DNA origami: Fold, stick, and beyond
Akinori
Kuzuya
* and
Makoto
Komiyama
*
Research Center for Advanced Science and Technology, The University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8904, Japan. E-mail: kuzu@mkomi.rcast.u-tokyo.ac.jp; komiyama@mkomi.rcast.u-tokyo.ac.jp; Fax: (+81) 3 5452 5209; Tel: (+81) 3 5452 5200
First published on 24th November 2009
Abstract
DNA origami is the process in which long single-stranded DNA molecules are folded into arbitrary planar nanostructures with the aid of many short staple strands. Since its initial introduction in 2006, DNA origami has dramatically widened the scope of applications of DNA nanotechnology based on the programmed assembly of branched DNA junctions. DNA origami can be used to construct not only arbitrary two-dimensional nanostructures but also nano-sized breadboards for the arraying of nanomaterials or even complicated three-dimensional nano-objects. In this review, we briefly look through the basic designs and applications of DNA origami and discuss the future of this technique.
 Akinori Kuzuya | Akinori Kuzuya received his BSc, MSc, and PhD degrees from the University of Tokyo in 1997, 1999, and 2002, respectively. Both his graduate and undergraduate research was carried out under the guidance of Professor Makoto Komiyama. After spending three years at the University of Tokyo as a postdoctoral fellow, he moved to New York University as a visting scholar to work with Professor Nadrian C. Seeman. He joined the faculty of the University of Tokyo as Assistant Professor in 2007. Among other awards, he is a recipient of the Award for Encouragement of Research in Polymer Science from The Society of Polymer Science, Japan. His principal research interests are in the areas of DNA nanotechnology, nucleic acids and supramolecular chemistry. |
 Makoto Komiyama | Makoto Komiyama graduated from the University of Tokyo in 1970, and got his PhD from the same University in 1975. After spending four years at Northwestern University (USA) as a postdoctoral fellow, he became an assistant professor at the University of Tokyo, and then an associate professor at University of Tsukuba. Since 1991, he has been a professor of the University of Tokyo. His main research area is bioorganic and bioinorganic chemistry. He has received Awards for Young Scientist from the Chemical Society of Japan, Japan IBM Science Award, Award from the Rare Earth Society of Japan, Inoue Prize for Science, The Award of the Society of Polymer Science, Japan, and others. |
1. Introduction
DNA nanotechnology based on the programmed assembly of branched DNA junctions, first demonstrated by Ned Seeman,1 has attracted broad interest from various research fields including chemistry, biology, materials science, and even computer science. Various DNA motifs have been developed, and used to construct beautiful two-dimensional DNA sheets or lattices of ∼10 nm resolution by self-assembly. Extensive studies are still being carried out to functionalize such structures.2 Although the pitch of the repeating units in the 2D assembly is sufficiently small, complicated nanofabrication of such lattices has not been easy because they are usually constructed by several kinds of DNA tiles, and thus the resulting structures are rather symmetric in a microscopic view. The most complicated DNAnanostructure was composed of 16 individual tiles.3 However, the yield of the correctly assembled species was only 34%. The density of address information in conventional DNA sheets or lattices has thus been limited. For “DNA origami”,4 by contrast, 2D addressing in a wide area (∼8500 nm2) with 6 nm resolution is possible in high yield since every part of the origami structure consists of distinguishable nucleotides. It is almost impossible to obtain such a complicated structure with a conventional tile-assembly strategy because of errors in hybridization. DNA origami is a landmark invention in the DNA nanotechnology field. Since its introduction in 2006, the use of DNA origami has been dramatically widened. Presently, DNA origami can provide not only arbitrary 2D nanostructures but also nano-sized breadboards for the arraying of nanomaterials and 3D nanostructures such as hollow polyhedrons or even more complicated nano-objects (Fig. 1). | ||
| Fig. 1 DNA origami and its applications. | ||
The term “DNA origami” is sometimes used in a broad sense. Paul Rothemund, the inventor of DNA origami, has classified the existing approaches in designing DNAnanostructures into three categories (Fig. 2): (1) “multi-stranded design” that is entirely composed of short oligonucleotides, (2) “single-stranded design” composed of one long “scaffold strand” and few or no “helper strand”, and (3) “scaffolded design” composed of one long scaffold strand and multiple short helper strands (Fig. 3).5 The multi-stranded approach is used to construct conventional designs based on the assembly of DNA tiles. The other two approaches, single-stranded and scaffolded designs, are termed DNA origami because one long scaffold is folded into any arbitrary pattern. The octahedron produced by Shih et al. in 2004 is a typical example—and the most successful—of the single-stranded DNA origami technique. However, most of the DNA origami studies reported today employ a scaffolded design. In this review, we will focus on DNA origami in this narrow sense, and we will briefly look through the basic design concepts and applications of DNA origami, and discuss its future.
 | ||
| Fig. 2 The three approaches in designs of DNAnanostructures: (a) “multi-stranded design” that is entirely composed of short oligonucleotides, (b) “single-stranded design” composed of one long scaffold strand and few or no “helper strand”, and (c) “scaffolded design” composed of one long “scaffold strand” (in blue) and multiple short helper strands (in red and green). | ||
 | ||
| Fig. 3 The three major motifs in DNA nanotechnology: DX, PX, and JX2 motifs. | ||
2. Basic elements of DNA nanotechnology
If one is familiar with a few of the basic elements used in DNA nanotechnology based on branched DNA junctions,6 it will be much easier to understand the concepts behind DNA origami designs (Fig. 3). The double crossover (DX) motif, which consists of two juxtaposed four-way junctions joined together by two double-helical domains, is the most fundamental motif in DNA nanotechnology. The most popular application of DX motifs is the construction of 2D arrays formed by the self-assembly of DX motifs.7 Almost all of the motifs developed in DNA nanotechnology so far are basically variations of the DX motif. The paranemic crossover (PX) motif,8 in which DNA strands of the same polarity are exchanged at every possible site between two adjacent double helices placed side-by-side, is another important motif in DNA nanotechnology. This motif is important because PX cohesion can be used as a mimic for sticky-ended cohesion to join two cyclic DNA strands without opening them.9 Another feature of the PX motif is that it can be isomerized to form its topo-isomer, the JX2 motif. The relative positions of the ends of the two helices in the PX and JX2 motifs are rotated 180° relative to one another, and this rotation can be triggered by exchanging two of the component strands in the motif with other strands. The PX motif is thus often used as the key component in DNA nanomechanical devices.103. Principles of DNA origami design and its preparation
DNA origami can be regarded, in a sense, as a large composite of DX motifs. A long scaffold runs back and forth throughout the whole area of the structure, and short single-stranded DNA molecules complementary to the scaffold, usually called “staple strands”, hold the adjacent portions of the scaffold together by forming crossovers at every (n + 0.5) helical turns of the DNA (Fig. 4). DNA origami uses more than 200 staple strands to fold the long scaffold, typically the 7249-nucleotide-long circular single-stranded M13 phage genome , into an arbitrary structure. | ||
| Fig. 4 Basic structure of DNA origami. The scaffold runs through the whole area of the shape back and forth, and the staple strands hold the structure together by binding to the multiple parts in the scaffold. (Reprinted with permission from ref. 4. © 2006 Nature Publishing Group). | ||
The first step in designing a DNA origami structure is to decide on the folding pattern of the scaffold. While the diameter of the canonical DNA helix is 2 nm and one helical turn is 10.5 nucleotides (nt) or 3.4 nm, in origami designing process, one helical turn of DNA is usually approximated to be 3–3.5 nm in length and 3.5 nm in width and is made up with 10.7 nt. This extended length is due to the inter-helix gap presumably induced by electrostatic repulsion. The 7249-nt scaffold can consequently cover ∼8500 nm2 when the scaffold is completely hybridized with staple strands. The folding path of the scaffold is chosen so that it passes through the whole area of the shape, running back and forth as if the area were painted in one stroke. In order to avoid any undesired strain on the helices, the scaffold can form a crossover (progression of the scaffold from one helix to another), but only at those locations where the scaffold is placed at a tangent point between helices. The distance between the crossovers formed by the scaffold should be an odd number of half helical turns when the scaffold progresses from the adjacent helix to a third helix, whereas distance between the crossovers should be an even number of half helical turns when the scaffold returns to the initial helix. The folding of the scaffold is fixed by the aid of many staple strands. Staple strands usually bind to three adjacent helices either in an S-shaped or Z-shaped geometry. The length is typically 32 nt when 1.5-turn spacing between the crossovers is used (52 nt for 2.5-turn spacing). The central 16-nt stretch binds to one helix, and each set of 8 nt at the ends binds to the adjacent helices. When all of the staples hybridize to the scaffold, a pair of helices is bundled by multiple crossovers located every 32 nt, and this pair of helices is connected to a third helix by framing a dihedral angle of 180°. DNA origami motifs with straight edges sometimes stick together at the edges since the DNAbase-pairs exposed at the edge are highly hydrophobic and tend to stack to each other. In order to prevent such aggregation, single-stranded portion (typically T4 loop) is often introduced to the staple strands located at the edges. Some of the staple strands can be modified with a “dumbbell hairpin” to provide “pixels” for surface patterning of origami structures with local height differences.
Once the staple strands are prepared, the origami structure can be obtained by simply mixing all of the staple strands and the scaffold in a buffered solution and allowing them to anneal. Usually 2–10 equivalents of staple strands are used for each equivalent of the scaffold, and they are mixed in a solution containing Tris (40 mM), acetic acid (20 mM), EDTA (2 mM), and magnesium acetate (12.5 mM, 1× TAE/Mg2+buffer). This mixture is first heated to 90 °C for up to 10 min in order to denature the DNA strands, and then the strands are annealed by slowly cooling the mixture to room temperature at a rate of −1.0 °C min−1 using a PCR thermal cycler. Confirmation of successful folding of the DNA origami structure is almost exclusively done by solution AFM imaging on freshly cleaved mica. The most popular buffer for imaging is 1× TAE/Mg2+, which is identical to that used in the annealing step. Mg2+ is essential to obtain the desired folding because it neutralizes and stabilizes the two closely spaced negatively-charged phosphodiesters at the crossovers by bridging them together. Mg2+ is also necessary to stick the resulting origami structure to the mica surface via an effective salt bridge.
More detailed guidelines are presented in the 82-page supporting information accompanying the original manuscript by Paul Rothemund.4 Various marvelous 2D nanostructures are shown in the manuscript, including a rectangle, a star, a disk with three holes (often called a smiley), triangles, a map of the western hemisphere, and a hexagon, and higher-order structures made of multiple triangle motifs (Fig. 5).
 | ||
| Fig. 5 The 2D nanostructures made by DNA origami. (Top, from left to right) A rectangle, a star, a disk with three holes, a triangle. (Bottom left) a map of the western hemisphere. (Bottom right) a hexagon made of six triangles. The bright spots in the map or the hexagon are the locally high “dumbbell hairpins” introduced to the staple strands (Reprinted with permission from ref. 4. © 2006 Nature Publishing Group). | ||
4. Hybrids of DNA origami and other DNAnanostructures
DNA origami is exclusively made of DNA, and therefore it can be readily combined with the abundant motifs developed in DNA nanotechnology (Fig. 6). Murata and co-workers have utilized a rectangular origami structure as a seed row for the algorithmic self-assembly of DX motifs,11 taking advantage of the fact that origami can easily provide multiple inputs at once on a single molecule (Fig. 6a). A Sierpinski triangle was chosen as the test pattern because it requires only a small set of DX tiles. Each DX tile returns exclusive-or (XOR) outputs at each of the two sticky ends at one side for the inputs at the other side. For example, when the DX tiles with the output (1,1) and the output (0,0) were vertically arrayed, the tile corresponding to the input (1,0) binds to the middle of the two tiles and presents the output (1,1) at the other side. If successful, a cone-shaped assembly is expected for this system. However, one-pot annealing of a simple mixture of the origami seed and the XOR tiles resulted in the formation of a large complex because multiple assemblies nucleated from distinct seeds tended to aggregate and merge together. In order to prevent such aggregation and merging of the 2D crystals and limit the exposure of sticky ends only at active growth fronts, a new series of tiles called “boundary tiles” was employed. These tiles were designed to force the crystal to grow in a ribbon-like shape by always implementing “0” boundary conditions for each side of the ribbon. The tiles consist of two types of single tiles and one type of the double tile, in which two single tiles are fused. Ribbon-growth in the presence of the boundary tiles was successfully accomplished, and clear Sierpinski patterns were imaged on AFM, revealing an error rate of only 1.4% before the 15th row of the DX array.![Hybrids of DNA origami and multi-stranded DNA motifs. (a) Ribbon growth of algorithmic self-assembly of DX motifs from a rectangular seed origami in the left. The scale bar is 100 nm. (b) Schematic illustration of origami arrays and capture molecules. (c) AFM images of (b). [Part (a) reprinted with permission from ref. 11. © 2007 American Chemical Society. Parts (b) and (c) reprinted with permission from ref. 12. © 2009 Nature Publishing Group].](/image/article/2010/NR/b9nr00246d/b9nr00246d-f6.gif) | ||
| Fig. 6 Hybrids of DNA origami and multi-stranded DNA motifs. (a) Ribbon growth of algorithmic self-assembly of DX motifs from a rectangular seed origami in the left. The scale bar is 100 nm. (b) Schematic illustration of origami arrays and capture molecules. (c) AFM images of (b). [Part (a) reprinted with permission from ref. 11. © 2007 American Chemical Society. Parts (b) and (c) reprinted with permission from ref. 12. © 2009 Nature Publishing Group]. | ||
DNA origami has also been used as a substrate to integrate a DNA nanomechanical device (Fig. 6b).12 A 120 × 50 nm origami tile was prepared with two slots that accommodate the cassette of a PX-JX2 rotary device and with a notch on one side that establishes their absolute positions and orientation when viewed by AFM. The two cassettes were designed to cooperatively capture one of the four different capture molecules depending on the combination of their states (PX-PX, PX-JX2, JX2-PX, and JX2-JX2) when the cassettes were set on the origami substrate. Each of the host arrangements selectively captured their expected target when a single target was added to the solution. However, half-correct binding of a target that is correct on one side and incorrect on the other side frequently occurred when a mixture of the four capture molecules was simply added to the system. This problem was solved by adding each of the capture molecules one at a time followed by a brief heating and cooling step to allow for error correction, based on the finding that the correct capture molecule displaces the half-correct molecules under such thermodynamic process but the converse does not occur.
5. Nanoarrays formed on DNA origami structures
DNA origami has been considered as a promising platform for the precise arraying of nanomaterials (Fig. 7). Theoretically, DNA origami can be addressed within a 3.5 Å resolution using the nucleotides in the scaffold, which are distributed all over the origami structure (the practical resolution of differentiating the surface of DNA origami is ca. 6 nm). In addition, extensive studies on DNA chemistry have resulted in the development of various techniques to chemically modify DNA oligomers, and there is almost no limitation in attaching functional molecules to DNA today. Such modified DNA can be readily attached to DNA origami structures via hybridization to a receptor portion connected to a staple strand, or, more directly, modified DNA can be used as a staple strand for the folding of the scaffold.![Nanoarrays made on DNA origami. (a) mRNA arrays on DNA origami with barcodes. (b) Attachment of gold nanoparticles on DNA origami. (c) His-tag/Ni-NTA interaction. (d) Distance-dependent bidentate binding of thrombin on DNA origami. [Part (a) reprinted with permission from ref. 13. © 2008 American Association for the Advancement of Science. Part (b) reprinted with permission from ref. 15. © 2008 American Chemical Society. Part (d) reprinted with permission from ref. 22. © 2008 Nature Publishing Group].](/image/article/2010/NR/b9nr00246d/b9nr00246d-f7.gif) | ||
| Fig. 7 Nanoarrays made on DNA origami. (a) mRNA arrays on DNA origami with barcodes. (b) Attachment of gold nanoparticles on DNA origami. (c) His-tag/Ni-NTA interaction. (d) Distance-dependent bidentate binding of thrombin on DNA origami. [Part (a) reprinted with permission from ref. 13. © 2008 American Association for the Advancement of Science. Part (b) reprinted with permission from ref. 15. © 2008 American Chemical Society. Part (d) reprinted with permission from ref. 22. © 2008 Nature Publishing Group]. | ||
When mRNA is attached to DNA origami structures, it can be used as a detector for gene expression at the single-molecule level (Fig. 7a).13 Yan and colleagues introduced capture probes composed of two single-stranded DNA portions protruding from a pair of neighboring staple strands on a rectangular origami. These probes selectively bind to mRNA and produce a stiff V-shaped junction that can be readily imaged by AFM. Three different probes corresponding to regions of three genes: Rag-1, c-myc, and β-actin, were initially incorporated into the surface of a single origami tile in three parallel lines. However, it was found that the exact position of the probe made a substantial difference in the hybridization efficiency. This problem was circumvented by manufacturing three “bar-coded” origami tiles in which all of the probes were placed in an optimal position (close to the edge of the origami), and each type of origami contained a group of dumbbell-shaped loops protruding out of the tile surface as a topographic marker. The detection of the three different targets using an equimolar mixture of these bar-coded tiles was highly specific, without non-specific cross-hybridization. Detection of β-actin mRNA from a mixture of synthetic RNA and total cellular RNA was also successful. Yan et al. suggested that the detection limit of the system could be as low as 1000 molecules if 1 pM solution of origami tiles as small as 1 nL could be placed on an optically indexed AFM stage for imaging.
Inorganic nanomaterials are an important target to be arrayed since various applications of inorganic nanoarrays are possible, including a surface-enhanced Raman spectroscopy (SERS) device.14 Yan and Liu have reported selective positioning of gold nanoparticles (AuNP) on a DNA origami structure (Fig. 7b).15 A lipoic acid-modified DNA molecule was first prepared for AuNP–DNA conjugation. The 1![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :1 conjugates of AuNP and DNA with a bivalent thiolate-Au linkage formed in a 1:1 mixture of the modified DNA and 10-nm AuNPs were purified by agarose gel electrophoresis and were passivated with a layer of short oligonucleotides composed of five thymine residues modified with a monothiol group. The AuNP–DNA conjugate was used as a staple strand in a rectangular DNA origami structure. The AuNP was imaged clearly on the resulting DNA origami structure using AFM. The yield of AuNP attachments was up to 91%, which was significantly higher than the yield of the control origami structure using a monovalent AuNP–DNA conjugate (48%). Yan and Liu further examined the attachment of two AuNPs on an origami structure by using another bivalent AuNP–DNA conjugate that delivers the second AuNP ∼47 nm apart from the first one. Here, the yield of the dual attachment was also higher (92%) than that with monovalent conjugates (41%).
:1 conjugates of AuNP and DNA with a bivalent thiolate-Au linkage formed in a 1:1 mixture of the modified DNA and 10-nm AuNPs were purified by agarose gel electrophoresis and were passivated with a layer of short oligonucleotides composed of five thymine residues modified with a monothiol group. The AuNP–DNA conjugate was used as a staple strand in a rectangular DNA origami structure. The AuNP was imaged clearly on the resulting DNA origami structure using AFM. The yield of AuNP attachments was up to 91%, which was significantly higher than the yield of the control origami structure using a monovalent AuNP–DNA conjugate (48%). Yan and Liu further examined the attachment of two AuNPs on an origami structure by using another bivalent AuNP–DNA conjugate that delivers the second AuNP ∼47 nm apart from the first one. Here, the yield of the dual attachment was also higher (92%) than that with monovalent conjugates (41%).
Nanopatterning of proteins is an important study subject in view of future applications in proteome studies.16 Yan and co-workers constructed protein nanoarrays on DNA origami structures.17 Two kinds of rectangular DNA origami were prepared. One was modified with platelet derived growth factor (PDGF)-binding DNA motifs (aptamer) in a line, and the other was modified with thrombin aptamers in an “S” shape. After addition of the protein to the origami solutions, the patterned proteins were clearly visible using AFM.
The most important subject in protein immobilization on DNA origami structures is how to selectively bind a staple strand to the target protein. Recently, an attempt to use the interaction between the histidine (His)-tag and Ni-nitrilotriacetic acid (NTA) to achieve reversible protein–DNA conjugation was reported.18 The His-tag is usually a row of six to ten consecutive His residues attached to the end of a protein's backbone. Two His residues together with one NTA can occupy all six coordination sites of a nickel(II) ion, and thus the His-tag strongly binds to multiple Ni-NTA complexes (Fig. 7c). The interaction is completely reversible because the His-tag can be easily displaced by excess imidazole in the solution. Due to these advantages, Ni-NTA columns are commonly used in affinity chromatography, and most of the proteins of interest are today purified as His-tagged proteins.
Norton and co-workers have reported the fixation of a His-tagged protein on a DNA origami structure.19 A DNA origami structure with a circular shape was prepared, and the NTA ligand was introduced at two positions on the surface using 5′-NTA-bearing staples. His-tagged EGFP was used as the target, and both of the proteins bound at the NTA sites were clearly imaged using AFM.
All of the attachments of nanomaterials to DNA origami structures in the above studies were done to the surface of the origami. Recently, we proposed a new strategy for the protein immobilization that leads to a robust and highly programmed 2D protein nanoarray (Fig. 8).20 This strategy is based on our previous finding that a nanometre-sized cavity embedded in a tape-like DNAnanostructure can serve as a well to size-selectively capture a single protein molecule and accommodate it quite stably under repetitive AFM scanning (Fig. 8a).21 We designed a stick-like punched DNA origami structure with nine wells with dimensions of 7 nm × 14 nm × 2 nm. Two of the edges of each well were modified with a biotinvia a triethylene glycol (TEG) linker that was 2.3 nm long. When excess streptavidin, which is a tetrameric protein with a 5-nm diameter and which binds strongly to biotins through each monomer, was added to the solution of this punched origami structure, exactly one streptavidin molecule was captured in a well to produce a streptavidin nanoarray with a 26-nm period. The size of the well was crucial for single molecule capture. While the 7-nm wide wells captured only one streptavidin even if two biotins were attached to each of the wells, a well twice the size often captured two streptavidins inside. The streptavidin molecules accommodated in the wells showed tremendous stability compared with those trapped on the origami surface (not in the wells) or those captured in the wells but attached by only one biotin. Simply by selecting the staple strand to be biotinylated, the well to capture a tetramer could be freely chosen. Even construction of a 2D streptavidin nanoarray with a zigzag arrangement was possible by assembling separately annealed two punched origami motifs with different biotinylation patterns (Fig. 8b).
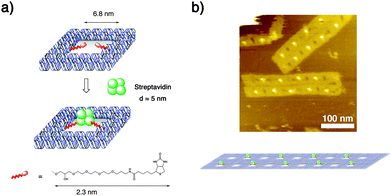 | ||
| Fig. 8 Size-selective capture of a protein molecule in a nanometre-sized DNA well. (a) Schematic illustration of the system. (b) 2D streptavidin nanoarray in a zig-zag arrangement formed in an assembly of two punched origami motifs. | ||
Bidentate binding of a protein to a DNAnanostructure was also independently reported by Liu and Yan's group (Fig. 7d).22 They used thrombin as a target molecule, and two thrombin aptamers, each of which recognizes and binds a different part of the protein, were used to capture one thrombin on a DNA origami structure. Two lines of each aptamer were put on a 60 × 90-nm rectangular DNA origami structure, with a distance of ∼20.7 nm and ∼5.8 nm between the neighboring lines of the two aptamers and with an intra-line distance of ∼12 nm for the same aptamer. When four equivalents of thrombin relative to the number of aptamers were added to the system, arrayed thrombin molecules were clearly visualized using AFM only on the line where the two aptamers were placed 5.8 nm apart. The dual-aptamer line showed a level of protein binding approximately tenfold better than that of the single aptamer lines.
Törmä and co-workers have examined the selective assembly of streptavidin on DNA origami structures using two approaches.23 The first approach was the use of DNA origami structures as prefabricated templates for streptavidin assembly, as in the other studies. In total, 24 staple strands were modified with biotin at the 5′ end. After the origami structure was annealed, streptavidin was added to the solution. Streptavidin assembled into the predetermined pattern with precision. The second approach was to anneal the DNA origami structure using preformed streptavidin–staple strand complexes. Each of the biotin-modified staple strands was functionalized with streptavidin separately before annealing the origami structure, and then mixed with the rest of the staple strands and the scaffold. The starting temperature for the annealing process was 70 °C since denaturation of streptavidin occurs at 75 °C. The second approach also produced the desired pattern with high yield and precision.
6. Selective deposition of DNA origami structures
Selective deposition of DNA origami structures on a desired location on a substrate is essential in linking bottom-up and top-down fabrication methods and in the development of hybrid nanodevices combining self-assembly of functional molecules and conventional nanofabrication techniques. Yurke and Törmä applied a dielectrophoresis (DEP) technique to trap DNA origami structures at a desired site.24 Fingertip-type gold electrodes with widths of 20–25 nm and gaps of 70–90 nm were fabricated on a SiO2 substrate using standard electron beam lithography. A rectangular origami structure and an origami smiley were used as the targets. Two thiol groups were introduced in the middle of each side of the origami structure to attach them to the gold electrodes after trapping and to prevent rapid diffusion after the DEP voltage was turned off. During AFM measurement of the device, the trapped origami structure was clearly imaged between or around the electrodes. For precise trapping of DNA origami structures between the electrodes, the DEP frequencies and the voltage were the crucial parameters. With optimal parameters, 5–10% yield was achieved for single origami trapping between the electrodes and almost 100% yield for multiple origami trapping. Origami structures trapped between the electrodes were often folded, although whether this is a technical problem or a fundamental problem with the system is not yet certain.The substrate used to deposit DNA origami structures for AFM measurements has been almost exclusively mica, which is a standard substrate not only for DNA origami but also for most DNAnanostructures. Negatively charged DNAnanostructures tend to stick to negatively charged mica via an effective salt bridge formed by Mg2+ in the solution. To find a new substrate that can be used in combination with conventional nanofabrication techniques, it is important to mimic this mechanism to bind DNA origami structures selectively at a desired position. Yan and Soh used a gold surface to make a patterned substrate upon which to deposit DNA origami structures.25 They made a self-assembled monolayer (SAM) of 11-mercaptoundecanoic acid (MUA) or 6-mercaptohexanol (MH) on a gold surface patterned on Si. Whereas MUA carries a carboxyl group that can bind Mg2+ and create efficient salt bridges, MH is not able to bind Mg2+. They deposited a 2-μm-thick gold layer on a 200-nm-thick titanium sticking layer on a silicon wafer using electron-beam physical evaporation. The wafer was then mechanically polished using colloidal silica and was thermally annealed at 300 °C for 3 h in air. Then the SAM was formed on the gold surface by incubating the substrate in a 1 mM solution of the thiols. On the MUASAM, many rectangular origami structures were clearly observed using AFM in both the height- and phase-imaging modes. On the MHSAM as expected, no origami structures were found. The selective delivery of DNA origami on gold spots was also examined. An array of gold dots with a diameter of ∼70 nm was prepared with the lift-off process via electron-beam evaporation of titanium/gold (3 nm/3 nm), and the gold dots were functionalized with MUA. After the rectangular origami structure was added, a 2-nm increase in height was observed, which is consistent with the added thickness of the origami structure. Yan and Soh further confirmed the positions of the origami by selectively attaching 10-nm gold nanoparticles functionalized with DNA to the surface of the origami structure.
Rothemund and researchers from IBM have also reported the selective deposition of DNA origami structures on patterned substrates (Fig. 9).26 They created sticky patches in the shape and size of a triangular DNA origami structure (the length of the sides is 127 nm) on a substrate using electron-beam lithography and dry oxidative etching, and they successfully deposited just one triangular origami on the resulting binding site in a fairly oriented fashion. Two kinds of substrates, SiO2 blocked with a trimethylsilyl (TMS) monolayer or diamond-like carbon (DLC) film on Si, were used for the lithographic patterning, and both of the etched surfaces nicely bound DNA origami structures. Interestingly, a relatively high Mg2+ concentration (∼100 mM), which is nearly ten times as high as the concentration sufficient for binding to the mica substrate, was necessary to get sufficient binding of the DNA origami structures to either of the substrates. The dynamic behavior of the binding was also examined, and they found the binding of the DNA origami structures to the surface reached a steady state within several minutes and remained approximately constant for a couple of hours.
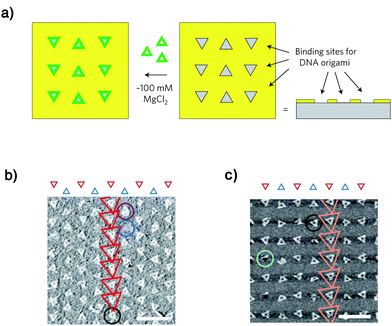 | ||
| Fig. 9 Alignment of triangular DNA origami on nanometre-sized binding sites (a), and AFM images on (b) SiO2 and (c) DLC. Scale bars are 500 nm. (Reprinted with permission from ref. 26. © 2009 Nature Publishing Group). | ||
7. Three-dimensional DNA origami
Although scaffolded DNA origami was originally introduced as a technique to obtain arbitrary 2D nanostructures, the technology itself does not involve any limitation that prevents creation of 3D structures. Until recently, William Shih was the only scientist to make 3D structures based on the principles of DNA origami. Now several independent research groups have published various 3D designs within a quite short period of time.The earliest example of a 3D structure based on the DNA origami idea is the DNA octahedron reported by Shih et al. in 2004 (Fig. 10).27 It was created even before the introduction of scaffolded DNA origami in 2006, and this DNA octahedron is the most successful example of single-stranded DNA origami. A 1.7-kilobase single-stranded DNA molecule, which was designed to fold into a hollow octahedron composed of five DX struts and seven PX struts in the presence of five 40-mer helper strands, was prepared by PCR. The folding of the single-stranded scaffold was designed to occur in two stages. A branched-tree structure with five DX struts and fourteen terminal branches, each corresponding to a half-strut, was first formed in the cooling step after heat denaturation of the mixture of the scaffold and the helper strands. The terminal branches then paired with their counterpart terminals by PX cohesion to form the octahedron. This study was also the first to adopt cryogenic-electron microscopy (cryo-EM) for the visualization of 3D DNAnanostructures. The octahedron structure with a diameter of 22 nm was clearly demonstrated from a 3D map of the structure reconstructed from 961 particles.
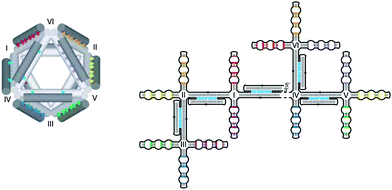 | ||
| Fig. 10 A DNA octahedron based on the single-stranded DNA origami approach. (Reprinted with permission from ref. 27. © 2009 Nature Publishing Group). | ||
Shih and co-workers also created a tube-like six-helix bundle with a scaffolded design.28 The main purpose of this study was to develop a detergent-resistant liquid crystal that could be used as an alignment media for accurate residual dipolar coupling (RDC) measurements from α-helical membrane proteins in NMR. Their design was based on a six-helix bundle created by Seeman's group with a conventional multistranded design.29 In Total, 168 staple strands of 42 nt were used to fold a 7308-nt M13-based scaffold into six parallel double helices for which every set of three adjacent helices framed a dihedral angle of 120°. This angle can be obtained by placing the crossovers 14 nt (4/3 helical turns) apart rather than the typical 16 nt (3/2 helical turns) or 26 nt (5/2 helical turns) spacing in a planar DNA origami structure. In order to obtain nanotubes with a uniform length of 0.8 μm, two kinds of origami six-helix bundles (one blocked at one side by some of the staple strands and the other blocked at the other side) were prepared and assembled into a hetero-dimer with a head-to-tail arrangement. The resulting nanotube heterodimers formed a stable liquid crystal, and they were tested for weak alignment of the transmembrane (TM) domain of the ζ–ζ chain of the T cell receptor complex. The measured RDCs agreed very well with the known NMR structure of the ζ–ζ TM domain. The nanotubes were also used for an RDC measurement of the BM2 channel protein, the 3D structure of which is still unknown. It is notable that this study is one of the few practical applications of DNA origami in a research field other than nanotechnology.
Shih and co-workers further extended the idea of making six-helix bundles with DNA origami to achieve sophisticated 3D structures (Fig. 11).30 They folded DNA into 3D shapes formed as pleated layers of helices constrained to a honeycomb lattice (Fig. 11a). Each helix was bundled in a parallel arrangement and was placed on the vertex of a hexagonal matrix just like a composite of multiple six-helix bundle tubes. Folding into such a densely packed structure required very slow annealing (up to 174 h) and an optimized Mg2+ concentration. However, various complicated shapes, such as a monolith, a square nut, a railed bridge, a genie bottle, a stacked cross, or a slotted cross of 10 to 100 nm, were successfully constructed with precision after agarose gel purification and were beautifully imaged using negative-staining TEM (Fig. 11b). Such shapes could be further assembled into larger 3D shapes, such as stacked-cross polymers longer than 1 μm or a wireframe icosahedron with a diameter of ca. 100 nm.
![(a) Design of a DNA honeycomb-array. (b) Negative-stain TEM images of a monolith, square nut, railed bridge, stacked cross, and slotted cross, respectively from left to right. (c) Negative-stain TEM images of six-tooth gears made of bent 3-by-6-helix DNA-origami bundles. Scale bars are 20 nm. [Part (a) and (b) reprinted with permission from ref. 30. © 2009 Nature Publishing Group. Part (c) reprinted with permission from ref. 31. © 2009 American Association for the Advancement of Science].](/image/article/2010/NR/b9nr00246d/b9nr00246d-f11.gif) | ||
| Fig. 11 (a) Design of a DNA honeycomb-array. (b) Negative-stain TEM images of a monolith, square nut, railed bridge, stacked cross, and slotted cross, respectively from left to right. (c) Negative-stain TEM images of six-tooth gears made of bent 3-by-6-helix DNA-origami bundles. Scale bars are 20 nm. [Part (a) and (b) reprinted with permission from ref. 30. © 2009 Nature Publishing Group. Part (c) reprinted with permission from ref. 31. © 2009 American Association for the Advancement of Science]. | ||
By using this honeycomb-array framework, even twisted or curved units can be created (Fig. 11c). Dietz et al. have tuned the number of nucleotides in each helix composing the honeycomb-array.31 Site-directed base-pair deletions made in selected array cells resulted in global left-handed twisting, whereas site-directed insertions resulted in global right-handed twisting. Similarly, the combination of site-directed deletions and insertions induced tunable global bending of the array. For the 3-by-6-helix bundle, tunable bending angles ranged from 30° to 180°, and the radius of curvature as low as 6 nm. By combining these bent modules, beautiful higher-order structures including gears with six or twelve teeth, a beach ball-like capsule, and a spiral-like object were constructed. This system seems to be the most feasible for the construction of complicated but practical mechanical nanodevices in the future.
While most of the polyhedral structures made with DNA, such as the DNA cube created by Ned Seeman in 1991,32 used DNA just for the edges of the faces, construction of a polyhedron by using planar origami for each face is also possible (Fig. 12). One of the advantages of this strategy is that filled planes of nanometre thickness might be useful for making isolated nanospaces for future applications such as a nanocontainer or a nanoreactor (the original meaning of the Japanese word “origami” is “paper folding”, so the term matches better with such 3D structures composed of multiple DNA sheets).
![3D DNA polyhedra made with origami faces. (a) A DNA origami box with controllable lid. (b) A DNA tetrahedron. (c) A box-shaped 3D origami with two-step folding mechanism. [Part (a) reprinted with permission from ref. 33. © 2009 Nature Publishing Group. Part (b) reprinted with permission from ref. 34. © 2009 American Chemical Society].](/image/article/2010/NR/b9nr00246d/b9nr00246d-f12.gif) | ||
| Fig. 12 3D DNA polyhedra made with origami faces. (a) A DNA origami box with controllable lid. (b) A DNA tetrahedron. (c) A box-shaped 3D origami with two-step folding mechanism. [Part (a) reprinted with permission from ref. 33. © 2009 Nature Publishing Group. Part (b) reprinted with permission from ref. 34. © 2009 American Chemical Society]. | ||
The first example of such 3D origami was a DNA box created by Gothelf and Kjems (Fig. 12a).33 They divided the 7249-nt M13 scaffold into six domains and folded each domain into six interconnected DNA sheets corresponding to the faces of the box. These faces were connected to each other at the vertices by the scaffold, and the angles between the faces were controlled using a set of “tension” strands joining the two faces. The resulting 42 × 36 × 36-nm hollow box shape was thoroughly characterized by AFM, cryo-EM, and small-angle X-ray scattering (SAXS). It was revealed that there were both slightly convex and slightly concave faces in the structure due to the differences in the design of these two groups of the faces. The most notable feature of the box's design was the dual lock–key system to open and close the lid of the box. They attached two sets of complementary DNA strands to the lid and an adjoining face to achieve the closed lid. The strands on the adjoining face had sticky-end extensions to provide a “toehold” for the displacement of the complementary DNA on the lid by an externally added “key” strand, which opens the lid. This selective lid opening was confirmed by measuring the fluorescence resonance energy transfer between the fluorescent dyes attached to both of the faces.
Liu and Yan have constructed a tetrahedron using DNA origami (Fig. 12b).34 They designed an origami structure composed of four interconnected regular triangles in a unique way suitable for constructing a 3D structure. In the design of 2D DNA origami structures, the scaffold is designed to turn and go backward at the edges of the sheet. By contrast, the scaffold in their tetrahedron runs through the entire structure without turning back at the edges except for the hairpin loops at two of the vertices. There is no need for the scaffold to turn back because there is no endpoint of the surface in a polyhedron. TEM was used to characterize the sample, and the size of the particle was further confirmed by dynamic light scattering (DLS) experiments.
We also independently developed a box-shaped 3D DNA origami structure (Fig. 12c).35 Although the size of the box is quite similar to the one from Kjems' group since the M13 scaffold is commonly used, the basic strategy used to construct the box was completely different. One of the differences was that the right angles between the faces in our design were rationally designed and were formed by selecting appropriate positions for the crossovers connecting the faces. The crossovers in DNA origami are usually placed every 16 bp, which corresponds to 1.5 DNA helical turns, to connect DNA helices at an angle of 180° and consequently bundle them into a planar structure. In our box design, by contrast, the number of nucleotides between the crossovers at the edges of the faces was reduced to 8 bp, which corresponds to 0.76 helical turns. Thus, the dihedral angle between the two faces next to the edge is uniformly fixed at 90° in a predetermined direction. Due to this strategy, the side of the DNA sheet that faces the inside of the box and the side that faces the outside is completely controlled. Another feature of the design is its two-step folding mechanism for future guest encapsulation. We designed the box to fold first into an open form composed of two units, each of which is made of three orthogonally connected faces. The complex then closes into a box shape in the presence of nine helper strands to connect the three edges of the two units. The shape change from the open form to the closed form was clearly imaged using AFM. DLS analysis revealed that quite uniform particles with a reasonable diameter were formed for the closed form.
8. Attempts to use scaffolds other than the M13 phage genome
Another hot topic in the field is to employ a scaffold other than the M13 phage genome . The length of M13mp18 genome is 7249 nt, and the net surface area covered by a fully base-paired genome is ca. 8500 nm2 when a 1.5-nm gap between the helices is assumed. This area may be enough to make an array of several nano-objects and observe their functions, but it is too small to construct more complicated nanodevices such as logic circuits. Consequently, the 2D assembly of multiple DNA origami motifs is necessary for this purpose, although it is not easy to do using the present system without sequence variation in the scaffold. Connection between multiple DNA motifs is usually achieved with complementary base pairing between single-stranded portions protruding from the motif (sticky-ended cohesion); the M13 scaffold itself does not have sufficient self-complementary portions in the sequence. Staple strands can substitute; however, formation of DNA origami structures is typically performed in the presence of excess staple strands in the solution, which prevents selective connection between successfully folded origami motifs. Thus, the most desirable way to achieve large assembly of multiple DNA origami motifs is to utilize complementary base paring between multiple kinds of scaffolds.In their honeycomb 3D origami study,30 Shih and colleagues compared the yield of a 3D origami using an M13-based scaffold with that using a single-stranded plasmid encoding the enhanced green fluorescent protein (pEGFP-N1). They observed superior yield with the M13-based scaffold. They ascribed this difference to the lower GC content of the M13 genome (43%) compared to that of pEGFP-N1 (53%).
Very recently, double-stranded sources have been successfully used as the scaffold for DNA origami.36 Shih and co-workers used nicked double-stranded circular M13 (7,560 bp), linearized pEGFP-N1 plasmid (4.7 kbp), and a 1.3 kbp PCR product as the source. The key was to completely denature long double-stranded DNA and to avoid the undesired aggregation observed during the incubation at 95 °C in the presence of divalent cations, which is a standard first step in a typical annealing protocol for DNA origami (∼2 h slow cooling from 90 °C or 95 °C to room temperature in 1× TAE/Mg buffer). For this purpose, they adopted the isothermal annealing system established by Simmel et al.,37 which utilizes a denaturant and dialysis to mimic the temperature drop at isothermal conditions. Formamide is known to lower DNA melting temperatures linearly by approximately 0.6 °C per percentage formamide in buffer. They incubated the annealing mixture at 80 °C in the presence of 40% formamide for 10 min and then rapidly cooled the solution to 25 °C to prevent reannealing of the scaffold. Next, they gradually removed the formamide from the solution by stepwise dialysis against buffer solutions with lower formamide concentration over 3 h. With this procedure, they realized a fast virtual temperature drop from 106 °C to 51 °C, followed by slow cooling steps down to 25 °C, and they succeeded in simultaneously obtaining both a six-helix bundle and a triangle from both of the strands in the source. This method was successful not only for the open circular M13 genome but also for the linear sources described above.
9. Tools for designing DNA origami structures
As easily imagined from the number of crossovers and staple strands in one DNA origami structure, the most time-consuming but somewhat monotonous part in designing a new structure is to assign the sequence of staple strands. A few open-source program packages, available as freeware, for designing DNA origami structures have been developed to ease this part of the process.SARSE-DNA origami, released by Kjems' group, is designed for 2D DNA origami and was developed based on their earlier semi-automated scientific data editor called SARSE, which was used for RNA structural alignments.38,39 This package provides an editor for the folding of the scaffold and staples with automatic sequence assignment capability, and it includes a 3D atomic-model generator for visualization of the designed structure. A notable feature of this software is that it can import a bitmap picture and automatically generate a folding path of the scaffold through the shape, which may be useful in designing non-geometrical structures, such as the dolphin shape shown as an example in the manuscript. The 3D DNA box reported by this group was also designed and visualized using this package.
Another software package, caDNAno, released by Shih's group is specialized for designing honeycomb DNA array.40 This software is composed of three panels: Slice, Path, and Render panels. Users can easily pick the points in the honeycomb lattice to place helices in the design, edit the folding pattern of the scaffold and staple strands with the aid of automatic staple-pattern assignment, and check the 3D model in real time.
10. Prospects
Since it was introduced in 2006, DNA origami has become a popular subject of study in the DNA nanotechnology field. The position of functional molecules on a DNA origami structure or of DNA origami structures themselves on a substrate is almost freely controllable today in the nanometre to micrometre range. Various 3D origami structures are now in hand and selective encapsulation of a guest molecule, such as an enzyme or an inorganic nanomaterial, is feasible in the near future.We would like to mention a few remaining issues in DNA origami systems that we may face upon widening the area of its applications. First, DNA origami might have to undergo a transition to a “dry” system in order to apply this technology to photonic and electronic systems. Almost all of the imaging of the origami structures constructed thus far, except for some TEM analyses, has been done only in a buffer solution, or in “wet” environments, because 2D origami structures often shrink in air or under vacuum even if the images taken on mica just before removing the solution showed correctly folded structures. Another issue is the requirement for Mg2+ in the solution. Some proteins or enzymes require particular ionic conditions for optimum function, and Mg2+ sometimes acts as an inhibitor. In addition, this issue is related to the first problem because Mg2+ (and other inorganic multivalent cations) does not evaporate and instead forms large, hard salt crystals when dry. This of course prevents clear imaging of the origami structures using AFM or other analytical systems. Possible solutions for these problems may be to use organic cations such as oligoamines or to find an appropriate way to functionalize cationic substrates to mimic the salt bridge.
Reading the papers on DNA origami published every month, we are confident that these problems will be elegantly solved and that DNA origami will become mainstream in the nanotechnology world very soon.
Acknowledgements
Works in the authors' laboratory were supported by a Grant-in-Aid for Specially Promoted Scientific Research (18001001) and a Grant-in-Aid for Young Scientists (B) (20750126) from the Ministry of Education, Science, Sports, Culture and Technology, Japan. Supports from the Global COE Program for Chemistry Innovation and from the Association for the Progress of New Chemistry are also acknowledged.References
- N. C. Seeman, J. Theor. Biol., 1982, 99, 237–247 CrossRef CAS.
- T. H. LaBean and H. Li, Nano Today, 2007, 2, 26–35 CrossRef.
- S. H. Park, C. Pistol, S. J. Ahn, J. H. Reif, A. R. Lebeck, C. Dwyer and T. H. LaBean, Angew. Chem., Int. Ed., 2006, 45, 735–739 CrossRef CAS.
- P. W. K. Rothemund, Nature, 2006, 440, 297–302 CrossRef CAS.
- P. W. K. Rothemund, in Nanotechnology: Science and Computation, ed. J. Chen, N. Jonoska, G. Rozenberg, Springer, Heidelberg, 2006, pp. 3–21 Search PubMed.
- N. C. Seeman, Biochemistry, 2003, 42, 7259–7269 CrossRef CAS.
- E. Winfree, F. R. Liu, L. A. Wenzler and N. C. Seeman, Nature, 1998, 394, 539–544 CrossRef CAS.
- Z. Y. Shen, H. Yan, T. Wang and N. C. Seeman, J. Am. Chem. Soc., 2004, 126, 1666–1674 CAS.
- X. P. Zhang, H. Yan, Z. Y. Shen and N. C. Seeman, J. Am. Chem. Soc., 2002, 124, 12940–12941 CrossRef CAS.
- H. Yan, X. P. Zhang, Z. Y. Shen and N. C. Seeman, Nature, 2002, 415, 62–65 CrossRef CAS.
- K. Fujibayashi, R. Hariadi, S. H. Park, E. Winfree and S. Murata, Nano Lett., 2008, 8, 1791–1797 CrossRef CAS.
- H. Gu, J. Chao, S.-J. Xiao and N. C. Seeman, Nat. Nanotechnol., 2009, 4, 245–248 CrossRef CAS.
- Y. Ke, S. Lindsay, Y. Chang, Y. Liu and H. Yan, Science, 2008, 319, 180–183 CrossRef CAS.
- S. Nie and S. R. Emory, Science, 1997, 275, 1102–1106 CrossRef CAS.
- J. Sharma, R. Chhabra, C. S. Andersen, K. V. Gothelf, H. Yan and Y. Liu, J. Am. Chem. Soc., 2008, 130, 7820–7821 CrossRef CAS.
- K. L. Christman, V. D. Enriquez-Rios and H. D. Maynard, Soft Matter, 2006, 2, 928–939 RSC.
- R. Chhabra, J. Sharma, Y. G. Ke, Y. Liu, S. Rinker, S. Lindsay and H. Yan, J. Am. Chem. Soc., 2007, 129, 10304–10305 CrossRef CAS.
- R. P. Goodman, C. M. Erben, J. Malo, W. M. Ho, M. L. McKee, A. N. Kapanidis and A. J. Turberfield, ChemBioChem, 2009, 10, 1551–1557 CrossRef CAS.
- W. Shen, H. Zhong, D. Neff and M. L. Norton, J. Am. Chem. Soc., 2009, 131, 6660–6661 CrossRef CAS.
- A. Kuzuya, M. Kimura, K. Numajiri, N. Koshi, T. Ohnishi, F. Okada and M. Komiyama, ChemBioChem, 2009, 10, 1811–1815 CrossRef CAS.
- A. Kuzuya, K. Numajiri and M. Komiyama, Angew. Chem., Int. Ed., 2008, 47, 3400–3402 CrossRef CAS.
- S. Rinker, Y. Ke, Y. Liu, R. Chhabra and H. Yan, Nat. Nanotechnol., 2008, 3, 418–422 CrossRef CAS.
- A. Kuzyk, K. T. Laitinen and P. Torma, Nanotechnology, 2009, 20, 235305 CrossRef.
- A. Kuzyk, B. Yurke, J. J. Toppari, V. Linko and P. Törmä, Small, 2008, 4, 447–450 CrossRef CAS.
- A. E. Gerdon, S. S. Oh, K. Hsieh, Y. Ke, H. Yan and H. T. Soh, Small, 2009, 5, 1942–1946 CrossRef CAS.
- R. J. Kershner, L. D. Bozano, C. M. Micheel, A. M. Hung, A. R. Fornof, J. N. Cha, C. T. Rettner, M. Bersani, J. Frommer, P. W. K. Rothemund and G. M. Wallraff, Nat. Nanotechnol., 2009, 4, 557–561 CrossRef CAS.
- W. M. Shih, J. D. Quispe and G. F. Joyce, Nature, 2004, 427, 618–621 CrossRef CAS.
- S. M. Douglas, J. J. Chou and W. M. Shih, Proc. Natl. Acad. Sci. U. S. A., 2007, 104, 6644–6648 CrossRef CAS.
- F. Mathieu, S. P. Liao, J. Kopatscht, T. Wang, C. D. Mao and N. C. Seeman, Nano Lett., 2005, 5, 661–665 CrossRef CAS.
- S. M. Douglas, H. Dietz, T. Liedl, B. Hogberg, F. Graf and W. M. Shih, Nature, 2009, 459, 414–418 CrossRef CAS.
- H. Dietz, S. M. Douglas and W. M. Shih, Science, 2009, 325, 725–730 CrossRef CAS.
- J. H. Chen and N. C. Seeman, Nature, 1991, 350, 631–633 CrossRef CAS.
- E. S. Andersen, M. Dong, M. M. Nielsen, K. Jahn, R. Subramani, W. Mamdouh, M. M. Golas, B. Sander, H. Stark, C. L. P. Oliveira, J. S. Pedersen, V. Birkedal, F. Besenbacher, K. V. Gothelf and J. Kjems, Nature, 2009, 459, 73–76 CrossRef CAS.
- Y. Ke, J. Sharma, M. Liu, K. Jahn, Y. Liu and H. Yan, Nano Lett., 2009, 9, 2445–2447 CrossRef CAS.
- A. Kuzuya and M. Komiyama, Chem. Commun., 2009, 4182–4184 RSC.
- B. Högberg, T. Liedl and W. M. Shih, J. Am. Chem. Soc., 2009, 131, 9154–9155 CrossRef CAS.
- R. Jungmann, T. Liedl, T. L. Sobey, W. Shih and F. C. Simmel, J. Am. Chem. Soc., 2008, 130, 10062–10063 CrossRef CAS.
- E. S. Andersen, M. Dong, M. M. Nielsen, K. Jahn, A. Lind-Thomsen, W. Mamdouh, K. V. Gothelf, F. Besenbacher and J. Kjems, ACS Nano, 2008, 2, 1213–1218 CrossRef CAS.
- E. S. Andersen, A. Lind-Thomsen, B. Knudsen, S. E. Kristensen, J. H. Havgaard, E. Torarinsson, N. Larsen, C. Zwieb, P. Sestoft, J. Kjems and J. Gorodkin, RNA, 2007, 13, 1850–1859 CrossRef CAS.
- S. M. Douglas, A. H. Marblestone, S. Teerapittayanon, A. Vazquez, G. M. Church and W. M. Shih, Nucleic Acids Res., 2009, 37, 5001–5006 CrossRef CAS.
| This journal is © The Royal Society of Chemistry 2010 |