
Small molecule–RNA targeting: starting with the fundamentals
Amanda E.
Hargrove

Department of Chemistry, Duke University, 124 Science Drive, Box 90346, Durham, NC 27708, USA. E-mail: amanda.hargrove@duke.edu
First published on 3rd November 2020
Abstract
The structural and regulatory elements in therapeutically relevant RNAs offer many opportunities for targeting by small molecules, yet fundamental understanding of what drives selectivity in small molecule:RNA recognition has been a recurrent challenge. In particular, RNAs tend to be more dynamic and offer less chemical functionality than proteins, and biologically active ligands must compete with the highly abundant and highly structured RNA of the ribosome. Indeed, the only small molecule drug targeting RNA other than the ribosome was just approved in August 2020, and our recent survey of the literature revealed fewer than 150 reported chemical probes that target non-ribosomal RNA in biological systems. This Feature outlines our efforts to improve small molecule targeting strategies and gain fundamental insights into small molecule:RNA recognition by analyzing patterns in both RNA-biased small molecule chemical space and RNA topological space privileged for differentiation. First, we synthesized libraries based on RNA binding scaffolds that allowed us to reveal general principles in small molecule:recognition and to ask precise chemical questions about drivers of affinity and selectivity. Elaboration of these scaffolds has led to recognition of medicinally relevant RNA targets, including viral and long noncoding RNA structures. More globally, we identified physicochemical, structural, and spatial properties of biologically active RNA ligands that are distinct from those of protein-targeted ligands, and we have provided the dataset and associated analytical tools as part of a publicly available online platform to facilitate RNA ligand discovery. At the same time, we used pattern recognition protocols to identify RNA topologies that can be differentially recognized by small molecules and have elaborated this technique to visualize conformational changes in RNA secondary structure. These fundamental insights into the drivers of RNA recognition in vitro have led to functional targeting of RNA structures in biological systems. We hope that these initial guiding principles, as well as the approaches and assays developed in their pursuit, will enable rapid progress toward the development of RNA-targeted chemical probes and ultimately new therapeutic approaches to a wide range of deadly human diseases.
 Amanda E. Hargrove | Amanda E. Hargrove is an Associate Professor of Chemistry at Duke University and a past ChemComm Emerging Investigator Lectureship awardee. Prof. Hargrove earned her PhD in Organic Chemistry from the University of Texas at Austin followed by a postdoctoral fellowship at Caltech. Her laboratory at Duke works to understand the fundamental drivers of selective small molecule:RNA recognition and to use this knowledge to functionally modulate viral and oncogenic RNA structures. Her passions outside the lab include developing course-based undergraduate research experiences, working toward equity in chemistry at the departmental and national level, and watching old movies with her awesome family. |
1. Introduction
RNA molecules are increasingly recognized both for their regulatory roles and as potential therapeutic targets in a range of human diseases.1,2 If developed, drugs that target these RNAs would offer novel treatment strategies toward multiple deadly illnesses, including multi-drug-resistant bacterial, fungal, and viral infections as well as metastatic cancer.3–9 Despite this potential, the development of drugs targeted to RNA other than bacterial ribosomes has been slow, leading many to term RNA “undruggable.” Indeed, the first small molecule drug targeting RNA other than the ribosome was just approved by the US FDA in August of 2020.10 While antisense oligonucleotides offer high RNA specificity via base pair complementarity and are beginning to be FDA approved, in vivo delivery outside of the liver or central nervous remains a significant barrier.11–13 Small molecules offer several potential benefits, including extensive tunability in terms of delivery, uptake, immunogenicity, and other medicinal parameters as well as the ability to access a broad range of size, shape, and chemical functionality through organic synthesis. However, selective targeting of RNA with small molecules has been elusive.14–16 Fundamental challenges of RNA targeting include the limited chemical functionality of RNA relative to protein, the generally dynamic structure of RNA, and the difficulty of specific RNA target engagement in a cellular environment where 85% of the total RNA is ribosomal (rRNA) and chemically similar genomic DNA abounds. These challenges are exacerbated by the protein-centric nature of currently available screening libraries and methodologies. Furthermore, many RNA-targeted screening campaigns yield nonspecific hits that rely on electrostatic interactions with the phosphate backbone and/or stacking interactions with the RNA bases. In addition to the lack of exploration into RNA-targeted small molecule chemical space, the limited number of distinct RNA targets pursued to date has hindered our understanding of the RNA structures that can be recognized by small molecules.17Another barrier to understanding small molecule:RNA recognition is the inherent difficulty of RNA structural characterization,18–20 which often prevents atomic-level interpretation of these interactions and limits both structure-based design toward specific targets and our ability to discern patterns in the small molecule recognition of RNA structures. For 2D RNA structures, computational predictions augmented by chemical probing data, which report on the likelihood of base-pairing at a given position, have seen great utility and are broadly implemented.21–23 At the same time, these methods are limited by the algorithms employed, which can yield different solutions for the same data set and overlook complex structures such as triple helices, thus requiring input from other experimental and phylogenetic analyses.24,25 For 3D RNA structures, de novo computational prediction is largely limited to short sequences26,27 while high-resolution experimental characterization of RNA can be difficult and time-consuming, particularly for large sequences, using traditional methods such as NMR and X-ray diffraction. Cryo-electron microscopy (cryo-EM) of RNA is becoming increasingly effective, though it has been used primarily for large RNA:protein complexes to date,28–31 with fewer examples of RNA alone.32,33 Continuous improvements on traditional methods, as well as ongoing work that combines 2D probing and 3D predictions34 or evaluates RNA dynamics and functional ensembles20 promises to further our understanding of 3D RNA structure and thus RNA molecular recognition.
Despite these challenges, a number of emerging examples have confirmed that non-ribosomal RNA can be targeted by small molecules (Fig. 1) and that a number of strategies, both RNA-centric and more general, may be successful.3,5,6,9,16,17,35–39 For example, the Disney laboratory has used selection-based strategies to match small molecules with specific RNA sequences,40 which ultimately led to small molecules with activity against RNA repeat-associated diseases41 and against microRNAs in triple negative breast cancer,42 both with efficacy in mouse models. Modular assembly of RNA binding units into large and often multivalent ligands can increase affinity and specificity and has also proven effective in biological systems. Examples include work by: the Zimmerman laboratory in which a multivalent ligand targeting repeat RNA of myotonic dystrophy reverses phenotype in fly and mouse models;43 the Miller laboratory in which dynamic combinatorial chemistry produced ligands targeting the HIV-1 frameshift sequence with antiviral activity;44,45 and the Disney laboratory using the above mentioned sequence-based approach.46,47 In another RNA-centric example, the Al-Hashimi laboratory identified novel ligands for HIV-1-TAR RNA by docking to an experimentally-informed ensemble of several RNA conformations, enabling a structure-based approach to be applied to this highly dynamic system.48,49
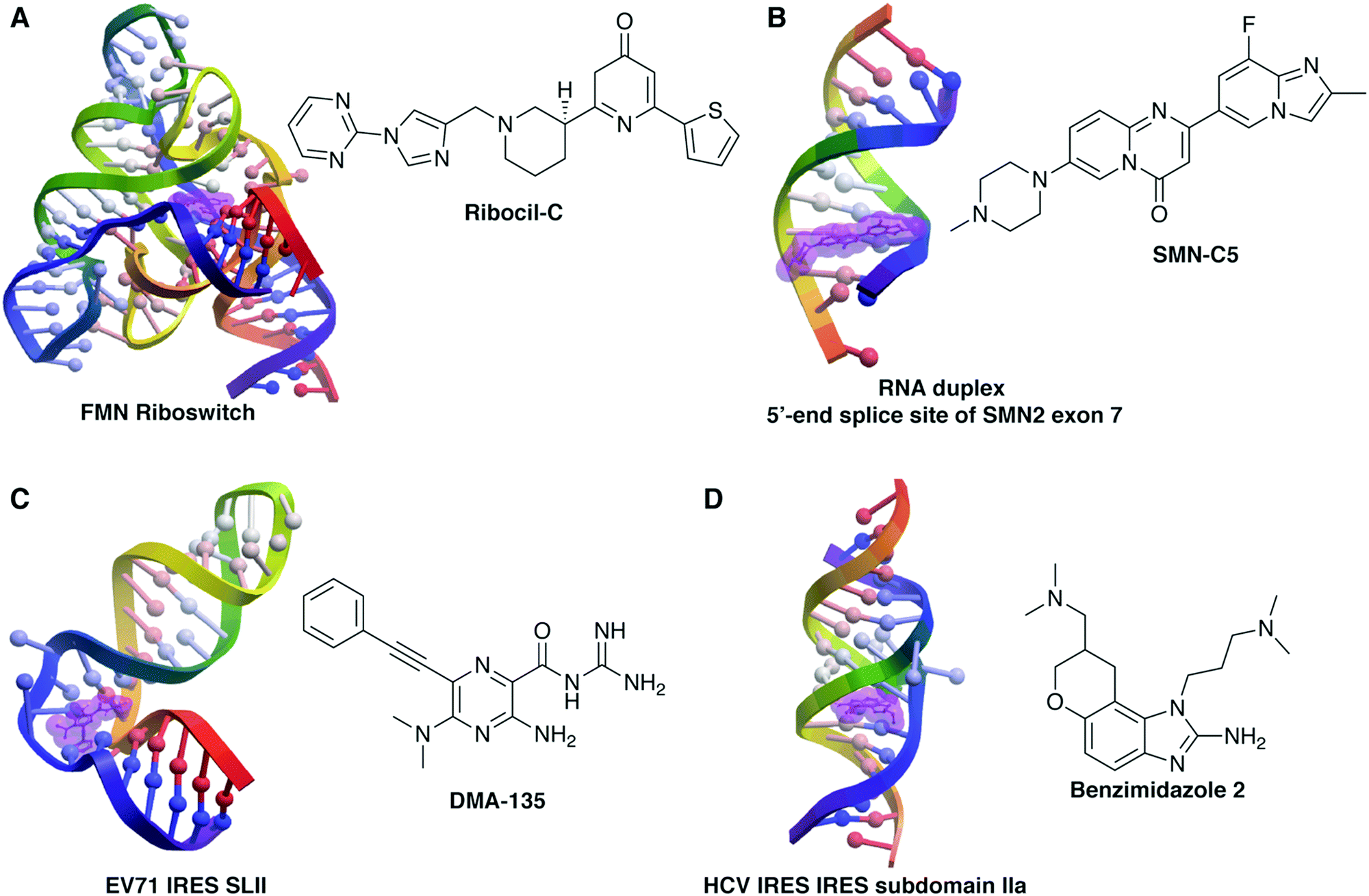 | ||
| Fig. 1 Example structures of small molecule:RNA complexes. RNA structures rendered in ICM (Molsoft, LLC) and small molecules highlighted in purple. (A) Ribocil-C bound to the flavin mononucleotide (FMN) riboswitch (PDB 5C45, ref. 76). (B) SMN-C5 bound to the RNA duplex of the 5′-end splice site of Survival of Motor Neuron 2 (SMN2) exon 7 (PDB 6HMO, ref. 132). (C) DMA-135 bound to stem loop II of the internal ribosomal entry site (IRES) of enterovirus 71 (EV71) (PDB 6XB7, ref. 91). (D) Benzimidazole 2 bound to subdomain IIa of the hepatitis C virus (HCV) IRES (PDB 3TZR, ref. 61). | ||
More traditional screening methods, using scaffold-based or general libraries, have also been successful. Well-studied scaffold-based libraries have included oxazolidinones,50–55 diphenylfurans,56–60 benzimidazoles,61–64 and aminoglycosides,65–69 with derivatives showing a range of RNA binding properties and biological activity. In a very recent example, Dutta and co-workers synthesized a library of quinoxaline derivatives that target the HCV IRES and inhibit viral translation and replication.70 Successful higher-throughput screens have included work by Schneekloth and co-workers, who leveraged microarray screening of roughly 20![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 000 molecules to identify selective ligands for HIV-1-TAR,71 miRNA-21,72 the pre-Q1 riboswitch,73 and the MALAT1 3′-triple helix,74 many of which show efficacy in cell-based systems, including evidence of anti-HIV and anti-cancer activity. The Pyle lab developed an activity-based screen for inhibition of the group II intron ribozyme and identified several active antifungal molecules from a library of 10000 compounds that were further optimized using traditional medicinal chemistry methods.75 Several examples from industrial laboratories have also come to the forefront. For example, a Merck group screened ∼57000 molecules with antibacterial activity to identify ribocil, a ligand for the flavin mononucleotide (FMN) riboswitch that was optimized (ribocil-C) to demonstrate efficacy in a murine model of sepsis (Fig. 1B).76 Finally, both Novartis77,78 and PTC/Roche79,80 have developed RNA-targeted small molecules that lead to exon 7 inclusion in the SMN2 gene in patients with spinal muscular atrophy (Fig. 1A). Both small molecules appear well-tolerated and are proceeding through clinical trials, with risdiplam (Evrysdi) recently approved by the US FDA.10 These examples, in addition to other success stories of RNA targeting in vivo, have led to a surge in RNA-targeted small molecule programs in the pharmaceutical industry, both within larger companies and in startups, with a corresponding increase in venture capital investment.81–83
000 molecules to identify selective ligands for HIV-1-TAR,71 miRNA-21,72 the pre-Q1 riboswitch,73 and the MALAT1 3′-triple helix,74 many of which show efficacy in cell-based systems, including evidence of anti-HIV and anti-cancer activity. The Pyle lab developed an activity-based screen for inhibition of the group II intron ribozyme and identified several active antifungal molecules from a library of 10000 compounds that were further optimized using traditional medicinal chemistry methods.75 Several examples from industrial laboratories have also come to the forefront. For example, a Merck group screened ∼57000 molecules with antibacterial activity to identify ribocil, a ligand for the flavin mononucleotide (FMN) riboswitch that was optimized (ribocil-C) to demonstrate efficacy in a murine model of sepsis (Fig. 1B).76 Finally, both Novartis77,78 and PTC/Roche79,80 have developed RNA-targeted small molecules that lead to exon 7 inclusion in the SMN2 gene in patients with spinal muscular atrophy (Fig. 1A). Both small molecules appear well-tolerated and are proceeding through clinical trials, with risdiplam (Evrysdi) recently approved by the US FDA.10 These examples, in addition to other success stories of RNA targeting in vivo, have led to a surge in RNA-targeted small molecule programs in the pharmaceutical industry, both within larger companies and in startups, with a corresponding increase in venture capital investment.81–83
Inspired by the potential of RNA targeting in drug discovery, the Hargrove Lab takes a very fundamental approach: to elucidate guiding principles for achieving selectivity in small molecule:RNA recognition and to apply these principles to develop RNA-targeted chemical probes that modulate RNA functions in cell culture. As has been seen with protein-targeted chemical probes, RNA-targeted chemical probes would be expected to both elucidate fundamental RNA biology and provide insight into how disease pathways might be modulated with RNA-targeted drugs. To begin, we have generated RNA-biased small molecule libraries and screening methodologies that are expected to allow rational targeting of a wide range of disease-related RNAs. Concurrently, we are utilizing the power of differential sensing and pattern recognition to elucidate the shape-based drivers of small molecule:RNA recognition and to classify functional RNAs. We hypothesize that this framework will facilitate characterization and targeting of regulatory RNAs with the resulting potential to transform our understanding of molecular biology. This Feature provides an overview of our work toward a fundamental understanding of selective small molecule:RNA interactions as well as an outlook on the future of the small molecule:RNA targeting field.
2. Understanding and engineering selectivity in small molecule:RNA recognition
To help overcome the selectivity barrier in small molecule:RNA targeting, we asked if specific chemical scaffolds and/or chemical properties of small molecules may bias them toward selective RNA interactions. In these efforts, we have investigated synthetically tractable scaffold-based libraries that allow atom-level tuning of individual molecules, globally analyzed chemical properties of known biologically active RNA ligands, and developed screening procedures that allow us to rapidly assess selectivity.2.1. Scaffold-based libraries
Scaffold-based libraries offer several advantages in the pursuit of guiding principles for selective small molecule:RNA targeting, including the ability to ask precise chemical questions, to build into a desired chemical space, and to rapidly generate structure–activity relationships that are not readily available with commercial libraries. We herein discuss how this strategy has been applied to the amiloride and diphenylfuran scaffolds and has revealed both preliminary guidelines for small molecule design as well as lead molecules for chemical probe development against viral and oncogenic noncoding RNAs.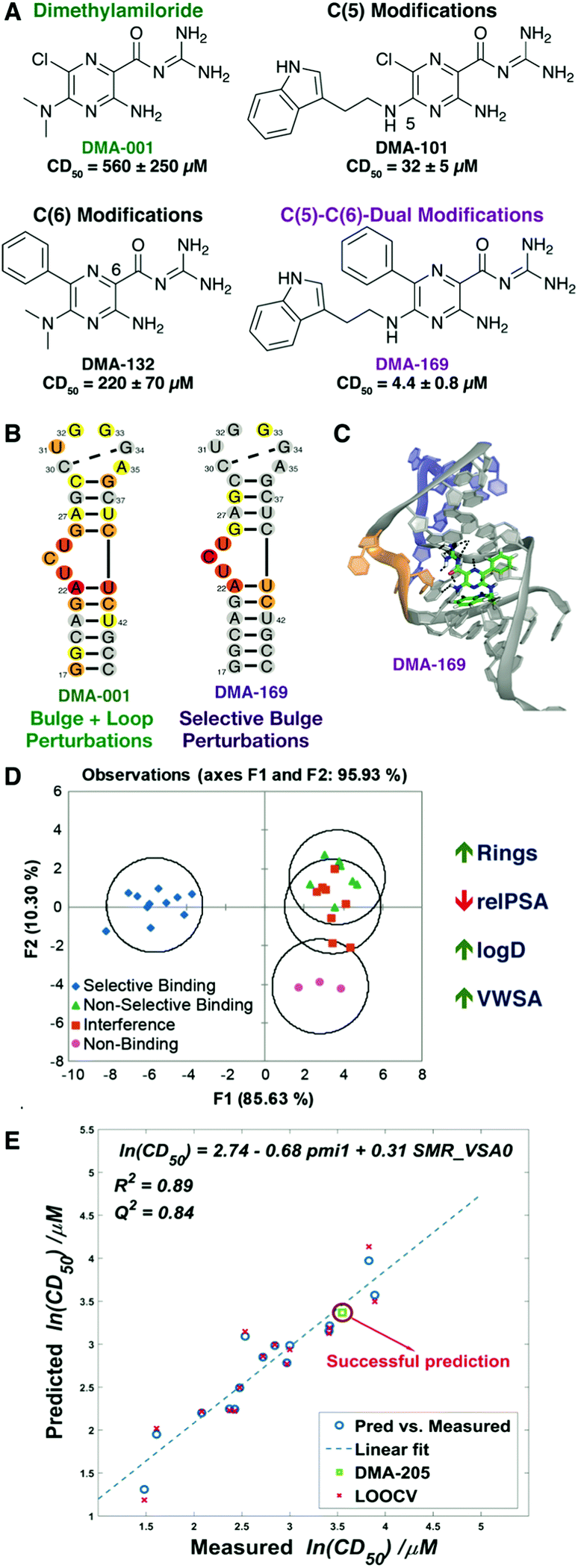 | ||
| Fig. 2 Dimethylamiloride (DMA) as a tunable RNA-binding scaffold. (A) Stepwise modification at the C(5) and C(6) positions of amiloride scaffold to give lead DMA-169. Competitive displacement dose (CD50) for Tat peptide assays shown below each ligand. (B) Heat maps of 1H–13C [HMQC] SOFAST NMR experiments with amiloride and HIV-1-TAR RNA. (C) Docked pose of DMA-169 with HIV-1-TAR, which shows interactions near the trinucleotide bulge (shown in orange). (D) Linear discriminate analysis based on 20 cheminformatic parameters clusters selective amiloride ligands from non-selective ligands. Sample parameters are shown to the right, with trend for selectivity indicated by the arrow. Panels (A–D) reproduced from ref. 88 with permission from the Royal Society of Chemistry. (E) QSAR study on ESSV ligands generated a robust model and predicted binding affinity of a new ligand (DMA-205). LOOCV = leave-one-out cross validation. Panel (E) reproduced from ref. 90 with permission from the Royal Society of Chemistry. | ||
In the course of developing general screening assays utilizing the Tat peptide,89 we demonstrated that some amilorides showed selectivity for HIV-1 TAR over other regulatory RNAs known to bind small molecules, including HIV RRE-IIB and the bacterial ribosomal A-site. However, a subset of amilorides that were selective against tRNA in the original study88 also bound the HIV RRE-IIB and A-site controls. These findings inspired us to perform a broader structure–activity relationship (SAR) study on amiloride derivatives, specifically focused on regulatory RNAs in HIV that may also represent promising therapeutic targets. We incorporated a range of modifications at the C(5) and C(6) positions based on previous work and expanded synthetic routes to study the structure–activity/selectivity relationships with a collection of HIV related RNA structures, namely HIV-1 TAR, HIV-2 TAR, HIV-1-RRE-IIB, HIV-1-FSS, and HIV-1-ESSV.90 Our profiling analysis revealed a number of interesting trends. For example, the C(6) phenyl group significantly improves the activity and selectivity of the amiloride derivatives for HIV-1-TAR, but other aryl subunits at C(6) such as biphenyl, naphthyl, or heteroaryl groups proved to be detrimental to activity. In contrast, large subunits at the C(6) position increased binding for ESSV. Reducing the length of the linker between the pyrazine core and indole ring at the C(5) position of DMA-169 increased both affinity and selectivity for HIV-1-TAR, suggesting that flexible ligands may pay an entropic cost in binding. Cheminformatic analysis further suggested that weakly binding ligands tended to have an increase in oxygen count and flexibility while promiscuous ligands had very high nitrogen counts. Quantitative structure–activity relationships correlated chemical properties to CD50 values of amilorides binding to both HIV-1-TAR and ESSV, with distinct driving properties identified for each target (Fig. 2E).
Leveraging the tunability of the amiloride scaffold, we then collaborated with the Tolbert and Brewer/Li laboratories to identify ligands for stem loop II (SLII) of the internal ribosomal entry site (IRES) of human enterovirus 71 (EV71),91 which had been previously shown to drive viral translation.92 We first screened our amiloride library by adapting the Tat peptide assay to identify a number of SLII ligands.91 Screening in a dual luciferase assay revealed that DMA-135 inhibited translation dependent on the EV71 IRES without impacting normal translation. Similar activity was observed in viral titer assays where viral replication was eliminated at concentrations with no observed toxicity. Mechanistic studies found that DMA-135 increased binding of human AUF1 repressive protein to SLII both in vitro via ITC and in cell culture via pull-down assays. Finally, DMA-135 induced a dramatic (∼77°) conformational change in the linear SLII structure by NMR (Fig. 1C). We hypothesized that this conformational change exposes an AUF1 binding site on SLII, leading to stabilization of a ternary DMA-135:SLII:AUF1 complex that prevents translation and ultimately viral replication. This example demonstrated the potential of modulating the conformational landscape of a dynamic RNA to impact function.
Finally, the amiloride scaffold provided the opportunity to establish a robust method for the selection of high affinity RNA ligands from a dynamic combinatorial pool using imine-based chemistry.93 This method allowed the identification of ligands for three RNA targets without a priori synthesis of discrete library members and is being expanded to additional, multifunctional scaffolds.
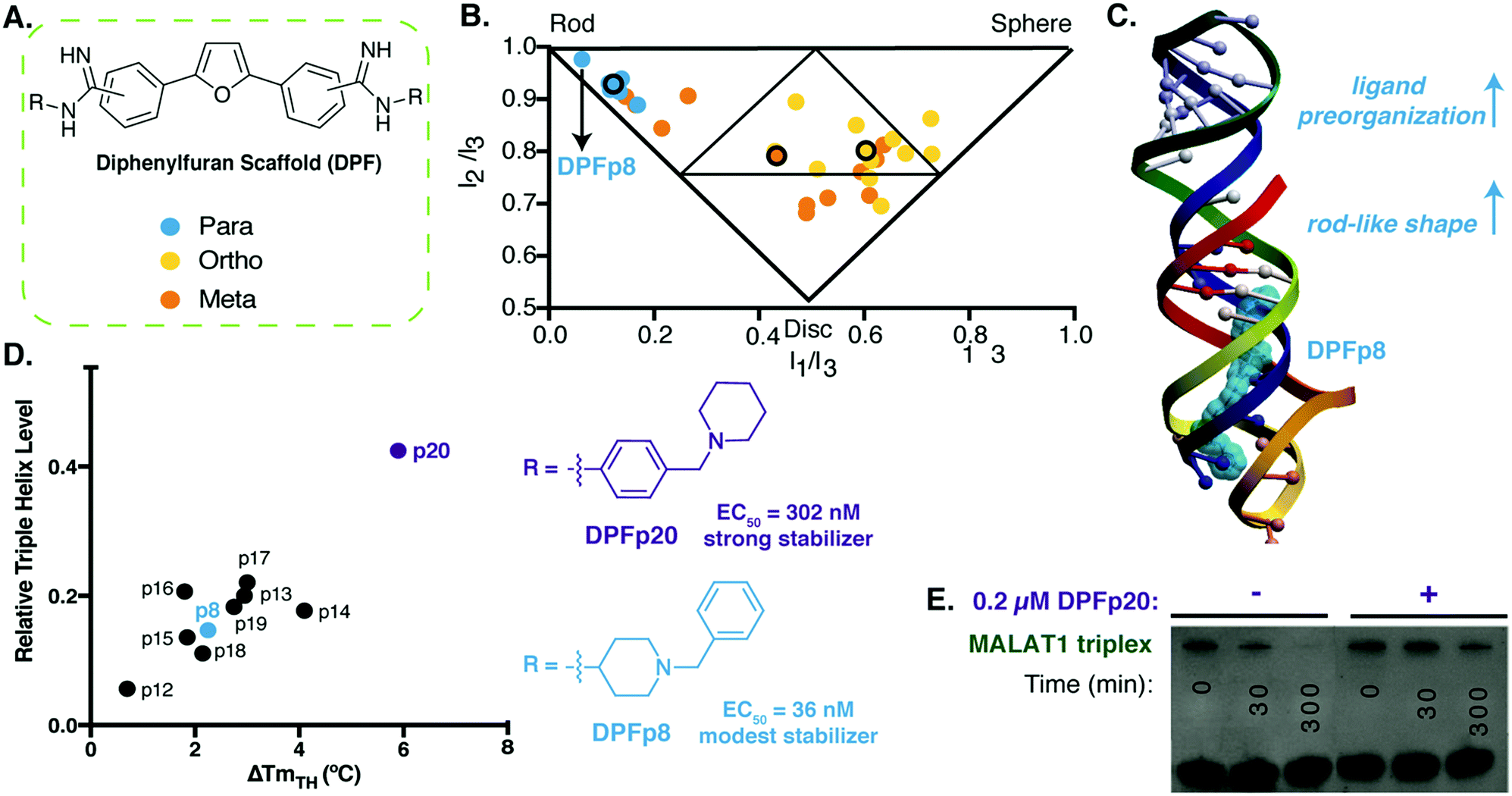 | ||
| Fig. 3 Diphenylfuran scaffold reveals shape-dependent RNA recognition of MALAT1 triplex. (A) Schematic of diphenylfuran (DPF) scaffold library with symmetric regio-substitution. (B) Principal moments of inertia (PMI) analysis of DPF library (blue-para, orange-meta, yellow-ortho substituted) revealed a correlation between triple helix binding strengths and small molecule 3D shape, with the highest affinity triplex binder (DPFp8) as the most rod-like. Reproduced from ref. 94 with permission from John Wiley and Sons. (C) Docking model of MALAT1 triple helix structure (PDB: 4PLX, ref. 98) with DPFp8 (blue) illustrating the importance of rod-like shape and preorganization. (D) Left: Correlation of DPF-induced changes in triplex melting temperature with amount of RNA remaining in an enzyme (RNaseR) degradation assay. Right: Structures of DPFp20, the most stabilizing DPF (purple) and DPFp8, the highest affinity DPF (blue). Shown EC50 values are based on RNA titration of fluorescent DPF scaffold. (E) Gel image showing stabilization of MALAT1 triplex by DPF20 to RNaseR degradation. Panels (D) and (E) reproduced from ref. 95 with permission from Oxford University Press. | ||
In follow up work, we generated additional para-substituted DPF derivatives that tested different aspects of the DPF-p8 subunit in a range of assays.95 We first performed docking against the triple helix (Fig. 3C), and the most favorable docking energies were found for small molecule structures that underwent minimal predicted conformational change between the starting minimized free energy structure and the bound structure, and these docking energies generally correlated with binding affinities. At the same time, we were able to observe selectivity trends between MALAT1 and other triple helices, including the mammalian NEAT1/MENβ. Finally, we evaluated the impact of these DPFs on MALAT1 triple helix stability and identified correlations between increased melting temperature and protection against ribonuclease R degradation (Fig. 3D). Interestingly, DPF-p20, a modest binder and the only molecule derived from an aniline subunit rather than an alkyl amine, led to the most dramatic protection from exonucleolytic degradation (Fig. 3E). This work reinforced the importance of pre-organization and shape-based recognition in selective triple helix binding but also the potential for discrepancies between affinity- and function-based assays.
Our studies with amiloride and the diphenylfuran scaffolds revealed design principles for these scaffolds against viral and lncRNA targets, respectively, and supported our hypothesis that chemical properties may bias small molecules toward selective RNA interactions. The initial amiloride studies provided one of the tightest selective ligands for HIV-1-TAR to date and the first reported ligand for ESSV while demonstrating that the scaffold is tunable to a range of RNA secondary structures and that QSAR can be used for rational RNA ligand design. In addition, both the HIV-1-TAR and EV71 studies highlighted the importance of conformational dynamics in small molecule:RNA targeting, with the EV71 ligand representing one of few examples where modulation of RNA conformation is shown to directly influence biological function. This data supports small molecule regulation of RNA dynamics as an emerging mode of action for functional targeting, shifting the view of RNA dynamics from an obstacle to an opportunity. With the diphenylfuran scaffold, we identified not only the first reported ligands for the MALAT1 3′-triple helix but also the first experimental support for the impact of molecular shape in RNA-ligand design. Observed discrepancies between binding affinity and function with this scaffold underscored considerations of binding mode and conformational landscapes in small molecule:RNA targeting. We are moving these scaffolds forward to test and refine these guiding principles in biological systems and to identify and optimize potential leads for targeting disease-related RNA. At the same time, we are expanding our repertoire of scaffolds and methods, including dynamic combinatorial chemistry, in the pursuit of fundamental discoveries.
2.2. Computational, screening and selection methods to evaluate RNA privileged small molecule space
Given the fundamental differences between RNA and proteins, including their chemical properties, it has been hypothesized that the small molecule space needed to selectively target RNA might be distinct. We have demonstrated preliminary support for this hypothesis by comparing bioactive non-ribosomal RNA-targeted ligands to bioactive protein-targeted ligands represented as FDA-approved small molecule drugs. This work also made it possible to compare discovery methods and techniques that have been successful in identifying these bioactive RNA-targeted ligands, curate a searchable database, and optimize an online platform to facilitate progression of the field.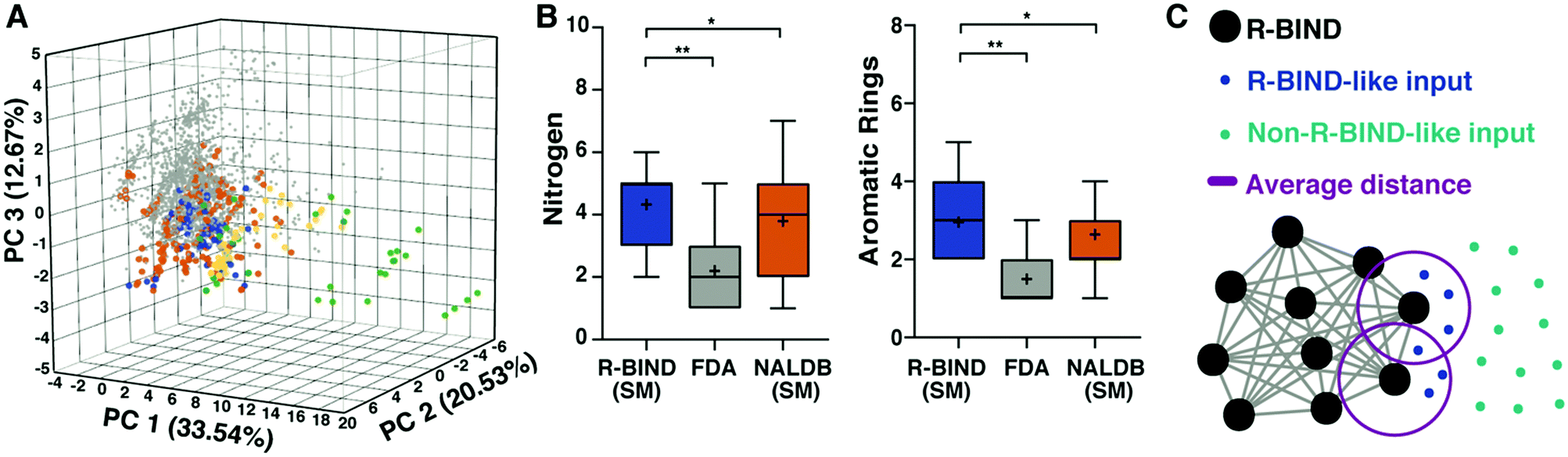 | ||
| Fig. 4 RNA-targeted BIoactive LigaNd Database (R-BIND) reveals distinct properties of RNA-targeted small molecules. (A) Principal component analysis of R-BIND small molecules (blue), nucleic acid ligand database (NALDB) RNA-binding small molecules (orange), FDA-approved drugs (gray), R-BIND multivalent ligands (green), NALDB multivalent ligands (yellow) based on 20 cheminformatic parameters showing that R-BIND small molecules represent a subset of traditional medicinal chemistry (FDA) space. (B) Box-whisker plots of representative parameters showing structural differences between RNA-targeted bioactives (R-BIND SM), protein-targeted bioactivities (FDA), and general RNA ligands (NALDB). Panel (A) and (B) reproduced from ref. 35 with permission from John Wiley and Sons. (C) Schematic of nearest neighbor analysis where the distance between R-BIND small molecules (black) and input ligands is measured using cheminformatic parameters. The distance between each R-BIND small molecule and its nearest neighbor is averaged (purple) and “R-BIND like ligands” (blue) are defined as those within the average distance to at least one R-BIND ligand. Reprinted with permission from ref. 36. Copyright 2019 American Chemical Society. | ||
The R-BIND collection also allowed for comparison of RNA targets, design and discovery strategies, and chemical probe characterization techniques.17 While a diverse range of discovery and development strategies were found to be successful, conclusions were limited by the relative paucity of distinct RNA targets explored and a lack of standardization in chemical probe characterization. Both will need to be addressed as the field moves forward.
To make this work more accessible, we developed an online platform that provides a user-friendly interface to search the available collection of R-BIND ligands along with tools to analyze existing and user-input molecules for similarity to the current set (https://rbind.chem.duke.edu).36 For example, users can search for and evaluate R-BIND ligands based on physicochemical, structural, and spatial properties as well functional groups and user-input substructures. Additional search features include RNA target, ligands with PDB-deposited structures, and types of in vitro or biological assays. Finally, a similarity search based on a nearest-neighbor algorithm allows researchers to identify RBIND ligands that are similar in the available parameter space, either to ligands within R-BIND or of user uploaded ligands (Fig. 4C). This analysis can be used to design “R-BIND-like” small molecule libraries, optimize lead ligands into RNA-biased chemical space, or select targets, probes, assays, and control experiments based on similarity to a known R-BIND ligand. We expect that this platform will provide the scientific community valuable insight into past successes in small molecule:RNA targeting along with tools for future discovery, ultimately reducing barriers in RNA-targeted chemical probe discovery.
Assays that directly relate small molecule impact on RNA function are less common but particularly valuable when available.75,77,79,105,106 For example, we recently tested differential scanning fluorimetry (DSF), in which a fluorescent dye (RiboGreen) reports on RNA melting temperatures via qPCR machine. We demonstrated the utility of this method for the 3′-MALAT1 triple helix and found that melting temperature changes observed in traditional UV-melts matched results from DSF.95 Importantly, changes in melting temperature correlated to stability in an RNase R enzyme degradation assay, suggesting that the results from this high-throughput screen may directly indicate the stabilizing or destabilizing function of the small molecule. We anticipate that this approach will allow for high-throughput stability-based screens for several RNA structures, including complex triple helices.
Moving forward, we are applying these and other screening methods to larger libraries. We hope to not only identify potential leads for chemical probe design but also to refine our cheminformatic analyses of selective RNA ligands and examine the influence of different screening methods, if any, on the outcome of these analyses. We expect the combination of binding and functional assays to yield additional and powerful insight into rational development of small molecule probes for RNA.
In summary, our combined small molecule-based efforts have led to the identification of small molecule characteristics that distinguish selective RNA-ligands from non-selective RNA and/or protein-targeted ligands as well as the identification of novel small molecule leads for viral and oncogenic ncRNAs. Importantly, this work enables the rational generation of RNA-biased libraries and/or rational lead optimization that, along with our identification of efficient screening procedures, will significantly increase the productivity of RNA-targeted screening campaigns and chemical probe development.
3. Differentiation and characterization of RNA structures: Pattern Recognition of RNA with Small Molecules (PRRSM)
As a complement to our understanding of small molecule properties that facilitate selective interactions, we also explored the properties of RNA structures that allow differentiation by small molecules, in this case using pattern recognition. This work has the potential to reveal selectively targetable RNA structures along with driving factors in small molecule:RNA recognition.Molecular-scale, pattern-based sensing relies on the use of receptors, in this case small molecules, that interact differentially with the analyte of interest, in this case RNA structures, to elucidate underlying patterns or classifications in the analytes without the need for highly specific receptor:analyte pairings.19,107,108 We have recently developed a method termed Pattern-Recognition of RNA using Small Molecules (PRRSM, Fig. 5)109,110 and published proof-of-concept studies demonstrating that small molecules can classify RNA secondary structure and that RNA and small molecule shape plays a critical role in RNA recognition.109 Follow up studies have revealed the importance of conformational dynamics in this recognition111 and the ability of this method to predict RNA secondary structures at specific nucleotide positions.112
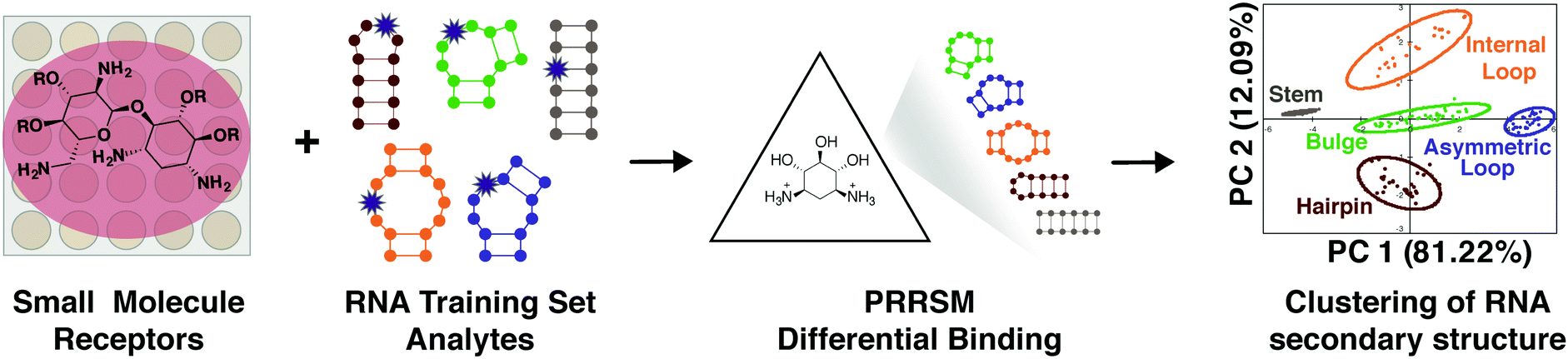 | ||
| Fig. 5 Pattern recognition of RNA by small molecules (PRRSM). An array of small molecule receptors is titrated with RNA secondary structure analytes. Utilizing the small molecule differential binding and an unbiased statistical method allows for clustering based on the RNA structural motifs. Reprinted with permission from ref. 19. Copyright 2019 American Chemical Society. | ||
3.1. Development of the PRRSM technique and preliminary insights
We first evaluated the ability of aminoglycosides, arguably the best characterized RNA ligands, to differentiate canonical RNA secondary structure motifs such as bulges, internal and apical loops.109 Eleven aminoglycosides, nine commercial and two synthetically modified, were evaluated for binding against a training set of 16 RNAs with well-predicted structures that varied in the size and sequence of the motifs (Fig. 6A). To measure site-specific binding, we incorporated the solvatochromic chemosensor benzofuranyluridine (BFU)113,114via solid-phase synthesis. The BFU-labeled RNA training set was incubated with the aminoglycosides at varying concentrations in a 384-well plate and the emission data was used as input for principal component analysis (PCA). PCA revealed an unbiased clustering based on secondary structure class and leave-one-out cross validation (LOOCV) confirmed that PRRSM was able to predict these secondary structure motif classes with 100% accuracy.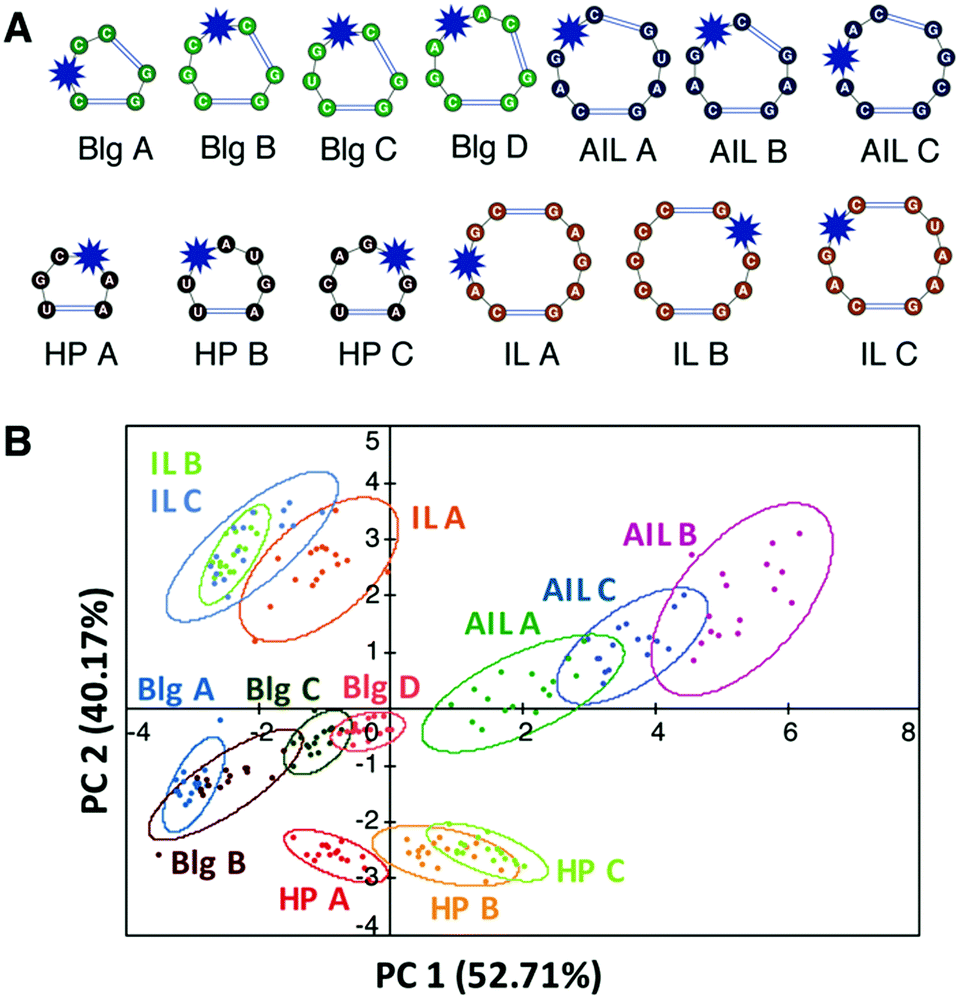 | ||
| Fig. 6 PRRSM classifies individual RNA secondary structures under dynamic conditions. (A) Schematic of secondary structures (unpaired regions) in PRRSM RNA training set with BFU-labeled sites noted with a blue star. Reprinted with permission from ref. 109. Copyright 2017 American Chemical Society. (B) PCA plot of training set under conditions including polyethylene glycol (PEG) and increased temperature. Open ovals indicate 95% confidence intervals. The predictive power for the sequences was 92%. Buffer: 10 mM NaH2PO4, 25 mM NaCl, 4 mM MgCl2, 0.5 mM EDTA, 8 mM PEG 12000, pH 7.4 at 37 °C. Reproduced from ref. 111 with permission from the Royal Society of Chemistry. | ||
These trends, including the modest differentiation of individual sequences, allowed preliminary insights into aminoglycoside:RNA molecular recognition. The largest amount of variance, i.e. differentiation, within the data was found to correlate with the motif size of the RNA secondary structures followed by sequence of the motif. This qualitative analysis aligned with previously published work showing that RNA recognition is heavily dependent on the topology of the RNA structure,115 which is driven by motif size and then sequence. To evaluate small molecule-based trends, we first compared Tanimoto coefficients among the aminoglycosides. While some trends were observed, globally consistent correlations could not be identified based on these fingerprints or through further analysis of simple physicochemical properties (total charge, molecular weight, etc.). The lack of correlation with physicochemical properties and fingerprint analysis, along with the influence of topology, are in line with other evidence that aminoglycoside recognition may be driven largely by three-dimensional properties or shape.116,117 While the local flexibility of aminoglycosides renders the in-solution structures difficult to predict computationally, this work suggests that different aminoglycosides access distinct conformations that ultimately allow differentiation of RNA structures.
3.2. PRRSM reveals impact of RNA dynamics
The initial success of the PRRSM method inspired a range of both fundamental and applied investigations, including further probing of the influence of RNA topology on small molecule:RNA recognition. One way to purposefully modulate RNA topology is through alteration of the RNA environment via changing buffer conditions. For example, the modulation of mono- and divalent cation concentrations, presence or absence of molecular crowders, and changes in pH and temperature are known to alter the stability of RNA secondary and tertiary structures.118,119 Utilizing predictive power (LOOCV) to assess RNA differentiation, we first evaluated the impact of several buffer conditions often used in small molecule:RNA assays.111 High sodium (140 mM) and low pH (5.0) were found to significantly reduce differentiation, likely due to a decrease in binding affinity as a result of interfering with the electrostatic nature of aminoglycoside:RNA interactions. Removal of magnesium, near neutral pH (6–8), and different buffer composition (phosphate versus Tris) had minimal impact relative to the original conditions. The addition of polyethylene glycol (PEG) and increased temperature (25 °C to 37 °C), however, significantly improved differentiation despite the reported destabilization of secondary structure motifs under these conditions (Fig. 6B).119 The opposite was observed for increased magnesium concentration, which would be expected to stabilize secondary structure, though the competition between the magnesium ions and the aminoglycosides for RNA binding may also play a role. These combined results suggested that specific RNA secondary structures are best recognized under conditions that favor dynamic motion, i.e. access to multiple conformations, which is consistent with previously published work demonstrating that RNA structures sample a set of defined but distinct conformations, thus facilitating differentiation.20 Such work, along with the examples above,88,91 is shifting the view of RNA dynamics from a hindrance to a property that can be leveraged for specific recognition by small molecules.3.3. PRRSM structural classification and prediction
Along with these fundamental insights, we investigated the power of the PRRSM method to gather site-specific structural information for RNA. We began with biologically relevant RNA constructs with multiple identified secondary structure motifs and/or inducible conformational changes.109,112 For each nucleotide position of interest, we synthesized the corresponding BFU-labeled construct. Samples included a truncated version of HIV-1 TAR RNA labeled at the 3 nucleotide (nt) bulge or 6 nt hairpin loop109 along with labeled constructs of the prequeuosine-1 riboswitch (PreQ1) and fluoride riboswitch (FR) (three each),112 which both undergo analyte-induced conformational changes (Fig. 7A).120–124 Of the eight RNA constructs analyzed via PRRSM, six of the constructs were classified as expected based on the experimentally determined or predicted structures (Fig. 7B). Control experiments, along with literature precedence,124 suggested that the two poorly-predicted constructs, the U6- and U11-sites of the fluoride riboswitch, were modified at positions that inhibit proper RNA folding. All PRRSM-based observations of unfolded and folded riboswitch states were confirmed via NMR. PRRSM was thus able to classify structures specific to RNA conformations, including folded and unfolded states of the same RNA, and provide insight into modification-induced changes in the structure.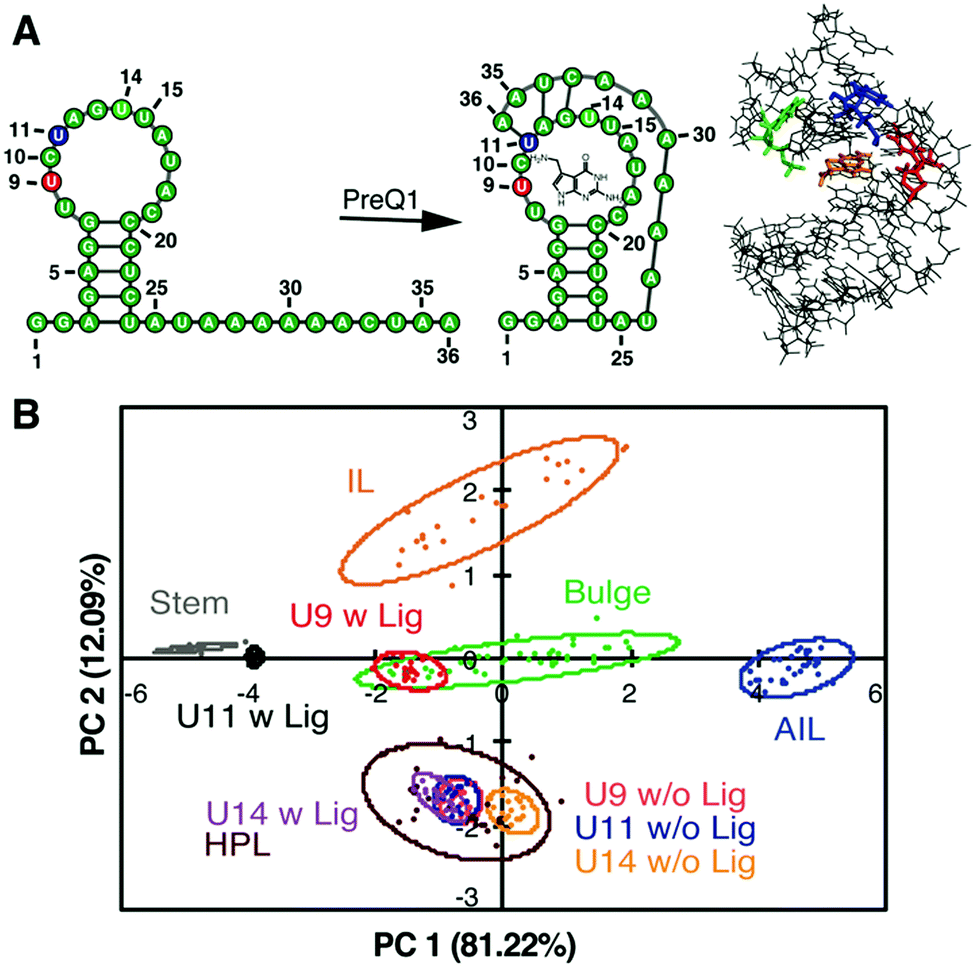 | ||
| Fig. 7 PRRSM classifies apo and bound secondary structures in prequeuosine-1 (PreQ1) riboswitch. (A) Left: PreQ riboswitch secondary structure in the unbound and bound state. Right: Bound structure of PreQ1 (PDB 2L1V) with highlighted sites of BFU fluorophore insertion (U9-red, U11-blue, U14- green) and PreQ1 ligand (orange). (B) PCA plot of the U9, U11, and U14 modified RNA in the absence (w/o Lig) and presence (w Lig) of PreQ1 ligand. All constructs were predicted to be the correct structure in both the unbound and bound states under standard conditions (10 mM NaH2PO4, 25 mM NaCl, 4 mM MgCl2, 0.5 mM EDTA, pH 7.3 at 25 °C). Reprinted with permission from ref. 112. Copyright 2019 American Chemical Society. | ||
In summary, this method has allowed us to: (1) elucidate small molecule properties that impact selective small molecule:RNA interactions; (2) identify the structural and topological determinants of RNA recognition along with the impact of environment; and (3) classify and predict functionally-relevant changes in RNA structure. Ongoing work includes using computational methods to understand the contribution of conformations/dynamics to differentiation, the development of more general (i.e. label free) methods to assess binding, and expansion in terms of both small molecule ligands and diversity of RNA structures evaluated. We are also applying this method to larger RNAs, both to gain site-specific structural information in complex structures and to pursue classification of molecules such as long noncoding RNAs (lncRNAs).
4. Summary and outlook
Our work has leveraged a range of approaches to elucidate the drivers of selective small molecule:RNA recognition. Scaffold-driven synthetic efforts have led to discoveries such as amiloride as an RNA-privileged scaffold and to design principles to tune amilorides to bind viral RNAs and to tune diphenylfurans for selective binding of the triple helix of oncogenic lncRNA MALAT1. In a complementary approach, we identified features of published RNA ligands with biological activity that distinguish them from protein-targeted drugs. We worked to generalize screening methods for assessing RNA binding and stability, including FRET-based peptide displacement, fluorescent indicator displacement, and differential scanning fluorimetry. To investigate targetable properties of RNA, we developed a pattern recognition method (PRRSM) and first elucidated distinguishing features of RNA secondary structures, which included not only the size and shape but also the conformational dynamics. Indeed, recurring themes in this work that are being further explored include the importance of shape/shape complementarity in small molecule:RNA interactions as well as opportunities in recognizing and modulating the RNA conformational landscape.Importantly, these approaches and insights complement and are bolstered by the growing body of research in the field. First, on the question of what properties biologically active RNA-targeting small molecules might require, it has become clear that RNA bioactives can be “drug-like” and can be identified in large chemical libraries.36 At the same time, RNA ligands tend to have distinct structural and chemical properties compared to protein-binding ligands, as seen in our work35,36 and supported by others.125,126 These results suggest that specifically curated or focused libraries may be even more effective for RNA ligand discovery and that such principles can be used to guide lead optimization. As the number of RNA bioactive ligands grows, it will be worthwhile to evaluate whether distinct classes of RNA select for specific properties similar to the way protein classes have distinct ligands. In addition, the fact that RNA bioactives have these distinguishing properties suggests that there might be historically underexplored chemical space for this class of chemical probes. Furthermore, larger molecules such as multivalent ligands, peptides, and aminoglycoside-conjugates are also showing promise. As broad, guiding principles for small molecules that target RNA continue to be refined, high-throughput screens that readily assess selectivity will be critical and screens that incorporate function especially valuable. Detailed studies of thermodynamic and kinetic drivers of small molecule:RNA interactions along with structural studies will provide the needed rationale for these distinguishing features.
Our understanding of what makes an ideal RNA target also continues to expand. The importance of carefully considering, and possibly leveraging, conformational dynamics observed via PRSSM was supported by previous and continuing work of the Al-Hashimi lab, who has shown that structure-based approaches are more successful for RNAs such as HIV-1-TAR and RRE when docking against multiple experimentally informed conformations.49,127 Along these lines, allosteric mechanisms in RNA-targeting were illustrated by Hermann and co-workers when targeting the HCV IRES sequence62 and in our work targeting the EV71 IRES.91 The Disney lab has targeted several functionally important secondary structures in pre-microRNAs that inhibit processing by the Dicer enzyme.128 Given that the conformation of these sites may impact protein binding129 and/or be altered upon binding to the enzyme,130 it would not be surprising if stabilization of alternative conformations inhibits processing. At the same time, Weeks and co-workers used lessons from protein-based targeting to propose that complex RNAs, such as ribosomal RNA, offer the greatest chance of success for selective RNA targeting due to the formation of “high-quality pockets.”16 The targeting of an RNA:protein complex by the SMN2 small molecule splicing modifiers supports this hypothesis.77,131,132 It indeed makes sense that these RNAs would follow protein-type rules given that they target similar functions as those targeted in traditional protein campaigns, i.e. sites of chemical reactivity (translation, splicing) or small molecule binding (riboswitches). In a complementary approach, Schneekloth and co-workers analyzed “ligandable” pockets in RNA PDB structures using similar approaches to those used for proteins and found significant overlap in the pocket characteristics between RNAs and proteins, particularly for more complex RNAs.133 Such analyses, and RNA-targeting in general, will be significantly bolstered by additional elucidation of RNA structures, particularly in ligand-bound states, and continued progress in RNA 3D structure prediction based on experimental inputs such as chemical probing.134
As we look to understand how in vitro knowledge transfers to biological systems, other important considerations will include the level of expression of a given RNA,42,135 which is influenced by multiple factors, including healthy versus disease states, the lifetime of the RNA, and the cell cycle. Highly expressed RNAs may be easier to target as the criteria for affinity and selectivity will be less stringent, and some have made the case that expression level may be one reason that the ribosome has been so successfully targeted.16 Additional work is needed to elucidate the criterion for the relative affinity and selectivity needed for a given small molecule:RNA interaction and whether this is truly influenced by the expression level of the RNA target. Methods to assess target engagement, such as the Chem-CLIP136,137 and Ribo-SNAP138,139 used by Disney or the use of sequencing in splicing targets, will be critical to answering this question and to progressing drug development. Methods that assess RNA structure and dynamics in cells, such as in-cell chemical probing methods,140 should also facilitate evaluation of target engagement.
While challenges remain, the progress being made in understanding small molecule:RNA recognition and the promise this holds for both elucidation of RNA function and therapeutic targeting is inspiring. As a field, we will need to both deepen and expand upon existing knowledge by pursuing a wide range of approaches to small molecule discovery and assessment. Given historic frustrations in RNA targeting, it is critically important that we maintain rigor and transparency in our analyses of chemical probes while also recognizing that many “rules” of affinity, selectivity, and assessment of target engagement may be different for RNA than proteins and many protein-targeting small molecules also break these rules. Without a doubt, it is an incredibly exciting and dynamic time to be in the small molecule:RNA targeting field, where so-called barriers are continuously overcome and each new success story re-shapes our view of RNA recognition. The potential for revealing new biology and for relieving suffering from incurable human diseases is overwhelming – won’t you join us?
Conflicts of interest
There are no conflicts to declare.Acknowledgements
The work described here was made possible by a brilliant and incredibly dedicated team of undergraduate, graduate, postdoctoral and staff researchers hailing from seven different countries over seven years. I am proud and grateful to have worked with each of them. This manuscript specifically relied on insight and edits from lab members Aline Umuhire Juru, Christopher Laudeman, Martina Zafferani, Giacomo Padroni, Emily McFadden, Anita Donlic, Sarah Wicks, Zhengguo Cai, Kamillah Kassam, James Falese, and Emily Swanson along with figure-making assistance from Martina Zafferani and Kamillah Kassam. Funding for this writing was provided by Duke University, the National Science Foundation (CAREER 1750375), and the U.S. National Institutes of Health (R35 GM124785; U54 AI150470).References
- K. V. Morris and J. S. Mattick, Nat. Rev. Genet., 2014, 15, 423 CAS.
- T. R. Cech and J. A. Steitz, Cell, 2014, 157, 77–94 CAS.
- K. E. Deigan and A. R. Ferre-D'Amare, Acc. Chem. Res., 2011, 44, 1329–1338 CAS.
- D. N. Wilson, Nat. Rev. Microbiol., 2014, 12, 35–48 CAS.
- T. Hermann, Wiley Interdiscip. Rev.: RNA, 2016, 7, 726–743 CAS.
- A. Donlic and A. E. Hargrove, Wiley Interdiscip. Rev.: RNA, 2018, 9, e1477 Search PubMed.
- A. M. Schmitt and H. Y. Chang, Cancer Cell, 2016, 29, 452–463 CrossRef CAS.
- H. Ling, M. Fabbri and G. A. Calin, Nat. Rev. Drug Discovery, 2013, 12, 847–865 CrossRef CAS.
- J. Sztuba-Solinska, G. Chavez-Calvillo and S. E. Cline, Bioorg. Med. Chem., 2019, 27, 2149–2165 CrossRef CAS.
- FDA Approves Oral Treatment for Spinal Muscular Atrophy, https://www.fda.gov/news-events/press-announcements/fda-approves-oral-treatment-spinal-muscular-atrophy, accessed August 7, 2020.
- R. L. Juliano, Nucleic Acids Res., 2016, 44, 6518–6548 CrossRef.
- C. A. Stein and D. Castanotto, Mol. Ther., 2017, 25, 1069–1075 CrossRef CAS.
- W. Yin and M. Rogge, Clin. Transl. Sci., 2019, 12, 98–112 CrossRef CAS.
- J. Thomas and P. Hergenrother, Chem. Rev., 2008, 108, 1172–1224 CrossRef.
- Y. Xie, V. K. Tam and Y. Tor, The Chemical Biology of Nucleic Acids, John Wiley & Sons, Ltd, 2010, pp. 115–140 DOI:10.1002/9780470664001.ch6.
- K. D. Warner, C. E. Hajdin and K. M. Weeks, Nat. Rev. Drug Discovery, 2018, 17, 547 CrossRef CAS.
- B. S. Morgan, J. E. Forte and A. E. Hargrove, Nucleic Acids Res., 2018, 46, 8025–8037 CrossRef CAS.
- E. J. Strobel, A. M. Yu and J. B. Lucks, Nat. Rev. Genet., 2018, 19, 615–634 CrossRef CAS.
- C. S. Eubanks and A. E. Hargrove, Biochemistry, 2019, 58, 199–213 CrossRef CAS.
- L. R. Ganser, M. L. Kelly, D. Herschlag and H. M. Al-Hashimi, Nat. Rev. Mol. Cell Biol., 2019, 20, 474–489 CrossRef CAS.
- M. G. Seetin and D. H. Mathews, Methods Mol. Biol., 2012, 905, 99–122 CAS.
- C. E. Hajdin, S. Bellaousov, W. Huggins, C. W. Leonard, D. H. Mathews and K. M. Weeks, Proc. Natl. Acad. Sci. U. S. A., 2013, 110, 5498–5503 CrossRef CAS.
- N. A. Siegfried, S. Busan, G. M. Rice, J. A. E. Nelson and K. M. Weeks, Nat. Methods, 2014, 11, 959–965 CrossRef CAS.
- W. Kladwang, C. C. VanLang, P. Cordero and R. Das, Biochemistry, 2011, 50, 8049–8056 CrossRef CAS.
- S. C. Keane, X. Heng, K. Lu, S. Kharytonchyk, V. Ramakrishnan, G. Carter, S. Barton, A. Hosic, A. Florwick, J. Santos, N. C. Bolden, S. McCowin, D. A. Case, B. A. Johnson, M. Salemi, A. Telesnitsky and M. F. Summers, Science, 2015, 348, 917–921 CrossRef CAS.
- R. Das, J. Karanicolas and D. Baker, Nat. Methods, 2010, 7, 291–294 CrossRef CAS.
- Z. C. Miao, R. W. Adamiak, M. F. Blanchet, M. Boniecki, J. M. Bujnicki, S. J. Chen, C. Cheng, G. Chojnowski, F. C. Chou, P. Cordero, J. A. Cruz, A. R. Ferre-D'amare, R. Das, F. Ding, N. V. Dokholyan, S. Dunin-Horkawicz, W. Kladwang, A. Krokhotin, G. Lach, M. Magnus, F. Major, T. H. Mann, B. Masquida, D. Matelska, M. Meyer, A. Peselis, M. Popenda, K. J. Purzycka, A. Serganov, J. Stasiewicz, M. Szachniuk, A. Tandon, S. Tian, J. Wang, Y. Xia, X. J. Xu, J. W. Zhang, P. N. Zha, T. Zok and E. Westhof, RNA, 2015, 21, 1066–1084 CrossRef CAS.
- G. Qu, P. S. Kaushal, J. Wang, H. Shigematsu, C. L. Piazza, R. K. Agrawal, M. Belfort and H. W. Wang, Nat. Struct. Mol. Biol., 2016, 23, 549–557 CrossRef CAS.
- D. E. Agafonov, B. Kastner, O. Dybkov, R. V. Hofele, W. T. Liu, H. Urlaub, R. Luhrmann and H. Stark, Science, 2016, 351, 1416–1420 CrossRef CAS.
- T. H. Nguyen, W. P. Galej, X. C. Bai, C. Oubridge, A. J. Newman, S. H. Scheres and K. Nagai, Nature, 2016, 530, 298–302 CrossRef CAS.
- R. Fernandez-Leiro and S. H. W. Scheres, Nature, 2016, 537, 339–346 CrossRef CAS.
- K. Zhang, S. C. Keane, Z. Su, R. N. Irobalieva, M. Chen, V. Van, C. A. Sciandra, J. Marchant, X. Heng, M. F. Schmid, D. A. Case, S. J. Ludtke, M. F. Summers and W. Chiu, Structure, 2018, 26, 490–498 CrossRef CAS.
- K. Zhang, S. Li, K. Kappel, G. Pintilie, Z. Su, T.-C. Mou, M. F. Schmid, R. Das and W. Chiu, Nat. Commun., 2019, 10, 5511 CrossRef CAS.
- C. Y. Cheng, F. C. Chou, W. Kladwang, S. Tian, P. Cordero and R. Das, eLife, 2015, 4, e07600 CrossRef.
- B. S. Morgan, J. E. Forte, R. N. Culver, Y. Zhang and A. E. Hargrove, Angew. Chem., Int. Ed., 2017, 56, 13498–13502 CrossRef CAS.
- B. S. Morgan, B. G. Sanaba, A. Donlic, D. B. Karloff, J. E. Forte, Y. Zhang and A. E. Hargrove, ACS Chem. Biol., 2019, 14, 2691–2700 CrossRef CAS.
- C. M. Connelly, M. H. Moon and J. S. Schneekloth, Cell Chem. Biol., 2016, 23, 1077–1090 CrossRef CAS.
- A. Ursu, S. Vezina-Dawod and M. D. Disney, Drug Discovery Today, 2019, 24, 2002–2016 CrossRef CAS.
- A. Di Giorgio and M. Duca, MedChemComm, 2019, 10, 1242–1255 RSC.
- M. D. Disney, S. P. Velagapudi, Y. Li, M. G. Costales and J. L. Childs-Disney, in Methods Enzymol., ed. A. E. Hargrove, Academic Press, 2019, vol. 623, pp. 45–66 Search PubMed.
- A. J. Angelbello, S. G. Rzuczek, K. K. Mckee, J. L. Chen, H. Olafson, M. D. Cameron, W. N. Moss, E. T. Wang and M. D. Disney, Proc. Natl. Acad. Sci. U. S. A., 2019, 116, 7799–7804 CrossRef CAS.
- M. G. Costales, C. L. Haga, S. P. Velagapudi, J. L. Childs-Disney, D. G. Phinney and M. D. Disney, J. Am. Chem. Soc., 2017, 139, 3446–3455 CrossRef CAS.
- J. Lee, Y. Bai, U. V. Chembazhi, S. Peng, K. Yum, L. M. Luu, L. D. Hagler, J. F. Serrano, H. Y. E. Chan, A. Kalsotra and S. C. Zimmerman, Proc. Natl. Acad. Sci. U. S. A., 2019, 116, 8709–8714 CrossRef CAS.
- T. A. Hilimire, J. M. Chamberlain, V. Anokhina, R. P. Bennett, O. Swart, J. R. Myers, J. M. Ashton, R. A. Stewart, A. L. Featherston, K. Gates, E. D. Helms, H. C. Smith, S. Dewhurst and B. L. Miller, ACS Chem. Biol., 2017, 12, 1674–1682 CrossRef CAS.
- V. S. Anokhina, J. D. McAnany, J. H. Ciesla, T. A. Hilimire, N. Santoso, H. Miao and B. L. Miller, Bioorg. Med. Chem., 2019, 27, 2972–2977 CrossRef CAS.
- S. G. Rzuczek, Y. Gao, Z. Z. Tang, C. A. Thornton, T. Kodadek and M. D. Disney, ACS Chem. Biol., 2013, 8, 2312–2321 CrossRef CAS.
- S. P. Velagapudi, M. D. Cameron, C. L. Haga, L. H. Rosenberg, M. Lafitte, D. R. Duckett, D. G. Phinney and M. D. Disney, Proc. Natl. Acad. Sci. U. S. A., 2016, 113, 5898–5903 CrossRef CAS.
- A. C. Stelzer, A. T. Frank, J. D. Kratz, M. D. Swanson, M. J. Gonzalez-Hernandez, J. Lee, I. Andricioaei, D. M. Markovitz and H. M. Al-Hashimi, Nat. Chem. Biol., 2011, 7, 553–559 CrossRef CAS.
- L. R. Ganser, J. Lee, A. Rangadurai, D. K. Merriman, M. L. Kelly, A. D. Kansal, B. Sathyamoorthy and H. M. Al-Hashimi, Nat. Struct. Mol. Biol., 2018, 25, 425–434 CrossRef CAS.
- J. Means, S. Katz, A. Nayek, R. Anupam, J. V. Hines and S. C. Bergmeier, Bioorg. Med. Chem. Lett., 2006, 16, 3600–3604 CrossRef CAS.
- R. Anupam, A. Nayek, N. J. Green, F. J. Grundy, T. M. Henkin, J. A. Means, S. C. Bergmeier and J. V. Hines, Bioorg. Med. Chem. Lett., 2008, 18, 3541–3544 CrossRef CAS.
- I. Maciagiewicz, S. Zhou, S. C. Bergmeier and J. V. Hines, Bioorg. Med. Chem. Lett., 2011, 21, 4524–4527 CrossRef CAS.
- C. M. Orac, S. Zhou, J. A. Means, D. Boehm, S. C. Bergmeier and J. V. Hines, J. Med. Chem., 2011, 54, 6786–6795 CrossRef CAS.
- M. R. Barbachyn and C. W. Ford, Angew. Chem., Int. Ed., 2003, 42, 2010–2023 CrossRef CAS.
- J. A. Ippolito, Z. F. Kanyo, D. Wang, F. J. Franceschi, P. B. Moore, T. A. Steitz and E. M. Duffy, J. Med. Chem., 2008, 51, 3353–3356 CrossRef CAS.
- M. Zhao, L. Ratmeyer, R. G. Peloquin, S. Yao, A. Kumar, J. Spychala, D. W. Boykin and W. D. Wilson, Bioorg. Med. Chem., 1995, 3, 785–794 CrossRef CAS.
- N. Gelus, C. Bailly, F. Hamy, T. Klimkait, W. D. Wilson and D. W. Boykin, Bioorg. Med. Chem., 1999, 7, 1089–1096 CrossRef CAS.
- G. Xiao, A. Kumar, K. Li, C. T. Rigl, M. Bajic, T. M. Davis, D. W. Boykin and W. D. Wilson, Bioorg. Med. Chem., 2001, 9, 1097–1113 CrossRef CAS.
- J. B. Chaires, J. Ren, D. Hamelberg, A. Kumar, V. Pandya, D. W. Boykin and W. D. Wilson, J. Med. Chem., 2004, 47, 5729–5742 CrossRef CAS.
- W. Y. Yang, R. Gao, M. Southern, P. S. Sarkar and M. D. Disney, Nat. Commun., 2016, 7, 11647 CrossRef CAS.
- S. M. Dibrov, K. Ding, N. D. Brunn, M. A. Parker, B. M. Bergdahl, D. L. Wyles and T. Hermann, Proc. Natl. Acad. Sci. U. S. A., 2012, 109, 5223–5228 CrossRef CAS.
- S. M. Dibrov, J. Parsons, M. Carnevali, S. Zhou, K. D. Rynearson, K. Ding, E. Garcia Sega, N. D. Brunn, M. A. Boerneke, M. P. Castaldi and T. Hermann, J. Med. Chem., 2014, 57, 1694–1707 CrossRef CAS.
- S. P. Velagapudi, S. M. Gallo and M. D. Disney, Nat. Chem. Biol., 2014, 10, 291–297 CrossRef CAS.
- R. Parkesh, J. L. Childs-Disney, M. Nakamori, A. Kumar, E. Wang, T. Wang, J. Hoskins, T. Tran, D. Housman, C. A. Thornton and M. D. Disney, J. Am. Chem. Soc., 2012, 134, 4731–4742 CrossRef CAS.
- F. Zhao, Q. Zhao, K. F. Blount, Q. Han, Y. Tor and T. Hermann, Angew. Chem., Int. Ed., 2005, 44, 5329–5334 CrossRef CAS.
- D. W. Staple, V. Venditti, N. Niccolai, L. Elson-Schwab, Y. Tor and S. E. Butcher, ChemBioChem, 2008, 9, 93–102 CrossRef CAS.
- S. Kumar, N. Ranjan, P. Kellish, C. Gong, D. Watkins and D. P. Arya, Org. Biomol. Chem., 2016, 14, 2052–2056 RSC.
- D. Watkins, K. Maiti and D. P. Arya, Methods Mol. Biol., 2019, 1973, 147–162 CrossRef CAS.
- P. Waduge, G. C. Sati, D. Crich and C. S. Chow, Bioorg. Med. Chem., 2019, 27, 1151212 CrossRef.
- J. Chakraborty, A. Kanungo, T. Mahata, K. Kumar, G. Sharma, R. Pal, K. S. Ahammed, D. Patra, B. Majhi, S. Chakrabarti, S. Das and S. Dutta, Chem. Commun., 2019, 55, 14027–14030 RSC.
- J. Sztuba-Solinska, S. R. Shenoy, P. Gareiss, L. R. Krumpe, S. F. Le Grice, B. R. O'Keefe and J. S. Schneekloth, Jr., J. Am. Chem. Soc., 2014, 136, 8402–8410 CrossRef CAS.
- C. M. Connelly, R. E. Boer, M. H. Moon, P. Gareiss and J. S. Schneekloth, Jr., ACS Chem. Biol., 2017, 12, 435–443 CrossRef CAS.
- C. M. Connelly, T. Numata, R. E. Boer, M. H. Moon, R. S. Sinniah, J. J. Barchi, A. R. Ferré-D’Amaré and J. S. Schneekloth, Nat. Commun., 2019, 10, 1501 CrossRef.
- F. A. Abulwerdi, W. Xu, A. A. Ageeli, M. J. Yonkunas, G. Arun, H. Nam, J. S. Schneekloth, T. K. Dayie, D. Spector, N. Baird and S. F. J. Le Grice, ACS Chem. Biol., 2019, 14, 223–235 CrossRef CAS.
- O. dorova, G. E. Jagdmann, R. L. Adams, L. Yuan, M. C. Van Zandt and A. M. Pyle, Nat. Chem. Biol., 2018, 14, 1073–1078 CrossRef.
- J. A. Howe, H. Wang, T. O. Fischmann, C. J. Balibar, L. Xiao, A. M. Galgoci, J. C. Malinverni, T. Mayhood, A. Villafania, A. Nahvi, N. Murgolo, C. M. Barbieri, P. A. Mann, D. Carr, E. Xia, P. Zuck, D. Riley, R. E. Painter, S. S. Walker, B. Sherborne, R. de Jesus, W. D. Pan, M. A. Plotkin, J. Wu, D. Rindgen, J. Cummings, C. G. Garlisi, R. M. Zhang, P. R. Sheth, C. J. Gill, H. F. Tang and T. Roemer, Nature, 2015, 526, 672–677 CrossRef CAS.
- J. Palacino, S. E. Swalley, C. Song, A. K. Cheung, L. Shu, X. L. Zhang, M. Van Hoosear, Y. Shin, D. N. Chin, C. G. Keller, M. Beibel, N. A. Renaud, T. M. Smith, M. Salcius, X. Y. Shi, M. Hild, R. Servais, M. Jain, L. Deng, C. Bullock, M. McLellan, S. Schuierer, L. Murphy, M. J. J. Blommers, C. Blaustein, F. Berenshteyn, A. Lacoste, J. R. Thomas, G. Roma, G. A. Michaud, B. S. Tseng, J. A. Porter, V. E. Myer, J. A. Tallarico, L. G. Hamann, D. Curtis, M. C. Fishman, W. F. Dietrich, N. A. Dales and R. Sivasankaran, Nat. Chem. Biol., 2015, 11, 511–517 CrossRef CAS.
- A. K. Cheung, B. Hurley, R. Kerrigan, L. Shu, D. N. Chin, Y. P. Shen, G. O'Brien, M. J. Sung, Y. Hou, J. Axford, E. Cody, R. Sun, A. Fazal, C. Fridrich, C. C. Sanchez, R. C. Tomlinson, M. Jain, L. Deng, K. Hoffmaster, C. Song, M. Van Hoosear, Y. Shin, R. Servais, C. Towler, M. Hild, D. Curtis, W. F. Dietrich, L. G. Hamann, K. Briner, K. S. Chen, D. Kobayashi, R. Sivasankaran and N. A. Dales, J. Med. Chem., 2018, 61, 11021–11036 CrossRef CAS.
- N. A. Naryshkin, M. Weetall, A. Dakka, J. Narasimhan, X. Zhao, Z. Feng, K. K. Y. Ling, G. M. Karp, H. Qi, M. G. Woll, G. Chen, N. Zhang, V. Gabbeta, P. Vazirani, A. Bhattacharyya, B. Furia, N. Risher, J. Sheedy, R. Kong, J. Ma, A. Turpoff, C.-S. Lee, X. Zhang, Y.-C. Moon, P. Trifillis, E. M. Welch, J. M. Colacino, J. Babiak, N. G. Almstead, S. W. Peltz, L. A. Eng, K. S. Chen, J. L. Mull, M. S. Lynes, L. L. Rubin, P. Fontoura, L. Santarelli, D. Haehnke, K. D. McCarthy, R. Schmucki, M. Ebeling, M. Sivaramakrishnan, C.-P. Ko, S. V. Paushkin, H. Ratni, I. Gerlach, A. Ghosh and F. Metzger, Science, 2014, 345, 688 CrossRef CAS.
- H. Ratni, M. Ebeling, J. Baird, S. Bendels, J. Bylund, K. S. Chen, N. Denk, Z. Feng, L. Green, M. Guerard, P. Jablonski, B. Jacobsen, O. Khwaja, H. Kletzl, C.-P. Ko, S. Kustermann, A. Marquet, F. Metzger, B. Mueller, N. A. Naryshkin, S. V. Paushkin, E. Pinard, A. Poirier, M. Reutlinger, M. Weetall, A. Zeller, X. Zhao and L. Mueller, J. Med. Chem., 2018, 61, 6501–6517 CrossRef CAS.
- A. Mullard, Nat. Rev. Drug Discovery, 2017, 16, 813–815 CrossRef CAS.
- S. Chakradhar, Nat. Med., 2017, 23, 532–534 CrossRef CAS.
- J. Petrone and L. DeFrancesco, Nat. Biotechnol., 2018, 36, 787–790 CrossRef CAS.
- M. Stevens, E. D. Clercq and J. Balzarini, Med. Res. Rev., 2006, 26, 595–625 CrossRef CAS.
- A. P. Massey, W. R. Harley, N. Pasupuleti, F. A. Gorin and M. H. Nantz, Bioorg. Med. Chem. Lett., 2012, 22, 2635–2639 CrossRef CAS.
- B. J. Buckley, A. Aboelela, E. Minaei, L. X. Jiang, Z. Xu, U. Ali, K. Fildes, C.-Y. Cheung, S. M. Cook, D. C. Johnson, D. A. Bachovchin, G. M. Cook, M. Apte, M. Huang, M. Ranson and M. J. Kelso, J. Med. Chem., 2018, 61, 8299–8320 CrossRef CAS.
- A. Massink, T. Amelia, A. Karamychev and A. P. Ijzerman, Med. Res. Rev., 2020, 40, 683–708 CrossRef CAS.
- N. N. Patwardhan, L. R. Ganser, G. J. Kapral, C. S. Eubanks, J. Lee, B. Sathyamoorthy, H. Al-Hashimi and A. E. Hargrove, MedChemComm, 2017, 8, 1022–1036 RSC.
- N. N. Patwardhan, Z. Cai, C. N. Newson and A. E. Hargrove, Org. Biomol. Chem., 2019, 17, 1778–1786 RSC.
- N. N. Patwardhan, Z. Cai, A. Umuhire Juru and A. E. Hargrove, Org. Biomol. Chem., 2019, 17, 9313–9320 RSC.
- J. Davila-Calderon, N. N. Patwardhan, L.-Y. Chiu, A. Sugarman, Z. Cai, S. R. Penutmutchu, M.-L. Li, G. Brewer, A. E. Hargrove and B. S. Tolbert, Nat. Commun., 2020, 11, 4775 CrossRef CAS.
- M. Tolbert, C. E. Morgan, M. Pollum, C. E. Crespo-Hernández, M. -L. Li, G. Brewer and B. S. Tolbert, J. Mol. Biol., 2017, 429, 2841–2858 CrossRef CAS.
- A. Umuhire Juru, Z. Cai, A. Jan and A. E. Hargrove, Chem. Commun., 2020, 56, 3555–3558 RSC.
- A. Donlic, B. S. Morgan, J. L. Xu, A. Liu, C. Roble, Jr. and A. E. Hargrove, Angew. Chem., Int. Ed., 2018, 57, 13242–13247 CrossRef CAS.
- A. Donlic, M. Zafferani, G. Padroni, M. Puri and A. E. Hargrove, Nucleic Acids Res., 2020, 48, 7653–7664 CrossRef.
- G. Arun, D. Aggarwal and D. L. Spector, Non-Coding RNA, 2020, 6, 22 CrossRef CAS.
- J. A. Brown, D. Bulkley, J. Wang, M. L. Valenstein, T. A. Yario, T. A. Steitz and J. A. Steitz, Nat. Struct. Mol. Biol., 2014, 21, 633–640 CrossRef CAS.
- J. E. Wilusz, Biochim. Biophys. Acta, Gene Regul. Mech., 2016, 1859, 128–138 CrossRef CAS.
- M. Zhao, L. Ratmeyer, R. G. Peloquin, S. J. Yao, A. Kumar, J. Spychala, D. W. Boykin and W. D. Wilson, Bioorg. Med. Chem., 1995, 3, 785–794 CrossRef CAS.
- W.-Y. Yang, R. Gao, M. Southern, P. S. Sarkar and M. D. Disney, Nat. Commun., 2016, 7, 11647 CrossRef CAS.
- L. Ratmeyer, M. Zapp, M. Green, R. Vinayak, A. Kumar, D. W. Boykin and W. D. Wilson, Biochemistry, 1996, 35, 13689–13696 CrossRef CAS.
- G. Padroni, N. N. Patwardhan, M. Schapira and A. E. Hargrove, RSC Med. Chem., 2020, 11, 802–813 RSC.
- S. L. Wicks and A. E. Hargrove, Methods, 2019, 167, 3–14 CrossRef CAS.
- C. Matsumoto, K. Hamasaki, H. Mihara and A. Ueno, Bioorg. Med. Chem. Lett., 2000, 10, 1857–1861 CrossRef CAS.
- M. Hung, P. Patel, S. Davis and S. R. Green, J. Virol., 1998, 72, 4819–4824 CrossRef CAS.
- D. A. Lorenz and A. L. Garner, Approaches for the Discovery of Small Molecule Ligands Targeting microRNAs, Springer Berlin Heidelberg, Berlin, Heidelberg, 2017, pp. 1–32 DOI:10.1007/7355_2017_3.
- P. Anzenbacher, P. Lubal, P. Bucek, M. A. Palacios and M. E. Kozelkova, Chem. Soc. Rev., 2010, 39, 3954–3979 RSC.
- A. Umali and E. Anslyn, Curr. Opin. Chem. Biol., 2010, 14, 685–692 CrossRef CAS.
- C. S. Eubanks, J. E. Forte, G. J. Kapral and A. E. Hargrove, J. Am. Chem. Soc., 2017, 139, 409–416 CrossRef CAS.
- G. Padroni, C. S. Eubanks and A. E. Hargrove, in Methods Enzymol., ed. A. E. Hargrove, Academic Press, 2019, vol. 623, pp. 101–130 Search PubMed.
- C. S. Eubanks and A. E. Hargrove, Chem. Commun., 2017, 53, 13363–13366 RSC.
- C. S. Eubanks, B. Zhao, N. N. Patwardhan, R. D. Thompson, Q. Zhang and A. E. Hargrove, J. Am. Chem. Soc., 2019, 141, 5692–5698 CrossRef CAS.
- A. A. Tanpure and S. G. Srivatsan, ChemBioChem, 2012, 13, 2392–2399 CrossRef CAS.
- A. A. Tanpure and S. G. Srivatsan, Nucleic Acids Res., 2015, 43, e149 CrossRef.
- M. H. Bailor, X. Sun and H. M. Al-Hashimi, Science, 2010, 327, 202–206 CrossRef CAS.
- Q. Vicens and E. Westhof, ChemBioChem, 2003, 4, 1018–1023 CrossRef CAS.
- J. Kondo, M. Hainrichson, I. Nudelman, D. Shallom-Shezifi, C. M. Barbieri, D. S. Pilch, E. Westhof and T. Baasov, ChemBioChem, 2007, 8, 1700–1709 CrossRef CAS.
- D. E. Draper, RNA, 2004, 10, 335–343 CrossRef CAS.
- J. Tyrrell, K. M. Weeks and G. J. Pielak, Biochemistry, 2015, 54, 6447–6453 CrossRef CAS.
- A. Roth, W. C. Winkler, E. E. Regulski, B. W. Lee, J. Lim, I. Jona, J. E. Barrick, A. Ritwik, J. N. Kim, R. Welz, D. Iwata-Reuyl and R. R. Breaker, Nat. Struct. Mol. Biol., 2007, 14, 308–317 CrossRef CAS.
- M. Kang, R. Peterson and J. Feigon, Mol. Cell, 2010, 39, 653–655 CrossRef CAS.
- Q. Zhang, M. Kang, R. D. Peterson and J. Feigon, J. Am. Chem. Soc., 2011, 133, 5190–5193 CrossRef CAS.
- A. Ren, K. R. Rajashankar and D. J. Patel, Nature, 2012, 486, 85–89 CrossRef CAS.
- B. Zhao, S. L. Guffy, B. Williams and Q. Zhang, Nat. Chem. Biol., 2017, 13, 968 CrossRef CAS.
- N. F. Rizvi, J. P. Santa Maria, A. Nahvi, J. Klappenbach, D. J. Klein, P. J. Curran, M. P. Richards, C. Chamberlin, P. Saradjian, J. Burchard, R. Aguilar, J. T. Lee, P. J. Dandliker, G. F. Smith, P. Kutchukian and E. B. Nickbarg, SLAS Discovery, 2020, 25, 384–396 CAS.
- H. S. Haniff, L. Knerr, X. H. Liu, G. Crynen, J. Bostrom, D. Abegg, A. Adibekian, E. Lekah, K. W. Wang, M. D. Cameron, I. Yildirim, M. Lemurell and M. D. Disney, Nat. Chem., 2020, 12, 952–961 CrossRef CAS.
- C. C. Chu, R. Plangger, C. Kreutz and H. M. Al-Hashimi, Nucleic Acids Res., 2019, 47, 7105–7117 CrossRef CAS.
- S. P. Velagapudi, B. R. Vummidi and M. D. Disney, Curr. Opin. Chem. Biol., 2015, 24, 97–103 CrossRef CAS.
- Y. Nam, C. Chen, R. I. Gregory, J. J. Chou and P. Sliz, Cell, 2011, 147, 1080–1091 CrossRef CAS.
- Z. Liu, J. Wang, H. Cheng, X. Ke, L. Sun, Q. C. Zhang and H.-W. Wang, Cell, 2018, 173, 1191–1203 CrossRef CAS.
- M. Sivaramakrishnan, K. D. McCarthy, S. Campagne, S. Huber, S. Meier, A. Augustin, T. Heckel, H. Meistermann, M. N. Hug, P. Birrer, A. Moursy, S. Khawaja, R. Schmucki, N. Berntenis, N. Giroud, S. Golling, M. Tzouros, B. Banfai, G. Duran-Pacheco, J. Lamerz, Y. Hsiu Liu, T. Luebbers, H. Ratni, M. Ebeling, A. Cléry, S. Paushkin, A. R. Krainer, F. H. T. Allain and F. Metzger, Nat. Commun., 2017, 8, 1476 CrossRef.
- S. Campagne, S. Boigner, S. Rüdisser, A. Moursy, L. Gillioz, A. Knörlein, J. Hall, H. Ratni, A. Cléry and F. H. T. Allain, Nat. Chem. Biol., 2019, 15, 1191–1198 CrossRef CAS.
- W. M. Hewitt, D. R. Calabrese and J. S. Schneekloth, Bioorg. Med. Chem., 2019, 27, 2253–2260 CrossRef CAS.
- K. Kappel, K. M. Zhang, Z. M. Su, A. M. Watkins, W. Kladwang, S. S. Li, G. Pintilie, V. V. Topkar, R. Rangan, I. N. Zheludev, J. D. Yesselman, W. Chiu and R. Das, Nat. Methods, 2020, 17, 699–707 CrossRef CAS.
- X. H. Liu, H. S. Haniff, J. L. Childs-Disney, A. Shuster, H. Aikawa, A. Adibekian and M. D. Disney, J. Am. Chem. Soc., 2020, 142, 6970–6982 CrossRef CAS.
- L. Guan and M. D. Disney, Angew. Chem., Int. Ed., 2013, 52, 10010–10013 CrossRef CAS.
- W. Y. Yang, H. D. Wilson, S. P. Velagapudi and M. D. Disney, J. Am. Chem. Soc., 2015, 137, 5336–5345 CrossRef CAS.
- S. G. Rzuczek, L. A. Colgan, Y. Nakai, M. D. Cameron, D. Furling, R. Yasuda and M. D. Disney, Nat. Chem. Biol., 2017, 13, 188–193 CrossRef CAS.
- Y. Li and M. D. Disney, ACS Chem. Biol., 2018, 13, 3065–3071 CrossRef CAS.
- D. Mitchell, S. M. Assmann and P. C. Bevilacqua, Curr. Opin. Struct. Biol., 2019, 59, 151–158 CrossRef CAS.
| This journal is © The Royal Society of Chemistry 2020 |