
SpectraFP: a new spectra-based descriptor to aid in cheminformatics, molecular characterization and search algorithm applications†
 *a
Vitor M.
Oliveira,
a
Flávio O.
Sanches-Neto,
ab
Renan Z.
Wilhelms
a
and
Luiz H. K.
Queiroz Júnior
*a
*a
Vitor M.
Oliveira,
a
Flávio O.
Sanches-Neto,
ab
Renan Z.
Wilhelms
a
and
Luiz H. K.
Queiroz Júnior
*a
Abstract
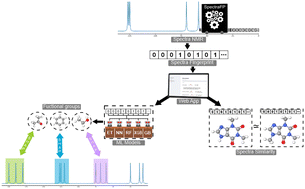
We have developed an algorithm to generate a new spectra-based descriptor, called SpectraFP, in order to digitalize the chemical shifts of 13C NMR spectra, as well as potentially important data from other spectroscopic techniques. This descriptor is a fingerprint vector with defined sizes and values of 0 and 1, with the ability to correct chemical shift fluctuations. To explore the applicability of SpectraFP, we outlined two application scenarios: (1) the prediction of six functional groups by machine learning (ML) models and (2) the search for structures based on the similarity between the query spectrum and spectra in an experimental database, both in the SpectraFP format. For each functional group, five ML models were built and validated following the OECD principles: internal and external validations, applicability domains, and mechanistic interpretations. All the models resulted in high goodness-of-fit for the training and test sets with MCC respectively between 0.626 and 0.909 and 0.653 and 0.917, and J ranging from 0.812 to 0.957 and 0.825 to 0.961. Using the SHAP (SHapley Additive exPlanations) approach, the mechanistic interpretations of the models were explored; the results indicated that the most important variables for model decision making were coherent with the expected chemical shifts for each functional group. Several metrics, including Tanimoto, geometric, arithmetic, and Tversky, can be used to perform the similarity calculation for the search algorithm. This algorithm can also incorporate additional variables, such as the correction parameter and the difference between the amount of signals in the query spectrum and the database spectra, while preserving its high performance speed. We hope that our descriptor can link information from spectroscopic/spectrometric techniques with ML models to expand the possibilities in understanding the field of cheminformatics. All databases and algorithms developed for this work are open sources and freely accessible.
 Please wait while we load your content...
Please wait while we load your content...

