
Nanoinformatics, and the big challenges for the science of small things
 *a
G.
Opletal
a
*a
G.
Opletal
a
Abstract
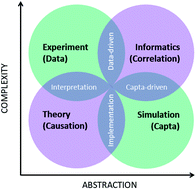
The combination of computational chemistry and computational materials science with machine learning and artificial intelligence provides a powerful way of relating structural features of nanomaterials with functional properties. However, combining these fundamentally different scientific approaches is not as straightforward as it seems. Machine learning methods were developed for large data sets with small numbers of consistent features. Typically nanomaterials data sets are small, with high dimensionality and high variance in the feature space, and suffer from numerous destructive biases. None of the established data science or machine learning methods in widespread use today were devised with (nano)materials data sets in mind, but there are ways to overcome these challenges and use them reliably. In this review we will discuss domain-specific constraints on data-driven nanomaterials design, and explore the differences between nanomaterials simulation and nanoinformatics that can be leveraged for greater impact.
- This article is part of the themed collections: Recent Review Articles and Nanoscale 10th Anniversary Special Issue
 Please wait while we load your content...
Please wait while we load your content...

