
 Open Access Article
Open Access Article This Open Access Article is licensed under a
This Open Access Article is licensed under a Creative Commons Attribution 3.0 Unported Licence
Multiplexed DNA detection based on positional encoding/decoding with self-assembled DNA nanostructures†
Sha
Sun
,
Huaxin
Yao
,
Feifei
Zhang
and
Jin
Zhu
*
Department of Polymer Science and Engineering, School of Chemistry and Chemical Engineering, State Key Laboratory of Coordination Chemistry, Nanjing National Laboratory of Microstructures, Nanjing University, Nanjing 210093, China. E-mail: jinz@nju.edu.cn
First published on 15th October 2014
Abstract
Current multiplexed analysis methods suffer from either slow reaction kinetics (planar arrays) or complicated encoding/decoding procedures (suspension arrays). We report herein a multiplexed DNA detection strategy that addresses these issues, based on positional encoding/decoding with self-assembled DNA nanostructures. The strategy enables the acquisition of high-resolution, consistent, and quantitative assay results in a single round of a transmission electron microscopy imaging operation. Applications in polymerase chain reaction-free settings and assays of other structurally distinct targets can be anticipated through the implementation of the strategy with miniaturized femtoliter/attoliter dispensing technology and readily accessible DNA conjugate structures.
Introduction
The ability to detect multiple biologically relevant species in parallel allows the utilization of molecular profiling as an elaborate tool for the elucidation of biological phenomena. Such an information-intensive multiplexed analysis process has been enabled by two distinct assay formats: planar arrays1 and suspension arrays.2 Planar arrays provide a convenient readout of targets through the positional encoding/decoding strategy, where the location of each spot in an ordered two-dimensional pattern defines the identity of a prospective target. This assay scheme is conceptually straightforward but suffers from slow reaction kinetics.1d–g Suspension arrays exhibit fast reaction kinetics, but both of the encoding and decoding processes are generally rather complicated. An assay system that combines facile positional encoding/decoding capability and fast reaction kinetics would be ideal for efficient extraction of biological information.3 Herein we report a multiplexed DNA detection strategy based on positional encoding/decoding with self-assembled DNA nanostructures (PED-SADNA) (Fig. 1). Specifically, a self-assembled three-dimensional core DNA structure4 with a registry marker asymmetrically positioned at one end and multiple types of target-binding capture probe sequences placed at regular intervals (collectively termed chip unit, or CU, by analogy to the planar DNA chip) is fabricated for the unambiguous positional encoding of DNA target information. Accordingly, multiple satellite DNA structures containing detection probe sequences (termed detection unit, or DU) for the remaining portions of corresponding targets are individually assembled. The presence of each target will direct the respective DU to the partner site of CU through hybridization. Staining of DNA nanostructures with uranyl formate and visualization with transmission electron microscopy (TEM) allow positional decoding and unambiguous identification of target DNA. | ||
| Fig. 1 Schematic illustration of the PED-SADNA strategy. A CU is designed and assembled for the positional encoding, featuring a core cuboid with binding sites for multiple targets (TT1, TT2, TB1, TB2) and a registry marker at the corner as a reference for the differentiation of both lateral surfaces (top surface for TT1 and TT2, bottom surface for TB1 and TB2) and longitudinal positions (remote positions for TT1 and TB1, proximal positions for TT2 and TB2) where those sites are located. Accordingly, multiple DU (DUT1, DUT2, DUB1, DUB2) containing sequences that can hybridize with the remaining portions of corresponding targets are individually assembled. Target binding will direct the respective DU to the partner CU site. Staining with uranyl formate and TEM visualization allow positional decoding and unambiguous identification of target DNA. | ||
Although self-assembled DNA nanostructures have been previously used for molecular diagnostics, they face major challenges with respect to the signal readout.5,6 Atomic force microscopy5,7 allows high-resolution imaging down to the single-molecule level under optimized conditions, but the exact surface feature observed depends heavily on technical variables of a particular operation (e.g. expertise of operating personnel, morphology of scanning tip). Fluorescence microscopy6,8 provides multi-color imaging capability, but limited spatial resolution and requirement for multiple imaging cycles/subsequent superposition processes (for the generation of pseudo-color images through multiple excitation source wavelengths or DNA strand exchange) poses significant restrictions on this sequential multiplexing methodology. The PED-SADNA method reported herein offers a robust solution to the above issues and delivers high-resolution, consistent, and quantitative assay results in a single round of a TEM imaging operation.
Results and discussion
The asymmetric design of CU enables positional encoding at both lateral and longitudinal directions through the differentiation of surfaces and positions where the capture probes are located. The proof-of-concept CU system reported herein is comprised of a 6H (helices)/6H/128BP (base pairs) (all DNA sequences for self-assembly were designed with program Sequin9 with a criton size of 7) square lattice core cuboid, which translates to a length scale of 15 nm/15 nm/43 nm, and a 3H/3H/64BP registry marker at a corner. The longitudinal dimension of the core cuboid and corner arrangement of the registry marker give a positional encoding capacity of four (two encoding positions for each surface × two surfaces). Accordingly, four types of capture probe sequences, each 11 nt (nucleotides) in length and in 14 copies (with the end of core cuboid opposite to the registry marker counted as 0 BP, the locations of two capture probes are: 3 strands at 8 BP, 3 at 16 BP, 2 at 24 BP, 3 at 40 BP and 3 at 48 BP; and the locations of two other capture probes are: 3 at 88 BP, 3 at 104 BP, 2 at 112 BP, 3 at 120 BP and 3 at 128 BP) specifically targeting a 26 nt sequence, were integrated into the design of the CU system. The gap distance between the two encoding sites on one surface is 13.5 nm, which can be readily resolved by TEM. For each of these targets, 15 copies of a 15 nt detection probe sequence were engineered into a 6H/6H/64BP DU framework. Positional readout of the CU–DU hybrid allows the extraction of target sequence information. In the CU/DU detection system reported herein, the location distributions of four target-binding sites in CU as described above secure a similar hybridization efficiency for each target. The size dimension of CU enables the docking of the CU–DU hybrid in a desired side-on orientation on the TEM grid, which allows straightforward visualization of DU.We commenced the evaluation of the feasibility of our detection system with a single-target (TT1) sample. This demands the fabrication and purification of the corresponding CU and DUT1. These tailorable CU and DU can be conveniently synthesized by slow annealing of hundreds of single-strand DNA (ssDNA) sequences and subsequent purification with gel electrophoresis. A commonly observed phenomenon for self-assembled DNA nanostructures is undesired multimerization, especially after their extended storage at 4 °C. As such, before purification, a 4 h pre-heating step at 37 °C for the annealing product is needed for the increase of discrete cuboid recovery yield. Experiments with other alternative purification methods prove to be not as convenient and effective as gel electrophoresis. Electro-elution10 allows purification but involves extra solution exchange steps, and direct ultra-filtration5a,11 can not completely eliminate excess ssDNA. In TEM imaging, instead of using glow discharge12 for the creation of negative staining, we intentionally add a ssDNA sequence, which does not interfere with the assay, as a means of generating a hydrophilic TEM grid surface13 for a convenient positive staining of CU and DU. Without assistance from such a ssDNA, limited access to aqueous solution due to the hydrophobicity of the TEM grid results in only partial staining and damaged outlook for CU and DU. This positive staining method provides such a high contrast for DNA nanostructures that we could image them easily in several minutes. With 5 nM each of purified CU and DUT1 placed in the detection system, the presence of TT1 (300 nM) leads to the formation of a lower mobility band in gel electrophoresis (Fig. 2A) and TEM imaging confirmed the generation of CU–DUT1 at the desired location (Fig. 2B). Consistent with the expected existence of a size effect for the docking orientation of CU on the TEM grid, an important experimental observation is that CU with a core cuboid size of 6H/6H/128BP can achieve the desired side-on settlement, whereas a switch of its core cuboid to 6H/6H/64BP renders the majority of CU in head-on settlement, whether being alone or in the form of a CU–DU hybrid. A screening of Mg2+ concentration indicates that hybridization proceeds efficiently at 11 mM. Statistical analysis by manual counting of each structurally resolved CU reveals a hybridization percentage (HP) of ∼41% (defined as the percentage of observed CU–DUT1 over all CU) after merely 5 min and ∼89% (a plateau value comparable to that reported previously on DNA tiles5a) after 1 h (Fig. 2C). Therefore, essentially, the whole assay can be accomplished within 74 min (1 h hybridization, 2 min loading of hybridization product onto the TEM grid, 2 min staining, and 10 min TEM imaging). A longer duration of hybridization (8 h) provides essentially identical HP (∼91%). Titration of TT1 shows a positive correlation of HP with TT1 concentration over the range of 10–30 nM, providing the possibility of target quantification (Fig. 2D), and the HP at 30 nM (∼89%) has reached the plateau value. It should be noted that DUT1 can be occasionally identified at a location other than that targeted, as has also been observed previously in other self-assembled DNA systems.6a This “misplacement” of DUT1, due to either accidental proximal settlement of CU and DUT1 on the TEM grid or non-specific interaction, can be counted as the background in our assay system. Indeed, such a phenomenon occurs even in the absence of a target DNA. The unoptimized detection limit therefore currently stands at 10 nM (HP ∼37%, compared with a background value of ∼4%, Fig. 2D). The ultimate measure of the assay sensitivity of a diagnostic method, in terms of absolute target quantity, is also dictated by the sample volume. In this regard, a major advantage of the PED-SADNA strategy reported herein is the ability to scale down the sample volume without affecting the assay quality because of the high resolving power of TEM. When combined with the recently developed femtoliter/attoliter dispensing technology,14 we anticipate that our detection system can be routinely applied in polymerase chain reaction (PCR, an amplification method that suffers from sensitivity to contamination and faces major issues in terms of multiplexing15)-free settings. Overall, although both DNA self-assembly and TEM imaging seem, at first glance, inconvenient for the implementation of an assay tool, recent advances in both fields4,16,17 with respect to automation and versatility render the PED-SADNA strategy demonstrated herein highly practical.
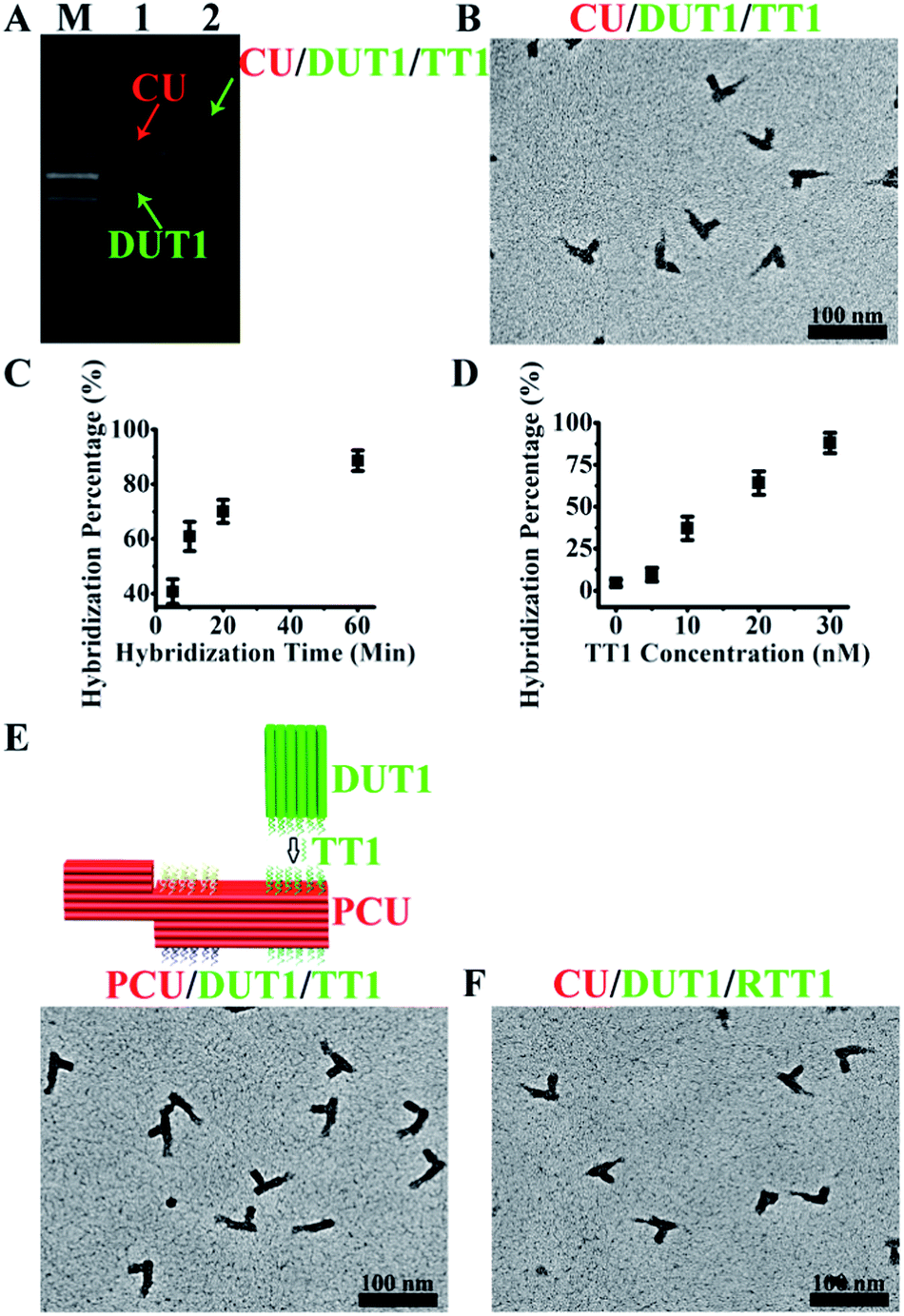 | ||
| Fig. 2 Single-target DNA and RNA detection with PED-SADNA. (A) Gel electrophoresis bands of CU and DUT1 in the absence (lane 1) and presence (lane 2) of target DNA TT1 (lane M represents the molecular weight marker). (B) TEM image of CU and DUT1 in the presence of target DNA TT1. (C) Hybridization percentage of CU and DUT1 in the presence of target DNA TT1 as a function of hybridization time. (D) Hybridization percentage of CU and DUT1 in the presence of target DNA TT1 as a function of concentration. (E) Schematic illustration and TEM image of PCU and DUT1 in the presence of target DNA TT1. (F) TEM image of CU and DUT1 in the presence of target RNA RTT1. | ||
The modular design of self-assembled DNA nanostructures allows the variation of registry marker to a protruded geometry (3H/6H/64BP) as an equally effective indicator of orientation for such a variant configuration, PCU (Fig. 2E). Also, the CU/DU assay system can be adapted to the detection of other types of targets as long as corresponding target-binding probes are in place. RNA exists in a variety of forms and is an important diagnostic and therapeutic target. Indeed, the CU/DUT1 design allows its direct application in the detection of a 26 nt RNA target (RTT1) (Fig. 2F).
With the single-target assay system validated, a two-target (TT1, TB2) sample was next examined. Accordingly, besides CU and DUT1, a second set of DU (DUB2) was fabricated and purified. The ability of TB2 to bind DUB2 to the target site of CU was then confirmed. For a two-target sample, the hybridization can be performed either separately with CU/DUT1 and CU/DUB2 (with a total ratio of CU/DUT1/DUB2 approximately 2![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :1:1; mixing before TEM imaging) or simultaneously with CU/DUT1/DUB2 (with a ratio of approximately 1:1:1). As expected, separate hybridization gives discrete CU–DUT1 and CU–DUB2 hybrids whereas simultaneous hybridization enables the formation of a CU–DUT1–DUB2 hybrid. In either case, DUT1 and DUB2 hybridize orthogonally with CU in high efficiency only in response to the presence of corresponding targets, TT1 and TB2 (Fig. 3A and S24†), thus demonstrating the high selectivity of the assay system. Although the designed CU system allows for the encoding of four targets, multiplexed interrogation of four targets is a demanding assay scenario because of its contingency upon the elimination of cross-hybridization. Satisfactorily, with the fabrication of two additional sets of DU (DUT2 and DUB1), four targets (TT1, TT2, TB1, TB2) can be unambiguously identified at the expected sites through high-yielding hybridization (Fig. 3B and S29†).
:1:1; mixing before TEM imaging) or simultaneously with CU/DUT1/DUB2 (with a ratio of approximately 1:1:1). As expected, separate hybridization gives discrete CU–DUT1 and CU–DUB2 hybrids whereas simultaneous hybridization enables the formation of a CU–DUT1–DUB2 hybrid. In either case, DUT1 and DUB2 hybridize orthogonally with CU in high efficiency only in response to the presence of corresponding targets, TT1 and TB2 (Fig. 3A and S24†), thus demonstrating the high selectivity of the assay system. Although the designed CU system allows for the encoding of four targets, multiplexed interrogation of four targets is a demanding assay scenario because of its contingency upon the elimination of cross-hybridization. Satisfactorily, with the fabrication of two additional sets of DU (DUT2 and DUB1), four targets (TT1, TT2, TB1, TB2) can be unambiguously identified at the expected sites through high-yielding hybridization (Fig. 3B and S29†).
 | ||
| Fig. 3 Two-target and four-target DNA detection with PED-SADNA. (A) TEM image of CU, DUT1, and DUB2 in the presence of targets TT1 and TB2. The hybridization was performed separately for CU/DUT1 and CU/DUB2, followed by mixing the two solutions for TEM imaging. (B) TEM image of CU, DUT1, DUT2, DUB1, and DUB2 in the presence of targets TT1, TT2, TB1, and TB2. The hybridization was performed separately for CU/DUT1, CU/DUT2, CU/DUB1 and CU/DUB2, and then the hybridization solutions were combined into a single sample for TEM imaging. | ||
In principle, the positional encoding capacity is dictated by the longitudinal dimension of CU as well as the number of CU surfaces that can be distinguished (maximum four surfaces for a cuboid design with a properly configured registry marker). As a proof-of-concept demonstration of the ability to increase longitudinal dimension, a separate cuboid with an identical size to that of the core cuboid part of CU was fabricated and allowed to hybridize with CU to form a double-sized DCU (∼86% yield at a Mg2+ concentration of 40 mM) (Fig. 4A). As expected, DCU allows positional encoding at discrete locations of both cuboids (Fig. 4B and C). A test with a two-target (TT1, TB3) sample confirmed orthogonal hybridization and therefore effectiveness of this DCU/DUT1/DUB3 system (Fig. 4D). In addition, the large separation between the two encoding sites enables the better spatially resolved staining and imaging of both DUT1 and DUB3 on one DCU in the case of simultaneous hybridization (Fig. 4E).
 | ||
| Fig. 4 Expansion of positional encoding capacity through an increase in longitudinal dimension. (A) Schematic illustration of DCU design and two-target identification at discrete locations of both cuboids. (B) TEM image of DCU and DUT1 in the presence of target DNA TT1. (C) TEM image of DCU and DUB3 in the presence of target DNA TB3. (D) TEM image of DCU, DUT1, and DUB3 in the presence of targets TT1 and TB3 (hybridization was performed separately for DCU and DU for each target and then the hybridization solutions were combined into a single sample for TEM imaging). (E) TEM image of DCU, DUT1, and DUB3 in the presence of targets TT1 and TB3 (hybridization was performed simultaneously for DCU and DU for two targets and then the sample was subjected to TEM imaging). | ||
Conclusions
In summary, a multiplexed DNA detection strategy based on PED-SADNA has been developed. This strategy allows the simultaneous achievement of facile positional encoding/decoding and fast hybridization kinetics in a solution assay format. Miniaturized implementation in an ultra-small volume format should enable the routine application of the detection system demonstrated herein in PCR-free settings. Extension of the strategy to the assay of other structurally distinct targets is also foreseeable because of the synthetic availability of a large repertoire of DNA conjugates.Acknowledgements
J.Z. gratefully acknowledges support from the National Natural Science Foundation of China (21274058) and the National Basic Research Program of China (2013CB922101, 2011CB935801).Notes and references
- (a) Microchip Methods in Diagnostics, ed. U. Bilitewski, Humana Press, New York, 2009 Search PubMed; (b) M. Debnath, G. B. K. S. Prasad and P. S. Bisen, Molecular Diagnostics: Promises and Possibilities, Springer, Dordrecht, 2010 Search PubMed; (c) Molecular Diagnostics: For the Clinical Laboratorian, ed. W. B. Coleman and G. J. Tsongalis, Humana Press, New York, 2006 Search PubMed; (d) M. Schena, D. Shalon, R. W. Davis and P. O. Brownt, Science, 1995, 270, 467–470 CAS; (e) L. Shi, et al. , Nat. Biotechnol., 2006, 24, 1151–1161 CrossRef CAS PubMed; (f) R. D. Canales, et al. , Nat. Biotechnol., 2006, 24, 1115–1122 CrossRef CAS PubMed; (g) M. J. Jonker, W. C. de Leeuw, M. Marinković, F. R. A. Wittink, H. Rauwerda, O. Bruning, W. A. Ensink, A. C. Fluit, C. H. Boel, M. de Jong and T. M. Breit, Nucleic Acids Res., 2014, 42, e94 CrossRef CAS PubMed.
- (a) J. Lee, P. W. Bisso, R. L. Srinivas, J. J. Kim, A. J. Swiston and P. S. Doyle, Nat. Mater., 2014, 13, 524–529 CrossRef CAS PubMed; (b) D. C. Appleyard, S. C. Chapin, R. L. Srinivas and P. S. Doyle, Nat. Protoc., 2011, 6, 1761–1774 CrossRef CAS PubMed; (c) H. Lee, J. Kim, H. Kim, J. Kim and S. Kwon, Nat. Mater., 2010, 9, 745–749 CrossRef CAS PubMed; (d) D. C. Pregibon, M. Toner and P. S. Doyle, Science, 2007, 315, 1393–1396 CrossRef CAS PubMed; (e) K. Braeckmans, S. C. De Smedt, C. Roelant, M. Leblans, R. Pauwels and J. Demeester, Nat. Mater., 2003, 2, 169–173 CrossRef CAS PubMed; (f) M. J. Dejneka, A. Streltsov, S. Pal, A. G. Frutos, C. L. Powell, K. Yost, P. K. Yuen, U. Müller and J. Lahiri, Proc. Natl. Acad. Sci. U. S. A., 2003, 100, 389–393 CrossRef CAS PubMed; (g) S. R. Nicewarner-Peña, R. G. Freeman, B. D. Reiss, L. He, D. J. Peña, I. D. Walton, R. Cromer, C. D. Keating and M. J. Natan, Science, 2001, 294, 137–141 CrossRef PubMed; (h) M. Han, X. Gao, J. Z. Su and S. Nie, Nat. Biotechnol., 2001, 19, 631–635 CrossRef CAS PubMed; (i) S. Birtwell and H. Morgan, Integr. Biol., 2009, 1, 345–362 RSC.
- (a) Y. Liu, H. Yao and J. Zhu, J. Am. Chem. Soc., 2013, 135, 16268–16271 CrossRef CAS PubMed; (b) X. Shu, Y. Liu and J. Zhu, Angew. Chem., Int. Ed., 2012, 51, 11006–11009 CrossRef CAS PubMed; (c) X. Zhou, S. Xia, Z. Lu, Y. Tian, Y. Yan and J. Zhu, J. Am. Chem. Soc., 2010, 132, 6932–6934 CrossRef CAS PubMed; (d) X. Zhou, P. Cao, Y. Tian and J. Zhu, J. Am. Chem. Soc., 2010, 132, 4161–4168 CrossRef CAS PubMed; (e) M. Hong, X. Zhou, Z. Lu and J. Zhu, Angew. Chem., Int. Ed., 2009, 48, 9503–9506 CrossRef CAS PubMed; (f) F. Qiu, D. Jiang, Y. Ding, J. Zhu and L. L. Huang, Angew. Chem., Int. Ed., 2008, 47, 5009–5012 CrossRef CAS PubMed.
- (a) B. Wei, M. Dai and P. Yin, Nature, 2012, 485, 623–627 CrossRef CAS PubMed; (b) Y. Ke, L. L. Ong, W. M. Shih and P. Yin, Science, 2012, 338, 1177–1183 CrossRef CAS PubMed.
- (a) Y. Ke, S. Lindsay, Y. Chang, Y. Liu and H. Yan, Science, 2008, 319, 180–183 CrossRef CAS PubMed; (b) Z. Zhang, Y. Wang, C. Fan, C. Li, Y. Li, L. Qian, Y. Fu, Y. Shi, J. Hu and L. He, Adv. Mater., 2010, 22, 2672–2675 CrossRef CAS PubMed; (c) Z. Zhang, D. Zeng, H. Ma, G. Feng, J. Hu, L. He, C. Li and C. Fan, Small, 2010, 6, 1854–1858 CrossRef CAS PubMed; (d) H. K. K. Subramanian, B. Chakraborty, R. Sha and N. C. Seeman, Nano Lett., 2011, 11, 910–913 CrossRef CAS PubMed.
- (a) C. Lin, R. Jungmann, A. M. Leifer, C. Li, D. Levner, G. M. Church, W. M. Shih and P. Yin, Nat. Chem., 2012, 4, 832–839 CrossRef CAS PubMed; (b) R. Jungmann, M. S. Avendaño, J. B. Woehrstein, M. Dai, W. M. Shih and P. Yin, Nat. Methods, 2014, 11, 313–318 CrossRef CAS PubMed.
- P. Eaton and P. West, Atomic Force Microscopy, Oxford University Press, Oxford, 2010 Search PubMed.
- (a) B. Huang, M. Bates and X. Zhuang, Annu. Rev. Biochem., 2009, 78, 993–1016 CrossRef CAS PubMed; (b) M. Fernández-Suárez and A. Y. Ting, Nat. Rev. Mol. Cell Biol., 2008, 9, 929–943 CrossRef PubMed.
- N. C. Seeman, J. Biomol. Struct. Dyn., 1990, 8, 573–581 CAS.
- G. Bellot, M. A. McClintock, C. Lin and W. M. Shih, Nat. Methods, 2011, 8, 192–194 CrossRef CAS PubMed.
- B. Ding, Z. Deng, H. Yan, S. Cabrini, R. N. Zuckermann and J. Bokor, J. Am. Chem. Soc., 2010, 132, 3248–3249 CrossRef CAS PubMed.
- C.-T. Bock, S. Franz, H. Zentgraf and J. Sommerville, Electron Microscopy of Biomolecules, in Encyclopedia of Molecular Cell Biology and Molecular Medicine, ed. R. A. Meyers, John Wiley & Sons, New York, 2006, pp. 103–128 Search PubMed.
- (a) M. Zheng, A. Jagota, E. D. Semke, B. A. Diner, R. S. Mclean, S. R. Lustig, R. E. Richardson and N. G. Tassi, Nat. Mater., 2003, 2, 338–342 CrossRef CAS PubMed; (b) J. Robertson and E. P. O'Reilly, Phys. Rev. B: Condens. Matter Mater. Phys., 1987, 35, 2946–2957 CrossRef CAS.
- (a) S.-Y. Teh, R. Lin, L.-H. Hung and A. P. Lee, Lab Chip, 2008, 8, 198–220 RSC; (b) P. W. Sutter and E. A. Sutter, Nat. Mater., 2007, 6, 363–366 CrossRef CAS PubMed; (c) B. Qian, M. Loureiro, D. A. Gagnon, A. Tripathi and K. S. Breuer, Phys. Rev. Lett., 2009, 102, 164502 CrossRef; (d) A. Meister, M. Liley, J. Brugger, R. Pugin and H. Heinzelmann, Appl. Phys. Lett., 2004, 85, 6260–6262 CrossRef CAS PubMed; (e) P. Actis, A. C. Mak and N. Pourmand, Bioanal. Rev., 2010, 1, 177–185 CrossRef PubMed; (f) T. Takami, B. H. Park and T. Kawai, Nano Convergence, 2014, 1, 17 CrossRef PubMed.
- N. L. Rosi and C. A. Mirkin, Chem. Rev., 2005, 105, 1547–1562 CrossRef CAS PubMed.
- (a) E. S. Andersen, M. Dong, M. M. Nielsen, K. Jahn, R. Subramani, W. Mamdouh, M. M. Golas, B. Sander, H. Stark, L. P. Oliveira, J. S. Pedersen, V. Birkedal, F. Besenbacher, K. V. Gothelf and J. Kjems, Nature, 2009, 459, 73–77 CrossRef CAS PubMed; (b) S. M. Douglas, H. Dietz, B. Liedl, F. Graf and W. M. Shih, Nature, 2009, 459, 414–418 CrossRef CAS PubMed; (c) D. Yan, S. Pal, J. Nangreave, Z. Deng, Y. Liu and H. Yan, Science, 2011, 332, 342–346 CrossRef PubMed.
- (a) J. B. Wagner, F. Cavalca, C. D. Damsgaard, L. D. L. Duchstein and T. W. Hansen, Micron, 2012, 43, 1169–1175 CrossRef CAS PubMed; (b) J. R. Jinschek, Chem. Commun., 2014, 50, 2696–2706 RSC; (c) F. Tao and M. Salmeron, Science, 2011, 331, 171–174 CrossRef CAS PubMed.
Footnote |
| † Electronic supplementary information (ESI) available: Experimental details, additional DNA detection figures, and DNA sequence information. See DOI: 10.1039/c4sc02696a |
| This journal is © The Royal Society of Chemistry 2015 |