
 Open Access Article
Open Access Article This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported Licence
This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported LicenceCumulant mapping as the basis of multi-dimensional spectrometry†
Leszek J.
Frasinski
Department of Physics, Imperial College London, London SW7 2AZ, UK. E-mail: l.j.frasinski@imperial.ac.uk
First published on 26th July 2022
Abstract
Cumulant mapping employs a statistical reconstruction of the whole by sampling its parts. The theory developed in this work formalises and extends ad hoc methods of ‘multi-fold’ or ‘multi-dimensional’ covariance mapping. Explicit formulae have been derived for the expected values of up to the 6th cumulant and the variance has been calculated for up to the 4th cumulant. A method of extending these formulae to higher cumulants has been described. The formulae take into account reduced fragment detection efficiency and a background from uncorrelated events. Number of samples needed for suppressing the statistical noise to a required level can be estimated using Matlab code included in Supplemental Material. The theory can be used to assess the experimental feasibility of studying molecular fragmentations induced by femtosecond or X-ray free-electron lasers. It is also relevant for extending the conventional mass spectrometry of biomolecules to multiple dimensions.
1 Introduction and motivation
Cumulant mapping is an extension of covariance mapping1 to more than two correlated variables. The covariance mapping technique in turn is an extension of the coincidence method2,3 to high counting rates, where several fragmentation events may occur in an elementary sample.From its invention covariance mapping has been used mostly in studies of ionization and fragmentation of small molecules, with some notable exceptions, such as X-ray scattering or brain studies.4,5 Since covariance mapping requires extensive data processing, two-dimensional maps have been most practical. With continued progress in computational power an extension of covariance mapping to higher dimensions is a timely proposition.
Two recent developments have motivated this work. One is a successful application of covariance mapping to two-dimensional mass spectrometry of large biomolecules,6,7 with good prospects for extending this technique to higher dimensions. The second development is the emergence of X-ray free-electron lasers (XFELs), which are powerful research tools for studying atomic and molecular dynamics on the femtosecond and attosecond timescales.8 The unprecedented intensity of X-rays in the XFEL pulses induces a large number of fragmentation events, which leaves covariance mapping as the only practical method for correlating the fragments. Moreover, recent XFEL upgrades to high repetition rates, including fast data acquisition,8 make the extension of covariance mapping to higher dimensions feasible.
2 Fragmentation scenario
The scheme for cumulant mapping is outlined in Fig. 1. A random sample of unknown objects is drawn from a Poisson distribution. The objects are fragmented, and the fragments are detected. To understand the basic principle, it is helpful to consider initially an ideal scenario where the objects are identical and always break up in the same way into distinguishable fragments. The fragments of each kind are collected in separate bins, and their number is recorded as Z, Y, X, etc. The sampling is repeated many times and the fragment numbers are used to reconstruct the parent objects.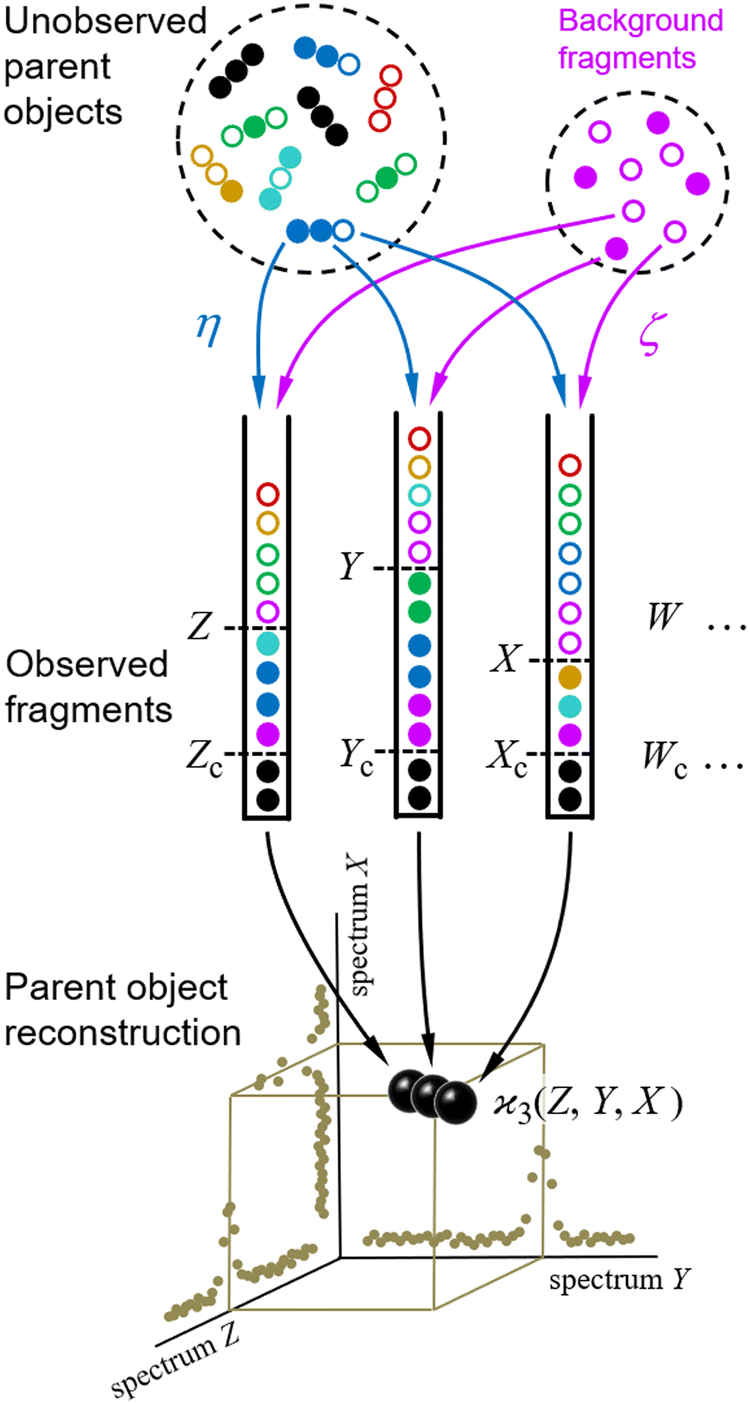 | ||
Fig. 1 The principle of reconstruction from fragments. A Poissonian sample of parent objects is fragmented and the fragments are detected with efficiency η, including some uncorrelated background in a mean proportion ζ. The detected fragments (filled circles) are counted and stored in discrete random variables Z, Y, X,…, which are processed over many samples using the cumulant formula. The cumulant value, 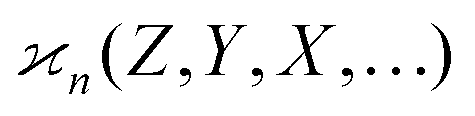 , measures the number of parent objects at a single point in an n-dimensional spectral map. , measures the number of parent objects at a single point in an n-dimensional spectral map. | ||
2.1 Realistic conditions
The reconstruction would be trivial under the ideal conditions outlined above. In practice, however, the collected fragment numbers require extensive statistical processing for several reasons.Firstly, each of the Z, Y, X,… random variables is usually measured at just one point on a fluctuating spectrum of mass, energy, or other quantity characterising the fragments, and normally it is not obvious in advance into which parts of the spectra the fragments may fall. Therefore it necessary to calculate the 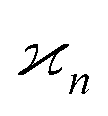 cumulant for each possible n-tuple of spectral points and display the reconstructed parent objects in an n-dimensional map, as shown at the bottom of Fig. 1. Moreover, the spectra of the Z, Y, X,… variables could be more than 1-dimensional, for example, they could be sourced from a position-sensitive timing detector, which effectively resolves fragments in 3D momentum space,9 and in principle would require mapping in 3n-dimensional space, unless the fragmentation kinematics can be used to reduce the dimensionality.
cumulant for each possible n-tuple of spectral points and display the reconstructed parent objects in an n-dimensional map, as shown at the bottom of Fig. 1. Moreover, the spectra of the Z, Y, X,… variables could be more than 1-dimensional, for example, they could be sourced from a position-sensitive timing detector, which effectively resolves fragments in 3D momentum space,9 and in principle would require mapping in 3n-dimensional space, unless the fragmentation kinematics can be used to reduce the dimensionality.
Secondly, in most experiments the fragments are detected with quantum efficiency η < 100%. This means that some of the fragments are undetected, as indicated by empty circles in Fig. 1. (The colours mark different detection patterns to enable the reader tracing them from the sample to the bins.) Therefore, the number of tuples (Zc, Yc, Xc,…) of only collectively-correlated detected fragments (black filled circles) is smaller than the number of all detected fragments Z, Y, X,… (all filled circles).
And thirdly, there may be a Poissonian background of fragments (magenta circles) completely unrelated to the sample of interest. This background is characterised by parameter ζ, which is the ratio of the mean number of the background fragments to the mean number of the sample fragments. Hence, ζ = 0 means no background, ζ = 1 means as much background as the sample signal, etc.
Taking into account reduced detection efficiencies and the presence of background fragments relaxes the idealized requirements of identical parent objects and a single fragmentation pattern, which makes cumulant mapping applicable to studies of mixtures and multiplicity of fragmentation channels. The aim of this work is to estimate the cumulant value and noise when the fragments are detected under the non-ideal conditions of η < 100% and ζ > 0.
2.2 Statistical concepts and notation
Statistics, like all natural sciences, encompasses two realms: the factual world of tangible measurements and the Platonic world of mathematical abstractions. The objects spanning both worlds are random variables, such as Z, denoted in this work with Roman capitals.On one hand, a random variable can be measured yielding sample values, which I denote giving it an index, e.g. Zi. On the other hand, the general properties of the random variables, such as probability distributions, moments, etc. are mathematical abstractions that cannot be known with absolute certainty. Nevertheless, we can infer these abstract properties by repetitive sampling of the random variable. I assume that in an experiment the conditions stay constant and that we draw N samples of Z, which are indexed by i = 1, 2, 3,…, N.
The parameters describing the properties of a random variable are denoted with Greek letters, such as 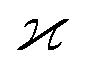 . To infer a parameter value we can use the samples to construct an estimator denoted by a hat, e.g.
. To infer a parameter value we can use the samples to construct an estimator denoted by a hat, e.g.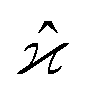 . For example, to estimate the first moment of variable Z, we use the sample average indicated by an overline:
. For example, to estimate the first moment of variable Z, we use the sample average indicated by an overline:
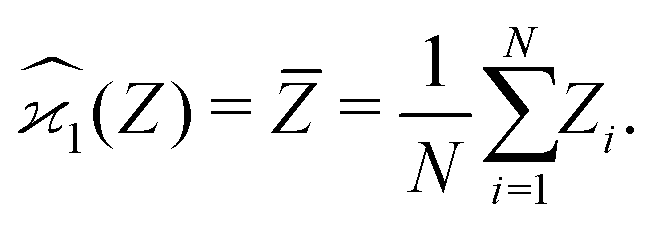 | (1) |
Since repeating the experiment gives us a new set of samples, the sample averages and the estimators are also random variables. However, calculating their expected values (or variance, or higher-order moments) fixes them to the theoretical limit when N → ∞. Angular brackets are used to denote the expected values:
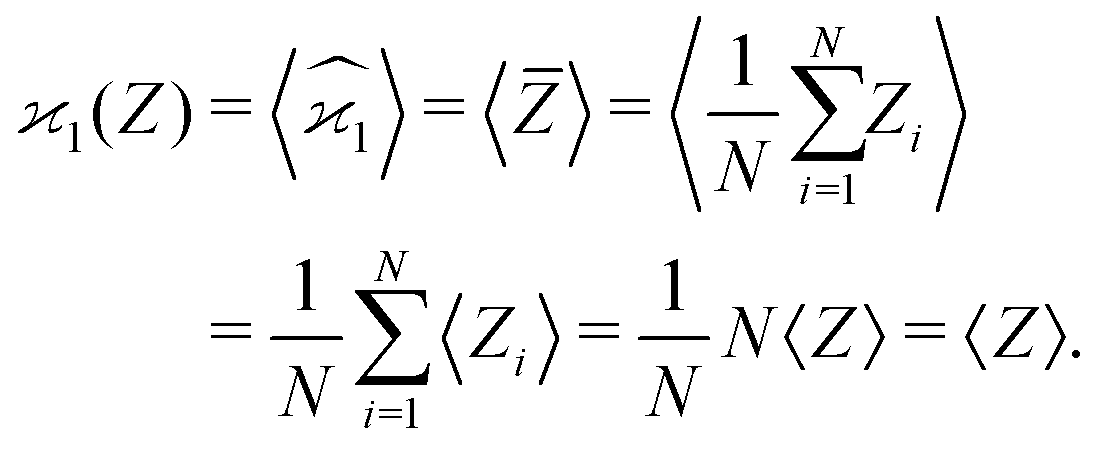 | (2) |
3 Fragment correlations
In general,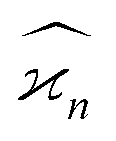 stands for an estimator of collective correlations among n fragments. When n = 1 the problem is degenerate and the best we can do is to estimate the mean number of only one kind of a fragment, Z, using the sample average according to eqn (1).
stands for an estimator of collective correlations among n fragments. When n = 1 the problem is degenerate and the best we can do is to estimate the mean number of only one kind of a fragment, Z, using the sample average according to eqn (1).
3.1 Covariance
When n = 2 the appropriate estimator is the sample covariance of the two fragments Z and Y:It is worth noting that that this estimator is biased. In principle, the bias can be removed by using Bessel's correction factor N/(N − 1) each time a degree of freedom of the sample has been used to calculate an inner average. In practice however, the bias is insignificant for N ≫ 1 and can be ignored where appropriate.
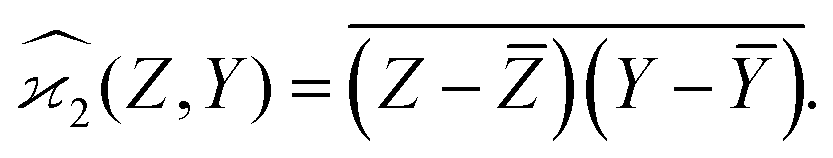
Calculating the expected value of this estimator leads to the well known formula for covariance:
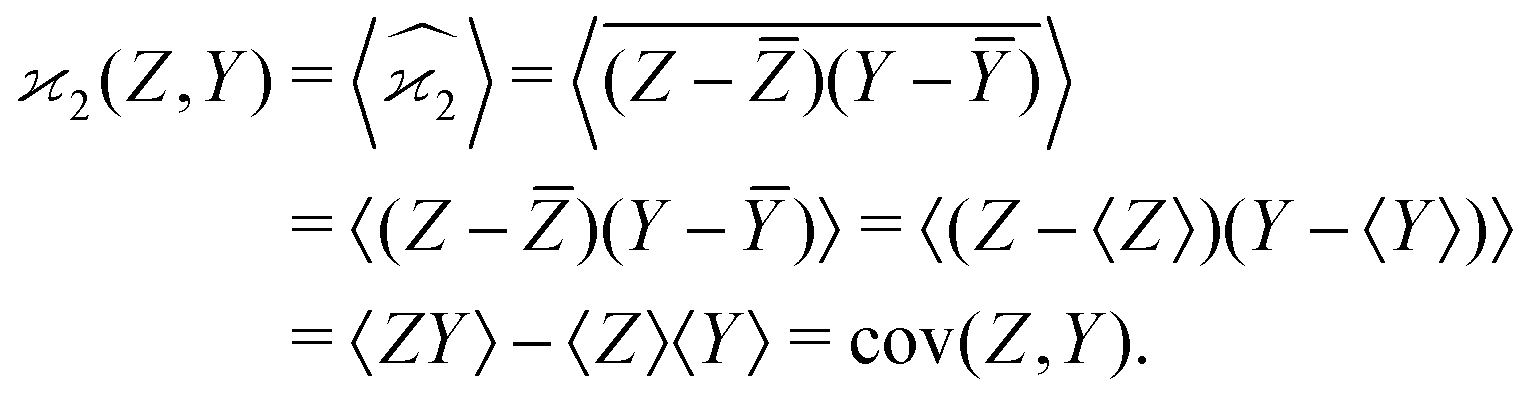
| z0 = Z − 〈Z〉, y0 = Y − 〈Y〉, | (3) |
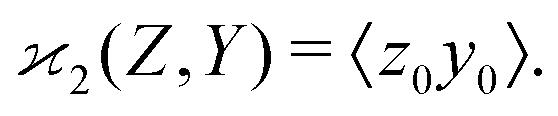 | (4) |
3.2 The problem of more than two fragments
When there are three fragments, an extension of eqn (4) has been proposed:10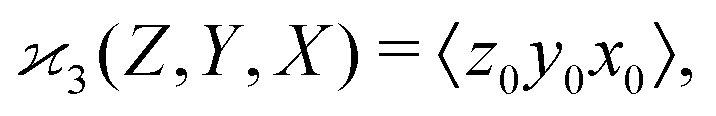 | (5) |
One may expect that this method of extending the covariance formula works for four fragments:
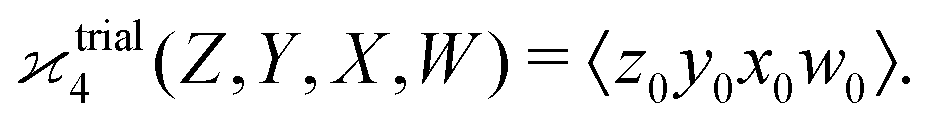
but we want
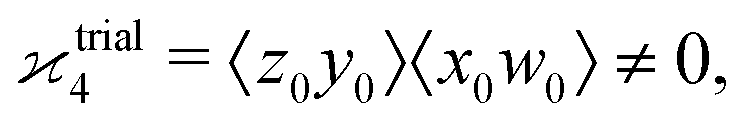
 because there is no collective correlation among all four fragments.
because there is no collective correlation among all four fragments.
3.3 The solution
To find the correct formula for n ≥ 4, I start with listing the desired properties of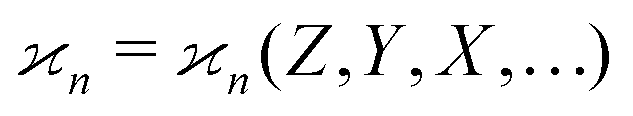 :
:
• 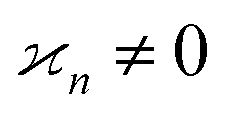 only if all arguments are collectively correlated;
only if all arguments are collectively correlated;
• 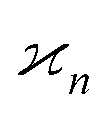 has units of the product of all arguments;
has units of the product of all arguments;
• 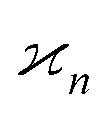 is linear in the arguments;
is linear in the arguments;
• 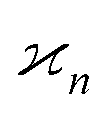 is invariant under interchange of any two arguments.
is invariant under interchange of any two arguments.
It turns out that these properties uniquely determine the formula. For example, the reader is invited to check that the following formula has the desired properties:
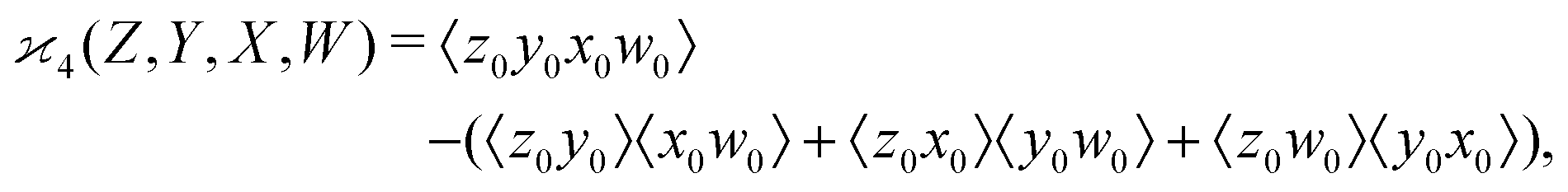
| 〈z0〉 = 〈Z − 〈Z〉〉 = 〈Z〉 − 〈Z〉 = 0. |
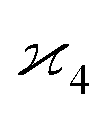 can be simplified by writing
can be simplified by writing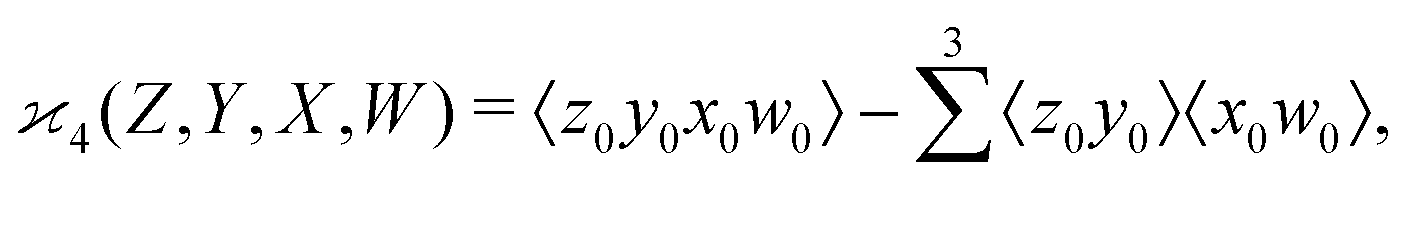 | (6) |
 denotes a sum over all ways of paring the four variables.
denotes a sum over all ways of paring the four variables.
Similarly,
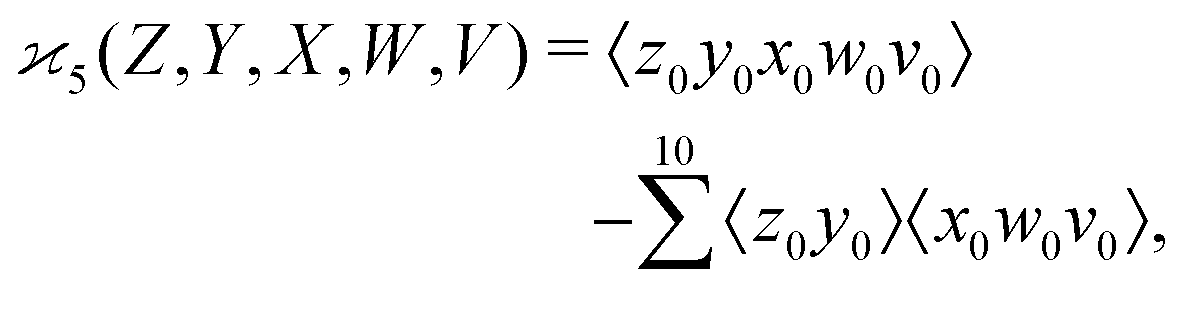 | (7) |
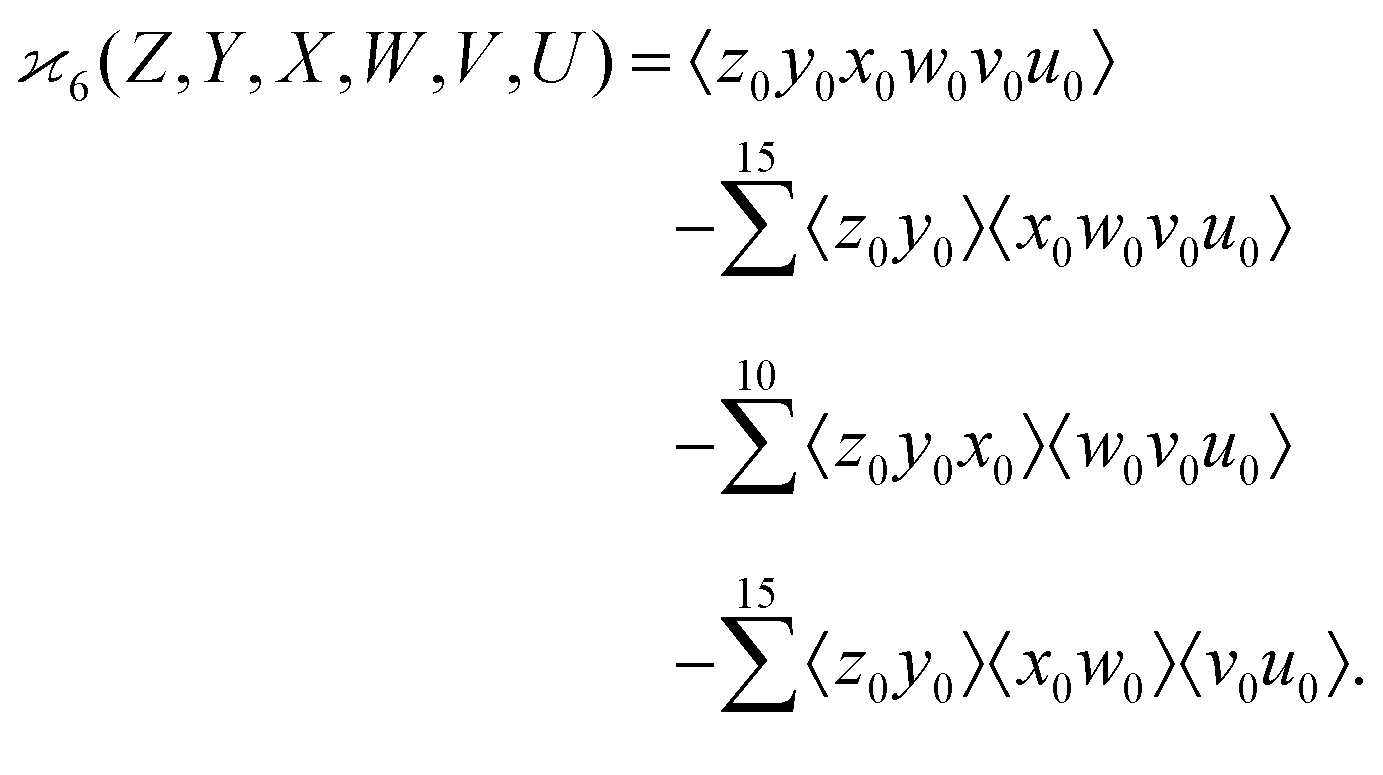 | (8) |
3.4 Cumulants
In statistics the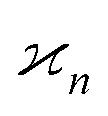 parameter that measure the collective correlations of n random variables is known as the n-variate joint cumulant of the first order14 (chapters 3, 12 and 13). In this work I shall shorten this name and call it simply the nth cumulant.
parameter that measure the collective correlations of n random variables is known as the n-variate joint cumulant of the first order14 (chapters 3, 12 and 13). In this work I shall shorten this name and call it simply the nth cumulant.
Cumulants are useful in seemingly disjoint areas of science, such as light–matter interactions,15 quantum theory of multi-electron correlations,16 bond breaking of diatomic molecules,17 neural network theory,18 financial data analysis,19 and gravitational interaction of dark matter.20 In physics multivariate cumulants are also known as the Ursell functions.21
3.5 Physical interpretation of 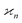
So far, the cumulants have been introduced as parameters describing multivariate distributions. Now we want to apply them to the problem of recovering the parent objects from their fragments.
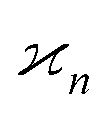
Let us suppose that we repetitively gather a sample of objects in a random manner, so the number of objects S in the sample follows the Poisson distribution:
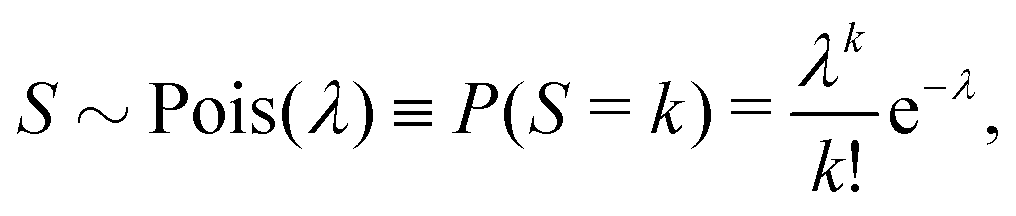 | (9) |
To understand why cumulants are useful in this task, we first consider ideal conditions: there is only one way of fragmenting the parent, we detect every fragment, and there is no background of fragments from other processes. Such fragmentation process can be written as
| S → (Z, Y, X,…), |
| Z = Y = X = … = S |
| z0 = y0 = y0 = … = s0, |
| 〈z0y0x0…〉 = 〈sn0〉 = 〈(S − 〈S〉)n〉 = μn. |
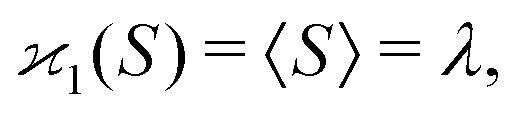 | (10a) |
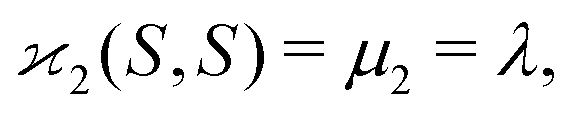 | (10b) |
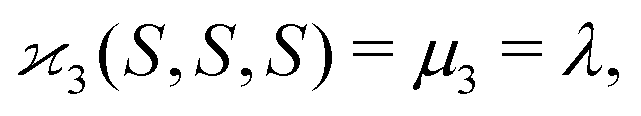 | (10c) |
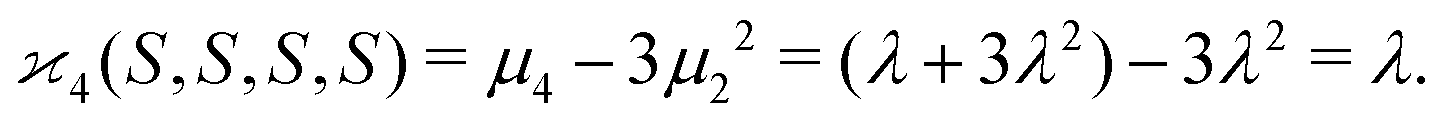 | (10d) |
We conclude that under the ideal fragmentation scenario cumulant mapping of fragments gives us a statistical estimate of the mean number of parent objects.
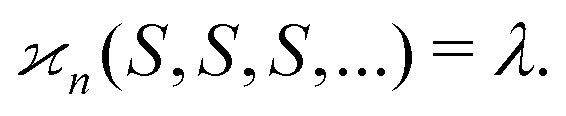
4 Uncorrelated background
Ideal conditions are rarely met in practice. We should estimate how a reduced detection efficiency and a background from uncorrelated fragments affect cumulant mapping. Both effects influence the statistics of the cumulant estimator in a similar manner; those fragments that are detected but have undetected siblings effectively contribute to the uncorrelated background, which is depicted in Fig. 1 using non-black filled circles.When η < 100% or ζ > 0, then the random variables S, Z, Y,… are only partially correlated. To find the formula for 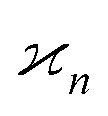 we need to separate the correlated and uncorrelated parts of these variables.
we need to separate the correlated and uncorrelated parts of these variables.
4.1 Correlated and uncorrelated parts
While the parent objects in the sample still follow the Poisson distribution given by eqn (9), the reduced detection efficiency effectively combines the parent distribution with a binomial distribution of the partial detection giving another Poisson distribution:| Z ∼ Pois(λ)*Binom(ηZ) → Pois(ηZλ). |
| Z ∼ Pois(ηZλ)⊞Pois(ηZζZλ) □ Pois(ηZ(1 + ζZ)λ). |
Since the binomial sampling of each of the Z, Y, X,… fragments is independent, their joint detection efficiency is a product of the individual efficiencies. Therefore the probability distribution of the detected fragments Z correlated with all the other detected fragments is given by
| Zc ∼ Pois(θnλ), |
| θn = ηZηYηX…. |
| Zc = Yc = Xc = … = Sc ∼ Pois(θnλ). | (11) |
Since the number of detected fragments is the sum of the correlated and uncorrelated parts:
| Z = Zc + Zu, Y = Yc + Yu, X = Xc + Xu,… | (12) |
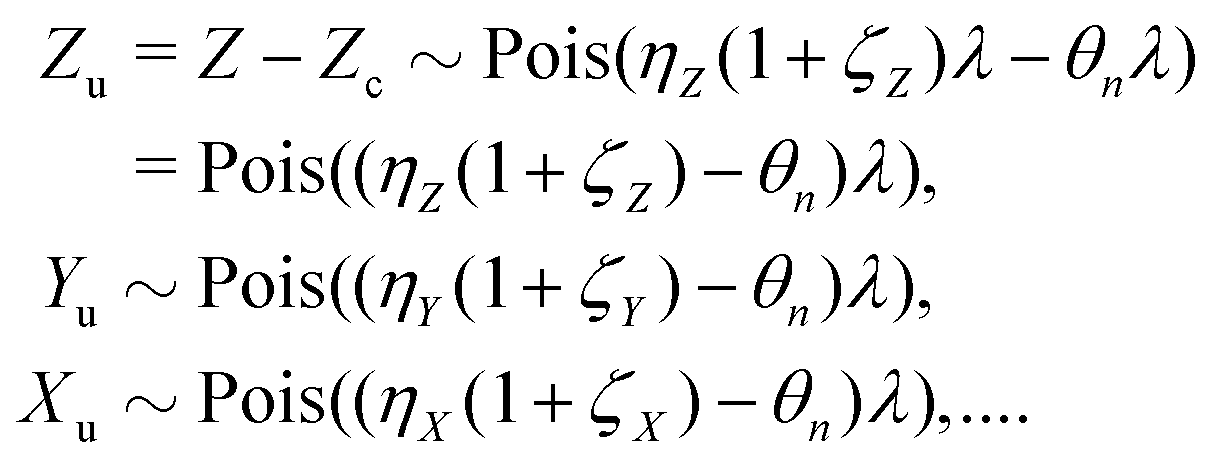
Further calculations are significantly simplified when mean-centered variables are introduced for the correlated and uncorrelated parts:
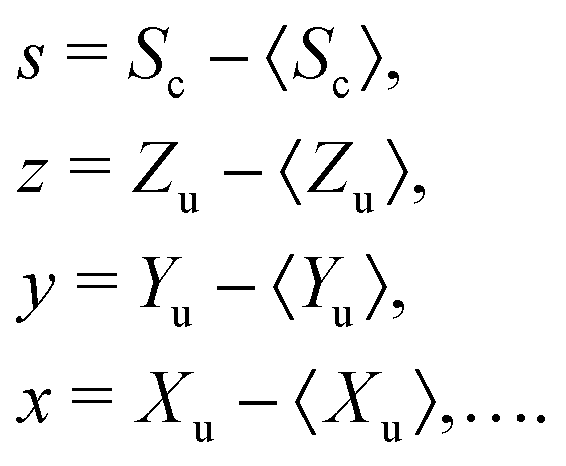 | (13) |
 | (14) |
One useful implication of eqn (13) is that the expected values of the mean-centered variables vanish:
| 〈s〉 = 〈z〉 = 〈y〉 = 〈x〉 = … = 0. | (15) |
The second useful property is that they can be regarded as independent, which is exactly true if only one or two detectable fragments are produced. For three or more fragments it may happen that one fragment that is not detected relegates the other fragments to the background in spite of their correlation. It can be shown that these residual correlations do not affect the expected values of cumulants, nor the variance of the first and second cumulant.
4.2 Expected values of cumulants
The first cumulant is unusual because formally it cannot distinguish between the sample fragments and the uncorrelated background. To deal with this ambiguity I shall redefine the first cumulant given by eqn (2), so it measures only the fragments coming from the sample: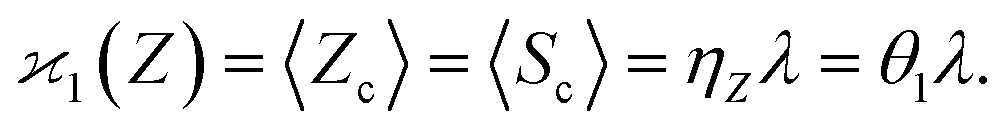 | (16) |
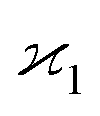 consistent with the higher cumulants but also gives it the meaning of a signal that is separate from the background. As illustrated in Fig. 2, when in spectral analysis the sample fragments form a peak riding on a broad background given by 〈Zu〉 = ηZζZλ, then 〈Zc〉 = ηZλ is just the peak height.
consistent with the higher cumulants but also gives it the meaning of a signal that is separate from the background. As illustrated in Fig. 2, when in spectral analysis the sample fragments form a peak riding on a broad background given by 〈Zu〉 = ηZζZλ, then 〈Zc〉 = ηZλ is just the peak height.
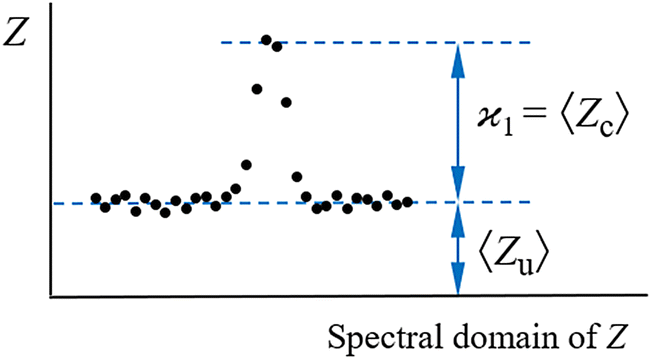 | ||
Fig. 2 How to separate the first cumulant from the uncorrelated background. Cumulant 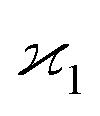 measures only the correlated fragments Zc that form a peak on a spectrum. The peak rides on a background of uncorrelated fragments Zu. This definition of measures only the correlated fragments Zc that form a peak on a spectrum. The peak rides on a background of uncorrelated fragments Zu. This definition of 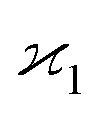 keeps the background parameter ζZ = 〈Zu〉/〈Zc〉 consistent with the higher cumulants. keeps the background parameter ζZ = 〈Zu〉/〈Zc〉 consistent with the higher cumulants. | ||
The higher cumulants can be calculated using the mean-centered variables, z0 = s + z,![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) y0 = s + y, etc. For example,
y0 = s + y, etc. For example,
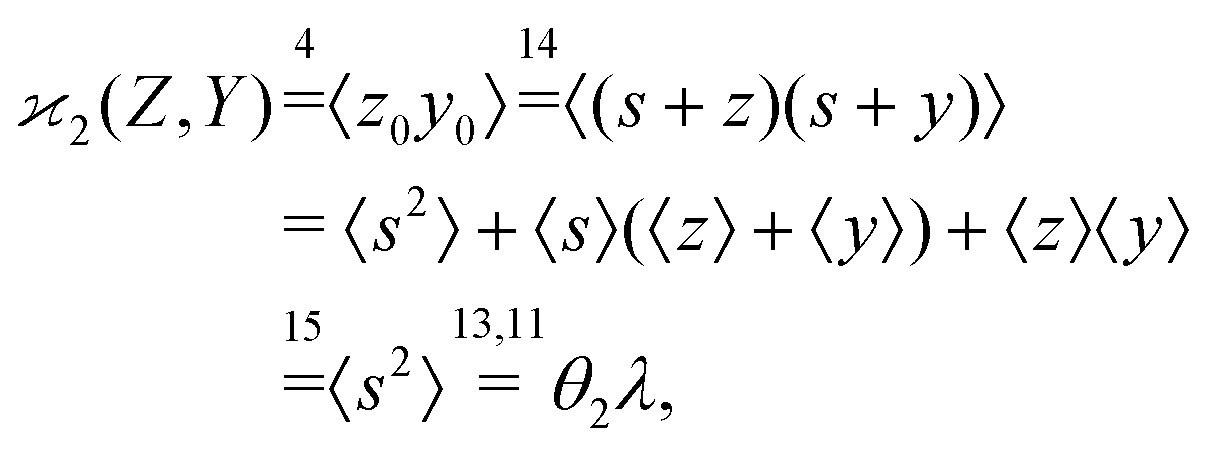 | (17) |
We notice that the formulae for all higher cumulants can be derived in a similar manner. When expanding 〈z0y0x0…〉, most of the terms vanish because of eqn (15), and we are left only with polynomials of moments of s. These polynomials are the same as in eqn (10) except now 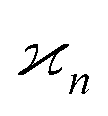 follows Pois(θnλ) rather then Pois(λ). Therefore, we obtain a general result:
follows Pois(θnλ) rather then Pois(λ). Therefore, we obtain a general result:
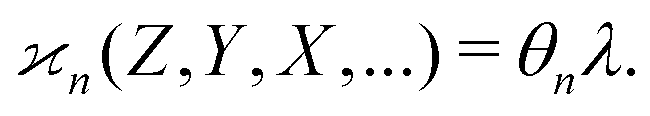 | (18) |
4.3 Estimators of cumulants
To construct cumulant estimators, the expected values in eqn (4)–(8) should be replaced with sample averages. The simplest action is to use eqn (1) everywhere. If, however, unbiased estimators are desired, factor 1/N should be replaced with 1/(N − 1) whenever a degree of freedom has already been used, for example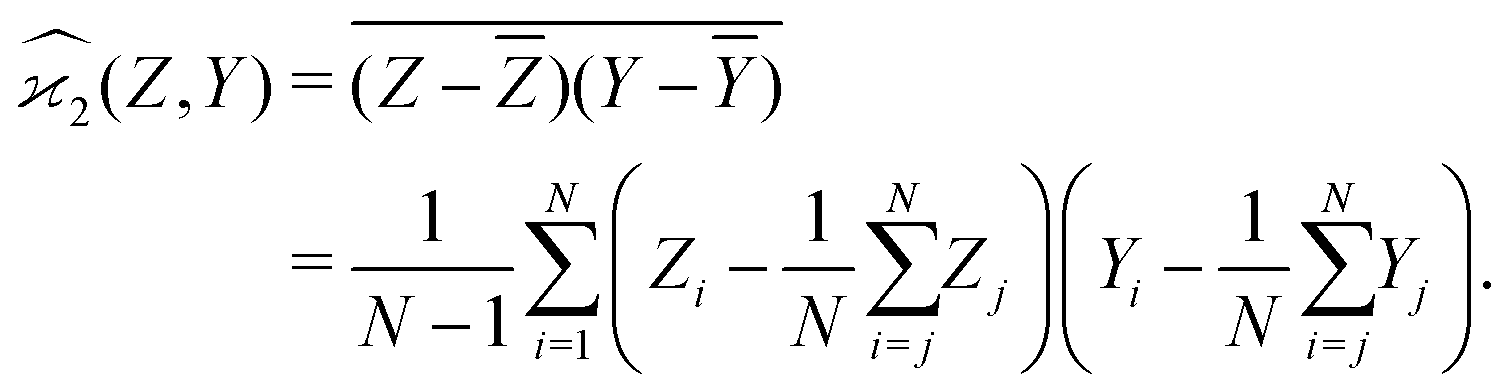 | (19) |
4.4 Noise of estimators
Due to the finite number of samples collected, cumulant estimators are noisy. When assessing the feasibility of an experiment involving a cumulant map, the expected noise on the map is of primary concern. It is known that with increasing dimensionality of the map, the noise-to-signal ratio (N/S) increases.10 There are two sources of this deterioration. Firstly, each time the map dimensionality is increased, the signal decreases because it is multiplied by the detection efficiency according to eqn (18). And secondly, the higher the cumulant, the more subtraction of lower correlations is needed, which contributes more noise from the subtrahends.These effects can be quantified by calculating the variance of the cumulant estimator, 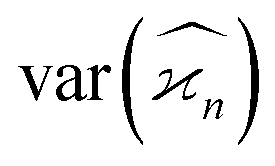 , and finding the noise-to-signal ratio:
, and finding the noise-to-signal ratio:
 | (20) |
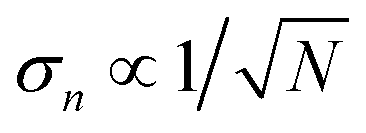 , therefore, once we know σn we can estimate the number of samples, N, needed for the required noise-to-signal ratio and assess the experimental feasibility.
, therefore, once we know σn we can estimate the number of samples, N, needed for the required noise-to-signal ratio and assess the experimental feasibility.
5 Summary of analytical results
The values and variances of the cumulants are quite complicated functions of the counting rate, λ, the detection efficiency, η, and the relative background, ζ. Rather than inspecting the analytical formulae, it is more informative to plot the results for some chosen argument ranges. Matlab code that calculates the values and variances of cumulants up to the 4th one is provided separately.† When reading and using the code, it is helpful to refer to the equations written in normal mathematical notation.The equations give cumulant estimates 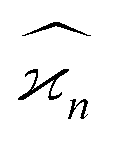 constructed from the samples according to eqn (1), the cumulant values
constructed from the samples according to eqn (1), the cumulant values 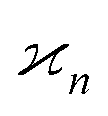 , and the cumulant variances
, and the cumulant variances 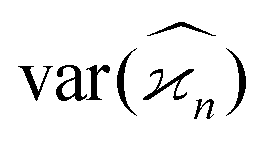 . The auxiliary quantities are the central moments of the correlated parts, 〈sn〉, and of the uncorrelated parts, 〈z2〉, 〈y2〉, 〈x2〉, and 〈w2〉 (see eqn (13)).
. The auxiliary quantities are the central moments of the correlated parts, 〈sn〉, and of the uncorrelated parts, 〈z2〉, 〈y2〉, 〈x2〉, and 〈w2〉 (see eqn (13)).
5.1 1D spectrum
Note that the expected value of the first cumulant depends only on the correlated part, which is justified in the discussion of eqn (16). Hencewhere
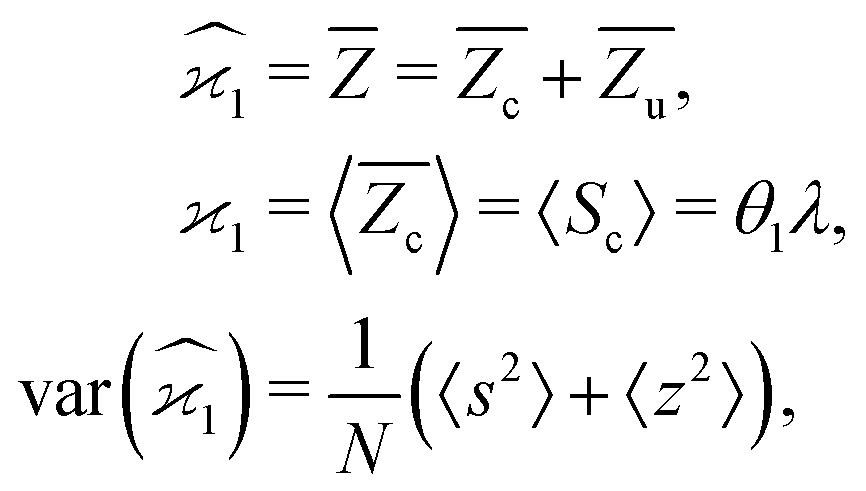
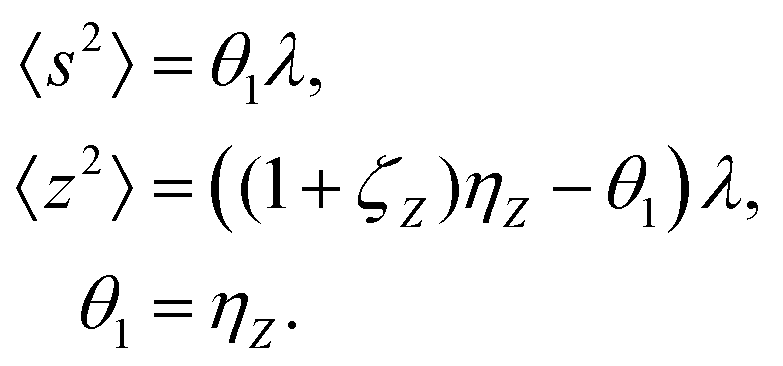
5.2 2D covariance map
The second cumulant is commonly known as covariance.where
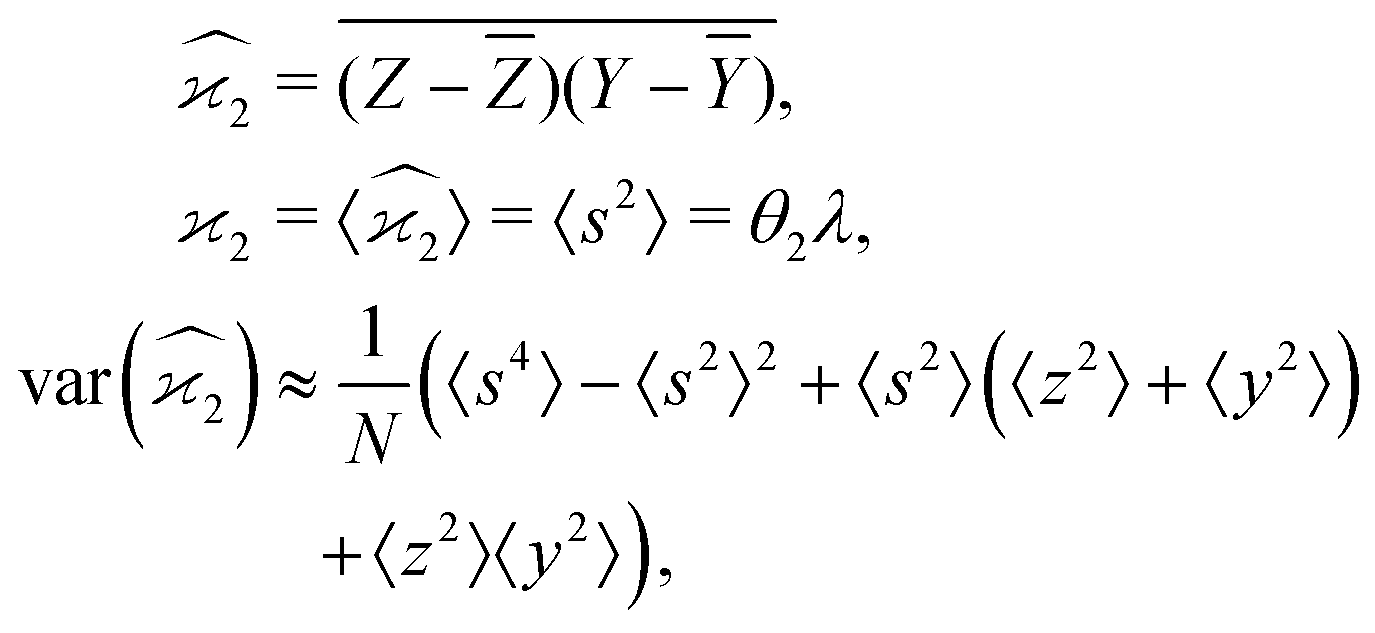
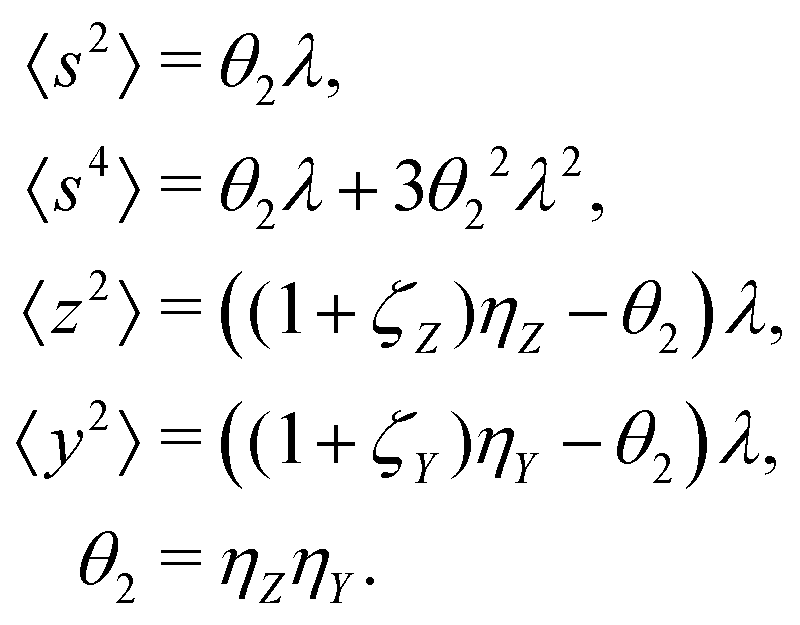
5.3 3D cumulant map
The third cumulant is sometimes called 3-fold covariance or 3-dimensional covariance.where
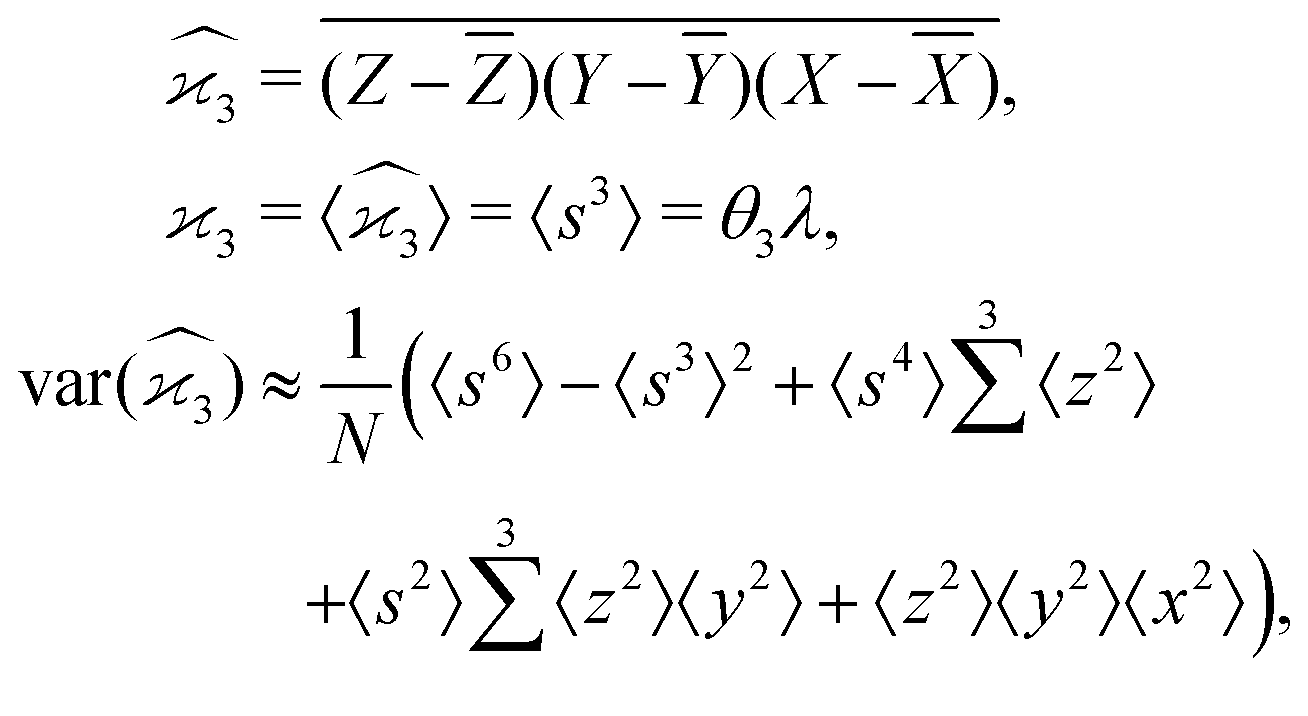
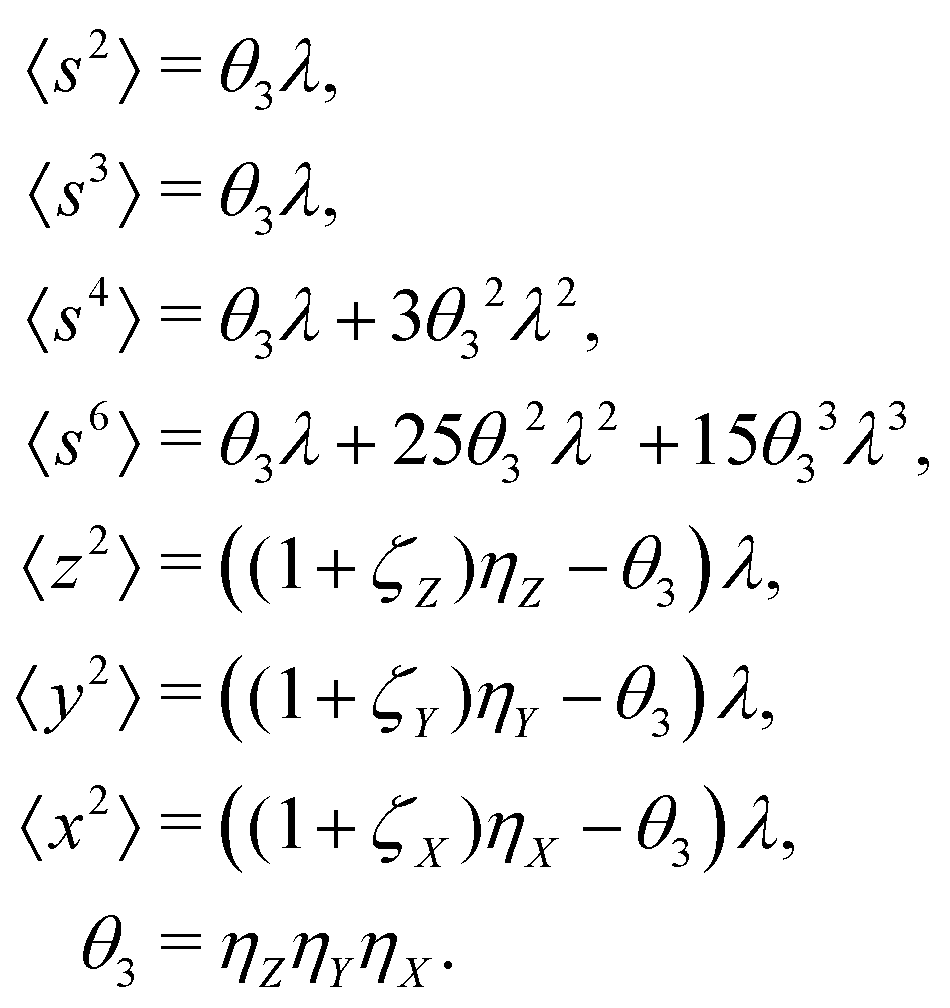
5.4 4D cumulant map
The fourth cumulant formulae are the main result of this work.where
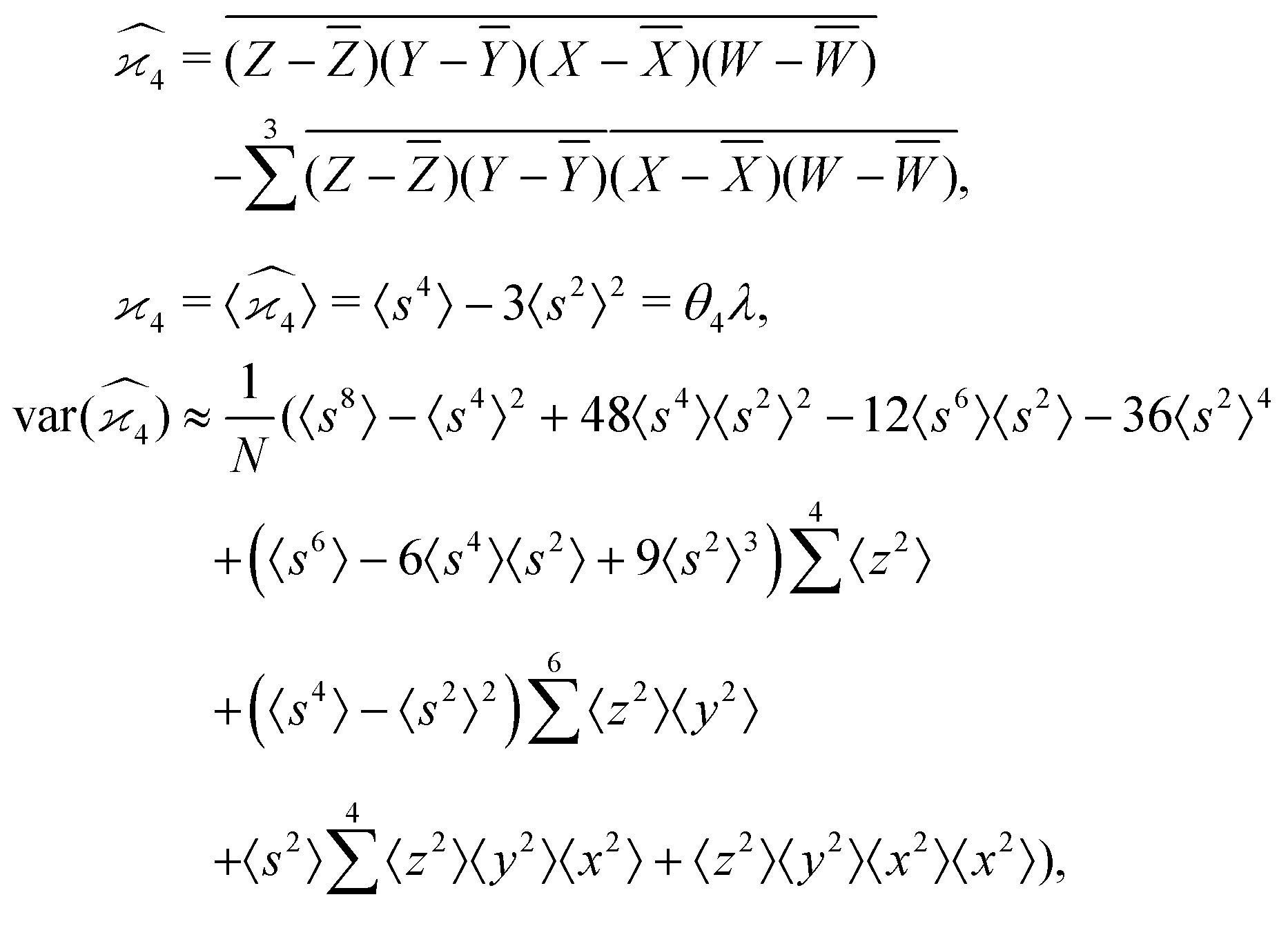
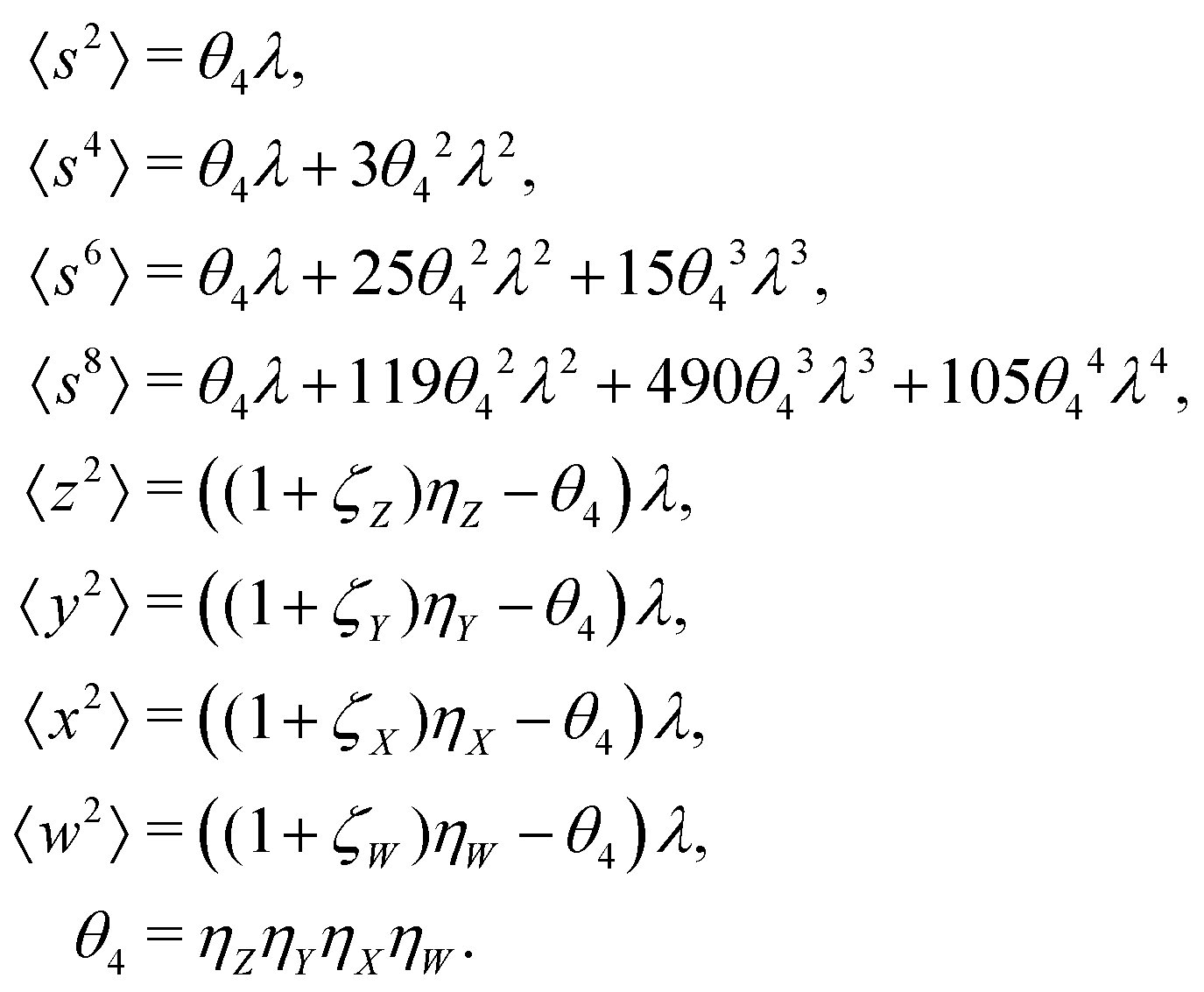
6 Discussion of the results
The figures in this section have been drawn using the Matlab code provided.† For a detailed inspection of the results, it is recommended to run the code and vary the figure options, such as rotate the 3D plots or change the argument ranges.6.1 Ideal conditions
It is instructive first to look at the results under the ideal conditions of full detection efficiency and no background. Substituting η = 100% and ζ = 0 into the equations in Section 5 we find that there is no contribution from the uncorrelated parts and the expressions for the noise-to-signal ratio (N/S) calculated from eqn (20) are relatively simple functions of λ. These functions are plotted in Fig. 3 for N = 1.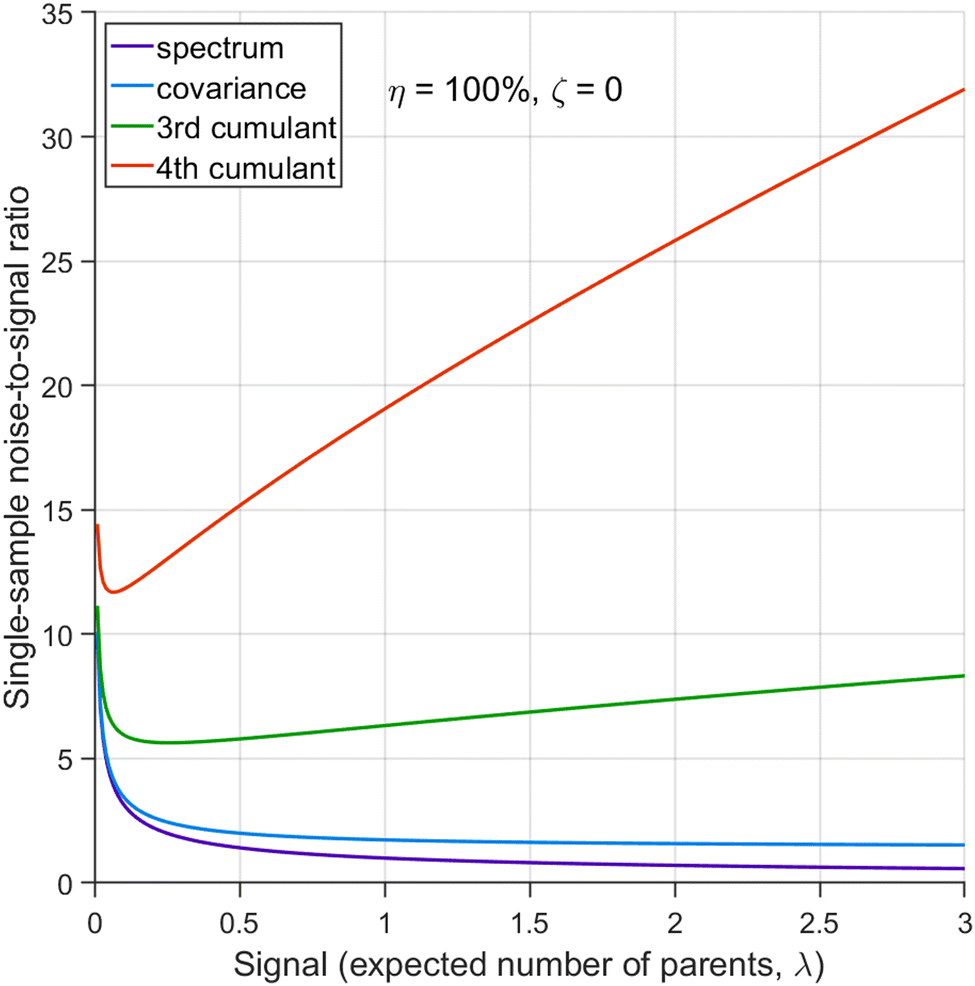 | ||
| Fig. 3 Cumulant noise as the function of the number of parent objects under the ideal conditions. Unlike for the first and second cumulants, the noise for the higher cumulants is minimal at low counting rates. | ||
With increasing counting rate, i.e. increasing λ, the noise of the first cumulant approaches zero as 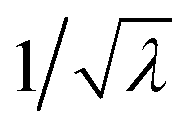 , which reflects the well-known fact that a high counting rate is always advantageous in collecting 1D spectra.
, which reflects the well-known fact that a high counting rate is always advantageous in collecting 1D spectra.
The N/S of the second cumulant (covariance) approaches a constant value of 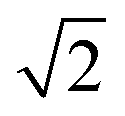 with an increasing counting rate. This tells us that for covariance mapping there is little advantage in increasing λ beyond 1 or 2, unless we want to accommodate weak and strong features on the same map. (In fact a high counting rate exacerbates map distortions due to fluctuations in experimental conditions, which induce common-mode fragment correlations.22,23)
with an increasing counting rate. This tells us that for covariance mapping there is little advantage in increasing λ beyond 1 or 2, unless we want to accommodate weak and strong features on the same map. (In fact a high counting rate exacerbates map distortions due to fluctuations in experimental conditions, which induce common-mode fragment correlations.22,23)
Cumulants higher than the second one have N/S increasing at high counting rates due to the higher powers of λ present in the expressions for 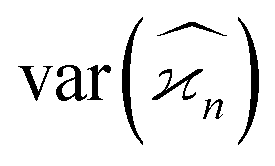 . Therefore, for n ≥ 3 there is an optimal counting rate at low values of λ as the minima of the green and orange curves show in Fig. 3.
. Therefore, for n ≥ 3 there is an optimal counting rate at low values of λ as the minima of the green and orange curves show in Fig. 3.
6.2 Reduced detection efficiency
To assess how a reduced detection efficiency affects the noise, we plot N/S as a function of η and ηλ, as shown in Fig. 4. The reason for choosing the latter argument rather than just λ is that ηλ is the mean number of only the detected fragments, which is what is observed experimentally on 1D spectra. For simplicity, it is assumed that η is the same for every fragment.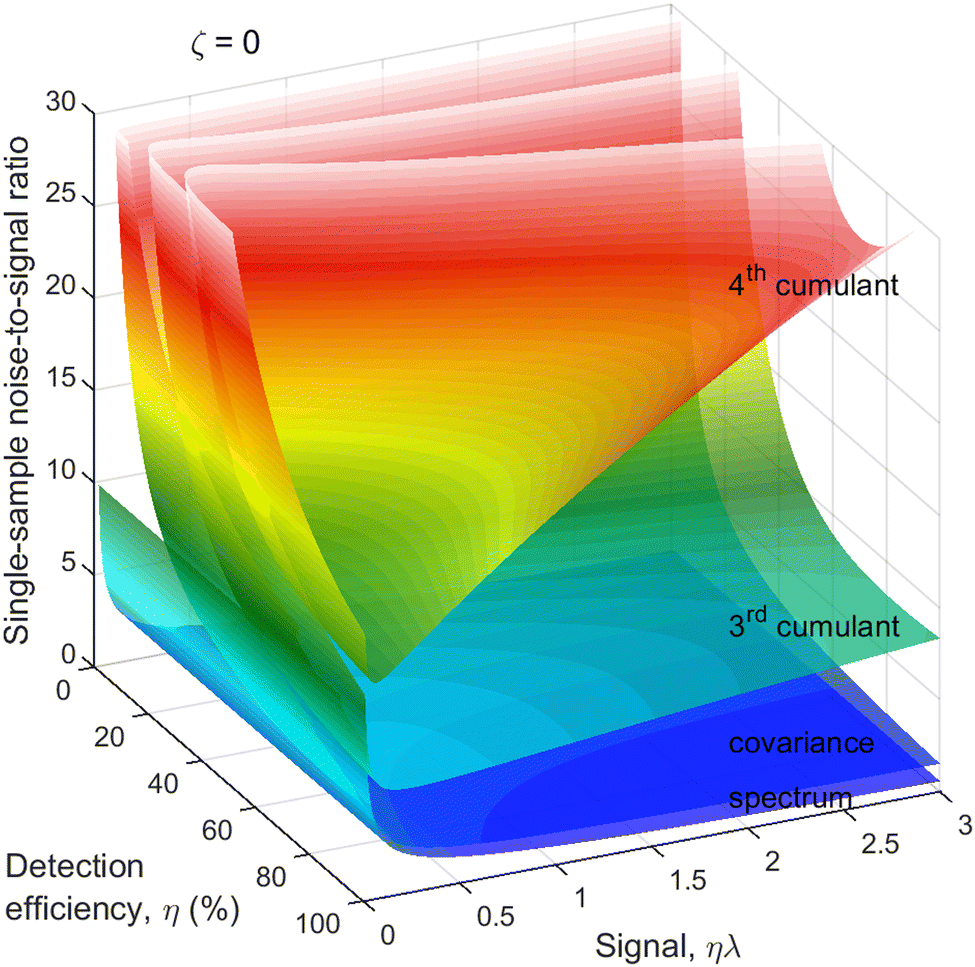 | ||
| Fig. 4 Cumulant noise as in Fig. 3 but resolved for η. When detection efficiency is reduced to about 50%, there is only a modest increase in the noise. | ||
As expected, the noise of the 2nd and higher cumulants substantially increases when the detection efficiency is very low. However, when the detection efficiency is reduced only moderately, to around 50%, the increase in the noise is also moderate, even for the 4th cumulant. Since 50% detection efficiency is within the reach of modern particle detectors, it makes cumulant mapping a feasible proposition.
6.3 Background fragments
The next correction to the ideal conditions worth considering is a background of uncorrelated fragments (magenta circles in Fig. 1). This is done using a realistic value of η = 50% and plotting N/S as a function of ζ and ηλ in Fig. 5. This choice of arguments means that they are proportional, respectively, to the relative background level and the height of a peak on a 1D spectrum, as shown in Fig. 2.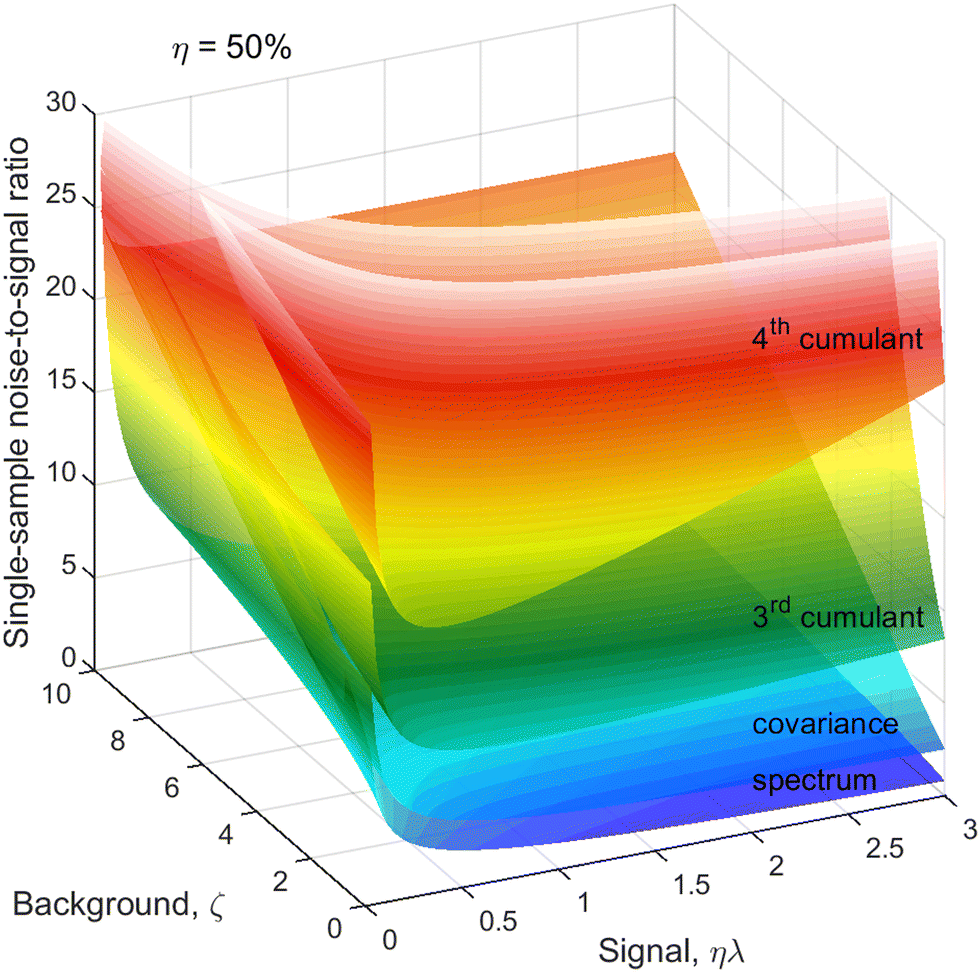 | ||
| Fig. 5 Cumulant noise as in Fig. 3 but at a reduced η and resolved for ζ. The noise increases with increasing background, especially for the higher cumulants and higher counting rates. | ||
For simplicity, we assume the same background level, ζ, for each kind of fragment, which makes the noise of higher cumulants to grow faster with increasing ζ than the lower ones because of the higher powers of ζ present in the expressions for 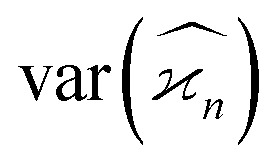 . In some experiments this may be an over-pessimistic assumption because some of the Z, Y, X, or W fragments may experience little or no background at all. The code provided† accepts ζ and η tailored to each kind of fragment.
. In some experiments this may be an over-pessimistic assumption because some of the Z, Y, X, or W fragments may experience little or no background at all. The code provided† accepts ζ and η tailored to each kind of fragment.
The optimum counting rate is broadly the same as for no background shown in Fig. 4. With an increasing background level, however, the optima for the higher cumulants shift to even lower counting rates.
6.4 Number of samples needed
When planning an experiment, the calculated noise is used to estimate the number of samples, N, needed to suppress N/S to an acceptable level. We can use eqn (20) to calculate N for a fixed noise level, e.g. N/S = 0.1. Taking η = 50%, the result is shown in Fig. 6 on a logarithmic scale. The need to reduce the counting rate is clearly visible for the higher cumulants, especially at high background levels. The optimal ηλ for the 3rd and 4th cumulants is below 0.05 at ζ > 5, which means that the observed fragments should be detected in less than 1 in 20 single-sample spectra. Such a low counting rate is comparable to the requirement of coincidence experiments. Unlike coincidences, however, cumulant mapping can accommodate higher counting rates if necessary, albeit at an increased noise.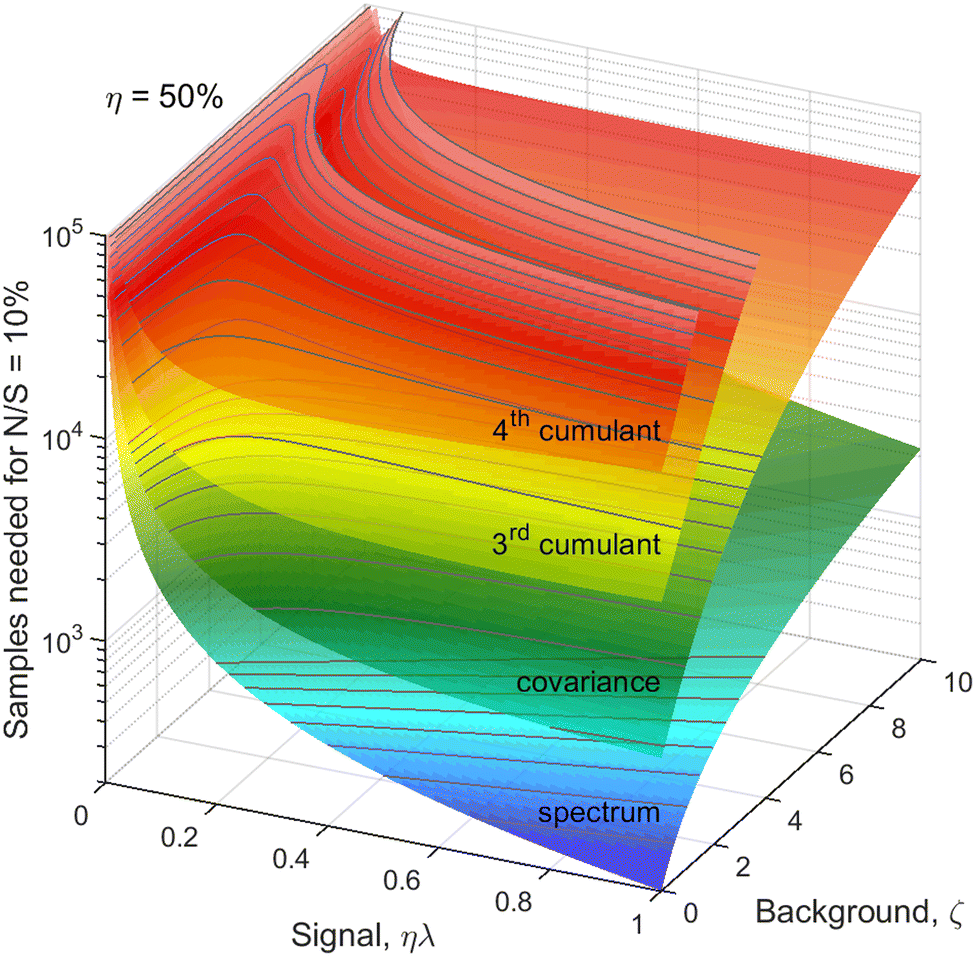 | ||
| Fig. 6 Number of samples needed for a fixed noise-to-signal ratio. In realistic experimental conditions about 105 samples are needed to build a clear 4th cumulant map. | ||
6.5 Practical implications
Fig. 6 tells us that at least on the order of 105 samples will be needed to obtain a good 4th cumulant map. If we want to complete data collections in 15–20 minutes, then the sampling rate should be at least 100 Hz, and 1 kHz or more is desirable.Such sampling rates are now routinely available from femtosecond lasers and becoming available from XFELs.8 For example, the LCLS-II XFEL will be operating at up to 1 MHz repetition rate, enabling researchers to probe over 109 samples in a single experimental run. In principle, such a large number of samples makes it possible to build clear cumulant maps of even higher order than the 4th one. In practice, however, the data acquisition speed is likely to be the limiting factor, since every single-sample spectrum needs to be recorded.
Cumulant mapping can significantly enhance the conventional mass spectrometry, whose main application is in identifying large biomolecules. The conventional approach is to obtain a high-quality mass spectrum of fragments and search for a match in a large database of molecular spectra. Therefore, the development of commercial spectrometers is driven towards the high mass resolution at the expense of the repetition rate, which is normally below 1 Hz.
Recently covariance mapping has been successfully applied to analyse mass spectra obtained from a commercial spectrometer.6,7 Rather than relying on the high mass resolution, the technique resolves the spectra in the second dimension and partially reconstructs the parent objects on a 2D map. Such a reconstruction allows some parent identifications that would be impossible using only a 1D spectrum of any quality. Clearly, this technique can utilise higher-cumulant mapping to perform a more complete parent reconstruction. Since many samples are needed to build cumulant maps, the spectrometer should operate at high repetition rates, for example, by employing the time-of-flight technique.
The volume of a multi-dimensional cumulant map can be very large and cumbersome to explore. In the simplest approach, cross-sections and projections of the map can be used to visualise the reconstructed molecules.10 If the locations of the reconstructed molecules are to be found, computational methods of artificial intelligence can be used to discover and identify them.
Cumulant mapping spectrometry can be combined with laser-induced fragmentation. On one hand, such combination allows us to elucidate the dynamics of molecular ionization and fragmentation,9 on the other hand, it makes it possible to tune the fragmentation to specific bonds in large biomolecules.24
7 Conclusions and outlook
Cumulant mapping forms a firm theoretical basis for the concept of ‘multi-fold covariance’. The derived formulae enable the experimentalist to assess quantitatively the feasibility of studying multiple correlations in a fragmentation experiment. The key requirements are detection efficiency of around 50%, and a sufficient number of samples, which in practice translates to sampling at high repetition rates.Studies of molecular fragmentations induced by femtosecond or X-ray lasers are obvious areas for applying cumulant mapping. The technique can be used to extend the conventional mass spectrometry to multiple dimensions and substantially enhance its selectivity. Extension to particles other than electrons or ions should be straightforward. In particular, photons in a wide spectral range from near infrared to hard gamma rays are the promising candidates.
Since cumulant mapping relies on the Poisson distribution of the samples, in principle, it is applicable to any repetitive Poissonian process. For example, the neuronal spike trains closely follow Poisson point processes.25,26 It could be speculated that cumulants represent the high-level brain functions emerging from correlations in low-level neuronal activity.
Conflicts of interest
There are no conflicts to declare.Appendix: variance calculations
Variance of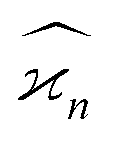 is needed to estimate the number of samples that have to be collected to measure the cumulant with given noise-to-signal ratio. Since only an estimate is needed, I will use approximations in deriving some of the formulae.
is needed to estimate the number of samples that have to be collected to measure the cumulant with given noise-to-signal ratio. Since only an estimate is needed, I will use approximations in deriving some of the formulae.
Useful formulae
The expected value of random variables, or functions of random variables, is distributive over summation:| 〈A + B〉 = 〈A〉 + 〈B〉. | (21) |
| 〈AB〉 = 〈A〉〈B〉 + cov(A, B). | (22) |
Their variances and the covariance can be expressed in terms of expected values:
| var(A) = 〈(A − 〈A〉)2〉 = 〈A2〉 − 〈A〉2, | (23) |
| cov(A, B) = 〈(A − 〈A〉)(B − 〈B〉)〉 = 〈AB〉 − 〈A〉〈B〉. | (24) |
An expected value of a sample average is equal to the expected value of the whole population:
| 〈Ā〉 = 〈A〉, | (25) |
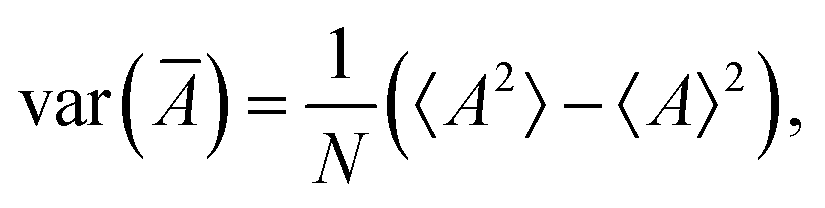 | (26) |
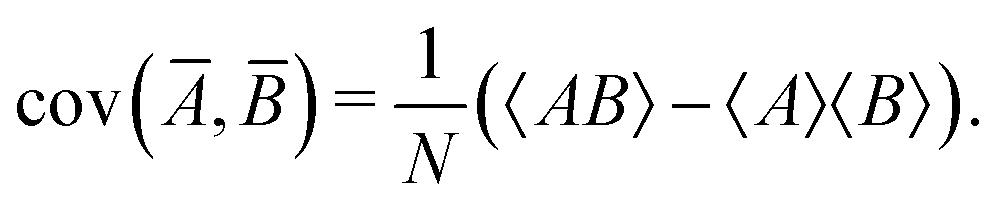 | (27) |
Since covariance is a linear function, the covariance of a random variable A with the sum of several other random variables X1, X2, X3,… is the sum of the covariances:
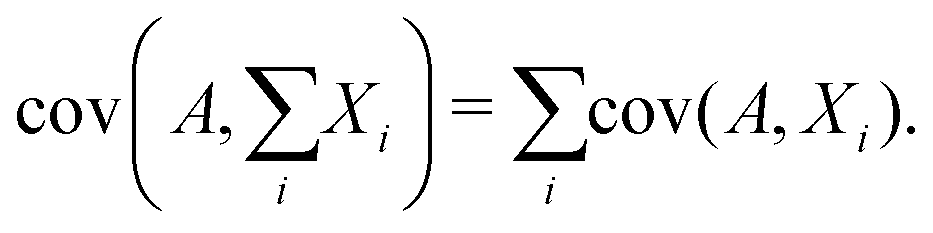 | (28) |
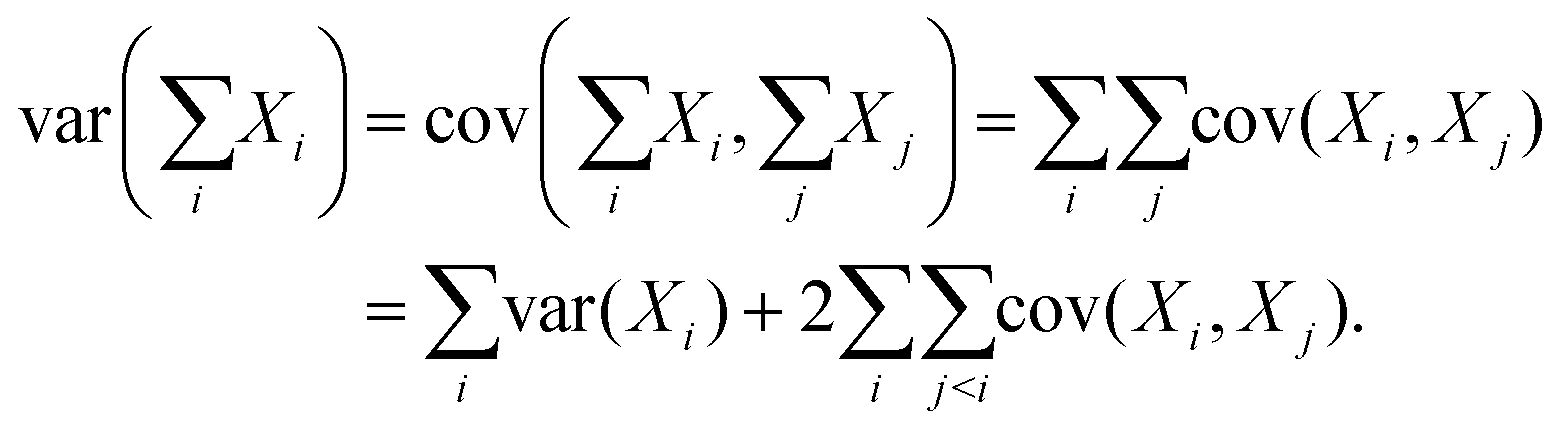 | (29) |
The variance and covariance of products of random functions can be calculated using the delta method. If F(X) and G(X) are functions of a random vector X = [X1, X2, X3,…], then the Taylor expansion of F and G gives14 (eqn (10.12) and (10.13))
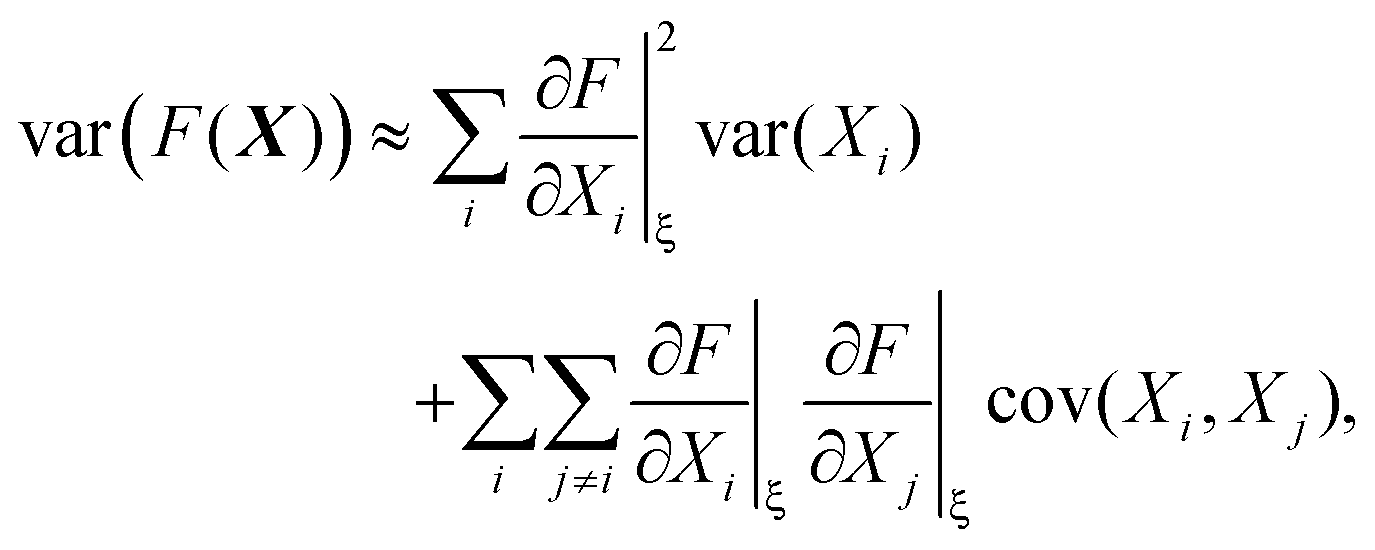 | (30) |
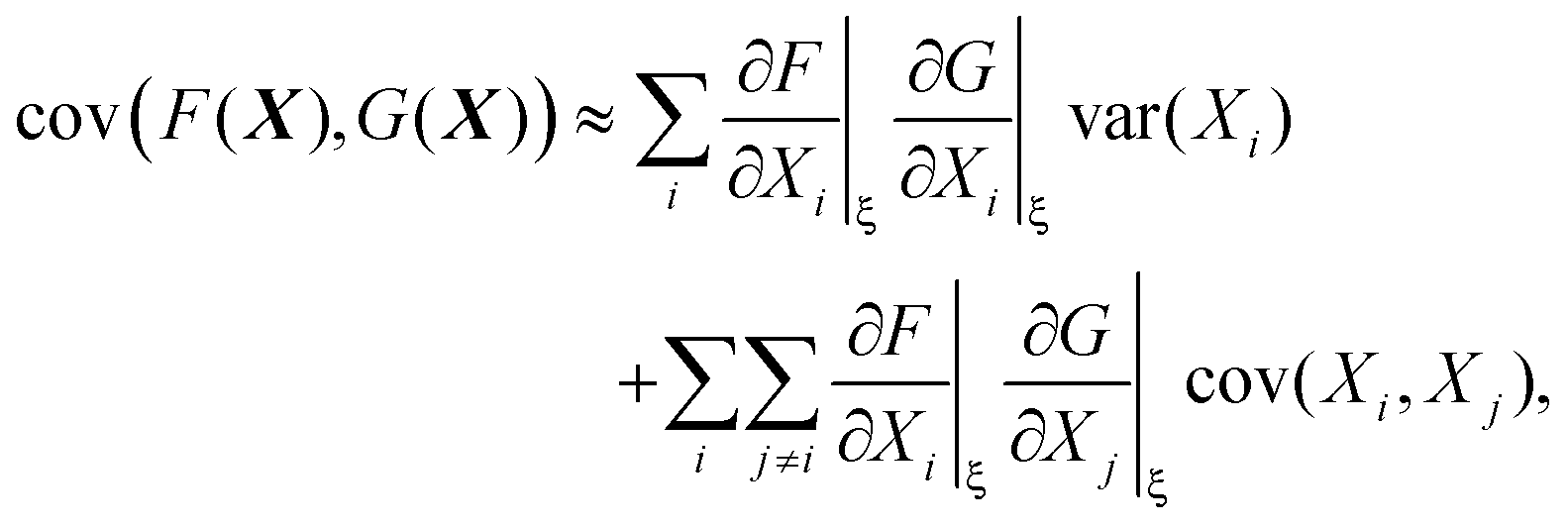 | (31) |
To calculate the variance of the product of two random variables, I make the following choice for eqn (30):
| F = AB, X = [A, B], ξ = [〈A〉, 〈B〉], |
Substituting these intermediate results into eqn (30) gives us the required formula:
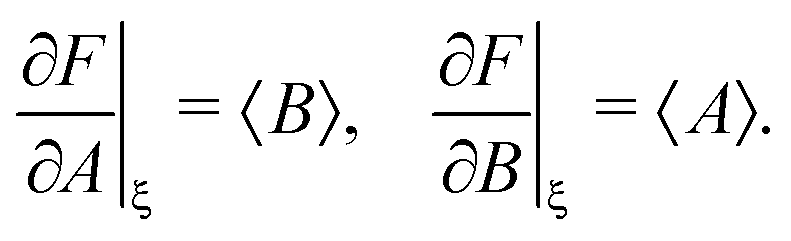
| var(AB) ≈ 〈A〉2var(B) + 〈B〉2var(A) + 2cov(A, B), | (32) |
| var(A2) ≈ 4〈A〉2var(A). | (33) |
In a similar way if I choose the following for eqn (31):
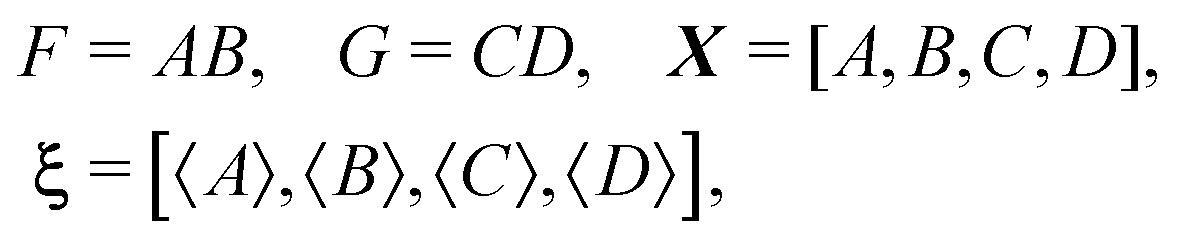
I obtain the formula for the covariance of products:
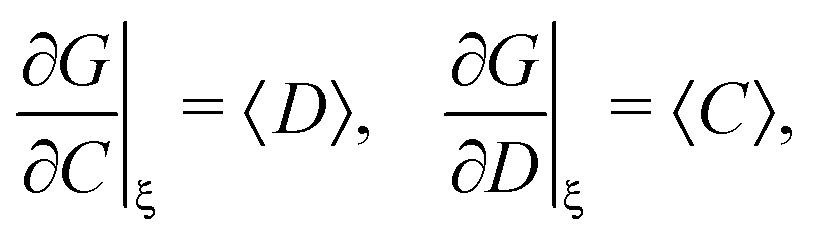
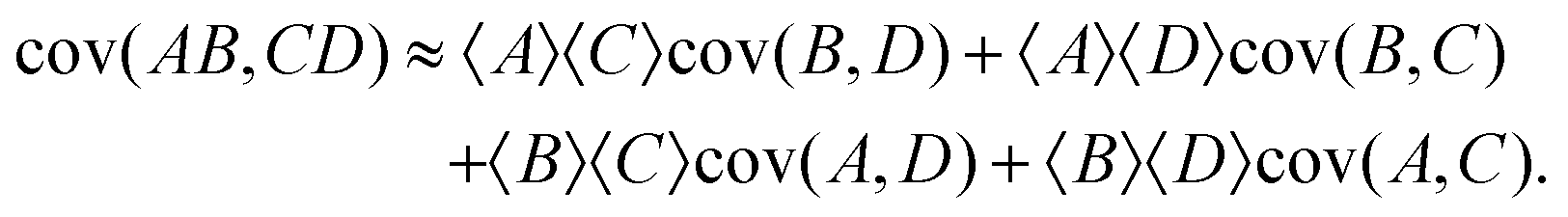 | (34) |
When estimating experimental cumulants we use sample averages, ![[X with combining macron]](https://www.rsc.org/images/entities/b_i_char_0058_0304.gif) , to center random variables. In theoretical estimations the expected values, 〈X〉, can be used instead, which significantly simplifies the calculations. These two versions of the cumulant estimators are asymptotically equal when the number of samples tends to infinity:
, to center random variables. In theoretical estimations the expected values, 〈X〉, can be used instead, which significantly simplifies the calculations. These two versions of the cumulant estimators are asymptotically equal when the number of samples tends to infinity:
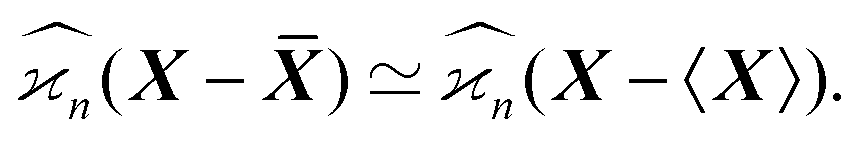 | (35) |
Another approximation I use, also affecting only the variance of the third and higher cumulants, is the neglect of the residual correlations that are discussed following eqn (15).
1D spectrum
The calculation of the variance quoted in Section 5.1 is straightforward:where the numbers above equality signs refer to the equations used. The last equality relies on the independence of s and z, which is always possible to satisfy having only one variable Z.

2D covariance map
To start variance calculations we write the estimator of the second cumulant in terms of mean-centered variables:and expand the variance of the sum:
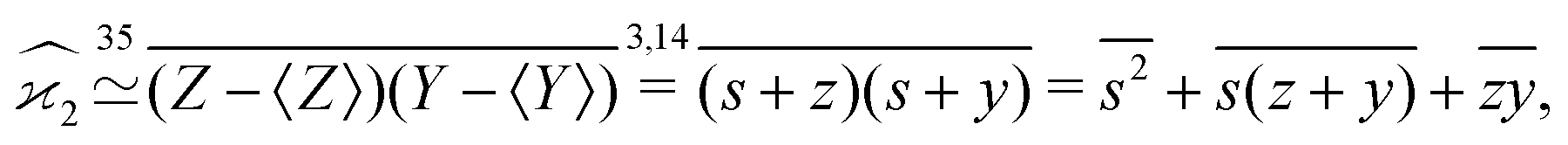
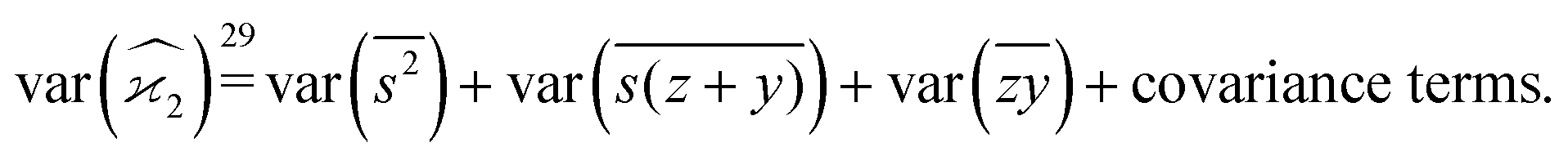
We calculate the variance terms one by one:
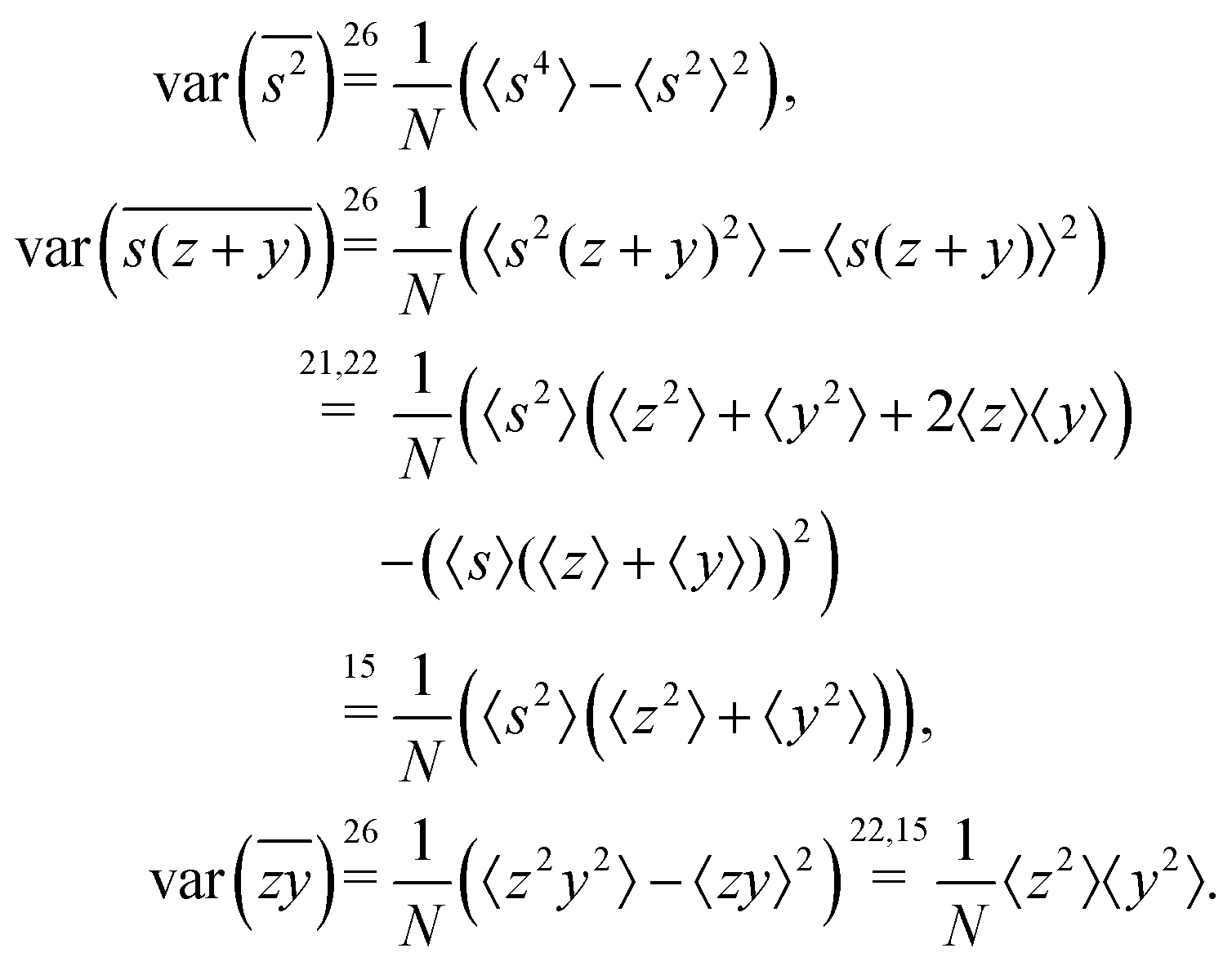
Note a useful simplification of eqn (15): a term vanishes if it has a factor linear in the expected value of a mean-centered variable. For this reason all the covariance terms are zero, for example
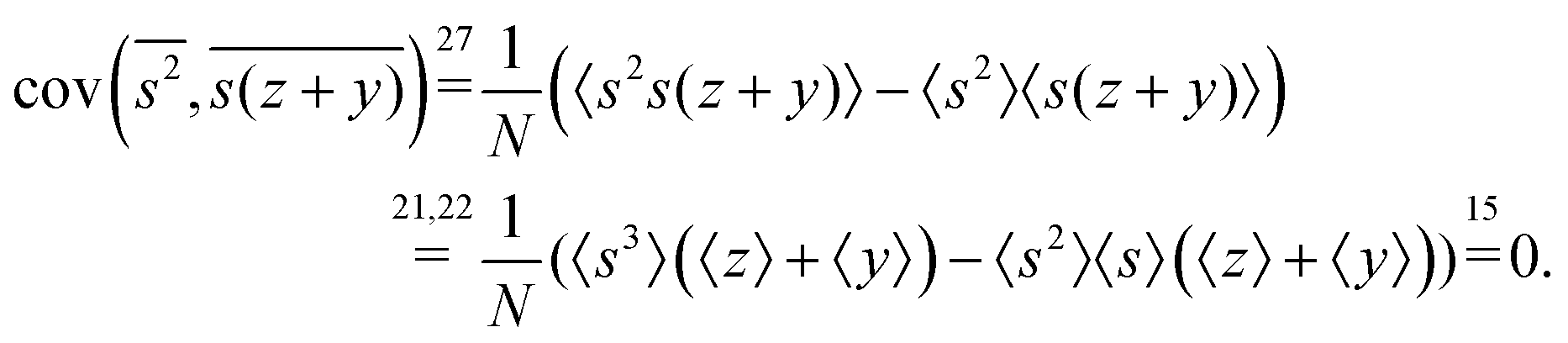
Gathering all the variance terms we obtain the formula for 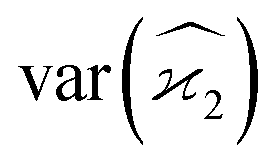 given in Section 5.2.
given in Section 5.2.
3D cumulant map
The calculation of the third cumulant estimator is similar to the second one: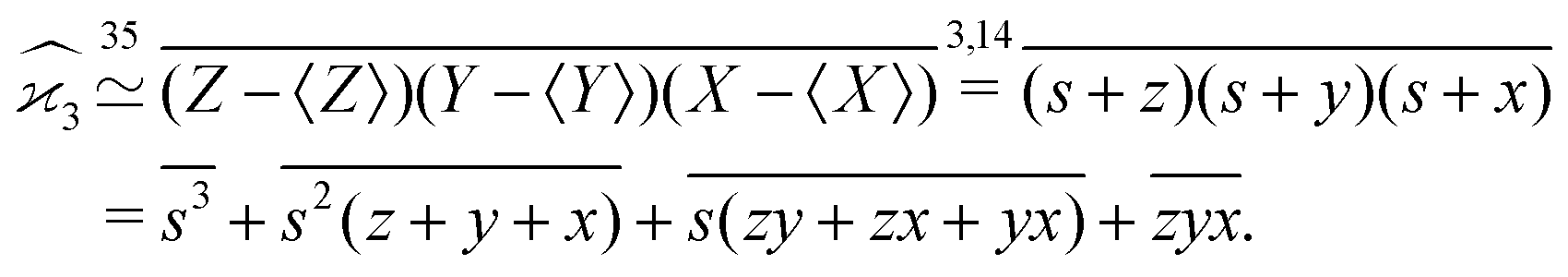
Expanding the variance of the sum we find that the covariance terms vanish again and we need to calculate only variances:
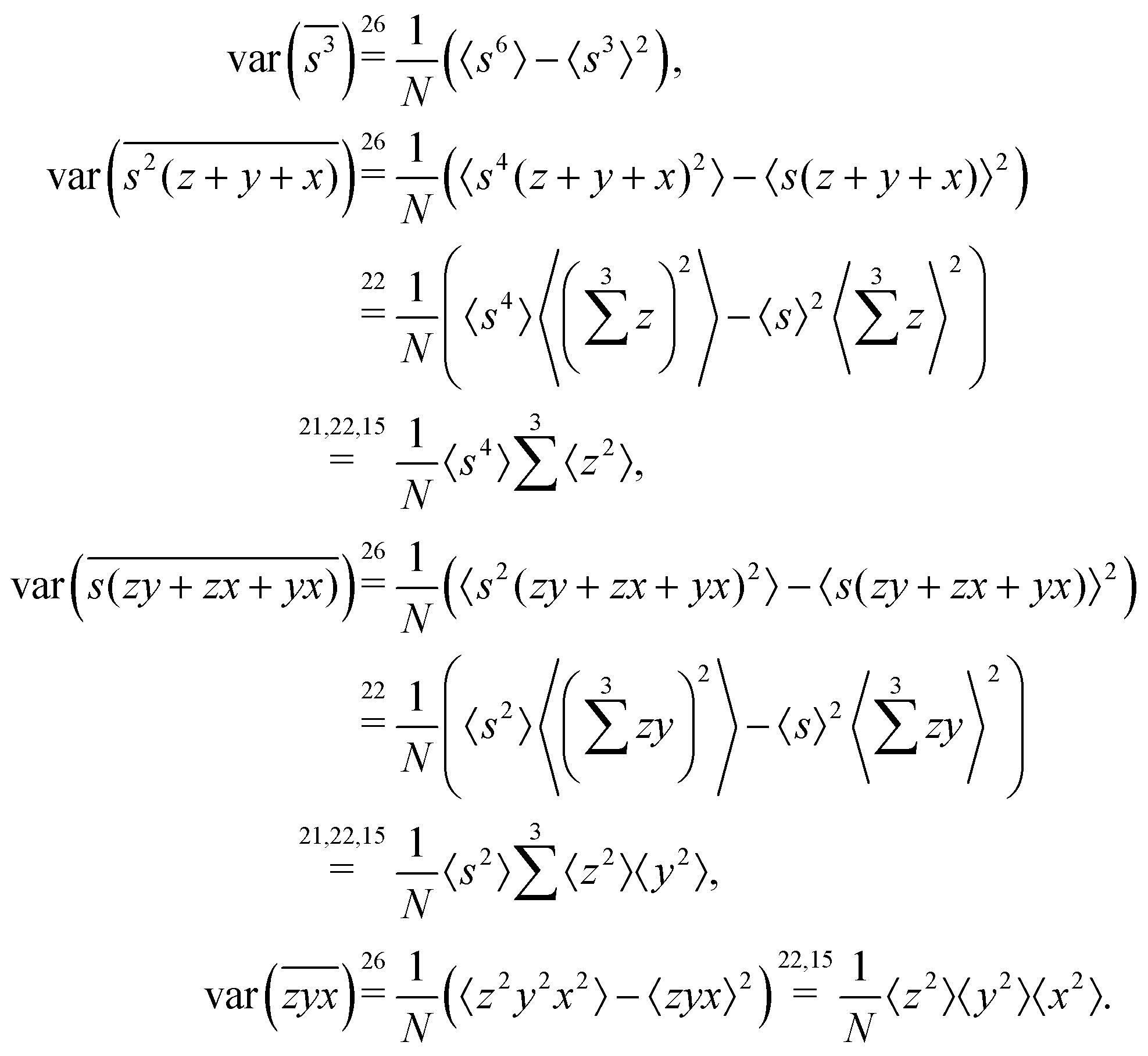
Gathering all the variance terms we obtain the formula for 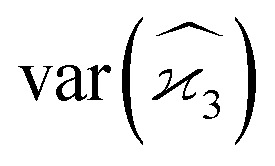 given in Section 5.3.
given in Section 5.3.
4D cumulant map
The calculation for the fourth cumulant is more laborious because not only the formula for the estimator is longer but also some of the covariance terms in the variance expansion do not vanish. While using more advanced tools, such as k-statistics,14 may shorten the calculations, I shall continue with the same method as before: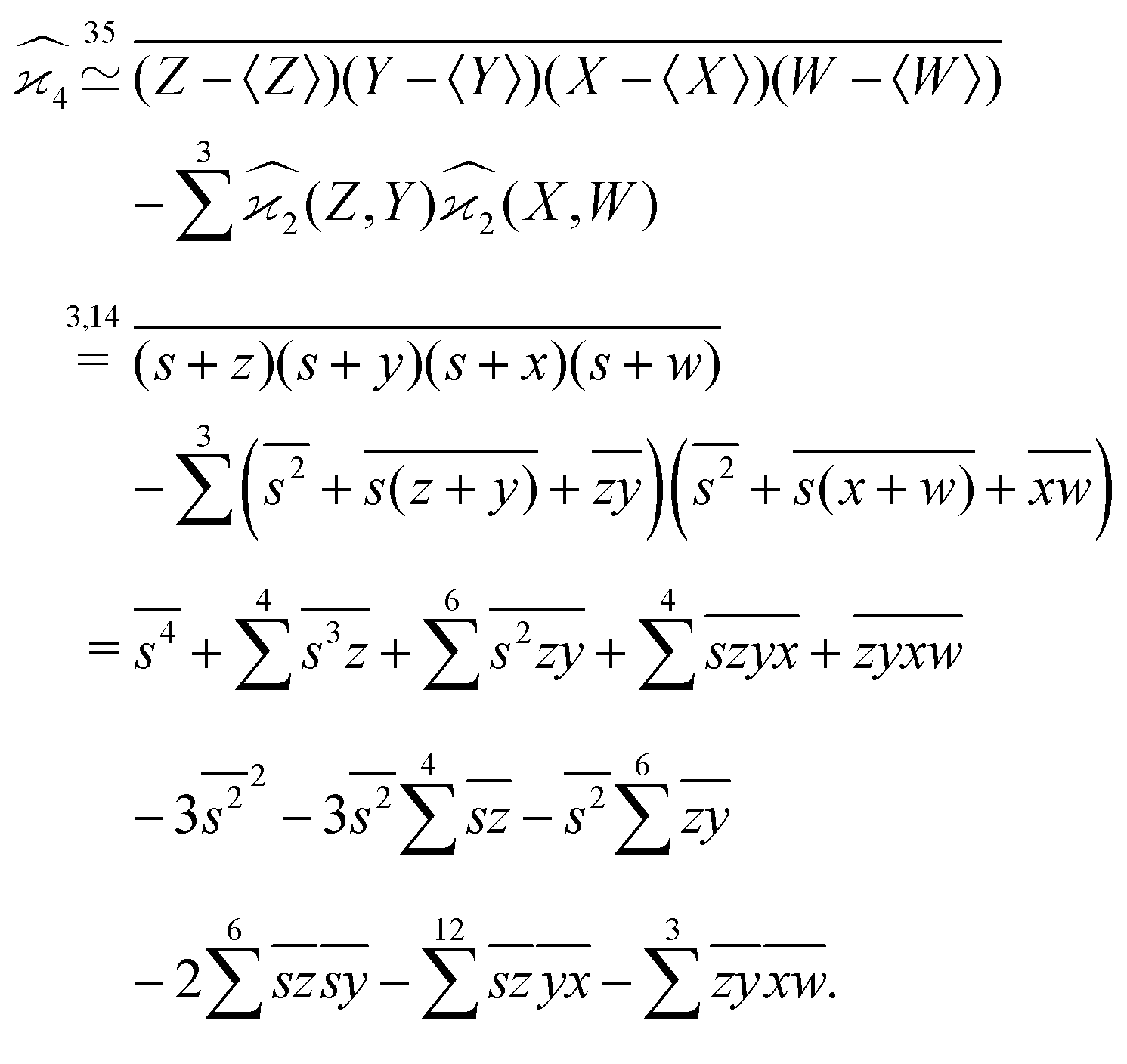
To calculate the variance of this estimator we apply eqn (29) and evaluate the variance of the first two terms:
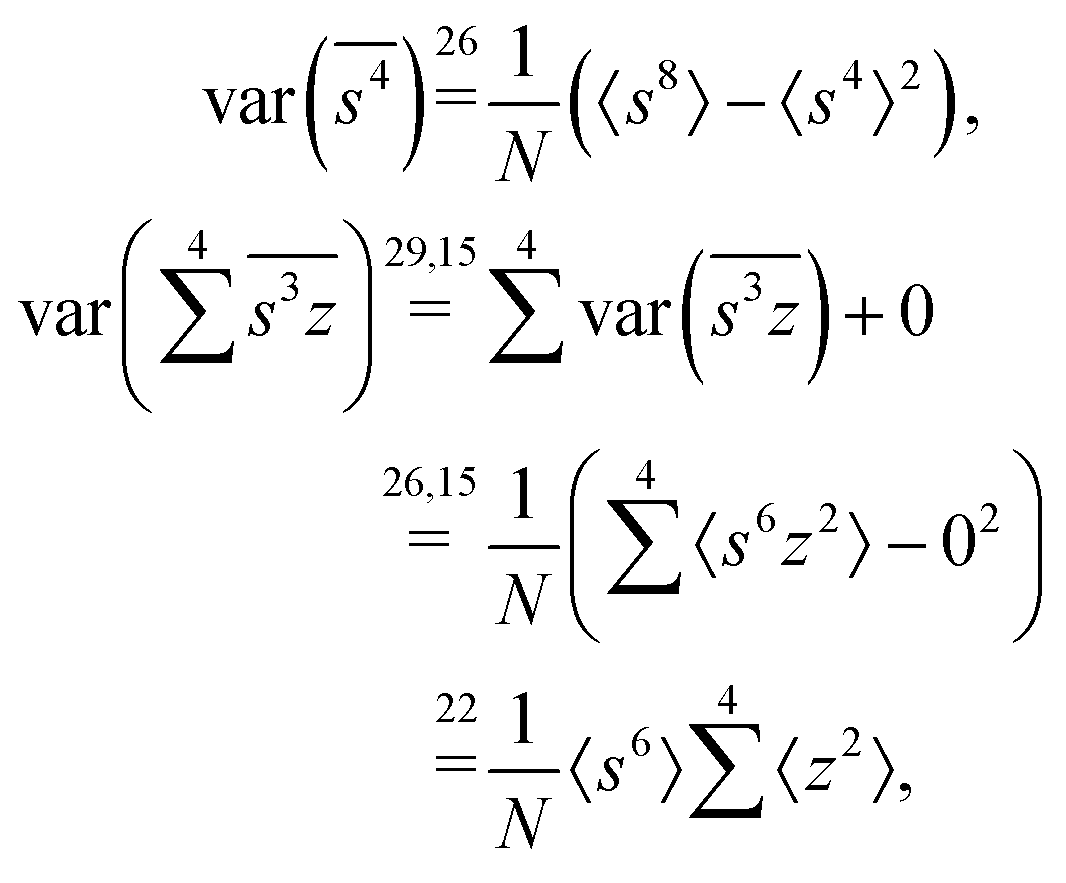
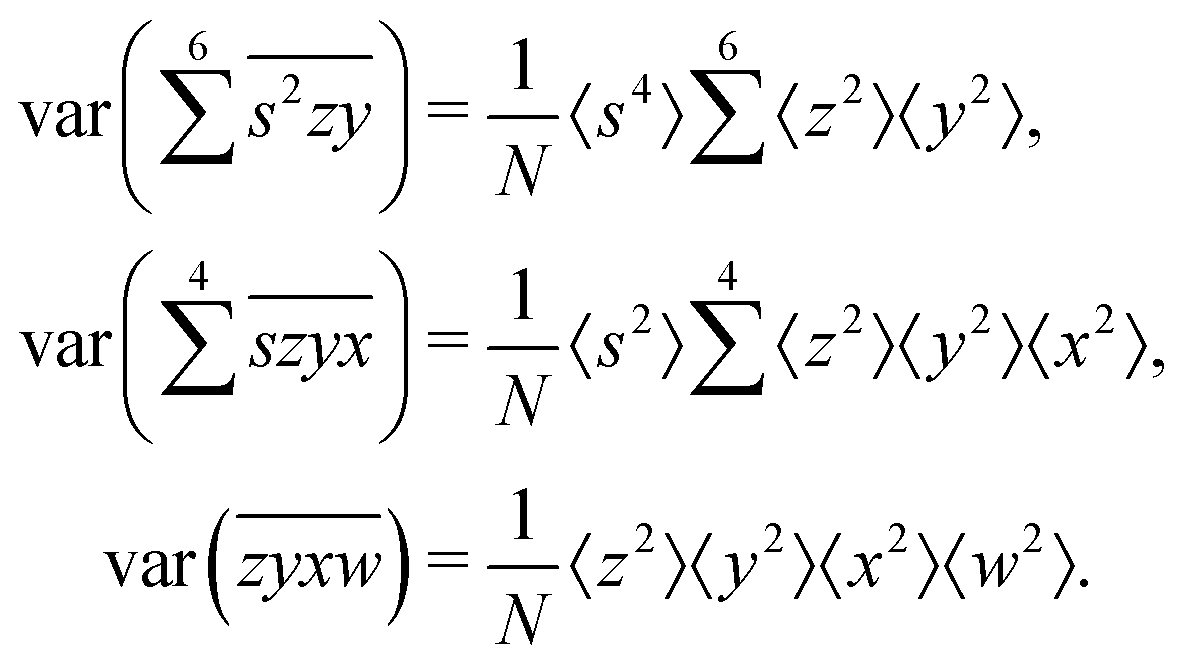
To calculate the variance of the next three terms we can use eqn (32) and (33) for the variance of a product of two variables:
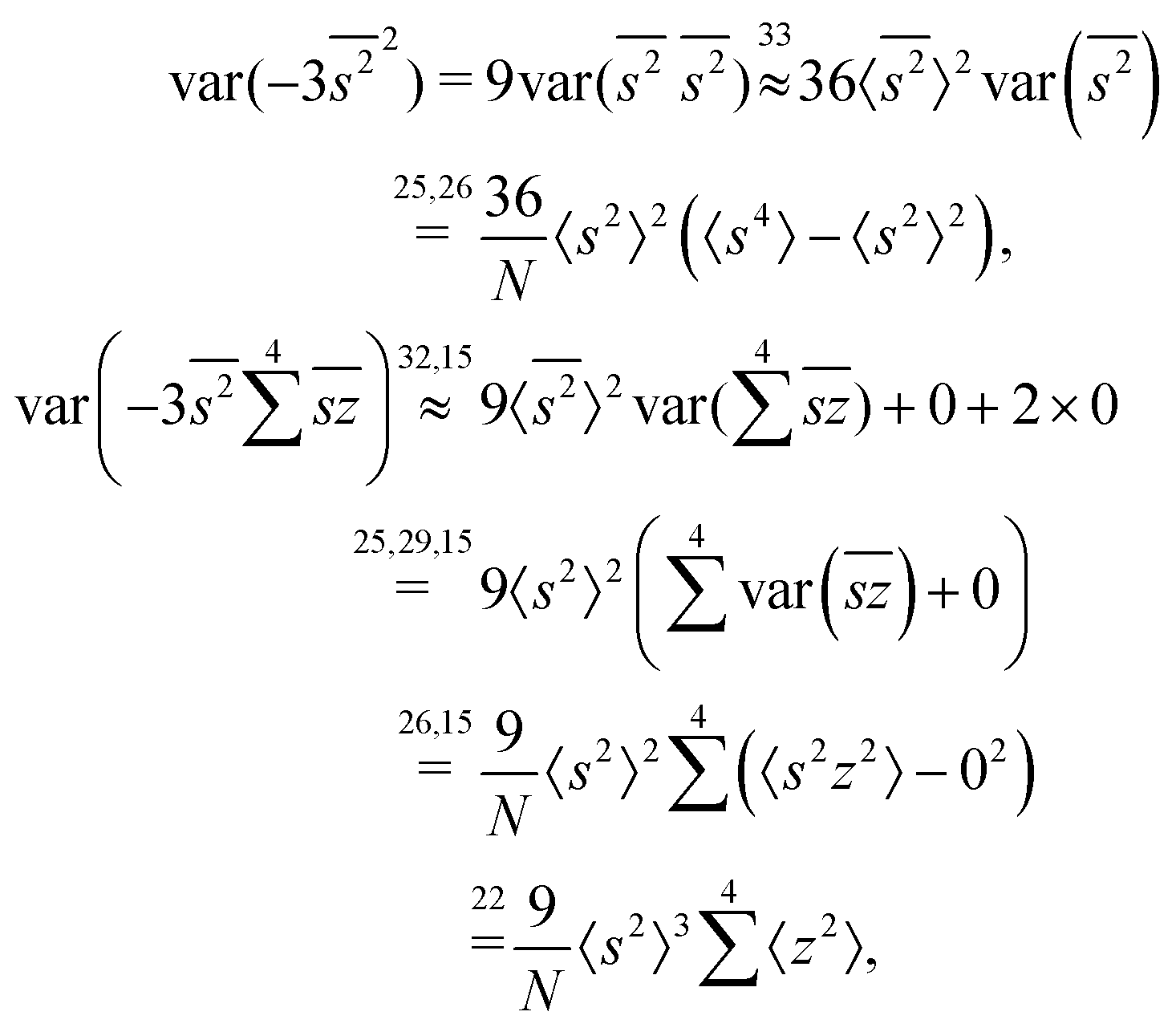
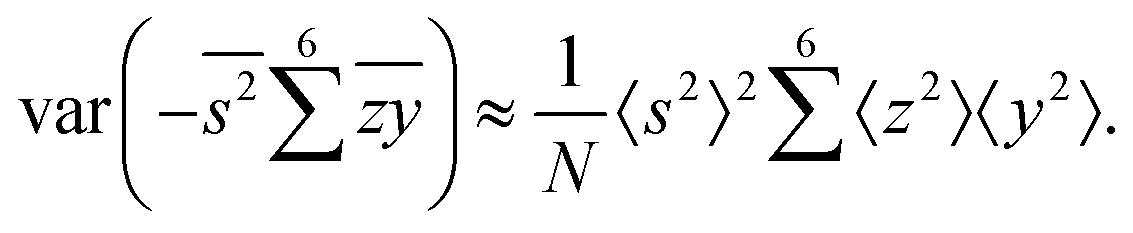
When we proceed to calculate the variances of the last line of 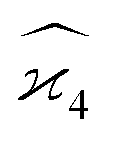 , we notice that all terms in eqn (32) vanish. Therefore all remaining variance terms are zero.
, we notice that all terms in eqn (32) vanish. Therefore all remaining variance terms are zero.
To calculate the covariance terms of 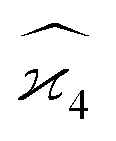 , we refer to eqn (27) and note that the covariance vanishes unless both A and B have the same subset of the z, y, x, w variables. Therefore, the only non-zero covariance terms are:
, we refer to eqn (27) and note that the covariance vanishes unless both A and B have the same subset of the z, y, x, w variables. Therefore, the only non-zero covariance terms are:
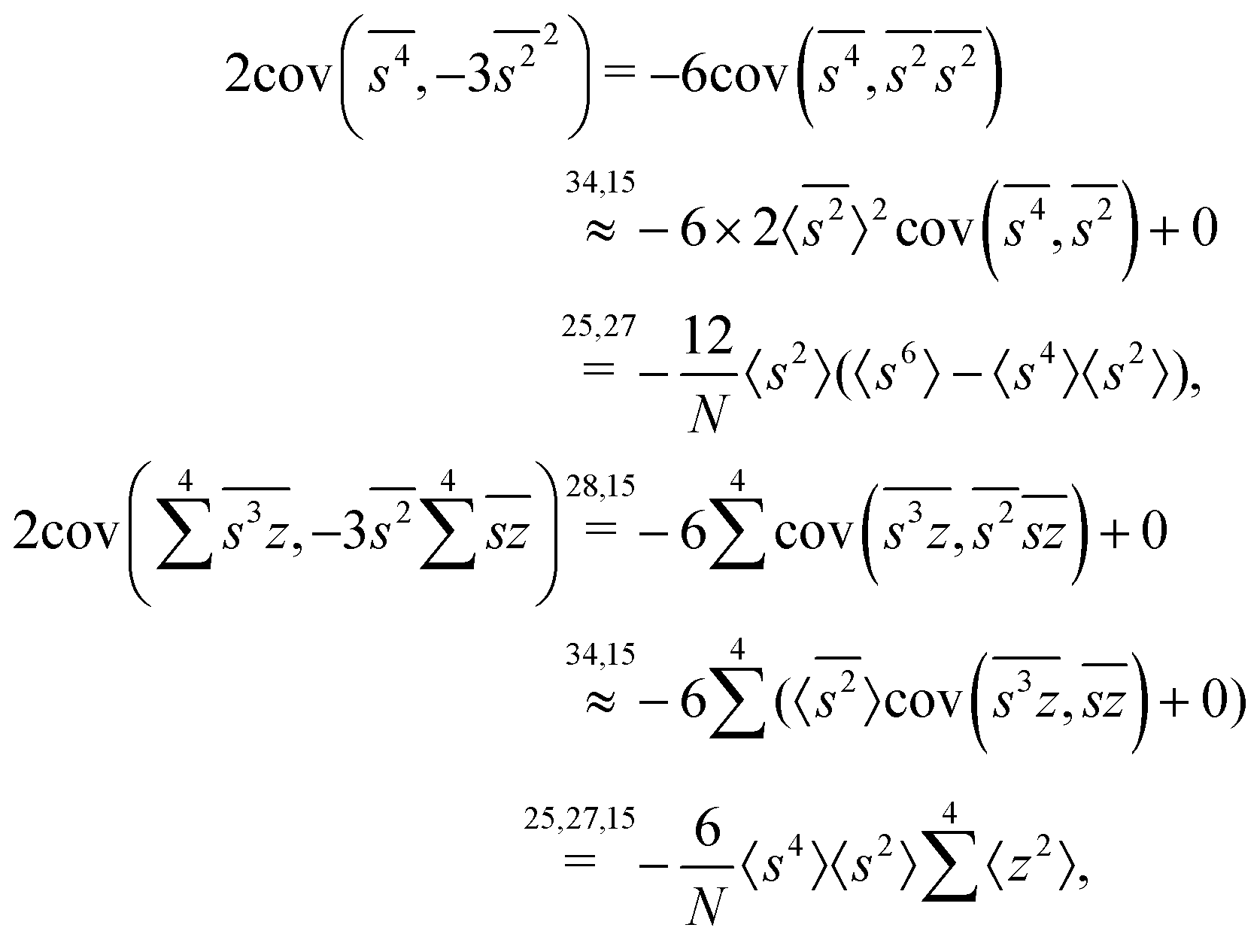
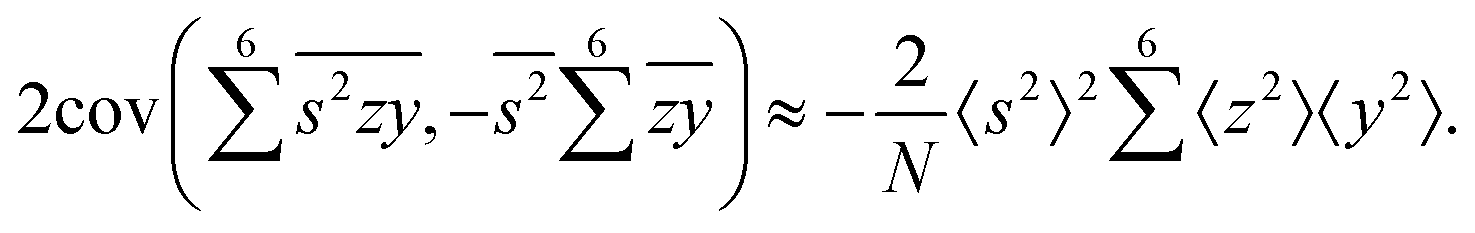
Gathering all the variance and covariance terms gives us the formula for 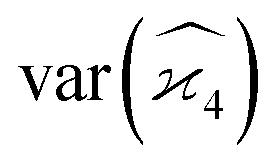 given in Section 5.4.
given in Section 5.4.
References
- L. J. Frasinski, K. Codling and P. A. Hatherly, Science, 1989, 246, 1029–1031 CrossRef CAS PubMed.
- J. H. D. Eland, F. S. Wort and R. N. Royds, J. Electron Spectrosc. Relat. Phenom., 1986, 41, 297–309 CrossRef CAS.
- L. J. Frasinski, M. Stankiewicz, K. J. Randall, P. A. Hatherly and K. Codling, J. Phys. B: Atom. Mol. Phys., 1986, 19, L819 CrossRef CAS.
- L. J. Frasinski, J. Phys. B: At., Mol. Opt. Phys., 2016, 49, 152004 CrossRef.
- C. Vallance, D. Heathcote and J. W. L. Lee, J. Phys. Chem. A, 2021, 125, 1117–1133 CrossRef CAS PubMed.
- T. Driver, B. Cooper, R. Ayers, R. Pipkorn, S. Patchkovskii, V. Averbukh, D. R. Klug, J. P. Marangos, L. J. Frasinski and M. Edelson-Averbukh, Phys. Rev. X, 2020, 10, 041004 CAS.
- T. Driver, V. Averbukh, L. J. Frasinski, J. P. Marangos and M. Edelson-Averbukh, Anal. Chem., 2021, 93, 10779–10788 CrossRef CAS PubMed.
- N. Huang, H. Deng, B. Liu, D. Wang and Z. Zhao, Innovation, 2021, 2, 100097 CAS.
- F. Allum, C. Cheng, A. J. Howard, P. H. Bucksbaum, M. Brouard, T. Weinacht and R. Forbes, J. Phys. Chem. Lett., 2021, 12, 8302–8308 CrossRef CAS PubMed.
- L. J. Frasinski, P. A. Hatherly and K. Codling, Phys. Lett. A, 1991, 156, 227–232 CrossRef CAS.
- W. A. Bryan, W. R. Newell, J. H. Sanderson and A. J. Langley, Phys. Rev. A: At., Mol., Opt. Phys., 2006, 74, 053409 CrossRef.
- J. Mikosch and S. Patchkovskii, J. Mod. Opt., 2013, 60, 1426–1438 CrossRef CAS.
- V. Zhaunerchyk, L. J. Frasinski, J. H. D. Eland and R. Feifel, Phys. Rev. A: At., Mol., Opt. Phys., 2014, 89, 053418 CrossRef.
- A. Stuart and K. Ord, Kendall's advanced theory of statistics. Vol. 1, Distribution theory, Hodder Arnold, London, 6th edn, 1994 Search PubMed.
- M. Sánchez-Barquilla, R. Silva and J. Feist, J. Chem. Phys., 2020, 152, 034108 CrossRef PubMed.
- W. Kutzelnigg and D. Mukherjee, J. Chem. Phys., 1999, 110, 2800–2809 CrossRef CAS.
- O. Brea, M. El Khatib, C. Angeli, G. L. Bendazzoli, S. Evangelisti and T. Leininger, J. Chem. Theory Comput., 2013, 9, 5286–5295 CrossRef CAS PubMed.
- M. Helias and D. Dahmen, Statistical field theory for neural networks, Springer, 2020 Search PubMed.
- K. Domino, Phys. A, 2020, 558, 124995 CrossRef.
- C. Uhlemann, J. Cosmol. Astropart. Phys., 2018, 030 CrossRef.
- H. D. Ursell, Math. Proc. Cambridge Philos. Soc., 1927, 23, 685–697 CrossRef CAS.
- L. J. Frasinski, V. Zhaunerchyk, M. Mucke, R. J. Squibb, M. Siano, J. H. D. Eland, P. Linusson, P. Vd Meulen, P. Salén and R. D. Thomas, et al. , Phys. Rev. Lett., 2013, 111, 073002 CrossRef CAS PubMed.
- O. Kornilov, M. Eckstein, M. Rosenblatt, C. P. Schulz, K. Motomura, A. Rouzée, J. Klei, L. Foucar, M. Siano and A. Lübcke, et al. , J. Phys. B: At., Mol. Opt. Phys., 2013, 46, 164028 CrossRef.
- R. K. Ayers, PhD thesis, Imperial College London, 2022.
- C. Gardella, O. Marre and T. Mora, Neural Comput., 2019, 31, 233–269 CrossRef PubMed.
- A. T. Campo, Comput. Struct. Biotechnol. J., 2020, 18, 2699–2708 CrossRef PubMed.
Footnote |
| † Electronic supplementary information (ESI) available: Matlab code that calculates the values and variances of the first four cumulants. See DOI: https://doi.org/10.1039/d2cp02365b |
| This journal is © the Owner Societies 2022 |