
Variation in chemistry instructors’ evaluations of student written responses and its impact on grading
Michelle
Herridge
 *,
Jenna
Tashiro
and
Vicente
Talanquer
*,
Jenna
Tashiro
and
Vicente
Talanquer
Department of Chemistry and Biochemistry, University of Arizona, Tucson, AZ 85721, USA. E-mail: mdhh99@email.arizona.edu
First published on 30th June 2021
Abstract
Evaluation of student written work during summative assessments is an important task for instructors at all educational levels. Nevertheless, few research studies exist that provide insights into how different instructors approach this task. In this study, we characterised variation in chemistry instructors’ approaches to the evaluation and grading of different student responses to conceptual questions in general chemistry summative assessments, and analysed the correlation of such variations with assigned grades. Our results revealed differences in the approaches followed by instructors along various dimensions, such as their focus of attention (e.g., knowledge vs. reasoning), the construction and use of a rubric to evaluate student work, and the extent to which instructors engaged in building inferences about student understanding. Most instructors, however, were consistent in the approaches they individually followed when analyzing different student responses. Differences in approaches along some dimensions correlated to assigned grades, but relevant dimensions differed for novice and experienced instructors (e.g., adopting an inferential versus a literal stance had a significant correlation with the grades assigned by experienced instructors but not by novice ones). The results of our study provide insights into strategies for the professional development of college instructors such as asking instructors to critically reflect on how the decisions they make along multiple dimensions during the grading process can affect the outcome.
Introduction
Written assessments are frequently used in chemistry courses for both formative and summative purposes, and often include free-response or open-ended questions in which students are asked to summarise ideas, build explanations, or show their numerical work (Stowe and Cooper, 2019). In evaluating these assessments, instructors make many explicit and implicit decisions as they read the question prompt, analyse and evaluate students’ responses, and assign grades to different components of students’ answers. Each of these decisions is influenced by instructors’ prior knowledge and experiences, as well as by their personal beliefs about teaching, learning, and the subject matter (Petcovic et al., 2013; Marshman et al., 2017). Thus, variation in assigned grades is expected and well documented in the educational literature (Henderson et al., 2004; Mutambuki and Fynewever, 2012). These variations in the evaluation of student work have led to concerns about fairness (Holmes and Smith, 2003) that are particularly relevant when working with large numbers of diverse students who may express their understanding in quite different ways.In a previous study, we characterised different dimensions of variation in the evaluation of students’ responses to a single conceptual question in a general chemistry exam (Herridge and Talanquer, 2020). In this study we extend our investigation to the analysis of variation in chemistry instructors’ approaches to the evaluation of a more diverse set of questions and analyse the impact of this variation on the grades that are assigned.
Evaluation and grading of student work
Grading is a common practice in college courses and its output is expected to be an indicator of students’ academic performance or achievement (Brookhart et al., 2016). Assigned grades may also serve alternative or additional purposes related to motivation, encouragement, or reward for student work (Stanley and Baines, 2001). Researchers in this area conceptualise grading as a judgement (Haagen, 1964) that is often constrained to marking students’ answers as right or wrong (Gotwals and Birmingham, 2016). Many instructors are known to engage in evaluative judgments while analysing students’ responses rather than trying to make sense of student understanding (Aydeniz and Dogan, 2016). Meaningful engagement with students’ ideas is frequently inhibited by the graders’ limited understanding of the learning objectives of a course (Ebby et al., 2019), misinterpretation of a rubric or its components (Eckes, 2008), low grading proficiency (Wolfe et al., 1998), and personal misconceptions about how understanding is demonstrated (Marshman et al., 2017).Prior research suggests that variations in the grading of student work are often linked to different conceptions on the “burden of proof” during the analysis of student work (Yerushalmi et al., 2016). Some instructors expect students to explicitly justify their ideas and procedures, but many others project correct reasoning on students’ answers based on limited evidence. For example, instructors may infer that a student knows how to solve a problem based on the presence of a correct numerical response even if mistakes are present in the procedure (Petcovic et al., 2013). Some faculty readily subtract points from explicitly incorrect answers but are hesitant to deduct points from more vague answers that could be interpreted as correct (Henderson et al., 2004).
Mutambuki and Fynewever (2012) and Petcovic et al. (2013) indicated that there is often a disconnect between what instructors claim to value on student work and what actually earns points during the evaluation. This leads to inconsistencies in grading. Efforts to align grading practices and narrow the variability in assigned grades often rely on the use of rubrics, and students’ perceptions of fairness increases with the use of these tools (Holmes and Smith, 2003; Andrade, 2005; Randall and Engelhard, 2010). Many of these studies highlight inter- and intra-rater reliability, where multiple instructors assign the same grade to the same work, or the same instructor assigns the same grade to the same work after an interval of time (Stellmack et al., 2009; Knight et al., 2012). Nevertheless, although ample resources exist on how to design and use rubrics in the classroom (Mertler, 2001; Dawson, 2017; Mohl et al., 2017; Reynders et al., 2020) and the laboratory (Fay et al., 2007; Harwood et al., 2020), their use does not remove all variation in evaluation (Rezaei and Lovorn, 2010; Howell, 2011).
Existing research in teacher thinking and practice suggests that what instructors notice in student work affects the inferences and judgments that they make. Teacher noticing has thus become a productive “line of research [which] investigates what teachers ‘see’ and how they make sense of what they see in classrooms” (Chan et al., 2020). Much of the work in this area has focused on formative assessment practices in K-12 classrooms (Ross and Gibson, 2010; Huang and Li, 2012; Amador et al., 2017; Luna, 2018), where the evaluation is expected to be continuous, iterative, and highly interpretive (Ainley and Luntley, 2007; Barnhart and Van Es, 2015; Ebby et al., 2019). But what teachers’ notice in student written work also influences their evaluation behaviour (Talanquer et al., 2013, 2015; Herridge and Talanquer, 2020).
Teacher noticing is often conceptualised as involving two major components: (a) attending to students’ expressed ideas and (b) building inferences about student understanding based on what is noticed (Luna, 2018). Personal and contextual factors affect what teachers notice (object of noticing) and the types of inferences they generate (noticing stance) (Van Es, 2011). In general, teachers often struggle to attend to student thinking and commonly adopt an evaluative rather than an interpretive stance in the analysis of students’ ideas (Aydeniz and Dogan, 2016; Murray et al., 2020). Many teachers also tend to make inferences based on little evidence (Talanquer et al., 2015).
What teachers notice in written work vary along different dimensions, some of them domain-neutral and others domain-dependent (Talanquer et al., 2015). In the domain-neutral dimensions teachers’ approaches to the evaluation have been characterised ranging from descriptive to inferential, evaluative (focus on correctness) to interpretive (focus on making sense), and from general to specific in the analysis of student understanding. In the domain-dependent dimensions, teachers’ approaches range from unsupported to supported with proper evidence, from narrow to broad in the scope of ideas that are evaluated, and from inaccurate to accurate from a disciplinary perspective. Based on this characterisation of dimensions of variations in teacher noticing, in a prior work we developed a framework to analyse variation in the evaluation approaches of chemistry instructors when grading exam questions (Herridge and Talanquer, 2020). This framework was developed using a subset of the data fully analysed in this research study and is described in the next section.
Dimensions of variation in evaluation
As summarised in Table 1, the analytical framework developed to characterise diversity in approaches to chemistry instructors’ evaluation and grading of student written responses considers four different stages in the evaluation process and several dimensions of variation within each stage (Herridge and Talanquer, 2020). The four major stages include: (1) reading and interpreting the prompt, (2) preparing for and engaging in the evaluation of student work, (3) noticing in student work, and (4) responding to student work. In each stage, several dimensions of analysis serve to characterise variations in approach to the evaluation of student work. For each dimension, two contrasting approaches are identified (e.g., close reading versus skimming in the dimension of Depth). Instructors may exhibit behaviours that include aspects of both categories in any given dimension. Nevertheless, in the development of the framework we found it possible to identify the dominant behaviour during each evaluation instance and treated contrasting categories as dichotomous in any dimension of analysis.| Dimension | Approaches (dichotomous spectrum) | |
|---|---|---|
| Stage 1: reading and interpreting the prompt | ||
| Depth | Close reading : grader carefully analyzes the prompt and makes notes or comments about different targets for assessment | Skimming : grader quickly reads the prompt, looking for target ideas. Focuses on one part of the question |
| Focus | Reasoning : grader focuses on the type of reasoning that is expected | Knowledge : grader identifies pieces of knowledge to be demonstrated |
| Stage 2: preparing for and engaging in the evaluation of student work | ||
| Rubric | Explicit : grader builds an explicit rubric which often includes distribution of points for target areas of assessment | Implicit : grader does not build an explicit rubric or system for point distribution |
| Expected answer | Generated : grader generates an expected answer in paragraph form or as a list of key points | Unexpressed : grader does not write or verbalize an expected answer |
| Grading system | Criterion referenced : grader assigns points to individual student responses based on some criterion | Norm referenced : grader assigns points to individual student responses in reference to answers from other students |
| Stage 3: noticing in student work | ||
| Stance | Inferential : grader builds inferences about student understanding that go beyond what is explicitly written | Literal : grader does not make assumptions about student understanding beyond what is expressed in writing |
| Lens | Adaptive : grader evaluates student work contextually and recognizes alternative ways of expressing ideas | Prescriptive : grader looks for key concepts and ideas as prescribed in a rubric or Expected Answer |
| Scope | Wholistic : grader analyzes an entire answer before making a final evaluation | Piecemeal : grader evaluates one idea or sentence at a time without much attention to connections across the answer |
| Stage 4: responding to student work | ||
| Interaction | Expressed : grader highlights or writes notes on elements of student work | Unexpressed : grader does not make any visual marks or annotations on students' responses |
| Intention | Evaluative : grader makes marks on student work to highlight correct or incorrect statements | Reactive : grader reacts to students' ideas by making marks on elements of student work that catch their attention |
| Feedback | Indirect : grader provides Feedback/guidance in the form of questions | Direct : grader provides Feedback/guidance in the form of statements |
The first stage of the evaluation and grading process characterise differences in how instructors read and interpret a question prompt. In this stage, instructors may differ in how closely they read the prompt (the dimension of Depth) and in their interpretation of the focus of a question (Focus). This is, whether they interpret the prompt as seeking to reveal student content knowledge or student reasoning.
The second stage in the evaluation and grading process considers different steps instructors may take in preparation for the evaluation of students’ responses. Major differences at this stage occur in whether instructors build an explicit rubric to guide their evaluation (rubric), generate an example target response to the prompt (Expected Answer), or apply a norm referenced versus criterion referenced grading scheme as they analyse different student responses (Grading System).
The third stage refers to differences in instructors’ attention to and interpretation of student work. Variations at this stage may occur along three major dimensions that serve to characterise the extent to which instructors are literal or inferential in their analysis of students’ responses (Stance), are prescriptive or adaptive to the ways in which students express ideas (Lens) or look at student work in a piecemeal versus wholistic manner (Scope).
Finally, the fourth stage in the evaluation and grading refers to the level of instructors’ explicit response students’ work. In this stage, we consider the first dimension of analysis as indicative of whether the instructor explicitly and visually interacted with student work or not (Interactions). When these interactions occurred, we describe them with two additional dimensions: how they differed on the purpose of the marks made by instructors on student work (Intention) and the nature of the feedback provided (Feedback).
Research questions
Based on the analytical framework summarised in the previous section, our work was guided by the research questions:1. What main approaches across different dimensions of variation in the evaluation and grading of student work do chemistry instructors more commonly follow?
2. How consistent are chemistry instructors in their approach to the evaluation and grading of student work across different dimensions of variation?
3. What individual variables and dimensions of variation correlate to assigned grades?
Methods
Setting and participants
This project was conducted at our institution, a large research-intensive public university in the southwest US. Study participants were faculty instructors (FIs) and graduate student instructors (GSIs) teaching a 100-level general chemistry curriculum that emphasizes the development of students’ chemical thinking (N = 29; 7 FIs, 22 GSIs). Detailed demographic information for the participants is presented in Table 2. All participants had taught at least one full semester of the course; FIs had taught the lecture section and the GSIs had taught at least one associated laboratory section and attended lecture. In these courses, all students complete several common midterm exams, and the FIs rotate exam writing responsibility. These exams include both multiple choice and free response questions. GSIs grade the free response questions guided by a rubric generated by the FIs. FIs and GSIs meet after students complete each exam to discuss how to use the given rubric and practice applying it to actual student responses. From now on, we refer to all study participants as instructors. This research project was approved by the IRB at our institution and all subjects consented to participate in the study.| Role | n | Teaching experience (range in years) |
|---|---|---|
| Faculty instructor (FI) | 7 | From 2 to > 10 |
| Graduate student instructor (GSI) | 22 | From 1 to 5 |
| Research area | n | Teaching experience (range in years) |
|---|---|---|
| Analytical | 4 | From 1 to 9 |
| Biochemistry | 8 | 1 |
| Inorganic | 4 | From 1 to > 10 |
| Physical | 9 | From 1 to 6 |
| Other | 4 | From 1 to > 10 |
| Gender | n | Teaching experience (range in years) |
|---|---|---|
| Male | 17 | From 1 to > 10 |
| Female | 12 | From 1 to 10 |
Exam questions & student responses
The findings reported in this paper emerged from the analysis of study participants' evaluation and grading of students' original answers to six free response questions from general chemistry exams given in 2016 or 2017 (see Table 3). Four of the selected questions corresponded to exams from the first semester of the course (GC I) and two questions came from exams from the second semester (GC II). These questions covered a wide range of topics in the curriculum. Five of the questions were worth six points, and the last question was worth eight points over a total of 100 per exam. These point values were retained when participants were asked to evaluate and grade student responses in our study.| Q1 – Particulate model of matter (PMM) GC I Fall 2016 |
| Pools constantly need to be replenished with water due to evaporation. One of the assumptions of the particulate model of matter is that particles exhibit a distribution of speed. Using the particulate model, explain how water evaporates and why the assumption about particles having a distribution of speed is essential to explaining evaporation. |
| Q2 – Resonance stabilization (RS) GC I Fall 2016 |
| Fluorescein exhibits a lot of resonance stabilization. Build an argument for why the presence of resonance is stabilizing based on the potential and kinetic energy of the electrons. |
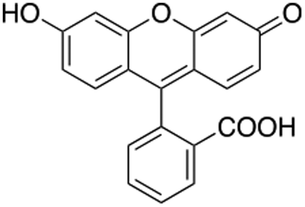
|
| Q3 – Structure–property relationships (SPR) GC I Fall 2016 |
| Other polymers commonly used in tattooing include the plastic cups used to hold water to rinse ink off the needles, and plastic wrap used to wrap the chair and table, as well as the skin after the tattoo is complete for healing and protection. Shown below are examples of each of these polymers. Justify why the polymeric unit corresponds to the specific type of plastic. Assume the chain length for both polymers is the same. |

|
| Q4 – Thermodynamic stability (TS) GC I Fall 2017 |
| Most proteins adopt a single unique structure when “folded” and many random structures when “unfolded”. Proteins can be unfolded (i.e., denatured) at high temperatures (ex: cooked eggs). Draw a PEC diagram [Potential Energy-Number of Configurations diagram] representing a “folded” protein (F) and an “unfolded” protein (UF). Explain how the two states of the protein differ (i.e., explain your logic in constructing this PEC diagram). |

|
| Q5 – Reaction directionality (RD) GC II Spring 2017 |
| Considering the reaction below, would you predict it to be reactant favoured (RF) or product favoured (PF)? Justify your reasoning. |
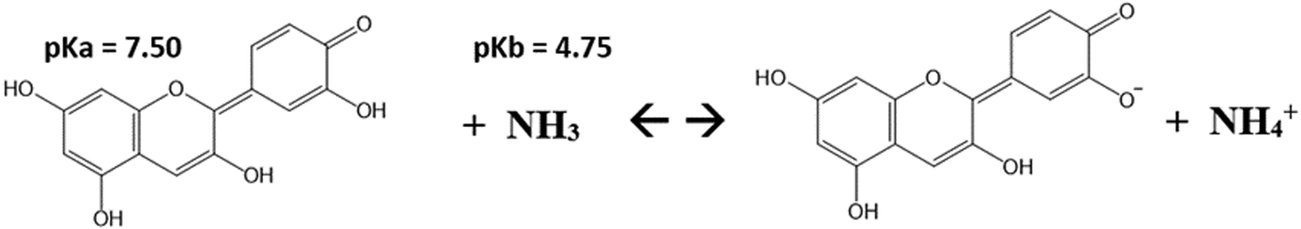
|
| Q6 – Perturbations to chemical equilibrium (PCE) GC II Spring 2017 |
| This equilibrium is established in the buffer from question 18: B + H2O ↔ BH+ + OH−. Build (a) thermodynamic and (b) kinetic arguments to explain how the equilibrium would shift if OH− is added to the solution. Justify your reasoning. Note: include a Q vs. time plot in your answer. (This question provided two boxes, one labelled “Thermodynamic argument” and one labelled “Kinetic argument” for students to write their answers in.) |
Two original student responses per question were selected for evaluation and grading by our study participants. The student responses used in this study were real students’ responses to actual exams given in prior years and were not artificially created. These responses were deidentified before use and each response was from a different student. The responses were unedited and retained handwriting, spacing, and notes exactly as written by the student during the exam. The researchers selected responses that were typical of those provided by students in the course and were expected to be judged as partially correct rather than completely right or wrong. Examples of the selected student responses can be requested from the authors.
Data collection
The first author of this paper met with each of the 29 instructors for an individual, video-recorded, semi-structured interview which lasted from half an hour to three hours. During the interview, participants were asked to evaluate and grade the provided student responses to the selected questions. For each question and its associated student responses, the instructor was first asked to read the question, prepare to evaluate, evaluate the students' answers, and then assign a score. All documents were provided as hard copies. The first page was the exam question written at the top of an otherwise blank sheet of paper. The instructor was asked to prepare as they would do in an exam grading setting, although recognizing that a rubric was not provided. Our goal was to investigate how they would spontaneously approach the evaluation of student work, but we recognized that their past experiences could influence their behaviour. To start the evaluation, the instructor was given a page with the student responses selected for that question. After completing the evaluation and grading of a question, both pages (preparation and evaluation pages) were collected from the instructor and the next question was provided following the same procedure. Once the evaluation and grading were completed, the interviewer explored the participants' rationale for each of their assigned grades. This interaction occurred after the evaluation of all questions had been completed to reduce the influence of the interviewer on the participants' evaluation decisions. Instructors were asked only to evaluate student responses to exam questions from semester materials they had taught and graded previously. Therefore, first-year GSI's (n = 18) and one experienced instructor evaluated only questions 1–4, which come from first semester content. All other instructors (n = 10) evaluated both student responses for all six questions. All instructors were given the option to skip the evaluation of student responses to any question if they were unfamiliar with the subject matter which occurred for one instructor for each Q1 and Q2. A total of 268 evaluations of individual students’ responses were collected and analysed for this study.Data analysis
Participants' assigned grades to the selected students' responses were analysed using descriptive statistical methods to characterise grading variability in our sample. Subsequently, interview recordings were transcribed, and all data (e.g., observation notes, participants' annotations) were qualitatively analysed using the framework developed in previous work (Herridge and Talanquer, 2020) and summarised in a prior section. This framework had been developed using a standard iterative approach (Miles and Huberman, 1994; Creswell, 2012) in the analysis of instructors’ evaluation of students’ responses to one single question in Table 3 (Q1). For this study, the framework was used to guide the analysis of the entire data set. The unit of analysis was the evaluation of a single student's response coded in each of the eleven dimensions in the framework. Each of these codes was assigned based on the predominant approach followed in the evaluation of a student response. To ensure interrater agreement in the qualitative analysis, a second researcher independently analysed and coded 19% of the collected data. The two researchers then met and discussed differences until agreement was reached on all eleven categories of analysis for each student response in the sample. Then the remaining samples were analysed by one of the researchers. Any samples in the remaining set that presented difficulty in assigning a code were discussed and confirmed by both researchers.During the data analysis, decisions about applying each code were made based on the diverse products collected during the interview. Preparatory work, notes, rubrics, marking, and assigned grades were the main source of codes for the rubric, Expected Answer, Interaction, Marking/Intention, and Feedback dimensions. The video with timestamps was used to inform decisions about applying codes to the dimensions of Depth, Grading System, and Scope. The transcripts were the main source of information for applying codes to the dimensions of Focus, Stance, and Lens. All three data sources were used together to confirm the overall approaches to evaluation followed by each participant.
Once all samples were coded, descriptive statistics was used to identify patterns in the data. This quantitative analysis included the determination of frequencies of each code overall and by participant, average scores assigned by participant and by evaluation approach, frequencies of shifts in evaluation approach from one question to another, and correlations between approaches across different dimensions of analysis.
Statistical modelling was used to evaluate the correlative relationships between the outcome variable of assigned grades and selected independent variables, including control and grader variables, as well as the eleven dimensions of the analytical framework described in this paper. The need for multilevel modelling was confirmed by the intraclass correlation coefficient (ρ = 0.128) and a likelihood ratio test (LRT) that showed a multilevel model with graders as the subunit had a better fit than a simpler, fixed-intercept model with χ2(1) = 12.2, p = 0.005 (Raudenbush and Bryk, 2001; Peugh, 2010). Assessment of assumptions of multilevel modelling indicated that the dependent variable was normally distributed with skew of −0.36 and kurtosis of −0.87, both within range of ±1 to be considered as normal (Kim, 2013). Both grade residuals and grader zetas showed constant variance (homoscedasticity) and normality when assessed graphically by quantile–quantile (Q–Q) plots and box plots.
Model building was conducted using the methods and with the results outlined in the Appendix: model building. Improvement in model fit, shown by LRT, was used for the determination of statistical significance and inclusion of independent variables and independent variable interactions. Although all possible random slope effects were assessed, only the random intercept effect was statistically significant and therefore all effects discussed in this paper can assumed to be fixed effects. R statistical software was used for the multilevel modelling (Wickham and Henry, 2018).
The proportion of variance in assigned grades accounted for by the variable “student response” was calculated by taking the difference in the proportion of variance explained by models with and without this variable. The effect size measure Cohen's f2 was given by the ratio of the proportion of variance in assigned grades accounted for by a variable to the unaccounted variance observed in assigned grades (Selya et al., 2012). Details for these calculations for categorical variables with and without interaction can be found in Tashiro et al. (2021). Cohen's f2 indicates effect size as small above 0.02, medium above 0.15, and large above 0.35 (Cohen, 1977).
Results
The main results of our analysis are presented in this section where we first qualitatively characterise variations in instructors’ approaches to the evaluation of student work by identifying the main approaches and how consistent instructors are in their approaches (research questions 1 and 2), and then present the results of a statistical analysis of assigned grades to determine how instructor-related variables account for observed assigned grade variability (research question 3). Our goal is to illustrate how the applied analytical framework can be used to characterise instructors’ evaluation behaviour, consistency in evaluation approaches, and the impact of these approaches on assigned grades.Characterization of variation in evaluation behaviour
Participating instructors differed in their approaches to the evaluation of student work in terms of (1) how they read and interpreted the question prompts, (2) how they prepared for and engaged in the evaluation of student work, (3) what they noticed in students' answers, and (4) how they responded to what students wrote. In the following subsections we characterise major differences in each of the dimensions included in the analytical framework in Table 1. A summary of the frequencies with which contrasting approaches along each dimension of analysis were followed by study participants across all graded samples (N = 268) is presented in Fig. 1.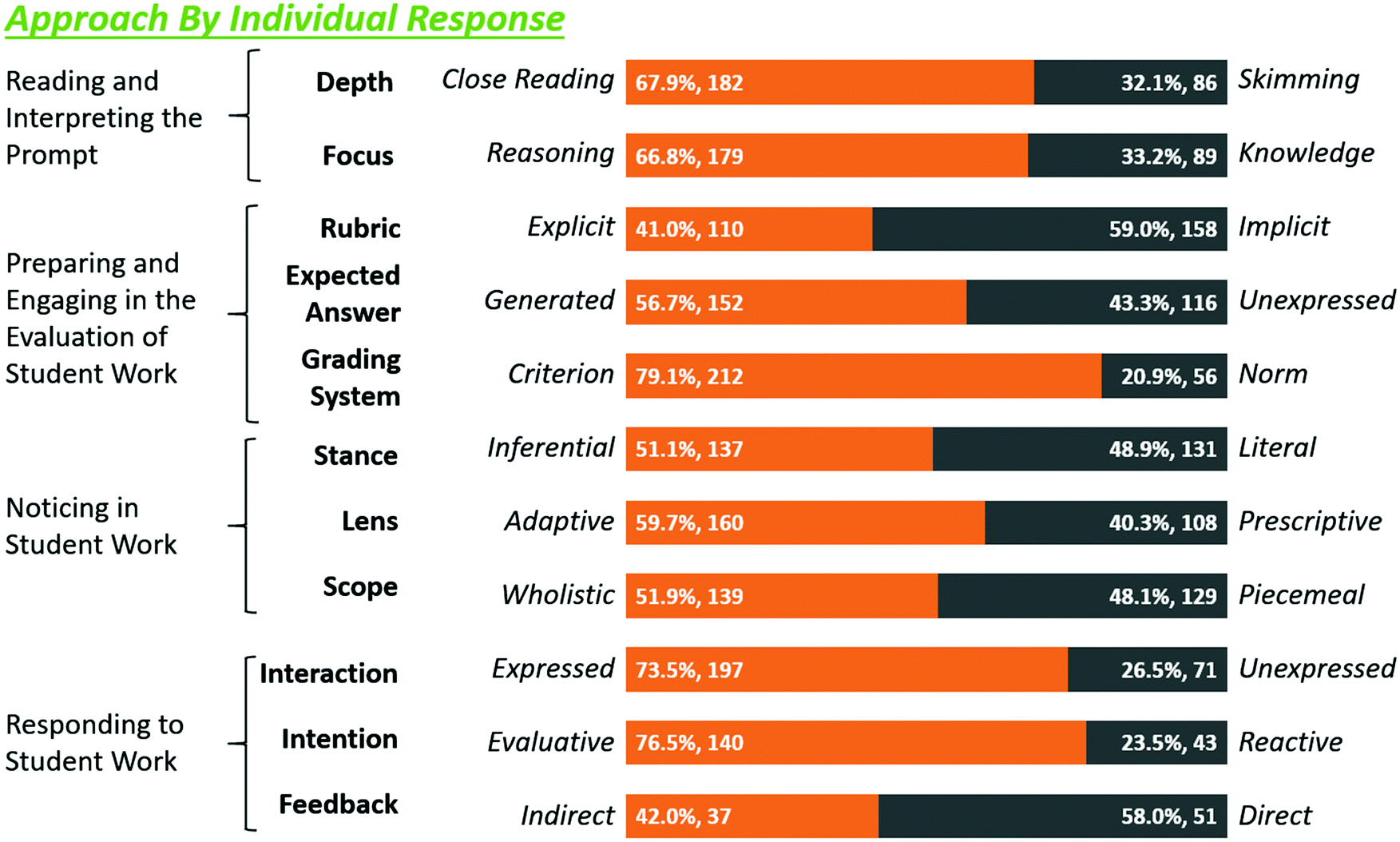 | ||
| Fig. 1 Distribution of behaviours in the evaluation of all samples of student work along each dimension of analysis in our study. Frequencies are expressed in terms of number of graded samples (N = 268). | ||
We further characterised the variation in evaluation behaviour through an analysis of consistency in instructors’ approaches to the evaluation. This metric was built by analysing instructors’ approaches across all samples graded. When instructors took a particular approach in at least 70% of the samples they evaluated, such an approach was considered as dominant in their behaviour. Any instructor who varied in their approach in over 30% of the instances was labelled “variable” in their evaluation approach in that dimension. This cut-off was chosen to only categorize those instructors as variable when they were oscillating between behaviours and not because a particular question caused a shift in the behavioural approach. For example, an experienced instructor recalled writing the first question prompt, and subsequently skimmed in the dimension of Depth. For all other questions, the instructor engaged in close reading. Therefore, this instructor's dominant approach was categorized as close reading for purposes of analysis. In contrast, the same instructor was categorized as variable in the dimension of Focus because they used both knowledge and reasoning approaches in equal amounts. Additionally, distributions of engagement in various approaches showed a trend of groups separated by the 30% mark. A summary of the main findings related to variation in evaluation approach is presented in Fig. 2. For each dimension, the relevant data from Fig. 1 and 2 are reproduced for clarity and comparison, retaining the respective colour keys.
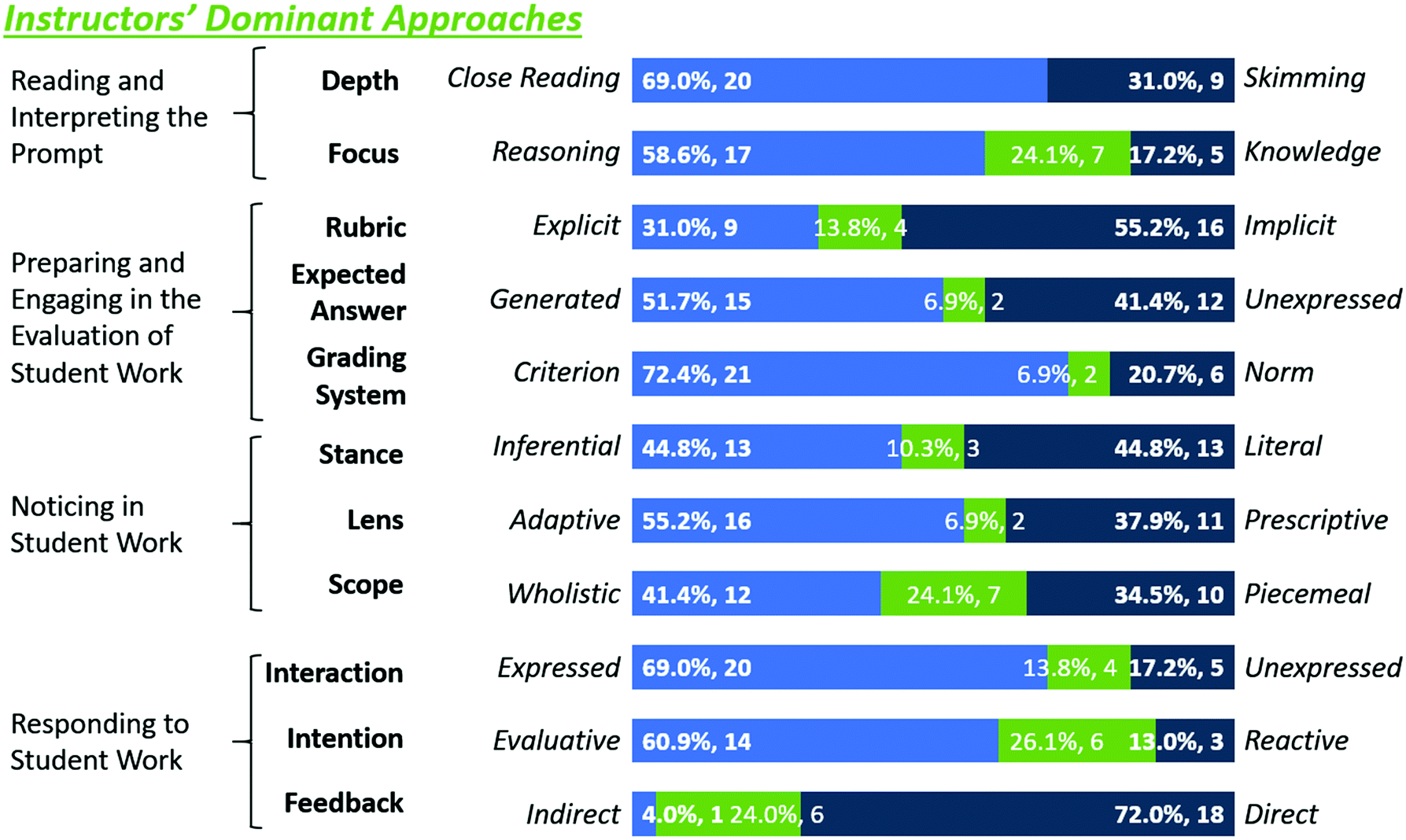 | ||
| Fig. 2 Dominant approaches in the evaluation of student work manifested by participating instructors in each dimension of analysis. Instructors who exhibited variable approaches are included in the middle bar in each dimension. Frequencies are expressed in terms of number of instructors (N = 29). | ||
Depth (Fig. 3). This dimension includes two main approaches to the evaluation of student work, close reading and skimming. As shown in Fig. 3, most instructors followed a close reading approach in the analysis of the question prompts (in 67.9% of all instances) and all of them were consistent in their behaviour. Of the 20 instructors who engaged in close reading with all prompts, 4 were FIs and 16 were GSIs. Eight instructors skimmed in all instances and one skimmed in all but one question prompt. The 3 FIs who skimmed were the most experienced FIs, but the 5 of the 6 GSIs who skimmed were all in their first-year of teaching.
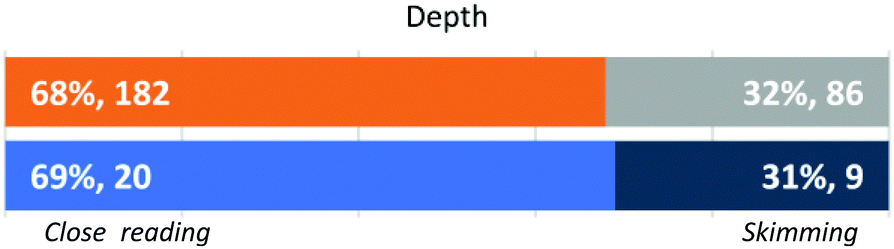 | ||
| Fig. 3 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
Instructors who engaged in close reading tended to spend more time analysing the prompt, identifying different parts of a question, highlighting words, or outlining expected requirements for a complete response. For example, GSI Georgie underlined portions of the prompt for every question to highlight different ideas or concepts thought to be targeted by the question. FI Jamie underlined and circled portions of each prompt in order to identify how to distribute total points among different parts of Expected Answers. When asked what their approach was for starting evaluations, GSI Robin stated, “I was trying to see what the question wanted to ask specifically.” Close reading was further evidenced by building rubric items based on the prompt's content and structure.
When skimming the prompt, instructors spent much less time looking at the question alone, often asking for the prompt and associated student responses at the same time. In these instances, instructors frequently indicated that they were already familiar with the question or remembered similar questions from prior grading experiences. In some cases, evidence of skimming the prompt was found in comments that revealed an instructor's confusion during the evaluation of student work, such as FI Blair asking “Why do they keep talking about wrapping the chair?” while evaluating the responses to Q3, which specifically mentions chairs in relation to the flexibility properties of plastic wrap (see Table 3). Other instructors, such as FI Quinn, explicitly expressed a preference for skimming the prompt, looking at student answers, and more carefully reviewing the prompt only if they could not make sense of an answer independently. In these instances, instructors could be seen using their grading pen to mark a student response, and then going back to hover over the question prompt while the student response was analysed.
Focus (Fig. 4). This dimension describes two categories of attention while analysing a question prompt and the associated students’ answers, attention to reasoning and attention to knowledge. As shown in Fig. 4, most instructors attended to student reasoning (in 66.8% of all graded samples) but some of them (24.7%) varied in their behaviour in this dimension. Behaviour in this dimension was characterised by analysing instructors’ comments while reading the question prompt and as they evaluated students’ answers.
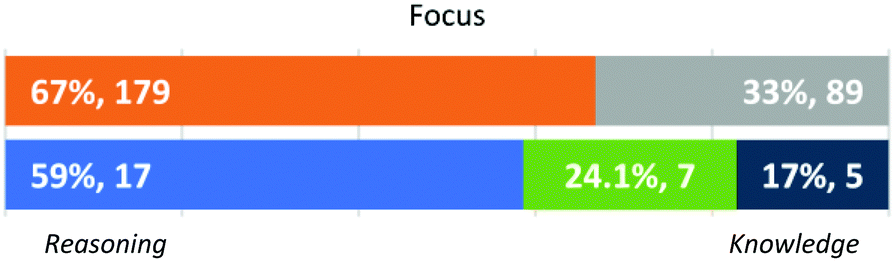 | ||
| Fig. 4 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
Instructors who mostly focused on reasoning often referred to the importance of students’ demonstrating understanding of an idea while reading a question prompt, and paid attention to the presence or lack of evidence related to sound reasoning or adequate understanding while evaluating students’ answers. Some instructors, for example, used phrases that referred to the extent to which students integrated or connected ideas: “a coherent train of thought” (GSI Riley, Kendall), “tied in” (GSI Finley), “integrated” (FI Quinn) or “a connection” (GSIs Pat, Emerson, Alexis, Ollie, and FIs Quinn, and Shiloh), or identified areas in which students seemed to lack understanding: “I was really looking for their understanding of resonance, which I didn’t feel that they have based on their answer” (GSI Oakley). Student understanding was often judged by the ability to use, apply, or connect different pieces of information to construct an argument or explanation, as illustrated by this interview excerpt from the analysis of student response 1 to question 5:
“OK, they recognize that that is weaker. So that's good. They can recognize that, but they cannot use it, or they didn't use it.” (FI Shiloh)
In contrast, instructors who mostly attended to knowledge tended to rely on the presence of keywords or proper definitions to make evaluation judgments and grading decisions as illustrated by this justification for points awarded in grading student response 2 to question 2:
“They actually got the definition of resonance. They mentioned both potential energy and kinetic energy” (GSI Jackie)
Of the 17 instructors who focused on reasoning, 2 were FIs and 15 were GSIs. All 5 instructors who focused on knowledge predominantly were GSIs. We had 5 FIs and 2 GSIs who varied in their approach, with 2 of them having an almost even split on their Focus. For example, FI Addison stated that the student must “link all that into a process of evaporation” while evaluating question 1, but based evaluation judgments on “looking for the word delocalization” when grading question 2. Variability in the Focus of attention was also observed when grading different student responses for the same question. The presence of certain keywords or phrases seemed to trigger a positive response in some instructors who awarded points independently of whether that knowledge fragment was properly integrated in a student response. The following interview excerpt illustrates this behaviour:
“They used one sentence, one little phrase, that I like. I guarantee that their professor probably said to them. ‘Resonance increases the stability of a molecule.’ Great. They were paying attention for that one sentence. I went ahead and gave them a point for that.” (GSI Micah)
This type of variability seemed associated with some instructors’ disposition to “find something to give points for” as explicitly stated by 11 instructors, both GSIs and FIs, in our sample (GSIs Micah, Morgan, Oakley, Emerson, Ollie, Parker, and Sidney, and FIs Logan, Blair, Shiloh, and Elliot).
Rubric (Fig. 5). Within this dimension, instructors could generate an explicit rubric that outlined the assignment of points per section of a question prompt or answer or could apply an implicit rubric that was not directly shared. Some instructors who generated and applied explicit rubrics built full expected responses, while others “would try to… list the key words or key points that I’m looking for in the answer” (GSI Lou). Examples of explicit rubrics for Q2 and Q3 built by the study participants are presented in Fig. 6 – FI Logan and GSIs Parker and Georgie. Instructors in this category indicated that they built and used rubrics to ensure consistency in the evaluation (FI Elliot) or because they were used to having one while grading (GSI Riley).
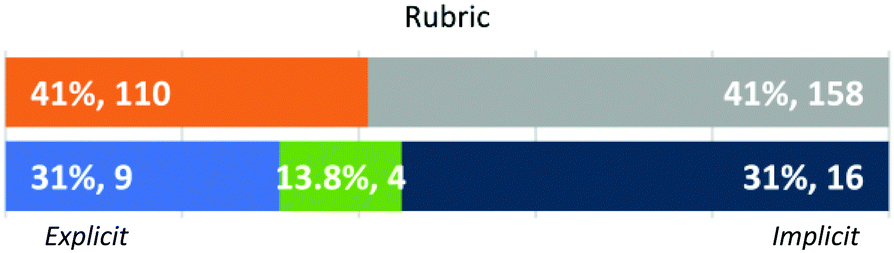 | ||
| Fig. 5 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
 | ||
| Fig. 6 Examples of rubrics and expected answers. | ||
In most instances (41%), instructors in our study relied on an implicit rubric while assigning points (see examples for GSI Micah and GSI Robin in Fig. 6). As illustrated by the following interview excerpt, several of these instructors could not justify their assignment of points when asked after the fact:
I: “How did you decide that part of the answer was worth two points?”
GSI Jackie: “I don't know. I guess I felt a little bit arbitrary about assigning two points to that. But I didn't really feel like it was a fully zero-point answer. And I don't know. I think I might just be a bit of a generous grader to be perfectly honest.”
Other instructors said they had a point breakdown in mind, but their assigned scores did not align with the assigned grades, such as with GSI Riley, who assigned 2/6 and 4/6 points to students’ responses to Q4 (TS), and said this:
I: Did you break down the points in your head in any particular way for this question?
GSI: Yeah. I kind of gave like 3 points to the… diagram just because it's probably what I’ve been habituated to do.
I: So, 3 points to the … diagram and 3 points for the response or the explanation…. How did you get to four points?
Other instructors chose not to write a rubric before engaging in the evaluation because of their desire to see what the students would say (GSIs Frankie, Alexis, and Oakley).
Instructor behaviour along this dimension was quite consistent. Four FIs and 5 GSIs consistently generated an explicit rubric before engaging in the evaluation of student work, while 3 FIs and 13 GSIs followed an implicit approach. Only four instructors (all GSIs) built explicit rubrics for some questions but not others.
Expected answer (Fig. 7). In this dimension, instructors varied in whether they explicitly expressed or not (unexpressed) an Expected Answer for each question before engaging in the evaluation of student work. Most instructors were consistent in this dimension. There were 2 GSIs (one novice and one experienced) who varied in their approach and wrote answers for some questions but not others. Expected answers varied from full paragraphs (GSI Micah in Fig. 6) to bulleted lists of main points (GSI Parker and GSI Robin in Fig. 6). Some instructors first wrote an expert answer that they then annotated to highlight salient points (FI Logan in Fig. 6). These instructors indicated that this allowed them to consider what the most important parts of the answer were for purposes of evaluation. Other instructors chose to simply write bullet points because they did not want to constrain themselves to a particular expression or construction of an answer, or because that allowed them to identify key words or phrases they expected to see in students’ answers. Similar to the use of rubrics discussed above, several instructors, particularly FIs, indicated their decision to include an expressed answer was due to habit in writing rubrics for others to use for exam grading.
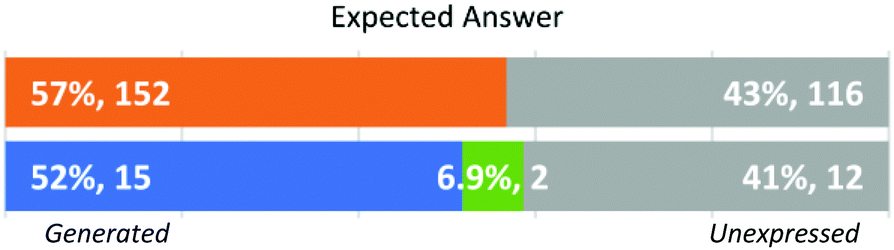 | ||
| Fig. 7 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
Some instructors did not generate an Expected Answer (unexpressed). The following excerpt illustrates the reasoning behind this behaviour:
“I just look at the question, try to understand what the question is about, and get a sense of what would be–I don't necessarily think about the answer, but what I would like to see in the answer. So typically, I don't write an answer of my own. So, I just start looking at the answers.” (FI Shiloh)
Some instructors in this category did have explicit rubrics while others did not. For example, GSI Georgie had an explicit rubric for every question but decided not to include an expressed answer for any of them. These rubrics described the allocation of points for different components of an answer without explicitly stating the expected response.
There was some correlation of instructors’ behaviours in the dimensions in the first two stages. Primarily, engaging in close reading of a prompt correlated moderately with building a generated answer and with writing an explicit rubric. There was also moderate correlation between generating an answer and building an explicit rubric. This latter correlation is indicative of the tendency of some instructors to build an Expected Answer that was then used as a rubric by assigning various points to different parts of the expected response. While this correlation between closely reading, having an explicit rubric, and generating an Expected Answer existed across all student responses, we feel this is particularly important to acknowledge in the context of significant effects on grades for those first-year GSIs, discussed in a later section. The moderate, but not strong, correlation of these dimensions further describes the variable nature of the instructors’ approaches and the need for multiple dimensions to describe the choices made in the first two stages.
Grading system (Fig. 8). In this dimension, instructor behaviour was categorised as criterion referenced and norm referenced. Most instructors applied a criterion referenced approach (in 79.1% of all graded samples) and were quite consistent in their approach. Only two instructors (1 FI and 1 GSI) manifested a highly variable behaviour, often grading the first student response for a given question using a criterion referenced approach but using a norm referenced approach when analysing the response from a second student.
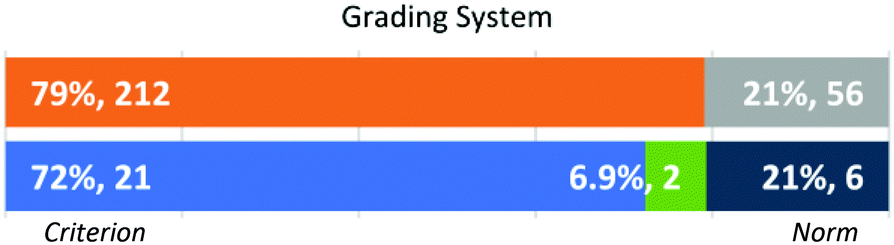 | ||
| Fig. 8 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
Instructors who used a criterion referenced system evaluated each student's work independently of others and referred to an explicit or implicit rubric when explaining their grading choices. Instructors’ approach in this dimension became apparent when they were pressed to justify their assigned grades. These instructors often referred to a rubric or an Expected Answer to defend their assignment of points, citing specific information that was necessary to answer a question.
Instructors who graded with a norm referenced system frequently expressed the need to analyse several answers before making an explicit rubric or generated an Expected Answer. The instructors who took this approach often expressed their preference explicitly, indicating their practices during exam grading were similar to those observed during the interview. The following interview excerpt illustrates this approach:
“I first looked at a relative thing. So, I didn't grade them one and then move on to the next. I looked at both answers and then made a relative grading kind of thing.” (GSI Lou)
Stance (Fig. 9). Within this dimension, an instructor could evaluate a student answer simply based on what was written (literal) or could construct inferences about student understanding that went beyond what was expressed (inferential). Instructors who took an inferential Stance often expressed a desire to “be on [the student's] side” (FI Addison), “[give] the benefit of the doubt” (GSI Parker) or expressed reluctance to take off points for “tiny mistakes” (GSI Riley). Some instructors who took an inferential approach did acknowledge that they were making assumptions (GSIs Jackie and Morgan) or inferring understanding (FIs Elliot, Jamie, and Shiloh and GSIs Frankie, Kendall, Morgan, and Riley), even if a student answers included mistakes. For example, GSI Oakley stated “I think I would still give them full credit because I think this was just a slip up here.”
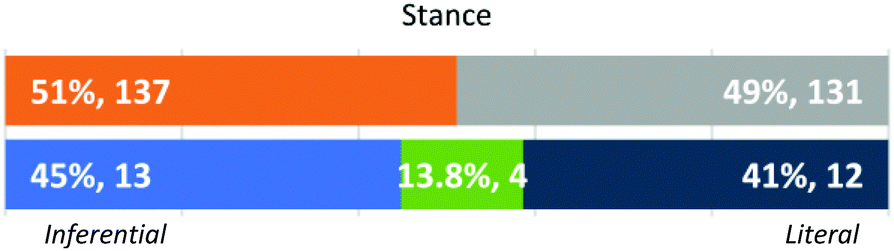 | ||
| Fig. 9 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
In contrast, those instructors who took a literal Stance did not make assumptions or built inferences, like GSI Finley, who was aware of their Stance when they talk about the student response to Q4 (TS):
“From their language, right, how they wrote their question, you can get the impression that they're trying to make us infer that if the unfolded is this way, then the folded has to be the other way. But that is not something that I think is OK with giving points for. If they don't directly state what they're talking about, I'm not supposed to be able to just assume because I already know what the answer is supposed to be. So, I can't just assume that they know what the right answer is supposed to be, which is why they received most of the points, but not all of the points.” (GSI Finley)
Other instructors manifested their literal Stance through comments about only grading what was on the paper (GSI Morgan) or “giving credit for things that are completely right” (GSI Dylan). FI Shiloh explicitly stated “I almost bet that if I ask this question to the student, they would be able to tell me. But I don’t have evidence [that they know the right answer]” about student response 1 to Q5 (RD).
Of 29 instructors participating in our study, 2 FIs and 1 GSI were variable in their approach. These three instructors seemed to be aware of the variability in their behaviour along this dimension, such as FI Blair, who stated, “This one was tough because this is someone who clearly gets it and completely went a different direction with the question. These are the ones that kill me” when discussing a student response to Q4 (TS). This instructor assigned 1 out of 6 points to the response to be consistent in the evaluation but felt conflicted because the student “grasped the idea of this [TS] diagram”.
Lens (Fig. 10). In this dimension, an instructor could approach the evaluation of student work looking for key ideas prescribed in an Expected Answer (Prescriptive) or could more flexibly recognize that students could express an idea in different ways (Adaptive). Participating instructors more frequently followed an adaptive approach (in 59.1% of all instances) and were quite consistent in their behaviour in this dimension.
 | ||
| Fig. 10 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
Instructors who took an adaptive approach often revised their rubric or Expected Answer (if they had been explicit and generated) in reaction to new student ideas (FIs Blair, Elliot, Logan, and GSIs Alexis, Dana, Emerson, Frankie, and Oakley), or even expressed a desire to look at student work before generating such a rubric or Expected Answer (GSIs Alexis, Taylor, Pat, Sidney, and Micah and FI Logan). In Fig. 6, a change to the rubric can be seen by the different colours used by GSI Parker. A few explicitly mentioned a need to be flexible in their approach (FI Addison, GSI Emerson) because of previous experiences. Some instructors took an adaptive Lens when confronted with unusual or unexpected arguments that had some validity, as illustrated by this evaluation of student response 1 to Q2 (RS):
“The student was making a point that I thought was an interesting one. I had never ever thought in that way, but it was an idea. It's not the way I would think about resonance, but you can think that one pair electrons for bonds and the formation of bonds typically lowers the energy of a system. So that was a clever argument.” (FI Shiloh)
In contrast, instructors who took a prescriptive Lens often claimed they could not give full credit because the student was missing a key term (GSIs Kendall, Frankie, Dana, Finley, Lou, Micah, and Riley and FI Blair) or expressed that the student answer was correct simply because it matched their key words (GSIs Alexis, Sidney, and Riley, and FI Addison). For example, FI Addison said this about Q2, “I'm looking for the word delocalization, right?”, while GSI Lou discussed whether or not the student “mentioned” a term for every response evaluated and said they were “looking for” a particular idea for each question. GSIs Alexis, Micah, and Morgan all explicitly used the term “key word” when talking about what they were looking for in the student response:
“Accelerates is a key word in that” – Morgan on Q6;
“I would mention randomness, because that's a key word in the question for that.” – Micah on Q4;
“They're saying, when you're adding more stuff, their action accelerates. That was the key word there.” – Alexis on Q6.
Most instructors in our sample were consistent in their behaviour along this dimension. Only two instructors (both FIs) were variable in their approaches in this dimension. This variation is exemplified by FI Elliot's behaviour, which included point deductions for not following directions on some questions while considering it “fair” to give points for different types of arguments on other questions.
There were correlations between approaches in the dimension of Stance and the dimension of Lens. Taking a literal Stance in the evaluation of student responses correlated moderately with having a prescriptive Lens. Instructors who were looking for specific terms in a student answer were often literal in the interpretation of what students wrote and less likely to engage in interpretation, as illustrated by this excerpt:
“They do mention speed, which, OK. But again, we're really specific that if they're going to mention speed, they have to tie it into this average kinetic energy, which we measure through temperature. And so, using this model, those are key points. And I just didn't see them in here at all.” (FI Elliot)
Alternatively, those who engaged in interpretation were also more likely to value answers that deviated from their initial expectations for normative responses.
Scope (Fig. 11). Along this dimension, instructors could evaluate student work by considering one expressed idea at a time (piecemeal) or analysing an entire answer (wholistic). As shown in Fig. 11, these different approaches were observed almost equally in all graded instances and more instructors varied in their behaviour in this dimension. Those instructors who graded in a wholistic fashion were looking for “the overall picture” (GSI Kendall) and were aware of their preference to read the full response first, before providing an evaluation (GSIs Dylan, Finley, and Micah). These instructors often deducted points for internal inconsistencies in a student's response, as illustrated by this evaluation of student response 1 to Q5 (RD):
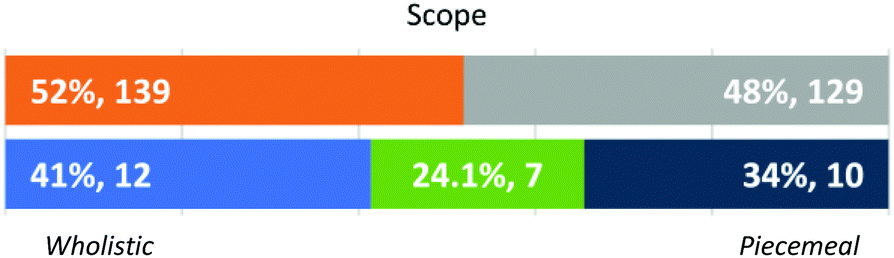 | ||
| Fig. 11 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
“The reaction would be reactant favoured. This is because the conjugate base is weaker than NH 3 . So, it is less likely to accept protons. Weaker, less likely. That is right, but it's not right… That sentence completely contradicts this sentence. That's wrong. The two just completely contradict each other. That doesn't make any sense to me. That's absolutely incorrect.” (GSI Micah)
This instructor gave 0 out of 6 points to this student's answer. The same response got 3 out of 6 points by another instructor who followed a piecemeal approach and identified the same pieces of correct information. A piecemeal approach was often linked to the use of explicit rubrics that had clear point breakdowns and each idea or key phrase was awarded points regardless of what else was in a student's answer. As GSI Ollie expressed, “I just leave a checkmark or highlight that sentence. So based on those highlighted portions, I decide how many points are recorded for the student's answer.” Several instructors (FI Addison, FI Logan, GSI Micah) explicitly noted their preference for assigning points to different parts of a response: “key of two points for this, two points for this, two points for this” (GSI Micah) and tended to highlight the specific portions of a response that earned those points: “if they just say the shift, it's worth points” (GSI Micah).
Compared to other dimensions, instructors were more variable in their evaluation Scope. Seven instructors (3 FIs and 4 GSIs) alternated between a wholistic and piecemeal approach when grading student work. In some cases, the shifting between approaches seemed to be linked to conflicting past experiences and personal preferences. For example, GSI Micah referred to the way rubrics were written in the department and how GSIs were expected to evaluate work in reference to those rubrics (which may favour a piecemeal approach) but this instructor did not use an explicit rubric when grading independently. Several of the FIs mentioned having a “team of graders” (Addison, Logan, and Elliot) and their need for building rubrics that assigned points to specific components of an answer. Nevertheless, they were more likely to follow a wholistic approach when personally evaluating student work.
In line with these comments, having a Focus on reasoning correlated mildly with having a wholistic Scope. Instructors who looked at an answer in its entirety when evaluating student work were more likely to pay attention to student reasoning, while those who took a piecemeal approach more often focused on the presence of pieces of knowledge. Instructors who manifested a wholistic Scope and a reasoning Focus often referred to the need for reading the whole response, sometimes multiple times, in order to understand what students were trying to communicate.
Taking an inferential Stance correlated moderately with having a wholistic Scope. Instructors who evaluated a response as a whole were more likely to engage in making sense of student ideas and infer understanding. Consider, for example, the following excerpt:
“I think I would still give them full credit. Because I think this was just a slip up here. Because later, they talk about—well, on the other hand, the plastic wrap has more branches that allow it to block the background and make it less rigid. So here, he's using less rigid in reference to the plastic cup as in my interpretation. So, it makes me to believe that this is just this word here is just a slip up. Because they even say that it makes it hard to move and is less flexible.” (GSI Oakley)
This instructor considered the entire answer to build an evaluation based on inferences about student understanding despite explicit inconsistencies in the written response.
 | ||
| Fig. 12 Sample of instructor response to student work: GSI Dylan, Q2, student response 2, including expressed interaction, evaluative intention, and indirect and direct feedback. | ||
Interaction (Fig. 13). During the evaluation of student work, most instructors and in most instances made explicit marks or gave feedback on student work (Expressed) and fewer did not (Unexpressed). In terms of dominant approach, 4 FIs and 16 GSIs consistently marked students’ answers, five instructors (all GSIs) consistently did not make any other marks beyond the final assigned grade, while 3 FIs and 1 GSI were variable in this dimension.
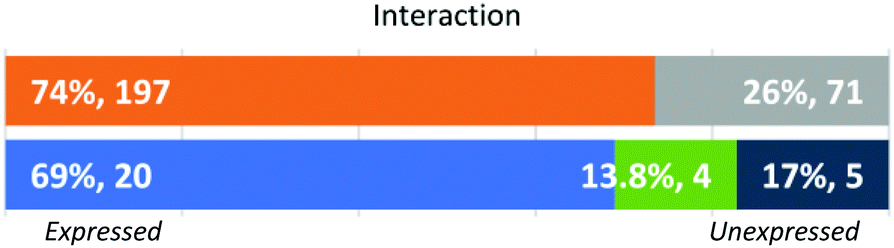 | ||
| Fig. 13 Approach by individual student response (N = 268) and instructors’ dominant approaches (N = 29). | ||
Intention (Fig. 14). Some instructors made marks of student work to highlight elements that caught their attention (reactive) while others made marks to highlight correct or incorrect statements (evaluative). There were 183 student responses with expressed marks. The most common evaluative marks included cross outs and question marks to point to incorrect elements and check marks for correct ones. Instructors who were more reactive in their approach tended to use circles and underlines to indicate positive or negative reactions to students’ answers. When asked what a circle or underline meant, these instructors’ answers ranged from “I made these marks more for me than for the students” (FI Shiloh) to “I’m like excited” (FI Addison) to “I’m not sure what they were saying” (GSI Emerson). As shown in Fig. 2, variability in this area was among the greatest in all dimensions.
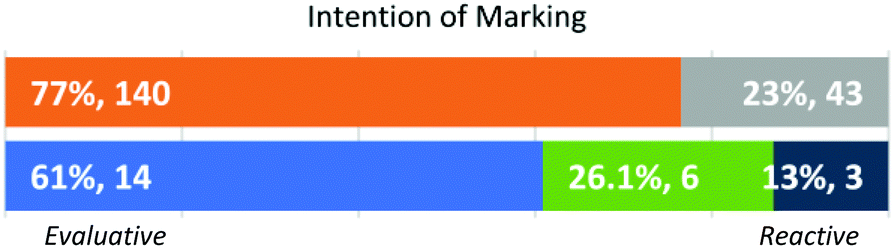 | ||
| Fig. 14 Approach by individual student response with expressed marking (n = 183) and instructors’ dominant approaches (N = 29). | ||
Feedback (Fig. 15). Instructors provided Feedback in the form of explicit statements (direct) or in the form of questions (indirect). There were 88 student responses with Feedback, Direct Feedback often mirrored statements or phrases that were found in an explicit rubric or generated Expected Answer. Other Feedback pointed out specific portions of the answer that were incorrect or missing. Much of the Feedback was directive in nature, prompting specific actions that would make the answer more correct or complete. Indirect Feedback also addressed these holes in the student responses, and frequently took the form of “Why?” (7 instances) or “How?” (4 instances). Also frequent was a key word or two followed by a question mark, such as “IMF's?” or “Only cup?” As shown in Fig. 2, variability in this area was among the greatest in all dimensions.
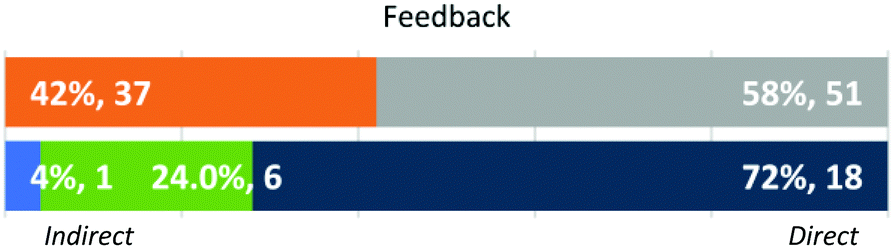 | ||
| Fig. 15 Approach by individual student response with expressed feedback (n = 88) and instructors’ dominant approaches (N = 29). | ||
Correlation of dimensions with assigned grades
Overall, we collected 268 instructor evaluations of pairs of individual students’ responses to six different general chemistry questions with an average assigned score of 61% ± 30%. Variability in the quality of students’ answers can be expected to result in variation in the grades assigned by participating instructors. Our quantitative analysis of the collected data indicated that 46% of the variance observed in all assigned grades was uniquely accounted for by which student response was being graded (within the multilevel model). The effect size of the student response variables was large as measured by Cohen's f2 = 0.88. The variation in the grades assigned to different student responses’ is summarized in Table 4. As shown in this table, three of the student responses were assigned grades ranging from 0% to 100% by different instructors. Seven student responses were scored at a 0% by at least one instructor and eight were scored at 100% by at least one instructor. The average range of assigned grades was 70%.| Student response | n | Average assigned score (%) | Min score assigned (%) | Max score assigned (%) |
|---|---|---|---|---|
| PMM i | 28 | 54.8 | 0 | 100 |
| PMM ii | 61.6 | 0 | 100 | |
| RS i | 28 | 31.8 | 0 | 83 |
| RS ii | 87.5 | 33 | 100 | |
| SPR i | 29 | 77.3 | 33 | 100 |
| SPR ii | 68.1 | 33 | 100 | |
| TS i | 29 | 56.3 | 0 | 100 |
| TS ii | 76.7 | 25 | 100 | |
| RD i | 10 | 21.7 | 0 | 50 |
| RD ii | 90.8 | 66 | 100 | |
| PCE i | 10 | 33.8 | 0 | 63 |
| PCE ii | 25.0 | 0 | 50 |
Instructor differences accounted for 12.8% of the variance observed in assigned scores as determined by the interclass correlation coefficient (ρ = 0.128). Modelled instructor variables, however, were found to have negligible effect sizes (Cohen's f2 < 0.02) indicating that these effects did not account for a substantial amount of the overall variance observed, leaving unexplained overall variance and between-grader variance. Instructor gender and research area did not have significant effects on grading outcome. Effects from the interaction between instructor role (FI or GSI) and teaching experience were, however, significant. In particular, being a first-year GSI had a significant effect on assigned grades compared to more experienced GSIs and FIs. Grades by the more novice GSIs were on average higher than those assigned by more experienced instructors.
Of the different dimensions of analysis in the framework applied in our study, four of them were found to be statistically significant effects on assigned grades but dependent on type of instructor. Differences in approach by first-year GSIs in the dimensions of Expected Answer (generated or unexpressed) and Grading System (criterion referenced or norm referenced) were significant effects.
For the more experienced instructors, the Stance (inferential or literal) dimension was a significant effect. Additionally, the dimension of the Marking Interaction (expressed or unexpressed) was a significant effect for experienced instructors, but not the Feedback Interaction (expressed or unexpressed) indicating that whether or not marks were made on the student work predicted a difference in assigned grades but writing or not writing Feedback was not correlated to a difference in assigned grades. The Marking Intention (evaluative or reactive) dimension that further categorized markings was not a significant effect.
To illustrate the effects on assigned grades of variation in approaches to the evaluation along the relevant dimensions for different types of instructors, the results of the multilevel model were used to calculate predicted scores for an average student response (a response with the average score of 61%). The results are summarised in Table 5. All predicted grades can be assumed to be on average, across all graders, and controlling for all other variables. The average predicted grade was 68% for first-year GSIs and 47% for more experienced instructors. The difference between the highest predicted grade (78%) and the lowest predicted grade (35%) was 43%.
| First-year graduate student instructors | ||
|---|---|---|
| Grading system (%) | ||
| Norm referenced | Criterion referenced | |
| a An average student response is said to be a student response with an average assigned score equal to 61%, the overall average of all assigned scores. b Experienced instructors are the group of all instructors excluding first-year GSI's. Predicted grades were calculated using the results from the final multilevel model and can be assumed to be on average, across all graders, and accounting for all other variables. | ||
| Expected answer | ||
| Unexpressed | 78 | 67 |
| Generated | 69 | 57 |
| Experienced instructorsb | ||
|---|---|---|
| Stance (%) | ||
| Inferential | Literal | |
| Marking | ||
| Expressed | 57 | 48 |
| Unexpressed | 48 | 35 |
Predicted scores for first-year GSIs of an average student response ranged from 57% to 78%. Grades from instructors in this category who had an unexpressed Expected Answer were likely to be 9% higher on average than those who generated an Expected Answer, while grades from those who used a norm referenced Grading System were likely to be 11% higher than those who applied a criterion referenced Grading System.
Predicted scores for the more experienced instructors ranged from 35% to 57%. The grades assigned by more experienced instructors who adopted an inferential Stance were likely to be 11% higher on average than those who took a literal Stance. The grades assigned by instructors in this category who interacted with student work were likely to be 11% higher than those assigned by instructors who did not make any Marking.
Discussion
Our study was guided by three research questions seeking to: (1) identify the main approaches to the evaluation and grading of student work that chemistry instructors in our sample more commonly followed, (2) characterise consistency in the application of those approaches across different evaluation instances, and (3) determine the potential impact of variations in approaches on assigned grades. In this section, we discuss our main results in these three areas.Common main approaches
Our analysis revealed major differences in the approaches followed by different instructors in the evaluation of student work. These differences manifested in all of the dimensions of analysis used in the study as summarised in Fig. 1 and 2. There were a few dimensions in which more than two thirds of our study participants followed a similar approach. These included Depth, with a majority of instructors engaging in close reading; Focus, with a majority of instructors paying attention to student reasoning; Grading System, with a majority of instructors using a criterion referenced approach; and Interaction, with a majority of instructors expressing interactions with student work by making some type of mark or feedback. In our small sample, no approach was found to correlate with specific instructor characteristics, such as gender, role, research area, or teaching experience.The lack of common main approaches by instructors is intriguing due to the similar justifications that kept appearing among instructors. For instance, several instructors seemed to justify their deduction or award of points based on the presence (or lack thereof) of particular “key words”. This word-search method of evaluation has been utilized in attempts for automated essay scoring (Klobucar et al., 2012) and shows up in the dimensions (categories) of Focus (knowledge), Lens (prescriptive), and Scope (piecemeal). While each of these dimensions had this overlapping justification, the dimensions did not have strong correlations, meaning the same justification was used in different ways for different instructors.
The most common approaches to the evaluation of student work followed by our study participants may have been influenced by contextual factors. For example, participating instructors taught a general chemistry curriculum that emphasizes the development of students’ chemical thinking. At the level of discourse, the general chemistry teaching team often highlights the importance of students building their own explanations and justifying their reasoning. Similarly, study participants were used to evaluating student work using a common rubric after holding a collective meeting in which expected answers, point assignments, and sample student responses are analysed and discussed. This practice may have favoured the application of a criterion referenced system when evaluating student work during the interview. Additionally, in grading meetings instructors were encouraged to justify their grades through explicit Marks and Feedback on student work, which may have also influenced their behaviour.
Reliance on a criterion-reference system when evaluating student work could be associated with instructors’ beliefs about fairness. During the interviews, multiple instructors referred to the need “to grade them all exactly the same” so that “it's fair” (GSI Dana). References to fairness also appeared in comments by instructors regarding the adoption of a particular stance or lens. For example, whether or not it was “fair” to award points to alternative ways of writing or thinking when evaluating student work. Nevertheless, judgments about fairness led instructors to follow contrasting approaches in these dimensions: GSI Robin was inferential and prescriptive, and stated, “Just grading, in general… I’m trying to be fair” while GSI Morgan was literal and adaptive and regularly justified their grading as “a fair way to do it.”
Although local curriculum and evaluation practices may have influenced the approaches that study participants followed during the interviews, the impact of these factors was limited in other areas. Despite, the institutional practice of using a provided rubric based on expected answers to evaluate student responses during grading meetings, only 41% of the instructors generated an explicit rubric to guide their evaluations during the interview. Comments from participants suggest mixed ideas about the value or utility of rubrics as they were judged to be “hit or miss” (GSI Dana), a “loose reference” (GSI Oakley), or they were openly disliked (GSI Parker).
Another reason for the commonality in the criterion referenced Grading System may be a sense of fairness by the instructor. Fairness has been discussed by multiple researchers as a reason for using rubrics (Holmes and Smith, 2003; Andrade, 2005; Randall and Engelhard, 2010), but here we see instructors citing fairness in regards to their preferred Grading System. Multiple instructors cited their beliefs about the need “to grade them all exactly the same” so that “it's fair” (GSI Dana), and this is easier to do with an external criterion referenced system. These instructors were able to apply this Grading System even when they did not have an explicit rubric or generated an Expected Answer. This sense of fairness also appears in comments by instructors regarding the Stance and Lens; whether or not it is “fair” to allow alternative ways of writing or thinking when evaluating student work. These dimensions were more evenly split between their categorical options, indicating the decision on which end was “fair” was less consistent. In fact, different instructors did cite fairness as their reason for each category. GSI Robin was inferential and prescriptive, and stated, “Just grading, in general… I’m trying to be fair.” GSI Morgan was literal and adaptive and regularly justified how they graded as “a fair way to do it.”
Another surprising lack of commonality is for the dimension of Focus. The curriculum used for general chemistry at our institution has a heavy Focus on reasoning and critical thinking skills (Talanquer and Pollard, 2010). However, a third of the student responses were graded with a knowledge Focus. This approach may be a result of instructors seeking to award points to students for providing some answer, even if the complete or ideal answer is not submitted. As noted in the results section related to Focus, parts of the answer could be identified as a good start or critical baseline information that earned points even if there was no connection or utilization of that information. This desire to find something to award point for is discussed further in the following section regarding consistency.
Consistency in approach to evaluation
While each instructor approached the evaluation of student work in different ways, each participant was generally consistent in the approach they followed during the evaluation of different student responses. These preferences may be indicative of strongly held beliefs regarding learning theories, purposes of assessment, and philosophies of teaching and education. Work in the area of beliefs about teaching and learning does indicate the strength of these preferences is likely to be high (Gess-Newsome et al., 2003; Gibbons et al., 2018). Evaluating consistency in the method presented in this paper also allows identification of trends even when actions are at a mismatch with stated values. While an instructor may state particular learning objectives and intentions but not actually grade in accordance with those values (Mutambuki and Fynewever, 2012; Petcovic et al., 2013), each instructor does tend to be consistent in their approach.It is possible that the observed preferences in the evaluation of student work across different questions was influenced by the number of responses that participants were asked to analyse. Under real conditions instructors typically grade a far larger sample of responses which may influence their behaviour. For example, under such conditions, a norm referenced Grading System may become more prevalent or compete with a criterion referenced Grading System if graders are influenced by dominant students’ responses.
As summarized in Fig. 16, most instructors exhibited variation in at least one category, but no instructor was variable in more than four dimensions. In general, faculty instructors were more variable in their approaches across student responses than GSIs. Close to 41% (9 out 22) GSIs were fully consistent in their approaches across all evaluations. Several instructors seemed to be aware of the variability in their behaviours, particularly when conflicted with a student answer.
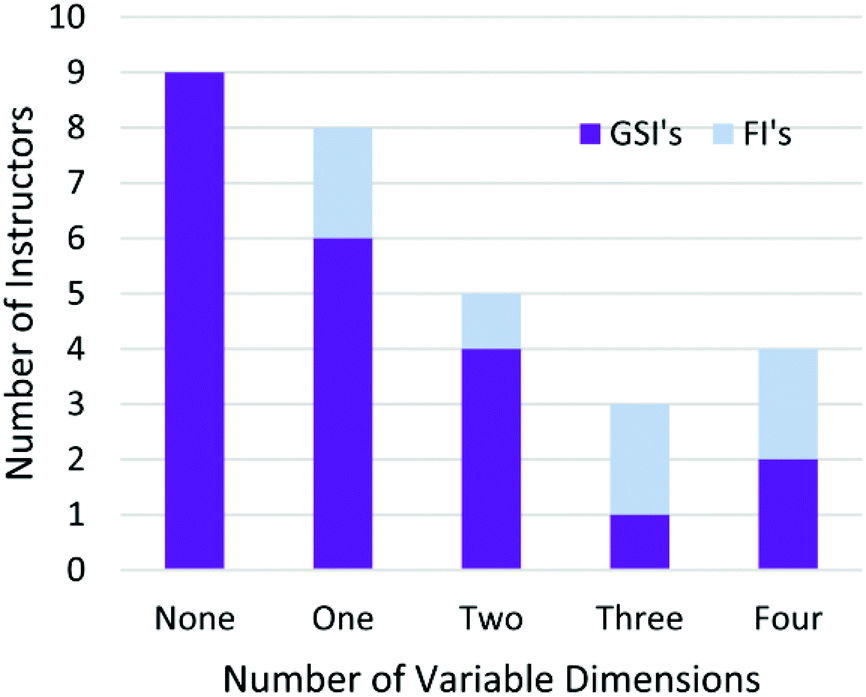 | ||
| Fig. 16 Number of dimensions in which instructors were variable. | ||
Some instructors expressed acknowledgement of their own preferences and frustration with these approaches, such as FI Blair, who assigned a 1/6 to a student response and stated, “This one was tough because this is someone who clearly gets it and completely went a different direction with the question. These are the ones that kill me.” This instructor had a strong preference for a literal Stance and prescriptive Lens, yet recognized that there were alternative ideas that might be productive. FI Blair went on to say that they felt they “had to be consistent with everyone” in order to justify the low grade.
For other instructors, they noticed a shift in their own behaviour because they were attempting to “find a point” for the student (GSI Parker) or were responding to experiences that they, again, felt was fair or reasonable. These shifts often related to the dimensions of Focus or Scope, both of which had the highest levels of variability. With reference to the Focus and Scope, three instructors were flexible in both dimensions: GSI Micah and FIs Logan and Elliot. These instructors were all experienced and gravitated towards adjustments to benefit students, having adaptive or flexible approaches to the dimension of Lens and utilizing generated Expected Answers and a criterion referenced Grading System. These instructors seemed to have some conflict between looking for well-reasoned answers and crediting students for “little snippets” of information that had “merit” (FI Logan).
FI Elliot was one of the most flexible instructors, with shifts in the dimensions of Focus, Lens, Scope, and Interaction. This instructor tended to make a claim and stick to it, but also adapted if there was sufficient volume. While talking about their approaches and experiences, this instructor stated,
“[If] there's a lot of misconceptions. Whether it's really how we teach or how they interpret it, it's hard to say. But I've always felt that if they're all my students and they all have the same misunderstanding, there's something I can do better and I'll adjust the rubric because I do take some of the, quote unquote, “blame” for that.”
This instructor's approaches were influenced by the content of students’ responses which led to changes in expectations and grading criteria. Further, this instructor's perceptions on misconceptions and learning objectives shapes how they respond to alternative, incomplete, or incorrect ideas that are represented on assignments. Understanding how these perspectives shape approaches, and by extension the grades assigned, can highlight the importance of the act of noticing during the evaluation of summative assessment responses.
While each question may have been considered using different approaches, the shift between approaches did not occur regularly between student answers. Shifting approaches between the two student responses only happened in 10 cases out of 134 questions, and most commonly noted a shift in Scope (n = 5) or Focus (n = 3). With this in mind, the variability within an instructor does not seem as critical as the differences between instructors, and how different approaches may impact the assigned grades. This highlights the productive use of noticing in understanding how instructors engage in evaluation of summative assessment and further demonstrates the contribution of the dimensions of variation framework in providing language to describe and discuss approaches.
Correlation of dimensions with assigned grades
Although our sample was small, our quantitative analysis indicated that the role and teaching experience of the instructors had a significant correlation with the assigned grades. The less experienced first-year GSIs tended to assign higher grades than more experienced instructors. Unfortunately, in our study we only had GSIs in their first, third, and fifth years. Additional research with a larger sample of GSIs of differing experience levels would be needed to further analyse the observed relationships.Interestingly, the dimensions of evaluation that were found to correlate to differences in assigned grades were not the same for these two groups of instructors. For first-year GSIs, Expected Answer and Grading System, both in the stage of “Preparing for and Engaging in the Evaluation of Student Work” had a significant effect on assigned grade, with instructors who generated an Expected Answer and/or adopted a criterion referenced approach assigning the lower grades. On the other hand, relevant dimensions for more experienced instructors included Stance and Marking Interaction dimensions in the stages of “Noticing in” and “Responding to Student Work”. In this case, instructors who adopted a literal Stance and/or did not express Marking on student work tended to assign lower grades.
For the least experienced GSIs, leaving the Expected Answer unexpressed was correlated with assigning higher grades to the student responses. The lack of significant effect of this dimension for more experienced instructors could be because they may have a more solid understanding of the evaluated concepts and have been exposed to similar questions in the past. The lack of a generated Expected Answer by less experienced instructors may indicate they have a weaker understanding or lack of familiarity with a topic and therefore be less harsh in their evaluation of student responses.
For first-year GSIs, having a norm referenced Grading System was correlated with assigning higher grades to the student responses. This could be explained as their comparison may be limited to only the two samples provided during the interview, leading to assigning the best possible score to the better of the two responses. Using a criterion referenced Grading System would not result in such high scores due to the lack of a polarized high score. The lack of significant effect in this dimension for more experienced instructors could be due to their experience with a broader range of student responses. Having experience with better student responses may have led them to not feel obligated to assign the best possible score to one of student responses for each question given to them in this study.
These findings regarding first-year GSIs align with work that shows a need for explicit discussion regarding grading practices with teaching assistants (Yerushalmi et al., 2016; Marshman et al., 2018), and the need for more intensive training for new instructors (Mutambuki and Schwartz, 2018). The differences between first-year GSIs and all other instructors shows that experience has a significant effect on assigned grades and further suggests a need for continued professional development related to the stages of noticing and responding to student work to help close the gap between instructors’ assigned grades that are not addressed by rubrics alone.
For more experienced instructors, having an inferential Stance was correlated with assigning higher grades to the student responses than having a literal Stance. It is possible that instructors who are inferential recognize and value productive reasoning in student responses even when stated in non-normative, incomplete, or confusing ways. This interpretive behaviour could explain the assignment of higher grades. This could be further explained by where those instructors placed the burden of proof. Instructors who are inferential make assumptions, possibly about expert heuristics being present or mistakes being made due to carelessness, rushing, or absentmindedness. Instructors who are literal do not allow for this benefit of the doubt and stay strictly to what is represented on the page by the student. This echoes results found about mismatches between instructor intention and practice and the burden of proof (Mutambuki and Fynewever, 2012).
It is somewhat surprising that the Marking Interaction was a significant effect on the grades assigned by more experienced instructors. Having an expressed Marking Interaction was correlated with assigning higher grades to the student responses. One may hypothesize that Marking is indicative of the depth to which instructors analysed student answers. Instructors who express Marking may thus be more likely to identify ideas or pieces of knowledge that are judged as worthy of points, which is reflected in the higher assigned grades.
The negligible effect sizes of the instructor-related variables and the substantial unexplained variance in assigned grades suggest that other effects are at play. Variables such as the specific content of the students’ responses, the value an instructor may place on specific information or reasoning displayed in such a response, and the instructor knowledge and understanding of the concepts and ideas under evaluation may be significant effects on assigned grades that could explain more of the observed variance. Further research is needed to determine the effects of these other variables.
Limitations
This study involved a small number of faculty and graduate student instructors within a specialized area (general chemistry) and our analysis focused on their approaches to the evaluation and grading of only six exam question and two associated student answers. The questions were representative of conceptual questions used in general chemistry exams at our institution, but different types of questions or additional student responses may trigger different evaluation and grading behaviours. Additionally, instructors are our institution follow particular procedures to evaluate student responses in exams (e.g., use of a rubric provided by FIs) and these experiences may induce non-generalisable behaviours. We cannot speak to the emotional or social experiences of the participants during the interview that may have affected their observed decisions and preferences.This study's ability to generalize the findings from the statistical modelling in the section “Correlation of dimensions with assigned grades” is limited by several factors. The small number of participants yielded limited group sizes of categorical variables and therefore the consideration of overfitting the model should limit the generalization of the findings. Additionally, as independent variables were not randomly assigned, no claims of causal relationships can be made, but only correlative relationships.
Conclusions and implications
Our work contributes to existing work in assessment and evaluation by demonstrating the utility of adopting a Noticing framework in the analysis of instructors’ approaches to the evaluation of student written responses in summative assessments. Previous work on Noticing has predominately focus on formative assessment and taken place in K-12 classrooms (Russ and Luna, 2013; Luna, 2018; Chan et al., 2020). In this study, we extend and connect ideas about how instructors approach formative assessment to how instructors approach summative evaluation and grading. While engaged in formative assessment, instructors must on-the-fly notice, interpret, and respond to student ideas. In this work, we operationalized and applied these formative assessment techniques to characterize differences in instructors’ approaches to the evaluation and grading of student written work and showed how these differences can greatly impact assigned grades. Particularly for experienced instructors, the choices made in the noticing and responding stages had significant effects on the grades assigned.Although the instructors who participated in this study taught the same courses, used the same curriculum, and worked collaboratively in developing (FIs) and grading (GSIs) exams, their approach to the evaluation of student written responses was quite varied. Some of the dimensions had a significant effect on the grades assigned. These results suggest that chemistry instructors, both FIs and GI's, would benefit from having more structured opportunities to engage in the critical discussion and reflection of how the implicit and explicit decisions they make in multiple dimensions during the grading process can affect the outcome. Instructors must analyse their common practices, preferences, and biases when reading and interpreting question prompts, preparing to evaluate student work, engaging with, noticing, and interpreting students’ ideas, as well as in responding to student written answers.
The analytical framework used in this study could be a useful tool in guiding the professional development of chemistry instructors by orienting discussions about implicit and explicit decisions made during evaluation and grading, how those decisions are affected by instructors’ individual beliefs about the purpose of assessing, evaluating, and grading student work, and how those beliefs align with the learning goals of their department or institution. The work presented provides a reference in order to communicate more clearly about what is noticed and how to respond to student work. The introduction of noticing to summative assessment practices allows practitioners and researchers the opportunity to discuss and decide how to engage in assessment and evaluate student work more consistently. Eliciting and characterising instructors’ beliefs about the purpose of assessment, evaluation, and grading may help understand the approaches they chose to follow and the reasons for their variation in different contexts. Opening opportunities for instructors to align their goals an develop common beliefs in this area could be critical to ensure the fair evaluation of student learning.
Our findings also indicate that further work is necessary to untangle the relationships between instructors’ approaches, philosophies, experience in evaluating student work, and the assigned grades. Although our investigation revealed important dimensions of variation, it also suggested that there are other relevant variables not considered in our study. Identifying the philosophical opinions may help to understand why instructors demonstrate a dominant approach and could speak to the strength of their preferences. Knowing how strongly a preference for an approach is held as well as how differences between instructors evaluating the same work are negotiated could further identify the best practices for implementing training and discussions related to this framework and help reduce variability. Beliefs about the purpose of assessment or the goals could further elucidate how best to reduce unwanted variation in the assigned grades. With this framework established, we can extend research to further identify how best to communicate assessment practices to instructors and better serve the students completing those assessments. Our results further suggest that instructor training may need to be tailored to teaching experience to focus on those areas that are more impactful in the grading behaviour of novice versus more experienced instructors.
Conflicts of interest
There are no conflicts to declare.Appendix: model building
The multilevel models used in model building all had assigned grade (%) as the outcome or dependent variable and grader as the subunit (random intercept effect) to account for the nesting of data within graders. All independent variables were treated as categorical variables and dummy coded. Likelihood ratio tests (LRTs) were used to assess improvement in model fit and determine significance of effects (Peugh, 2010; Snijders and Bosker, 2012). We divided the model building into two parts by type of independent variable. First, control modelling with control and grader variables being assessed. And second, dimension modelling with the dimension variables being assessed.Methods for control model
Model building for the control model was conducted in a stepwise manner similar to the methods laid out in Tashiro et al. (2021). As the control models were distinguished only by fixed effects and not random effects, all models used full maximum likelihood (ML) estimation. Details of the control models can be found in Table 6.| a Degrees of freedom are in reference to the variables. ‡ indicates an added effect that improved model fit. × indicates an added effect that did not improve model fit. + indicates an effect included in the model carried over from the continued model. Highlighted entries indicate how that model is distinguished from the previous model. |
|---|

|
Model building: control model
As the grades assigned would ideally reflect what the student responses were and as student response was anticipated as a significant main effect, the control variable of Student Response was the first control variable loaded during model building, in ModelC1. Student Response was dummy coded with the PMM1 response as the reference variable because it had an average assigned grade equal to that of the overall average assigned grade. Using it as the reference variable, therefore allowed for the coefficients of the multilevel model to be in reference to a student response with the overall average grade, or “an average student response”. ModelC1 with Student Response as a fixed effect was compared by a likelihood ratio test (LRT) to the smaller intercept-only or unconditional means model (UCM). The addition of Student Response as a fixed effect in ModelC1 was shown to have statistically significant improvement in model fit, χ2(11) = 170.1, p < 0.0001, and therefore model building was continued with ModelC1.As we suspected graduate student instructors (GSIs) may have differed from faculty instructors (FIs), Role (GSI or FI) was assessed as a fixed effect in ModelC2. As Role was constant for each grader and therefore could not vary within a grader's data set, but only vary between graders, Role could only be a fixed effect and not a random effect. ModelC2 showed a statistically significant improvement in model fit from ModelC1 with LRT χ2(1) = 6.4, p = 0.0113 and therefore Role was considered a significant effect on assigned grade.
We additionally hypothesized that the amount of experience an instructor had may also be an effect on the assigned grade; however, years of experience as a GSI could not be equated to years of experience as a FI. The GSIs in our study were first-year, third-year, and fifth-year graduate students and as such had either one, three, or five years of experience. Each of the FIs had a different amount of experience, ranging from two to thirty years. For FIs, upon initial simple evaluation of the average grade assigned by the FIs and their years of experience, there did not appear to be a significant correlation, R2 = 0.1673. There did appear to be a difference in the average assigned grades of first-year GSIs (71%) compared to the third-year GSIs (51%), fifth-year GSIs (50%), and FIs (50%).
The initial evaluation of average assigned grades indicated that the differences between GSIs and FIs accounted for in the modelling by Role, may be only due to the difference between first-year GSIs (Grad1) and all other instructors (AOI). To assess if this was the case, ModelC3 without Role as a fixed effect but instead with Exp1 as a fixed effect, separating Grad1s and AOIs. ModelC3 showed a statistically significant improvement in model fit from ModelC1 with LRT χ2(1) = 15.9, p = 0.0001. As ModelC2 and ModelC3 have the same degrees of freedom of fixed effects, an LRT comparing the two cannot assess the difference between the models. However, ModelC3 improved model fit over ModelC1 more than ModelC2 improved model fit over ModelC1 as evidenced by lower AIC (2416.9; 2426.5), lower BIC (2470.8; 2480.3), and a less negative log likelihood (−1193.5; −1198.2) of ModelC3 and ModelC2 respectively. These results indicated that the significance of the effect of Role was not due to differences between all GSIs and FIs, but due to the differences between Grad1s and FIs or that Exp1 should be used instead of Role in the modelling. Model building was continued using Exp1 (ModelC3) instead of Role (ModelC2) as a fixed effect.
To further conclude that experience was not significant for the other instructors in predicting assigned grades, two additional models were constructed and evaluated. ModelC4 included a fixed effect GradEC, separating all three experience levels of GSIs into different categories and one category for FIs of all experience levels. ModelC5 included a fixed effect RoleExp, with ten categories for all combinations of role and experience. ModelC4 and ModelC5 both did not show a statistically significant improvement in model fit over the smaller ModelC3 with LRTs χ2(2) = 0.01, p = 0.9958 and χ2(8) = 7.2, p = 0.5164 respectively. Model building was continued using ModelC3. As discussed in the body of this paper, with a limited number of instructor participants, further research would need to be conducted to assess experience effects and experience-role interaction effects as the lack of statistical significance could be due to the low N-value.
We additionally assessed if other instructor characteristics were significant effects of assigned grades. Whether gender was a significant effect on assigned grades was assessed with ModelC6. The addition of Gender as a fixed effect did not show a statistically significant improvement in model fit with LRT χ2(1) = 0.05, p = 0.4867. The chemistry division of the instructor was evaluated for significant effect on assigned grades with ModelC7. The addition of Division as a fixed effect also did not show a statistically significant improvement in model fit with LRT χ2(4) = 1.9, p = 0.7578. To ensure that the lack of significance was not due to the loading order of the instructor characteristic variables, we also ran models with these variables being loaded before Exp1. ModelC6o and ModelC7o still did not show Gender or Division as significant effects with no improvement in model fit over the smaller ModelC2 with LRTs χ2(1) = 0.56, p = 0.4556 and χ2(4) = 6.8, p = 0.1448 respectively. Model building was continued using ModelC3.
Methods for dimension model
Each dimension was first individually assessed with two types of models, constructed by adding the dimension as a predictor or independent variable to the final control model, ModelC3. Fixed-slope models had the dimension added as only a fixed effect. Results demonstrating significant fixed effects would be indicative of a correlative relationship between the dimension and assigned grades. Unconditional slope models had the dimension added as both a fixed and random (slope) effect. Results demonstrating significant random (slope) effects would be indicative of between-grader differences in the correlative relationship between the dimension and assigned grades.To initially assess if a dimension was a significant effect on assigned grades across all instructors, methods from Pedhazur (1997) were used. For a dimension with categories, D1 and D2, a vector (V1) was added that corresponded to D1. For a graded response where the instructor used D1, V1 = 1 and for a graded response where the instructor used D2, V1 = 0. Using R statistical software, this is equivalent to having one variable (D) with “D1” and “D2” as factors with D2 set as the reference variable. Models loaded with the D variable would be labelled ModelD# with the number corresponding to the dimension being assessed. A series of LRTs to assess model fit would then be performed that compared models, predicting assigned grades, with and without D as a predictor or independent variable. A statistically significant improvement in model fit by a model with D (ModelD#) over a model without D (ModelC3) indicated that dimension was a significant effect on assigned grades across all instructors.
To assess if a dimension was a significant effect on assigned grades for only first-year graduate student instructors (Grad1s) and not all other instructors (AOIs), if it was a significant effect on assigned grades for only AOIs and not Grad1s, or if it had a significant interaction effect on assigned grades with Exp1 (Grad1s or AOIs) across all instructors, the following adapted methods for testing interaction effects were used.
Models were constructed to assess if a dimension was a significant effect on assigned grades for only Grad1s. For a dimension with categories, D1 and D2, two vectors (Vg1 and Vg2) were added that corresponded to D1 and D2 for Grad1s. For a graded response by a Grad1 that used D1, Vg1 = 1 and Vg2 = 0. For a graded response by a Grad1 that used D2, Vg1 = 0 and Vg2 = 1. For a graded response by a grader that was not a Grad1 (AOI), Vg1 = 0 and Vg2 = 0. This places the AOI as the reference variable. Using R, this is equivalent to having one variable (Grad1D) with “Grad1D1”, “Grad1D2”, and “AOI” as factors with “AOI” set as the reference variable. With that equivalence, the set of vectors Vg1 and Vg2 can and will be referred to as Grad1D. Adding Grad1D effectively adds the D effect but only for Grad1s. Models loaded with Grad1D as an effect would be labelled with a “g” in the notation ModelD#g.
Similarly, models were also constructed to assess if a dimension was a significant effect on assigned grades for only AOIs. Two vectors (Vo1 and Vo2) were added that corresponded to D1 and D2 for AOIs. For a graded response by AOI that used D1, Vo1 = 1 and Vo2 = 0. For a graded response by AOI that used D2, Vo1 = 0 and Vo2 = 1. For a graded response by a Grad1, Vo1 = 0 and Vo2 = 0. This places Grad1s as the reference variable. Using R, this is equivalent to having one variable (AOID) with “AOID1”, “AOID2”, and “Grad1” as factors with “Grad1” set as the reference variable. The set of vectors Vo1 and Vo2 will be referred to as AOID. The addition of AOID would effectively add the effect of D for only AOIs. The models with AOID would be labelled with an “o” in the notation ModelD#o.
Lastly, for the interaction effect of Exp1 with D (Exp1*D) over all instructors, three vectors (Vig1, Vig2, and Vio1) were added. For a graded response by a Grad1 that used D1, Vig1 = 1, V1g2 = 0, and Vio1 = 0. For Grad1 that used D2, Vig1 = 0, V1g2 = 1, and Vio1 = 0. For AOI that used D1, Vig1 = 0, V1g2 = 0, and Vio1 = 1. And for AOI that used D2, Vig1 = 0, V1g2 = 0, and Vio1 = 0. Using R, this is equivalent to using Exp1*D or a variable (Exp1D) with “Grad1D1”, “Grad1D2”, “AOID1”, and “AOID2” as factors with “AOID2” set as the reference variable. The set of vectors Vig1, Vig2, and Vio1 will be referred to as Exp1D. The models with Exp1D would be labelled with an “i” in the notation ModelD#i.
A series of LRTs to assess model fit were then performed that compared models (ModelD#, ModelD#g, ModelD#o, and ModelD#i). Details of the models and comparisons are given by example for the first dimension of Depth in the following section. A summary of the Depth models is presented in Table 7. Dimensions #2–#8 were analysed in the same manner.
| a ModelC3 is not a dimension model, but the control model used for comparison with the dimension models. b Degrees of freedom are in reference to the variables. c Exp1Depth is equivalent to having both Exp1, Depth, and an Interaction effect for Exp1 and Depth. * indicates the reference variable ‡ indicates an added effect that improved model fit. × indicates an added effect that did not improve model fit. + indicates an effect included in the model carried over from the continued model. Highlighted entries indicate how that model is distinguished from the previous model it is being compared to. |
|---|
|
Dimension #9, Interaction (Inter) was divided into Marking Interactions (IMark) and Feedback Interactions (IFeed) both with approaches or categories of Expressed (exp) or Unexpressed (unex). Dimension #10, Intention (Intent) further subcategorized the Expressed IMark category as Evaluative (eval) or Reactive (react). Dimension #11, Feedback (Ftype) further subcategorized the Expressed IFeed category as Indirect (in) or Direct (dir). As the complexity and dependence of these dimensions differ from previous dimensions, a set of effects was made to evaluate them (see Table 8). Each of these effects was evaluated in the same manner that the previous dimensions were such that an effect with categories, D1 and D2 could be thought of as a dimension. For effects with more than two categories, an additional vector was created per additional category for Grad1D (ModelD#g) and AOID (ModelD3o) and an additional two vectors were created per additional category for Exp1D (ModelD#i).
| Model | Added effect (dimension) | Category (approach) | Category description |
|---|---|---|---|
| ModelD9 | Inter | Either | Grader marked, gave feedback, or did both |
| Neither | Grader neither marked nor gave feedback | ||
| ModelD9C | InterC | Mark | Grader marked |
| Feed | Grader gave feedback | ||
| Both | Grader marked and gave feedback | ||
| Neither | Grader neither marked nor gave feedback | ||
| ModelD9M | IMark | Mark | Grader marked (grader could or could not have given feedback) |
| Nomark | Grader did not mark (grader could or could not have given feedback) | ||
| ModelD9F | IFeed | Feed | Grader gave feedback (grader could or could not have marked) |
| Nofeed | Grader did not give feedback (grader could or could not have marked) | ||
| Model10 | Intent | Eval | Grader did an evaluative mark (grader could or could not have given feedback) |
| React | Grader did a reactive mark (grader could or could not have given feedback) | ||
| Nomark | Grader did not mark (grader could or could not have given feedback) | ||
| Model11 | Ftype | Indir | Grader gave indirect feedback (grader could or could not have marked) |
| Dir | Grader gave direct feedback (grader could or could not have marked) | ||
| Nofeed | Grader did not give feedback (grader could or could not have marked) | ||
As the dimension models were distinguished by both fixed effects (f) and random effects (r), not all models used full maximum likelihood (ML) estimation as with the control models. When comparing models distinguished only by random effects, restricted maximum likelihood (REML) estimation was used. When comparing models distinguished only by fixed effects or both fixed and random effects, ML estimation was used. Although random (slope) effects for each dimension were assessed, none were found to be significant and as such all reported models (except Depth, with all models and analysis being reported) in the following model building process can be assumed to be fixed-slope models distinguished only by fixed effects and using ML estimation.
Model building: dimension models
The main findings for the dimensions can be found in the first paragraph of each subsection and for dimensions with significant effects on assigned grades, the model building evidence and reasoning are in the subsequent paragraph(s). For the first dimension (Depth) all models and analysis are reported to show the full process of model building taken in this study. For the dimensions thereafter, models and analysis not reported can be assumed to have not shown statistically significant improvement in model fit and/or did not explicitly contributed to the conclusions of the analysis.As all models and analysis are being reported for Depth models, the model notation further includes the type of effect (fixed (f) or random (r)) and estimation method used (ML or REML). Details of the Depth models can be found in Table 7.
The addition of Depth as a fixed effect in ModelD1.f.ML did not show statistically significant improvement in model fit from the smaller ModelC3.ML with LRT χ2(1) = 0.37, p = 0.5407. The addition of Depth as both a fixed and random effect in ModelD1.f&r.ML also did not show statistically significant improvement in model fit from the smaller ModelC3.ML with LRT χ2(3) = 3.93, p = 0.2687. Lastly, the addition of Depth as a fixed and random effect in ModelD1.f&r.REML did not show statistically significant improvement in model fit from the smaller ModelD1.f.REML with Depth as only a fixed effect with LRT χ2(2) = 3.03, p = 0.2195. As evidenced by a lack of improvement in model fit, Depth was found to not be a significant effect (fixed or random) on assigned grades across all graders.
The addition of Grad1Depth as a fixed effect in ModelD1g.f.ML did not show statistically significant improvement in model fit from the smaller ModelC3.ML with LRT χ2(1) = 0.56, p = 0.4560. The addition of Grad1Depth as both a fixed and random effect in ModelD1g.f&r.ML also did not show statistically significant improvement in model fit from the smaller ModelC3.ML with LRT χ2(6) = 0.86, p = 0.9904. Lastly, the addition of Grad1Depth as a fixed and random effect in ModelD1g.f&r.REML did not show statistically significant improvement in model fit from the smaller ModelD1g.f.REML with Grad1Depth as only a fixed effect with LRT χ2(5) = 0.11, p = 0.9998. As evidenced by a lack of improvement in model fit, Grad1Depth was found to not be a significant effect (fixed or random) on assigned grades and as such Depth was said to not be a significant effect on assigned grades for only Grad1s.
The addition of AOIDepth as a fixed effect in ModelD1o.f.ML did not show statistically significant improvement in model fit from the smaller ModelC3.ML with LRT χ2(1) = 2.83, p = 0.0927. The addition of AOIDepth as both a fixed and random effect in ModelD1o.f&r.ML also did not show statistically significant improvement in model fit from the smaller ModelC3.ML with LRT χ2(6) = 6.24, p = 0.3964. Lastly, the addition of AOIDepth as a fixed and random effect in ModelD1o.f&r.REML did not show statistically significant improvement in model fit from the smaller ModelD1o.f.REML with AOIDepth as only a fixed effect with LRT χ2(5) = 1.99, p = 0.8509. As evidenced by a lack of improvement in model fit, AOIDepth was found to not be a significant effect (fixed or random) on assigned grades and as such Depth was said to not be a significant effect on assigned grades for only AOIs.
The addition of Exp1Depth as a fixed effect in ModelD1i.f.ML did not show statistically significant improvement in model fit from the smaller ModelC3.ML with LRT χ2(2) = 3.39, p = 0.1832. The addition of the interaction of Exp1Depth being added as a fixed effect in ModelD1i.f.ML did not show statistically significant improvement in model fit from the smaller ModelD1.f.ML with Exp1 and Depth as fixed effects, but without the interaction of Exp1 and Depth with LRT χ2(1) = 3.02, p = 0.0822. ModelD1i.f.ML (interaction across all instructors) additionally did not show statistically significant improvement in model fit from ModelD1g.f.ML (for only Grad1s) or ModelD1o.f.ML (for only AOIs) with LRTs χ2(1) = 2.84, p = 0.0920 and χ2(1) = 0.57, p = 0.4517 respectively. The addition of Exp1Depth as both a fixed and random effect in ModelD1i.f&r.ML also did not show statistically significant improvement in model fit from the smaller ModelC3.ML with LRT χ2(11) = 7.12, p = 0.7891. Lastly, the addition of Exp1Depth as a fixed and random effect in ModelD1i.f&r.REML did not show statistically significant improvement in model fit from the smaller ModelD1i.f.REML with Exp1Depth as only a fixed effect with LRT χ2(9) = 3.05, p = 0.9668. As evidenced by a lack of improvement in model fit, Depth was found to not have a significant interaction effect (fixed or random) on assigned grades across all graders.
The addition of Grad1Answer in ModelD4g showed statistically significant improvement in model fit from the smaller ModelC3 with LRT χ2(1) = 6.26, p = 0.0123. Although, the addition of Exp1Answer in ModelD4i also showed statistically significant improvement in model fit from ModelC3 with LRT χ2(2) = 8.04, p = 0.0179, it did not when compared directly to ModelD4g with LRT χ2(1) = 1.78, p = 0.1823. The categories of Grad1Answer are “Grad1gen”, “Grad1unex”, and “AOI”. The categories of Exp1Answer are “Grad1gen”, “Grad1unex”, “AOIgen”, and “AOIunex”. The effect of Grad1Answer is embedded in Exp1Answer as they both have categorization of Answer for Grad1s. As the further categorization of Answer for AOIs in Exp1Answer did not improve model fit, the significance of the Exp1Answer effect was likely due to the embedded effect of Grad1Answer and therefore Answer was said to be a significant effect for only Grad1s.
Similar to Answer, the addition of Grad1System in ModelD5g and the addition of Exp1System in ModelD5i showed statistically significant improvement in model fit from the smaller ModelC3 with LRT χ2(1) = 6.20, p = 0.0128 and LRT χ2(2) = 6.87, p = 0.0322 respectively. The additional categorization of System for AOIs with Exp1System in ModelD5i did not show statistically significant improvement in model fit from the categorization of System for Grad1s with Grad1System in ModelD5g with LRT χ2(1) = 0.67, p = 0.4130. With the likelihood of the significance effect of Exp1System being due to the embedded effect of Grad1System, System was said to be a significant effect for only Grad1s.
The addition of AOIStance in ModelD6o showed statistically significant improvement in model fit from the smaller ModelC3 with LRT χ2(1) = 3.90, p = 0.0483. As evidenced by improvement in model fit, Stance was said to be a significant effect for only AOIs.
The addition of each effect in the corresponding set of models, assessed if it was a significant effect on assigned grades. For example, the addition of the Inter effect in the set of D9 Models (ModelD9, ModelD9g, ModelD9o, and ModelD9i) assessed if Inter was a significant effect on assigned grades. This can also be interpreted as an assessment of whether the student responses, that the grader either marked, gave feedback on, or did both, were given assigned grades that were significantly different than the student responses where the grader did not mark or give feedback on the student work (controlling for all control model variables and across all instructors). All discussion for dimensions #9–#11 hereafter can be assumed to be controlling for all control model variables and across all instructors. Tested by a series of LRTs, the Inter effect was not found to be a significant effect on assigned grades.
The addition of the InterC effect in the set of D9C Models (ModelD9C, ModelD9Cg, ModelD9Co, and ModelD9Ci) assessed InterC was a significant effect on assigned grades. Said another way, was there a significant observed difference in assigned grades of the student responses where the grader marked, gave feedback, did both, or did neither. Tested by a series of LRTs, the InterC effect was also not found to be a significant effect on assigned grades.
The addition of the IMark effect in the set of D9M Models (ModelD9M, ModelD9Mg, ModelD9Mo, and ModelD9Mi) assessed if there was a significant difference in assigned grades when the grader marked compared to when the grader did not mark, regardless of whether or not they gave feedback. Specifically, the addition of AOIIMark with categories of “AOImark”, “AOInomark”, and “Grad1” in ModelD9Mo assessed if marking was a significant effect on assigned grades for AOIs, but not Grad1s. ModelD9Mo showed statistically significant improvement in model fit compared to the smaller ModelC3 with LRT χ2(1) = 5.71, p = 0.0169. As evidenced by significant improvement in model fit, IMark was said to be a significant effect on assigned grades for AOIs only. The further classification of AOI grader markings by AOIIntent as Evaluative (eval) or Reactive (react) in ModelD10o was not found to have statistically significant improvement in model fit from the smaller Model9Mo with LRT χ2(1) = 10.56, p = 0.8054 and as such was found to not be a significant effect on assigned grades for AOIs.
The addition of the IFeed effect in the set of D9F Models (ModelD9F, ModelD9Fg, ModelD9Fo, and ModelD9Fi) assessed if there was a significant difference in assigned grades when the grader gave feedback compared to when the grader did not mark, regardless of whether or not they marked. The addition of the FType effect in the set of D11 models (ModelD10, ModelD10g, ModelD10o, and ModelD10i) assessed if the further classification of the type of feedback (FType) as Indirect (in) or Direct (dir) was significant. As anticipated from the previous results, IFeed and FType were not found to be significant effect on assigned grades.
Final model
The combination of Answer and System with interaction for Grad1s in ModelFG had statistically significant improvement in model fit from the smaller ModelC3 with LRT χ2(3) = 11.64, p = 0.0087. The combination of Stance and IMark with interaction for AOIs in ModelFO also had statistically significant improvement in model fit from ModelC3 with LRT χ2(3) = 9.71, p = 0.0212. The combination of Answer and System with interaction for Grad1s and Stance and IMark with interaction for AOIs in ModelFinal showed statistically significant improvement in model fit from ModelC3, ModelFG, and ModelFO with LRTs χ2(6) = 24.08, p = 0.0005, χ2(3) = 12.45, p = 0.0060, χ2(3) = 14.37, p = 0.0024 respectfully. Additionally, model building was conducted on the Grad1 data set and the AOI data set separately. The same dimension effects for each were found to be significant (controlling for Student Response) when the analysis was conducted separately. The final model used for the calculations presented in the results section is shown in Table 9.| Predictor (fixed effects) | B | SE | 95% CI | |
|---|---|---|---|---|
| LL = −1181.4, AIC = 2404.9, BIC = 2480.3.a Reference variable. | ||||
| (Intercept) | 56.7 | 5.1 | (46.6, 66.8) | |
| Student response | ||||
| Particulate model of matter – Answer 1 (PMM1)a | ||||
| Particulate model of matter – Answer 2 (PMM2) | −7.0 | 5.4 | (−17.7, 3.7) | |
| Resonance stabilization Answer 1 (RS1) | −28.0 | 5.5 | (−38.9, −17.2) | |
| Resonance stabilization Answer 2 (RS2) | 26.7 | 5.5 | (15.9, 37.5) | |
| Structure–property-relationships Answer 1 (SPR1) | 17.9 | 5.5 | (7.1, 28.7) | |
| Structure–property-relationships Answer 2 (SPR2) | 9.0 | 5.5 | (−1.8, 19.8) | |
| Thermodynamic stability Answer 1 (TS1) | −1.2 | 5.5 | (−12.2, 9.7) | |
| Thermodynamic stability Answer 2 (TS2) | 18.3 | 5.6 | (7.3, 29.2) | |
| Reaction directionality Answer 1 (RD1) | −29.9 | 7.8 | (−45.2, −14.6) | |
| Reaction directionality Answer 2 (RD2) | 41.2 | 7.8 | (25.8, 56.5) | |
| Perturbations to chemical equilibrium Answer 1 (PCE1) | −18.9 | 7.8 | (−34.3, −3.4) | |
| Perturbations to chemical equilibrium Answer 2 (PCE2) | −27.7 | 7.8 | (−43.1, −12.2) | |
| For all other instructors (AOIs) | ||||
| Stance: inferential; | Marking Interaction: marka | |||
| Stance: inferential; | Marking Interaction: no mark | −8.9 | 7.7 | (−24.2, 6.4) |
| Stance: literal; | Marking Interaction: mark | −8.3 | 4.5 | (−17.1, 0.5) |
| Stance: literal; | Marking Interaction: no mark | −21.7 | 6.2 | (−33.9, −9.4) |
| For first-year graduate student instructors (Grad1s) | ||||
| Expected Answer: generated | Grading System: criterion referenced | 0.7 | 4.9 | (−9.1, 10.4) |
| Expected Answer: generated | Grading System: norm referenced | 12.7 | 7.3 | (−1.6, 27.0) |
| Expected Answer: unexpressed | Grading System: criterion referenced | 10.5 | 4.7 | (1.3, 19.7) |
| Expected Answer: unexpressed | Grading System: norm referenced | 21.0 | 5.5 | (10.2, 31.9) |
| Component (random effects) | Variance | SD | 95% CI (SD) |
|---|---|---|---|
| (Intercept) | 13.1 | 3.6 | (0.95, 13.7) |
| Residual | 413.8 | 20.3 | (18.5, 22.3) |
Acknowledgements
We appreciate the work on this project performed by Kayla Bansback, an undergraduate research assistant. We appreciate the time and openness of our study participants.References
- Ainley J. and Luntley M., (2007), The role of attention in expert classroom practice. J. Math. Teach. Educ., 10(1), 3–22.
- Amador J. M., Estapa A., Araujo Z. de, Kosko K. W. and Weston T. L., (2017), Eliciting and Analyzing Preservice Teachers’ Mathematical Noticing. Math. Teach. Educ., 5(2), 158–177.
- Andrade H. G., (2005), Teaching With Rubrics: The Good, the Bad, and the Ugly. Coll. Teach., 53(1), 27–31.
- Aydeniz M. and Dogan A., (2016), Exploring pre-service science teachers’ pedagogical capacity for formative assessment through analyses of student answers. Res. Sci. Technol. Educ., 34(2), 125–141.
- Barnhart T. and Van Es E. A., (2015), Studying teacher noticing: EXAMINING the relationship among pre-service science teachers’ ability to attend, analyze and respond to student thinking. Teach. Teach. Educ., 45, 83–93.
- Brookhart S. M., Guskey T. R., Bowers A. J., McMillan J. H., Smith J. K., Smith L. F., et al., (2016), A Century of Grading Research: Meaning and Value in the Most Common Educational Measure. Rev. Educ. Res., 86(4), 803–848.
- Chan K. K. H., Xu L., Cooper R., Berry A. and van Driel J. H., (2020), Teacher noticing in science education: do you see what I see? Stud. Sci. Educ., 57(1), 1–44.
- Cohen J., (1977), F-Tests of Variance Proportions in Multiple Regression/Correlation Analysis, Statistical Power Analysis for the Behavioral Sciences, pp. 407–453.
- Creswell J. W., (2012), Educational research: Planning, conducting, and evaluating quantitative and qualitative research, 4th edn, Pearson.
- Dawson P., (2017), Assessment rubrics: towards clearer and more replicable design, research and practice. Assess. Eval. Higher Educ., 42(3), 347–360.
- Ebby C. B., Remillard J. and D’Olier J., (2019), Pathways for Analyzing and Responding to Student Work for Formative Assessment: The Role of Teachers’ Goals for Student Learning Pathways for Analyzing and Responding to Student Work for Formative Assessment. https://repository.upenn.edu/cpre_workingpapers/22/.
- Eckes T., (2008), Rater types in writing performance assessments: A classification approach to rater variability. Lang. Test., 25(2), 155–185.
- Fay M. E., Grove N. P., Towns M. H., Bretz S. L. and Lowery Bretz S., (2007), A rubric to characterize inquiry in the undergraduate chemistry laboratory. Chem. Educ. Res. Pract., 8(2), 212–219.
- Gess-Newsome J., Southerland S. A., Johnston A. and Woodbury S., (2003), Educational Reform, Personal Practical Theories, and Dissatisfaction: The Anatomy of Change in College Science Teaching. Am. Educ. Res. J., 40(3), 731–767.
- Gibbons R. E., Villafañe S. M., Stains M., Murphy K. L. and Raker J. R., (2018), Beliefs about learning and enacted instructional practices: An investigation in postsecondary chemistry education. J. Res. Sci. Teach., 55(8), 1111–1133.
- Gotwals A. W. and Birmingham D., (2016), Eliciting, Identifying, Interpreting, and Responding to Students’ Ideas: Teacher Candidates’ Growth in Formative Assessment Practices. Res. Sci. Educ., 46(3), 365–388.
- Haagen C. H., (1964), The Origins of a Grade. J. Higher Educ., 35(2), 89–91.
- Harwood C. J., Hewett S. and Towns M. H., (2020), Rubrics for Assessing Hands-On Laboratory Skills. J. Chem. Educ., 97(7), 2033–3035.
- Henderson C., Yerushalmi E., Kuo V. H., Heller P. and Heller K., (2004), Grading student problem solutions: The challenge of sending a consistent message. Am. J. Phys., 72(2), 164–169.
- Herridge M. and Talanquer V., (2020), Dimensions of Variation in Chemistry Instructors’ Approaches to the Evaluation and Grading of Student Responses. J. Chem. Educ., 98(2), 270–280.
- Holmes L. E. and Smith L. J., (2003), Student Evaluations of Faculty Grading Methods. J. Educ. Bus., 78(6), 318–323.
- Howell R. J., (2011), Exploring the impact of grading rubrics on academic performance. J. Excell. Coll. Teach., 22(2), 31–49.
- Huang R. and Li Y., (2012), What Matters Most: A Comparison of Expert and Novice Teachers’ Noticing of Mathematics Classroom Events. Sch. Sci. Math., 112(7), 420–432.
- Kim H.-Y., (2013), Statistical notes for clinical researchers: assessing normal distribution (2) using skewness and kurtosis. Restor. Dent. Endod., 38(1), 52–54.
- Klobucar A., Deane P., Elliot N., Ramineni C., Deess P. and Rudniy A., (2012), International Advances in Writing Research: Cultures, Places, Measures, in Bazerman C., Dean C., Early J., Lunsford K., Null S., Rogers P. and Stansell A. (ed.), International advances in writing research: Cultures, places, measures, pp. 103–119.
- Knight J., Allen S. and Mitchell A. M., (2012), Establishing Consistency Measurements of Grading for Multiple Section Courses. J. Acad. Bus. Educ., 13, 28–47.
- Luna M. J., (2018), What Does it Mean to Notice my Students’ Ideas in Science Today? An Investigation of Elementary Teachers’ Practice of Noticing their Students’ Thinking in Science. Cogn. Instr., 36(4), 297–329.
- Marshman E., Sayer R., Henderson C. and Singh C., (2017), Contrasting grading approaches in introductory physics and quantum mechanics: The case of graduate teaching assistants. Phys. Rev. Phys. Educ. Res., 13(1), 1–16.
- Marshman E., Sayer R., Henderson C., Yerushalmi E. and Singh C., (2018), The challenges of changing teaching assistants’ grading practices: Requiring students to show evidence of understanding. Can. J. Phys., 96(4), 420–437.
- Mertler C. A., (2001), Designing scoring rubrics for your classroom. Pract. Assessment, Res. Eval., 7(25), 2000–2001.
- Miles M. B. and Huberman A., (1994), An expanded sourcebook: Qualitative data analysis, 2nd edn.
- Mohl E., Fifield C., Lafond N., Mickman S., Saxton R. and Smith B., (2017), Using Rubrics to Integrate Crosscutting Concepts. Sci. Scope, 40(5), 84.
- Murray S. A., Huie R., Lewis R., Balicki S., Clinchot M., Banks G., et al., (2020), Teachers’ Noticing, Interpreting, and Acting on Students’ Chemical Ideas in Written Work. J. Chem. Educ., 97(10), 3478–3489.
- Mutambuki J. M. and Fynewever H., (2012), Comparing chemistry faculty beliefs about grading with grading practices. J. Chem. Educ., 89(3), 326–334.
- Mutambuki J. M. and Schwartz R., (2018), We don’t get any training: the impact of a professional development model on teaching practices of chemistry and biology graduate teaching assistants. Chem. Educ. Res. Pract., 19(1), 106–121.
- Pedhazur E., (1997), Multiple Regression in Behavioral Research, 3rd edn, Wadsworth Publishing.
- Petcovic H. L., Fynewever H., Henderson C., Mutambuki J. M. and Barney J. A., (2013), Faculty Grading of Quantitative Problems: A Mismatch between Values and Practice. Res. Sci. Educ., 43(2), 437–455.
- Peugh J. L., (2010), A practical guide to multilevel modeling. J. Sch. Psychol., 48(1), 85–112.
- Randall J. and Engelhard G., (2010), Examining the grading practices of teachers. Teach. Teach. Educ., 26(7), 1372–1380.
- Raudenbush S. W. and Bryk A. S., (2001), Hierarchical Linear Models: Applications and Data Analysis Methods, 2nd edn, Sage.
- Reynders G., Lantz J., Ruder S. M., Stanford C. L. and Cole R. S., (2020), Rubrics to assess critical thinking and information processing in undergraduate STEM courses. Int. J. STEM Educ., 7, 9.
- Rezaei A. R. and Lovorn M., (2010), Reliability and validity of rubrics for assessment through writing. Assess. Writ., 15(1), 18–39.
- Ross P. and Gibson S. A., (2010), Exploring a conceptual framework for expert noticing during literacy instruction. Lit. Res. Instr., 49(2), 175–193.
- Russ R. S. and Luna M. J., (2013), Inferring teacher epistemological framing from local patterns in teacher noticing. J. Res. Sci. Teach., 50(3), 284–314.
- Selya A. S., Rose J. S., Dierker L. C., Hedeker D. and Mermelstein R. J., (2012), A practical guide to calculating Cohen's f 2, a measure of local effect size, from PROC MIXED. Front. Psychol., 3, 111.
- Snijders T. and Bosker R., (2012), Multilevel Analysis: An Introduction to Basic and Advanced Multilevel Modeling, 2nd edn, Sage.
- Stanley G. and Baines L. A., (2001), No More Shopping for Grades at B-mart: Re-establishing Grades as Indicators of Academic Performance. Clear. House A J. Educ. Strateg. Issues Ideas, 74(4), 227–230.
- Stellmack M. A., Konheim-Kalkstein Y. L., Manor J. E., Massey A. R. and Schmitz J. A. P., (2009), An Assessment of Reliability and Validity of a Rubric for Grading APA-Style Introductions. Teach. Psychol., 36(2), 102–107.
- Stowe R. L. and Cooper M. M., (2019), Assessment in Chemistry Education. Isr. J. Chem., 59(6), 598–607.
- Talanquer V. and Pollard J., (2010), Let's teach how we think instead of what we know. Chem. Educ. Res. Pract., 11(2), 74–83.
- Talanquer V., Tomanek D. and Novodvorsky I., (2013), Assessing students’ understanding of inquiry: What do prospective science teachers notice? J. Res. Sci. Teach., 50(2), 189–208.
- Talanquer V., Bolger M. and Tomanek D., (2015), Exploring prospective teachers’ assessment practices: Noticing and interpreting student understanding in the assessment of written work. J. Res. Sci. Teach., 52(5), 585–609.
- Tashiro J., Parga D., Pollard J. and Talanquer V., (2021), Characterizing change in students'self-assessments of understandingwhen engaged in instructional activities, Chem. Educ. Res. Pract. 10.1039/D0RP00255K.
- Van Es E. A., (2011), A framework for learning to notice student thinking, Mathematics Teacher Noticing Seeing Through Teachers’ Eyes.
- Wickham H. and Henry L., (2018), tidyr: Easily Tidy Data with “spread()” and “gather()” Functions. R Packag. version 0.8.0. http://https//CRAN.R-project.org/package=tidyr.
- Wolfe E. W., Kao C. W. and Ranney M., (1998), Cognitive differences in proficient and nonproficient essay scorers. Writ. Commun., 15(4), 465–492.
- Yerushalmi E., Sayer R., Marshman E., Henderson C. and Singh C., (2016), Physics graduate teaching assistants’ beliefs about a grading rubric: Lessons learned. PERC Proc., 408–411.
| This journal is © The Royal Society of Chemistry 2021 |