Artificial intelligence-based classification of breast cancer using cellular images
Rajesh Kumar Tripathy,
Sailendra Mahanta and
Subhankar Paul*
Structural Biology and Nanomedicine Laboratory, Department of Biotechnology and Medical Engineering, National Institute of Technology Rourkela, Rourkela-769008, Odisha, India. E-mail: spaul@nitrkl.ac.in; Fax: +91-0661-2462022; Tel: +91-0661-2462284 Tel: +91-0661-2463284
First published on 21st January 2014
Abstract
Detection and classification of breast cancer at the cellular level is one of the most challenging problems. Since the morphology and other cellular features of cancer cells are different from normal heathy cells, it is possible to classify cancer cells and normal cells using such features. Although various artificial intelligence (AI) techniques including least square support vector machine (LS-SVM) have been used for pattern recognition, their use in classifying breast cancer from cellular images has yet not been established. In this communication, we developed an alternative approach using various AI techniques to classify breast cancer and normal cells using cellular image texture features extracted from cell images of various breast cancer cell lines like MCF-7, MDAMB-231 and the human normal breast cell line MCF-10A. Applying pattern recognition techniques upon various human breast cancer/normal cell images, we successfully performed cellular image segmentation, texture based image feature extraction and subsequent classification of cancer and normal breast cells. Four different AI techniques: Kth nearest neighbour (KNN), artificial neural network (ANN), support vector machine (SVM) and LS-SVM were applied to classify cancer using optimal features obtained from cell segmented images. Our results demonstrated that LS-SVM with both radial basis function (RBF) and linear kernel classifier had the highest classification rate of 95.34% among all. Thus, our LS-SVM classifier was found to be a suitable trained model that could classify the cancer and normal cells using cell image features in a short time unlike other approaches reported so far.
Introduction
Breast cancer is the second most diagnosed cancer worldwide.1 In order to find a cure, it is necessary to diagnose the disease accurately and quickly for initiating treatment. Breast cancer is caused, when a single cell or a group of cell escapes from the usual controls that regulate the cellular growth, and begins to multiply and spread.2 Although mammography has gained recognition as the single most successful technique for the detection of early stage breast cancer, however, detection and classification of breast cancer at the cellular level has remained a challenge.3 Till now only the impedance spectroscopy technique was developed to analyze the cancer and normal cells on the basis of bioimpedance responses which have been used as an adjunct to mammography for the evaluation of equivocal breast lesions.4,5 Recently, Microelectromechanical system (MEMS) based diagnosis of diseased cell has also been demonstrated to be a sensitive and accurate method for capturing and enriching cells of interest.6 Here the efficiency of an antibody-based MEMS platform has been used in recognizing and capturing cervical cancer cells.6 However, there is a strong need to detect the diseased cells based on the training-mediated learning using various cell image texture features data for a quick diagnosis of the disease. The technique would be much easier and once trained well, can be used for unknown cell types for the classification of cancer. Such model will detect cancer cells quickly and therefore, the treatment can be started at an early stage of the disease which will reduce the probability of life risk.In the last two decades, a variety of classification models have been proposed on pattern recognition and artificial intelligence techniques including KNN, ANN, ANFIS (Adaptive neuro fuzzy inference system), SVM and other models.7–10 Due to the smoothness and effectiveness of ANN model, it is widely used in various applications of science related to non linear function estimation and classification.11,12 KNN is also known for being a simple but robust classifier and is capable to produce high performance results even for the complex applications.13 Similarly the SVM technique is also an attractive machine learning algorithm-based method which was first introduced by Vapnik and his co-workers.9 This method was further improved by various investigators for different applications like function estimation, nonlinear binary and multiclass classification in the different disciplines of modern engineering and medical science. SVM has remarkable generalization performance and more advantages over other methods that makes it as one of the best classification tool for solving current signal and image processing problem.8
Machine learning models have already been used for the classification of disease like cancer. Aliferis et al. developed machine learning models that classify non-small Lung Cancers according to histopathology types.14 They extracted DNA from tumors of 37 patients (21 squamous carcinomas, and 16 adenocarcinomas) and hybridized onto a 452 BAC clone array. They used KNN, Decision Tree Induction, Support Vector Machines and Feed-Forward Neural Networks models and measured the performance as leave-one-out classification accuracy where the best accuracy was found to be 89.2%. Guyon et al. developed a model for the classification of cancer and normal patients using available training examples. The model was suitable for genetic diagnosis, as well as drug discovery.15 Using Support Vector Machine methods based on recursive feature elimination, they demonstrated that the genes selected by their techniques yield better classification performance and are biologically relevant to cancer.16 In the colon cancer database, using only 4 genes their method was 98% accurate, while the baseline method demonstrated only 86% accuracy.
Shi and his group proposed the method for detection and classification of masses in breast ultrasound images. They used the textural features, fractal features as feature extraction tools and Fuzzy Support vector machine as classifier to obtain an accuracy of 94.25%.17 Similarly, Schaefer and his group used statistical features such as feature extraction method and fuzzy rule based classifier to classify the thermogram image with an accuracy of 80%.18 However, the use of cellular images and the features extracted from cell images for the classification of cancer and normal cell have not been attempted earlier. Since cancer cells have various features that differs from normal cells which include marginal adhesion, ununiformity of cell size/shape etc., a cancer cell can be classified accurately if such features provides a broad gap of difference between normal and cancer cells.
Here, in our present investigation, we attempted to develop a technique to classify breast cancer cells using AI-based classifier that would extract various features of cellular images and classify them into breast cancer and normal cells. We applied various pattern recognition techniques using various kinds of features extracted from 81 cell images. Under this pattern recognition techniques, we successfully performed image segmentation, texture based feature extraction of images and classification of cancer and normal cells. We used four different machine learning classifiers i.e. KNN, ANN, SVM and LS-SVM for classification of given cellular images. We observed that our LS-SVM with both Radial Basis Function (RBF) and linear kernel classifiers proved to have the highest classification rate of 95.34% compared to other classifiers used in the study. Besides, SVM with linear kernel resulted in a classification rate of 93.02% which was close to LS-SVM classifier.
Materials and methods
Materials
DMEM (Dulbecco's Minimum Essential Medium), fetal bovine serum, glutamine and penicillin and streptomycin were purchased from HiMedia, India. Breast cancer cell lines like MDAMB-231 and MCF-7 were procured from NCCS, Pune, India. Normal breast cell line MCF-10A was procured from ATCC (CRL-10317). Olympus CKX41 inverted microscope was used for capturing cultured cell images. All the glass-wares used were purchased from Borosil (India). Milli-Q (HPLC grade) water was used in all preparations.Culture of various cell lines and image collection
DMEM (Dulbecco's Minimum Essential Medium) was used for the culture of MDAMB-231 cancer cells supplemented with 10% fetal bovine serum, 2 mM glutamine and 0.1 mg ml−1 penicillin and streptomycin. DMEM (Dulbecco's Minimum Essential Medium) was used to culture of MCF-7 and MCF-10A cancer cells supplemented with 10% fetal bovine serum, 0.01 mg ml−1 bovine insulin, 2 mM glutamine and 0.1 mg ml−1 penicillin and streptomycin. The various cell lines were seeded at a density of 1 × 10 5 cells in T 25 flasks and the cells were grown in 5% CO2 incubators to achieve 80% confluence. The various cultured images were captured by an Olympus inverted phase contrast microscope (CKX-41) after 80% of confluence of cells was achieved. The images collected from the above experiments were used for the segmentation followed by feature extraction using various techniques.Model design
The main objective of this investigation was to classify breast cancer and non-cancer cells from cell images using image processing and artificial intelligence (AI) techniques. Our proposed pattern recognition architecture was shown in Fig. 1. The work used 81 numbers of cell images out of which 55 numbers of images belonged to breast cancer cells and 26 numbers are non-cancer breast cells. | ||
| Fig. 1 Flow chart depicts the pattern recognition procedure for the classification of breast cancer and normal cells. | ||
Initially, we applied image segmentation techniques to segment the cells from the image background. After segmentation, the tamura texture features, chip histogram features and wavelet based texture features were extracted from each of the images. The image segmentation and feature extraction were carried out using MATLAB software. After extracting all these features, we combined them to prepare a dataset of features. Further, by applying the Principal Component Analysis (PCA) we reduced the number of features from 90 to 15 for better performance and execution. The reduced features were applied as the input to the classifier for the purpose of testing and training. We considered 50% instances as training of the reduced feature numbers and rest as testing. We presented the performance of each classifier in terms of classification rate (CR). The CR was expressed as a confusion matrix given in Table 1.
| TP | FN |
| FP | TN |
Where, classification rate CR can be expressed as follows:
 | (1) |
Image segmentation
We performed image segmentation to segment cells from image backgrounds using gradient and morphological operations. Segmented cells mainly differ from the background of the images by image contrast. The change in contrast was detected by calculating the gradient of an image. After calculating the gradient value using Sobel mask (shown in Fig. 2B), we tuned it to a threshold value to get segmented images. In order to get a proper view of segmented images, we used certain morphological image processing operations like dilation, hole filling and smoothing.19 The segmented image for cancer cells was shown in Fig. 2A.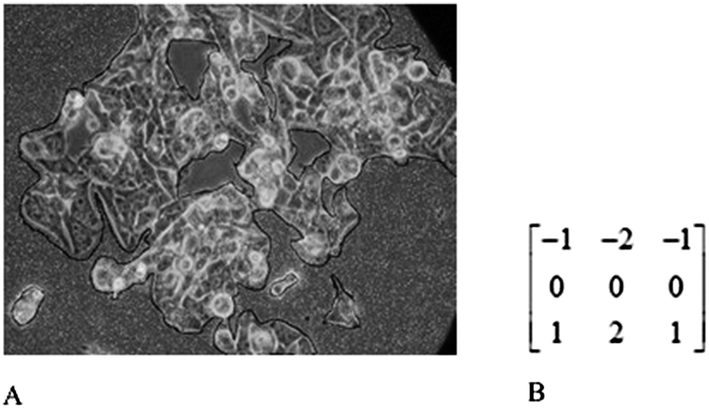 | ||
| Fig. 2 (A) Segmented cell cultured image for MDA-MB-231 cancer cell. (B) Sobel mask used to detect the edges. | ||
Feature extraction
The feature extraction is a technique used for collecting various features from image and dimensionality reduction. Here we used three different texture feature extraction techniques (Chip Histogram-based texture features, Tamura texture features, Wavelet based texture features) to extract features from each segmented images (see Fig. 2A).Chip Histogram-based texture features utilize various statistical features like mean, variance, kurtosis, skewness, energy and entropy.20 Here, these features were extracted from both cancer (MCF-7 and MDAMB-231) and normal breast cell (MCF-10A) images. Tamura texture features extraction technique was used to extract various features of 81 cell images using features such as coarseness, contrast and directionality extracted from each segmented image.21 Wavelet based texture features are typically used for the decomposition and compression of images, by simply reversing the decomposition process. Wavelets calculate average intensity as well as several detailed contrast levels distributed throughout the images.22,23 Here, we used three level 2D wavelet decomposition techniques to estimate vertical, horizontal and diagonal coefficients of images which are shown in Fig. 3.
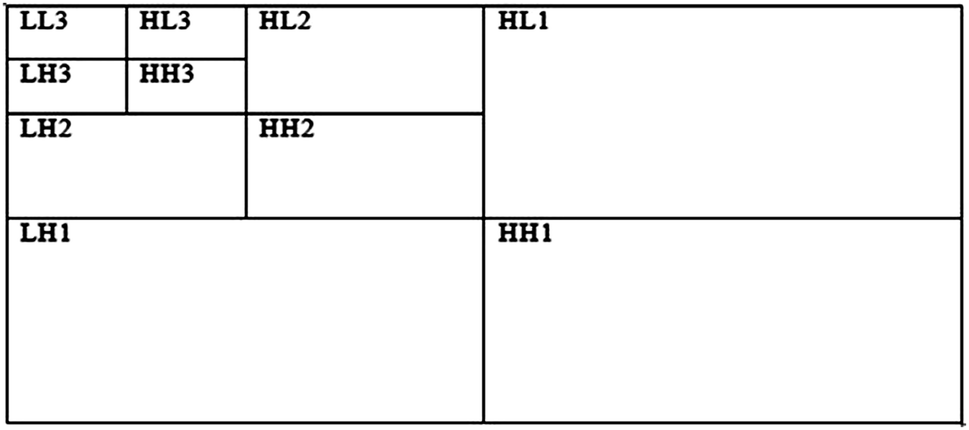 | ||
| Fig. 3 It shows three levels wavelet based decomposition of each images with horizontal, diagonal and vertical details (explained in the text). | ||
The wavelet coefficients obtained from an image is expressed as:
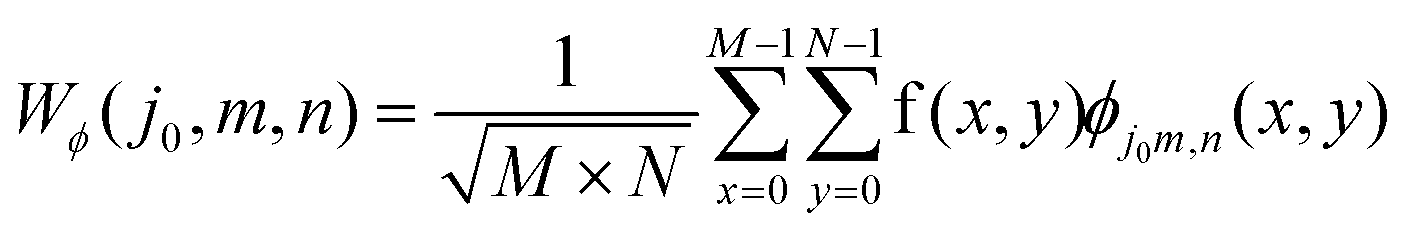 | (2) |
 | (3) |
Here the energy was calculated along all the directions i.e. horizontal, vertical and diagonal (Fig. 3). Since there were three level of decomposition, the energy for each wavelet coefficient was given as:
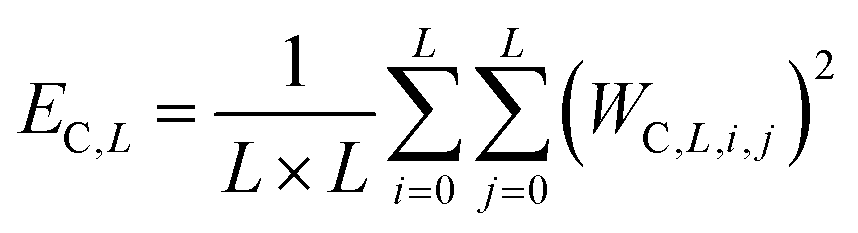 | (4) |
{C ∈ (LH, HL, HH)} is the sub band level decomposition.
Here, for a single wavelet coefficient, we obtained 9 features. Hence, for three level wavelet based decomposition of a single image, total 81 features were extracted. This procedure was repeated for all images, i.e. cancer and normal image class.
After getting all these features from feature extraction techniques, we combined them to make a dataset that contains the features as input variable and the output as classes. Here the output was abbreviated as a binary value ‘0’ for noncancerous breast cells and ‘1’ for cancerous breast cell. To reduce the dimensions of feature datasheet, we used PCA algorithm.
Dimensionality reduction using PCA algorithm
Before using PCA, it is important to first normalize the data by subtracting the mean value of each feature from the dataset, and scaling each dimension so that they are in the same range. After normalizing the data, we applied PCA to compute the principle components.24(a) First, we compute the covariance matrix of the data, which is given by:
 , where x is the data matrix with examples in rows, ‘m’ is the number of examples in the dataset and ‘S’ is the n × n matrix.
, where x is the data matrix with examples in rows, ‘m’ is the number of examples in the dataset and ‘S’ is the n × n matrix.
(b) Then select P to be a matrix, where each row pi is an Eigenvector of matrix S.
(c) As per example A is a square matrix, a non zero vector v is an Eigenvector of A if there is a scalar λ such that Av = λ v.
(d) Reduction methodology: as there is ‘m’ Eigen vectors so we reduce the m dimension to ‘k’ dimensions by choosing k Eigen vectors related to k largest Eigen values of λ.
Classification using various classifiers
After reducing the feature dataset using PCA algorithm, these reduced features were fed to various classifiers to differentiate cancer and normal class. The block diagram in Fig. 1 shows the use of various classifiers like KNN, ANN, SVM, LS-SVM to distinguish both cancerous and normal type of cells.Results and discussions
KNN and MFNN classifiers
The two parameters used to achieve better accuracy in KNN classifier, were the number of nearest neighbors (K) and the minimum distance from nearest neighbors. After setting the different values of K and the minimum distance from nearest neighbors as Euclidean, we calculated the classification rate of KNN classifier (Table 2).| KNN parameter setting | Accuracy |
|---|---|
| K = 1, distance = Euclidean | 81.34% |
| K = 2, distance = Euclidean | 83.95% |
| K = 3, distance = Euclidean | 79.63% |
| K = 4, distance = Euclidean | 79.63% |
| K = 5, distance = Euclidean | 80.42% |
| K = 6, distance = Euclidean | 80.42% |
| K = 7, distance = Euclidean | 81.86% |
The classification rate (CR) for different number of nearest neighbors (K) was reported in Table 2. From Table 2, we observed that at K = 2, the classification rate was found to be 83.85% which was highest among all. If we consider more number of neighbors, according to the eqn (1) the number of FP and FN will increase. This will lead to reduction in the CR or accuracy value and this fact was also proved from the results shown in Table 2. All accuracy values were lower than the accuracy obtained in the case of K = 2. Therefore, to get optimized model of KNN, K = 2 should be used.
Similarly, for the case of MFNN classifier, the different parameters which were used for training, to obtain the optimized training performance are the number of hidden neurons, learning rate, momentum factor, the number of iterations and the training parameter goal. The values of these parameters to obtain the optimized training performance were shown in Table 3. To get optimized solution, we have used only five parameters. We have limited the no. of parameters to five, since increasing more number of parameters will delay the generation of optimized value.
| MFNN parameters | Values |
|---|---|
| Number of hidden neurons | 9 |
| Learning rate | 0.05 |
| Momentum factor | 0.7 |
| Number of iterations | 1000 |
| Training parameter goal | 10−9 |
The variation of MSE with respect to the number of iteration was shown in Fig. 4. From the Fig. 4, it is quite clear that the MSE gradually decreased when the number of iterations increased from 1 to 1000. At 632 numbers of iterations, the training was resumed because the optimum training performance was already achieved. The CR was observed to be 90.69% (see Table 6).
 | ||
| Fig. 4 Variations of training mean square error (MSE) with respect to number of iterations in MFNN classifier. | ||
Although by the increase or decrease of number of hidden layers, we could compromise the CR of the classifier for a specific problem, however, here learning rate was moderate but training parameter goal or MS error was kept very low.
SVM and LS-SVM classifiers: The performance of SVM classifier was evaluated in terms of classification rate of the testing data. First, the SVM model was trained with respect to linear and RBF kernel functions to get optimized training performance.
The values of different parameters used to obtain the optimal training performance for SVM classifier was given in Table 4. Furthermore, the test data was evaluated by passing it through the SVM linear and RBF kernel classifier (already optimized and trained). The evaluation of testing data was expressed in the form of confusion matrix. CR was estimated and reported in Table 6 and receiver operating characteristics (ROC) plot was shown in the Fig. 6 (A) and (B).
| SVM parameters | ||
|---|---|---|
| Kernel function | RBF | Linear |
| Number of support vector | 37 | 17 |
| Number of iterations | 1000 | 1000 |
 | ||
| Fig. 5 (A) Data separation with respect to hyperplane for RBF kernel LS-SVM. (B) Data separation with respect to hyperplane for linear kernel LS-SVM. Here the green colored area indicates class 1 which is corresponding to cancer class and similarly pink colored area indicates class 2 that corresponds to normal cell class. | ||
The performance of LS-SVM classifier was also evaluated in a way similar to that of SVM by considering both linear and RBF kernel functions. The values of the parameters for obtaining the optimized training performance were given as in Table 5.
| LS-SVM parameters | ||
|---|---|---|
| Kernel type | Linear | RBF |
| Gamma (γ) | 5.169 | 128.3341 |
| Sig2 (σ2) | — | 59.4891 |
The distribution of data with respect to optimal hyperplane for both LS-SVM with linear and RBF kernel classifier is shown in Fig. 5(A) and (B). This plot specifies the variation of training output (classes) with respect to the most important features of the training data. From the Fig. 5(A) it is clear that the hyperplane turns wider with parabolic structure which cause better separation of training data for class 1 (cancer cell) and class 2 (normal cell).
 | ||
| Fig. 6 ROC plot for testing data evaluation. (A) RBF kernel SVM classifier (B) linear kernel classifier SVM. (C) RBF kernel LS-SVM classifier. (D) Linear kernel LSSVM classifier. Area under the ROC curve indicates the performance of the classifier. | ||
Furthermore, the testing data was evaluated using the optimized trained LS-SVM model with linear and RBF kernel functions. The performance of LS-SVM classifier in the form of classification rate/CR is reported in Table 6. The ROC plot for LS-SVM classifiers with linear and RBF kernel function is also shown in Fig. 6(C) and (D). Table 6 also shows the confusion matrix elements of all the classifiers and the CR. From the tabular data we observed that the LS-SVM with RBF kernel and LS-SVM with linear kernel have the highest accuracy of 96.34% in the classification of cells into cancer and normal.
| Classifiers | TP | FP | TN | FN | Classification rate(CR) |
|---|---|---|---|---|---|
| MFNN | 28 | 1 | 11 | 3 | 90.69% |
| SVM with linear kernel | 31 | 10 | 2 | 0 | 76.74% |
| SVM with RBF kernel | 28 | 0 | 12 | 3 | 93.02% |
| LS-SVM with linear kernel | 29 | 0 | 12 | 2 | 95.34% |
| LS-SVM with RBF kernel | 29 | 0 | 12 | 2 | 95.34% |
Although, from the results of Table 6, it is clear that the CR for RBF kernel LS-SVM and linear kernel LS-SVM are same, there was difference in the area under ROC curve (Fig. 6). The area under ROC curve for RBF kernel LS-SVM classifier was 0.96 which was more than the area for linear kernel LSSVM classifier (see Fig. 6). The area under the ROC curve indicates the performance of a classifier. Therefore, it was concluded that LS-SVM with RBF kernel classifier was the best classifier among all used in the present investigation for the classification of cancer and normal cell. For validation, testing data evaluation was also performed and significant ROC (receiver operating characteristic) curve was obtained which is shown in Fig. 6. Area under the ROC curve normally defines the performance of a binary classifier system.
It is produced by plotting the fraction of true positives out of the positives (TPR = true positive rate) vs. the fraction of false positives out of the negatives (FPR = false positive rate), at various threshold settings. TPR is also known as sensitivity, and FPR is one minus the specificity or true negative rate. It was found from Fig. 6 that RBF kernel LS-SVM classifier (Fig. 6C) was the best classifier as it possess the highest area under ROC curve.
We have used 81 cellular images out of which 55 were of cancer images (MDAMB231 and MCF-7 cell lines) and 26 were of normal cell images (MCF-10). It apparently looks like one class had more instances than the other, however, in reality, the similarity of features among normal cells are more than the cancer cells which show huge variety among them. Therefore, using more cancer cell images and features in the testing, higher will be the chance of obtaining accuracy to detect the cancer class will lead to higher chance of getting accuracy for detecting the cancer class. Therefore, in our present communication the class imbalance will not be an issue. Moreover, ∼32% instances were of normal cells which were comparatively higher than other cases reported earlier.
Conclusion
The image analysis of the morphological features of the cultured breast cancer cell lines is the closest possible way of replicating the status of breast cells in the human body. Since, the cells have been cultured from the human breast cancer cells lines hence the characteristics of these cells remain the same for humans. The characteristics of the cells obtained from the cancerous breast tissue and differentiation remains the same as that of the cell lines. In our present investigation, the pattern recognition techniques were successfully implemented to classify the cancer and normal cells from cultured cell images. The real challenges were involved in the identification of features. These features were successfully classified as cancerous and normal cells by various artificial intelligence classifiers like KNN, ANN, SVM and LS-SVM. The selected LS-SVM model successfully exhibited to have the best predictive capability with higher classification rate of 95.34% for testing data compared to other classifiers. The classification rate determines the performance of the classifier. Since, it is a single value determined for respective classifiers hence, the statistical comparison between the classification rates cannot be performed. However, the comparison between the classification rate is provided in Table 6.All the images for classification were obtained from the cultured breast cancer cell lines hence; the morphological features of these cells remain limited to the breast cells. Although similar strategies can be designed for different cancer cells our current strategy focuses particularly on the breast cancer cells and may not work for the cells other than the breast.
To solve this problem we need to have a large image database of cells from different organs along with their cancer types.
Accurately detecting/diagnosing of the disease like breast cancer in the early stage is extremely essential for early treatment or to avoid death chances. If we achieve more than 95% accuracy by the use of artificial intelligence techniques, this fact will enhance the detection and diagnosis of the disease and hence pave the way for a treatment at an earlier stage. This may lead to reduce the time of detecting and analyzing the cancer cells in many other existing methods and prevent death in cancer like lethal disease.
Acknowledgements
We sincerely acknowledge the support provided by National Institute of Technology Rourkela, Govt. of India for carrying out this work.References
- S. Germano and L. O'Driscoll, Curr. Cancer Drug Targets, 2009, 9, 398–418 CrossRef CAS
.
- R. M. Rangayyan, Biomedical image analysis, CRC press, 2004 Search PubMed
- R. M. Rangayyan, S. Banik, J. Chakraborty, S. Mukhopadhyay and J. E. Desautels, Int. J. Comput. Assist. Radiol. Surg., 2013, 8, 527–545 CrossRef PubMed
- J. Hong, K. Kandasamy, M. Marimuthu, C. S. Choi and S. Kim, Analyst, 2011, 136, 237–245 RSC
- T. P. Sun, C. T. Ching, C. S. Cheng, S. H. Huang, Y. J. Chen, C. S. Hsiao, C. H. Chang, S. Y. Huang, H. L. Shieh, W. H. Liu, C. M. Liu and C. Y. Chen, Cancer Epidemiol., 2010, 34, 207–211 CrossRef PubMed
- S. Gao and X. Wang, J. Cancer Res. Clin. Oncol., 2011, 137, 1721–1727 CrossRef PubMed
- H. Baseri and G. Alinejad, Proc. World Acad. Sci. Eng. Tech., 2011, 49, 499–503 Search PubMed
- H. L. Chen, B. Yang, G. Wang, S. J. Wang, J. Liu and D. Y. Liu, J. Med. Syst., 2012, 36, 2505–2519 CrossRef PubMed
- N. Kausar, B. Belhaouari Samir, A. Abdullah, I. Ahmad and M. Hussain, in Informatics Engineering and Information Science, ed. A. Abd Manaf, S. Sahibuddin, R. Ahmad, S. Mohd Daud and E. El-Qawasmeh, Springer, Berlin, Heidelberg, 2011, vol. 253, pp. 24–34 Search PubMed
- S. Mohanty and S. Ghosh, IET Sci., Meas. Technol., 2010, 4, 278–288 CrossRef PubMed
- B. M. Ozyildirim and M. Avci, Neural Netw., 2013, 39, 18–26 CrossRef PubMed
- M. Karabatak and M. C. Ince, Expert Syst. Appl., 2009, 36, 3465–3469 CrossRef PubMed
- B. Chen, W. Gu and J. Hu, Int. J. Comput. Biol. Drug Des., 2010, 3, 133–145 CrossRef PubMed
- C. F. Aliferis, D. Hardin and P. P. Massion, Proc. AMIA Symp., 2002, 7–11 Search PubMed
- I. Guyon, J. Weston, S. Barnhill and V. Vapnik, Mach. Learn., 2002, 46, 389–422 CrossRef
- X. Lin, F. Yang, L. Zhou, P. Yin, H. Kong, W. Xing, X. Lu, L. Jia, Q. Wang and G. Xu, J. Chromatogr. B: Anal. Technol. Biomed. Life Sci., 2012, 910, 149–155 CrossRef CAS PubMed
- X. Shi, H. D. Cheng, L. Hu, W. Ju and J. Tian, Digit. Signal Process, 2010, 20, 824–836 CrossRef PubMed
- G. Schaefer, M. Závišek and T. Nakashima, Pattern. Recogn., 2009, 42, 1133–1137 CrossRef PubMed
- D. Anoraganingrum, Image Analysis and Processing, Proceedings. International Conference on, 1999, 1999 Search PubMed
- M. C. Barretto, D. A. Kulkarni and G. R. Udupi, Int. J. Bioinf. Res. Appl., 2012, 8, 366–381 CrossRef CAS PubMed
- H. Tamura, S. Mori and T. Yamawaki, IEEE Trans. Syst. Man Cybern. Syst. Hum., 1978, 8, 460–473 CrossRef
- E. Alegre, V. Gonzalez-Castro, R. Alaiz-Rodriguez and M. T. Garcia-Ordas, Comput. Meth. Programs Biomed., 2012, 108, 873–881 CrossRef PubMed
- D. Bhattacharjee, A. Seal, S. Ganguly, M. Nasipuri and D. K. Basu, Comput. Intell. Neurosci., 2012, 2012, 261089 Search PubMed
- I. Koch and K. Naito, Neural Comput., 2007, 19, 513–545 Search PubMed
| This journal is © The Royal Society of Chemistry 2014 |