
 Open Access Article
Open Access Article This Open Access Article is licensed under a
This Open Access Article is licensed under a Creative Commons Attribution 3.0 Unported Licence
Sizing multimodal suspensions with differential dynamic microscopy
Joe J.
Bradley
 *,
Vincent A.
Martinez
,
Jochen
Arlt
,
John R.
Royer
and
Wilson C. K.
Poon
*,
Vincent A.
Martinez
,
Jochen
Arlt
,
John R.
Royer
and
Wilson C. K.
Poon
School of Physics & Astronomy, The University of Edinburgh, Peter Guthrie Tait Road, Edinburgh EH9 3FD, UK. E-mail: w.poon@ed.ac.uk
First published on 16th October 2023
Abstract
Differential dynamic microscopy (DDM) can be used to extract the mean particle size from videos of suspensions. However, many suspensions have multimodal particle size distributions, for which a single ‘mean’ is not a sufficient description. After clarifying how different particle sizes contribute to the signal in DDM, we show that standard DDM analysis can extract the mean sizes of two populations in a bimodal suspension given prior knowledge of the sample's bimodality. Further, the use of the CONTIN algorithm obviates the need for such prior knowledge. Finally, we show that by selectively analysing portions of the DDM images, we can size a trimodal suspension where the large particles would otherwise dominate the signal, again without prior knowledge of the trimodality.
1 Introduction
Particle sizing is important across many industrial sectors. A modern text1 lists seven categories of methods: microscopy, sieving, electrozoning, laser diffraction (= static light scattering, SLS), ultrasound extinction, sedimentation, and dynamic light scattering (DLS). Some of these measure particles one at a time (microscopy, electrozoning), others deal with collections of particles en masse. Many are optically based (various light microscopies, SLS, DLS).These methods are calibrated against quasi-monodisperse spherical particles, where the polydispersity, defined as the standard deviation of the particle size distribution (PSD) normalised by the mean, is typically ≲10%, and can even be ≲2%.2 The sizing of such particles poses few problems; reporting simply a mean diameter and a polydispersity generally suffices.
While quasi-monodisperse spheres find use in research and specialised applications, most real-life suspensions are significantly polydisperse, often with strongly-peaked, multimodal PSDs. Examples include raw and UHT milk, with a bimodal mixture of large fat droplets and smaller casein micelles,3 sunflower tahini with a reported trimodal PSD,4 and chocolate, where the PSD shifts from trimodal to bimodal as refining proceeds.5 Multimodal PSDs can result from aggregation, for example nanoparticles used for biomedical applications often develop a second population of large agglomerates when dispersed in a physiological buffer.6
Reporting a mean and polydispersity for a multimodal suspension is almost meaningless; ideally, one wants to capture the full PSD. In practice, it is often difficult to detect multimodality in the first place, let alone obtain mean sizes for each population.
Direct imaging is perhaps the ‘gold standard’ of sizing. However, the PSD must be built up particle by particle, requiring a large number, N, to accumulate statistics, with the relative uncertainty dropping only weakly as  . Moreover, it is difficult to guarantee representative sampling, and preparation (e.g. drying for electron microscopy) can affect the particles.
. Moreover, it is difficult to guarantee representative sampling, and preparation (e.g. drying for electron microscopy) can affect the particles.
Scattering allows better statistical averaging, because the scattering volume typically contains many more particles than can be practically imaged. However, analysis requires inverting a Laplace transform, where the unknown PSD occurs under an integral sign, so that a unique solution does not exist and the problem is notoriously noise sensitive.7 Nevertheless, various scattering methods, especially SLS and DLS, are popular, with many available commercial instruments and sophisticated analysis software (e.g. CONTIN for DLS). Impressive answers can be obtained if some sample details are known. For example, SLS has been applied to a multimodal suspension with 5 populations varying in size over several orders of magnitude,8 but requires the particles' refractive indices which are not trivial to obtain.
Differential dynamic microscopy (DDM) is a technique for high-throughput sizing in which the intermediate scattering function (ISF), familiar from DLS, is obtained from images without the need to resolve the particles.9 Since DDM and DLS both access the ISF, there is significant overlap in data analysis. However, DDM offers certain advantages, such as the ability to cope with significant turbidity.10 Here we show that DDM is well-suited for sizing multimodal suspensions because it probes spatial fluctuations at very low wave vector, k, even ≲0.5 μm−1, by imaging large fields of view. Equivalent scattering angles of ≲2° in DLS require complex instrumentation,11,12 and are seldom attempted.
In SLS and DLS, the electric field scattered by a single homogeneous sphere of radius R at scattering vector k is given by13
 | (1) |
| P(kR) = 3[sin(kR) − (kR)cos(kR)]/(kR)3, | (2) |
 | ||
| Fig. 1 Theoretical squared form factor, P2(kR), for a monodisperse sphere of radius R as a function of the scattering vector or Fourier component k non-dimensionalised by the radius, kR, eqn (2), with minima positions given. The red curve is the Guinier approximation. | ||
The DDM signal is also dependent on P(kR).16 However, its first minimum has little effect, because for all Brownian suspensions DDM can operate with kR ≪ 1 where P(kR) → 1. So, Safari et al.17 were able to use DDM to size a bidisperse suspension with a 1![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :20 particle size ratio and up to 3% by volume of the large particles, where in all but one case, DLS fails to size the minority (large) species. However, these authors explicitly input the bimodality of their suspensions to their DDM analysis.
:20 particle size ratio and up to 3% by volume of the large particles, where in all but one case, DLS fails to size the minority (large) species. However, these authors explicitly input the bimodality of their suspensions to their DDM analysis.
In this work, we demonstrate the use of DDM to size a bidisperse suspension with a significantly smaller size ratio of 1:4.6 without assuming bimodality in the analysis, and probe the technique's efficacy when the number ratio of the species is systematically changed. Furthermore, we show how to extend the limits of applicability of DDM further by selecting regions of interest in our image sequences for analysis. The method is demonstrated by sizing a trimodal system in which the signal from the largest particles dominates, without assuming trimodality a priori.
Below, we first present expressions for fitting DDM results to data from polydisperse suspensions, explaining how signal contribution scales with particle size. Next, we explain our experimental and data fitting methods. After validating our predicted signal vs. size scaling, we demonstrate the application of DDM to bi- and tri-modal dispersions, concluding with a recommended protocol for sizing multimodal suspensions with DDM.
2 DDM for polydisperse suspensions
The original implementation of DDM9,18 used partially coherent illumination (see further Appendix A). Since we perform bright-field imaging with a condenser of numerical aperture ≈ 0.5, our illumination is incoherent. We have previously shown16 that for N identical particles in an incoherent image, the differential image correlation function (DICF), g(k,τ), which is the squared Fourier transform of the difference between an image at time τ and a reference image at time zero, is related to the ISF, f(k,τ) by:| g(k,τ) = A(k)[1 − f(k,τ)] + B(k), | (3) |
| A(k) = 2Na2(k)S(k). | (4) |
In a monodisperse suspension of non-interacting spherical particles of radius R, the ISF is f(k,τ) = exp[−Dk2τ], with the diffusivity D = kBT/6πηR in a suspending medium of viscosity η at temperature T (and kB is Boltzmann's constant). So, fitting the measured g(k,τ) to eqn (3) returns D and therefore R. Appendix C shows that these results generalise naturally to a suspension of polydisperse spheres, with A(k) and the ISF now being suitably-weighted sums over the M particles species i = 1 to M:
 | (5) |
 | (6) |
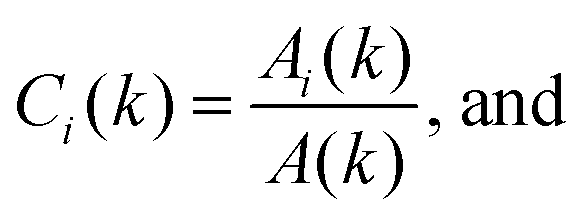 | (7) |
 | (8) |
To interpret results obtained by fitting these expressions to data, we need to understand how the population weights, {Ci(k)} in eqn (6), scale with particle radius, R. Interpretation of image intensity fluctuations from a coherent (heterodyne) scattering perspective implicitly predicts19 a scaling of A(k) ∝R6 for Rayleigh scatterers,§ but it is unclear how the use of incoherent illumination affects this scaling.
To analyse size scaling in the incoherent limit, note that a(k) in eqn (4) is the two-dimensional (2D) Fourier Transform (FT) of a(r), the intensity pattern of the image of one particle centred at the origin of the image plane (with radial coordinate r only in the case of circular symmetry).16 For a homogeneously fluorescent particle that is much smaller than the depth of focus, a(r) should, to a good first approximation, be given by the 2D projection of a solid sphere (mathematically, a 3-ball, B3) onto the equatorial plane,  , transmitted through the microscope's optics. The Projection-Slice Theorem states that the 2D FT of a projection of a 3D object is given by a slice (perpendicular to the projection) through the origin of the FT of the 3D object.21 So, the FT of
, transmitted through the microscope's optics. The Projection-Slice Theorem states that the 2D FT of a projection of a 3D object is given by a slice (perpendicular to the projection) through the origin of the FT of the 3D object.21 So, the FT of  is
is 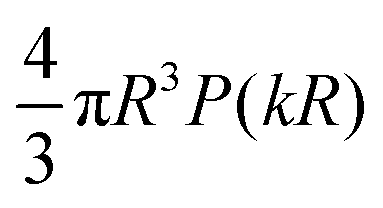 with the P(kR) in eqn (2), only now k is the magnitude of wave vectors in a 2D rather than 3D Fourier space. In the dilute limit, where S(k) → 1, eqn (3) becomes
with the P(kR) in eqn (2), only now k is the magnitude of wave vectors in a 2D rather than 3D Fourier space. In the dilute limit, where S(k) → 1, eqn (3) becomes
 | (9) |
In phase contrast imaging, the image is a projection of the optical path length, so can again be approximated by 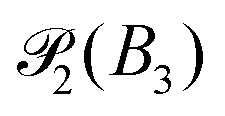 . The bright-field image in the geometric limit is a shadowgraph which can be approximated by
. The bright-field image in the geometric limit is a shadowgraph which can be approximated by  , where I0 and β are constants. In either case, eqn (9) is recovered. Quite generally, whenever the contributions of a particle's volume elements to the image intensity contrast are additive, one finds
, where I0 and β are constants. In either case, eqn (9) is recovered. Quite generally, whenever the contributions of a particle's volume elements to the image intensity contrast are additive, one finds
| A(k) ∼ NR6P2(kR) ∼ ϕR3P2(kR). | (10) |
The above discussion readily generalises to arbitrary-shaped anisotropic particles when there are enough (independently oriented) particles to sample the orientational distribution, or when their rotational diffusion is fast compared to the relevant timescales in a DDM experiment. In this limit, a slice through the spherically-symmetric orientationally-averaged 3D form factor is the single particle contribution to a(k) in eqn (4). The well-known Guinier approximation to the low k form factor,22Fig. 1, then gives 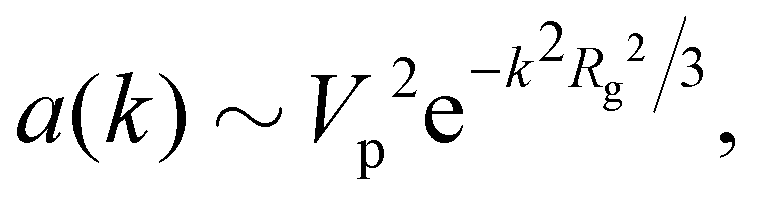 where Rg (
where Rg ( for a sphere) is the particle's gyration radius. Now, the DDM signal A(k) scales as NVp2∼ ϕVp, which is the generalisation of eqn (10).
for a sphere) is the particle's gyration radius. Now, the DDM signal A(k) scales as NVp2∼ ϕVp, which is the generalisation of eqn (10).
Eqn (9) does not take into account the finite depth of field in the z direction. To do so, note first that for bright-field imaging at low numerical apertures typical in DDM, kz ≲ NA × k, so that the longitudinal dynamics are much slower than the in-plane dynamics. We can then take f(k,kz,τ) ≈ f(k,0,τ).18,23 The effect of a finite depth of field and limited lateral resolution on A(k) can then be included by convolving the real-space density with the optical point-spread function, or multiplying the density by the optical transfer function, OTF(k,kz), in reciprocal space to obtain
 | (11) |
| A(k) ∼ NR6Peff2(k,R) ∼ ϕR3Peff2(k,R), | (12) |
 | (13) |
3 Materials and methods
3.1 Experimental
We used polystyrene spheres, which have been routinely characterised using DDM.9,18,24 Dispersions from Thermo Scientific 5000 series with sizes (diameters here and throughout) of 60 nm, 120 nm, 240 nm, 500 nm, 1.1 μm and 2.1 μm were diluted using Milli-Q water to give stock solutions of various concentrations, from which we prepared various bimodal or trimodal mixtures. Note that only the smallest of these particles are Rayleigh scatterers. Samples were loaded into 0.4 × 4 × 50 mm glass capillaries (Vitrocom Inc.) and sealed with Vaseline to prevent evaporation. Bright-field videos were captured using a Nikon Ti-E inverted microscope with a Hamamatsu Orca Flash 4.0 camera. We imaged far from the sides of the capillary and 100 μm from the base. For each measurement a series of five videos were captured immediately after loading to minimise sedimentation. Each video is 5000–6000 frames of 512 × 512 pixels. Specific choices of frame rate and objective, detailed below, reflect these considerations:Pixel size – DDM does not require resolvable particles and pixel ≳ particle size typically gives the best results: large pixels mean lower k, minimising form factor effects.
Frame rate – Chosen to capture ≲4 Gb 16-bit TIFF data including both short- and long-time plateaus of the ISF. In this work the range is 100–400 fps.
Small changes to the settings did not in general significantly impact results except in the extreme cases treated in Section 6.
The DICF is extracted from videos using previously-described LabView software.25 The uncertainty in the DICF is estimated as the standard error on the mean from the azimuthal averaging of k. A more theoretical approach requires quantifying the variance of background image intensity;26 but such rigour is not needed here and is likely too demanding for general application.
3.2 Data fitting
The extracted DICFs are fitted to eqn (3) with model f(k,τ) to extract the diffusivities, {Di}; here we outline the case of bidispersity. To decide a suitable range of k for analysing each system, we carried out DDM experiments with the two individual populations of particles used to make a bidisperse sample, and used independent 1D fits to each k dataset to extract the k-dependent average diffusivities D1(k) and D2(k). The range of k values over which these are both flat to within noise is used for all subsequent data fitting with these particles and microscope settings.1. f(k,τ) = exp(−Dk2τ) – for monodisperse diffusing particles.
2. ln(f(k,τ)) = −μ1k2τ + μ2(k2τ)2/2 − μ3(k2τ)3/6 + … – the cumulant expansion28–30 typically used to extract the mean diffusivity (μ1) and polydispersity (from μ2) in low-polydispersity monomodal samples.
3. f(k,τ) = C1exp(−D1k2τ) + (1 − C1)exp(−D2k2τ) – for two monodisperse populations with diffusivities D1 and D2 contributing fractions C1 and 1 − C1 to the signal respectively.
Fig. 2a illustrates the information extracted by fitting these models to a simulated ISF from a bidisperse distribution of diffusivities. Model (1) finds an essentially meaningless ‘average’ that misses both populations. Model (2) suffers from the same problem as far as the mean value is concerned, but gives a credible description of the notional ‘polydispersity’. Model (3) returns more or less correct average sizes and contributions for the two populations, but does not deal with the polydispersity within each.
 | ||
| Fig. 2 Extracted particle diffusivity distributions, P(D), from a simulated ISF based on a defined bimodal P(D) (red curves, μ1 = 1, μ2 = 3, σ1 = 0.25, σ2 = 0.4, C1 = 0.25). ISF generated with Gaussian noise at each f(k,τ); σ = 10−5. (a) Graphical representation of output from three different least squares fits; monodisperse (blue), bidisperse (orange), and a cumulant expansion (green). (b) Output from a CONTIN fit. | ||
Fig. 2b illustrates the result of this procedure in fitting the ISF from a bimodal distribution of diffusivities, inputting only the desired binning of the output histogram. CONTIN's regularisation selection works exceptionally well because the only noise applied to the simulated f(k,τ) is Gaussian with a known amplitude (σ = 10−5), and is independent for each k-τ pair. With real experimental noise, the selection of α is generally more difficult.
CONTIN is designed for linear problems, but extracting {Ci} from the DICF by fitting eqn (5)–(8) to eqn (3) is non-linear, because A(k) and B(k) are unknown. We therefore must estimate these parameters before using CONTIN. One approach is to perform a least-squares fit of g(k,τ) with an approximate model (e.g. a cumulant expansion) and use the returned A(k) and B(k) to extract an ISF to pass on to CONTIN. However, we found that this encoded the approximate model into the CONTIN results.
Alternatively, since g(k,τ → 0) = B(k) and g(k,τ → ∞) = A(k) + B(k), the long- and short-time ‘plateau values’ of g(k,τ) can in principle give A(k) and B(k).24 Under practical experimental conditions, however, it is often challenging to access one or the other of these limits. For us, the long-time plateau g(k,τ → ∞) is typically accessible whilst the short-time plateau g(k,τ → 0) is difficult to reach even at the highest frame rates, and errors in estimating B(k) can significantly impact results.26
Instead, we extract B(k) by fitting the first 10–15 time points of g(k,τ) to a second order polynomial of the form
| g(k,τ) ≈ B(k) + β1(k)τ − β2(k)τ2 | (14) |
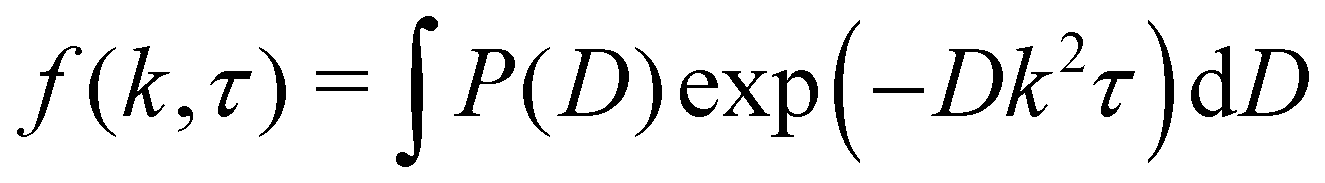 , the continuum version of eqn (6), into eqn (3) and Taylor expanding around τ = 0, using the fact that P(D) is normalised. For completeness, we find
, the continuum version of eqn (6), into eqn (3) and Taylor expanding around τ = 0, using the fact that P(D) is normalised. For completeness, we find  and
and  . The fitted value of B(k) can then be subtracted from the average of the final 10–15 data points to obtain A(k). With this, the ISF can be extracted from g(k,τ) and passed to CONTIN with an uncertainty estimate based on propagation of errors in g(k,τ), the standard error of the data points averaged for A(k), and the polynomial fit uncertainties for B(k).
. The fitted value of B(k) can then be subtracted from the average of the final 10–15 data points to obtain A(k). With this, the ISF can be extracted from g(k,τ) and passed to CONTIN with an uncertainty estimate based on propagation of errors in g(k,τ), the standard error of the data points averaged for A(k), and the polynomial fit uncertainties for B(k).
4 Results: scaling of DDM Signal with particle size
To verify eqn (12), we performed DDM experiments on quasi-monodisperse suspensions with a range of radii, R. A sample of each suspension from Section 3.1 was diluted to a mass fraction ψ = 10−5. Five bright-field videos of each were captured at 200 fps using a 20×/0.5 objective without binning, giving 325 nm pixels. Using phase-contrast illumination produced equivalent results. A least squares 3rd order cumulant fit of the DICF from each video gives A(k), B(k), and average diffusion coefficient. Identical microscope settings ensured that changes in A(k) are solely due to particle size, and there is no measurable systematic trend in average intensity with R so turbidity is negligible in all cases. Each A(k) was normalised by that of the 60 nm particles, for which P(kR) ≈ 1 for all k. This removes the significant k dependence of the OTF. The range 1.0 μm−1 ≤ k ≤ 2.5 μm−1 was used for all videos to remove the effect of any additional k dependence. To isolate the power-law dependence on particle size, we remove the form factor contribution to A(k) by dividing by the squared form factor for a sphere, P2(kR) (eqn (2)).For all sizes, the measured diffusivity agrees with the Stokes–Einstein value, Fig. 3a. We can therefore size particles over two orders of magnitude of R without changing experimental settings, even though A(k) < B(k) for the smaller particles.
 | ||
| Fig. 3 DDM results for polystyrene spheres of different sizes. (a) Extracted diffusion coefficients as a function of manufacturer provided radius. Dashed line shows Stokes–Einstein prediction (b) Average normalised (see main text) A(k) against particle radius. Green triangles indicate average A(k) as extracted from videos. Black crosses are the same data corrected for form factor effects. The dashed line has slope 3. In both plots there are 5 points for each size, which often overlap. | ||
Fig. 3b shows that for R ≲ 0.55 μm, A(k) ∝ R3 at constant ψ (and therefore ϕ), verifying eqn (12). Since N ∝ ψ/R3 and we have previously confirmed experimentally34 that A(k) ∝ N, this is equivalent to a signal of R6 per particle, matching DLS scaling (assuming Rayleigh scatterers) and our theoretical prediction. This R6 scaling sets the weight of signal contributions in the case of mixtures with multiple particle sizes. Note however, that the (temporal) intensity fluctuations which form the basis for DLS measurements also scale as R6, whereas the (spatio-temporal) fluctuations that form the basis of the DDM measurements only scale as R3. So, it is experimentally much less challenging to capture intensity fluctuations faithfully for DDM.
For the largest particles, A(k) increases with R slower than R3, even after correcting for form factor effect, Fig. 3b. As already suggested at the end of Section 2, this is not unexpected as several assumptions of our simple model start to fail.
5 Results: bidisperse systems
The simplest multimodal suspension is bimodal, with milk35 being an everyday example. We mixed 10−4 mass fraction dispersions of 240 nm and 1.1 μm particles (size ratio ≈1:4.6) to produce bidisperse mixtures in which the small particles should contribute between 1% and 99% of the signal to the ISF according to eqn (12); Table 1. Videos of each sample and of the parent populations were captured at 100 fps, with a 10×/0.3 objective and 1.5× extra magnification (pixel size 433 nm). Examples of the extracted DICFs and fits are shown in Appendix B.
| Large-particle mass fraction | Expected small-particle ISF contribution |
|---|---|
| 70% | 1% |
| 50% | 2% |
| 25% | 5% |
| 10% | 13% |
| 5% | 25% |
| 2.5% | 40% |
| 1% | 63% |
| 0.5% | 77% |
| 0.1% | 95% |
| 0.02% | 99% |
5.1 Least squares fits
Fitting model 3 in Section 3.2.1 to our data, which assumes bidispersity, we extract the mean diffusion coefficient and the relative contribution of each population to the ISF, Fig. 4. Comparison with values obtained from fitting a monodisperse model to the unmixed samples, Fig. 4a, shows that the method works well provided that the ‘low-signal component’¶ contributes at least ≈2%. We found little quantitative difference in taking C1 in model 3 to be constant or allowing it to vary with k, confirming minimal form factor effects. Practically, allowing C1 to vary increased processing time and occasionally caused issues with convergence. | ||
| Fig. 4 Results of DDM analysis of 240 nm/1.1 μm sphere mixtures with different compositions, showing five measurements at each composition. Red crosses indicate results of least-squares fits to an explicit bimodal PDD, blue triangles are extracted from CONTIN fits. CONTIN results are shifted slightly along the x-axis for clarity, and are only plotted where each population is expected to contribute ≳5% of the DICF. (a) Diffusion coefficients (points) compared to average values for the monomodal suspensions (dotted lines). (b) Signal fraction from large particles (points), and theoretical expectations for DDM, eqn (12) (solid line) and DLS at various angles (dashed lines). | ||
The spread of the five measurements of each sample shows that fit uncertainties shown by the error bars are underestimated, although this is not indicated by fit statistics (reduced-χ2 ≈ 1). The uncertainties are comparable across different fitting algorithms, including Minuit's MINOS error estimation,36 which accounts for correlations between fit parameters. The underestimate could be due to correlations in 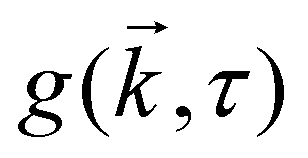 that are not accounted for when calculating DICF uncertainty or in the fitting algorithms. We did not investigate these uncertainties because the final error bar in the fitted diffusivities (and therefore size) is clearly defined by variability between measurements.
that are not accounted for when calculating DICF uncertainty or in the fitting algorithms. We did not investigate these uncertainties because the final error bar in the fitted diffusivities (and therefore size) is clearly defined by variability between measurements.
Note that using DLS to obtain the correct diffusivities for the two populations would only be possible if the scattering angle, θ, is optimised to avoid the form factor minima of each. To highlight this, we plot the theoretical fractional contribution of large particles to the DLS signal at different θ for DLS using a 532 nm laser and polystyrene spheres (refractive index = 1.59), Fig. 4b, with θ = 12.8° and 173° being typical of some popular commercial devices. Note that these curves assume that each population is monodisperse; any polydispersity would cause significant shifts.
By contrast, there is a unique theoretical prediction for DDM, which is calculated only using eqn (12) from the mean sizes of the two populations, with the latter being extracted from the same experiment, Fig. 4. Since we remain at low k far from the form factor minimum, polydispersity of the individual populations can be neglected in calculating this curve. Thus, our protocol can give direct information on the composition of the sample.
If the size ratio of our bidisperse suspension is reduced from 1:4.6 to 1:2, fitting DDM data to model 3 yields a significantly biased diffusivity for the smaller particles even when they contribute as much as 40% of the signal (Appendix F.1). At this size ratio, the corresponding timescales for decorrelation are too close for them to be separated cleanly. There is some indication of local minima in the χ2 minimisation, suggesting that alternative approaches may improve results. However, we also observed this bias in analysis of simulated bimodal ISFs when the peaks in P(D) begin to overlap, so this may represent a more general limitation that is not unique to DDM. DDM therefore cannot be solely relied upon to size bidisperse samples with such low size ratios.
5.2 CONTIN analysis
Least-squares fitting delivered the correct mean diffusivities of the two populations and their number ratio by assuming bidispersity. Alternatively, the cumulant model (model 2 in Section 3.2.1) can be fitted to the data without this assumption to obtain a single mean and polydispersity (see Appendix D), with no indication of bidispersity or poor fit quality. To do better, we turn to CONTIN.CONTIN delivers P(D), the particle diffusivity distribution (PDD) histogram on a predefined grid of 60 linearly spaced bins in the interval 0.01 μm2 s−1 ≤ D ≤ 5 μm2 s−1. Fig. 14 (Appendix F.3) shows the result for each sample in Table 1. Fig. 5 shows the PDDs from the third video of each mixture in which the large particles contribute 0.1%, 1%, 10%, and 25% of the particle mass (or 5%, 37%, 87%, and 95% of the signal).
 | ||
| Fig. 5 CONTIN results for various 240 nm/1.1 μm sphere mixtures (see legend) with expected signal contributions from large particles of 5%, 37%, 87%, and 95% respectively. Purple vertical lines show average diffusivities from least-squares fits to the monodisperse suspensions. | ||
This analysis convincingly returns a bimodal distribution of diffusivities provided that the contribution of low-signal component to the DICF remains ≳5%, comparable but slightly more stringent than for least-squares fitting. This is because too small a contribution to f(k,τ) from either species will be removed as ‘noise’ by the CONTIN regularisation algorithm, whilst least squares will always return two sizes – fitting noise if necessary.
Fitting the weighted sum of two Gaussian distributions to the returned PDDs for each video with ≥5% minority signal yields the mean diffusivity and relative signal contribution of each population, Fig. 4. The variation in these properties is comparable to the equivalent least-squares values, and the more stringent signal contribution requirements are visible as the signal reaches ≈5%. These fits also return a polydispersity; but there are significant run-to-run variations in the fitted PDD at each composition, Fig. 14, because the regularisation parameter α is highly noise sensitive. However, CONTIN fits the data to an integral of the PDD, so that there is a priori reason to surmise that the area of each peak may be far less noise sensitive than either the peak width or height. The peak area is a measure of the (weighted) number of particles, eqn (12). Fig. 4b validates this surmise. So, a CONTIN analysis is able to deliver the sizes and relative number of the two populations in our 1:4.6 bidisperse suspension.
We also tested CONTIN analysis for a bidisperse suspension in which the two populations differ in size by only a factor of 2. The method again returns a bimodal diffusivity distribution with essentially the same means as least-squares fits (including the aforementioned bias) whenever the low-signal component contributes ≳5% of the DICF, Fig. 12 (Appendix F.1).
6 Spatial aspects of DDM
The NR6 scaling in DLS and DDM means that even a low concentration of large particles will dominate the signal and render it difficult, if not impossible, to detect smaller species. Thus, for example, in our 1:4.6 bidisperse suspension, we need at least 75% mass fraction of the smaller species to contribute at least 5% of the DICF, Table 1, for this population to show up in the PDD from a CONTIN analysis. Such considerations are important, e.g., when sizing biomedical nanoparticles, where buffers at physiological ionicity often lead to aggregation. The presence of micron-sized aggregates leads to highly distorted PSDs37 or even irreproducible results when DLS was used to size nanoparticles.6 We next show how to use DDM to size one or more populations of small particles in the presence of a numerically-minor population of large particles that dominate the signal.
The key is to make use of the spatial information encoded in the images collected in a DDM experiment. The numerical minority of the largest particles means that they are relatively sparse in the images. So, it should be possible to analyse selectively only those portions of the collected images from which these particles are essentially absent, Fig. 6. This can be accomplished either by combining dilution and control of magnification or by using a spatially-resolved analysis. We demonstrate these two approaches using a trimodal stock, Table 2.
 | ||
| Fig. 6 Schematic of a trimodal suspension showing how by selecting a suitable region of interest, we can enhance the DDM signal from smaller particles by removing the contribution from large particles. | ||
| Particle diameter | 60 nm | 240 nm | 1.1 μm |
|---|---|---|---|
| Weight fraction | 10−4 | 10−6 | 10−6 |
| Signal contribution, Ci | 2% | 1% | 97% |
| Number density (per mm3) | 8 × 108 | 1 × 105 | 2 × 103 |
First, we measured a sequence of samples obtained by successively diluting the stock by a factor of 3. The idea is to identify, if possible, a window of concentration in which the field of view typically does not include any of the largest particles, but the signal level from the smaller populations is still measurable.
Videos of each dilution were captured at 400 fps using both 10×/0.3 and 60×/0.7 objectives without pixel binning, for pixel sizes of 650 nm and 108 nm respectively. For 512 × 512 pixel images (the maximum square images possible at this frame rate with our camera) this corresponds to 2D imaging areas of 1 × 105 μm2 and 3 × 103 μm2 respectively. The exact volume imaged is difficult to estimate since the depth of field is strongly k dependent;10,18 an estimate based on geometric optics38 would be 9 μm and 1 μm for the 10× and 60× objective respectively.
By design, the number of modes found by the analysis should vary as dilution progresses, with the largest population disappearing to reveal smaller particles. With no a priori fixed number of modes to input to least-squares fitting, we used CONTIN, with the input being a grid of 60 logarithmically spaced bins for 1 × 10−2 μm2 s−1 ≤ D ≤ 1 × 102 μm2 s−1. To avoid logarithmically scaled bin heights, the quadrature weight of each bin is set to 1, so that the sum of bin heights describes the contribution from each population rather than the bin area.31,32Fig. 7 shows the fitted P(D) from each repeat using the two different objectives with the stock suspension and three successive dilutions.
 | ||
| Fig. 7 CONTIN fits to videos of the trimodal system defined in Table 2 and dilutions. Each pair of graphs shows the result with 10× magnification (top) and 60× magnification (bottom) for the labelled dilution. Vertical dotted lines show expected peak positions. | ||
With the larger field of view (10× magnification) the large particles dominate the signal at all dilutions. At the higher (60×) magnification, there is still no convincing evidence of the two smaller populations until we reach 32-fold dilution, and their signals remaining robust at 33-fold dilution. Again, there is significant variability in peak shape from run to run, but the overall picture is clear. Further dilution reduces the signal to the extent that peaks appear and disappear in the 5 repeats.
A disadvantage of the dilution method is that the optimal concentration window is rather narrow, and so can be easily missed in a real-life application. More robustly, one may eliminate the contribution from the largest particles by selecting an appropriate region of interest (ROI) for analysis from the original video. Fig. 8 compares the PDDs obtained from one of the 60× magnification videos of the stock suspension when we analysed the full video (512 × 512 pixels), and when we analysed a smaller ROI (128 × 128 pixels) chosen to exclude all large particles. Not surprisingly, the former PDD shows only the largest particles, while the latter shows the two smaller populations.
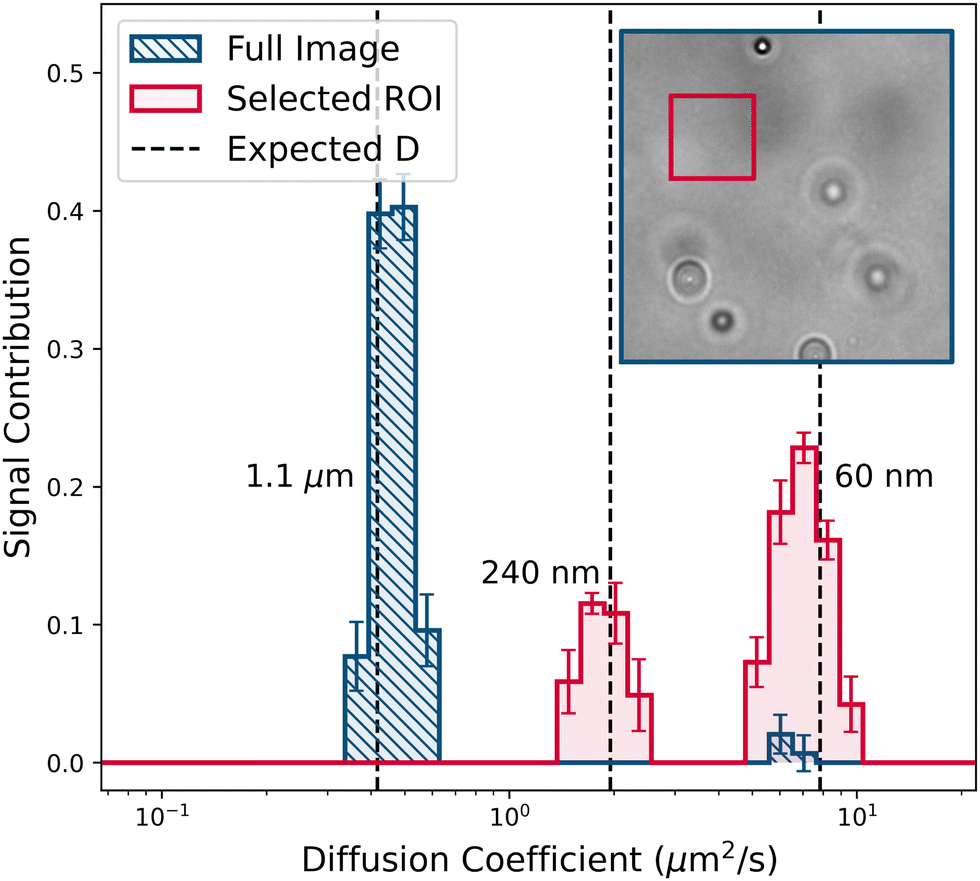 | ||
| Fig. 8 CONTIN fits to data extracted from 60x magnification videos of the (undiluted) mixture in Table 2, and from a 128 × 128 pixel selected ROI. Dashed vertical lines show the diffusivities of the monomodal suspensions. Inset shows example frame and the selected ROI. | ||
Obviously, success depends on selecting and optimising an ROI. Fig. 13 in Appendix F.2 reports the PDD obtained as the size of the ROI is progressively reduced for 60× magnification videos of the stock solution, again showing five runs at each stage. That the two smaller populations show up strongly after reducing the ROI by a factor of 42 is consistent with diluting the stock by 32–33 times to give optimal performance, Fig. 7. The full data set, Fig. 13, illustrates the superiority of this method compared to dilution. Here, the user varies the ROI size and position in real time while analysing a single data set until correct sizing is achieved; dilution requires multiple experiments in which the user must ‘hit’ the right dilution window and sample position by chance.
As we already noted, the peak areas in the CONTIN output contain compositional information via the relative values of A(k). Following the procedure described in Appendix E, we extracted relative volume fractions, finding 98.1 ± 0.1%, 1.0 ± 0.1%, and 0.9 ± 0.1% for the 60 nm, 240 nm, 1.1 μm populations, in excellent agreement with the known 10−4:10−6:10−6, Table 2.
Conceptually, our technique is similar to centrifuging out large particles prior to DLS. However, our methods need lower quantities of suspension and do not require physical processing, which could be relevant for sparse or delicate samples. Note also that our ROI selection may be compared with the use of spatially-resolved DDM to verify a theorem in active matter physics.39
7 Summary and conclusions
Our results show that DDM is a facile and robust method for sizing suspensions with multimodal PSDs, but must be coupled with a suitable method for deducing diffusivity distributions from measured ISFs. Specifically, we have demonstrated the use of CONTIN, which is already familiar from long use in DLS. In future work, more advanced algorithms designed for DLS analysis should be explored for potential improvements in resolution and performance.40–43 In addition, for accurate uncertainty estimates in fitted parameters, correlations between g(k,τ) points could be included and a Bayesian fitting algorithm may be advantageous as an alternative to least-squares fits.We have used bright-field microscopy, but phase-contrast or fluorescence should also be suitable. The method is extendable to turbid systems if suitable k ranges and g(k,τ) models are used.10 However, deviation from standard DDM is strongest at low k, which may obviate some of the benefits discussed in Section 1.
In Section 5 we have shown how our analysis breaks down when signal contribution ≲2% or for size ratio ≈1:2. However, breaking these conditions does not necessarily lead to failure; neither is satisfying them a guarantee of success. For example, both conditions are dependent on polydispersity and overlap of populations in the PSD; separately, the limit of applicability may be improved by reducing the uncertainties in the DICF with larger videos, or increasing the signal to noise ratio A(q)/B(q) – so could be affected by absolute size. Perhaps more important than enunciating hard-and-fast ‘limits of applicability’ is to note how failure occurs. In the case of a small signal from one population, the spread of the 5 repeats typically becomes very large around the mean (accurate but imprecise), which is easy to identify; however, in the case of comparable sizes, the reported values could be consistent but biased (inaccurate but high precision), which might be mistaken for a good measurement.
Before concluding, we summarise a protocol for sizing multimodal suspensions using DDM. One starts by visually inspecting images of the sample, increasing the magnification from a low value until the first particles become visible. At this point, when the largest particles should be comparable to pixel size, record a set of videos and back out the ISF. A CONTIN analysis may already reveal multimodality, or only show a single large population. Regardless, one would then dilute the suspension (and/or increase the magnification) until the signal from the largest particles disappears to reveal smaller populations. If no signal remains, indicated by a time-independent DICF, one may be reasonably confident any small particles are at a number density comparable to or lower than that of the large particles.
We conclude that DDM can fill an important gap between low-throughput electron microscopy and high-throughput DLS. While DLS can access shorter timescales and is likely more sensitive,19 form factor effects make multimodal systems challenging. In contrast, access to real space images and low-k information makes DDM uniquely suited for sizing multimodal suspensions, which are ubiquitous in applications.
Author contributions
Joe J. Bradley: investigation, methodology, formal analysis, software, visualization, writing – original draft. Vincent A. Martinez: conceptualisation, methodology, investigation, supervision, formal analysis. Jochen Arlt: conceptualisation, formal analysis, methodology, software, supervision. John R. Royer: supervision. Wilson C. K. Poon: conceptualisation, formal analysis, funding acquisition, supervision. All authors: writing – review and editing.Conflicts of interest
There are no conflicts to declare.Appendices
A DDM – scattering perspective
The first demonstration of DDM particle sizing9 used bright-field imaging with a condenser lens of numerical aperture NA = 0.9 and an objective of NA = 0.5. In a follow-up publication,18 it was stated that NA of the condenser was ‘about ten times smaller than the numerical aperture of the objective’. We take this to mean that an iris restricts the actual condenser NA to be around 0.05, giving partially coherent incident light. Consistent with this, the authors analyse their experiment in terms of the interference of the electric fields of light that has and has not been scattered by particles in the sample, treating their technique as a development of dynamic heterodyne near field scattering (HNFS).44,45 Again, consistent with this understanding, a subsequent review23 shows (their Fig. 3b) that their raw images consist of speckle (= random interference) patterns.Other researchers have been able obtain results without stopping down the condenser. Thus, our bright-field imaging uses a condenser iris with NA an order of magnitude larger than in the original implementation; others have implemented DDM using fluorescence or absorbance to generate contrast. In all of these cases, there is no coherence in the incident light, but DDM still extracts the ISF. This is because, generally, linear space-invariant images can be treated as density maps, so that correlating images directly gives density autocorrelations. Whilst there are subtle differences, the overall outcome remains the same, with the notable exception that scattering requires a small correction to k for phase shifts due to motion perpendicular to the image plane.18
In Section 2 we show theoretically that A(k) ∼ NR6. Our derivation implicitly assumes that the light is incoherent, as we only consider intensities: the overall intensity contrast of a single particle is calculated by integrating over the particle's volume, where each volume element contributes with the same intensity contrast density ρ. The correctness of this result for small to moderately large particles is then demonstrated experimentally in Section 4 for brightfield DDM with incoherent illumination.
In the heterodyne scattering mode of DDM, the fluctuations in the camera signal will be proportional to the scattering field.19,23 The scattering of light by particles is well understood in terms of size and shape;13,46 in particular, the scattered field will scale with Vp ∼ R3 for sufficiently small (Rayleigh) scatterers, therefore from a heterodyne perspective we can obtain the same A(k) ∼ NR6 scaling when calculating the correlation function. Note that for larger particles, such as those typically sized using DDM (including this work), the size scaling of the scattered field is no longer trivial, as the Mie scattering pattern shows strong directional dependence.
B Example DICFs
Fig. 9 shows the extracted DDM signals (in the form of the DICF, g(k,τ)) for two monomodal suspensions and a mixture of the pair. By eye, it is not obvious that the DICF for the bimodal suspension is not monomodal, however by fitting appropriate models it is possible to extract both sizes and their relative contribution to the signal (see Section 5).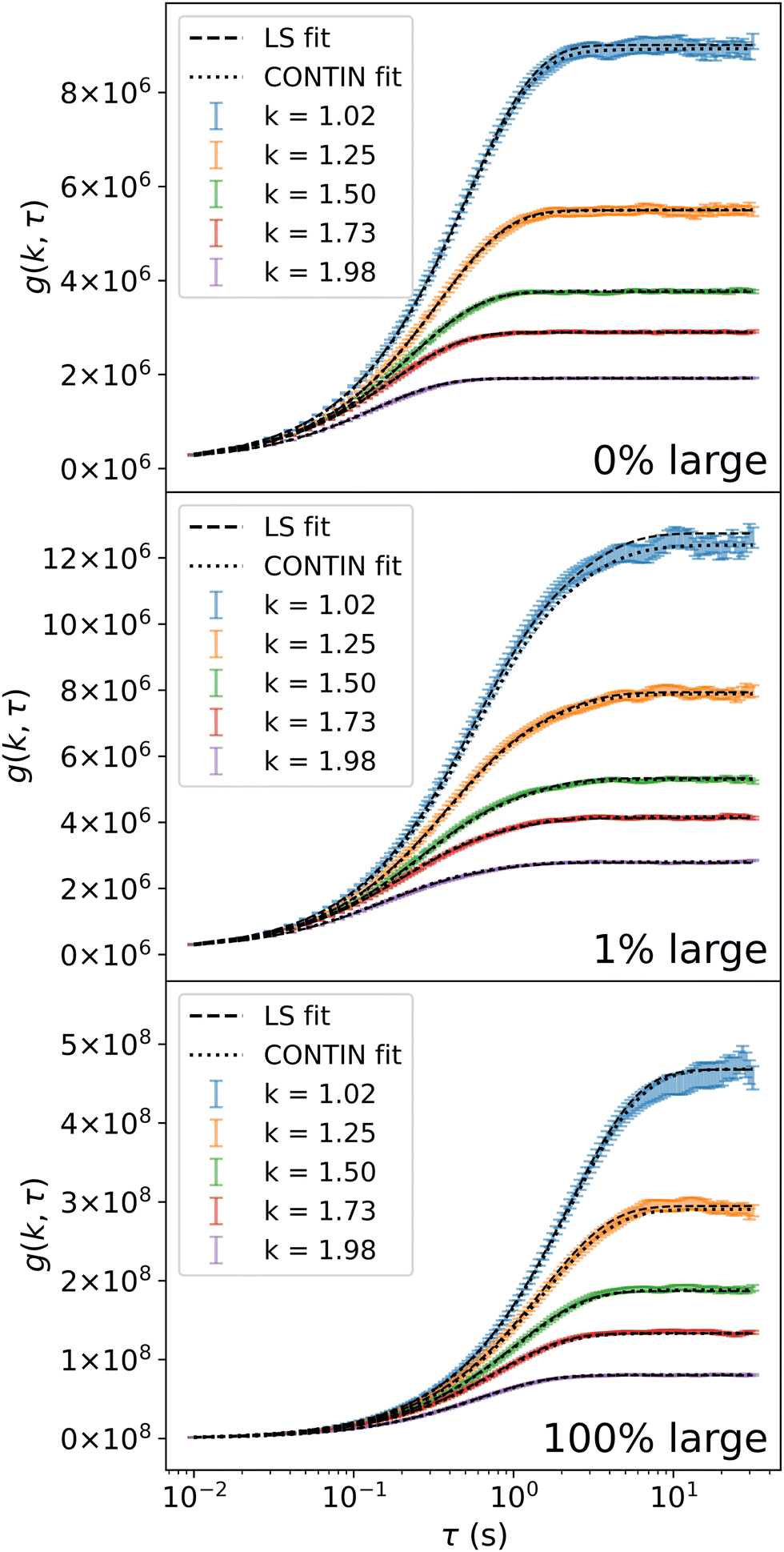 | ||
| Fig. 9 Representative differential image correlation functions, g(k,τ), at selected k values for the monomodal and bimodal suspensions discussed in Section 5, along with the corresponding least-squares (LS) and CONTIN fits. The top and bottom frames show the signal from suspensions of 240 nm and 1.1 μm respectively, and the middle frame corresponds to a mixture which is 1% large particles by mass (contributing ≈37% of the signal). | ||
C DDM with multiple populations
The derivation of Wilson et al.47 assumes that intensity fluctuations are proportional to density fluctuations. However, signal from a given population depends on particle size as well as concentration (see Sections 2 and 4). Therefore, this assumption does not hold outside of monodisperse suspensions. Instead, consider M independent populations of particles, where overall fluctuations in intensity are given by additive components proportional to fluctuations in density of each population; | (15) |
 are the fluctuations in the density ρi of population i. The constants κi will depend on imaging setup and particle properties which determine contrast – such as refractive index, size, and physical image formation mechanisms. The Fourier transformed difference images are then given by
are the fluctuations in the density ρi of population i. The constants κi will depend on imaging setup and particle properties which determine contrast – such as refractive index, size, and physical image formation mechanisms. The Fourier transformed difference images are then given by | (16) |
 | (17) |
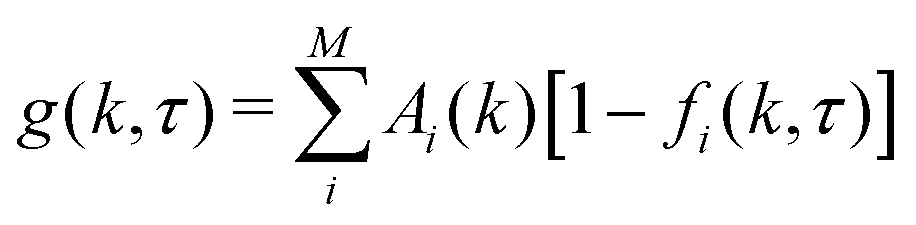 | (18) |
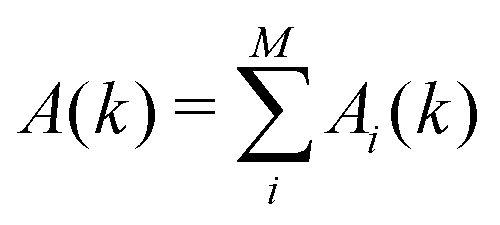 and Ci(k) = Ai(k)/A(k), so
and Ci(k) = Ai(k)/A(k), so  , we can write this in the more familiar form
, we can write this in the more familiar form| g(k,τ) = A(k)[1 − f(k,τ)] + B(k), | (19) |
 | (20) |
The full theoretical calculation of population signal strength Ai(k) ∝ κi2〈|ρi(k)|2〉 is challenging, although fortunately not a requirement to use DDM.
D Cumulant fit to bidisperse measurements
Fig. 4 shows least-squares results from fitting an explicit bidisperse model (model 3 in Section 3.2.1) to bimodal suspensions with compositions in Table 1, obtaining good results for each particle size. If we did not know a priori of bimodality, we may instead fit model 2 in Section 3.2.1, Fig. 10. Such a cumulant fit to the same data extracts moments comparable with the eqn (12) weighted mean and variance of the diffusion coefficient distribution; in other words, the fit returns reasonable first and second moments of the PDD. The reported variance is slightly less accurate than the mean, which is expected as the accuracy of terms in cumulant fits is known to decrease with increasing order,29 and the cumulant is designed for reasonably narrow distributions where a continuous curvature is observed at the mean, which is not generally true for a bimodal system. Nevertheless, the results are reasonable, although do not obviously indicate the model's inappropriateness for a bidisperse system. | ||
| Fig. 10 Fitted PDD moments for the bimodal mixtures described in Table 1 (Section 5), obtained using 3rd order cumulant fits to the ISF. Each data point is the result from fits to a single video, with corresponding uncertainties as error bars. Top – mean diffusion coefficients, the dotted horizontal lines show the average fitted diffusion coefficient for the monomodal suspensions, the dashed green line shows the mean diffusion coefficient, weighted by the expected signal contributions. Bottom – corresponding variance from the same fits. Dashed green line shows the weighted variance predicted (assuming monodispersity of each population). | ||
E Extracting composition of the trimodal suspension
In Section 6 we showed that by selecting subregions of an image to analyse it is possible to identify three distinct populations in the PDD of a trimodal suspension. However, these analyses are performed independently, so the relative contributions of each population to the signal is not extracted directly in a single histogram. Here we outline a procedure by which the relative volume fractions of the populations can be extracted from the CONTIN analyses.The full video contains signal from all particles, and the selected 128 × 128 ROI only contains signal from the two smaller populations. Therefore, the fraction of the signal from the two smaller populations is AROI(k)/Afull(k), and the fraction from large particles alone can be obtained as
 | (21) |
The relative contributions of the small and medium particles to the signal in the reduced video can be extracted from the CONTIN result by summing the bins contributing to each peak (as noted in the main text, due to quadrature weight settings it is the sum of bin heights which determines contribution in this case, not the area). This fraction is labelled cj. The fractional contribution of the small/intermediate population j to the total signal is therefore
 | (22) |
 | (23) |
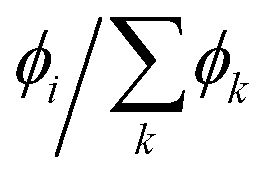 , the value of γ is irrelevant.
, the value of γ is irrelevant.
This can be done for each of the 5 pairs of videos (full video and subregion) to obtain a measure of uncertainty; for each ϕi five values will be obtained. The mean can then be quoted along with the standard error 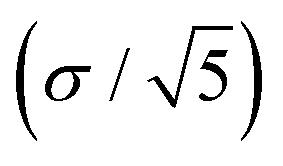 for final values and uncertainties which we find are in very good agreement with the true composition of the trimodal mixture used for these experiments.
for final values and uncertainties which we find are in very good agreement with the true composition of the trimodal mixture used for these experiments.
F Additional data and plots
F.1 Least-squares and CONTIN fits to 240 nm/500 nm videos
Bidisperse mixtures of 240 nm and 500 nm particles were prepared by mixing mass fraction 10−4 suspensions of monodisperse particles, with ratios of 4:1, 1:1, and 1:4. Large particles are expected to contribute 71%, 91%, and 97% of the signal respectively, based on eqn (12). These were recorded at 200 fps with 20× magnification and no binning (pixel size 325 nm). They were then fitted to the DICF with a bidisperse model (see Section 5 of the main text) to obtain a mean diffusivity for each population and the relative contribution to the signal, Fig. 11. We see that in the five repeats the bimodal suspension shows significant variability, switching between accurate results and underestimated values for both populations. This grouping could be an indication of local minima in χ2.
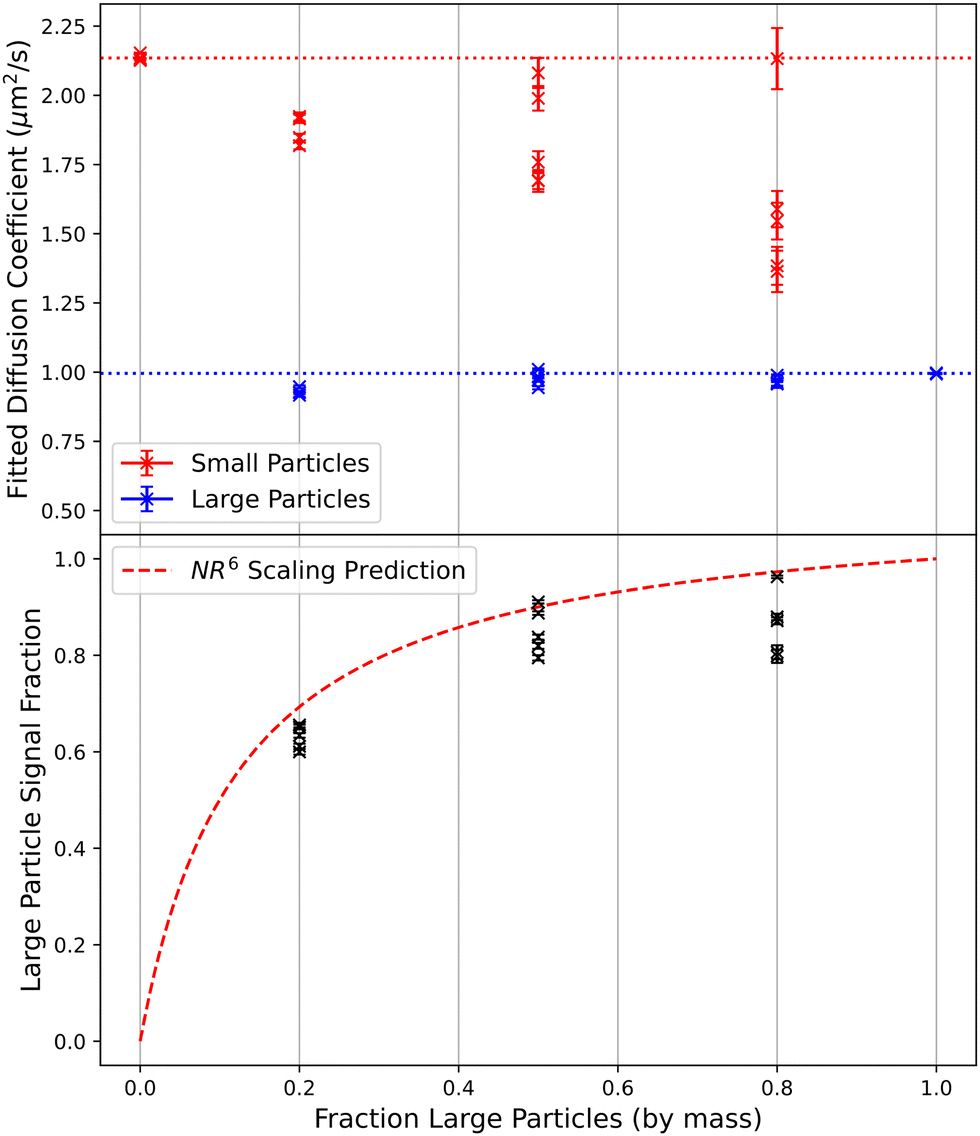 | ||
| Fig. 11 Parameters obtained from bidisperse least squares fits of the DICFs from 4:1, 1:1, and 1:4 mixtures (by mass) of 240 nm and 500 nm particles. Each data point is the result from fits to a single video, with corresponding uncertainties as error bars. (a) Fitted diffusion coefficients, the dotted horizontal lines show the average fitted diffusion coefficient for the monomodal suspensions. (b) Fitted signal fraction from the large particles, with a prediction based on the NR6 scaling of eqn (12). | ||
CONTIN fits were performed to the same videos, Fig. 12. Again we see two populations when the contribution of the minority signal component ≳5%, with diffusion coefficients comparable to the values obtained by LS fits (Fig. 11).
 | ||
| Fig. 12 CONTIN results for mixtures of 240 nm and 500 nm spheres mixed in different proportions. Each plot is labelled and had identical analyses performed, the vertical dotted lines show the average diffusion coefficient fit to videos of the separate populations. | ||
F.2 All CONTIN results from ROI selection (Section 6)
Fig. 13 shows all results for the ROI selection to exclude large particles from a trimodal suspension. An example for a single video with full and 128 × 128 ROI was shown in Fig. 8 of Section 6. In Fig. 13 we plot all 5 repeats for each video and selected subregions of various sizes. As the ROI is reduced, the largest particles are removed with increasing levels of success, until at 128 × 128 pixels the two smaller populations are clearly visible in all repeats with no contribution from the large particles. As with the bimodal CONTIN experiments, we see significant variation in shape between repeats, although the overall trend is clear. | ||
| Fig. 13 CONTIN fits applied to sub-regions of the 60 × magnification videos of the original stock mixture from Table 2. Each plot is labelled with the size of the ROI, which is illustrated for the first video in each set by the blue box in the inset. Vertical dotted lines show expected peak positions, labelled with particle diameter. | ||
F.3 Complete CONTIN results for 240 nm/1.1 μm videos
Fig. 14 shows the results for CONTIN fits to every one of the videos recorded to produce Fig. 4 and 5 in Section 5. The CONTIN particle diffusivity distributions (PDDs) agree reasonably well with the least-squares fits as discussed in the main text, and as long as the signal from a population exceeds 5% the peak is consistently present in the PDD, and as the signal drops towards this limit the position and presence of the peak becomes much less reliable. In addition, we can see variation in the width of the peaks between repeats, which we attribute to variability in the selection of the regularisation parameter α. This could potentially be eliminated in certain situations (e.g. repeatedly sizing a suspension for consistency as part of quality control) by selecting a fixed α for the analysis. | ||
| Fig. 14 Complete CONTIN results for mixtures of 240 nm and 1.1 μm spheres mixed in different proportions listed in Table 1 (Section 5). Each PDD in each plot is from a single video and had identical analyses performed. The vertical dotted lines show the average diffusion coefficient from least-squares fits to videos of the separate populations. | ||
Acknowledgements
JJB was funded by the EPSRC SOFI2 CDT (EP/S023631/1) and Solvay. VAM, JA and WCKP were funded by ERC PoC award GA 882559 NoChaPFI.Notes and references
- H. Merkus, Particle Size Measurements: Fundamentals, Practice, Quality, Springer, Netherlands, 2009 Search PubMed.
- A. Van Blaaderen and A. Vrij, Langmuir, 1992, 8, 2921–2931 CrossRef CAS.
- G. Amador-Espejo, A. Suàrez-Berencia, B. Juan, M. Bárcenas and A. Trujillo, J. Dairy Sci., 2014, 97, 659–671 CrossRef CAS PubMed.
- V. Muresan, S. Danthine, E. Racolta, S. Muste and C. Blecker, J. Food Proc. Eng., 2014, 37, 411–426 CrossRef CAS.
- J. Tan and W. L. Kerr, J. Food Meas. Charact., 2018, 12, 641–649 CrossRef.
- C. Gollwitzer, D. Bartczak, H. Goenaga-Infante, V. Kestens, M. Krumrey, C. Minelli, M. Pálmai, Y. Ramaye, G. Roebben, A. Sikora and Z. Varga, Anal. Methods, 2016, 8, 5272–5282 RSC.
- S. Twomey, Introduction to the Mathematics of Inversion in Remote Sensing and Indirect Measurements, Elsevier, 1977 Search PubMed.
- Y. Pei, B. A. Hinchliffe and C. Minelli, ACS Omega, 2021, 6, 14049–14058 CrossRef CAS PubMed.
- R. Cerbino and V. Trappe, Phys. Rev. Lett., 2008, 188102 CrossRef PubMed.
- R. Nixon-Luke, J. Arlt, W. C. K. Poon, G. Bryant and V. A. Martinez, Soft Matter, 2022, 18, 1858–1867 RSC.
- E. Tamborini and L. Cipelletti, Rev. Sci. Instrum., 2012, 83, 093106 CrossRef CAS PubMed.
- L. Cipelletti and D. A. Weitz, Rev. Sci. Instrum., 1999, 70, 3214–3221 CrossRef CAS.
- P. N. Pusey, in Neutron, X-rays and Light. Scattering Methods Applied to Soft Condensed Matter, ed. P. Lindner and T. Zemb, Elsevier, Amsterdam, 2002, pp. 3–21 Search PubMed.
- P. N. Pusey and W. van Megen, J. Chem. Phys., 1984, 80, 3513–3520 CrossRef CAS.
- K. Fischer and M. Schmidt, Biomater., 2016, 98, 79–91 CrossRef CAS PubMed.
- M. Reufer, V. A. Martinez, P. Schurtenberger and W. C. K. Poon, Langmuir, 2012, 28, 4618–4624 CrossRef CAS PubMed.
- M. S. Safari, R. Poling-Skutvik, P. G. Vekilov and J. C. Conrad, NPJ Microgravity, 2017, 3, 1–8 CrossRef.
- F. Giavazzi, D. Brogioli, V. Trappe, T. Bellini and R. Cerbino, Phys. Rev. E: Stat., Nonlinear, Soft Matter Phys., 2009, 031403 CrossRef PubMed.
- R. Cerbino and P. Cicuta, J. Chem. Phys., 2017, 147, 110901 CrossRef PubMed.
- K. He, M. Spannuth, J. C. Conrad and R. Krishnamoorti, Soft Matter, 2012, 8, 11933–11938 RSC.
- R. Janaswamy, Engineering Electrodynamics, IOP Publishing, 2020, pp. 14.1–14.3 Search PubMed.
- A. Guinier, G. Fournet and C. Walker, Small-angle Scattering of X-rays, Wiley, 1955 Search PubMed.
- F. Giavazzi and R. Cerbino, J. Opt., 2014, 16, 083001 CrossRef.
- R. Cerbino, F. Giavazzi and M. E. Helgeson, J. Polym. Sci., 2022, 60, 1079–1089 CrossRef CAS.
- J. Schwarz-Linek, J. Arlt, A. Jepson, A. Dawson, T. Vissers, D. Miroli, T. Pilizota, V. A. Martinez and W. C. K. Poon, Colloids Surf., B, 2016, 2–16 CrossRef CAS PubMed.
- M. Gu, Y. Luo, Y. He, M. E. Helgeson and M. T. Valentine, Phys. Rev. E, 2021, 104, 034610 CrossRef CAS PubMed.
- P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman, N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey, I. Polat, Y. Feng, E. W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen, E. A. Quintero, C. R. Harris, A. M. Archibald, A. H. Ribeiro, F. Pedregosa, P. van Mulbregt and SciPy 1.0 Contributors, Nat. Meth, 2020, 17, 261–272 CAS.
- B. J. Frisken, Appl. Opt., 2001, 40, 4087–4091 CrossRef CAS PubMed.
- A. G. Mailer, P. S. Clegg and P. N. Pusey, J. Phys.: Condens. Matter, 2015, 27, 145102 CrossRef PubMed.
- R. Finsy, Adv. Colloid Interface Sci., 1994, 52, 79–143 CrossRef CAS.
- S. W. Provencher, Comput. Phys. Commun., 1982, 27, 213–227 CrossRef.
- S. W. Provencher, Comput. Phys. Commun., 1982, 27, 229–242 CrossRef.
- A. Scotti, W. Liu, J. S. Hyatt, E. S. Herman, H. S. Choi, J. W. Kim, L. A. Lyon, U. Gasser and A. Fernandez-Nieves, J. Chem. Phys., 2015, 142, 234905 CrossRef CAS PubMed.
- J. Arlt, V. A. Martinez, A. Dawson, T. Pilizota and W. C. K. Poon, Nat. Commun., 2018, 9, 768 CrossRef.
- M. Alexander, L. Rojas-Ochoa, M. Leser and P. Schurtenberger, J. Colloid Interface Sci., 2002, 253, 35–46 CrossRef CAS PubMed.
- F. James and M. Roos, Comput. Phys. Commun., 1975, 10, 343–367 CrossRef.
- N. Hondow, R. Brydson, P. Wang, M. D. Holton, M. R. Brown, P. Rees, H. D. Summers and A. Brown, J. Nanopart. Res., 2012, 14, 977 CrossRef.
- R. Oldenbourg and M. Shribak, in Handbook of Optics: Volume I - Geometrical and Physical Optics, Polarized Light, Components and Instruments, ed. M. Bass, McGraw-Hill Education, New York, 3rd edn, 2010, pp. 28.1–28.62 Search PubMed.
- J. Arlt, V. A. Martinez, A. Dawson, T. Pilizota and W. C. K. Poon, Nat. Commun., 2019, 10, 2321 CrossRef PubMed.
- J. Langowski and R. Bryan, Macromol., 1991, 24, 6346–6348 CrossRef CAS.
- S. L. Nyeo and R. R. Ansari, J. Comput. Appl. Math., 2011, 235, 2861–2872 CrossRef.
- S. Schintke and E. Frau, Appl. Sci., 2020, 10, 8969 CrossRef CAS.
- LS Instruments, DLS Data Analysis: The CORENN Method, Webpage, available online, https://lsinstruments.ch/en/theory/dynamic-light-scattering-dls/dls-data-analysis-the-corenn-method.
- D. Magatti, M. D. Alaimo, M. A. C. Potenza and F. Ferri, Appl. Phys. Lett., 2008, 92, 241101 CrossRef.
- F. Ferri, D. Magatti, D. Pescini, M. A. C. Potenza and M. Giglio, Phys. Rev. E: Stat., Nonlinear, Soft Matter Phys., 2004, 70, 041405 CrossRef CAS PubMed.
- H. C. van de Hulst, Light Scattering by Small Particles, Dover Publications, Dover, 1981 Search PubMed.
- L. G. Wilson, V. A. Martinez, J. Schwarz-Linek, J. Tailleur, G. Bryant, P. N. Pusey and W. C. K. Poon, Phys. Rev. Lett., 2011, 018101 CrossRef CAS PubMed.
Footnotes |
| † There is no literature consensus on this nomenclature, descriptions of A(k) include DDM ‘signal’,19 ‘signal amplitude’,17 and ‘signal prefactor’ and ‘signal term’.20 Crucially, this should not be confused with the camera signal. |
| ‡ To show that the signal measured at scattering vector k in DLS in fact characterises density fluctuations with that wave vector requires considerable analysis.13 |
| § What is clear from the heterodyne DDM literature is that the image intensity scales as NR3; but additional steps are needed to show that A(k) ∼ NR6. |
| ¶ I.e., the component of the bidisperse suspension that contributes <50% of the g(k,τ) signal; because of the NR6 scaling, this is not the ‘minority component’ by number. |
| This journal is © The Royal Society of Chemistry 2023 |