
 Open Access Article
Open Access Article This Open Access Article is licensed under a
This Open Access Article is licensed under a Creative Commons Attribution 3.0 Unported Licence
An XAI-enabled 2D-CNN model for non-destructive detection of natural adulterants in the wonder hot variety of red chilli powder†
Dilpreet Singh
Brar
 *a,
Birmohan
Singh
b and
Vikas
Nanda
a
*a,
Birmohan
Singh
b and
Vikas
Nanda
a
aDepartment of Food Engineering and Technology, Sant Longowal Institute of Engineering and Technology, Longowal 148106, Punjab, India. E-mail: singhdilpreetbrar98@gmail.com
bDepartment of Computer Science and Engineering, Sant Longowal Institute of Engineering and Technology, Longowal 148106, Punjab, India
First published on 14th May 2025
Abstract
AI revolutionizes the food sector by improving production, supply chains, quality assurance, and consumer safety. Therefore, this work addresses the alarming issue of red chilli powder (RcP) adulteration, with the introduction of an AI-driven framework for RcP adulteration detection, leveraging an empirical evaluation of DenseNet-121 and 169. To optimize convergence and enhance the performance, the AdamClr optimizer was incorporated, in a learning rate range between 0.00005 and 0.01. Two datasets (DS I and DS II) were developed for evaluation of DenseNet models. DS I consists of two classes: Class 1 (Label = C1_PWH) representing pure RcP (variety = Wonder Hot (WH)) and Class 2 (Label = C2_AWH) containing samples adulterated with five natural adulterants (wheat bran (WB), rice hull (RB), wood saw (WS), and two low-grade RcP), whereas DS II comprises 16 classes, including one class of pure RcP and 15 classes representing adulterated RcP with varying concentrations of the five adulterants (each at 5%, 10%, and 15% concentration). For binary classification (for DS I), DenseNet-169 at batch size (BS) 16 delivered an accuracy of 99.99%, while, in multiclass classification (for DS II) for determination of the percentage of adulterant, DenseNet-169 at BS 64 produced the highest accuracy of 95.16%. Furthermore, Grad-CAM explains the DenseNet-169 predictions, amd the obtained heatmaps highlighting the critical regions influencing classification decisions. The proposed framework demonstrated high efficacy in detecting RcP adulteration in binary as well as multiclass classification. Overall, DenseNet-169 and XAI present a transformative approach for enhancing quality control and assurance in the spice industry.
Sustainability spotlightEnsuring food safety and sustainability is essential in the global spice industry. This study presents an AI-driven framework to detect red chili powder (RcP) adulteration, enhancing food quality assessment using DenseNet-121 and DenseNet-169 with the AdamClr optimizer. The model accurately identifies contaminants like wheat bran, rice hulls, and wood sawdust, improving consumer safety and regulatory compliance. This approach promotes ethical food production, minimizes economic losses, and reduces the environmental impact of food fraud. explainable AI (XAI) through Grad-CAM ensures transparency, fostering stakeholder trust. Additionally, the model's efficiency optimizes testing and quality control, supporting sustainable supply chains. By detecting adulteration and ensuring RcP purity, this study advances sustainable food security. The AI-powered method revolutionizes quality assurance in the spice industry and establishes a foundation for future AI applications in food fraud detection, reinforcing global efforts for a safer and more sustainable food system. |
1. Introduction
Artificial Intelligence (AI) is revolutionising the food sector from farm to fork by enhancing production methods, streamlining supply chain management, advancing quality assurance protocols, and strengthening consumer safety.1 Moreover, as the food industry addresses critical challenges such as food safety, waste reduction, labour shortages, and evolving consumer demands, the AI-driven food technology market is projected to reach USD 27.73 billion by 2029.2 This growth is propelled by the demand for tailored nutrition, stricter safety standards, supply chain optimisation, and sustainability. These changes create a new era for producing, distributing, and consuming food worldwide.3 Additionally, there remains a long way to go to fully advance the application of AI technology in food quality evaluation, particularly in the accurate detection of adulteration. This progress can be accelerated by focusing on specific sectors, such as detecting adulteration in spices and refining AI-based technology to address the challenges.4 By systematically analysing the limitations and errors encountered during implementation, these insights can inform iterative improvements, leading to more robust and effective applications in future deployments across the food industry.5Despite India's legacy as the global leader in spice production and export, the spice market remains highly vulnerable to adulteration, driven by the pursuit of higher profits at the expense of consumer health and safety. Among the diverse spices produced in India, red chilli powder (RcP) stands out as one of the most economically motivated products for adulteration due to its high commercial and industrial demand, vibrant colour, pungency, and significant market value.5 The substances used as adulterants to increase the bulk and the colour intensity of RcP are broadly categorised into two major classes. Class I adulterants are natural materials primarily added to increase bulk, including low-grade or diseased red chilli peppers, wheat bran, rice hulls, wood sawdust, chalk powder, and brick powder. In contrast, Class II adulterants consist of synthetic colouring agents such as Sudan dyes and rhodamine B, which are added to enhance the visual appeal of the product.6 Regular consumption of these adulterants, even in small quantities, can lead to severe health issues ranging from gastrointestinal disorders to carcinogenic effects.7 Therefore, it is imperative to detect and prevent the illegitimate adulteration of RcP to safeguard consumer health and ensure food safety. These growing concerns underscore the urgent need for more effective enforcement strategies, the development of advanced rapid detection technologies, and increased public awareness to mitigate the risks associated with adulterated RcP.8 Traditional methods such as chromatography, DNA fingerprinting, and spectroscopy are sophisticated in terms of operations, require trained professionals, are time-consuming, and are economically expensive.9 The limitations of traditional methods can easily be overcome using AI-driven approaches, such as Deep Learning (DL), which deliver rapid and non-destructive solutions for detecting RcP adulteration.
DL, a specialised subset of Machine Learning (ML), transforms various industries by enabling machines to mimic human cognitive abilities. This advancement is largely driven by Two-Dimensional Convolutional Neural Networks (2D-CNNs), which excel in image analysis tasks.10 One of the core strengths of DL lies in its ability to autonomously identify and learn relevant patterns from extensive datasets, thus eliminating the need for manual feature extraction.11 This makes DL particularly effective in domains like food quality assessment, especially for adulteration detection.5 However, the dataset is crucial for developing deep learning-based techniques for detecting adulterated test products, as carefully prepared and labelled data are the foundation for AI models' wider and more accurate applications. Therefore, several pre-trained 2D-CNN models are currently utilised for food classification, including ResNet,12 EfficientNet,13 DenseNet,14 and Visual Geometry Group (VGG) networks.15
Despite their impressive performance, DL models often face criticism due to their lack of transparency, functioning as “black boxes” with limited interpretability.16 This opacity raises concerns in critical sectors like food safety, where trust and accountability are paramount.17 To mitigate this challenge, explainable artificial intelligence (XAI) emerges as a promising field to make DL models more understandable.18 Techniques such as Shapley additive explanations (SHAP) and local interpretable model-agnostic explanations (LIME) help identify key features that influence model predictions, thereby improving the clarity and transparency of AI systems.19 Additionally, visualisation tools like Gradient-weighted Class Activation Mapping (Grad-CAM) and saliency maps highlight the crucial regions within an image that guide the model's decision-making, offering a more intuitive grasp of AI outputs.20 Collectively, these methods enhance AI's reliability, trustworthiness, and user acceptance in detecting natural adulterants in RcP.
The objective of this study is to develop an AI-driven model capable of detecting adulteration in RcP. We designed the model to detect the illegal blending of RcP with natural adulterants through empirical evaluation and fine-tuning of DenseNet (121 and 169) architectures in combination with the AdamClr optimizer. To facilitate this, a dataset comprising images of both pure and adulterated RcP from the Wonder Hot (also known as Wonder Heart) variety was created under controlled laboratory conditions. This dataset is used to evaluate 2D-CNN models with specified hyperparameters to classify pure and adulterated RcP at various concentrations. To further enhance interpretability, the explainable AI (XAI) method, Grad-CAM is applied to visualise and justify the predictions made by the most effective model. The results of this research underscore the potential of AI technologies in ensuring food quality assessment. Moreover, the developed model can serve as a valuable tool for food safety authorities in identifying the illegal addition of low-cost adulterants to RcP and similar food products, thereby supporting global initiatives to mitigate food fraud.
2. Materials and methods
2.1. Framework
The experimental design of the proposed methodology is presented in Fig. 1. This study leverages the integration of 2D-CNNs with XAI tools to detect five naturally occurring adulterants in the finest Indian RcP variety (Wonder Hot/Wonder Heart, WH). The methodological framework encompasses systematic sample selection, preparation, controlled dataset acquisition, and preprocessing. A comparative evaluation of pre-trained DenseNet_121 and DenseNet_169 architectures optimized using the Adam cyclic learning rate (AdamClr), is conducted to assess classification performance. Furthermore, the interpretability of the optimal model's predictions is achieved through the application of Grad-CAM and LIME, offering insights into the model's decision-making process.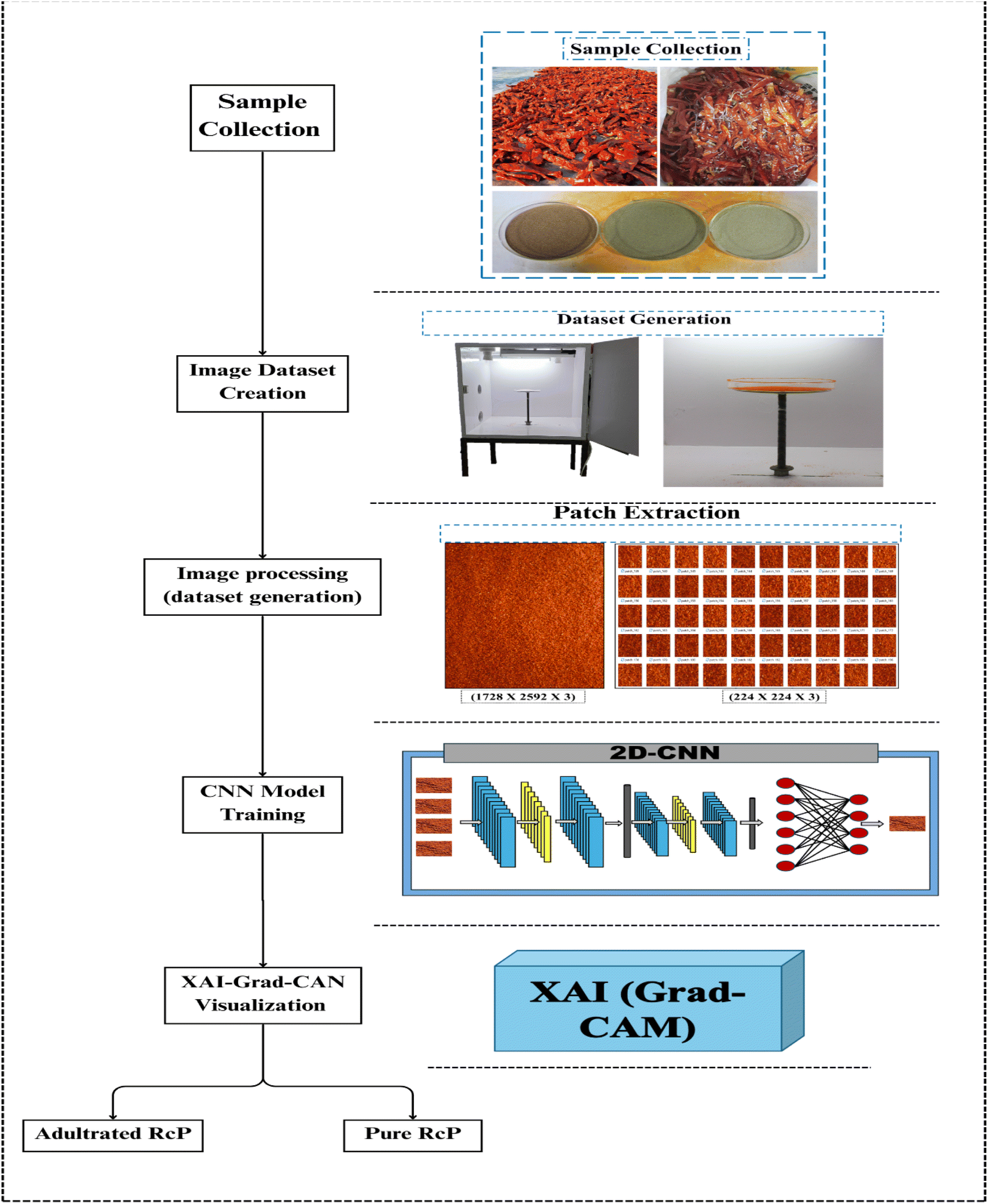 | ||
| Fig. 1 Experimental framework for detection of adulteration in RcP (variety WH). | ||
2.2. Sample collection
In this study, a digital image dataset was developed comprising images of pure RcP and RcP adulterated with five different natural adulterants. A premium-grade chilli variety, Wonder Hot/Wonder Heart (WH), was sourced from Warangal, Telangana, India, for pure sample preparation. The adulterants included two lower-grade RcP varieties: Boriya Chilli (BM) from Kanyakumari and Guntur Sanam (GM) from Andhra Pradesh—along with three common natural adulterants: wheat bran (WB), wood sawdust (WS), and rice hulls (RB), all procured from Sangrur, Punjab.Prior to grinding, all raw materials are washed to eliminate surface contaminants and subsequently sun-dried. Once the moisture content of the chilli pods and adulterants is reduced to 7% or lower, the samples are ground using a rotating hammer mill (Make: Natraj, Ahmedabad, Gujarat) equipped with a mesh No. 3 sieve (650 microns). We blended the pure RcP and adulterants to prepare adulterated samples. Each adulterant is incorporated into the pure RcP (WH) at three concentration levels—5%, 10%, and 15%—yielding 15 distinct adulterated classes and a pure class, resulting in a total of 16 classes. To ensure homogeneity, each mixture is thoroughly blended in a planetary mixer for 10 minutes and then passed through a sieve (British Standard Sieve (BSS) No. 30). The final samples are stored in glass containers under refrigeration conditions (4 °C) until further analysis.
2.3. Sample preparation
We captured image samples of five natural adulterants mixed with high-grade RcP of the WH variety using a Canon EOS 7D digital single-lens reflex (DSLR) camera. The camera features a 22.3 × 14.9 mm image sensor with a 3![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :2 aspect ratio and is equipped with a Canon EF-S 18–55 mm f/3.5–5.6 IS STM lens. Imaging parameters are set with an ISO sensitivity of 300, a shutter speed of 1/50th second, and manual focus at 35 mm.
:2 aspect ratio and is equipped with a Canon EF-S 18–55 mm f/3.5–5.6 IS STM lens. Imaging parameters are set with an ISO sensitivity of 300, a shutter speed of 1/50th second, and manual focus at 35 mm.
All images are taken under controlled conditions within a custom-designed, white-walled wooden image box (IB). The IB measures 1.5 × 1.5 × 1.5 feet (length × width × height) and includes an adjustable sample stage, a voltage-regulated light source, and a fixed eyepiece (camera mount) positioned perpendicular to the sample holder. The distance between the camera and sample stage is adjustable between 10 cm and 25 cm; for this study, it is fixed at 10 cm.
To ensure uniform sample presentation, powders are evenly spread on 250 ml glass dishes using a 25 BSS sieve to avoid clumping or empty spaces. The prepared dish is then placed on the image box stage. For each of the 16 sample classes, four high-resolution images (1728 × 2592 pixels) are taken by rotating the camera to capture varied perspectives. All images are stored and labelled for further analysis.
2.4. Data set preparation
Original images (1728 × 2592 × 3 pixels) were captured and resized to 224 × 224 × 3 pixels to meet the input requirements of the 2D-CNN model. Labelled images were processed to extract patches of uniform dimensions and assigned to their respective class folders.Two datasets were developed for model training and evaluation. Dataset I (DS I) targeted binary classification, comprising pure WH samples (C1_PWH) and adulterated WH samples (C2_AWH) with a total of 1638 images. To ensure class balance in DSI, 62 images were randomly selected for each adulterant group, as detailed in ESI Table 1.† Furthermore, Dataset II (DS II) supported multi-class classification and included 16 classes: one for pure WH RcP (WH00) and 15 for adulterated samples, representing five natural adulterants at three concentration levels (5%, 10%, and 15%) and the total number of images in DSII is 5852 (doi: https://10.0.68.224/mszn5hk9nv.1). A complete class distribution is provided in ESI Table 1.†
2.5. Dataset processing
Prior to training the 2D-CNN model, both datasets (DS I and DS II) are split into training and testing subsets, allocating 80% of the data for training and the remaining 20% for testing. Subsequently, normalization is applied by scaling the pixel intensity values through division by 255, effectively transforming the original pixel range of [0, 255] to a normalized range of [0, 1]. This normalization step is critical to ensure a consistent data scale, which facilitates stable model training, mitigates the risk of gradient explosion or vanishing, enhances the convergence speed during the optimization process, and ultimately improves the model's generalization performance on unseen data.2.6. Proposed approach
The DenseNet-121 and DenseNet-169 2D-CNN models were initially trained on DS I for binary classification of pure WH and adulterated WH. Furthermore, similar models are trained on DS II for determining the percentage of natural adulterants in the WH variety. Besides the learning rate and epoch number were fixed. However, three Batch Sizes (BSs) (16, 32, and 64) were used to train the 2D-CNN model to analyse the classification performance.2.7. Deep learning 2D-CNN models
The CNNs have proven highly effective in classification tasks where understanding spatial correlations is essential. The convolutional layers in 2D-CNNs systematically extract multi-level features from grid-like data structures, such as images, facilitating efficient and meaningful feature representation. Due to their robust design, 2D-CNNs have found widespread applications in domains like computer vision, image recognition, and data analysis. Their architecture typically consists of a series of convolutional layers, often followed by pooling layers, which serve to down sample spatial dimensions while retaining essential information. By identifying detailed local features, including edges and textures, 2D-CNNs excel in a broad spectrum of image-related tasks.10 In the present study, DenseNet-121 and 169 models are integrated with the AdamClr optimizer, and their performance is assessed to determine the most effective approach for detecting adulteration in RcP (variety: WH). DenseNet (Dense Convolutional Network) is a deep learning architecture that enhances information flow across layers in a neural network. Unlike standard models, which only connect one layer to the next, DenseNet provides direct connections between all layers, allowing the network to reuse features and learn more effectively. This architecture minimizes the number of parameters, addresses the vanishing gradient problem, and improves model performance, particularly for difficult picture classification problems. A brief overview of DenseNet-121 and 169 models is provided below.| Component | Configuration | |
|---|---|---|
| DenseNet-121 | DenseNet-169 | |
| Initial convolution | 7 × 7 conv., stride 2 | 7 × 7 conv., stride 2 |
| Initial pooling | 3 × 3 max pooling, stride 2 | 3 × 3 max pooling, stride 2 |
| Dense block 1 | 6 × (1 × 1 conv. + 3 × 3 conv.) | 6 × (1 × 1 conv. + 3 × 3 conv.) |
| Transition layer 1 | 1 × 1 conv. + 2 × 2 avg. pooling | 1 × 1 conv. + 2 × 2 avg. pooling |
| Dense block 2 | 12 × (1 × 1 conv. + 3 × 3 conv.) | 12 × (1 × 1 conv. + 3 × 3 conv.) |
| Transition layer 2 | 1 × 1 conv. + 2 × 2 avg. pooling | 1 × 1 conv. + 2 × 2 avg. pooling |
| Dense block 3 | 24 × (1 × 1 conv. + 3 × 3 conv.) | 32 × (1 × 1 conv. + 3 × 3 conv.) |
| Transition layer 3 | 1 × 1 conv. + 2 × 2 avg. pooling | 1 × 1 conv. + 2 × 2 avg. pooling |
| Dense block 4 | 16 × (1 × 1 conv. + 3 × 3 conv.) | 32 × (1 × 1 conv. + 3 × 3 conv.) |
| Classification layer | Global avg. pooling + fully connected softmax layer | Global avg. pooling + fully connected softmax layer |
| Total parameters | ∼7.57 million | ∼13.51 million |
| Growth rate | 32 | 32 |
| Total depth | 242 layers | 338 layers |
2.8. Optimizers
In deep learning (DL), optimizers play a crucial role by automatically refining a model's parameters during the training phase to minimize a predefined loss function. These algorithms support neural network training by continuously adjusting the weights and biases based on incoming data, thereby improving the learning process over successive iterations.Several optimizers are commonly utilized in training 2D-Convolutional Neural Networks (2D-CNNs), each providing distinct advantages. Stochastic Gradient Descent (SGD) is a fundamental technique that updates model parameters using calculated gradients, while momentum-based SGD accelerates convergence by incorporating a fraction of the previous gradient into current updates. Root mean square propagation (RMSprop) dynamically adjusts learning rates by normalizing gradients, making it well-suited for tasks with non-stationary objectives.21 Adaptive moment estimation (Adam) merges the strengths of RMSprop and momentum by applying adaptive learning rates, and its variant, AdamW, further enhances generalization by decoupling weight decay from gradient updates.22 Optimizers like AdaGrad and AdaDelta also adjust learning rates based on the accumulation of past gradients, which is particularly beneficial for handling sparse datasets, although they may lead to diminishing learning rates over time.
For this research, AdamClr (Adam with a cyclical learning rate) is selected due to its capacity to dynamically modulate the learning rate, which aids in avoiding entrapment in local minima and accelerates the convergence process. The cyclical learning rate (Clr) strategy employed here allows the learning rate to vary between a minimum of 0.00005 and a maximum of 0.001, promoting efficient exploration of the loss landscape and mitigating premature convergence.23 The learning rate was adjusted at a frequency determined by the step size, calculated as 25 × (training size/batch size), enabling periodic updates across training epochs. Additionally, a scaling function defined as  is applied to gradually decrease the amplitude of learning rate oscillations over time, further refining the training process. The Adam optimizer, enhanced with Clr, effectively leveraged both momentum and adaptive learning rates to improve the overall model performance. The model's training objective was guided by the categorical cross-entropy loss function, expressed as:
is applied to gradually decrease the amplitude of learning rate oscillations over time, further refining the training process. The Adam optimizer, enhanced with Clr, effectively leveraged both momentum and adaptive learning rates to improve the overall model performance. The model's training objective was guided by the categorical cross-entropy loss function, expressed as:  where N represents the number of classes, yi denotes the true label for class i (in the one-hot encoded form), and yi signifies the predicted probability for class i, obtained through the softmax activation function in the output layer of the network. This loss function quantifies how closely the predicted probability distribution ŷi aligns with the actual class distribution, ensuring that the model learns to assign higher probabilities to correct classifications. Accuracy was used as the primary evaluation metric for model performance.
where N represents the number of classes, yi denotes the true label for class i (in the one-hot encoded form), and yi signifies the predicted probability for class i, obtained through the softmax activation function in the output layer of the network. This loss function quantifies how closely the predicted probability distribution ŷi aligns with the actual class distribution, ensuring that the model learns to assign higher probabilities to correct classifications. Accuracy was used as the primary evaluation metric for model performance.
2.9. Performance metrics
The effectiveness of the trained models is assessed through various performance evaluation matrices derived from the collected values of True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). These values are obtained from the confusion matrix generated during the model's training and evaluation phases. Using these data, key metrics, including accuracy, precision, recall, and the F1-score, are computed according to standard formulae,8 as presented in Table 2.| Metric | Formulae |
|---|---|
| a TP: True Positive; TN: True Negative; FP: False Positive; FN: False Negative. | |
| Accuracy |

|
| Precision |

|
| Recall (sensitivity) |

|
| F 1-score |

|
2.10. Explainable AI (XAI)
With the increased use of deep learning in food quality evaluation, model transparency and trustworthiness are critical. Therefore, the XAI model Gradient-weighted Class Activation Mapping (Grad-CAM) provides insights into how trained 2D-CNN delivers classification predictions by identifying critical visual regions that influence the decision-making of the model.The Grad-CAM process started by selecting the final convolutional layer of the network, as this layer retains essential spatial features while encapsulating high-level patterns critical for classification tasks. The selection of this layer is key because it maintains the spatial integrity of features relevant to the target class. Following this, automatic differentiation was used to compute the gradients of the output class score with respect to the selected layer's feature maps. These gradients reflect how variations in the activation maps affect the model's confidence in its prediction.
Subsequently, a global average pooling operation was applied to these gradients, yielding importance weights for each feature map. These weights quantify the influence of individual feature maps on the final output. To create the heatmap, a weighted combination of the activation maps is calculated, spotlighting regions with the highest contribution to the classification outcome. The ReLU function is employed at this stage to remove negative values, ensuring that only features with positive influence are visualised. The resultant heatmap is normalised to a 0–1 scale for consistency in intensity representation.
For better visualisation, the heatmap is colour-coded using OpenCV, where regions of high model attention are highlighted in red or yellow, indicating strong activation. This coloured heatmap is then overlaid onto the original image to provide a clear depiction of the areas most responsible for the model's decision.
This visualisation pipeline is applied across all test samples in the dataset, and the generated heatmaps are stored for comprehensive analysis. This approach enabled a detailed examination of the model's reasoning, providing insights into feature importance and enhancing model interpretability.
The important weights αk for each feature map Ak as eqn (1).
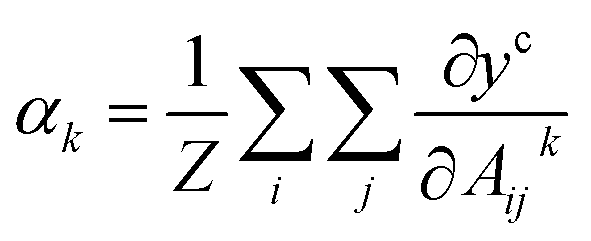 | (1) |
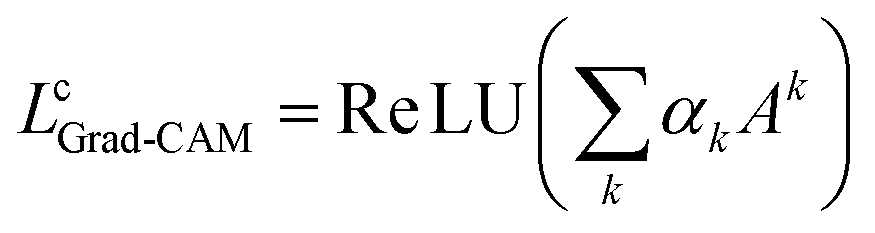 | (2) |
The ReLU activation ensures that only positively contributing regions are highlighted. Grad-CAM thus helps identify the specific parts of an image that most influenced the model's prediction, making it a valuable tool for model debugging, transparency, and increasing confidence in AI-driven decisions.
2.11. Computational specifications
The 2D-CNN models employed in this work are developed using the Keras Applications module, which offers access to pre-trained networks designed for transfer learning and efficient feature extraction.24 These architectures are obtained from the Keras repository [https://keras.io/api/applications/], ensuring that the experiments are reproducible and aligned with standardised deep learning protocols. Model training and evaluation are conducted on a workstation equipped with dual Intel Xeon-4215 CPUs and a Nvidia A6000 GPU (48 GB), supplemented by Kaggle's free GPU resources for additional computational support.3. Results and discussion
This study conducted an empirical analysis of two 2D-CNN models i.e. DenseNet-121 and DenseNet-169 integrated with AdamClr, at a fixed epoch and cyclical learning rate with varying BSs of 16, 32, and 64.Both models are trained using two datasets (DS I and DS II). DS I is utilized for binary classification to determine whether a sample is pure or adulterated. In contrast, DS II is employed to train the same models for multi-class classification, enabling them to accurately classify test samples based on the concentration of specific natural adulterants (WS, WB, RB, BM, and GM) in pure RcP (WH). The classification performance of the trained models is evaluated to detect and quantify adulteration in RcP. Furthermore, the decision-making process of the best-performing 2D-CNN model is analyzed using Grad-CAM and explainable AI (XAI) techniques.
3.1. Results of 2D-CNN for binary classification for detection of RcP adulteration
The DenseNet-121 and DenseNet-169 models are trained using DS I for identifying the pure RcP from adulterated samples. During the training cycle of the model, the BS (16, 32, and 64) is varied, while the epochs (100), optimizer (AdamClr), and learning rate (0.00005) are kept constant. The results of model performance are reported in Table 4, which reveals the efficiency of DenseNet-121 and DenseNet-169 trained at three BSs (i.e., 16, 32, and 64) for binary classification to discriminate pure and adulterated RcP. The reported values of performance matrices, namely, accuracy, precision, recall and F1-score are, 99.99%, 99.99%, 99.99% and 99.99%, respectively (Table 3).| Model | Optimizer | Batch_size | Accuracy | Precision | Recall | F 1 score |
|---|---|---|---|---|---|---|
| DenseNet_121 | Adam Clr | 16 | 99.99 | 99.99 | 99.99 | 99.99 |
| 32 | 99.99 | 99.99 | 99.99 | 99.99 | ||
| 64 | 99.99 | 99.99 | 99.99 | 99.99 | ||
| DenseNet_169 | Adam Clr | 16 | 99.99 | 99.99 | 99.99 | 99.99 |
| 32 | 99.99 | 99.99 | 99.99 | 99.99 | ||
| 64 | 99.99 | 99.99 | 99.99 | 99.99 |
Fig. 2 and 3 illustrate the confusion matrix alongside the model accuracy versus epoch plot and ROC-AUC, collectively clarifying the model's performance and facilitating a comprehensive understanding of its predictive capabilities. The DenseNet-121 achieves better classification accuracy across all BSs, as demonstrated by the confusion matrix (Fig. 2(a, d and g)), where no misclassifications are observed. However, the training and validation accuracy plots (Fig. 2(b, e and h)) indicated that smaller BSs produced more stable learning trends, whereas larger BSs (BS 64) exhibited more pronounced fluctuations. These fluctuations might be attributed to the noisier gradient estimates associated with larger BSs, which also supports the outcomes of the paper, Masters & Luschi.25 Nevertheless, the ROC-AUC curves (Fig. 2(c, f and i)) consistently yield an AUC of 1.00 across all configurations, proclaiming the model's excellent discriminatory power.
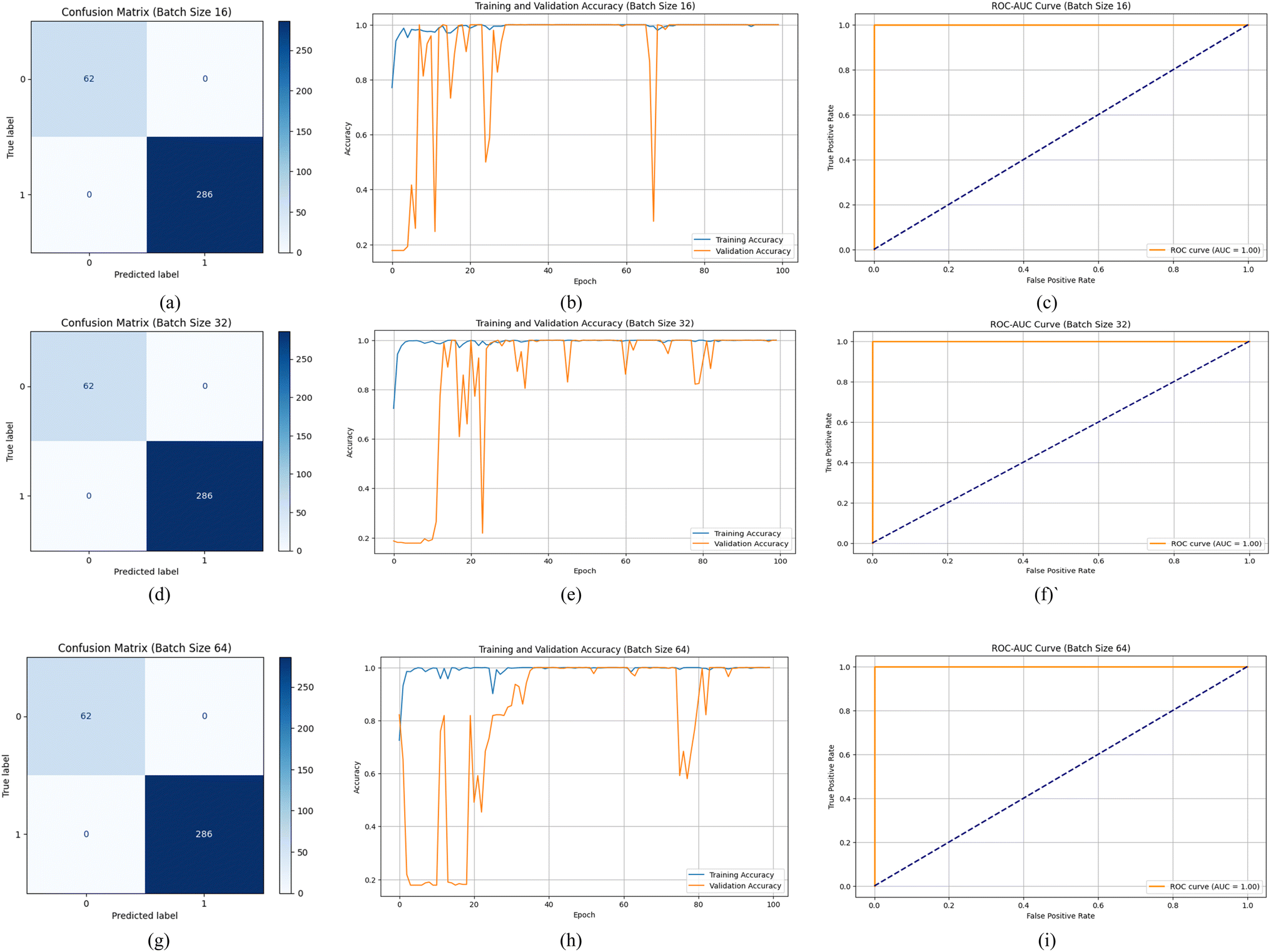 | ||
| Fig. 2 Confusion matrix ((a) BS 16, (d) BS 32 & (g) BS 64), training accuracy vs. epoch ((b) BS 16, (e) BS 32 & (h) BS 64), and ROC_AUC curve ((c) BS 16, (f) BS 32 & (i) BS 64), obtained from DenseNet-121 for binary classification of pure and adulterated RcP. | ||
 | ||
| Fig. 3 Confusion matrix ((a) BS 16, (d) BS 32 & (g) BS 64), training accuracy vs. epoch ((b) BS 16, (e) BS 32 & (h) BS 64) and ROC_AUC curve ((c) BS 16, (f) BS 32 & (i) BS 64) obtained from DenseNet-169 for binary classification of pure and adulterated RcP. | ||
Similar to DenseNet-121, DenseNet-169 demonstrates good classification accuracy, reflected in the confusion matrix (Fig. 3(a, d and g)), with zero misclassifications observed. The training and validation accuracy plots (Fig. 3(b, e and h)) also reveal a high accuracy, but the model displays smoother learning curves with smaller BSs, indicative of more stable gradient updates. The ROC-AUC curves (Fig. 3(c, f and i)) achieve consistently high AUC scores of 1.00, indicating better class discrimination.
This robust performance of evaluated models in this work aligns with the dense connectivity principles of DenseNets, which help to alleviate the vanishing gradient problem and enhance feature reuse throughout the network. Moreover, both DenseNet-121 and DenseNet-169 exhibit strong performance in binary classification, attributable to their inherent architectural advantages in feature propagation and gradient flow. The findings of the proposed research work are in accordance with the findings of research conducted by Huang et al.14 However, DenseNet-169 may exhibit greater stability and convergence due to its deeper architecture, which facilitates more complex feature learning and gradient propagation. The observed fluctuations with larger BSs, particularly in DenseNet-121, are consistent with the literature on large-batch training, where noisier gradient estimates can affect convergence behaviour.26
Besides, this research work extends the application of DenseNets to multiclass classification to determine the percentage of adulteration in RcP. The dataset size (DS II) is increased further to evaluate the DenseNets' efficiency in RcP adulteration detection.
3.2. Results of 2D-CNN for multiclass classification for detection of RcP adulteration
Additionally, DenseNet-121 and DenseNet-169 are trained on DS II for detecting the percentage of adulteration in RcP; the results of various performance evaluations are presented in Table 4. The results reveal that DenseNet-121 and DenseNet-169 trained at BS 16 show an accuracy of 91.93% and 89.98%, respectively, whereas with an increase in the BS, an increase in the classification accuracy of both models is also observed. DenseNet-121 at BS 32 and BS 64 delivers an accuracy of 92.03% and 94.05%, respectively. On the other hand, the highest accuracy (95.16%) is observed in DenseNet-169 trained at BS 64; besides the values of precision, recall and F1-score are 95.16, 95.16 and 95.10, respectively (Table 4).| Model | Optimizer | Batch_size | Accuracy | Precision | Recall | F 1 score |
|---|---|---|---|---|---|---|
| DenseNet_121 | Adam Clr | 16 | 91.93 | 92.26 | 91.93 | 91.80 |
| 32 | 92.03 | 92.46 | 92.03 | 92.02 | ||
| 64 | 94.05 | 94.35 | 94.05 | 93.96 | ||
| DenseNet_169 | Adam Clr | 16 | 89.98 | 90.50 | 89.98 | 89.79 |
| 32 | 91.93 | 92.32 | 91.93 | 91.81 | ||
| 64 | 95.16 | 95.16 | 95.16 | 95.10 |
Converse to binary classification, in the multiclass problem, the model must learn more complex feature representations. Larger BSs provide more stable gradients, enhancing convergence and class discrimination.27 Additionally, batch normalization is more effective with larger batches, further improving training stability in multiclass settings with high classification accuracy.28
Furthermore, both models demonstrate strong classification performance, as reflected in the confusion matrices and ROC-AUC curves (Fig. 4 and 5). However, training and validation accuracy plots from DenseNet-169 reveal key differences (Fig. 5(d, e and f)). Smaller BSs in multiclass settings often introduce greater variations in validation accuracy, suggesting higher sensitivity to individual training examples, while the larger BSs result in smoother learning curves but slower initial convergence.
 | ||
| Fig. 4 Confusion matrix ((a) BS 16, (d) BS 32 & (g) BS 64), training accuracy vs. epoch ((b) BS 16, (e) BS 32 & (h) BS 64) and ROC_AUC ((c) BS 16, (f) BS 32 & (i) BS 64) curve obtained from DenseNet-121 multiclass classification to determine the percentage of adulteration in RcP. | ||
 | ||
| Fig. 5 Confusion matrix ((a) BS 16, (d) BS 32 & (g) BS 64), training accuracy vs. epoch ((b) BS 16, (e) BS 32 & (h) BS 64) and ROC_AUC curve ((c) BS 16, (f) BS 32 & (i) BS 64) obtained from DenseNet-169 multiclass classification to determine the percentage of adulteration in RcP. | ||
The trade-off in gradient noise is also evident, where larger BSs provide more stable but potentially less precise gradient estimates, leading to consistent model updates but possibly overlooking finer data details.25 In contrast, the smaller BS, though noisier, can escape local minima but exhibit more unstable training dynamics in multiclass settings.26 The consistently high AUC scores (close to 1.0) across all classes and BSs suggest that both models are highly effective in class distinction, likely due to the inherent separability of extracted features.29 Scientifically, specific BSs play a crucial role in multiclass classification. And the results of this research work reveal that multiclass classification using DenseNet-169 with a BS 64 exhibits a gradual and stable increase in both training and validation accuracy (95.16%), ensuring smooth convergence and improved generalisation, while minor fluctuations indicate better handling of overfitting in complex feature hierarchies (Fig. 5(f)).
The consistently high AUC scores suggest that the model is effective at discriminating between classes across different BSs, highlighting their potential for real-world applications. The above findings indicate that DenseNet-169, trained with a BS 64, outperforms comparable models in multiclass classification problems for detecting natural adulterants in pure RcP (WH). By leveraging compound scaling to optimise parameter efficiency, DenseNet-169 demonstrated superior adaptability to the image dataset, efficiently differentiating adulterated samples from authentic RcP. The synergy between its architectural enhancements and BS optimisation (BS 64) established DenseNet-169 as the most effective model for the classification task, achieving an impressive accuracy of 99.99% for binary classification and 95.16% for multiclass classification in RCP adulteration detection.
3.3. Evaluation of the best performing 2D-CNN model using Grad-CAM
To ensure the reliability and transparency of DenseNet-169, a multiclass classifier trained with BS 64, Grad-CAM is applied to analyse feature importance and decision-making patterns. It visualises the key regions in an image that influence the predictions of the 2D-CNN model by generating a class-discriminative heatmap. Grad-CAM calculates the gradients of the predicted class score that contribute to the convolution layer's feature maps. These feature maps are weighted based on their significance, and a heatmap is overlaid on the original image. Red and yellow regions indicate high importance, while blue signifies lower relevance.20,30The overlaid heatmaps generated by Grad-CAM are presented in Fig. 6, illustrating DenseNet-169's decision-making process in detecting natural adulterants in pure RcP, which involves a multiclass classification problem. The model detects concentrations of five natural adulterants, ranging from 5% to 15% (class = 15), with respect to the pure class of RcP. According to Fig. 6, the original image is displayed alongside the corresponding Grad-CAM heatmap visualisation used to interpret the DenseNet-169 decision-making process. The model predicts each class with a confidence level greater than 0.95, demonstrating the perfect alignment of the predicted sample with the true label and explaining the accurate classification of adulteration in RcP at different concentration levels.
 | ||
| Fig. 6 Visualisation of DensNet-169 prediction for classification of pure RcP and percentage of adulteration by using the Grad-CAM heatmap; (a) to (o) adulterated class and (p) pure WH. | ||
The colour intensity corresponds to the region of interest, with red indicating the highest relevance, highlighting features that play a crucial role in the decision-making process. These regions may correspond to natural adulterant particles in Rcp, which are associated with granule size, particle distribution, colour intensity, and other physical attributes that are not easily detectable by the human eye (Fig. 6). Meanwhile, blue regions cover less critical areas, signifying minimal influence on the decision-making process.
This visualisation underscores the effectiveness of Grad-CAM in offering valuable insights into the focal regions of DenseNet-169, ensuring that multiclass classification decisions are based on scientifically relevant features rather than extraneous artefacts. Fig. 6(a, d, g, j and m) present heatmaps corresponding to classes containing 5% natural adulterants in RcP, where the red regions indicate the presence of adulterant particles. Furthermore, as the adulterant concentration in samples increases up to 15%, the intensity of the red regions in the heatmaps also increases, which is particularly evident in the representations of classes with 10% and 15% adulteration (Fig. 6). By highlighting the specific regions influencing the model's predictions, Grad-CAM enhances the interpretability of the DenseNet-169 model and aids in validating its reliability for detecting adulteration in RcP.31,32
3.4. Comparison with other studies
Existing literature includes limited studies on detecting RcP adulteration using digital imaging techniques. However, these studies primarily focus on identifying a single type of adulterant in RcP. For instance, Sarkar et al.9 constructed a dataset containing images of RcP (variety: Bullet Lanka) adulterated with brick powder and employed various ML models based on colour space features and achieved a maximum classification accuracy of 90.49%. Building on this work, our research group addressed dataset limitations by applying preprocessing, extracting texture and histogram features, and implementing feature selection, which increased the brick powder detection accuracy to 99.31%.31Expanding the scope of AI applications for detecting unethical adulteration in RcP, the presented research work develops a more comprehensive labelled dataset incorporating multiple types of natural adulterants (five) consisting of 16 classes. DenseNet-169 with an AdamClr optimizer is trained to identify adulteration, achieving an accuracy of 99.99% in binary classification, and for multiclass classification the accuracy is 95.16% for distinguishing pure and adulterated RcP samples at various concentrations. Furthermore, the interpretability of the trained DenseNet-169 model is enhanced using the XAI technique, which explains the novelty of the proposed study.
On the other hand, various studies applied AI methods for quality evaluation of various food products. In a study Fatima et al.32 implemented a Siamese network to detect papaya seed adulteration in black pepper, achieving an accuracy of 92%. Similarly, Rady et al.33 developed an adulteration detection method for minced meat by integrating colour space and texture features to train an ensemble linear discriminant classifier, which attained 98% accuracy in differentiating pure and adulterated samples. In another study, Brar et al.8 utilized a 2D-CNN model to identify corn syrup adulteration in honey by analysing images extracted from test sample videos, achieving 99% classification accuracy. Additionally, Sehirli et al.34 investigated butter adulteration with vegetable fat, where both artificial neural networks (ANNs) and support vector machines (SVMs) achieved an accuracy of 99%.
Moreover, the integration of explainable AI (XAI) with 2D-CNN was explored for determining seabream freshness, where the DenseNet-121 model achieved 100% classification accuracy. This model was further analysed using Grad-CAM and LIME to enhance interpretability.30 Moreover, InceptionV3 was employed alongside LIME to enhance transparency and accuracy in sorting chicken meat into fresh and rotten categories, attaining a sorting accuracy of 96.3%. A 2D-CNN-LIME-based system further guided a robotic arm in processing 1000 fresh and 300 rotten chicken meat samples, achieving precision rates of 94.19% for fresh meat and 97.24% for rotten meat.16 Besides, Benjamin,35 employed the YOLOv5 model for the accurate recognition and classification of bread quality attributes. The model was trained on a comprehensive dataset comprising images of various bread types, each annotated with the corresponding quality labels. By leveraging the advanced object detection capabilities of YOLOv5, the system effectively identifies and categorizes different quality attributes with an accuracy of 92.00%, ensuring a robust and efficient evaluation of bread quality.
All in all, this research work demonstrates that the proposed model serves as a reliable and effective approach for detecting adulteration in RcP. Furthermore, explainable AI technique Grad-CAM is utilized to interpret the decision-making process of the highest-performing 2D-CNN model. Grad-CAM provides visual insights by identifying key image regions that influenced classification. The combined analysis validates the model's reliability and confirmed its ability to focus on adulteration-specific features.
3.5. Limitations and future research directions
While the proposed framework demonstrates high accuracy in detecting adulteration in RcP using DenseNet architectures, several limitations must be acknowledged. First, the study is currently limited to a specific variety (WH) of RcP and selected natural adulterants; 36 thus, the scalability of the model to other food products with varying physical characteristics remains untested. Additionally, real-world deployment could face challenges such as variations in sample presentation, lighting conditions, and adulterant types not included in the training dataset, potentially affecting model robustness and generalization.Therefore, future research should focus on expanding the dataset to include a broader range of food products and adulterants under diverse environmental conditions to enhance model adaptability. Furthermore, investigating the performance of alternative AI models, such as vision transformers, lightweight CNN architectures, or hybrid deep learning approaches, could further optimize detection accuracy and computational efficiency. Incorporating real-time data acquisition systems and transfer learning strategies could also facilitate the practical deployment of AI-based adulteration detection tools in industrial and regulatory settings.
4. Conclusion
This work addresses the critical issue of RcP adulteration by introducing a dataset and an advanced 2D-CNN-XAI framework to detect the unauthorized blending of natural adulterants in the most prominent RcP (WH) variety. The proposed system includes a newly developed dataset comprising 16 labelled classes, representing pure RcP and RcP adulterated with five natural adulterants at concentrations ranging from a minimum of 5% to a maximum of 15%. An empirical evaluation of DenseNet-121 and DenseNet-169 with the AdamClr optimizer is conducted to identify the most effective model for classifying pure and adulterated RcP. Additionally, explainability technique Grad-CAM is employed to interpret the classification decisions of the best-performing model. Each model was trained using two datasets (DS I for binary classification and DS II for multiclass classification) at three different BSs (16, 32, and 64) with a fixed cyclic learning rate (ranging from 0.00005 to 0.001). For binary classification an accuracy of 99.99% is delivered by DenseNet-169 at BS 16. Whereas, for multiclass classification DenseNet-169 at BS 64 effectively detects different concentrations of adulterants in RcP with an accuracy value of 95.16%. Furthermore, XAI techniques, specifically Grad-CAM validated the decision-making process of DenseNet-169, confirming its ability to accurately differentiate between pure and adulterated RcP samples. The superior performance of DenseNet-169 underscores its potential for application in quality assessment and adulteration detection in RcP. Therefore, this study provides a highly effective and reliable AI-driven solution for combating RcP adulteration. By integrating the XAI-2D-CNN model, the framework ensures exceptional specificity and reliability in quality evaluation.Data availability
Data will be made available on request to the authors.Conflicts of interest
There is no conflict of interest between the authors.References
- N. R. Mavani, J. M. Ali, S. Othman, M. A. Hussain, H. Hashim and N. A. Rahman, Application of artificial intelligence in food industry—a guideline, Food Eng. Rev., 2022, 14(1), 134–175 CrossRef.
- The Business Research Company, Artificial intelligence (AI) in FoodTech global market report, 2025, [cited 2025 May 14], Available from: https://www.thebusinessresearchcompany.com/report/artificial-intelligence-ai-in-foodtech-global-market-report Search PubMed.
- V. Zatsu, A. E. Shine, J. M. Tharakan, D. Peter, T. V. Ranganathan, S. S. Alotaibi, R. Mugabi, A. B. Muhsinah, M. Waseem and G. A. Nayik, Revolutionizing the food industry: the transformative power of artificial intelligence—a review, Food Chem.: X, 2024, 101867 CAS.
- M. Shamsuddoha, E. A. Khan, M. M. H. Chowdhury and T. Nasir, Revolutionizing supply chains: unleashing the power of AI-driven intelligent automation and real-time information flow, Information, 2025, 16(1), 26 CrossRef.
- D. S. Brar, B. Singh and V. Nanda, Application of image-based features and machine learning models to detect brick powder adulteration in red chili powder, J. Food Process Eng., 2024, 47(11), e14762 CrossRef CAS.
- A. Ullah, M. W. H. Chan, S. Aslam, A. Khan, Q. Abbas and S. Ali, et al., Banned Sudan dyes in spices available at markets in Karachi, Pakistan, Food Addit. Contam.: Part B, 2023, 16(1), 69–76 CrossRef CAS PubMed.
- Y. Sadef, S. Shakil, D. Majeed, N. Zahra, F. B. Abdallah and M. B. Ali, Evaluating aflatoxins and Sudan dyes contamination in red chili and turmeric and its health impacts on consumer safety of Lahore, Pakistan, Food Chem. Toxicol., 2023, 182, 114116 CrossRef CAS PubMed.
- D. S. Brar, A. K. Aggarwal, V. Nanda, S. Saxena and S. Gautam, AI and CV based 2D-CNN algorithm: botanical authentication of Indian honey, Sustainable Food Technol., 2024, 2(2), 373–385 RSC.
- T. Sarkar, T. Choudhury, N. Bansal, V. R. Arunachalaeshwaran, M. Khayrullin, M. A. Shariati and J. M. Lorenzo, Artificial intelligence aided adulteration detection and quantification for the resultant pure RcP and adulterants were then blended, Food Anal. Methods, 2023, 16(4), 721–748 CrossRef.
- G. Hinton, Y. LeCun and Y. Bengio, Deep learning, Nature, 2015, 521(7553), 436–444 CrossRef PubMed.
- L. H. Yao, K. C. Leung, C. L. Tsai, C. H. Huang and L. C. Fu, A novel deep learning–based system for triage in the emergency department using electronic medical records: retrospective cohort study, J. Med. Internet Res., 2021, 23(12), e27008 CrossRef PubMed.
- H. He and E. A. Garcia, Learning from imbalanced data, IEEE Trans. Knowl. Data Eng., 2009, 21(9), 1263–1284 Search PubMed.
- M. Tan and Q. Le, EfficientNet: rethinking model scaling for convolutional neural networks, in Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, 2019, pp 6105–6114, DOI:10.48550/arXiv.1905.11946.
- G. Huang, Z. Liu, L. van der Maaten and K. Q. Weinberger, Densely connected convolutional networks, IEEE Trans. Pattern Anal. Mach. Intell., 2017, 41(12), 2753–2769 Search PubMed.
- K. Simonyan, Very deep convolutional networks for large-scale image recognition, arXiv, 2014, preprint, arXiv:1409.1556, DOI:10.48550/arXiv.1409.1556.
- M. Hasan, N. Vasker and M. S. H. Khan, Real-time sorting of broiler chicken meat with robotic arm: XAI-enhanced deep learning and LIME framework for freshness detection, J. Agric. Food Res., 2024, 18, 101372 CAS.
- O. Buyuktepe, C. Catal, G. Kar, Y. Bouzembrak, H. Marvin and A. Gavai, Food fraud detection using explainable artificial intelligence, Expert Syst., 2023, 42(1), e13387, DOI:10.1111/exsy.13387.
- A. Adak, B. Pradhan, N. Shukla and A. Alamri, Unboxing deep learning model of food delivery service reviews using explainable artificial intelligence (XAI) technique, Foods, 2022, 11(14), 2019, DOI:10.3390/foods11142019.
- S. Bhatia and A. S. Albarrak, A blockchain-driven food supply chain management using QR code and XAI-Faster RCNN architecture, Sustainability, 2023, 15(3), 2579, DOI:10.3390/su15032579.
- R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh and D. Batra, Grad-CAM: visual explanations from deep networks via gradient-based localization, Int. J. Comput. Vis., 2020, 128, 336–359, DOI:10.1007/s11263-019-01228-7.
- R. Elshamy, O. Abu-Elnasr, M. Elhoseny and S. Elmougy, Improving the efficiency of RMSProp optimizer by utilizing Nestrove in deep learning, Sci. Rep., 2023, 13(1), 8814 CrossRef CAS PubMed.
- D. P. Kingma and J. Ba, Adam: a method for stochastic optimization, arXiv, 3rd Int Conf Learn Represent, San Diego, 2015, preprint, arXiv:1412.6980, DOI:10.48550/arXiv.1412.6980.
- L. N. Smith, Cyclical learning rates for training neural networks, in Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), IEEE, 2017, pp 464–472, DOI:10.1109/WACV.2017.58.
- F. Chollet, Keras Applications API Documentation, 2025 [cited 2025 Mar 12]. Available from: https://keras.io/api/applications/ Search PubMed.
- D. Masters and C. Luschi, Revisiting small batch training for deep neural networks, arXiv, 2018, preprint, arXiv:1804.07612, DOI:10.48550/arXiv.1804.07612.
- N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy and P. T. P. Tang, On large-batch training for deep learning: generalization gap and sharp minima, arXiv, 2016, preprint, arXiv:1609.04836, DOI:10.48550/arXiv.1609.04836.
- S. Santurkar, D. Tsipras, A. Ilyas and A. Madry, How does batch normalization help optimization?, in Proceedings of the 33rd International Conference on Neural Information Processing Systems, 2019, vol. 32, pp. 2483–2493, Available from: https://arxiv.org/abs/1805.11604 Search PubMed.
- S. Ioffe and C. Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift, in Proceedings of the 32nd International Conference on International Conference on Machine Learning, 2015, vol. 37, pp. 448–456, Available from: http://proceedings.mlr.press/v37/ioffe15.html Search PubMed.
- C. M. Bishop and N. M. Nasrabadi, Pattern Recognition and Machine Learning, Springer, New York, 2006 Search PubMed.
- I. Y. Genc, R. Gurfidan and T. Yigit, Quality prediction of seabream (SPARUS AURATA) by deep learning algorithms and explainable artificial intelligence, Food Chem., 2025, 143150 CrossRef CAS PubMed.
- D. S. Brar, A. K. Aggarwal, V. Nanda, S. Kaur, S. Saxena and S. Gautam, Detection of sugar syrup adulteration in unifloral honey using deep learning framework: an effective quality analysis technique, Food Humanit., 2024, 2, 100190, DOI:10.1016/j.foohum.2023.11.017.
- N. Fatima, Q. M. Areeb, I. M. Khan and M. M. Khan, Siamese network–based computer vision approach to detect papaya seed adulteration in black peppercorns, J. Food Process. Preserv., 2022, 46(9), e16043 CAS.
- A. M. Rady, A. Adedeji and N. J. Watson, Feasibility of utilizing color imaging and machine learning for adulteration detection in minced meat, J. Agric. Food Res., 2021, 6, 100251 Search PubMed.
- E. Sehirli, C. Dogan and N. Dogan, Determination of margarine adulteration in butter by machine learning on melting video, J. Food Meas. Charact., 2023, 17(6), 6099–6108 CrossRef.
- R. M. Benjamin, Bread quality assessment using deep learning with shape and volume metrics, in 2024 10th International Conference on Advanced Computing and Communication Systems (ICACCS), IEEE, 2024, vol. 1, pp. 2125–2130 Search PubMed.
- D. S. Brar, Red Chilli Adulteration: Digital image Dataset (DS-WH-1), Mendeley Data, V1, 2025, DOI:10.17632/mszn5hk9nv.1.
Footnote |
| † Electronic supplementary information (ESI) available. See DOI: https://doi.org/10.1039/d5fb00118h |
| This journal is © The Royal Society of Chemistry 2025 |