swissprot proteins
We studied the distribution of disordered proteins expressed in the different human tissues, with special respect to their chromosomal location, to see in what tissues the X- and Y-coded proteins with higher disorder are preferentially expressed. We considered only the “tissue specificity” information in the annotation of Swissprot proteins as this seems to have provided a more accurate picture than the simple tissue occurrence annotation lines. Fig. 5 shows the results, the autosome- and sex chromosome-coded proteins all lumped together and distributed into 8 tissue categories. | ||
| Fig. 5 Tissue-specific human proteins expressed in various reproductive and other tissues, on the sex chromosomes and the autosomes. Standard deviations are shown. | ||
As expected, the most disordered sex chromosome-coded proteins were in reproductive tissues, more so in male than female reproductive organs. It also became clear that sex chromosome-coded proteins expressed in tumor tissues were much more disordered than the autosome-coded ones. Additionally, we found that not all reproductive tissues are equal in this respect: there are significantly more disordered X-chromosome coded proteins expressed in the ovary than in other female reproductive organs. Similarly, significantly more disordered proteins were expressed in the testis coded on X or Y than in other male reproductive tissues (49% vs. 24%, respectively, data not shown). Remarkably, the autosome-coded tissue differences were similarly biased toward reproductive and tumor tissues (albeit to a lesser extent) and were also more disordered in the brain. As we remarked in a recent publication, this latter observation is most certainly due to the higher complexity of brain tissues4 also associated with more protein binding capacity based on binding site predictions in disordered proteins.
Other organisms
The next question to answer was whether a similar bias occurs in other organisms, both in mammalians and other, more distantly related species. Applying the chi-square test we found that all studied mammalian species had a significantly higher disorder among the proteins coded on the sex chromosomes, with a high significance (p < 1 × 10−6). Even Platypus showed this phenomenon based on the portion of its X-chromosomes that have been sequenced and annotated for proteins so far, although with a lesser significance (p = 0.005). The median percentage disorder for the whole proteomes and for proteins coded on the sex chromosomes is shown in Table 1 for the 7 species we investigated. While all mammalian species showed this bias, the chicken did not, and the proteins coded on the W and Z sex chromosomes were actually slightly less disordered than the rest of the proteome (Table 1). However, the fruit fly also showed significantly more disorder amongst its X-coded proteins than for the rest of the proteome (20.4% vs. 15.5%, respectively).| Species | Autosomes | Sex chroms |
|---|---|---|
| Chicken | 9.8 | 8.1 |
| Horse | 10.7 | 15.7 |
| Chimpanzee | 13.0 | 18.8 |
| Platypus | 9.9 | 12.0 |
| Mouse | 10.2 | 21.4 |
| Human | 13.5 | 25.7 |
| Fruit fly | 14.2 | 19.9 |
Comparing the human and mouse proteomes
We compared the entire human proteome to that of the mouse, based on their annotated gene names and also their sequences, to see if there is any difference in disorder between the shared and the species-specific proteins in either organisms, whether for the total proteomes or specifically in proteins on the X chromosomes. We calculated the median disorder for each chromosome individually for both organisms, the shared and unique (species-specific) genes separately, and also for the total of them (Fig. 6). There is a dramatic difference in disorder between the unique and the shared set on the X chromosome for both species but to a larger extent for humans (Fig. 6A) where the median disorder of the human-specific X-coded proteins is more than double that of the shared human X proteins (41.3% vs. 19.7%, respectively). It is also apparent from Fig. 6B that in the mouse for all but one autosome (chromosome 18) the unique proteins are significantly less disordered (for all mouse autosomes the median disorder of unique proteins is only 3.8%) than the shared ones. On the other hand in humans on 10 of the 22 autosomes the unique i.e. human-specific proteins are more disordered than the shared ones (for all human autosomes the median disorder of unique proteins is 11.3%). Nevertheless, the X-coded unique human proteins are still about 15% more disordered than the most disordered autosome-coded unique proteins on human chromosome 18. (It must be noted that while for both organisms chromosome 18 has the most disordered species-specific proteins among the autosomes, it is purely coincidental: chromosome 18 in mouse shares the most, 292, common genes with human chromosome 16 followed by human chromosome 19 with 162 common genes and none with human chromosome 18.) | ||
| Fig. 6 Median disorder for each chromosome in the human (A) and mouse (B) proteome. Shared and unique proteins are also indicated. | ||
In Fig. S2 (ESI‡) all the autosome- and sex chromosome-coded, shared and unique proteins are lumped together both in human and mouse. The disorder of the shared proteins on either the autosomes or sex chromosomes does not differ significantly between the human and mouse proteins but the unique human proteins are significantly more disordered than the unique mouse ones both on the autosomes (24.1% vs. 17.5%) and the sex chromosomes (43.7% vs. 32.7%, p-value < 0.0001). In addition, the unique mouse proteins on the autosomes are significantly less disordered than the shared ones (17.5% vs. 22.3%, respectively).
Comparing the human and mouse X chromosomes
The human X chromosome has so far 860 annotated protein-coding genes, the mouse has 933. They share 542 genes that are coded on the X chromosome in both organisms, which corresponds to 60% shared genes, about the same ratio as for the rest of the proteomes. The human X has 14 additional genes that are also shared by mouse but in the latter they are not on the X chromosome, these are: SPRY3, HDHD1A, CRLF2, GTPBP6, TMLHE, IL3RA, STK3, PLCXD1, IL9R, DHRSX, VAMP7, CSF2RA, MAGEB3, H2AFB1. Their median disorder was very small, less than 1% in humans and about 9% in mouse. The mouse X also has four genes that are shared by humans but not coded on the X chromosome: EIF1AY, KIR3DL2, KIR3DL1, PRAME. Fig. 7 shows the alignment of the human and mouse X chromosomes, where identically colored blocks show syntenic regions in the two X chromosomes. The grey areas in both chromosomes correspond to species-specific regions. The disorder for each protein is indicated in the accompanying graphs, where each red dot corresponds to a protein, and the continuous black lines correspond to moving averages of 10 consecutive proteins. The five most disordered clusters were indicated for both organisms, marked by the most representative gene names, usually present in several variants. Four of the five clusters were completely species-specific, with the exception of the BEX-TCEAL gene families that are present in both organisms. A moving average of %disorder of 10 consecutive proteins calculated for both the entire human and mouse proteomes, respectively, also showed that of the 50 highest values of such moving averages 40 (41 for the mouse) values were found on the X chromosomes, in five clusters for both organisms, as shown in Fig. 7.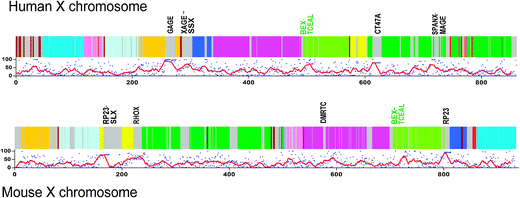 | ||
| Fig. 7 Syntenic regions (color-coded) and species-specific proteins (grey) on the human and mouse X chromosomes. The disorder of each protein is marked with a dot under the colored schematics of each X chromosome. The continuous red lines indicate the moving averages of 10 consecutive proteins in each. The five most disordered clusters correspond to the five peaks in each moving average graph. The clusters are delineated with the representative gene names. | ||
Human-specific clusters with high disorder
The four most disordered, human-specific gene clusters (Fig. 7) are all known for their antigenic properties, hence their names (GAGE, G antigen; MAGE, Melanoma-associated antigen; XAGE, G antigen family D and CT47, Cancer/testis antigen 47). They are known to express mostly in testis and in different cancers. Little else is known about them, except that one of them, GAGE-12I, is anti-apoptopic and confers resistance to Fas/CD95/APO-1, Interferon-c, taxol and c-irradiation.16 According to a recent bioinformatic analysis, the GAGE family is a novel one, found only in humans, chimpanzee and macaque.17 Running Blastp with the longest member of each of the human-specific clusters as query against NCBI's non-redundant protein database (nr) we also found that both GAGE and SPANX are found only in primates. Regarding XAGE we found only partial sequence matches with chimpanzee and macaque proteins but it was not clear whether the genes underwent an extremely fast evolution or they have not been properly annotated yet in other primates. The SSX family is named after its frequent presence in synovial sarcoma where it is found as a hybrid protein fused to gene SS18 on chromosome 18, acting as an oncogenic fusion protein.18 The SSX family is also found in mouse but it has less than 50% sequence similarity with the human members and they are also predicted considerably less disordered with IUPred. Interestingly, some members were also identified in tumors in the mouse.19The CT47 cancer/testis antigen cluster is another highly disordered and recently expanded family with at least 13 copies on Xq24.20 It is more widely distributed or more conserved than the aforementioned 3 clusters as it is present not only in primates but also in the cow, pig and rabbit, according to Ensembl (uniprot id: A6H6Y8_BOVIN). The SPANX (sperm protein associated with the nucleus on the X chromosome) proteins are another recently expanded cluster of human proteins expressed in sperm also found in other primates. Similarly to other male reproductive proteins, they are known to evolve very fast.
Discussion
By analyzing the chromosomes for local attributes we found that neither the GC content of the transcripts of the genes in question nor the GC content of the neighboring genes affected the X and Y chromosomes in a fashion that would account for the disparity in structural disorder between the sex chromosomes and the autosomes. While most autosomes did show significant correlations between the two variables (Fig. 2A), chromosome 19 showing exceptionally high values for the correlations between the GC content of transcripts and %IU of the coded proteins, and particularly so between the moving averages of 10s of the two values, chromosome X showed a decreased value for the latter and chromosome Y did not have a significant correlation between GC content and %disorder (Fig. 2A). On the other hand, both GC content and %disorder had relatively high correlation values between the neighboring genes on the sex chromosomes, Y having the highest and X the second highest correlation for the neighbors' %disorder values (Fig. 2B).Upon collecting the GO functions for the X chromosome and the four most closely related chromosomes in terms of known and annotated genes, we saw some functional bias on chromosome X, such as the more frequent occurrence of transcription-related and nucleus-located genes and less extracellular ones, which would both point in the direction of more protein disorder. However, these functional biases do not fully explain the disparity in disorder and the most disordered sex chromosome-coded proteins do not have functional characterization assigned by GO (as shown in Table 2) so this kind of analysis can provide only a limited picture.
| 30 Transcription | 30 Non-transcription | All transcription | All non-transcr | All GO categories | No GO categories | |
|---|---|---|---|---|---|---|
| Autosomes | 34.6 (1331) | 9.6 (4949) | 32.5 (1617) | 12.1 (9649) | 11.7 (17221) | 25.2 (2713) |
| Sex chroms | 48.3 (110) | 14.9 (401) | 45.3 (122) | 20.7 (741) | 21.1 (743) | 49.5 (177) |
Regarding protein–protein interactions, interestingly but not completely unexpectedly, we found that sex-chromosome coded proteins have fewer interactions on average than the autosome-coded ones (Fig. 4). This was especially true of chromosome Y, which has about 2.4 times less interaction for its proteins than an average autosome (63 vs. 150). This finding also largely eliminates the possibility that sex-chromosome coded proteins might be more disordered because they have more interacting partners.
Comparing the human and mouse proteomes with respect to their chromosomal distribution we reached the somewhat surprising conclusion that the mouse-specific proteins on the autosomes have less protein disorder on average than the ones shared with humans (17.4% and 22.3%, respectively). In comparison, the same values for the human-specific and shared autosome-coded proteins were 24.1% and 22.5%, respectively. This disparity was reflected in the values for the individual chromosomes too, as 10 out of the 22 human chromosomes had more disordered unique proteins but only chromosome 18 in the mouse had this feature (Fig. 6B). This might reflect the different directions the evolution of the two organisms took since the speciation between the two roughly 75 million years ago.21 However, the sex chromosomes in the mouse also have significantly more disordered proteins compared to the autosomes, also appearing in clusters (Fig. 7). All mammalian species studied here showed the same kind of bias, including the Platypus, the most ancient mammal. However the chicken, the only bird so far with a fully sequenced genome did not show a similar bias between the W,Z sex chromosomes and the autosomes. On the other hand, Drosophila again had a positive disorder bias on the X chromosome. It will be interesting to see how this feature plays out in other organisms with sex chromosomes.
While this is the first time an increase in structural disorder of proteins on the sex chromosomes has been detected, it has been known that reproduction-related proteins are evolving at a much faster rate than other proteins.22 This phenomenon has been also observed in other species, e.g. comparing sperm proteins in closely related abalone species showed that exons evolve 20 times faster than introns.23 Thus, the intriguing possibility that the two phenomena, i.e. the fast evolution and high disorder of reproductive proteins might be related could be raised.
Several pieces of evidence point in this direction:
1. The most disordered clusters of proteins on the human X chromosome tend to be unique, species-specific or confined to a few related primate species.
2. Disordered proteins are capable of evolving at a much faster rate than globular ones as there are no structural limitations trying to preserve an existing fold. This has been observed before in several instances.24,25
3. The most disordered proteins tend to occur in clusters of similar proteins in relative proximity on the X chromosomes, pointing toward recent evolutionary events: the members of these clusters are highly similar, therefore the probable results of recent gene duplications. In fact, it is known of several members of these clusters being the result of recent segmental duplications.26
It has been the subject of intense debate why the reproduction-related proteins tend to evolve at such an exceptionally high rate. There have been various attempts to explain it such as a competition between the individual sperms or as a way of speciation. However, speciation cannot be the driver of evolution in established, stable species—it can be only the consequence of selection processes driven by other forces—or else the existence of species would be a rather ephemeral phenomenon only.
We tend to think that the speed of the evolution comparable to that of the immune system might actually offer a more plausible explanation. As the sperm proteins are foreign to the female immune system, there is an elaborate mechanism taking place over the course of fertilization to make sure sperm are not eliminated by it. First, to evade histocompatibility-based responses mediated by MHC class I-restricted cytotoxic T lymphocytes, mature human sperm cells become MHC class I negative.27 On the other hand, natural killer (NK) cells target and lyse those cells that lack such markers during the leukocyte reaction.28 To avoid the NK cell-mediated cytotoxicity human sperm express on their surface at least 3 classes of N-glycans terminated with Lewisx and Lewisy sequences, the latter localized to the sperm acrosome.29 It was also shown that these N-glycans bind with high affinity DC-SIGN, a pathogen-recognition receptor.30
The above short description shows that sperm proteins and oligosaccharides interact in several direct and indirect ways with the female immune system to ensure a successful fertilization process therefore it is rather plausible that the two systems also evolve in a concerted manner. While this study might not provide a full answer to the intriguing question of fast evolution of reproductive proteins, at least it offers an insight from the side of facilitation: they evolve fast because they can. Being disordered means there is little structural constraint while having relatively few interactions with other proteins (as we have seen for the X- and especially the Y-coded proteins) also means relatively few functional constraints on the fast evolution of these proteins.
Methods
Proteome sequences
The various mammalian, chicken and Drosophila proteome and transcript sequences were downloaded from the Ensembl data repository:11ftp://ftp.ensembl.org/pub/release-59/fasta/. Annotation, including gene names and tissue-related information, were taken from the Swissprot subset of Uniprot.31Prediction of structural disorder
Structural disorder of all proteins in a proteome was predicted with the IUPred algorithm,32 available at http://iupred.enzim.hu/. A residue was classified as locally disordered if its score was above the threshold of 0.5, and disorder of a protein was taken as the percent of such residues in the protein. We call the latter %disorder (or %IU, short for intrinsically unstructured) throughout the paper. The median disorder of whole proteomes was calculated as the median of the percentage of disordered residues of the proteins (i.e. median of %disorder).Protein–protein interactions in the human proteome
We extracted data on binary protein–protein interactions in the human proteome from the STRING database13 (http://string-db.org/).Tissue specificity of human proteins
We studied tissue-specific expression of human proteins based on their annotation lines in Swissprot. We took into account only those proteins that had “tissue specificity” in their annotation, which limited the number of proteins to 6179 but provided a more correct picture than the simple tissue occurrence annotation lines.Statistical analysis and programming
For calculating standard deviation values of intrinsic disorder random sampling was used. We selected random subsets of 200–500 members depending on the proteome size of the original dataset, and calculated the median and/or mean of disorder. We repeated the selection 500–1000 times, and the standard deviation of the mean was calculated. The significance of differences between selected groups was assessed by the nonparametric Mann–Whitney and chi-square tests. For correlation analysis we used the Pearson correlation. All local programs were written in Perl.References
- P. Tompa, Unstructural biology coming of age, Curr. Opin. Struct. Biol., 2011, 21, 419–425 CrossRef CAS.
- H. Hegyi, E. Schad and P. Tompa, Structural disorder promotes assembly of protein complexes, BMC Struct. Biol., 2007, 7, 65 CrossRef.
- J. J. Ward, J. S. Sodhi, L. J. McGuffin, B. F. Buxton and D. T. Jones, Prediction and functional analysis of native disorder in proteins from the three kingdoms of life, J. Mol. Biol., 2004, 337, 635–645 CrossRef CAS.
- E. Schad, P. Tompa and H. Hegyi, The relationship between proteome size, structural disorder and organism complexity, Genome Biol., 2011 Search PubMed , submitted.
- G. M. Pavlovic-Lazetic, N. S. Mitic, J. J. Kovacevic, Z. Obradovic, S. N. Malkov and M. V. Beljanski, Bioinformatics analysis of disordered proteins in prokaryotes, BMC Bioinf., 2011, 12, 66 CrossRef CAS.
- P. V. Burra, L. Kalmar and P. Tompa, Reduction in structural disorder and functional complexity in the thermal adaptation of prokaryotes, PLoS One, 2010, 5, e12069 Search PubMed.
- L. M. Iakoucheva, C. J. Brown, J. D. Lawson, Z. Obradovic and A. K. Dunker, Intrinsic disorder in cell-signaling and cancer-associated proteins, J. Mol. Biol., 2002, 323, 573–584 CrossRef CAS.
- V. N. Uversky, C. J. Oldfield, U. Midic, H. Xie, B. Xue, S. Vucetic, L. M. Iakoucheva, Z. Obradovic and A. K. Dunker, Unfoldomics of human diseases: linking protein intrinsic disorder with diseases, BMC Genomics, 2009, 10(Suppl 1), S7 CrossRef.
- H. Hegyi, L. Kalmar, T. Horvath and P. Tompa, Verification of alternative splicing variants based on domain integrity, truncation length and intrinsic protein disorder, Nucleic Acids Res., 2010, 39, 1208–1219 CrossRef.
- H. Hegyi, L. Buday and P. Tompa, Intrinsic structural disorder confers cellular viability on oncogenic fusion proteins, PLoS Comput. Biol., 2009, 5, e1000552 Search PubMed.
- P. Flicek, M. R. Amode, D. Barrell, K. Beal, S. Brent, Y. Chen, P. Clapham, G. Coates, S. Fairley and S. Fitzgerald, et al., Ensembl 2011, Nucleic Acids Res., 2010, 39, D800–D806 CrossRef.
- J. A. Blake and M. A. Harris, The Gene Ontology (GO) project: structured vocabularies for molecular biology and their application to genome and expression analysis, Curr. Protoc. Bioinformatics, 2008, ch. 7, unit 7.2 Search PubMed.
- L. J. Jensen, M. Kuhn, M. Stark, S. Chaffron, C. Creevey, J. Muller, T. Doerks, P. Julien, A. Roth and M. Simonovic, et al., STRING 8—a global view on proteins and their functional interactions in 630 organisms, Nucleic Acids Res., 2009, 37, D412–D416 CrossRef CAS.
- D. Szklarczyk, A. Franceschini, M. Kuhn, M. Simonovic, A. Roth, P. Minguez, T. Doerks, M. Stark, J. Muller and P. Bork, et al., The STRING database in 2011: functional interaction networks of proteins, globally integrated and scored, Nucleic Acids Res., 2011, 39, D561–D568 CrossRef.
- C. von Mering, L. J. Jensen, M. Kuhn, S. Chaffron, T. Doerks, B. Kruger, B. Snel and P. Bork, STRING 7—recent developments in the integration and prediction of protein interactions, Nucleic Acids Res., 2007, 35, D358–D362 CrossRef CAS.
- Z. M. Cilensek, F. Yehiely, R. K. Kular and L. P. Deiss, A member of the GAGE family of tumor antigens is an anti-apoptotic gene that confers resistance to Fas/CD95/APO-1, Interferon-gamma, taxol and gamma-irradiation, Cancer Biol. Ther., 2002, 1, 380–387 CrossRef CAS.
- Y. Liu, Q. Zhu and N. Zhu, Recent duplication and positive selection of the GAGE gene family, Genetica, 2008, 133, 31–35 CrossRef CAS.
- C. T. Storlazzi, F. Mertens, N. Mandahl, D. Gisselsson, M. Isaksson, P. Gustafson, H. A. Domanski and I. Panagopoulos, A novel fusion gene, SS18L1/SSX1, in synovial sarcoma, Genes, Chromosomes Cancer, 2003, 37, 195–200 CrossRef CAS.
- Y. T. Chen, B. Alpen, T. Ono, A. O. Gure, M. A. Scanlan, W. H. Biggs 3rd, K. Arden, E. Nakayama and L. J. Old, Identification and characterization of mouse SSX genes: a multigene family on the X chromosome with restricted cancer/testis expression, Genomics, 2003, 82, 628–636 CrossRef CAS.
- Y. T. Chen, C. Iseli, C. A. Venditti, L. J. Old, A. J. Simpson and C. V. Jongeneel, Identification of a new cancer/testis gene family, CT47, among expressed multicopy genes on the human X chromosome, Genes, Chromosomes Cancer, 2006, 45, 392–400 CrossRef CAS.
- R. H. Waterston, K. Lindblad-Toh, E. Birney, J. Rogers, J. F. Abril, P. Agarwal, R. Agarwala, R. Ainscough, M. Alexandersson and P. An, et al., Initial sequencing and comparative analysis of the mouse genome, Nature, 2002, 420, 520–562 CrossRef CAS.
- W. J. Swanson and V. D. Vacquier, The rapid evolution of reproductive proteins, Nat. Rev. Genet., 2002, 3, 137–144 CrossRef CAS.
- E. C. Metz, R. Robles-Sikisaka and V. D. Vacquier, Nonsynonymous substitution in abalone sperm fertilization genes exceeds substitution in introns and mitochondrial DNA, Proc. Natl. Acad. Sci. U. S. A., 1998, 95, 10676–10681 CrossRef CAS.
- C. J. Brown, S. Takayama, A. M. Campen, P. Vise, T. W. Marshall, C. J. Oldfield, C. J. Williams and A. K. Dunker, Evolutionary rate heterogeneity in proteins with long disordered regions, J. Mol. Evol., 2002, 55, 104–110 CrossRef CAS.
- D. P. Denning and M. F. Rexach, Rapid evolution exposes the boundaries of domain structure and function in natively unfolded FG nucleoporins, Mol. Cell. Proteomics, 2007, 6, 272–282 CAS.
- X. Tian, G. Pascal and P. Monget, Evolution and functional divergence of NLRP genes in mammalian reproductive systems, BMC Evol. Biol., 2009, 9, 202 CrossRef.
- H. Hutter and G. Dohr, HLA expression on immature and mature human germ cells, J. Reprod. Immunol., 1998, 38, 101–122 CrossRef CAS.
- L. A. Thompson, C. L. Barratt, A. E. Bolton and I. D. Cooke, The leukocytic reaction of the human uterine cervix, Am. J. Reprod. Immunol., 1992, 28, 85–89 CAS.
- P. C. Pang, B. Tissot, E. Z. Drobnis, P. Sutovsky, H. R. Morris, G. F. Clark and A. Dell, Expression of bisecting type and Lewisx/Lewisy terminated N-glycans on human sperm, J. Biol. Chem., 2007, 282, 36593–36602 CrossRef CAS.
- H. Feinberg, D. A. Mitchell, K. Drickamer and W. I. Weis, Structural basis for selective recognition of oligosaccharides by DC-SIGN and DC-SIGNR, Science, 2001, 294, 2163–2166 CrossRef CAS.
- E. Boutet, D. Lieberherr, M. Tognolli, M. Schneider and A. Bairoch, UniProtKB/Swiss-Prot., Methods Mol. Biol., 2007, 406, 89–112 CAS.
- Z. Dosztanyi, V. Csizmok, P. Tompa and I. Simon, IUPred: web server for the prediction of intrinsically unstructured regions of proteins based on estimated energy content, Bioinformatics, 2005, 21, 3433–3434 CrossRef CAS.
Footnotes |
| † Published as part of a Molecular BioSystems themed issue on Intrinsically Disordered Proteins: Guest editor M. Madan Babu. |
| ‡ Electronic supplementary information (ESI) available. See DOI: 10.1039/c1mb05285c |
| This journal is © The Royal Society of Chemistry 2012 |