Global assessment of scaffold hopping potential for current pharmaceutical targets
Ye
Hu
and
Jürgen
Bajorath
*
Department of Life Science Informatics, B-IT, LIMES Program Unit Chemical Biology and Medicinal Chemistry, Rheinische Friedrich-Wilhelms-Universität, Dahlmannstr. 2, D-53113 Bonn, Germany. E-mail: bajorath@bit.uni-bonn.de; Fax: +49-228-2699-341; Tel: +49-228-2699-306
First published on 13th October 2010
Abstract
Scaffold hopping is an intensely investigated topic, both in the context of computational method evaluation and practical compound screening applications. Scaffold hopping refers to the identification of different compound classes having similar biological activity and is typically explored on a case-by-case basis. However, how frequently scaffold hops occur across different targets is presently not well understood. We have investigated global scaffold hopping potential by systematically analyzing topologically distinct scaffolds in currently available bioactive compounds with defined target and activity annotations. The analysis reveals that for the majority of target proteins, active compounds representing between five and 49 topologically distinct scaffolds are available. Moreover, for 70 targets, between 50 and more than 300 distinct scaffolds are found. Thus, scaffold hops occur with rather high frequency among active compounds.
In medicinal chemistry, the search for different structural classes (chemotypes) having similar activity is generally of high interest,1,2 for example, to support chemical optimization efforts or secure intellectual property positions. Moreover, the demonstration of scaffold hopping potential has become the “holy grail” of computational screening methods.3–9 The “value” of any virtual screening approach is essentially judged upon its ability to identify different chemotypes having similar activity, mostly in benchmark calculations. Beyond the often rather artificial scenario provided by typical benchmark studies, in prospective applications, a virtual screen is generally claimed to be a “success” if at least one or a few novel compounds with different core structures (scaffolds) and desired biological activity have been identified. Unfortunately, the assessment of scaffold hopping potential often suffers from the lack of clear scaffold definitions and inconsistent analysis of scaffold hops.9 Moreover, it is currently unclear how “difficult” scaffold hopping really might be. No studies are available at present that provide a general assessment of scaffold hopping potential across different targets, although such insights would be of general interest, both for the evaluation of computational screening methods and practical medicinal chemistry applications.
General scaffold hopping potential might be estimated by systematically analyzing, on a per-target basis, how many well-defined scaffold hops are “encoded” by currently available bioactive compounds. Accordingly, we have carried out a large-scale analysis of scaffold hops among publicly available active compounds. All calculations reported herein were carried out with in-house Perl and Scientific Vector Language (SVL)10 programs and Pipeline Pilot11 tools.
From two major public repositories of bioactive compounds, CHEMBLdb (CDB)12 and BindingDB (BDB),13 31,158 and 17,745 molecules with activity annotations (Ki or IC50 values) against human targets were selected, respectively. These compounds were organized in 586 and 433 individual target sets and 12,047 and 6,291 atomic property-based Bemis & Murcko scaffolds14 were extracted from them, respectively. CDB and BDB currently show limited compound overlap15 and we therefore merged the CDB and BDB compound and scaffold sets, yielding a total of 795 individual target sets containing 45,263 compounds and 16,873 unique scaffolds.
As illustrated in Fig. 1, property-based Bemis & Murcko scaffolds consist of core ring structures and linkers between them.14 Scaffolds only distinguished by heteroatom substitutions and bond orders display the same topology, as reflected by carbon skeletons (CSKs; i.e. scaffolds with all atom types set to carbon and all bond orders to one), as also illustrated in Fig. 1. We deliberately focused our analysis on topologically distinct scaffolds that are more relevant for scaffold hopping than scaffolds that are only distinguished by minor heteroatom substitutions or bond order alterations. Therefore, for each target set, we determined all Bemis & Murcko scaffolds yielding the same CSKs. In each of these cases, we only retained the scaffold that was represented by the largest number of compounds or, if several scaffolds had the same number of compounds, the scaffold represented by the largest number of compounds with highest median potency. An individual scaffold was retained instead of the CSK because compounds representing the scaffold were required for score calculations, as described below. Importantly, by retaining one Bemis & Murcko scaffold per CSK, all scaffolds selected for a target set at this stage were topologically distinct. This selection scheme yielded 10,989 topologically distinct scaffolds corresponding to 35,004 compounds. In order to further streamline the collection of target sets for meaningful scaffold hopping analysis, we only retained target sets containing at least five compounds with at least 1 μM potency (i.e., pKi or pIC50 > = 6) and at least two scaffolds. Accordingly, our analysis was ultimately based on 8,693 topologically distinct scaffolds represented by 26,664 compounds organized into 502 different target sets. For the assignment of targets to families, we followed the CDB classification scheme and combined targets available in CDB and BDB. Table 1 reports the 19 target families considered in our analysis that contained between three and 137 individual targets.
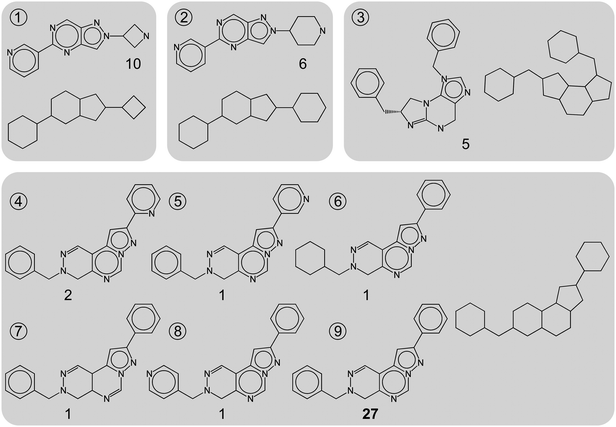 | ||
| Fig. 1 Topologically distinct scaffolds. Nine representative scaffolds extracted from phosphodiesterase 5A inhibitors are shown. For each scaffold, the corresponding carbon skeleton (CSK) is shown and the number of compounds each scaffold represents is reported. Scaffolds 1 to 3 yield distinct CSKs, whereas scaffolds 4 to 9 share the same CSK. Scaffold 9 is selected for further analysis because it represents the largest number of compounds (i.e., 27), and the other five scaffolds are not further considered. This selection scheme ensures that only topologically distinct scaffolds are analyzed. | ||
| FamilyID | Target Family | # Targets | ||||||
|---|---|---|---|---|---|---|---|---|
| Source | # Scaffolds | |||||||
| BDB | CDB | Total | < 5 | [5, 50) | [50, 100) | > = 100 | ||
| a Nineteen target families are listed following the CHEMBLdb classification scheme. For each family, the numbers of targets taken from CHEMBLdb, BindingDB, and the total number of targets are reported (taking target overlap between these databases into account). In addition, for each family, the number of targets is reported whose compound sets contain different numbers of scaffolds. Target family abbreviations: GPCR, G-Protein Coupled Receptor; Others, all none classified targets. | ||||||||
| 1 | Tyr protein kinases | 30 | 32 | 38 | 4 | 28 | 2 | 4 |
| 2 | Ser_Thr protein kinases | 37 | 38 | 49 | 6 | 37 | 4 | 2 |
| 3 | Ser_Thr_Tyr kinases | 9 | 7 | 13 | 4 | 9 | 0 | 0 |
| 4 | Phosphadiesterases | 8 | 7 | 9 | 0 | 9 | 0 | 0 |
| 5 | Protein phosphatases | 1 | 3 | 3 | 0 | 3 | 0 | 0 |
| 6 | Aspartic proteases | 4 | 7 | 7 | 2 | 3 | 2 | 0 |
| 7 | Cysteine proteases | 11 | 12 | 14 | 1 | 9 | 2 | 2 |
| 8 | Matrix metalloproteases | 14 | 17 | 19 | 2 | 11 | 5 | 1 |
| 9 | Serine proteases | 18 | 21 | 25 | 2 | 20 | 0 | 3 |
| 10 | Carbonic anhydrases | 12 | 10 | 12 | 0 | 9 | 2 | 1 |
| 11 | Histone deacetylases | 8 | 5 | 8 | 0 | 7 | 1 | 0 |
| 12 | CytochromeP450 enzymes | 8 | 9 | 13 | 1 | 12 | 0 | 0 |
| 13 | Transferases | 4 | 4 | 8 | 1 | 7 | 0 | 0 |
| 14 | Ion channels | 4 | 20 | 22 | 8 | 14 | 0 | 0 |
| 15 | GPCRs | 45 | 129 | 137 | 13 | 92 | 19 | 13 |
| 16 | Cytosolic-others | 9 | 7 | 14 | 8 | 6 | 0 | 0 |
| 17 | Electrochemical transporters | 6 | 15 | 15 | 5 | 8 | 2 | 0 |
| 18 | Nuclear receptors | 15 | 16 | 20 | 5 | 13 | 2 | 0 |
| 19 | Others | 44 | 57 | 76 | 16 | 57 | 1 | 2 |
We first determined the number of distinct scaffolds present in each target set. The results are reported in Table 1 on a target family basis. Surprisingly, the majority of target sets were found to contain significant numbers of distinct scaffolds. A total of 354 target sets contained between five and 49 scaffolds, 42 target sets between 50 and 99, and 28 sets at least 100 scaffolds. Thus, the range of five to 49 scaffolds represents “average” scaffold diversity across current targets corresponding to average scaffold hopping potential. This is further illustrated by monitoring the scaffold distributions within target families (Fig. 2a). Many of these scaffolds were represented by compounds with in part very large potency differences (Fig. 2b).
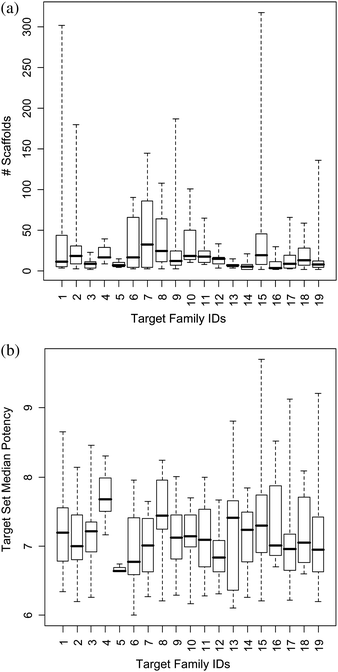 | ||
| Fig. 2 Target family statistics. (a) Scaffold distribution and (b) target set median potency; presented as box plots. Target family IDs are according to Table 1. The box plots report the smallest value (bottom line), lower quartile (lower boundary of the box), median (thick horizontal line), upper quartile (upper boundary of the box), and the largest value (top line). | ||
A total of 70 target sets from twelve different target families (covering ∼14% of the current target spectrum) were characterized by what we considered high to very high scaffold diversity, each containing between 50 and more than 300 topologically distinct scaffolds. We next analyzed these sets in more detail. Table 2 shows the top 30 targets ranked by scaffold numbers. Well-known pharmaceutical targets appear high on the ranking. These targets, which are also popular for virtual compound screening studies, include, for example, different adenosine and dopamine receptor subtypes and other GPCRs, protein kinases, and various proteases. These targets are chemically well explored. We have recently shown that more than 80% of scaffolds from currently available bioactive compounds are topologically equivalent and/or display substructure relationships.16 Here we have exclusively focused on topologically distinct scaffolds, but we also determined substructure relationships between them, as reported in Table 2. For the target sets containing most scaffolds, at least approx. half of these scaffolds, but often more than 70% or 80% were found to be involved in substructure relationships (i.e. one scaffold is a substructure of another in the same set). From this point of view, it might not be very surprising that these targets have high scaffold hopping probability, also in benchmark calculations, and we would hence consider them “easy” virtual screening targets.
| Target Name | #Sc | FamilyID | %Sc-in-Sub |
|---|---|---|---|
| a The top 30 target sets ranked according to scaffold numbers are reported. For each set, the number of scaffolds (#Sc) and the percentage of these scaffolds (%Sc-in-Sub) that are involved in substructure relationships are reported. | |||
| Melanin-concentrating hormone receptor 1 | 318 | 15 | 57.2 |
| Vascular endothelial growth factor receptor 1 | 302 | 1 | 66.2 |
| Melanocortin receptor 4 | 207 | 15 | 63.3 |
| Factor Xa | 187 | 9 | 59.4 |
| Cyclin-dependent kinase 2 | 180 | 2 | 70.6 |
| Src tyrosinekinase | 174 | 1 | 46.0 |
| Thrombin | 162 | 9 | 41.4 |
| Adenosine receptor A3 | 160 | 15 | 73.1 |
| Mu opioid receptor | 157 | 15 | 86.6 |
| Kappa opioid receptor | 155 | 15 | 80.6 |
| Delta opioid receptor | 154 | 15 | 89.0 |
| Cathepsin K | 145 | 7 | 53.1 |
| Serotonin receptor 5HT 1a | 136 | 15 | 81.6 |
| Acetylcholinesterase | 136 | 19 | 53.7 |
| Endothelial growth factorreceptor | 134 | 1 | 76.1 |
| Dopamine receptor D2 | 134 | 15 | 50.7 |
| Adenosine receptor A1 | 129 | 15 | 74.4 |
| Mitogen-activated proteinp38 alpha | 129 | 2 | 64.3 |
| Cathepsin S | 129 | 7 | 55.8 |
| Dipeptidyl peptidase 4 | 119 | 9 | 81.5 |
| Adenosine receptor A2A | 115 | 15 | 80.0 |
| Serotonin transporter | 110 | 15 | 43.6 |
| Matrix metalloproteinase 3 | 108 | 8 | 61.1 |
| Leukocyto-specific tyrosinekinase | 106 | 1 | 69.8 |
| Butyrylcholinesterase | 104 | 19 | 51.9 |
| Carbonic anhydrase II | 101 | 10 | 55.4 |
| Nociceptin receptor 1 | 100 | 15 | 72.0 |
| Histamine H3 receptor | 100 | 15 | 75.0 |
| Protein kinase B Akt1 | 95 | 2 | 75.8 |
| Matrix metalloproteinase 2 | 94 | 8 | 75.5 |
In order to assess scaffold hopping potential in quantitative terms, beyond scaffold numbers, we have also designed a function yielding a “hopping score” that incorporates compound potency information and is calculated over individual scaffold pairs in target sets. For a scaffold pair ij in target set T, all possible compound pairs Cij are enumerated (i.e., compounds in a pair contain scaffold i and j, respectively). For each scaffold pair ij, a “raw” score is calculated as:
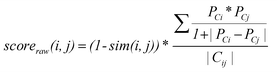
It should be noted that the large-scale analysis of compound data inevitably involves at this stage the risk of comparing IC50 and Ki values, which represents a potential error source. However, for compounds from a series representing an individual scaffold, as used for our raw score calculations, consistent potency measurements are usually reported. In addition, it should also be noted that IC50 values are generally assay-dependent and hence often less reliable than Ki measurement. However, the potency weighting factor emphasizes large potency differences and the score is balanced by multiple pairwise contributions. Furthermore, the raw scores are converted into Z-scores. Taken together, these procedures make the scoring scheme fairly insensitive to limited fluctuations or inaccuracies of potency values.
On the basis of this scoring scheme, scaffold pairs will be prioritized (and obtain scores close to 1) that consist of scaffolds with low similarity yielding comparably potent compounds; identifying such scaffolds is a primary goal of scaffold hopping analysis.9 By contrast, it is a priori not desired to facilitate scaffold transitions from highly potent to only weakly potent molecules. Therefore, not only target annotations, but also compound potency should be taken into consideration when assessing scaffold hopping potential on a large scale. For a target set T, the hopping score is then calculated as the median of all normalized scaffold pair scores:
| score(T) = median{scorenorm(i,j)|i,j ∈ T;i < j} |
This score was calculated for the 70 target sets that were then ranked on the basis of decreasing scores, as reported in Table 3. This ranking differed from the one in Table 2 and highest scores were in this case obtained for carbonic anhydrases. Most of the target sets with significant scaffold hopping potential reported in Table 3 contained fewer than 100 scaffolds. Matrix metalloproteases and various GPCRs were also highly ranked. The rankings in Tables 2 and 3 were also combined on the basis of rank fusion. Table 4 shows the top 30 targets organized by increasing sum of ranks. These targets include many popular GPCRs, kinases, and proteases. Hence, on the basis of currently available compound data, these targets have highest scaffold hopping potential.
| Target Name | #Sc | FamilyID | MedianPot | PotRange | Score |
|---|---|---|---|---|---|
| a The top 30 target sets ranked according to scaffold hopping scores are reported. For each set, the number of scaffolds (#Sc), median compound potency (MedianPot), potency range (PotRange), and hopping score are reported. | |||||
| Carbonic anhydrase II | 101 | 10 | 7.7 | 3.7 | 0.849 |
| Carbonic anhydrase IX | 84 | 10 | 7.4 | 3.8 | 0.839 |
| Carbonic anhydrase I | 67 | 10 | 7.2 | 3.2 | 0.744 |
| Matrix metalloproteinase 8 | 53 | 8 | 8.0 | 4.0 | 0.741 |
| Cannabinoid receptor 1 | 84 | 15 | 7.6 | 3.8 | 0.719 |
| Matrix metalloproteinase 13 | 76 | 8 | 7.9 | 4.8 | 0.705 |
| Neurokinin receptor 1 | 70 | 15 | 8.9 | 4.7 | 0.698 |
| Estrogen receptor alpha | 59 | 18 | 7.4 | 3.6 | 0.693 |
| Histone deacetylase 1 | 65 | 11 | 7.2 | 3.0 | 0.689 |
| Matrix metalloproteinase 2 | 94 | 8 | 7.9 | 4.0 | 0.665 |
| Matrix metalloproteinase 9 | 79 | 8 | 7.7 | 3.6 | 0.663 |
| Cannabinoid receptor 2 | 74 | 15 | 7.4 | 3.9 | 0.660 |
| Estrogen receptor beta | 57 | 18 | 7.7 | 3.8 | 0.659 |
| Matrix metalloproteinase 3 | 108 | 8 | 7.3 | 3.6 | 0.628 |
| Norepinephrine transporter | 51 | 17 | 7.1 | 3.2 | 0.584 |
| Matrix metalloproteinase 6 | 68 | 15 | 7.8 | 3.4 | 0.568 |
| Acetylcholinesterase | 136 | 19 | 7.3 | 5.1 | 0.567 |
| Dopamine transporter | 66 | 17 | 7.1 | 3.4 | 0.550 |
| Cyclin-dependent kinase 1 | 80 | 2 | 6.9 | 4.0 | 0.546 |
| Vascular endothelial growth factor receptor 2 | 302 | 1 | 7.3 | 3.3 | 0.545 |
| Histamine H3 receptor | 100 | 15 | 7.9 | 4.1 | 0.538 |
| Beta-secretase 1 | 89 | 6 | 7.4 | 3.5 | 0.519 |
| Protein kinase B Akt1 | 95 | 2 | 7.5 | 3.8 | 0.517 |
| Alpha-1a adrenergic receptor | 73 | 15 | 8.3 | 4.3 | 0.516 |
| Poly (ADP-ribose) polymerase-1 | 75 | 19 | 7.5 | 3.0 | 0.513 |
| Adenosine receptor A3 | 160 | 15 | 7.6 | 3.9 | 0.501 |
| Matrix metalloproteinase 1 | 90 | 8 | 7.3 | 4.0 | 0.490 |
| Checkpoint kinase | 62 | 2 | 7.7 | 3.9 | 0.486 |
| Cyclin-dependent kinase 2 | 180 | 2 | 7.2 | 3.5 | 0.483 |
| Serotonin transporter | 110 | 15 | 7.9 | 4.4 | 0.477 |
| Target Name | #Sc | FamilyID | MedianPot | PotRange | Score | Rank | ||
|---|---|---|---|---|---|---|---|---|
| Scaffold | Score | Sum | ||||||
| a Target sets are ranked according to the sum of the scaffold number- and scaffold score-based rankings. The top 30 targets are listed. For each set, the number of scaffolds (#Sc), median compound potency (MedianPot), potency range (PotRange), scaffold hopping score, and individual ranks (Scaffold and Score) and sum (SUM) are given. | ||||||||
| Vascular endothelial growth factor receptor 2 | 302 | 1 | 7.3 | 3.3 | 0.545 | 2 | 20 | 22 |
| Carbonic anhydrase II | 101 | 10 | 7.7 | 3.7 | 0.849 | 26 | 1 | 27 |
| Acetylcholinesterase | 136 | 19 | 7.3 | 5.1 | 0.567 | 13 | 17 | 30 |
| Adenosine receptor A3 | 160 | 15 | 7.6 | 3.9 | 0.501 | 8 | 26 | 34 |
| Cyclin-dependent kinase 2 | 180 | 2 | 7.2 | 3.5 | 0.483 | 5 | 29 | 34 |
| Matrix metalloproteinase 3 | 108 | 8 | 7.3 | 3.6 | 0.628 | 23 | 14 | 37 |
| Carbonic anhydrase IX | 84 | 10 | 7.4 | 3.8 | 0.839 | 37 | 2 | 39 |
| Matrix metalloproteinase 2 | 94 | 8 | 7.9 | 4.0 | 0.665 | 30 | 10 | 40 |
| Cannabinoid receptor 1 | 84 | 15 | 7.6 | 3.8 | 0.719 | 37 | 5 | 42 |
| Cathepsin K | 145 | 7 | 7.6 | 5.5 | 0.464 | 12 | 32 | 44 |
| Histamine H3 receptor | 100 | 15 | 7.9 | 4.1 | 0.538 | 27 | 21 | 48 |
| Cathepsin S | 129 | 7 | 7.4 | 3.9 | 0.467 | 17 | 31 | 48 |
| Src tyrosinekinase | 174 | 1 | 7.3 | 3.8 | 0.406 | 6 | 42 | 48 |
| Melanin-concentrating hormone receptor 1 | 318 | 15 | 7.6 | 4.0 | 0.397 | 1 | 48 | 49 |
| Matrix metalloproteinase 13 | 76 | 8 | 7.9 | 4.8 | 0.705 | 44 | 6 | 50 |
| Thrombin | 162 | 9 | 7.1 | 6.0 | 0.404 | 7 | 44 | 51 |
| Protein kinase B Akt1 | 95 | 2 | 7.5 | 3.8 | 0.517 | 29 | 23 | 52 |
| Serotonin transporter | 110 | 15 | 7.9 | 4.4 | 0.477 | 22 | 30 | 52 |
| Mitogen-activated proteinp38 alpha | 129 | 2 | 7.6 | 4.3 | 0.436 | 17 | 36 | 53 |
| Factor Xa | 187 | 9 | 7.9 | 5.3 | 0.395 | 4 | 49 | 53 |
| Matrix metalloproteinase 9 | 79 | 8 | 7.7 | 3.6 | 0.663 | 43 | 11 | 54 |
| Endothelial growth factorreceptor | 134 | 1 | 7.3 | 5.5 | 0.435 | 15 | 39 | 54 |
| Neurokinin receptor 1 | 70 | 15 | 8.9 | 4.7 | 0.698 | 49 | 7 | 56 |
| Carbonic anhydrase I | 67 | 10 | 7.2 | 3.2 | 0.744 | 54 | 3 | 57 |
| Beta-Secretase 1 | 89 | 6 | 7.4 | 3.5 | 0.519 | 35 | 22 | 57 |
| Cannabinoid receptor 2 | 74 | 15 | 7.4 | 3.9 | 0.660 | 46 | 12 | 58 |
| Leukocyto-specific tyrosinekinase | 106 | 1 | 7.9 | 5.0 | 0.436 | 24 | 36 | 60 |
| Cyclin-dependent kinase 1 | 80 | 2 | 6.9 | 4.0 | 0.546 | 42 | 19 | 61 |
| Matrix metalloproteinase 1 | 90 | 8 | 7.3 | 4.0 | 0.490 | 34 | 27 | 61 |
| Dipeptidyl peptidase 4 | 119 | 9 | 7.5 | 4.0 | 0.408 | 20 | 41 | 61 |
Vascular endothelial growth factor receptor-2 is the top-ranked target in Table 4 followed by carbonic anhydrase II. Fig. 3 shows scaffold pairs for these targets that yield high or low hopping scores. The top-scoring scaffold pairs display an astonishing degree of structural diversity, whereas low-scoring pairs are involved in close structural relationships. These observations are representative for many target sets that were found to contain a spectrum of topologically distinct scaffolds, ranging from closely related to virtually unrelated structures.
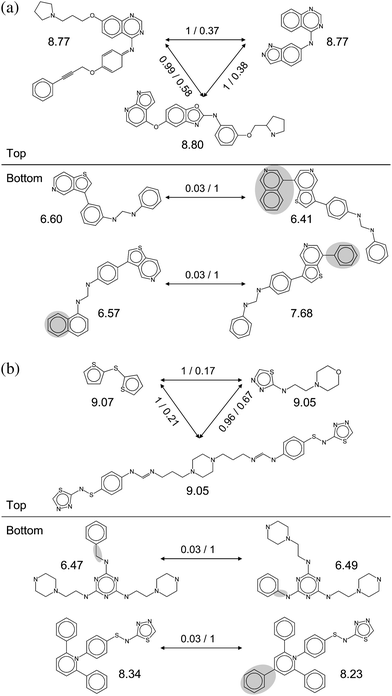 | ||
| Fig. 3 Highly ranked target sets. Scaffold pairs with high (Top) and low (Bottom) hopping scores are shown for two top-ranked target sets; (a) vascular endothelial growth factor receptor 2 ligands and (b) carbonic anhydrase II inhibitors. For each set, three high scoring and two low scoring scaffold pairs are shown. For each scaffold, the median potency of the compounds it represents is reported. For each scaffold pair, the hopping score and MACCS Tanimoto similarity are reported. For example, 1/0.17 means that the scaffold pair has score of 1 and their Tanimoto similarity is 0.17. For low-scoring scaffold pairs, structural differences are highlighted. | ||
Finally, we also determined scaffold overlap between different target sets. The results are reported in Fig. 4 as a scaffold-based target network (drawn with Cytoscape19). Sixty of the 70 target sets shared one or more scaffolds with others. A total of 142 pair-wise target set relationships were detected among the 70 target sets; 106 of these relationships were formed exclusively within target families and 36 across different families. Substantial scaffold overlap between target sets was observed within the GPCR, kinase, and matrix metalloprotease target families. By contrast, inter-target family scaffold overlap was rather limited. These 142 relationships involved 1,298 scaffolds of a total of 5,232 scaffolds contained in the 70 target sets, i.e. ∼25%. Hence, scaffold overlap was generally limited and the majority of scaffolds belonged to individual target sets.
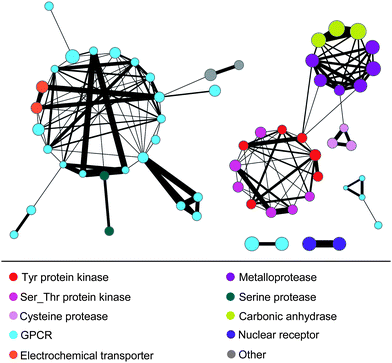 | ||
| Fig. 4 Scaffold-based target network. Scaffold overlaps between target sets are viewed in a network representation. Nodes represent target sets that are connected by an edge if they share one or more scaffolds. The width of edges is scaled by scaffold numbers. Nodes are colored to reflect target family membership and their size is scaled by median scaffold hopping scores. | ||
In summary, in order to better understand how frequently scaffold hops occur in compounds active against different targets, we have systematically derived topologically distinct scaffolds for sets of compounds representing 502 targets belonging to 19 target families. The occurrence of different scaffolds in target sets provides an estimate for the likelihood that scaffold hops can be identified for given targets. In 354 of our target sets, between five and 49 distinct scaffolds were detected, providing a range for average scaffold hopping frequency. In 70 target sets, between 50 and 318 different scaffolds were found. A subset of these scaffolds was structurally highly diverse but yielded similarly potent compounds, thus meeting “ideal” scaffold hopping criteria. However, many other scaffolds (on average ∼60% of all scaffolds in a target set) displayed well-defined substructure relationships. Thus, in these cases, it is not surprising that similarity-based virtual screening methods often display scaffold hopping potential (although scaffold hopping ability is usually considered the ultimate “proof” that a computational screening method is useful). By contrast, identifying scaffolds that are truly distinct is much more difficult, given the observed distributions of structurally related and unrelated scaffolds. However, on the basis of our analysis, we conclude that there is considerable scaffold hopping potential across the spectrum of currently available targets. Thus, searching for structurally diverse active compounds should be promising in many cases.
References
- J. Brown and E. Jacoby, Mini-Rev. Med. Chem., 2006, 6, 1217–1229 CrossRef.
- H. Zhao, Drug Discovery Today, 2007, 12, 149–155 CrossRef CAS.
- S. Renner and G. Schneider, ChemMedChem, 2006, 1, 181–185 CrossRef CAS.
- E. J. Barker, D. Buttar, D. A. Cosgrove, E. J. Gardiner, V. J. Gillet, P. Kitts and P. Willett, J. Chem. Inf. Model., 2006, 46, 503–511 CrossRef CAS.
- K. Tsunoyama, A. Amini, M. J. E. Sternberg and S. H. Muggleton, J. Chem. Inf. Model., 2008, 48, 949–957 CrossRef CAS.
- N. Wale, I. A. Watson and G. Karypis, J. Chem. Inf. Model., 2008, 48, 730–741 CrossRef CAS.
- S. Senger, J. Chem. Inf. Model., 2009, 49, 1514–1524 CrossRef CAS.
- M. Vogt, D. Stumpfe, H. Geppert and J. Bajorath, J. Med. Chem., 2010, 53, 5707–5715 CrossRef CAS.
- H. Geppert, M. Vogt and J. Bajorath, J. Chem. Inf. Model., 2010, 50, 205–216 CrossRef CAS.
- MOE (Molecular Operating Environment); Chemical Computing Group Inc.: Montreal, Quebec, Canada, 2007 Search PubMed.
- Scitegic Pipeline Pilot, Student Edition, Version 6.1; Accelrys, Inc.: San Diego, CA, 2007 Search PubMed.
- CHEMBLdb. http://www.ebi.ac.uk/chembl/(accessed May 11, 2010).
- T. Liu, Y. Lin, X. Wen, R. N. Jorissen and M. K. Gilson, Nucleic Acids Res., 2007, 35, D198–D201 CrossRef CAS.
- G. W. Bemis and M. A. Murcko, J. Med. Chem., 1996, 39, 2887–2893 CrossRef CAS.
- Y. Hu, A. M. Wassermann, E. Lounkine and J. Bajorath, J. Med. Chem., 2010, 53, 752–758 CrossRef CAS.
- Y. Hu and J. Bajorath, ChemMedChem, 2010, 5, 1681–1685 CrossRef.
- P. Willett, J. M. Barnard and G. M. Downs, J. Chem. Inf. Comput. Sci., 1998, 38, 983–996 CrossRef CAS.
- MACCS Structural Keys; Symyx Software: San Ramon, CA, 2005 Search PubMed.
- P. Shannon, A. Markiel, O. Ozier, N. S. Baliga, J. T. Wang, D. Ramage, N. Amin, B. Schwikowski and T. Ideker, Genome Res., 2003, 13, 2498–2504 CrossRef CAS.
| This journal is © The Royal Society of Chemistry 2010 |