
Data undersampling models for the efficient rule-based retrosynthetic planning†
 *a
*a
Abstract
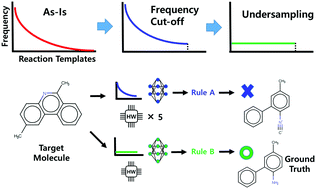
Computer-aided retrosynthetic planning for organic molecules, which is based on a large synthetic database, is a significant part of the recent development of autonomous robotic chemists. As in other AI fields, however, the class imbalance problem in the dataset affects the prediction performance of retrosynthetic paths. Here, we demonstrate that applying undersampling models to the imbalanced reaction dataset can improve the prediction of retrosynthetic templates for target molecules. We report improvements in the top-1 and top-10 prediction accuracies by 13.8% (13.1, 5.4%) and 8.8% (6.9, 2.4%) for undersampling based on the similarity (random, dissimilarity) clustering of molecular structures of products, respectively. These results demonstrate the importance of deep understanding of the statistical distribution, internal structure, and sampling for the training dataset. For practical applications, the target-oriented undersampling model is proposed and confirmed by the improved prediction performance of 9.3 and 4.2% for the top-1 and top-10 accuracies, respectively.
 Please wait while we load your content...
Please wait while we load your content...

