
 Open Access Article
Open Access Article This Open Access Article is licensed under a
This Open Access Article is licensed under a Creative Commons Attribution 3.0 Unported Licence
Experimentally designed chemometric models for the assay of toxic adulterants in turmeric powder†
Shymaa S. Solimana,
Alaadin E. El-Haddadb,
Ghada A. Sedikc,
Mohamed R. Elghobashyca,
Hala E. Zaazaac and
Ahmed S. Saad *cd
*cd
aAnalytical Chemistry Department, Faculty of Pharmacy, October 6 University, PO Box 12858, 6 October City, Giza, Egypt
bPharmacognosy Department, Faculty of Pharmacy, October 6 University, PO Box 12858, 6 October City, Giza, Egypt
cAnalytical Chemistry Department, Faculty of Pharmacy, Cairo University, El-Kasr El-Aini Street, Cairo, 11562, Egypt. E-mail: ahmed.bayoumy@pharma.cu.edu.eg; ahmedss_pharm@yahoo.com
dMedicinal Chemistry Department, PharmD Program, Egypt-Japan University of Science and Technology (E-JUST), New Borg El-Arab City, Alexandria 21934, Egypt
First published on 23rd March 2022
Abstract
Turmeric is an indispensable culinary spice in different cultures and a principal component in traditional remedies. Toxic metanil yellow (MY), acid orange 7 (AO) and lead chromate (LCM) are deliberately added to adulterate turmeric powder. This work compares the ability of multivariate chemometric models with those of artificial intelligent networks to enhance the selectivity of spectral data for the rapid assay of these three adulterants in turmeric powder. Using a custom experimental design, we provide a data-driven optimization for the sensitive parameters of the partial least squares model (PLS), artificial neural network (ANN) and genetic algorithm (GA). The optimized models are validated using sets of genuine turmeric samples from five different geographical regions spiked with standard adulterant concentrations. The optimized GA-PLS and GA-ANN models reduce the root mean square error of prediction by 18.4%, 31.1% and 55.3% and 25.0%, 69.9% and 88.4% for MY, AO and LCM, respectively.
1. Introduction
Food provides the human body with the energy necessary to function and exist, provided that safety and quality are guaranteed. The latter is sometimes perturbed deliberately through the inclusion of inferior admixtures or the exclusion of valuable ingredients to increase profit margins at the expense of customer health and social consequences. Laws, traditions and religions incriminate any form of the above practices.Turmeric rhizome, known as Indian saffron, is one of the largest selling natural food products in the world, and receives a great deal of attention from both medical and culinary specialists.1 Turmeric comprises more than 100 compounds. Curcumin is the main active compound and is credited with most of turmeric's health benefits due to its antioxidant and anti-inflammatory properties.2 Turmeric can be used to flavor or color many food substances, such as curry powder, mustard, butter and cheese. Medically, it treats several inflammatory conditions,3 metabolic syndromes,4 inflammatory degenerative eye conditions,5 kidney and heart diseases,3 cancer,6 rheumatoid arthritis,7 and several psychiatric disorders.8
The relatively high global consumption and demand for turmeric in different applications (such as nutraceuticals, food flavorings and cosmetics) make it more vulnerable to adulteration with low-quality ingredients such as starch, chalk, yellow soapstone, lead chromate and synthetic dyes.9 The mentioned adulterants can result in cardiovascular, neurological, hepatotoxic and nephrotoxic health hazards for consumers. For instance, lead chromate (LCM) and synthetic dyes such as metanil yellow (MY) and acid orange 7 (AO) are deliberately added to mimic the color appearance of turmeric despite their hazardous health effects.9 The electron-withdrawing character of the azo group in the synthetic dyes sometimes develops an electron deficiency and is reduced to carcinogenic amino compounds.10
Long-term consumption of metanil yellow (MY) (sodium 3-[4-anilinophenylazo]benzene sulfonate) causes severe damage to the heart and nervous tissues,11,12 degenerative changes in the lining of the stomach, kidneys and liver,13 as well as adversely affects the ovaries and testes.14,15
Acid orange 7 (AO) (sodium 4-[(2E)-2-(2-oxo-naphthalene-1-ylidene)hydrazinyl]benzene sulfonate) and lead chromate are deliberately added to adulterate turmeric powder.16,17 Acid orange 7 irritates the eyes, skin, mucous membrane and upper respiratory tract in addition to causing severe headaches, nausea, water-borne diseases, such as dermatitis, and to loss of bone marrow, leading to anemia.16 Lead chromate (LCM) can lead to lung and renal cancer, neuropathy, osteopathy, and respiratory tract toxicity.18
Analytical chemistry guarantees food safety and quality through the development of reliable sensitive and selective analytical methods to detect and quantify food adulterants and food ingredients.19–22 Analytical reports provide authorities, food suppliers and consumers with the evidence necessary to build confidence in food authenticity, safety and quality.23
Analyzing pharmaceutical and food products is a highly multivariate process, as many factors (parameters) may be involved during the analysis. Powerful data collection and statistical tools are required to identify the factors that may affect the results of the experiment. Design of experiment technique (DoE) is a robust statistical tool that is successfully deployed in different types of systems, product design, process development and optimization. It plays a prevalent role in decision-making processes through providing useful experimental information, and planning the type and the number of experiments to reach the optimal parameters settings. Consequently, this allows for overcoming the inability defects of generating a large amount of useful experimental data with proper human interpretation.
The DoE technique has been used extensively in several fields, such as chemistry,24–29 agriculture,30,31 engineering,32,33 industry34,35 (in particular food industry36–38), and even in non-scientific aspects, such as predicting sports results,39 especially soccer and basketball. DoE can be used in other disciplines, such as energy40–44 and sensors optimization.45–49 Previously, many empirical studies in science materials have been made through one factor at a time experimentation (OFAT), which provides uncorrelated material-based systems. This may be attributed to the complexity, safety-critical nature of the energy systems, the high number of components, and the processing conditions. However, DoE evaluates the contribution of different factors simultaneously and defines the needed redundancies for meaningful statistical assessment of the outcomes, allowing for the consistent establishment of energy behavioral-based strategies, a good prediction of energy yields, and integral optimization of electrochemical sensors for higher sensitivity and selectivity.
A literature survey revealed several methods to detect and/or quantify the adulteration of turmeric, such as HPLC,50,51 HPTLC,52,53 voltammetry,54 multispectral imaging,55 spectrophotometry56 and FTIR.57–60 However, the reported literature failed to reveal a single analytical method for the simultaneous assay of MY, AO and LCM in turmeric powder.
In the current work, an investigation and comparison were conducted on the ability of (1) traditional chemometric models, (2) artificially intelligent neural networks, (3) genetic algorithm variable selection tool, and finally (4) experimentally designed optimization for discrimination and simultaneous quantitation of toxic adulterants in the complex natural matrix of turmeric powder. Once fed with a single UV-spectrum of the turmeric powder extract, the models decode the UV-absorbances to discriminate and quantify the adulterants within the complex turmeric powder. The ICH validation parameters were computed to ensure the validity of the method. The model represents a simple, direct and fast analytical tool for quality control laboratories to investigate turmeric samples, and support food suppliers and authorities with scientific evidence regarding food safety and quality.
2. Materials and methods
2.1 Samples and reagents
Standard metanil yellow (purity 98.00%) and acid orange 7 (purity 98.00%) were purchased from Techno Pharmchem (India). Lead chromate standard (purity 98.00%) was purchased from OTTO (India). Genuine turmeric rhizomes (Curcuma longa L.) were purchased from the local markets in Egypt: Ragab (RG), Abu-Auf (ABU), Harraz (HZ) and Medrar (MD). In addition, rhizomes were obtained from Danube (DA) in a Saudi Arabian market. They were kindly identified by the Pharmacognosy Department, Faculty of Pharmacy, October 6 University, Cairo, Egypt. The rhizomes were ground separately to obtain the pure turmeric powder.Methanol, ethanol, acetonitrile, acetone, acetic acid, nitric acid and sodium hydroxide (NaOH) pellets were purchased from El-NASR Pharmaceutical Chemicals Co., (Egypt). Sodium hydroxide solution (0.2 M) was prepared in distilled water and used as a solvent.
2.2 Instrumentation
The spectrophotometric measurements were carried out using a Shimadzu UV-visible spectrophotometer dual beam, model UV-1800 with a 1 cm quartz cell supplied with UV-Probe 2.32 software (Shimadzu Scientific Instruments inc., Kyoto, Japan). All chemometric methods were implemented in MATLAB® 8.1.0.604 (R2013a) and the PLS version 2.1 toolbox. Design-Expert® 13.0.1.0 software was used to analyze the results.2.3 Standard solutions
Stock standard solutions (500 μg mL−1) of MY, AO and LCM were prepared using NaOH (0.2 M) as a solvent.2.4 Procedure
3. Results and discussion
Detection of food adulteration has become an increasing concern for governments and institutions to guarantee food safety and quality. Therefore, a single, fast and cheap analytical method was developed for the detection of possible turmeric adulterants. The method should be able to assay the hazardous adulterants in different sources of turmeric powder with minimal sample preparation, only extract and measure. Thus, a simple and cheap UV-visible spectrophotometry method was a good choice to apply. The spectral data were analyzed using multivariate chemometric models. Chemometric combined with spectrophotometric techniques to recognize and assay compounds from their combined spectral data.3.1 Spectral characteristics
The absorption spectra of the different turmeric extracts absorb light with a similar pattern, but at different extents. While the absorption spectra of the three adulterants (MY, AO, LCM) show different absorption patterns and extents from each other and turmeric powder (Fig. 1), the application of chemometric was applied for the resolution of the three adulterants in turmeric powder from their spectral data. | ||
| Fig. 1 Zero-order absorption spectra of (A) 200 μg mL−1 turmeric extracts from different sources, (B) 10 μg mL−1 metanil yellow (—), 10 μg mL−1 acid orange 7 (- - -) and 10 μg mL−1 lead chromate (……). | ||
3.2 Multivariate analysis of different turmeric rhizomes
Five different sources of turmeric rhizomes were purchased from different markets and ground to obtain the pure turmeric powder. Then, the spiked turmeric powders were successfully analyzed using four different multivariate chemometric models, such as partial least square (PLS), genetic algorithm—partial least square (GA-PLS), optimized genetic algorithm—partial least square (GA(DoE)-PLS), and artificial neural network using optimized genetic algorithm dataset (GA(DoE)-ANN), in which each source was given a specific level coded as (−2, −1, 0, 1 and 2).3.3 Solvent selection
Many trials were carried out trying to find the suitable solvent to freely dissolve the three adulterants. Different solvents were tried, such as methanol, ethanol, acetonitrile, acetone, acetic acid, diluted nitric acid and aqueous NaOH. The three adulterants were freely soluble in aqueous NaOH (0.2 M).3.4 Wavelength selection
The wavelengths used were in the range of 230–570 nm, which achieved good linearity for the three adulterants. Meanwhile, the other wavelengths were discarded due to the noise appearing within the range of 200–229 nm and the poor absorbance within the range of 571–800 nm.3.5 Construction of the models
A multilevel multifactor design was used to prepare a calibration set of 25 laboratory prepared mixtures and a validation set of 5 mixtures containing different concentration levels of the three adulterants ranging from 2–10 μg mL−1 for MY, 8–16 μg mL−1 for AO and 20–40 μg mL−1 for LCM. Each model was constructed using the optimum number of latent variables to avoid the unnecessary noise and loss of meaningful data required to build the models.3.6 Implementation of design of experiment technique
The GA reduced the RMSEP, and the standard deviation of the results was obtained using the PLS model. The quality-by-design principles was applied to maximize the accuracy and precision using an experimental design to optimize the parameters of the genetic algorithm-PLS model (ml, fit% and LV). The latter reduced the error and increased the precision of the PLS model for the prediction of MY, AO, and LCM in the five commercially available sources of turmeric. Finally, the resolution of the classical PLS chemometric model was compared to an artificially intelligent neural network. The latter exhibited better predictability for the three adulterants in the five commercial sources of turmeric powder.3.7 Predictive powers of PLS and GA-PLS models
A PLS model was constructed using six latent variables (Fig. S1†). The model successfully determined MY, AO and LCM in spiked turmeric samples within the calibration and validation sets. The mean recovery, % RSD, RMSE and other statistical parameters were calculated for each adulterant (Table 1).| Parameters | Calibration set | Validation set | |||||
|---|---|---|---|---|---|---|---|
| Metanil yellow | Acid orange 7 | Lead chromate | Metanil yellow | Acid orange 7 | Lead chromate | ||
| a Root mean square error of calibration.b Root mean square error of prediction.c Data of the straight line plotted between predicted versus actual concentrations.d Partial least square.e Genetic algorithm-partial least square.f Optimized genetic algorithm-partial least square.g Artificial neural network using optimized genetic-algorithm. | |||||||
| PLS modeld | Concentration range (μg mL−1) | 2–10 | 8–16 | 20–40 | 2–10 | 8–16 | 20–40 |
| Mean | 100.09 | 100.51 | 100.05 | 99.00 | 100.03 | 99.36 | |
| % RSD | 1.892 | 1.984 | 1.794 | 2.120 | 2.097 | 1.756 | |
| Repeatability precision (±RSD) | ±1.903 | ±1.924 | ±1.536 | — | — | — | |
| Intermediate precision (±RSD) | ±1.917 | ±2.084 | ±1.969 | — | — | — | |
| RMSE | 0.101a | 0.224a | 0.592a | 0.057b | 0.166b | 0.377b | |
| Slopec | 0.9996 | 0.9943 | 0.9920 | 1.0025 | 0.8327 | 0.9884 | |
| Intercept | −0.0019 | 0.1163 | 0.2327 | −0.0378 | 1.5232 | 0.1192 | |
| r | 0.9993 | 0.9970 | 0.9965 | 0.9987 | 0.9998 | 0.9900 | |
| Latent variables | 6 | ||||||
| GA-PLS modele | Concentration range (μg mL−1) | 2–10 | 8–16 | 20–40 | 2–10 | 8–16 | 20–40 |
| Mean | 100.14 | 100.54 | 99.97 | 98.95 | 100.21 | 98.82 | |
| % RSD | 1.814 | 1.629 | 1.604 | 1.894 | 1.714 | 0.813 | |
| Repeatability precision ± RSD | ±1.799 | ±2.066 | ±1.122 | — | — | — | |
| Intermediate precision ± RSD | ±1.887 | ±2.082 | ±1.642 | — | — | — | |
| RMSE | 0.090a | 0.171a | 0.547a | 0.049b | 0.135b | 0.309b | |
| Slopec | 0.9990 | 0.9865 | 0.9976 | 1.0123 | 0.8790 | 1.0020 | |
| Intercept | 0.0061 | 0.2099 | 0.0531 | −0.0663 | 1.1197 | −0.3112 | |
| r | 0.9995 | 0.9984 | 0.9969 | 0.9992 | 0.9972 | 0.9979 | |
| Latent variables | 6 | ||||||
| GA(DoE)-PLS modelf | Concentration range (μg mL−1) | 2–10 | 8–16 | 20–40 | 2–10 | 8–16 | 20–40 |
| Mean | 100.22 | 100.24 | 100.05 | 99.40 | 99.52 | 99.58 | |
| % RSD | 1.542 | 1.143 | 1.388 | 0.918 | 0.919 | 0.576 | |
| Repeatability precision (±% RSD) | ±1.540 | ±1.785 | ±1.398 | — | — | — | |
| Intermediate precision (±% RSD) | ±1.687 | ±1.859 | ±1.589 | — | — | — | |
| RMSE | 0.071a | 0.127a | 0.428a | 0.040b | 0.093b | 0.138b | |
| Slopec | 1.0000 | 0.9968 | 0.9878 | 0.9856 | 0.9596 | 1.0166 | |
| Intercept | 0.0034 | 0.0624 | 0.3587 | 0.0256 | 0.3245 | −0.4702 | |
| r | 0.9997 | 0.9989 | 0.9982 | 0.9994 | 0.9972 | 0.9993 | |
| Latent variables | 5 | ||||||
| GA(DoE)-ANN modelg | Concentration range (μg mL−1) | 2–10 | 8–16 | 20–40 | 2–10 | 8–16 | 20–40 |
| Mean | 100.02 | 100.05 | 100.17 | 100.15 | 99.86 | 100.02 | |
| % RSD | 0.415 | 0.631 | 0.613 | 0.782 | 0.313 | 0.054 | |
| Repeatability precision ± RSD | ±0.564 | ±0.932 | ±0.584 | — | — | — | |
| Intermediate precision ± RSD | ±0.722 | ±1.167 | ±1.052 | — | — | — | |
| RMSE | 0.030a | 0.062a | 0.191a | 0.030b | 0.028b | 0.016b | |
| Slopec | 1.0015 | 0.9974 | 1.0039 | 1.0113 | 0.9879 | 1.0019 | |
| Intercept | −0.0011 | 0.0400 | −0.0615 | −0.0226 | 0.1016 | −0.0343 | |
| r | 0.9999 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 1.0000 | |
| Latent variables | 5 | ||||||
The small RMSEP values indicate good predictability and high-resolution power of the model. A good correlation coefficient (r) for each adulterant was achieved, which indicates a good fit between the predicted and the actual concentrations.
Genetic algorithm tool improved the predictive power of the PLS model by selecting the most informative wavelengths and excluding the less informative ones. It reduced the number of wavelengths to about 68.9% of the original ones (106 wavelengths for the three adulterants). We constructed the GA-PLS model using the GA-selected wavelength of the calibration set. RMSECV calculations show that six latent variables are adequate for the construction of the GA-PLS model (Fig. S1†). Unfortunately, GA did not reduce the number of latent variables compared to the previously mentioned PLS model. The RMSEP values were relatively small compared to that of the PLS model (Fig. 2), which indicates an increase in the predictive power of the GA-PLS method compared to the classical PLS method.
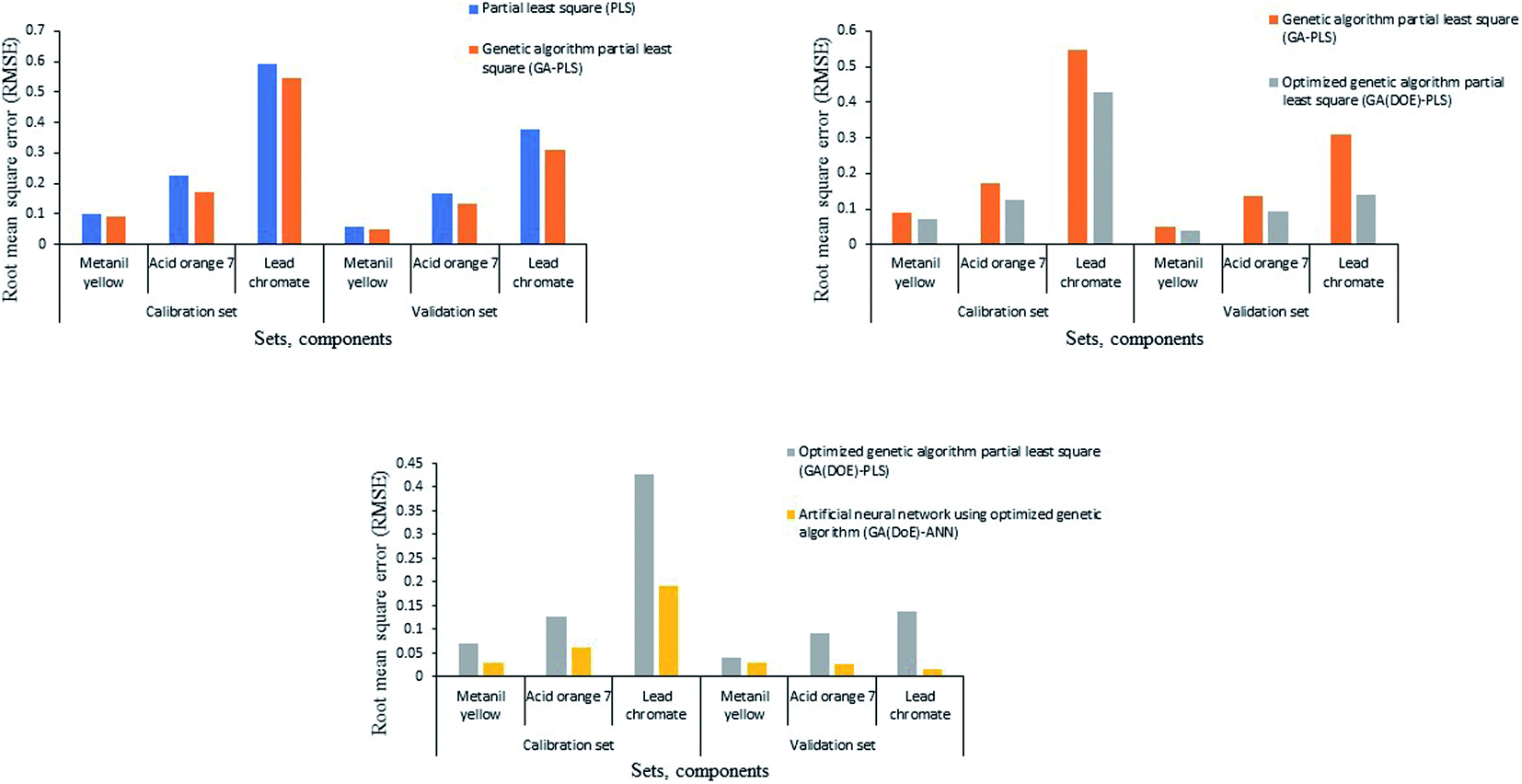 | ||
| Fig. 2 Root mean square error of calibration and validation sets for the three adulterants using the four chemometric models. | ||
3.8 Optimization of GA-PLS model
Even with the preference of the GA-PLS model over the classical one, there was a necessity to optimize its predictive ability using the design of experiment technique (DoE). The DoE evaluates the impact of different factors on the desired response, and identifies important interactions that are missed when experimenting with one factor at a time. The results were analyzed using one-way ANOVA (Table S4†). The small p-values (less than 0.05) and large F-value prove the fitness of the model, and its ability to determine the concentration of the three adulterants. These results indicate that there is only a 0.01% chance that an F-value this large could occur due to noise. However, the lack of fit (p-values more than 0.05) implies that the curvature of the model is not significant relative to the pure error, which could occur due to noise. Non-significant lack of fit is desirable as we want the model to fit, which means that the curvature is not significant. The relatively small difference between the adjusted and predicted R2 indicates good predictability of the model. Adequate precision measures the signal-to-noise ratio. A ratio greater than 4 is achieved, which indicates an adequate signal and proves that the model can be used to navigate the design space. Residuals versus predicted data plots (Fig. S2†) indicated the good fitness of the model as the residuals (errors) are within the specified limits. No significant interaction between the factors was observed. The desirability function selected the best level of each factor, which was then used to optimize the predictive ability of the GA-PLS model. The function suggested using ml, fit% and LV of 10, 82% and 5, respectively (Fig. S3†), with 97.60% desirability.The suggested ml was applied to GA parameters, while the suggested fit% was used to select the optimum set of wavelengths. The PLS model was constructed using the calibration set and the optimum number of LV (Fig. S1†). The smaller RMSEP of the GA(DoE)-PLS model relative to that of the GA-PLS model suggests better predictive ability of the former model (Fig. 2).
3.9 Optimization of ANN model
The ANN model was constructed using the GA (DoE) dataset. Different numbers of hidden neurons were tested to select the optimum number of neurons that improved the ANN predictive ability. The optimum number of hidden neurons was seven, which gave a small MSE and correlation coefficient r near unity (Fig. 3). The ANN architecture indicated the different layers used for the prediction of the concentration of the three adulterants (Fig. S4†). Purelin–Purelin transfer function was suitable owing to the linear absorbances–concentrations relationship. The TRAINLM-Levenberg–Marquardt backpropagation was preferred as a training function. The GA(DoE)-ANN model was performed on the validation set, and RMSEP was calculated.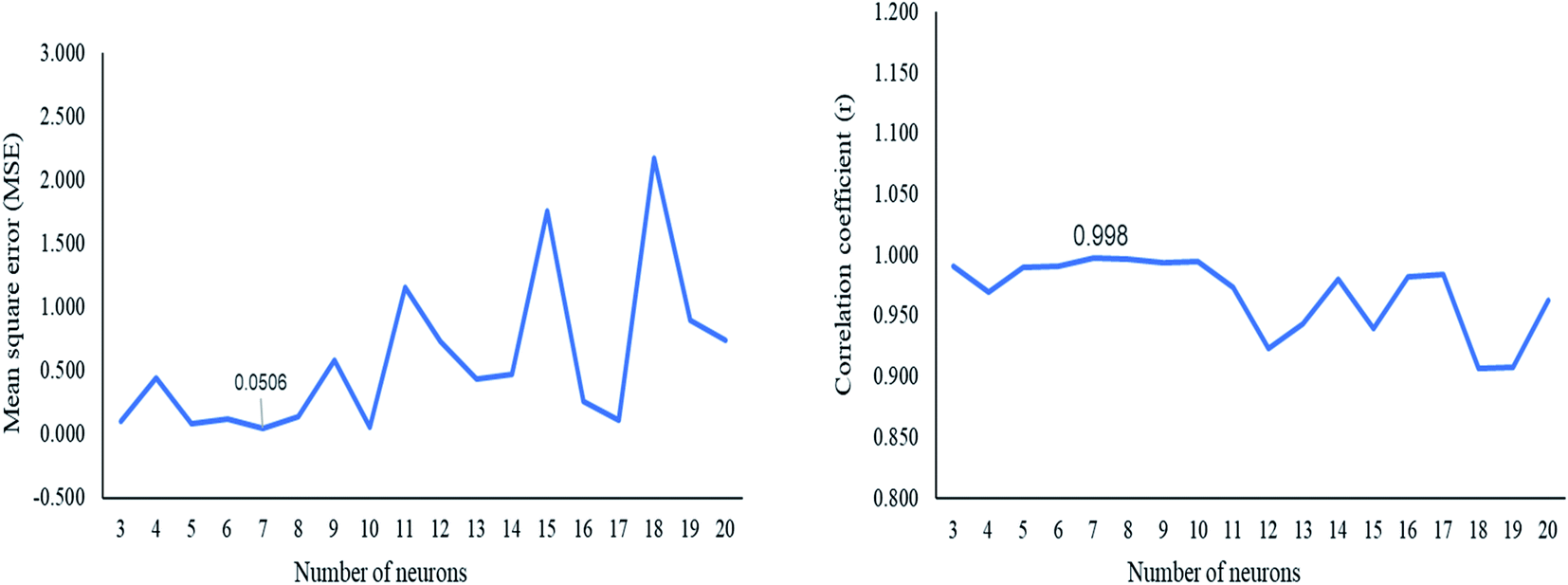 | ||
| Fig. 3 Plot of the mean square error (MSE) and the correlation coefficient (r) against the number of neurons in the architecture of GA(DoE)-ANN. | ||
3.10 Model reproducibility and data prediction
The four models successfully predicted the concentration of the three analytes in the calibration and validation sets (Table 1). Reproducible and precise results (% RSD) were obtained for repeatability and intermediate precision, indicating the success of the four models in analyzing the three adulterants (Table 1). The GA(DoE)-PLS and GA(DoE)-ANN models achieved the best accuracy (low RMSEP) and precision (low % RSD) compared to the other models (Fig. S5 and S6†), owing to the useful GA variable selection tool, the effective DoE optimization approach, and the powerful ANN artificial intelligence (Fig. 2).3.11 Validation of the models
Few methods were reported for the assay of MY in turmeric powder. However, no method was reported for the simultaneous assay of the three adulterants in turmeric powder. Accordingly, we validated the developed chemometric models as per the ICH guidelines.61 This was achieved through spiking of the pure turmeric powder with known concentrations of the three adulterants, and the ability of the proposed models to recover the concentration of the spiked adulterants was then assessed. The recovery percentages and the relative standard deviation percentages were calculated (Table 2).| Models | Metanil yellow (recovery% ± RSD%)a | Acid orange 7 (recovery% ± RSD%)a | Lead chromate (recovery% ± RSD%)a |
|---|---|---|---|
| a Average of three determinations. | |||
| Partial least square | 98.67 ± 1.876 | 100.07 ± 1.840 | 100.28 ± 1.650 |
| Genetic algorithm-partial least square | 99.00 ± 1.746 | 100.33 ± 1.685 | 99.65 ± 0.923 |
| Optimized genetic algorithm-partial least square | 99.42 ± 1.338 | 99.28 ± 0.976 | 100.05 ± 0.477 |
| Artificial neural network using optimized genetic algorithm | 99.75 ± 0.938 | 99.93 ± 0.577 | 99.97 ± 0.200 |
4. Conclusion
Four multivariate chemometric models (PLS, GA-PLS, GA (DoE)-PLS and GA(DoE)-ANN) successfully quantified three toxic turmeric adulterants (MY, AO and LCM) in turmeric powder samples to determine the type and amount of the adulterant. The work demonstrated the augmented influence of the GA and the experimental design on the predictive ability of the PLS and ANN models. The four chemometric methods were validated as per the ICH guidelines. The developed methods proved to be fast, cheap and involved minimal sample preparation. The methods can be used for fast surveillance of turmeric powder adulteration in quality control laboratories before including the powder in food recipes to guarantee authenticity, safety and quality.Author contributions
All authors contributed to the conceptualization of the work, analysis, investigation and visualization of the data.Funding
This research did not receive any specific grant from funding agencies in the public, commercial or not-for-profit sectors.Conflicts of interest
There are no conflicts to declare.References
- S. M. A. El-Halim, M. A. Mamdouh, A. E. El-Haddad and S. M. Soliman, Sci. Pharm., 2020, 88, 1–16 CrossRef.
- F. Forouzanfar, M. Majeed, T. Jamialahmadi and A. Sahebkar, in Advances in Experimental Medicine and Biology, Springer, 2021, vol. 1291, pp. 363–373 Search PubMed.
- B. B. Aggarwal and K. B. Harikumar, Int. J. Biochem. Cell Biol., 2009, 41, 40–59 CrossRef CAS PubMed.
- Y. Panahi, M. S. Hosseini, N. Khalili, E. Naimi, L. E. Simental-Mendía, M. Majeed and A. Sahebkar, Biomed. Pharmacother., 2016, 82, 578–582 CrossRef CAS PubMed.
- S. Togni and F. Mazzolani, Clin. Ophthalmol., 2013, 7, 939 CrossRef PubMed.
- W. Li, L. Sun, J. Lei, Z. Wu, Q. Ma and Z. Wang, Oncol. Rep., 2020, 44, 382–392 CrossRef CAS.
- B. Chandran and A. Goel, Phytother. Res., 2012, 26, 1719–1725 CrossRef CAS.
- L. L. Hurley, L. Akinfiresoye, E. Nwulia, A. Kamiya, A. A. Kulkarni and Y. Tizabi, Behav. Brain Res., 2013, 239, 27–30 CrossRef CAS PubMed.
- B. Sasikumar, J. Spices Aromat. Crop., 1970, 28, 96–105 CrossRef.
- R. A. Cartwright, Environ. Health Perspect., 1983, 49, 13–19 CrossRef CAS.
- R. N. Dome, S. Hazra, D. Ghosh and S. Ghosh, Int. J. Pharm. Pharm. Sci., 2017, 9, 203 CrossRef CAS.
- T. N. Nagaraja and T. Desiraju, Food Chem. Toxicol., 1993, 31, 41–44 CrossRef CAS PubMed.
- P. P. Nath, K. Sarkar, M. Mondal and G. Paul, Environ. Toxicol., 2010, 29, 453–460 CrossRef PubMed.
- P. P. Nath, K. Sarkar, M. Mondal and G. Paul, Environ. Toxicol., 2016, 31, 2057–2067 CrossRef CAS PubMed.
- R. Sarkar and A. R. Ghosh, Int. J. Basic Appl. Med. Sci., 2012, 2, 40–42 Search PubMed.
- V. K. Gupta, A. Mittal, V. Gajbe and J. Mittal, Ind. Eng. Chem. Res., 2006, 45, 1446–1453 CrossRef CAS.
- W. Cowell, T. Ireland, D. Vorhees and W. Heiger-Bernays, Public Health Rep., 2017, 132, 289–293 CrossRef PubMed.
- J. Singh, D. E. Pritchard, D. L. Carlisle, J. A. Mclean, A. Montaser, J. M. Orenstein and S. R. Patierno, Toxicol. Appl. Pharmacol., 1999, 161, 240–248 CrossRef CAS PubMed.
- D. I. Ellis, H. Muhamadali, S. A. Haughey, C. T. Elliott and R. Goodacre, Anal. Methods, 2015, 7, 9401–9414 RSC.
- I. Khalil, W. A. Yehye, N. Muhd Julkapli, A. A. I. Sina, S. Rahmati, W. J. Basirun and A. Seyfoddin, Analyst, 2020, 145, 1414–1426 RSC.
- N. Kusnin, N. A. Yusof, J. Abdullah, S. Sabri, F. Mohammad, S. Mustafa, N. A. Ab Mutalib, S. Sato, S. Takenaka, N. A. Parmin and H. A. Al-Lohedan, RSC Adv., 2020, 10, 27336–27345 RSC.
- S. Karimi, J. Feizy, F. Mehrjo and M. Farrokhnia, RSC Adv., 2016, 6, 23085–23093 RSC.
- Y. Huang, X. Mu, J. Wang, Y. Wang, J. Xie, R. Ying and E. Su, J. Mater. Chem. B, 2022, 10, 1359 RSC.
- P. M. Murray, F. Bellany, L. Benhamou, D.-K. Bučar, A. B. Tabor and T. D. Sheppard, Org. Biomol. Chem., 2016, 14, 2373–2384 RSC.
- S. Choudhary, K. Sharma, M. S. Bhatti, V. Sharma and V. Kumar, RSC Adv., 2022, 12, 4780–4794 RSC.
- C. Waldron, A. Pankajakshan, M. Quaglio, E. Cao, F. Galvanin and A. Gavriilidis, React. Chem. Eng., 2020, 5, 112–123 RSC.
- A. Elik, A. Demirbaş and N. Altunay, Food Chem., 2022, 371, 131138 CrossRef CAS PubMed.
- N. Taoufik, W. Boumya, R. Elmoubarki, A. Elhalil, M. Achak, M. Abdennouri and N. Barka, Mater. Today Chem., 2022, 23, 100732 CrossRef.
- F. H. Edrees, A. S. Saad, M. T. Alsaadi, N. H. Amin and N. S. Abdelwahab, RSC Adv., 2021, 11, 1450–1460 RSC.
- S. B. Kim, D. S. Kim and C. Magana-Ramirez, PLoS One, 2021, 16, e0257472 CrossRef CAS PubMed.
- A. Łacka, Agronomy, 2021, 11, 2406 CrossRef.
- M. Picard, A. K. Mohanty and M. Misra, RSC Adv., 2020, 10, 36058–36089 RSC.
- R. W. Baker, L. Forfar, X. Liang and P. J. Cameron, React. Chem. Eng., 2021, 6, 709–719 RSC.
- N. S. Eyke, W. H. Green and K. F. Jensen, React. Chem. Eng., 2020, 5, 1963–1972 RSC.
- M. A. Abou-Shamat, J. L. Stair, S. B. Kirton, J. Calvo-Castro and M. T. Cook, Mol. Syst. Des. Eng., 2020, 5, 1538–1546 RSC.
- Y. Ayaz Atalan and A. Atalan, İstatistik ve Uygulamalı Bilim. Derg., 2021, 2, 1–7 Search PubMed.
- D. Galvan, L. Effting, H. Cremasco and C. A. Conte-Junior, Foods, 2021, 10, 1941 CrossRef CAS PubMed.
- M. Fidaleo, Food Bioprocess Technol., 2020, 13, 1035–1047 CrossRef CAS.
- F. Liu, Y. Shi and L. Najjar, Procedia Comput. Sci., 2017, 122, 720–726 CrossRef.
- D. Pugliese, F. Bella, V. Cauda, A. Lamberti, A. Sacco, E. Tresso and S. Bianco, ACS Appl. Mater. Interfaces, 2013, 5, 11288–11295 CrossRef CAS PubMed.
- S. Galliano, F. Bella, M. Bonomo, F. Giordano, M. Grätzel, G. Viscardi, A. Hagfeldt, C. Gerbaldi and C. Barolo, Sol. RRL, 2021, 5, 2000823 CrossRef CAS.
- S. Galliano, F. Bella, M. Bonomo, F. Giordano, M. Grätzel, G. Viscardi, A. Hagfeldt, C. Gerbaldi and C. Barolo, Sol. RRL, 2021, 5, 2000823 CrossRef CAS.
- F. Bella, M. Imperiyka and A. Ahmad, J. Photochem. Photobiol., A, 2014, 289, 73–80 CrossRef CAS.
- S. Galliano, F. Bella, G. Piana, G. Giacona, G. Viscardi, C. Gerbaldi, M. Grätzel and C. Barolo, Sol. Energy, 2018, 163, 251–255 CrossRef CAS.
- I. Reichert, P. Olney and T. Lahmer, J. Civ. Struct. Health Monit., 2021, 11, 223–234 CrossRef.
- P. García-Manrique, M. B. González-García and M. C. Blanco-López, in Laboratory Methods in Dynamic Electroanalysis, Elsevier, 2020, pp. 361–371 Search PubMed.
- Y. Xu, X. Gao, C. Yang, B. Man and J. Leng, J. Mater. Chem. C, 2021, 9, 2763–2774 RSC.
- D. Suriano, G. Cassano and M. Penza, J. Sens., 2020, 2020, 1–20 CrossRef.
- M. E. Wahba, D. El Wasseef, A. S. Saad and M. E. Draz, RSC Adv., 2021, 11, 12833–12844 RSC.
- P. K. Sahu, J. Panda, Y. V. V. Jogendra Kumar and S. K. Ranjitha, J. Liq. Chromatogr. Relat. Technol., 2020, 43, 247–254 CrossRef CAS.
- L. Sabatino, M. Scordino, M. Gargano, A. Belligno, P. Traulo and G. Gagliano, Nat. Prod. Commun., 2011, 6, 1873–1876 CrossRef CAS.
- A. Girme, G. Saste, A. K. Balasubramaniam, S. Pawar, C. Ghule and L. Hingorani, J. Pharm. Biomed. Anal., 2020, 191, 113603 CrossRef CAS PubMed.
- A. Rohman, T. Wijayanti, A. Windarsih and S. Riyanto, Molecules, 2020, 25, 1–13 Search PubMed.
- R. M. Shereema, T. P. Rao, V. B. Sameer Kumar, T. V. Sruthi, R. Vishnu, G. R. D. Prabhu and S. Sharath Shankar, Mater. Sci. Eng., C, 2018, 93, 21–27 CrossRef CAS PubMed.
- W. G. Chaminda Bandara, G. W. Kasun Prabhath, D. W. Sahan Chinthana Bandara Dissanayake, V. R. Herath, G. M. Roshan Indika Godaliyadda, M. P. Bandara Ekanayake, D. Demini and T. Madhujith, J. Food Eng., 2020, 266, 109700 CrossRef CAS.
- S. Varliklioz Er, H. Eksi-Kocak, H. Yetim and I. H. Boyaci, Food Anal. Methods, 2017, 10, 1547–1555 CrossRef.
- S. Kar, B. Tudu, A. K. Bag and R. Bandyopadhyay, Food Anal. Methods, 2018, 11, 1291–1302 CrossRef.
- S. Dhakal, K. Chao, J. Qin, M. Kim, W. Schmidt and D. Chan, Sens. Agric. Food Qual. Saf. VIII, 2016, vol. 9864, p. 98640A Search PubMed.
- I. R. Rukundo, M. G. C. Danao, C. L. Weller, R. L. Wehling and K. M. Eskridge, J. Near Infrared Spectrosc., 2020, 28, 81–92 CrossRef CAS.
- E. A. Petrakis and M. G. Polissiou, Talanta, 2017, 162, 558–566 CrossRef CAS PubMed.
- N. Baber, Br. J. Clin. Pharmacol., 1994, 37, 401–404 CrossRef CAS PubMed.
Footnote |
| † Electronic supplementary information (ESI) available. See DOI: 10.1039/d2ra00697a |
| This journal is © The Royal Society of Chemistry 2022 |