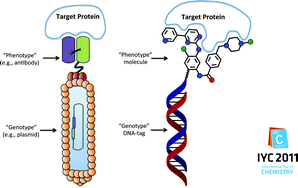
The identification of specific binding molecules is a central problem in chemistry, biology and medicine. Therefore, technologies, which facilitate ligand discovery, may substantially contribute to a better understanding of biological processes and to drug discovery. DNA-encoded chemical libraries represent a new inexpensive tool for the fast and efficient identification of ligands to target proteins of choice. Such libraries consist of collections of organic molecules, covalently linked to a unique DNA tag serving as an amplifiable identification bar code. DNA-encoding enables the in vitro selection of ligands by affinity capture at sub-picomolar concentrations on virtually any target protein of interest, in analogy to established selection methodologies like antibody phage display. Multiple strategies have been investigated by several academic and industrial laboratories for the construction of DNA-encoded chemical libraries comprising up to millions of DNA-encoded compounds. The implementation of next generation high-throughput sequencing enabled the rapid identification of binding molecules from DNA-encoded libraries of unprecedented size. This article reviews the development of DNA-encoded library technology and its evolution into a novel drug discovery tool, commenting on challenges, perspectives and opportunities for the different experimental approaches.
You have access to this article
 Please wait while we load your content...
Something went wrong. Try again?
Please wait while we load your content...
Something went wrong. Try again?


