
A database assisted protein structure prediction method via a swarm intelligence algorithm
 a
a
Abstract
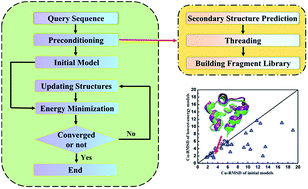
The complex and rugged potential energy landscape has made protein structure prediction a challenging task in computational biology. Here, we propose an efficient protein structure prediction method combining both template-based and template-free methods. Specifically, the initial protein conformations can be built by a non-redundant protein database and random sampling method with constraints of the secondary structure of the proteins. Three different structure evolution methods including improved particle swarm optimization (PSO) algorithm, random perturbation and fragment substitution are employed to update the protein structures while keeping the secondary structures the same. The present method is benchmarked on several known protein structures with distinct folding patterns, including α proteins, β proteins and αβ proteins. The high success rate and the accuracy of the results demonstrate the reliability of this method.
 Please wait while we load your content...
Please wait while we load your content...

