
Machine learning based interpretation of microkinetic data: a Fischer–Tropsch synthesis case study†

Abstract
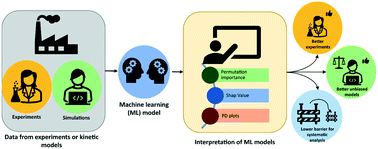
Machine-learning (ML) methods, such as artificial neural networks (ANNs), bring the data-driven design of chemical reactions within reach. Simultaneously with the verification of the absence of any bias in the machine learning model as compared to the microkinetic data, interpretation techniques such as permutation importance, SHAP values and partial dependence plots allow for a more systematic (model agnostic) analysis of these data. In the present work, this methodology is demonstrated for Fischer–Tropsch synthesis (FTS) on a cobalt catalyst, with methane yield as the single dominant output, as a case study. For the purpose of this case study, the dataset required for training the ANN model is synthetically generated using a single-event microkinetic (SEMK) model. With a number of 3 hidden layers with 20 nodes, the ANN model is able to adequately reproduce the SEMK results. The relative ranking of the process variables, as learnt by the ANN model, is identified using interpretation techniques, with the methane yield being most dependent on the temperature, followed by the space-time and syngas molar inlet ratio, in the investigated range of operating conditions. This is in line with the physicochemical understanding from SEMK. A systematic approach for analysing microkinetic data, generally analysed on a case-specific basis, is thus developed by combining more widely used interpretation techniques in data science with the ANN.
- This article is part of the themed collection: Digitalization in Reaction Engineering
 Please wait while we load your content...
Please wait while we load your content...

