
Development and use of a multiple-choice item writing flaws evaluation instrument in the context of general chemistry†
Jared
Breakall
 *,
Christopher
Randles
and
Roy
Tasker
*,
Christopher
Randles
and
Roy
Tasker
Department of Chemistry, Purdue University, 560 Oval Drive, West Lafayette, Indiana, USA. E-mail: jbreakal@purdue.edu
First published on 28th January 2019
Abstract
Multiple-choice (MC) exams are common in undergraduate general chemistry courses in the United States and are known for being difficult to construct. With their extensive use in the general chemistry classroom, it is important to ensure that these exams are valid measures of what chemistry students know and can do. One threat to MC exam validity is the presence of flaws, known as item writing flaws, that can falsely inflate or deflate a student's performance on an exam, independent of their chemistry knowledge. Such flaws can disadvantage (or falsely advantage) students in their exam performance. Additionally, these flaws can introduce unwanted noise into exam data. With the numerous possible flaws that can be made during MC exam creation, it can be difficult to recognize (and avoid) these flaws when creating MC general chemistry exams. In this study a rubric, known as the Item Writing Flaws Evaluation Instrument (IWFEI), has been created that can be used to identify item writing flaws in MC exams. The instrument was developed based on a review of the item writing literature and was tested for inter-rater reliability using general chemistry exam items. The instrument was found to have a high degree of inter-rater reliability with an overall percent agreement of 91.8% and a Krippendorff Alpha of 0.836. Using the IWFEI in an analysis of 1019 general chemistry MC exam items, it was found that 83% of items contained at least one item writing flaw with the most common flaw being the inclusion of implausible distractors. From the results of this study, an instrument has been developed that can be used in both research and teaching settings. As the IWFEI is used in these settings we envision an improvement in MC exam development practice and quality.
Introduction
Assessing what students know and can do is an integral part of the teaching process and the responsibility of chemistry instructors (Bretz, 2012). This is because assessment informs instructional decisions and grade assignments, and can be used to alter curriculum (Pellegrino, 2001). Using assessment data in these ways is important for the improvement of how chemistry is being taught (Holme et al., 2010).With the improvement of the teaching process being fundamentally connected with assessment, the quality of assessment has been an area of focus in the chemical education community since the 1920s (Bretz, 2013). Research into the assessment of student learning is diverse as represented by publications in Table 1. From this sizeable but not exhaustive list, we can see that improving assessment practice and quality has been a focus of those interested in bettering chemistry instruction.
| Research topic | Ref. |
|---|---|
| Investigating faculty familiarity with assessment terminology | (Raker et al., 2013a; Raker and Holme, 2014) |
| Surveying chemistry faculty about their assessment efforts | (Emenike et al., 2013) |
| Developing two-tier multiple-choice instruments | (Chandrasegaran et al., 2007), |
| Analyzing ACS exam item performance | (Schroeder et al., 2012; Kendhammer et al., 2013) |
| Investigating teachers use of assessment data | (Harshman and Yezierski, 2015) |
| Studying content coverage based on administered ACS exams | (Reed et al., 2017) |
| Creation of exam data analysis tools | (Brandriet and Holme, 2015) |
| Using Rasch modeling to understand student misconceptions and multiple-choice item quality | (Herrmann-Abell and DeBoer, 2011) |
| Development of instruments that can be used to measure the cognitive complexity of exam items | (Knaus et al., 2011; Raker et al., 2013b) |
| Aligning exam items with the Next Generation Science Standards | (Cooper, 2013; Laverty et al., 2016; Reed et al., 2016) |
| Creating exams that discourage guessing | (Campbell, 2015) |
| Outlining how to develop assessment plans | (Towns, 2010) |
Self-constructed assessments, particularly multiple-choice (MC) assessments, are popular in undergraduate chemistry courses. In a recent survey, 93.2% of 1282 chemistry instructors from institutions that confer bachelor's degrees in chemistry, reported creating their own assessments (Gibbons et al., 2018). Furthermore, in a survey of 2750 biology, chemistry, and physics instructors from public and private US institutions, 56% of chemistry instructors reported using MC exams in some or all of their courses (Goubeaud, 2010). A practical reason for the popularity of MC assessments is their ease and reliability of grading for large groups of students (Thorndike and Thorndike-Christ, 2010).
Although MC exams tend to have high grading reliability, creating valid MC items that perform reliably is difficult and requires skill to do properly (Pellegrino, 2001). Against this background, chemistry instructors typically have little to no formal training in appropriate assessment practices (Lawrie et al., 2018). In addition to a lack of training, another reason creating MC assessments can be difficult is because there are numerous ways to lessen an exam's validity based on how it is designed. When designing MC exams, it is important to follow appropriate design recommendations to increase the exams validity. Many of these recommendations are outlined in the literature as item writing guidelines (Haladyna et al., 2010).
Disregarding these guidelines can introduce variance in student performance that stems from something other than the student's knowledge of what is being tested (Downing, 2002). This is known as construct irrelevant variance (CIV) (Thorndike and Thorndike-Christ, 2010). Examples of CIV include students using test-taking strategies, teaching to the test, and cheating (Downing, 2002).
CIV in the form of testwiseness, which is defined as a student's capacity to utilize the characteristics and formats of a test and/or the test taking situation to receive a high score (Millman and Bishop, 1965), has been studied in students answering MC chemistry exam items (Towns and Robinson, 1993). Although it was found that students do use testwise strategies when answering exam items (Towns and Robinson, 1993), these exams can be written so as to reduce CIV in the form of testwiseness (Towns, 2014).
Multiple-choice item format and writing guidelines
A MC item typically consists of a stem, or problem statement, and a list of possible answer choices known as a response set. The response set usually contains one correct answer and incorrect options known as distractors. The ability to write MC items that test a desired construct and avoid CIV is difficult and takes time and practice to develop (Pellegrino, 2001).MC items can be evaluated in several ways which can help a test creator make judgements about how an item functions and what performance on that item means about student learning. Two common quantitative measures of MC items are the difficulty and discrimination indices. Item difficulty, which is typically reported as a percentage, is the proportion of students who got an item correct over the total number of students who attempted the item. This can give an idea of how hard or easy an item is for the students tested. Item discrimination, which can be measured in several ways, is a measure of how well an item separates students based on ability. The higher the discrimination value the better the item can differentiate between students of different ability levels. These measures, although they cannot tell you all things about an items quality, can give an idea of how the item functions for the students tested.
Guidelines for how to write MC items have been published (Frey et al., 2005; Moreno and Martı, 2006; Haladyna et al., 2010; Towns, 2014). Following or disregarding these guidelines can affect how students perform on exams (Downing, 2005).
Neglecting to adhere to item writing guidelines can affect exam performance in ways that are significant to both instructors and students. For example, in a 20 item MC general chemistry exam, each item is worth five percent of a student's exam score. Therefore, if even a few of the items are written in a way where a student either answers correctly or incorrectly based on features of the item instead of their understanding of the chemistry, this can unjustifiably inflate or deflate the student's exam grade by 10–20%. This has been demonstrated in a study where flawed items may have led to the incorrect classification of medical students as failed when they should have been classified as passing (Downing, 2005).
Many item writing guidelines exist, and they apply to five main aspects of MC exams including, preparing the exam, the overall item, the stem, the answer set, and the exam as a whole. These guidelines will now be outlined.
Preparing the exam
Linking multiple-choice items to one or more objectives of the course can help to ensure that the items are appropriate and valid for the exam being administered (Towns, 2010). This is often accomplished through the creation of a test blueprint. A test blueprint outlines the content and skill coverage for any given exam (Thorndike and Thorndike-Christ, 2010). It is important to note that the more objectives an item is testing the less the item can tell you about a student's knowledge of a specific objective.The overall item
Multiple-choice items need to be written clearly (Holsgrove and Elzubeir, 1998; Haladyna and Rodriguez, 2013). This is because if an item is not clearly written, (i.e. can be interpreted incorrectly), students may select an incorrect answer choice even though they understand the chemistry being tested. It has been found that even small changes in the wording of an item can have significant effects on student performance (Schurmeier et al., 2010). For instance, using simpler vocabulary in chemistry exam items was found to significantly improve student performance when compared to the same items using more complex terminology (Cassels and Johnstone, 1984). This may be due to an increased demand on working memory capacity when more complex/unclear vocabulary is used (Cassels and Johnstone, 1984). Therefore, it is important that MC items are written using the simplest language possible, without sacrificing meaning.Additionally, MC items need to be written succinctly (Haladyna et al., 2010). If an item is not succinctly written, unwanted CIV can be introduced. In a study of overly wordy accounting items, average student performance was worse when compared to more succinct versions of items testing the same content (Bergner et al., 2016). This may be because overly wordy items can decrease reliability, make items more difficult, and increase the time it takes to complete an exam (Rimland, 1960; Board and Whitney, 1972; Schrock and Mueller, 1982; Cassels and Johnstone, 1984). This may be because if an item is overly wordy, it can be testing reading ability or constructs other than the chemistry concepts being tested. Fig. 1 shows examples of wordy and succinct items.
 | ||
| Fig. 1 Example from (Towns, 2014) wordy item left; succinct item right. https://pubs.acs.org/doi/abs/10.1021/ed500076x further permissions related to this figure should be directed to the ACS. | ||
Items should be free from grammatical and phrasing cues (Haladyna and Steven, 1989). These are inconsistences in the grammar or phrasing of an item that can influence how a student interprets, understands, and answers the item (Haladyna et al., 2010). These can include associations between the stem and the answer choices that may cue a student to the correct answer. Grammatical inconsistencies can provide cues to students that can affect the psychometric properties of the exam item (Dunn and Goldstein, 1959; Plake, 1984; Weiten, 1984). See Fig. 2 for examples of grammatically inconsistent and grammatically consistent items. In the grammatically inconsistent item in Fig. 2, the answer choice (a) “one” is not consistent with the stem in that it would read, “Carbon has one protons”. This may cue students into the fact that this may not be the correct answer choice. Therefore, MC items should be written without grammatical or phrasing cues.
 | ||
| Fig. 2 Grammatically inconsistent item left; grammatically consistent item right (examples from Appendix 1). | ||
Items that contain multiple combinations of answer choices (known as K-type items) should be avoided when constructing MC exams (Albanese, 1993; Downing et al., 2010). An example of this format is shown in Fig. 3. K-type items have been shown to contain cueing that decreases reliability and inflates test scores when compared to multiple true-false (select all that are true) items (Albanese et al., 1979; Harasym et al., 1980). This is likely due to the fact that examinees can easily eliminate answer choices by determining the validity of only a few responses (Albanese, 1993). Therefore, K-type items should be avoided as they can contain cues that decrease reliability and increase test scores.
 | ||
| Fig. 3 Example of K-type item format. | ||
Items should be kept to an appropriate level of cognitive demand. Although there are several ways to determine cognitive demand, including thorough and effective instruments such as the cognitive complexity rating tool (Knaus et al., 2011), one simple guideline is that an item should not require more than six ‘thinking steps’ to answer. A thinking step is defined by Johnstone as a thought or process that must be activated to answer the question (Johnstone and El-Banna, 1986). If more than six thinking steps are involved in an item, student performance can decrease sharply due to working memory overload (Johnstone and El-Banna, 1986; Johnstone, 1991, 2006; Tsaparlis and Angelopoulos, 2000). This working memory overload may interfere with the student's ability to demonstrate their understanding of the concept(s) being tested (Johnstone and El-Banna, 1986). Furthermore, in studies of M-demand (defined as the maximum number of steps that a subject must activate simultaneously in the course of executing a task), it has been shown that student performance decreases as the M-demand of an item increases (Niaz, 1987, 1989; Hartman and Lin, 2011). Although, the number of thinking steps in an item can be difficult to determine due to chunking, and varying ability levels, keeping the general number of thinking steps in an item to six or less can help ensure that an item is assessing understanding of chemistry and not cognitive capabilities.
Stem creation guidelines
When writing a MC item, the central idea should be included in the stem (Haladyna et al., 2010; Towns, 2014). In other words, an item should be answerable without looking at the answer choices. Items with a stem that fails to include the central idea (unfocused stems), have been shown to increase item difficulty and decrease reliability (Board and Whitney, 1972; Dudycha and Carpenter, 1973). Thus, writing stems that include the central idea is recommended. See Fig. 4 for examples of focused and unfocused stems. | ||
| Fig. 4 Unfocused (left) focused (right) reproduced from (Dudycha and Carpenter, 1973) with permission. | ||
Positively worded items are recommended over negatively worded items (Haladyna and Rodriguez, 2013). This is because negative phrasing in an item can increase reading and reasoning difficulty, introduce cueing, and that testing a student's understanding of an exception is not always the same as testing their understanding of the actual learning objective (Cassels and Johnstone, 1984; Harasym et al., 1992; Thorndike and Thorndike-Christ, 2010). If an item must be worded negatively to test a desired skill or construct, the negative phrase should be highlighted (Haladyna et al., 2010). Negatively phrased items were shown to be more difficult when the negative phrase was not emphasized (Casler, 1983). This may be because highlighting the negative phrase minimizes the risk that a student will miss the negative phrase while reading the item. Therefore, if negative phrasing must be used, it is recommended that it is emphasized.
Answer choice creation guidelines
The first guideline in creating answer choice sets is that all distractors should be plausible (Weitzman, 1970; Haladyna and Steven, 1989; Haladyna et al., 2010). This is because non-plausible distractors can be eliminated easily by students, decrease item difficulty, increase reading time, and lessen the number of items that can be included in an exam (Ascalon et al., 2007; Tarrant and Ware, 2010; Edwards et al., 2012; Schneid et al., 2014; Papenberg and Musch, 2017). One way to attempt to create distractors are plausible, is to create them by using student errors or misconceptions (Case and Swanson, 2002; Moreno and Martı, 2006; Tarrant et al., 2009; Gierl et al., 2017). This strategy can help ensure that distractors are errors that students may make and therefore are more likely to choose (Tarrant et al., 2009; Gierl et al., 2017). Several studies have defined and operationalized implausible distractors as ones that fewer than 5% of students select (Wakefield, 1958; Tarrant et al., 2009; Tarrant and Ware, 2010).The second answer choice set creation guideline is that ‘all of the above’ should be avoided (Haladyna et al., 2002; Downing et al., 2010). This is because its use has been shown to significantly enhances student performance on MC items due to an inherent cueing effect (Harasym et al., 1998). This improvement in student performance is likely due to students being able to more easily eliminate or select ‘all of the above’ when compared to items in a ‘select all that are true’ format (Harasym et al., 1998).
Third, answer choices should be arranged in a logical order (Haladyna and Steven, 1989; Moreno and Martı, 2006). For example, in ascending or descending numerical order. In a study that found higher discrimination values on items with randomly ordered answer choices verses ones that were logically ordered, it was concluded that although answer choice order is not likely an influencing factor for higher-ability students, it may affect lower-ability students in their exam performance (Huntley and Welch, 1993). Additionally, arranging answer choices in logical or numerical order was found to be unanimously supported in a review of measurement textbooks (Haladyna et al., 2010).
The fourth recommendation is that the answer choices should be kept to approximately the same length/level of detail (Frey et al., 2005; Haladyna et al., 2010; Towns, 2014). This is because students can use the ‘choose the longest answer’ heuristic when taking an examination. Students may believe that if an answer choice is significantly longer or provides more detail than the other answer choices, then it is more likely to be correct. Research has shown that items with inconsistent length of answer choices are easier and less discriminating than items where the length of the answer choices are approximately equal (Dunn and Goldstein, 1959; Weiten, 1984).
Guidelines for the exam overall
Item placement in an exam relative to the other items can affect the psychometric properties of the item (Meyers et al., 2008). An exam creator should avoid placing three or more items that test the same cognitive tasks next to each other on an exam. This can lead to cueing effects from the previous items that can inflate performance on the target item (Schroeder et al., 2012).Additionally, placing three or more difficult items next to each other is also poor practice in MC exam creation. This has been found to decrease performance on general chemistry items in ACS exams (Schroeder et al., 2012). Possible causes of this effect may be self-efficacy or exam fatigue (Galyon et al., 2012; Schroeder et al., 2012)
An exam should have an approximately even distribution of correct answer choices, a practice known as key balancing (Towns, 2014). This is because in unbalanced exams, it has been shown that test makers and test takers have a tendency to choose the middle options in a MC item for the correct response (Attali, 2003). This produces a bias that effects the psychometric properties of an exam by making items with middle keyed answer choices easier and less discriminating (Attali, 2003). Additionally, test takers tend to expect different answers on subsequent items when they see a “run” of answer choices even though this is not necessarily true (Lee, 2018). Thus, it is good practice to ensure that there is an approximately even distribution of correct answer choices.
An exam should not link performance on one item with performance on another (Haladyna et al., 2002; Moreno and Martı, 2006; Hogan and Murphy, 2007). All items should be independent from each other so that a student has a fair chance to answer each item correctly.
With this said, linked “two-tier” multiple-choice items have been used to assess student reasoning by asking them to explain, or choose an explanation to, their answer choice in a previous item (Tan et al., 2002; Chandrasegaran et al., 2007). While this practice has merit when used with purpose, simply linking items that test chemistry content can disadvantage students who incorrectly answer the first item.
Item writing guideline violations in higher education
Violations of item writing guidelines have been studied across different disciplines in higher education for their frequency in examinations as shown in Table 2. The frequency of these violations has been noted as an area of concern and a focus for improvement in their respective papers.| Discipline | Ref. | Sample size | Frequency of flawed items | Most common flaws |
|---|---|---|---|---|
| Nursing | (Tarrant et al., 2006) | 2770 MC items | 46.2% | Unclear stem 7.5% |
| Negative stem 6.9% | ||||
| Implausible distractors 6.6% | ||||
| (Tarrant and Ware, 2008) | 664 MC items | 47.3% | Unfocused stem 17.5% | |
| Negative Stem 13% | ||||
| Overly wordy 12.2% | ||||
| Pharmacy | (Pate and Caldwell, 2014) | 187 MC items | 51.8% | All of the above 12.8% |
| Overly wordy 12.8% | ||||
| K-type 10.2% | ||||
| Medical Education | (Stagnaro-Green and Downing, 2006) | 40 MC items | 100% | Phrasing Cues 100% |
| Unfocused stem 100% | ||||
| Overly wordy 73% |
Purpose of the study
Since many guidelines exist for how to construct MC items, it can be difficult to remember these guidelines during the test creation or test evaluation process. Therefore, in this work an instrument has been developed that can assist instructors and researchers to assess if MC exams are adhering to accepted guidelines. The developed instrument should:• Represent common item writing guidelines
• Be able to identify item writing guideline violations in MC items
• Be able to be used reliably between raters
• Be able to be used with a minimal amount of training
Additionally, although adherence to item writing guidelines has been a topic of research in other academic disciplines (Tarrant et al., 2006; Pate and Caldwell, 2014), there have been few research studies that have addressed the extent that general chemistry exams adhere to MC item writing guidelines. Therefore, once developed, the instrument was used to evaluate the adherence of 43 general chemistry exams (1019 items) to item writing guidelines.
Methods
This study occurred in two phases: instrument development and item analysis. These two phases are outlined in Fig. 5 and will be described here in detail.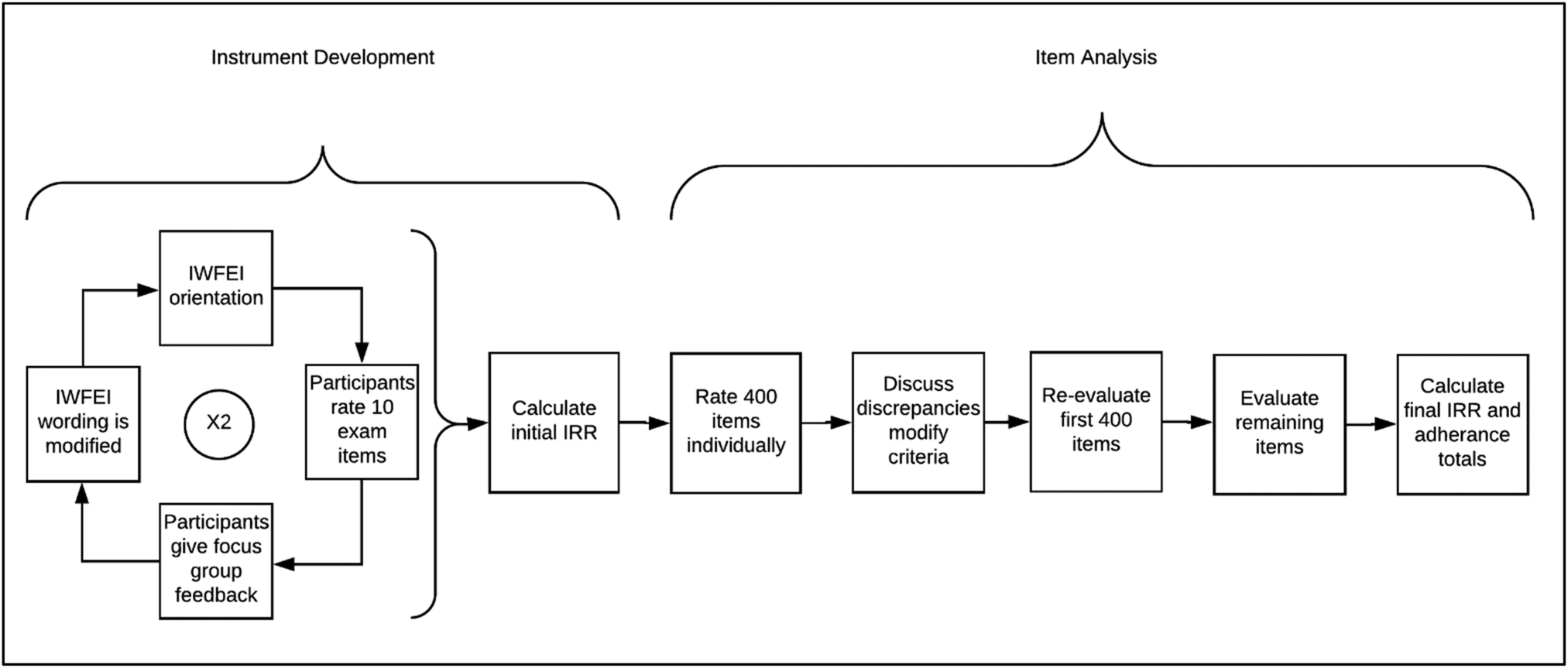 | ||
| Fig. 5 Flowchart of instrument development and item analysis. | ||
Instrument development
The instrument was developed based on a review of the guidelines and literature described in the introduction. An appendix of definitions and examples of each item writing guideline was also created to help guide the instrument's users (see Appendix 1). The instrument, known as the Item Writing Flaws Evaluation Instrument (IWFEI), was revised in a pilot testing cycle with four chemistry education graduate students as shown in the cyclic portion of Fig. 5. The participants were given a 20 minute orientation on how to use the IWFEI along with the IWFEI appendix. They then rated 10 general chemistry MC items individually and gave their feedback on the clarity of the IWFEI and definitions in a focus group setting. This cycle went thought two iterations. The revised instrument was tested for initial inter-rater reliability among raters with various levels of teaching and MC exam writing experience (Table 3).| Rater | Position | Discipline | Years of experience teaching general chemistry | Number of general chemistry MC exams created |
|---|---|---|---|---|
| 1 (1st author) | Graduate Student | Chemical Education | 0–2 | 1–4 |
| 2 | Assistant Professor | Inorganic | 2–4 | 1–4 |
| 3 | Instructor | Chemical Education | 10+ | 20+ |
Raters 2 and 3 (Table 3) received a 20 minute orientation (from rater 1) on how to use the IWFEI and then raters 1–3 used the instrument to individually rate 10 general chemistry MC exam items. The 10 items were chosen because they contained a variety of item writing guideline violations that were within what the IWFEI intended to test. These items are found in Appendix 2.
Item analysis of past exams
The resulting instrument was then applied to 43 1st semester general chemistry exams to evaluate their adherence to item writing guidelines and to further refine the instrument. The two raters (the 1st and 2nd authors) have degrees in chemistry and are familiar with the course content. The 2nd author received a 20 minute orientation from the 1st author on how to use the IWFEI.The chemistry exams analyzed were from a 1st semester general chemistry course for scientists and engineers at a public, R1 university in the midwestern United States. The exams were created by committees of instructors who taught different sections of the same course. A total of 33 unit exams and 10 final exams were analyzed. A unit exam is given during a semester and covers a subset of the course content. Typically, a unit exam covers approximately a fourth of the courses material. A final exam is typically cumulative and given at the end of the semester. The exams included topics common in first semester general chemistry such as: stoichiometry, gas laws, light and energy, radioactivity, periodic trends, thermochemistry, Lewis structures, polarity of molecules, intermolecular forces, etc. The items contained various levels of representations including chemical formula, diagrams, molecular level representations, graphs, etc. If a representation in an item (such as chemical formulas) affected how to interpret a criterion in the IWFEI, it was noted in appendix 1 for the use of the instrument. The exams were administered between 2011 and 2016 and were composed of MC items exclusively. Unit and final exams contained 20 items and approximately 40 items, respectively. A total of 1019 items were evaluated.
The two raters first evaluated 400 items individually. Then they discussed discrepancies in ratings among those 400 items. These discussions led to the modification of criteria wording and definitions in the IWFEI. Once modifications were made, the initial 400 items were re-evaluated using the updated instrument. Lastly, the remaining items in the data set were evaluated using the IWFEI.
Percent agreement and Krippendorff alpha statistics were then calculated between the two raters using the IRR package in R software. The raters then reached consensus on any disagreements. Once consensus was reached, percentages of how many items adhered to the various item writing guidelines in the instrument were calculated.
This study was approved by the institutional review board at the institution where the study took place.
Results
Item writing guidelines evaluation instrument
The final version of the IWFEI (Fig. 6) contains 11 criteria which apply to individual items and four criteria which apply to an exam overall. The IWFEI's format consists of a list of item writing guidelines, in the form of questions, and three choices of “yes”, “no”, or “not applicable”. A “yes” suggests adherence to the item writing guideline and a “no” suggests a violation of the guideline. A user of the IWFEI would rate each item in an exam with Criteria 1–11 and the exam as a whole using Criteria 12–15.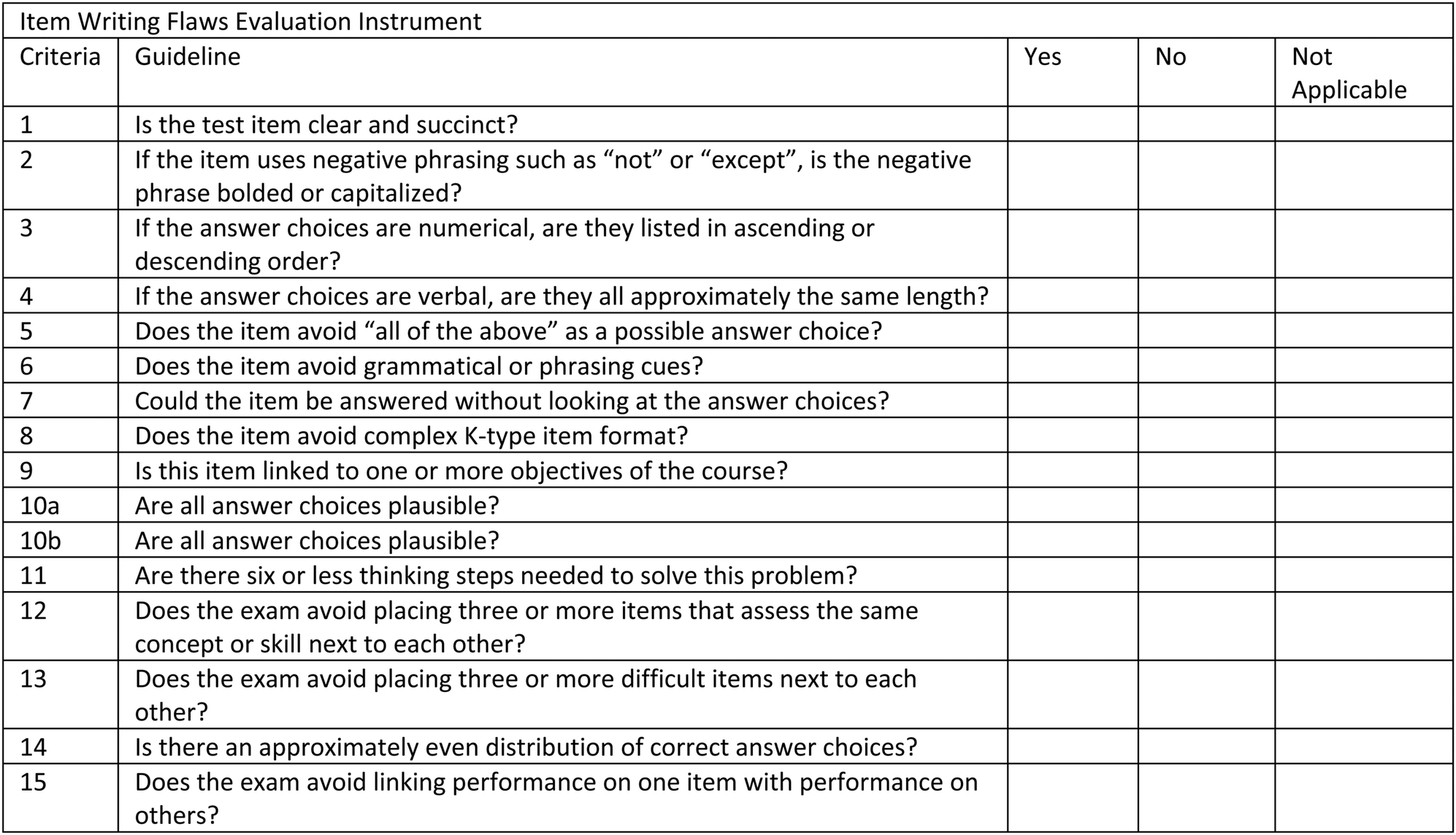 | ||
| Fig. 6 Item writing flaws evaluation instrument. | ||
Criterion 10, ‘Are all answer choices plausible?’ was given two definitions. Definition 10a being ‘All distractors need to be made with student errors or misconceptions.’ This definition may have utility as a reflective tool when the IWFEI is being used to analyze one's own exam before it is administered, yet it was shown to have poor reliability when used to analyze exam items made by other instructors. Definition 10b is based on item statistics and defines an implausible distractor as one that fewer than 5% of students selected. This definition, (10b) should be used when using the IWFEI to evaluate historical exam items made by other instructors.
When the initial inter-rater reliability was calculated, a 78.2% agreement was found between the three raters with a 0.725 Krippendorff alpha. This suggests that there was a substantial level of agreement between the raters (Landis and Koch, 1977). Furthermore, when looking at the agreement between individual raters in Table 3, raters 1 and 2, 2 and 3, and 1 and 3 had a percent agreement of 83.3, 87.5, and 85.0%, respectively. Because all raters in Table 3 (less experienced and more experienced) agreed above an 80% level, we moved forward with the item analysis phase of the study. During that phase, when the final version of the instrument was used by the 1st and 2nd authors to rate the 1019 items (10![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 458 total ratings) it had a 91.8% agreement and a 0.836 Krippendorff Alpha. As these reliability statistics were both above 80% and 0.80, respectively the authors decided this was an acceptable level of agreement.
458 total ratings) it had a 91.8% agreement and a 0.836 Krippendorff Alpha. As these reliability statistics were both above 80% and 0.80, respectively the authors decided this was an acceptable level of agreement.
Criterion 9 was used to analyze a subset of 96 items from the fall of 2016, instead of all 1019 items, because of the lack of availability of learning objectives from previous semesters. Criterion 10 (using the 10a definition) had a consistently low level of reliability at 68.9%. Criteria 12–15 were rated 43 times, instead of 1019 times, because they apply only once per exam being analyzed.
The inter-rater reliability statistics for the individual criteria of the IWFEI as used across the 1019 items are found in Table 4.
| Criteria | Guidelines | Percent agreement (%) |
|---|---|---|
| 1 | Is the test item clear and succinct? | 93.9 |
| 2 | If the item uses negative phrasing such as “not” or “except”, is the negative phrase bolded? | 97.0 |
| 3 | If the answer choices are numerical, are they listed in ascending or descending order? | 95.9 |
| 4 | If the answer choices are verbal, are they all approximately the same length? | 90.8 |
| 5 | Does the item avoid “all of the above” as a possible answer choice? | 96.9 |
| 6 | Does the item avoid grammatical and phrasing cues? | 98.4 |
| 7 | Could the item be answered without looking at the answer choices? | 85.4 |
| 8 | Does the item avoid complex K-type item format? | 97.5 |
| 9 | Is the item linked to one or more objectives of the course? | 84.4 |
| 10a | Are all distractors plausible? | 68.9 |
| 11 | Are there six or less thinking steps needed to solve this problem? | 94.5 |
| 12 | Does the exam avoid placing three or more items that assess the same concept or skill next to each other? | 95.3 |
| 13 | Does the exam avoid placing three or more difficult items next to each other? | 100.0 |
| 14 | Is there an approximately even distribution of correct answer choices? | 86.0 |
| 15 | Does the exam avoid linking performance on one item with performance on others? | 100.0 |
Item analysis
An analysis of Criteria 1–11, when applied to individual items, revealed that on average, items contained 1.4 ± 0.8 violations per item. It was found that 80 items (7.9%) contained no violations, 505 items (49.6%) contained one violation, 347 items (34.1%) contained two violations, 73 items (7.2%) contained three violations, 11 items (1.1%) contained four violations, and 3 items (0.3%) contained five violations of item writing guidelines. This is shown in Fig. 7. | ||
| Fig. 7 Frequency of item writing guideline violations per item. | ||
The number and percentages of items that adhered to and violated specific item writing guidelines (1–11), are found in Table 5. Boxes highlighted in bold represent guidelines classified as having a high level of adherence (above 90%) where those highlighted in italics represent guidelines classified as having a low level of adherence (below 75%).
| Abbreviated criterion | Applicable items | Adhered (yes) | Violated (no) | N/A | Adhered % | Violated % | |
|---|---|---|---|---|---|---|---|
| Bold: above 90% adherence. Italics: below 75% adherence. | |||||||
| 1 | Clear/succinct | 1019 | 960 | 59 | — | 94.2 | 5.8 |
| 2 | Bolded negative phrase | 77 | 65 | 12 | 942 | 84.4 | 15.6 |
| 3 | Ascending/descending order of choices | 311 | 226 | 85 | 708 | 72.7 | 27.3 |
| 4 | Approx. even answer choice length | 298 | 249 | 49 | 721 | 83.6 | 16.4 |
| 5 | Avoid ‘all of the above’ | 1019 | 973 | 46 | — | 95.5 | 4.5 |
| 6 | Avoid grammar/phrasing cues | 1019 | 1013 | 6 | — | 99.4 | 0.6 |
| 7 | Answer without answer choices | 1019 | 720 | 299 | — | 70.7 | 29.3 |
| 8 | Avoid K-type | 1019 | 963 | 55 | — | 94.5 | 5.4 |
| 9 | Linked to objective | 96 | 87 | 9 | — | 90.6 | 9.4 |
| 10a | Plausible distractors | 1019 | 447 | 542 | — | 46.8 | 53.2 |
| 10b | Plausible distractors | 1019 | 206 | 813 | — | 20.2 | 79.8 |
| 11 | Six or less thinking steps | 1019 | 972 | 44 | — | 95.4 | 4.3 |
Criteria 12–15, found in Table 6, apply to exams as a whole and not to individual items. Boxes highlighted in bold represent guidelines classified as having a high level of adherence (above 90%) where those highlighted in italics represent guidelines classified as having a low level of adherence (below 75%).
| Abbreviated criterion | Applicable exams | Adhered (yes) | Violated (no) | N/A | Adhered % | Violated % | |
|---|---|---|---|---|---|---|---|
| Bold: above 90% adherence. Italics: below 75% adherence. | |||||||
| 12 | Avoid 3+ items testing the same concept next to each other | 43 | 35 | 8 | 0 | 81.4 | 18.6 |
| 13 | Avoid 3+ difficult items next to each other | 43 | 42 | 1 | 0 | 97.7 | 2.3 |
| 14 | Approx. even answer key distribution | 43 | 17 | 26 | 0 | 39.5 | 60.5 |
| 15 | Avoid linking items based on performance | 43 | 43 | 0 | 0 | 100 | 0 |
Criteria two, three, and four only applied to a small portion of the items analyzed. See Table 4. Criterion two applied to 77 items with 84.4% of those items adhering to the guideline and 15.6% in violation. Criterion three applied to 311 items with 72.7% of those items adhering to the guideline and 27.3% in violation. Criterion four applied to 298 items with 83.6% of those items adhering to the guideline and 16.4% in violation. The remaining criteria applied to all available items or exams.
Discussion
In this work, we developed the IWFEI based on accepted item writing guidelines and demonstrated that it can be used reliably to identify item writing guideline violations in 1st semester general chemistry multiple-choice exams. The development of the IWFEI addresses the lack of research literature on multiple-choice item writing guideline adherence in chemistry exams and provides a tool that can be used to continue research in this field. Its use has shown the frequency of item writing guideline violations in a sample of 1019 1st semester chemistry exam items.Development
The development and refinement process used for the IWFEI has been used before in the creation of other instruments (Naeem et al., 2012) and this process was used to improve wording and understandability of the instruments criteria. The criteria in the instrument were chosen based on accepted item writing guidelines that were discussed in the introduction section of this paper.Additionally, the inter-rater reliability procedure of rating items individually, calculating agreement, and then coming to consensus on differences has been used in other studies successfully (Srinivasan et al., 2018).
Once developed, the instrument was tested for reliability and was shown to have a high level of reliability (91.8% agreement and 0.836 Krippendorff alpha) which is similar to other exam evaluation instruments such as the Cognitive Complexity Rating Instrument (Knaus et al., 2011) and the Three Dimensional Learning Assessment Protocol (3D-LAP) (Laverty et al., 2016). It is important to note that the Cognitive Complexity Rating Instrument uses an interval rating scale verses the categorical scale used by the IWFEI. Although this makes it difficult to directly compare reliability values, they are at a similar high level.
The criterion that presented the greatest difficulty in using reliably was criterion 10 ‘Are all answer choices plausible?’. Initially, we began our analysis of the historical exam data using definition 10a which defines implausible distractors as being made with student errors or misconceptions. This proved to be an unreliable way to evaluate historical, non-self-constructed exam items with a percent agreement between raters of 68.9%. Although definition 10a may have utility when evaluating one's own exam items before administration, it was not appropriate when evaluating items created by other instructors. Conversely, definition 10b which defines implausible distractors as ones that fewer than five percent of students select, would be appropriate for evaluating non-self-constructed exams, but would be impossible for analyzing exam items before administration or without exam statistics available. We see both definitions as having merit when used in appropriate situations. We foresee that having both definitions will increase the utility of the IWFEI and make it more useful to researchers and instructors alike.
Use of the instrument
The IWFEI has been used in this study to identify items of concern in a sample of 43 general chemistry exams. For example, the item on the left-hand side of Fig. 8 was identified by using the IWFEI as not being succinct (violation of criterion one). We notice that this item is overly wordy in the stem and the answer choices. This item would take students a significant amount of time to read and this may disadvantage some students in their exam performance. In the literature, Towns described similar items as being overly wordy as shown on the right-hand side of Fig. 8 (Towns, 2014). | ||
| Fig. 8 Overly wordy item identified using the IWFEI (left); overly wordy item example from (Towns, 2014) (right) https://pubs.acs.org/doi/abs/10.1021/ed500076x further permissions related to the right side of this figure should be directed to the ACS. | ||
In another example, the item on the left-hand side of Fig. 9 was identified as a K-type item by using the IWFEI. This item format has answer choices that can be easily eliminated based on analytic reasoning and thus may not provide the most valid data on what students know. The item on the right in Fig. 9 is an example of a K-type item as found in the literature.
 | ||
| Fig. 9 K-type item identified using the IWFEI (left); K-type item example right; Reproduced from (Albanese, 1993) with permission. | ||
In a third example, the items in Fig. 10 were identified as containing implausible distractors by using the IWFEI. In the literature, an implausible distractor has been given an operational definition as a distractor that fewer than 5% of students select. The percentage of students who selected each answer choice is indicated. From this, we see that the item on the left-hand side contains two implausible distractors, b and e, while the item on the right-hand side contains one implausible distractor, e. In the item on the right, e quintinary, is not a level of protein structure. This may indicate that the instructor included this as an answer choice solely for formatting reasons or a belief that in MC items more choices are better, despite their quality.
 | ||
| Fig. 10 Items with implausible distractors identified using the IWFEI; percentages of students choosing each answer choice is indicated. | ||
The three cases discussed above show examples of item writing flaws identified with the IWFEI and how they are comparable to what is described in the literature. This provides evidence that the IWFEI can be used in a valid way to identify items that contain flaws in their construction.
Once an item has been identified that contains violations of accepted guidelines, the user can then decide if/how they will modify the item. It is important to note that the IWFEI is not intended to identify bad items, but to identify items that may need to be modified based on the instructors or researcher's discretion.
To demonstrate this, a flawed item and its revision are shown in Fig. 11. The original item in Fig. 11 was identified as containing two flaws, an incomplete stem and implausible distractors (violations of criterion 7 and 10). In the revised version of the item, the stem was rewritten to contain a complete problem statement and the implausible distractors were removed.
 | ||
| Fig. 11 Flawed item identified by using the IWFEI and a revised version. | ||
The most common flaw in the exams analyzed was the inclusion of implausible distractors at 79.8% of items. Although initially surprising, this percentage was similar to results in other studies where 90.2% and 100% of items, respectively contained implausible distractors (Haladyna and Downing, 1993; Tarrant and Ware, 2010).
The most common flaws found in the chemistry exams analyzed were different than the most common flaws found in nursing, pharmacy and medical examinations (Stagnaro-Green and Downing, 2006; Tarrant et al., 2006; Tarrant and Ware, 2008; Pate and Caldwell, 2014). In this study the most common flaws were: including implausible distractors (79.8%), uneven answer choice distribution (60.5%), and including incomplete stems (29.3%). When compared to the most common flaws in other studies (Table 1), the only overlapping most common flaw was including incomplete stems.
Limitations
The exams analysed as part of this study were not representative of all 1st semester chemistry exams and therefore generalizations about the quality of MC general chemistry exams cannot be made from this study.Additionally, the IWFEI has been used and validated with a sample of 43 1st semester general chemistry exams, so it is unclear how it will perform with exams from other disciplines or content areas. With that said, we do foresee the IWFEI being able to be used for a wider variety of courses than introductory chemistry, it has just not been used in these contexts yet. However, the criteria or guidelines in the IWFEI have been used in other disciplines, so we do not envision further validation to be an issue. We invite those from other disciplines to use the IWFEI.
We recognize that there are many other facets to consider when creating MC assessments that are not included in this instrument. The IWFEI was not intended to address all aspects of MC assessment design, but to help identify common item writing guideline violations found in the literature. Using this instrument alone does not guarantee an item or exam will perform as desired, although we do foresee its use improving the quality of MC assessment in regards to item writing guideline adherence.
Conclusions and implications
In this study, an instrument has been developed that can be used to analyze MC general chemistry exams for item writing guideline violations. The IWFEI can be used by researchers and practitioners to identify ways to improve the quality of MC assessments. We see the IWFEI being used in both research and teaching settings. In research settings, we see the IWFEI being used to evaluate MC chemistry exams for item writing guideline violations as demonstrated in this study. Additionally, we see the IWFEI being used in teaching settings in two ways. First, as a tool to help guide chemistry instructors in the development and revision of their own exams, and secondly, as a tool to be used in professional development settings to advise instructors about MC assessment design. As the IWFEI is used in these three ways, we envision an improvement in multiple-choice assessment design practice and quality.Conflicts of interest
There are no conflicts to declare.Acknowledgements
We would like to acknowledge the assistance of the anonymous participants who took part in the refinement and initial inter-rater reliability testing of the IWFEI.References
- Albanese M., (1993), Type K and Other Complex Multiple-Choice Items: An Analysis of Research and Item Properties, Educ. Meas.: Issues Pract., 12(1), 28–33, DOI:10.1111/j.1745-3992.1993.tb00521.x.
- Albanese M., Kent T. and Whitney D., (1979), Cluing in Multiple-Choice Test Items with Combinations of Correct Responses, J. Med. Educ., 54, 948–950.
- Ascalon M. E., Meyers L. S., Davis B. W. and Smits N., (2007), Distractor Similarity and Item-Stem Structure: Effects on Item Difficulty, Appl. Meas. Educ., 20(2), 153–170, DOI:10.1080/08957340701301272.
- Attali Y., (2003), Guess Where: The Position of Correct Answers in Multiple-Choice Test Items as a Psychometric Variabie, J. Educ. Meas., 40(2), 109–128.
- Bergner J., Filzen J. J. and Simkin M. G., (2016), Why use multiple choice questions with excess information? J. Account. Educ., 34, 1–12, DOI:10.1016/j.jaccedu.2015.11.008.
- Board C. and Whitney D. R., (1972), The Effect of Selected Poor Item-Writing Practices on Test Difficulty, Reliability and Validity, J. Educ. Meas., 9(3), 225–233.
- Brandriet A. and Holme T., (2015), Development of the Exams Data Analysis Spreadsheet as a Tool to Help Instructors Conduct Customizable Analyses of Student ACS Exam Data, J. Chem. Educ., 92(12), 2054–2061, DOI:10.1021/acs.jchemed.5b00474.
- Bretz S. L., (2012), Navigating the landscape of assessment, J. Chem. Educ., 89(6), 689–691, DOI:10.1021/ed3001045.
- Bretz S. L., (2013), A Chronology of Assessment in Chemistry Education, in Trajectories of Chemistry Education Innovation and Reform, pp. 145–153.
- Campbell M. L., (2015), Multiple-Choice Exams and Guessing: Results from a One-Year Study of General Chemistry Tests Designed to Discourage Guessing, J. Chem. Educ., 92(7), 1194–1200, DOI:10.1021/ed500465q.
- Case S. M. and Swanson D. B., (2002), Constructing Written Test Questions For the Basic and Clinical Sciences, National Board of Medical Examiners, vol. 27, retrieved from http://www.nbme.org/PDF/ItemWriting_2003/2003IWGwhole.pdf.
- Casler L., (1983), Emphasizing the negative: a note on“ not” in multiple-choice questions, Teach. Psychol., 10(1), 51, DOI:10.1207/s15328023top1001_15.
- Cassels J. and Johnstone A., (1984), The effect of language on student performance on multiple choice tests in chemistry, J. Chem. Educ., 61(7), 613–615, DOI:10.1021/ed061p613.
- Chandrasegaran A. L., Treagust D. F. and Mocerino M., (2007), The development of a two-tier multiple-choice diagnostic instrument for evaluating secondary school students’ ability to describe and explain chemical reactions using multiple levels of representation, Chem. Educ. Res. Pract., 8(3), 293, 10.1039/b7rp90006f.
- Cooper M. M., (2013), Chemistry and the next generation science standards, J. Chem. Educ., 90(6), 679–680, DOI:10.1021/ed400284c.
- Downing S. M., (2002), Construct-irrelevant Variance and Flawed Test Questions: Do Multiple-choice Item-writing Principles Make Any Difference? Acad. Med., 77(10), 103–104.
- Downing S. M., (2005), The effects of violating standard item writing principles on tests and students: the consequences of using flawed test items on achievement examinations in medical education, Adv. Health Sci. Educ., 10(2), 133–143, DOI:10.1007/s10459-004-4019-5.
- Downing S. M., Haladyna T. M. and Rodriguez M. C., (2010), A Review of Multiple-Choice Item-Writing, Appl. Meas. Educ., 15(3), 309–333, DOI:10.1207/S15324818AME1503.
- Dudycha A. L. and Carpenter J. B., (1973), Effects of item format on item discrimination and difficulty, J. Appl. Psychol., 58(1), 116–121, DOI:10.1037/h0035197.
- Dunn T. F. and Goldstein L. G., (1959), Test difficulty, validity, and reliability as functions of selected multiple-choice item construction principles, Educ. Psychol. Meas., 19(2), 171–179, DOI:10.1177/001316445901900203.
- Edwards B. D., Arthur W. and Bruce L. L., (2012), The Three-option Format for Knowledge and Ability Multiple-choice Tests: a case for why it should be more commonly used in personnel testing, Int. J. Select. Assess., 20(1), 65–81, DOI:10.1111/j.1468-2389.2012.00580.x.
- Emenike M. E., Schroeder J., Murphy K. and Holme T., (2013), Results from a national needs assessment survey: a view of assessment efforts within chemistry departments, J. Chem. Educ., 90(5), 561–567, DOI:10.1021/ed200632c.
- Frey B. B., Petersen S., Edwards L. M., Pedrotti J. T. and Peyton V., (2005), Item-writing rules: collective wisdom, Teach. Teach. Educ., 21(4), 357–364, DOI:10.1016/j.tate.2005.01.008.
- Galyon C. E., Blondin C. A., Yaw J. S., Nalls M. L. and Williams R. L., (2012), The relationship of academic self-efficacy to class participation and exam performance, Soc. Psychol. Educ., 15(2), 233–249, DOI:10.1007/s11218-011-9175-x.
- Gibbons R. E., Reed J. J., Srinivasan S., Villafañe S. M., Laga E., Vega J. and Penn J. D., (2018), Assessment in Postsecondary Chemistry Education: A Comparison of Course Types, Assessment Update, 30(3), 8–11, DOI:10.1002/au.30131.
- Gierl M. J., Bulut O., Guo Q. and Zhang X., (2017), Developing, Analyzing, and Using Distractors for Multiple-Choice Tests in Education: A Comprehensive Review, Rev. Educ. Res., 87(6), 1082–1116, DOI:10.3102/0034654317726529.
- Goubeaud K., (2010), How is science learning assessed at the postsecondary level? Assessment and grading practices in college biology, chemistry and physics, J. Sci. Educ. Technol., 19(3), 237–245, DOI:10.1007/s10956-009-9196-9.
- Haladyna T. M. and Downing S. M., (1993), How Many Options is Enough For a Multiple-Choice Test Item? Educ. Psychol. Meas., 53, 999–1010.
- Haladyna T. M. and Rodriguez M. C., (2013), Developing and Validating Test Items, New York, NY: Routledge.
- Haladyna T. M. and Steven M., (1989), Validity of a Taxonomy of Multiple-Choice Item-Writing Rules, Appl. Meas. Educ., 2(1), 37–41, DOI:10.1207/s15324818ame0201.
- Haladyna T. M., Downing S. M. and Rodriguez M. C., (2002), A Review of Multiple-Choice Item-Writing Guidelines for Classroom Assessment, Appl. Meas. Educ., 7347(April 2011), 37–41, DOI:10.1207/S15324818AME1503.
- Haladyna T. M., Downing S. M. and Rodriguez M. C., (2010), A Review of Multiple-Choice Item-Writing Guidelines for Classroom Assessment, DOI:10.1207/S15324818AME1503_5.
- Harasym P. H., Norris D. and Lorscheider F. L., (1980), Evaluating Student Multiple-Choice Responses: Effects of Coded and Free Formats, Eval. Health Professions, 3(1), 63–84.
- Harasym P., Brant V. and Lorscheider., (1992), Evaluation of Negation in Stems of Multiple-Choice Items, Eval. Health Professions, 15(2), 198–220.
- Harasym P. H., Leong E. J., Violato C., Brant R. and Lorscheider F. L., (1998), Cuing effect of“ all of the above” on the reliability and validity of multiple-choice test items, Eval. Health Professions, 21(1), 120–133.
- Harshman J. and Yezierski E., (2015), Guiding teaching with assessments: high school chemistry teachers’ use of data-driven inquiry, Chem. Educ. Res. Pract., 16, 93–103, 10.1039/C4RP00188E.
- Hartman J. R. and Lin S., (2011), Analysis of Student Performance on Multiple-Choice Questions in General Chemistry, J. Chem. Educ., 88, 1223–1230.
- Herrmann-Abell C. F. and DeBoer G. E., (2011), Using distractor-driven standards-based multiple-choice assessments and Rasch modeling to investigate hierarchies of chemistry misconceptions and detect structural problems with individual items, Chem. Educ. Res. Pract., 12(2), 184, 10.1039/c1rp90023d.
- Hogan T. P. and Murphy G., (2007), Recommendations for preparing and scoring constructed-response items: what the experts say, Appl. Meas. Educ., 20(4), 427–441, DOI:10.1080/08957340701580736.
- Holme T., Bretz S. L., Cooper M., Lewis J., Paek P., Pienta N. and Towns M., (2010), Enhancing the Role of Assessment in Curriculum Reform in Chemistry. Chem. Educ. Res. Pract., 11(2), 92–97, 10.1039/c005352j.
- Holsgrove G. and Elzubeir M., (1998), Imprecise terms in UK medical multiple-choice questions: what examiners think they mean, Med. Educ., 32(4), 343–350, DOI:10.1046/j.1365-2923.1998.00203.x.
- Huntley R. and Welch C., (1993), Numerical Answer Options: Logical or Random Order? Paper Presented at the Annual of Meeting of the American Educational Research Association, Atlanta, GA.
- Johnstone A., (1991), Why is science difficult to learn? Things are seldom what they seem, J. Comput. Assist. Learn., 7(2), 75–83, DOI:10.1111/j.1365-2729.1991.tb00230.x.
- Johnstone A., (2006), Chemical education research in Glasgow in perspective, Chem. Educ. Res. Pract., 7(2), 49, 10.1039/b5rp90021b.
- Johnstone A. and El-Banna H., (1986), Capacities, demands and processes – a predictive model for science education, Educ. Chem., 23, 80–84.
- Kendhammer L., Holme T. and Murphy K., (2013), Identifying Differential Performance in General Chemistry: Differential Item Functioning Analysis of ACS General Chemistry Trial Tests, J. Chem. Educ., 90, 846–853.
- Knaus K., Murphy K., Blecking A. and Holme T., (2011), A Valid and Reliable Instrument for Cognitive Complexity Rating Assignment of Chemistry Exam Items, J. Chem. Educ., 554–560.
- Landis J. R. and Koch G. G., (1977), The Measurement of Observer Agreement for Categorical Data, Int. Biometrics Soc., 33(1), 159–174, DOI:10.2307/2529310.
- Laverty J. T., Underwood S. M., Matz R. L., Posey L. A., Carmel J. H., Caballero M. D. and Cooper M. M., (2016), Characterizing college science assessments: the three-dimensional learning assessment protocol, PLoS One, 11(9), 1–21, DOI:10.1371/journal.pone.0162333.
- Lawrie G. A., Schultz M., Bailey C. H. and Dargaville B. L., (2018), Personal journeys of teachers: an investigation of the development of teacher professional knowledge and skill by expert tertiary chemistry teachers, Chem. Educ. Res. Pract., 10.1039/C8RP00187A.
- Lee C. J., (2018), The test taker's fallacy: how students guess answers on multiple-choice tests, J. Behav. Decis. Making, 1–12, DOI:10.1002/bdm.2101.
- Meyers J. L., Miller G. E. and Way W. D., (2008), Item Position and Item Difficulty Change in an IRT-Based Common Item Equating Design, Appl. Meas. Educ., 22(1), 38–60, DOI:10.1080/08957340802558342.
- Millman J. and Bishop C. H., (1965), An Analysis of Test-Wiseness, Educ. Psychol. Meas., XXV(3), 707–726.
- Moreno R. and Martı R. J., (2006), New Guidelines for Developing Multiple-Choice Items, Methodology-EUR, 2(2), 65–72, DOI:10.1027/1614-1881.2.2.65.
- Naeem N., van der Vleuten C. and Alfaris E. A., (2012), Faculty development on item writing substantially improves item quality, Adv. Health Sci. Educ., 17(3), 369–376, DOI:10.1007/s10459-011-9315-2.
- Niaz M., (1987), Relation between M-Space of Students and M-Demand of Different Items of General-Chemistry and Its Interpretation Based Upon the Neo-Piagetian Theory of Pascual-Leone. J. Chem. Educ., 64(6), 502–505, DOI:10.1021/ed064p502.
- Niaz M., (1989), The relationship between M-demand, algorithms, and problem solving: a neo-Piagetian analysis, J. Chem. Educ., 66(5), 422, DOI:10.1021/ed066p422.
- Papenberg M. and Musch J., (2017), Of Small Beauties and Large Beasts: The Quality of Distractors on Multiple-Choice Tests Is More Important Than Their Quantity, Appl. Meas. Educ., 30(4), 273–286, DOI:10.1080/08957347.2017.1353987.
- Pate A. and Caldwell D. J., (2014), Effects of multiple-choice item-writing guideline utilization on item and student performance, Curr. Pharm. Teach. Learn., 6(1), 130–134, DOI:10.1016/j.cptl.2013.09.003.
- Pellegrino J. W., (2001), Knowing what students know. National Academy of the Sciences, National Academy Press, DOI:10.17226/10019.
- Plake B., (1984), Can Relevant Grammatical Cues Result In Invalid Test Items, Educ. Psychol. Meas.
- Raker J. R. and Holme T. A., (2014), Investigating faculty familiarity with assessment terminology by applying cluster analysis to interpret survey data, J. Chem. Educ., 91(8), 1145–1151, DOI:10.1021/ed500075e.
- Raker J. R., Emenike M. E. and Holme T. A., (2013a), Using structural equation modeling to understand chemistry faculty familiarity of assessment terminology: results from a national survey, J. Chem. Educ., 90(8), 981–987, DOI:10.1021/ed300636m.
- Raker J. R., Trate J. M., Holme T. A. and Murphy K., (2013b), Adaptation of an Instrument for Measuring the Cognitive Complexity of Organic Chemistry Exam Items, J. Chem. Educ., 130918144937002, DOI:10.1021/ed400373c.
- Reed J. J., Brandriet A. R. and Holme T. A., (2016), Analyzing the Role of Science Practices in ACS Exam Items, J. Chem. Educ., acs.jchemed.6b00659, DOI:10.1021/acs.jchemed.6b00659.
- Reed J. J., Villafañe S. M., Raker J. R., Holme T. A. and Murphy K. L., (2017), What We Don’t Test: What an Analysis of Unreleased ACS Exam Items Reveals about Content Coverage in General Chemistry Assessments, J. Chem. Educ., acs.jchemed.6b00863, DOI:10.1021/acs.jchemed.6b00863.
- Rimland B., (1960), The Effect of Including Extraneous Numerical Information in a Test of Arithmetic Reasoning, Educ. Psychol. Meas., (4), 787–794.
- Schneid S. D., Armour C., Park Y. S., Yudkowsky R. and Bordage G., (2014), Reducing the number of options on multiple-choice questions: response time, psychometrics and standard setting, Med. Educ., 48(10), 1020–1027, DOI:10.1111/medu.12525.
- Schrock T. J. and Mueller D. J., (1982), Effects of Violating Three Multiple-Choice Item Construction Principles, J. Educ. Res., 75(5), 314–318, DOI:10.1080/00220671.1982.10885401.
- Schroeder J., Murphy K. L. and Holme T. A., (2012), Investigating factors that influence item performance on ACS exams, J. Chem. Educ., 89(3), 346–350, DOI:10.1021/ed101175f.
- Schurmeier K. D., Atwood C. H., Shepler C. G. and Lautenschlager G. J., (2010), Using item response theory to assess changes in student performance based on changes in question wording. J. Chem. Educ., 87(11), 1268–1272, DOI:10.1021/ed100422c.
- Srinivasan S., Reisner B. A., Smith S. R., Stewart J. L., Johnson A. R., Lin S. and Raker J. R., (2018), Historical Analysis of the Inorganic Chemistry Curriculum Using ACS Examinations as Artifacts, J. Chem. Educ., 95(5), 726–733, DOI:10.1021/acs.jchemed.7b00803.
- Stagnaro-Green A. S. and Downing S. M., (2006), Use of flawed multiple-choice items by the New England Journal of Medicine for continuing medical education, Med. Teach., 28(6), 566–568, DOI:10.1080/01421590600711153.
- Tan K. C. D., Goh N. K., Chia L. S. and Treagust D. F., (2002), Development and application of a two-tier multiple choice diagnostic instrument to assess high school students’ understanding of inorganic chemistry qualitative analysis, J. Res. Sci. Teach., 39(4), 283–301, DOI:10.1002/tea.10023.
- Tarrant M. and Ware J., (2008), Impact of item-writing flaws in multiple-choice questions on student achievement in high-stakes nursing assessments, Med. Educ., 42(2), 198–206, DOI:10.1111/j.1365-2923.2007.02957.x.
- Tarrant M. and Ware J., (2010), A comparison of the psychometric properties of three- and four-option multiple-choice questions in nursing assessments, Nurse Educ. Today, 30(6), 539–543, DOI:10.1016/j.nedt.2009.11.002.
- Tarrant M., Knierim A., Hayes S. K. and Ware J., (2006), The frequency of item writing flaws in multiple-choice questions used in high stakes nursing assessments, Nurse Educ. Today, 26(8), 662–671, DOI:10.1016/j.nedt.2006.07.006.
- Tarrant M., Ware J. and Mohammed A. M., (2009), An assessment of functioning and non-functioning distractors in multiple-choice questions: a descriptive analysis, BMC Med. Educ., 9, 40, DOI:10.1186/1472-6920-9-40.
- Thorndike R. M. and Thorndike-Christ T. M., (2010), Measurement and Evaluation in Psychology and Education, Pearson, 8th edn.
- Towns M., (2010), Developing learning objectives and assessment plans at a variety of institutions: examples and case studies, J. Chem. Educ., 87(1), 91–96, DOI:10.1021/ed8000039.
- Towns M., (2014), Guide to developing high-quality, reliable, and valid multiple-choice assessments, J. Chem. Educ., 91(9), 1426–1431, DOI:10.1021/ed500076x.
- Towns M. and Robinson W. R., (1993), Student Use of Test-Wiseness Strategies in Solving Multiple-Choice Chemistry Examinations, J. Res. Sci. Teach., 30(7), 709–722, DOI:10.1002/tea.3660300709.
- Tsaparlis G. and Angelopoulos V., (2000), A model of problem solving: its operation, validity, and usefulness in the case of organic-synthesis problems, Sci. Educ., 84(2), 131–153, DOI:10.1002/(SICI)1098-237X(200003)84:2<131::AID-SCE1>3.0.CO;2-4.
- Wakefield J. A., (1958), Does the fifth choice strengthen a test item? Pub. Pers. Rev., 19, 44–48.
- Weiten W., (1984), Violation of selected item construction principles in educational measurement, J. Exp. Educ., 52(3), 174–178, DOI:10.1080/00220973.1984.11011889.
- Weitzman R. A., (1970), Ideal Multiple-Choice Items, J. Am. Statist. Assoc., 65(329), 71–89.
Footnote |
| † Electronic supplementary information (ESI) available. See DOI: 10.1039/c8rp00262b |
| This journal is © The Royal Society of Chemistry 2019 |