
Bayesian analysis of data from segmented super-resolution images for quantifying protein clustering†

Abstract
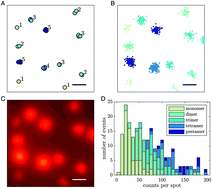
Super-resolution imaging techniques have largely improved our capabilities to visualize nanometric structures in biological systems. Their application further permits the quantitation relevant parameters to determine the molecular organization and stoichiometry in cells. However, the inherently stochastic nature of fluorescence emission and labeling strategies imposes the use of dedicated methods to accurately estimate these parameters. Here, we describe a Bayesian approach to precisely quantitate the relative abundance of molecular aggregates of different stoichiometry from segmented images. The distribution of proxies for the number of molecules in a cluster, such as the number of localizations or the fluorescence intensity, is fitted via a nested sampling algorithm to compare mixture models of increasing complexity and thus determine the optimum number of mixture components and their weights. We test the performance of the algorithm on in silico data as a function of the number of data points, threshold, and distribution shape. We compare these results to those obtained with other statistical methods, showing the improved performance of our approach. Our method provides a robust tool for model selection in fitting data extracted from fluorescence imaging, thus improving the precision of parameter determination. Importantly, the largest benefit of this method occurs for small-statistics or incomplete datasets, enabling an accurate analysis at the single image level. We further present the results of its application to experimental data obtained from the super-resolution imaging of dynein in HeLa cells, confirming the presence of a mixed population of cytoplasmic single motors and higher-order structures.
- This article is part of the themed collection: 2020 PCCP HOT Articles
 Please wait while we load your content...
Please wait while we load your content...

