
Training fully connected networks with resistive memories: impact of device failures

Abstract
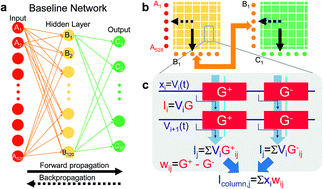
Hardware accelerators based on two-terminal non-volatile memories (NVMs) can potentially provide competitive speed and accuracy for the training of fully connected deep neural networks (FC-DNNs), with respect to GPUs and other digital accelerators. We recently proposed [S. Ambrogio et al., Nature, 2018] novel neuromorphic crossbar arrays, consisting of a pair of phase-change memory (PCM) devices combined with a pair of 3-Transistor 1-Capacitor (3T1C) circuit elements, so that each weight was implemented using multiple conductances of varying significance, and then showed that this weight element can train FC-DNNs to software-equivalent accuracies. Unfortunately, however, real arrays of emerging NVMs such as PCM typically include some failed devices (e.g., <100% yield), either due to fabrication issues or early endurance failures, which can degrade DNN training accuracy. This paper explores the impact of device failures, NVM conductances that may contribute read current but which cannot be programmed, on DNN training and test accuracy. Results show that “stuck-on” and “dead” devices, exhibiting high and low read conductances, respectively, do in fact degrade accuracy performance to some degree. We find that the presence of the CMOS-based and thus highly-reliable 3T1C devices greatly increase system robustness. After studying the inherent mechanisms, we study the dependence of DNN accuracy on the number of functional weights, the number of neurons in the hidden layer, and the number and type of damaged devices. Finally, we describe conditions under which making the network larger or adjusting the network hyperparameters can still improve the network accuracy, even in the presence of failed devices.
- This article is part of the themed collection: New memory paradigms: memristive phenomena and neuromorphic applications
 Please wait while we load your content...
Please wait while we load your content...

