
Characterizing change in students' self-assessments of understanding when engaged in instructional activities
Jenna
Tashiro
 *a,
Daniela
Parga
b,
John
Pollard
a and
Vicente
Talanquer
a
*a,
Daniela
Parga
b,
John
Pollard
a and
Vicente
Talanquer
a
aDepartment of Chemistry and Biochemistry, University of Arizona, Tucson, AZ 85721, USA
bDepartment of Physiology, University of Arizona, Tucson, AZ 85721, USA
First published on 22nd March 2021
Abstract
Students’ abilities to self-assess their understanding can influence their learning and academic performance. Different factors, such as performance level, have been shown to relate to student self-assessment. In this study, hierarchical linear modeling was used to identify factors and quantify their effects on the changes observed in chemistry students’ self-assessed understanding when engaging in instructional activity. This study replicates and expands on previous findings regarding performance by showing that the worse students performed on a task, the more likely they were to lower their self-assessed understanding after that activity. Task difficulty was found to be a significant effect on change in students' self assessments with students being more likely to lower their self-assessed understanding after a more difficult task and raise it following an easier task independent of performance. Perceived comparative understanding (how students thought they compared to their surrounding peers) was also found to be a significant effect. Students who later reported their understanding to be lower than their peers, as compared to those who later reported their understanding to be about the same as their peers, were observed to have lowered their self-assessed understanding. Actual comparative performance (difference in performance of the student to their surrounding peers), gender, and feedback were not found to be significant effects on change in students’ self-assessed understanding. The results of this investigation may inform instructors on how their instructional decisions differentially impact changes in students’ judgements about their understanding.
Introduction
Students’ abilities to self-assess their understanding has consistently been shown to affect learning and academic performance (Wang et al., 1990). Self-assessment during a learning situation is a critical aspect of monitoring cognition which, together with planning and evaluation, are considered essential components of regulation of cognition, a subcomponent of metacognition (Schraw et al., 2006). A variety of studies in recent years have provided solid evidence of the significant impact that metacognition has on student learning and academic achievement (Ohtani and Hisasaka, 2018).Different authors have linked the effects of self-assessment on academic performance to differences in study behavior. For example, in deciding what topics to focus on during study time, students self-assess their level of understanding of the targeted topics (Thomas et al., 2016). In deciding how long to spend studying something, students self-assess their learning compared to what the desired level of understanding may be (Dunlosky and Thiede, 1998).
Research in many content areas, including chemistry, has shown that many students, especially lower performing students, tend to over-estimate what they know or have learned, (Kruger and Dunning, 1999; Austin and Gregory, 2007; Bell and Volckmann, 2011; Mathabathe and Potgieter, 2014; Pazicni and Bauer, 2014; Hawker et al., 2016; Sharma et al., 2016). Flawed self-assessment can impact academic performance. For example, chemistry students' overconfidence negatively affects student performance when not corrected, especially when that overconfidence was developed during the learning process (Mathabathe and Potgieter, 2014). Long-term consequences of flawed self-assessment, such as the dangers associated with a health professional's inability to assess their competence, have been cited as reasons to focus on it while students are learning (Austin and Gregory, 2007).
Researchers have looked at different factors that may affect student self-assessment of understanding. Some of the studied factors are personal or characteristic of the student, such as gender (Hawker et al., 2016; Kim et al., 2016), while others are contextual or characteristic of the classroom, such as task difficulty or the level and nature of feedback provided (Butler et al., 2008; Thomas et al., 2016). Although research on the factors that affect self-assessment can be found in a variety of fields, there is no comprehensive study in chemistry education. Much of the existing research has focused on the analysis of self-assessment related to summative assessment events rather than during the learning process. Student engagement in instructional activities in the classroom does not only facilitate cognitive development, but also impacts the way students perceive their own understanding. Completion of instructional tasks can help students realize that they may not know as much as they thought, affecting their study behavior and leading to improved performance.
Based on what areas were perceived to need additional research, this exploratory, theory-building study was designed to characterize how engaging in instructional activity relates to general chemistry students’ self-assessments of understanding. The major findings of this investigation are summarized in this paper. The central goal was to provide a comprehensive characterisation of student factors and classroom factors that correlate to changes in students’ self-assessments of understanding when engaging in classroom activities. This analysis is important because instructional decisions may have unintended consequences on students' self-assessments of understanding that instructors must recognize when planning their lessons (Rickey and Stacy, 2000; Sargeant et al., 2007).
Self-assessment of understanding
Self-assessment of understanding is an important aspect of metacognition. Flavell (1979) provided the first comprehensive theoretical framework for metacognition and defined it as “knowledge and cognition about cognitive phenomena,” or colloquially, “thinking about thinking.” Metacognition is often thought as similar to self-efficacy; however, Moores et al. (2006) distinguished between these two constructs by proposing that self-efficacy refers to belief in one's ability to perform, while metacognition involves judgment of one's level of performance.Schraw and Moshman (1995) thought of metacognition as having two major components: knowledge of cognition and regulation of cognition, also referred to as metacognitive skilfulness. Knowledge of cognition refers to different types of knowledge, such as what someone knows about themselves as a learner, different learning strategies and when to use them. Regulation of cognition comprises different skills, such as planning, monitoring, and evaluation. Several studies in chemistry education have investigated the effect of different instructional interventions on the development of these metacognitive skills (Cooper et al., 2008; Cooper and Sandi-Urena, 2009; Sandi-Urena et al., 2012).
Nelson and Narens (1990) proposed a mechanism for metacognition in which information flows from the object-level to a meta-level via monitoring, and flows back to the object-level via control. These authors characterized metacognitive monitoring using terms like judgments, feeling-of-knowing, and confidence suggesting that student ability for self-assessment of understanding is a monitoring activity. They noted, however, that using self-assessment as a measure of metacognitive monitoring is problematic as an individual's self-assessment of understanding can be distorted.
Distortions in self-assessment of understanding were most notably studied by Kruger and Dunning (1999). These researchers found that lower performers tended to overestimate their ability while higher performers often underestimated their ability. The participants estimated their ability following tasks of various topics outside of the normal classroom experience. These results, often referred to as the ‘Dunning and Krueger effect,’ were also found when topic relevant tasks were performed in groups.
Studies focused on metacognitive monitoring have been conducted in different domains. For example, undergraduate senior-level pharmacy students of all performance levels were found to overestimate their clinical knowledge and communication skills (Austin and Gregory, 2007). Similarly, Sharma et al. (2016) found 74% of undergraduate medical students overestimated their grades on a physiology test, but their self-grading had a high correlation with the instructors’ grading. High correlation indicating that although students overestimated, the general trend was that as self-grading increased, so did the instructors’ grading.
In chemistry education, several studies have looked into the ability of students to self-assess their understanding in testing situations (Bell and Volckmann, 2011; Mathabathe and Potgieter, 2014; Pazicni and Bauer, 2014). Students have been found to be generally overconfident in their understanding, with higher performing students being less overconfident. This trend was observed in general chemistry courses when confidence was measured at the specific question level using both an 11-point scale with their score on a low-stakes quiz as the performance measure (Mathabathe and Potgieter, 2014), and a 3-point scale on a knowledge survey with their score on a high-stakes final exam as the performance measure (Bell and Volckmann, 2011). Similar results were reported when undergraduate general chemistry students predicted their exam grades (Hawker et al., 2016). Looking at comparative performance percentiles following exams, general chemistry students were found to overestimate at the lower performance levels and underestimate at the higher performance levels (Pazicni and Bauer, 2014).
Although individual performance is the factor most frequently accounted for in these types of studies, there has been inconsistent reporting on how influential it really is. A review of self-assessment studies found a low average correlation between performance and self-assessment measures (Mabe III and West, 1982), while other studies have reported moderate (Bol and Hacker, 2001) and high (Sharma et al., 2016) correlations. Kruger and Dunning (1999) did note that the effect of performance using simple regression was not a statistically significant predictor of the self-assessment percentiles. However, Pazicni and Bauer (2014) found performance to be a statistically significant predictor of the accuracy of self-assessment, defined by the difference between performance and self-assessment.
In addition to performance, it is widely accepted that other factors could relate to student self-assessment of understanding and therefore are worthy of investigation (Veenman et al., 2006). For example, Carvalho and Moises (2009) have identified personal, task-related, and environmental factors that may affect metacognitive monitoring. Personal factors include gender and cognitive ability; task-related factors include different characteristics of the activity individuals are asked to complete, and environmental factors refer to characteristics of the learning environment.
The effect of gender on self-assessment has been investigated in a number of studies. Kruger and Dunning (1999) did not find gender to significantly impact comparative self-assessment measures for different types of tasks on various subjects. Similar results were reported by Kim et al. (2016) but a study in the domain of chemistry found gender to be of significance under some conditions, although its impact had a small effect size (Hawker et al., 2016).
Feedback is a task-related or classroom factor that can be direct or indirect. Direct feedback is provided to individual students based on their performance, while indirect feedback results from the comparison of a student's performance to that of others. Direct feedback can be provided by indicating what questions are right or wrong or posting the correct answers. Graded tasks provide direct feedback via the grade received. In a study based on two general knowledge survey tasks, lack of feedback combined with lower confidence in the first task resulted in a greater likelihood of changing a correct answer to an incorrect answer on the second task (Butler et al., 2008). Receiving direct immediate feedback in the first task resulted in correct answers being unlikely to change in the second task, independent of confidence level.
Kruger and Dunning (1999) looked at the relationship between peer evaluation and self-assessment. Following an initial post-task self-assessment, students evaluated their peers’ work. Lower performing students were less accurate when evaluating their peers' performance than the higher performing students. Lower performing students following peer evaluation did not improve their self-assessment accuracy, but higher performing students re-evaluated themselves closer to their actual percentile rankings. The evaluation of peer performance is an example of indirect feedback, as it provides insights into an individual's performance by comparison. In general, there is a lack of research in chemistry education on the effect of feedback, direct or indirect, on students’ self-assessed understanding.
Task difficulty is another classroom factor that affects self-assessment of understanding. It has been shown that when actual or perceived task difficulty increases, self-assessment decreases in a variety of topics (Kruger and Dunning, 1999; Burson et al., 2006; Thomas et al., 2016). Kim et al. (2016) found that task difficulty mediated the impact of performance on self-assessed ability.
Environmental factors, such as culture, have also been assessed in previous research. While many of the studies regarding self-assessment of understanding have been conducted at universities in the United States, several studies have also been conducted cross-culturally with similar results (Mathabathe and Potgieter, 2014; Kim et al., 2016).
Methods
Goal and research questions
The goal of this exploratory research study was to provide a comprehensive characterization of factors that relate to changes in students’ self-assessments of understanding following engagement in instructional activity in a chemistry classroom. For factors under analysis, the following research questions were sought to be answered:1. Is the effect of the factor on the change in students’ self-assessments of their understanding statistically significant?
2. For a factor that is a statistically significant effect, what is the size of that effect, it's practical significance?
Participants and research setting
Study participants were undergraduate students enrolled in the second semester of the introductory general chemistry courses for science and engineering majors (regular and honors students) at the University of Arizona in the US. The curricular model for these courses emphasizes the development of chemical thinking to answer questions of relevance in the world (Talanquer and Pollard, 2010). Active and collaborative learning are essential components to the classroom experience in this curriculum. Students in these courses engaged in the tasks/activities analysed in this study as part of the regular tasks/activities of the course; however, only data for students who gave consent were used in analysis. Participating students in each course section received no incentive for their participation. This study was approved by the Institutional Review Board at the University of Arizona.Data were collected in three course sections as summarized in Table 1 (N = 407; 62% female, 38% male). Data were collected on four occasions or sessions about evenly distributed throughout the semester for each course section. Participants with incomplete or missing self-reports of their self-assessed understanding for a data collection session were excluded from the study for that data collection session only. In two later data collection sessions, the instructor asked the students additional metacognitive questions. Due to the concern that those additional questions could have influenced the students’ self-assessments, the data collected in those sessions were not included in this study.
| Section 1 | Section 2 | Section 3 | ||||
|---|---|---|---|---|---|---|
| N = 221 | N = 158 | N = 28 | ||||
| Type | Regular | Honors | Regular | |||
| Semester | Spring | Spring | Summer | |||
| Gender | Female | 67.0% | Female | 55.1% | Female | 67.9% |
| Male | 33.0% | Male | 44.9% | Male | 32.1% | |
Measurement instruments
| Scale | ||
|---|---|---|
| Score | Title | Description |
| 1 | Lost | I am unsure of the definitions and meanings of the key concepts (I just guess) |
| 2 | Novice | I know the definitions and meanings of the key concepts, but not how to apply them (I can't get the right answers) |
| 3 | Middle | I know how to apply the key concepts, but not explain them (I hope for multiple choice) |
| 4 | Advanced | I know how to use the key concepts to explain things (I'm great with the free response questions) |
| 5 | Master | I think about how these key concepts apply to things we haven't talked about |
As with any measurement, especially with self-reporting, measuring may have its own effect. Because this study was interested in what changes happened during classroom activities and not as a result of having students self-reflect or the addition of any metacognitive intervention or training, an attempt was made to limit the amount of self-reflection being asked of the students. Participants were asked to report their self-assessed level of understanding before and after the performance task.
Dunning et al. (1989) looked at the role of trait ambiguity in the inaccuracy in self-assessments of ability. In the development of the research tool, “understanding” was considered as a reasonably ambiguous trait given that different students could use different criteria in their self-assessment. To reduce such an ambiguity, criteria was provided for assessment in the form of descriptions of different levels of understanding that were specific to the types of activities that students experienced (see Table 2).
To validate the research instrument, a pilot study was conducted and the results were compared to those previously reported. This pilot study was conducted in the year prior to this investigation. Pilot study participants (N = 65) were also undergraduate students enrolled in the second semester of the introductory general chemistry courses for science and engineering majors. Data were collected with the tool for self-assessment of understanding on two occasions throughout a semester. During each occasion, students were asked to use the tool before and after a performance task. These tasks were in-class quizzes similar to the knowledge surveys used by Bell and Volckmann (2011) but administered through an online quizzing site. At the end of the semester, student performance was evaluated using a standardized general chemistry conceptual exam from the American Chemistry Society.
Pilot study participants with missing data were excluded from use in the analysis giving a total of 48 participants in the first occasion and 53 in the second. As a comparison to prior research was being made, the data were represented and analysed using the same types of plots developed to analyse equivalent data in those prior studies, shown in Fig. 1 and 2. These plots compare self-assessment measures to performance measures grouped by performance quantiles. This analytical approach was outlined by Bell and Volckmann (2011), who used a 3-point scale in their study. Students were separated into performance tertiles based on their final exam scores. The post-task self-assessment of understanding scores (5-point scale) were scaled up to make them comparable to the 100-point scale used in the final exam. The results from the first pilot study data collection, shown in Fig. 1 are similar to those presented by Bell and Volckmann (2011). The trend of overestimation in the two lower performance quantiles and a more accurate estimation in the higher performance quantiles is similar to that seen in studies that used a variety measures or tools for self-assessment such as a Likert-like confidence scale (Mathabathe and Potgieter, 2014), expected grades (Hawker et al., 2016), and analytical checklists (Austin and Gregory, 2007). The results from the second pilot study data collection, shown in Fig. 2, are similar to the results of the “Dunning and Kruger effect” (Kruger and Dunning, 1999) using a measure of self-assessed comparative percentile rankings of ability compared to actual performance of the given task. These results, which have been replicated using the same measures as Kruger and Dunning (Pazicni and Bauer, 2014; Kim et al., 2016), still indicate an overestimation in the lower performance quantiles, but an underestimation in the higher performance quantile.
 | ||
| Fig. 1 First data collection of pilot study for instrument validation. Scaled self-assessment of understanding scores and final exam scores sorted by final exam performance tertiles. | ||
 | ||
| Fig. 2 Second data collection of pilot study for instrument validation. Scaled self-assessment of understanding scores and final exam scores sorted by final exam performance tertiles. | ||
 | ||
| Fig. 3 Flow chart for data collection. Data collection procedure is shown in the series arrowed boxes in the center of the figure. Measurements collected at different points in the data collection procedure or regarding different aspects of the data collection process are shown as white boxes. | ||
| Self-assessed understanding | |||
|---|---|---|---|
| Pre-task | Post-task | Change (ΔSAU) | |
| Mean | 3.19 | 3.18 | −0.01 |
| Standard deviation | 0.75 | 0.95 | 0.8 |
| Median | 3 | 3 | 0 |
| Minimum | 1 | 1 | −3 |
| Maximum | 5 | 5 | 3 |
| Range | 4 | 4 | 6 |
| Skew | −0.22 | −0.41 | −0.3 |
| Kurtosis | 0.09 | −0.34 | 0.53 |
Measure of gender. In line with previous studies, “gender” was used to differentiate participants into two main categories (male, female). It is important to recognize, however, the limitations of this binary categorization in light of modern interpretations of gender identity.
Measure of initial self-assessed understanding. “Initial self-assessed understanding” was defined as the group-mean centred pre-task self-assessed understanding score. For example, an initial self-assessed understanding of one would indicate that student had a pre-task self-assessment score one unit above the class average on that day. Positive values for initial self-assessment indicate that students pre-task self-assessed themselves higher than the class average. Negative values for initial self-assessment indicate that students pre-task self-assessed themselves lower than the class average. An initial self-assessed understanding of zero indicates that the level a student pre-task self-assessed their understanding to be was equal to the class average.
Measure of student performance. “Student performance” was defined as the group mean centred score the student received on the performance task. The student's original task score was converted to be on a 0–100 point scale to ensure that the assigned score was independent of the number of questions per task. With this transformation, a one unit increase in a student performance score indicated that a student received a score one percent above the average for that class on that task. Positive student performance scores indicating higher than average performance and negatives score indicating lower than average.
Measure of perceived comparative understanding. Perceived comparative understanding was measured as a categorical variable corresponding to the student responses in the post-collaborative task survey when asked to rate their understanding of the given subject compared to the other members of their group. Their rate could be “higher”, “lower”, or “about the same”.
Measure of actual comparative performance. Actual comparative performance was measured by the difference in the performance score of a student and the average of their collaborative group. Students with performance scores within plus or minus ten percentage points of the collaborative group average were categorized as having “about the same actual comparative performance”. Students with performance scores below ten percentage points of the collaborative group average were categorized as having “lower actual comparative performance”. Students with performance scores ten percentage points above the collaborative group average were categorized as having “higher actual comparative performance”.
Measure of feedback. Feedback was assessed as a categorical variable as either “no feedback” for tasks that did not give any feedback to the student or “immediate feedback” for tasks that showed the correct answer after students completed a task.
Measure of task difficulty. Task difficulty was measured by taking the average performance score of all students across semesters who completed that task. The scores were converted to be on a 0–100 point scale such that all tasks were on the same scale independently of how many questions were asked. Tasks were then separated into tertiles based on these scaled average performance scores. Additionally, the tasks were given to faculty that taught general chemistry at the University of Arizona. Faculty ranked the tasks from easiest to most difficult and those rankings were also separated into tertiles. Faculty rankings were in alignment with the categorization based on the scaled average performance scores with the tasks faculty ranked into the bottom tertile for difficulty also being in the bottom tertile of the scaled average performance scores and so forth. Tasks were categorized in order of difficulty: “low task difficulty,” “moderate task difficulty,” and “high task difficulty.”
Data analysis
In this exploratory study, data were analysed using statistical modelling to build a theory detailing the factors that relate to changes in students’ self-assessments and quantifying those relationships.The LRTs gave indication of the statistical significance of accounting for the issues of nested data (Peugh, 2010). LRT compares two statistical models, in this case a basic HLM and a simpler linear regression model. The comparison or “model fit” determines if the given data fit the larger model significantly better than the smaller one. If there was a statistically significant difference in model fit, the need to account for the nesting of data was supported. The first LRT used students as the subunit, the second LRT used data collection sessions as the subunit for the larger model, and the third LRT used course sections as the subunit for the larger model. For each possible subunit, an unconditional means model (UCM) using restricted maximum likelihood (REML) estimation was conducted with a fixed intercept and random intercept for each subunit.
The ICCs gave indication of the practical significance of accounting for the variance between-subunits (Lorah, 2018). The ICC (ρ) was calculated as the random intercept variance divided by the sum of the random intercept variance and the residual variance (Raudenbush and Bryk, 2002; Lorah, 2018; Theobald, 2018). The ICC, in this case, was the percentage of the variance in the change in students’ assessments of their understanding (ΔSAU) that was explained by the between-subunit differences. The higher the ICC, the greater the practical significance of accounting for the nesting of data by use of HLM. When the ICC is above 10%, it is considered non-trivial and is evidence of the need to account for the nesting of data by use of a multilevel method such as HLM (Lee, 2000).
The first UCM model that allowed for consideration of nesting within students (random intercept effect with student as a subunit) did not show a statistically significant difference in model fit from the linear regression model (fixed intercept only) with LRT χ2(1) = 3.1 × 10−7, p = 0.9996. Less than 0.1% of the ΔSAU variance was explained by the between-student differences (ρ = 1.12 × 10−8). Given no significant improvement in model fit and negligible ΔSAU variation between students, accounting for the nesting of data within students was not needed.
The second UCM model that allowed for consideration of nesting within data collection sessions (random intercept effect with data collection session as a subunit) did show a statistically significant difference in model fit from the linear regression model (fixed intercept only) with LRT χ2(1) = 24.4, p < 0.0001. 11.6% of the ΔSAU variance was explained by the between data collection session (session) difference (ρ = 0.116). The significant improvement to model fit and ΔSAU variation between sessions supported the need to account for nesting of data within sessions. Given this, data analysis moved forward with a two-level HLM with session as the subunit.
The third UCM model that allowed for consideration of nesting within course sections (random intercept effect with course section as a subunit) did not show a statistically significant difference in model fit from the linear regression model (fixed intercept only) with LRT χ2(1) = 0.47, p = 0.4922. 0.6% of the ΔSAU variance was explained by the between course section difference (ρ = 0.00581). Given no significant improvement in model fit and negligible ΔSAU variation between sections, accounting for the nesting of data within course sections was not needed.
R statistical computing software was used to analyse the data applying HLM (Wickham and Henry, 2018).
In this study, a large sample size was used, if treated ordinally ΔSAU would be a 7-category scale (observed range of −3 to +3), ΔSAU is normally distributed, and the other key assumptions for HLM were assessed and are reported in the following subsections. As such, in this study's characterization of the change in students’ self-assessed understanding (ΔSAU), the ordinal self-assessment data was treated as interval. For example, with the methods used, a change (ΔSAU = −1) from initially self-reporting an “Advanced” level understanding and then post-task self-reporting a “Middle” level of understanding is assumed to be the same as a change (ΔSAU = −1) from initially self-reporting a “Middle” level of understanding and then post-task self-reporting a “Novice” level of understanding. Additionally, a two-level decrease in self-assessment (ΔSAU = −2) would be treated as twice as larger as any single-level decrease in self-assessment (ΔSAU = −1).
Assumptions of HLM. The following key assumptions of HLM were assessed (Raudenbush and Bryk, 2002; Cohen et al., 2003; Ferron et al., 2008; Woltman et al., 2012):
Normality of the dependent variable. Descriptive statistics for the self-assessed understanding variables are shown in Table 3. The dependent/predicted variable of change in students’ assessments of their understanding (ΔSAU) was found to be normally distributed. Both skew and kurtosis were within a more than acceptable range of ±1 (Kim, 2013). The normality of ΔSAU for each session were additionally evaluated with Box plots (Albers, 2017).
Multicollinearity. Multicollinearity of independent continuous variables were assessed by calculation of variance inflation factors (VIF). VIF values greater than 10 are considered indicators of multicollinearity (Craney and Surles, 2002). The pre-task self-assessed understanding scores displayed multicollinearity with student performance scores with VIF scores ranging from 15.28 to 43.29. To address this issue, the pre-task self-assessed understanding scores and student performance scores were group-mean centred by session (Cohen et al., 2003). The resulting VIF values, calculated using the group-mean centred variables ranged from 1.00 to 1.01 indicating that the multicollinearity was accounted for.
Homoscedasticity. Following the completion of model building, both student residuals and classroom zetas showed constant variance (homoscedasticity) in graphical analysis. Student standardized residuals were plotted against predicted scores for each section subunit. Additionally, the classroom variable of task difficulty was plotted against intercept zetas and slope zetas.
Normality of residuals and zetas. Following completion of model building, both student residuals and classroom zetas were found to be normally distributed through graphical analysis. Student residuals were evaluated by boxplots for each section and classroom intercept zetas and slope zetas were evaluated by quantile–quantile (qq) plots.
First, practical significance was assessed by evaluation and comparison of standardized and partially standardized fixed effect coefficients. Fixed effect coefficients indicate the magnitude of the relationship, but do not indicate the strength of the relationship or how correlated the factor is to ΔSAU. Similar to how, with a simple linear regression or trendline, the slope of the line indicates the magnitude of the relationship while the R2 indicates the strength of the relationship or how correlated the variables are. A standardized coefficient can generally be interpreted as the amount of observed change, in standard deviations, of students’ self-assessed understanding per standard deviation change in the fixed effect across all subunits accounting for all other variables. A partially standardized coefficient for a category can be interpreted as the difference in observed change, in standard deviations, of students’ self-assessed understanding between the category and the reference category across all subunits accounting for all other variables. Using standardized and partially standardized coefficients allows for comparison of the factor's effect sizes for factors with different units and observed ranges, while also accounting for all other variables and variance between subunits (Snijders and Bosker, 2012; Lorah, 2018).
Second, practical significance was assessed by evaluation and comparison of residual variances using a local effect size measure, Cohen's f2. This analysis speaks to how much the factor characterizes the change in students’ self-assessed understanding. Cohen's f2 accounts for all other variables and variance between subunits, unlike the more commonly known effect size measure Cohen's d (Selya et al., 2012; Lorah, 2018). Change in students’ self-assessed understanding was observed to vary. Cohen's f2 can be interpreted as the proportion of that variance in students’ self-assessed understanding accounted for by one factor relative to the proportion of unexplained variance in students’ self-assessed understanding across all subunits accounting for all other variables. For Cohen's f2, the effect size or practical significance can be considered small above 0.02, medium above 0.15, and large above 0.35 (Cohen, 1977; Selya et al., 2012; Lorah, 2018).
Results
Results for research question #1
The following results from model building are presented to answer the first research question: Is the effect of the factor on the change in students’ self-assessments of their understanding statistically significant? The main findings for each factor can be found in italics followed by the evidence and reasoning to support those claims. The statistical models discussed in this section were labelled by number, type of effect (fixed (f) or fixed and random (f&r)), and the method of estimation (maximum likelihood (ML) or restricted maximum likelihood (REML)). Table 6 details what factors were in each model.The addition of initial self-assessed understanding as measured by the group mean centred pre-task self-assessed understanding score as a fixed effect in Model 1.f.ML showed a statistically significant improvement in model fit from the smaller unconditional means (UCM) model with likelihood ratio test (LRT) with χ2(1) = 60.0, p < 0.0001. As evidenced by improved model fit, the fixed effect of initial self-assessed understanding was found to be a significant effect on change in students’ self-assessments of their understanding (ΔSAU).
The addition of both the fixed and random effects in Model 1.f&r.ML showed a statistically significant improvement in model fit from the smaller UCM model (without either the fixed or random effects) with LRT χ2(3) = 61.1, p < 0.0001. The addition of the random effect in Model 1.f&r.REML did not show a statistically significant improvement in model fit from the smaller Model 1.f.REML (with only the fixed effect and not the random effect) with LRT χ2(2) = 1.2, p = 0.5579. As such, the addition of initial self-assessed understanding as a random effect (random slope for each session subunit) to account for between-session differences in the relationship of initial self-assessed understanding and ΔSAU was determined to not be needed. As the addition of the fixed effect of initial self-assessed understanding improved model fit, model building was continued with the Model 1.f.ML and Model 1.f.REML.
The addition of gender as a categorical variable fixed effect (females as the reference variable) in Model 2.f.ML did not show a statistically significant improvement in model fit from the smaller Model 1.f.ML with LRT χ2(1) = 0.02, p = 0.8948. As model fit did not improve, gender (fixed effect) was determined to not be a significant effect on change in students’ self-assessments of their understanding (ΔSAU) when controlling for their initial self-assessment. With no improvement to model fit, model building was continued with Model 1.f.ML and Model 1.f.REML.
The addition of student performance as measured by the group mean centred performance task score as a fixed effect in Model 3.f.ML showed a statistically significant improvement in model fit from the small Model 1.f.ML with χ2(1) = 126.6, p < 0.0001. Student performance, as a fixed effect, was found to be a significant effect on the change in students’ self-assessed understanding (ΔSAU) when controlling for their initial self-assessment as evidenced by the improvement in model fit and therefore said to be a factor that relates to ΔSAU.
The addition of both the fixed and random effects in Model 3.f&r.ML showed a statistically significant improvement in model fit from the smaller Model 1.f.ML (without either the fixed or random effects) with LRT χ2(3) = 135.8, p < 0.0001. The addition of the random effect in Model 3.f&r.REML also showed a statistically significant improvement in model fit from the smaller Model 3.f.REML (with only the fixed effect and not the random effect) with LRT χ2(2) = 9.5, p = 0.0088. As such, the addition of student performance as a random effect (random slope for each session subunit) to account for between-session differences in the relationship of student performance and ΔSAU was determined to be needed. As the addition of both the fixed and random effects of student performance improved model fit, model building was continued with the Model 3.f&r.ML and Model 3.f&r.REML.
The addition of the interaction variable for initial self-assessed understanding and student performance in Model 4.f.ML showed a statistically significant improvement in model fit from the smaller Model 3.f&r.ML with LRT χ2(1) = 5.5, p = 0.0185. The addition of both the fixed and random effects in Model 4.f&r.ML did not show a statistically significant improvement in model fit from the smaller Model 3.f&r.ML (without either the fixed or random effects) with LRT χ2(8) = 9.3, p = 0.3154. The addition of the random effect in Model 4.f&r.REML also did not show a statistically significant improvement in model fit from the smaller Model 4.f.REML (with only the fixed effect and not the random effect) with LRT χ2(7) = 4.3, p = 0.7407. As such, the addition of the interaction variable as a random effect (random slope for each session subunit) to account for between-session differences in the relationship of the interaction variable and ΔSAU was determined to not be needed. As the addition of the fixed effect of the interaction variable improved model fit, model building was continued with the Model 4.f.ML and Model 4.f.REML.
The addition of perceived comparative understanding as fixed effects with the categorical variable of reporting about the same perceived comparative understanding as the reference variable in Model 5.f.ML showed a statistically significant improvement in model fit from the small Model 4.f.ML with χ2(2) = 14.3, p = 0.0008. The categorical variables of perceived comparative understanding, as fixed effects, were found to be significant effects on change in students’ self-assessments of their understanding (ΔSAU) when controlling for all other variables loaded prior in the model building progression as evidenced by the improved model fit.
The addition of both the fixed and random effects in Model 5.f&r.ML did not show a statistically significant improvement in model fit from the smaller Model 4.f.ML (without either the fixed or random effects) with LRT χ2(9) = 14.9, p = 0.0939. The addition of the random effects in Model 5.f&r.REML also did not show a statistically significant improvement in model fit from the smaller Model 5.f.REML (with only the fixed effects and not the random effects) with LRT χ2(7) = 0.89, p = 0.9964. As such, the addition of perceived comparative understanding as random effects (random slopes for each session subunit) to account for between-session differences in the relationships of perceived comparative understanding and ΔSAU were determined to not be needed. As the addition of the fixed effects of perceived comparative understanding were determined to improve model fit, model building was continued with the Model 5.f.ML and Model 5.f.REML.
The addition of the interaction variable between lower perceived comparative understanding and initial self-assessed understanding in Model 6.f.ML did not show a statistically significant improvement in model fit from the smaller Model 5.f.ML with LRT χ2(1) = 3.4, p = 0.0667. The addition of the interaction variable between higher perceived comparative understanding and initial self-assessed understanding in Model 7.f.ML also did not show a statistically significant improvement in model fit from the smaller Model 5.f.ML with LRT χ2(1) = 0.001, p = 0.9707. The addition of the interaction variable for lower perceived comparative understanding and student performance in Model 8.f.ML did not show a statistically significant improvement in model fit from the smaller Model 5.f.ML with LRT χ2(1) = 0.003, p = 0.9534. The addition of the interaction variable for higher perceived comparative understanding and student performance in Model 9.f.ML also did not show a statistically significant improvement in model fit from the smaller Model 5.f.ML with LRT χ2(1) = 1.7 × 10−5, p = 0.9967. Interaction variables of perceived comparative understanding were therefore determined to not be significant predictors of ΔSAU when controlling for all other variables. As such, model building was continued with Model 5.f.ML and Model 5.f.REML.
The addition of actual comparative performance as fixed effects with the categorical variable of having about the same comparative understanding as the reference variable in Model 10.f.ML did not show a statistically significant improvement in model fit from the small Model 5.f.ML with χ2(2) = 1.0, p = 0.6038.
An additional LRT was performed to evaluate if the lack of significance of actual comparative performance was due to the order of the modelling in the analysis or in other words, to see if significance could be found for actual comparative performance if the model was not controlling for perceived comparative understanding. Actual comparative performance variables were added as a fixed effects and perceived comparative understanding variables were removed in Model 11.f.ML. Model 11.f.ML however, did not show a statistically significant improvement in model fit from the smaller Model 4.f.ML (without either fixed effect) with LRT χ2(2) = 1.3, p = 0.5346. Actual comparative performance variables, as fixed effects, were therefore found to not be significant effects on change in students’ self-assessed understanding (ΔSAU) when controlling for all other variables (including or not including perceived comparative understanding) due to the lack of improvement in model fit. Model building was continued with Model 5.f.ML and Model 5.f.REML.
The addition of feedback as a fixed effect with the categorical variable of “no feedback” as the reference variable in Model 12.f.ML did not show a statistically significant improvement in model fit from the smaller Model 5.f.ML with χ2(1) = 0.95, p = 0.3296.
An additional LRT was performed to evaluate if the lack of significance of giving feedback was due to the order of the modelling in the analysis or in other words, to see if significance could be found if the model was not controlling for all other variables. Model 13.f.ML was conducted with feedback as the only fixed effect. Model 13.f.ML however, did not show a statistically significant improvement in model fit from the smaller UCM model (without any fixed or random effects) with LRT χ2(1) = 3.2, p = 0.0758. Giving feedback (fixed effect) was therefore not found to be a significant effect on change in students’ self-assessed understanding (ΔSAU) when controlling for all other variables and when not controlling for other variables as evidenced by the lack of improvements in models fit. Model building was continued with Model5.f.ML and Model 5.f.REML.
The addition of task difficulty as fixed effects with the categorical variable of moderate task difficulty as the reference variable in Model 14.f.ML showed a statistically significant improvement in model fit from the smaller Model 5.f.ML with LRT χ2(2) = 14.1, p = 0.0009. As evidenced by an improvement in model fit, task difficulty variables as fixed effects were found to be significant effects on change in students’ self-assessed understanding (ΔSAU). As the addition of the fixed effects of task difficulty improved model fit, model building concluded with the Model 14.f.ML and Model 14.f.REML.
Results for research question #2
The final model for change in students’ assessments of their understanding (ΔSAU), Model 14.f.REML, is presented in Table 4. The final model includes all factors that were found to be significant effects on ΔSAU. For fixed effects presented in the final model, along with the unstandardized coefficients (B), the standardized coefficients (β) and Cohen's f2 values are also reported. For each of the factors, the following results of the final model are presented to answer the second research question: For a factor that is a statistically significant effect on the change in students’ self-assessments of their understanding, what is the size of that effect, it's practical significance? The main findings of the effect size measures and interpretations of the practical significance of the correlative relationships between the factors (predictor variables) and ΔSAU (predicted variable) are shown in italics.| Predictor (fixed effects) | B | SE | 95% CI | β | Cohen's f2 |
|---|---|---|---|---|---|
| LL = −379.2, AIC = 782.5, BIC = 830.3. | |||||
| (Intercept) | −0.014 | 0.055 | (−0.121, 0.094) | — | — |
| Initial self-assessed understanding | −0.533 | 0.043 | (−0.617, −0.449) | −0.480 | 0.39 |
| Student performance | 0.022 | 0.003 | (0.016, 0.029) | 0.441 | <0.01 |
| Perceived comparative understanding | 0.03 | ||||
| Higher | 0.147 | 0.109 | (−0.068, 0.362) | 0.184 | — |
| Lower | −0.428 | 0.121 | (−0.666, −0.190) | −0.535 | — |
| Task difficulty | 0.25 | ||||
| Higher | −0.627 | 0.102 | (−0.952, −0.303) | −0.784 | — |
| Lower | 0.190 | 0.069 | (−0.029, 0.409) | 0.238 | — |
| Interaction variable for initial self-assessed | 0.006 | 0.003 | (0.001, 0.011) | 0.086 | <0.01 |
| Understanding and student performance | |||||
| Component (random effects) | Variance | SD | 95% CI (SD) |
|---|---|---|---|
| (Intercept) session | 0.00136 | 0.03691 | (0.0002, 5.6780) |
| Student performance | 0.00004 | 0.00624 | (0.0025, 0.0155) |
| Error | 0.34246 | 0.58520 | (0.5457, 0.6276) |
This result is indicative of a regression towards the mean and the inclusion of initial self-assessed understanding into the model helps control for this effect (Allison, 1990). Given that initial self-assessed understanding and student performance were found to have significant interaction, the individual interpretation of the coefficient, standardized or not, speaking to the magnitude or size of the effect of initial self-assessed understanding on change in students’ self-assessed understanding (ΔSAU), is limited to only students with average performance (student performance score = 0). A full examination of the magnitude or size of the fixed effects with interactions on ΔSAU is more complex and should include the interaction variable.
The standardized coefficient (β = −0.480) for initial self-assessed understanding indicates that for students with average performance, for each standard deviation higher they were than the average in initial self-assessed understanding, the observed change in their self-assessment following the task (ΔSAU) was a decrease of 0.480 standard deviations and for each standard deviation lower they were than the average, the observed change in ΔSAU was an increase of 0.480 standard deviations across all subunits, accounting for all other variables. The strength of that relationship between initial self-assessed understanding and ΔSAU was found to be strong; initial self-assessed understanding was found to have a large effect size with Cohen's f 2 = 0.39.
Again, due to the interaction with initial self-assessed understanding the individual evaluation of effect size for student performance is limited to only students with average initial self-assessed understanding (initial self-assessed understanding = 0).
For student performance, β = 0.441, indicating that for students with average initial self-assessed understanding, for each standard deviation higher they were than average in task performance, the observed change in self-assessed understanding following that task (ΔSAU) was an increase of 0.441 standard deviations and for each standard deviation lower than average in task performance, the observed changed in ΔSAU was a decrease of 0.441 standard deviations on average across all subunits, accounting for all other variables. The strength of that relationship between student performance and ΔSAU was found to be negligible; student performance was found to have a negligible effect size with Cohen's f2< 0.01.
This result generally indicates that students that initially assessed their understanding to be lower, were more likely to have their performance have a bigger effect on the observed change in their self-assessed understanding (ΔSAU). The strength of the interaction effect on ΔSAU was found to be negligible; the interaction variable was found to have a negligible effect size with Cohen's f2< 0.01.
To illustrate the effects an interaction plot was constructed using the standardized coefficients and is shown in Fig. 4. The combination of the fixed effects of initial self-assessed understanding, student performance, and the interaction on the outcome variable, ΔSAU, on average across all subunits and accounting for all other variables is shown. By accounting for all other variables, the plot looks at the cumulative, but isolated (above and beyond the other factors) effect on ΔSAU for different variable combinations; the plot does not show the average ΔSAU for the different variable combinations.
 | ||
| Fig. 4 Standardized interaction plot for student performance and initial self-assessment. Observed changes, in standard deviations, of students’ self-assessed understanding (ΔSAU) accounted for by per standard deviation changes in student performance, initial self-assessment, and the interaction of student performance and initial self-assessment on average across all subunits and accounting for all other variables. Combinations of initial self-assessment group and student performance group are indicated with groups said to be “accurate initial assessments” highlighted in green, “overestimated initial assessments” highlighted in red, and “underestimated initial assessments” and highlighted in blue. | ||
Initial self-assessment and student performance were each divided into the categories of low, average, and high. “Low” is designated as being one standard deviation or more below average and “high” is designated as one standard deviation or more above average.
The negative relationship between initial self-assessed understanding and ΔSAU is observed graphically by the different lines shown in Fig. 4. For each performance level, moving upwards from the high to the average to the low initial self-assessment lines shows the contribution of the effect – as initial self-assessment decreases, ΔSAU increases. The positive relationship between student performance and ΔSAU is graphically represented by the positive slopes of three lines and shows the contribution of the effect – as student performance increases, ΔSAU increases. The interaction of the fixed effects is observed in the graphical representation by the differences in the slopes of the lines. The slope indicates the magnitude of the relationship between student performance and ΔSAU. Moving from the low to average to high initial self-assessment lines shows the contribution of the effect – as initial self-assessment increases, the relationship between student performance and ΔSAU increases with slopes of 0.36, 0.44, and 0.53 respectively.
With initial self-assessment and student performance each grouped into low, average, and high categories, there are nine combinations of initial self-assessment and student performance. The three combinations that match, for example the group of students that had low initial self-assessment and then low performance, are said to have “accurate initial assessments”. Highlighted in green in Fig. 4, these three groups, showed little to no change in self-assessment following the task (all ΔSAU ≤ ±0.15) accounted for by their initial assessment and performance.
The three combinations with mismatched with initial self-assessment higher than performance are groupings of students said to have “overestimated initial assessments”. Highlighted in red in Fig. 4, these three groups that initially overestimated themselves all showed a decrease in self-assessment accounted for by those effects. The group that overestimated by having average initial self-assessment followed by low performance had an about equal decrease in self-assessment following the task (ΔSAU = −0.44) as the group that overestimated by having high initial self-assessment followed by average performance (ΔSAU = −0.48). The group that overestimated the most with high initial self-assessment followed by low performance had a decrease in self-assessment almost twice as much less after the task (ΔSAU = −1.01) as the other two groups that overestimated themselves less.
The three combinations with the initial self-assessment lower than performance are said to be “underestimated initial assessments” and highlighted in blue in Fig. 4. These three groups that initially underestimated themselves all showed an increase in self-assessment accounted for by those effects. The group that underestimated themselves by having average initial self-assessment followed by high performance had an about equal increase in self-assessment following the task (ΔSAU = +0.48) as the group that underestimated themselves by having low initial self-assessment followed by average performance (ΔSAU = +0.44). The group that underestimated themselves the most with low initial self-assessment followed by high performance reported they understood more after the task than they originally reported with ΔSAU = +0.84, a change twice that of the other two groups that underestimated themselves less.
As this is a categorical factor, any coefficient indicates the total isolated impact of the factor and not a per unit or per standard deviation impact as was so for the previous continuous variables. For perceived comparative understanding, β = 0.184 for higher perceived comparative understanding and β = −0.535 for lower perceived comparative understanding. This indicates that students that later reported a higher or lower comparative understanding, as compared to those students that reported about the same comparative understanding, were observed to have had an increase of 0.184 standard deviations or a decrease of 0.535 standard deviations, respectively, in self-assessed understanding (ΔSAU), across all subunits and accounting for all other variables. The strength of the relationship between perceived comparative understanding and ΔSAU was found to be small; perceived comparative understanding was found to have a small effect size with Cohen's f2= 0.03.
For task difficulty, β = −0.784 for higher task difficulty and β = 0.238 for lower task difficulty. This indicates that students were observed, across all subunits and accounting for all other variables, to have lowered their self-assessed understanding by 0.784 standard deviations after tasks categorized as being more difficult as compared to students performing tasks categorized as having average difficulty and raised their self-assessed understanding by 0.238 standard deviations after tasks categorized as being less difficult as compared to students performing tasks categorized as having average difficulty. The strength of the relationship between task difficulty and ΔSAU was found to be moderate; task difficulty was found to have a moderate effect size with Cohen's f2= 0.25.
Results for follow-up questions
Several follow-up questions were assessed following the completion of the initial analysis for the two primary research questions. The follow-up questions and results are presented below.A follow-up analysis was performed to address the question: Is gender a statistically significant effect on how students assessed their understanding at a given point as opposed to how students changed their self-assessments? The addition of gender as a categorical variable fixed effect (females as the reference variable) in a hierarchical linear model with session as the subunit, predicting the initial self-assessed understanding score pre-task showed statistically significant improvement in model fit (χ2(1) = 4.21, p = 0.0401). As evidenced by improved model fit, gender was found to be a significant effect on initial self-assessment. A positive coefficient for the male category generally indicates that male students were more likely to have a higher self-assessment of their understanding (pre-task). As model building for the pre-task self-assessment outcome variable was limited and as such no other variables were controlled for, only the sign of the coefficient is being reported.
Descriptive statistics were used to address the second follow-up question: Is perceived comparative understanding an accurate representation of actual comparative performance? Descriptive statistics for perceived comparative understanding and actual comparative performance are presented in Table 5. Overall, 12% of students reported having lower understanding compared to their peers, 75% reporting about the same, and 14% reporting higher. The percentage of students from each category of actual comparative performance and perceived comparative understanding are also presented. For example, of the students that were categorized as having lower actual comparative performance, 18% of them were said to be accurate by reporting that they perceived themselves as having lower understanding compared to their peers, 67% inaccurately said they had about the same level of understanding as their peers, and 16% even more inaccurately said that they had higher understanding than their peers. Of the students that were categorized as having higher actual comparative performance, 20% of them reported perceiving themselves as having a higher level of understanding, and where therefore said to be accurate.
| Overall frequency (%) | Actual comparative performance | |||
|---|---|---|---|---|
| Lower (%) | About the same (%) | Higher (%) | ||
| Perceived comparative understanding | ||||
| Lower | 12 | 18 | 12 | 8 |
| About the same | 75 | 67 | 80 | 72 |
| Higher | 14 | 16 | 9 | 20 |
Discussion and implications
The central goal of this research study was to assess if and how student and classroom factors relate to change in students’ self-assessed understanding as a result of participation in classroom activities. By assessing student factors, how students are differentially impacted by participation in in-class tasks can be discussed. By assessing classroom factors, awareness of and provide evidence to support how instructional decisions impact students’ self-assessed understanding can increase. The following discussion and implications are organized by sorting the main findings into three categories:1. Contributions to the large body of research regarding the effect of student performance on self-assessment of understanding.
2. Discussion of findings that provide further evidence to the relationship or lack thereof for factors that have inconclusive effects based on previous research: gender, feedback, and task difficulty.
3. Novel findings regarding the factors that have not previously assessed in the literature: perceived and actual comparative performance.
Insights on the effects of student performance
While student performance has often been linked to student self-assessment of understanding, it has not always shown to have a significant relationship. Using simple regression, Kruger and Dunning (1999) did not find task performance to be a statistically significant factor for self-assessment at a given time, specifically post-task self-assessment. In contrast, Pazicni and Bauer (2014) found test performance to be a statistically significant factor for self-assessment accuracy, as measured by the difference in post-task comparative self-assessment and comparative performance, using hierarchical linear modelling (HLM). In this study, also using HLM, task performance was found to be a statistically significant factor for self-assessment change, as measured by the difference in pre-task and post-task self-assessment.The overestimation of ability by lower performing students has been well documented within the domain of chemistry (Bell and Volckmann, 2011; Mathabathe and Potgieter, 2014; Pazicni and Bauer, 2014; Hawker et al., 2016), within other science domains (Austin and Gregory, 2007; Sharma et al., 2016), and outside of science (Kruger and Dunning, 1999; Butler et al., 2008; Kim et al., 2016; Thomas et al., 2016). The pilot study that was conducted in the development of the self-assessment of understanding tool yielded similar results.
In this investigation, three student groups were designated as having overestimated initial assessments due to their initial-self assessment categorization being higher than their performance categorization. With all three of these groups, the combination of their initial self-assessment and performance accounted for a decrease in self-assessment following the performance task and the group that most overestimated their initial assessment showing the greatest decrease, as shown in Fig. 3. These results indicate that some of those that initially overestimated their ability made adjustments towards greater accuracy in their self-assessment following the instructional task and the more inaccurate they were initially, the more likely they were to adjust or adjust to a greater degree. Even though this regulation (pre-task to post-task) was observed, lower performing students may still, on average exhibit the Dunning-Kruger effect by overestimating their ability post-task. This could possibly be due to the level of adjustment not being great enough to fully correct the inaccuracy of their initial overestimation. It could also be that although enough students make adjustments for the average change in self-assessment to be significant, enough students do not make adjustments for the post-task self-assessment to be on average accurate.
Lower performing students that overestimate their ability are often the target of interventions as the misalignment between perception and reality is seen as detrimental to learning (Schraw et al., 2006; Pazicni and Bauer, 2014). Some researchers have discussed the negative emotional impact of overestimation on students (Jones et al., 2012). Nevertheless, some authors have argued that overestimation may not be entirely detrimental as people might be more eager to climb a mountain if they are unaware of how far they are from the top (Pajares, 1996; Zimmerman, 2000; Ehrlinger, 2008). The results of this study suggest that independently of planned interventions, participation in in-class tasks affects students' self-assessments of understanding. Regardless of whether an instructor aims to correct the inaccuracy of self-estimation made by students or not, they should recognize the effects that performance on classroom work has on their students' perceptions of understanding.
The analysis of interaction between variables indicated that when students initially self-assessed higher understanding, their performance on that task had a greater effect on how they changed their self-assessment. This finding implies that overconfident students are more affected by poor performance in an activity than underconfident students are affected by their positive performance (i.e., it is easier to correct overconfidence than under-confidence).
Insights on the effect of other variables (inconclusive in previous research)
Given existing research that links poor performance to inaccurate self-assessment, it would be reasonable to assume that lower performing students do not know that they are performing poorly (Kruger and Dunning, 1999). If these students were completely unaware, it would be beneficial to inform them about their actual level of performance to help them better regulate their self-assessment. Given this line of reasoning, it could be hypothesised that the observed changes in self-assessment, showing regulation toward greater accuracy, made by students that initially overestimated their ability would only occur if the students were told how they performed. However, these changes were observed regardless of whether or not feedback, that indicated whether answers were right or wrong, was given. Providing immediate and direct feedback regarding performance was found to not be a significant effect on change in students’ self-assessed understanding. This may seem counter intuitive at first, but given these results, it can be speculated that though students are at least somewhat inaccurate in their self-assessment at any given point in time, they do have enough awareness of their performance that “right or wrong” feedback is neither necessary for the amount of regulation observed to occur nor initiates regulation above and beyond what is accounted for by their initial self-assessment and performance.
A previous study reported a dependency between task difficulty and performance (Kim et al., 2016). In this work, however, that dependency was not found. Additionally, the relationship between initial self-assessment and change in self-assessment was also found to be independent of task difficulty.
Recall that observed change in self-assessment accounted for by initial self-assessment and performance showed little change for students that were designated as initially accurate in their self-assessment, while for students that initially overestimated or underestimated themselves there was observed regulation, decreasing those inaccuracies. The lack of significant interaction effects on change in students’ self-assessments of these variables with task difficulty indicates that, for example, the students that initially overestimated themselves did not have to be given a difficult task for the observed change in self-assessment to occur that was accounted for by initial self-assessment and performance. So, having a difficult task was not a necessary condition for the observed decreases in inaccuracies.
The lack of significant interaction effects on change in students’ self-assessments of initial self-assessment, performance, and task difficulty also suggests when more difficult tasks are given, the general decrease in self-assessment that is observed may give the appearance of correction in overestimation. However, the observed decreases may not be reflective of low performance, but rather reflective of task difficulty, across the board for all performance levels. This would make it seem like lower performing students that were overestimating themselves were doing so less and becoming more accurate when given harder tasks. Accuracy in self-assessment though, means self-assessment that is representative of ability or performance, not representative of task difficulty. So ideally, performance would independently and accurately predict self-assessment (at any given time) with an effect size measure that indicates a strong relationship. And, if there were an inaccuracy, the change in self-assessment would be a full correction of and only in response to that inaccuracy, not in response to task difficulty. So, for students that initially overestimated themselves, the observed change in self-assessment accounted for by higher task difficulty, though a decrease cannot truly be thought of as a decrease in inaccuracy as it is not representative of a change in response to performance.
The lack of significant interaction effects on change in students’ self-assessments of initial self-assessment, performance, and task difficulty also indicates students did not have to perform poorly on a difficult task to observe the decrease in self-assessment accounted for by the task being difficult. The results indicate that engagement in more difficult tasks decreased self-assessments for students of all performance levels. Again, this suggests that students that initially overestimated their ability would lower their self-assessments and seemingly become more accurate. This also suggests students that were initially accurate would also lower their self-assessments possibly causing them to then underestimate their ability. Lastly, this suggests students that initially underestimated their ability would do so even more. Using the standardized coefficient results of this study, an illustrative example can be made. For students that had the greatest initial underestimations of ability (low initial self-assessment and high performance), there was an observed increase in self-assessment indicating regulation towards greater accuracy that was almost equal to the observed average decrease in student self-assessment accounted for by task difficulty. So, in this study, students that initially underestimated themselves the most, after completing a difficult task as compared to a task with average difficulty, were observed, on average, to have little cumulative change in their self-assessment, leaving them to continue to underestimate themselves greatly. Focus and decisions made by instructors to correct overestimation can not only impact those students, but all students and should be kept in mind.
Comparing the standardized coefficients for lower task difficulty and higher task difficulty, having higher task difficulty appears to impact self-assessment over three times as much. This suggests that for tasks of low difficulty, the possible opposite differential impacts are not as great. For example, the decrease accounted for by high task difficulty (as compared to average task difficulty) would cancel out almost all the increase accounted for by initial self-assessment and performance by those that initially underestimated themselves. Whereas, the increase accounted for by low task difficulty (as compared to average task difficulty) would cancel out only some of the decrease accounted for by initial self-assessment and performance by those that initially overestimated themselves. That is to say, the correction by students that initially overestimated themselves would appear smaller when given an easier task, but still be present.
The suggested conclusions presented in this study, that are evidenced by the magnitude of the coefficients, standardized or not, are limited by the range of task difficulty. For a full examination of task difficulty, a non-categorical measure with a large range of difficulties is recommended. The magnitude of change in self-assessment observed with varied task difficulty is worthy of further research as the results of this study suggest that the use of more difficult instructional tasks may cause the appearance of correction in overestimation and block correction in underestimation. The appearance of correction in overestimation is suggested by the observed decreases in self-assessment reflective of task difficulty independent of performance or accuracy. Blocking correction in underestimation is suggested by the observed decreases in self-assessment accounted for by task difficulty cancelling out the observed increases accounted for by initial self-assessment and performance. Further, the results of this study indicate the importance of controlling for task difficulty when looking at self-assessment.
The effect size or strength of the relationship between task difficulty and change in students’ self-assessments was found to be moderate with only initial self-assessment being found to have a stronger relationship. The effect size or strength of the relationship between performance and change in students’ self-assessments was found to be negligible. Factors other than initial self-assessment and performance with greater effect sizes and larger standardized coefficients, like task difficulty suggest the high influence of instructional decisions differentially impacting students’ self-assessments.
Insights on the effects of comparative understanding variables
Many researchers have used comparative measures of understanding like percentile rankings and categorical comparisons as dependent variables (Dunning et al., 1989; Kruger and Dunning, 1999; Mathabathe and Potgieter, 2014; Pazicni and Bauer, 2014; Hawker et al., 2016). Fewer studies have asked students to self-assess their understanding in an absolute manner as the dependent variable (Bell and Volckmann, 2011). Research in chemistry education lacks studies that evaluate the effect on self-assessment of understanding of comparative measures of understanding as independent variables. The findings of this study contribute in this area by providing insights into the relationship between how students think their understanding compares to that of their peers and self-assessment, and the relationship between how they actually differ in performance from their peers and self-assessment.Findings of this study may provide evidence that suggest possible causal relationships and/or hypothesize possible causal relationships worthy of further research; however, only correlative relationships and what the observed changes were accounted for by the different effects can be indicated by the results of this study. In the sequence of events that occurred during this study's data collection, the measure for perceived comparative understanding was the only measure that occurred after the pre-task and post-task self-assessment measures used to calculate the change in self-assessed understanding. Causality cannot be implied by a sequence of events or measurements. Nor can a sequence of measurements imply a lack of causality, as what is being measured may not change over time. Even so, a causal relationship between change in students’ self-assessed understanding and perceived comparative understanding is not being suggested. Results from this study indicate that students who later reported their understanding to be lower than their peers, as compared to those who later reported their understanding to be about the same as their peers, were observed to have lowered their self-assessed understanding across all subunits and accounting for all other variables and vice versa for students who later reported their understanding to be higher than their peers.
The correlative relationship could suggest that students that lowered their self-assessment beyond what was accounted for by initial self-assessment, performance, and task difficulty, were then more likely to report having a lower understanding than their peers. If perceived comparative understanding is something that is not easily impacted and was present prior to and during the data collection, that perception may have influenced the changes in self-assessment. Further research would need to be conducted to explore these possibilities. The relative magnitude of the standardized coefficients being as high as they were and the strength of the correlative relationship being found to be small, but not negligible suggest that how students perceive their understanding as compared to their peers is worthy of further research that could answer questions the results this study simply cannot speak to.
Actual comparative performance was not found to significantly relate to change in students’ assessments of their understanding following an individual task. The results this study for actual comparative performance and perceived comparative understanding triggered the consideration of possible challenges for instructors as it is easier to assess how a student compares to their peers by looking at their performance (scores/grades) than it is to assess how a student thinks they compare to their peers and these may not be aligned.
In follow-up results, evaluation was performed to assess how accurately perceived comparative understanding matched actual comparative performance. As shown in Table 5, most students in our sample (74%) reported that they had about the same level of understanding as that of their peers. Of the students that were categorized as having lower actual comparative performance, only 18% accurately reported thinking that they understood less than their peers, 67% inaccurately reported about the same understanding as their peers, and 16% overestimated themselves even more by reporting having higher understanding than their peers. Of the students that were categorized as having higher actual comparative performance, only 20% accurately thought they had higher understanding, 72% inaccurately reported about the same understanding as their peers, and 8% underestimated themselves even more by reporting having lower understanding than their peers.
Further research is suggested to investigate if similar results would be found if exploring the change in students’ self-assessments following a collaborative task. A study looking at the change in self-assessment following a collaborative task could have possible instructional implications regarding the formation of small collaborative groups in chemistry classrooms. Instructors may want to reflect on the use of performance measures to assign students to groups, if for instance, they were attempting to make decisions that could impact self-assessment of understanding. Having lower performing students work with higher performing students on in-class collaborative activities may or may not impact students’ self-assessed understanding as one might initially think. The results this study lead to the recommendation for further research to see if students’ self-assessments following a collaborative activity are impacted by perceptions of comparative understanding and actual comparative performance
Limitations of study
This study's ability to make causal inferences regarding student factors is limited as they are not randomly assigned independent variables. Because the student variables are trait-variables, only correlative conclusions can be made regarding their relationships.The goal of this study was to present a characterization of the changes in self-assessed understanding that were observed following an instructional activity. This study's ability to generalize the findings was limited by several factors. First, the statistical methods used have the potential for generating false positives. Second, this study was conducted at single university with a student population that may differ from those in other settings. Further testing is recommended with different populations, conditions, and analytical methods to provide additional evidence for the generalizability of the characterization, ensuring it is not situational to the given population, conditions, or analyses of this study.
This study focused on change in self-assessment of understanding. This research thus focused on a small, but important aspect of metacognition. Veenman (2006, 2011, 2017) has emphasized that studies like ours that are centred on a single metacognitive skill like monitoring, although important, may not provide enough information to design effective instructional interventions.
Conflicts of interest
There are no conflicts to declare.Appendix 1: model building
Model building was conducted based on the best practice of evaluation of the inclusion of fixed effects and random effects by statistically significant improvement to model fit (Peugh, 2010; Snijders and Bosker, 2012; Theobald, 2018). The p-values for likelihood ratio tests (LRTs) were reported and are indicative of the significance of the effect on ΔSAU as evidenced by the statistical significance of the improvement in model fit.To determine if a factor was a significant effect on ΔSAU, a series of LRTs was performed, comparing a model with the factor as an effect to a model without such a factor (three to four models were conducted per factor) (Peugh, 2010; Snijders and Bosker, 2012). For a summary of the fixed and random effects used in the model building progression see Table 6. A fixed-slope model (FSM) using full maximum likelihood (ML) estimation (Model j.f.ML) and a FSM using restricted maximum likelihood (REML) estimation (Model j.f.REML), were completed with the previous model and the addition of the factor (j) as a fixed effect (f). The addition of the fixed effect added a fixed slope across all session subunits to the model equation which quantified the overall effect of the factor on the change in students’ self-assessments of their understanding (ΔSAU) overall or across all sessions. An unconditional slopes model (USM) using ML estimation (Model j.f&r.ML) and a USM using REML estimation (Model j.f&r.REML), was conducted with the previous model and the addition of the factor as both fixed and random effects (f&r). The addition of the random effect added a random slope for each session subunit to the model equation that allowed for differences in the factor's relationship with ΔSAU between sessions. If the between-session variation of the factor's relationship with ΔSAU is significant, the random effect should be included in the model (Peugh, 2010; Theobald, 2018). With the addition of the random slopes, the fixed slope still quantified the overall effect of the factor on ΔSAU, but controlled for or remove the impact of between-session differences for that factor's relationship with ΔSAU.
| Estimation methods (ML or REML) are not shown. ‡ Additional effect that improved model fit. + Effect included in the model. × Additional effect that did not improve model fit. Highlighted boxes signify the difference in that model from that prior in model building.a Categorical variable. |
|---|

|
For each factor considered, a series of LRTs comparing the models were performed. First, a LRT was performed comparing that factor's Model j.f.ML to the previous ML estimated model to determine if the addition of the fixed effect had a statistically significant improvement to the model fit. If there was a statistically significant improvement in model fit, the factor as a fixed effect was determined to be a significant predictor of ΔSAU and therefore said to relate to ΔSAU. If the fixed effect was not found to significantly predict ΔSAU, the remaining LRTs were performed, but not reported. Second, a LRT was performed comparing Model j.f&r.ML to the previous ML estimated model to determine if the addition of both the fixed and random effects had a significant improvement to the model fit. Third, a LRT was performed comparing Model j.f&r.REML to Model j.f.REML to determine if the addition of the factor as a random effect was needed as indicated by a statistically significant improvement to the model fit. REML estimation was used for the third LRT as the only difference between the two models was a random effect (Raudenbush and Bryk, 2002; Peugh, 2010; Theobald, 2018).
Dummy coding
Factors that were categorical variables were “dummy coded” using the following methods from Pedhazur (1997). If a factor (C) had three categories (C1, C2, and C3), two vectors (V1 and V2) would be added that matched the description of two of those three categories. The category without a matching vector, in this example C3, would be the reference category and reported as the “reference variable”. For those in C1, V1 = 1 and V2 = 0. For those in C2, V1 = 0 and V2 = 1. And for those in C3, V1 = 0 and V2 = 0.The following model building methods for the categorical variable factors based on methods and recommendations from previous research (Cohen, 1991; Nezlek, 2008; Darlington and Hayes, 2016). To determine if a categorical factor (C) was a significant effect on ΔSAU, the series of LRTs were performed comparing a model with V1 and V2 as variables to a model without those variables. This method tests the statistical significance of the factor (all categories) in a single step by model fit. This method was done as the alternative method having each category of a factor individually added in model building, to test each as a fixed effect would, mathematically result in the issue of singularity. To avoid this issue a reference category must be selected. Reference categories were selected based on the interpretability of the results. For example, if a factor had three categories – below average, about average, and above average, about average would be selected as the reference category. This allows for the below average category to logically describe what occurs below the reference of the average. The model building progression summarized in Table 6 would therefore result in a final model (Table 4) that included all the factors identified as significant effects on ΔSAU.
Appendix 2: practical significance
Standardized and partially standardized fixed effect coefficients
This analysis speaks to how big of an effect the factor is or how much change is observed in students’ self-assessments when that factor varies. Coefficients of fixed effects indicate the relationship between the variables – as the factor changes, how does ΔSAU change across all subunits accounting for all other variables. If a fixed effect is also a random effect, the coefficient still indicates the relationship between the variables, but is on average across all subunits accounting for all other variables.Standardized fixed effect coefficients can be calculated for factors that are continuous variables without significant interactions with another fixed effects by multiplying the fixed effect coefficient by the standard deviation of the factor and dividing by the standard deviation of the outcome variable (Snijders and Bosker, 2012). Standardized fixed effect coefficients for factors that are continuous variables with significant interactions with another fixed effect cannot be calculated in this manner, however. Following Friedrich's procedure for variables with interactions, a standardized model was used (1982). z-Scores for the factors and the cross-product of the z-scores as the interaction variable were substituted into the final model for the unstandardized variables and the z-score for the outcome variable was substituted in for the unstandardized outcome variable, ΔSAU. The fixed effect coefficients, without manipulation, from this model are the standardized fixed effect coefficients for the variables with interactions and the interaction variable. A more detailed procedure and analysis of the method can be found in Friedrich (1982) and Aiken and West (1991).
Partially standardized fixed effect coefficients were calculated for each category (other than the reference category) for factors that were dummy coded categorical variables by dividing the fixed effect coefficient for that category by the standard deviation of the outcome variable (Lorah, 2018).
Cohen's f2
Practical significance was additionally assessed by calculating the local effect size measure, Cohen's f2, a function of proportional variance. The values for the proportion of variance accounted for by a set of fixed effects were calculated as a function of residual variances (Selya et al., 2012):where Vnull is the residual variance of a model without any fixed effects and Vi is the residual variance of a model with the set of fixed effects, i, and with both Vnull and Vi calculated holding the variance accounted for by random effects constant.

For a given fixed effect, A, that did not have significant interactions with other fixed effects, Cohen's f2 was calculated as a measure of effect size (Cohen, 1977; Selya et al., 2012; Lorah, 2018):

For a given fixed effect, B, that did have significant interaction with another fixed effect, Cohen's f2 was calculated as a measure of effect size (Cohen, 1977):
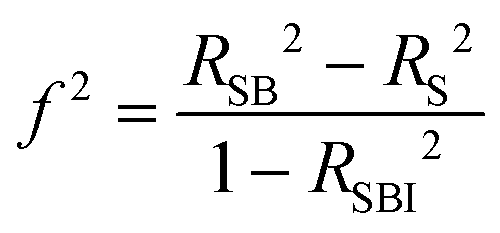
For a given interaction variable, I, between fixed effects j and k, Cohen's f2 was calculated as a measure of effect size (Cohen, 1977):

Acknowledgements
We would like to thank Dr Monica Erbacher for the guidance and support she provided in the statistical analysis of the data and Alex Nathe, an undergraduate researcher, for her contributions to this work.References
- Aiken L. S. and West S. G., (1991), Multiple Regression: Testing and Interpreting Interactions, Sage Publications.
- Albers M. J., (2017), Graphically representing data, in Introduction to Quantitative Data Analysis in the Behavioral and Social Sciences, John Wiley & Sons Inc., pp. 63–85.
- Allison P. D., (1990), Change scores as dependent variables in regression analysis, Sociol. Methodol., 20, 93–114.
- Austin Z. and Gregory P. A. M., (2007), Evaluating the accuracy of pharmacy students’ self-assessment skills. Am. J. Pharm. Educ., 71(5).
- Bacchetti P., (2002), Peer review of statistics in medical research: The other problem. BMJ, 324(7348), 1271–1273.
- Bauer D. J. and Sterba S. K., (2011), Fitting multilevel models with ordinal outcomes: Performance of alternative specifications and methods of estimation, Psychol. Methods, 16(4), 373–390.
- Bell P. and Volckmann D., (2011), Knowledge surveys in general chemistry: Confidence, overconfidence, and performance, J. Chem. Educ., 88(11), 1469–1476.
- Bloom B., (1956), Taxonomy of educational objectives; the classification of educational goals, 1st edn, New York, Longmans, Green.
- Bol L. and Hacker D. J., (2001), A comparison of the effects of practice tests and traditional review on performance and calibration., J. Exp. Educ., 69(2), 133–151.
- Burson K. A., Larrick R. P. and Klayman J., (2006), Skilled or unskilled, but still unaware of it: How perceptions of difficulty drive miscalibration in relative comparisons, J. Person. Soc. Psychol., 90(1), 60–77.
- Butler A. C., Karpicke J. D. and Roediger H. L., (2008), Correcting a metacognitive error: Feedback increases retention of low-confidence correct responses, J. Exp. Psychol.: Learn., Mem., Cogn., 34(4), 918–928.
- Carifio J. and Perla R., (2008), Resolving the 50-year debate around using and misusing Likert scales, Med. Educ., 42(12), 1150–1152.
- Carvalho F. and Moises K., (2009), Confidence judgments in real classroom settings: Monitoring performance in different types of tests, Int. J. Psychol., 44(2), 93–108.
- Cohen A., (1991), Dummy variables in stepwise regression, Am. Stat., 45(3), 226–228.
- Cohen J., (1977), F tests of variance proportions in multiple regression/correlation analysis, in Statistical Power Analysis for the Behavioral Sciences, Elsevier, pp. 407–453.
- Cohen J., Cohen P., West S. G. and Aiken L. S., (2003), Applied multiple regression/correlation analysis for the behavioral sciences, 3rd edn.
- Cooper M. M. and Sandi-Urena S., (2009), Design and validation of an instrument to assess metacognitive skillfulness in chemistry problem solving, J. Chem. Educ., 86(2), 240–245.
- Cooper M. M., Sandi-Urena S. and Stevens R., (2008), Reliable multi method assessment of metacognition use in chemistry problem solving, Chem. Educ. Res. Pract., 9(1), 18–24.
- Craney T. A. and Surles J. G., (2002), Model-dependent variance inflation factor cutoff values, Qual. Eng., 14(3), 391–403.
- Crowe A., Dirks C. and Wenderoth M. P., (2008), Biology in bloom: Implementing bloom's taxonomy to enhance student learning in biology, CBE – Life Sci. Educ., 7(4), 368–381.
- Darlington R. and Hayes A., (2016), Regression analysis and linear models: Concepts, applications, and implementation, Guilford Publications.
- Dolan C. V., (1994), Factor analysis of variables with 2, 3, 5 and 7 response categories: A comparison of categorical variable estimators using simulated data, Br. J. Math. Stat. Psychol., 47(2), 309–326.
- Dunlosky J. and Thiede K. W., (1998), What makes people study more? An evaluation of factors that affect self-paced study, Acta Psychol., 98, 37–56.
- Dunning D., Meyerowitz J. A. and Holzberg A. D., (1989), Ambiguity and self-evaluation: The role of idiosyncratic trait definitions in self-serving assessments of ability, J. Pers. Soc. Psychol., 57(6), 1082–1090.
- Ehrlinger J., (2008), Skill level, self-views and self-theories as sources of error in self-assessment, Soc. Pers. Psychol. Compass, 2(1), 382–398.
- Ferron J. M., Hogarty K. Y., Dedrick R. F., Hess M. R., Niles J. D. and Kromrey J. D., (2008), Reporting results from multilevel analyses, in Multilevel Modeling of Educational Data, O’Connell A. and McCoach D. B. (ed.), Quantitative Methods in Education and the Behavior Sciences: Issues, Research, and Teaching, Information Age Publishing Inc., pp. 391–426.
- Flavell J. H., (1979), Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry, Am. Psychol., 34(10), 906–911.
- Friedrich R. J., (1982), In defense of multiplicative terms in multiple regression equations, Am. J. Pol. Sci., 26(4), 797–833.
- Gaito J., (1980), Measurement scales and statistics: Resurgence of an old misconception, Psychol. Bull., 87, 564–567.
- Grilli L. and Rampichini C., (2012), Multilevel models for ordinal data, in Modern Analysis of Customer Surveys: with Applications using R, Kenett R. S. and Salini S. (ed.), John Wiley & Sons, Ltd, pp. 391–411.
- Hawker M. J., Dysleski L. and Rickey D., (2016), Investigating general chemistry students’ metacognitive monitoring of their exam performance by measuring postdiction accuracies over time, J. Chem. Educ., 93(5), 832–840.
- Jamieson S., (2004), Likert scales: How to (ab)use them, Med. Educ., 38(12), 1217–1218.
- Jones H., Hoppitt L., James H., Prendergast J., Rutherford S., Yeoman K. and Young M., (2012), Exploring students’ initial reactions to the feedback they receive on coursework, Biosci. Educ., 20(1), 3–21.
- Kim H.-Y., (2013), Statistical notes for clinical researchers: Assessing normal distribution (2) using skewness and kurtosis, Restor. Dent. Endod., 38(1), 52–54.
- Kim Y.-H., Kwon H., Lee J. and Chiu C.-Y., (2016), Why do people overestimate or underestimate their abilities? A cross-culturally valid model of cognitive and motivational processes in self-assessment biases, J. Cross-Cult. Psychol., 47(9), 1201–1216.
- Kruger J. and Dunning D., (1999), Unskilled and unaware of it: How difficulties in recognizing one's own incompetence lead to inflated self-assessments, J. Pers. Soc. Psychol., 77(6), 1121–1134.
- Kuzon W. M., Urbanchek M. G. and McCabe S., (1996), The seven deadly sins of statistical analysis, Ann. Plast. Surg., 37(3), 265–272.
- Lee V. E., (2000), Using hierarchical linear modeling to study social contexts: The case of school effects, Educ. Psychol., 35(2), 125–141.
- Lorah J., (2018), Effect size measures for multilevel models: Definition, interpretation, and TIMSS example, Large-scale Assess. Educ., 6(8).
- Luo W. and Azen R., (2013), Determining predictor importance in hierarchical linear models using dominance analysis, J. Educ. Behav. Stat., 38(1), 3–31.
- Mabe III P. and West S., (1982), Validity of self-evaluation of ability: A review and meta-analysis, J. Appl. Psychol., 67(3), 280–296.
- Mathabathe K. C. and Potgieter M., (2014), Metacognitive monitoring and learning gain in foundation chemistry, Chem. Educ. Res. Pract., 15(1), 94–104.
- Moores T. T., Chang J. C.-J. and Smith D. K., (2006), Clarifying the role of self-efficacy and metacognition as indicators of learning: Construct development and test. DATA BASE Adv. Inform. Syst., 37, 125–132.
- Muthén B. and Kaplan D., (1985), A comparison of some methodologies for the factor analysis of non-normal Likert variables, Br. J. Math. Stat. Psychol., 38(2), 171–189.
- Nelson T. O. and Narens L., (1990), Metamemory: A theoretical framework and new findings, in Psychology of Learning and Motivation, Bower G. (ed.), Academic Press, pp. 125–173.
- Nezlek J. B., (2008), An introduction to multilevel modeling for social and personality psychology, Soc. Pers. Psychol. Compass, 2(2), 842–860.
- Norman G., (2010), Likert scales, levels of measurement and the “laws” of statistics, Adv. Health Sci. Educ., 15(5), 625–632.
- Ohtani K. and Hisasaka T., (2018), Beyond intelligence: A meta-analytic review of the relationship among metacognition, intelligence, and academic performance, Metacogn. Learn., 13(2), 179–212.
- Olsson U., (1979), On the robustness of factor analysis against crude classification of the observations, Multivar. Behav. Res., 14(4), 485–500.
- Pajares F., (1996), Self-efficacy beliefs in academic settings, Rev. Educ. Res., 66(4), 543–578.
- Pazicni S. and Bauer C. F., (2014), Characterizing illusions of competence in introductory chemistry students, Chem. Educ. Res. Pract., 15(1), 24–34.
- Pedhazur E., (1997), Multiple Regression in Behavioral Research: Explanation and Prediction, 3rd edn, Harcourt Brace College Publishers.
- Peugh J. L., (2010), A practical guide to multilevel modeling, J. Sch. Psychol., 48(1), 85–112.
- Raudenbush S. and Bryk A., (2002), Hierarchical linear models: applications and data analysis methods, 2nd edn, Sage.
- Rickey D. and Stacy A. M., (2000), The role of metacognition in learning chemistry, J. Chem. Educ., 77(7), 915.
- Salmoni A., Schmidt R. and Walter C., (1984), Knowledge of results and motor learning: A review and critical reappraisal, Psychol. Bull., 95(3), 355–386.
- Sandi-Urena S., Cooper M. and Stevens R., (2012), Effect of cooperative problem-based lab instruction on metacognition and problem-solving skills, J. Chem. Educ., 89(6), 700–706.
- Sargeant J., Mann K., Sinclair D., van der Vleuten C. and Metsemakers J., (2007), Challenges in multisource feedback: Intended and unintended outcomes, Med. Educ., 41(6), 583–591.
- Schraw G. and Moshman D., (1995), Metacognitive theories, Educ. Psychol. Rev., 7(4), 351–371.
- Schraw G., Crippen K. J. and Hartley K., (2006), Promoting self-regulation in science education: Metacognition as part of a broader perspective on learning, Res. Sci. Educ., 36(1–2), 111–139.
- Selya A., Rose J., Dierker L., Hedeker D. and Mermelstein R., (2012), A practical guide to calculating Cohen's f2, a measure of local effect size, from PROC MIXED, Front. Psychol., 3.
- Sharma R., Jain A., Gupta N., Garg S., Batta M. and Dhir S., (2016), Impact of self-assessment by students on their learning, Int. J. Appl. Basic Med. Res., 6(3), 226–229.
- Snijders T. and Bosker R., (2012), Multilevel Analysis: An Introduction to Basic and Advanced Multilevel Modeling, 2nd edn, Sage.
- Stevens S. S., (1946), On the theory of scales of measurement, Sci., New Series, 103(2684), 677–680.
- Stevens S. S., (1958), Measurement and man, Science, 127(3295), 383–389.
- Talanquer V. and Pollard J., (2010), Let's teach how we think instead of what we know, Chem. Educ. Res. Pract., 11(2), 74–83.
- Theobald E., (2018), Students are rarely independent: When, why, and how to use random effects in discipline-based education research. CBE – Life Sci. Educ., 17(rm2).
- Thomas R. C., Finn B. and Jacoby L. L., (2016), Prior experience shapes metacognitive judgments at the category level: The role of testing and category difficulty, Metacogn. Learn., 11(3), 257–274.
- Veenman M. V. J., (2011), Learning to self-monitor and self-regulate, in Handbook of Research on Learning and Instruction, Routledge.
- Veenman M. V. J., (2017), Assessing metacognitive deficiencies and effectively instructing metacognitive skills, Teach. Coll. Rec., 119(130307), 1–20.
- Veenman M. V. J., Van Hout-Wolters B. H. A. M. and Afflerbach P., (2006), Metacognition and learning: Conceptual and methodological considerations, Metacogn. Learn., 1, 3–14.
- Velleman P. F. and Wilkinson L., (1993), Nominal, ordinal, interval, and ratio typologies are misleading, Am. Stat., 47(1), 65–72.
- Wang M. C., Haertel G. D. and Walberg H. J., (1990), What influences learning? A content analysis of review literature, J. Educ. Res., 84(1), 30–43.
- Wickham H. and Henry L., (2018), tidyr: easily tidy data with ‘spread()’ and ‘gather()’ functions: R package version 0.8.1., retrieved from https://CRAN.R-project.org/package=tidyr.
- Woltman H., Feldstain A., MacKay J. C. and Rocchi M., (2012), An introduction to hierarchical linear modeling, TQMP, 8(1), 52–69.
- Zimmerman B. J., (2000), Self-efficacy: An essential motive to learn. Contemp. Educ. Psychol., 25(1), 82–91.
| This journal is © The Royal Society of Chemistry 2021 |