
Understanding the molecular information contained in principal component analysis of vibrational spectra of biological systems
Abstract
K-means clustering followed by Principal Component Analysis (
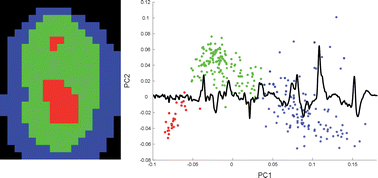
K-means clustering followed by Principal Component Analysis (
F. Bonnier and H. J. Byrne, Analyst, 2012, 137, 322 DOI: 10.1039/C1AN15821J
To request permission to reproduce material from this article, please go to the Copyright Clearance Center request page.
If you are an author contributing to an RSC publication, you do not need to request permission provided correct acknowledgement is given.
If you are the author of this article, you do not need to request permission to reproduce figures and diagrams provided correct acknowledgement is given. If you want to reproduce the whole article in a third-party publication (excluding your thesis/dissertation for which permission is not required) please go to the Copyright Clearance Center request page.
Read more about how to correctly acknowledge RSC content.
 Please wait while we load your content...
Please wait while we load your content...

