
What if the number of nanotoxicity data is too small for developing predictive Nano-QSAR models? An alternative read-across based approach for filling data gaps

Abstract
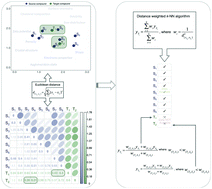
Over the past decade, computational nanotoxicology, in particular Quantitative Structure–Activity Relationship models (Nano-QSAR) that help in assessing the biological effects of nanomaterials, have received much attention. In effect, a solid basis for uncovering the relationships between the structure and property/activity of nanoparticles has been created. Nonetheless, six years after the first pioneering computational studies focusing on the investigation of nanotoxicity were commenced, these computational methods still suffer from many limitations. These are mainly related to the paucity of widely available, systematically varied, libraries of experimental data necessary for the development and validation of such models. This results in the still-low acceptance of these methods as valuable research tools for nanosafety and raises the query as to whether these methods could gain wide acceptance of regulatory bodies as alternatives for traditional in vitro methods. This study aimed to give an answer to the following question: How to remedy the paucity of experimental nanotoxicity data and thereby, overcome key roadblock that hinders the development of approaches for data-driven modeling of nanoparticle properties and toxicities? Here, a simple and transparent read-across algorithm for a pre-screening hazard assessment of nanomaterials that provides reasonably accurate results by making the best use of existing limited set of observations will be introduced.
 Please wait while we load your content...
Please wait while we load your content...

