
Multi-omics data integration approaches for precision oncology

Abstract
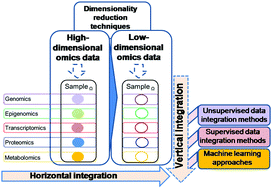
High-throughput technologies used in molecular biology have been pivotal to enhance the molecular characterization of human malignancies, allowing multiple omics data types to be available for cancer researchers and practitioners. In this context, appropriate data integration strategies are required to gain new insights from omics high-dimensional data. Yet, in order to extract valuable knowledge from this kind of information in an efficient manner, different approaches to reduce data dimensionality should be considered in multi-omics data integration pipelines. Multi-omics data integration approaches are mainly classified according to the label availability. Unsupervised data integration only draws inference from inputs without prior labels, whereas its supervised counterpart models allow incorporating known phenotype labels to improve the accuracy of high-throughput biomedical data analyses. However, the real value of the above mentioned approaches lies in their sequential combination with machine learning methods. It represents a major challenge for implementing multi-omics data analysis pipelines but it can certainly improve the decision-making process in the diagnosis and clinical management of cancer. The present review addresses the impact of current multi-omics data integration approaches, and their synergy with machine learning approaches, on the precision oncology field.
 Please wait while we load your content...
Please wait while we load your content...