Characterization of Galician (N.W. Spain) quality brand potatoes: a comparison study of several pattern recognition techniques
P. M. Padína, R. M. Peñaa, S. Garcíaa, R. Iglesiasb, S. Barrob and C. Herrero*a
aDepartamento Química Analítica, Nutrición y Bromatología, Facultad de Ciencias, Universidad de Santiago de Compostela, Augas Férreas s/n, Campus Universitario, 27002, Lugo, Spain.. E-mail: cherrero@lugo.usc.es.
bDepartamento Electrónica y Computación, Grupo de Sistemas Inteligentes, Facultad de Física, Universidad de Santiago de Compostela, Campus Universitario, 15706, Santiago de Compostela, Spain
First published on 1st December 2000
Abstract
Authenticity is an important food quality criterion and rapid methods to guarantee it are widely demanded by food producers, processors, consumers and regulatory bodies. The objective of this work was to develop a classification system in order to confirm the authenticity of Galician potatoes with a Certified Brand of Origin and Quality (CBOQ) ‘Denominación Específica: Patata de Galicia’ and to differentiate them from other potatoes that did not have this CBOQ. Ten selected metals were determined by atomic spectroscopy in 102 potato samples which were divided into two categories: CBOQ and non-CBOQ potatoes. Multivariate chemometric techniques, such as cluster analysis and principal component analysis, were applied to perform a preliminary study of the data structure. Four supervised pattern recognition procedures [including linear discriminant analysis (LDA), K-nearest neighbours (KNN), soft independent modelling of class analogy (SIMCA) and multilayer feed-forward neural networks (MLF-ANN)] were used to classify samples into the two categories considered on the basis of the chemical data. Results for LDA, KNN and MLF-ANN are acceptable for the non-CBOQ class, whereas SIMCA showed better recognition and prediction abilities for the CBOQ class. A more sophisticated neural network approach performed by the combination of the self-organizing with adaptive neigbourhood network (SOAN) and MLF network was employed to optimize the classification. Using this combined method, excellent performance in terms of classification and prediction abilities was obtained for the two categories with a success rate ranging from 98 to 100%. The metal profiles provided sufficient information to enable classification rules to be developed for identifying potatoes according to their origin brand based on SOAN–MLF neural networks.
1. Introduction
Research on the determination of the geographic origin or quality brand of food products is a very active area for the application of chemometric classification procedures.1 The subject of food authenticity has great economic importance for the sectors involved in food production, processing and packaging and also for the consumer since authenticity helps to guarantee the characteristics and quality of food products and to prevent overpayment. Chemical analysis coupled with different pattern recognition procedures has been applied to diverse food products to establish criteria for quality, genuineness and geographical origin; recent examples include wines,2–7 cocoa,8,9 coffee,10,11 vegetable and olive oil,12,13 vinegar14–16 and honey.17,18 In most of these cases the chemical variables used to perform the classification were organic molecules such as aroma compounds, phenols, vitamins, amino acids and terpenic compounds. In other studies, determination of metallic composition was performed; the relationships between their concentrations can be a useful tool in differentiating food products and commodities (such as potatoes) produced in a delimited region and subjected to certain quality requirements on the basis of chemometric pattern recognition procedures.19–21 The metal composition of food products, and particularly potato samples, is influenced by many factors: the production area, varieties, soil and climate, agricultural practices, storage, bottling and commercialization conditions. The mineral and trace metal composition of fresh commodities is a primary candidate for a ‘fingerprint’ because it reflects the mineral composition of the soil and the environment in which the plants grow. Moreover, it is stable and not influenced by storage conditions that might affect the analytical classification technique.Galicia is a region in N.W. Spain well known for its quality food products including wine, alcoholic distillates, meat, cheese, honey and potatoes. According to European Union legislation, for each of these products the local governments have established the criteria for quality, food labelling and geographical origin that must be complied with in order to receive the Certified Brand of Origin and Quality (CBOQ) ‘Denominación Específica’.22 For the case at hand, Galician legislation indicates that to receive a CBOQ brand ‘Denominación Específica: Patata de Galicia’, potatoes must be of the only variety authorized by the CBOQ Council (Kennebec); furthermore, the potatoes must be cultivated in a controlled geographical area following the agricultural practices indicated by the CBOQ regulations including fertilization, irrigation procedures and harvesting time. Finally, the product is subjected to a few rules to check the required chemical characteristics. In order to ensure quality, the CBOQ regulations also specify the packaging and storage conditions.
The objective of this work was to develop and compare several supervised pattern recognition approaches that would confirm the authenticity of Galician-CBOQ labelled potatoes and also differentiate them from potatoes not subjected to CBOQ quality requirements and from potatoes cultivated in other geographical areas. The classification systems are based on the concentrations of 10 elements measured in fresh potatoes by atomic spectroscopy. The interest in this classification is based on the fact that non-CBOQ potatoes, owing to their lower price and quality, can be improperly marketed as genuine CBOQ potatoes. Therefore, the classification of a sample as being a genuine quality brand or not is a sure way to detect fraud. It has special economic importance in potato producing sectors because it both preserves the quality name of their product and protects the consumer from overpayment and deception.
2. Experimental
2.1. Potato samples
The number of samples analysed was 102. One of the most important criteria in authenticity studies is that there should not be any doubt as to geographic origin, quality type and varieties of the samples. To be sure about this aspect, the potato samples for this work were collected as follows: 45 representative samples from Galicia with guaranteed origin and indication CBOQ (coded as D) were provided by the Certification Council of the CBOQ ‘Denominación Específica: Patata de Galicia’. In this set, a significant number of samples from the three production sub-areas for this CBOQ, A Limia, Vilalba and Bergantiños, were included. Also, 57 potato samples without the CBOQ brand were obtained from different suppliers: (i) 42 of them (coded as W) corresponded to Galician potatoes and (ii) the other 15, coded as X, were samples coming from other Spanish geographic areas outside Galicia. All samples, harvested during September–October 1999, corresponded to the same variety Kennebec, the only one authorized by the CBOQ ‘Denominación Específica: Patata de Galicia’, and all of them came from unsuspicious origins. For differentiation purposes, Galician samples with a CBOQ were considered class 1 and foreign samples and Galician samples without the CBOQ class 2.For each potato sample, five tubers were rinsed with water to remove dirt and dried. From the skinned tubers, cross-section slices were cut, minced and freeze-dried using a Labconco Freeze Dry System (Labconco, Kansas City, MO, USA). Aliquots of 2 g of the lyophilized sample were ashed at 550 ± 25 °C to constant weight according to the AOAC protocol.23 The working sample solution for mineral analysis was obtained by dissolving the ash in 10 mL of 0.6 M hydrochloric acid and subsequent dilution to 25 mL with ultra-pure water provided by a Milli-Q water purification system (Millipore, Bedford, MA, USA).
2.2. Analytical determinations
Samples were analysed to determine K, Na, Rb, Li, Zn, Fe, Mn, Cu, Mg and Ca using an AA10-Plus spectrometer (Varian, Palo Alto, CA, USA). Na, K, Li and Rb were determined by flame atomic emission spectrometry (FAES) and the other elements by flame atomic absorption spectrometry (FAAS). The analytical procedures have been published elsewhere.192.3. Data analysis and chemometric procedures
A starting 102 × 10 data matrix (X) with rows representing the different potato samples (objects) analysed and columns corresponding to the 10 mineral elements was constructed. Each potato sample was represented by a data vector which is an assembly of the 10 variables (features). Data vectors belonging to the same class or category (CBOQ group and non-CBOQ group) were analysed. The multivariate procedures used in this work were as follows.Pattern recognition analysis was performed by means of the statistical software packages Statgraphics,31 Parvus32 and Pirouette.33 The neural networks computation was done using a program written in MatLab code.34
3. Results and discussion
The results for the 10 elements determined in the potato samples are summarised in Table 1 according to the established categories of CBOQ and non-CBOQ potatoes. The levels obtained in the samples analysed are in the range of those reported by other workers for potatoes from various origins such as Poland,35 Canada and the USA21 and Spain.36 However, it is not possible to compare the levels obtained for Li and Rb owing to the lack of published data for potatoes other than those analysed in the present work. Differences in the mean values for the CBOQ and non-CBOQ categories were detected for Fe, Na and Li.| CBOQ samples | Non-CBOQ samples | |||
|---|---|---|---|---|
| Element | Mean | s | Mean | s |
| K | 378 | 84 | 475 | 64 |
| Na | 15.0 | 9.4 | 4.6 | 2.5 |
| Rb | 0.25 | 0.12 | 0.25 | 0.16 |
| Li | 0.30 | 0.18 | 0.11 | 0.06 |
| Zn | 0.40 | 0.15 | 0.41 | 0.13 |
| Fe | 1.03 | 0.40 | 0.60 | 0.09 |
| Mn | 0.13 | 0.04 | 0.14 | 0.05 |
| Cu | 0.16 | 0.04 | 0.12 | 0.03 |
| Mg | 27.0 | 5.5 | 21.7 | 8.2 |
| Ca | 7.7 | 2.0 | 9.3 | 2.2 |
3.1. Cluster analysis
As indicated in Section 2.3, cluster analysis is a well known technique of data analysis, commonly applied before other multivariate procedures owing to its unsupervised character, that reveals the natural clusters existing in a data set on the basis of the information provided for the measured variables. The results obtained in the case at hand, using the distance and agglomerative procedure indicated in Section 2.3, are presented as a dendrogram in Fig. 1. At a similarity level of 0.5 four clusters that can be identified as follows were found: from the left, the first cluster (cluster A) is composed of 28 CBOQ samples. The second cluster (B) is a group made up of the 15 non-CBOQ samples of non-Galician origin plus two Galician samples with CBOQ. The third cluster (C) includes 26 non-CBOQ and three CBOQ samples. The last cluster (D) is formed by 16 Galician non-CBOQ and 12 CBOQ samples. Cluster A included only samples of class 1 (CBOQ potatoes); clusters B (non-CBOQ foreign samples) and C (non-CBOQ samples from Galicia) can be related to class 2. Cluster D, formed of samples belonging to class 1 plus class 2, indicated a certain overlap between the two categories considered in the 10-dimensional space defined by the variables. However, the presence of clusters mainly composed by each potato type showed that the elemental composition data may contain adequate information to obtain a sample differentiation according to the established classes.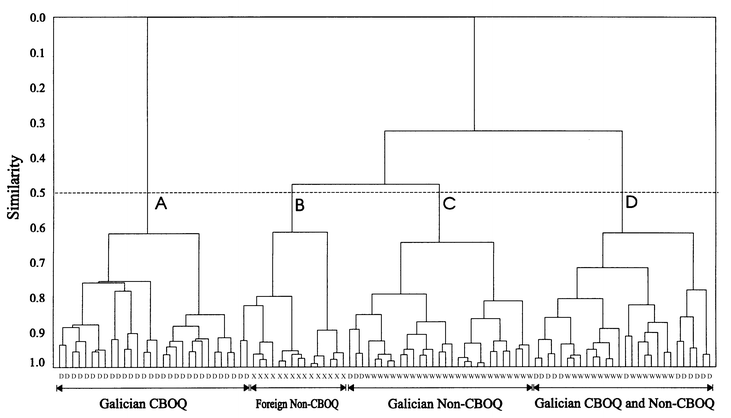 | ||
| Fig. 1 Dendrogram of cluster analysis. Sample codes: D, Galician CBOQ; W, Galician non-CBOQ; X, non-Galician non-CBOQ. | ||
3.2. Principal component analysis
PCA was performed on the autoscaled data using the Statgraphics software package in order to provide partial visualization of the data set in a reduced dimension. From the loadings of the variables (see Table 2), Na, Fe and K are the dominant features in the first principal component, accounting for 35.15% of the total variability, and Mg, Zn, Rb and Li dominate in the second principal component, representing 22.37% of the total variance. The first principal component or eigenvector can be related with the agricultural component; CBOQ potatoes are obtained according to the CBOQ Council regulations concerning agricultural and irrigation practices, fertilisation, and harvesting time. The main contribution to the first eigenvector of K, Na and Fe can be explained by the different fertilisation methods employed by CBOQ producers; because of this, the first eigenvector is important in distinguishing D and W samples. The second and third eigenvectors are related to the different soil characteristics (high loadings for Rb, Li and Mg in CP2 and for Mn and Ca in CP3); this justifies the contribution of these two factors to separate Galician (W and D) from foreign samples (X) which were grown in a different soil type. In Fig. 2, when the scores of each potato sample are examined in a three-dimensional plot of the first three principal components (68.05% of total variability), interesting results were afforded. A natural separation between CBOQ and non-CBOQ samples was found. In this factor space, two main groups that can be associated with the two-category arrangement indicated in Section 2.1 were identified. The first of them, in the negative part of principal component 1, is mainly composed by CBOQ potatoes from class 1 (coded D), whereas the second group of class 2, in the positive part of principal component 1, is mainly made up of non-CBOQ samples (coded W and X) plus certain D samples. This last group is less homogeneous because the samples without ‘Denominación Específica’ of non-Galician origin (coded X) are included in it as a clear subgroup. The adequate agreement of these results with those obtained by cluster analysis confirms the conclusion that metal data provide enough information to develop a classification system that can authenticate CBOQ samples. However, the presence of D potatoes in the non-CBOQ group also indicates a certain overlap of the two categories in the multidimensional space. Therefore, certain supervised chemometric classification procedures (LDA, KNN, MLF-ANN, SIMCA and SOAN–MLF-ANN) were compared on the basis of their capability for distinguishing samples according to their class.| Variable | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Principal component | K | Na | Rb | Li | Zn | Fe | Mn | Cu | Mg | Ca |
| 1 | 0.396 | −0.490 | 0.249 | −0.216 | 0.299 | −0.455 | 0.207 | −0.313 | 0.023 | 0.253 |
| 2 | −0.026 | 0.103 | 0.414 | 0.376 | 0.422 | 0.138 | 0.277 | 0.315 | 0.548 | 0.011 |
| 3 | −0.120 | 0.060 | −0.332 | 0.059 | −0.361 | −0.141 | −0.453 | 0.158 | 0.173 | 0.675 |
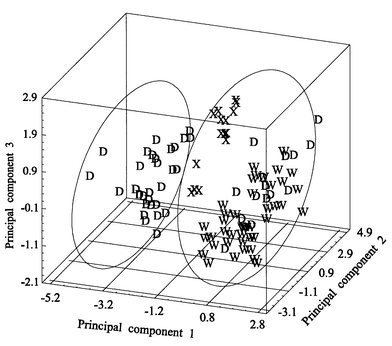 | ||
| Fig. 2 Eigenvector projection of potato samples. Sample codes: D, Galician CBOQ; W, Galician non-CBOQ; X, non-Galician non-CBOQ. | ||
3.3. Supervised pattern recognition methods
As indicated above, several different supervised pattern recognition methods have been applied, after autoscaling, to the initial data matrix X102 × 10 in order to characterise the potato samples into either class 1 or 2. To validate the derived classification rules and their stability for prediction, the complete data set was divided into a training (or learning) set and a test (or evaluation) set. Samples were assigned randomly to a training set consisting of 75% of them and the test set was composed of the remaining 25% samples. Such a division allows for a sufficient number of samples in the training set and a representative number of members among the test set. In order to perform a cross-validation procedure, the same process was repeated four times with different constitutions of both sets, to ensure that all samples were included in the evaluation set at least once. The different pattern recognition techniques were applied to the four training-test sets obtained. The reliability of the classification models achieved was studied in terms of recognition and prediction abilities. The recognition ability is characterized by the percentage of the members of the training set correctly classified and the prediction ability by the percentage of the test set members adequately classified by using the rules developed in the training step. Prior to the application of the classification methods, it is important to indicate the differences in their characteristics and in the way in which each of them define the classification rules. The principal distinction to be made is between methods focusing on discrimination (such as LDA, KNN and MLF-ANN) and those that are directed towards modelling classes (such as SIMCA). LDA is a parametric method which searches for optimal boundaries between classes while it assumes that all the classes have the same multinormal distribution and that they are linearly separable. KNN is a non-parametric method which is very simple from a mathematical point of view and free from statistical assumptions; however, it is very sensitive to gross inequalities in the number of objects in each class. MLF-ANN does not impose any condition on the data structure, but the information provided concerning the different categories is poor. SIMCA is based on the principal components for each category and critical distances with probabilistic signification; hence this implies that a spatial and probabilistic structure is present in the data.When LDA was applied to the data sets described above, the discriminant function derived (with high coefficients for K and Li, related to different fertilisation and soil, respectively) produced good percentages of correct recognition and prediction (Table 3). The values attained were in the 81–84% range for class 1, and a high level of correct classification, with success in recognition and prediction between 96 and 99%, was achieved for class 2. KNN was also applied to the same data sets using the square inverse of the Euclidean distance. The number of neighbours was selected after the study of the success in classification with K values between 1 and 10. It can be concluded that the same result was achieved using K = 1, 2 or 3. Values of K >5 produce less successful results. Therefore, K = 3 was selected for the application of KNN. Under these conditions, the percentages of correct recognition and prediction abilities for KNN were as summarized in Table 3. According to these data, similar results to those for LDA were obtained, the only difference being that KNN provided a slightly better level of hits for class 1. With the two methods considered, the probability of a non-CBOQ being classified as CBOQ is very low. However, the low level of hits using these two procedures in class 1 suggests that there exists a certain probability of a genuine CBOQ sample being classified as non-CBOQ. This result is consistent with the sample distribution in the multidimensional space visualized by PCA and cluster analysis, where certain genuine CBOQ potatoes of class 1 were included in the class 2 group.
| Procedure | Class | Recognition ability (%) | Prediction ability (%) |
|---|---|---|---|
| LDA | 1 | 84.1 | 81.7 |
| 2 | 98.8 | 96.4 | |
| KNN (K = 3); inverse squared Euclidean distance | 1 | 90.5 | 90.9 |
| 2 | 98.1 | 97.1 | |
| MLF−ANN (10 × 5 × 1); η = 0.2; μ = 0.5; sigmoid transfer function | 1 | 100 | 91.7 |
| 2 | 100 | 99.0 | |
| SIMCA; normal range; 3 components; α = 0.05 | 1 | 96.3 | 93.2 |
| 2 | 82.0 | 80.3 | |
| SOAN–MLF-ANN (see details in the text). | 1 | 100 | 98.3 |
| 2 | 100 | 98.0 |
Artificial neural networks have been used in chemometrics for classification purposes. In the case at hand, an MLF neural network was employed for predicting the category on the basis of an input consisting of the autoscaled chemical variables. Some empirical preliminary trials were performed to determine an adequate MLF structure. As can be seen in Table 4, the best result was obtained by applying a 10–5–1 network. Thus, the neural architecture used to model the proposed problem was an MLF with three layers: an input layer with 10 neurons, one hidden layer with five neurons, and an output layer consisting of a neuron with binary output. The target output was written as 1 for class 1 (CBOQ) and 0 for class 2 (non-CBOQ). A sigmoidal function f(x) = 1/[1 + exp(−x)] was employed as a transfer function. The neural network was trained by means of an algorithm that combines the use of an adaptative learning rate parameter ALRP (η) and a momentum (μ). The ALRP is automatically corrected according to the training progress; if the rms error decreases, the value of ALRP is increased, and vice versa. The momentum permitted a network response to be based on the local gradient and on the recent trends in error surface. Maximum epochs selected were 2000; the initial values of ALRP (η) and μ were 0.2 and 0.5, respectively, and the target error was 0.1. Initial weights were taken randomly between −3 and 3. To test the stability of the model built for prediction, a cross-validation in four steps was performed following the same procedure as indicated above. The classification results using MLF-ANN (see Table 3) indicated that the MLF network showed highly satisfactory results with a complete recalling performance in the two groups; the prediction ability for class 2 was also satisfactory. However, the classification rule obtained produced some misprediction for class 1 (9%); hence certain genuine CBOQ samples could be considered as false. These results are better than but similar to those provided by the other two discriminant techniques, LDA and KNN. In this case, the probability of a non-CBOQ being classified as CBOQ is zero in practice; however, the level of hits achieved for prediction in class 1 indicated some probability of a genuine CBOQ sample being classified as non-CBOQ. These results are comparable to those obtained by Anderson et al.,21 who also use MLF-ANN in the differentiation of North American potatoes of Idaho and non-Idaho origins on the basis of the elemental profile with a prediction error rate in the 3.5–9.3% range according to the different test sets employed.
| MLF network architecture | Prediction ability (%) | Rms error |
|---|---|---|
| 10, 3, 1 | 91.3 | 0.06 |
| 10, 5, 1 | 92.1 | 0.03 |
| 10, 7, 1 | 88.5 | 0.10 |
| 10, 5, 2 | 88.5 | 0.13 |
SIMCA afforded models based on three components for each category, normal range and 5% as the significance level for critical distance. Fig. 3 shows a Coomans plot for the squared SIMCA distances obtained in the complete data set; the main part of the samples from class 1 presented large distances from the model of non-CBOQ class. However, samples belonging to class 2 have shorter distances from the CBOQ class model and an important number of samples (24%) are also accepted by the CBOQ model. To study the predictive capability of SIMCA, the same cross-validation procedure was applied in four steps. The previous results were confirmed: better results were obtained for class 1 with recognition and prediction abilities higher than 93%; however, only an 80% hit level was reached for class 2 (Table 3). The classification rules developed by SIMCA are adequate for the CBOQ class; in practice, a very high percentage of CBOQ samples are assigned to their category. However, there exists a 0.2 probability of accepting a false CBOQ sample as genuine. The different results achieved by SIMCA with respect to those provided by the three previously used techniques can be explained by taking into account the fact that SIMCA is a disjoint class modelling technique; therefore, more emphasis was placed on similarity within a class than on discrimination between classes.
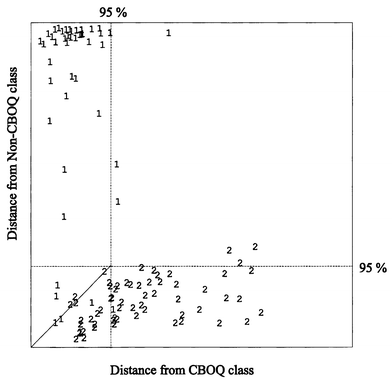 | ||
| Fig. 3 Coomans plot for the squared SIMCA distances. Codes: 1, class 1 (CBOQ samples); 2, class 2 (non-CBOQ samples). | ||
At this point, considering that the results provided for the neural network are the most promising, a more sophisticated approach based on a neural network combination was employed to try to optimise the classification. The use of MLF-ANN with a back-propagation learning rule might be adequate to solve the proposed classification problem. Nevertheless, the determination of suitable architecture for an MLF-ANN to solve the classification in the best manner is laborious and, after considerable work, the network obtained might be less successful than expected, particularly if the distribution of the samples in the multidimensional input space follows a complex structure and has input data clusters which contain samples of different classes, as in the case at hand (Fig. 1 and 2). A way to simplify the problem is to solve it at a more local level, particularly in each of the resulting regions obtained once the input space is partitioned. The partition of the input space for a given pattern distribution can be performed by different approaches. An interesting choice consists in using neural networks based on the vector quantization principle (self-organizing maps,37 neural gas38); in this case, owing to their special network characteristics (as indicated in Section 2.3), SOAN was employed. Particularly useful for the present problem is the capability of SOAN to establish (in the network training) neural clusters that clearly represent one or more pattern clusters in the input space. Each of the established neural clusters is associated with the space region formed by the input space points for which the best neuronal representation is one of the neurons of the neural cluster being considered. The inputspace partition obtained tends to group patterns belonging to the same class (CBOQ or non-CBOQ) around the same neural cluster.
The integration of SOAN in a complete process intended to design a suitable classifier for the present problem was carried out as follows. The SOAN network is trained by using a training set formed of independent potato samples. After the learning phase, the input space is partitioned into regions on the basis of the final position of the neurons and the different neural clusters obtained. The final step consists in learning how to classify the data included in each of these regions; this objective was achieved, once again, using the training set samples. Thus, as can be seen in Fig. 4, for a given pattern x (a potato sample), SOAN is able to get its projection over the network and to determine the space region R(x) to which x belongs. If R(x) only contains training set samples belonging to one of the two classes discriminated (CBOQ or non-CBOQ), the input pattern will be directly classified as a member of this class. For the other regions (in which training set samples belonging to both classes appear), an MLF network has been associated with each of them. Using the training set samples contained in these regions, the associated MLF network is trained to classify any input space pattern included in these regions.
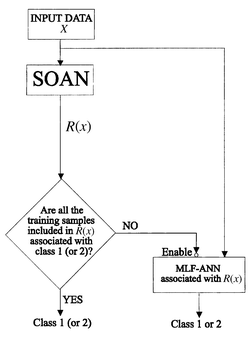 | ||
| Fig. 4 Combination of SOAN and MLF neural networks. | ||
Following this approach, and in order to classify potato samples, the SOAN network employed was composed of 30 neurons. The MLF networks associated with the regions R(x) provided by SOAN have different suitable structures according to the considered region. In all cases the input and the output layers were composed of 10 (dimension of the input space) and one neurons, respectively. The learning parameter was η = 0.1 (ratio to increase learning rate = 1.05; ratio to decrease = 0.7), μ = 0.95, target error = 0.1 and sigmoidal transfer functions were used in all cases.
The results obtained by the combination of these two types of neural networks, (after a cross-validation procedure carried out four times with 25% of samples as the test set) are excellent (Table 3). In addition, the number of regions in which SOAN divides the input space and the training set sample classes included in each of them provided information that reconfirms what was previously obtained by PCA and cluster analysis. In fact, it can also be indicated that the majority of the non-CBOQ samples of non-Galician origin (objects coded as X) are always associated with a separated neural cluster assigned to class 2; this result is also consistent with that provided by cluster analysis in which X samples formed an individual cluster (marked B in the dendrogram presented in Fig. 1) with a 0.47 similarity with the cluster composed of Galician non-CBOQ potatoes (marked C in the dendrogram). As can be seen in Table 3, the recognition ability for the two classes is complete; moreover, the prediction abilities were always higher than 98%. The appropriate agreement between recognition and prediction abilities means that the decision rule derived is not dependent on the actual objects in the training set: the solution achieved is stable. The output values obtained for the four test sets employed to study the prediction capability and the stability of the method are presented as a box and whisker plot in Fig. 5. Non-overlapped outputs were obtained for each category; one member of each class was misclassified. The combination of SOAN and MLF performs a classification method that has been demonstrated to be very suitable for the typification of Galician CBOQ potatoes.
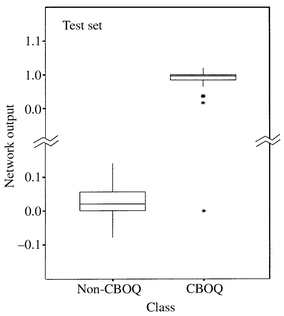 | ||
| Fig. 5 Box and whisker plot for SOAN–MLF output values in test sets. | ||
4. Conclusion
This study has demonstrated that the pattern recognition approach using diverse chemometric procedures is adequate to develop classification rules for the authentication of Galician potatoes with certified Brand of Origin and Quality based on their elemental profile determined by atomic spectroscopy. The classical pattern recognition methods LDA, KNN and SIMCA were complementary; in two cases, the classification rules developed by LDA and KNN permitted the detection of false CBOQ; however, there is a risk of genuine CBOQ samples being considered as false. In contrast, SIMCA achieved a model in which all samples with CBOQ are correctly classified in practice, but there exists a certain probability of non-CBOQ samples being considered as genuine Galician CBOQ. The classification performed by means of an MLF neural network provided better results than the three methods indicated above. The combination of two neural networks (SOAN and MLF) permitted the decomposition of the global problem into certain local subproblems, thanks to the partition of the input space in regions that are related to the distribution of the samples in clusters. Thus, in this case, the performance was better than when using the MLF neural network only, achieving an authentication system that permitted the classification of each sample as being a genuine quality brand or not. Hence this is a method to detect fraud, to preserve the quality name of the CBOQ product and to protect the consumer from overpayment and deception using chemical data information processed by multivariate chemometric techniques.Acknowledgements
The authors express their gratitude to the Certification of Origin Council ‘Denominación Específica: Patata de Galicia’ for providing potato samples. This work was financed in part by the Union European, Project UE-FEDER/DGSIC, Reference 1FD97-0154.References
- P. R. Ashurst and M. J. Dennis, Food Authentication, Chapman and Hall, London, 1996. Search PubMed.
- J. M. Nogueira and A. M. Nascimento, J. Agric. Food Chem., 1999, 47, 566 CrossRef CAS.
- M. Forina and G. Grava, Analusis, 1997, 25, M-38 Search PubMed.
- J. Weber, M. Beeg, C. Bartzsch, K. H. Feller, D. García, M. Reichenbaecher and M. Danzer, J. High Resolut. Chromatogr., 1999, 22, 322 CrossRef CAS.
- M. J. Baxter, H. M. Crews, M. J. Dennis, I. Goodall and D. Anderson, Food Chem., 1997, 60, 443 CrossRef CAS.
- L. Rosillo, M. R. Salinas, J. Garijo and G. L. Alonso, J. Chromatogr., A, 1999, 847, 155 CrossRef CAS.
- S. Rebolo, R. M. Peña, M. J. Latorre, S. García, A. M. Botana and C. Herrero, Anal. Chim. Acta, 2000, 417, 211 CrossRef CAS.
- C. V. Hernández and D. N. Rutledge, Analyst, 1994, 119, 1171 RSC.
- E. Anklam, M. R. Bassani, T. Eiberger, S. Kriebel, M. Lipp and R. Matissek, Fresenius’ J. Anal. Chem., 1997, 357, 981 CrossRef CAS.
- S. J. Haswell and A. D. Walmsley, J. Anal. At. Spectrom., 1998, 13, 131 RSC.
- F. Carrera, M. León-Camacho, F. Pablos and A. G. González, Anal. Chim. Acta, 1998, 370, 131 CrossRef CAS.
- L. Webster, P. Simpson, A. M. Shanks and C. F. Moffat, Analyst, 2000, 125, 97 RSC.
- D. Lee, B. Noh, S. Bae and K. Kim, Anal. Chim. Acta, 1998, 358, 163 CrossRef CAS.
- M. I. Guerrero, C. Herce, A. M. Cameán, A. M. Troncoso and A. Gustavo, Talanta, 1997, 45, 379 CrossRef CAS.
- M. J. Benito, M. C. Ortíz, M. S. Sánchez, L. A. Sarabia and M. Iñiguez, Analyst, 1999, 124, 547 RSC.
- A. Signore, B. Campisi and F. Giacomo, J. AOAC Int., 1998, 81, 1087 Search PubMed.
- M. Feller, B. Vincent and F. Beaulieau, Apidology, 1989, 20, 77 Search PubMed.
- M. J. Latorre, R. Peña, S. García and C. Herrero, Analyst, 2000, 125, 307 RSC.
- R. Peña, M. J. Latorre, S. García, A. Botana and C. Herrero, J. Sci. Food Agric., 1999, 79, 2052 CrossRef CAS.
- M. J. Latorre, R. Peña, C. Pita, S. García, A. Botana and C. Herrero, Food Chem., 1999, 66, 263 CrossRef CAS.
- K. A. Anderson, B. A. Magnuson, M. L. Tschirgi and B. Smith, J. Agric. Food Chem., 1999, 47, 1568 CrossRef CAS.
- Orden de 19 de Septiembre de 1996 de la Consellería de Agricultura Pesca y Alimentación de ‘Reconocimiento de la Denominación Específica Patata de Galicia’, Diario Oficial de Galicia, October 7, 1996..
- AOAC, Official Methods of Analysis of the AOAC, AOAC International, Arlington, VA, 16th edn., 1995..
- I. T. Joliffe, Principal Component Analysis, Springer, New York, 1986. Search PubMed.
- M. Meloun, M. Militky and M. Forina, Chemometrics for Analytical Chemistry, Ellis Horwood, Chichester, 1992, vol. I, pp. 244–269. Search PubMed.
- R. G. Brereton, Chemometrics, Applications of Mathematics and Statistics to Laboratory Systems, Ellis Horwood, Chichester, 1990, pp. 263–269. Search PubMed.
- B. G. Vandeginste, L. Massart, L. M. Buydens, S. De Jong, P. J. Lewi and J. Smeyers-Verbeke, Handbook of Chemometrics and Qualimetrics: Part B.Elsevier, Amsterdam, 1998, ch. 33. Search PubMed.
- S. Wold, C. Albano, W. J. Dunn, U. Edlund, K. Esbensen, P. Geladi, S. Hellberg, E. Johansson, W. Lindberg and M. Sjöström, in Chemometrics, Mathematics and Statistics in Chemistry, ed. B. R. Kowalski, Reidel, Dordrecht, 1984, pp. 17–96. Search PubMed.
- J. Zupan and J. Gasteiger, Neural Networks for Chemists, VCH, New York, 1993, pp. 119–148. Search PubMed.
- R. Iglesias and S. Barro, in Foundations and Tools for Neural Modelling, ed. J. Mira and J. V. Sánchez, Springer, New York, 1999, pp. 591–600. Search PubMed.
- Statgraphics, Version 5.0, Statistical Graphics, Rockville, MD, 1991..
- M. Forina, R. Leardi, C. Armanino and S. Lanteri, Parvus: an Extendable Package of Programs for Data Exploration, Classification and Correlation, Elsevier, Amsterdam, 1988. Search PubMed.
- Pirouette: Multivariate Data Analysis, Version 2.51, Infometrix, Woodinville, WA, 1998..
- MATLAB, Version 5.2, MathWorks, Natick, MA, 1998..
- E. Cieslik and E. Sikora, Food Chem., 1998, 63, 525 CrossRef CAS.
- F. J. Mataix, M. Mañas, J. Llopis and E. Martínez, Tablas de Composición de Alimentos Españoles, Instituto de Nutrición y Tecnología de Alimentos, University of Granada, Granada, 1998, p. 132. Search PubMed.
- T. Kohonen, Neural Networks, 1988, 1, 3 CrossRef.
- T. M. Martinetz, S. G. Berkovich and K. J. Schulten, IEEE Trans. Neural Networks, 1993, 4, 558 CrossRef.
| This journal is © The Royal Society of Chemistry 2001 |