
Development of a machine learning-based tool to evaluate correct Lewis acid–base model use in written responses to open-ended formative assessment items
Brandon J.
Yik
 ,
Amber J.
Dood
,
Daniel
Cruz-Ramírez de Arellano
,
Kimberly B.
Fields
and
Jeffrey R.
Raker
*
,
Amber J.
Dood
,
Daniel
Cruz-Ramírez de Arellano
,
Kimberly B.
Fields
and
Jeffrey R.
Raker
*
Department of Chemistry, University of South Florida, Tampa, FL 33620, USA. E-mail: jraker@usf.edu
First published on 1st July 2021
Abstract
Acid–base chemistry is a key reaction motif taught in postsecondary organic chemistry courses. More specifically, concepts from the Lewis acid–base model are broadly applicable to understanding mechanistic ideas such as electron density, nucleophilicity, and electrophilicity; thus, the Lewis model is fundamental to explaining an array of reaction mechanisms taught in organic chemistry. Herein, we report the development of a generalized predictive model using machine learning techniques to assess students’ written responses for the correct use of the Lewis acid–base model for a variety (N = 26) of open-ended formative assessment items. These items follow a general framework of prompts that ask: why a compound can act as (i) an acid, (ii) a base, or (iii) both an acid and a base (i.e., amphoteric)? Or, what is happening and why for aqueous proton-transfer reactions and reactions that can only be explained using the Lewis model. Our predictive scoring model was constructed from a large collection of responses (N = 8520) using a machine learning technique, i.e., support vector machine, and subsequently evaluated using a variety of validation procedures resulting in overall 84.5–88.9% accuracies. The predictive model underwent further scrutiny with a set of responses (N = 2162) from different prompts not used in model construction along with a new prompt type: non-aqueous proton-transfer reactions. Model validation with these data achieved 92.7% accuracy. Our results suggest that machine learning techniques can be used to construct generalized predictive models for the evaluation of acid–base reaction mechanisms and their properties. Links to open-access files are provided that allow instructors to conduct their own analyses on written, open-ended formative assessment items to evaluate correct Lewis model use.
Introduction
Acidity and basicity are foundational concepts in the postsecondary organic chemistry curriculum (Friesen, 2008; Cartrette and Mayo, 2011; McClary and Talanquer, 2011; Bhattacharyya, 2013; Stoyanovich et al., 2015; Brown et al., 2018; Nedungadi and Brown, 2021). Acid–base reactions are among the introductory reaction types (sometimes referred to as reaction mechanism motifs) covered (Stoyanovich et al., 2015) and are routine components of more complex reaction mechanisms (Friesen, 2008; Stoyanovich et al., 2015). Concepts surrounding acid–base chemistry are universal in rationalizing organic reaction mechanisms and therefore it is critical that students have a strong foundation in acid–base theories (Graulich, 2015). Thus, how acid–base chemistry knowledge is taught and evaluated influences learning.Current assessment items and tools are limited in measuring understanding of acids and bases. Concept inventories and multiple-choice-based assessments exist to measure such understanding. For example, the ACID-I concept inventory is a multi-choice assessment that evaluates student conceptions about acid strength (McClary and Bretz, 2012). Other examples of concept inventories include a test measuring high school students’ understanding of acids and bases (Cetin-Dindar and Geban, 2011), the Acid–Base Reactions Concept Inventory (ABCI) used to measure understanding of acid–base reactions in high school students through postsecondary organic chemistry (Jensen, 2013), and the Measuring Concept progressions in Acid–Base chemistry (MCAB) instrument intended to address concepts covered in general chemistry (Romine et al., 2016). However, a known shortcoming of multiple-choice assessments is that students are forced to choose an answer; this may give the false illusion that students hold certain conceptions when they could have been guessing (Birenbaum and Tatsuoka, 1987). An alternative to multi-choice-based assessments are oral examinations (including research-based think-aloud interview protocols). For example, through interviews McClary and Talanquer (2011) found that students use several different models and even mixed models when explaining acid and base strength. Such Socratic, dialogue-rooted assessments are impractical, particularly in courses with large enrollments (e.g., Roecker, 2007; Dicks et al., 2012). Measurement of acid–base concept understanding is further complicated in that observation-based studies have shown that students are able to draw acid–base mechanisms, or other mechanisms without understanding the concepts behind the representation (Bhattacharyya and Bodner, 2005; Ferguson and Bodner, 2008; Grove et al., 2012).
Constructed-response assessment items that require a student to explain better measure acid–base understanding and chemistry concepts in general. Such open-ended items are vital for instructors to gain insight into students’ understanding and important for amending instruction to improve student learning (Bell and Cowie, 2001; Fies and Marshall, 2006; MacArthur and Jones, 2008). Assessments where students are free to respond in complete thoughts to demonstrate their conceptual understanding provide deeper insight to instructors and send a message to students that deep understanding is important (Birenbaum and Tatsuoka, 1987; Scouller, 1998; Cooper et al., 2016; Stowe and Cooper, 2017; Underwood et al., 2018). However, open-response items, as with oral examinations, are not pragmatic for instructors’ use in large-enrollment courses and are not feasible for use with just-in-time-teaching (Novak et al., 1999).
Computer-assisted predictive scoring models have been built to evaluate text-based responses to open-ended items. Use of predictive scoring models reduce evaluation time, making in-class use possible (e.g., Haudek et al., 2011, 2012; Prevost et al., 2016; Dood et al., 2018, 2020a; Noyes et al., 2020). Some of these models have been designed to specifically evaluate student understanding of acid–base chemistry through written explanations; for example, Haudek et al. (2012) used a predictive model to identify levels of correct explanations of acid–base chemistry use in a biology course and Dood et al. (2018, 2019) built a predictive model to classify use of the Lewis acid–base model in responses to a proton-transfer reaction. A meta-analysis of machine learning-based science assessments has shown that these techniques are primarily employed in middle/secondary and postsecondary environments, spanning the general science domain to more specific STEM disciplines (Zhai et al., 2020). These predictive models serve a multitude of functions (e.g., assigning scores, classifying responses, identification of key concepts), use a variety of computational algorithms (e.g., regression, decision trees, Bayes, and support vector machines), and are built with an array of software (e.g., SPSS Text Analytics, Python, R, c-rater, SIDE/LightSIDE; cf., Zhai et al., 2020). Such scoring models, though, have been prompt-specific, meaning that varying the prompt by an instructor may yield the scoring models invalid; thus, new predictive scoring models must be developed for each assessment item, a process that requires hundreds of responses and multiple hours of development.
Use of the Lewis model in explaining acid–base reactions is key to mastery of organic chemistry. The goal of the work we report herein is to construct a computer-assisted predictive scoring model that detects correct use of the Lewis acid–base model in response to open-ended acid–base assessment items. This work seeks to build a single generalized predictive model that has demonstrable accuracy across an array of assessment items with the potential for instructors to use the predictive scoring model to evaluate responses to assessment items beyond those reported herein. Our results provide a foundation for more complex and nuanced predictive models built by technologies based on machine learning to evaluate understanding of reaction mechanisms beyond the foundational acid–base reaction.
Student understanding of acid–base models
Paik (2015) outlined the three main acid–base models taught in the introductory, postsecondary chemistry curricula: Arrhenius, Brønsted–Lowry, and Lewis. In the Arrhenius model, acids dissociate in water and increase the concentration of hydrogen ions (H+) and bases dissociate in water and increase the concentration of hydroxide ions (OH−). In the Brønsted–Lowry model, acids act as proton donors and bases act as proton acceptors. In the Lewis model, acids are defined as electron pair acceptors and bases are defined as electron pair donors. Students are typically introduced to the Arrhenius and Brønsted–Lowry models in secondary education (i.e., high school) chemistry courses and in postsecondary general chemistry courses. It has been noted by many that the Lewis model is glanced over, if at all presented in these courses, and emphasis is placed on the other two models (Shaffer, 2006; Drechsler and Van Driel, 2008; Cartrette and Mayo, 2011; Paik, 2015).While the three models are interconnected, mental conceptions of acidity and basicity by learners suggest a lack of distinctness between the models: McClary and Talanquer (2011) reported that student conceptions are dependent on a compound's surface features and that students struggle to switch between models. Studies suggest that learners struggle with acid–base models across the postsecondary curriculum and even into the graduate chemistry curriculum (Bhattacharyya, 2006; Cartrette and Mayo, 2011; McClary and Talanquer, 2011; Bretz and McClary, 2015; Stoyanovich et al., 2015; Dood et al., 2018; Schmidt-McCormack et al., 2019). This key confusion originates partially in the ambiguous relationships between acid–base models, a lack of clear distinction between the models (Schmidt and Volke, 2003; Drechsler and Schmidt, 2005). Additionally, the sheer number of models may also cause confusion (Ültay and Çalik, 2016).
Students have difficulty switching between acid–base models when solving problems, especially when the Lewis model is the most appropriate model (Cartrette and Mayo, 2011; Tarhan and Acar Sesen, 2012). Model confusion results when students attempt to apply models in circumstances where they are not applicable; for example, Tarhan and Acar Sesen (2012) found that students had greatest difficulty with Lewis acid–base reactions, such as with the reaction between ammonia and trifluoroborane, in which less than half of the participants in their study could correctly identify the Lewis acid–base reaction. Students also struggle to incorporate concepts of the Lewis model within their current understanding of acids and bases; for example, Cartrette and Mayo (2011) observed that study participants struggled with using terminology such as nucleophilicity and electrophilicity when trying to apply those concepts to a proton-transfer reaction. However, Crandell et al. (2019) noted that when students are primed to consider “why a reaction can only be described using the Lewis model,” those students are more likely to describe the transfer of electrons when asked what is happening in a given reaction and why that reaction occurs.
Students struggle with defining, giving examples, and explaining the function of acids and bases (Bhattacharyya, 2006; Cartrette and Mayo, 2011; Tarhan and Acar Sesen, 2012; Schmidt-McCormack et al., 2019). Cartrette and Mayo (2011) found that second-semester organic chemistry students could correctly define and give examples of Brønsted–Lowry acids and bases; however, less than half of their sample could do the same for Lewis acids and bases. In a study by Tarhan and Acar Sesen (2012), a majority of students also could not correctly classify a substance as a Lewis base. Schmidt-McCormack et al. (2019) reported that students were able to correctly identify Lewis acids, but were unable to describe how or why the compound acts as a Lewis acid. Additionally, Bhattacharyya (2006) showed that chemistry graduate students were able to provide definitions for acids and bases but were unable to apply their mental models to different situations. This suggests that despite the centrality of Lewis acids and bases in the curriculum, many students are leaving our courses with an underdeveloped understanding of acidity and basicity.
The amphoteric property of some chemical species, i.e., the species can act as both an acid and a base, poses further complications in Lewis acid–base understanding (Schmidt and Volke, 2003; Drechsler and Schmidt, 2005; Drechsler and Van Driel, 2008). The amphoteric property of water can be explained using both the Brønsted–Lowry and Lewis models; however, that explanation fails when the Arrhenius model is invoked. Students are perhaps uncomfortable with the classification of water as an acid or a base due to a reliance on the Arrhenius model (Schmidt and Volke, 2003; Drechsler and Schmidt, 2005). Schmidt (1997) found that some students hold the conception that conjugate acid–base pairs must be charged ions; students struggled with identifying a neutral conjugate acid or base as such. While such confusion is not limited to amphoteric species, charged species versus neutral species is central to the concept of amphoterism. While the Brønsted–Lowry model can be used to describe the amphoteric property, not all amphoteric compounds are proton donors and acceptors; therefore, understanding amphoterism using the Lewis acid–base model is more generalizable.
Understanding the Lewis acid–base model is vital to explaining reactivity in organic chemistry (Shaffer, 2006; Bhattacharyya, 2013; Stoyanovich et al., 2015; Cooper et al., 2016; Dood et al., 2018). Cooper et al. (2016) found that students who utilized the Lewis model to explain an aqueous, acid–base proton-transfer reaction had a higher likelihood of producing its accepted arrow-pushing mechanism. Expanding upon that work, Dood et al. (2018) found that students who were able to explain a proton-transfer reaction using the Lewis model had higher scores on an acid–base related examination in an organic chemistry course. Crandell et al. (2019) built upon the work of Cooper et al. (2016) by adding a mechanism that can only be explained using the Lewis acid–base model, demonstrating that features of the assessment prompt influences the degree to which particular acid–base models are invoked in explanations.
Role of formative assessments in developing acid–base model use by students
Writing is a way of knowing (Reynolds et al., 2012); in the context of chemistry courses, writing is an opportunity to reflect on processes about chemical concepts and on solving problems. The process of writing by explaining primes thinking and engagement at a deeper level (Rivard, 1994; Bangert-Drowns et al., 2004; Reynolds et al., 2012). Deliberate constructed-response items, centered on writing to learn, can better promote student understanding of chemical concepts (Birenbaum and Tatsuoka, 1987; Cooper, 2015; Stowe and Cooper, 2017; Underwood et al., 2018). Construction of explanations and engagement in argument from evidence are two practices that aid in the development of conceptual understanding (National Research Council, 2012). Therefore, constructed-response items can be used to elicit reasoning through argumentation and construction of explanations. It has been suggested that deeper learning can be accomplished by asking students why a phenomenon occurs (Cooper, 2015). Cooper et al. (2016) reported that asking what is happening and why it happens for chemical reactions better elicited student explanations. This scaffold has been expanded upon by Dood et al. (2018, 2019) and Crandell et al. (2019) for acid–base chemistry; similarly, asking students what is happening and why for SN1 (Dood et al., 2020a) and SN2 (Crandell et al., 2020) reactions better elicited mechanistic understanding. While constructed-response items provide a formative means for evaluation of student understanding, they are limited in the time required to provide feedback to students.There has been one instance, to date, of the development of a computer-assisted scoring model used to evaluate written responses to an acid–base assessment item in chemistry courses. Dood et al. (2018) reported a predictive scoring model that was then further optimized and generalized by Dood et al. (2019). While the model reported by Dood et al. (2018, 2019) is a key first step to solving the issue of practicality of speed in scoring and for use with large-enrollment courses, the work of Dood et al. still falls into the category of a predictive scoring model for a single assessment item. For evaluation of responses to open-ended assessment items, which includes predictive scoring models, to become widely developed, more generalizable models are necessary.
Argument for a generalized predictive model
Computer-assisted scoring models, based on brute-force lexical analyses (Haudek et al., 2011) and machine learning (Zhai et al., 2020) techniques are becoming more commonplace in the analysis of open-ended written assessments in postsecondary STEM course contexts: for example, chemistry (Haudek et al., 2012; Dood et al., 2018, 2020a; Noyes et al., 2020), biology (Haudek et al., 2012; Moharreri et al., 2014; Prevost et al., 2016; Carter and Prevost, 2018; Sieke et al., 2019; Uhl et al., 2021), and statistics (Kaplan et al., 2014). These predictive models are assessment item-specific; that is, each predictive model is designed and optimized to evaluate responses to a specific assessment prompt or prompt type. The time necessary to develop a single predictive model, including data collection (and sometimes additional data collection with a modified prompt), is somewhat prohibitive (Urban-Lurain et al., 2009). Rather than generalized predictive models, more limited models have been developed. For example, predictive models have been developed to measure structure–function relationships in biology with a specific assessment prompt (Carter and Prevost, 2018), rather than a generalized predictive model to measure structure–function understanding with an array of assessment prompts. When considering evaluating knowledge of Lewis acid–base understanding, we noted that while specific chemical species were needed as context from which a student would respond, the language about those species and the interaction of multiple species is consistent. For example, when describing an acid–base reaction, identifying areas of electron sufficiency and deficiency are key to correctly invoking a Lewis acid–base explanation; thus, a predictive scoring model focused on identifying instances of electron density is more important than if the name of a chemical species was identified (e.g., a chloride ion), the latter being prompt specific.In an effort to provide more tools to evaluate understanding of Lewis acid–base chemistry coupled with a desire to advance work in predictive scoring models for assessments in STEM, we sought to develop a generalized predictive model to evaluate correct use of the Lewis acid–base model in responses to an array of assessment items.
Research question
This study was guided by one primary research question:What level of accuracy can be achieved for a generalized predictive model developed using machine learning techniques that predicts correct use of the Lewis acid–base model for a variety of constructed response items?
Methods
This work was conducted under application Pro#00028802, “Comprehensive evaluation of the University of South Florida's undergraduate and graduate chemistry curricula” as reviewed by the University of South Florida's Institutional Review Board on December 13, 2016. Per Institutional Review Board criteria, the activities were determined to not constitute research.Constructed response items
The constructed response item for the proton-transfer reaction used in this study was first reported by Cooper et al. (2016), modified for use by Dood et al. (2018), and lastly expanded to other hydrohalic acids and water reactions by Dood et al. (2019). Data used in this study in determining correct Lewis acid–base model use in response to aqueous proton-transfer constructed items were used previously (Dood et al., 2018, 2019) in logistic regression predictive models; herein, those data are analyzed differently and in conjunction with broader data.In total, response to 15 constructed response items were collected and used in the training set for the reported machine learning model (see Appendix 1 for a complete list of constructed response items). The items are characterized by five types: (i) aqueous proton-transfer reaction; (ii) acid–base reaction that can only be explained using the Lewis model; and why a compound can act as (iii) an acid, (iv) a base, or (v) amphoteric (see Fig. 1 for an example for each prompt type).
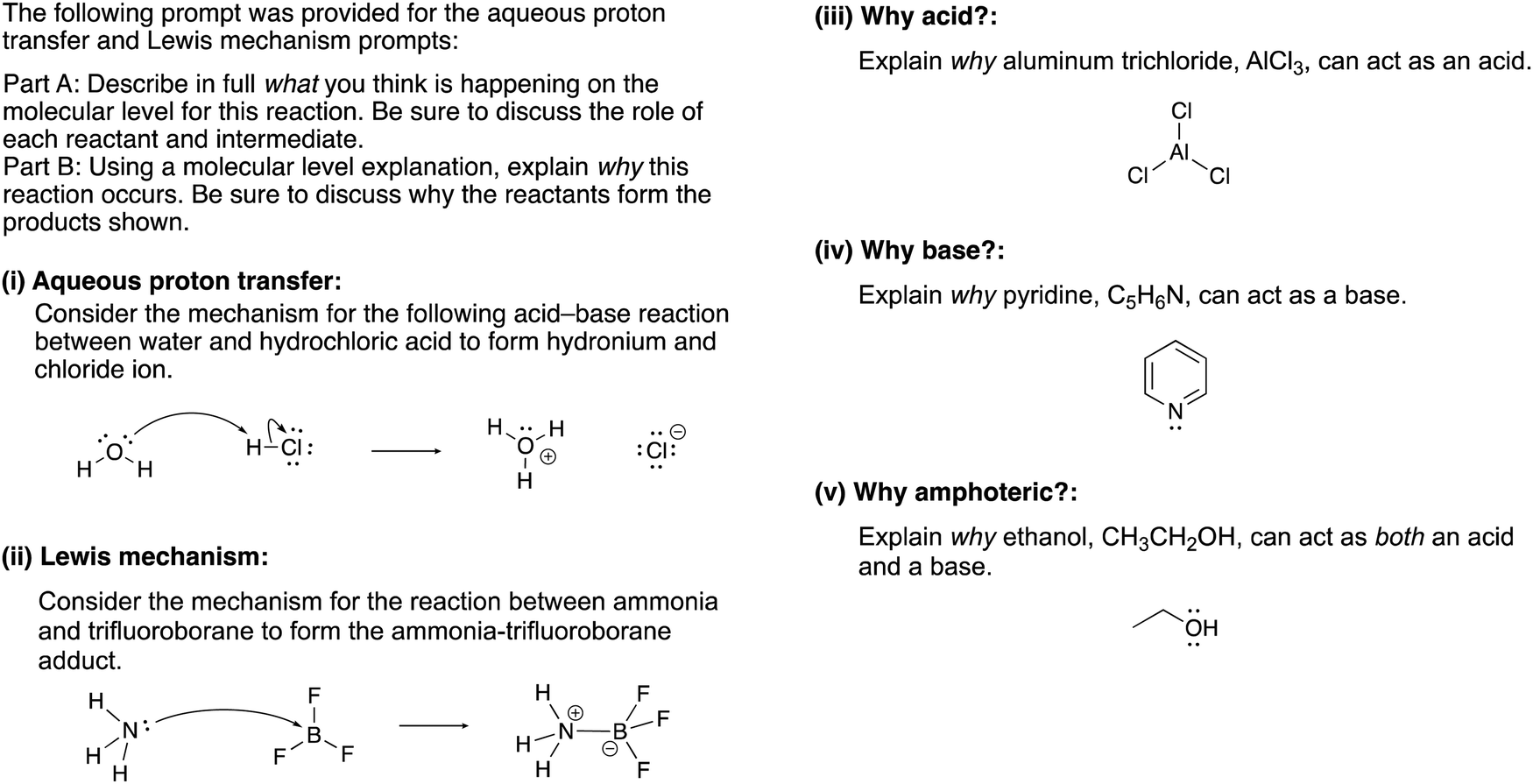 | ||
| Fig. 1 Example of constructed-response items. For a comprehensive list of all prompts used in this study, see Appendices 1 and 2. | ||
Data collection
Data were collected from six semesters (Fall 2017 through Fall 2020) of the first semester and one semester (Fall 2018) of the second semester of the year-long organic chemistry course as taught by three instructors at a large, research-intensive, public university in the southeastern United States. Data were collected in author DCR's first semester course in Spring 2018, Fall 2018, Spring 2019, Fall 2019, Spring 2020, and Fall 2020. Data were collected in author KBF's first semester course in Fall 2017, Fall 2018, Fall 2019, and Fall 2020. Data were collected in author JRR's first semester course in Fall 2017, Fall 2019, and Spring 2020, and second semester course in Fall 2018. The textbook used between Fall 2017 and Spring 2019 was Solomons, Fryhle, and Synder's Organic Chemistry, 12th edn(2016); the textbook used between Fall 2019 and Fall 2020 was Klein's Organic Chemistry, 3rd edn(2017).Constructed response items were given in a survey via Qualtrics. Participants received extra credit towards their examination grade for completing the assessment. Participants completed only one survey on acidity and basicity in the term. In total, 8520 responses from 15 different constructed response items (see Appendix 1) were collected and used in the training set of the machine learning model between Fall 2017 and Spring 2020. An additional 2162 responses from 11 constructed response items with new mechanisms and compounds were collected for additional validation of the machine learning model in Fall 2020 (see Appendix 2 for a complete list of constructed response items).
Development of classification scheme
Responses to the assessment items were classified by correct use or incorrect use/non-use of the Lewis acid–base model based on the terminology and ideas associated with the model. Responses were classified as correct use if the response had ideas about electrons and actions of those electrons: the transfer of electrons or a lone pair, electrons attacking, or about electron densities and partial charges. An action verb or an implied action was necessary for a response to be classified as correct use; mentioning the presence of electrons or lone pairs was not enough. We also include the Ingold–Robinson approach of using reactivity vernacular to describe electrophiles as Lewis acids and nucleophiles as Lewis bases (Robinson, 1932; Ingold, 1934), such that ideas about nucleophiles attacking were classified as correct use. For responses to the aqueous proton-transfer reactions that generically explained how to interpret the curved-arrow formalism, i.e., without mentioning the specific compounds in the prompt, were classified as incorrect use/non-use as the response did not satisfy the requirements of the prompt. The classification scheme for generic explanations was also applied to the reactions that can only be explained using the Lewis model. Additionally, responses to the why acid, why base, and why amphoteric prompts that simply mentioned that the compound was a Lewis acid or base without describing the actions of electrons were classified as incorrect use/non-use.Responses classified as correct use may have solely used the Lewis model or a combination of models including the Arrhenius or Brønsted–Lowry models. However, all statements had to be correct for a given response to be classified as correct use. Representative examples of correct use responses using the example constructed-response items given in Fig. 1 are provided in Table 1.
| Prompt type | Response |
|---|---|
| Aqueous proton transfer | “The lone pair on the oxygen is forming a new bond with the hydrogen from the HCl. The chlorine then takes the electron pair from the hydrogen chlorine bond and becomes a chlorine anion. This reaction occurs because HCl is a strong acid and water is a weak base. This causes the Cl to want to break off. This is because chlorine is a good leaving group.” |
| Lewis mechanism | “A Lewis acid–base reaction is occurring creating the ammonia-trifluoroborane adduct. The lone pair on the nitrogen donates its pair of electrons to the BF3 making the boron now have a negative charge and the nitrogen now have +1 formal charge. BF3 is a very good Lewis acid as its valence shell only contains six electrons and does not have a complete octet. Nitrogen is considered the Lewis base as it donates its pair of electrons. The base forms a covalent bond with the acid making the acid–base adduct.” |
| Why acid? | “There is an empty p-orbital on the aluminum atom, which can act as an acid and accept an electron pair.” |
| Why base? | “A base is considered an electron pair donor. The nitrogen atom in pyridine has one lone pair, in which it can donate this pair of electrons; therefore, this makes it a base.” |
| Why amphoteric? | “Ethanol can act as both an acid and a base because it can accept and donate lone pairs. When it acts as an acid, the hydroxyl proton accepts an electron pair from the strong base. When it acts as a base, it donates an electron pair to a strong acid.” |
In the first sample of 8520 responses, author BJY classified all responses. Then, author JRR independently classified 250 randomly selected responses (n = 50 of each prompt type; 3% overall). Authors BJY and JRR originally agreed on 83% (n = 208) of the items; after discussing disagreements, classifications were changed for 15% (n = 38) of the items with a 98% final agreement. Author BJY then reevaluated a random sample of 1500 responses (n = 300 of each prompt type; 17.6% overall) in light of the conversation. A discussion of disagreements is presented in the Limitations section.
In the additional set of 2162 responses, author BJY again classified all responses. Author JRR independently classified 150 randomly selected responses (n = 10 of each prompt type; 7% overall). Authors BJY and JRR originally agreed on 93% (n = 139) of the items; after discussing disagreements, classifications were changed for 5% (n = 8) of the items with a 98% final agreement. No reevaluation of the set of responses was conducted as author BJY did not change any classifications during the conversation of disagreements.
A summary of the human classifications for all responses by prompt type and training/validation set is given in Table 2.
| Set | Prompt type | N | Correct use (%) | Incorrect use/non-use (%) |
|---|---|---|---|---|
| Training/cross-validation set | Aqueous proton transfer | 419 | 292 (70) | 127 (30) |
| Lewis mechanism | 419 | 352 (84) | 67 (16) | |
| Why acid? | 419 | 243 (58) | 176 (42) | |
| Why base? | 419 | 231 (55) | 188 (45) | |
| Why amphoteric? | 419 | 198 (47) | 221 (53) | |
| Overall | 2095 | 1316 (63) | 779 (37) | |
| Stratified split-validation set | Aqueous proton transfer | 100 | 70 (70) | 30 (30) |
| Lewis mechanism | 100 | 88 (88) | 12 (12) | |
| Why acid? | 100 | 51 (51) | 49 (49) | |
| Why base? | 100 | 49 (49) | 51 (51) | |
| Why amphoteric? | 100 | 48 (48) | 52 (52) | |
| Overall | 500 | 306 (70) | 194 (30) | |
| Remaining split-validation set | Aqueous proton transfer | 3146 | 2289 (73) | 857 (27) |
| Lewis mechanism | 100 | 88 (88) | 12 (12) | |
| Why acid? | 990 | 547 (55) | 443 (45) | |
| Why base? | 1005 | 526 (52) | 479 (48) | |
| Why amphoteric? | 1184 | 556 (47) | 628 (53) | |
| Overall | 6425 | 4006 (62) | 2419 (38) | |
Development of machine learning model
There are four main components of our machine learning model development process: (i) obtaining/collecting data, (ii) data preprocessing and feature extraction, (iii) model training, and (iv) model evaluation (see Fig. 2 for an overview of the process). After data are obtained, data are preprocessed and “cleaned”, for example, so that only words with chemical meaning remain. Remaining words, also referred to as the bag of words in text analysis methodologies, represent features that are extracted into a matrix and used in training the predictive model. The predictive model is evaluated using three approaches.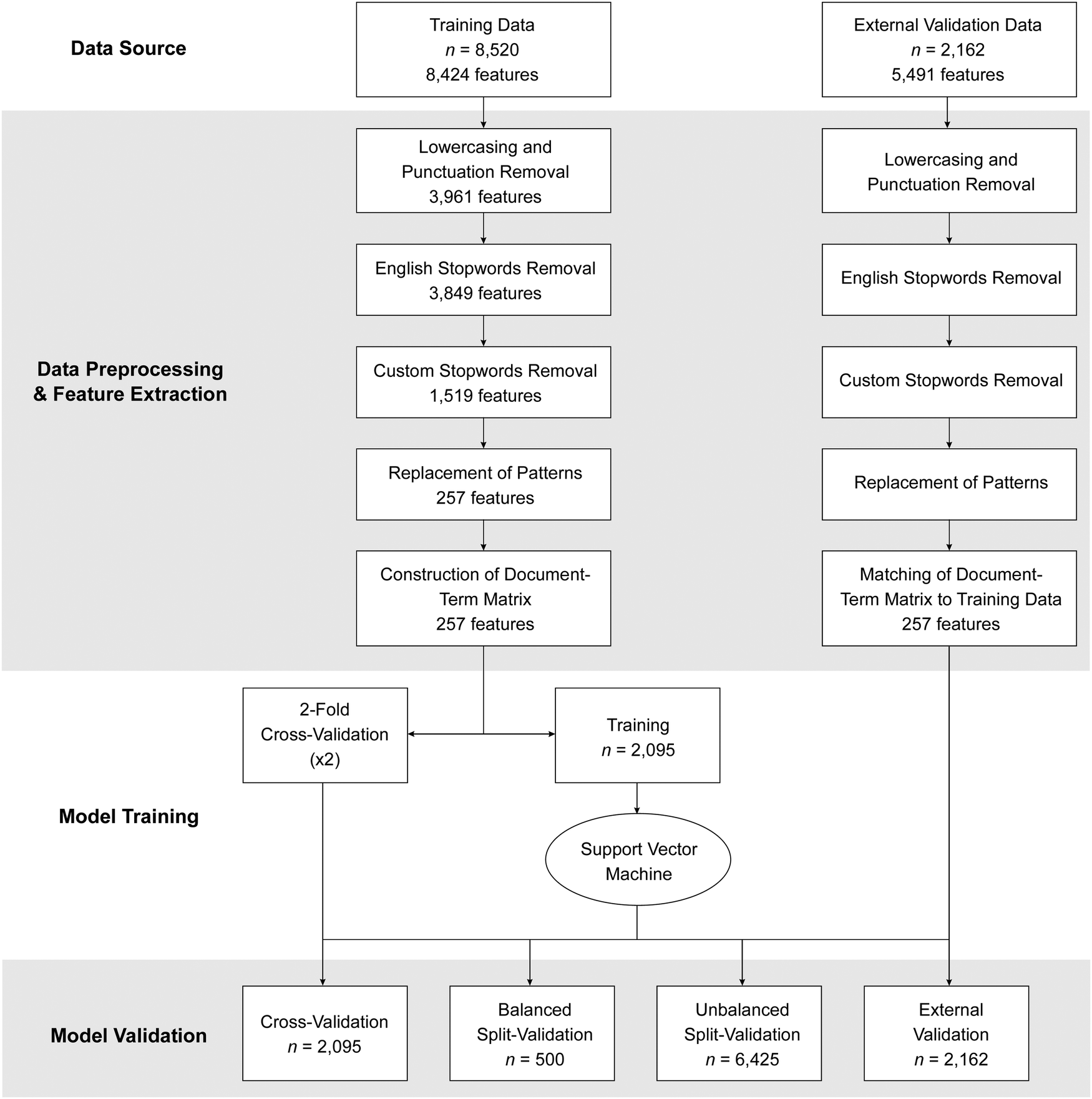 | ||
| Fig. 2 Process of model development and evaluation. | ||
Initial data (n = 8520) were split into two sets: training and validation. The training set consisted of a random set of 419 responses from each of the five prompts (i.e., a total of 2095 responses). The minimum number of responses of each prompt type was 519; therefore, 419 responses were chosen for the training set such that the remaining 100 responses could be set aside for validation. A stratified data set for predictive model building was chosen as to prevent model building from being heavily influenced by one prompt type. We refer to the general set of responses as the data corpus. All machine learning work was completed in RStudio version 1.2.5033 (R Core Team, 2019).
The training corpus first underwent data preprocessing. Preprocessing first involved a function to convert all characters in the corpus to lowercase (Kwartler, 2017), then all non-alphanumeric, special characters, and punctuation are removed using the ‘tm’ and ‘qdap’ packages in R (Feinerer et al., 2008; Rinker, 2020). Stopwords, commonly used words in the English language that usually provide little meaning (e.g., articles), are then removed using the ‘tm’ package (Feinerer et al., 2008). Additionally, a curated dictionary of 2413 custom stopwords was created and used to remove words; this custom dictionary was built by authors BJY and JRR by compiling words without general meaning concerning the use of acid–base models (e.g., specific names of chemical species) or words that do not specifically describe reactions.
Misspelled words were defined in a list of patterns that were substituted by corresponding replacements. This processing is needed as standard text analysis libraries do not recognize technical and discipline-specific vocabulary (Urban-Lurain et al., 2009; Dood et al., 2020a) such as the chemistry words in our data corpus. For example, misspelled words such as “nuclaeophilic” are replaced with the correct spelling, “nucleophilic.” Many studies skip this step; however, misspellings are noted as common error sources in human–computer score disagreements (e.g., Ha et al., 2011; Moharreri et al., 2014); thus, spending time to construct a database of commonly misspelled words and their many variations, as suggested by Ha and Nehm (2016), results in higher predictive model accuracy.
A process called lemmatization was used for text/word normalization. In lemmatization, inflected words are reduced such that the root word is the canonical (dictionary) form in the English language; it is usually coupled with part-of-speech tagging which is a process in which words are assigned part of speech tags associated with the language of the corpus (e.g., “was” becomes “be”). We chose singular verbs to lemmatize; for example, “attack”, “attacked”, and “attacking” all become “attacks”. Additionally, synonyms in a chemical context were grouped together; patterns with lower instance counts (e.g., “cleaves”, “disconnects”, “lyses”, “severs”, “splits”, “tears”) were replaced by the replacement (e.g., “breaks”) that was more common. A total of 1625 words to be replaced were included in the dictionary to account for misspelled words and lemmatization. This process was conducted the ‘qdap’ package in R (Rinker, 2020).
The final corpus preprocessing step was to remove leading, trailing, and excess white spaces. The ‘tm’ package was used to remove these spaces (Feinerer et al., 2008).
Following preprocessing, the next step in machine learning model building is feature extraction; this involves converting the remaining words in the data corpus (i.e., the bag of words) into independent features. The processed data corpus consists of 257 unique words called unigrams (i.e., instance of single words); Lintean et al. (2012) found that unigrams performed the best across a number of machine learning text analysis algorithms. We also considered and tested other n-grams, such as bigrams (i.e., pair of consecutive words), and a combination of both unigrams and bigrams. However, the use of unigrams was found to give the best model performance metrics (see discussion of performance metrics in Results and discussion). Our 257 unigrams were parsed into a document-term matrix, or the pattern of the presence or absence of the terms, with individual student written responses (i.e., documents) representing the rows and unigrams (i.e., terms) representing the columns in the matrix. The document-term matrix was weighted using term frequency, i.e., calculated as the number of times term t appears in the document (Kwartler, 2017). We, as well, tested other feature weightings such as term frequency-inverse document frequency which weights a feature as a product of term frequency and inverse term frequency (i.e., the log of the total number of documents divided by the number of document that term t appears; Kwartler, 2017); term frequency outperformed term frequency-inverse document frequency.
Machine learning algorithms use a document-term matrix to generate a predictive model in a process called model construction. While many machine learning algorithms exist (cf., Ramasubramanian and Singh, 2019, for an overview of possible algorithms), with several recent studies using an ensemble of algorithms (cf., Kaplan et al., 2014; Moharreri et al., 2014; Noyes et al., 2020), we chose a single algorithm for optimizing predictive performance due to a lack of interpretability of the many predictive model outputs when an ensemble of methods is used (cf., Sagi and Rokach, 2018). In other words, it is prohibitively difficult to determine contributing error and limitations, such as false positives and negatives, of each algorithm within ensemble-based models.
In this study, we use support vector machine (SVM) with a linear basis function kernel (Cortes and Vapnik, 1995) algorithm for our classification. SVM is reported as robust when compared to other algorithms for text analysis classifications (Ha et al., 2011; Nehm et al., 2012; Kim et al., 2017) and in a meta-analysis, has shown to have substantial machine-human score agreement (Zhai et al., 2021). Other algorithms were also tested: regularization (ridge regression, least absolute shrinkage and selection operator (LASSO), and elastic net), Bayesian (naïve Bayes), ensemble (random forest), and other instance-based methods (SVM with radial and polynomial basis kernel functions). A baseline model (naïve Bayes) was compared with the performance of the linear SVM classifier. For a twice repeated, two-fold cross-validation (described below), the naïve Bayes classifier performed poorly (accuracy = 56.18%, Cohen's kappa = 0.22) compared to linear SVM (accuracy = 88.93%, Cohen's kappa = 0.76). Linear SVM performed best of all the algorithms tested and was therefore used for model training.
Support vector machine with a linear basis function kernel was used for model training in our analyses. In SVM, data are first mapped in multidimensional space (Cortes and Vapnik, 1995). In this process, for linear SVM, the C or cost penalty parameter is optimized; this hyperparameter regulates how much the algorithm should avoid misclassifying the training data by looking for the optimal hyperplane to classify the data (Cortes and Vapnik, 1995; Joachims, 2002; Gaspar et al., 2012). Then, linear SVM calculates the optimal hyperplane in which it attempts to maximize the margin (i.e., greatest distance) between support vectors (i.e., data points nearest to the hyperplane) between the two classes of data (i.e., use and non-use of the Lewis model); in other words, SVM tries to find the hyperplane that best discriminates the data (Cortes and Vapnik, 1995). For our reported predictive model, hyperparameter C = 0.0055. The ‘caret’ package in R used was for model training (Kuhn, 2008).
To validate the predictive model, three validation methods are performed: (i) cross-validation, (ii) split-validation (also known as holdout validation), and (iii) external validation. First, cross-validation: this process involves breaking up the data into k groups that are repeatedly shuffled with model construction performed on k − 1 group(s) with the last group used for model cross-validation. We used a 2-fold cross-validation that was repeated twice, i.e., the data was equally split into half, trained on one half, then tested on the other; this process was repeated once more. While 5- to 10-fold cross-validation is considered standard (Rodríguez et al., 2010), a 2-fold cross-validation with a smaller number of repeats is considered acceptable when there are small samples as a result of the k-fold division (Wong and Yeh, 2020). Additionally, we did not find better performance metrics with an increase in the number of folds or repeats; a greater number of folds and repeats increases computation costs.
Second, split-validation was performed; the split validation used a stratified set and a remaining set both comprising of the remaining responses that were not used in the training set. Note that the split-validation data is different from that of the cross-validation data as the cross-validation data was constructed from the training data. The stratified set was assembled from a random set of 100 responses from each of the five prompt types (i.e., a total of 500 responses); it is inclusive of the remaining set and was assembled from all of the remaining data that was not used for model training and construction (N = 6425 total responses). We chose 100 responses from each prompt type as to mimic a typical large-enrollment organic chemistry course.
Finally, external validation was performed; the machine learning model was evaluated using a data set of responses collected after the model was constructed. This set consisted of an additional 11 items that included reactions and compounds that were not used in the 15 items used in the construction of the predictive model; the external validation set consisted of 2162 responses. The 11 prompts for external validation are reported in Appendix 2. The external validation corpus first underwent the same data preprocessing as the training data corpus. In feature extraction, the features in the validation corpus were matched to the 257 features identified in the training corpus using a match matrix function as described by Kwartler (2017).
Results and discussion
Consistent with some studies (e.g., Cooper et al., 2016; Galloway et al., 2017; Bhattacharyya and Harris, 2018; Crandell et al., 2019; Dood et al., 2020a) and in contrast to other studies (e.g., Cartrette and Mayo, 2011; Schmidt-McCormack et al., 2019; Petterson et al., 2020; Watts et al., 2020), a majority of responses (62.4%) in our sample used language to describe the movement of electrons in mechanistic prompts. Such language is consistent with the Lewis acid–base model, and further evidence that some students do use correct language while invoking the Lewis model when explaining acidity and basicity.Performance metrics
Performance of our machine learning model, i.e., congruence of human and computer scoring, is evaluated using several metrics. Each scoring prediction can be one of four outcomes: true positive (TP; human- and computer-classified as correct Lewis use), true negative (TN; human- and computer-classified as incorrect Lewis use/non-use), false positive (FP; human-classified as incorrect/non-use and computer-classified as correct Lewis use), or false negative (FN; human-classified as correct and computer-classified as incorrect Lewis use/non-use). A confusion matrix (see Fig. 3) shows how each prediction outcome is made through the combination of the actual (human-classified) and predicted (computer-classified) scores. False positives (FP) are analogous to Type I errors and false negatives (FN) analogous to Type II errors.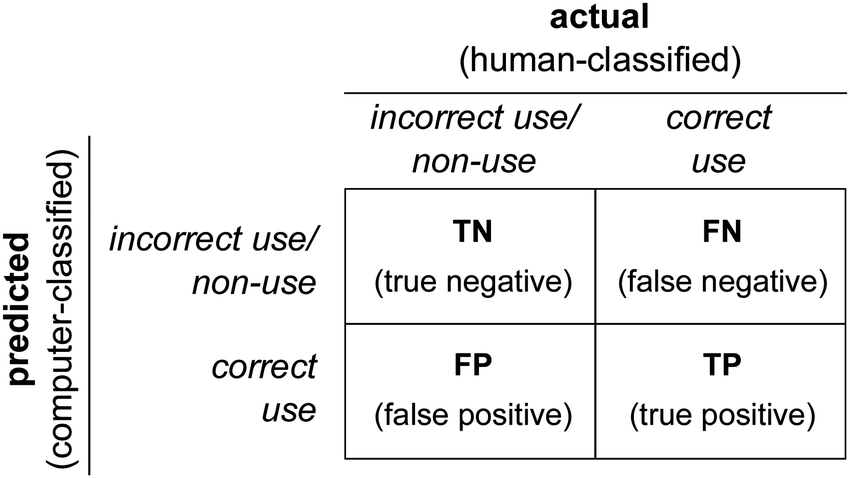 | ||
| Fig. 3 Confusion matrix showing the outcomes of predicted vs. actual classifications. | ||
Three other metrics are Cohen's kappa, percent accuracy, and the F1 score. Cohen's kappa is a statistic for interpreting interrater reliability testing that accounts for the probability that raters agree due to chance (Cohen, 1960). However, we can assume that both human and computer classifications are purposeful and informed; therefore, percent accuracy is a reliable measure (McHugh, 2012). Accuracy (eqn (1)) is calculated as
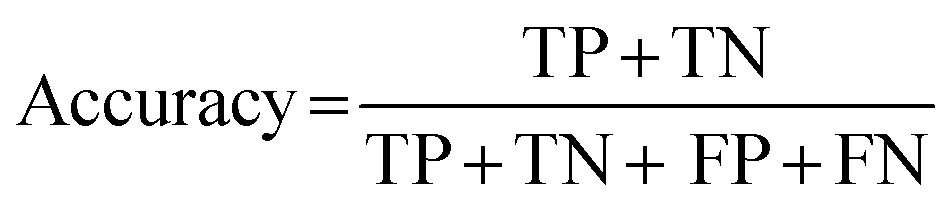 | (1) |
Cohen's kappa and percent accuracy are typical measures reported for models developed to evaluate written responses to assessment items. However, these metrics are most accurate with balanced data sets (i.e., same number of each classification; Kwartler, 2017). For example, if there were near equal numbers of students who correctly used and did not correctly use the Lewis acid–base model in their responses to the assessment items. Our data is heavily unbalanced for most of the individual prompt types and is skewed toward correct use of the Lewis model for the overall data set (Table 2). Due to this imbalance, a more accurate model performance metric is needed: the F1 score (Kwartler, 2017). The F1 score (eqn (2)) is a classification model performance metric that attempts to balance precision (eqn (3)) and recall (eqn (4)).
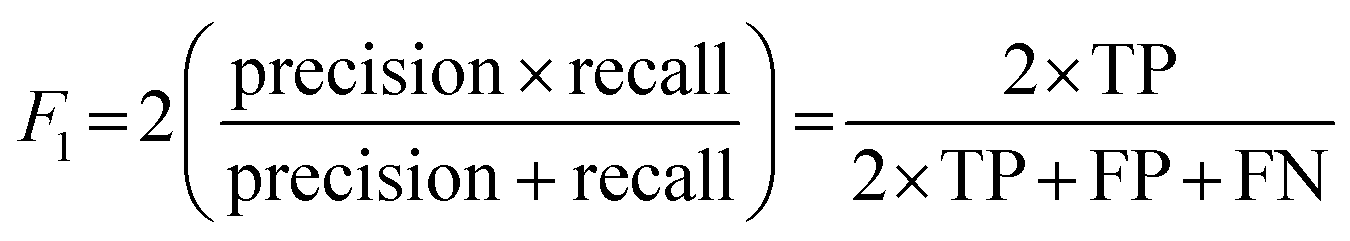 | (2) |
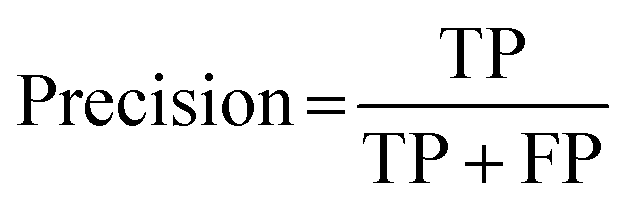 | (3) |
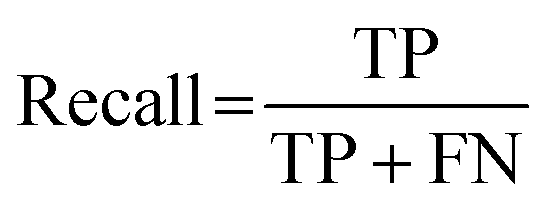 | (4) |
While F1 is commonly used as a performance metric, one limitation is that F1 is independent from TN (see eqn(2)). In unbalanced cases, such as ours, F1 can be misleading as it does not consider the proportion of each class (i.e., TP, FP, TN, and FN) in the confusion matrix (Chicco and Jurman, 2020). An alternative metric is the Matthews correlation coefficient (MCC; eqn (5)), which is advantageous as its calculation is unaffected by unbalanced datasets (Matthews, 1975; Baldi et al., 2000; Chicco and Jurman, 2020).
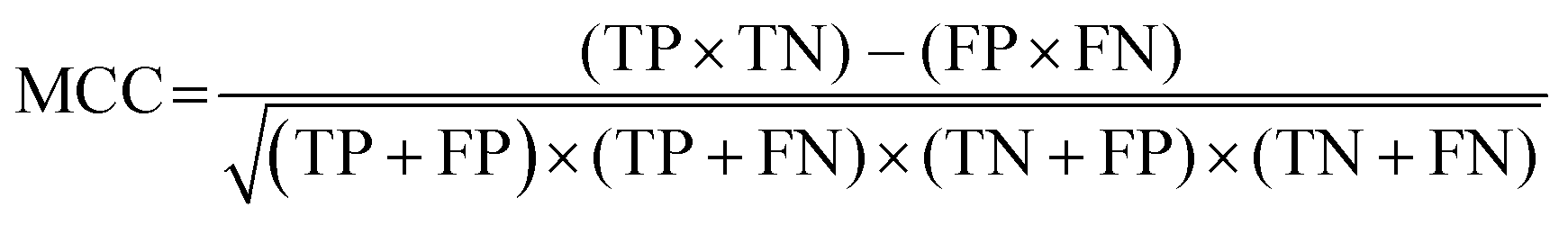 | (5) |
Evaluation of machine learning algorithm
Evaluation of the predictive model is conducted using three validation methods: cross-validation, split-validation (stratified and remaining), and external validation. In addition to the confusion matrix classes (i.e., TP, FN, TN, and FP), we also report Cohen's kappa, accuracy, F1, and MCC for each prompt type and overall data set for the different validation methods.Overall accuracy of our twice-repeated, 2-fold cross-validation (Table 3) is 88.93% with individual prompt-type accuracy ranging from 83.05% to 93.08%. Overall F1 score is 0.91 with individual prompt F1 scores ranging from 0.86 to 0.96; overall MCC value is 0.75 with individual prompt MCC values ranging from 0.69 to 0.81. These three metrics are in good agreement with higher accuracies having larger F1 scores and MCC values. Varying prompt accuracies, F1 scores, and MCC values are indicative that the predictive model performs better for certain prompt types (e.g., reaction mechanism that can be only explained with the Lewis model) over others (e.g., why is the compound a base). There are relatively low false negative rates (i.e., computer-scored as correct use of the Lewis model where a human classifier would have scored the response as incorrect use/non-use), with moderate rates for the false positives.
| Prompt type | N | κ | Accuracy (%) | F 1 | MCC | TP (%) | FN (%) | TN (%) | FP (%) |
|---|---|---|---|---|---|---|---|---|---|
| Aqueous proton transfer | 419 | 0.74 | 89.26 | 0.92 | 0.73 | 93.84 | 6.16 | 78.73 | 21.27 |
| Lewis mechanism | 419 | 0.72 | 93.08 | 0.96 | 0.69 | 97.73 | 2.27 | 68.66 | 31.34 |
| Why acid? | 419 | 0.81 | 90.93 | 0.92 | 0.81 | 93.00 | 7.00 | 88.07 | 11.93 |
| Why base? | 419 | 0.65 | 83.05 | 0.86 | 0.65 | 92.64 | 7.36 | 71.28 | 28.72 |
| Why amphoteric? | 419 | 0.77 | 88.31 | 0.92 | 0.77 | 91.92 | 8.08 | 85.07 | 14.93 |
| Overall | 2095 | 0.76 | 88.93 | 0.91 | 0.75 | 94.22 | 5.78 | 79.97 | 20.03 |
It can be noted that the accuracy for positive instances (TP vs. FN) is much greater than the accuracy of negative instances (TN vs. FP). This is likely due to the imbalance in the training data set of correct Lewis use instances (63%) and incorrect Lewis use/non-use instances (37%; see Table 2). This means that the training set is trained more heavily on positive instances, causing there to be a discrepancy between accuracy of correctly predicting positive instances and correctly predicting negative instances. This discrepancy is even more pronounced when looking specifically at the Lewis mechanism prompt type where the model is 97.73% accurate for positive instances and 68.66% accurate for negative instances (see Table 3).
Overall, this 2-fold cross-validation demonstrates that there are varying metrics by prompt type; however, the predictive model holds for all of these prompt types when considered as a whole and therefore there is evidence that the predictive model can be generalized for all these different prompt types.
A predictive model using lexical analysis and binomial logistic regression model predicting Lewis acid–base use, including correct and incorrect use/non-use, had an accuracy of 82% (Dood et al., 2018). The predictive model was further improved with new data to 86% accuracy (Dood et al., 2019); however, this model is only applicable to aqueous proton transfer reactions. Our results are more accurate, in general, to prior work from Dood et al. (2018, 2019). When our results are compared to other computer-assisted predictive scoring models, the predictive model we report is just as or more accurate than those predictive models developed for single assessment items. Thus, these initial findings and comparisons suggest that our generalized predictive model meets current/reported accuracy standards (Zhai et al., 2020).
The stratified split-validation set (Table 4) aims to mimic the class size of a large-enrollment organic chemistry course. This validation set has comparable accuracies, F1 scores, and MCC to the cross-validation set. The prompt asking “why a compound is a base” is the worst performing prompt type and the mechanistic prompt that can be only explained with the Lewis model is the best performing when considering accuracy and F1. However, in this stratified split-validation set and also in the remaining split-validation set, there are only 12 negative instances for the Lewis mechanism prompt type versus the 88 positive instances; thus, the accuracy for negative instances is lower than the cross-validation set and is reflected in the lower MCC value. We posit that if the Lewis mechanism prompt type had a larger sample size and a larger number of negative instances, we would see a smaller discrepancy here.
| Prompt type | N | κ | Accuracy (%) | F 1 | MCC | TP (%) | FN (%) | TN (%) | FP (%) |
|---|---|---|---|---|---|---|---|---|---|
| Aqueous proton transfer | 100 | 0.73 | 89.0 | 0.92 | 0.71 | 95.71 | 4.29 | 73.33 | 26.67 |
| Lewis mechanism | 100 | 0.45 | 90.0 | 0.94 | 0.46 | 96.59 | 3.41 | 41.67 | 58.33 |
| Why acid? | 100 | 0.70 | 85.0 | 0.86 | 0.70 | 88.24 | 11.76 | 81.63 | 18.37 |
| Why base? | 100 | 0.50 | 75.0 | 0.78 | 0.53 | 89.80 | 10.20 | 60.78 | 39.22 |
| Why amphoteric? | 100 | 0.80 | 90.0 | 0.90 | 0.79 | 88.24 | 11.76 | 90.38 | 9.62 |
| Overall | 500 | 0.69 | 85.8 | 0.89 | 0.69 | 92.81 | 7.19 | 74.74 | 25.26 |
As with the smaller sample sizes, the errors of these predictions increase, explaining the larger percentages of false positives and false negatives in addition to the slightly lower F1 scores and MCC values; although, these accuracy metrics are comparable to the cross-validation set. For the stratified split-validation set, accuracies are greater than 75% and F1 scores are greater than 0.78 which demonstrate that sufficient accuracies can be obtained with sample sizes of 100. While F1 scores indicate that the predictive model performs well in correctly classifying positive cases (i.e., human classifications are correct Lewis use), the lower MCC values for mechanism prompts that can only be explained by the Lewis model and prompts asking why a compound is a base indicate that the predictive model has a difficult time classifying negative cases (i.e., human classifications are incorrect Lewis use/non-use).
The penultimate validation test was to explore model performance metrics for all data not used in the training data set. The remaining split-validation set (Table 5) consists of all the remaining data not used in the training (and cross-validation) set. This validation set allows for appraisal of the predictive model with a large sample size, indicative of overall predictive performance. Accuracies are greater than 80% with F1 scores above 0.80; MCC values are generally above 0.60, with exceptions of the Lewis mechanism prompts (as previously discussed). A lower rate of false negatives is observed with comparably higher rates of false positives. These results suggest that the number of computer-classified correct use may be slightly inflated for this large corpus. For example, in a class of 200 students, if the model predicts that the number of correct use classifications is 175, the actual value may be slightly lower due to higher false positive than false negative rates. Overall, the predictive model performs well for each of the prompt types.
| Prompt type | N | κ | Accuracy (%) | F 1 | MCC | TP (%) | FN (%) | TN (%) | FP (%) |
|---|---|---|---|---|---|---|---|---|---|
| Aqueous proton transfer | 3146 | 0.62 | 84.01 | 0.89 | 0.65 | 85.71 | 14.29 | 79.46 | 20.54 |
| Lewis mechanism | 100 | 0.45 | 90.00 | 0.94 | 0.46 | 96.59 | 3.41 | 41.67 | 58.33 |
| Why acid? | 990 | 0.73 | 86.67 | 0.88 | 0.73 | 91.59 | 8.41 | 80.59 | 19.41 |
| Why base? | 1005 | 0.59 | 79.60 | 0.82 | 0.60 | 90.68 | 9.32 | 67.43 | 32.57 |
| Why amphoteric? | 1184 | 0.75 | 87.67 | 0.87 | 0.76 | 90.47 | 9.53 | 85.19 | 14.81 |
| Overall | 6425 | 0.67 | 84.50 | 0.88 | 0.67 | 88.07 | 11.93 | 78.59 | 21.41 |
The external validation set (Table 6) allows us to evaluate performance of the predictive model on a set of new data that includes a variety of new prompts and a new prompt type: specifically, a non-aqueous proton transfer mechanism. We recognized when planning to collect the new, external validation data that the proton-transfer reactions from which the predictive model was developed were all aqueous; thus, we included a non-aqueous proton transfer in the external validation set to further evaluate the generalizability of our predictive model. A summary of the human classifications for the external validation set is given in Table 7. This new prompt type has an accuracy of 91.3%, F1 score of 0.95, and MCC of 0.73; thus, we can conclude that the predictive model performs well when used to evaluate these new data. Additionally, not only do we see that kappa, accuracy, F1 scores, and MCC values generally increase across all prompt types, but we find that false negative and false positive rates also decrease. The high true positive rate indicates that the predictive model has high recall, being able to correctly classify a response as correct use of the Lewis model out of all the possible correct classifications given by a human classifier. These external validation results show analogous or better metrics when compared to the cross-validation and split-validations, and to other studies that use machine learning techniques (e.g., Dood et al., 2018, 2020a; Noyes et al., 2020; cf., Zhai et al., 2020). Additionally, the level of prediction accomplished by our model exceeds the 70% accuracy recommendation for use in formative assessments (cf., Haudek et al., 2012; Nehm et al., 2012; Prevost et al., 2016) and is generally within range for accepted measures for summative assessments (cf., Williamson et al., 2012). Therefore, we conclude that an accurate, generalizable, predictive model using machine learning techniques for correct use of the Lewis acid–base model was developed. However, despite this level of accuracy, we reiterate that use of this generalized predictive model should only be used with formative assessments.
| Prompt type | N | κ | Accuracy (%) | F 1 | MCC | TP (%) | FN (%) | TN (%) | FP (%) |
|---|---|---|---|---|---|---|---|---|---|
| Non-aqueous proton transfer | 715 | 0.74 | 91.33 | 0.95 | 0.73 | 96.01 | 3.99 | 75.46 | 24.54 |
| Lewis mechanism | 716 | 0.62 | 94.41 | 0.97 | 0.61 | 97.86 | 2.14 | 58.73 | 41.27 |
| Why acid? | 294 | 0.81 | 89.61 | 0.93 | 0.79 | 97.81 | 2.19 | 80.18 | 19.82 |
| Why base? | 292 | 0.86 | 93.15 | 0.94 | 0.85 | 94.94 | 5.06 | 90.35 | 9.65 |
| Why amphoteric? | 145 | 0.88 | 93.79 | 0.93 | 0.88 | 96.92 | 3.08 | 91.25 | 8.75 |
| Overall | 2162 | 0.80 | 92.74 | 0.95 | 0.78 | 96.87 | 3.13 | 80.04 | 19.96 |
| Prompt type | N | Correct use (%) | Incorrect use/non-use (%) |
|---|---|---|---|
| Non-aqueous proton transfer | 715 | 552 (77) | 163 (23) |
| Lewis mechanism | 716 | 653 (91) | 63 (9) |
| Why acid? | 294 | 183 (62) | 111 (38) |
| Why base? | 292 | 178 (61) | 114 (39) |
| Why amphoteric? | 145 | 65 (45) | 80 (55) |
| Overall | 2162 | 1631 (75) | 531 (25) |
Limitations
The immediate findings of this research are constrained by several key limitations: (i) homogeneity of the sample, (ii) accuracy of the predictive scoring model, (iii) machine learning methodology, (iv) students “gaming” the system, (v) when the machine learning model fails, and (vi) use of mixed-models in a response. However, we do note that future work may minimize or nullify several of these limitations based on a broader use and evaluation of the predictive model.Sample homogeneity
The open-ended written responses collected in this study were from students who took organic chemistry at a single institution with one of three instructors over the span of seven different semesters. We report no evidence for generalizing these constructed response item types and findings to other institutions and to other curricula. However, Ha et al. (2011) found that their machine learning model was able to, in most cases, accurately evaluate the degree of sophistication between biology majors and non-majors at two different institutions. This suggests that machine learning models could be utilized with student populations at different institutions; nonetheless, these models should be tested at multiple institution types (e.g., two-year colleges, primarily-undergraduate institutions, research-intensive institutions) and with multiple curricula, such as the Chemistry, Life, the Universe and Everything curriculum (Cooper et al., 2019) or Mechanisms before Reactions curriculum (Flynn and Ogilvie, 2015).Predictive model accuracy
The reported machine learning model has percent accuracies for the given data between 84.5% and 92.7%. While the predictive model is not 100% perfect, the model performs at similar percent accuracies and Cohen's kappa levels compared to reported models for constructed response assessment items (Haudek et al., 2012; Prevost et al., 2012, 2016; Dood et al., 2018, 2020a; Noyes et al., 2020; Zhai et al., 2020) and is in line with the agreement between authors BJY and JRR before discussion. As with the supermajority of those developing and disseminating similar models for text analysis of assessment items, we reiterate that the predictive models, ours included, should only serve as a method for evaluating formative assessment items.Machine learning methodology
While there are many methodological approaches to machine learning model development, our choices could be construed as a limitation. For example, in feature extraction, we chose to use the term frequency weighting in the document-term matrix; that is, each time a term (or feature) t appears in a student's response, it will weight that feature more in the matrix. While we found that this weighting method gave the best model metrics overall, students could “game” the system where their response would contain a of surplus key words relating to Lewis acid–base chemistry (e.g., “Lewis”, “electrons”, “nucleophilic”, “electrophilic). This would trigger the predictive model to assign a correct use classification for the response that otherwise would be assigned as incorrect use/non-use when holistically evaluated by a human classifier.Model shortcomings
There are several reasons why a response could be a false positive. First, student's use of the term “electrons” while identifying or discussing irrelevant features of a compound or reaction. For example, determining number of valence electrons or formal charge:
Cyclohexanaminium can act as an acid because it can donate a proton and be left with a lone pair and 2 bonds. This would neutralize its charge since, 2 electrons + 3 bonds = 5, 5 valence electrons − 5 = 0.
This specific example demonstrates that instances of terms such as, “electrons”, “bonds”, “lone”, and “pair”, terminology associated with the Lewis model, can lead the computer to predict correct Lewis acid–base model use.
Second, students mention “a lone pair” or “lone pairs” without an action verb, usually in the surface-level description of a compound. For example,
Nitrogen has a lone pair and it is the weakest amine.
In this specific instance, a structural feature of a compound is noted that is associated with correct Lewis acid–base model; however, the answer as a whole is insufficient to be classified as correct.
Additionally, responses may contain a broad example of the movement of electrons or the arrow-pushing formalism without any specific details. For example,
The reactants of the mechanism are undergoing a reaction in which the bonds are broke and then reformed to create the two products on the right. The curved arrows represent where the exchange/attraction of the electrons will be moving to create the bonds. This reaction occurs because the reactants are less stable then [sic] what they would be as the products.
We note that shorter responses without sufficient chemical terminology or longer responses without specific details may trigger our predictive model to give a false positive because the model is simply analyzing term frequencies.
(CH 3 ) 2 CHO − can act as a base because it can donate electrons.
At the other end of response length, term frequency can also play a role in longer responses when a student uses both Brønsted–Lowry and Lewis models together in a response. For example,
An amphoteric substance means it can act as both an acid and a base. Water is the most common example of this. tert-Butanol can also act as both an acid or a base. This is because the hydrogen atom attached to the oxygen can be donated making it a Brønsted–Lowry acid. However, the lone pairs on the oxygen can accept a proton (H + ion) making another bond making it a Brønsted–Lowry base.
In this instance, greater attention given to the Brønsted–Lowry base model, including explicit naming of the model gave rise to a false negative for this response. We also found instances of this in response to one of the mechanism prompts:
Part A: negatively charged ethanethiolate transfers electrons to the hydrogen atom of benzoic acid to form a single covalent bond. The electrons from the sigma bond between hydrogen and oxygen in benzoic acid gather around the oxygen atom, causing it to go from a neutral to a negative formal charge. In this way, enthanethiol [sic] is formed which has a neutral formal charge and negatively charged benzoate is produced. Part B: this reaction occurs because according to the Brønsted–Lowry definition, ethanethiolate is a base or a proton acceptor while benzoic acid is an acid or a proton donor. When ehtanetholate [sic] accepts the H atom or proton it becomes the conjugate acid, ethanethiol, and when benzoic acid gives up its proton it becomes the conjugate base, benzoate.
The first molecule in the reactant side [methoxide] is serving as a base because it is accepting a proton, while the second molecule in the reactant side [propaninium] is acting as an acid because it is donating a proton. Since the second molecule is donating its H to the first molecule, the single bond transfers as a lone pair to nitrogen. On the product side, the first molecule is the conjugate acid while the second molecule is the conjugate base. On a molecular level, the negative charge means that the atom wants to form a bond while the positive charge wants to donate hydrogen.
This response heavily invokes the Brønsted–Lowry model with concepts about accepting and donating protons in addition to conjugate acids and bases. One human classifier in the interrater discussion classified this response as incorrect use/non-use due to the lack of Lewis model use with too much discussion using the Brønsted–Lowry model. However, the other human classifier argued that while this model does focus on the Brønsted–Lowry model, there are aspects within the response (“the single bond transfers as a lone pair”) that demonstrates correct use of the Lewis model. This response was ultimately classified as correct use and the predictive model also correctly classified the response as correct use.
Prior research has indicated that students hold unclear relationships between acid–base models in their mental models (Schmidt and Volke, 2003; Drechsler and Schmidt, 2005; Bhattacharyya, 2006). Additionally, students struggled to incorporate broader models, such as the Lewis model, into more specific models, such as the Brønsted–Lowry model (Cartrette and Mayo, 2011). While use of the Lewis model has been shown to increase student performance (Dood et al., 2018), it is unclear whether students that use mixed models clearly understand when each model is appropriate, based solely on their responses, or if they default to the most specific model (e.g., Brønsted–Lowry) that can explain a phenomenon over the broader model (e.g., Lewis). The scoring model developed in our research only predicts whether a student has correctly used the Lewis acid–base model in their written response and is limited in understanding if students can differentiate between using mixed models correctly.
Implications
Implications for instructors
Instructors should select assessments that send clear and bold messages to students about what is important in the classroom (Holme et al., 2010). A growing number of chemical education researchers (Becker et al., 2016; Cooper et al., 2016; Finkenstaedt-Quinn et al., 2017; Bodé et al., 2019; Caspari and Graulich, 2019; Crandell et al., 2019), in addition to other researchers across the educational research community (Birenbaum and Tatsuoka, 1987; Scouller, 1998), have called for the use of open-ended assessments to facilitate deeper learning and provide diagnostic data for educators. For example, being able to describe how and why a phenomenon (e.g., a reaction mechanism) occurs is critical for efficacious scientific reasoning (Abrams et al., 2001; Cooper, 2015). In chemistry, researchers have advocated for students to answer “why?” in assessments (Goodwin, 2003; Cooper, 2015; Cooper et al., 2016; Stowe and Cooper, 2017; Caspari et al., 2018a; Underwood et al., 2018; Bodé et al., 2019; Caspari and Graulich, 2019; Crandell et al., 2019; Dood et al., 2020a). One type of assessment that instructors should be using in their courses are low-stakes, formative assessments to gauge understanding.Written formative assessments can help students develop skills in explaining how and why reactions occur. Numerous studies have advocated for students to explain how and why to enrich their productive ideas about how reactions work (e.g., Becker et al., 2016; Cooper et al., 2016; Dood et al., 2018, 2020a; Crandell et al., 2019, 2020). Research has shown that targeted formative feedback allows for students to learn about their competency level, suggestions for improvement, and may positively affect students’ exam scores (Hattie and Timperley, 2007; Hedtrich and Graulich, 2018; Young et al., 2020). Written assessments can reveal students’ understanding or lack thereof; therefore, such assessments should serve as an approach for instructors to use to get students to think more deeply about scientific explanations.
The predictive model developed in this study is a practical, quick, and efficient way to formatively evaluate student understanding of the Lewis acid–base model. We have freely made available the files along with a set of instructions necessary for instructors to conduct their own analyses (cf., Yik and Raker, 2021); files are to be used with R, a free statistical software environment (R Core Team, 2019). Written formative assessments can be easily scored using computer-scoring models, like the one developed in this study, to support just-in-time teaching in large enrollment courses (Novak et al., 1999; Prevost et al., 2013; Urban-Lurain et al., 2013, Prevost et al., 2016). For example, instructors may administer constructed response questions as homework assignments (with low point value for completion credit) and then utilize the predictive model to classify student responses. Quantitative results are nearly instantaneous, providing quick feedback to instructors and students; the R program outputs result in a spreadsheet with paired student predictive scores that can uploaded into learning management systems with little modification. If instructors intend to hand score responses in addition to using the predictive model, we suggest that hand scoring be conducted first to avoid anchoring bias (Sherif et al., 1958). In the classroom, student responses can be used to create clicker questions and/or as a starting point for classroom discussion. Another option is that instructors can use quantitative results to reshape lessons or homework activities to promote correct understanding and use of the Lewis acid–base model.
Information provided by the predictive model can allow instructors to provide additional resources to students to support learning. One method is to couple predictive models with corresponding topic-specific online tutorials; such tutorials have been shown to increase student understanding and achievement in organic chemistry courses (e.g., O’Sullivan and Hargaden, 2014; Richards-Babb et al., 2015; Dood et al., 2019, 2020b). Tutorial-based learning interventions can be utilized to facilitate better construction of explanations when paired with adaptive learning opportunities based on quick results from computer-assisted scoring. Furthermore, online learning tools can supplement learning. One such open educational resource tool is OrgChem101 (https://orgchem101.com), which contains modules on acid–base reactions, nomenclature, and organic mechanisms; the latter two modules have been shown to increase students’ learning gains (Bodé et al., 2016; Carle et al., 2020).
Implications for researchers
Tools used to construct our predictive model are open-access and are available for researchers to develop other predictive models. Our machine learning model was developed using R, a free statistical software environment (R Core Team, 2019). By removing the limitation of financial burdens and barriers that other software may impose, researchers are able to more freely use and develop their own predictive models. We have also made available all of our files (cf., Yik and Raker, 2021) containing the R code, custom stopwords dictionary, and patterns and replacements; these tools can be used as a starting point to develop other predictive models. There has been limited exploration in the development of predictive models in chemistry (Haudek et al., 2012; Prevost et al., 2012; Dood et al., 2018, 2019, 2020a; Noyes et al., 2020), which leaves a multitude of different predictive models that can be built to evaluate students’ written responses to constructed-response items. For example, predictive models for other aspects of the postsecondary organic chemistry curriculum are ripe for future exploration; two examples of particular interest are understanding of nucleophiles and electrophiles (Anzovino and Bretz, 2015, 2016) and leaving groups (Popova and Bretz, 2018).There is ample opportunity to evaluate student understanding of acids and bases in the postsecondary chemistry curriculum using predictive models. For example, in our study, we primarily evaluated first semester organic chemistry students’ understanding of acid–base reaction mechanisms and why compounds can act as an acid, base, or be amphoteric using the Lewis model. As acid–base models are generally first introduced in general chemistry (Paik, 2015), further research can evaluate the effectiveness of our predictive model in this setting. Additionally, our predictive model can be evaluated with students in other organic chemistry courses; Dood et al. (2019) found that students benefited from a tutorial to review Lewis acid–base concepts at the beginning of the second-semester organic chemistry course. While the Brønsted–Lowry and Lewis models are considered in postsecondary general chemistry and organic chemistry courses, other models to describe acids and bases are introduced in upper-level courses (e.g., Raker et al., 2015). In inorganic chemistry, the Lux–Flood model is based on oxide ion donors and acceptors (Lux, 1939; Flood and Förland, 1947), the Usanovich model defines acids and bases as charged species donors and acceptors (Finston and Rychtman, 1982), and the concept of hard and soft acids and bases (HSABs) describes polarizable acids and bases as soft and nonpolarizable acids and bases as hard (Pearson, 1963). While each of these models have their own advantages and criticisms (Miessler et al., 2014), it may be beneficial for students to preferentially use and understand one of these models in particular scenarios; there are avenues to build predictive models for other acid–base contexts.
Predictive models have the potential to be a practical way to change the nature of formatively assessing student understanding. Researchers have studied reasoning in chemistry, for example: teleological (e.g., Wright, 1972; Talanquer, 2007; Caspari et al., 2018b), mechanistic (e.g., Bhattacharyya and Bodner, 2005; Ferguson and Bodner, 2008; Bhattacharyya, 2013; Galloway et al., 2017; Caspari et al., 2018a), causal (e.g., Ferguson and Bodner, 2008; Crandell et al., 2019, 2020), and causal mechanistic (e.g., Becker et al., 2016; Cooper et al., 2016; Bodé et al., 2019; Noyes and Cooper, 2019; Crandell et al., 2020). Studies have also been conducted on student reasoning through case comparisons between reaction mechanisms (e.g., Graulich and Schween, 2018; Bodé et al., 2019; Caspari and Graulich, 2019; Watts et al., 2021). Student understanding via argumentation has likewise been investigated (e.g., Moon et al., 2016, 2017, 2019; Pabuccu, 2019; Towns et al., 2019). Regardless of the mode of reasoning, these different routes offer researchers comparative and contrasting means to study student understanding. While predictive models have begun to consider classification or levels of reasoning (Haudek et al., 2012; Prevost et al., 2012; Dood et al., 2018, 2019, 2020a; Noyes et al., 2020), the question remains: can generalized predictive models be built for other chemistry concepts? The development of future predictive models have to potential to expand work communicated in this study by using levels of reasoning and additionally analyses that instructors can use to further support student learning.
Conclusion
This study has shown that a generalized predictive model using machine learning techniques can be developed to accurately predict correct use of the Lewis acid–base model with overall accuracies ranging from 84.5% to 92.7%. We have demonstrated that this predictive model is applicable to a total of six different prompt types: what is happening and why for (i) an aqueous proton-transfer reaction, (ii) a non-aqueous proton-transfer reaction, (iii) a mechanism that can be explained by only the Lewis model, (iv) why is this compound an acid? (v) why is this compound a base? and (vi) why is this compound amphoteric? Our results suggest promising avenues for the development of machine learning-based scoring tools to efficiently and accurately evaluate student understanding of chemical concepts beyond acid–base chemistry. Additionally, our predictive model was built using open-access statistical software (i.e., R) and is freely accessible to be used by instructors as a formative assessment tool to predict students’ correct use of the Lewis acid–base model.Conflicts of interest
There are no conflicts to declare.Appendix
Appendix 1: constructed response items used in the training, cross-validation, and split-validation sets
All mechanism questions were given the following prompt:Part A: describe in full what you think is happening on the molecular level for this reaction. Be sure to discuss the role of each reactant and intermediate.
Part B: using a molecular level explanation, explain why this reaction occurs. Be sure to discuss why the reactants form the products shown.
[pt-HCl]: consider the mechanism for the following acid–base reaction between water and hydrochloric acid to form hydronium and chloride ion.
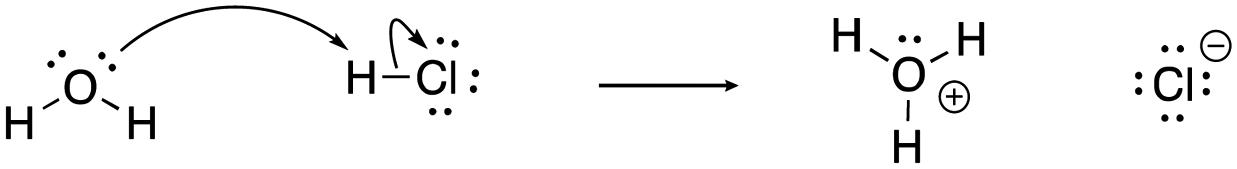
[pt-HBr]: consider the mechanism for the following acid–base reaction between water and hydrobromic acid to form hydronium and bromide ion.
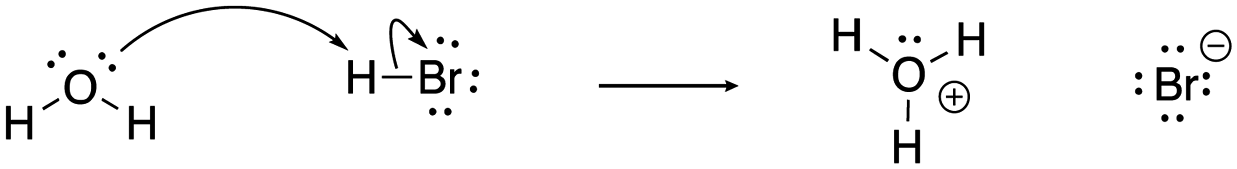
[pt-HI]: consider the mechanism for the following acid–base reaction between water and hydroiodic acid to form hydronium and iodide ion.
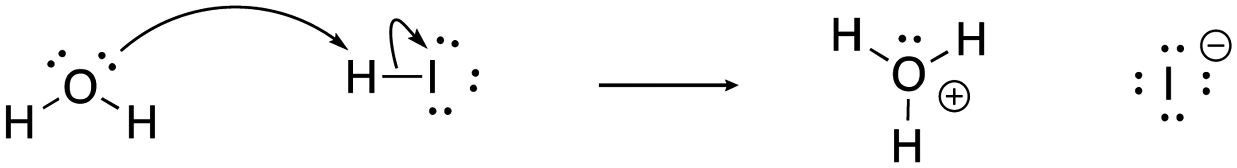
[lew-carbocation]: consider the mechanism for the reaction between ethanol and 2-methyl-2-propanylium to form tert-butyl(ethyl)oxonium.

[lew-BMe3]: consider the mechanism for the reaction between bromide and trimethylborane to form bromotrimethylborate.
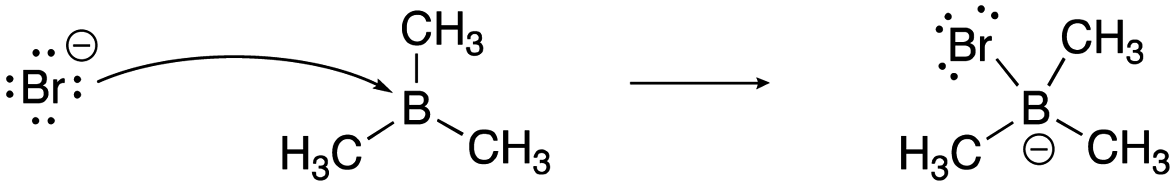
[lew-BF3]: consider the mechanism for the reaction between ammonia and trifluoroborane to form the ammonia–trifluoroborane adduct.

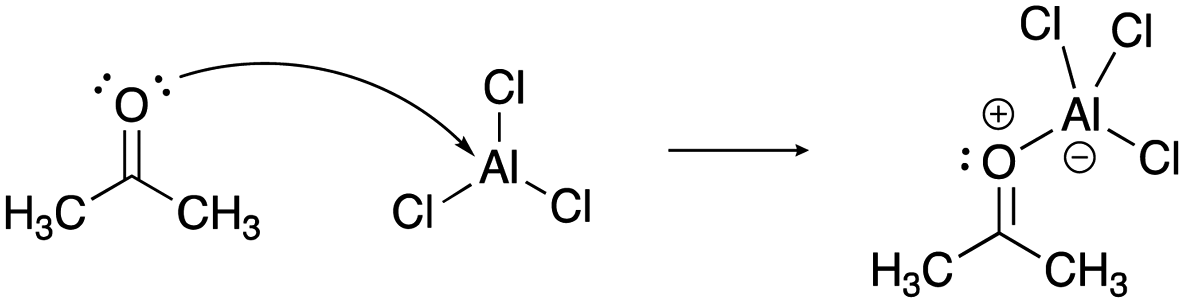
[lew-AlCl3]: consider the mechanism for the reaction between acetone and aluminum trichloride to form the acetone–aluminum trichloride adduct.
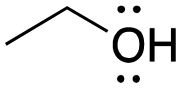
[ampho-EtOH]: explain why ethanol, CH3CH2OH, can act as both an acid and a base.
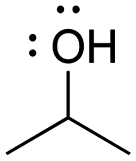
[ampho-IPA]: explain why isopropanol, (CH3)2CHOH, can act as both an acid and a base.
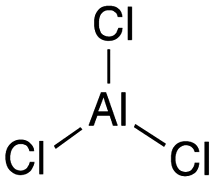
[acid-AlCl3]: explain why aluminum trichloride, AlCl3, can act as an acid.
[acid-BH3]: explain why borane, BH3, can act as an acid.
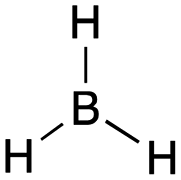
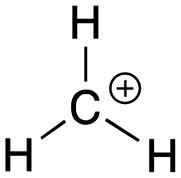
[acid-carbocation]: explain why methylium, CH3+, can act as an acid.
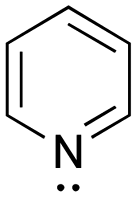
[base-py]: explain why pyridine, C5H6N, can act as a base.
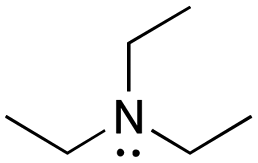
[base-NEt3]: explain why triethylamine, N(CH2CH3)3, can act as a base.
[base-PPh3]: explain why triphenylphosphine, P(C6H5)3, can act as a base.
Appendix 2: constructed response items used in the external validation set
All mechanism questions were given the following prompt:Part A: describe in full what you think is happening on the molecular level for this reaction. Be sure to discuss the role of each reactant and intermediate.
Part B: using a molecular level explanation, explain why this reaction occurs. Be sure to discuss why the reactants form the products shown.
[pt-acetone]: consider the mechanism for the reaction between diisopropylamide and acetone to form diisopropylamine and acetone enolate.

[pt-BzOH]: consider the mechanism for the reaction between ethanethiolate and benzoic acid to form ethanethiol and benzoate.

[pt-ammonium]: consider the mechanism for the reaction between methoxide and propanaminium to form methanol and propanamine.

[lew-BCl3]: consider the mechanism for the reaction between imidazole and trichloroborane to form the imidazole–trichloroborane adduct.

[lew-AcCl]: consider the mechanism for the reaction between ethanamine and acetyl chloride to form chloro(ethylammonio)ethanolate.
[lew-CO2]: consider the mechanism for the reaction between water and carbon dioxide to form carbonic acid.
[acid-BF3]: explain why trifluoroborane, BF3, can act as an acid.
[acid-ammonium]: explain why cyclohexanaminium, (C6H11)NH3+, can act as an acid.

[base-HNEt2]: explain why diethylamine, (CH3CH2)2NH, can act as a base.

[base-propoxide]: explain why isopropoxide, (CH3)2CHO−, can act as a base.
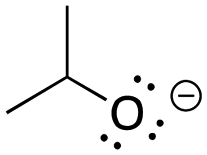
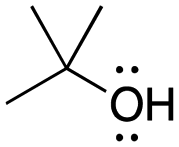
[ampho-tBuOH]: explain why tert-butanol, (CH3)3COH, can act as both an acid and a base.
Acknowledgements
We would like to thank all the students who participated in our study.References
- Abrams E., Southerland S. and Cummins C., (2001), The how's and why's of biological change: how learners neglect physical mechanisms in their search for meaning, Int. J. Sci. Educ., 23(12), 1271–1281.
- Anzovino M. E. and Bretz S. L., (2015), Organic chemistry students' ideas about nucleophiles and electrophiles: the role of charges and mechanisms, Chem. Educ. Res. Pract., 16(4), 797–810.
- Anzovino M. E. and Bretz S. L., (2016), Organic chemistry students' fragmented ideas about the structure and function of nucleophiles and electrophiles: a concept map analysis, Chem. Educ. Res. Pract., 17(4), 1019–1029.
- Baldi P., Brunak S., Chauvin Y., Andersen C. A. F. and Nielsen H., (2000), Assessing the accuracy of prediction algorithms for classification: an overview, Bioinformatics, 16(5), 412–424.
- Bangert-Drowns R. L., Hurley M. M. and Wilkinson B., (2004), The effects of school-based writing-to-learn interventions on academic achievement: a meta-analysis, Rev. Educ. Res., 74(1), 29–58.
- Becker N., Noyes K. and Cooper M., (2016), Characterizing students’ mechanistic reasoning about London dispersion forces, J. Chem. Educ., 93(10), 1713–1724.
- Bell B. and Cowie B., (2001), The characteristics of formative assessment in science education, Sci. Educ., 85(5), 536–553.
- Bhattacharyya G., (2006), Practitioner development in organic chemistry: how graduate students conceptualize organic acids, Chem. Educ. Res. Pract., 7(4), 240–247.
- Bhattacharyya G., (2013), From source to sink: mechanistic reasoning using the electron-pushing formalism, J. Chem. Educ., 90(10), 1282–1289.
- Bhattacharyya G. and Bodner G. M., (2005), “It gets me to the product”: how students propose organic mechanisms, J. Chem. Educ., 82(9), 1402.
- Bhattacharyya G. and Harris M. S., (2018), Compromised structures: verbal descriptions of mechanism diagrams, J. Chem. Educ., 95(3), 366–375.
- Birenbaum M. and Tatsuoka K. K., (1987), Open-ended versus multiple-choice response formats—it does make a difference for diagnostic purposes, Appl. Psychol. Meas., 11(4), 385–395.
- Bodé N. E., Caron J. and Flynn A. B., (2016), Evaluating students' learning gains and experiences from using nomenclature101.com, Chem. Educ. Res. Pract., 17(4), 1156–1173.
- Bodé N. E., Deng J. M. and Flynn A. B., (2019), Getting past the rules and to the why: causal mechanistic arguments when judging the plausibility of organic reaction mechanisms, J. Chem. Educ., 96(6), 1068–1082.
- Bretz S. L. and McClary L., (2015), Students’ understandings of acid strength: how meaningful is reliability when measuring alternative conceptions? J. Chem. Educ., 92(2), 212–219.
- Brown C. E., Henry M. L. M. and Hyslop R. M., (2018), Identifying relevant acid–base topics in the context of a prenursing chemistry course to better align health-related instruction and assessment, J. Chem. Educ., 95(6), 920–927.
- Carle M. S., Visser R. and Flynn A. B., (2020), Evaluating students’ learning gains, strategies, and errors using orgchem101's module: organic mechanisms—mastering the arrows, Chem. Educ. Res. Pract., 21(2), 582–596.
- Carter K. P. and Prevost L. B., (2018), Question order and student understanding of structure and function, Adv. Physiol. Educ., 42(4), 576–585.
- Cartrette D. P. and Mayo P. M., (2011), Students' understanding of acids/bases in organic chemistry contexts, Chem. Educ. Res. Pract., 12(1), 29–39.
- Caspari I. and Graulich N., (2019), Scaffolding the structure of organic chemistry students’ multivariate comparative mechanistic reasoning, Int. J. Phys. Chem. Educ., 11(2).
- Caspari I., Kranz D. and Graulich N., (2018a), Resolving the complexity of organic chemistry students' reasoning through the lens of a mechanistic framework, Chem. Educ. Res. Pract., 19(4), 1117–1141.
- Caspari I., Weinrich M. L., Sevian H. and Graulich N., (2018b), This mechanistic step is “productive”: organic chemistry students' backward-oriented reasoning, Chem. Educ. Res. Pract., 19(1), 42–59.
- Cetin-Dindar A. and Geban O., (2011), Development of a three-tier test to assess high school students’ understanding of acids and bases, Procedia Soc. Behav. Sci., 15, 600–604.
- Chicco D. and Jurman G., (2020), The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation, BMC Genomics, 21(1), 6.
- Chicco D., Tötsch N. and Jurman G., (2021), The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation, BioData Min., 14(1), 13.
- Cohen J., (1960), A coefficient of agreement for nominal scales, Educ. Psychol. Meas., 20(1), 37–46.
- Cooper M. M., (2015), Why ask why? J. Chem. Educ., 92(8), 1273–1279.
- Cooper M. M., Kouyoumdjian H. and Underwood S. M., (2016), Investigating students’ reasoning about acid–base reactions, J. Chem. Educ., 93(10), 1703–1712.
- Cooper M. M., Stowe R. L., Crandell O. M. and Klymkowsky M. W., (2019), Organic Chemistry, Life, the Universe and Everything (OCLUE): a transformed organic chemistry curriculum, J. Chem. Educ., 96(9), 1858–1872.
- Cortes C. and Vapnik V., (1995), Support-vector networks, Mach. Learn., 20(3), 273–297.
- Crandell O. M., Kouyoumdjian H., Underwood S. M. and Cooper M. M., (2019), Reasoning about reactions in organic chemistry: starting it in general chemistry, J. Chem. Educ., 96(2), 213–226.
- Crandell O. M., Lockhart M. A. and Cooper M. M., (2020), Arrows on the page are not a good gauge: evidence for the importance of causal mechanistic explanations about nucleophilic substitution in organic chemistry, J. Chem. Educ., 97(2), 313–327.
- Dicks A. P., Lautens M., Koroluk K. J. and Skonieczny S., (2012), Undergraduate oral examinations in a university organic chemistry curriculum, J. Chem. Educ., 89(12), 1506–1510.
- Dood A. J., Fields K. B. and Raker J. R., (2018), Using lexical analysis to predict Lewis acid–base model use in responses to an acid–base proton-transfer reaction, J. Chem. Educ., 95(8), 1267–1275.
- Dood A. J., Fields K. B., Cruz-Ramírez de Arellano D. and Raker J. R., (2019), Development and evaluation of a Lewis acid–base tutorial for use in postsecondary organic chemistry courses, Can. J. Chem., 97(10), 711–721.
- Dood A. J., Dood J. C., Cruz-Ramírez de Arellano D., Fields K. B. and Raker J. R., (2020a), Analyzing explanations of substitution reactions using lexical analysis and logistic regression techniques, Chem. Educ. Res. Pract., 21(1), 267–286.
- Dood A. J., Dood J. C., Cruz-Ramírez de Arellano D., Fields K. B. and Raker J. R., (2020b), Using the research literature to develop an adaptive intervention to improve student explanations of an SN1 reaction mechanism, J. Chem. Educ., 97(10), 3551–3562.
- Drechsler M. and Schmidt H.-J., (2005), Textbooks’ and teachers’ understanding of acid-base models used in chemistry teaching, Chem. Educ. Res. Pract., 6(1), 19–35.
- Drechsler M. and Van Driel J., (2008), Experienced teachers’ pedagogical content knowledge of teaching acid–base chemistry, Res. Sci. Educ., 38(5), 611–631.
- Feinerer I., Hornik K. and Meyer D., (2008), Text mining infrastructure in R, J. Stat. Softw., 25(5), 1–54.
- Ferguson R. and Bodner G. M., (2008), Making sense of the arrow-pushing formalism among chemistry majors enrolled in organic chemistry, Chem. Educ. Res. Pract., 9(2), 102–113.
- Fies C. and Marshall J., (2006), Classroom response systems: a review of the literature, J. Sci. Educ. Technol., 15(1), 101–109.
- Finkenstaedt-Quinn S. A., Halim A. S., Chambers T. G., Moon A., Goldman R. S., Gere A. R. and Shultz G. V., (2017), Investigation of the influence of a writing-to-learn assignment on student understanding of polymer properties, J. Chem. Educ., 94(11), 1610–1617.
- Finston H. L. and Rychtman A. C., (1982), A new view of current acid-base theories, New York: Wiley.
- Flood H. and Förland T., (1947), The acidic and basic properies of oxides, Acta Chem. Scand., 1(6), 592–606.
- Flynn A. B. and Ogilvie W. W., (2015), Mechanisms before reactions: a mechanistic approach to the organic chemistry curriculum based on patterns of electron flow, J. Chem. Educ., 92(5), 803–810.
- Friesen J. B., (2008), Saying what you mean: teaching mechanisms in organic chemistry, J. Chem. Educ., 85(11), 1515.
- Galloway K. R., Stoyanovich C. and Flynn A. B., (2017), Students’ interpretations of mechanistic language in organic chemistry before learning reactions, Chem. Educ. Res. Pract., 18(2), 353–374.
- Gaspar P., Carbonell J. and Oliveira J. L., (2012), On the parameter optimization of support vector machines for binary classification, J. Integr. Bioinform., 9(3), 33–43.
- Goodwin W., (2003), Explanation in organic chemistry, Ann. N. Y. Acad. Sci., 988(1), 141–153.
- Graulich N., (2015), The tip of the iceberg in organic chemistry classes: how do students deal with the invisible? Chem. Educ. Res. Pract., 16(1), 9–21.
- Graulich N. and Schween M., (2018), Concept-oriented task design: making purposeful case comparisons in organic chemistry, J. Chem. Educ., 95(3), 376–383.
- Grove N. P., Cooper M. M. and Rush K. M., (2012), Decorating with arrows: toward the development of representational competence in organic chemistry, J. Chem. Educ., 89(7), 844–849.
- Ha M. and Nehm R. H., (2016), The impact of misspelled words on automated computer scoring: a case study of scientific explanations, J. Sci. Educ. Technol., 25(3), 358–374.
- Ha M., Nehm R. H., Urban-Lurain M. and Merrill J. E., (2011), Applying computerized-scoring models of written biological explanations across courses and colleges: prospects and limitations, CBE Life Sci. Educ., 10(4), 379–393.
- Hattie J. and Timperley H., (2007), The power of feedback, Rev. Educ. Res., 77(1), 81–112.
- Haudek K. C., Kaplan J. J., Knight J., Long T., Merrill J., Munn A., Nehm R., Smith M. and Urban-Lurain M., (2011), Harnessing technology to improve formative assessment of student conceptions in STEM: forging a national network, CBE Life Sci. Educ., 10(2), 149–155.
- Haudek K. C., Prevost L. B., Moscarella R. A., Merrill J. and Urban-Lurain M., (2012), What are they thinking? Automated analysis of student writing about acid–base chemistry in introductory biology, CBE Life Sci. Educ., 11(3), 283–293.
- Hedtrich S. and Graulich N., (2018), Using software tools to provide students in large classes with individualized formative feedback, J. Chem. Educ., 95(12), 2263–2267.
- Holme T., Bretz S. L., Cooper M., Lewis J., Paek P., Pienta N., Stacy A., Stevens R. and Towns M., (2010), Enhancing the role of assessment in curriculum reform in chemistry, Chem. Educ. Res. Pract., 11(2), 92–97.
- Ingold C. K., (1934), Principles of an electronic theory of organic reactions, Chem. Rev., 15(2), 225–274.
- Jensen J. D., (2013), Students’ understandings of acid–base reactions investigated through their classification schemes and the acid–base reactions concept inventory, PhD dissertation, Miami University. Available at https://etd.ohiolink.edu/.
- Joachims T., (2002), Learning to classify text using support vector machines, Boston, MA: Springer.
- Kaplan J. J., Haudek K. C., Ha M., Rogness N. and Fisher D. G., (2014), Using lexical analysis software to access student writing in statistics, Technol. Innov. Stat. Educ., 8(1), retrieved from https://escholarship.org/uc/item/57r90703.
- Kim K. J., Pope D. S., Wendel D. and Meir E., (2017), Wordbytes: exploring an intermediate constraint format for rapid classification of student answers on constructed response assessments, J. Educ. Data Mining, 9(2), 45–71.
- Klein D. R., (2017), Organic chemistry, Hoboken, NJ: John Wiley & Sons, Inc.
- Kuhn M., (2008), Building predictive models in R using the caret package, J. Stat. Softw., 28(5), 1–26.
- Kwartler T., (2017), Text mining in practice with R, Hoboken, NJ: Wiley.
- Lintean M., Rus V. and Azevedo R., (2012), Automatic detection of student mental models based on natural language student input during metacognitive skill training, Int. J. Artif. Intell. Educ., 21169–21190.
- Lux H., (1939), “Säuren” und “basen” im schmelzfluss: Die bestimmung der sauerstoffionen-konzentration, Z. Elektrochem., 45(4), 303–309.
- MacArthur J. R. and Jones L. L., (2008), A review of literature reports of clickers applicable to college chemistry classrooms, Chem. Educ. Res. Pract., 9(3), 187–195.
- Matthews B. W., (1975), Comparison of the predicted and observed secondary structure of T4 phage lysozyme, Biochim. Biophys. Acta, Proteins Proteomics, 405(2), 442–451.
- McClary L. M. and Bretz S. L., (2012), Development and assessment of a diagnostic tool to identify organic chemistry students’ alternative conceptions related to acid strength, Int. J. Sci. Educ., 34(15), 2317–2341.
- McClary L. and Talanquer V., (2011), College chemistry students' mental models of acids and acid strength, J. Res. Sci. Teach., 48(4), 396–413.
- McHugh M. L., (2012), Interrater reliablity: the kappa statistic, Biochem. Medica, 22(3), 276–282.
- Miessler G. L., Fischer P. J. and Tarr D. A., (2014), Inorganic chemistry, Boston: Pearson.
- Moharreri K., Ha M. and Nehm R. H., (2014), Evograder: an online formative assessment tool for automatically evaluating written evolutionary explanations, Evol. Educ. Outreach, 7(1), 15.
- Moon A., Stanford C., Cole R. and Towns M., (2016), The nature of students' chemical reasoning employed in scientific argumentation in physical chemistry, Chem. Educ. Res. Pract., 17(2), 353–364.
- Moon A., Stanford C., Cole R. and Towns M., (2017), Analysis of inquiry materials to explain complexity of chemical reasoning in physical chemistry students’ argumentation, J. Res. Sci. Teach., 54(10), 1322–1346.
- Moon A., Moeller R., Gere A. R. and Shultz G. V., (2019), Application and testing of a framework for characterizing the quality of scientific reasoning in chemistry students' writing on ocean acidification, Chem. Educ. Res. Pract., 20(3), 484–494.
- National Research Council, (2012), A framework for K-12 science education: practices, crosscutting concepts, and core ideas, Washington, DC: The National Academies Press.
- Nedungadi S. and Brown C. E., (2021), Thinking like an electron: concepts pertinent to developing proficiency in organic reaction mechanisms, Chem. Teach. Int. Best Pract. Chem. Educ., 3(1), 9–17.
- Nehm R. H., Ha M. and Mayfield E., (2012), Transforming biology assessment with machine learning: automated scoring of written evolutionary explanations, J. Sci. Educ. Technol., 21(1), 183–196.
- Novak G. M., Patterson E. T., Gavrin A. D. and Christian W., (1999), Just in time teaching, Am. J. Phys., 67(10), 937–938.
- Noyes K. and Cooper M. M., (2019), Investigating student understanding of London dispersion forces: a longitudinal study, J. Chem. Educ., 96(9), 1821–1832.
- Noyes K., McKay R. L., Neumann M., Haudek K. C. and Cooper M. M., (2020), Developing computer resources to automate analysis of students’ explanations of London dispersion forces, J. Chem. Educ., 97(11), 3923–3936.
- O’Sullivan T. P. and Hargaden G. C., (2014), Using structure-based organic chemistry online tutorials with automated correction for student practice and review, J. Chem. Educ., 91(11), 1851–1854.
- Pabuccu A., (2019), Argumentation in organic chemistry education, Croydon: The Royal Society of Chemistry.
- Paik S.-H., (2015), Understanding the relationship among Arrhenius, Brønsted–Lowry, and Lewis theories, J. Chem. Educ., 92(9), 1484–1489.
- Pearson R. G., (1963), Hard and soft acids and bases, J. Am. Chem. Soc., 85(22), 3533–3539.
- Petterson M. N., Watts F. M., Snyder-White E. P., Archer S. R., Shultz G. V. and Finkenstaedt-Quinn S. A., (2020), Eliciting student thinking about acid–base reactions via app and paper–pencil based problem solving, Chem. Educ. Res. Pract., 21(3), 878–892.
- Popova M. and Bretz S. L., (2018), Organic chemistry students’ understandings of what makes a good leaving group, J. Chem. Educ., 95(7), 1094–1101.
- Prevost L. B., Haudek K. C., Merrill J. E. and Urban-Lurain M., (2012), Deciphering student ideas on thermodynamics using computerized lexical analysis of student writing, Presented at the 2012 ASEE Annual Conference & Exposition, pp. 1–10.
- Prevost L. B., Haudek K. C., Henry E. N., Berry M. C. and Urban-Lurain M., (2013), Automated text analysis facilitates using written formative assessments for Just-in-Time teaching in large enrollment courses, Presented at the 2013 ASEE Annual Conference & Exposition, pp. 1–15.
- Prevost L. B., Smith M. K. and Knight J. K., (2016), Using student writing and lexical analysis to reveal student thinking about the role of stop codons in the central dogma, CBE Life Sci. Educ., 15(4), ar65.
- R Core Team, (2019), R: A language and environment for statistical computing, Vienna, Austria: R Foundation for Statistical Computing.
- Raker J. R., Reisner B. A., Smith S. R., Stewart J. L., Crane J. L., Pesterfield L. and Sobel S. G., (2015), Foundation coursework in undergraduate inorganic chemistry: results from a national survey of inorganic chemistry faculty, J. Chem. Educ., 92(6), 973–979.
- Ramasubramanian K. and Singh A., (2019), Machine leanring using R, Berkeley, CA: Apress.
- Reynolds J. A., Thaiss C., Katkin W. and Thompson R. J., (2012), Writing-to-learn in undergraduate science education: a community-based, conceptually driven approach, CBE Life Sci. Educ., 11(1), 17–25.
- Richards-Babb M., Curtis R., Georgieva Z. and Penn J. H., (2015), Student perceptions of online homework use for formative assessment of learning in organic chemistry, J. Chem. Educ., 92(11), 1813–1819.
- Rinker T. W., (2020), Qdap: Quantitative discoure analysis package, 2.4.2, https://github.com/trinker/qdap.
- Rivard L. O. P., (1994), A review of writing to learn in science: implications for practice and research, J. Res. Sci. Teach., 31(9), 969–983.
- Robinson R., (1932), Outline of an electrochemical (electronic) theory of the course of organic reactions, London: Institute of Chemistry.
- Rodríguez J. D., Pérez A. and Lozano J. A., (2010), Sensitivity analysis of k-fold cross validation in prediction error estimation, IEEE Trans. Pattern Anal. Mach. Intell., 32(3), 569–575.
- Roecker L., (2007), Using oral examination as a technique to assess student understanding and teaching effectiveness, J. Chem. Educ., 84(10), 1663.
- Romine W. L., Todd A. N. and Clark T. B., (2016), How do undergraduate students conceptualize acid–base chemistry? Measurement of a concept progression, Sci. Educ., 100(6), 1150–1183.
- Sagi O. and Rokach L., (2018), Ensemble learning: a survey, WIREs Data Mining Knowl. Discov., 8(4), e1249.
- Schmidt H.-J., (1997), Students' misconceptions—looking for a pattern, Sci. Educ., 81(2), 123–135.
- Schmidt H. J. and Volke D., (2003), Shift of meaning and students' alternative concepts, Int. J. Sci. Educ., 25(11), 1409–1424.
- Schmidt-McCormack J. A., Judge J. A., Spahr K., Yang E., Pugh R., Karlin A., Sattar A., Thompson B. C., Gere A. R. and Shultz G. V., (2019), Analysis of the role of a writing-to-learn assignment in student understanding of organic acid–base concepts, Chem. Educ. Res. Pract., 20(2), 383–398.
- Scouller K., (1998), The influence of assessment method on students' learning approaches: multiple choice question examination versus assignment essay, High. Educ., 35(4), 453–472.
- Shaffer A. A., (2006), Let us give Lewis acid-base theory the priority it deserves, J. Chem. Educ., 83(12), 1746.
- Sherif M., Taub D. and Hovland C. I., (1958), Assimilation and contrast effects of anchoring stimuli on judgments, J. Exp. Psychol., 55(2), 150–155.
- Sieke S. A., McIntosh B. B., Steele M. M. and Knight J. K., (2019), Characterizing students’ ideas about the effects of a mutation in a noncoding region of DNA, CBE Life Sci. Educ., 18(2), ar18.
- Solomons T. W. G., Fryhle C. B. and Snyder S. A., (2016), Organic chemistry, Hoboken, NJ: John Wiley & Sons, Inc.
- Stowe R. L. and Cooper M. M., (2017), Practicing what we preach: assessing “critical thinking” in organic chemistry, J. Chem. Educ., 94(12), 1852–1859.
- Stoyanovich C., Gandhi A. and Flynn A. B., (2015), Acid–base learning outcomes for students in an introductory organic chemistry course, J. Chem. Educ., 92(2), 220–229.
- Talanquer V., (2007), Explanations and teleology in chemistry education, Int. J. Sci. Educ., 29(7), 853–870.
- Tarhan L. and Acar Sesen B., (2012), Jigsaw cooperative learning: acid–base theories, Chem. Educ. Res. Pract., 13(3), 307–313.
- Towns M. H., Cole R. S., Moon A. C. and Stanford C., (2019), Argumentation in physical chemistry, Croydon: The Royal Society of Chemistry.
- Uhl J. D., Sripathi K. N., Saldanha J. N., Moscarella R. A., Merrill J., Urban-Lurain M. and Haudek K. C., (2021), Introductory biology undergraduate students' mixed ideas about genetic information flow, Biochem. Mol. Biol. Educ., 49(3), 372–382.
- Ültay N. and Çalik M., (2016), A comparison of different teaching designs of ‘acids and bases’ subject, Eurasia J. Math. Sci. Technol. Educ., 12(1), 57–86.
- Underwood S. M., Posey L. A., Herrington D. G., Carmel J. H. and Cooper M. M., (2018), Adapting assessment tasks to support three-dimensional learning, J. Chem. Educ., 95(2), 207–217.
- Urban-Lurain M., Moscarella R. A., Haudek K. C., Giese E., Sibley D. F. and Merrill J. E., (2009), Beyond multiple choice exams: Using computerized lexical analysis to understand students' conceptual reasoning in STEM disciplines, Presented at the 2009 39th IEEE Frontiers in Education Conference, pp. 1–6.
- Urban-Lurain M., Prevost L., Haudek K. C., Henry E. N., Berry M. and Merrill J. E., (2013), Using computerized lexical analysis of student writing to support Just-in-Time teaching in large enrollment STEM courses, Presented at the 2013 IEEE Frontiers in Education Conference, pp. 1–7.
- Watts F. M., Schmidt-McCormack J. A., Wilhelm C. A., Karlin A., Sattar A., Thompson B. C., Gere A. R. and Shultz G. V., (2020), What students write about when students write about mechanisms: analysis of features present in students’ written descriptions of an organic reaction mechanism, Chem. Educ. Res. Pract., 21(4), 1148–1172.
- Watts F. M., Zaimi I., Kranz D., Graulich N. and Shultz G. V., (2021), Investigating students’ reasoning over time for case comparisons of acyl transfer reaction mechanisms, Chem. Educ. Res. Pract., 22(2), 364–381.
- Williamson D. M., Xi X. and Breyer F. J., (2012), A framework for evaluation and use of automated scoring, Educ. Meas. Issues Pract., 31(1), 2–13.
- Wong T.-T. and Yeh P.-Y., (2020), Reliable accuracy estimates from k-fold cross validation, IEEE Trans. Knowl. Data Eng., 32(8), 1586–1594.
- Wright L., (1972), Explanation and teleology, Philos. Sci., 39(2), 204–218.
- Yik B. J. and Raker J. R., (2021), Lewis acid–base - R files for instructors and researchers DOI:10.17605/OSF.IO/TNBEV.
- Young K. R., Schaffer H. E., James J. B. and Gallardo-Williams M. T., (2020), Tired of failing students? Improving student learning using detailed and automated individualized feedback in a large introductory science course, Innov. High. Educ., 46(2), 133–151.
- Zhai X., Yin Y., Pellegrino J. W., Haudek K. C. and Shi L., (2020), Applying machine learning in science assessment: a systematic review, Stud. Sci. Educ., 56(1), 111–151.
- Zhai X., Shi L. and Nehm R. H., (2021), A meta-analysis of machine learning-based science assessments: factors impacting machine-human score agreements, J. Sci. Educ. Teach., 30(3), 361–379.
| This journal is © The Royal Society of Chemistry 2021 |