
 Open Access Article
Open Access Article This Open Access Article is licensed under a
This Open Access Article is licensed under a Creative Commons Attribution 3.0 Unported Licence
Artificial design of organic emitters via a genetic algorithm enhanced by a deep neural network†
AkshatKumar
Nigam‡
ab,
Robert
Pollice‡§
 *ab,
Pascal
Friederich
abcd and
Alán
Aspuru-Guzik
*abefghi
*ab,
Pascal
Friederich
abcd and
Alán
Aspuru-Guzik
*abefghi
aChemical Physics Theory Group, Department of Chemistry, University of Toronto, 80 St. George St, Toronto, Ontario M5S 3H6, Canada. E-mail: r.pollice@rug.nl; aspuru@utoronto.ca
bDepartment of Computer Science, University of Toronto, 40 St. George St, Toronto, Ontario M5S 2E4, Canada
cInstitute of Nanotechnology, Karlsruhe Institute of Technology, Hermann-von-Helmholtz-Platz 1, 76344 Eggenstein-Leopoldshafen, Germany
dInstitute of Theoretical Informatics, Karlsruhe Institute of Technology, Am Fasanengarten 5, 76131 Karlsruhe, Germany
eVector Institute for Artificial Intelligence, 661 University Ave Suite 710, Toronto, Ontario M5G 1M1, Canada
fDepartment of Chemical Engineering & Applied Chemistry, University of Toronto, 200 College St., Ontario M5S 3E5, Canada
gDepartment of Materials Science & Engineering, University of Toronto, 184 College St., Ontario M5S 3E4, Canada
hLebovic Fellow, Canadian Institute for Advanced Research (CIFAR), 661 University Ave, Toronto, Ontario M5G, Canada
iAcceleration Consortium, Toronto, Ontario M5G 3H6, Canada
First published on 11th January 2024
Abstract
The design of molecules requires multi-objective optimizations in high-dimensional chemical space with often conflicting target properties. To navigate this space, classical workflows rely on the domain knowledge and creativity of human experts, which can be the bottleneck in high-throughput approaches. Herein, we present an artificial molecular design workflow relying on a genetic algorithm and a deep neural network to find a new family of organic emitters with inverted singlet-triplet gaps and appreciable fluorescence rates. We combine high-throughput virtual screening and inverse design infused with domain knowledge and artificial intelligence to accelerate molecular generation significantly. This enabled us to explore more than 800![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 000 potential emitter molecules and find more than 10000 candidates estimated to have inverted singlet-triplet gaps (INVEST) and appreciable fluorescence rates, many of which likely emit blue light. This class of molecules has the potential to realize a new generation of organic light-emitting diodes.
000 potential emitter molecules and find more than 10000 candidates estimated to have inverted singlet-triplet gaps (INVEST) and appreciable fluorescence rates, many of which likely emit blue light. This class of molecules has the potential to realize a new generation of organic light-emitting diodes.
Introduction
The introduction of SELFIES as a strictly robust molecular string representation not only allowed to enforce complete validity of every point in the latent space of deep generative models,1 but also enabled molecular generation via random string operations,2 which is an extremely inefficient process with the SMILES representation,3 as the overwhelming majority of random string modifications will lead to invalid SMILES strings. Accordingly, making use of SELFIES, the STONED algorithm allows for efficient and comprehensive navigation of the organic chemical space via random string modification and string interpolation.2 These unique capabilities of SELFIES can be leveraged in population-based metaheuristic optimization algorithms for inverse molecular design such as genetic algorithms4–9 (GAs) without relying on domain-specific genetic operators.10,11 Further enhancements of evolutionary algorithms via artificial neural networks (ANNs) have recently been demonstrated to improve molecular space exploration significantly leading to good performance in established artificial design benchmarks.10–12 Additionally, genetic algorithms for inverse molecular design showed consistently strong performance across multiple realistic molecular design domains in the Tartarus benchmarking suite.12 Specifically, genetic algorithms outperformed more sophisticated deep generative models such as variational autoencoders, sequence generation models, and flow-based generative models, without requiring any pre-training before initiating the inverse molecular design run. Thus, importantly, artificial molecular design workflows relying on genetic algorithms can be applied to any molecular design task with well-defined target properties out of the box even without prior knowledge of well-performing structural families.13,14 Furthermore, genetic algorithms are particularly suitable for target-oriented open ended design tasks as they explore the chemical space of interest as comprehensively as desired and they are not bound by the structure distribution of the training data.State-of-the-art organic light-emitting diodes rely on molecules with energy differences below around 0.1 eV between the first excited singlet and the first excited triplet state,15 which enables efficient upconversion of non-emissive excited triplets to emissive excited singlets via reverse intersystem crossing in a mechanism referred to as thermally activated delayed fluorescence.16 While this mechanism enabled the realization of emissive devices with internal quantum efficiencies of 100%, long-term device performance can still suffer from substantial degradation caused by excited triplets, which are always present in substantial amounts, a problem particularly pronounced in blue organic emitters.17,18 In principle, this drawback could be overcome when molecules possess first excited singlet states that are lower in energy than the corresponding first excited triplet states. However, when Hund's first rule is applied to the first excited states, the first excited triplet state is predicted to be lower in energy compared to the corresponding singlet state.19 While Hund's first rule is not a fundamental law of physics, it provides an accurate description of the electronic structure of the vast majority of known molecules.20
Organic molecules with first excited singlet states lower in energy than the first excited triplet states are said to possess an inverted singlet-triplet gap (STG), which is referred to as INVEST.21 As they violate Hund's first rule, these molecules have been assumed to be extremely rare,22,23 however, recent work has uncovered a considerable number of structural families with that property,21 followed by systematic computational studies of their excited state properties.24,25 The inverted energy ordering between the first excited states stems from dynamic spin polarization stabilizing the first excited singlet relative to the triplet and this spin polarization is largely localized on a core structure.26 Hence, these core structures are responsible for the inverted energy gaps in all the known INVEST molecules, and recent experimental demonstrations have confirmed some of the predictions.27 Despite the promise of inverted STGs to increase device lifetimes in organic light-emitting diodes, most of the INVEST core structures found to date correlate with intrinsically low oscillator strengths (OSs) and, thus, slow fluorescence rates, which renders them ineffective as emitters. Accordingly, the design of organic emitters with both inverted STGs and appreciable OSs, resulting in high fluorescence rates, remains challenging and only a few studies relying on virtual screening of systematic datasets28–30 or with structure suggestions from human experts have been demonstrated.21,26
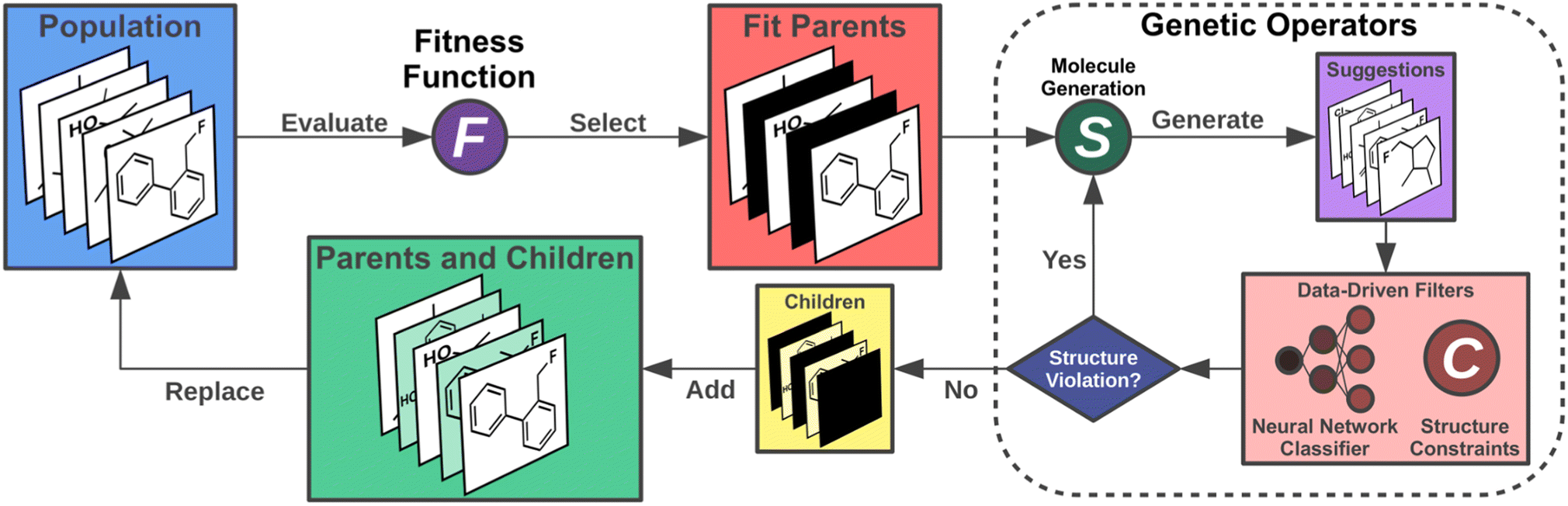
In this work, we implement an artificial molecular design workflow to find organic INVEST emitters relying on a GA for efficient molecular generation making use of SELFIES and the STONED algorithm in the genetic operators. The complete workflow consists of hit identification via virtual screening, artificial molecular design and lead validation (Fig. 1). Sampling of the relevant molecular space is enhanced by a comprehensive set of filters based on domain knowledge and a data-driven ANN classifier that learns the structures of the best candidates encountered previously. This workflow relies on an efficient property simulation workflow for the relevant excited state properties implementing double-hybrid time-dependent density functional approximation (DH-TD-DFA) calculations. Thus, it enables us to explore more than 800000 organic emitter candidates and uncover a new class of molecules with both inverted STG and appreciable OS possessing azulene core structures. More than 13000 of the best candidates are evaluated with a reliable wavefunction-based excited state simulation method confirming that at least more than one thousand promising structures were uncovered, including potential blue emitters. Additionally, in the entire dataset, there are more than ten thousand molecules likely to have inverted STGs and appreciable OSs. Hence, this work expands the space of INVEST emitters dramatically and is the next step towards realizing the fifth generation of organic light-emitting diode materials.
 | ||
| Fig. 1 Accelerated molecular discovery workflow adopted in this work starting from high-throughput virtual screening, proceeding to artificial molecular design via a genetic algorithm enhanced by neural networks and filters based on domain knowledge, and finishing with lead validation. | ||
Results
Virtual screening
We started this work by identifying promising new core structure families that both allow for the design of INVEST emitters with appreciable OS and are likely realizable in the laboratory. In a recent work, bottom-up construction rules for molecules with inverted STGs were established that facilitated the identification of 15 new core structure families predicted to have members being INVEST molecules.26 In that work, in addition to their excited state properties, their synthesizability and stability were assessed and one of the most promising core structures was proposed to be azulene due to the existence of reliable syntheses for a considerable range of derivatives.26 Azulenes are known to be very stable and are already widely used organic electronic materials.31–35 Based on that work, azulene was selected for further investigation.However, we were still interested in identifying additional promising structures. Hence, by developing a comprehensive set of filters (cf. methods) we created a subset of GDB-13,36 originally comprising more than 970 million organic molecules, with over 400000 structures possessing cycles and a high degree of conjugation. Subsequently, we performed high-throughput virtual screening of the corresponding structures relying on a quantum chemical DH-TD-DFA, namely ωB2PLYP’.37 This method has been benchmarked extensively against various reference methods that are based on excited state wavefunction theory approaches for simulating INVEST molecules and was shown to reproduce the property trends of INVEST molecules reliably.21 Additionally, based on these benchmarks, it provides the best trade-off between robustness and simulation cost, which is critical for high-throughput virtual screening. Notably, it is key to use computational methods that account for double excitations.22 Among the 292 structures with small predicted STGs below 0.25 eV, 61 structures (21%) were based on azulene, whereas 38 (13%) were based on pentalene, recently identified as INVEST motif using bottom-up construction rules,26 and only 11 (4%) on phenalene, which was studied extensively as core structure for INVEST emitters with appreciable fluorescence rates.21 Accordingly, azulene was again highlighted as promising INVEST core structure and we decided to focus our molecular design on this family for the rest of this work.
Thus, as established in a previous work on INVEST emitters based on phenalene cores,21 we generated all 144 systematic permutations of core structure nitrogen substitutions of azulene and simulated the corresponding excited state properties at the ωB2PLYP’,37 ADC(2),38–44 SOS-ADC(2)41,45–53 and EOM-CCSD54–58 levels of theory. The corresponding property maps at the EOM-CCSD level of theory are depicted in Fig. 2.
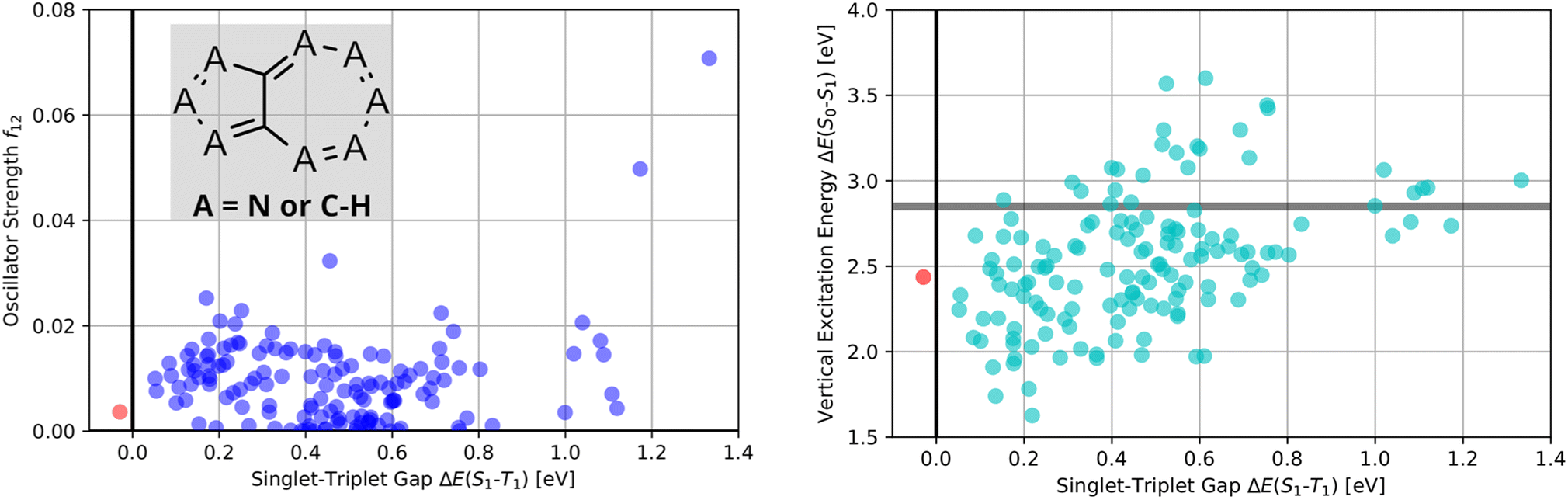 | ||
| Fig. 2 Property maps of all systematic permutations of nitrogen core structure substitutions of azulene at the EOM-CCSD/cc-pVDZ level of theory. (A) Singlet-triplet gap plotted against oscillator strength. (B) Singlet-triplet gap plotted against vertical excitation energy. The red data point denotes the only structure predicted to have an inverted singlet-triplet gap at this level of theory. | ||
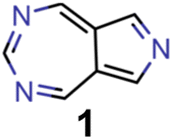
They reveal that only one of the nitrogen-substituted core structures, namely 2,5,7-triazaazulene (molecule 1, cf.Table 2), is predicted to have an inverted STG at that level of theory. Accordingly, we selected 1 as the starting point for our artificial design campaign described in the next section. Notably, the simulation results for all 144 azulene cores were compared to EOM-CCSD as reference method (cf. Supplementary Fig. 1 and Table 1†). The methods employed, while showing both deviations and uncertainties relative to EOM-CCSD, can reproduce trends in the three properties of interest, namely, STGs, OSs and vertical excitation energies (VEEs), and are, thus, appropriate for the subsequent artificial design workflow.59 Importantly, SOS-ADC(2) showed the most reliable property predictions compared to EOM-CCSD at only a fraction of the computational expense and, hence, it was decided to be used for the lead validation (vide infra).
Artificial design
Having chosen the structural family to be investigated, next, we implemented the artificial design workflow (Fig. 3). We used a development version of JANUS,11 an extension of a previously published GA for inverse molecular design,10 that relies on the STONED algorithm2 for genetic operators but only propagates one generation of molecules. To evaluate the fitness of the proposed molecules, the excited state properties were simulated at the ωB2PLYP’ level of theory. The filters developed for the GDB-13 subset consisting of cyclic π-systems were implemented as necessary requirements for every structure generated, leading to increased sampling of the relevant structural space. Additionally, these filters were continuously updated based on expert opinion to eliminate infeasible structures proposed by our artificial design workflow. Furthermore, in each run, the first 11 generations were proposed without the use of ANNs enhancing sampling. Subsequently, all molecules encountered until generation 11 in each but the first experiment (vide infra) were used to train ANN classifiers identifying high-performing candidates at low computational cost and with high classification accuracy (cf.Table 1).| Run | Classification accuracy | Success rate | Candidates | |||
|---|---|---|---|---|---|---|
| Validation | Holdout | G 11, without classifier | G 12, with classifier | STG < 0.36 eV | STG < 0.36 eV, OS > 0.05 | |
| 1 | — | — | — | — | 809 | 2 |
| 2 | 92.0% | 91.0% | 7.8% | 31.3% | 25503 |
312 |
| 3 | 98.0% | 98.0% | 7.0% | 23.3% | 24142 |
293 |
| 4 | 91.0% | 90.0% | 7.5% | 24.8% | 27867 |
334 |
| 5 | 89.0% | 89.0% | 6.6% | 28.9% | 34235 |
6811 |
| 6 | 90.0% | 89.0% | 6.9% | 27.1% | 50266 |
3074 |
| All | — | — | — | — | 148311 |
10736 |
 | ||
| Fig. 3 Artificial design workflow with a genetic algorithm employed for the design of organic INVEST emitters based on azulene enhanced by data-driven structure filters including an artificial neural network. | ||
These classifiers were incorporated into the genetic operators and used as additional filters. Hence, only molecules classified as good were passed on to the fitness evaluation to reduce the number of costly DFT simulations for 4 subsequent generations and improve the exploration of promising candidates even further. This is demonstrated based on the success rates of generating molecules with low singlet-triplet gaps (STGs) and non-zero OSs in each of the experiments which increased to 3-4 times the original value when the classifier was incorporated (cf.Table 1). Notably, as detailed below, we also explored the use of a few alternative fitness evaluation procedures. In all runs, structures with STGs above a certain threshold were assigned a very low fitness. Finally, to avoid prohibitively expensive quantum chemistry simulations, we capped the size of the molecules generated at 70 atoms, including hydrogens, and we only allowed previously unseen structures.
As the first artificial design experiment, we used methane as seed molecule for the first generation and used OS minus STG as a fitness function, with an upper STG threshold of 0.6 eV for high fitness (see computational methods and Table 5 for details and mathematical expressions). We wanted to test our workflow for its ability to discover potential INVEST core structures without bias from the seed. The corresponding optimization progress is depicted in Fig. 4A. After three generations that explore the property space very extensively, the optimization trajectory focusses on promising candidates with low STGs and non-negligible OSs. Notably, in this run we did not train a classifier after 11 generations of experiments but stopped the study, as the goal of the experiment was to find potential interesting hits rather than perform comprehensive optimization. Indeed, azulenes were already explored in the first generation suggesting that the implemented filters strongly bias the molecular generation towards relevant cyclic π-systems. Apart from azulenes, several other known INVEST core structures were identified as promising candidates including cyclobuta-1,3-diene, cycloocta-1,3,5,7-tetraene, pentalene, bowtiene, heptalene, zurlene and anthrazulene.26 Importantly, azulenes accounted for 6% of all the structures explored and they were also most prevalent among the best candidates proposed in our first experiment. This reaffirmed our decision to focus all subsequent artificial design efforts on azulenes. Finally, while the best candidates possessed promising STGs, the OSs were only improved to a limited extent.
 | ||
| Fig. 4 Progress of the property distributions spanned by the 200 molecules with highest fitness with respect to singlet-triplet gaps (STGs) and oscillator strengths (OSs) as a function of the generation numbers in each of the six artificial design experiments carried out (A)–(F) and the corresponding legend (G). The individual data points mark the properties of the molecules encountered, the enclosed areas of each generation are the corresponding alpha shapes of the point clouds. The dashed and dotted lines in each plot are at identical coordinates and are visual anchors indicating the edge of the property distribution reached in experiment 6. | ||
In the second, third and fourth artificial design experiments, we used molecule 1 as initial seed. Additionally, only structures containing azulene-like π-systems were accepted in the molecular generation to ensure extensive exploration of that structural family. Furthermore, the upper STG threshold for high fitness values was 0.3 eV in all these runs. The only difference between these three experiments was the fitness function employed. In experiment 2, as in experiment 1, a linear combination of the additive inverse of the STG and OS was used. In experiment 3, only the OS determined the fitness. In experiment 4, the fitness was a linear combination of the additive inverse of the STG, the OS and the absolute difference to a VEE of 3.2 eV. The latter value corresponds to the energy of blue light absorption, but only after correction for the inherent systematic offset of ωB2PLYP’.21 Again, optimization progresses are depicted in Fig. 4B–D. Most importantly, compared to the first run, both lower STGs and higher OSs are attained in all three runs resulting in promising INVEST emitter candidates (cf.Fig. 6A). When comparing experiments 2 and 3, we were surprised to see that including the STG explicitly into the fitness function does not seem to result in molecules with lower STGs. However, as we expected, experiment 3 results in property distributions biased towards higher OS values. Strikingly, experiment 4 resulted in candidates with both the highest OSs and the lowest STGs among the three runs discussed in this paragraph. Notably, the corresponding optimization progress with respect to the VEEs is depicted in Fig. 5 showing that the optimization trajectory moved continuously towards higher VEEs.
 | ||
| Fig. 5 Progress of the property distributions spanned by the 200 molecules with highest fitness with respect to singlet-triplet gaps, oscillator strengths and vertical excitation energies as a function of the generation numbers in artificial design experiment 4 (A) and (B) and the corresponding legend (C). The individual data points mark the properties of the molecules encountered, the enclosed areas of each generation are the corresponding alpha shapes of the point clouds. STG: Singlet-triplet gap, OS: oscillator strength, VEE: vertical excitation energy. | ||
 | ||
| Fig. 6 Comparison of the property distributions spanned by the 200 molecules with highest fitness proposed in each of the six artificial design experiments conducted (A)–(C). The individual data points mark the properties of the molecules encountered, the enclosed areas of each generation are the corresponding alpha shapes of the point clouds. | ||
In order to test whether the OSs can be further increased without compromising the STGs, we analyzed the high performing molecules and noticed that several promising candidates had substituents both in the 1- and 6-positions of the azulene core (cf. Supplementary Fig. 2†). Hence, to narrow down the space to be explored, focus on more promising structures and increase synthesizability, we decided to not only constrain the molecules generated in experiment 5 to possess an azulene-like π-system, but also enforce them to be identically substituted at the 1- and 6-positions. This was achieved by first generating the structures of the substituents which were subsequently attached to an azulene core structure only at the respective positions. Additionally, we decided to again use a linear combination of the additive inverse of the STG and the OS as fitness function. The corresponding optimization progress and property distributions (cf.Fig. 4E and 6) confirmed that this design choice indeed resulted in significantly better candidates as both STGs tended to be lower and OSs tended to be higher.
Encouraged by the results of experiment 5, we wanted to increase the sampling of promising molecules even further and decided to enforce the structures to have a plane of symmetry through the azulene core. Additionally, we also kept the core nitrogen substitutions equivalent to molecule 1 in all proposed structures. Furthermore, we decided to only allow substitutions at the 4- and 8-positions as these would be preferred for the introduction of donor moieties based on the bottom-up design principles for INVEST emitters established previously.26 As evident from the results (cf.Fig. 4F and 6), this design space resulted in by far the best organic emitter candidates among all the six artificial design experiments carried out. While the STG distributions were essentially equivalent to experiment 5, the OSs made a significant leap, reaching values far larger than 1. Importantly, these are better property trade-offs than have been attained in previous expert-guided INVEST emitter designs.21 Additionally, even though the VEEs were not explicitly optimized in this run, a significant fraction of the structures generated in experiment 6 had VEEs in the blue light region. Furthermore, our artificial design workflow incorporated intramolecular hydrogen-bonding to the core nitrogen atoms in the most promising candidates, which has been proposed before as a very effective strategy to increase OSs of INVEST emitters.21
A comparison of the property distributions of the molecules with highest fitness in each experiment is depicted in Fig. 6. It suggests that, by altering the setups in each run, we successfully directed our artificial design workflow to ever more promising organic INVEST emitters. Additionally, in Table 2 we also compared some of the molecules with high fitness in each of the runs and their properties as this comparison provides an overview of the structural features characteristic of each artificial design experiment and of the diversity of structures generated. Importantly, all the molecules shown are likely stable and, thus, should in principle be realizable in the laboratory. A combined property distribution map of all the 869365 molecules generated and simulated in the course of the artificial design experiments can be found in Fig. 7A–C. Individual property distribution maps for each experiment are depicted in Supplementary Fig. 3–8.†
| Experiment | Molecule | ΔE(S1–T1) [eV] | f 12 | ΔE(S0–S1) [eV] |
|---|---|---|---|---|
| 0 (seed) |
|
0.24 | 0.005 | 2.71 |
| 1 |

|
0.39 | 0.045 | 2.14 |
| 1 |

|
0.23 | 0.024 | 1.70 |
| 2 |

|
0.13 | 0.269 | 2.63 |
| 2 |

|
0.30 | 0.079 | 3.19 |
| 3 |

|
0.08 | 0.087 | 1.71 |
| 3 |

|
0.25 | 0.083 | 2.65 |
| 4 |
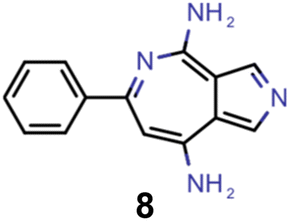
|
0.30 | 0.048 | 3.23 |
| 4 |

|
0.29 | 0.073 | 2.94 |
| 5 |

|
0.16 | 0.548 | 1.80 |
| 5 |

|
0.01 | 0.111 | 2.34 |
| 6 |

|
0.30 | 1.356 | 3.10 |
| 6 |

|
−0.07 | 0.529 | 2.54 |
 | ||
| Fig. 7 Property distributions of all the compounds generated during the artificial design stage (A)–(C) and the subset that is estimated to consist of INVEST compounds (D)–(F) at the ωB2PLYP’ level of theory colored by the number of molecules in the respective property windows. STG: Singlet-triplet gap, OS: oscillator strength, VEE: vertical excitation energy. | ||
Finally, we wanted to get insight into what the ANN classifiers, which were used as pre-filters for DFT simulations, learned in each of the experiments they were trained and used. To do that, we used the exmol package60 that implements the model agnostic counterfactual compounds with STONED (MACCS) methodology, that was recently developed. We adapted the corresponding workflow by implementing our filters for π-systems in the counterfactual generation to mimic the genetic operators of our GA. Additionally, while in the field of explainable artificial intelligence the generation of counterfactuals to understand decisions and predictions is well established,61 we were also interested in generating profactuals, i.e., instances that are most similar to the reference and retain the same predictions. The idea is to not only find the smallest feature changes altering predictions60,62 but also to explore equally small feature changes not altering them. Accordingly, profactuals can be regarded as counterfactuals to the counterfactuals themselves and provide additional insight into the significance of counterfactual explanations.
Hence, we extended the implementation of MACCS to analyze both profactuals and counterfactuals in a consistent way. Subsequently, we applied this extended workflow to explain the predictions of the ANN classifiers based on the most promising candidates of each experiment listed in Table 2 except the first. The corresponding results for molecules 4–13 are illustrated in Supplementary Fig. 9–18.† Based on the structural comparison between the profactuals and counterfactuals, we find that changes to the core ring system are always counterfactuals. Additionally, the classifiers are sensitive to the nitrogen substitution pattern of the azulene π-system which is exemplified by some being regarded as acceptable and others being discarded. Furthermore, they are also sensitive to the type and position of substituents directly attached to the azulene core which is consistent with the bottom-up construction of INVEST molecules established recently. Moreover, some substituents, in particular when consisting of 4-membered and 8-membered ring systems, are always discarded regardless of whether they are directly attached to the core or further away. However, the classifiers are less sensitive to structural changes further away from the core ring system which is particularly apparent from the results for larger candidates where the introduction of additional substituents or the incorporation of heteroatoms is largely accepted. It should also be noted that substituent changes not affecting the electronic structure significantly are more likely to be accepted by the classifiers. Nevertheless, some counterfactuals correspond to structural changes that should not affect the properties of interest significantly. Similarly, some profactuals, in particular for the last two experiments with fixed substituent positions, break the corresponding constraints and, thus, move away from the structural space used for training.
Lead validation
After having found a large number of INVEST emitter candidates through artificial design, we proceeded to validate the best compounds across all runs using more reliable quantum chemistry simulations at the SOS-ADC(2) level of theory.41,45–53 This is important as the best-performing structures are significantly different from the initial candidates found in the high-throughput virtual screening. Additionally, using a different level of theory as employed by the genetic algorithm is key to check whether the algorithm exploited inherent methodology deficiencies. Accordingly, we combined the molecules from all experiments and applied Chimera63 to scalarize multiple objectives and select the best-performing molecules based on the resulting rankings. Thus, two independent rankings were established, one based on both STGs and OSs (Objective A), the other based on STGs, OSs and VEEs (objective B). In each of these rankings, the 7500 best molecules were selected for further validation, resulting in a total set of 13222 unique compounds as some compounds appeared in both rankings. The corresponding property distributions at the ωB2PLYP’ and SOS-ADC(2) levels are depicted in Fig. 8 and the property correlations between the two methods are shown in Supplementary Fig. 19.† It should be noted that the distributions depicted in Fig. 8 result from concatenating two subsets with distinct property distributions. Consequently, the combined property distributions, especially at the ωB2PLYP’ level, show abrupt changes. These abrupt changes are much less pronounced at the SOS-ADC(2) level due to random noise when comparing the properties at the ωB2PLYP’ and SOS-ADC(2) levels (cf. Supplementary Fig. 19†).
 | ||
| Fig. 8 Property distributions of the validation set compounds at the ωB2PLYP’ (A)–(C) and the SOS-ADC(2) (D)–(F) levels of theory colored by the number of molecules in the respective property windows. STG: Singlet-triplet gap, OS: oscillator strength, VEE: vertical excitation energy. | ||
Using SOS-ADC(2), 1310 (10%) of these compounds were predicted to have an inverted STG. Importantly, the relatively low number of confirmed INVEST molecules in the validation set mainly stems from the selection criteria and not from inaccuracies in the original predictions. We wanted to give the OS a considerable weight and focus on promising emitters rather than overemphasizing INVEST molecules with low oscillator strengths in the lead validation. This is evident from the ωB2PLYP’ properties of the validation compounds as only 1300 (10%) molecules have an STG below 0.36 eV. 566 of these 1300 compounds with lowest ωB2PLYP’ STGs are confirmed by SOS-ADC(2) to have an inverted STG, 1045 are predicted to have an STG lower than 0.10 eV based on SOS-ADC(2) results. This shows that ωB2PLYP’ simulations are not perfect predictors of STGs for the molecules investigated but they are sufficiently good in terms of accuracy to guide our artificial design workflow. Additionally, these results illustrate again the systematic offset between ωB2PLYP’ and SOS-ADC(2) (cf. Supplementary Fig. 1 and 19†). Using an STG of 0.36 eV at the ωB2PLYP’ level as heuristic to estimate the number of INVEST compounds in the entire set explored, we predict that there are 148311 (17%) structures with inverted STG (cf.Table 1). The property distributions of this set of INVEST candidates are depicted in Fig. 7D–F. By requiring these INVEST candidates to have an OS of more than 0.05, there are in total likely 10736 (1%) INVEST molecules with appreciable OS (cf.Table 1).
The property distributions at the SOS-ADC(2) level suggest that we successfully found organic molecules with both inverted STGs and OSs up to approximately 0.8 (cf.Fig. 8D). Additionally, we found INVEST molecules with VEEs spanning the entire visible light energy range (cf.Fig. 8E), and we also found emitters with appreciable OSs in that range (cf.Fig. 8F). Furthermore, the property correlations in the validation set indicate that while VEEs show excellent agreement between the two methods (cf. Supplementary Fig. 19A and B†), STGs and OSs of the validation set of high-performing candidates only show a moderate correlation between ωB2PLYP’ and SOS-ADC(2) (cf. Supplementary Fig. 19C–F†) indicating the optimization of these two properties in our workflow to be most challenging and that fine-tuning of STG and OS is difficult based on ωB2PLYP’ simulations.
A more cautious estimation of the number of potential INVEST molecules both in the validation set and in the full set of structures can be carried out by accounting for the systematic deviation between the EOM-CCSD, SOS-ADC(2), and ωB2PLYP’ levels observed in the nitrogen-substituted azulenes (cf.Fig. 2, Supplementary Fig. 1, and Table 1†). While it is not clear that this set of structures would show a similar systematic deviation between methods as the full set of structures generated by the genetic algorithm, especially because the underlying structures are not necessarily very similar, accounting for this deviation can still be insightful to provide a more careful estimate. When correcting all STG values at the SOS-ADC(2) level in the validation dataset, the number of candidates with inverted STGs is estimated to be reduced to 7. When doing the same with the values at the ωB2PLYP’ level, the number of candidates with inverted STG is estimated to be reduced to 923. This confirms that at least several INVEST candidates with appreciable OS were identified in the validation set, but it also suggests that the corresponding number is likely considerably smaller. Performing this type of correction for the entire set of structures using the ωB2PLYP’ results, the total number of candidates with inverted STGs is estimated to be 133728 and the number of INVEST molecules with appreciable OS is estimated to be 8698, which is reasonably close to the estimates obtained via the alternative approach described above. Overall, these more cautious estimations show a considerable spread thus putting significant uncertainty on the number of INVEST candidates found. Nevertheless, all these additional estimates agree that many INVEST candidates were uncovered by our artificial design workflow.
We were also interested in the comparison of synthetic accessibility and complexity metrics between the entire set of compounds investigated, the structures predicted to possess an inverted STG, and a set of comparable reference structures that are known to be synthesizable. As no such dataset of reference structures existed, we created a subset of ZINC20 (ref. 64) containing 11631 in-stock compounds that passed the filters used in the genetic algorithm (details in the supplementary computational details†). To quantify synthesizability, we used the synthetic accessibility score (SAscore),65 the synthetic complexity score (SCScore),66 the synthetic Bayesian accessibility metric (SYBA)67 and the retrosynthetic accessibility score (RAscore).68 In addition to providing an estimation as to how likely these molecules can be synthesized, at least some of them also incorporate an assessment of stability. First, we compared histograms of these metrics between the entire set of compounds generated during the artificial design stage, the subset of molecules estimated to possess an inverted STG, and the ZINC20 subset (cf. Supplementary Fig. 20†). They reveal that the subset of INVEST compounds does not have a considerably different distribution of synthesizability metrics. While the SAscore suggests them to be essentially identical, the SCScore indicates that the structural complexity is somewhat higher in the INVEST candidates. Compared to the ZINC20 subset, the SAscore distributions are considerably higher but there is still a significant overlap. The corresponding SCScore of the ZINC20 subset are also lower, but the overlap with compounds generated by the genetic algorithm is even larger. In contrast, using SYBA, the candidates are predicted to be somewhat more likely to be synthesizable. Similarly, the ZINC20 subset shows higher overlap of SYBA values to the algorithmically generated structures. The RAscore also shows the differences between all compounds generated and the subset of INVEST compounds not to be big. The corresponding differences are not only a consequence of the molecular properties themselves but also of the structural constraints employed in the artificial design experiments as demonstrated in Supplementary Fig. 21.† The runs with the largest fraction of INVEST compounds, i.e. experiments 5 and 6, have a large influence on the corresponding histograms. In contrast, experiment 1 largely only contributes to the histogram of all compounds as it has the lowest fraction of candidates estimated to have an inverted STG. Overall, while we find that these four metrics, based on their numeric values alone, suggest the majority of the compounds investigated to be likely synthesizable, the significant differences to the corresponding distributions of the ZINC20 subset suggest that synthesizability is not as high as readily available compounds. Notably, the corresponding threshold values for the SAscore has been suggested to be 4.5 and, for SYBA, −19.67 Additionally, the majority of compounds have an RAscore of 0.5 or higher, i.e., it is very likely that AiZynthFinder69 will be able to propose a retrosynthetic route.
Finally, based on the properties at the SOS-ADC(2) level, six of the best candidates for each of the two objectives were selected. Their structures and simulated properties are provided in Table 3. Notably, all the compounds listed there emerged from experiment 6 and are likely stable. Additionally, they all possess at least two hydrogen-bond donors allowing for intramolecular interactions controlling their conformations. Importantly, for the tri-objective optimization of STG, OS and VEE, the target VEE for blue emitters at the SOS-ADC(2) level is 2.83 eV due to the systematic property differences relative to ωB2PLYP’ (cf. Supplementary Table 3†).
| Objective | Molecule | ΔE(S1–T1) [eV] | f 12 | ΔE(S0–S1) [eV] |
|---|---|---|---|---|
| A |

|
−0.01 | 0.401 | 2.26 |
| A |

|
−0.01 | 0.336 | 2.19 |
| A |

|
−0.02 | 0.298 | 2.38 |
| A |

|
−0.39 | 0.137 | 2.51 |
| A |
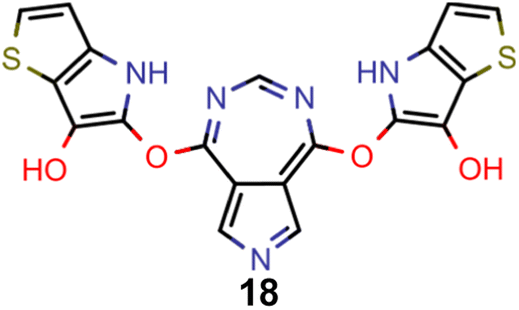
|
−0.11 | 0.169 | 2.50 |
| A |

|
−0.08 | 0.268 | 2.38 |
| B |

|
−0.02 | 0.307 | 2.79 |
| B |

|
−0.01 | 0.305 | 2.86 |
| B |

|
−0.03 | 0.296 | 2.83 |
| B |

|
−0.11 | 0.121 | 2.79 |
| B |
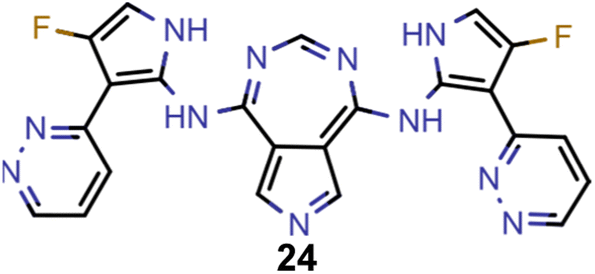
|
−0.10 | 0.132 | 2.79 |
| B |

|
−0.08 | 0.111 | 2.84 |
Discussion
We set out this work by establishing a comprehensive three-stage workflow for the artificial design of organic emitters relying on high-throughput virtual screening via quantum chemical simulations for property evaluation and a GA based on a robust molecular string representation enhanced by ANNs for efficient structure generation. After identifying promising core structures with inverted STGs via virtual screening, we explored the corresponding design space extensively, resulting in the generation of more than 800000 emitter candidates with the goal to co-optimize STGs, OSs and VEEs. Overall, we found more than 10000 candidates that likely possess both inverted STGs and appreciable OSs, many of which with predicted VEEs in the blue light energy range. In the following section, we will put our findings into perspective and outline future improvements for artificial design workflows.
In the first phase of our workflow, we developed and tested the simulation methodology, including the filters for π-systems, and defined the structural space to be explored. Our simulation protocol relies on both efficient and reliable methods to account for double excitations in the description of excited states, in particular double-hybrid time-dependent density functional approximations (DH-TD-DFAs),37,70–73 equation-of-motion coupled-cluster singles and doubles (EOM-CCSD),54–58 and second-order algebraic diagrammatic construction methods (ADC(2), SOS-ADC(2)),38–53 which is essential to describe molecules with inverted STGs appropriately.21–23,74–76 In the absence of reliable experimental reference data and robust experimental methods to characterize INVEST molecules, comparison against robust reference methods for the simulation of excited states such as ADC(2) and EOM-CCSD as performed in this work is a viable alternative to verify the validity of the simulated properties. Notably, even reliable methods such as EOM-CCSD have been shown to systematically overestimate STGs in related molecules,29 thus leading to more positive results. Thus, future research is required to verify our predictions experimentally.
Based on a combination of the INVEST design principles established previously26 and our virtual screening results, we selected azulenes as our core structures for further investigation. Importantly, while azulenes are notorious for violating Kasha's rule77,78 by emitting light mainly from their second rather than from their first excited singlet state,79,80 substituted azulenes emitting predominantly from their first excited electronic singlet states are known.81 As discussed previously,26 azulenes are promising candidates to realize INVEST emitters as fifth generation of organic light-emitting diode materials because they have intrinsically low STGs that can be inverted with proper modification, because they are stable structures with already several well-known synthetic pathways and because their excitation energies can be tuned over the entire visible light spectrum. To achieve that, the almost negligible OSs of the first electronically excited singlet states of azulene cores need to be enhanced with adequate structural substitution, which is why we chose azulenes as our target in this work. Future work will be necessary to understand the dominant excited state processes in substituted azulenes and enable conical intersection design in some of the most promising candidates.
Next, we set up our artificial design workflow by implementing the virtual screening approach into a development version of JANUS,11 a GA relying on SELFIES1 as representation and the STONED algorithm2 for robust and efficient molecular structure generation. One of the advantages of this approach is that it can be applied to any molecular design problem with a well-defined fitness function without prior knowledge of the structural space to be investigated. Additionally, it allows us to incorporate domain knowledge, which is what we did by enforcing our filters for π-systems in the molecular generation. These filters are the main reason that, in experiment 1, with methane as seed, azulene was rediscovered already in the first generation. We rationalize this observation by azulene being a very simple π-system with only two annulated rings satisfying our filters. To the best of our knowledge, it is one of the simplest core structures promoting inverted STGs.26 The filters were designed to avoid the exploration of structures that are unlikely to lead to sizable improvement of the properties we simulated but likely to distract our artificial design workflow and make the property simulations more time-consuming. Notably, while alkyl groups can lead to favorable device properties in organic light-emitting diodes, the corresponding impact is not captured by the simulated excited state properties and fitness functions we employed. Accordingly, we did not allow for the presence of alkyl groups in any of the molecules generated. Importantly, we believe this to be one of the reasons for the high number of hydrogen-bonding moieties in many of the best-performing molecules found. Our workflow allows for amines, alcohols and thiols to be introduced as electron-donating groups but cannot satisfy the corresponding valences with alkyl groups that would also make them more stable. The potential benefit of introducing alkyl groups into the best candidates we found is beyond the scope of this work as it requires to extend the range of properties considered and needs to be addressed in future studies.
Importantly, while we applied the artificial molecular design workflow to find potential blue emitters, the workflow we developed is not limited to this particular excitation energy range. It is general and can be applied to any excitation energy range of interest such as green, red, or even near infrared emitters. This can simply be done by changing the fitness function of the genetic algorithm, specifically the term that incorporates the excitation energy. By choosing a different target value for the excitation energy, emitters with different colors can be designed.
Furthermore, we found it to be crucial to narrow down the design space continuously as we explored more structures. This is demonstrated by experiments 5 and 6 where we constrained the substituent positions in the azulene cores and required the substituents to be identical. This led to a dramatic improvement of the inverse design and molecules with superior properties. We believe that this inability to narrow down the space to be investigated autonomously is still one weakness of the JANUS version we employed in this work. It has been partially addressed already in the published version of JANUS,11 and we aim to improve upon this issue in upcoming work even further. Moreover, using the generation of both counterfactuals and profactuals, we obtained insight into what the ANN classifiers learned. In that regard, it is encouraging to observe that changes to the core structure are regarded as crucial whereas modifications further away are more readily accepted which is essential to enhance the sampling of promising candidates.
Finally, in the lead validation stage, we confirmed the findings of the artificial design by performing more reliable quantum chemistry simulations of the excited state properties. The method we adopted for that purpose, SOS-ADC(2), is considered one of the state-of-the-art approaches to simulate excited state properties for molecules of considerable size, especially INVEST compounds. Altogether, we identified more than 1000 candidates for INVEST emitters with appreciable OS in the validation set, and estimate that there are more than 10000 in the full set of compounds explored in this work. Notably, this is more than one order of magnitude larger than the number of INVEST emitters found in out previous high-throughput virtual screening approach relying on expert design.21 This vast number of molecules with both inverted STGs and considerable OSs shows that the INVEST compound space is much larger than initially thought,22,23 and that artificial molecular design enables the comprehensive exploration of extreme property spaces with unprecedented efficiency.
Ultimately, the findings in this work need to be verified in the laboratory. While many of the molecules proposed are likely stable, due to the intrinsic stability of azulenes, most of the azaazulene core structures explored have never been synthesized. In particular, to the best of our knowledge, 2,5,7-triazaazulene (molecule 1) has not been reported before. This suggests that the results of the synthetic accessibility and complexity metrics should be interpreted with care. They likely indicate that there is no obvious structural feature that makes the proposed compounds hard to synthesize. However, the lack of literature precedence suggests that the metrics are applied outside their original application domain and, hence, cannot be expected to give a highly reliable estimation of whether these compounds can actually be synthesized. In particular, fully conjugated nitrogen-containing heterocycles are generally not straightforward to synthesize as they often require distinct synthesis routes. This demonstrates that new synthetic approaches for these compounds need to be developed before azulene-based INVEST emitters can unlock their full potential as organic electronic materials. Accordingly, we hope that our findings will inspire other groups to explore the synthesis of azaazulenes and their substituted derivatives, and realize some of the most promising emitter candidates that were proposed in our workflow. Overall, our work showcases the combination of state-of-the-art quantum chemistry simulations and artificial molecular design infused with machine learning and domain knowledge to tackle real-world design challenges in chemistry. Accordingly, we believe that the inverse molecular design workflow implemented in this work can serve as a model for future studies defining a new standard for accelerated inverse design campaigns.
Computational methods
High-throughput virtual screening
Ground state conformational ensembles were generated using crest82 (version 2.10.1) with the iMTD-GC83,84 workflow (default option) using the GFN2-xTB85,86//GFN-FF87–89 composite method. The composite method was selected as it provides comparable results to the use of GFN2-xTB for the full workflow at a fraction of the computational cost. The lowest energy conformers were first reoptimized using xtb90 (version 6.3.0) at the GFN2-xTB85,86 level of theory, to reduce the number of required subsequent optimization steps, followed by another reoptimization using Orca91,92 (version 4.2.1) at the B97-3c93 level of theory, which has been shown to be a good choice for accurate ground-state geometry optimizations at comparably low computational cost. Notably, accurate ground-state structures are a prerequisite for reliable vertical excited state properties. The corresponding geometries were used for subsequent ground and excited state single-point calculations. Single points at the RKS-ωB2PLYP’37/def2-mSVP94 level of theory were performed using Orca91,92 (version 4.2.1), single points at the RI-ADC(2)38–44/cc-pVDZ95 and the RI-EOM-CCSD54–58/cc-pVDZ95 levels of theory were performed using Q-Chem96 (version 5.2). Single points at the RI-SOS-ADC(2)41,45–53/cc-pVDZ95 level of theory were performed using MRCC97 (version 2020). Importantly, in the Orca version used (version 4.2.1), the perturbative doubles correction is not applied to the excited triplet states when using restricted Kohn–Sham (RKS) calculations.98 Hence, to indicate this explicitly in our results, we term the corresponding method ωB2PLYP’ as opposed to ωB2PLYP. Simulations at the RI-SOS-ADC(2) level of theory were performed with 9 roots in the singlet and 8 roots in the triplet manifold. Hence, 8 excited roots were selected for both. For all other excited state single point calculations, four roots were chosen each for both the singlet and the triplet manifold. The filters used to create the π-systems subset of GDB-13 (ref. 36) were implemented using RDKit99 and are summarized in Table 4. The source code of these filters can be found in our GitHub repository ¶.| Number | Feature | Definition | Value |
|---|---|---|---|
| 1 | Charge | Charge of the molecule | x = 0 |
| 2 | Radicals | Number of radical electrons | x = 0 |
| 3 | Bridgehead atoms | Number of bridgehead atoms | x = 0 |
| 4 | Spiro atoms | Number of spiro atoms | x = 0 |
| 5 | Aromaticity degree | Percentage of aromatic non-hydrogen atoms | x ≥ 0.5 |
| 6 | Conjugation degree | Percentage of conjugated bonds between non-hydrogen atoms | x ≥ 0.7 |
| 7 | Maximum ring size | Size of the largest ring | 4 ≤ x ≤ 8 |
| 8 | Minimum ring size | Size of the smallest ring | 4 ≤ x ≤ 8 |
| 9 | Substructures | List of forbidden substructures. The code can be found in the GitHub repository | False |
Artificial design
Simulations of excited state properties for fitness evaluation were carried out as described in the previous section by generation of conformational ensembles using crest,82 geometry optimizations at the GFN2-xTB85,86 and the B97-3c93 levels of theory and single points at the RKS-ωB2PLYP’37/def2-mSVP94 level of theory.Artificial design was performed using a development version of JANUS,11 a genetic algorithm (GA) for molecular design. Every run was seeded with a single molecule (cf.Table 5). The first generation in each run was created from random mutations of the seed using the STONED algorithm.2 All genetic operations with STONED were performed using version 1.0.1 of SELFIES.1 The fitness of each molecule was evaluated as a sum of three fitness components (cf.Table 5), one for each property of interest, namely, singlet-triplet gap (STG, ΔE(S1–T1)), oscillator strength (OS, f12) and vertical excitation energy (VEE, ΔE(S0–S1)). In case any of the properties of interest carries a unit, we formally divide the corresponding property by a property value of unity with the same unit, which leads to dimensionless numbers for all properties. These dimensionless numbers were then used for arbitrary linear combinations. Additionally, for each of the fitness components, very low fitness values of −106 were assigned when the properties did not fulfill minimum requirements. For the STG component, the corresponding fitness value was required to be non-negative. For the OS component, the corresponding fitness value was required to be non-negative. For the VEE component, the property value was required to be non-negative. The molecules in each generation were ranked based on the fitness from best, i.e., highest fitness value, to worst, i.e., lowest fitness value. The top 20% of each generation were propagated to the subsequent one. The other molecules were replaced by structures generated by the genetic operators applied to the top 20%. The molecules in each generation were required to be unique across all previous generations during each experiment, which was checked explicitly in the genetic operators by maintaining a dictionary of all previous structures. The number of atoms in each molecule was capped at 70 throughout this work. Additionally, the filters developed in the virtual screening were used in the genetic operators to only generate structures satisfying them. The source code of these filters can be found in our GitHub repository. The number of molecules per generation was capped at 10000. All experiments except for the first were stopped after generation 15, experiment 1 was stopped after generation 11 (cf.Table 5).
| Run | Seed molecule | STG fitness | OS fitness | VEE fitness | Generations |
|---|---|---|---|---|---|
| 1 | Methane | 0.6 − ΔE(S1–T1) | f 12 | 0 | 11 |
| 2 | 2,5,7-Triazaazulene | 0.3 − ΔE(S1–T1) | f 12 | 0 | 15 |
| 3 | 2,5,7-Triazaazulene | 0 | f 12 | 0 | 15 |
| 4 | 2,5,7-Triazaazulene | 0.3 − ΔE(S1–T1) | f 12 | −|ΔE(S0–S1) − 3.2| | 15 |
| 5 | 2,5,7-Triazaazulene | 0.3 − ΔE(S1–T1) | f 12 | 0 | 15 |
| 6 | 2,5,7-Triazaazulene | 0.3 − ΔE(S1–T1) | f 12 | 0 | 15 |
Subsequently, for all runs except for the first, an artificial neural network (ANN) classifier was incorporated into the GA after generation 11. For each experiment, the data from the first 11 generations were collected and used to train a fully-connected 2-layer ANN classifying molecules as either good (i.e., output of 1) or bad (i.e., output of 0). As molecular features, we used the binary representation of Morgan fingerprints100 consisting of 1024 bits. In the data from previous generations, all structures with an STG below 0.6 and an OS larger than 0.0 were classified as good, the others as bad. These data were split into three separate sets. First, 20% of the data were used as a holdout set to test model performance. The remaining 80% was split again into 48% of the total used for training and 32% of the total used as validation set. The validation set was used to tune hyperparameters with the package Optuna.101 In that regard, we decided to optimize the number of training epochs, the number of epochs to continue training without validation loss improvement, the learning rate, the number of neurons in each layer and the dropout rate. The final classification accuracy of the models was evaluated based on the holdout set (cf.Table 1). Classification accuracy was calculated as the percentage of molecules that was classified correctly as either good or bad. Subsequently, the classifiers were incorporated into the genetic operators of each run and combined with the other filters used therein (vide supra). Only molecules classified as good were passed on to the fitness evaluation via property simulation, molecules classified as bad were discarded. Our choice to incorporate a classifier was influenced by an early attempt to use ANNs predictors of singlet-triplet gaps and oscillator strengths. However, we found direct property prediction to be hard and only obtained poor correlations (Supplementary Table 2†).
Finally, to get insight into what the ANN classifiers learned, we used the exmol package (version 0.6.0).102 We modified the default workflow established in that package by implementing the filters we developed in the virtual screening to only generate structures satisfying them as potential counterfactuals. Additionally, we also added the generation of profactuals, i.e., molecules in the structural vicinity of the reference that still retains the same classification, to the workflow. For each baseline molecule, 9 profactuals and 9 counterfactuals were generated. Sampling was performed via the STONED algorithm with version 1.0.4 of SELFIES1 using the medium settings implemented in exmol but increasing the number of samples to 15000. The corresponding source code can be found in our GitHub repository.
Lead validation
The best candidates generated throughout all the artificial design experiments were selected using Chimera.63 Two separate rankings were performed, one based on a bi-objective optimization of both STGs and OSs, another based on a tri-objective optimization of STGs, OSs and VEEs. The corresponding parameters used in Chimera for these two rankings are provided in Table 6. The 7500 best candidates in each of these two rankings were concatenated and the corresponding molecules were validated with a more reliable computational method. To validate the properties of the selected candidates, the geometries at the B97-3c93 level of theory obtained from the fitness evaluation were used for subsequent single point calculations at the RI-SOS-ADC(2)41,45–53/cc-pVDZ95 level of theory.| Objectives | Tolerances | Absolutes | Goals |
|---|---|---|---|
| (A) Bi-objective optimization | |||
| (1) Singlet-triplet gap | 5.00 | True | Minimize |
| (2) Oscillator strength | 0.35 | True | Maximize |
|
|||
| (B) Tri-objective optimization | |||
| (1) Singlet-triplet gap | 3.000 | True | Minimize |
| (2) Oscillator strength | 0.175 | True | Maximize |
| (3) Absolute difference of excitation energy to 3.2 eV | 0.350 | True | Minimize |
Data availability
Detailed results are provided in our GitHub repository: https://github.com/aspuru-guzik-group/Artificial-Design-of-Organic-Emitters.Code availability
Code to run our experiments are provided in our GitHub repository: https://github.com/aspuru-guzik-group/Artificial-Design-of-Organic-Emitters.Author contributions
A. N. and R. P. conceived the idea of the project. P. F. and R. P. designed the simulation methodology, performed the high-throughput virtual screening and analyzed the corresponding results. A. N. developed the code of the genetic algorithm. A. N. and R. P. designed the genetic algorithm setup, performed the corresponding computations and analyzed the respective results. All authors discussed and refined the scientific results. The manuscript was mainly written by A. N. and R. P. with input from all other authors.Conflicts of interest
The University of Toronto has filed a provisional application for a US patent based on the technology described in this paper, naming A. N., R. P., P. F., and A. A.-G. as inventors. A. A.-G. is co-founder and Chief Visionary Officer of Kebotix, Inc.Acknowledgements
R.P. acknowledges funding through a Postdoc. Mobility fellowship by the Swiss National Science Foundation (SNSF, Project No. 191127). A. A.-G. thanks Dr Anders G. Frøseth for his generous support. A. A.-G. also acknowledges the generous support of Natural Resources Canada and the Canada 150 Research Chairs program. This research was undertaken thanks in part to funding provided to the Acceleration Consortium of the University of Toronto from the Canada First Research Excellence Fund. We thank the SciNet HPC Consortium for support regarding the use of the Niagara supercomputer. SciNet is funded by the Canada Foundation for Innovation, the Government of Ontario, Ontario Research Fund – Research Excellence, and the University of Toronto. Computations were also performed on the Cedar supercomputer situated at the Simon Fraser University in Burnaby. In addition, we acknowledge support provided by Compute Ontario and Compute Canada.References
- M. Krenn, F. Häse, A. Nigam, P. Friederich and A. Aspuru-Guzik, Self-Referencing Embedded Strings (SELFIES): A 100% Robust Molecular String Representation, Mach. Learn.: Sci. Technol., 2020, 1(4), 045024, DOI:10.1088/2632-2153/aba947.
- A. Nigam, R. Pollice, M. Krenn, G. Gomes, P. Dos and A. Aspuru-Guzik, Beyond Generative Models: Superfast Traversal, Optimization, Novelty, Exploration and Discovery (STONED) Algorithm for Molecules Using SELFIES, Chem. Sci., 2021, 12(20), 7079–7090, 10.1039/D1SC00231G.
- D. Weininger, SMILES, a Chemical Language and Information System. 1. Introduction to Methodology and Encoding Rules, J. Chem. Inf. Comput. Sci., 1988, 28(1), 31–36, DOI:10.1021/ci00057a005.
- V. D. Mouchlis, A. Afantitis, A. Serra, M. Fratello, A. G. Papadiamantis, V. Aidinis, I. Lynch, D. Greco and G. Melagraki, Advances in De Novo Drug Design: From Conventional to Machine Learning Methods, Int. J. Mol. Sci., 2021, 22(4), 1676, DOI:10.3390/ijms22041676.
- X. Liu, A. P. IJzerman and G. J. P. van Westen, Computational Approaches for De Novo Drug Design: Past, Present, and Future, In Artificial Neural Networks, ed. H. Cartwright, Methods in Molecular Biology, Springer US, New York, NY, 2021, pp. 139–165, DOI:10.1007/978-1-0716-0826-5_6.
- G. Schneider and U. Fechner, Computer-Based de Novo Design of Drug-like Molecules, Nat. Rev. Drug Discovery, 2005, 4(8), 649, DOI:10.1038/nrd1799.
- M. Hartenfeller and G. Schneider, Enabling Future Drug Discovery by de Novo Design, Wiley Interdiscip. Rev. Comput. Mol. Sci., 2011, 1(5), 742–759, DOI:10.1002/wcms.49.
- R. V. Devi, S. S. Sathya and M. S. Coumar, Evolutionary Algorithms for de Novo Drug Design – A Survey, Appl. Soft Comput., 2015, 27, 543–552, DOI:10.1016/j.asoc.2014.09.042.
- E. H. B. Maia, L. C. Assis, T. A. de Oliveira, A. M. da Silva and A. G. Taranto, Structure-Based Virtual Screening: From Classical to Artificial Intelligence, Front. Chem., 2020, 8, 343, DOI:10.3389/fchem.2020.00343.
- A. Nigam, P. Friederich, M. Krenn and A. Aspuru-Guzik, Augmenting Genetic Algorithms with Deep Neural Networks for Exploring the Chemical Space. In International Conference on Learning Representations, 2020 Search PubMed.
- A. Nigam, R. Pollice and A. Aspuru-Guzik, Parallel Tempered Genetic Algorithm Guided by Deep Neural Networks for Inverse Molecular Design, Digital Discovery, 2022, 1(4), 390–404, 10.1039/D2DD00003B.
- A. Nigam, R. Pollice, G. Tom, K. Jorner, J. Wiles, L. A. Thiede, A. Kundaje and A. Aspuru-Guzik: Tartarus: A Benchmarking Platform for Realistic And Practical Inverse Molecular Design, in Advances in Neural Information Processing Systems, arXiv, 2023, arXiv:2209.12487, DOI:10.48550/arXiv.2209.12487.
- R. Pollice, G. dos Passos Gomes, M. Aldeghi, R. J. Hickman, M. Krenn, C. Lavigne, M. Lindner-D’Addario, A. Nigam, C. T. Ser, Z. Yao and A. Aspuru-Guzik, Data-Driven Strategies for Accelerated Materials Design, Acc. Chem. Res., 2021, 54(4), 849–860, DOI:10.1021/acs.accounts.0c00785.
- G. Gomes, P. Dos, R. Pollice and A. Aspuru-Guzik, Navigating through the Maze of Homogeneous Catalyst Design with Machine Learning, TRECHEM, 2021, 3(2), 96–110, DOI:10.1016/j.trechm.2020.12.006.
- M. Y. Wong and E. Zysman-Colman, Purely Organic Thermally Activated Delayed Fluorescence Materials for Organic Light-Emitting Diodes, Adv. Mater., 2017, 29(22), 1605444, DOI:10.1002/adma.201605444.
- H. Uoyama, K. Goushi, K. Shizu, H. Nomura and C. Adachi, Highly Efficient Organic Light-Emitting Diodes from Delayed Fluorescence, Nature, 2012, 492(7428), 234–238, DOI:10.1038/nature11687.
- Y. Liu, C. Li, Z. Ren, S. Yan and M. R. Bryce, All-Organic Thermally Activated Delayed Fluorescence Materials for Organic Light-Emitting Diodes, Nat. Rev. Mater., 2018, 3(4), 1–20, DOI:10.1038/natrevmats.2018.20.
- R. K. Konidena and J. Y. Lee, Molecular Design Tactics for Highly Efficient Thermally Activated Delayed Fluorescence Emitters for Organic Light Emitting Diodes, Chem. Rec., 2019, 19(8), 1499–1517, DOI:10.1002/tcr.201800136.
- F. Hund, Zur Deutung verwickelter Spektren, insbesondere der Elemente Scandium bis Nickel, Z. Physik, 1925, 33(1), 345–371, DOI:10.1007/BF01328319.
- W. T. Borden, H. Iwamura and J. A. Berson, Violations of Hund's Rule in Non-Kekule Hydrocarbons: Theoretical Prediction and Experimental Verification, Acc. Chem. Res., 1994, 27(4), 109–116, DOI:10.1021/ar00040a004.
- R. Pollice, P. Friederich, C. Lavigne, G. Gomes, P. Dos and A. Aspuru-Guzik, Organic Molecules with Inverted Gaps between First Excited Singlet and Triplet States and Appreciable Fluorescence Rates, Matter, 2021, 4(5), 1654–1682, DOI:10.1016/j.matt.2021.02.017.
- P. de Silva, Inverted Singlet–Triplet Gaps and Their Relevance to Thermally Activated Delayed Fluorescence, J. Phys. Chem. Lett., 2019, 10(18), 5674–5679, DOI:10.1021/acs.jpclett.9b02333.
- J. Ehrmaier, E. J. Rabe, S. R. Pristash, K. L. Corp, C. W. Schlenker, A. L. Sobolewski and W. Domcke, Singlet–Triplet Inversion in Heptazine and in Polymeric Carbon Nitrides, J. Phys. Chem. A, 2019, 123(38), 8099–8108, DOI:10.1021/acs.jpca.9b06215.
- G. Ricci, J.-C. Sancho-García and Y. Olivier, Establishing Design Strategies for Emissive Materials with an Inverted Singlet–Triplet Energy Gap (INVEST): A Computational Perspective on How Symmetry Rules the Interplay between Triplet Harvesting and Light Emission, J. Mater. Chem. C, 2022, 10(35), 12680–12698, 10.1039/D2TC02508F.
- L. Tučková, M. Straka, R. R. Valiev and D. Sundholm, On the Origin of the Inverted Singlet–Triplet Gap of the 5th Generation Light-Emitting Molecules, Phys. Chem. Chem. Phys., 2022, 24(31), 18713–18721, 10.1039/D2CP02364D.
- R. Pollice, B. Ding and A. Aspuru-Guzik, Rational Design of Organic Molecules with Inverted Gaps between First Excited Singlet and Triplet, ChemRxiv, 2023, DOI:10.26434/chemrxiv-2023-nrxtl.
- N. Aizawa, Y.-J. Pu, Y. Harabuchi, A. Nihonyanagi, R. Ibuka, H. Inuzuka, B. Dhara, Y. Koyama, K. Nakayama, S. Maeda, F. Araoka and D. Miyajima, Delayed Fluorescence from Inverted Singlet and Triplet Excited States, Nature, 2022, 609(7927), 502–506, DOI:10.1038/s41586-022-05132-y.
- J. Terence Blaskovits, M. H. Garner and C. Corminboeuf, Symmetry-Induced Singlet-Triplet Inversions in Non-Alternant Hydrocarbons**, Angew. Chem., Int. Ed., 2023, 62(15), e202218156, DOI:10.1002/anie.202218156.
- M. H. Garner, J. T. Blaskovits and C. Corminboeuf, Double-Bond Delocalization in Non-Alternant Hydrocarbons Induces Inverted Singlet–Triplet Gaps, Chem. Sci., 2023, 14(38), 10458–10466, 10.1039/D3SC03409G.
- Ö. H. Omar, X. Xie, A. Troisi and D. Padula, Identification of Unknown Inverted Singlet–Triplet Cores by High-Throughput Virtual Screening, J. Am. Chem. Soc., 2023, 145(36), 19790–19799, DOI:10.1021/jacs.3c05452.
- J.-X. Dong and H.-L. Zhang, Azulene-Based Organic Functional Molecules for Optoelectronics, Chin. Chem. Lett., 2016, 27(8), 1097–1104, DOI:10.1016/j.cclet.2016.05.005.
- H. Xin and X. Gao, Application of Azulene in Constructing Organic Optoelectronic Materials: New Tricks for an Old Dog, ChemPlusChem, 2017, 82(7), 945–956, DOI:10.1002/cplu.201700039.
- H. N. Zeng, Z. M. Png and J. Xu, Azulene in Polymers and Their Properties, Chem. Asian J., 2020, 15(13), 1904–1915, DOI:10.1002/asia.202000444.
- J. Huang, S. Huang, Y. Zhao, B. Feng, K. Jiang, S. Sun, C. Ke, E. Kymakis and X. Zhuang, Azulene-Based Molecules, Polymers, and Frameworks for Optoelectronic and Energy Applications, Small Methods, 2020, 4(10), 2000628, DOI:10.1002/smtd.202000628.
- H. Xin, B. Hou and X. Gao, Azulene-Based π-Functional Materials: Design, Synthesis, and Applications, Acc. Chem. Res., 2021, 54(7), 1737–1753, DOI:10.1021/acs.accounts.0c00893.
- L. C. Blum and J.-L. Reymond, 970 Million Druglike Small Molecules for Virtual Screening in the Chemical Universe Database GDB-13, J. Am. Chem. Soc., 2009, 131(25), 8732–8733, DOI:10.1021/ja902302h.
- M. Casanova-Páez, M. B. Dardis and L. Goerigk, ωB2GPPLYP: The First Two Double-Hybrid Density Functionals with Long-Range Correction Optimized for Excitation Energies, J. Chem. Theory Comput., 2019, 15(9), 4735–4744, DOI:10.1021/acs.jctc.9b00013.
- E. S. Nielsen, P. Jo/rgensen and J. Oddershede, Transition Moments and Dynamic Polarizabilities in a Second Order Polarization Propagator Approach, J. Chem. Phys., 1980, 73(12), 6238–6246, DOI:10.1063/1.440119.
- S. P. A. Sauer, Second-Order Polarization Propagator Approximation with Coupled-Cluster Singles and Doubles Amplitudes - SOPPA(CCSD): The Polarizability and Hyperpolarizability Of, J. Phys. B: At., Mol. Opt. Phys., 1997, 30(17), 3773–3780, DOI:10.1088/0953-4075/30/17/007.
- J. J. Eriksen, S. P. A. Sauer, K. V. Mikkelsen, H. J. A. Jensen and J. Kongsted, On the Importance of Excited State Dynamic Response Electron Correlation in Polarizable Embedding Methods, J. Comput. Chem., 2012, 33(25), 2012–2022, DOI:10.1002/jcc.23032.
- J. Schirmer, Beyond the Random-Phase Approximation: A New Approximation Scheme for the Polarization Propagator, Phys. Rev. A, 1982, 26(5), 2395–2416, DOI:10.1103/PhysRevA.26.2395.
- A. B. Trofimov and J. Schirmer, An Efficient Polarization Propagator Approach to Valence Electron Excitation Spectra, J. Phys. B: At., Mol. Opt. Phys., 1995, 28(12), 2299–2324, DOI:10.1088/0953-4075/28/12/003.
- J. H. Starcke, M. Wormit and A. Dreuw, Unrestricted Algebraic Diagrammatic Construction Scheme of Second Order for the Calculation of Excited States of Medium-Sized and Large Molecules, J. Chem. Phys., 2009, 130(2), 024104, DOI:10.1063/1.3048877.
- M. Wormit, D. R. Rehn, P. H. P. Harbach, J. Wenzel, C. M. Krauter, E. Epifanovsky and A. Dreuw, Investigating Excited Electronic States Using the Algebraic Diagrammatic Construction (ADC) Approach of the Polarisation Propagator, Mol. Phys., 2014, 112(5–6), 774–784, DOI:10.1080/00268976.2013.859313.
- N. O. C. Winter and C. Hättig, Scaled Opposite-Spin CC2 for Ground and Excited States with Fourth Order Scaling Computational Costs, J. Chem. Phys., 2011, 134(18), 184101, DOI:10.1063/1.3584177.
- S. Grimme, Improved Second-Order Møller–Plesset Perturbation Theory by Separate Scaling of Parallel- and Antiparallel-Spin Pair Correlation Energies, J. Chem. Phys., 2003, 118(20), 9095–9102, DOI:10.1063/1.1569242.
- C. Hättig and F. Weigend, CC2 Excitation Energy Calculations on Large Molecules Using the Resolution of the Identity Approximation, J. Chem. Phys., 2000, 113(13), 5154–5161, DOI:10.1063/1.1290013.
- O. Christiansen, H. Koch and P. Jørgensen, The Second-Order Approximate Coupled Cluster Singles and Doubles Model CC2, Chem. Phys. Lett., 1995, 243(5), 409–418, DOI:10.1016/0009-2614(95)00841-Q.
- D. Mester and M. Kállay, Combined Density Functional and Algebraic-Diagrammatic Construction Approach for Accurate Excitation Energies and Transition Moments, J. Chem. Theory Comput., 2019, 15(8), 4440–4453, DOI:10.1021/acs.jctc.9b00391.
- D. Mester, P. R. Nagy and M. Kállay, Reduced-Cost Linear-Response CC2 Method Based on Natural Orbitals and Natural Auxiliary Functions, J. Chem. Phys., 2017, 146(19), 194102, DOI:10.1063/1.4983277.
- D. Mester, P. R. Nagy and M. Kállay, Reduced-Cost Second-Order Algebraic-Diagrammatic Construction Method for Excitation Energies and Transition Moments, J. Chem. Phys., 2018, 148(9), 094111, DOI:10.1063/1.5021832.
- D. Mester and M. Kállay, Reduced-Scaling Approach for Configuration Interaction Singles and Time-Dependent Density Functional Theory Calculations Using Hybrid Functionals, J. Chem. Theory Comput., 2019, 15(3), 1690–1704, DOI:10.1021/acs.jctc.8b01199.
- D. Mester, P. R. Nagy and M. Kállay, Reduced-Scaling Correlation Methods for the Excited States of Large Molecules: Implementation and Benchmarks for the Second-Order Algebraic-Diagrammatic Construction Approach, J. Chem. Theory Comput., 2019, 15(11), 6111–6126, DOI:10.1021/acs.jctc.9b00735.
- D. J. ROWE, Equations-of-Motion Method and the Extended Shell Model, Rev. Mod. Phys., 1968, 40(1), 153–166, DOI:10.1103/RevModPhys.40.153.
- K. Emrich, An Extension of the Coupled Cluster Formalism to Excited States (I), Nucl. Phys. A, 1981, 351(3), 379–396, DOI:10.1016/0375-9474(81)90179-2.
- J. Geertsen, M. Rittby and R. J. Bartlett, The Equation-of-Motion Coupled-Cluster Method: Excitation Energies of Be and CO, Chem. Phys. Lett., 1989, 164(1), 57–62, DOI:10.1016/0009-2614(89)85202-9.
- J. F. Stanton and R. J. Bartlett, The Equation of Motion Coupled-cluster Method. A Systematic Biorthogonal Approach to Molecular Excitation Energies, Transition Probabilities, and Excited State Properties, J. Chem. Phys., 1993, 98(9), 7029–7039, DOI:10.1063/1.464746.
- A. I. Krylov, Equation-of-Motion Coupled-Cluster Methods for Open-Shell and Electronically Excited Species: The Hitchhiker's Guide to Fock Space, Annu. Rev. Phys. Chem., 2008, 59(1), 433–462, DOI:10.1146/annurev.physchem.59.032607.093602.
- A. Nigam, R. Pollice, M. F. D. Hurley, R. J. Hickman, M. Aldeghi, N. Yoshikawa, S. Chithrananda, V. A. Voelz and A. Aspuru-Guzik, Assigning Confidence to Molecular Property Prediction, Expert Opin. Drug Discovery, 2021, 16(9), 1009–1023, DOI:10.1080/17460441.2021.1925247.
- P. G. Wellawatte, A. Seshadri and D. White, A. Model Agnostic Generation of Counterfactual Explanations for Molecules, Chem. Sci., 2022, 13(13), 3697–3705, 10.1039/D1SC05259D.
- T. Miller, Explanation in Artificial Intelligence: Insights from the Social Sciences, Artif. Intell., 2019, 267, 1–38, DOI:10.1016/j.artint.2018.07.007.
- S. Wachter, B. Mittelstadt and C. Russell, Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR, Harv. j. law technol., 2017, 31, 841 Search PubMed.
- F. Häse, L. M. Roch and A. Aspuru-Guzik, Chimera: Enabling Hierarchy Based Multi-Objective Optimization for Self-Driving Laboratories, Chem. Sci., 2018, 9(39), 7642–7655, 10.1039/C8SC02239A.
- J. J. Irwin, K. G. Tang, J. Young, C. Dandarchuluun, B. R. Wong, M. Khurelbaatar, Y. S. Moroz, J. Mayfield and R. A. Sayle, ZINC20—A Free Ultralarge-Scale Chemical Database for Ligand Discovery, J. Chem. Inf. Model., 2020, 60(12), 6065–6073, DOI:10.1021/acs.jcim.0c00675.
- P. Ertl and A. Schuffenhauer, Estimation of Synthetic Accessibility Score of Drug-like Molecules Based on Molecular Complexity and Fragment Contributions, J. Cheminf., 2009, 1(1), 8, DOI:10.1186/1758-2946-1-8.
- C. W. Coley, L. Rogers, W. H. Green and K. F. Jensen, SCScore: Synthetic Complexity Learned from a Reaction Corpus, J. Chem. Inf. Model., 2018, 58(2), 252–261, DOI:10.1021/acs.jcim.7b00622.
- M. Voršilák, M. Kolář, I. Čmelo and D. Svozil, SYBA: Bayesian Estimation of Synthetic Accessibility of Organic Compounds, J. Cheminf., 2020, 12(1), 35, DOI:10.1186/s13321-020-00439-2.
- A. Thakkar, V. Chadimová, E. J. Bjerrum, O. Engkvist and J.-L. Reymond, Retrosynthetic Accessibility Score (RAscore) – Rapid Machine Learned Synthesizability Classification from AI Driven Retrosynthetic Planning, Chem. Sci., 2021, 12(9), 3339–3349, 10.1039/D0SC05401A.
- S. Genheden, A. Thakkar, V. Chadimová, J.-L. Reymond, O. Engkvist and E. Bjerrum, AiZynthFinder: A Fast, Robust and Flexible Open-Source Software for Retrosynthetic Planning, J. Cheminf., 2020, 12(1), 70, DOI:10.1186/s13321-020-00472-1.
- S. Grimme and F. Neese, Double-Hybrid Density Functional Theory for Excited Electronic States of Molecules, J. Chem. Phys., 2007, 127(15), 154116, DOI:10.1063/1.2772854.
- L. Goerigk, J. Moellmann and S. Grimme, Computation of Accurate Excitation Energies for Large Organic Molecules with Double-Hybrid Density Functionals, Phys. Chem. Chem. Phys., 2009, 11(22), 4611–4620, 10.1039/B902315A.
- L. Goerigk and S. Grimme, Double-Hybrid Density Functionals Provide a Balanced Description of Excited 1La and 1Lb States in Polycyclic Aromatic Hydrocarbons, J. Chem. Theory Comput., 2011, 7(10), 3272–3277, DOI:10.1021/ct200380v.
- T. Schwabe and L. Goerigk, Time-Dependent Double-Hybrid Density Functionals with Spin-Component and Spin-Opposite Scaling, J. Chem. Theory Comput., 2017, 13(9), 4307–4323, DOI:10.1021/acs.jctc.7b00386.
- J. Sanz-Rodrigo, G. Ricci, Y. Olivier and J. C. Sancho-García, Negative Singlet–Triplet Excitation Energy Gap in Triangle-Shaped Molecular Emitters for Efficient Triplet Harvesting, J. Phys. Chem. A, 2021, 125(2), 513–522, DOI:10.1021/acs.jpca.0c08029.
- G. Ricci, E. San-Fabián, Y. Olivier and J. C. Sancho-García, Singlet-Triplet Excited-State Inversion in Heptazine and Related Molecules: Assessment of TD-DFT and Ab Initio Methods, ChemPhysChem, 2021, 22(6), 553–560, DOI:10.1002/cphc.202000926.
- F. Dinkelbach, M. Bracker, M. Kleinschmidt and C. M. Marian, Large Inverted Singlet–Triplet Energy Gaps Are Not Always Favorable for Triplet Harvesting: Vibronic Coupling Drives the (Reverse) Intersystem Crossing in Heptazine Derivatives, J. Phys. Chem. A, 2021, 125(46), 10044–10051, DOI:10.1021/acs.jpca.1c09150.
- M. Kasha, Characterization of Electronic Transitions in Complex Molecules, Discuss. Faraday Soc., 1950, 9, 14–19, 10.1039/DF9500900014.
- J. C. Valle del and J. Catalán, Kasha's Rule: A Reappraisal, Phys. Chem. Chem. Phys., 2019, 21(19), 10061–10069, 10.1039/C9CP00739C.
- M. Beer and H. C. Longuet-Higgins, Anomalous Light Emission of Azulene, J. Chem. Phys., 1955, 23(8), 1390–1391, DOI:10.1063/1.1742314.
- G. Viswanath and M. Kasha, Confirmation of the Anomalous Fluorescence of Azulene, J. Chem. Phys., 1956, 24(3), 574–577, DOI:10.1063/1.1742548.
- G. Eber, F. Grüneis, S. Schneider and F. Dörr, Dual Fluorescence Emission of Azulene Derivatives in Solution, Chem. Phys. Lett., 1974, 29(3), 397–404, DOI:10.1016/0009-2614(74)85131-6.
- P. Pracht and S. Grimme, Conformer-Rotamer Ensemble Sampling Tool, https://github.com/grimme-lab/crest(accessed 2020-06-04) Search PubMed.
- S. Grimme, Exploration of Chemical Compound, Conformer, and Reaction Space with Meta-Dynamics Simulations Based on Tight-Binding Quantum Chemical Calculations, J. Chem. Theory Comput., 2019, 15(5), 2847–2862, DOI:10.1021/acs.jctc.9b00143.
- P. Pracht, F. Bohle and S. Grimme, Automated Exploration of the Low-Energy Chemical Space with Fast Quantum Chemical Methods, Phys. Chem. Chem. Phys., 2020, 22(14), 7169–7192, 10.1039/C9CP06869D.
- S. Grimme, C. Bannwarth and P. A. R. Shushkov, Accurate Tight-Binding Quantum Chemical Method for Structures, Vibrational Frequencies, and Noncovalent Interactions of Large Molecular Systems Parametrized for All Spd-Block Elements (Z = 1–86), J. Chem. Theory Comput., 2017, 13(5), 1989–2009, DOI:10.1021/acs.jctc.7b00118.
- C. Bannwarth, S. Ehlert and S. Grimme, GFN2-xTB—An Accurate and Broadly Parametrized Self-Consistent Tight-Binding Quantum Chemical Method with Multipole Electrostatics and Density-Dependent Dispersion Contributions, J. Chem. Theory Comput., 2019, 15(3), 1652–1671, DOI:10.1021/acs.jctc.8b01176.
- S. Spicher and S. Grimme, Robust Atomistic Modeling of Materials, Organometallic, and Biochemical Systems, Angew. Chem., Int. Ed., 2020, 59(36), 15665–15673, DOI:10.1002/anie.202004239.
- S. Spicher and S. Grimme, Efficient Computation of Free Energy Contributions for Association Reactions of Large Molecules, J. Phys. Chem. Lett., 2020, 11(16), 6606–6611, DOI:10.1021/acs.jpclett.0c01930.
- P. Pracht, D. F. Grant and S. Grimme, Comprehensive Assessment of GFN Tight-Binding and Composite Density Functional Theory Methods for Calculating Gas-Phase Infrared Spectra, J. Chem. Theory Comput., 2020, 16(11), 7044–7060, DOI:10.1021/acs.jctc.0c00877.
- S. Grimme, Semiempirical Extended Tight-Binding Program Package, https://github.com/grimme-lab/xtb(accessed 2020-06-04) Search PubMed.
- F. Neese, The ORCA Program System, Wiley Interdiscip. Rev.: Comput. Mol. Sci., 2012, 2(1), 73–78, DOI:10.1002/wcms.81.
- F. Neese, Software Update: The ORCA Program System, Version 4.0, Wiley Interdiscip. Rev.: Comput. Mol. Sci., 2018, 8(1), e1327, DOI:10.1002/wcms.1327.
- J. G. Brandenburg, C. Bannwarth, A. Hansen and S. Grimme, B97-3c: A Revised Low-Cost Variant of the B97-D Density Functional Method, J. Chem. Phys., 2018, 148(6), 064104, DOI:10.1063/1.5012601.
- F. Weigend and R. Ahlrichs, Balanced Basis Sets of Split Valence, Triple Zeta Valence and Quadruple Zeta Valence Quality for H to Rn: Design and Assessment of Accuracy, Phys. Chem. Chem. Phys., 2005, 7(18), 3297–3305, 10.1039/B508541A.
- T. H. Dunning, Gaussian Basis Sets for Use in Correlated Molecular Calculations. I. The Atoms Boron through Neon and Hydrogen, J. Chem. Phys., 1989, 90(2), 1007–1023, DOI:10.1063/1.456153.
- Y. Shao, Z. Gan, E. Epifanovsky, A. T. B. Gilbert, M. Wormit, J. Kussmann, A. W. Lange, A. Behn, J. Deng, X. Feng, D. Ghosh, M. Goldey, P. R. Horn, L. D. Jacobson, I. Kaliman, R. Z. Khaliullin, T. Kuś, A. Landau, J. Liu, E. I. Proynov, Y. M. Rhee, R. M. Richard, M. A. Rohrdanz, R. P. Steele, E. J. Sundstrom, H. L. W. III, P. M. Zimmerman, D. Zuev, B. Albrecht, E. Alguire, B. Austin, G. J. O. Beran, Y. A. Bernard, E. Berquist, K. Brandhorst, K. B. Bravaya, S. T. Brown, D. Casanova, C.-M. Chang, Y. Chen, S. H. Chien, K. D. Closser, D. L. Crittenden, M. Diedenhofen, R. A. D. Jr, H. Do, A. D. Dutoi, R. G. Edgar, S. Fatehi, L. Fusti-Molnar, A. Ghysels, A. Golubeva-Zadorozhnaya, J. Gomes, M. W. D. Hanson-Heine, P. H. P. Harbach, A. W. Hauser, E. G. Hohenstein, Z. C. Holden, T.-C. Jagau, H. Ji, B. Kaduk, K. Khistyaev, J. Kim, J. Kim, R. A. King, P. Klunzinger, D. Kosenkov, T. Kowalczyk, C. M. Krauter, K. U. Lao, A. D. Laurent, K. V. Lawler, S. V. Levchenko, C. Y. Lin, F. Liu, E. Livshits, R. C. Lochan, A. Luenser, P. Manohar, S. F. Manzer, S.-P. Mao, N. Mardirossian, A. V. Marenich, S. A. Maurer, N. J. Mayhall, E. Neuscamman, C. M. Oana, R. Olivares-Amaya, D. P. O'Neill, J. A. Parkhill, T. M. Perrine, R. Peverati, A. Prociuk, D. R. Rehn, E. Rosta, N. J. Russ, S. M. Sharada, S. Sharma, D. W. Small, A. Sodt, T. Stein, D. Stück, Y.-C. Su, A. J. W. Thom, T. Tsuchimochi, V. Vanovschi, L. Vogt, O. Vydrov, T. Wang, M. A. Watson, J. Wenzel, A. White, C. F. Williams, J. Yang, S. Yeganeh, S. R. Yost, Z.-Q. You, I. Y. Zhang, X. Zhang, Y. Zhao, B. R. Brooks, G. K. L. Chan, D. M. Chipman, C. J. Cramer, W. A. G. III, M. S. Gordon, W. J. Hehre, A. Klamt, H. F. S. III, M. W. Schmidt, C. D. Sherrill, D. G. Truhlar, A. Warshel, X. Xu, A. Aspuru-Guzik, R. Baer, A. T. Bell, N. A. Besley, J.-D. Chai, A. Dreuw, B. D. Dunietz, T. R. Furlani, S. R. Gwaltney, C.-P. Hsu, Y. Jung, J. Kong, D. S. Lambrecht, W. Liang, C. Ochsenfeld, V. A. Rassolov, L. V. Slipchenko, J. E. Subotnik, T. V. Voorhis, J. M. Herbert, A. I. Krylov, P. M. W. Gill and M. Head-Gordon, Advances in Molecular Quantum Chemistry Contained in the Q-Chem 4 Program Package, Mol. Phys., 2015, 113(2), 184–215, DOI:10.1080/00268976.2014.952696.
- M. Kállay, P. R. Nagy, D. Mester, Z. Rolik, G. Samu, J. Csontos, J. Csóka, P. B. Szabó, L. Gyevi-Nagy, B. Hégely, I. Ladjánszki, L. Szegedy, B. Ladóczki, K. Petrov, M. Farkas, P. D. Mezei and Á. Ganyecz, The MRCC Program System: Accurate Quantum Chemistry from Water to Proteins, J. Chem. Phys., 2020, 152(7), 074107, DOI:10.1063/1.5142048.
- M. Casanova-Páez and L. Goerigk, Assessing the Tamm–Dancoff Approximation, Singlet–Singlet, and Singlet–Triplet Excitations with the Latest Long-Range Corrected Double-Hybrid Density Functionals, J. Chem. Phys., 2020, 153(6), 064106, DOI:10.1063/5.0018354.
- https://github.com/rdkit/rdkit(accessed 2021-12-17).
- D. Rogers and M. Hahn, Extended-Connectivity Fingerprints, J. Chem. Inf. Model., 2010, 50(5), 742–754, DOI:10.1021/ci100050t.
- T. Akiba, S. Sano, T. Yanase, T. Ohta and M. Koyama, Optuna: A next-Generation Hyperparameter Optimization Framework, In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining; KDD ’19, Association for Computing Machinery, New York, NY, USA, 2019, pp. 2623–2631, DOI:10.1145/3292500.3330701.
- Explaining why that molecule, https://github.com/ur-whitelab/exmol (accessed 2021-12-22) Search PubMed.
Footnotes |
| † Electronic supplementary information (ESI) available. See DOI: https://doi.org/10.1039/d3sc05306g |
| ‡ These authors contributed equally. |
| § Current affiliation: Stratingh Institute for Chemistry, University of Groningen, Nijenborgh 4, Groningen, 9747 AG, The Netherlands. |
| ¶ GitHub: https://github.com/aspuru-guzik-group/Artificial-Design-of-Organic-Emitters. |
| This journal is © The Royal Society of Chemistry 2024 |