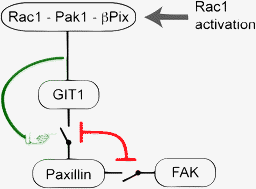
Biochemical research has yielded an extensive amount of information about dependencies between protein interactions, as generated by allosteric regulations, steric hindrance and other mechanisms. Collectively, this information is valuable for understanding large intracellular protein networks. However, this information is sparsely distributed among millions of publications and documented as freely styled text meant for manual reading. Here we develop a computational approach for extracting information about interaction dependencies from large numbers of publications. First, keyword-based tokenization reduces full papers to short strings, facilitating an efficient search for patterns that are likely to indicate descriptions of interaction dependencies. Sentences that match such patterns are extracted, thereby reducing the amount of text to be read by human curators. Application of this approach to the integrin adhesome network extracted from 59 933 papers 208 short statements, close to half of which indeed describe interaction dependencies. We visualize the obtained hypernetwork of dependencies and illustrate that these dependencies confine the feasible mechanisms of adhesion sites assembly and generate testable hypotheses about their switchability.
You have access to this article
 Please wait while we load your content...
Something went wrong. Try again?
Please wait while we load your content...
Something went wrong. Try again?
