
DNA nanotechnology-empowered finite state machines
Shuting
Cao
ab,
Fei
Wang
c,
Lihua
Wang
de,
Chunhai
Fan
 *c and
Jiang
Li
*cd
*c and
Jiang
Li
*cd
aDivision of Physical Biology, CAS Key Laboratory of Interfacial Physics and Technology, Shanghai Institute of Applied Physics, Chinese Academy of Sciences, Shanghai 201800, China
bUniversity of Chinese Academy of Sciences, Beijing 100049, China
cSchool of Chemistry and Chemical Engineering, Frontiers Science Center for Transformative Molecules and National Center for Translational Medicine, Shanghai Jiao Tong University, Shanghai 200240, China. E-mail: fanchunhai@sjtu.edu.cn; lijiang@zjlab.org.cn
dThe Interdisciplinary Research Center, Shanghai Synchrotron Radiation Facility, Zhangjiang Laboratory, Shanghai Advanced Research Institute, Chinese Academy of Sciences, Shanghai 201210, China
eShanghai Key Laboratory of Green Chemistry and Chemical Processes, School of Chemistry and Molecular Engineering, East China Normal University, Shanghai 200127, China
First published on 29th April 2022
Abstract
A finite state machine (FSM, or automaton) is an abstract machine that can switch among a finite number of states in response to temporally ordered inputs, which allows storage and processing of information in an order-sensitive manner. In recent decades, DNA molecules have been actively exploited to develop information storage and nanoengineering materials, which hold great promise for smart nanodevices and nanorobotics under the framework of FSM. In this review, we summarize recent progress in utilizing DNA self-assembly and DNA nanostructures to implement FSMs. We describe basic principles for representative DNA FSM prototypes and highlight their advantages and potential in diverse applications. The challenges in this field and future directions have also been discussed.
1. Introduction
In nature, living systems can execute regulatory programs in response to complex internal and external signals depending on their timing. For example, during embryonic development, the fertilized egg divides and differentiates into cells carrying identical genomic DNA yet presenting different forms and functions, depending on the timing and order of transcription factor activation.1 The evolution of tumors correlates to the temporal order of gene mutations.2 Viral particles perform sequential transformations to adapt to the heterogeneous environments at different stages of invasion.3–5During the last several decades, we have witnessed rapid progress in the development of synthetic biomolecular computing circuits, which have enabled the processing of multiple input signals (i.e., combinational logic calculations). Particularly, compared to conventional electronic circuits, biomolecular circuits can be massively produced by biological synthesis or self-assembly, which allows highly parallel computation with minimum power consumption (e.g., ∼1012 parallel threads in 10−4 L solution, with the power <10−10 W).6 They have shown promise in applications such as molecular computing, nanorobotics, smart diagnosis, and drug delivery. There have been several comprehensive reviews on these directions.7–9 Nevertheless, these prototypes generally lack the capability of treating inputs in a temporally dependent manner akin to that in living systems.
To address this limitation, the concept of the finite state machine (FSM) has been proposed.6 As a special case of the Turing machine, an FSM (or an automaton) is a notional device that can switch among a finite number of states in response to different input orders (Fig. 1). That is, the next state of the machine is determined not only by the input signal but also by its current state.10 This principle means that FSMs allow the storage and processing of time-sequence-dependent information. Since the 1990s, the abstract concept of FSM has been used to develop algorithms for biological analysis.11–14 Further, it is highly desirable to substantialize FSMs at the molecular level, which may endow artificial molecular machines and nanorobots with responsiveness to temporally ordered information.
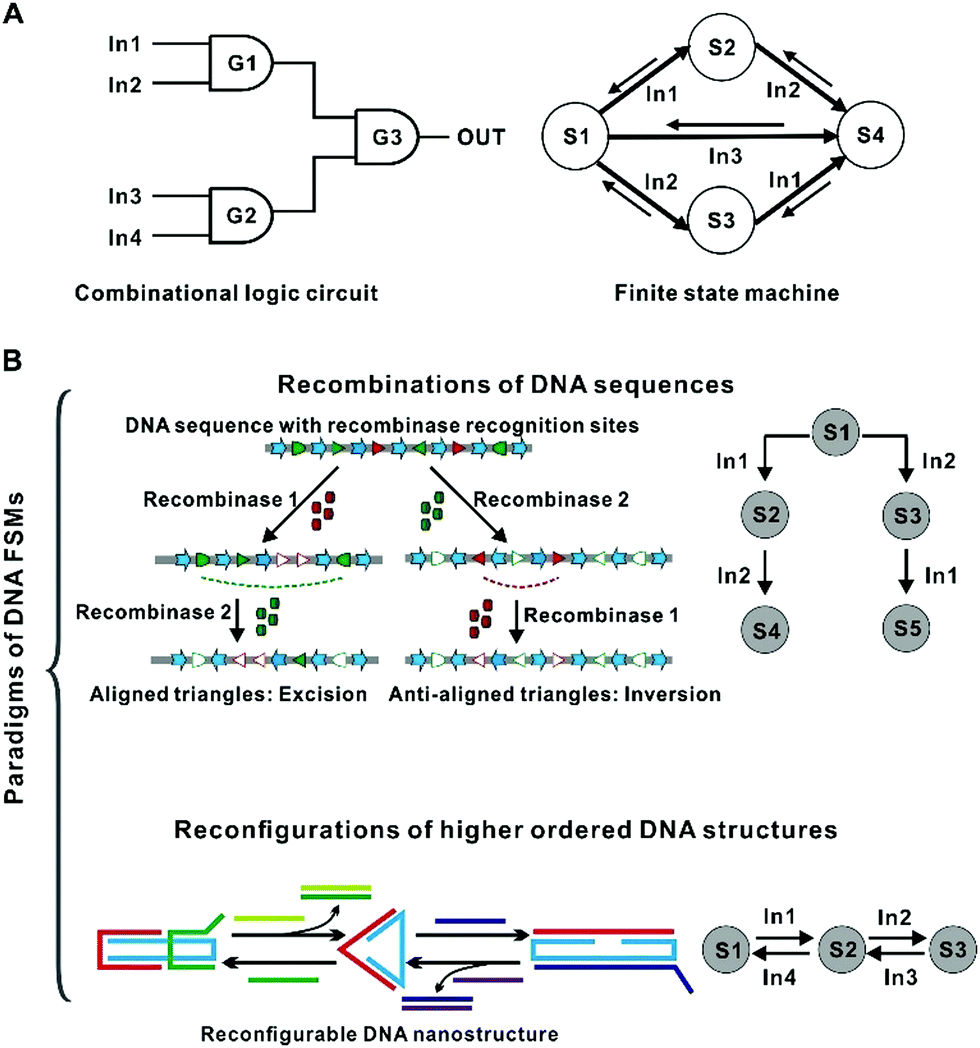 | ||
| Fig. 1 Principles of DNA FSMs. (A) The difference between combinational logic circuits and finite state machines. (B) Different principles of DNA FSMs: Recombination of the primary sequence and structural switching among different DNA secondary (or higher-ordered) configurations. | ||
DNA has long been known as the information media of living systems chosen by nature. Since the pioneering work of Adleman,15 DNA molecules have shown great potential in molecular computing. Recently, the rise of synthetic biology and DNA nanotechnology has enabled the construction of FSMs with DNA molecules and their assemblies.16,17 The cutting-edge gene-editing technologies, such as those based on CRISPR (clustered, regularly interspaced, short palindromic repeats)-Cas endonuclease systems, have enabled nearly arbitrary modifications of DNA primary structures (i.e., DNA base sequences) at the single nucleotide level.18 On the other hand, since Yurke et al. demonstrated switchable DNA tweezers using DNA strands as ‘fuel’,19 dynamic DNA nanotechnology has allowed the construction of nanostructures capable of switching responsively and reversibly among different configurations.20–22 In recent years, more complex DNA nanomachines or nanorobots with precise dimensions and specified functions have emerged.9 For example, a series of nanorobots that can transport molecular cargos on DNA tracks have been reported.23,24 Han et al. and Fan et al. designed reconfigurable topological structures which could reshape based on DNA hybridization and strand displacement reaction.25–27 Gerling et al. reported a class of shape-complementary DNA objects which could reversibly switch between open and closed states by changes in cation concentration or temperature.28 These features together make DNA a promising material for implementing FSMs.
In this review, we aim to summarize recent progress in DNA-based FSMs. We highlight the advantages of DNA nanotechnology in building programmable FSMs. We also discuss current challenges and possible solutions, and provide perspectives on their potential applications.
2. Recombination-based FSMs
The first representative approach of building DNA FSMs is by harnessing the recombination mechanisms existing in nature to edit DNA primary structures (i.e., DNA sequences). In this approach, DNA sequences as the storage medium can be used to record state information (including input, current states, and output) as well as the operating instructions (“software”); whereas the recombination machinery (DNA processing enzymes) serves as the “hardware”, performing the state switching reactions involving P–O bond breaking and bond making driven by ATP consumption. This approach is analogous to tape cutting and splicing (Fig. 2), in which the next state of the tape is dependent not only on the next round of operations but also on its current state, enabling time-sequence-sensitive information recording and processing. The recorded state information can be read by DNA sequence analysis (e.g., gel electrophoresis and DNA sequencing) or by sequence-dependent activation/deactivation of downstream reporter genes. This FSM concept coincides with a variety of mechanisms evolved by nature. For example, the adaptive immune systems in bacteria use certain regions on the host genomic DNA (e.g., clustered regularly interspaced short palindromic repeats, or CRISPR) to record the information of the invaders’ nucleic acids in a time-sequence-dependent manner. Thus, the existing mechanisms in nature can in turn inspire the design of these DNA FSMs.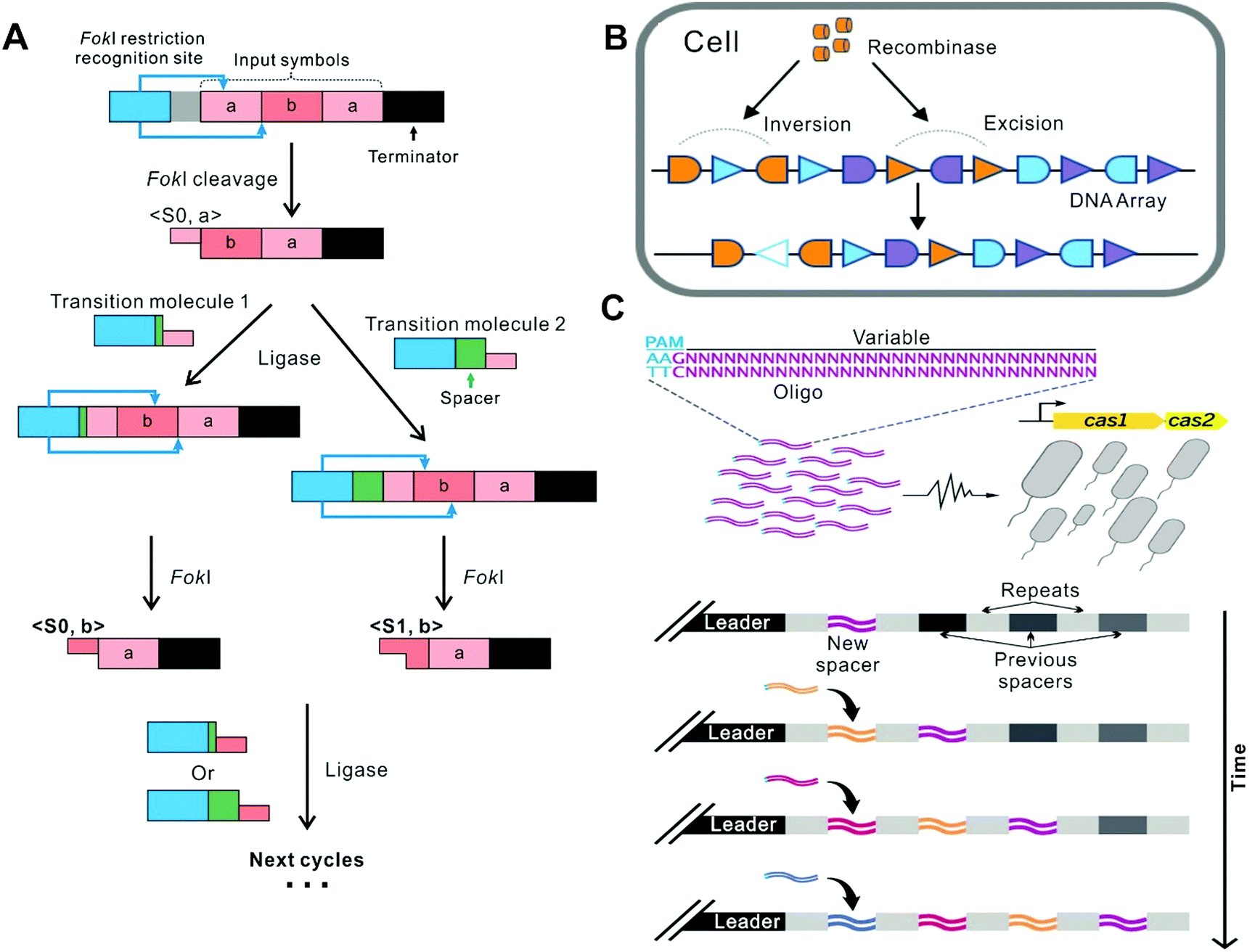 | ||
| Fig. 2 FSMs based on recombination. (A) In the system where restriction enzymes and ligases coexist, the operation stops under the termination command.6 (B) A FSM based on 3 kinds of recombinases (The schematic shows one of them as an example). The FSM recorded the temporal order of all inputs and perform multi-input/output control of gene expression.32 Copyright: 2016, American Association for the Advancement of Science. (C) A FSM based on the CRISPR-Cas system. It realized continuous genetic recording in a time-dependent manner.39 Copyright: 2016, American Association for the Advancement of Science. | ||
This class of FSMs possesses several advantages. First, they in principle can be deployed in living organisms by genetic engineering, thus empowering the hosts with the capability of massively parallel artificial FSM computations.29–31 Second, due to the high information capacity of DNA primary structures, these FSMs can achieve a large state space (a large number of states).32,33 Moreover, they allow “permanent” and heritable storage of state information owing to the good structural stability and replicability of DNA molecules.31 On the other hand, this class of FSMs also faces similar challenges as in the field of genetic engineering, such as the difficulty in transgenic delivery of the systems,18 the effectivity of DNA recombination, and the off-target issue.30
2.1 FSMs based on restriction enzymes and ligases
Conventional restriction enzymes and ligases have long been employed to build FSMs working in test tubes. In 2001, Benenson et al. established a two-state DNA FSM, which utilizes the restriction nuclease FokI and T4 DNA ligase as the hardware which is driven by ATP. Different dsDNA molecules were designed to serve as the inputs (each encoding an array composed of two 6-bp “symbols”) and the software (called “transition molecules”), respectively (Fig. 2A).6 Upon their mixing, the machine starts autonomous processing of the symbols on the input molecule successively, via the cleavage-ligation reaction cycles. In each cycle, the headmost symbol on the input molecule is cleaved by FokI, producing a four-nucleotide sticky end that is then ligated to a transition molecule with the complimentary sticky end and a new FokI recognition site, forming a new molecule for the next cycle. Particularly, each transition molecule provides a spacer sequence, whose length can determine the cleavage location within the symbol being processed, generating two alternative cleavage frames which are defined as the two states (S0 and S1) of the system. Thus, the next state of this FSM is determined not only by the next symbol on the input molecule but also by the current state. This FSM proceeds until all the matching transition molecules are exhausted or until the terminator symbol in the input molecule is cleaved. Finally, the resulting molecule ligates to an output detector to form an output reporter, which can be identified by gel electrophoresis. Based on this paradigm, Soreni et al. further developed a 3-symbol-3-state FSM with an updated design of the transition molecules.34 As an application, Shoshani et al. demonstrated image encryption and deciphering based on this kind of FSMs.35 The output signal is amplified by asymmetric PCR and labeled with a fluorescent tag, which subsequently can site-specifically hybridize with the designed surface-bound connecting molecules to render the fluorescence image. Nevertheless, this type of FSMs can hardly be deployed in living cells, due to that the recognition sequences of conventional restriction enzymes are short (typically 4–8 bp), which can cause high-frequency cleavage of the host genomic DNA.2.2 Recombinase-based FSMs in living cells
Recombinases can site-specifically invert or excise DNA elements flanked by the recognition sequences, which possess higher orthogonality than conventional restriction enzymes, thus can directly encode states in the genomic DNA of the hosts, allowing for the construction of FSMs to implement permanent memory in living cells with low burden.32,36,37 For example, Siuti et al. constructed a strategy that used two species of recombinases as the hardware to switch the expression of the reporter protein GFP.38 On the DNA template, the GFP gene elements, including promoters, terminators, and the coding region of GFP, are arranged in different orientations, which are flanked by recombinase recognition sites, respectively. Thus, this DNA template as the input can be processed by specific excisions or inversions. Given that the GFP expression (on or off) is determined by whether the elements are correctly arranged, this system can switch the GFP level states depending on the current arrangement of the elements and the recombinase recognition sites, as well as the species of the recombinases introduced. In this way, all 16 two-input logic functions can be implemented in living cells. Besides, Yang et al. identified 34 orthogonal phage integrases and employed some of them to construct 11 memory switches, which thus recorded the transient state of transcriptional logic gates in the living cells.31 In the memory switch that contains integrases In2, In5 and In7, almost 92% of the entire population progressed to the final state of the cascade.Later, Roquet et al. constructed a 16-state FSM which realized the recording and responding to three kinds of recombinases and their temporal orders (Fig. 2B).32 In this system, they introduced several fluorescent reporter genes in the DNA template and tested each state in an E.coli population by Sanger sequencing and detection of the set of fluorescent reports. For the 16-state FSM, at least 88% of cells treated with each order of inputs adopted their expected state. However, in this way, the context effects arising from unexpected parts interactions may influence recombination efficiency and the following gene expression.40 To address this limitation, Zúñiga et al. implemented the highly modular control of input-order-dependent gene expression in the multicellular system.33 Each specific order of the inputs corresponds to a lineage, and for a certain number of inputs, all different lineages are decomposed into submodules that are implemented by different strains. In each linear lineage of decomposition, the switching efficiency of states supposed to express an aimed protein was over 90%. By simply mixing strains in equal proportions, the full program is implanted.
However, due to the limited species of orthogonal recombinases that can be used in a single cell, the scalability and recording capacity of current recombinase-based cellular memories are constrained.41 To overcome this challenge, Farzadfard et al. proposed a method based on only one kind of recombinase (beta recombinase), whose mechanism is similar to that of the CRISPR-Cas adaptive immune system.41 On this platform, ssDNA of interest is generated by a widespread bacterial reverse transcription system in living cells. The system could respond to arbitrarily designed transcriptional signals and translate them into corresponding ssDNAs. When coexpressed with the beta recombinase, these ssDNAs could target specific loci of the genomic DNA, resulting in precise mutations accumulated over time.
2.3 CRISPR-Cas systems-based FSMs in the living cells
In nature, CRISPR/Cas nuclease machinery in bacteria serves as the adaptive immune system, which can record, recognize and specifically digest foreign nucleic acids. In recent decades, CRISPR/Cas systems have been intensively exploited as genome editing platforms. For example, the well-established CRISPR-Cas9 system relies on a single-guide RNA (sgRNA) carrying a specificity determining sequence (SDS) for the recognition of the target DNA sequence with a protospacer adjacent motif (PAM). Compared to conventional restriction enzymes and recombinases, CRISPR-Cas systems can recognize longer target sequences (typically ∼20 bp), possessing higher site-specificity and thus holding greater potential synthesis, CRISPR-Cas systems allow high freedom in target positioning, compared to the technologies based on Zinc-finger nucleases (ZFNs) or transcription activator-like effector nucleases (TALENs) that require case-by-case protein engineering.18Recently, Perli et al. reported an analog memory device that could implement continuous genetic recording on the DNA sequence over time with a self-targeting CRISPR-Cas system deployed in human cells.30 They modified the sgRNA's template DNA, introducing a PAM downstream the SDS. Thus, the transcript, called self-targeting guide RNA (stgRNA), could direct Cas9 to target its own template DNA locus and cause indel mutations (state recording) via the error-prone DNA repair mechanisms in human cells. The mutant template then generated a new stgRNA carrying the mutations for the next round of cleavage. This process could also be controlled by inducible promoters upstream of the coding regions of the stgRNA or Cas9. In this way, this system allows genetic recording dependent on the temporal order of external inducers.
In another example, Shipman et al. harnessed the natural CRISPR–Cas adaptive immune system in Escherichia coli to encode information in spacer nucleotide space, which endows it potential to exceed any other synthetic biological system to date in the capacity to store information (Fig. 2C).39 In this system, CRISPR adaptation proteins, Cas1 and Cas2, can combine into a complex and integrate foreign DNA sequences into the host genomic CRISPR arrays in the form of short spacers. In this study, arbitrary short DNA strands, serving as the inputs, were sequentially electroporated into bacterial cells overexpressing Cas1 and Cas2. As a result, these inputs were integrated into the CRISPR arrays in the host genomic DNA (i.e., recording the states) in a time-sequence-dependent manner. Besides, they produced many Cas1–Cas2 mutants with modified PAM specificity to control the orientations of the integration. By varying expression ratios of wild-type and mutant-type Cas1–Cas2, they generated a record encoding not only the sequences but also the orientations of the inputs.
3. DNA FSMs based on higher-order structural reconfiguration
Another important category of DNA FSMs relies on the switching of DNA secondary or higher-ordered structures, rather than on the recombination of their base sequences. Thus, the state information is recorded in the form of three-dimensional conformations/configurations, which can be read by structural characterizations (e.g., AFM imaging, TEM imaging) or optical signal detections (e.g., fluorescence spectroscopy, CD spectroscopy).42–45 This class of FSMs has several features in comparison with those recombination-based FSMs. First, given that DNA structural conformations are sensitive to diverse external stimuli such as pH, metal ions, and many molecules (e.g., targets of DNA aptamers), this class of FSMs can in principle respond to such a wide range of input forms besides DNA strands. Second, the state switching kinetics of these FSMs based on structural reconfigurations are generally fast (usually in seconds) compared to those based on primary sequence recombinations.46 Third, the switching processes are usually driven by the free energy provided by the input molecules and the energy landscapes of the states, thus are not dependent on DNA manipulating enzymes driven by ATP, enabling the construction of protein-free FSM systems.9,47 Particularly, DNA strand displacement reactions (SDRs) mediated by ‘toeholds’ (single-stranded DNA domains to which an invader strand can bind to initiate the displacement) have been widely used to drive the DNA structural state switching.9,20,48,49 And, due to the orthogonality empowered by the toeholds, SDRs have been widely used to build complex DNA circuits and nanomachines, which have proved good accuracy and scalability. Fourth, these FSMs usually allow reversible state switching, endowing them with reusability.10,42,50 Moreover, the risks of inducing permanent mutations in the host genome, as the recombination-based FSMs may cause, can be minimized.3.1 FSMs based on combinations of multiple DNA nanostructures
One approach to implementing DNA FSMs based on higher-order structural reconfigurations is to utilize the combinations of multiple DNA structures. For example, in 2010, Soloveichik et al. reported the use of multiple DNA strands to construct arbitrary chemical reaction networks (CRNs) driven by SDRs.51 They demonstrated several complex systems, including an FSM capable that can serve as an incrementor.Wang et al. reported an FSM system comprising three pairs of DNA tweezers that could be separately activated/inactivated by the inputs of Hg2+/OH−, Hg2+/cysteine, and nucleic acid linker/complementary anti-linker (Fig. 3). A DNA tweezer is a DNA structure with two rigid arms and can be opened or closed by external inputs. By labeling one arm with a fluorophore while the other with a quencher, the conformational change of the tweezer (open or closed) can be read by measuring the fluorescence intensity. In this way, this system can specifically respond to input signals with different orders, and switch across up to 16 different states defined by the conformation combinations of the three tweezers.10
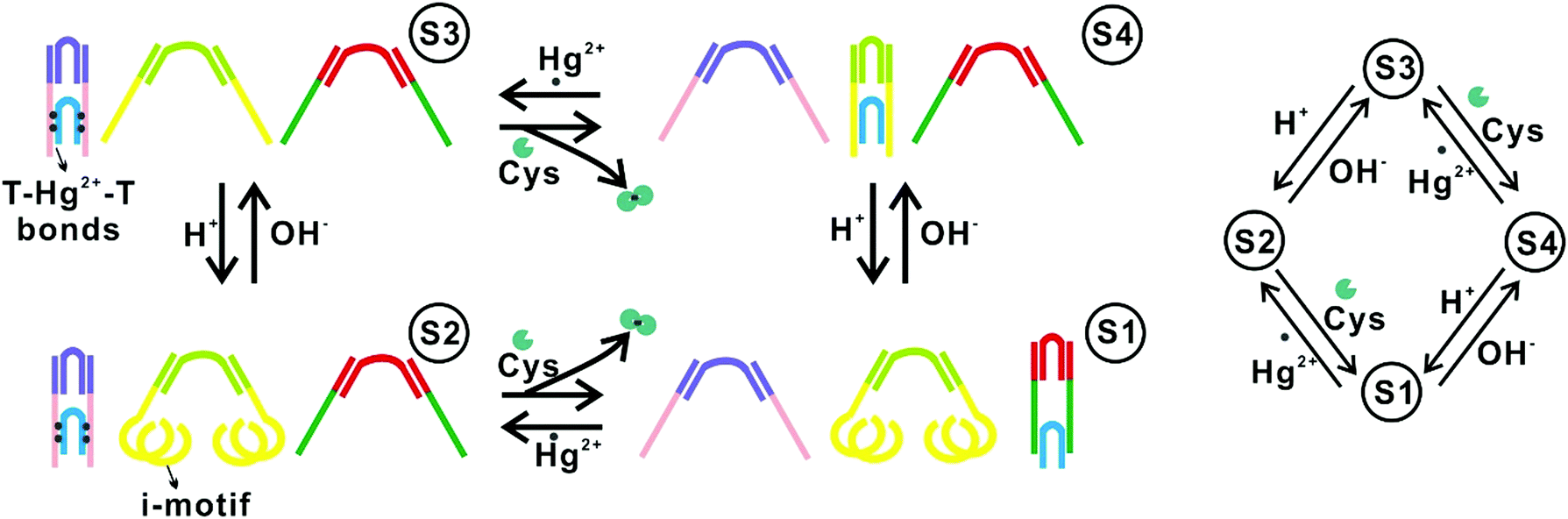 | ||
| Fig. 3 FSMs based on combinations of multiple DNA nanostructures.10 Copyright: 2010, National Academy of Sciences. | ||
Another FSM prototype is based on deoxyribozymes (DNAzymes, or catalytic DNA motifs) with nucleic acid cleavage activities. For example, a Mg2+-dependent DNAzyme E6 can cleave the ribonucleotide phosphodiester.53 In this DNAzyme, a stem-loop motif serves as the catalytic core, whose flanking sequences can be designed to recognize and capture the target ssDNA containing a ribonucleotide, leading to specific cleavage of the latter. The substrate DNA is labeled with a fluorophore-quencher pair so that the cleavage can be indicated by the fluorescence recovery. By introducing extra stem-loop motifs at the substrate recognition domains, the access of the DNA substrate to the catalytic core is blocked, leading to the “switch off” of the cleaving activity. These blocking stem-loops can be opened by the complementary oligonucleotides (inputs), resulting in the restoration of the cleaving activity (“switch on”). Individual structures based on this principle have been used to implement basic combinational logic calculations. Whereas, by utilizing their combinations, Milan N Stojanovic et al. designed a series of board games (called MAYA) under the concept of FSM.54–56 For example, the game “MAYA-I”54 comprises nine reaction wells serving as the 3 × 3 checkerboard. The game rule is programmed by specifying the combinations of the E6-derived structures (responsive to different inputs but having the same substrate) in each well. In each round, the human opponent makes a move by inputting an oligonucleotide to all the nine wells, and the system responds by giving a fluorescence pattern reflecting the cleavage activity states of the nine wells. Thus, the states in the next round are not only dependent on the input but also on the states in the current round.
3.2 FSMs based on individual DNA nanostructures
In this class of FSMs, an individual DNA nanostructure is competent to switch among multiple states in response to the sequential inputs. In 2000, Yurke et al. reported a tweezer-like DNA molecular machine that is regarded as the first DNA FSM of this class.19 This DNA machine was a partially double-stranded DNA structure with a single-stranded hinge and two toehold domains, which could reversibly switch between two configurations (closed and opened) through SDRs fueled by corresponding ssDNAs. The operation of such a machine could be monitored by fluorescence resonance energy transfer (FRET) sensitive to the structural changes at the nanometer scale. Later, they built a three-state FSM by combining the DNA tweezers with a DNA actuator.57 It could be switched between a ‘‘straightened,’’ a ‘‘relaxed,’’ and a ‘‘closed’’ form. In 2013, Santini et al. implemented a clocked FSM assembled by multiple DNA structures (hairpins and ssDNAs, for state transition, input, and clocking, respectively).58 The operations would form a DNA polymer structure by hybridization, whose current state was represented by a ssDNA domain at the growing end of this structure. A molecular beacon labeled with a fluorophore and a quencher was used to report the state. Particularly, the state transitions were triggered by a DNA strand serving as the clock signal, which allows synchronized, parallel operation of multiple FSMs. Li et al. reported a reversible logic circuit based on a pseudocatenane comprising three rings interlocked by dsDNA segments (Fig. 4A and B).52 The circuit was initially “activated” by two oligonucleotides through SDRs, which unlocked the rings, allowing their rotational mobility. Then the acidic pH allowed the formation of the i-motif structure and finally the formation of the G-quadruplex. The reaction cascade was time-sequence-sensitive, that is, the G-quadruplex can only form when the input of the two oligonucleotides and the acidic pH were satisfied in the right order. In another case, Wang et al. described the assembly of a DNA transporter that captured and transported a molecular DNA unit across three predefined sites (states) via SDRs (Fig. 4C).50 In the situation that transporting the DNA unit to site C, the yield of the transported cargo on the correct site was over 80%. Recently, our group reported a multicolor fluorescent DNA nanostructure anchored on the interface, which can release different parts in response to different input orders of DNA sequences, resulting in different fluorescent states.59 Overall, these prototypes could translate the structural states into distinct fluorescence signals. In another example, Zhang et al. reported a ‘fold-release-fold’ strategy that could reconfigure a square DNA origami structure into two kinds of more complex structures (states) step by step utilizing multiple SDRs and hybridization reactions (Fig. 4D).42 In this system, the yield of each reconfiguration step was ∼85%. Whereas, to gain a fully reversible reconfiguration, the overall yield was ∼50%. More recently, Liu et al. developed a two-input, five-state FSM based on spatially constrained SDRs on a DNA origami structure, which could sense and record the temporal orders of two miRNA sequences. This FSM allowed precise control of the reactions along predefined paths on the DNA origami structure for different input orders, resulting in minimized leakage and fast kinetics.61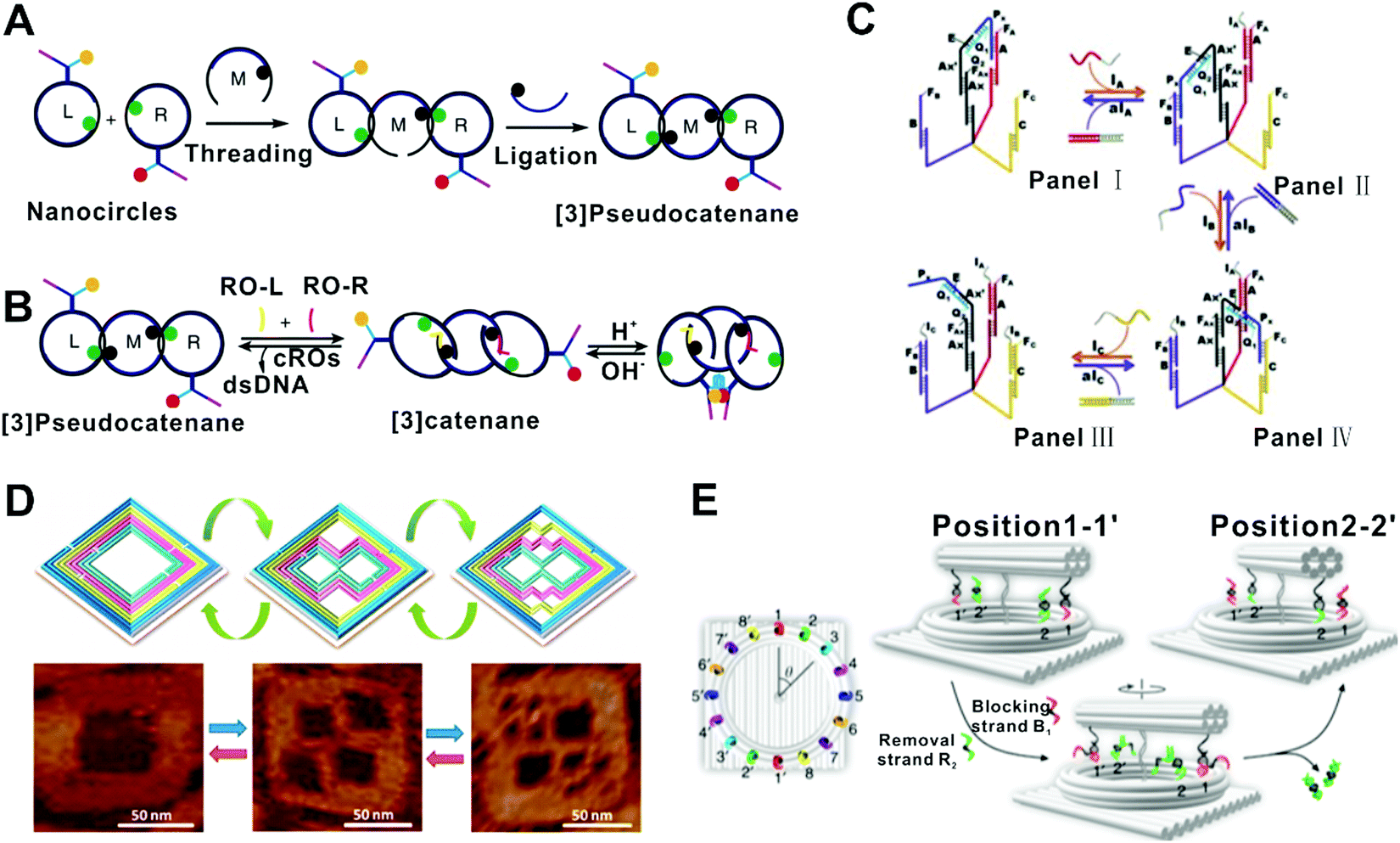 | ||
| Fig. 4 FSMs based on single DNA nanostructures. (A and B) Synthesis and state switching of a DNA-programmed pseudocatenane.52 Copyright: 2014, Li et al. (C) A DNA transporter that captured and transported a molecular DNA unit across three predefined sites (states) via SDR.50 Copyright: 2012, Wiley-VCH. (D) A ‘fold-release-fold’ strategy that could reconfigure a square DNA origami structure into two kinds of more complex structures step by step by using the SDR principle.42 Copyright: 2012, American Chemical Society. (E) A rotary plasmonic nanoclock that could adjust the angle between two nanorods, switching among 16 well-defined states fueled by DNA.43 Copyright: 2019, Xin et al. | ||
Some strategies demonstrated FSMs enabling rearrangement of other functional materials (e.g., metal nanoparticles) based on SDR-mediated DNA structural reconfigurations. For example, Kuzyk et al. reported a DNA-fueled reconfigurable three-dimensional plasmonic metamolecule. The system utilized a switchable DNA origami template comprising two angle-tunable connected bundles to organize the arrangement and angle a pair of gold nanorods (AuNRs).62 Later, Zhou et al. designed a plasmonic walker system that contained a DNA origami platform (a 2D double-layer DNA origami platform or a 3D triangular prism DNA origami platform) and two perpendicularly arranged AuNRs which are called walker and stator, respectively.44 In the system, the stator is still, while the walker can move stepwise on the origami track in response to specific DNA inputs, leading to the relative position changes of the two AuNRs. Similarly, Urban et al. built a plasmonic walker system comprising two AuNRs walkers.45 They were placed one at each end of a double-layer DNA origami platform, and could walk simultaneously or separately toward the center stepwise by SDR, resulting in multiple states considering their relative positions. Based on these works, Xin et al. described a nanodevice that could switch like a real clock across 16 states defined by the directions of two rotary AuNRs (Fig. 4E).43 Recently, they extended walking modules in this rotation-based FSM, which enabled a variety of higher dimensional motion modes by dimerization and oligomerization of the DNA structures.63
4. Applications of state machines
4.1 Molecular detection and diagnostics
In the realm of molecular detection and diagnostics, the capability to resolve the temporal orders of multiple cues is desired due to their relevance to biological processes. Several demonstrations on this direction have been reported recently. For example, Li et al. implemented the order-sensitive single-molecular recognition based on a DNA framework fluorescence probe anchored on the interface.59 Two DNA targets appeared in different orders could trigger different reconfigurations of the probe structure via SDR, resulting in distinct fluorescence states corresponding to the input order (Fig. 5A). In another example, the DNA origami-based FSM was used to sense the temporal orders of two miRNAs (miR21 and miR122), which suggests the potential of DNA FSMs for temporally resolved biosensing and smart therapeutics.61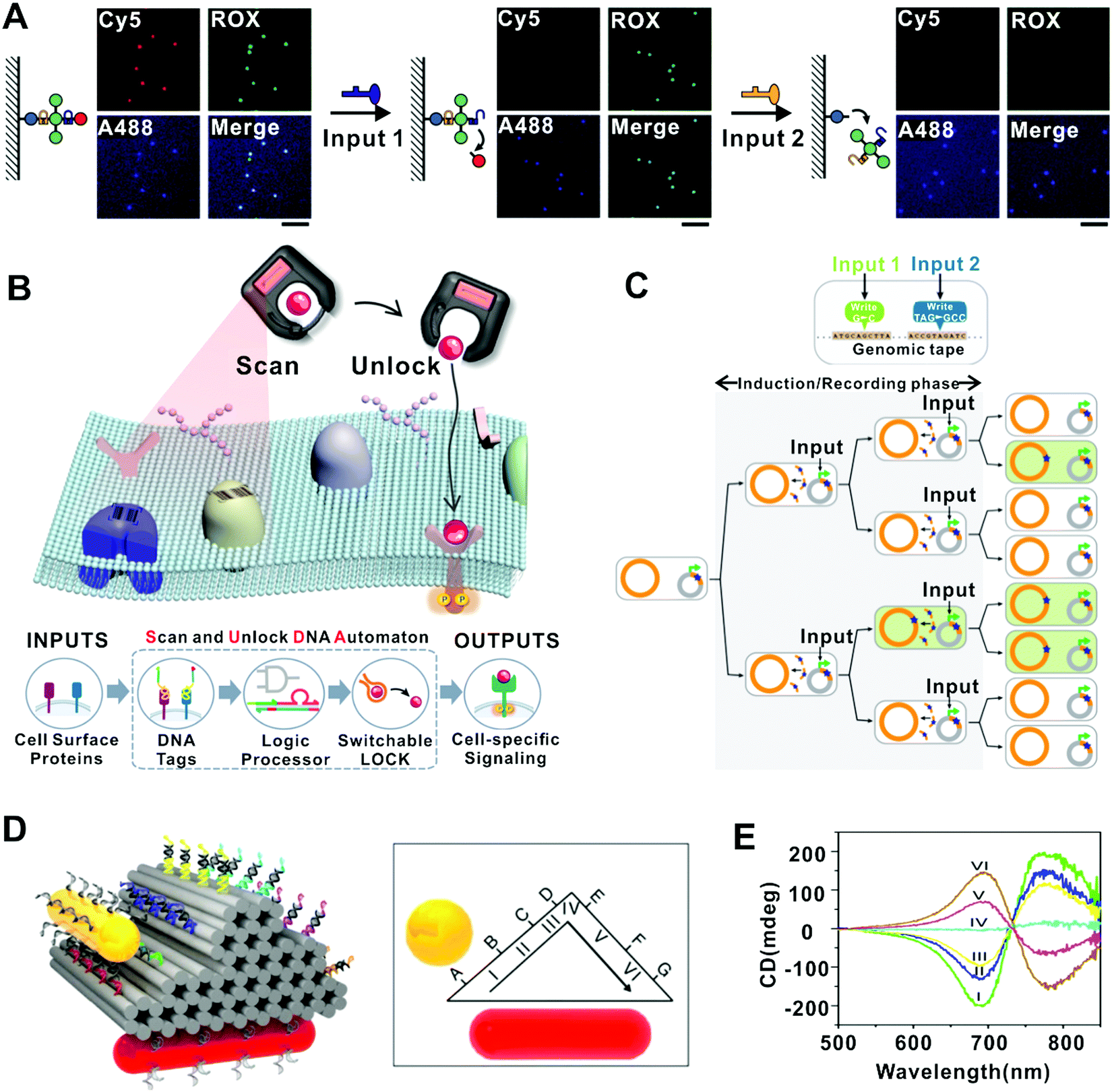 | ||
| Fig. 5 Functions of DNA-based FSMs. (A) A multi-molecule recognition strategy that translates SDR-mediated probe cleavage into quantized fluorescence state changes.59 Copyright: 2020, Li et al. (B) An intelligent “Scan and Unlock” DNA automaton system that can realize cell-specific signal modulation by quickly unlocking protein–ligand near the target cell-surface, which in turn activated its cognate receptor.60 Copyright: 2020, Wiley-VCH. (C) A ssDNA-based method to record genetic events. The FSM switched genomic DNA into a “tape recorder” for recording information in living cells.41 Copyright: 2014, American Association for the Advancement of Science. (D and E) A plasmonic nanorod that walks stepwise on 3D DNA origami.44 Copyright: 2015, Zhou et al. (D) Schematic of the 6-state plasmonic walker on a 3D origami platform. (E) CD spectra of the 6 states of the plasmonic walker. | ||
Another important challenge in molecular sensing is to achieve high precision and multiplexity in complex physiological environments. Molecular probes generating switchable signals in response to specific cues are desired for such applications. DNA nanostructures have proved efficient in producing target-specific structural state switching, which can be translated into specific signals. For example, Surana et al. demonstrated a two-state DNA nanodevice that can be reversibly switched by H+/OH−, enabling the mapping of spatiotemporal pH changes in cellular organelles within living nematodes.64 Later, a series of nanodevices have been built by using DNA structures to integrate multiple modules responsive to different cues (e.g., chloride, calcium, and hypochlorous acid) in addition to pH, allowing the mapping of these chemicals or their combinations in living cells with improved precision.65–68 In another example, the DNA FSM based on restriction/ligation has been applied to simultaneously sense different disease indicators including mRNA, microRNA (miRNA), small molecule and DNA-binding protein.69 Several DNA FSMs have been applied for the recognition of multiple molecules on cell surfaces. Rudchenko et al. demonstrated a molecular FSM which could identify different combinations of cells’ surface markers to recognize different types of cells.70 In the system, specific cell surface markers are marked by different DNA circuits. An original DNA input that activates one of the circuits is added to the system and the output of this circuit served as the input of the next circuit on the same cell. The cascade reaction is terminated when the output of the last circuit couldn’t recognize any other circuit on the same cell. Later, Zhang et al. designed a similar intelligent “Scan and Unlock” DNA FSM to realize cell-specific signal modulation (Fig. 5B).60 They marked the proteins near the target receptor with different DNA circuits, which could release an expected DNA output only when the expected protein profiles are present on the cell surface. The DNA output then hybridized to its complementary strand that was bound to the target ligand before, thus releasing the ligand and inducing the receptor-ligand interaction. These FSMs significantly improved the precision in targeting cells of interest and reduced pleiotropic effects and off-target toxicity.
4.2 Information storage
It is highly desired yet challenging to record temporally varying biological states or artificial signals in living cells.30,31,41 In recent years, some cases of continuously recording genetic events based on FSM systems have been reported. For example, as mentioned in Section 2.3, the memory device constructed by Perli and coworkers, which is based on stgRNA and Cas9, showed programmable and multiplexed memory storage in human cells triggered by exogenous inducers or inflammation.30 They placed stgRNA loci under the control of exogenous inducers so that they could record the time sequences of chemical inputs on the DNA arrays. In addition, Sheth et al. described a biological signal recorder with a mechanism similar to Shipman's work, in which the biological signal was transformed to DNA abundance at first.29 The device could record the temporal availability of three metabolites (copper, trehalose, and fucose) in the living cells over time. These memory devices allowed continuous recording of time-varying biological events into precise genetic memory in mammalian cells. Farzadfard et al. used an ssDNA-based method to record genetic events, which required beta recombinases (Fig. 5C).41 Compared to other cellular memory devices based on recombinases which could only work within a few hours, the intermediate recombination rate of their system achieved 10−4 recombination events per generation, which promoted the recording of long-term information (up to 12 days).These studies enable the measurement of cellular transient state and environmental changes and have shown the potential for recording biological events on a large scale. Besides, these approaches could be utilized to map dynamical gene regulatory events by simple sequencing of the final DNA output, without continuous imaging of cells or destructive sampling. However, the limitations of CRISPR-Cas systems have also long been discussed. The off-target effect is a major concern that limits its applications in vivo.71 Higher homology-directed repair (HDR) efficiency and more efficient and specific delivery systems are also needed.72 Fortunately, several strategies have been reported to overcome these challenges, which are detailed in another review by Li's group.72 Further optimized CRISPR/Cas9 system may show more potential in the time-dependent information storage in living cells.
4.3 Dynamic manipulation of plasmonic chirality
Smart materials capable of giving plasmonic responses against time-sequence-dependent inputs are of great interest in the realms of nanoelectronics and nanophotonics. CD response of natural molecules to external stimuli (e.g., light, electric field, and thermal stimuli) is generally weak, whereas chiral structures assembled from DNA materials have highly programmable CD based on SDR.73 Some DNA FSMs involving metal nanomaterials can realize dynamic manipulation of plasmonic chirality, such as a plasmonic nanorod that walks on a 3D triangular prism DNA origami platform (Fig. 5D and E),44 a plasmonic walker couple that presents different relative positions on the double-layer DNA origami platform,45 and a rotary plasmonic nanoclock that switches among 16 different states.43 In these studies, the relative positions of two AuNRs (the states of the system) change stepwise in response to the introduction of specific blocking strands and removal strands, resulting in different CD spectra corresponding to the different states. The strategy of using optical spectroscopy to resolve nanoscale dynamic motion is well below the optical diffraction limit.73 This series of studies is a combination of precise control of nanoscale motion by DNA nanotechnology and rich plasmonics information, which can inspire the development of smart nanophotonic platforms.5. Challenges and perspectives
In summary, we reviewed recent advances in DNA-based FSMs and highlighted representative FSM-based demonstrations. Despite the progress, their broad applications are yet hampered by several grand challenges. First, the computing speed and scale of DNA FSMs (as well as almost all present DNA-based computing devices) are still very limited compared to conventional electronic devices, due to the inherent nature of biochemical reactions. Thus, DNA FSMs are unlikely to be compelling for general computing tasks in the foreseeable future. Nevertheless, endeavors have been made to speed up the DNA reaction kinetics via, for example, spatial constraints.74–77 And, instead of using DNA strands as fuel, external powers such as mechanical forces,78,79 pH changes,80 light waves,81–83 and enzymatic networks,84 can be introduced to drive fast yet recyclable switching of DNA structures,22 which may accelerate the reactions and enable perpetual operations. On the other hand, approaches for expanding the computing scale have also emerged. One approach is to cascade multiple DNA computing units into circuits or networks with high complexity.47,85,86 Although still challenging, there has been some progress in suppressing the leakage and crosstalk that limit the scale-up.61,85–90 Another promising approach is to utilize DNA self-assembly/disassembly systems,91–94 which in theory can generate an infinite variety of distinct structures, thus might implement computing machines with almost infinite states.For now, it seems that DNA FSMs are more suitable to be applied in biological and biomedical applications such as smart biosynthesis and theranostics, where the compatibility to living systems is in preference to the computing capacity. However, the in vivo/intracellular environments are highly heterogeneous and crowded with diverse interfering biomolecules (e.g., degradative enzymes), posing difficulty in deploying DNA nanostructure-based FSMs. Thus, the structural stability and functional robustness of DNA nanostructures in physiological environments need to be interrogated.95 Thus far, several strategies have been reported for improving the stability of DNA nanostructures, by introducing additional covalent bonds,96 catenane structures,97 and protecting materials (e.g., lipid bilayers,95 protein,98 silica99). Meanwhile, reliable structural reconfigurations of DNA nanostructures in biological environments have also been demonstrated. For example, a class of logic-gated DNA nanorobots could sense multiple cell signals and logically open the structures for payload exposure in living insects.100,101 Another series of DNA robots have proved capable of working in living mammals, which can be opened by tumor biomarkers in vivo and release their payloads for tumor therapies.102,103 These examples are not strictly FSMs yet, but may inspire the future development of DNA FSMs which can function in vivo. Taken together, we envision that the development of DNA-based machines with more intelligent yet robust functionality may shed new light on future biomedical applications in living systems.
Conflicts of interest
There are no conflicts to declare.Acknowledgements
This work was financially supported by the National Key R&D Program of China (2020YFA0908900), the National Natural Science Foundation of China (T2188102, 21991134, 21834007), and the Shanghai Municipal Science and Technology Commission (19JC1410300).References
- N. Yosef, A. K. Shalek, J. T. Gaublomme, H. Jin, Y. Lee, A. Awasthi, C. Wu, K. Karwacz, S. Xiao, M. Jorgolli, D. Gennert, R. Satija, A. Shakya, D. Y. Lu, J. J. Trombetta, M. R. Pillai, P. J. Ratcliffe, M. L. Coleman, M. Bix, D. Tantin, H. Park, V. K. Kuchroo and A. Regev, Nature, 2013, 496, 461–468 CrossRef CAS PubMed.
- F. Delhommeau, N. Engl. J. Med., 2015, 372, 1865 CrossRef PubMed.
- P. A. Bullough, F. M. Hughson, J. J. Skehel and D. C. Wiley, Nature, 1994, 371, 37–43 CrossRef CAS PubMed.
- J. Chen, K. H. Lee, D. A. Steinhauer, D. J. Stevens, J. J. Skehel and D. C. Wiley, Cell, 1998, 95, 409–417 CrossRef CAS PubMed.
- D. K. Das, R. Govindan, I. Nikic-Spiegel, F. Krammer, E. A. Lemke and J. B. Munro, Cell, 2018, 174, 926–937 CrossRef CAS PubMed.
- Y. Benenson, T. Paz-Elizur, R. Adar, E. Keinan, Z. Livneh and E. Shapiro, Nature, 2001, 414, 430–434 CrossRef CAS PubMed.
- J. Li, A. A. Green, H. Yan and C. Fan, Nat. Chem., 2017, 9, 1056–1067 CrossRef CAS PubMed.
- Q. Hu, H. Li, L. Wang, H. Gu and C. Fan, Chem. Rev., 2019, 119, 6459–6506 CrossRef CAS PubMed.
- H. Ramezani and H. Dietz, Nat. Rev. Genet., 2020, 21, 5–26 CrossRef CAS PubMed.
- Z.-G. Wang, J. Elbaz, F. Remacle, R. D. Levine and I. Willner, Proc. Natl. Acad. Sci. U. S. A., 2010, 107, 21996–22001 CrossRef CAS PubMed.
- R. Gao, W. Hu and T.-J. Tarn, IEEE Trans. Nanobiosci., 2013, 12, 265–274 Search PubMed.
- J. A. Grant, J. A. Haigh, B. T. Pickup, A. Nicholls and R. A. Sayle, J. Chem. Inf. Model., 2006, 46, 1912–1918 CrossRef CAS PubMed.
- C. Lefevre and J. E. Ikeda, Nucleic Acids Res., 1994, 22, 404–411 CrossRef CAS PubMed.
- S. Benner, R. J. A. Chen, N. A. Wilson, R. Abu-Shumays, N. Hurt, K. R. Lieberman, D. W. Deamer, W. B. Dunbar and M. Akeson, Nat. Nanotechnol., 2007, 2, 718–724 CrossRef CAS PubMed.
- L. M. Adleman, Science, 1994, 266, 1021–1024 CrossRef CAS PubMed.
- S. Modi, D. Bhatia, F. C. Simmel and Y. Krishnan, J. Phys. Chem. Lett., 2010, 1, 1994–2005 CrossRef CAS.
- F. Zhang, J. Nangreave, Y. Liu and H. Yan, J. Am. Chem. Soc., 2014, 136, 11198–11211 CrossRef CAS PubMed.
- H.-X. Wang, M. Li, C. M. Lee, S. Chakraborty, H.-W. Kim, G. Bao and K. W. Leong, Chem. Rev., 2017, 117, 9874–9906 CrossRef CAS PubMed.
- B. Yurke, A. J. Turberfield, A. P. Mills, F. C. Simmel and J. L. Neumann, Nature, 2000, 406, 605–608 CrossRef CAS PubMed.
- F. C. Simmel, B. Yurke and H. R. Singh, Chem. Rev., 2019, 119, 6326–6369 CrossRef CAS PubMed.
- D. Y. Zhang and G. Seelig, Nat. Chem., 2011, 3, 103–113 CrossRef CAS PubMed.
- F. Wang, X. Liu and I. Willner, Angew. Chem., Int. Ed., 2015, 54, 1098–1129 CrossRef CAS PubMed.
- A. J. Thubagere, W. Li, R. F. Johnson, Z. Chen, S. Doroudi, Y. L. Lee, G. Izatt, S. Wittman, N. Srinivas, D. Woods, E. Winfree and L. Qian, Science, 2017, 357, eaan6558 CrossRef PubMed.
- H. Z. Gu, J. Chao, S. J. Xiao and N. C. Seeman, Nature, 2010, 465, 202–205 CrossRef CAS PubMed.
- D. Han, S. Pal, Y. Liu and H. Yan, Nat. Nanotechnol., 2010, 5, 712–717 CrossRef CAS PubMed.
- S. Fan, D. Wang, J. Cheng, Y. Liu, T. Luo, D. Cui, Y. Ke and J. Song, Angew. Chem., Int. Ed., 2020, 59, 12991–12997 CrossRef CAS PubMed.
- S. Fan, J. Cheng, Y. Liu, D. Wang, T. Luo, B. Dai, C. Zhang, D. Cui, Y. Ke and J. Song, J. Am. Chem. Soc., 2020, 142, 14566–14573 CrossRef CAS PubMed.
- T. Gerling, K. F. Wagenbauer, A. M. Neuner and H. Dietz, Science, 2015, 347, 1446–1452 CrossRef CAS PubMed.
- R. U. Sheth, S. S. Yim, F. L. Wu and H. H. Wang, Science, 2017, 358, 1457–1461 CrossRef CAS PubMed.
- S. D. Perli, C. H. Cui and T. K. J. S. Lu, Science, 2016, 353, aag0511 CrossRef PubMed.
- L. Yang, A. A. K. Nielsen, J. Fernandez-Rodriguez, C. J. McClune, M. T. Laub, T. K. Lu and C. A. Voigtwill, Nat. Methods, 2014, 11, 1261–1266 CrossRef CAS PubMed.
- N. Roquet, A. P. Soleimany, A. C. Ferris, S. Aaronson and T. K. Lu, Science, 2016, 353, aad8559 CrossRef PubMed.
- A. Zuniga, S. Guiziou, P. Mayonove, Z. Ben Meriem, M. Camacho, V. Moreau, L. Ciandrini, P. Hersen and J. Bonnet, Nat. Commun., 2020, 11, 4758 CrossRef CAS PubMed.
- M. Soreni, S. Yogev, E. Kossoy, Y. Shoham and E. Keinan, J. Am. Chem. Soc., 2005, 127, 3935–3943 CrossRef CAS PubMed.
- S. Shoshani, R. Piran, Y. Arava and E. Keinan, Angew. Chem., Int. Ed., 2012, 51, 2883–2887 CrossRef CAS PubMed.
- T. S. Ham, S. K. Lee, J. D. Keasling and A. P. Arkin, Biotechnol. Bioeng., 2006, 94, 1–4 CrossRef CAS PubMed.
- A. J. Podhajska, N. Hasan and W. Szybalski, Gene, 1985, 40, 163–168 CrossRef CAS PubMed.
- P. Siuti, J. Yazbek and T. K. Lu, Nat. Biotechnol., 2013, 31, 448–452 CrossRef CAS PubMed.
- S. L. Shipman, J. Nivala, J. D. Macklis and G. M. Church, Science, 2016, 353, aaf1175 CrossRef PubMed.
- S. Guiziou, P. Mayonove and J. Bonnet, Nat. Commun., 2019, 10, 456 CrossRef CAS PubMed.
- F. Farzadfard and T. K. Lu, Science, 2014, 346, 1256272 CrossRef PubMed.
- F. Zhang, J. Nangreave, Y. Liu and H. Yan, Nano Lett., 2012, 12, 3290–3295 CrossRef CAS PubMed.
- L. Xin, C. Zhou, X. Duan and N. Liu, Nat. Commun., 2019, 10, 5394 CrossRef PubMed.
- C. Zhou, X. Duan and N. Liu, Nat. Commun., 2015, 6, 8102 CrossRef CAS PubMed.
- M. J. Urban, C. Zhou, X. Duan and N. Liu, Nano Lett., 2015, 15, 8392–8396 CrossRef CAS PubMed.
- C. A. Figg, P. H. Winegar, O. G. Hayes and C. A. Mirkin, J. Am. Chem. Soc., 2020, 142, 8596–8601 CrossRef CAS PubMed.
- G. Seelig, D. Soloveichik, D. Y. Zhang and E. Winfree, Science, 2006, 314, 1585–1588 CrossRef CAS PubMed.
- J. Bath and A. J. Turberfield, Nat. Nanotechnol., 2007, 2, 275–284 CrossRef CAS PubMed.
- R. M. Dirks, M. Lin, E. Winfree and N. A. Pierce, Nucleic Acids Res., 2004, 32, 1392–1403 CrossRef CAS PubMed.
- Z.-G. Wang, J. Elbaz and I. Willner, Angew. Chem., Int. Ed., 2012, 51, 4322–4326 CrossRef CAS PubMed.
- D. Soloveichik, G. Seelig and E. Winfree, Proc. Natl. Acad. Sci. U. S. A., 2010, 107, 5393–5398 CrossRef CAS PubMed.
- T. Li, F. Lohmann and M. Famulok, Nat. Commun., 2014, 5, 4940 CrossRef CAS PubMed.
- R. R. Breaker and G. F. Joyce, Chem. Biol., 1995, 2, 655–660 CrossRef CAS PubMed.
- M. N. Stojanovic and D. Stefanovic, Nat. Biotechnol., 2003, 21, 1069–1074 CrossRef CAS PubMed.
- J. Macdonald, Y. Li, M. Sutovic, H. Lederman, K. Pendri, W. Lu, B. L. Andrews, D. Stefanovic and M. N. Stojanovic, Nano Lett., 2006, 6, 2598–2603 CrossRef CAS PubMed.
- R. J. Pei, E. Matamoros, M. H. Liu, D. Stefanovic and M. N. Stojanovic, Nat. Nanotechnol., 2010, 5, 773–777 CrossRef CAS PubMed.
- F. C. Simmel and B. Yurke, Appl. Phys. Lett., 2002, 80, 883–885 CrossRef CAS.
- C. C. Santini, J. Bath, A. M. Tyrrell and A. J. Turberfield, Chem. Commun., 2013, 49, 237–239 RSC.
- J. Li, J. Dai, S. Jiang, M. Xie, T. Zhai, L. Guo, S. Cao, S. Xing, Z. Qu, Y. Zhao, F. Wang, Y. Yang, L. Liu, X. Zuo, L. Wang, H. Yan and C. Fan, Nat. Commun., 2020, 11, 2185 CrossRef CAS PubMed.
- J. Zhang, Z. Qiu, J. Fan, F. He, W. Kang, S. Yang, H.-H. Wang, J. Huang and Z. Nie, Angew. Chem., Int. Ed., 2020, 60, 6733–6743 CrossRef PubMed.
- L. Liu, F. Hong, H. Liu, X. Zhou, S. Jiang, P. Šulc, J.-H. Jiang and H. Yan, Sci. Adv., 2022, 8, eabm9530 CrossRef PubMed.
- A. Kuzyk, R. Schreiber, H. Zhang, A. O. Govorov, T. Liedl and N. Liu, Nat. Mater., 2014, 13, 862–866 CrossRef CAS PubMed.
- L. Xin, X. Duan and N. Liu, Nat. Commun., 2021, 12, 3207 CrossRef CAS PubMed.
- S. Surana, J. M. Bhat, S. P. Koushika and Y. Krishnan, Nat. Commun., 2011, 2, 340 CrossRef PubMed.
- N. Narayanaswamy, K. Chakraborty, A. Saminathan, E. Zeichner, K. Leung, J. Devany and Y. Krishnan, Nat. Methods, 2019, 16, 95–102 CrossRef CAS PubMed.
- K. Leung, K. Chakraborty, A. Saminathan and Y. Krishnan, Nat. Nanotechnol., 2019, 14, 176–183 CrossRef CAS PubMed.
- S. Saha, V. Prakash, S. Halder, K. Chakraborty and Y. Krishnan, Nat. Nanotechnol., 2015, 10, 645–651 CrossRef CAS PubMed.
- S. Thekkan, M. S. Jani, C. Cui, K. Dan, G. Zhou, L. Becker and Y. Krishnan, Nat. Chem. Biol., 2019, 15, 1165–1172 CrossRef CAS PubMed.
- B. Gil, M. Kahan-Hanum, N. Skirtenko, R. Adar and E. Shapiro, Nano Lett., 2011, 11, 2989–2996 CrossRef CAS PubMed.
- M. Rudchenko, S. Taylor, P. Pallavi, A. Dechkovskaia, S. Khan, V. P. Butler, S. Rudchenko and M. N. Stojanovic, Nat. Nanotechnol., 2013, 8, 580–586 CrossRef CAS PubMed.
- Y. Fu, J. A. Foden, C. Khayter, M. L. Maeder, D. Reyon, J. K. Joung and J. D. Sander, Nat. Biotechnol., 2013, 31, 822–826 CrossRef CAS PubMed.
- X. Zhang, L. Wang, M. Liu and D. Li, Sci. China: Life Sci., 2017, 60, 468–475 CrossRef CAS PubMed.
- N. Liu and T. Liedl, Chem. Rev., 2018, 118, 3032–3053 CrossRef CAS PubMed.
- J. Li, A. Johnson-Buck, Y. R. Yang, W. M. Shih, H. Yan and N. G. Walter, Nat. Nanotechnol., 2018, 13, 723–729 CrossRef CAS PubMed.
- F. Wang, H. Lv, Q. Li, J. Li, X. Zhang, J. Shi, L. Wang and C. Fan, Nat. Commun., 2020, 11, 121 CrossRef CAS PubMed.
- W. Engelen, S. P. W. Wijnands and M. Merkx, J. Am. Chem. Soc., 2018, 140, 9758–9767 CrossRef CAS PubMed.
- G. Chatterjee, N. Dalchau, R. A. Muscat, A. Phillips and G. Seelig, Nat. Nanotechnol., 2017, 12, 920–927 CrossRef CAS PubMed.
- W. Bae, K. Kim, D. Min, J. K. Ryu, C. Hyeon and T. Y. Yoon, Nat. Commun., 2014, 5, 5654 CrossRef CAS PubMed.
- S. Lauback, K. R. Mattioli, A. E. Marras, M. Armstrong, T. P. Rudibaugh, R. Sooryakumar and C. E. Castro, Nat. Commun., 2018, 9, 1446 CrossRef PubMed.
- N. Wu and I. Willner, Nano Lett., 2016, 16, 6650–6655 CrossRef CAS PubMed.
- Y. Y. Yang, M. Endo, K. Hidaka and H. Sugiyama, J. Am. Chem. Soc., 2012, 134, 20645–20653 CrossRef CAS PubMed.
- C. Zhang, X. Jing, L. Guo, C. Cui, X. Hou, T. Zuo, J. Liu, J. Shi, X. Liu, X. Zuo, J. Li, C. Chang, C. Fan and L. Wang, Nano Lett., 2021, 21, 5834–5841 CrossRef CAS PubMed.
- X. Xiong, M. Xiao, W. Lai, L. Li, C. Fan and H. Pei, Angew. Chem., Int. Ed., 2021, 60, 3397–3401 CrossRef CAS PubMed.
- J. Deng and A. Walther, Nat. Commun., 2020, 11, 3658 CrossRef CAS PubMed.
- L. Qian, E. Winfree and J. Bruck, Nature, 2011, 475, 368–372 CrossRef CAS PubMed.
- L. Qian and E. Winfree, Science, 2011, 332, 1196–1201 CrossRef CAS PubMed.
- R. U. Sheth and H. H. Wang, Nat. Rev. Genet., 2018, 19, 718–732 CrossRef CAS PubMed.
- T. Masubuchi, M. Endo, R. Iizuka, A. Iguchi, D. H. Yoon, T. Sekiguchi, H. Qi, R. Iinuma, Y. Miyazono, S. Shoji, T. Funatsu, H. Sugiyama, Y. Harada, T. Ueda and H. Tadakuma, Nat. Nanotechnol., 2018, 13, 933–940 CrossRef CAS PubMed.
- J. Y. Kishi, T. E. Schaus, N. Gopalkrishnan, F. Xuan and P. Yin, Nat. Chem., 2018, 10, 155–164 CrossRef CAS PubMed.
- S. F. J. Wickham, J. Bath, Y. Katsuda, M. Endo, K. Hidaka, H. Sugiyama and A. J. Turberfield, Nat. Nanotechnol., 2012, 7, 169–173 CrossRef CAS PubMed.
- D. Woods, D. Doty, C. Myhrvold, J. Hui, F. Zhou, P. Yin and E. Winfree, Nature, 2019, 567, 366–372 CrossRef CAS PubMed.
- R. D. Barish, R. Schulman, P. W. K. Rothemund and E. Winfree, Proc. Natl. Acad. Sci. U. S. A., 2009, 106, 6054–6059 CrossRef CAS PubMed.
- E. Winfree, F. Liu, L. A. Wenzler and N. C. Seeman, Nature, 1998, 394, 539–544 CrossRef CAS PubMed.
- C. Mao, T. H. LaBean, J. H. Reif and N. C. Seeman, Nature, 2000, 407, 493–496 CrossRef CAS PubMed.
- S. D. Perrault and W. M. Shih, ACS Nano, 2014, 8, 5132–5140 CrossRef CAS PubMed.
- T. Gerling, M. Kube, B. Kick and H. Dietz, Sci. Adv., 2018, 4, eaau1157 CrossRef CAS PubMed.
- V. Cassinelli, B. Oberleitner, J. Sobotta, P. Nickels, G. Grossi, S. Kempter, T. Frischmuth, T. Liedl and A. Manetto, Angew. Chem., Int. Ed., 2015, 54, 7795–7798 CrossRef CAS PubMed.
- H. Auvinen, H. Zhang, Nonappa, A. Kopilow, E. H. Niemela, S. Nummelin, A. Correia, H. A. Santos, V. Linko and M. A. Kostiainen, Adv. Healthcare Mater., 2017, 6, 1700692 CrossRef PubMed.
- X. Liu, F. Zhang, X. Jing, M. Pan, P. Liu, W. Li, B. Zhu, J. Li, H. Chen, L. Wang, J. Lin, Y. Liu, D. Zhao, H. Yan and C. Fan, Nature, 2018, 559, 593–598 CrossRef CAS PubMed.
- S. M. Douglas, I. Bachelet and G. M. Church, Science, 2012, 335, 831–834 CrossRef CAS PubMed.
- Y. Amir, E. Ben-Ishay, D. Levner, S. Ittah, A. Abu-Horowitz and I. Bachelet, Nat. Nanotechnol., 2014, 9, 353–357 CrossRef CAS PubMed.
- S. Li, Q. Jiang, S. Liu, Y. Zhang, Y. Tian, C. Song, J. Wang, Y. Zou, G. J. Anderson, J.-Y. Han, Y. Chang, Y. Liu, C. Zhang, L. Chen, G. Zhou, G. Nie, H. Yan, B. Ding and Y. Zhao, Nat. Biotechnol., 2018, 36, 258–264 CrossRef CAS PubMed.
- S. Liu, Q. Jiang, X. Zhao, R. Zhao, Y. Wang, Y. Wang, J. Liu, Y. Shang, S. Zhao, T. Wu, Y. Zhang, G. Nie and B. Ding, Nat. Mater., 2021, 20, 431–433 CrossRef CAS PubMed.
| This journal is © The Royal Society of Chemistry 2022 |