
 Open Access Article
Open Access Article This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported Licence
This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported LicenceA liquid crystal-based biomaterial platform for rapid sensing of heat stress using machine learning
Prateek
Verma
 a,
Elizabeth
Adeogun
a,
Elizabeth S.
Greene
b,
Sami
Dridi
b,
Ukash
Nakarmi
c and
Karthik
Nayani
*a
a,
Elizabeth
Adeogun
a,
Elizabeth S.
Greene
b,
Sami
Dridi
b,
Ukash
Nakarmi
c and
Karthik
Nayani
*a
aDepartment of Chemical Engineering, University of Arkansas, Fayetteville, Arkansas, USA. E-mail: knayani@uark.edu
bDepartment of Poultry Science, University of Arkansas, Fayetteville, Arkansas, USA
cDepartment of Computer Science and Computer Engineering, University of Arkansas, Fayetteville, Arkansas, USA
First published on 18th September 2024
Abstract
Novel biomaterials that bridge the knowledge gap in coupling molecular/protein signatures of disease/stress with rapid readouts are a critical need of society. One such scenario is an imbalance between bodily heat production and heat dissipation which leads to heat stress in organisms. In addition to diminished animal well-being, heat stress is detrimental to the poultry industry as poultry entails fast growth and high yields, resulting in greater metabolic activity and higher body heat production. When stressed, cells overexpress heat shock proteins (such as HSP70, a well-established intracellular stress indicator) and may undergo changes in their mechanical properties. Liquid crystals (LCs, fluids with orientational order) are facile sensors as they can readily transduce chemical signals to easily observable optical responses. In this work, we introduce a hybrid LC–cell biomaterial within which the difference in the expression of HSP70 is linked to optical changes in the response pattern via the use of convolutional neural networks (CNNs). The machine-learning (ML) models were trained on hundreds of such LC-response micrographs of chicken red blood cells with and without heat stress. The trained models exhibited remarkable accuracy of up to 99% on detecting the presence of heat stress in unseen microscopy samples. We also show that cross-linking chicken and human RBCs using glutaraldehyde in order to simulate a diseased cell was an efficient strategy for planning, building, training, and evaluating ML models. Overall, our efforts build towards designing biomaterials that can rapidly detect disease in organisms that is accompanied by a distinct change in the mechanical properties of cells. We aim to eventuate CNN-enabled LC-sensors that can rapidly report the presence of disease in scenarios where human judgment could be prohibitively difficult or slow.
Liquid crystals (LCs, fluids with orientational ordering) have been used as the basis for a range of chemical and biological sensors.1–6 The long-range order of LCs that leads to fast reorganization of the molecules on macro-scales in response to molecular-level changes that the LC detects at an interface makes them suitable materials for a range of sensor-related contexts. However, despite these advances, reports utilizing LCs to detect molecular level changes in cellular expression are scarce. From a fundamental perspective, our study advances a fundamentally new class of biomaterials with internal ordering and properties that can be finely tuned, enabling the sharing of curvature strain between cells and LCs. These biomaterials therefore can act as sensors/reporters of the mechanical properties of cells – which are intimately tied to their health. We connect these changes in cellular properties to molecular signatures of stress using a machine leaning based approach to rapidly report on the health of the organism.
Heat stress (HS) occurs when an animal is unable to regulate its body temperature in response to high environmental temperature, resulting in hyperthermia (increased body temperature). HS is detrimental to the well-being of an animal, causing discomfort, organ damage, or even death. In the livestock and poultry industry, HS is known to lead to massive economic losses in addition to decreased welfare of the animals.7 Increasing global temperatures due to climate change and the ever-increasing demand for meat production have prompted research efforts toward better understanding the effects of heat stress and ways to alleviate them.8,9 HS is a particularly important stressor for the poultry industry, as poultry entails fast growth and high yields, resulting in greater metabolic activity, higher body heat production, and decreased thermo-tolerance.7,10–13 In fact, it is estimated that the amount of metabolic heat produced by the modern broiler has increased by 30% over the last 20 years.9 In poultry, studies of HS and its effect on feed intake,10,14,15 immunosuppression,16–18 growth,10,13 gut health,10,11,15 meat yields,10,13,19etc., as well as its effect on physiological responses, such as increased production of heat shock proteins (HSPs, such as HSP70)20,21 or any other biomarker (such as GRP75 or orexin),22–24 have gained momentum recently. Facile methods to rapidly characterize the health of poultry and livestock are important in a broad range of contexts, which include understanding their health/stress status, welfare, and prediction of diseases and stressors.7,9 However, there remains a wide knowledge gap in coupling molecular/protein signatures of disease/stress to rapid readouts. Aside from economic concerns, overall animal well-being is greatly diminished by HS and has become a prominent concern for consumers. Therefore, there is an urgent need to develop rapid-reporting methods that can inform on whether the organism is experiencing HS.
Here, we introduce the concept of rapidly characterizing the mechanical properties of red blood cells (RBCs) using LCs. A key aspect of the development of our LC–cell sensor platform involves building ML-based convolutional neural networks (CNNs) that can generate classifiers to separate image sets of RBCs dispersed within LCs into healthy ones and those of chickens experiencing HS.25–27
The fundamental hypothesis that drives our research is that cells overexpressing well-established intracellular stress chaperones such as heat shock proteins (HSP70) also undergo cellular changes, for instance, the mechanical properties of cellular membranes, which, in turn, can be detected by dispersing them in LCs. The expression levels of HSP70 in the LC–cell biomaterial will be used to define our classes for the CNN framework we develop. Current methods for monitoring stress rely on the identification of molecular and protein markers such as corticosterone and HSPs.28,29 Although methods that report on molecular and protein markers have increased our understanding of HS, these methods are usually time-intensive and are not immediately accessible to the end user (farmer, technician on a production line) seeking to make informed decisions on the health and stress levels of chickens. Therefore, there is a critical need to identify reliable and rapid ways to monitor HS in poultry.28,29
A key innovation in this work and our methodology is to connect the expression of HSP70 to rapid optical readouts, which characterize the health of the blood cells of chickens. Recently, an LC-based technique has been employed to rapidly report on the mechanical properties of human RBCs.30 The underlying principle is depicted in Fig. 1. Molecules of LC (blue ellipsoids) are perturbed from the preferred parallel orientation when an inclusion, for instance, a colloidal particle, is present within the LC fluid (blue ellipsoids bend around the yellow particle in Fig. 1A). This creates an orientational strain within the LC, as depicted in Fig. 1A. However, if the inclusion is soft, such as an RBC, the LC can stretch out the cell and release some of the strain contained within the fluid. This sharing of strain is intimately coupled with the mechanical properties of RBCs, which we expect to change as they experience HS. Critically, we have previously shown that the mechanical properties of individual cells (elastic shear modulus from 2 to 16 × 10−6 N m−1) are stretched by an LC to different extents. The energetic cost associated with straining an LC about an RBC was estimated as Ka, in which K ∼ 10 pN (a Frank elastic constant of the LC) and a ∼10 μm (size of a cell), corresponding to ∼104kT, which is a sufficiently large energy for deforming a cell membrane.30 This simple scaling argument leads to the prediction that the magnitudes of the elastic energies associated with deformation of the LC and RBC are comparable, and thus that RBCs dispersed in LCs would exhibit shape-responses that reflect an interplay of the mechanical properties of both the LC and RBC. Thereby we hypothesize that LCs enable rapid readouts of the mechanical properties of cells, for instance, a simple experiment of dispersing a few μl of blood in LCs can be used to understand the health status of over a thousand cells within a few minutes.30,31
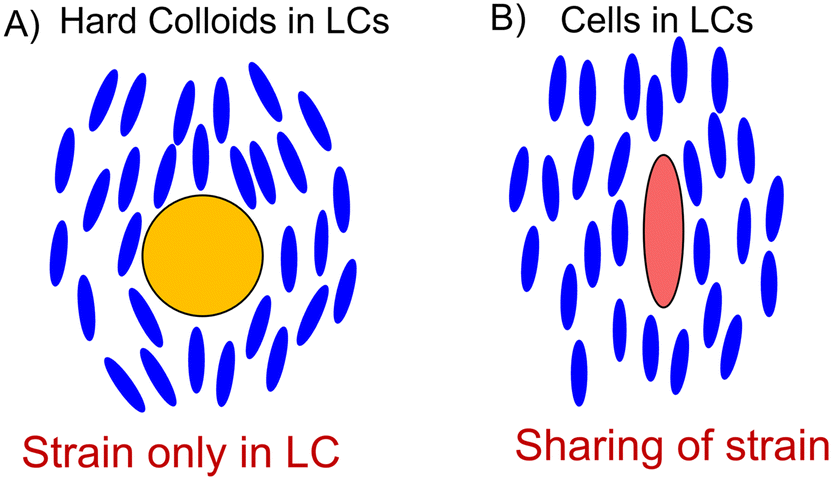 | ||
| Fig. 1 Schematic depicting the fundamental principle involved in our work. A) A hard colloid such as a silica particle induces strain in the LC fluid. B) A soft cell membrane stretches along the LC direction and releases the strain. | ||
Physiological mechanisms of chickens' response to HS or to any ‘cure' employed to fight HS are far from being understood. Such studies require controlled and careful broiler studies, spanning weeks, and more often than not, the blood (for elaborate examination of genes or the biomarkers) or even sacrificing the chickens. Steps are being taken towards non-invasive examination of HS, such as using feather HSP70 (a specific HS protein).21 To help with this, the authors ideate that the wealth of existing information, and more easily obtainable information, could be put to good use by training ML algorithms to aid in rapid identification of HS, HS biomarkers, HS susceptibility of various chicken subspecies, effectiveness of HS treatments, and so on.
The motivation for this work lies in our initial observation that there was a dramatic difference in the extent of the strain of RBCs of modern-day broiler chickens and their jungle fowl ancestors, as presented in Fig. 2. The LC we use is disodium cromoglycate, whose disc-shaped molecular structure is shown in Fig. 2A.30,32,33 The self-assembly of the disc-like DSCG molecules into rod-like stacks is depicted in Fig. 2B.1,30,32,34,35Fig. 2C depicts the ailments experienced by chickens experiencing heat stress. Consistent with past observations, we see in Fig. 2D that the HSP70 expression is distinct between two poultry species, namely, jungle fowl and the Cobb 700 strain (strain D).10,21,23 Our RT-qPCR studies using the 2−ΔΔCT method reveal that HSP70 is overexpressed in the Cobb 700 strain whereas the jungle fowl expresses HSP70 at normal levels when the cells are subjected to HS (maintained at 45 °C for 2 h) as shown in Fig. 2D. Briefly, the 2−ΔΔCT method is a simple formula used in order to calculate the relative fold HSP70 expression of samples when performing qPCR. The key takeaway from Fig. 2D is that the HSP70 expression is significantly higher in the Cobb 700 strain in comparison with the jungle fowl under heat stress conditions. Our preliminary observations reveal that transfer of chicken blood cells into LCs formed by DSCG leads to qualitative changes in the shapes of the RBCs as presented in Fig. 2E and F. Chicken blood cells that assume ellipsoidal shapes under stress-free conditions in a buffer solution are strained to spindle-like morphologies with pointed tips when placed within an LC (Fig. 2E and F). Fig. 2E comprises RBCs extracted from a commercial boiler strain (Cobb 700) while Fig. 2F shows RBCs extracted from south-east jungle fowl. The micrographs of Fig. 2E and F are feature rich and reveal several key differences. For instance, the extent of stretching of RBCs, the orientation of RBCs and the texture of the LC around the RBCs are all distinct in the two micrographs. These image features are a direct result of the sharing of the strain between the RBCs and the LCs (as depicted in Fig. 1).
 | ||
| Fig. 2 (A) A disodium cromoglycate (DSCG) liquid crystal molecule. (B) DSCG molecules, represented by a purple oval, stack to form a liquid crystal phase. C) Qualitative effects of heat stress on chickens and D) relative expression of HSP70 determined using the 2−ΔΔCT method, with normalization to 18 s expression. (E and F) Optical micrographs of red blood cells (RBCs) dispersed in the disodium cromoglycate (DSCG) liquid crystal from E) the Cobb 700 strain and F) jungle fowl. Imaging was performed in cross-polarized mode. | ||
Motivated by the scaling arguments, we employ CNNs in this study to classify the state of health of the cells. CNNs have emerged as an ideal machine learning architecture for classification of images. Image classification through CNNs works by identifying and separating critical information (features) in the image using nonlinear convolutional operation and finding an optimum hyper plane/threshold for classification (Fig. 3A). Since the advent of architectures such as AlexNet36 and VGGNet,37 classification of images has become faster and more accurate. CNNs consist of convolutional layers that perform a mathematical convolution operation on the incoming image using a small filter (also called ‘kernel’) of size such as 3 × 3 pixels (shown in green in Fig. 3B). CNNs learn by optimizing the values of the filter which results in correct identification of the images. Sets of images with known labels (also called ‘classes’) are fed through the CNNs repeatedly for learning until a good enough accuracy is achieved. Through convolutional learning, CNNs have shown to be able to detect edges, shapes, and other, sometimes imperceptible, features of an image which enables them to perform the classification. Fig. 3B shows progression of data through a typical CNN, composed of convolutional layers, each followed by a max-pooling layer (that reduces the 2D-image size) ending in a single output (for binary classifications) that denotes the probability of the data belonging to one out of the two classes. In this study, we train the CNN algorithm on healthy human and chicken cells, heat-stressed chicken cells and also crosslinked human cells which simulate unhealthy RBCs (glutaraldehyde was used to crosslink the RBCs and stiffen them). Crosslinking of cells with glutaraldehyde has been used as a mimic for diseased cells, for instance for cells inflicted with malaria, wherein availability of real samples might be challenging.38 Therefore, we started training the CNN model with glutaraldehyde crosslinked data for mimicking unhealthy cells for scenarios where getting actual sample data might be challenging. In this particular study, we have plenty of actual sample data of the unhealthy cells and therefore the crosslinked data set provides additional information for the algorithm to classify cells as unhealthy. Optical micrographs of healthy RBCs in DSCG and of crosslinked and heat-stressed RBCs in DSCG were used to train a simple convolutional neural network (CNN).39 Eventually, chicken RBCs expressing HSP70 were dispersed in LCs to test our hypothesis and confirm whether HS could be detected through visual observation as well as through CNN classification.
 | ||
| Fig. 3 (A, top) A hyperplane obtained through nonlinear transformation during neural network training helps separate data into different classes. Inseparable data (squares and circles) are made separable after the calculation of the hyperplane. (B, bottom) The CNN-based machine learning model used in this study. Data in image pixels flow from left to right through three convolutional (green) and three pooling (gray) layers culminating in a single output value. A 3 × 3 kernel, pixel sizes of images, and activation functions used in this study are noted in the figure. | ||
Experimental section
Live subject statement
All animal procedures were performed in accordance with the guidelines for care and use of laboratory animals as per the University of Arkansas's Institutional Animal Care and Use Committee (IACUC) with an approved protocol #21050. Blood was collected via heart puncture from 7d old males and placed into K2 EDTA blood collection tubes (Becton Dickinson, Franklin Lakes, NJ) to prevent coagulation. To isolate RBCs, blood collection tubes were centrifuged at 3000 rpm for 3 min at 4 °C. Isolated cells were diluted in RPMI1640 (Life Technologies, Carlsbad, CA) supplemented with 10% FBS and 1% penicillin/streptomycin. All cells were maintained at 37 °C in a humidified atmosphere of 5% CO2 and 95% air. Heat stress (HS) was induced by incubating cells at 45 °C for 2 h.Materials
Human RBCs (extracted from whole blood) were purchased from Innovative Research Inc. (Novi, Michigan, USA). A 154 mM solution of NaCl was prepared for dispersing RBCs. Cross-linking of RBCs was performed using glutaraldehyde (grade I, 25% aqueous) purchased from Sigma Aldrich. Disodium cromoglycate (DSCG) was purchased from TCI America (Portland, Oregon, USA). The molecular structure of DSCG and its LC stacking are shown in Fig. 2. Deionized water with a resistivity of 18.2 MΩ cm was obtained using a Milli-Q system (by Millipore) and was used wherever water was required.Computational
All computations and programs were run on a Linux machine running Ubuntu 20.04 LTS using hardware consisting of an i7-11700K 3.6 GHz CPU, 32 GB of DDR4 3200 MHz RAM, and a GTX 1660 Ti GPU. Python (version 3.9.5) was primarily used for programming. Within Python, the TensorFlow library using Keras API was used to build and train neural network models, image processing was performed using the Python Image Library (PIL), and numerical data were primarily plotted using the Matplotlib library.Sample preparation and optical microscopy
As-received RBCs were dispersed in a 154 mM NaCl isotonic solution; an isotonic solution ensured that cells maintained their natural elliptical shape. Typically, about 5 μL RBCs were mixed in about 60 μL isotonic NaCl solution to obtain the RBC dispersion. A 17.3% (w/v) DSCG aqueous solution was prepared by mixing DSCG in water in a vortex mixer for 4 hours. Previous studies have shown that 17.3% (w/v) aqueous DSCG is isotonic with the interiors of an RBC, which ensured that the RBC shape change was solely due to the mechanical interaction between the LC field and the RBC.Since RBCs naturally strain when put in a DSCG solution, strained cell samples were obtained by adding 2 μL of dispersed RBCs to 60 μL of DSCG solution and gently swirled. To prevent straining in DSCG and obtain crosslinked cell samples, glutaraldehyde was used to crosslink and stiffen the RBCs. A stock solution of 5% v/v of glutaraldehyde in water was used; 5 μL RBCs were slowly pipetted into 0.2 μL of this stock to effect crosslinking. The final glutaraldehyde concentration in the cells was chosen to be around 0.2% to make sure that the individual cells are fixated and do not form aggregates. The solution was slowly mixed on a shaker for an hour to allow glutaraldehyde to completely crosslink. About 2 μL of crosslinked RBCs were then added to 60 μL of DSCG solution and gently swirled. HSP70 RBCs were collected from 21 day old broiler chickens that were exposed to acute heat stress (35 °C for 2 hours). Whole blood was collected into EDTA coated tubes and the RBCs were isolated from the whole blood by centrifugation and washing with PBS three times.
For imaging, RBC samples were transferred (post swirling) to microscope slides. Micrographs were obtained using an Olympus BX41 optical microscope fitted with a 40× objective lens. Polarized and brightfield micrograph images were captured in the presence and absence of a polarizer, respectively.
Building datasets
Images from the microscope(s) were obtained in a variety of sizes, aspect ratios and formats. Images with differences in tint, brightness, contrast, and lighting were included. Images with scratch marks on the microscope slides or of samples containing foreign objects (like dirt or lint) or containing things other than the RBCs were also included. This was done to increase the diversity in the dataset, keeping in mind the plausible diversity that the trained model may encounter during testing and after employment.Collected images were at least 1800 px in height and either 3![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :2 or 4:3 in aspect ratio (width to height ratio), and were saved in jpeg, bmp, tiff, or raw format. All images were RGB (containing information in red, green, and blue channels). Before building the dataset, all images were cropped and resized to the same size and converted to jpeg format. A square section from the center of the image was selected. This was done to (1) discard the sides which sometimes contained portion of the microscope slide or stage outside of the actual sample and (2) standardize the aspect ratio to 1:1 from 3:2 or 4:3. The resulting square image was scaled down in size to exactly 1000 px wide and 1000 px tall using the bicubic resizing algorithm in the PIL.
:2 or 4:3 in aspect ratio (width to height ratio), and were saved in jpeg, bmp, tiff, or raw format. All images were RGB (containing information in red, green, and blue channels). Before building the dataset, all images were cropped and resized to the same size and converted to jpeg format. A square section from the center of the image was selected. This was done to (1) discard the sides which sometimes contained portion of the microscope slide or stage outside of the actual sample and (2) standardize the aspect ratio to 1:1 from 3:2 or 4:3. The resulting square image was scaled down in size to exactly 1000 px wide and 1000 px tall using the bicubic resizing algorithm in the PIL.
Each image was assigned labels (such as species, chemicals used, magnification, etc.) that were stored in a tabular form within excel files. These labels were used to programmatically find images matching a certain criterion. For instance, polarized images of crosslinked chicken RBCs were found by logical querying of these labels: polarized is “True”, chemicals used contain “glutaraldehyde”, species is “chicken”, and cell type is “RBC”.
Ten distinct subsets of the dataset (called classes) were built using this process and are summarized in Table 1. Each class was shuffled and split into training (train), validation (val), and test (test) sets in a 70:15:15 ratio, respectively.
| Class or dataset name | Train | Val | Test |
|---|---|---|---|
| Brightfield micrograph | |||
| A. Crosslinked chicken | 112 | 24 | 24 |
| B. Healthy chicken | 585 | 125 | 125 |
| C. Crosslinked human | 350 | 75 | 75 |
| D. Healthy human | 350 | 75 | 75 |
| E. HS chicken | 489 | 105 | 105 |
| Polarized | |||
|---|---|---|---|
| A. Crosslinked chicken | 798 | 171 | 171 |
| B. Healthy chicken | 1264 | 271 | 271 |
| C. Crosslinked human | 390 | 83 | 83 |
| D. Healthy human | 350 | 75 | 75 |
| E. HS chicken | 423 | 90 | 90 |
Building the CNN
Convolutional neural networks (CNNs) were built using the TensorFlow library (that utilizes Keras API) in Python. Images from the datasets were imported using the flow_from_directory function of the Keras preprocessing module, which yields batches of images indefinitely during training. The preprocessing module was also set to randomly flip the images horizontally or vertically during training, to add to the richness of the dataset as part of the data augmentation process. The batch size was set to 32 and the imported image size was set to 500 × 500 pixels.A simple binary classifier CNN, meaning that it classified images into one of two input classes, was built. The model is schematically shown in Fig. 3B. The network begins with an input layer of 500 × 500 pixel images, which undergo convolution operations using a filter. These convolutional layers, each followed by a ReLU (rectified linear unit) activation function, extract features such as edges and textures from the images. Max-pooling layers are employed after each convolutional layer to downsample the feature maps, reducing their spatial dimensions while retaining essential information. The final layers involve flattening the pooled feature maps into a single vector, which is passed through a dense layer with a sigmoid activation function (maps the input to a value between 0 and 1) to classify the images at a single neuron. This neuron yielded the probability that a particular image belonged to one of the two classes. This architecture efficiently identified distinguishing features between healthy and stressed cells. The model's parameters are shown in Table 2. The model was compiled using the optimizer Adam and the loss function sparse_categorical_crossentropy. The performance of the model was measured using accuracy as the metric.
| Layer name (type) | Output shape | Params |
|---|---|---|
| conv2d_1 (conv2D) | (None, 498, 498, 16) | 448 |
| maxPooling-1 (maxpooling2D) | (None, 249, 249, 16) | 0 |
| conv2d_2 (conv2D) | (None, 247, 247, 32) | 4640 |
| maxPooling-2 (maxpooling2D) | (None, 123, 123, 32) | 0 |
| conv2d-3 (conv2D) | (None, 121, 121, 64) | 18496 |
| maxPooling-3 (maxpooling2D) | (None, 60, 60, 64) | 0 |
| Flatten_1 (flatten) | (None, 230400) |
0 |
| Dense_1 (dense) | (None, 1) | 230401 |
| Total params: 253985 |
||
| Trainable params: 253985 |
||
Training the CNN
In a given machine-learning experiment, a model could be trained to distinguish between two of any of the classes shown in Table 1. Specifically, models were trained to distinguish between crosslinked and healthy cells (‘A and B’, ‘C and D’, ‘F and G’, ‘H and I’) and between healthy and HS chicken cells (‘B and E’, ‘G and J’). Experiments were depicted as the first initials of the class names (such as ‘AB’, ‘CD’ and so on) used in them, for convenience. Training was performed using the fit function on the training image set, and accuracy was calculated and recorded during training for both training and validation sets. The validation dataset plays a crucial role in any machine learning pipeline. It is used to assess the model's performance during training, providing a measure of how well the model generalizes to new, unseen data. This dataset helps in detecting overfitting by ensuring that the model does not simply memorize the training data but learns patterns that are applicable to broader contexts. Adjustments to the model's hyperparameters are made based on validation performance.A receiver operating characteristic (ROC) curve was plotted for each experiment for a range of decision thresholds (101 linearly spaced threshold values from 0 to 1) for predictions made on validation sets. The best threshold was selected to be the one that was closest to the point (0, 1) in the ROC plot. The confusion matrix corresponding to the best threshold has been reported. A confusion matrix was also calculated for the predictions made on the test set using the best threshold (that was evaluated on the validation set) and has been reported.
Fine-tuning hyperparameters
Hyperparameters – the batch size and learning rate (for Adam) – were found to be optimal (fastest conversion to maximum validation accuracy) when set to 32 and 0.0001, respectively. This optimization was performed for the experiments ‘AB’ and ‘GH’ and the hyperparameters were set as constants for all other experiments as they resulted in adequate convergence rates.Results and discussion
Datasets
One representative microscopy image from each class is shown in Fig. 4. Brightfield micrograph images (classes A–E) and the corresponding polarized images (classes F and G) are shown side-by-side. Fig. 4A through Fig. 4J show the optical micrographs of cells suspended in nematic LC phases of 17.3 wt% DSCG at 25 °C. Inspection of Fig. 4 reveals that the RBCs in the nematic phase of DSCG assume extended shapes with major axes aligned parallel to the far-field orientation of the LC (white arrow in Fig. 4). Cells crosslinked with glutaraldehyde (A, C, F and H) before suspending in the nematic phase of DSCG were observed to be less strained than the corresponding cells that were not crosslinked (B, D, G and I). In the selected images, this was evident when looking at the lengths, widths, and the shapes of the cells; the length and the aspect ratio of the strained (and therefore, healthy) cells were larger than those of the crosslinked cells. Between chicken and human RBCs, it was observed that the strained (i.e., healthy) chicken cells (B and G) had a higher aspect ratio than the human cells (D and I). This was also true for crosslinked chicken (A and F) and human cells (C and H). Notably, the shape difference between crosslinked and healthy chicken cells (A vs. B and F vs. G) was not as pronounced as the difference between crosslinked and healthy human cells (C vs. D and H vs. I). Lastly, heat-stressed chicken RBCs were observed to have a strain somewhere between the healthy (i.e., crosslinked) (B and G) and crosslinked (A and F) chicken RBCs. This observation was consistent with our hypothesis that heat stress causes changes in a healthy cell that can manifest as mechanical stiffening. | ||
| Fig. 4 Brightfield images of (A) crosslinked chicken red blood cells, (B) healthy chicken red blood cells, (C) crosslinked human red blood cells, (D) healthy human red blood cells and (E) heat stressed chicken red blood cells. Cross-polarized images of (F) crosslinked chicken red blood cells, (G) healthy chicken red blood cells, (H) crosslinked human red blood cells, (I) healthy human red blood cells and (J) heat stressed chicken red blood cells. The crosslinked cells were obtained by crosslinking with glutaraldehyde. The scale bar represents 20 μm. | ||
Classification of healthy and crosslinked RBCs
Fig. 5 shows the results from experiments AB, CD, FG, and HI that aimed towards the classification of healthy RBCs and crosslinked (unhealthy) RBCs submerged in LCs for both chickens and humans. These experiments served as a prelude to the core objective of this work, i.e., the successful identification of cells experiencing HS. These experiments served at least three important purposes – (1) establish the ability of CNNs to successfully identify straining of cells in LCs, (2) establish generalizability of this approach towards identification of cells with different mechanical properties not only due to HS, but also due to any biological response, and (3) assess the applicability of this approach to species other than chickens. Top to bottom in Fig. 5, the panels show the accuracies and the loss calculated on the training and the validation sets across 100 epochs of training, followed by the ROC curve and the confusion matrix obtained for the validation set, followed, finally, by the confusion matrix obtained for the test set. A validation accuracy of 100% was obtained for experiments using unpolarized images and greater than 97% for the experiments using polarized images at the end of the training. While the losses calculated for the training and validation sets were close to each other and reached zero for the unpolarized experiments, the loss for the validation set did not drop in sync with the training set for the polarized experiments and did not reach zero. | ||
| Fig. 5 Results from experiments for the classification of strained (healthy) and crosslinked (unhealthy) chicken or human RBCs carried out on datasets A and B (column AB), C and D (column CD), E and G (column EG), and H and I (column HI). Each column (top to bottom) shows accuracy achieved on training and validation sets over 100 epochs of training; loss on training and validation sets over 100 epochs of training; ROC curve for the validation set; confusion matrix for the validation set for the best threshold established from the ROC curve; confusion matrix for the test set obtained using the best threshold obtained on the validation set. | ||
Clearly, polarized images posed a greater challenge to CNNs. Polarized images have richer information concerning the cellular response in an LC field. The color gradients around a cell are representative of the LC director being disrupted by the presence, the shape, and the physical properties of the cell. These color gradients, which are absent in unpolarized images, may contain information about the cell’s physical properties, its biochemical signatures, and hence its health, which are not readily perceptible to human visual analysis. Longer range color gradients visible in the polarized images, which are not centered on the cell and not perturbed by the presence of the cells or foreign objects (like dust or a piece of fiber), likely don't contain information linked directly to the cell's response. Because the data labels for crosslinked or healthy samples were derived solely from the fact whether glutaraldehyde was used or not, the CNN's accuracy denoted the level at which it could successfully map the complex information in the images (especially the polarized ones) to the effects of glutaraldehyde on the cells. In this light, the accuracy of 97% was remarkable, given the complexities in the images.
Individual ‘accuracy vs. epoch curves’ revealed that accuracy improved faster for unpolarized images when compared to polarized images. A training accuracy of 99% was achieved, as early as, at the end of epoch 6 for AB, epoch 13 for CD, epoch 49 for EG, and epoch 41 for HI. Thus, learning was more difficult on polarized images. Additionally, a training duration of 100 epochs seemed to be sufficient for achieving the highest possible accuracy (indicated by the plateau in the curve), except in the case of EG, where just the training (not validation) accuracy looked like it could improve further if the training wasn't stopped. Neither the accuracy nor the loss curves showed any quintessential signs of over- or under-fitting. The imbalance and the diversity in the sizes of the classes did not affect the learning in any noticeable way as observed here, in turn, demonstrating the applicability of this approach in a testing environment where it will not be feasible to collect much data or collect data in a balanced way.
The ROC curves helped determine a binary decision threshold (probability above which the trained model decides that a particular image sample belongs to a particular class) that yielded the highest possible true positive rate at the lowest possible false positive rate. In simpler terms, the best threshold is one for which a point on the ROC curve is closest to the point (0, 1). There was some variation in the appearance of the ROC curves, with the curvature increasing as training became more difficult, but most data points were still nicely bunched up towards the upper left corner and edges. The confusion matrices corresponding to this ‘best threshold' for both the validation and test datasets revealed nothing out of the ordinary. Predictions were near perfect on the unpolarized images and at least 97% accurate on the polarized images, concurrent with the accuracies calculated by the model at the end of the training. A test accuracy of 100, 98.7, 97.7, and 98.1% was obtained for the experiments AB, CD, EG, and HI, respectively.
Classification of healthy and heat-stressed chicken RBCs
Fig. 6 shows the results from experiments BE and GJ performed on chicken RBCs, which aimed towards the classification of healthy cells and cells experiencing HS (unhealthy) submerged in LCs. Qualitatively, the results were similar to the results from the experiments in Fig. 5. Accuracy and loss plots had similar shapes and approached similar values by the time the training ended. ROC plots were similar too. A validation accuracy of 100% was obtained for experiments using unpolarized images and greater than 92% for experiments using polarized images. While the losses calculated for the training and validation sets were close to each other and reached zero for the unpolarized experiments, the loss for the validation set did not drop in sync with the training set for the polarized experiments and did not reach zero. | ||
| Fig. 6 Results from experiments for the classification of healthy and HS (unhealthy) chicken RBCs. Each column (top to bottom) shows the (1) accuracy and (2) loss achieved on training and validation sets, (3) the ROC curve and the corresponding (using the best threshold) confusion matrix for the (4) validation set and (5) test set. | ||
Here too, polarized images posed a greater challenge to the CNN algorithm. As described before, the color gradients around a cell, present in polarized images and absent in unpolarized images, are representative of the LC director being disrupted by the presence, the shape, and the physical properties of the healthy/HS cell and representative of the cell's physical properties, its biochemical signatures (like the production of HSP70), and health. Because the classification labels were derived solely from the fact whether the cell was heat-stressed or not, the CNN's performance denoted the level at which it could successfully map the complex information present in the images (especially the polarized ones) to the effects of HS. In this light, the accuracy of 92/94% for validation/test sets and higher was remarkable, given the myriad of humanly indistinguishable information present in the images: these complexities presumably being greater than the effects of glutaraldehyde alone.
Similar to the glutaraldehyde crosslinked system, individual ‘accuracy vs. epoch curves’ for healthy/HS cells revealed that accuracy improved faster for unpolarized images when compared to polarized images indicating that learning was more difficult on polarized images. A training duration of 100 epochs seemed to be sufficient for achieving the highest possible accuracy (indicated by the plateau in the curves). Neither the accuracy nor the loss curves, especially in conjunction with the ROC curves and the confusion matrices, showed any quintessential signs of over- or under-fitting. The dataset was still imbalanced and small for the healthy/HS pair but did not affect the learning in any noticeable way as observed here, in turn, demonstrating the applicability of this approach in a testing environment where it will not be feasible to collect much data or collect data in a balanced way.
The visual differences between healthy and crosslinked cells were more prominent than the differences between healthy and HS cells (Fig. 4). We characterized the shapes of the healthy and heat-stressed chicken RBCs by quantifying the cell major (rx) and minor axes (ry). A higher aspect ratio (rx/ry) indicates a more significant strain. Chicken RBCs, prior to straining, had an average aspect ratio of 1.5; upon applying mechanical strain, the aspect ratio increased to an average of 2.12 ± 0.64 for healthy cells and 1.85 ± 0.32 for heat-stressed cells. By comparing the variations in aspect ratio values of healthy and heat-stressed chicken RBCs, we observed that the healthy cells have a slightly higher strain than the heat-stressed cells; however, the datasets are not statistically different. Critically, the ML algorithm is able to identify the HS chicken cells with excellent accuracy (100% for unpolarized) even though the data sets are not statistically different.
Conclusions
A simple, lightweight, convolutional neural network ML model, 3 convolution layers deep, was found to be capable of distinguishing between minute differences in the shapes or the aspect ratios of RBCs. The model was trained on microscopy images of cells immersed in an isotonic solution of a nematic liquid crystal (DSCG). We demonstrate that the LC biomaterial would ‘sense’ small differences in the mechanical properties of cells, as evident from the changed shape of the cell or the liquid crystalline color pattern around the cells (in the polarized images), and could be used to detect the presence/onset of diseases or microbes in air or water in tandem with trained ML models. An underlying and important hypothesis that biochemical changes in an organism could affect mechanical changes in its cells makes for a rich and interesting endeavor for future researchers, similar to how the expression of HSP70 protein was shown to make the heat-stressed RBCs stiffer in this study.The 250k parameter model is easily trainable on GPU equipped personal computers using just a few hundred study-specific micrographs. The trained model is lightweight enough to fit in a sensor computer and fast enough to virtually instantly perform the classification on every new ‘photograph’. In the context of the current rise of foundation vision models, whose fine-tuning and training are prohibitively expensive and possible only at very large research laboratories, our approach is geared towards empowering labs and individuals all around the world to construct and train their own ML models on general or niche tasks related to imaging and/or sensing.
In experiments, it was found that crosslinking chicken and human RBCs using glutaraldehyde in order to simulate a diseased cell was an adequate strategy for planning, building, training, and evaluating valid ML models ahead of collecting actual training data. In our case, no model-tweaking was found to be necessary while going from the simulated to the real heat-stressed cells. Because biological data could often be available in less quantities and later in the study, we believe that our simulation example might come in handy for researchers looking to work on their ML models while waiting, or those looking to simply augment their data in an appropriate manner. The successful implementation of the CNN algorithm to rapidly identify HS also opens up new questions related to our line of investigation including: i) are final static responses (micrographs) enough to develop a ML classifier to discriminate (specify) different RBC strains? ii) How do the dynamic conditions (response of cells as a function of time under HS) contribute to developing efficient and specific classifiers? iii) Can static images under TN conditions predict the expression levels of HSP70 under HS conditions? To answer these questions, in future work we will focus on collecting and maintaining a large and diverse image database of strained and unstrained samples and develop dedicated deeper CNNs that are computationally efficient through the use of ResNets. Additionally, CNN frameworks that process multi-channel image datasets, that include spectral channels, and dynamic images, beyond conventional 3 channel RGB images will be developed.
Data availability
The code used in our paper is available here: https://github.com/pv-is-nrt/cnn-lc-sensors-paper.Optical microscopy images used for training and validating the models can be provided upon request to the corresponding author.
Author contributions
KN conceptualized the idea. PV performed the ML analysis. EA performed the LC experiments. EG performed the PCR experiments. All authors analysed the data and wrote the manuscript.Conflicts of interest
The authors declare no competing financial interest.Acknowledgements
KN acknowledges funding from USDA NIFA Award 2022-67021-36644.References
- K. Nayani, Y. Yang, H. Yu, P. Jani, M. Mavrikakis and N. Abbott, Areas of opportunity related to design of chemical and biological sensors based on liquid crystals, Liq. Cryst. Today, 2020, 29(2), 24–35 CrossRef CAS.
- T. Szilvási, N. Bao, K. Nayani, H. Yu, P. Rai, R. J. Twieg, M. Mavrikakis and N. L. Abbott, Redox-Triggered Orientational Responses of Liquid Crystals to Chlorine Gas, Angew. Chem., Int. Ed., 2018, 57(31), 9665–9669 CrossRef PubMed.
- C. Peng and O. Lavrentovich, Chirality Amplification and Detection by Tactoids of Lyotropic Chromonic Liquid Crystals, Soft Matter, 2015, 11, 7257–7263 RSC.
- X. G. Wang, E. Bukusoglu, D. S. Miller, M. A. B. Pantoja, J. Xiang, O. D. Lavrentovich and N. L. Abbott, Synthesis of Optically Complex, Porous, and Anisometric Polymeric Microparticles by Templating from Liquid Crystalline Droplets, Adv. Funct. Mater., 2016, 26(40), 7343–7351 CrossRef CAS.
- U. Manna, Y. M. Zayas-Gonzalez, R. J. Carlton, F. Caruso, N. L. Abbott and D. M. Lynn, Liquid Crystal Chemical Sensors That Cells Can Wear, Angew. Chem., Int. Edit., 2013, 52(52), 14011–14015 CrossRef CAS PubMed.
- L. N. Tan, R. Carlton, K. Cleaver and N. L. Abbott, Liquid Crystal-Based Sensors for Rapid Analysis of Fatty Acid Contamination in Biodiesel, Mol. Cryst. Liq. Cryst., 2014, 594(1), 42–54 CrossRef CAS.
- N. Silanikove, Effects of heat stress on the welfare of extensively managed domestic ruminants, Livest. Prod. Sci., 2000, 67(1–2), 1–18 CrossRef.
- J. Smith, K. Sones, D. Grace, S. MacMillan, S. Tarawali and M. Herrero, Beyond milk, meat, and eggs: Role of livestock in food and nutrition security, Anim. Front., 2013, 3(1), 6–13 CrossRef.
- Y. Vizzier Thaxton, K. D. Christensen, J. A. Mench, E. R. Rumley, C. Daugherty, B. Feinberg, M. Parker, P. Siegel and C. G. Scanes, Symposium: Animal welfare challenges for today and tomorrow, Poult. Sci., 2016, 95(9), 2198–2207 CrossRef PubMed.
- N. K. Emami, E. S. Greene, M. H. Kogut and S. Dridi, Heat Stress and Feed Restriction Distinctly Affect Performance, Carcass and Meat Yield, Intestinal Integrity, and Inflammatory (Chemo)Cytokines in Broiler Chickens, Front. Physiol., 2021, 12, 1–13 Search PubMed.
- W. M. Quinteiro-Filho, A. Ribeiro, V. Ferraz-de-Paula, M. L. Pinheiro, M. Sakai, L. R. M. Sá, A. J. P. Ferreira and J. Palermo-Neto, Heat stress impairs performance parameters, induces intestinal injury, and decreases macrophage activity in broiler chickens, Poult. Sci., 2010, 89(9), 1905–1914 CrossRef CAS PubMed.
- L. Star, E. Decuypere, H. K. Parmentier and B. Kemp, Effect of Single or Combined Climatic and Hygienic Stress in Four Layer Lines: 2. Endocrine and Oxidative Stress Responses, Poult. Sci., 2008, 87(6), 1031–1038 CrossRef CAS PubMed.
- G. Zaboli, X. Huang, X. Feng and D. U. Ahn, How can heat stress affect chicken meat quality? - A review, Poult. Sci., 2019, 98(3), 1551–1556 CrossRef CAS PubMed.
- N. Abdelli, A. Ramser, E. S. Greene, L. Beer, T. W. Tabler, S. K. Orlowski, J. F. Pérez, D. Solà-Oriol, N. B. Anthony and S. Dridi, Effects of Cyclic Chronic Heat Stress on the Expression of Nutrient Transporters in the Jejunum of Modern Broilers and Their Ancestor Wild Jungle Fowl, Front. Physiol., 2021, 12 DOI:10.3389/fphys.2021.733134.
- T. W. Tabler, E. S. Greene, S. K. Orlowski, J. Z. Hiltz, N. B. Anthony and S. Dridi, Intestinal Barrier Integrity in Heat-Stressed Modern Broilers and Their Ancestor Wild Jungle Fowl, Front. Vet. Sci., 2020, 7, 1–12 CrossRef PubMed.
- S. Ghazi, M. Habibian, M. M. Moeini and A. R. Abdolmohammadi, Effects of Different Levels of Organic and Inorganic Chromium on Growth Performance and Immunocompetence of Broilers under Heat Stress, Biol. Trace Elem. Res., 2012, 146(3), 309–317 CrossRef CAS PubMed.
- D. A. Padgett and R. Glaser, How stress influences the immune response, Trends Immunol., 2003, 24(8), 444–448 CrossRef CAS PubMed.
- J. I. Webster Marketon and R. Glaser, Stress hormones and immune function, Cell. Immunol., 2008, 252(1–2), 16–26 CrossRef CAS PubMed.
- S. Orlowski, J. Flees, E. S. Greene, D. Ashley, S. O. Lee, F. L. Yang, C. M. Owens, M. Kidd, N. Anthony and S. Dridi, Effects of phytogenic additives on meat quality traits in broiler chickens, J. Anim. Sci., 2018, 96(9), 3757–3767 CrossRef PubMed.
- X. H. Gu, Y. Hao and X. L. Wang, Overexpression of heat shock protein 70 and its relationship to intestine under acute heat stress in broilers: 2. Intestinal oxidative stress, Poult. Sci., 2012, 91(4), 790–799 CrossRef CAS PubMed.
- E. S. Greene, H. Rajaei-Sharifabadi and S. Dridi, Feather HSP70: a novel non-invasive molecular marker for monitoring stress induced by heat exposure in broilers, Poult. Sci., 2019, 98(9), 3400–3404 CrossRef CAS PubMed.
- A. E. Dhamad, E. Greene, M. Sales, P. Nguyen, L. Beer, R. Liyanage and S. Dridi, 75-kDa glucose-regulated protein (GRP75) is a novel molecular signature for heat stress response in avian species, Am. J. Physiol., 2020, 318(2), C289–C303 CrossRef CAS PubMed.
- E. Greene, S. Khaldi, P. Ishola, W. Bottje, T. Ohkubo, N. Anthony and S. Dridi, Heat and oxidative stress alter the expression of orexin and its related receptors in avian liver cells, Comp. Biochem. Physiol., Part A: Mol. Integr. Physiol., 2016, 191, 18–24 CrossRef CAS PubMed.
- K. Lassiter, E. Greene, A. Piekarski, O. B. Faulkner, B. M. Hargis, W. Bottje and S. Dridi, Orexin system is expressed in avian muscle cells and regulates mitochondrial dynamics, Am. J. Physiol., 2015, 308(3), R173–R187 CAS.
- Y. Cao, H. Yu, N. L. Abbott and V. M. Zavala, Machine Learning Algorithms for Liquid Crystal-Based Sensors, ACS Sens., 2018, 3(11), 2237–2245 CrossRef CAS PubMed.
- S. Jiang, J. Noh, C. Park, A. D. Smith, N. L. Abbott and V. M. Zavala, Using machine learning and liquid crystal droplets to identify and quantify endotoxins from different bacterial species, Analyst, 2021, 146(4), 1224–1233 RSC.
- A. D. Smith, N. Abbott and V. M. Zavala, Convolutional Network Analysis of Optical Micrographs for Liquid Crystal Sensors, J. Phys. Chem. C, 2020, 124(28), 15152–15161 CrossRef CAS.
- A. E. Dhamad, E. Greene, M. Sales, P. Nguyen, L. Beer, R. Liyanage and S. Dridi, 75-kDa glucose-regulated protein (GRP75) is a novel molecular signature for heat stress response in avian species, Am. J. Physiol., 2020, 318(2), C289–C303 CrossRef CAS PubMed.
- E. S. Greene, H. Rajaei-Sharifabadi and S. Dridi, Feather HSP70: a novel non-invasive molecular marker for monitoring stress induced by heat exposure in broilers, Poult. Sci., 2019, 98(9), 3400–3404 CrossRef CAS PubMed.
- K. Nayani, A. A. Evans, S. E. Spagnolie and N. L. Abbott, Dynamic and reversible shape response of red blood cells in synthetic liquid crystals, Proc. Natl. Acad. Sci. U. S. A., 2020, 117(42), 26083 CrossRef CAS PubMed.
- P. C. Mushenheim, J. S. Pendery, D. B. Weibel, S. E. Spagnolie and N. L. Abbott, Straining soft colloids in aqueous nematic liquid crystals, Proc. Natl. Acad. Sci. U. S. A., 2016, 113(20), 5564–5569 CrossRef CAS PubMed.
- K. Nayani, R. Chang, J. Fu, P. W. Ellis, A. Fernandez-Nieves, J. O. Park and M. Srinivasarao, Spontaneous emergence of chirality in achiral lyotropic chromonic liquid crystals confined to cylinders, Nat. Commun., 2015, 6(1), 8067 CrossRef CAS PubMed.
- K. Nayani, J. Fu, R. Chang, J. O. Park and M. Srinivasarao, Using chiral tactoids as optical probes to study the aggregation behavior of chromonics, Proc. Natl. Acad. Sci. U. S. A., 2017, 114(15), 3826 CrossRef CAS PubMed.
- K. Nayani, A. A. Evans, S. E. Spagnolie and N. L. Abbott, Dynamic and reversible shape response of red blood cells in synthetic liquid crystals, Proc. Natl. Acad. Sci. U. S. A., 2020, 117(42), 26083–26090 CrossRef CAS PubMed.
- P. C. Mushenheim, J. S. Pendery, D. B. Weibel, S. E. Spagnolie and N. L. Abbott, Straining soft colloids in aqueous nematic liquid crystals, Proc. Natl. Acad. Sci. U. S. A., 2016, 113(20), 5564–5569 CrossRef CAS PubMed.
- A. Krizhevsky, I. Sutskever and G. E. Hinton, ImageNet classification with deep convolutional neural networks, Commun. ACM, 2017, 60(6), 84–90 CrossRef.
- K. Simonyan and A. Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition, arXiv, 2015, preprint, arXiv:1409.1556 [cs.CV], DOI:10.48550/arXiv.1409.1556.
- A. Abay, G. Simionato, R. Chachanidze, A. Bogdanova, L. Hertz, P. Bianchi, E. van den Akker, M. von Lindern, M. Leonetti, G. Minetti, C. Wagner and L. Kaestner, Glutaraldehyde – A Subtle Tool in the Investigation of Healthy and Pathologic Red Blood Cells, Front. Physiol., 2019, 10, 514 CrossRef PubMed.
- F. Cui, Y. Yue, Y. Zhang, Z. Zhang and H. S. Zhou, Advancing Biosensors with Machine Learning, ACS Sens., 2020, 5(11), 3346–3364 CrossRef CAS PubMed.
| This journal is © The Royal Society of Chemistry 2024 |