
Information-theoretical measures identify accurate low-resolution representations of protein configurational space†

Abstract
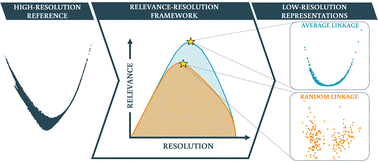
The steadily growing computational power employed to perform molecular dynamics simulations of biological macromolecules represents at the same time an immense opportunity and a formidable challenge. In fact, large amounts of data are produced, from which useful, synthetic, and intelligible information has to be extracted to make the crucial step from knowing to understanding. Here we tackled the problem of coarsening the conformational space sampled by proteins in the course of molecular dynamics simulations. We applied different schemes to cluster the frames of a dataset of protein simulations; we then employed an information-theoretical framework, based on the notion of resolution and relevance, to gauge how well the various clustering methods accomplish this simplification of the configurational space. Our approach allowed us to identify the level of resolution that optimally balances simplicity and informativeness; furthermore, we found that the most physically accurate clustering procedures are those that induce an ultrametric structure of the low-resolution space, consistently with the hypothesis that the protein conformational landscape has a self-similar organisation. The proposed strategy is general and its applicability extends beyond that of computational biophysics, making it a valuable tool to extract useful information from large datasets.
- This article is part of the themed collection: Soft Matter Emerging Investigators Series
 Please wait while we load your content...
Please wait while we load your content...

