
 Open Access Article
Open Access Article This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported Licence
This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported LicenceAccelerating colloidal quantum dot innovation with algorithms and automation
Neal
Munyebvu
 a,
Esmé
Lane
a,
Enrico
Grisan
b and
Philip D.
Howes
*a
a,
Esmé
Lane
a,
Enrico
Grisan
b and
Philip D.
Howes
*a
aDivision of Mechanical Engineering and Design, School of Engineering, London South Bank University, 103 Borough Road, London SE1 0AA, UK. E-mail: howesp@lsbu.ac.uk
bDivision of Computer Science and Informatics, School of Engineering, London South Bank University, 103 Borough Road, London SE1 0AA, UK
First published on 12th August 2022
Abstract
Quantum dots (QDs) have received an immense amount of research attention and investment in the four decades since their discovery, and fantastic progress has been made. However, they are complex materials exhibiting distinctive behaviors, and they have been slow to proliferate in real-world applications. QDs occupy an intermediate state of matter, being neither bulk nor molecular materials. Their unique and useful properties arise exactly because of this, but massive challenges in product and device stability and reproducibility also follow as a consequence. Chief amongst the many challenges faced in bringing QD-based devices to market are managing heavy-metal content and device instability. In this review, the possibility of using emerging data-driven methodologies from artificial intelligence (AI) and machine learning (ML) to expedite the translation of QDs from the lab bench to impactful energy-related applications is explored. These approaches will help us go from scarce and patchy knowledge of highly complex parameter spaces to accurate and broad 'maps', intelligently targeted synthesis and advanced quality control.
 Neal Munyebvu | Neal Munyebvu obtained his MChem in Chemistry from the University of Southampton (Southampton, UK) in 2016 where he conducted a research project with the UK National Crystallography Service (Southampton, UK). Following this, he spent time in the chemical engineering sector focused on the support and development of automated batch and flow chemical reactor systems. In 2021, he joined the group of Dr Philip D. Howes at London South Bank University (London, UK) where his research interests include the batch to flow conversion of chemical syntheses, reaction automation, continuous flow technology development, and the use of algorithms to accelerate nanomaterial development. |
 Esmé Lane | Esmé Lane received an MChem in Chemistry from the University of York (York, UK) in 2020 before joining London South Bank University (LSBU, London, UK) in 2021 as a PhD researcher working with Dr Philip D. Howes. Her research interests span chemistry and climate, with an interest in systems chemistry and sustainable technologies. She is currently investigating nanomaterials for energy applications. |
 Enrico Grisan | Enrico Grisan received an MSc degree in Electrical Engineering from the University of Padua, Padua, Italy, in 2000, and a joint PhD degree in bioengineering from the University of Padua and City University, London, UK, in 2004. After an internship with Siemens Corporate Research, Princeton, NJ, USA, he was a postdoctoral fellow with the University of Padua, where he has been an Assistant Professor of Biomedical Engineering, from 2008 to 2022. In 2019, he joined London South Bank University, where he is now a Senior Lecturer in Artificial Intelligence. His main research activity is devoted to the understanding of medical images and to the identification of relevant biomarkers from medical data with applications to neuroimaging, confocal microscopy and microendoscopy, and ultrasound. |
 Philip D. Howes | Dr Philip D. Howes is a Senior Lecturer in Mechanical Engineering and Design at London South Bank University. He has previously completed postdoctoral positions at Imperial College London (Department of Materials), and ETH Zurich (Department of Chemistry and Applied Biosciences) where he held an Individual Marie Skłodowska Curie Fellowship. His research focuses on the design and synthesis of nanomaterials for applications in healthcare, energy and environmental applications. Particular interests include the automation of materials synthesis through microfluidic engineering, and algorithm-driven optimisation and discovery. |
1 Introduction
The advent of nanoscale manipulation of semiconductors has long been expected to provide a step change in technology.1 Inorganic semiconductor nanoparticles (quantum dots, QDs) show remarkable properties, and have attracted an immense amount of research attention and investment over the last thirty years. Indeed, the value of the global QD market reached $3.5 billion in 2019, and is projected to surpass $8.5 billion by 2026.2 Despite this, it has sometimes been difficult not to feel that they have been slow to reach their potential in the forty years since their discovery.Interest in inorganic semiconductor nanoparticles began in research during the 1980s, as it emerged that particles in the range of 2–10 nm diameter exhibit intriguing properties that are distinct from the bulk behavior of the materials.1,3 These nanoparticles became known as quantum dots (QDs), although the term has subsequently expanded to include a plethora of other material classes, for example carbon QDs,4 silicon QDs,5 and noble metal QDs.6 Inorganic semiconductor QDs possess many attractive optical and electronic properties, the most prominent being their size-dependent emission. In the regime where the QD radius is smaller than the Bohr excitonic radius, quantum confinement gives rise to a bandgap that varies as a function of particle size.7 Therefore, the bandgap can be readily and precisely tuned across and beyond the visible spectrum – a useful property for many applications.
The useful and distinct properties of QDs emerge because they sit in a size regime that is between the bulk and the molecular. A combination of spatial confinement and surface effects means that the characteristics of semiconductors translate into many new but complex ‘nanoscale’ phenomena that have taken many years to elucidate. Further, precisely engineering nano-materials by controlling their size, shape, structure and composition (both internal and surface) as well as the subsequent impact on their physical properties and stability is simply quite demanding. Combining these two factors with the numerous different possible QD compositions, synthetic pathways, purification techniques and processing conditions, it is apparent that the field faces severe challenges.
The archetypal QDs stem from the II–VI semiconductor class (e.g. CdSe, ZnS, HgTe), but over time the breadth of compositions has grown to encompass all the major semiconductor classes. An important concept in QDs is shelling, where protective layers are grown over cores to preserve their structural and compositional integrity (e.g. CdSe/ZnS, CdSe/CdS/ZnS). One of the most recent and impactful classes is the metal halide perovskites,8 which emerged in the mid-2010s,9,10 and have attracted huge attention in research with many examples of application in optoelectronics.11,12 Further, there are well established research lines looking to move away from heavy metal-containing QDs in search of less toxic alternatives.13,14 Altogether, this means that there is a vast wealth of options when investigating and optimizing QD compositions for different applications, which brings significant challenges and opportunities in research.
It is testament to the many interesting properties of colloidal quantum dots (CQDs) that they have been investigated for so many different applications. Although they have been used in many biological studies,15 it is their deployment in energy-related applications, and in particular optoelectronics, that has garnered the most attention and traction.16 CQD photovoltaics (PVs),17–19 photodetectors20–22 and LEDs23–25 are key examples of optoelectronic applications,26 and there is much excitement and anticipation that these devices will go on to make a significant positive impact in their applications. CQDs strongly absorb energy, typically light, then manipulate and transform it in various useful ways, for example the conversion of light energy into electrical energy in photovoltaic or photodetector devices, the conversion of electrical energy into light in a light-emitting device (LED), or the conversion of light energy into chemical bonds in photocatalytic devices.27
The bottom-up colloidal synthesis of QDs, yielding CQDs, is adaptable to high-throughput experimentation (HTE). Bottom-up chemical synthesis allows precision control of CQD growth and is very popular and effective for many applications. Grinding-based approaches, including both wet milling28 and dry milling,29 have merged as convenient and effective ways of making CQDs, but these methods are not readily adaptable to HTE. The original and most well-established approach to CQD synthesis is the hot-injection method.30,31 However, when attention turned to production scale up in the early 2000s, synthesis methods were sought that achieve better reproducibility. This gave rise to the ‘heat-up’ method, where the reaction precursors are combined in a single vessel, and nanoparticle nucleation and growth is initiated by controlled heating.32 Knowledge gained from the early days of hot-injection has been critical in informing the heat-up approach, and there have been many examples of CQD syntheses being adapted from hot-injection to the heat-up method.33
A major advantage in the commercial application of CQDs in devices is their solution processibility.12 Small ‘lab-scale’ films (i.e. <1 cm2) are readily obtainable by simple methods such as drop-casting or spin-coating with a ‘layer-by-layer’ approach. For large-scale manufacturing, there is very active research into scale-up strategies, which currently include inkjet printing, spray coating, slot-die coating and blade coating.19 Critically, the last three are compatible with roll-to-roll fabrication, which allows low-cost and large-scale production of electronic devices on flexible substrates.
With the number of considerations required at each stage of the workflow, it is clear experimentation using traditional flask-based techniques would take many years to explore this large parameter space and to properly elucidate and translate to technological applications. Thus, new approaches that accelerate this voyage of discovery will be key in translating promise into reality.
Our current age of innovation and discovery has been labelled the ‘Fourth Industrial Revolution’, where artificial intelligence (AI) is being used to process and exploit unprecedented volumes of data (‘big data’) to both speed up and advance our approach to R&D and industrial exploitation.34 Machine learning (ML) is a particularly successful AI methodology, and is already achieving significant impact in molecular and materials science,35 where experimental, computational and property data is being compiled and processed to elucidate multiscale processing-structure–property relationships with levels of performance and complexity that would be impossible for human operators to achieve alone.36
In this review, an extended discussion of the main challenges in CQD development is presented, followed by an evaluation of how data-driven and high-throughput experimental approaches can be applied to overcome these challenges. We contend that the field is approaching a tipping point where QDs will emerge and proliferate, and that this will in part be powered by new data-driven approaches that are emerging as part of Industry 4.0. Beyond this point, QDs will progress from being perpetually promising to showing impactful and increasingly diverse applications.
2 What are the challenges in making QDs for real applications?
2.1 Expansive reaction and compositional parameter space
QD properties change as a continuous function of their size, shape, composition and surface structure. This means that a single ‘type’ of QD (e.g. cesium lead bromide) can yield a wide range of behaviors and characteristics. Efficient synthesis of high-purity CQDs depends on a variety of factors: precursor and ligand concentration; solvent and anti-solvent or carrier gas selection; rate and order of reagent addition, as well as reaction conditions (time, temperature, pressure, use of dry or inert environment, and extent of solution stirring). Independent variation of any one of these factors can alter the size, shape and composition of the resultant nanoparticles and hence their macroscopic properties. This is an advantage in that it allows precise tunability of properties and wide ranging applications. However, it also presents distinct challenges especially with regards to product reproducibility as even small changes in precursors or reaction conditions can yield large shifts in properties. An example is the conversion of Cs4PbBr6 to CsPbBr3 upon addition of excess ligand (oleic acid and oleylamine) to stabilize.37 This has a marked impact on the structure, converting from 0D nanoparticles to 3D nanosheets, and hence the photoluminescence (PL).37,38Another challenge presented by CQDs is the fact that, as multiple output variables vary continuously as a function of many input variables (see Fig. 1), the reaction parameter space is extremely large and challenging to navigate. Practically, this means mapping the resultant particle composition, size, shape, structure, absorption and emission characteristics, etc. to the choice and concentration of precursors, choice and concentration of ligands, choice and blends of solvents, reaction temperature, reaction time, and more. Clearly, exploring this parameter space with a one-factor-at-time (OFAT) approach is not going to be sufficient. Even using a more sophisticated approach such as design of experiments (DoE),39 quite drastic simplifications and assumptions have to be made and still a large experimental data set needs to be acquired. In all, this means that it is practically impossible to comprehensively map the reaction parameter space, leaving much latent potential in the discovery and optimization of QD materials. This brings to mind the question that, during the decades of development in this field, what have we missed along the way? Associating multiple output variables with multiple/many input variables is an extremely demanding task for a human experimenter, and often leaves vast regions of the parameter space unexplored. This can be compounded when standard syntheses are perpetuated by the presumption that they have been optimized, when in fact they often have not.
 | ||
| Fig. 1 An overview of the main variables involved in bottom-up colloidal QD synthesis. Enclosed in the dashed line are the input and output variables that can be readily controlled and measured in an automated high-throughput experimental (HTE) approach, allowing real-time synthesis and characterization and the possibility of closed-loop experimentation. | ||
The popular hot injection approach to QD synthesis exemplifies some of the difficulties in QD science. These syntheses involve multiple complicated mechanisms, including molecular decomposition, monomer formation and coordination, particle nucleation, and crystal growth. The complicated interplay between these, their strong dependence on reaction conditions, and the many input and output variables (Fig. 1), makes it difficult to develop an in depth understanding and difficult to produce reaction models.
The above discussion has only considered the reaction variables and product characteristics. But of course for device applications, we need to consider how the QDs perform in the device (in situ), where they have been exposed to the rigors of processing and are required to maintain operational performance and stability for long time periods. If we include the metrics of QD device performance into our data set (an absolute necessity), then it is apparent that mapping device performance back to the initial materials and reaction choices is an extreme challenge.
2.2 Toxic components
Heavy metals are commonly used in CQDs. For example, the most successful CQDs in solar cell applications to date are those based on lead, as either lead chalcogenides (e.g. PbS) or lead halide perovskites (e.g. CsPbI3).19 For photodetectors, mercury and lead QDs are common,40 and for LEDs, there is a long history of using cadmium-based QDs.26 On the face of it, it seems that given the toxicity of such heavy metals,41 we should strive to limit their use in devices. It is undeniable that heavy metal toxicity presents a problem throughout the product life cycle, from mining and processing through to manufacture, use and disposal. Further, there are restrictions on the use of heavy metals in electrical and electronic equipment,42 which will impact the proliferation of heavy metal-based QD-containing devices. However, there are also good arguments that the use of lead can be safely managed, and that its benefits outweigh its risks.43Regardless, great advances have been made in the field of CQD synthesis with low toxicity and earth-abundant constituent elements.44,45 For example, ternary I–III–VI2 QDs (e.g. CuInSe2, AgInS2) offer many of the key advantages (e.g. widely tunable luminescence (ca. 470–1200 nm) and broad absorption), whilst offering additional properties such as large global Stokes shift and plasmonic character.46 Further, their near-infrared absorption onset allows excellent harvesting of solar photons. However, understanding of the synthesis routes and optoelectronic properties of I–III–VI2 QDs is somewhat immature versus other QD systems. Therefore, we must further our understanding and translate promise into real applications. Meanwhile, studies pursuing heavy-metal-free perovskite QDs have focused on replacing lead with tin, germanium, antimony, bismuth, palladium, copper, indium and silver, with varying levels of success,45 with products typically being of a lesser quality than lead-based ones. Despite this, there is significant evidence that there is great potential waiting to be unlocked in this research space,14,47 given more time and better experimental approaches to explore the vast material and reaction parameter space involved.
2.3 Surface chemistry and instability
The percentage of atoms in a solid that are positioned at or near a surface increases dramatically as dimensions approach the nanoscale (<100 nm). This means that surface effects become significant or even dominant in nanoparticles. This poses both advantages (e.g. in nanocatalysis48) and disadvantages (e.g. in nanoparticle instability49). In the QD device context, the interfaces between QDs in films, and between QDs and adjacent layers in devices, are key areas that require careful engineering. For QDs, instabilities such as through oxidation, photocorrosion and thermal degradation, are a big problem, both during synthesis and processing, and in device operation. For commercial applications, QD devices need to operate in ambient conditions, at elevated temperature, and often under exposure to UV (e.g. in QDPV). This is critical, because the rationale for pursuing QD devices does not rest solely on peak performance or efficiency, but also on the lifetime of the device. Accordingly, a huge amount of research attention is being focused on the understanding and engineering of QD surface chemistry.50 Surface defects raise the surface energy through the increased number of dangling bonds, raising the materials sensitivity to its surroundings. The increased number of dangling bonds introduces mid-gap electronic states (known as trap states) which can capture an excited electron, encouraging non-radiative electron–hole recombination and decreasing the photoluminescence quantum yield (PLQY).51 To counteract the impact of surface defects, passivation of the inorganic centre via selected ligand coordination or through shelling is required.38,52QD ligands are normally designed with a QD-coordinating ligand head group (such as carboxylates, amines and thiols), an alkyl bridging group and a functionalized tail group.51,53 Aside for their impact on electronic effects, the coordinating ligands act to shield the metal centre from outside attack, both sterically by use of a long alkyl tail and through the relief of surface energy. This has the benefit of preventing impurity adsorption however can also prevent carrier transport in some applications.53 Compact, ordered and highly-stable QD films are vital for device realization. QDs are typically synthesized using long chain ligands (e.g. oleylamine), which are necessary for modulating and stabilizing particle growth. However, when these QDs are cast into films, these long ligands act as insulating layers that inhibit charge transport in to or out of the QDs. This can be alleviated by exchanging the long ligands with short ones e.g. short chain thiols,17,54,55 metal halides,56,57 or even atomic ligands (e.g. halides58), but this is not generally to the benefit of QD stability. For example, during the ligand exchange process, sites left vacant by outgoing long ligands might not be fully replaced with short ligands, which allows oxygen to occupy vacancies, introducing detrimental mid-gap trap states.
Nevertheless, QD-based devices have reached commercialization, and many more are moving towards it. These will inevitably have an increasing impact over time. However, we do not want to be in a position where there is vast latent potential in the QD field that is not being tapped because we lack the ability to effectively explore the experimental options and the related parameter spaces. There are big opportunities for significant gains through QD surface and ligand engineering, and it is vital that we look for better ways of exploring this space.
3 How can we approach data-driven discovery?
3.1 Adapting for flow and microfluidics
In parallel with the development of bulk- or flask-based QD synthesis approaches, many researchers have looked at adapting CQD synthesis to the flow chemistry approach, particularly using microfluidic engineering.59 Microfluidics relates to the study and manipulation of fluids at the micro-scale, and in the chemical sciences context it is often referred to as flow chemistry. The general benefits of flow include enhanced reaction control and highly efficient use of materials.60 A major benefit is enhanced thermal and mass transport in miniaturized reaction volumes. This is key in CQD synthesis, where narrower distributions in temperature and mass throughout reaction volumes lead directly to lower nanoparticle size polydispersity and thus improved color purity.61,62 Further, microfluidic systems can allow the use of more extreme reactions that are practically problematic at larger scales (high pressures, volatile solvents, etc.), due to the possibility of making closed systems with precise and modular reaction control.However, while microfluidics offer many opportunities in CQD synthesis, there are barriers to overcome. In particular the need for short, fast syntheses restricts the number of attainable CQDs simply because not all will be adaptable to this methodology. Further, while the hot-injection and heat-up methods can be utilized in this framework, they are limited by their scalability and sustainability. When adapting flask to flow, fast room-temperature syntheses are a highly desirable starting point. A 2017 work by Yang et al. details such a synthesis.37 Cs4PbBr6 and CsPbBr3 were produced by harnessing supersaturation recrystallisation (SR) as a natural descendent of the arrested precipitation technique.37 As with the archetypal method, SR harnesses the difference in solubility of the metal precursors and the target product to induce precipitation. However the method has evolved to incorporate the differing solubilities of the precursors using a multi-solvent:antisolvent system. Recrystallisation is initiated by fast injection of the solvated precursors into excess antisolvent inducing sudden supersaturation of the ions and rapid nucleation. The utilisation of solvent effects to overcome the kinetic (precursor dispersion and migration) and thermodynamic (solvent ordering effects) barriers to CQD formation offers a practical and potential more sustainable alternative to high temperatures and pressures usually required.
Microfluidic reactor-based systems can be designed to be extremely versatile and modular, with the ease of system construction from smaller components and tailoring to specific applications. A relatively low-cost and simple system can use a variety of off-the-shelf components and custom technologies. Fig. 2 shows a schematic of the basic microfluidic requirements for an effective CQD synthesis and analysis platform. Fluid delivery components are used to transport precursors through the system and control the flow rate. For liquids—syringe pumps, pressure pumps and peristaltic pumps are commonly used. Whilst for gases, gas cylinders connected to mass flow controllers can be used for fine adjustment. For mixing, a microfluidic mixer is employed. This can be simple mixing junction (T-Piece, cross-piece), connected to a length of tubing, or a chip-based microfluidic device which can be easily fabricated to different designs and geometries depending on the desired application. Niculescu et al. present a review of current microreactor technology and fabrication techniques, alongside a comparison of available materials and their features as used for a variety of applications.63
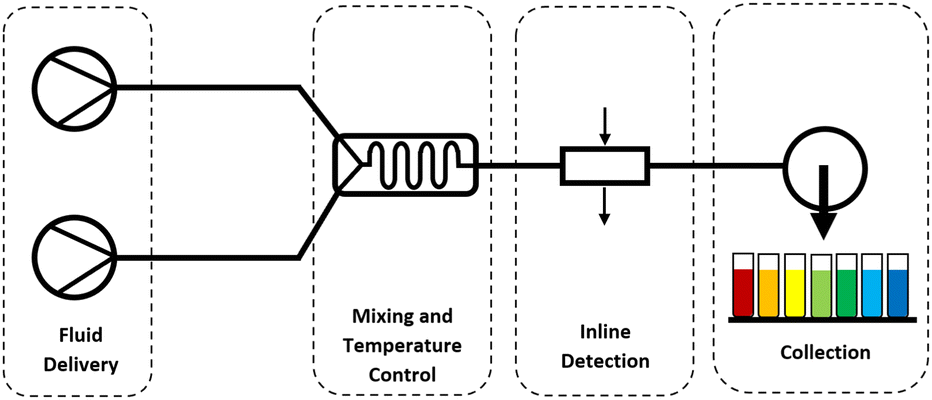 | ||
| Fig. 2 Basic set-up for a flow reactor system for CQD synthesis consisting of fluid delivery, a reaction zone and collection. This can be typically made up of low cost components. Both off-the-shelf and custom made systems have been reported in the literature. | ||
Inline detection (e.g. UV-Vis absorption spectroscopy) allows for live measurement and monitoring of particle properties. Taking spectroscopic measurements inline yields information of reaction kinetics, whilst taking end-point measurements provides a snapshot of QD character that can either be logged as part of a larger scale multidimensional parameter screen or can be fed back into a control algorithm to then influence the next set of reaction parameters in a closed-loop experiment. Although inline measurements will typically be PL and absorbance spectroscopy due to the relative ease of these techniques, there have been many demonstrations of other techniques such as X-ray-based compositional and structural measurements.59,64 Sample collection can be done manually, or by using automated collectors to eliminate the need for user intervention. Fraction collectors are common, and allow the collection of products into multiple vials in a single run or to generate libraries of materials. More sophisticated systems can be designed using precursor refill devices to enable a series of different experiments, sample loops which allow use of smaller volumes of precursors during development, back-pressure regulation and inline purification (e.g. liquid–liquid separators).
Automated microfluidic reactors combine the multiple operations that are followed in CQD synthesis into a simplified series workflow. For example, using a syringe pump precursors are pre-prepared in syringes, which then deliver the solutions into the reactor. Changing flow rates provides ready control over precursor ratios (and therefore reaction stoichiometry), ligand concentration and composition, as well as solvent dilutions and combinations. In closed-loop formats, an algorithm can be used to either drive the reaction towards a desired outcome, or to drive it into areas of the parameter space that has high uncertainty and/or low coverage.
Note that the automation aspect involves running the reaction itself (i.e. heating and mixing of precursors). Although reaction precursor workup needs to be performed manually as with flask-based synthesis, researchers can derive hundreds of experimental results from a single batch with the automated microfluidic approach, making it very material efficient. Further, it should be noted that inline spectroscopy yields data on the as-synthesized particles. Given that CQDs will nearly always require washing and purification steps to remove excess ligands and unreacted precursors, and maybe change the solvent in which the CQDs are dispersed, one needs to consider any potential change in properties during purification, and whether a clear correlation can be drawn between those and the characteristics of the as-synthesized products. In the future, it is likely that the purification and solvent exchange steps, plus other downstream processes, will increasingly be incorporated into the reactor workflow, thus closing this gap.
3.2 Big data and high-throughput experimentation
High-throughput experimentation (HTE) aims to create and process samples at a rate that significantly surpasses a manual operator and will typically encompass the use of highly parallelized systems, robotic apparatus, and/or automated fluid handling. This allows for more efficient collection of larger volumes of data than what is possible using the traditional iterative approach to experimentation, ultimately allowing researchers to solve challenges more rapidly than using traditional approaches.As materials science establishes itself in the realm of big data, HTE enables researchers the ability to generate significantly more results in the same amount of time; the increased volume, variety, and velocity of the data means that data-processing becomes too large or complex to be dealt with by traditional methods. This paves the way for the use of machine learning (ML), where algorithms can be trained for data interpretation, experiment prediction and experiment planning purposes. However, a clear point that should be emphasised from the outset is that the difficulty level in converting to HTE varies extremely widely depending on the exact nature of the process being automated. It is vital to establish whether the investment in capital and time to employ HTE is worth the eventual output from the studies. Fortunately with CQDs, conversion to HTE is relatively accessible, and there have been many excellent demonstrations in the literature to date.59,61
Several studies looking at the development of microreactor-based systems that can perform HTE in the literature have already been developed. In 2017, Epps et al. developed a modular microfluidic system that was designed specifically to explore the large parameter space of such nanoparticles.65 This system allows researchers to screen different material compositions to explore the large parameter space, specifically managing this by performing multiple characterizations within a single experiment. By using a translational flow cell, the reactor can monitor and track progress of a reaction along its reactor length by taking inline optical measurements at up to 40 unique points along the reactor within a single experiment. In this study, they explored nanocrystal growth within a flow reactor running at specific mixing timescales (flow velocities) and could acquire up to 30![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 000 spectra per day, corresponding to 15000 experimental conditions.65 This type of study demonstrated the sheer scale of the potential parameter space, and how such interesting engineering design choices could further expand data generation capabilities.
000 spectra per day, corresponding to 15000 experimental conditions.65 This type of study demonstrated the sheer scale of the potential parameter space, and how such interesting engineering design choices could further expand data generation capabilities.
A recent study by Lüdicke et al. explored the development of a flow reactor capable of performing HTE to study the performance of automated solid phase purification of QDs.66 This sophisticated system is capable of synthesizing and immediately analyzing material inline, as it is produced, by optical measurements (Fig. 3). Then automatically purifying collected material and performing a secondary characterization. Alongside fast and efficient data capture and collection, this type of system allows researchers to quickly screen the nanomaterials both as-synthesized and post-purification without the time-consuming manual handling typical for the purification-step of these types of material.
 | ||
| Fig. 3 Lüdicke et al.66 built a flow reactor platform consisting of CdSe/ZnS synthesis and purification, with fully integrated reactor control. Reprinted with permission from ref. 66. | ||
Beyond examples looking directly at semiconductor nanoparticles, a review from Zhou et al. explores microfluidic-based high throughput platforms capable of synthesizing a range of nanomaterials,67 highlighting works that, with thoughtful design, can be transferred across fields. Throughout the rest of this review, the main examples highlighted incorporate systems performing HTE, or have the potential to be expanded further to allow for such a platform.
3.3 Automation, algorithms and artificial intelligence
To reiterate the problem, QD researchers face the critical challenge of translating the immense promise of these materials from fundamental science through to valuable and positive real-world impact. The major challenges involve discovering and optimizing materials with high performance in applications, that are stable for long periods of time, and to accomplish this using a range of elements that minimize negative impacts when considered in the context of device use, full product life cycle and environmental impact assessment. The key difficulty is the huge parameter space to be navigated here, including many reaction, processing and performance variables with complex interactions. Although four decades of research in QDs has seen immense progress, we know there is so much latent potential waiting to be unlocked.Faced with this challenge, and a pressing need to accelerate innovation in the energy field, it is prudent to look for tools that augment our R&D capabilities. The combination of automation and algorithms, and their application to the experimental sciences, does just that.68 Automation allows significant acceleration of experimentation and data collection, while algorithms facilitate rapid and efficient experimental control and data analysis. This dramatically improves our powers of prediction, discovery, characterization and optimization.
Materials science is currently entering the realm of artificial intelligence (AI)-driven experimentation, with ML gaining particular traction.69,70 ML is a field of AI that involves designing and building algorithms and/or models that learn patterns by processing training data, and then to make predictions given new input data. It can yield sophisticated algorithms that are able to predict properties or reveal hidden features in data sets.
ML algorithms can also be classified into supervised and unsupervised learning. Supervised learning takes in labelled input data and attempts to map output variables back to known inputs. For example, you might use tabulated QD synthesis data as your input (precursor concentration, reaction stoichiometry, temperature, etc.), and attempt to map an output variable such as PLQY back to those to reveal what combination of input variables maximizes PLQY. Supervised algorithms are used for experiment prediction and such platforms are trained with data containing previously known inputs and their associated outputs (Table 1). Common algorithms here include artificial neural networks (ANNs),71 decision trees (DTs),72 and support vector machines (SVMs).73 In contrast, unsupervised learning takes unlabelled input data and attempts to reveal intrinsic relationships within it that are not previously understood or expected. For example, you might use QD spectral data as your input (e.g. PL spectra), and see how an algorithm clusters them, or if it identifies outliers, through which you can understand non-obvious trends or differences in your data based on spectral features.74 Common algorithms used here include principal component analysis (PCA) for dimensionality reduction,74 K-means clustering for identifying regularities in the input data75,76 or clustering QDs based on specific output properties such as size and shape.77,78 Deep neural networks (DNNs), or autoencoders can also be used for more sophisticated dimensionality reduction challenges, feature learning, and also to predict materials that have a specific property based on a trained ML model.79
| Prediction algorithms | Optimization algorithms | |
|---|---|---|
| Basic principle | Uses labelled input data and attempts to map output variables against the selected input(s) | Inputs are continually optimised against a desired property (e.g. PLQY) |
| Inputs | Experiment parameters | Previous experiment parameters |
| e.g. precursor concentration, ligand concentration, stoichiometry, temperature, etc. |
e.g. Stoichiometry = 1:1, temperature = 40 °C, reaction time = 6 min, PLQY = 40% |
|
| Outputs | QD properties | Next experiment parameters |
| e.g. size, FWHM, PLQY, yield |
e.g. stoichiometry = 1:2, temperature = 20 °C, reaction time = 6 min |
|
| Example algorithms | Support vector machines | Bayesian optimization |
| Decision trees/random forests | Genetic algorithms | |
| Neural networks | SNOBFIT |
Additional approaches include reinforcement learning (RL) algorithms that utilize a trial and error style approach to gain feedback, typically in the form of a reward function to learn from the consequences of the model's decisions.80 Whilst active learning (AL) is a special case of supervised learning that can intuitively identify and request datapoints from the next set of experiments that the model expects to give the most suitable results based on the original training dataset.81
In the context of QD synthesis, optimization algorithms are used for experiment planning. Here, the inputs are the QD synthesis data (reaction stoichiometry, temperature, residence time, etc.) alongside the reaction data (QD size, PLQY, PL full-width-half-maximum (FWHM)). Such algorithms aim to optimize desired material properties, by suggesting new experiment conditions based on the properties observed as a result of previous experimental parameters (Table 1). Examples of algorithms here are Bayesian Optimization (BO),82 Genetic Algorithms (GA)83 and SNOBFIT (Stable Noisy Optimization by Branch and FIT).84
A key point is that the algorithm needs to be fed with enough training data to ensure the efficacy of the model that it builds. Consequently, pairing ML with HTE presents an attractive option. ML is particularly well-suited to translating complex and unintuitive high-dimensional parameter spaces to a single or small numbers of understandable and applicable outputs. Interested readers can find more information on these algorithms in some excellent published reviews.36,69,85–92
In summary, the major thrust of the ML approach here is to reduce time to discovery, and to expedite the transition of impactful discoveries from the lab and into the real world. In the context of QD devices, and our pressing need to bring energy-efficient products to market, we can see the attraction of bringing AI into the fold. The idea is to plan smart experiments based on predictions derived from past knowledge, theoretical simulation, and modelling. To execute efficient experiments that yield rich data on the target parameter space, analyze that data in a smart way that maximizes utility, and feedback the information gained into our knowledge bank to inform future experiments and applications. Ultimately, the goal is an overarching methodology that brings all this data together in a coherent workflow (Fig. 4).
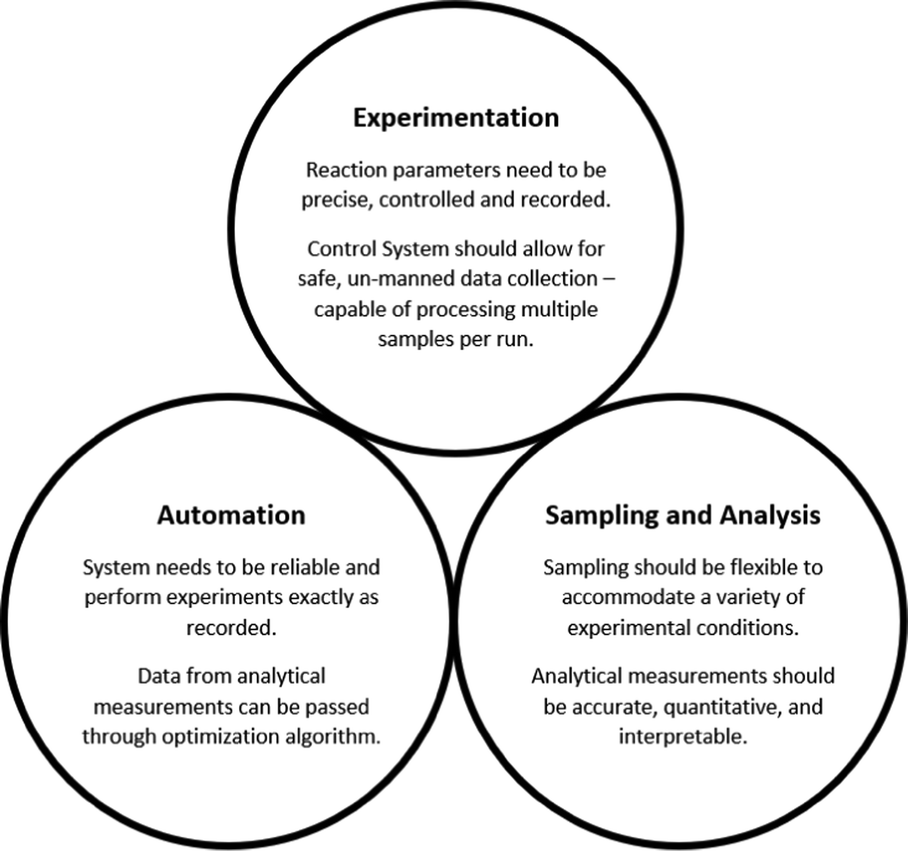 | ||
| Fig. 4 Pre-requisites for designing a high quality data collection system, bringing together the ideas of microfluidics, high-throughput experimentation and automation using optimization algorithms. | ||
4 How can data-led strategies help us overcome the challenges of producing QDs for commercial applications?
4.1 Constantly evolving microfluidic synthetic strategies
The benefits and challenges of using microfluidics specifically for nanoparticle synthesis are well documented in the literature.93,94 Microreactors inherently require smaller volumes of reagents, minimizing the handling of potentially hazardous materials and reducing solvent waste—important in both development and scale up. Additionally, microfluidic processes can be easily sealed from the atmosphere, or incorporate inert gas flow to reduce exposure to air or moisture—useful for toxic or air-sensitive materials. Relative to the alternative flask-based processes, microfluidics enables efficient heat transfer and mass transport within the reactor, allowing for mixing, heating and/or cooling of reagents to be reduced to milliseconds in a microreactor, reducing the reaction time and providing a facile route to manipulate particle properties against specific input variables.95 Ma et al. designed a precise temperature controllable microreactor for the rapid synthesis of AgInS2 QDs. They found that an increase of temperature from 30 °C to 70 °C, resulted in a direct increase in particle size, shifting the fluorescence peak of the synthesized QDs from 590 nm to 720 nm.96 Liu et al. combined a microreactor with a spinning platform (microfluidic spinning technique) to produce CdSe QDs for white light emitting diodes. This unique method successfully enabled synthesis of the QDs at a process temperature of 110 °C, 190 °C lower than the temperature used in the hot injection technique.97 Yang et al. used ultrasonic radiation to create droplets within a microreactor to improve the quantum yield of ZnO QDs. From this they found that the flow rate, ultrasonic power and temperature were influential in the PL properties of the synthesized QDs, resulting in QDs with a QY of 64.7% using this method.98 These works demonstrate that with smart design, a relatively simple system can easily investigate the effect of a wide range of specific input variables on the QD properties, and with a shorter reaction time and less aggressive conditions than the corresponding flask-based reactions.Upon reaching steady-state conditions within a microreactor, reagents are exposed to the same conditions through the flow path between each experimental run, limiting the effect of uncontrolled ‘mixing zones’ and temperature gradients on the polydispersity and improving the reproducibility of the obtained QDs. Different configurations of reactors can also be linked together for more complex reactions, or to control different stages of particle formation. Baek et al. describe a multi-stage approach where they were able to reliably screen four different types of core/shell QDs. In this work, they used up to six microreactors for a single QD type, with five specific designs for different aspects of the synthesis mechanism: mixing; aging; sequential growth; shell formation; annealing.99
There have been many elegant demonstrations of colloidal particle synthesis in microfluidic reactors.100 Reviews from Niculescu et al.93 and Chen et al.101 summarize the variety of techniques centered around microfluidics that are used in the synthesis of functional nanomaterials, highlighting how this field has introduced several novel methods for the synthesis of a wide range of nanoparticles, alongside various additional papers focusing specifically on QD synthesis.61,62,102 The pioneering work in this specific area was published in 2003, which demonstrated the feasibility of synthesizing CQDs in both chip-based103 and tube-based104 microfluidic flow systems.
4.2 Towards big data with high-throughput experimentation
Early work in the high-throughput synthesis of QDs was conducted by the team of Chan et al. at the Lawrence Berkeley National Laboratory, who in 2010 reported a custom-built automated workstation, capable of performing up to 8 parallel batch reactions to synthesize CQDs.105 This sophisticated system uses a variety of features to enable automated HTE including a liquid handling robot, heated needles for phase control, a vial gripper to manipulate solid objects and an automated balance to record mass. The work performed in this study specifically aimed to assess how well the system could reproduce particle properties between different batches, showing a 0.2% coefficient of variation in the mean diameters across particles generated in the different reactors. This was an excellent representation of how using automation could lower the requirements of human handlers in producing reliable, reproducible batches of QD material—vital for manufacturing. One additional highlight of this work was that the researchers demonstrated how they were able to screen various different reaction parameter data to optimize properties specifically for emerging QD applications.105 As shown in later works, the concepts used in this work could be easily transferred to upgrade a basic flow reactor system to enable greater automation performance.In the last two decades, there has been steady progress in the development of automated microfluidic flow reactors, which offer the possibility of combining HTE with real-time data logging and analytics. In 2012, the Maeda group published two papers on the application of ML, specifically NNs, as a tool to make sense of data sets on the CdSe QDs amassed using a microreactor with inline PL and absorption spectroscopy.106,107 An automated microreactor was used to perform CQD synthesis, working through a combinatorial experiment set of six reactions conditions (reaction temperature, reaction time, Cd concentrations, Se/Cd ratio, amine concentrations, and amine type), yielding a dataset of 3387 experiments. Using PL and absorption spectra collected inline after the reaction endpoint, an automated script extracted PL peak wavelengths, PL FWHM, PL peak area, absorption peak wavelength, and absorbance of absorption peak, which were then used to calculate particle diameter, reaction yield, and PLQY.106 They then trained 1600 separate NNs and combined them to form an ensemble NN (ENN), which was used to perform NN-based data interpolation for mapping multidimensional condition-property landscapes.107 The result was basically a navigable multidimensional parameter space that could be explored in search of optimal properties (i.e. maximizing PLQY and reaction yield, minimizing FWHM). Fig. 5 shows an example of how these parameters vary as a function of reaction temperature and time, for a given surface ligand (dodecylamine).
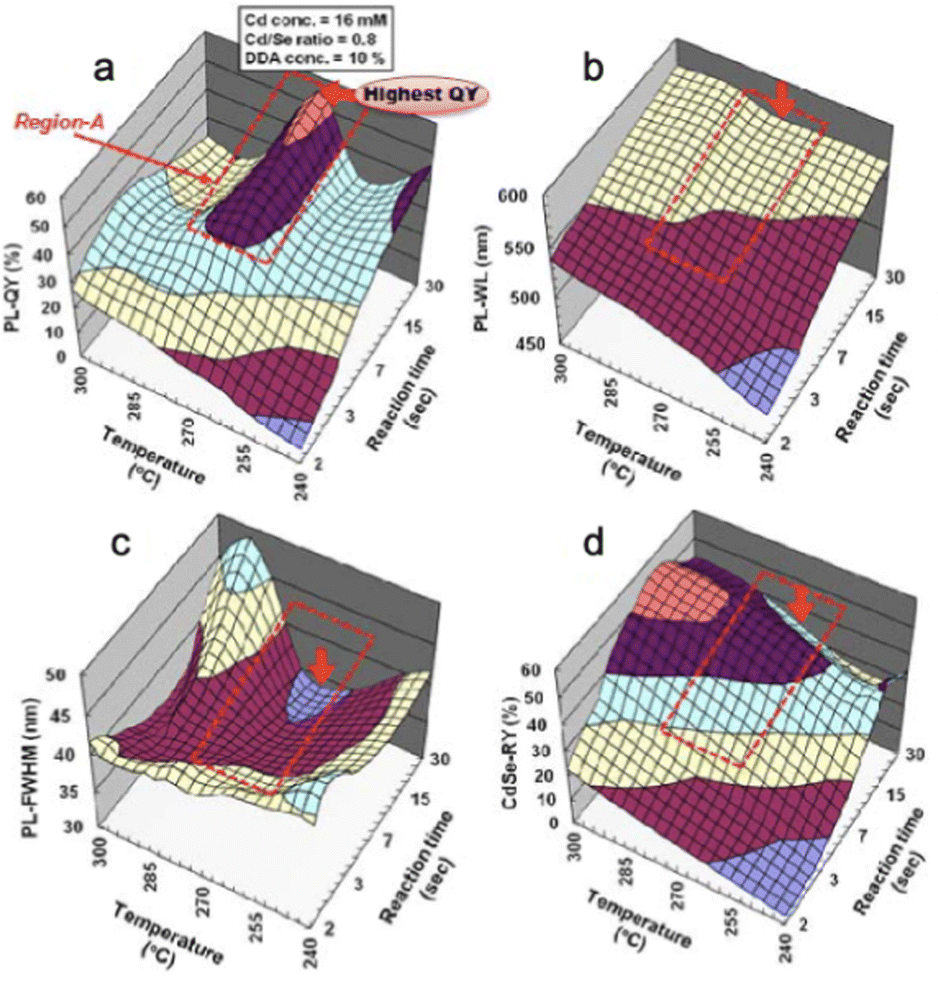 | ||
| Fig. 5 A study of CdSe QDs by Orimoto et al.107 An NN model of a 3D parameter space, where the output variables of (a) PLQY, (b) PL wavelength (nm), (c) FWHM (nm), and (d) reaction yield (RY, %), varying as a function of temperature (°C) and reaction time (s). The red arrow indicates the point corresponding to the highest PLQY. Reprinted with permission from ref. 107. Copyright 2021 American Chemical Society. | ||
Alongside inline measurements, in situ and online monitoring techniques can be seamlessly coupled to a high-throughput microfluidic platform. A good example of how such techniques are used in the growth of core–shell QDs in microreactors was performed by Yashina et al. who developed a two stage microfluidic platform coupled with real-time optical detection for CuInS2/ZnS synthesis. In stage one they grew CuInS2 core QDs and monitored the emission spectra produced, followed by a second stage injection of precursors to grow the ZnS shells and the resulting emission spectra was monitored, all within a single workflow.108 With this they could observe and analyze the effect of shell formation inline—offering a clear route to exploring CQD surface effects by simply altering solvent choice, precursors, and reaction conditions.
A review by Li et al. offers insight on the different types of inline sensors and measurement techniques currently used in the field of microfluidics that have the potential for utility in the CQD synthetic process.109 For CQD synthesis, PL spectroscopy, UV-vis absorbance spectroscopy and X-ray absorbance spectroscopy are highly practical and relevant techniques,110 which can be performed on CQDs without post-synthesis work-up. Incorporating effective monitoring and sensing techniques into the CQD workflow allows for efficient quality control, as well the ability to identify by-products or contaminants.
4.3 Advanced data analysis and prediction
One of the primary advantages of ML techniques, is that they can help map complex parameter spaces and uncover relationships within relatively large datasets which cannot be easily done by human researchers. In the context of QD research, there have been some excellent studies demonstrating the utility of ML in advancing understanding and performance of QDs. An early study by Singulani et al., published in 2008, demonstrated the utility of ML in QD development.111 Here, the authors applied an artificial neural network (ANN) and a genetic algorithm (GA) to associate the height of epitaxially-grown InAs QDs with the synthesis parameters. In the epitaxial approach, QDs are formed by epitaxial deposition of semiconductor heterostructures (by e.g. molecular beam epitaxy (MBE), or metalorganic vapor phase epitaxy (MOVPE)) where there is a lattice mismatch between layers.112 The resultant strain sees ‘islands’ or material form, which are QDs. In this work, the growth of InAs on top of InGaAlAs was studied. Considering six reaction variables (including the indium flux in the reactor, growth temperature, deposition time, aluminium and indium content of the substrate), they demonstrated that with even a relatively sparse data set (67 parameter sets), the correlation between their model and experimental data exhibited a mean average percentage error of only 8.3%. Fig. 6a shows the correlation data for the whole data set, whilst Fig. 6b shows a parameter map of QD mean height varying as a function of deposition time and aluminium content. It is obvious how such a parameter map would be a real benefit when optimizing this QD fabrication process.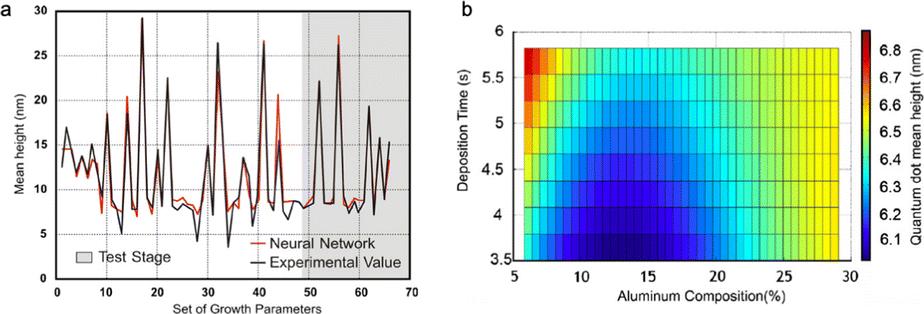 | ||
| Fig. 6 A study of epitaxially-grown InAs QDs by Singulani et al.111 (a) A comparison of an NN prediction for QD mean height with the obtained AFM experimental data. (b) A parameter map showing the output variable InAs QD height (nm) as a function of deposition time (s) and aluminium content of the InGaAlAs substrate. Reprinted from ref. 111, Copyright 2008, with permission from Elsevier. | ||
A paper from the Sargent group recently demonstrated ML-based optimization of PbS QDs,82 specifically targeting the minimization of particle size dispersity, which is a key challenge in order to improve the open-circuit voltage in QDPVs. The model was based on BO implemented using a neural network (NN). By analyzing a large data set compiled from historical records of PbS QD synthesis in their lab (2300 syntheses collected over 6 years, see Fig. 7a), the group first used their model to make predictions about which parameter combinations should achieve the desired reduction in polydispersity (closed circles in Fig. 7a), with an associated uncertainty level. Then following these predictions, they performed additional experiments whose data was incorporated into the model to allow further iterative improvements (open circles in Fig. 7a). In the end, they observed that oleylamine addition was key in reducing size and polydispersity, and that use of a high Pb:S ratio at a lowered injection temperature, and addition of metal chlorides (Fig. 7b) allowed for a successful reduction in PbS QD size polydispersity (55 meV at 950 nm and 24 meV at 1500 nm) which were both improvements over the previously reported bests. This study is a great example of how employing ML allows a broad and readily interpreted overview of trends in a very large experimental data set.
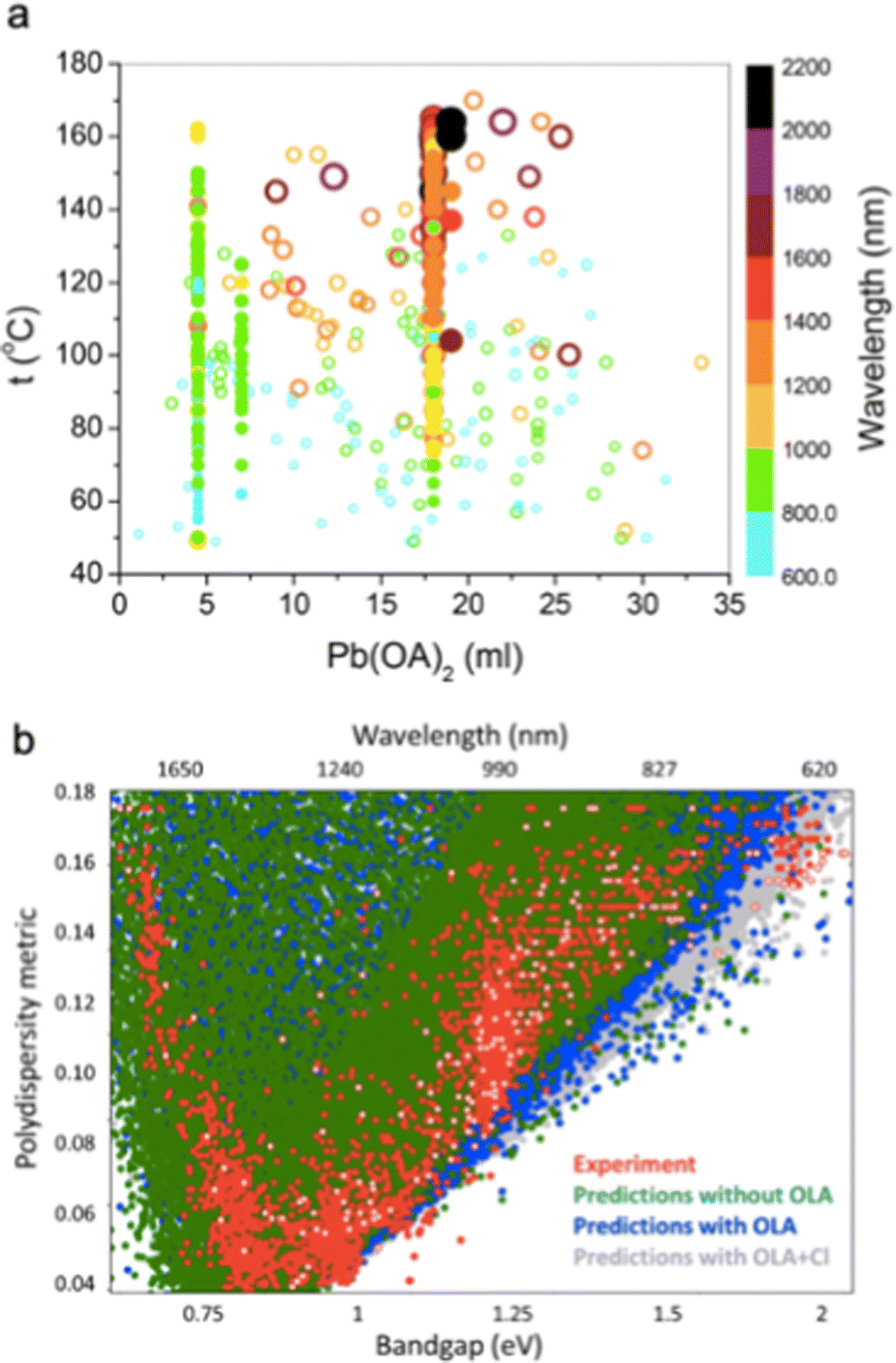 | ||
| Fig. 7 A study of PbS QDs by Vozny et al.82 (a) The parameter space, with input variables of Pb precursor volume and injection temperature, and an output variable of bandgap wavelength (nm) on the colour scale. Filled circles are the original pre-ML data, and open circles are subsequent ML-guided experiments. (b) A scatter plot showing the effect of oleylamine and chlorides on bandgap energy and particle polydispersity, showing the correlation between the experimental data (red points) and predictions made by the NN model. Reprinted with permission from ref. 82. Copyright 2019 American Chemical Society. | ||
Given that the exciton energy (and therefore absorption and PL emission) varies as a function of QD diameter, it is extremely important to be able to exert precise control of final diameter of synthesized products. Using historical data extracted from published works on the hot-injection syntheses of CdSe, CdS, PbS, PbSe, and ZnSe QDs, Baum et al. applied ML algorithms to identify the most important variables in defining the final diameter of QDs.72 The database was assembled using data on injection and growth temperature, reaction time, metal salt precursors, solvents, ligands, and associated concentrations. The group looked at both random forest and gradient boosting algorithms, concluding that the reaction duration, temperature, and metal precursor types were the dominant factors. Although this study did not provide any definitive answers for QD optimization, it does present an interesting case study for the application of ML to historical literature data, which could prove to be an extremely powerful technique for the better exploitation of past research. Here, it was apparent that a key reaction variable was identified by ML that could have been easily overlooked by a human investigator.
Another report on the use of ML in QD synthesis was published by the Banerjee group.73 Here, they were interested in predictive control of layer thickness of 2D CsPbBr3 nanoparticles, to see whether they could model layer thickness as a function of reaction variables, and also to provide some fundamental insight into the reaction itself. A specific interest was to see if they could do this with a relatively sparse data set (74 samples). Support vector machine (SVM) classification was used to differentiate between bulk and quantum-confined QDs, then a regression model was used for the prediction of thickness of the QDs in the quantum-confined regime, given an arbitrary set of reaction conditions. Estimations were shown to correlate well with predictions. The authors presented an interesting study of how layer thickness varies as a function of alkylamine ligand chain lengths, ligand concentration, and reaction temperature, where they used the SVM regression to map this parameter space (Fig. 8). Visual analysis clearly reveals relationships that would have been hard to identify in lower-dimensional or lower-resolution plots. For example, at a constant temperature of 82 °C, longer chain lengths at higher concentrations yield thin nanoplatelets (ca. 2–3 layers), whereas short chain lengths at lower concentration yield much thicker (ca. 7 layers) products, which was explained by the fact that the stabilization of the thicker platelets results from increased diffusion coefficients of monomeric species, facilitating faster crystal growth.
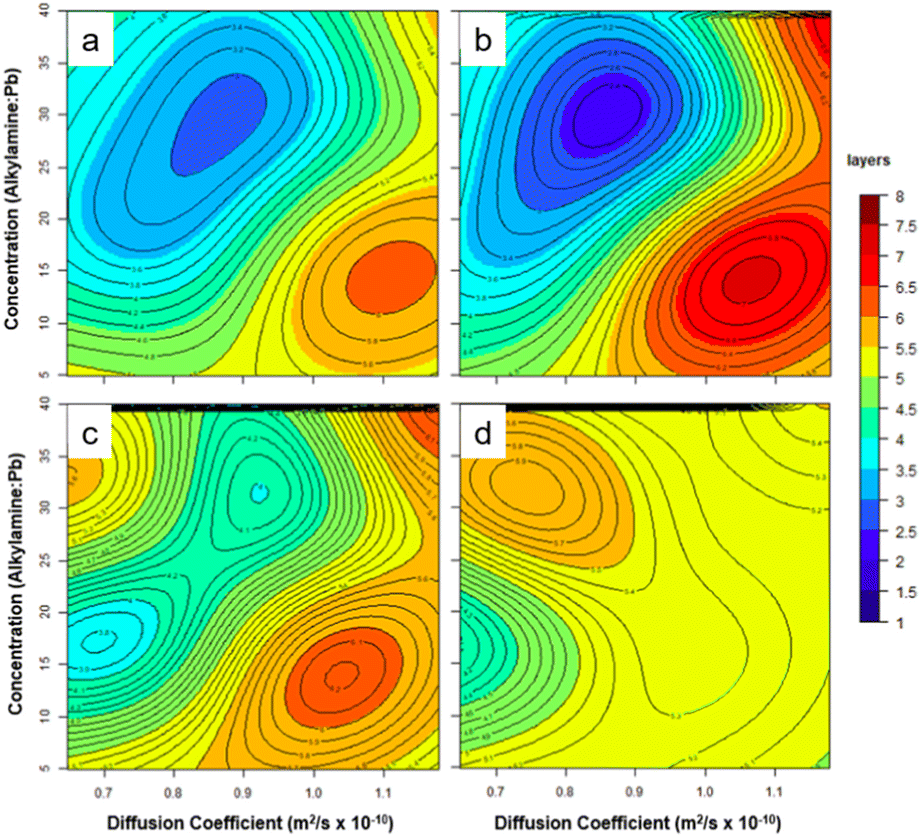 | ||
| Fig. 8 A study of 2D CsPbBr3 nanoparticles by Braham et al.73 A set of contour plot slices of the support vector machine (SVM) regression. The output variable (layer thickness) varies as a function of three input variables (concentration ratio alkylamine:Pb, diffusion coefficient of the different lengths of n-alkylamine ligands (C4, C8, C12, and C18), and temperature). Temperatures shown are (a) 50 °C, (b) 82 °C, (c) 120 °C, and (d) 150°C. Reprinted with permission from ref. 73. Copyright 2019 American Chemical Society. | ||
A paper published by Fu et al. demonstrated the use NN-based modelling and simulation to analyze data on CuInS2/ZnS QDs, studying PLQY and emission peak position as a function of seven reaction parameters.113 Based on a data set of 94 experiments, the authors demonstrated a good correlation between their model and the experimental data of over 90%. Through a combination of a Monte Carlo-based method and gradient-based local optimization, they extracted a final ‘optimal’ reaction parameter set, which included fixing 1-dodecanethiol (DDT) as the capping ligand, with a CuInS2 core reaction temperature of 240 °C, with a final prediction that a PLQY of 90% is feasible for an emission peak between 600–650 nm. Although this work is somewhat limited in its application, it does nicely demonstrate how ML modelling can be used to guide data analysis.
The above studies clearly show the potential of using ML to navigate complex parameter spaces. However, they possess two basic drawbacks: data sets that are either relatively small (typically less than 100 samples), or take a very long time to compile. The low-sample-number studies tend to emphasize the fact that they achieve good correlation between their model and their experimental data set despite having relatively small data sets. This demonstrates the interpolative abilities of ML algorithms, essentially allowing mapping of a complex parameter space. However, it is well known that the true power of AI and ML comes with big data, whereby complex questions can only be answered upon processing/analysis of thousands or millions of samples. But, compiling such large data sets by the traditional chemical synthesis approaches is simply too time- and resource-intensive. To bypass this, it is necessary to rethink the way in which we conduct QD discovery, characterization and optimization, and the field of microfluidics enabled HTE can take us towards the big data ideal.
4.4 Combining algorithms for reactor control and data analysis
Although relatively few studies demonstrating QD synthesis in microfluidic reactors have used real-time reactor control and/or algorithm-based control and analysis, this field is beginning to hit its stride and we are seeing some high impact work emerging. The first demonstration of algorithm-controlled rapid synthesis optimization was published in 2007, where inline PL spectroscopy was used to feed data into a control algorithm that could drive the reactor toward a target product (specifically, obtaining maximum emission intensity at a specified wavelength).114 This work demonstrated the potential of using an algorithm for target-oriented nanoparticle synthesis in microfluidics.Later, the deMello group demonstrated the use of a metamodeling algorithm based on Universal Kriging for the controlled synthesis of CdSe and CdSeTe QDs.115 Here, the reaction parameter space was scanned (changing stoichiometry and reaction time), with the FWHM, PL emission maximum and intensity being extracted for each QD reading. Kriging was then used to achieve data interpolation, yielding a model that could accurately predict the reactor output at arbitrary points within the chosen parameter space. This work was extended by the same group, when Bezinge et al. developed an automated microfluidic reactor for controlled synthesis of quinary (Cs/FA)Pb(I/Br)3 and senary (Rb/Cs/FA)Pb(I/Br)3 perovskite QDs.116 This time, the algorithm was incorporated within the reactor control loop, allowing real time modelling and navigation of the reaction parameter space. Given an arbitrary target emission wavelength, the reactor scans a sparse array of points in the parameter space (varying the stoichiometry), models the data, then starts iteratively testing and re-modelling, eventually producing a list of reaction conditions that will yield QDs with the desired emission wavelength. Such closed-loop experimentation is extremely powerful when it comes to both fundamental studies (e.g. mapping parameter spaces to guide materials discovery and optimization) and for applied synthesis (e.g. for product quality control during flow manufacture).
The combination of algorithmic control of closed-loop QD synthesis experiments and ML algorithms for data analysis and modelling has culminated in the development of advanced autonomous ML-driven closed-loop systems that show extraordinary potential in QD development and commercial translation.
A recent publication by Fong et al. describes an intelligent closed-loop automated 5-pump reactor system incorporating an inline small-angle X-ray scattering (SAXS) device for automated inline X-ray results to predict and control palladium nanoparticle size.117 The system is capable of performing over 50 unique syntheses over 24 hours, accelerating R&D, and selects recipes using a joint BO with Gaussian process regression. With this approach, the system will be capable of tackling various colloidal particle synthetic challenges where the generated material can be detected using SAXS, accelerating discovery.
An interesting approach by Mekki-Berrada et al. used a two-step ML process to optimise silver nanoparticle formation. Their approach allowed for prediction of the full UV-Vis absorption spectra, rather than a specific output feature, enabling investigation of a high dimensional space without handling multiple individual output parameters.118 They used flow-based HTE to generate an initial spectral dataset, then trained and applied a Gaussian process-based BO to suggest input parameters for subsequent experiments. The difference between the actual spectra generated from the suggested parameters and the target spectra—calculated as a loss function—was evaluated by the optimization algorithm to select the next experimental parameters. To more efficiently sample the parameter space the trained BO algorithm was used to train an offline deep neural network (DNN) alongside the fully resolved absorption spectra from the real experiments. Once introduced into the HTE loop, the trained DNN successfully extended the prediction capabilities of the system, whilst also giving the researchers fundamental insight on the chemical synthesis. Additionally, using SHAP (SHApley Additive exPlanations) analysis, they could also identify and rank the most influential input parameters for predicting the absorption spectra.118 This work offers a clear demonstration of how researchers can exploit the limitations of individual algorithms by merging techniques to more intelligently explore and exploit the wide parameter space.
At the time of writing this review, the most advanced systems that combine high-throughput QD synthesis/processing with advanced algorithms for both reactor control and data analysis are those of the Abolhasani group.119 Their many developments recently culminated in a publication detailing an ‘Artificial Chemist’, which uses an ML-based control system to guide an automated and highly-efficient fluidic reactor for metal halide perovskite QD synthesis.71 The system is composed of a precursor formulation module (seven syringe pumps with refill systems, and two inline passive micromixers), a flow reaction module, and an inline QD characterization module (PL and absorption), all driven by an ML-based algorithm. In the initial report, they used the system to perform bandgap tuning of pre-synthesized CsPbBr3 perovskite QDs through halide exchange.120 In terms of variables, the system is able to vary flow rates (therefore dosing) of the reaction precursors (a mixed ZnI2/ZnCl2 solution, and a ZnBr2 solution), oleic acid and oleylamine, which then allows optimization of PLQY and FWHM of QDs of any desired peak emission wavelength in the visible range. The overall aim is to accelerate the process of synthetic route discovery and optimization, whilst moving towards viable approaches for continuous manufacturing of CQDs with precisely-tuned optoelectronic properties.121 A key point is that this intends to move away from user-driven experiment selection in the materials discovery and optimization phase, instead opting to give the automated reactor the ingredients it needs, and the product targets it needs to hit, and time to let it learn independently in a closed-loop process. Following this, a further vision for this system is to use archived experimental data as a guide for future manufacturing, and real-time quality control. This could, for example, help to overcome problems with batch-to-batch variability in precursors, or in ambient conditions, thus making the QD synthesis more robust.
Although HTE and inline reaction data provides a wealth of information on the as-synthesized products, the ultimate test of QDs is how they perform in a device, and how stable they are over time. Device performance and stability testing cannot be conducted rapidly, as device fabrication is typically complex, and stability studies necessarily require extended time frames.
Before application to devices, QDs must be processed post-synthesis—this can involve separation, purification and application of QDs to the target material. Currently, QDs are typically washed and purified separate from the reactor system and then applied to devices via variety of different methodologies including spin-coating,122 inkjet printing,123 spray coating,124 and blade coating,125 as typical examples. Bridging this gap between synthesis and application, current research is exploring how altering the structural properties of QDs affect the stability and efficacy when applied, to ensure developments in production methods can meet industry requirements.126
ML can also be employed in this space. Sun et al. used HTE to generate PV thin films made up of 75 unique perovskite-based compositions and performed structural analysis, supported by a neural network algorithm, to intuitively classify the different compositions.127 From their work, they found that their algorithm had a 90% accuracy in distinguishing the crystal dimensionality (0D, 2D or 3D), at a rate over 10 times faster than a human analyst. The interesting aspect of this work is how such algorithms can speed up analysis of a wide parameter set to allow researchers to confidently identify more effective compositions. Here, the researchers used this platform to investigate lead-free perovskite materials appropriate for the thin films and successfully identified four suitable compositions. Being able to tune compositions to avoid toxic or heavy-metal dependent materials is important for overcoming a key challenge for wider commercial application.
In a recent study by Hartono et al., a supervised learning-based ML framework was used to optimize the capping layer deposited on a methylammonium lead iodide (MAPbI3) film, aiming to improve the environmental stability of a perovskite solar cell.128 The capping layer was formed by the deposition of halide salts, of which they investigated a set of 21 combinations of organic molecules and halide anions, assessing the stability of the final films under accelerated aging conditions. They used random forest regression and SHAP values to find which features exhibited strongest correlation with improved stability, which suggested that minimizing the number of hydrogen-bonded donors, and maintaining a small topological polar surface area of the organic capping layer molecules should yield improved stability. They then used this information to guide their choice of capping, eventually demonstrating an improved stability versus the previous standard capping layer choice. The key point here is the possibility of deriving design rules with the aid of ML, given a small data set.
4.5 Building larger integrated systems
Another option for correlating long term device performance with synthesis and processing parameters is to develop more sophisticated systems that extend the scope of HTE beyond purely the synthesis and into the processing and physical end states relevant to the downstream application. We want to build automated systems that can directly probe the phenomena that are critical in device operation (e.g. cycling stability), rather than making indirect assessment based solely on more-readily measured properties (e.g. PLQY, colloidal stability). Such ‘self-driving laboratories’ are likely to play a big part in driving innovation forwards across the materials sciences.129When thinking about flow chemistry and microfluidics, the field of organic synthesis and medicinal chemistry has been thoroughly examined using this technology, alongside the centuries of parameter and compound data in comparison to the relatively newer field of QD particle synthesis. As such, it is useful for us to understand how flow chemistry has been used in other fields to accelerate our approach. Taking inspiration from conventional organic synthesis, another example of how automated QD manufacturing could be approached in the future comes from an interesting project from Coley et al.130 The team combined the concepts of flow chemistry, HTE and AI to produce a robotic platform which could be used for data-driven synthesis planning and experimentation for more intelligent synthesis of organic compounds. The output was a fully flexible system, capable of incorporating a variety of plug and play components including pumps, fluid lines reactors and separators. A six-axis robotic arm and fluidic switchboard is used to select and arrange these reaction components for a specific synthesis (Fig. 9), and this is done ‘on-demand’ based on the parameters defined by the NN, which has been trained using millions of previously published reactions. The key takeaway is that if a process can be performed in flow and guided by AI principles, theoretically this process can be applied to such a system, opening the door for many opportunities to adapt existing methods for CQDs.
 | ||
| Fig. 9 A study by Coley et al.130, where an AI-driven automated flow chemistry system using a microfluidic reactor platform was embedded in a larger system, including a robot arm for configuring the system between each run. From ref. 130. Reprinted with permission from AAAS. | ||
Two publications from the Zhu group recently demonstrated the possibility of embedding a microfluidic reactor into a larger workflow, which included sample collection and robot-arm-controlled sample transfer to a circular diochroism (CD) spectrometer (Fig. 10a). Centred around their ‘materials acceleration operation system’ (MAOS), they have applied this system to the synthesis of both CdSe,131 and CsPbBr3 perovskite QDs.84 The system was developed with the vision of allowing users to perform experiments remotely, for the automatic execution of pre-planned experiments, and the incorporation of AI-based quality control, all aiming at increased safety and efficiency. At the heart of this is a microfluidic reactor for QD synthesis, in the vein of what has been discussed above. For reaction input variables of temperature and precursor concentration, the system used a SNOBFIT based reinforcement learning algorithm to guide real time navigation of a 3D parameter space, looking to maximize CD intensity (Fig. 10b). Regarding the study of CsPbBr3 perovskite nanoplates, they used their system to investigate optical chirality, where the products exhibiting maximized CD signal were investigated offline by transmission electron microscopy (TEM), which they then extended into a quantum mechanical theory for semiconductor nanoplates with temperature-dependent chirality. The work is a good demonstration of an extended workflow with an automated microfluidic reactor at its core.
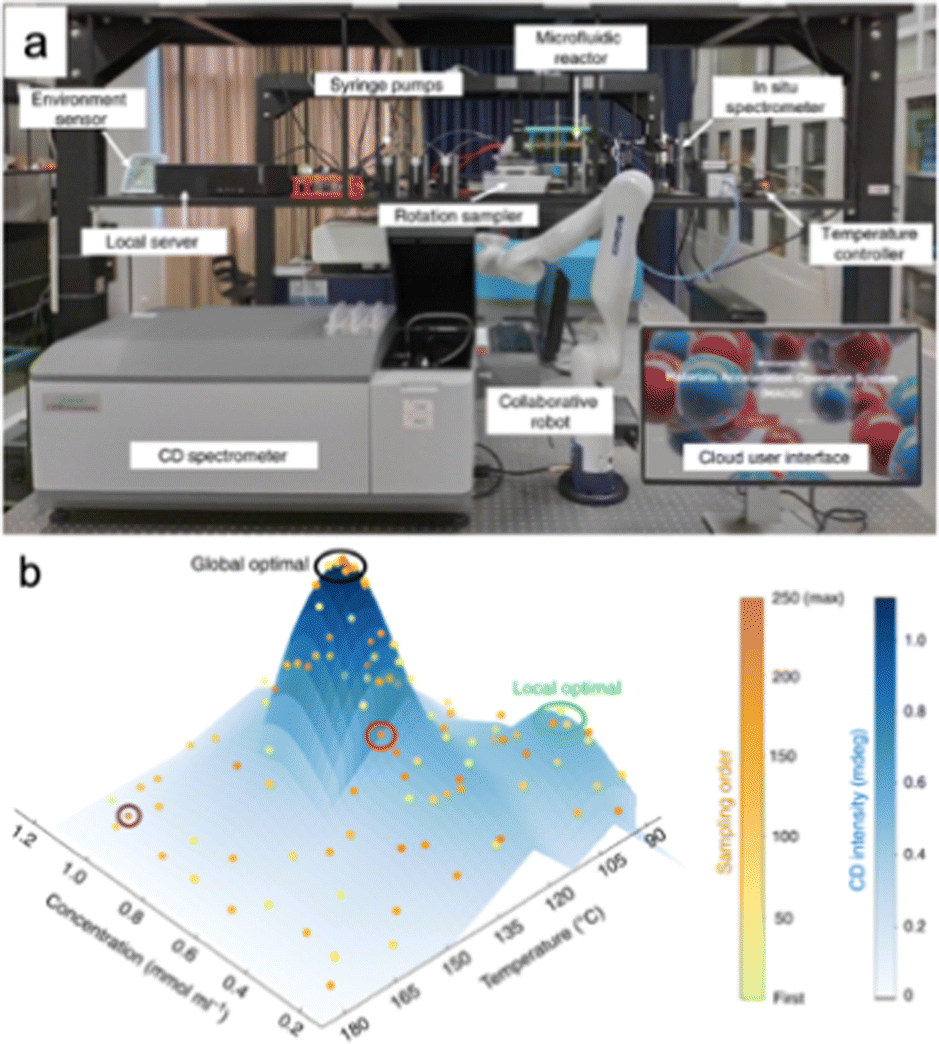 | ||
| Fig. 10 A study of CsPbBr3 perovskite QDs by Li et al.84 (a) The automated system, showing the automated microfluidic reactor embedded in a larger system, including a robot arm for sample handling. (b) The SNOBFIT guided parameter space search, where the output variable (CD intensity) is varying as a function of two input variables (precursor concentrations and reaction temperature). The plot shows how the system had to navigate a parameter space containing a local maximum to eventually find a global maximum. Reprinted with permission from ref. 84. | ||
Two recent publications nicely exemplify the potential of automated HTE with ML-based control for optimizing thin film materials for solar cells. Although these studies did not use QDs, it is evident that they represent a direction in which the QD field could move, in order to extend data sets beyond as-synthesized product characterization and towards the collection of downstream data where the QDs are tested in scenarios that are closer to the final operational conditions. Langner et al. demonstrated how HTE could be used in the fabrication and characterization of optoelectronic thin films, targeting optimization of multicomponent polymer blends for organic photovoltaics (OPVs).132 Their automated film formation system allowed the fabrication of up to 6048 films per day, and used a BO algorithm to analyze data and design new experiments in a closed-loop experimental format. As a demonstration, they studied four-component OPV blend (two polymers and two small molecule additives, Fig. 11a), tuning those four concentration ratios as input variables, with photostability as the output variable. Films were cast in 96 well plates by a dispensing robot (Fig. 11b), then absorption spectra were collected before and after one sun intensity illumination for 18 hours. Interestingly, they compared their ML algorithm directly with a simple grid-based parameter scan (Fig. 11c), and found that the ML approach was ca. 33× faster at identifying the most stable blends. The methodology also uses only a fraction of the precursor required in standard manual methods, highlighting the economic and efficiency gains of the automation with ML approach.
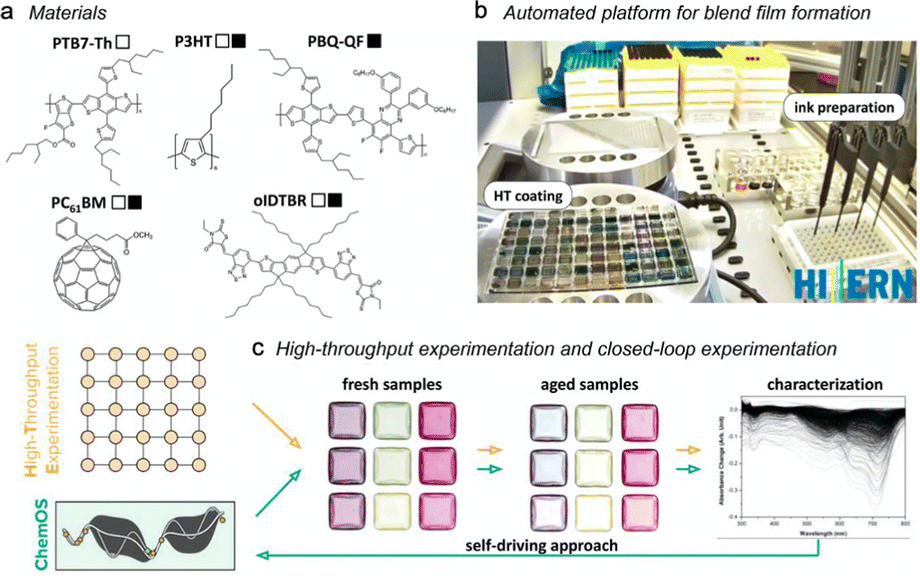 | ||
| Fig. 11 A study of organic photovoltaic (OPV) thin films by Langner et al.132 (a) The three polymer donors and the two small molecule acceptors studied, where the open and closed squares indicate the two sets of four that were studied. (b) The automated system for ink formulation, deposition, film formation and characterization. (c) The process workflow showing the two approaches used (HTE grid-based versus ML-guided). Reprinted with permission from ref. 132. | ||
MacLeod et al. reported a modular robotic platform (Fig. 12a) driven by a BO algorithm for the optimization of hole mobility in an organic hole transport material commonly used in perovskite PVs (specifically spiro-OMeTAD).133 The sophisticated system can autonomously measure and mix precursor solutions, deposit them as thin films on rigid substrates by spin-coating, anneal each film, then image them to detect morphology defects and impurities, and characterize the film optical and conductivity properties. The data are processed live by the algorithm, which then designs new experiments in a closed-loop format. Each sample took 20 minutes start to finish, and the final data set comprised two 35-sample campaigns. With annealing time and dopant concentration as their input variables, they sought to maximize hole mobility in the films (Fig. 12b). An important detail of this study is that while they were looking to optimize hole mobility, they did not directly measure hole mobility in the films, because valid hole mobility measurements necessitate the fabrication of multilayer films, which is too complex and time-consuming in the context of this HTE workflow. Instead, they used a diagnostic quantity, pseudomobility, which could be readily measured in single layer films using a four-point probe conductivity measurement and UV-Vis-NIR spectroscopy and is proportional to hole mobility. This illustrates the point that autonomous HTE often requires the monitoring of accessible properties that then act as proxies for inaccessible properties. This is an intrinsic limitation of the approach, as many processes and measurement techniques simply cannot be sufficiently adapted in duration and/or complexity to make big data accessible.
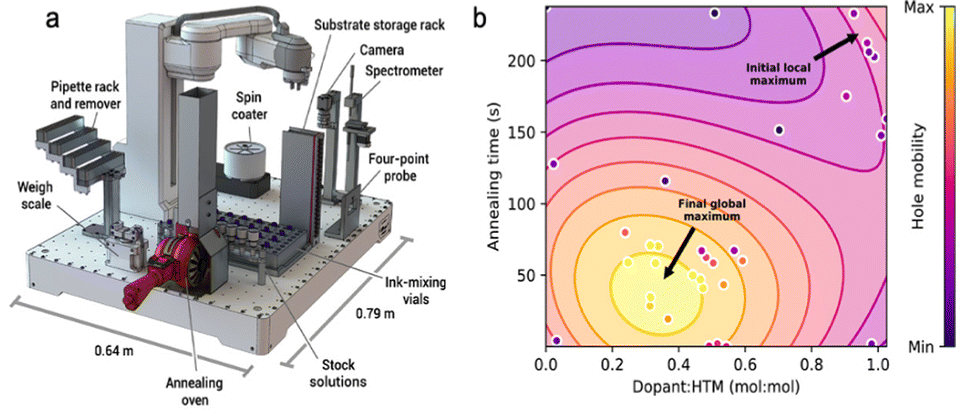 | ||
| Fig. 12 A study of organic hole transport materials by MacLeod et al.133 (a) The self-driving modular robotic system that automates the experimental workflow. (b) A parameter map showing the output variables (pseudomobility (dimensionless) and annealing time (s)). The plot shows how the system had to navigate a parameter space containing a local maximum to eventually find a global maximum. Reprinted with permission from ref. 133. | ||
5 Conclusions
This review paper has aimed to provide a bridge between the world of traditional quantum dot (QD) chemistry and the frontier of big data and artificial intelligence. We have looked at why QDs present an R&D challenge that is primed for revolution with advanced experimental methodologies and analytical approaches, and we have seen a set of examples that nicely illustrate the potential in this field. We have seen that microfluidic reactors and larger robotic systems provide tools that can translate traditional flask chemistry QD synthesis approaches into high-throughput and data-rich automated experiments, and that machine learning (ML) can provide an algorithmic framework for advanced navigation of complex multidimensional parameter space. This scale of analysis will allow for the rapid discovery and development of new safer materials and greener synthetic routes which will help us to tackle challenges with toxic components and processing. We have also explored how current research is exploring the potential of synthesized QDs directly on thin films specifically to evaluate device performance—here ML algorithms can also be used to examine performance against the wider QD parameter space, with particular attention on examining surface effects. We believe future research will involve flow reactor-based end-to-end manufacturing systems that incorporate ML-centered analysis and quality control of QD technologies, such as PV thin films, into an overall workflow, and that this will be a key part of accelerating QD-based device development.However, it is important to acknowledge that there is significant barrier to entry for both the reaction automation and the ML tasks. The required skillsets are not generally part of a natural sciences education, and those are typically the people working in the QD development space. Additionally, there is a time and capital consideration in developing automated ML-enabled systems, especially when exploring beyond the R&D scale. Therefore, truly interdisciplinary working, with chemical and mechanical engineers, and data scientists, amongst others, is what is going to push the frontier forward in this field.
Nevertheless, we can all push our disciplinary limits, and the microfluidics space can be relatively accessible. Although microfluidics can require expensive and specialized facilities to fabricate custom fluidic chips, from polydimethylsiloxane (PDMS), glass, polytetrafluoroethylene (PTFE), etc., it does not have to. A big part of the beauty of the approaches described for colloidal quantum dot (CQD) synthesis herein is that that the reactors are most often built from commercially available parts (e.g. solvent-resistant tubing, HPLC fittings, heated stages, etc.). This gives these systems a ‘plug-and-play’ sensibility, and in fact means that there is a low physical/economical barrier-to-entry. Although, running chemistry in flow does present distinct challenges, and requires some patience,60 these can be overcome with practice. Similarly with AI and ML, the more sophisticated algorithms are an extreme challenge, but significant gains can be made with even relatively simple algorithms, for example using freely available ML tools for multidimensional regression and parameter space visualization. To help intelligently guide ML research, introductory and best practice guides for incorporating ML practices have been published as researchers consistently look to improve standardization in this space, particularly in data management and reporting.134,135 However, given the relatively low proliferation of even well-established and accessible design of experiments (DoE) methodologies in materials science, the transition to AI and ML will take time, emphasizing the prioritization of interdisciplinary working.
Beyond the scientific and technological interest of employing emerging technologies for advanced automation and analysis, the approach is also attractive from a moral perspective. We have a duty to maximize the utility of the resources that we consume in doing research. We not only want to find the best CQD formulations, but we want to find the most environmentally friendly and sustainable ways of producing and processing them. Further, we are facing global challenges in energy management in attempts to mitigate catastrophic climate change.136 It is an absolute necessity that we accelerate the translation of clean and efficient energy conversion technologies. This review paper has covered many very promising proof-of principle studies concerning QDs in this direction, moving HTE and ML towards applications that accelerate the impact of QDs in the real world. Further, although the ideas discussed herein focus on QDs, these are in fact just a portion of the much larger revolution in materials science. The opportunity is clearly there for us to make significant and likely revolutionary gains, and we must make the most of it as a global and multidisciplinary research community.
Conflicts of interest
The authors have no conflicts of interest to declare.Acknowledgements
PDH would like to acknowledge support from the Royal Society of Chemistry via a Research Enablement Grant entitled ‘Ligand Engineering of Heavy-Metal Free Quantum Dots for Solar Cells’.Notes and references
- A. L. Efros and L. E. Brus, ACS Nano, 2021, 15, 6192–6210 CrossRef CAS PubMed.
- Quantum Dots Market Size & Share|Industry Report, 2021–2026|Markets and Markets™, https://www.marketsandmarkets.com/Market-Reports/quantum-dots-qd-market-694.html (accessed 07/07/2022).
- A. I. Ekimov and A. A. Onushchenko, J. Exp. Theor. Phys. Lett., 1981, 34, 345–349 Search PubMed.
- G. Liu, X. Wang, G. Han, J. Yu and H. Zhao, Mater. Adv., 2020, 1, 119–138 RSC.
- S. Zhao, X. Liu, X. Pi and D. Yang, J. Semicond., 2018, 39, 061008 CrossRef.
- J. Zheng, P. R. Nicovich and R. M. Dickson, Annu. Rev. Phys. Chem., 2007, 58, 409–431 CrossRef CAS PubMed.
- L. E. Brus, J. Chem. Phys., 1984, 80, 4403–4409 CrossRef CAS.
- J. Shamsi, A. S. Urban, M. Imran, L. De Trizio and L. Manna, Chem. Rev., 2019, 119, 3296–3348 CrossRef CAS PubMed.
- L. C. Schmidt, A. Pertegás, S. González-Carrero, O. Malinkiewicz, S. Agouram, G. Mínguez Espallargas, H. J. Bolink, R. E. Galian and J. Pérez-Prieto, J. Am. Chem. Soc., 2014, 136, 850–853 CrossRef CAS PubMed.
- L. Protesescu, S. Yakunin, M. I. Bodnarchuk, F. Krieg, R. Caputo, C. H. Hendon, R. X. Yang, A. Walsh and M. V. Kovalenko, Nano Lett., 2015, 15, 3692–3696 CrossRef CAS PubMed.
- X. Wang, Z. Bao, Y. C. Chang and R. S. Liu, ACS Energy Lett., 2020, 5, 3374–3396 CrossRef CAS.
- H. Lee, H. J. Song, M. Shim and C. Lee, Energy Environ. Sci., 2020, 13, 404–431 RSC.
- A. A. M. Brown, B. Damodaran, L. Jiang, J. N. Tey, S. H. Pu, N. Mathews and S. G. Mhaisalkar, Adv. Energy Mater., 2020, 2001349 CrossRef CAS.
- I. Infante and L. Manna, Nano Lett., 2021, 21, 6–9 CrossRef CAS PubMed.
- I. V. Martynenko, A. P. Litvin, F. Purcell-Milton, A. V. Baranov, A. V. Fedorov and Y. K. Gun'ko, J. Mater. Chem. B, 2017, 5, 6701–6727 RSC.
- S. V. Kershaw, L. Jing, X. Huang, M. Gao and A. L. Rogach, Mater. Horiz., 2017, 4, 155–205 RSC.
- J. Du, R. Singh, I. Fedin, A. S. Fuhr and V. I. Klimov, Nat. Energy, 2020, 5, 409–417 CrossRef CAS.
- H. Li and W. Zhang, Chem. Rev., 2020, 120, 9835–9950 CrossRef CAS PubMed.
- L. Duan, L. Hu, X. Guan, C. Lin, D. Chu, S. Huang, X. Liu, J. Yuan and T. Wu, Adv. Energy Mater., 2021, 2100354 CrossRef CAS.
- H. P. Wang, S. Li, X. Liu, Z. Shi, X. Fang and J. H. He, Adv. Mater., 2021, 33, 1–42 Search PubMed.
- X. Yin, C. Zhang, Y. Guo, Y. Yang, Y. Xing and W. Que, J. Mater. Chem. C, 2021, 9, 417–438 RSC.
- W. Gong, P. Wang, D. Dai, Z. Liu, L. Zheng and Y. Zhang, J. Mater. Chem. C, 2021, 9, 2994–3025 RSC.
- Y. Shu, X. Lin, H. Qin, Z. Hu, Y. Jin and X. Peng, Angew. Chem., Int. Ed., 2020, 59, 22312–22323 CrossRef CAS PubMed.
- Y.-M. Huang, K. J. Singh, A.-C. Liu, C.-C. Lin, Z. Chen, K. Wang, Y. Lin, Z. Liu, T. Wu and H.-C. Kuo, Nanomaterials, 2020, 10, 1327 CrossRef CAS.
- Z. Yang, Q. Wu, G. Lin, X. Zhou, W. Wu, X. Yang, J. Zhang and W. Li, Mater. Horiz., 2019, 6, 2009–2015 RSC.
- A. P. Litvin, I. V. Martynenko, F. Purcell-Milton, A. V. Baranov, A. V. Fedorov and Y. K. Gun'Ko, J. Mater. Chem. A, 2017, 5, 13252–13275 RSC.
- H. Lu, Z. Huang, M. S. Martinez, J. C. Johnson, J. M. Luther and M. C. Beard, Energy Environ. Sci., 2020, 13, 1347–1376 RSC.
- L. Protesescu, S. Yakunin, O. Nazarenko, D. N. Dirin and M. V. Kovalenko, ACS Appl. Nano Mater., 2018, 1, 1300–1308 CrossRef CAS PubMed.
- Z.-Y. Zhu, Q.-Q. Yang, L.-F. Gao, L. Zhang, A.-Y. Shi, C.-L. Sun, Q. Wang and H.-L. Zhang, J. Phys. Chem. Lett., 2017, 8, 1610–1614 CrossRef CAS.
- M. A. Green, Semiconductor Quantum Dots, Royal Society of Chemistry, Cambridge, 2014 Search PubMed.
- C. B. Murray, D. J. Norris and M. G. Bawendi, J. Am. Chem. Soc., 1993, 115, 8706–8715 CrossRef CAS.
- S. G. Kwon and T. Hyeon, Small, 2011, 7, 2685–2702 CrossRef CAS PubMed.
- J. Van Embden, A. S. Chesman and J. J. Jasieniak, Chem. Mater., 2015, 27, 2246–2285 CrossRef CAS.
- K. Schwab, The fourth industrial revolution, Penguin UK, 2017, p. 184 Search PubMed.
- S. Hong, C. H. Liow, J. M. Yuk, H. R. Byon, Y. Yang, E. Cho, J. Yeom, G. Park, H. Kang, S. Kim, Y. Shim, M. Na, C. Jeong, G. Hwang, H. Kim, H. Kim, S. Eom, S. Cho, H. Jun, Y. Lee, A. Baucour, K. Bang, M. Kim, S. Yun, J. Ryu, Y. Han, A. Jetybayeva, P.-P. Choi, J. C. Agar, S. V. Kalinin, P. W. Voorhees, P. Littlewood and H. M. Lee, ACS Nano, 2021, 15, 3971–3995 CrossRef CAS PubMed.
- K. T. Butler, D. W. Davies, H. Cartwright, O. Isayev and A. Walsh, Nature, 2018, 559, 547–555 CrossRef CAS.
- L. Yang, D. Li, C. Wang, W. Yao, H. Wang and K. Huang, J. Nanopart. Res., 2017, 19, 1–13 CrossRef.
- J. Yin, H. Yang, L. Gutiérrez-Arzaluz, Y. Zhou, J.-L. Brédas, O. M. Bakr and O. F. Mohammed, ACS Nano, 2021, 15, 17998–18005 CrossRef CAS PubMed.
- S. A. Weissman and N. G. Anderson, Org. Process Res. Dev., 2015, 19, 1605–1633 CrossRef CAS.
- C. Gréboval, A. Chu, N. Goubet, C. Livache, S. Ithurria and E. Lhuillier, Chem. Rev., 2021, 121, 3627–3700 CrossRef PubMed.
- Cadmium: health effects, incident management and toxicology, https://www.gov.uk/government/publications/cadmium-properties-incident-management-and-toxicology (accessed 07/07/2022).
- RoHS Directive, https://environment.ec.europa.eu/topics/waste-and-recycling/rohs-directive_en (accessed 07/07/2022).
- M. V. Kovalenko, L. Protesescu and M. I. Bodnarchuk, Science, 2017, 358, 745–750 CrossRef CAS.
- P. Reiss, M. Carrière, C. Lincheneau, L. Vaure and S. Tamang, Chem. Rev., 2016, 116, 10731–10819 CrossRef CAS PubMed.
- Q. Fan, et al. , Angew. Chem., Int. Ed., 2020, 59, 1030–1046 CrossRef CAS PubMed.
- A. C. Berends, M. J. J. Mangnus, C. Xia, F. T. Rabouw and C. De Mello Donega, J. Phys. Chem. Lett., 2019, 10, 1600–1616 CrossRef CAS PubMed.
- Y. Liu, A. Nag, L. Manna and Z. Xia, Angew. Chem., Int. Ed., 2021, 60, 11592–11603 CrossRef CAS PubMed.
- X. Du and R. Jin, ACS Nano, 2019, 13, 7383–7387 CrossRef CAS PubMed.
- M. Albaladejo-Siguan, E. C. Baird, D. Becker-Koch, Y. Li, A. L. Rogach and Y. Vaynzof, Adv. Energy Mater., 2021, 11, 2003457 CrossRef CAS.
- H. Moon, C. Lee, W. Lee, J. Kim and H. Chae, Adv. Mater., 2019, 31, 1804294 CrossRef PubMed.
- M. A. Boles, D. Ling, T. Hyeon and D. V. Talapin, Nat. Mater., 2016, 15, 141–153 CrossRef CAS PubMed.
- Y. Wang, J. Zhang, S. Chen, H. Zhang, L. Li and Z. Fu, J. Mater. Sci., 2018, 53, 9180–9190 CrossRef CAS.
- Y. Shang and Z. Ning, Nat. Sci. Rev., 2017, 4, 170–183 CrossRef CAS.
- D. H. Webber and R. L. Brutchey, J. Am. Chem. Soc., 2012, 134, 1085–1092 CrossRef CAS PubMed.
- C.-H. M. Chuang, P. R. Brown, V. Bulovic and M. G. Bawendi, Nat. Mater., 2014, 13, 796–801 CrossRef CAS.
- H. Aqoma, M. Al Mubarok, W. T. Hadmojo, E.-H. Lee, T.-W. Kim, T. K. Ahn, S.-H. Oh and S.-Y. Jang, Adv. Mater., 2017, 29, 1605756 CrossRef PubMed.
- M. Liu, O. Voznyy, R. Sabatini, F. P. García de Arquer, R. Munir, A. H. Balawi, X. Lan, F. Fan, G. Walters, A. R. Kirmani, S. Hoogland, F. Laquai, A. Amassian and E. H. Sargent, Nat. Mater., 2017, 16, 258–263 CrossRef CAS PubMed.
- Z. Ning, O. Voznyy, J. Pan, S. Hoogland, V. Adinolfi, J. Xu, M. Li, A. R. Kirmani, J.-P. Sun, J. Minor, K. W. Kemp, H. Dong, L. Rollny, A. Labelle, G. Carey, B. Sutherland, I. Hill, A. Amassian, H. Liu, J. Tang, O. M. Bakr and E. H. Sargent, Nat. Mater., 2014, 13, 822–828 CrossRef CAS PubMed.
- J. Nette, P. D. Howes and A. J. deMello, Adv. Mater. Technol., 2020, 5, 2000060 CrossRef CAS.
- M. B. Plutschack, B. Pieber, K. Gilmore and P. H. Seeberger, Chem. Rev., 2017, 117, 11796–11893 CrossRef CAS PubMed.
- Z. S. Campbell, F. Bateni, A. A. Volk, K. Abdel-Latif and M. Abolhasani, Part. Part. Syst. Charact., 2020, 37, 1–29 CrossRef.
- J. Shen, M. Shafiq, M. Ma and H. Chen, Nanomaterials, 2020, 10, 1–29 Search PubMed.
- A.-G. Niculescu, C. Chircov, A. C. Birca and A. M. Grumezescu, Int. J. Mol. Sci., 2021, 22, 2011 CrossRef CAS PubMed.
- R. M. Maceiczyk, I. G. Lignos and A. J. deMello, Curr. Opin. Chem. Eng., 2015, 8, 29–35 CrossRef.
- R. W. Epps, K. C. Felton, C. W. Coley and M. Abolhasani, Lab Chip, 2017, 17, 4040–4047 RSC.
- M. G. Lüdicke, J. Hildebrandt, C. Schindler, R. A. Sperling and M. Maskos, Nanomaterials, 2022, 12, 1983 CrossRef PubMed.
- P. Zhou, J. He, L. Huang, Z. Yu, Z. Su, X. Shi and J. Zhou, Nanomaterials, 2020, 10, 2514 CrossRef CAS PubMed.
- P. S. Gromski, A. B. Henson, J. M. Granda and L. Cronin, Nat. Rev. Chem., 2019, 3, 119–128 CrossRef.
- A. Y.-T. Wang, R. J. Murdock, S. K. Kauwe, A. O. Oliynyk, A. Gurlo, J. Brgoch, K. A. Persson and T. D. Sparks, Chem. Mater., 2020, 32, 4954–4965 CrossRef CAS.
- K. A. Brown, S. Brittman, N. Maccaferri, D. Jariwala and U. Celano, Nano Lett., 2020, 20, 2–10 CrossRef CAS PubMed.
- R. W. Epps, M. S. Bowen, A. A. Volk, K. Abdel-Latif, S. Han, K. G. Reyes, A. Amassian and M. Abolhasani, Adv. Mater., 2020, 32, 2001626 CrossRef CAS PubMed.
- F. Baum, T. Pretto, A. Köche and M. J. L. Santos, J. Phys. Chem. C, 2020, 124, 24298–24305 CrossRef CAS.
- E. J. Braham, J. Cho, K. M. Forlano, D. F. Watson, R. Arròyave and S. Banerjee, Chem. Mater., 2019, 31, 3281–3292 CrossRef CAS.
- A. Dager, T. Uchida, T. Maekawa and M. Tachibana, Sci. Rep., 2019, 9, 1–10 CrossRef CAS PubMed.
- C. Barth and C. Becker, Commun. Phys., 2018, 1, 1–11 CrossRef.
- Y. Jeong, J. Lee, J. Moon, J. H. Shin and W. D. Lu, Nano Lett., 2018, 18, 4447–4453 CrossRef CAS PubMed.
- X. Wang, J. Li, H. D. Ha, J. C. Dahl, J. C. Ondry, I. Moreno-Hernandez, T. Head-Gordon and A. P. Alivisatos, JACS Au, 2021, 1, 316–327 CrossRef CAS PubMed.
- H. Wen, J. M. Luna-Romera, J. C. Riquelme, C. Dwyer and S. L. Y. Chang, Nanomaterials, 2021, 11, 2706 CrossRef CAS PubMed.
- D. A. Winkler, Small, 2020, 16, 2001883 CrossRef CAS PubMed.
- C. Szepesvari, Algorithms for Reinforcement Learning, Morgan and Claypool Publishers, 2010, pp. 3–4 Search PubMed.
- D. Cohn, L. Atlas and R. Ladner, Mach. Learn., 1994, 15, 201–221 Search PubMed.
- O. Voznyy, L. Levina, J. Z. Fan, M. Askerka, A. Jain, M.-J. Choi, O. Ouellette, P. Todorovic, L. K. Sagar and E. H. Sargent, ACS Nano, 2019, 13, 11122–11128 CrossRef CAS PubMed.
- L. A. Bawazer, J. Ihli, T. P. Comyn, K. Critchley, C. J. Empson and F. C. Meldrum, Adv. Mater., 2015, 27, 223–227 CrossRef CAS PubMed.
- J. Li, J. Li, R. Liu, Y. Tu, Y. Li, J. Cheng, T. He and X. Zhu, Nat. Commun., 2020, 11, 2046 CrossRef CAS PubMed.
- H. Lv and X. Chen, Nanoscale, 2022, 14, 6688–6708 RSC.
- R. W. Epps and M. Abolhasani, Appl. Phys. Rev., 2021, 8, 041316 CAS.
- H. Tao, T. Wu, M. Aldeghi, T. C. Wu, A. Aspuru-Guzik and E. Kumacheva, Nat. Rev. Mater., 2021, 6, 701–716 CrossRef.
- A. Chen, X. Zhang and Z. Zhou, InfoMat, 2020, 2, 553–576 CrossRef CAS.
- G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto and L. Zdeborová, Rev. Mod. Phys., 2019, 91, 045002 CrossRef CAS.
- H. H. Rashidi, N. K. Tran, E. V. Betts, L. P. Howell and R. Green, Acad. Pathol., 2019, 6, 2374289519873088 CrossRef PubMed.
- R. Ramprasad, R. Batra, G. Pilania, A. Mannodi-Kanakkithodi and C. Kim, npj Comput. Mater., 2017, 3, 54 CrossRef.
- M. I. Jordan and T. M. Mitchell, Science, 2015, 349, 255–260 CrossRef CAS PubMed.
- A.-G. Niculescu, C. Chircov, A. C. Birca and A. M. Grumezescu, Nanomaterials, 2021, 11, 864 CrossRef CAS PubMed.
- M. Wojnicki and V. Hessel, Chem. Eng. J., 2022, 438, 135616 CrossRef CAS.
- A. A. Volk and M. Abolhasani, Trends Chem., 2021, 3, 519–522 CrossRef CAS.
- H. Ma, L. Pan, J. Wang, L. Zhang and Z. Zhang, Chinese Chem. Lett., 2019, 30, 79–82 CrossRef CAS.
- W. Liu, Y. Zhang, C.-F. Wang and S. Chen, RSC Adv., 2015, 5, 107804–107810 RSC.
- W. Yang, H. Yang, W. Ding, B. Zhang, L. Zhang, L. Wang, M. Yu and Q. Zhang, Ultrason. Sonochem., 2016, 33, 106–117 CrossRef CAS PubMed.
- J. Baek, Y. Shen, I. Lignos, M. G. Bawendi and K. F. Jensen, Angew. Chem., Int. Ed., 2018, 57, 10915–10918 CrossRef CAS PubMed.
- F. Bian, L. Sun, L. Cai, Y. Wang, Y. Wang and Y. Zhao, Small, 2020, 16, 1903931 CrossRef CAS PubMed.
- T. Chen, S. Yin and J. Wu, TrAC, Trends Anal. Chem., 2021, 142, 116309 CrossRef CAS.
- S. Li, J. C. Hsiao, P. D. Howes and A. J. deMello, Microfluidic Tools for the Synthesis of Bespoke Quantum Dots, John Wiley & Sons, Ltd, 2020, ch. 4, pp. 109–148 Search PubMed.
- E. M. Chan, R. A. Mathies and A. P. Alivisatos, Nano Lett., 2003, 3, 199–201 CrossRef CAS.
- B. Yen, N. Stott, K. Jensen and M. Bawendi, Adv. Mater., 2003, 15, 1858–1862 CrossRef CAS.
- E. M. Chan, C. Xu, A. W. Mao, G. Han, J. S. Owen, B. E. Cohen and D. J. Milliron, Nano Lett., 2010, 10, 1874–1885 CrossRef CAS PubMed.
- K. Watanabe, Y. Orimoto, K. Nagano, K. Yamashita, M. Uehara, H. Nakamura, T. Furuya and H. Maeda, Chem. Eng. Sci., 2012, 75, 292–297 CrossRef CAS.
- Y. Orimoto, K. Watanabe, K. Yamashita, M. Uehara, H. Nakamura, T. Furuya and H. Maeda, J. Phys. Chem. C, 2012, 116, 17885–17896 CrossRef CAS.
- A. Yashina, I. Lignos, S. Stavrakis, J. Choo and A. J. deMello, J. Mater. Chem. C, 2016, 4, 6401–6408 RSC.
- J. Li, H. Šimek, D. Ilioae, N. Jung, S. Bräse, H. Zappe, R. Dittmeyer and B. P. Ladewig, React. Chem. Eng., 2021, 6, 1497–1507 RSC.
- I. Lignos, V. Morad, Y. Shynkarenko, C. Bernasconi, R. M. Maceiczyk, L. Protesescu, F. Bertolotti, S. Kumar, S. T. Ochsenbein, N. Masciocchi, A. Guagliardi, C.-J. Shih, M. I. Bodnarchuk, A. J. deMello and M. V. Kovalenko, ACS Nano, 2018, 12, 5504–5517 CrossRef CAS PubMed.
- A. P. Singulani, O. P. Vilela Neto, M. C. Aurélio Pacheco, M. B. Vellasco, M. P. Pires and P. L. Souza, J. Cryst. Growth, 2008, 310, 5063–5065 CrossRef CAS.
- T. M. Zhao, Y. Chen, Y. Yu, Q. Li, M. Davanco and J. Liu, Adv. Quantum Technol., 2020, 3, 1–25 Search PubMed.
- M. Fu, T. Mrziglod, W. Luan, S. Tu and L. Mleczko, Eng. Rep., 2020, 2, 1–11 Search PubMed.
- S. Krishnadasan, R. J. C. Brown, A. J. deMello and J. C. deMello, Lab Chip, 2007, 7, 1434 RSC.
- R. M. Maceiczyk and A. J. deMello, J. Phys. Chem. C, 2014, 118, 20026–20033 CrossRef CAS.
- L. Bezinge, R. M. Maceiczyk, I. Lignos, M. V. Kovalenko and A. J. deMello, ACS Appl. Mater. Interfaces, 2018, 10, 18869–18878 CrossRef CAS PubMed.
- A. Y. Fong, L. Pellouchoud, M. Davidson, R. C. Walroth, C. Church, E. Tcareva, L. Wu, K. Peterson, B. Meredig and C. J. Tassone, J. Chem. Phys., 2021, 154, 224201 CrossRef CAS PubMed.
- F. Mekki-Berrada, Z. Ren, T. Huang, W. K. Wong, F. Zheng, J. Xie, I. P. S. Tian, S. Jayavelu, Z. Mahfoud, D. Bash, K. Hippalgaonkar, S. Khan, T. Buonassisi, Q. Li and X. Wang, npj Comput. Mater., 2021, 7, 1–10 CrossRef.
- A. A. Volk, R. W. Epps and M. Abolhasani, Adv. Mater., 2021, 33, 1–19 CrossRef PubMed.
- K. Abdel-Latif, R. W. Epps, C. B. Kerr, C. M. Papa, F. N. Castellano and M. Abolhasani, Adv. Funct. Mater., 2019, 29, 1900712 CrossRef.
- A. R. Kirmani, J. M. Luther, M. Abolhasani and A. Amassian, ACS Energy Lett., 2020, 5, 3069–3100 CrossRef CAS.
- X. Pi, Q. Li, D. Li and D. Yang, Sol. Energy Mater. Sol. Cells, 2011, 95, 2941–2945 CrossRef CAS.
- P. Yang, L. Zhang, D. J. Kang, R. Strahl and T. Kraus, Adv. Opt. Mater., 2020, 8, 1901429 CrossRef CAS.
- K. Song, J. Yuan, T. Shen, J. Du, R. Guo, T. Pullerits and J. Tian, Nanomaterials, 2019, 9, 1738 CrossRef CAS PubMed.
- N. Sukharevska, D. Bederak, V. M. Goossens, J. Momand, H. Duim, D. N. Dirin, M. V. Kovalenko, B. J. Kooi and M. A. Loi, ACS Appl. Mater. Interfaces, 2021, 13, 5195–5207 CrossRef CAS PubMed.
- C. Xiang, L. Wu, Z. Lu, M. Li, Y. Wen, Y. Yang, W. Liu, T. Zhang, W. Cao, S. W. Tsang, B. Shan, X. Yan and L. Qian, Nat. Commun., 2020, 11, 1646 CrossRef PubMed.
- S. Sun, N. T. Hartono, Z. D. Ren, F. Oviedo, A. M. Buscemi, M. Layurova, D. X. Chen, T. Ogunfunmi, J. Thapa, S. Ramasamy, C. Settens, B. L. DeCost, A. G. Kusne, Z. Liu, S. I. Tian, I. M. Peters, J. P. Correa-Baena and T. Buonassisi, Joule, 2019, 3, 1437–1451 CrossRef CAS.
- N. T. P. Hartono, J. Thapa, A. Tiihonen, F. Oviedo, C. Batali, J. J. Yoo, Z. Liu, R. Li, D. F. Marrón, M. G. Bawendi, T. Buonassisi and S. Sun, Nat. Commun., 2020, 11, 4172 CrossRef CAS PubMed.
- M. A. Soldatov, V. V. Butova, D. Pashkov, M. A. Butakova, P. V. Medvedev, A. V. Chernov and A. V. Soldatov, Nanomaterials, 2021, 11, 1–17 CrossRef.
- C. W. Coley, D. A. Thomas, J. A. M. Lummiss, J. N. Jaworski, C. P. Breen, V. Schultz, T. Hart, J. S. Fishman, L. Rogers, H. Gao, R. W. Hicklin, P. P. Plehiers, J. Byington, J. S. Piotti, W. H. Green, A. J. Hart, T. F. Jamison and K. F. Jensen, Science, 2019, 365, eaax1566 CrossRef CAS PubMed.
- J. Li, Y. Tu, R. Liu, Y. Lu and X. Zhu, Adv. Sci., 2020, 7, 1901957 CrossRef CAS PubMed.
- S. Langner, F. Häse, J. D. Perea, T. Stubhan, J. Hauch, L. M. Roch, T. Heumueller, A. Aspuru-Guzik and C. J. Brabec, Adv. Mater., 2020, 32, 1907801 CrossRef CAS PubMed.
- B. P. MacLeod, F. G. L. Parlane, T. D. Morrissey, F. Häse, L. M. Roch, K. E. Dettelbach, R. Moreira, L. P. E. Yunker, M. B. Rooney, J. R. Deeth, V. Lai, G. J. Ng, H. Situ, R. H. Zhang, M. S. Elliott, T. H. Haley, D. J. Dvorak, A. Aspuru-Guzik, J. E. Hein and C. P. Berlinguette, Sci. Adv., 2020, 6, eaaz8867 CrossRef CAS PubMed.
- A. Y. T. Wang, R. J. Murdock, S. K. Kauwe, A. O. Oliynyk, A. Gurlo, J. Brgoch, K. A. Persson, K. A. Persson and T. D. Sparks, Chem. Mater., 2020, 32, 4954–4965 CrossRef CAS.
- N. Artrith, K. T. Butler, F.-X. Coudert, S. Han, O. Isayev, A. Jain and A. Walsh, Nat. Chem., 2021, 13, 505–508 CrossRef CAS PubMed.
- O. Hoegh-Guldberg, D. Jacob, M. Taylor, T. Guillén Bolaños, M. Bindi, S. Brown, I. A. Camilloni, A. Diedhiou, R. Djalante, K. Ebi, F. Engelbrecht, J. Guiot, Y. Hijioka, S. Mehrotra, C. W. Hope, A. J. Payne, H.-O. Pörtner, S. I. Seneviratne, A. Thomas, R. Warren and G. Zhou, Science, 2019, 365, eaaw6974 CrossRef CAS PubMed.
| This journal is © The Royal Society of Chemistry 2022 |