
A novel electronic nose for simultaneous quantitative determination of concentrations and odor intensity analysis of benzene, toluene and ethylbenzene mixtures
Shen Jiang,
Jiemin Liu*,
Di Fang,
Luchun Yan and
Chuandong Wu
University of Science and Technology Beijing, School of Chemistry and Biological Engineering, Beijing 100083, China. E-mail: liujm@ustb.edu.cn; Fax: +86-10-6234-7649; Tel: +86-10-6233-3751
First published on 1st September 2015
Abstract
Aromatic hydrocarbons (benzene, toluene, ethylbenzene etc.) are part of the main components of air pollution and odor nuisance. However, previous studies on simultaneous detection of aromatic mixtures and odor intensity analysis by an electronic nose (E-nose) are limited. The aim of this study is to develop a novel E-nose system to simultaneously determine chemical concentrations and odor intensity of benzene, toluene and ethylbenzene mixtures. The system consists of a sensor array with 5 gas sensors, a signal converter and a pattern recognition system which is based on a Back Propagation (BP) neural network. 300 groups of aromatic hydrocarbon mixtures (benzene, toluene and ethylbenzene) with different concentrations were determined by sensor array and gas chromatography (GC) to build, test and optimize the BP neural network. Then the optimum structure and functions of the BP network were verified by about 50 runs of contrast tests. The results showed that the average relative error of concentrations measured by the E-nose system was 9.71% relative to the results of GC. Furthermore, six odor intensity prediction models were used to convert the concentrations of the aromatic mixtures to their odor intensity. Based on the comparison with sensory analysis, the Weber–Fechner law model, the vector model and the simplified extended vectorial model were adopted to predict the odor intensity of single, binary and ternary compounds respectively.
1. Introduction
Aromatic hydrocarbons (benzene, toluene, ethylbenzene etc.) form an important group of volatile organic compounds (VOCs) and have been confirmed as part of the most malodorous components.1,2 Previous studies showed that the emission of aromatic hydrocarbons may occur in both indoor (living rooms, plants etc.)3,4 and outdoor (landfill, industrial areas, oil refineries etc.) environments5,6 which may cause leukemia, lung tumors, myelitis, epilepsy and other occupational health problems to nearby residents.7,8 With the increase of public concern, monitoring aromatic hydrocarbons became vital and the analysis methods as well as the apparatus have attracted much attention.Since the start of 21st century, there has been increasing research in order to achieve more objective and faster methods to analyze VOCs, which led to the development of the E-nose system. An E-nose system is a gas monitoring instrument that mainly comprises a sensor array and an appropriate pattern-recognition system capable of recognizing samples.9–11 At present, the pattern-recognition system is the key part because it affects analysis results greatly. For example, principal component analysis (PCA), support vector machines (SVM) and partial least squares (PLS) were most used for qualitative analysis of multiple VOCs,12–14 independent component analysis (ICA) and singular value decomposition (SVD) were most applied in quantitative analysis of a single gas,12,15–17 while the most common method for odor identification and determination of odor intensity were artificial neural networks (ANNs).9,17–19
However, to the best of our knowledge, most existing E-noses always fail to achieve precise quantitative analysis of gas mixtures. In addition, most E-noses associated the sensors response values with odor intensity directly and used an odor sensory method to test the odor intensity.20–22 When the target compound was changed, the whole E-nose system had to be rebuilt, requiring more effort. In previous studies, odor intensity prediction models, which can convert chemical concentrations to odor intensity by mathematical formulas, had been applied for odor determination.17,23–25 The formulas can be compiled to code and written into an ANN that expanded the scope of the application. Meanwhile, the air quality needs to be evaluated by both odor intensity and chemical concentrations of VOCs.26 Taking the complicated sources of aromatic hydrocarbons into account, it is necessary to develop a novel E-nose system to analyze concentrations and odor intensity of aromatic hydrocarbons.
In this study, a novel E-nose system which included a sensor array, a signal converter and a pattern recognition system was developed to simultaneously determine chemical concentrations and odor intensity of benzene, toluene and ethylbenzene mixtures. The sensor array was equipped with 5 selected sensors. The signal converter converted electrical signals to response values and a back propagation (BP) neural network was chosen as the pattern recognition system which converted the response values of the components in the mixtures to individual concentrations. Then the concentrations determined by the E-nose were correlated to the results from a gas chromatography-flame ionization detector (GC-FID).27 Furthermore, six prediction models were adopted to convert the concentrations to odor intensity of mixtures and the results were verified by the comparison with sensory analysis.
2. Materials and methods
2.1 Sensor array for E-nose
The most significant component of an artificial olfaction system is the sensor array. The signal of the sensor array is interpreted by some computational methods to present the measured results of gas concentrations or other characteristics. Among most E-noses, metal oxide sensors were mostly used due to its long-term stability.28 Catalytic combustion type and electrochemical type were also selected occasionally.29 In this study, 12 sensors, which belong to the three types listed above and were from three manufacturers, were selected to compose the sensor array. Their basic data is shown in Table 1.| Name | Manufacturer | Type |
|---|---|---|
| 2M008 | Guotaihengan | Metal oxide |
| TGS2610 | Figaro | Metal oxide |
| TGS822 | Figaro | Metal oxide |
| TGS823 | Figaro | Metal oxide |
| TGS825 | Figaro | Metal oxide |
| TGS826 | Figaro | Metal oxide |
| MQ6 | Winsen | Metal oxide |
| WSP2620 | Winsen | Metal oxide |
| MC115 | Winsen | Catalytic combustion |
| MC119 | Winsen | Catalytic combustion |
| ME3-C6 | Winsen | Electrochemical |
| ME3-C7 | Winsen | Electrochemical |
2.2 E-nose system setup
A customized E-nose has been developed and used for determining concentrations of aromatic hydrocarbon gases in this study and the schematic is presented in Fig. 1. A cylindrical glass container (volume of 17.3 L) with a hole (diameter of 4 cm) in its lid worked as the gas vessel. A simple plug was used to seal the vessel, then another one was used to seal and connect to the sensor array. Therefore, when the latter was used, the hole was plugged up and the gas in the sealed vessel would have full contact with the array at the same time. The conditions of the whole gas vessel were kept constant using a temperature and humidity instrument, the temperature was 25 ± 0.5 °C and the relative humidity was 45–50%.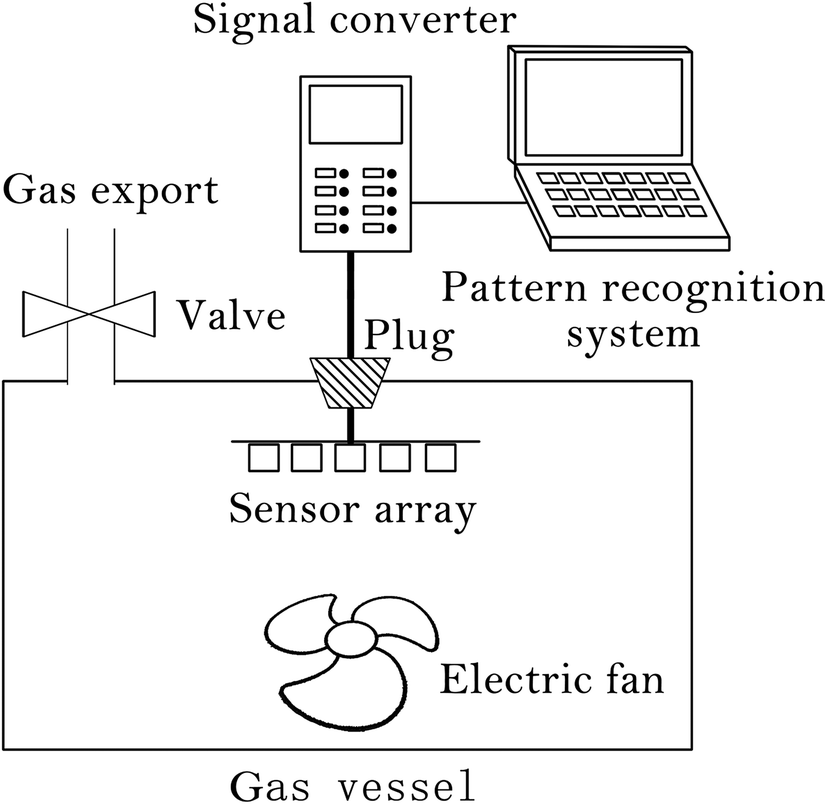 | ||
| Fig. 1 The basic structure of the E-nose system. | ||
Originally, the sensor array was composed of 12 gas sensors, a temperature sensor and a humidity sensor. As the experiments proceeded, the unsuitable sensors were removed while the suitable sensors were retained (the selection method is shown in Section 2.4). The response values of the sensor array were converted from electrical signals to digital signals by the signal converter, and recorded by the pattern recognition system. The method of pattern recognition used in this study was a BP neural network30 and its procedure code was compiled by Matlab (Matrix & Laboratory, programming software).
2.3 Database measurement method
![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :10. The column oven temperature was set at 60 °C for 3 min and increased up to 150 °C at a rate of 10 °C min−1 and held for 3 min.
:10. The column oven temperature was set at 60 °C for 3 min and increased up to 150 °C at a rate of 10 °C min−1 and held for 3 min.GC-measured concentrations and E-nose response values composed the databases used to build, test and optimize the BP network.
2.4 Selection and characterization of the sensor array
In accordance with the method in Section 2.3, 0.4 μL working solution of benzene was injected into the vessel. After completely volatilizing, the concentration of gaseous benzene in the vessel was 20 mg m−3. If the response value of a sensor remained on the baseline, this meant that the sensor was not suitable for measuring benzene. The same procedure was used to select the suitable sensors for toluene and ethylbenzene. Finally, the sensors unsuitable for all three compounds were weeded out and the rest of the sensors composed the array of the E-nose.2.5 Concentration determination
Another database composed of different response values and the corresponding chemical concentrations was needed to test and optimize the E-nose system, which was called the test database and the data in it were called test data. The test database included 80 groups of data which were also uniformly distributed in the range of 5 mg m−3 to 200 mg m−3. All test data were different from training data and were measured by the method in Section 2.3.
The BP neural network is a nonlinear and self-adaptive information processing system and consists of a large number of processing units.30 The basic structure includes input layers, hidden layers and output layers. Each layer is composed of neurons and a transfer function. In this study, the dimensions of the input and output vectors were consistent with that of input and output layers and were determined by the number of sensors and the types of measured gases. The number of input layer neurons was five and the number of output layer neurons was three. The hidden layers had a most important influence on the BP neural network’s results, so the amount of hidden layers and neurons in each layer as well as the transfer function types need to be tested and optimized.
The BP neural network can be built with the simplest hidden layer structure, but the training failed to converge with too few hidden layers or neurons. Therefore, the system began with only one hidden layer and added one each time until the convergence started.
Before the training, the training data were normalized,35 the normalization formula was
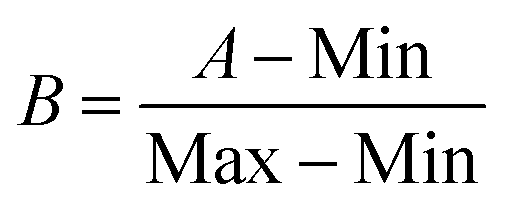 | (1) |
After normalization and training convergence, the BP network was built. Since the result of each training was different, in order to reduce the random error, the data were trained three times, and every result was stored respectively. These three same networks were called parallel networks.
After training completion, each parallel neural network was invoked again, and the 80 groups of test data (which were normalized by the same method) were led in, the measuring results were calculated by Matlab. Because of the simple structure of the network, the results were of low accuracy, so the BP neural network needed be tested and optimized. Firstly, the transfer function and the training function were tested in sequence to make the measuring more accurate. Then, a number of hidden layers were added from the minimum to the number which could make the measuring result achieve the best accuracy. The same method was used for testing and optimizing the number of neurons in each hidden layer. The whole process of modification was a single variable experiment and all tests were repeated three times.
2.6 Odor intensity determination
To date, many prediction models have proven their ability to convert concentrations to odor intensity.24 In this study, the optimum models for aromatic hydrocarbons were selected and the constants for each model were calculated. The odor intensity of a series of aromatic hydrocarbon gases of different concentrations (5 mg m−3 to 200 mg m−3) were measured by an odor sensory method. Then, linear regression and nonlinear regression were used to calculate the constants. The detailed measurement method was as follows: each compound tested was respectively injected into an olfactory-bag (3 L volume and full of clean air), when all the compounds had completely evaporated, an odor sample was prepared by transferring a certain quantity of the gas from the previous olfactory-bag to a new bag by an injector. Then 6 sniffing panelists evaluated the testing gas according to the odor intensity referencing scale (OIRS, from level 1 (aqueous solution of 1-butanol of 12 mg m−3) to level 8 (1550 mg m−3) with a geometric progression of two),23 and the mean results were calculated as the final odor intensity.After all of the constants were confirmed, the odor intensity of the gases, whose concentrations were same as the test database, was measured by the odor sensory method. The prediction models were employed to predict the odor intensity and the results were compared with the sniffed values, then the optimum models were determined.
3. Results and discussion
3.1 The sensor array
After selecting all sensors, the suitable sensors MC119, MQ6 and TGS2610 responded to benzene, toluene and ethylbenzene. Sensor 2M008 responded to toluene and ethylbenzene. Sensor WSP2620 only responded to ethylbenzene.For the E-nose, the very short measuring time is one of the significant advantages, while the response and recovery time are the main restricting factors. So in accordance with the method in Section 2.3, the response values for 100 mg m−3 benzene, toluene and ethylbenzene were measured. As shown in Fig. 2, the response values, response time and recovery time were all recorded and the response recovery curve was drawn. The values of MC119 were not very stable, so the average of 15 continuous tested values was defined as its response value.36 The response time of all sensors was less than 4 minutes and the recovery time was less than 2 minutes. The rapid measuring speed made the determination process finish in 10 minutes, compared with the traditional method, the determination time was greatly shortened.
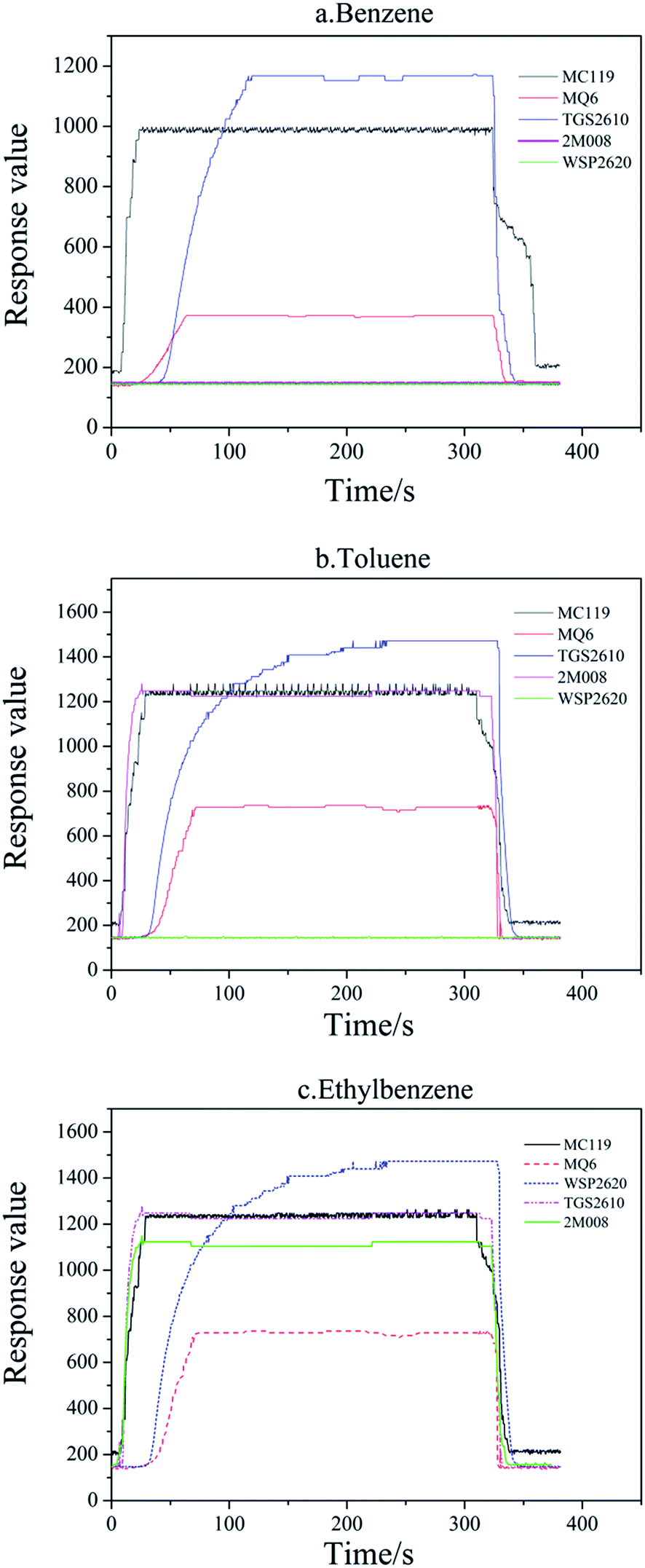 | ||
| Fig. 2 The sensor array response recovery curves. | ||
In order to test the stability of the sensor array, twenty groups of response values for the single gases benzene, toluene and ethylbenzene were measured respectively. The concentrations ranged from 5 mg m−3 to 200 mg m−3 and the interval was 10 mg m−3. All data was measured three times and the relative standard deviations (RSD) of the response values were calculated, the results are shown in Fig. 3. All RSD values were less than 7%, which show that the experiment had good precision.
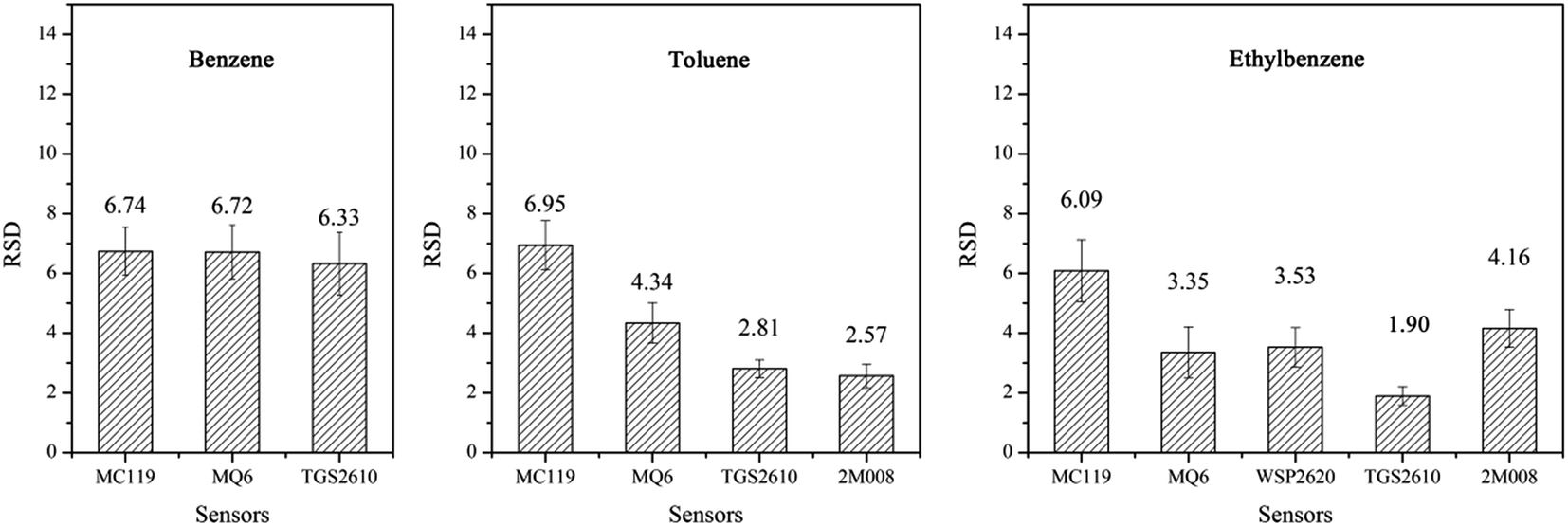 | ||
| Fig. 3 The relative standard deviation of benzene, toluene and ethylbenzene. | ||
3.2 BP network test and optimization
The purpose of this section is to get the minimum error results by testing and optimizing the BP network structure. As the method in 2.5 states, transfer function, training function, the number of hidden layers and the number of neurons in each hidden layer all needed to be modified. The functions ‘logsig’, ‘purelin’ and ‘trainbfg’ were set as default, and the minimum number of hidden layers and neurons which can make training convergent were 3 and 16 respectively. Other parameters would then be discussed.Relative to the transfer function, the training functions have a greater significance. In Matlab, fifteen kinds of training functions were provided. With ‘logsig’ and ‘purelin’, 3 hidden layers and 16 neurons as the parameters, all training functions were used to train the network. The AREs of all functions were calculated and the results showed that ‘trainlm’ had the smallest error and the value was 12.77%.
As discussed above, the BP neural network used ‘logsig’ and ‘purelin’ as transfer functions and ‘trainlm’ as the training function and was composed of 210 groups of training data, a 5 dimension input layer and a 3 dimension output layer, 6 hidden layers and 20 neurons in every layer.
3.3 Comparative analysis of the E-nose and GC-FID
From the measurements of 80 groups of test data, the results show that the network could measure the chemical concentrations of benzene, toluene and ethylbenzene in the range of 5 mg m−3 to 200 mg m−3. The test set was used to validate the determination capabilities of the E-nose (Fig. 4). The Pearson correlation coefficient, the significance of paired-sample T-test with 95% confidence interval, the ARE of the predicted results and the correlation coefficient between the E-nose and GC-FID measured values are shown in Table 2. The results show that the E-nose system could determine respective concentrations of aromatic hydrocarbon mixtures simultaneously and it had a high accuracy relative to GC-FID.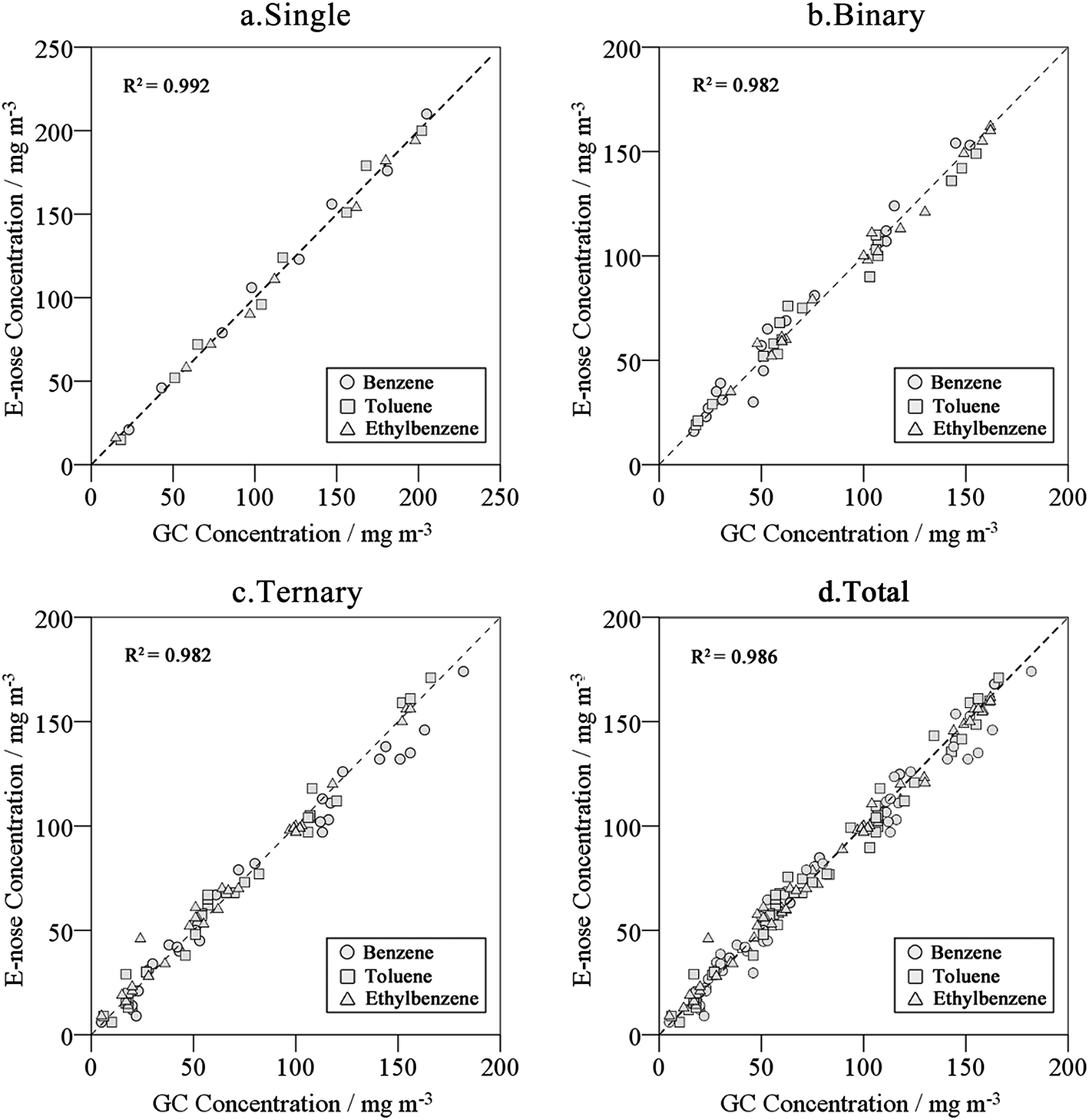 | ||
| Fig. 4 The relationship of CG-FID versus E-nose results from linear regression. | ||
| Pearson | Significance | ARE/% | R2 | |
|---|---|---|---|---|
| Single | 0.996 | 0.911 | 4.90 | 0.992 |
| Binary | 0.991 | 0.982 | 7.13 | 0.982 |
| Ternary | 0.984 | 0.559 | 12.34 | 0.982 |
| Total | 0.990 | 0.622 | 9.71 | 0.986 |
3.4 Odor intensity analysis
Odor pollution has been one of the seven major environmental pollution hazards and aromatic hydrocarbons are one of the most common causes of odor pollutants. After years of experimental research, a conclusion had been found that for a single material, the odor intensity increased with increasing chemical concentration, but it was not a simple linear relationship. Furthermore, due to the interaction between odor compounds, the total odor intensity of multiple mixtures is not simply the sum of all the components which make the prediction become difficult.| Models | Formula |
|---|---|
| a I: odor intensity, C: odorant concentration (mg m−3), It: the total odor intensity, Ii, IA, IB and IC: independent odor intensity of every component, P: the number of gases, k, n and cosα: constant specific to the odorant, OAV: the result of concentration value divided by odor threshold. |
|
| Weber–Fechner law | I = KlogC + n |
| Power law model | I = KCn |
| Linear model | I = Kln(OAV) + n |
| Vector model | It2 = IA2 + IB2 + 2cosαIAIB |
| EV model | It2 = IA2 + IB2 + IC2 + 2IAIBcosαAB + 2IAICcosαAC + 2IBICcosαBC |
| EA model | 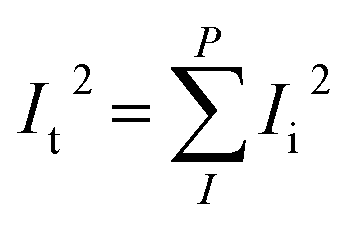 |
| SC model | It = MAX(Ii) |
Through the study of the interaction of odor, for the ternary mixtures, there was a linear relationship between the sum of the odor intensity of the entire single compound (sum intensity, Is) and the odor intensity of the mixture (total intensity, It). If the odor intensity of each single compound (single intensity, IA) is approximately equal, the degree of interaction of the compounds remains the same.24 For the benzene, toluene and ethylbenzene, through sniff and calculation, the formula was
| It = 0.36815Is = 0.36815(3IA) = 1.10445IA | (2) |
When the single intensity was approximately equal, the formula of EV model was
|
It2 = 3IA2 + 2IA2(cosαAB + cosαAC + cosαBC)
| (3) |
For this study, the constants were confirmed, so set
|
cosαAB + cosαAC + cosαBC = 3cosα
| (4) |
The formula was changed to
|
It2 = 3IA2 + 6IA2cosα = 3IA2(1 + 2cosα)
| (5) |
When formula (2) was put into formula (5), the formula was changed to
|
(1.10445IA)2 = 3IA2(1 + 2cosα)
| (6) |
Then, the cosα was calculated, the result was −0.30. The formula for the simplified extended vectorial (SEV) model was
| It2 = IA2 + IB2 + IC2 − 0.60(IAIB + IAIC + IBIC) | (7) |
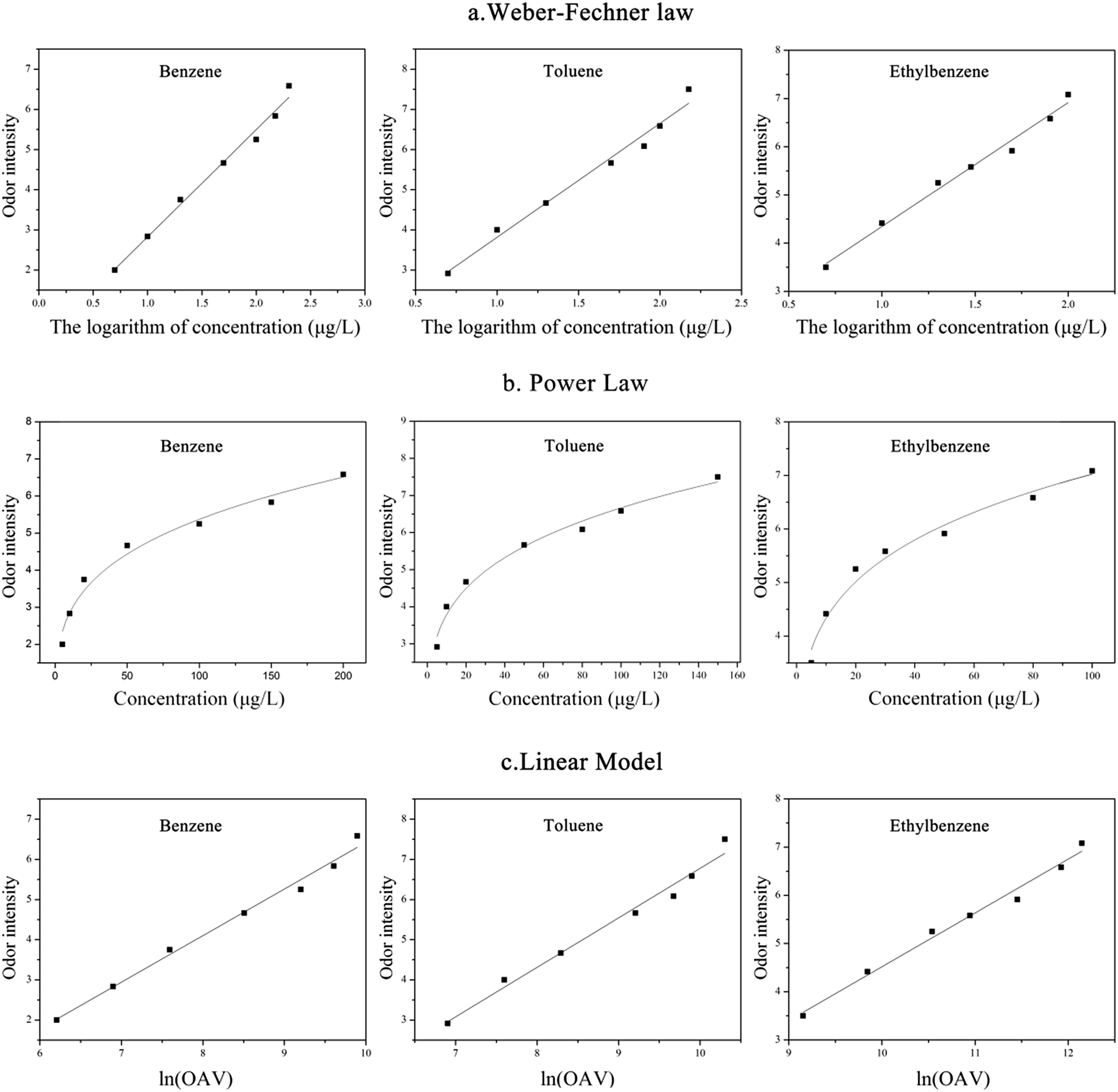 | ||
| Fig. 5 The results of regression of Weber–Fechner law, power law model and linear model. | ||
| Compound | Weber–Fechner law | R2 | Power law | R2 | Linear model | R2 |
|---|---|---|---|---|---|---|
| a I: odor intensity, C: odorant concentration (mg m−3), OAV: the result of concentration value divided by odor threshold. | ||||||
| Benzene | I = 2.6704logC + 0.1531 |
0.9893 | I = 1.5040C0.2765 | 0.9803 | I = 1.1598ln(OAV) − 5.1174 |
0.9871 |
| Toluene | I = 2.8372logC + 0.9766 |
0.9823 | I = 2.1482C0.2459 | 0.9845 | I = 1.2322ln(OAV) − 5.5470 |
0.9787 |
| Ethylbenzene | I = 2.5710logC + 1.7742 |
0.9875 | I = 2.6727C0.2098 | 0.9798 | I = 1.1166ln(OAV) − 6.6476 |
0.9851 |
The measuring method in Section 2.5 was used to measure the chemical concentrations for the test database by the E-nose, then the prediction models were used to convert the chemical concentrations to the odor intensity. These results were called the predicted results. The method in Section 2.7 was used to measure the odor intensity of all samples, these results were called the measured results.
These predicted results and measured results were compared and the best models were applied in the E-nose system. The Pearson correlation coefficient, the significance of paired-sample T-test with 95% confidence interval and the ARE of the predicted results were shown in Table 5. As shown in the results, the Weber–Fechner law model, the vector model and the SEV model had the smallest average relative error which meant the best precision and accuracy. So these three models were used to predict the odor intensity. The total ARE was 5.31%, the Pearson correlation coefficient was 0.947 and significance of paired-sample T-test was 0.175.
| Sample quantity | Models | Pearson | Significance | ARE | |
|---|---|---|---|---|---|
| Single | 24 | Weber–Fechner law | 0.971 | 0.468 | 4.96% |
| Power law model | 0.971 | 0.524 | 6.10% | ||
| Linear model | 0.971 | 0.089 | 6.67% | ||
| Binary | 27 | Vector model | 0.929 | 0.596 | 5.21% |
| SC model | 0.818 | 0.255 | 8.37% | ||
| EA model | 0.934 | 0 | 20.58% | ||
| Ternary | 29 | SEV model | 0.909 | 0.301 | 5.86% |
| SC model | 0.731 | 0.025 | 9.98% | ||
| EA model | 0.884 | 0 | 53.85% |
Finally, Matlab was used to edit the code and the formula for each of the best prediction models was written into the program to realize the function that can simultaneously determine the chemical concentrations and the odor intensity.
3.5 Comparison with previously reported E-noses
Compared with previously reported E-noses, the testing time for one test was less than ten minutes, which has the advantage of fast determination.On the analysis of error, the relative errors of the chemical concentrations and odor intensity were 9.71% and 5.31%, respectively. Therefore, the accuracy of the novel E-nose maintained a similar level in comparison to previously reported E-noses.
In the field of environmental research, the application of previously reported E-noses focused on the qualitative analysis of single or mixed gases, quantitative determination of concentrations of single gases or odor analysis. However, there have been few studies on the simultaneous quantitative analysis of mixed gases, so it was still a problem that needed to be solved. The E-nose in this paper could quantitatively determine the chemical concentrations and measure the odor intensity of aromatic hydrocarbon mixed gases simultaneously, which extends the range of its application.
4. Conclusion
In the present study, an E-nose system which is based on a BP neural network was designed. It could rapidly, conveniently and accurately determine the chemical concentrations and odor intensity of mixtures of benzene, toluene and ethylbenzene in the range of 5 mg m−3 to 200 mg m−3. The average relative errors of the concentrations and odor intensity were 9.71% and 5.31%, respectively. The concentrations were measured by a BP neural network while the odor intensity was measured by a model prediction. The different models for single, binary and ternary compounds were the Weber–Fechner law model, the vector model and the simplified extended vectorial model respectively. The overall results of the study indicate the potential of the E-nose as a device for the determination of chemical concentrations and odor intensity of aromatic hydrocarbon mixtures.Acknowledgements
This work was jointly supported by the National Natural Science foundation of the People’s Republic of China (No. 21277011 and No. 21576023), National High Technology Research and Development Program of (863) China (No. 2012AA030302) and the Fundamental Research Funds for the Central Universities (No. FRF-BR-13-005). The authors would like to thank Mr Zhanwu Ning and Mr Jinhua Liu, from Beijing Municipal Institute of Labour Protection for their help with the signal converter design.References
- MEPPRC, Ministry of Environmental Protection of the People’s Republic of China, China, 1993.
- MEPPRC, Ministry of Environmental Protection of the People’s Republic of China, China, 1996.
- K. Demeestere, J. Dewulf, B. de Witte, A. Beeldens and H. van Langenhove, Build. Environ., 2008, 43, 406–414 CrossRef PubMed.
- S. K. Lim, H. S. Shin, K. S. Yoon, S. J. Kwack, Y. M. Um, J. H. Hyeon, H. M. Kwak, J. Y. Kim, T. Y. Kim, Y. J. Kim, T. H. Roh, D. S. Lim, M. K. Shin, S. M. Choi, H. S. Kim and B. M. Lee, J. Toxicol. Environ. Health, Part A, 2014, 77, 1502–1521 CrossRef CAS PubMed.
- M. Kitwattanavong, T. Prueksasit, D. Morknoy, T. Tunsaringkarn and W. Siriwong, Hum. Ecol. Risk Assess., 2013, 19, 1424–1439 CrossRef CAS PubMed.
- E. Durmusoglu, F. Taspinar and A. Karademir, J. Hazard. Mater., 2010, 176, 870–877 CrossRef CAS PubMed.
- S. Billet, V. Paget, G. Garcon, N. Heutte, V. Andre, P. Shirali and F. Sichel, Arch. Toxicol., 2010, 84, 99–107 CrossRef CAS PubMed.
- G. T. Johnson, S. C. Harbison, J. D. McCluskey and R. D. Harbison, Regul. Toxicol. Pharmacol., 2009, 55, 361–366 CrossRef CAS PubMed.
- M. Peris and L. Escuder-Gilabert, Anal. Chim. Acta, 2009, 638, 1–15 CrossRef CAS PubMed.
- C. Wongchoosuk, K. Subannajui and C. Wang, RSC Adv., 2014, 66, 35084–35088 RSC.
- S. Yang, S. Xie and M. Xu, Anal. Methods, 2015, 7, 943–952 RSC.
- L. Zhang and F. C. Tian, Anal. Chim. Acta, 2014, 816, 8–17 CrossRef CAS PubMed.
- M. Delgado-Rodríguez, M. Ruiz-Montoya, I. Giraldez, R. López, E. Madejón and M. J. Díaz, Atmos. Environ., 2012, 51, 278–285 CrossRef PubMed.
- L. Zhang, F. Tian, H. Nie, L. Dang, G. Li, Q. Ye and C. Kadri, Sens. Actuators, B, 2012, 174, 114–125 CrossRef CAS PubMed.
- D. Gao, F. Liu and J. Wang, Sens. Actuators, B, 2012, 161, 578–586 CrossRef CAS PubMed.
- T. Feng, H. Zhuang, R. Ye, Z. Jin, X. Xu and Z. Xie, Sens. Actuators, B, 2011, 160, 964–973 CrossRef CAS PubMed.
- S. Deshmukh, A. Jana, N. Bhattacharyya, R. Bandyopadhyay and R. A. Pandey, Atmos. Environ., 2014, 82, 401–409 CrossRef CAS PubMed.
- S. Deshmukh, K. Kamde, A. Jana, S. Korde, R. Bandyopadhyay, R. Sankar, N. Bhattacharyya and R. A. Pandey, Anal. Chim. Acta, 2014, 841, 58–67 CrossRef CAS PubMed.
- B. Karlik and Y. Bastaki, WSEAS Transactions on Electronics, 2004, 1, 337–342 Search PubMed.
- O. Ramalho, Analusis, 2000, 28, 207–215 CrossRef CAS.
- B. Raman, T. Yamanaka and R. Gutierrez-Osuna, Sens. Actuators, B, 2006, 119, 547–555 CrossRef CAS PubMed.
- A. Szczurek and M. Maciejewska, Sens. Actuators, B, 2005, 106, 13–19 CrossRef CAS PubMed.
- L. Yan, J. Liu, G. Wang and C. Wu, Sensors, 2014, 14, 12256–12270 CrossRef CAS PubMed.
- B. Berglund and M. J. Olsson, Percept. Psychophys., 1993, 53, 475–782 CrossRef CAS.
- J. P. Groten, Food Chem. Toxicol., 2000, 38, S65–S71 CrossRef CAS.
- MEPPRC, Ministry of Environmental Protection of the People’s Republic of China, 2012.
- N.-s. Ai, H.-l. Liu and J. Wang, Anal. Methods, 2015, 10, 4278–4284 RSC.
- M. M. Arafat, B. Dinan, S. A. Akbar and A. S. Haseeb, Sensors, 2012, 12, 7207–7258 CrossRef CAS PubMed.
- J. R. S. J. Li, Chem. Rev., 2008, 108, 352–366 CrossRef PubMed.
- W. J. Zhao, Z. Zhou, M. Y. Yu, M. M. Wang and Y. B. Shi, Appl. Mech. Mater., 2013, 274, 587–591 CrossRef.
- B. Adhikari and S. Majumdar, Prog. Polym. Sci., 2004, 29, 699–766 CrossRef CAS PubMed.
- L. Zhang, F. Tian, C. Kadri, G. Pei, H. Li and L. Pan, Sens. Actuators, B, 2011, 160, 760–770 CrossRef CAS PubMed.
- MHPRC, Ministry of Health of the People’s Republic of China, China, 1999.
- L. Zhang, F. Tian, C. Kadri, B. Xiao, H. Li, L. Pan and H. Zhou, Sens. Actuators, B, 2011, 160, 899–909 CrossRef CAS PubMed.
- S. Pashami, A. J. Lilienthal and M. Trincavelli, Sensors, 2012, 12, 16404–16419 CrossRef CAS PubMed.
- E. Kim, S. Lee, J. H. Kim, C. Kim, Y. T. Byun, H. S. Kim and T. Lee, Sensors, 2012, 12, 16262–16273 CrossRef CAS PubMed.
- P. Laffort, Chem. Senses, 1982, 7, 153–174 CrossRef PubMed.
- J. B. Rosenholm, Adv. Colloid Interface Sci., 2010, 156, 14–34 CrossRef CAS PubMed.
- J. E. Cometto-Muniz, W. S. Cain and M. H. Abraham, Indoor Air, 2004, 14, 108–117 CrossRef PubMed.
| This journal is © The Royal Society of Chemistry 2015 |