
Identification of bioprivileged molecules: expansion of a computational approach to broader molecular space†
 b
and
Linda J.
Broadbelt
*c
b
and
Linda J.
Broadbelt
*c
Abstract
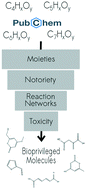
As interest in biobased chemicals grows, and their application space expands, computational tools to navigate molecule space as a complement to experimental approaches are imperative. This work expands upon previous work that identified candidate bioprivileged molecules from the C6HxOy (C6) subspace. It refines the framework that was developed previously to better refine the molecules according to their biological origin and applies it to three new subspaces of chemical structure: C4HxOy (C4), C5HxOy (C5), and C7HxOy (C7). For C5 and C7, roughly the top 100 bioprivileged candidates were identified, and the enhanced framework was applied to recast slightly the previous list of the top 100 C6 molecules. In addition, all top candidates were analyzed for their key functional moieties using a random forest model, and this algorithm was applied to compare the functional group space occupied by bioprivileged molecules of various databases of molecules with a focus on evaluating how closely the molecules were aligned with those known to biology. Furthermore, with the present work's focus on automation and data science principles, the framework can be easily expanded to include other chemical formulae to screen for bioprivileged candidates. This in turn facilitates the retrosynthesis process inherent in the framework to identify those bioprivileged intermediates in other subspaces that lead to target molecules.
- This article is part of the themed collection: 2021 MSDE Symposium Collection
 Please wait while we load your content...
Please wait while we load your content...

