Metallochaperone-like genes in Arabidopsis thaliana†
Muhammad
Tehseen
,
Narelle
Cairns
,
Sarah
Sherson
and
Christopher S.
Cobbett
*
Department of Genetics, University of Melbourne, Parkville, Victoria 3010, Australia. E-mail: ccobbett@unimelb.edu.au; Fax: +61 3 8344 5139; Tel: +61 3 8344 6246
First published on 1st July 2010
Abstract
A complete inventory of metallochaperone-like proteins containing a predicted HMA domain in Arabidopsis revealed a large family of 67 proteins. 45 proteins, the HIPPs, have a predicted isoprenylation site while 22 proteins, the HPPs, do not. Sequence comparisons divided the proteins into seven major clusters (I–VII). Cluster IV is notable for the presence of a conserved Asp residue before the CysXXCys, metal binding motif, analogous to the Zn binding motif in E. coli ZntA. HIPP20, HIPP21, HIPP22, HIPP26 and HIPP27 in Cluster IV were studied in more detail. All but HIPP21 could rescue the Cd-sensitive, ycf1 yeast mutant but failed to rescue the growth of zrt1zrt2, zrc1cot1 and atx1 mutants. In Arabidopsis, single and double mutants did not show a phenotype but the hipp20/21/22 triple mutant was more sensitive to Cd and accumulated less Cd than the wild-type suggesting the HIPPs can have a role in Cd-detoxification, possibly by binding Cd. Promoter-GUS reporter expression studies indicated variable expression of these HIPPs. For example, in roots, HIPP22 and HIPP26 are only expressed in lateral root tips while HIPP20 and HIPP25 show strong expression in the root vasculature.
Introduction
Metals have essential roles as trace elements in biological systems. It has been estimated that over half of all proteins are metalloproteins, containing metal ions either as a structural component or as a catalytic factor.1 Both eukaryotes and prokaryotes have evolved mechanisms that ensure efficient metal homeostasis. These include membrane metal transport proteins, metallochaperones for trafficking of metal ions within cells and compounds which bind and sequester metals in sub-cellular compartments.Metallochaperones which deliver copper to specific intracellular targets have been well characterised.2 In yeast, for example, the three copper metallochaperones, Atx1, Lys7 and Cox17, are responsible for delivering copper to the copper transporting ATPase, Ccc2, in the Golgi network,3,4 to copper-zinc superoxide dismutase (Cu/Zn SOD)5 and to the mitochondria for incorporation into cytochrome c oxidase,6,7 respectively.
Functional homologs of Atx1 have been identified in numerous organisms.8,9 These homologs contain a characteristic 60–70 amino acid heavy metal-binding domain (HMA, pfam 00403.6) characterized by a highly conserved CysXXCys motif.8,9 Coordination of Cu ions by these Cys residues is essential for the transfer of Cu between Cu chaperones and Cu transporters.10
Cu-transporting ATPases are found in most organisms from bacteria to mammals and include, for example, the human Menkes11,12 and Wilson13,14 proteins, A. thaliana HMA5, HMA6, HMA7 and HMA815,16 and CopA and CopB from E. hirae.17 Most have one or more N-terminal HMA domains that are believed to play roles in catalysis and/or regulation.18 The Menkes and Wilson proteins, for example, each have six HMA domains, Ccc2 (yeast) has two and Cau-1 (C. elegans) has three.
High-resolution structures of several Cu-ATPase and Cu chaperone HMA domains have identified a characteristic βαββαβ-fold structure19–21 which can also be predicted in most HMA-like sequences.
Other ATPases such as Staphylococcus aureus Cad A,22E. coli ZntA21 and Arabidopsis HMA1, HMA2, HMA3 and HMA415,23,24 transport divalent cations. Many of these, such as CadA and ZntA, also contain N-terminal HMA domains with the conserved CysXXCys motif, where the Cys residues can bind Cu+, Cu2+, Zn2+ and Cd2+ with different affinities depending upon the individual HMA domain sequence.9,20,21 For example, for ZntA, Banci et al., reported that the first Cys and an adjacent Asp are essential for Zn2+ binding specificity.21 Other Zn2+-ATPases, such as HMA2, HMA3 and HMA4 in Arabidopsis, have a CysCysXXGlu motif within a similar βαββαβ-fold HMA domain. In vitro studies show that the N-MBD domain of HMA2 binds Zn2+ and Cd2+ with high affinity and the conserved Cys and Glu residues function in coordination of Zn2+ and Cd2+.25
In most organisms where genome sequences are available only a small number of HMA-containing metallochaperones can be identified. In plants such as Arabidopsis, however, there are many metallochaperone-like sequences.26,27 In this study we have compiled an inventory of genes in Arabidopsis encoding metallochaperone-like proteins with a predicted HMA domain and have explored the functions of a sub-group of this family by characterising heterologous expression in yeast, mutant phenotypes and tissue specificity of expression.
Results and discussion
An inventory of Arabidopsis HMA domain, heavy metal chaperone-like proteins
BLAST searches of the Arabidopsis genome database using the HMA domain amino acid sequences of heavy metal ATPases or known copper chaperones from different organisms, including prokaryotes, animals and plants, identified overlapping groups of Arabidopsis proteins containing heavy metal-associated domains (HMA) (pfam 00403.6). These include HMA-like proteins and heavy metal ATPases. The full-length amino acid sequences of these proteins were used in a series of iterative searches to identify the full complement of this family of proteins in Arabidopsis. We identified 67 Arabidopsis proteins including the previously characterised copper chaperones, AtCCS (At1g12520), AtCCH (At3g56240) and AtATX1 (At1g66240), and most of the HIPPs (heavy metal associated isoprenylated plant proteins) with an isoprenylation motif catalogued by Barth et al. (2009). Our analysis excluded At4g16380, At1g49420 and At1g51090 notwithstanding that the latter two had recently been included by Barth et al. (2009) (and named HIPP38 and HIPP40, respectively) because pfam and NCBI both fail to predict the presence of HMA domains (See ESI Table 1†). In addition, we include a further 19 proteins, called here HPPs (![[h with combining low line]](https://www.rsc.org/images/entities/char_0068_0332.gif) eavy metal associated
eavy metal associated ![[p with combining low line]](https://www.rsc.org/images/entities/char_0070_0332.gif) lant roteins), that lack an isoprenylation motif but still contain a predicted HMA domain (ESI Table 1†). All of these proteins contain one or two domains with similarity to the HMA (pfam 00403.6) consensus sequence shown in Fig. 1. The HMA domains of known Cu ATPases and Cu chaperones generally contain the core functional motif, CysXXCys while the N-terminal HMA domains of some Zn-ATPases contain the CysCysXXGlu motif. However, there are other relatively well-conserved amino acids as indicated in consensus sequence (Fig. 1). For this reason metal chaperone-like proteins which contained an apparent HMA domain but lacked the core conserved CysXXCys or CysCysXXGlu motif are included in this inventory.
lant roteins), that lack an isoprenylation motif but still contain a predicted HMA domain (ESI Table 1†). All of these proteins contain one or two domains with similarity to the HMA (pfam 00403.6) consensus sequence shown in Fig. 1. The HMA domains of known Cu ATPases and Cu chaperones generally contain the core functional motif, CysXXCys while the N-terminal HMA domains of some Zn-ATPases contain the CysCysXXGlu motif. However, there are other relatively well-conserved amino acids as indicated in consensus sequence (Fig. 1). For this reason metal chaperone-like proteins which contained an apparent HMA domain but lacked the core conserved CysXXCys or CysCysXXGlu motif are included in this inventory.
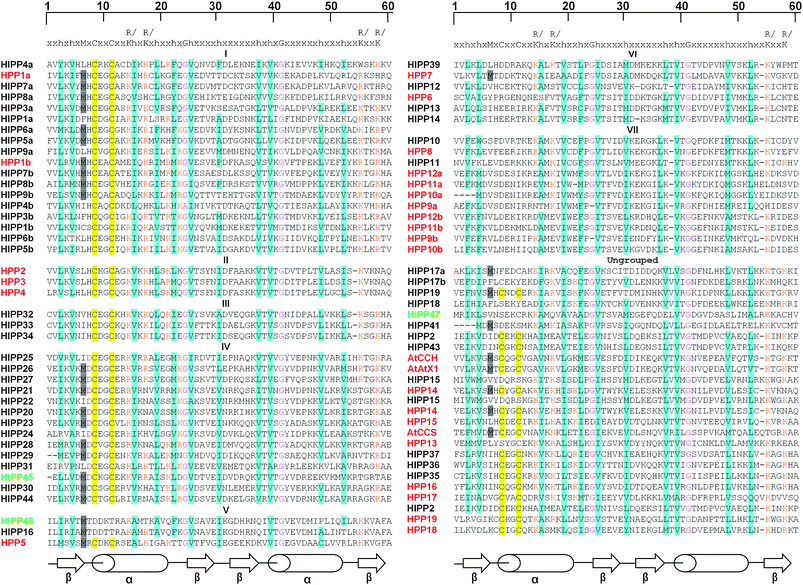 | ||
| Fig. 1 HMA domain sequences of HIPPs and HPPs. The amino acid sequences of the HMA domains are aligned with the consensus sequence derived from HMA domain sequence from pfam. Amino acids conserved relative to the consensus are highlighted in different colours: hydrophobic residues in turquoise, Met (M) before CxxC in grey, CxxC motif in yellow, positively charged residues (Lys and Arg) in orange and conserved Gly (G) in pink. In addition, the conserved Asp (D) residue in cluster IV is indicated in red. Where a protein has two HMA domains (a) indicates first and (b) the second. The βαββαβ-fold secondary structure of the consensus HMA domain is also highlighted. | ||
The size of the proteins is variable, ranging from 77 to 587 amino acids and most are predicted to be localised in the cytoplasm (ESI Table 1†). Recently, two studies investigated the sub-cellular localisation of HIPP26.27,33 Barth et al., found that HIPP26 is localised in the nucleus consistent with the localisation of its interacting partner, the transcription factor, ATHB29.27 Interestingly, Gao et al., reported that HIPP26 localised at the plasma membrane consistent with the localisation of its interacting partner, ACBP2.33 These observations are inconsistent even though both groups constructed a GFP-HIPP26 fusion expressed from CaMV 35S promoter (although in different vectors) and transformed these into onion epidermal cells. Nonetheless, the expression systems were not obviously dissimilar and it is difficult to account for the different results obtained.
With respect to gene structure generally each HMA domain coding sequence is associated with two introns with one immediately upstream and one within the HMA domain at the sequence coding for the highly conserved GlyVal. Nonetheless, there is a series of variants which lack one or more intron positions (Fig. 2 and ESI Table 1†).
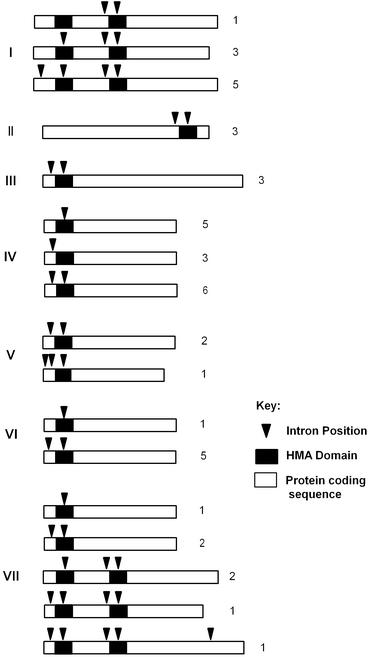 | ||
| Fig. 2 HIPP and HPP protein and gene structures. Schematic representation of protein coding sequences (approximately to scale) of HIPP/HPP protein clusters I to VII showing the positions of HMA domains (black boxes) and introns (black triangles). Different configurations of introns are shown with the number of representatives with each configuration at the right. | ||
Neighbour-joining (NJ) phylogenetic analysis was performed on the predicted full- length amino acid sequences of the HIPP/HPPs in MEGA4 (Fig. 3).28 NJ analysis divided the proteins into seven major clusters (I–VII) which contained three or more proteins while twenty-two proteins were either in a single branch or in a group of two with bootstrap values less than 50 (Fig. 3). Similar topology was obtained when an analysis was performed using only the HMA domain amino acid sequences (data not shown). Except for several conserved residues and overall structural conservation, the protein sequences of HIPPs and HPPs exhibit considerable variability. This variability resulted in low statistical support for some of the internal branches of the phylogenetic tree.
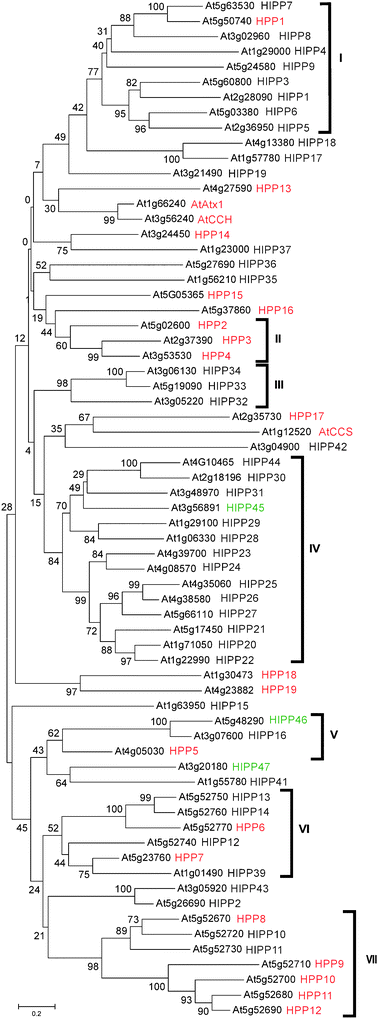 | ||
| Fig. 3 Phylogenetic relationship of HIPP and HPP proteins. The tree was generated using predicted full-length amino acid sequences using the neighbour-joining method in MEGA4,28 bootstrap mode with 1000 replications. The AGI code is shown. The proteins cluster in seven major groups. HIPPs previously catalogued by Barth et al.27 (black); not previously catalogued (green); HPPs (red). | ||
The spatial arrangement of HIPPs and HPPs within the Arabidopsis genome was investigated by mapping the loci onto virtual chromosomes using the Chromosome Map Tool at TAIR (http://www.Arabidopsis.org/jsp/ChromosomeMap/tool.jsp) (ESI Fig. 3†). In this inventory there was a single tandem pair of genes, HIPP22/HIPP37, in addition to a tandem array of eleven genes on the bottom of Chromosome 5. Four of the six members of cluster VI and all seven members of cluster VII lie within the tandem array on Chromosome 5. Fig. 4 shows the arrangement of genes in this array. Amino acid sequence alignment showed the sequence similarity between the proteins in cluster VI is about 60% and all proteins in this cluster have a single HMA domain. Proteins in cluster VII have less than 40% similarity to each other. This degree of sequence similarity suggests that even if this tandem array was generated by local duplication events these are not relatively recent events in evolutionary history.
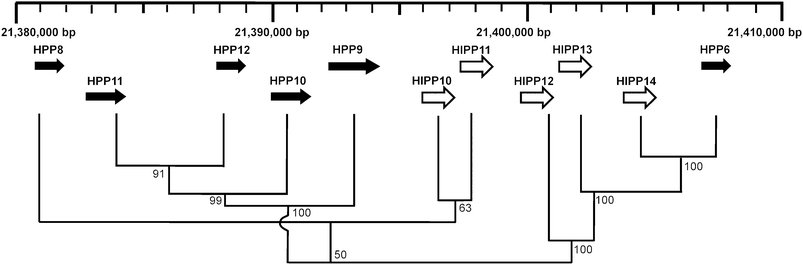 | ||
| Fig. 4 Arrangement and phylogenetic relationship of cluster VI and VII genes in a tandem array on Chromosome 5. The scale indicates base-pairs along Chromosome 5. Direction of transcription of genes is indicated by an arrow. HIPPs (white) and HPPs (black). The tree showing the relationships between the protein sequences was generated using the neighbour-joining method in the MEGA4,28 bootstrap mode with 1000 replications. Percentage bootstrap values are indicated. | ||
By comparison, BLAST searches of rice genome database using the HMA domain amino acid sequences of heavy metal ATPases or known copper chaperones identified 57 proteins HIPP/HPP’s and 9 of these contain two HMA domains (not shown). As seen in Arabidopsis, 14 proteins in rice lack the classical CysXXCys motif. Rice contains only 33 HIPP proteins, compared to 45 in Arabidopsis, while there are 19 and 24 HPPs in Arabidopsis and rice, respectively. The similar number of genes in both Arabidopsis and rice is seen in other gene families including P-type ATPases,34 despite the larger size of the rice genome relative to Arabidopsis.
What might be the functions of such a large family in Arabidopsis? Some, in addition to AtATX1, AtCCH and AtCCS mentioned above, may also be primarily Cu chaperones with specific functions, although the number of potential targets is likely to be limited. Some might chaperone other metals or regulate other functions through the binding of metals. This might also include those that lack a CysXXCys motif. In general, the Cys residues in functional Cu chaperones are essential for Cu binding. It is, however, possible that those that lack a CysXXCys motif may still bind metal ions through coordination with other amino acid residues. Alternatively, they may have evolved some further function not dependent on metal binding. In this work we have focused on cluster IV which generally contains a conserved AspCysXXCys, metal binding motif (Fig. 1). In ZntA in E. coli a corresponding Asp residue is essential for binding Zn.21 In this study, we explore the possible roles in metal homeostasis of HIPP20 (At1g71050), HIPP21 (At5g17450), HIPP22 (At1g22990), HIPP26 At4g38580) and HIPP27 (At5g66110) in cluster IV through heterologous expression in yeast, mutant analysis and tissue-specificity of expression.
Expression of HIPP20, HIPP21, HIPP22, HIPP26 and HIPP27 in yeast
The function of HIPP20, HIPP21, HIPP22, HIPP26 and HIPP27 was explored following heterologous expression in yeast. The entire open reading-frame of all five genes was cloned into the yeast expression vector, pVT100-U or pVT102-U35 and the constructs were transformed into S. cerevisiae strains, zrt1zrt2, zrc1cot1, ycf1 and atx1. The ZRT1 and ZRT2 transporters catalyse Zn uptake and zrt1zrt2 is Zn-dependent.36,37zrt1zrt2 transformants were selected on LZM/-U medium containing 1 mM added Zn and then tested for growth in the presence of 350 μM Zn. The zinc transporter, AtZIP1, was used as a positive control that can rescue the zrt1zrt2 phenotype.38 All strains grew equally in the presence of 1 mM Zn while in the presence of 350 μM Zn, the ZIP1 positive control but none of the HIPP constructs could rescue the Zn-dependent phenotype (ESI Fig. 4†).The zrc1cot1 yeast mutant lacks CDF vacuolar membrane transporters and is hypersensitive to Zn because Zn accumulates in the cytosol.39 AtHMA4 as a positive control can functionally rescue zrc1cot1 phenotype because it effluxes Zn at the plasma membrane.40,41 AtHMA4, but none of the HIPP expression constructs, conferred resistance to 450 and 550 μM added Zn (ESI Fig. 4†).
Previously, Arabidopsis Cu chaperones, AtAtx1 and AtCCH have been successfully used to complement yeast atx1.42,43atx1 strains exhibit growth defects in iron-deficient conditions due to impaired Cu delivery to the Cu-dependent multicopper oxidase, Fet3, which is essential for high affinity iron uptake.4 To test whether these HIPP proteins have roles as Cu chaperones and can functionally complement atx1, all five HIPP constructs the vector, pVT100-U, and, as a positive control, a plasmid carrying the yeast Atx1 gene (generously provided by Lola Peñarrubia, University de Valencia, Spain) were transformed into atx1. We tested atx1 functional complementation by growth on media containing both the extracellular Cu chelator bathocuproine disulfonic acid (BCS), and the extracellular iron chelator bathophenantholine disulfonic (BPS) which together inhibit the growth of atx1. While the positive control could complement the mutant phenotype neither the vector-only nor any of the HIPP constructs were able to confer growth on SD/-U media in the presence of BPS/BCS (ESI Fig. 4†).
YCF1 (Yeast Cadmium Factor 1) transports Cd-diglutathione complexes to the vacuole and ycf1 mutant is Cd-hypersensitive.44 AtHMA4 can also rescue ycf1 by effluxing Cd at the plasma membrane.40,41 To test whether the HIPP expression constructs could rescue the ycf1 phenotype, all strains were grown on SD/-U in the absence and presence of 20 μM added Cd (Fig. 5A). All strains grew equally in the absence of Cd while in the presence of 20 μM Cd, cells expressing AtHMA4 and HIPP26 grew well. Cells expressing HIPP20, HIPP22, and HIPP27 grew weakly at 20 μM Cd while cells transformed with the HIPP21 expression construct and the empty vector, pVT100-U, failed to grow (Fig. 5A). This was confirmed in liquid culture in the absence and presence of 20 μM Cd over a period of up to 56 h. All strains exhibited similar growth rates in the absence of Cd (Fig. 5B1). In the presence of 20 μM Cd, after 56 h, all HIPP strains showed slower growth rate than the positive control, AtHMA4. However, strains expressing HIPP20, HIPP22, HIPP26 and HIPP27 grew 1.7, 2.0, 2.7 and 1.9 times faster, respectively, than the vector-only strain. No difference was observed in the growth between the HIPP21 and vector-only strains (Fig. 5B2).
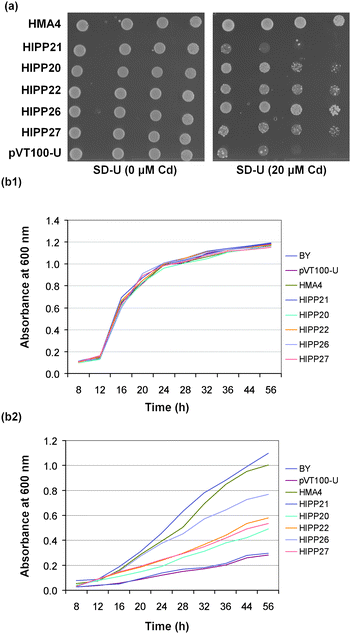 | ||
| Fig. 5 Heterologous expression of HIPP20, HIPP21, HIPP22, HIPP26 and HIPP27 cDNAs in ycf1. (a) ycf1 (Cd-sensitive) expressing HIPPs, AtHMA4 (as a positive control) and vector-only (pVT100-U) after 4 d growth at 30 °C on SD-U media with and without Cd. Cells were spotted as one-tenth serial dilutions starting at A600 nm 1.2; (b) ycf1 (Cd-sensitive) transformed with HIPPs, AtHMA4 and pVT100-U. Cells were grown at 30 °C in liquid culture in SD-U medium in the (1) absence of Cd2+ and (2) in the presence of 20 μM Cd2+. Cell growth was monitored at the indicated time intervals by measuring the absorbance at 600 nm. | ||
These data confirm that four of the HIPP proteins when expressed in yeast were able to confer increased Cd-resistance to the Cd-sensitive yeast strain, ycf1 (Fig. 5A and B). It is likely that they rescue the phenotype through binding Cd in the cytosol rather than influencing the transport of Cd into the vacuole or out of the cell. In addition, Gao et al., have shown using metal-chelate affinity chromatography in vitro that HIPP26 can bind Cd2+, Cu2+ and Pb2+ and over-expression of HIPP26 in A. thaliana enhances tolerance to Cd33 which indicate that this family of proteins are able to bind Cd in vivo and can have a role in Cd detoxification in planta.
Characterisation of hipp mutants
We obtained T-DNA insertion alleles of hipp20, hipp21, hipp22, hipp26, hipp27 from the Arabidopsis stock centre (see Experimental). To test whether these are true knock-out mutants, quantitative RT-PCR was used to detect the level of transcript from the mutant gene in each of the mutant lines. The primer positions used are shown in ESI Fig. 2A.† The absence of detectable transcript indicated hipp20 and hipp26 are null mutants (ESI Fig. 2B†). In hipp21, although cDNA up-stream of the T-DNA could be amplified, only a low level of transcript was detected but for hipp27 no difference in expression level as compared to wild-type was observed (ESI Fig. 2B†). In hipp21 and hipp27, the T-DNA insertions are only 34 and 37 codons, respectively, upstream of the stop codon and well downstream of the predicted HMA domain (ESI Table 2†). If these transcripts are translated they could, in theory, produce a product containing an HMA domain but presumably lacking the C-terminal isoprenylation sequence. Such a protein product may or may not retain much of its function. In hipp22, a low level of transcription of sequences downstream of the T-DNA insertion was detected (ESI Fig. 2B†) but, because the T-DNA insertion is in the region of the gene encoding the HMA domain, these transcripts are unlikely to encode a functional product. Thus, it is likely that hipp20, hipp22 and hipp26 are null mutations and that hipp21 has a significant loss of function. No definitive conclusion could be drawn about hipp27.The single mutants were grown alongside their corresponding WT parent on both agar medium and in soil and exhibited no apparent phenotype. They were also tested on agar for increased sensitivity to Zn, Cd and Cu using a range of concentrations. Shoot fresh weight (FW) was measured after 7 d and no significant difference in growth was observed in all five mutants as compared to the wild-type (data not shown). This may be because these genes may have partially redundant functions in planta. The hipp20, hipp21 and hipp22 mutations were all in the Col ecotype. So, to avoid complications of mixed genetic background, we focused on creating the hipp20/21/22 double and triple mutant combinations. hipp20 and hipp21 were crossed to produce F1 individuals which were then crossed with hipp22. Progeny heterozygous for all three loci were allowed to self-fertilise. F2 progeny were then screened by PCR to isolate double, hipp20/21, hipp20/22, hipp21/22, and triple hipp20/21/22 mutant combinations.
The double hipp mutants were tested for altered sensitivity to Zn, Cd and Cu in agar medium, and no distinct phenotype was observed (data not shown). In contrast, the hipp20/21/22 triple mutant, showed a significant decrease in shoot fresh weight (FW) compared to Col wild-type on medium containing 4, 5 and 6 μM Cd (Fig. 6B) while no difference in growth was detected in the absence of Cd indicating the triple mutant is Cd sensitive. The Cd-sensitive phenotype of the triple mutant was characterised by chlorosis and reduced shoot FW compared to the wild-type (Col). No altered sensitivity in the shoot FW was observed in the presence of Zn and Cu (data not shown).
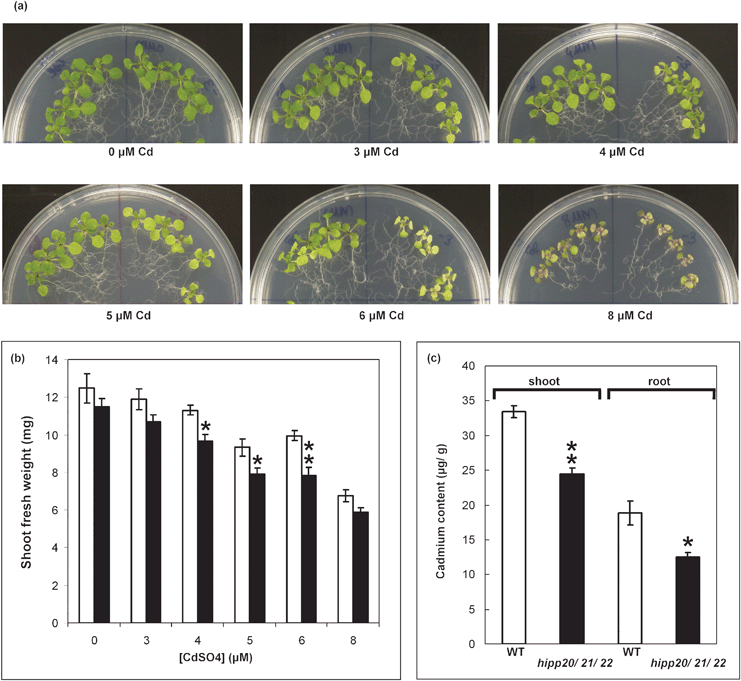 | ||
| Fig. 6 Cd-sensitivity and metal content of the hipp20/21/22 mutant. (a) 14 d old Col (left) and triple mutant (right) seedlings growing on MMS and MMS containing 3, 4, 5, 6 and 8 μM CdSO4. 7 d old seedlings were transferred to the indicated medium and grown for further 7 d. (b) Shoot FW of plants shown in (a).Values are mean ± SE (n = 20). Significant differences from Col were determined by Student’s t-test. Bonferroni correction was performed to adjust the P-value to account for multiple comparisons (*p < 0.05 and (**p < 0.01). (c) Shoot (white bars) and root (black bars) metal content in 15 d old triple mutant as compared to Col wild-type. 8 d old seedlings were transferred to MMS agar medium with and without 0.6 μM CdSO4. Cd contents was measured using ICP-AES in shoots and roots of tissues pooled from twenty-four seedlings in four independent replicates. Values represent means ± SE (n = 4). Significant differences were determined by Student’s t-test (*p < 0.05) and (**p < 0.01). | ||
Although the hipp20/21/22, triple mutant is more sensitive to Cd (Fig. 6A), when Cd accumulation was measured in plants exposed to a level of Cd not observed to inhibit growth (0.6 μM) , accumulation in shoots and roots was less than in the WT by about 27 and 35%, respectively (Fig. 6C). This has also been observed for phytochelatin (PC)-deficient, cad1, mutants of Arabidopsis.31 PCs bind Cd and are sequestered to the vacuole and PC-deficient mutants both accumulate less Cd and are more sensitive to Cd inhibition. By analogy this may suggest that an important role of the HIPPs is also to bind Cd and prevent its inhibitory effects.
Tissue-specific expression of HIPPs
To visualize the cellular pattern of HIPP20, HIPP21, HIPP22, HIPP25, HIPP26 and HIPP27 in planta, promoter-β-glucuronidase (HIPP20p-GUS, HIPP21p-GUS, HIPP22p-GUS, HIPP25p-GUS, HIPP26p-GUS and HIPP26p-GUS) fusion constructs were expressed in transgenic Col wild type plants. The promoter-GUS studies indicate expression is variable in different tissues. HIPP20p-GUS expression was strongest and predominantly associated with the vasculature, flowers and shoot apical meristem (Fig. 7A and F). Similarly in roots, HIPP20p-GUS expression was highest in older roots and mainly associated with vascular tissues but absent in root tips (Fig. 7A). | ||
| Fig. 7 HIPPp-GUS expression in transgenic plants. (a) to (e) Sixteen-day-old seedlings (bars = 5 mm), (f) to (j) Inflorescences (bars = 1 mm), (a) and (f) HIPP20p-GUS, (b) and (g) HIPP21p-GUS, (c) and (h) HIPP22p-GUS, (d) and (i) HIPP26p-GUS, (e) and (j) HIPP25p-GUS. | ||
In HIPP21p-GUS transgenic plants expression was very weak in leaf (Fig. 7B). Weak expression was also found in the sepals of mature flowers (Fig. 7G). In HIPP22p-GUS transgenic plants expression was mostly found in lateral roots but not in roots tips (Fig. 7C). In inflorescences, the expression was highest in the mature anthers (Fig. 7H). In HIPP25p-GUS expression was high in older roots, the shoot apical meristem region, trichomes and flower buds but absent in lateral roots (Fig. 7E and J). Previously published expression analysis using HIPP26p-GUS indicated expression in vascular tissues of the whole plant.27 However, in this study HIPP26p-GUS expression was only detected in lateral roots, shoot apical meristem, petals of unopened flowers and weak expression in leaf vasculature (Fig. 7D and I). This may be due to the fact that we included some part of the coding region and the first intron of the gene while Barth et al., used only the intergenic region.27 There may be regulatory elements in the first intron acting to modulate HIPP26 expression. No expression was detected in HIPP27p-GUS transgenic plants.
Overall, the expression of promoter-GUS transgenic constructs showed variable expression of the five genes suggesting variable sites of function in planta. Nonetheless, rescue of the ycf1 Cd-sensitive strain and the Cd-sensitive phenotype of the triple mutant suggests that all or most of these genes have a similar function at a cellular level.
Experimental
Sequence analysis and construction of phylogenetic trees
BLAST Server at www.arabidopsis.org was used to identify putative HMA domain containing proteins from A. thaliana. Alignment of amino acid sequences was made using Clustal X (Thompson et al., 1997). Phylogenetic trees were constructed by using predicted amino acid sequences in MEGA4.28Yeast strains and media
The S. cerevisiae strains: zrc1cot1 (MATα;his3Δ1;leu2Δ0;met15Δ0; ura3Δ0;zrc1::natMX cot1::kanMX4) and ycf1 mutant (MATα;his3Δ1;leu2Δ0;lys2Δ0;ura3Δ0;YDR135c::kanMX4) were obtained from Dr Lorraine E. Williams (University of Southampton, UK). Δatx1 (MATα;his3Δ1;leu2Δ0;met15Δ0; ura3Δ0; atx1::kanMX4 was obtained from Dr Lola Peñarrubia (University of Valencia, Spain) and zrt1zrt2 (MATαzrt1::LEU2 zrt2::HIS ade6 can1 his3 leu2 trp1 ura3) were used for heterologous expression studies. Synthetic dropout (SD)29 and LZM media30 lacking specific nutrients were used for the selection and maintenance of yeast transformed with plasmids.Plant materials and genotype determination
Arabidopsis plants were grown in agar and soil as described previously.31 To investigate the function of HIPP20, HIPP21, HIPP22, HIPP26 and HIPP27 in planta, we obtained T-DNA mutant alleles from SALK and INRA. Three T-DNA insertion lines in the Columbia ecotype: SALK_048115, (referred to here as hipp20-1), SALK_131715 (hipp21-1), CS112068 (hipp22-1) and one in the Ler ecotype: CS180249 (hipp27-1) were obtained from the SALK collection; and FLAG_631G11 (hipp26-1) in the Ws ecotype was obtained from INRA. These mutants will be referred to as hipp20, hipp21, hipp22, hipp26 and hipp27, respectively. In back-crosses to the wild type, these mutants segregated for a single T-DNA. The genotype of plants was determined by PCR using primers flanking the insertion for the wild-type allele and a gene-specific and left border-specific primer pair for the insertion allele. The positions of the T-DNA left border insertion sites are shown in ESI Fig. 1† and ESI Table 1.† For RT-PCR analysis of gene expression in the mutants, total RNA was isolated from 14-d-old plants. cDNA was synthesized using the SuperScriptIII First Strand Synthesis system (Invitrogen) and amplified using gene-specific primers. The primer positions and the amounts of transcript detected in the mutant lines relative to the wild-type are shown in ESI Fig. 2.†Inductively coupled plasma atomic emission spectroscopy (ICP-AES) determination of metal content
Plant tissues were harvested and dried at 70 °C for 4 d. Weighed (DW) samples were digested in 70% HNO3 overnight at room temperature then at 90 °C for 2 h. Digested samples were diluted to a final concentration of 7% HNO3 with dH2O and metal content was measured using Inductivity Coupled Plasma Atomic Emission Spectrometer (ICP-AES) with a Vista-Pro (Varian) instrument.Promoter-GUS fusion constructs lines
The regions upstream of HIPP20 from −1707 to +3 (where +1 is the A of the predicted ATG start codon), HIPP21 from −2435 to +465, HIPP22 from −3615 to +234, HIPP25 from −7951 to +201, HIPP26 from −2263 to +759 and HIPP27 from −664 to +192 were amplified by PCR, digested with suitable restriction enzymes and cloned into pBI101 (Clontech, Palo Alto, CA) so that the start codons of all six genes and uidA were in frame. All cloned fragments were sequenced and no differences from publicly available sequences (www.Arabidopsis.org) were identified. The promoter-GUS constructs were transformed into Col plants via the Agrobacterium tumefaciens-mediated floral dip method.32 Two independent lines of each construct were selected for GUS analysis. Tissues were incubated in GUS staining buffer [0.2% Triton-X 1000 (v/v), 50 mM NaPO4 pH 7.2, 2 mM Potassium Ferrocyanide, 2 mM Potassium Ferricyanide, 2 mM X-Gluc in dimethyl formamide] at 37 °C for 16 h. Chlorophyll was removed from leaves by serial washing in 100% ethanol.Acknowledgements
This research was supported by the Australian Research Council (Grant DP0879336 to CSC). MT was supported by MIRS and MIFRS scholarships from the University of Melbourne. The authors are grateful to the Arabidopsis Stock Centre from supplying mutant lines and to Dr Lorraine E. Williams (University of Southampton, UK) and Dr Lola Peñarrubia (University of Valencia, Spain) for mutant yeast strains.References
- K. N. Degtyarenko, Bioinformatics, 2000, 16, 851–864 CrossRef CAS.
- T. V. O'Halloran and V. C. Culotta, J. Biol. Chem., 2000, 275, 25057–60 CrossRef CAS.
- S. Lin and V. C. Culotta, Proc. Natl. Acad. Sci. U. S. A., 1995, 92, 3784–3788 CrossRef CAS.
- R. A. Pufahl, C. P. Singer, K. L. Peariso, S. J. Lin, P. J. Schmidt, C. J. Fahrni, V. C. Culotta, J. E. Penner-Hahn and T. V. O’Halloran, Science, 1997, 278, 853–856 CrossRef CAS.
- V. C. Culotta, L. Klomp, J. Strain, R. Casarino, B. Krems and J. D. Gitlin, J. Biol. Chem., 1997, 272, 23469–23472 CrossRef CAS.
- D. M. Glerum, A. Shtanko and A. Tzagoloff, J. Biol. Chem., 1996, 271, 14504–14509 CrossRef CAS.
- C. Srinivasan, M. C. Posewitz, G. N. George and D. R. Winge, Biochemistry, 1998, 37, 7572–7577 CrossRef CAS.
- A. C. Rosenzweig, Acc. Chem. Res., 2001, 34, 119–128 CrossRef CAS.
- F. Arnesano, L. Banci, I. Bertini, S. Ciofi-Baffoni, E. Molteni, D. L. Huffman and T. V. O’Halloran, Genome Res., 2002, 12, 255–271 CrossRef CAS.
- F. Arnesano, L. Banci, I. Bertini, D. L. Huffman and T. V. O’Halloran, Biochemistry, 2001, 40, 1528–1539 CrossRef CAS.
- C. Vulpe, B. Levinson, S. Whitney, S. Packman and J. Gitschier, Nat. Genet., 1993, 3, 7–13 CAS.
- J. F. Mercer, J. Livingston, B. Hall, J. A. Paynter, C. Begy, S. Chandrasekharappa, P. Lockhart, A. Grimes, M. Bhave, D. Siemieniak and T. W. Glover, Nat. Genet., 1993, 3, 20–25 CrossRef CAS.
- P. C. Bull, G. R. Thomas, J. M. Rommens, J. R. Forbes and D. W. Cox, Nat. Genet., 1993, 5, 327–337 CrossRef CAS.
- P. J. Lockhart, S. A. Wilcox, H. M. Dahl and J. F. Mercer, Biochim. Biophys. Acta., 2000, 1491, 229–39 CAS.
- C. M. Palmer and M. L. Guerinot, Nat. Chem. Biol., 2009, 5, 333–40 CrossRef CAS.
- I. Yruela, Funct. Plant Biol., 2009, 36, 409–430 CrossRef CAS.
- M. Solioz and C. Vulpe, CPx-type ATPases: a class of P-type ATPases that pump heavy metals, Trends Biochem. Sci., 1996, 21, 237–241 CAS.
- J. M. Arguello, E. Eren and M. Gonzalez-Guerrero, BioMetals, 2007, 20, 233–248 Search PubMed.
- J. Gitschier, B. Moffat, D. Reilly, W. I. Wood and W. J. Fairbrother, Nat. Struct. Biol., 1998, 5, 47–54 CrossRef CAS.
- L. Banci, I. Bertini, S. Ciofi-Baffoni, D. L. Huffman and T. V. O'Halloran, J. Biol. Chem., 2001, 276, 8415–8426 CrossRef CAS.
- L. Banci, I. Bertini, S. Ciofi-Baffoni, L. A. Finney, C. E. Outten and T. V. O'Halloran, J. Mol. Biol., 2002, 323, 883–897 CrossRef CAS.
- D. M. Ivey, A. A. Guffanti, Z. H. Shen, N. Kudyan and T. A. Krulwich, J. Bacteriol., 1992, 174, 4878–4884 CAS.
- I. Moreno, L. Norambuena, D. Maturana, M. Toro, C. Vergara, A. Orellana, A. Zurita-Silva and V. R. Ordenes, J. Biol. Chem., 2008, 283, 9633–41 CrossRef CAS.
- M. Morel, J. Crouzet, A. Gravot, P. Auroy, N. Leonhardt, A. Vavasseur and P. Richaud, Plant Physiol., 2008, 149, 894–904 CrossRef.
- E. Eren, M. Gonzalez-Guerrero, B. M. Kaufman and J. M. Arguello, Biochemistry, 2007, 46, 7754–7764 CrossRef CAS.
- P. E. Dykema, P. R. Sipes, A. Marie, B. J. Biermann, D. N. Crowell and S. K. Randall, Plant Mol. Biol., 1999, 41, 139–150 CrossRef CAS.
- O. Barth, S. Vogt, R. Uhlemann, W. Zschiesche and K. Humbeck, Plant Mol. Biol., 2009, 69, 213–226 CrossRef CAS.
- K. Tamura, J. Dudley, M. Nei and S. Kumar, Mol. Biol. Evol., 2007, 24, 1596–1599 CrossRef CAS.
- M. D. Rose, F. Winston and P. Hieter, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 1990.
- R. S. Gitan H. Luo, J. Rodgers, M. Broderius and D. Eide, J. Biol. Chem., 1998, 273, 2817–28624 CrossRef.
- R. Howden, P. B. Goldsbrough, C. R. Andersen and C. S. Cobbett, Plant Physiol., 1995, 107, 1059–1066 CrossRef CAS.
- S. J. Clough and A. F. Bent, Plant J., 1998, 16, 735–743 CrossRef CAS.
- W. Gao, S. Xiao, H. Ye Li, S. W. Tsao and M. L. Chye, New Phytol., 2009, 181, 89–102 Search PubMed.
- I. Baxter, J. Tchieu, M. R. Sussman, M. Boutry, M. G. Palmgren, M. Gribskov, J. F. Harper and K. B. Axelsen, Plant Physiol., 2003, 132, 618–628 CrossRef CAS.
- T. Vernet, D. Dignard and D. Y. Thomad, Gene, 1987, 52, 225–233 CrossRef CAS.
- H. Zhao and D. Eide, Proc. Natl. Acad. Sci. U. S. A., 1996, 93, 2454–2458 CrossRef CAS.
- H. Zhao and D. Eide, J. Biol. Chem., 1996, 271, 23203–23210 CrossRef CAS.
- N. Grotz, T. Fox, E. Connolly, W. Park, M. L. Guerinot and D. Eide, Proc. Natl. Acad. Sci. U. S. A., 1998, 95, 7220–7224 CrossRef CAS.
- M. Becher, I. N. Talke, L. Krall and U. Krämer, Plant J., 2004, 37, 251–68 CAS.
- R. F. Mills, G. C. Krijger, P. J. Baccarini, J. L. Hall and L. E. Williams, Plant J., 2003, 35, 164–176 CrossRef CAS.
- F. Verret, A. Gravot, P. Auroy, S. Preveral, C. Forestier, A. Vavasseur and P. Richaud, FEBS Lett., 2005, 579, 1515–1522 CrossRef CAS.
- H. Mira, M. Vilar, E. Pérez-Raya and L. Peñarrubia, Biochem. J., 2001, 357, 545–549 CrossRef CAS.
- S. Puig, H. Mira, E. Dorcey, V. Sancenón, N. Andrés-Colás, A. Garcia-Molina, J. L. Burkhead, K. A. Gogolin, S. E. Abdel-Ghany, D. J. Thiele, J. R. Ecker, M. Pilon and L. Peñarrubia, Biochem. Biophys. Res. Commun., 2007, 354, 385–90 CrossRef CAS.
- Z. S. Li, M. Szczypka, Y. P. Lu, D. J. Thiele and P. A. Rea, J. Biol. Chem., 1996, 271, 6509–6517 CrossRef CAS.
Footnote |
| † Electronic supplementary information (ESI) available: Supplementary figures and tables. See DOI: 10.1039/c003484c |
| This journal is © The Royal Society of Chemistry 2010 |