
 Open Access Article
Open Access Article This Open Access Article is licensed under a
This Open Access Article is licensed under a Creative Commons Attribution 3.0 Unported Licence
Molecular computing: paths to chemical Turing machines
Shaji
Varghese
*,
Johannes A. A. W.
Elemans
,
Alan E.
Rowan
and
Roeland J. M.
Nolte
*
Radboud University, Institute for Molecules and Materials, Heyendaalseweg 135, 6525 AJ Nijmegen, The Netherlands. E-mail: s.varghese@science.ru.nl; r.nolte@science.ru.nl
First published on 6th August 2015
Abstract
To comply with the rapidly increasing demand of information storage and processing, new strategies for computing are needed. The idea of molecular computing, where basic computations occur through molecular, supramolecular, or biomolecular approaches, rather than electronically, has long captivated researchers. The prospects of using molecules and (bio)macromolecules for computing is not without precedent. Nature is replete with examples where the handling and storing of data occurs with high efficiencies, low energy costs, and high-density information encoding. The design and assembly of computers that function according to the universal approaches of computing, such as those in a Turing machine, might be realized in a chemical way in the future; this is both fascinating and extremely challenging. In this perspective, we highlight molecular and (bio)macromolecular systems that have been designed and synthesized so far with the objective of using them for computing purposes. We also present a blueprint of a molecular Turing machine, which is based on a catalytic device that glides along a polymer tape and, while moving, prints binary information on this tape in the form of oxygen atoms.
 From left to right: Johannes A. A. W. Elemans, Shaji Varghese, Roeland J. M. Nolte and Alan E. Rowan | Hans Elemans completed his Ph.D. with Prof. Roeland J. M. Nolte at the Radboud University Nijmegen, The Netherlands, in 2001. After that he initiated a new line of research at the interface of chemistry and physics, in which dynamic molecular processes on a surface are studied with scanning probe techniques at the single molecule level. After a postdoctoral stay with Prof. Steven De Feyter at K.U. Leuven (Belgium) in 2008–2009, he returned to Nijmegen to start his independent research group in nanochemistry. For his research he received Veni (2004) and Vidi (2008) grants from the Dutch National Science Foundation, and in 2010 an ERC Starting Grant from the European Research Council. His scientific interests are in the areas of functional supramolecular architectures, (surface-based) catalysis, and scanning probe microscopy. Shaji Varghese obtained his Ph.D. in Chemistry from Bharathiar University in 2013. During his study, he spent research periods at the National Institute for Materials Science in Tsukuba, Japan and at the University of Queensland in Brisbane, Australia. He is currently a postdoctoral researcher in the group of Prof. Roeland J. M. Nolte working on molecular Turing machines. Roeland J. M. Nolte is Emeritus Professor of Organic Chemistry at the Radboud University Nijmegen, The Netherlands, and former Director of the Institute for Molecules and Materials of this university. He is a member of the Royal Netherlands Academy of Science and holds a special Royal Academy of Science Chair in Chemistry. His research interests span a broad range of topics at the interfaces of Supramolecular Chemistry, Macromolecular Chemistry, and Biomimetic Chemistry, in which he focuses on the design of catalysts and materials. His contributions to science have been recognized with numerous award lectureships, prizes, and a knighthood in 2003. He has served on many editorial boards, including those of the journal Science (Washington) and the RSC journal Chemical Communications (as Chairman). Alan E. Rowan studied at the University of Liverpool, where he obtained a BSc 1st Honours in Chemistry and subsequently a Ph.D. in Physical Organic Chemistry. In 1992 he moved to New Zealand, where he worked as a postdoctoral researcher in the group of Prof. C. Hunter on a topic in the field of Supramolecular Chemistry. In 1994 he joined the Radboud University in Nijmegen (The Netherlands) as a Marie Curie Fellow, after which he became an Assistant and later Associate Professor with Prof. Roeland J. M. Nolte. In 2005, he set up a new department of Molecular Materials and was promoted to Full Professor. His research interests are manifold, including topics such as the relationship between molecular architecture and function, self-assembly, and molecular and macromolecular materials. |
1 Introduction
In 1936, mathematician Alan Turing put forward the first concept of a device for abstract computing, now called the Turing machine.1 Although a hypothetical device, it could manipulate sets of operations according to a table of prescribed rules to compute anything with a written algorithm. It was demonstrated that all problems with a probable solution could, in principle, be cracked by the Turing device. Turing's proposal triggered a revolution in computing, leading to the birth of modern computing science (Fig. 1). The significance of this simple conceptual device in the domains of information processing and storage remains to this day. | ||
| Fig. 1 Timeline showing the discovery and progression of modern computing technology and futuristic molecular computing. | ||
Essentially, a Turing machine works on an infinitely long tape and contains a head that can write and read symbols, while moving forward and backward on the tape. Although all modern computers obey the Turing machine concept, to date, no practically useful computing device that acts according to the original blueprint has been constructed.† The resemblance of the Turing machine to naturally occurring molecular machineries that are capable of processing information, such as the ribosome and processive DNA (and RNA) polymerase enzymes, is striking and has recently motivated researchers to start programs on the development of biomolecular computers.2,3 Charles H. Bennett of IBM proposed such a computer conceptually in 1982, and predicted that designer enzymes and polymer substrates might be used for the construction of energy-efficient autonomous Turing machines.4
Herein, we describe recent developments in the construction of molecular and bio(macro)molecular systems for computing by focusing on information processing systems based on catalytic reaction routes that resemble information processing found in nature. We highlight catalytic enzyme approaches for developing logic gates, and the DNA-manipulating enzyme approach for information processing. Furthermore, we introduce the concept of processive catalysis as an important aspect of biological and future chemical Turing machines, and discuss our own efforts to construct such a synthetic molecular Turing device that works on a polymer tape encoded by inputs given by a tape head.
2 Computing at the molecular level
In the last seven decades, after the invention of the von Neumann-type computer architecture (Fig. 1), enormous progress has been made in computing technology, both with respect to computer software and hardware, but in the coming years a plateau is foreseen. Moore's law, which predicts that the performance of chip devices doubles every 18 months,5 cannot proceed infinitely due to foreseen technological barriers and fundamental limits.6 The ever-increasing load of data will require novel approaches for information storage and processing. Hence, an innovative and cost-effective technology is required and, in this sense, nanoscale molecular systems and devices are promising alternatives. The main advantage of molecular systems is that they can be adjusted and customized at small scales, even at the molecular level, by chemical modification. They can also handle more levels of information than just the binary codes 0 and 1, which may lead to more efficient programming and processing.7 Molecular information processing technology, therefore, is a promising long-term solution to the miniaturization challenge and to validate Moore's law into the coming century. Researchers are increasingly focusing on bottom-up approaches based on the self-assembly of molecular components, which include molecule-to-molecule and atom-by-atom assembly. Such approaches allow researchers to control vital properties and dimensions, as well as the composition of nanoscale components for computing.8Molecular computing gets its inspiration from biology, where information processing at the nanoscale is commonly found. Our brains, which carry out a myriad of information processing operations that rely heavily on chemical and electrical signals, are the best examples of natural, complex, molecular computer systems.9 Taking cues from these systems, a large number of programs have recently been launched in the USA and Europe to study the architecture and (nano)molecular structure of the brain with the objective of understanding what the essential elements of this organ are and how it functions. One of the long-term goals is to use this information for the development of a general-purpose computer. We may ask ourselves whether computers without any fixed algorithms can mimic the human brain by self-learning protocols. Can computers that do not depend on up-to-date software instructions and device components be constructed from molecular materials? Is there any possibility of replacing silicon-based computer devices by systems based on molecular components?
Such captivating questions require renewed efforts in broad fields of science and paradigm shifts in the way we think about computer technologies. The majority of efforts to emulate the function of a brain involves the creation of artificial chemical analogues of neural-networks-like systems for computation.10,11 As logic devices, analogous polymer memristors capable of mimicking the learning and memory functions of biological synapses have been developed.12 Nevertheless, such proof-of-concept studies are yet to be applied to real-world technologies. The idea of using chemical transformations to process information may strengthen the links between chemistry and computer science, but the experimental realization of these theoretical concepts13 require insights into the behavior and function of complex chemical systems. In this connection, substantial attempts have been made by studying oscillating systems, such as the Belousov–Zhabotinsky (BZ) reaction, to imitate the dynamics of neural networks, which may lead to conceptually new, complex, information processing systems.14
In recent years, a great deal of effort has been made to mimic current silicon-based computing technology with the help of molecular systems. Some of these efforts are highlighted in the next section.
2.1 Molecular logic gates
Modern computers are built on vast networks of transistor-based logic gates that execute binary arithmetic and Boolean logic operations. Logic gates are electronic switches, the output states (binary digits 0 or 1) of which are governed by the input conditions (binary digits 0 or 1); therefore, all information is encoded in a series of zeros and ones.15,16 Advances in information storage and processing at the molecular level would be conceivable if molecular logic gates could be constructed.16Theoretically, individual molecules or self-assembled molecular systems (i.e., based on supramolecular interactions) that change between two distinctive states in response to external optical or chemical signals could be utilized as molecular switches, and hence be applied, at least in principle, to construct transistors for storage devices and molecular computing. The idea of information storage, with the help of molecular switches, was already proposed by Hirshberg back in 1956.17 Later, de Silva and co-workers noticed the similarity between Boolean logic gates and molecular switches.18a Rotaxanes and catenanes are mechanically interlocked molecular systems19 that can be applied as molecular switches for the development of logic gates and memory devices.20 Catenanes represent a class of supramolecular assemblies that are composed of several distinct molecular constituents organized into a closed unit, without being chemically linked. A recent example from our own work, which is being used in the construction of a molecular Turing machine (see below), is shown in Fig. 2a. It consists of a porphyrin macrocyclic ring encircling a thread (compound A), which can be positioned at different locations through weak supramolecular interactions that can be regulated by an external stimulus, in this case acid.21
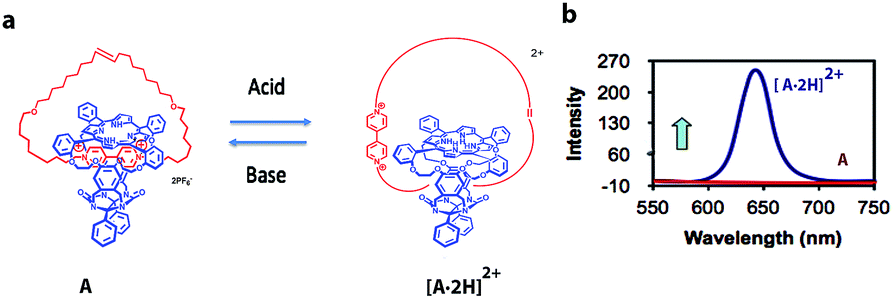 | ||
| Fig. 2 (a) Acid-driven switching of porphyrin[2]catenane A.21 (b) Fluorescence spectra of [2]catenanes A (red) and [A·2H]2+ (blue). | ||
[2]Catenane A is nonfluorescent due to efficient fluorescence quenching by the electron-accepting viologen present inside its cavity (Fig. 2b). The compound becomes strongly fluorescent upon the addition of acid, as a result of the expulsion of the viologen moiety from the cavity of A; thus providing protonated [2]catenane [A·2H]2+. The addition of base to the solution results in the deprotonation of the latter compound and the disappearance of the fluorescence. These results demonstrate that [2]catenane A can be switched between two states by using simple acid–base addition as a chemical input. Catenanes, rotaxanes, and other molecular systems that can execute similar simple logic processes, such as YES, NOT, AND, OR, NOR, and NAND, monitored by fluorescence have already been reported.18,20,22 The first molecular-level system capable of performing a complex logic operation, namely, a XOR gate was constructed by Balzani, Stoddart and co-workers.16 They used the following components: (i) a pseudorotaxane system based on an electron-donating host molecule (2,3-dinaphtho[30]crown-10) and an electron-accepting guest molecule (2,7-dibenzyldiazapyrenium dication), (ii) acid/base as a chemical input signal, and (iii) host fluorescence as an indicator signal.
Later, Stoddart, Heath and co-workers developed electronically addressable molecular logic gates,23 which were composed of monolayers of bistable [2]catenanes sandwiched between n-type polycrystalline silicon and metallic electrodes. They used these to construct a device that could be switched between ‘on’ and ‘off’ by using an applied bias. This work is an excellent example of the successful combination of electronic and chemical concepts and the potential benefits of modern molecular nanotechnology. The same team went one step further and in 2007 (ref. 24) demonstrated that by using bistable [2]rotaxane-based molecular systems (as the data storage element) a 160 kilobit molecular electronic memory circuit could be fabricated with densities of 1011 bits per cm2 (Fig. 3), which was more than 30 times larger than state-of-art dynamic random access memory (DRAM) or flash devices.25
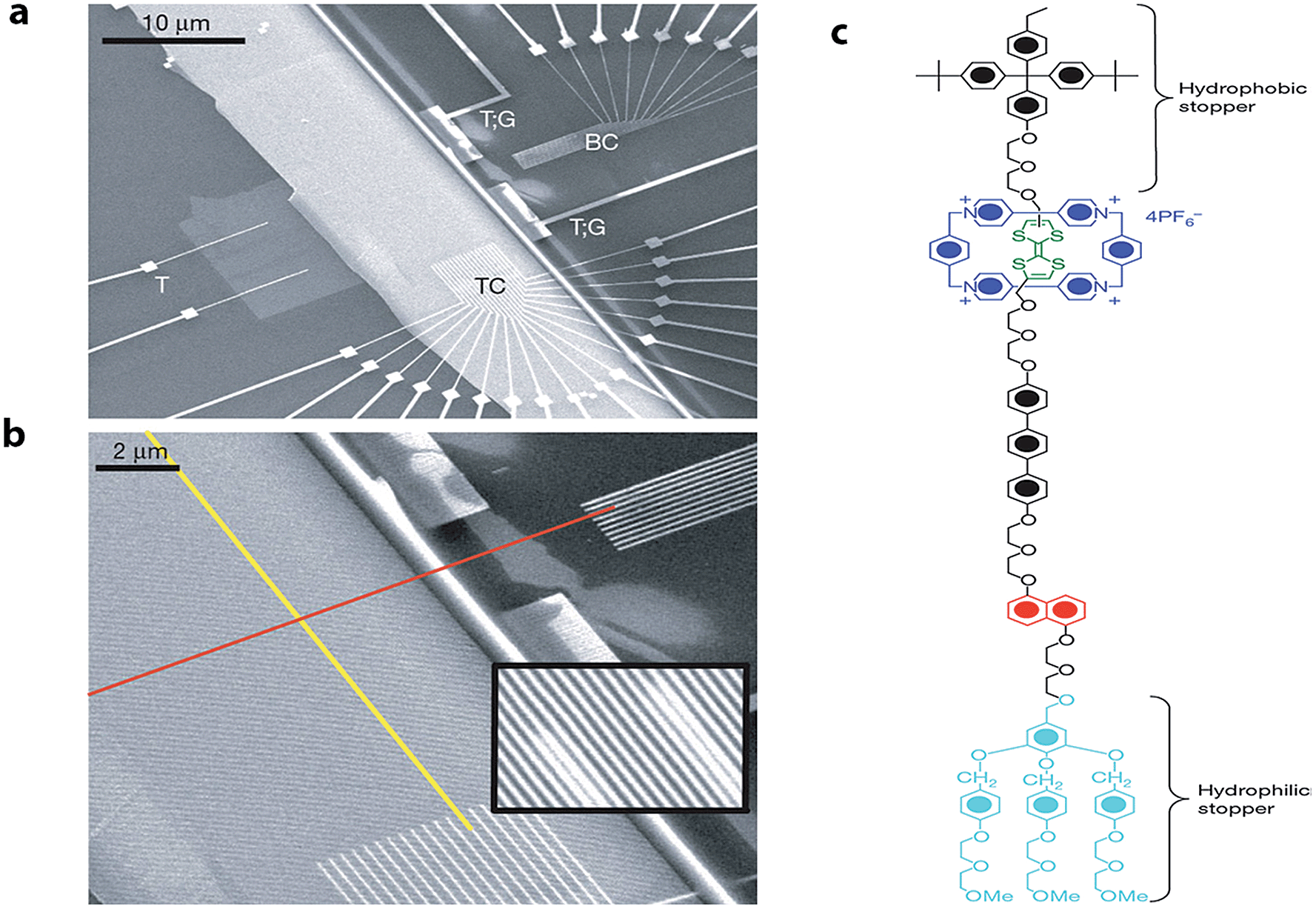 | ||
| Fig. 3 Electronically configurable logic gates based on monolayers of a bistable rotaxane system. (a) SEM image of the entire circuit of a nanowire crossbar memory made up of 400 silicon wires overlapping 400 similar titanium wires. (b) SEM image showing the cross-point of the top (red) and bottom (yellow) nanowire electrodes, each cross-point corresponds to an ebit in memory testing. (c) Structure of the rotaxane system used in the crossbar memory. Reproduced with permission from ref. 24. Copyright (2007) Nature Publishing Group. | ||
This work is an excellent example of how nanoscale molecular devices can be constructed by using current silicon-based logic technology as a guide. It is not unlikely, however, that in the future the real potential of molecular computing may lie in less conventional systems that are developed for special needs, for example, biocompatible computing systems based on enzyme catalysis, which can be used for biological or medical applications. In the following sections, we discuss some of these developments.
3 Computing with enzymes
Enzymatic catalysis is increasingly being studied as a tool in the field of information processing.26 For example, the enzyme glucose oxidase (GOx) can act as a YES gate (one-input logic gate) to produce a high output signal (gluconic acid) when only the substrate glucose is supplied as an input signal (Fig. 4).27 The output signal of the gate is monitored as a change in the UV-vis absorbance, resulting from a colorimetric follow-up reaction with the formed gluconic acid. To date, a number of enzyme catalytic systems, which perform simple logic operations, such as XOR, AND, NOR, OR, NAND, XNOR, and INHIB, using chemical inputs have been described.15,26,28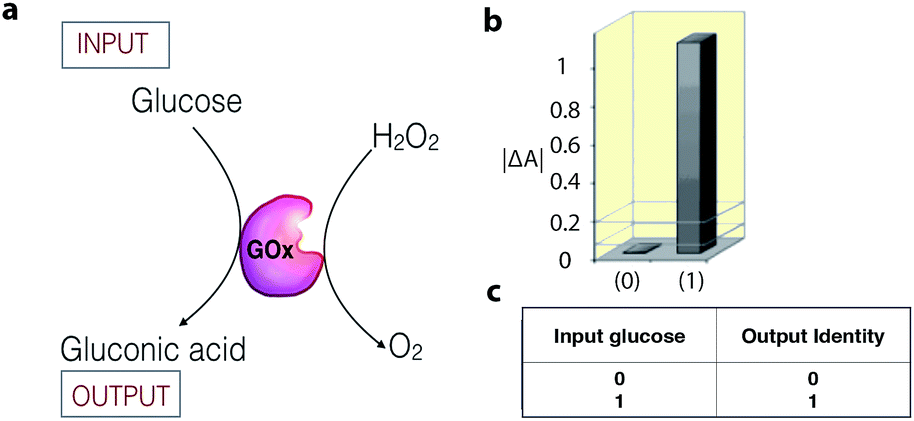 | ||
| Fig. 4 (a) Schematic representation of a biocatalytic YES logic gate. (b) Bar presentation of the YES gate UV-vis absorbance outputs at λ = 500 nm. (c) Truth table of the corresponding operation. Adapted with permission from ref. 27. Copyright (2006) American Chemical Society. | ||
On the other hand, much more versatile complex logic behavior can be achieved when multiple enzymatic pathways or cascades are considered.15,29,30 For example, Willner30 and co-workers developed a system of concatenated (i.e., the outputs of one gate are used as the inputs of a preceding gate; thus allowing the cascade of information downstream, as in conventional semiconductor logic28d) logic gates using a four-enzyme coupled system composed of acetylcholine esterase (AChE), choline oxidase (ChOx), microperoxidase-11 (MP-11), and the NAD+-dependent glucose dehydrogenase (GDH), and four chemical inputs, namely, acetylcholine, butyrylcholine, O2, and glucose. The system can perform three logic gate operations in series, namely, OR, AND, and XOR (Fig. 5). The use of several enzyme-based logic gates that operate in series is important from the viewpoint of creating chemical electronic circuits with scaled-up complexity, and to realize molecular systems that can perform sophisticated arithmetic functions.26,28d It was recently shown that such biocatalytic systems mimicking logic operations could even be assembled in a flow device.31
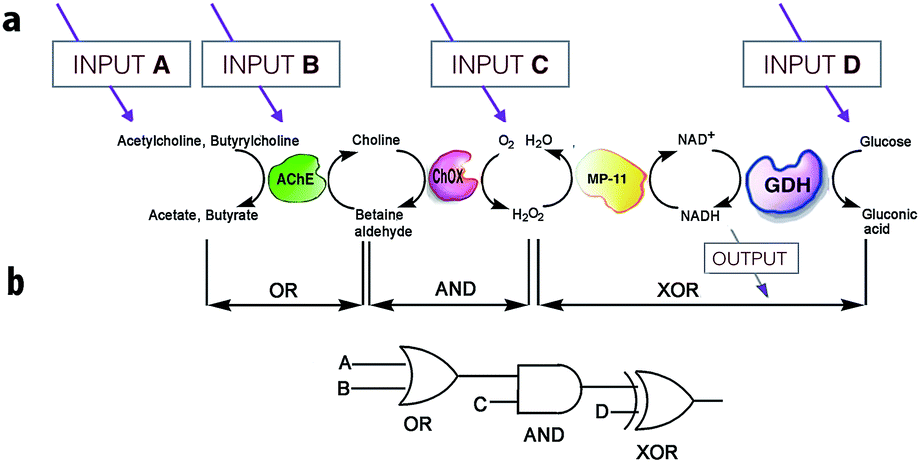 | ||
| Fig. 5 Scheme illustrating the operation of concatenated logic gates based on four coupled enzyme systems. (a) Cascade of reactions catalyzed by AChE, ChOx, MP-11, and the NAD+-dependent GDH; all triggered by input signals that include acetylcholine, butyrylcholine, O2, and glucose added in different combinations. (b) Network performing OR–AND–XOR operations. Adapted with permission from ref. 30. Copyright (2006) National Academy of Sciences, U.S.A. | ||
Apart from being of interest for computing, biocatalytic systems that act through enzyme logic networks may have great implications in the fields of biomedicine and biosensing. On a fundamental level, enzyme-based logic network systems may help in the study of how living systems manage to control extremely complex biochemical reactions and cell signalling. Furthermore, such systems may help to enhance our ability to control biological processes,32 eventually leading to disease diagnosis and better healthcare.
Other elegant examples of molecular information processing involving biocatalytic systems are based on oligonucleotides and on systems in which enzymes act on DNA polymers (see below).33
4 DNA computing
In nature, living cells function as universal Turing devices by reading, storing, and processing the myriad of information present in the intra- or extracellular environment. A prominent natural material present in cells that has been explored for molecular computing is DNA. DNA-based computing was first demonstrated by Adleman,3 who realized that the information present in biomolecules, namely, in DNA, could be of use to solve a difficult mathematical problem. He tested the feasibility of his idea by applying it to the Hamilton path question known as the problem of the traveling salesman. In brief, given an arbitrary collection of cities between which a salesman has to travel, what is the shortest route to visit these cities and pass through them only once? Adelman synthesized a set of DNA strands that contained all of the required information (cities and paths between cities) in the form of combinations of base pairs that could possibly be included to answer this problem. The DNA strands were mixed, which resulted in the generation of all possible random paths through the cities. To find the correct answer to the problem, he filtered out all DNA strands that represented the “wrong” answers (paths that were too long or too short and paths that did not start and finish in the correct city) and eventually retained the strand with the correct answer.3 Adleman's experiment makes use of DNA recognition and duplication and there is a parallel with the classical Turing machine. Since then, many attempts have been reported for solving related mathematical problems, some of which have been successful.34,35 The remarkable properties of DNA can also be utilized to realize other innovative information technologies, such as high-capacity storage of digital information.36 For example, it has been shown recently that computer files of upto 1 megabyte (e.g., all 154 sonnets of Shakespeare and the speech of Martin Luther King) could be stored in the form of DNA and retrieved with high, nearly 100%, precision.37 The high accuracy in re-reading was achieved by using an error-correcting encoding scheme. Another recent study demonstrated that such information programmed in DNA could be stored for very long periods of time (estimated up to millennia) when properly protected by encapsulating the DNA strands in silica glass.38 This may turn out to be the preferred method of storage in the future because books retain information for only about 500 years and today's digital systems only for 50 years.A biomolecular copying nanomachine, such as the DNA polymerase enzyme system, which moves along a single strand of DNA, reading each base and writing its complementary base onto a new, growing strand of DNA, is one of the best natural examples of a classical Turing machine.39a This resemblance has attracted much interest from researchers to design DNA-based molecular computers.3,39–41 Rothemund presented theoretical models for such DNA Turing machines by utilizing DNA oligonucleotides as software and DNA restriction enzymes as hardware.42 Shapiro and co-workers employed DNA and DNA-manipulating enzymes, such as the DNA restriction enzyme FokI and a DNA ligase, to construct a simple DNA computer that could solve computational problems autonomously.43 Another elegant example of an enzyme-based DNA computer, based on RNA polymerase (RNA Pol), was developed by Endy and co-workers (Fig. 6).44 They used a combination of enzymes to control the sliding of RNA polymerase across a DNA strand to construct a transistor-like, three-terminal device, named a transcriptor. Transcriptors can mimic traditional AND, NAND, OR, NOR, XOR, and XNOR logic gates by controlling the movement of RNA polymerase along DNA.
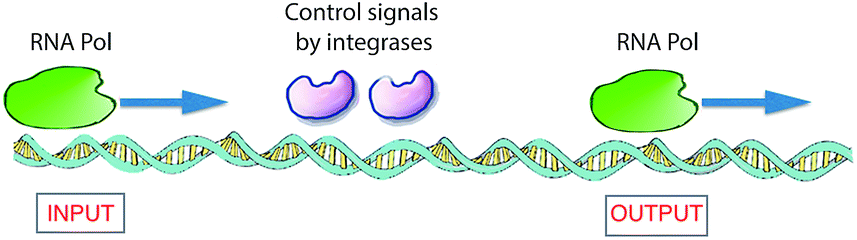 | ||
| Fig. 6 Logic gates based on DNA expression. To translate DNA into mRNA, the enzyme RNA Pol receives control signals through two integrase enzymes, which allow or block the flow of RNA polymerase through it, subsequently realizing the synthesis of RNA. This constitutes a model for a XOR gate.41,44 | ||
Another recent development is the construction of the biomolecular equivalent of an electronic transducer. Transducers are electronic devices that can encode new information using their output for subsequent computing in an iterative way.45 Keinan and co-workers recently constructed a DNA-based device that acted in a similar way.46 It reads DNA plasmids as inputs and processes this information using a predetermined algorithm represented by molecular software (so-called transition molecules, i.e., short encoded double-stranded DNA molecules). The output is written on the same plasmid using DNA-manipulating enzymes as hardware. This advanced computing machine can algorithmically manipulate genetic codes.46 Apart from being capable of performing computational operations, these intelligent biomolecular computing machines have the potential to regulate and change biomolecular processes in vivo because they can interact directly with biochemical environment, offering potentially new approaches for gene therapy and cloning.46 These additional features of biological Turing-like machines could have great implications in the fields of pharmacy and biomedical science. In the future, biocomputing might become equally as important as, or even more attractive than, electronic computing.
Some weaknesses of DNA-based computing systems include the fact that they are fragile and also complex, that is, they make use of a quaternary (four-base code A, C, T, and G of DNA) instead of a binary coding system.47 Hence, it might be more useful in the future to switch to synthetic polymers, which can be more easily modulated at the molecular level (both with respect to structural diversity and scalability) by making chemical changes in other solvents than water, which is difficult in the case of DNA. In this connection, it is worth mentioning that the idea of encoding information in any polymer chain composed of more than one type of monomer was reported long ago.47,48 For example, a binary sequence information code can be generated in a synthetic polymer chain by using two different co-monomers, with the resulting chain composition representing strings of ones and zeroes.39 Despite this success, there are few reports on encoding molecular information into a synthetic polymer backbone.47–49 Lutz described the synthesis of sequence-controlled synthetic polymers with diverse chemical structures by using sequence-regulated polymerization processes, such as controlled chain-growth copolymerization.50 Recently, Lutz and co-workers were able to show that binary code could be implemented in a sequence-controlled poly(alkoxyamine amide) polymer chain by using three monomers,51 namely, one nitroxide spacer and two interchangeable anhydrides defined as 0 bit and 1 bit and used a tandem mass spectrometry technique to sequence or read the polymer.52 Leigh and co-workers reported a rotaxane-based nanomachine that mimicked ribosomes, which synthesizes peptides in a sequence-regulated fashion.53 Their approach involved a macrocyclic host molecule containing a thiol group that moved along a thread with predetermined amino acids as building blocks. The directed movement of the macrocyclic ring along the thread allows for the sequence-specific synthesis of peptides, which is elegant and the first synthetic device of its kind. Such sequence-controlled polymerizations are important for developing ‘writing’ mechanisms on synthetic polymers (see below). The problem is that robust pathways for writing, reading, and erasing/rewriting information on a polymer chain are still lacking; this remains a challenge for the future.
5 Processive catalysis: towards a catalytic molecular Turing machine
Recent years have witnessed a large growth in the development of molecular machines based on interlocked molecules (catenanes and rotaxanes) and their application in the field of molecular electronics.54 We realized that encoding information on a tape, as originally proposed by Turing, might be possible in a rotaxane-like architecture, if a ring-like catalyst could bind to a polymer chain and glide along it and, at the same time, modify it by performing a catalytic reaction. In 2003, we made the first steps in this direction by designing a manganese porphyrin-based cage compound derived from glycoluril (of the type shown in Fig. 2) that could thread onto a polybutadiene chain and move along it, while oxidizing the double bonds of the polymer to form epoxides (Fig. 7).55 The presence (binary digit 1/ON) or absence (binary digit 0/OFF) of oxygen atoms and the locations where these oxygen atoms are present can be seen as information that is encoded on the polymer chain. We define the above mentioned catalytic reaction as being “processive”, which means that the catalyst can perform numerous cycles of reactions without being separated from the substrate, in this case a polymer chain.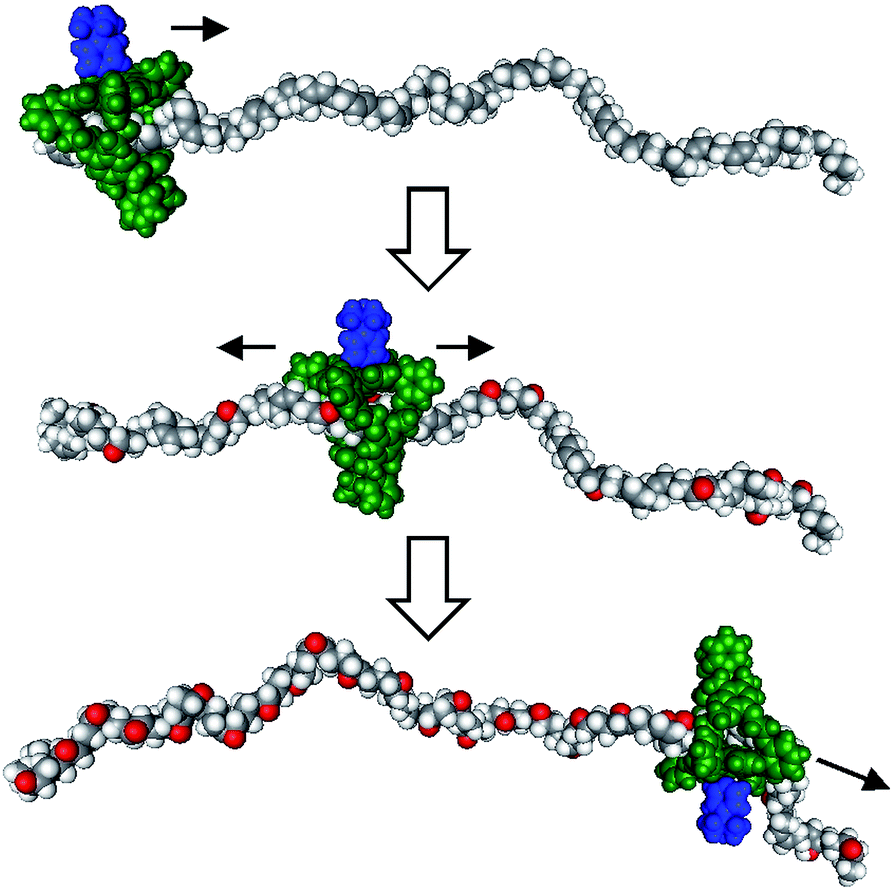 | ||
| Fig. 7 Processive catalysis exerted on a synthetic polymer chain (polybutadiene) by a porphyrin-based molecular machine. Reproduced with permission from ref. 56. Copyright (2014) Wiley-VCH. | ||
The turnover number of this processive oxidation reaction is relatively high, as a result of the high effective molarity created because the catalyst remains attached to the polymeric substrate. This behavior is remarkably different from that of a distributive catalyst, which detaches itself from the substrate after every catalytic cycle.56 In nature, processive catalysis is common and processivity is utilized as a way to increase the efficiency and fidelity of a process, particularly in systems where no or only few errors can be tolerated, such as in the replication of genetic information.57–59 DNA polymerase is a nice example of a processive biocatalyst; it assembles nucleotides in a processive manner to synthesize new strands of DNA. Our artificial processive catalyst mimicked naturally occurring processive enzymes, such as DNA polymerase and λ-exonuclease. The difference from the polymerase enzyme is that the artificial system is not sequentially processive, that is, it does not oxidize the double bonds of polybutadiene in a stepwise fashion, but follows a so-called hopping mechanism (see Fig. 7).60 Recently, however, we synthesized a semisynthetic biohybrid catalyst (a water-soluble manganese porphyrin conjugated to a C-shaped protein ring, the T4 clamp) that bound to a DNA plasmid and cleaved it in a sequential processive fashion at AAA sites, while moving along it (Fig. 8).61 Hybrid clamps of this type can modify a polymer tape (DNA) in a way that might be useful for the future development of a DNA-based biohybrid catalytic molecular Turing machine. The next step in the development of a synthetic catalytic Turing machine will be the construction of a second-generation processive catalytic system, in which information from a tape head is used to control the catalytic writing event on the polymer chain.
 | ||
| Fig. 8 Processive catalysis on DNA by a biohybrid catalyst. The blue C-shaped ring is the T4 clamp protein and the green bars are the manganese porphyrin catalysts.61 | ||
A blueprint of such a system is presented in Fig. 9. As a tape, polymers with sites that can be modified chemically are utilized, for instance, alkene double bonds of different types (e.g., cis-alkene, trans-alkene, and pendant alkene55a), which can be converted into epoxide functions. These alkenes and their corresponding epoxides represent the symbols on the tape. In the above example of three alkenes, this amounts to a total of six symbols (i.e., 3 alkene and 3 epoxide functions). The required tape head (polymer-manipulating catalyst) will be a chemically linked porphyrin double cage compound of the type depicted in Fig. 9. One of the cages contains a ring strand (i.e., a catenane) that can rotate and deliver commands exerted by external stimuli. The other cage would then be threaded onto the above mentioned polymer tape. The catenane compound can be synthesized by employing a ring-closing metathesis reaction with a Grubbs catalyst, as we have shown previously.21 This catenane has to switch between at least two different states, which are controlled by external stimuli (e.g., light, electrons, or acid/base; see Fig. 2a). In our design, these two states are chiral (R or S) states, which can be attained by binding chiral guests (i.e., R or S viologen moieties present in the catenane ring) in the upper cavity of the double cage compound. This chiral information will be transferred to the other cage by allosteric modulation, that is, shape changes, which is, in principle, possible, as we have already shown for the binding and threading of (polymeric) guests in double cage porphyrin systems.62,63 The objective is to transfer information present in the ring in a controlled fashion to the polymer substrate, that is, by catalytically oxidizing the alkene groups located in the polymer chain in an enantioselective way, all controlled by the external stimulus applied to the catenane ring. Such a system would be the first example of a synthetic molecular Turing machine for information processing and storage.
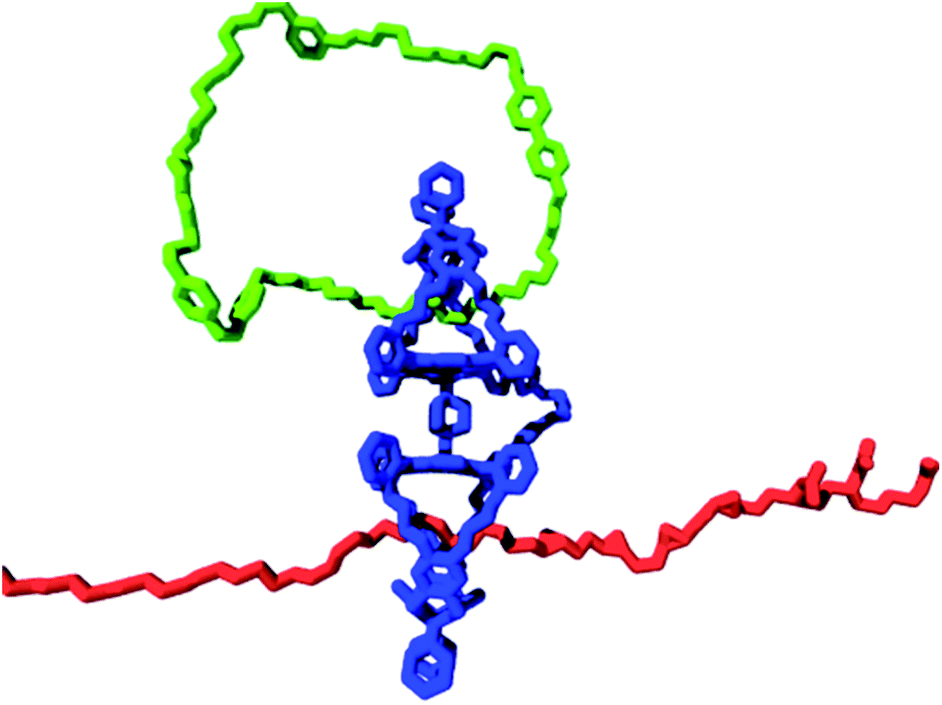 | ||
| Fig. 9 Blueprint for a catalytic molecular Turing machine. Information is transferred from a catenane ring (green oval) to a polymer tape (red chain), see text. | ||
To become a universal Turing machine that can perform computations, many more criteria have to be met, even for simple machines with state/symbol pairs of (2, 3), (2, 4), and (2, 5).64 Apart from writing, the catalytic machine must also have the capacity to read and erase symbols on the tape, and to interconvert these symbols reversibly. For example, apart from forming epoxides, it should also be able to convert them back into alkene functions, which is, in principle, possible by a catalytic reaction.65 Furthermore, the various processes (catenane ring rotation, chiral information transfer, rates of threading, writing, and reading) have to be synchronized and controllable. Finally, the machine must be provided with chemical functions that allow it to go forwards and backwards on command, for instance, by an energy-driven molecular ratchet mechanism. All of these different items are great opportunities for challenging and exciting research in the future; this is already in progress.
6 Conclusions
We have highlighted the ambition and possibilities of using molecular and bio-macromolecular systems for logic operations and computing. We also presented a catalytic approach, an operation denoted as “processive catalysis”, as a potential key element in the design of a future molecular Turing machine that would be completely synthetic. The field of molecular computing is rapidly developing, with new ideas coming from groups working in very different fields of science. This is opening the door for the design and construction of novel molecule-based computational devices. Although such future devices might execute operations similar to those of a Turing machine, one might ask if it could practically process information on a reasonable timescale. Further studies will have to answer this question, but it is evident that the development of molecular computers is an interesting and exciting direction of research in the bustling field of computer technology. Substantial progress can only be made if computer scientists, mathematicians, physicists, chemists, and biologist get together and work jointly on new, unorthodox programs.An interesting perspective, which has not yet received enough attention, is the application of Turing-like machines in medicine. In particular, DNA-based computing systems, which can read and transform genetic information, have the possibility to produce computational results in the form of genetic material that can directly interact with living organisms, which might prove to be useful in gene therapy, for example.2,46,66,67
Processive catalysis is one of nature's most frequently used tools whenever polymers are involved. For instance, almost all translational processes seen in the cell are processive, and proteins are literally born from processive catalysis.68 It is not hard to imagine that a molecular machine based on a processive catalyst could be used in the future to replace or supplement natural enzymes. If these processive machines can, for example, repair damage to biopolymers, or can switch the activity of gene promoters, this may have great implications for therapeutic treatments of complex diseases.
Acknowledgements
This research was supported by the European Research Council in the form of an ERC Advanced grant to R. J. M. N. and S. V. (ALPROS-290886) and an ERC Starting grant to J. A. A. W. E. (NANOCAT-259064). Further financial support was obtained from the Council for the Chemical Sciences of the Netherlands Organization for Scientific Research (CW-NWO) (Vidi grant for J. A. A. W. E. and Vici grant for A. E. R.) and from the Ministry of Education, Culture and Science (Gravity program 024.001.035). We would like to thank Prof. F. Vaandrager, S. F. M. van Dongen and A. G. Rekha for valuable discussions and comments.References
- A. M. Turing, Proc. Lond. Math. Soc., 1936, 42, 230–265 Search PubMed.
- (a) Y. Benenson, Nat. Rev. Genet., 2012, 13, 455–468 CrossRef CAS PubMed; (b) A. Regev and E. Shapiro, Nature, 2002, 419, 343–343 CrossRef CAS PubMed.
- L. M. Adleman, Science, 1994, 266, 1021–1024 CAS.
- C. H. Bennet, Int. J. Theor. Phys., 1982, 21, 905–940 CrossRef.
- G. E. Moore, Electronics, 1965, 38, 114–117 Search PubMed.
- (a) R. W. Keyes, Proc. IEEE, 2001, 89, 227–239 CrossRef CAS; (b) I. L. Markov, Nature, 2014, 512, 147–154 CrossRef CAS PubMed.
- A. Bandyopadhyay and A. Acharya, Proc. Natl. Acad. Sci. U. S. A., 2008, 105, 3668–3672 CrossRef CAS PubMed.
- (a) F. M. Raymo, Adv. Mater., 2002, 14, 401–414 CrossRef CAS; (b) L. Sun, Y. A. Diaz-Fernandez, T. A. Gschneidtner, F. Westerlund, S. Lara-Avila and K. Moth-Poulsen, Chem. Soc. Rev., 2014, 43, 7378–7411 RSC; (c) B. Xu and N. J. Tao, Science, 2003, 301, 1221–1223 CrossRef CAS PubMed; (d) B. Capozzi, J. Xia, O. Adak, E. J. Dell, Z. F. Liu, J. C. Taylor, J. B. Neaton, L. M. Campos and L. Venkataraman, Nat. Nanotechnol., 2015, 10, 522–527 CrossRef CAS PubMed.
- S. Tsuda, M. Aono and Y.-P. Gunji, BioSystems, 2004, 73, 45–55 CrossRef PubMed.
- L. Qian, E. Winfree and J. Bruck, Nature, 2011, 475, 368–372 CrossRef CAS PubMed.
- (a) S. Ghosh, K. Aswani, S. Singh, S. Sahu, D. Fujita and A. Bandyopadhyay, Information, 2014, 5, 28–100 CrossRef PubMed; (b) A. Bandyopadhyay, R. Pati, S. Sahu, F. Peper and D. Fujita, Nat. Phys., 2010, 6, 369–375 CrossRef CAS PubMed.
- (a) Y. Chen, G. Liu, C. Wang, W. B. Zhang, R. W. Li and L. Wang, Mater. Horiz., 2014, 1, 489–506 RSC; (b) Y. Li, A. Sinitskii and J. M. Tour, Nat. Mater., 2008, 7, 966–971 CrossRef CAS PubMed.
- A. M. Turing, Philos. Trans. R. Soc. London, Ser. B, 1952, 237, 37–72 CrossRef.
- (a) D. Lebender and F. W. Schneider, J. Phys. Chem., 1994, 98, 7533–7537 CrossRef CAS; (b) P. L. Gentili, RSC Adv., 2013, 3, 25523–25549 RSC.
- K. Szacilowski, Chem. Rev., 2008, 108, 3481–3548 CrossRef CAS PubMed.
- (a) A. Credi, V. Balzani, S. J. Langford and J. F. Stoddart, J. Am. Chem. Soc., 1997, 119, 2679–2681 CrossRef CAS; (b) V. Balzani, A. Credi and M. Venturi, Proc. Natl. Acad. Sci. U. S. A., 2002, 99, 4814–4817 CrossRef CAS PubMed.
- Y. Hirshberg, J. Am. Chem. Soc., 1956, 78, 2304–2312 CrossRef CAS.
- (a) A. P. de Silva, N. H. Q. Gunaratne and C. P. McCoy, Nature, 1993, 364, 42–44 CrossRef PubMed; (b) A. P. de Silva and S. Uchiyama, Nat. Nanotechnol., 2007, 2, 399–410 CrossRef CAS PubMed; (c) J. Ling, B. Daly, V. A. D. Silverson and A. P. de Silva, Chem. Commun., 2015, 51, 8403–8409 RSC.
- (a) G. Barin, R. S. Forgan and J. F. Stoddart, Proc. R. Soc. London, Ser. A, 2012, 468, 2849–2880 CrossRef CAS PubMed; (b) D. A. Leigh, J. K. Y. Wong, F. Dehez and F. Zerbetto, Nature, 2003, 424, 174–179 CrossRef CAS PubMed.
- (a) V. Balzani, A. Credi, F. M. Raymo and J. F. Stoddart, Angew. Chem., Int. Ed., 2000, 39, 3348–3391 CrossRef CAS; (b) N. H. Evans and P. D. Beer, Chem. Soc. Rev., 2014, 43, 4658–4683 RSC.
- R. G. E. Coumans, J. A. A. W. Elemans, A. E. Rowan and R. J. M. Nolte, Chem.–Eur. J., 2013, 19, 7758–7770 CrossRef CAS PubMed.
- (a) A. P. de Silva, H. Q. N. Gunaratne, T. Gunnlaugsson, A. J. M. Huxley, C. P. McCoy, J. T. Rademacher and T. E. Rice, Chem. Rev., 1997, 97, 1515–1566 CrossRef CAS PubMed; (b) V. Balzani, A. Credi, S. J. Langford, F. M. Raymo, J. F. Stoddart and M. Venturi, J. Am. Chem. Soc., 2000, 122, 3542–3543 CrossRef CAS; (c) U. Pischel, Angew. Chem., Int. Ed., 2007, 46, 4026–4040 CrossRef CAS PubMed.
- C. P. Collier, G. Mattersteig, E. W. Wong, Y. Luo, K. Beverly, J. Sampaio, F. M. Raymo, J. F. Stoddart and J. R. Heath, Science, 2000, 289, 1172–1175 CrossRef CAS.
- J. E. Green, J. W. Choi, A. Boukai, Y. Bunimovich, E. Johnston-Halperin, E. DeIonno, Y. Luo, B. A. Sheriff, K. Xu, Y. S. Shin, H. R. Tseng, J. F. Stoddart and J. R. Heath, Nature, 2007, 445, 414–417 CrossRef CAS PubMed.
- W. Lu and C. M. Lieber, Nat. Mater., 2007, 6, 841–850 CrossRef CAS PubMed.
- E. Katz and V. Privman, Chem. Soc. Rev., 2010, 39, 1835–1857 RSC.
- R. Baron, O. Lioubashevski, E. Katz, T. Niazov and I. Willner, J. Phys. Chem. A, 2006, 110, 8548–8553 CrossRef CAS PubMed.
- (a) R. Baron, O. Lioubashevski, E. Katz, T. Niazov and I. Willner, Angew. Chem., Int. Ed., 2006, 45, 1572–1576 CrossRef CAS PubMed; (b) S. Domanskyi and V. Privman, J. Phys. Chem. B, 2012, 116, 13690–13695 CrossRef CAS PubMed; (c) J. Zhou, M. A. Arugula, J. Halámek, M. Pita and E. Katz, J. Phys. Chem. A, 2009, 113, 16065–16070 CrossRef CAS PubMed; (d) N. Wagner and G. Ashkenasy, Chem.–Eur. J., 2009, 15, 1765–1775 CrossRef CAS PubMed.
- M. Privman, T. K. Tam, M. Pita and E. Katz, J. Am. Chem. Soc., 2009, 131, 1314–1321 CrossRef CAS PubMed.
- T. Niazov, R. Baron, E. Katz, O. Lioubashevski and I. Willner, Proc. Natl. Acad. Sci. U. S. A., 2006, 103, 17160–17163 CrossRef CAS PubMed.
- B. E. Fratto, L. J. Roby, N. Guz and E. Katz, Chem. Commun., 2014, 50, 12043–12046 RSC.
- (a) M. Pita, S. Minko and E. Katz, J. Mater. Sci.: Mater. Med., 2009, 20, 457–462 CrossRef CAS PubMed; (b) M. Zhou, X. Zheng, J. Wang and S. Dong, Bioinformatics, 2011, 27, 399–404 CrossRef CAS PubMed.
- M. N. Stojanovic, D. Stefanovic and S. Rudchenko, Acc. Chem. Res., 2014, 47, 1845–1852 CrossRef CAS PubMed.
- Y. Beneson, B. Gil, U. Ben-Dor, R. Adar and E. Shapiro, Nature, 2004, 429, 423–429 CrossRef PubMed.
- J. MacDonald, Y. Li, M. Sutovic, H. Lederman, K. Pendri, W. Lu, B. L. Andrews, D. Stefanovic and M. N. Stojanovic, Nano Lett., 2006, 6, 2598–2603 CrossRef CAS PubMed.
- G. M. Church, Y. Gao and S. Kosuri, Science, 2012, 337, 1628 CrossRef CAS PubMed.
- N. Goldman, P. Bertone, S. Chen, C. Dessimoz, E. M. LeProust, B. Sipos and E. Birney, Nature, 2013, 494, 77–80 CrossRef CAS PubMed.
- R. N. Grass, R. Heckel, M. Puddu, D. Paunescu and W. J. Stark, Angew. Chem., Int. Ed., 2015, 54, 2552–2555 CrossRef CAS PubMed.
- (a) L. Adleman, Sci. Am., 1998, 297, 54–61 CrossRef PubMed; (b) E. Winfree, F. Liu, L. A. Wenzler and N. C. Seeman, Nature, 1998, 394, 539–544 CrossRef CAS PubMed.
- K. Sakamoto, D. Kiga, K. Komiya, H. Gouzu, S. Yokoyama, S. Ikeda, H. Sugiyama and M. Hagiya, BioSystems, 1999, 52, 81–91 CrossRef CAS.
- B. Hayes, Am. Sci., 2001, 89, 204–208 CrossRef.
- P. W. K. Rothemund, Proceedings of the DIMACS Workshop, ed. R. J. Lipton and E. B. Baum, American Mathematical Society, Washington DC, 1995, pp. 75–119 Search PubMed.
- (a) Y. Beneson, T. Paz-Elizur, R. Adar, E. Keinan, Z. Livneh and E. Shapiro, Nature, 2001, 414, 430–434 CrossRef PubMed; (b) Y. Benenson, R. Adar, T. Paz-Elizur, Z. Livneh and E. Shapiro, Proc. Natl. Acad. Sci. U. S. A., 2003, 100, 2191–2196 CrossRef CAS PubMed.
- J. Bonnet, P. Yin, M. E. Ortiz, P. Subsoontorn and D. Endy, Science, 2013, 340, 599–603 CrossRef CAS PubMed.
- J. E. Hopcroft, R. Motwani, and J. D. Ullman, Introduction to Automata Theory, Languages, and Computation, Addison-Wesley, Boston, 2001 Search PubMed.
- T. Ratner, R. Piran, N. Jonoska and E. Keinan, Chem. Biol., 2013, 20, 726–733 CrossRef CAS PubMed.
- (a) R. Dawkins, The Blind Watchmaker, Longman Scientific and Technical, Harlow, 1986 Search PubMed; (b) H. M. Colquhoun and J.-F. Lutz, Nat. Chem., 2014, 6, 455–456 CrossRef CAS PubMed; (c) H. M. Colquhoun and Z. Zhu, Angew. Chem., Int. Ed., 2004, 43, 5040–5045 CrossRef CAS PubMed.
- (a) Z. Zhu, C. J. Cardin, Y. Gan and H. Colquhoun, Nat. Chem., 2010, 2, 653–660 CrossRef PubMed; (b) J.-F. Lutz, B. V. K. J. Schmidt and S. Pfeifer, Macromol. Rapid Commun., 2011, 32, 127–135 CrossRef CAS PubMed; (c) J.-F. Lutz, Macromolecules, 2015, 48, 4759–4767 CrossRef CAS.
- J.-F. Lutz, M. Ouchi, D. R. Liu and M. Sawamoto, Science, 2013, 341, 1238149 CrossRef PubMed.
- J.-F. Lutz, Acc. Chem. Res., 2013, 46, 2696–2705 CrossRef CAS PubMed.
- R. K. Roy, A. Meszynska, C. Laure, L. Charles, C. Verchin and J. F. Lutz, Nat. Commun., 2015, 6, 7237 CrossRef CAS PubMed.
- H. Mutlu and J.-F. Lutz, Angew. Chem., Int. Ed., 2014, 53, 13010–13019 CrossRef CAS PubMed.
- (a) B. Lewandowski, G. de Bo, J. W. Ward, M. Papmeyer, S. Kuschel, M. J. Aldegunde, P. M. E. Gramlich, D. Heckmann, S. M. Goldup, D. M. D'Souza, A. E. Fernandes and D. A. Leigh, Science, 2013, 339, 189–193 CrossRef CAS PubMed; (b) G. de Bo, S. Kuschel, D. A. Leigh, B. Lewandowski, M. Papmeyer and J. W. Ward, J. Am. Chem. Soc., 2014, 136, 5811–5814 CrossRef CAS PubMed; (c) C. M. Wilson, A. Gualandi and P. G. Cozzi, ChemBioChem, 2013, 14, 1185–1187 CrossRef CAS PubMed.
- (a) J. F. Stoddart, Angew. Chem., Int. Ed., 2014, 53, 11102–11104 CrossRef CAS PubMed; (b) S. F. M. van Dongen, S. Cantekin, J. A. A. W. Elemans, A. E. Rowan and R. J. M. Nolte, Chem. Soc. Rev., 2014, 43, 99–112 RSC; (c) A. Coskun, J. M. Spruell, G. Barin, W. R. Dichtel, A. H. Flood, Y. Y. Botros and J. F. Stoddart, Chem. Soc. Rev., 2012, 41, 4827–4859 RSC.
- (a) P. Thordarson, E. J. A. Bijsterveld, A. E. Rowan and R. J. M. Nolte, Nature, 2003, 424, 915–918 CrossRef CAS PubMed; (b) C. Monnereau, P. Hidalgo Ramos, A. B. C. Deutman, J. A. A. W. Elemans, R. J. M. Nolte and A. E. Rowan, J. Am. Chem. Soc., 2010, 132, 1529–1531 CrossRef CAS PubMed.
- S. F. M. van Dongen, J. A. A. W. Elemans, A. E. Rowan and R. J. M. Nolte, Angew. Chem., Int. Ed., 2014, 53, 11420–11428 CrossRef CAS PubMed.
- C. Wyman and M. Botchan, Curr. Biol., 1995, 5, 334–337 CrossRef CAS.
- L. Stryer, J. M. Berg and J. L. Tymoczko, Biochemistry, W. H. Freeman, New York, 5th edn, 2002 Search PubMed.
- W. A. Breyer and B. W. Matthews, Protein Sci., 2001, 10, 1699–1711 CrossRef CAS PubMed.
- (a) R. G. E. Coumans, J. A. A. W. Elemans, R. J. M. Nolte and A. E. Rowan, Proc. Natl. Acad. Sci. U. S. A., 2006, 103, 19647–19651 CrossRef CAS PubMed; (b) A. B. C. Deutman, C. Monnereau, J. A. A. W. Elemans, G. Ercolani, R. J. M. Nolte and A. E. Rowan, Science, 2008, 322, 1668–1671 CrossRef CAS PubMed; (c) A. B. C. Deutman, S. Varghese, M. Moalin, J. A. A. W. Elemans, A. E. Rowan and R. J. M. Nolte, Chem.–Eur. J., 2015, 21, 360–370 CrossRef CAS PubMed.
- (a) S. F. M. van Dongen, J. Clerx, K. Nørgaard, T. G. Bloemberg, J. J. L. M. Cornelissen, M. A. Trakselis, S. W. Nelson, S. J. Benkovic, A. E. Rowan and R. J. M. Nolte, Nat. Chem., 2013, 5, 945–951 CrossRef CAS PubMed; (b) L. J. Prins and P. Scrimin, Nat. Chem., 2013, 5, 899–900 CrossRef CAS PubMed.
- (a) P. Thordarson, E. J. A. Bijsterveld, J. A. A. W. Elemans, P. Kasák, R. J. M. Nolte and A. E. Rowan, J. Am. Chem. Soc., 2003, 125, 1186–1187 CrossRef CAS PubMed; (b) P. Thordarson, R. G. E. Coumans, J. A. A. W. Elemans, P. J. Thomassen, J. Visser, A. E. Rowan and R. J. M. Nolte, Angew. Chem., Int. Ed., 2004, 43, 4755–4759 CrossRef CAS PubMed.
- S. Cantekin, A. J. Markvoort, J. A. A. W. Elemans, A. E. Rowan and R. J. M. Nolte, J. Am. Chem. Soc., 2015, 137, 3915–3923 CrossRef CAS PubMed.
- (a) S. A. Wolfram, New Kind of Science, Wolfram Media, Champaign, IL, 2002 Search PubMed; (b) T. Neary and D. Woods, Theor. Comput. Sci., 2006, 362, 171–195 CrossRef PubMed.
- T. Nakagiri, M. Murai and K. Takai, Org. Lett., 2015, 17, 3346–3349 CrossRef CAS PubMed.
- (a) F. Farzadfard and T. K. Lu, Science, 2014, 436, 1256272 CrossRef PubMed; (b) S. Ausländer and M. Fussenegger, Science, 2014, 346, 813–814 CrossRef PubMed.
- S. Mailloux, Y. V. Gerasimova, N. Guz, D. M. Kolpashchikov and E. Katz, Angew. Chem., Int. Ed., 2015, 54, 6562–6566 CrossRef CAS PubMed.
- K. C. Keiler, Nat. Rev. Microbiol., 2015, 13, 285–297 CrossRef CAS PubMed.
Footnote |
| † It should be noted that in old style computers magnetic tapes were used for information storage but not for computing. |
| This journal is © The Royal Society of Chemistry 2015 |