DOI:
10.1039/C5RA17978E
(Paper)
RSC Adv., 2015,
5, 106959-106970
The classification and prediction of green teas by electrochemical response data extraction and fusion approaches based on the combination of e-nose and e-tongue†
Received
4th September 2015
, Accepted 2nd December 2015
First published on 3rd December 2015
Abstract
Aroma and taste are the most important attributes that influence the pleasantness of tea infusion. In this paper, e-nose and e-tongue were combined to identify the tea samples of various grades, and two fusion feature datasets from the electrochemical response were established for the analysis on the basis of the partial-area fusion dataset (PAFD, not including the ‘aftertaste values’) and total-area fusion dataset (TAFD, including the ‘aftertaste values’). Principal component analysis (PCA), discriminant factor analysis (DFA) and partial least-squares regression (PLSR) were applied to classify the samples and make predictions. DFA with TAFD yielded the best classification results, and the distribution of compounds within the tea samples was identified. The taste and smell compounds of teas were detected by using high-performance liquid chromatography (HPLC) and gas chromatography-mass spectrometry (GC-MS). TAFD was more effective than PAFD in predicting the quality grade, water extract, polyphenol, and geraniol; the correlation coefficients of PLSR with TAFD were 0.9518, 0.9298, 0.9202 and 0.9258, respectively. The addition of ‘aftertaste values’ improved the analysis results; the quality grades of green teas can be detected by using the e-nose and e-tongue in combination and the main volatile and flavor compounds of green teas of different quality grades can be also well determined.
1. Introduction
Green tea has been known to confer health benefits (such as anti-oxidant and anti-microbial properties) along with its attractive and pleasant flavor.1–3 In the marketplace, there is a wide range of prices for green teas of different qualities, which are difficult to distinguish by their appearance because of the similar processing procedures.4 A common fraudulent practice in the commercialization of green tea is to sell inferior goods as superior ones; this is difficult for normal consumers to detect. This fraudulent behavior not only harms the interests of consumers but also damages the interests of producers.
The quality grades of green tea, which are influenced by variety, picking season, soil, fertilization, climate, and post-harvest treatment,5 are always ranked by leaf appearance, color, aroma, and taste of tea infusion.6,7 Among these factors, aroma and taste are considered the most important attributes that influence the pleasantness of tea infusion and have contributed to the increase in tea consumption.8 Traditionally, the evaluation of quality grades of green tea is determined by human sensory panels.9 However, sensory evaluation is a time-consuming and difficult-to-reproduce method with low objectivity. In addition, even trained panelists can be influenced by several physiological, economic, and personal issues; and human perception is not constant across time or among people. Analytical methods and some modern analysis techniques could fit these requirements: gas chromatography/mass spectroscopy (GC-MS),9,10 high performance liquid chromatography (HPLC),11–13 and visible near infrared (Vis-NIR) spectroscopy.14,15 However, the application of these instruments has significant limitations: (1) the taste and smell substances of teas cannot be completely detected by these instruments, therefore, they cannot accurately reproduce the gustatory and olfactory sensations of teas to human. (2) The interactions between different taste and smell substances, such as the synergistic effect or the suppression effect, cannot be detected by these instruments.
Electronic nose (e-nose) and tongue (e-tongue) are systems that closely mimic the performance of human olfactory bulbs and taste buds (with the following application of pattern recognition tools).16–18 Both the instruments can obtain global information about samples through “soft” measurement techniques, where a quality (e.g. taste or smell) can be measured, instead of traditional measurement techniques, where a single parameter (e.g. temperature or conductivity) is measured.19 Global information, which is considered to be fingerprints of taste and smell substances, could be used to classify and forecast the quality of detected samples with appropriate pattern-recognition methods. Because of their fast operation and low cost, e-noses and e-tongues are now widely applied to various food products analyses.20–25
Although the quality of the tea has a high correlation with aroma and taste, aftertaste is also often used as a positive term to describe a good tea infusion.26 Aftertaste is the stimulus intensity perceived in the moments immediately following removal of the stimulus (to differentiate with adaptation, in which the stimulus is constantly present), it can vary strongly over time after taste effect and the length of aftertaste is much different in various tea samples.27 In this study, a combination of an e-nose and e-tongue is applied to detect different grades of green tea. Meanwhile, the aftertaste of the tea infusion is also detected during the experiment for improving the identification precision. The sensory features were extracted by the area method (the sum of the areas between the corresponding curves and x-axis) from the original response values. Three types of pattern recognition methods: principal component analysis (PCA), discriminant factor analysis (DFA), and partial least-squares regression (PLSR) based on those feature data were applied for classification and prediction of the green tea samples. In addition, the volatile and flavor compounds of teas were also detected by gas chromatography-mass spectrometry (GC-MS) and high-performance liquid chromatography (HPLC) as references. PLSR was used to predict the chemicals on the basis of usage of an e-nose or e-tongue alone, as well as the combined usage of an e-nose and e-tongue.
The objectives of this study were: (1) to demonstrate whether the combined usage of e-nose and e-tongue systems to discriminate tea samples with different grades and to the predict the volatility and flavor compounds is more efficient than the solo usage of an e-nose or e-tongue; (2) to determine the effectiveness of the area method as the extraction method for response features; and (3) whether obtaining additional aftertaste signals could improve the classification and prediction results.
2. Materials and methods
2.1. Chemicals
The reference aromatic compounds for the qualitative analysis, and ethyl caprate (99.99% purity), used as an internal standard for the quantitative analysis, were obtained from Sigma-Aldrich, Milwaukee, WI, USA. N-Alkanes (C5–C20) were used for the linear-retention-index (LRI) calculations and were purchased from J&K Chemical Ltd., Beijing, China. An internal standard solution was prepared at a concentration of 0.4 μl in 1 ml of methanol (HPLC grade, Fishier, Scientific Pittsburg, PA, USA) prior to use.
2.2. Tea samples
Longjing tea, which is a type of flat-shaped Chinese green tea, is used as the experimental sample in the study. Seven tea groups of different qualities were picked from Jiyun city (28°25′ 119°52′, Zhejiang province). All tea leaves, which were pan-fried by skilled workers, were processed by the same method. The grades of Longjing are variable depending on the plucking time: the teas plucked before Tomb-Sweeping Day (TSD, April, 5th) are of higher quality and price than the teas plucked after the TSD. Seven tea groups with different price were plucked at different times (Table 1): the samples of jy280, jy360, jy450, and jy510 were plucked before TSD; and the samples of jy120, jy170, and jy190 were plucked after TSD. Fourteen samples of each quality group were identified, and all samples were packed in aluminum foil, sealed by a vacuum packing machine, and stored at 4 °C before testing.
Table 1 Different grades of green tea
| Tea |
Grade |
Price (¥ per 500 g) |
Plucking time |
Reference values |
| Jy120 |
Low-level |
120 |
After TSD |
7 |
| Jy170 |
Low-level |
170 |
After TSD |
6 |
| Jy190 |
Low-level |
190 |
After TSD |
1 |
| Jy280 |
High-level |
280 |
Before TSD |
2 |
| Jy360 |
High-level |
360 |
Before TSD |
3 |
| Jy450 |
High-level |
450 |
Before TSD |
4 |
| Jy510 |
High-level |
540 |
Before TSD |
5 |
2.3. Electronic nose setup and measurement
A PEN2 portable electronic nose (AIRSENSE Company, German) was applied in the experiment. The device was equipped with 10 metal oxide semiconductor (MOS) type chemical sensors (W1C, W5S, W3C, W6S, W5C, W1S, W1W, W2S, W2W and W3S) whose responses were expressed as the ratio of conductance.
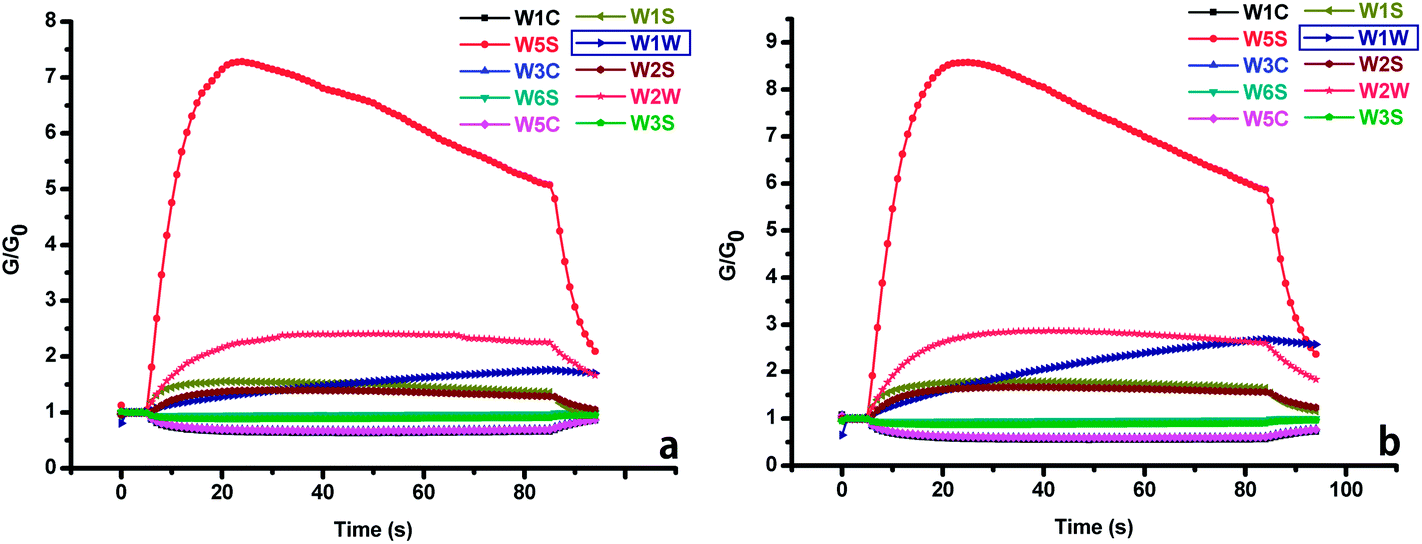
In this experiment, each 10 g tea sample was placed in a beaker (500 ml), which was sealed with plastic wrap. Afterwards, the headspace collected the volatiles from the samples during 60 min (headspace-generation time). During the measurement process, the headspace gas was pumped into the sensor chamber at a constant rate of 400 ml min−1. The measurement includes three parts: the sampling phase (85 s), the slightly purging phase (10 s), and the purging phase (40 s). At beginning of the sampling phase, the ratio of conductance of each sensor was low; then, it increased continuously and finally stabilized after approximately 50 s. The following slightly purging phase consisted of a short time clean-testing (with air) for the detection of the adsorb ability of the MOS sensors to the volatiles (it could be taken as one type of aftertaste detection). At the end of the experiment, the sensors were purged to their baseline by air in the purging phase. A computer recorded the response signals at every second. When the measurement was completed, the acquired data were properly stored for later analysis. Fourteen samples of each tea group were identified, and temperature of the laboratory was kept at 25 ± 1 °C during experiment. It can be seen from Fig. 1 that the response signals obtained from jy190 and jy510 samples were different, and that the volatiles of different tea samples presented different cohesion to gas sensors. Jy190 samples belong to low-level Longjing teas, and their sensor signal values ranged from 0–8. The sensors have the highest sensitivity to jy510, and the responses were in range of 0–9. Aside from these differences, the response values obtained by W1W sensor changed significantly. Those differences among the response signals could be applied to discriminate different quality grades of Longjing tea samples, and the differences among “aftertaste signals” might improve the discrimination.
 |
| | Fig. 1 Response curves of the ten gas sensors (W1C, W5S, W3C, W6S, W5C, W1S, W1W, W2S, W2W and W3S) to the tea samples: (a) jy190, (b) jy510. | |
2.4. Electronic tongue setup and measurement
The α-Astree e-tongue (Alpha MOS company, France), which comprises seven potentiometric chemical sensors (ZZ, BA, BB, CA, GA, HA, and JB), was performed in the measurements. Those cross-sensitivity working sensors are composed of polymer membranes which could adsorb different taste substances, and they could provide global gustatory information to the five basic tastes (sourness, saltiness, sweetness, bitterness, and umami). During the measurements, the voltage intensity (mV) variation between chemical sensor and Ag/AgCl reference electrode would be recorded by basic data analysis software for the further chemometrics analysis.
According to the “Methodology of Sensory Evaluation of Tea”,28 the suitable proportion of tea to water applied in the measurements is 1![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :50 (g/v). A total of 10.0 g of dry tea sample was brewed in 500 ml of freshly boiled distilled water for 5 min, and then the tea leaves were then filtered with a sieve. After cooling down to room temperature (25 °C), 80 ml of tea infusion was poured into an airtight glass jar with a volume of 150 ml (concentration chamber) for the potentiometric measurements. This experiment also consisted of three measurement phases: the sample detection phase (120 s), the “aftertaste” detection phase (40 s), and the cleaning phase (10 s). During the sample detection phase, the measurement time was set to 120 s for sampling, and the response signals stabilized after approximately 75 s. After the detection phase, the sensor array was immersed in an artificial human saliva solution for approximately 40 s to detect the changes of membrane potential caused by adsorption (this could be also called the “aftertaste”). During the cleaning phase, the sensors were rinsed for 10 s using de-ionized water before detecting the next sample. Five samples could be detected at one time, and fourteen samples of each tea grade were tested. All samples were detected at room temperature (25 ± 1 °C).
:50 (g/v). A total of 10.0 g of dry tea sample was brewed in 500 ml of freshly boiled distilled water for 5 min, and then the tea leaves were then filtered with a sieve. After cooling down to room temperature (25 °C), 80 ml of tea infusion was poured into an airtight glass jar with a volume of 150 ml (concentration chamber) for the potentiometric measurements. This experiment also consisted of three measurement phases: the sample detection phase (120 s), the “aftertaste” detection phase (40 s), and the cleaning phase (10 s). During the sample detection phase, the measurement time was set to 120 s for sampling, and the response signals stabilized after approximately 75 s. After the detection phase, the sensor array was immersed in an artificial human saliva solution for approximately 40 s to detect the changes of membrane potential caused by adsorption (this could be also called the “aftertaste”). During the cleaning phase, the sensors were rinsed for 10 s using de-ionized water before detecting the next sample. Five samples could be detected at one time, and fourteen samples of each tea grade were tested. All samples were detected at room temperature (25 ± 1 °C).
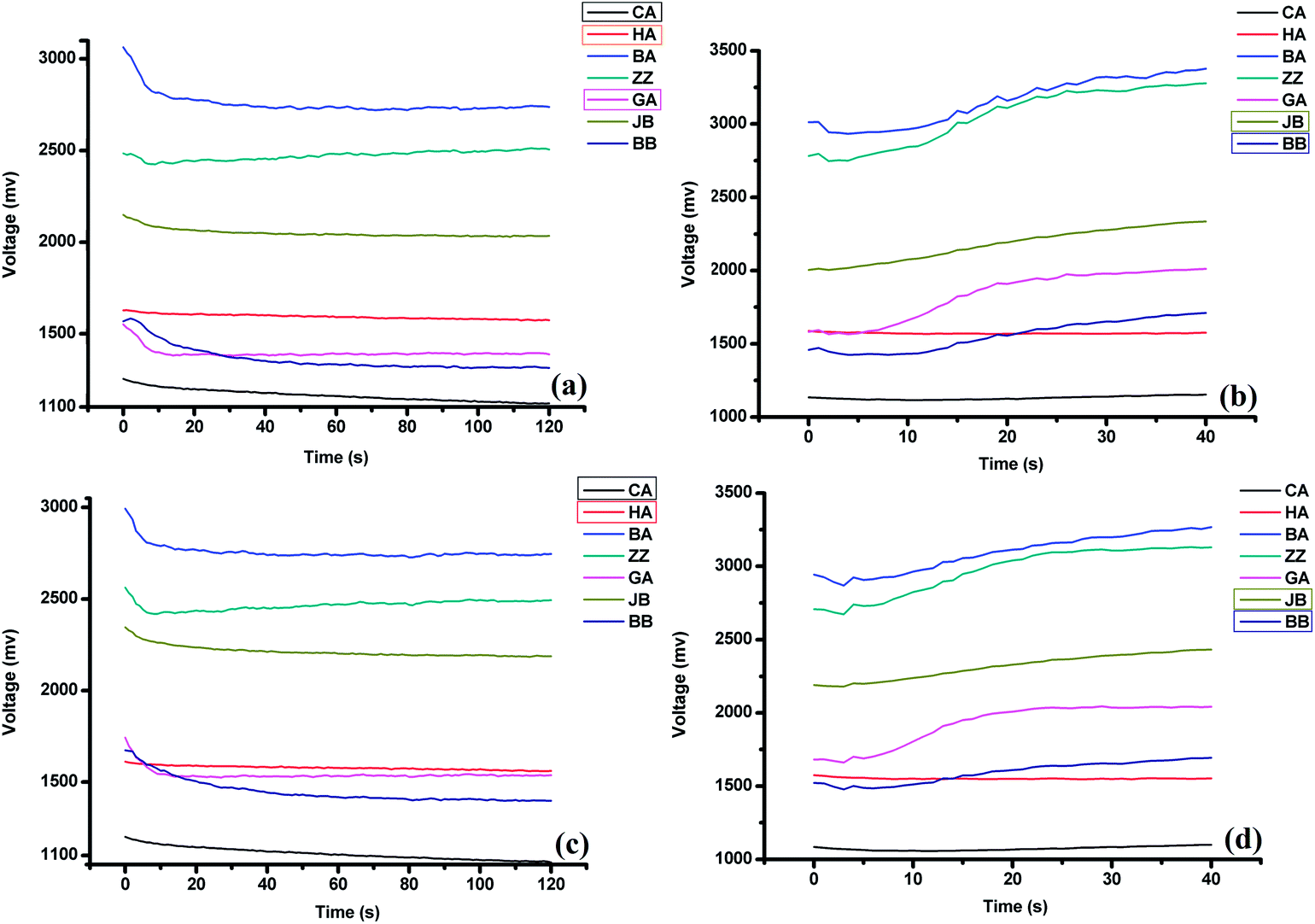
As shown in Fig. 2, the sampling and aftertaste signals obtained from jy190 and jy510 are quite different. The signal ranges of jy190 samples were from 0 to 3100 mV, and the signal ranges of jy510 samples were from 0 to 3000 mV. The sampling signals obtained by CA, GA, and HA sensors from the tea samples of the two quality grades exhibited the greatest differences. The aftertaste values obtained by BB and JB sensors exhibited significant changes among the four plots. The classification results from the e-nose and e-tongue were compared in the following sections.
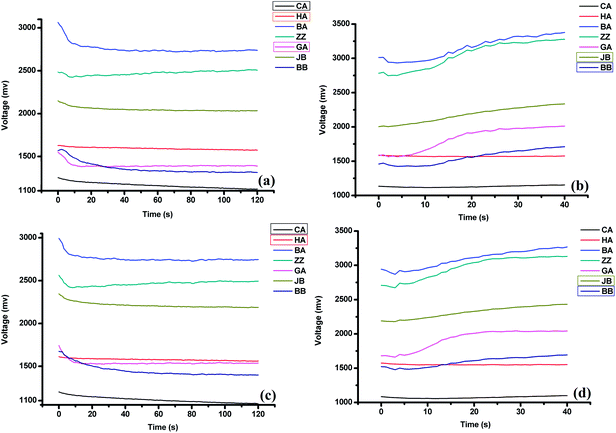 |
| | Fig. 2 The response curves obtained by liquid potentiometric sensors (CA, HA, BA, ZZ, GA, JB and BB) from different tea samples: (a) and (b) were the responses and aftertaste values obtained from jy190, respectively; (c) and (d) were the responses and aftertaste values obtained from jy510, respectively. | |
2.5. Characterization of tea extract
The contents of polyphenol, amino acid, protein, and total sugar were determined by a spectrophotometer using the following methods: polyphenol by ferrum tartrate method, amino acid by ninhydrin method, protein by coomassie brilliant blue method, and total sugar by anthrone reagent method. The water extracts contents were determined by the methods described by Seo et al. (three samples was tested, the average values for the water extracts contents were described and the standard deviation was applied for demonstrating stability of the test).29
2.6. HPLC & GC-MS
2.6.1. HPLC for detection of catechins and caffeine. After filtering through a 0.22 μ membrane filter, the tea infusion was analyzed by a Shimadzu (Kyoto, Japan) HPLC system equipped with an SPD-10Avp UV detector, and the UV absorbance was monitored at 280 nm. The chromatographic separation was carried out on a Wondasil C18-WR column (250 mm × 4.6 mm, 5 μm). Acetic acid–acetonitrile–water (0.5:3:96.5, v/v/v) and acetic acid–acetonitrile–water (0.5:30:69.5, v/v/v) mixtures were employed as mobile phases A and B, respectively, in HPLC, and the gradient program as follows: 0–40 min, linear gradient 30%–85% B.
2.6.2. HS-SPME/GC-MS for the detection of volatile components. The extraction of the volatile compounds was carried out using an a HS-SPME method with a PDMS/DVB fibre (65 μm film thickness, Supelco, Bellafonte, PA, USA), prior to the analysis the fiber was preconditioned for 60 min in the injection port of the GC, as suggested by the manufacture. The tea infusion (6 ml) was spiked with 0.4 μl of an internal standard (ethyl caprate), placed in a 20 ml glass vial sealed with a PTFE-coated septum (Beijing Bomex Co., China), and subsequently equilibrated for 5 min in a water bath at 60 °C. For the extraction, the fiber was immersed in the sample (the stainless steel needle was kept 2.5 cm below the septum) for 80 min. Afterwards, the SPME fiber was introduced into the hot injection port of the GC/MS for 5 min for the complete desorption of the analyte. Temperature program was as follows: hold at 40 °C for 2 min, increase 3 °C min−1 up to 110 °C, increase 5 °C min−1 up to 200 °C, hold at 200 °C for 10 min. Helium was the carrier gas (purity > 99.999%) and the flow velocity was constant at 1 ml min−1. The mass spectrometer conditions was as follows: ionization mode, EI; electron energy, 70 eV; interface temperature, 280 °C; ion source temperature, 230 °C; mass scan range, 47–401 u. The identification of volatile compounds was achieved by comparing their LRIs, MS fragmented patterns, and aroma quality with those of reference compounds and published data. The concentration of the volatile compounds was calculated in ng g−1 based on the internal standard.
2.7. Data processing
Principal component analysis (PCA) is a variable-oriented data analysis technique that used to detect patterns and to visualize the information present in the data of the e-nose and e-tongue measurements. PCA allowed the extraction of useful information (discrimination of sample types) from the data and to explore their structure, including correlation between variables and the relationship between subjects.29
Discriminant factor analysis (DFA) is probably the most frequently used supervised pattern recognition. The optimal transformation in classical DFA is obtained by minimizing the within-class distance and maximizing the between-class distance simultaneously, thus achieving maximum class discrimination.30
Partial least squares regression (PLSR) is used to model the relationships between the observable variables (Y-variables) to the variation of predictors (X-variables), it finds a linear regression model by projecting the predicted variables and the observable variables to a new space. Because both the X and Y data are projected to new spaces, the PLSR family of methods is known as bilinear factor models.31
PCA and DFA were performed by using SAS v8 (SAS Institute, Cary, NC, USA), PLSR was performed by using MATLAB (version 7.0, The MathWorks, Inc., USA).
3. Results and discussion
3.1. Feature data extraction
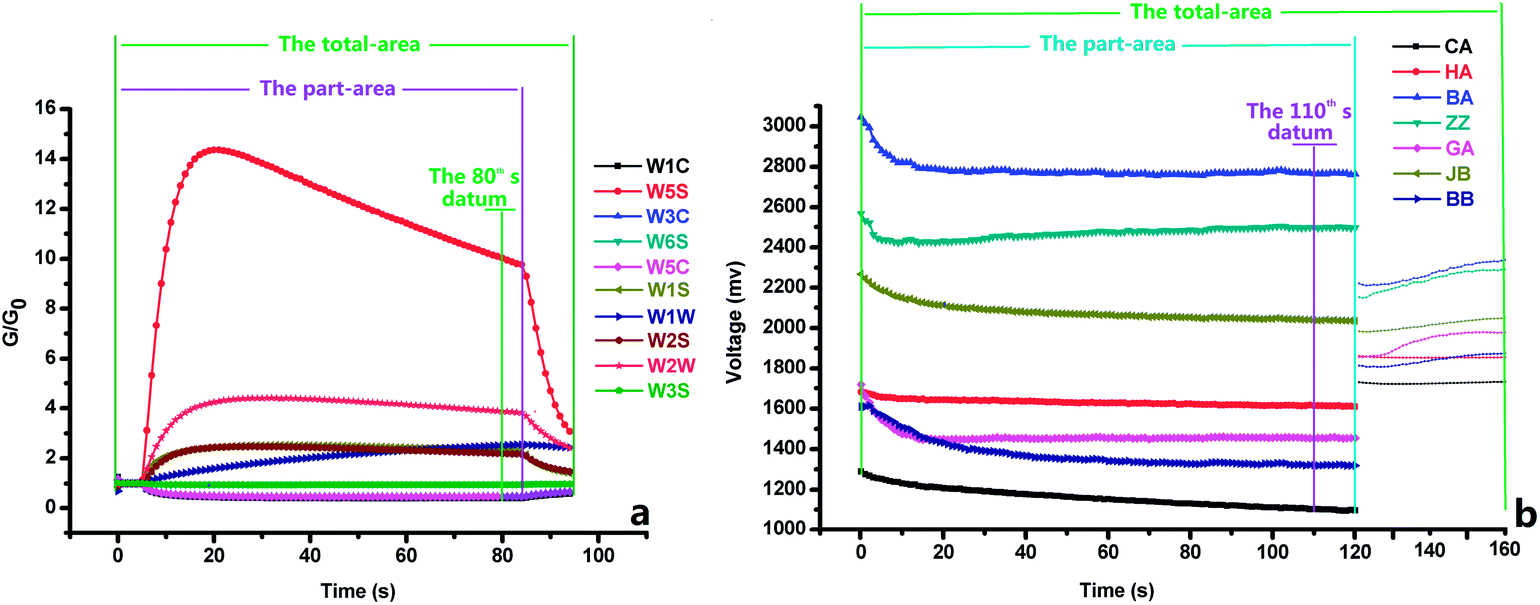
The typical e-nose response curves are shown in Fig. 3a. During the measurement, the signals of each sensor were low during the initial period; then, it continuously changed, started to stabilize approximately after 20 s, and stabilized approximately at the 80th s. These signals were changed again after 85 s until 95 s in order to obtain the aftertaste values for 10 s. According to the characteristics of the e-nose response curves, three methods were employed to extract the feature data from the electrochemical response values of the e-nose: (1) the 80th s datum method, where the signals became stable approximately at the 80th s, and the response values of each sensor at the 80th s were taken as the feature data; (2) the partial-area method, where the sum of the areas under the response curves obtained between the 0th s and 85th s was taken as the feature data, not including the areas under the aftertaste values; and (3) the total-area method, where the sum of the areas under the response curves obtained between the 0th s and 95th s was taken as the feature data. As shown in Fig. 3b, the response curves of the e-tongue exhibited similar changes in the trends as those of the e-nose during measurement. The three methods were also employed to extract the e-tongue's feature data, which were obtained for the different times and intervals: (1) the 110th s datum method, where the time for extracting features was at 110 s; (2) the partial-area method, where the time interval was from the 0th s to the 120th s; and (3) the total-area method, where the time interval was from the 0th s to the 160th s.
 |
| | Fig. 3 The four methods for extracting the feature data from e-nose and e-tongue responses: (a) e-nose, (b) e-tongue. | |
3.2. The classification results of PCA using e-nose and e-tongue
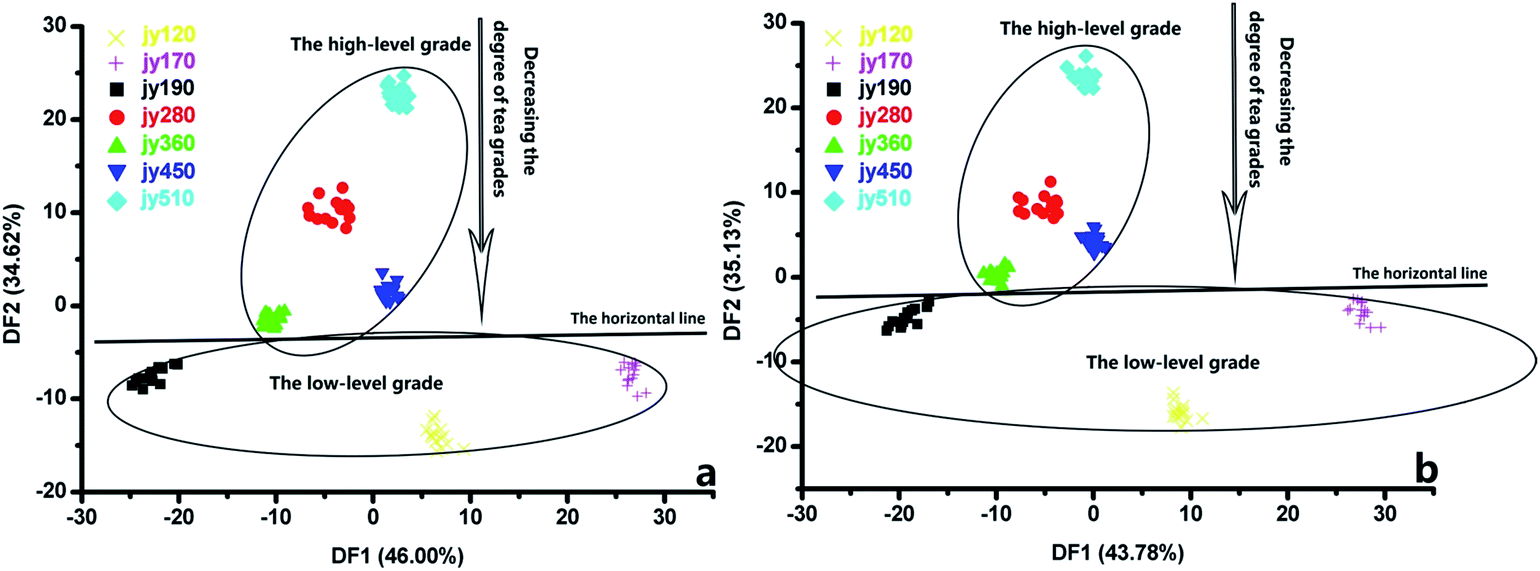
3.2.1. The PCA result of e-nose and GC-MS. Seven quality grades of Longjing tea were classified using the e-nose with a PCA (Fig. 4), and the results on the basis of the three feature-extracting methods were compared with each other. Fig. 4a shows a score plot of the first two PCs (86.31% of total variance explained) of the e-nose data after pretreatment by the 80th s datum method. Because the response data have a high correlation with each other, only one datum was always extracted from the responses as the feature data in past studies. However, the sample information contained in one datum was incomplete, and the classification result indicated that the 80th s datum method was weak for the classification. To improve the classification results, the area methods were employed. In comparison, a PCA analysis on the basis of an area method (the partial-area method) was performed (Fig. 4b). The PCA plot shows a classification of Longjing tea samples with 86.34% of total variance explained, and the classification result was the similar chaotic type as that presented in Fig. 4a. The area under the initial phase (0–20 s) of the response curves was included in the feature data by the partial-area method. The response values changed constantly during the stage, and the areas under those transient values were unstable (RSD > 8%), which might led to poor classification results. In the end, the efficiency of the total-area method for classifying tea samples on the basis of the PCA was tested, where PC1 versus PC2 together explains 77.82% of variance (Fig. 4c). Although jy170, jy190, jy360, and jy510 overlapped with each other, y120, jy360, and jy450 samples can be separated from the other samples. The areas under the response curves obtained during the entire measurement were taken as the feature data, and the aftertaste values were taken as one part of the features. The aftertaste signals made the olfactory information more complete and increased the differences among the samples. This may be the reason that the total-area method worked more effective than other methods in the classification works.
 |
| | Fig. 4 The PCA classification results using e-nose on the basis of the four features extracting methods: (a) the 80 s' datum method, (b) the partial-area method, (c) the total-area method. | |
As discussed above, these tea samples could not be separated from each other completely using the e-nose. The e-nose was not sensitive enough to identify the slight differences between the volatile compounds of the samples. To explain the differences between the main volatile compounds of each kind of Longjing tea, GC-MS was employed to detect the same samples as a reference. The concentrations of five main volatile flavor compounds, nonanal, linalool oxide I (trans, furanoid), decanal, β-lonone and methyl salicylate, are summarized in the Table 2. It is obvious that teas plucked before TSD have higher concentrations of nonanal and decanal, and lower concentrations of methyl salicylate, β-lonone, and geraniol than the teas plucked after TSD. The teas plucked in these two time phases have similar concentrations of linalool oxide I (trans, furanoid). The concentrations of nonanal and decanal increased as the tea grade became higher, revealing their positive contribution to the Longjing tea aroma; however, the levels of β-lonone, methyl salicylate, and geraniol decreased as the tea grade became higher, revealing their negative contribution to the Longjing tea aroma. Furthermore, we could determine why jy120, jy360 and jy450 samples could be separated from the other samples in the PCA plot: the jy120 sample has the highest concentrations of methyl salicylate and β-lonone, and the lowest concentrations of nonanal and decanal. Further, the jy450 sample has the highest concentrations of nonanal and decanal and the lowest concentrations of methyl salicylate. The jy360 sample has medium concentrations of almost all of the six volatile compounds.
Table 2 Average values and standard deviation (SD) for the main volatile compounds in different grades of green teas (ng g−1) obtained by GC-MSa
| Violate compound |
RIb |
Jy120 |
Jy170 |
Jy190 |
Jy280 |
Jy360 |
Jy450 |
Jy510 |
| Three samples of each group were tested, and the SD of each values demonstrated high stability of the test. Retention index (RI), defined as a relationship between the retention of the analyte and two members of an homologous series enclosing it. RI is always applied as the reference value to qualitative discrimination of the volatiles based on GC-MS. |
| Nonanal |
1104 |
675 ± 72 |
739 ± 87 |
751 ± 75 |
965 ± 102 |
813 ± 73 |
1044 ± 121 |
1167 ± 138 |
| Linalool oxide |
1099 |
1003 ± 119 |
1139 ± 156 |
987 ± 123 |
829 ± 130 |
788 ± 110 |
1049 ± 128 |
1212 ± 149 |
| Decanal |
1205 |
309 ± 36 |
327 ± 42 |
321 ± 31 |
502 ± 67 |
409 ± 60 |
618 ± 59 |
662 ± 64 |
| β-Lonone |
1485 |
125 ± 18 |
118 ± 23 |
120 ± 17 |
88 ± 14 |
84 ± 11 |
109 ± 20 |
96 ± 12 |
| Methyl salicylate |
1190 |
737 ± 139 |
707 ± 128 |
720 ± 124 |
640 ± 136 |
457 ± 119 |
420 ± 97 |
427 ± 145 |
| Geraniol |
1255 |
1749 ± 297 |
1780 ± 380 |
1486 ± 346 |
1153 ± 245 |
771 ± 162 |
969 ± 176 |
825 ± 163 |
3.2.2. The PCA result of e-tongue and HPLC. The e-tongue data obtained from the tea samples were calculated with a PCA. As shown in Fig. 5, the total accumulative variance contributions from PC1 and PC2 are 69.07% (Fig. 5a), 66.37% (Fig. 5b), and 66.9% (Fig. 5c). None of the contributions rate over 85%, and the samples cannot be separated from each other completely using the three feature-data extraction methods. Moreover, the samples have similar distributions in the PCA score plot: the samples of jy120, jy280, jy360, and jy510 could be separated from other samples on the basis of the data obtained by the three methods: the 110th s datum, the partial-area, and the total-area methods; the jy170, jy190, and jy450 samples overlapped with each other in the three PCA plots. The PCA analysis results for the e-tongue data could not be improved by including the aftertaste responses. Because there was very little change in the response values during the e-tongue measurement (even the slightly oscillations in the initial phase of measurement), the feature data based on the three feature-extraction methods have high correlations. PC1 vs. PC2 explains the similar contributions of variance. The classification results on the basis of the e-tongue data with the PCA were better than those on the basis of e-nose data.
 |
| | Fig. 5 The PCA classification results using e-tongue on the basis of the four features extracting methods: (a) the 120 s' datum method, (b) the partial-area method, (c) the total-area method. | |
The concentrations of polyphenol (bitterness, astringent), amino acids (umami), total sugars (sweetness), water extracts (kokumi), and the protein (umami) of Longjing teas were analyzed by chemical methods; the catechins (bitterness, astringent) and caffeine (bitterness) of the Longjing teas were analyzed by HPLC. Table 3 lists the chemical compositions identified in Longjing teas. The teas plucked after TSD have higher concentrations of polyphenol, amino acids, total sugars, water extracts, catechins, and caffeine contents than the teas plucked before TSD. Therefore, the tea infusions made by soft buds and/or the first young leaves may have a mild taste; whereas the tea infusions made by more mature, fresh leaves have a stronger taste. The high price of the high-grade Longjing teas may be caused by two reasons: (1) young leaves are few in number, and their values are determined by the number and (2) although the tea infusions made by the young leaves have a mild taste, they may have suitable flavor for most people. Jy170 and jy190 samples have similar concentrations of the seven chemical substances, which is the reason why the two grades of samples could not be separated from each other in the PCA plots. However, it was not possible to determine a reason for the distribution of jy450 from Table 3. There might be substances other than the chemical compounds detected that could influence the classification results, or the sensitivity of the e-tongue was not high enough to classify the Longjing tea samples. There were four type of tea samples (jy120, jy280, jy360, and jy510) that could be separated from the other samples, and the e-tongue worked better than the e-nose for the classification. Therefore, even though the classification results were not good enough, the clearly distributed results of the tea samples in the PCA plots have confirmed that the e-tongue was able to accurately respond to different tea samples.
Table 3 Average values and standard deviation (SD) for the main chemical substances in different grades of green teas (% dry weight) obtained by chemical methods and HPLCa
| Tea |
Polyphenol |
Amino acid |
Protein |
Total sugar |
Water extracts |
Catechins |
Caffeine |
| Three samples of each group were tested, and the SD of each values demonstrated high stability of the test. |
| Jy120 |
23.42 ± 0.17 |
6.17 ± 0.01 |
2.65 ± 0.01 |
8.39 ± 0.07 |
44.19 ± 0.55 |
14.43 ± 0.00 |
3.45 ± 0.01 |
| Jy170 |
24.51 ± 0.50 |
5.90 ± 0.01 |
2.76 ± 0.02 |
8.51 ± 0.08 |
43.66 ± 0.06 |
14.39 ± 0.00 |
3.75 ± 0.07 |
| Jy190 |
24.56 ± 0.07 |
5.91 ± 0.01 |
2.70 ± 0.04 |
7.86 ± 0.20 |
44.64 ± 0.44 |
13.37 ± 0.10 |
3.64 ± 0.08 |
| Jy280 |
23.64 ± 0.11 |
6.09 ± 0.00 |
2.36 ± 0.12 |
7.87 ± 0.14 |
43.58 ± 0.07 |
13.67 ± 0.00 |
3.71 ± 0.01 |
| Jy360 |
23.77 ± 0.13 |
5.71 ± 0.05 |
2.22 ± 0.17 |
7.83 ± 0.02 |
41.59 ± 0.88 |
11.56 ± 0.00 |
3.56 ± 0.06 |
| Jy450 |
23.72 ± 0.05 |
5.61 ± 0.03 |
2.45 ± 0.02 |
8.33 ± 0.04 |
42.29 ± 0.04 |
14.63 ± 0.00 |
3.43 ± 0.03 |
| Jy510 |
22.74 ± 0.03 |
5.24 ± 0.04 |
3.01 ± 0.03 |
8.50 ± 0.11 |
41.62 ± 0.95 |
14.66 ± 0.00 |
3.25 ± 0.06 |
3.3. The classification results on the basis of the fusion data
Owing to the high complexity of the tea samples, the use of only the e-nose or e-tongue data for the identification is insufficient. Only one type of sensor array (the MOS gas or liquid potentiometric sensor array) restricted the amount of useful information. Emerging strategies (multi-sensor data fusion techniques) have recently been demonstrated to efficiently overcome these problems. In a study, the e-nose and e-tongue sensing systems were combined to enhance the classification between tea samples of different grades. The e-nose and e-tongue data were simultaneously obtained to form a feature data matrix with its number of rows equal to the number of measures, and its number of columns equal to the total number of sensors in the e-nose plus the e-tongue. Furthermore, two fusion feature datasets were established on the basis of the partial-area (partial-area fusion dataset, PAFD) and total-area (total-area fusion dataset, TAFD) methods, and a comparison of the efficiency of the two fusion feature datasets in classifying the tea samples using PCA and DFA were presented.
3.3.1. The PCA results. Fig. 6 shows a PCA description of the data structure of the seven tea groups on the basis of the fusion data. The tea samples could not be completely classified completely on the basis of the PAFD (Fig. 6a), and the total contribution to variance of PC1 and PC2 was 61.21%, which is lower than 85%, meaning that the first two PCs are insufficient for explaining the total variance of the dataset. Jy120, jy170, jy190, jy360, and jy450 could be separated from the other samples, except for one jy360 sample and three jy170 samples. In Fig. 6b, PC1 versus PC2 versus PC3 is shown and explains 73.37% of total variance. Only jy360 and jy450 overlapped with each other, and five other group samples could be separated from the other samples. It was obvious that use of fusion data improves the classification result; however, the tea samples on the basis of the PAFD still could not be completely separated. The PCA results using the TAFD are shown in Fig. 6c and d. PC1 versus PC2 is shown and explains 55.39% of total variance. All of the samples could be separated from each other except for the jy170 and jy190 samples which have similar volatile compounds and chemical substance concentrations. As shown in Fig. 6c, the teas under the black stripe were plucked before TSD, and the teas above the black stripe were plucked after TSD, except for jy280. The interval of the plucking time between the jy190 and jy280 samples was few days, which made the tea samples have similar gustatory and olfactory sensations. PC1 versus PC2 versus PC3 are shown, and explains 70.25% of total variance (Fig. 6d). Although the distributions of each group of samples were close to each other, and samples with the same grade did not group very well, all samples could be separated using a 3D-PCA on the basis of the TAFD. For the fusion model using e-nose and e-tongue, the classification error is much smaller compared with the individual systems for tea classification, and differentiating the varieties of tea samples is distinctly more effective.
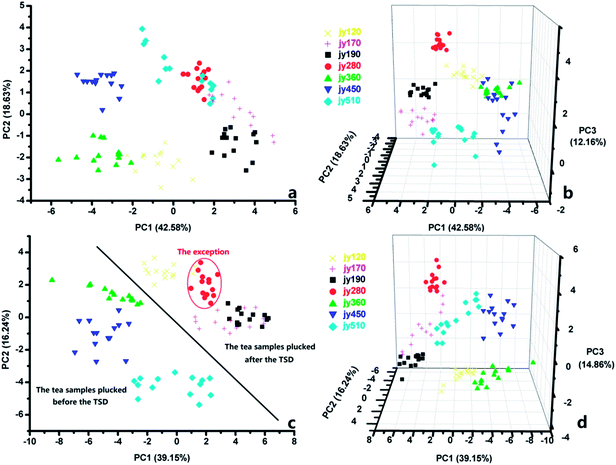 |
| | Fig. 6 The PCA classification results on the basis of PAFD and TAFD: (a) 2D-PCA and (b) 3D-PCA on the basis of PAFD, (c) 2D-PCA and (d) 3D-PCA on the basis of TAFD. | |
3.3.2. The DFA results. The classification results of the tea samples using the DFA on the basis of the PAFD are shown in Fig. 7a, where DF1 vs. DF2 explains 80.62% of variance. All seven grades of tea samples were well separated in the 2D plot. The DFA assumes that replicated samples are clustered, whereas the PCA treats each replicated sample as an individual data point. Therefore, the rice wine samples were grouped much better in the DFA plots than in the PCA plots. In addition, the tea samples that were close to one another shared more similar characteristics in the DFA score plots, according to which the samples were divided into three independent parts (Fig. 7a): jy280, jy360, jy450, and jy510 (it belong to the high grade) located at the top of the plot; jy120, jy170, and jy190 (it belong to the low grade) located further below, and jy120 located at the bottom of the plot (according to the Tables 2 and 3, jy120 located at the right place). Otherwise, the tea samples plucked before TSD were located above the horizontal line, and the tea samples plucked after TSD were located below the horizontal line. Fig. 7b shows the DFA scores on the basis of the TAFD, where DF1 versus DF2 explains 78.91% of the variance. All of the tea samples could also be well separated from each other, and the distributions of each sample group in Fig. 7b were similar to those in Fig. 7a. Although the addition of the aftertaste values did not result in a significant improvement in the classification results, samples of the same grade were grouped slightly better than those in Fig. 7b.
 |
| | Fig. 7 The DFA classification results on the basis of PAFD and TAFD: (a) on the basis of PAFD, (b) on the basis of TAFD. | |
As discussed above, the aftertaste values are positively correlated with the same characteristics of the sensors indirectly, and the ability of each gas sensor and liquid potentiometric sensor for desorbing the flavor substances and volatile compounds. The aftertaste values enriched the samples' information, and the classification results demonstrated that the pattern-recognition methods on the basis of the TAFD performed more efficiently than those on the basis of the PAFD. Moreover, all of the samples could be separated from each other using a 2D-DFA, which presented more accurate and clearer classification results than the PCA. The good performance of the DFA indicated that it is possible to classify the Longjing teas of different grades using the TAFD.
3.4. The prediction results on the basis of the fusion data
In this study, each grade of tea sample was given a reference value (Table 1), and PLSR was employed for forecasting using the PAFD and TAFD. Overall, 280 samples (40 samples of each grade) in the experimental session were divided randomly into calibrating and test subsets: 182 samples (26 samples of each category) for the training set and 98 samples (14 samples of each category) for the testing set. The PAFD and TAFD were condensed by a PCA in the Section 3.3.1. The accumulative explanations rates of the first seven PCs (for PAFD was 95.53%, and for TAFD was 95.22%) were greater than 95%, which contained the majority of information and features of the tea samples. Therefore, the first seven PCs were used as regression factors to be analyzed by PLSR.
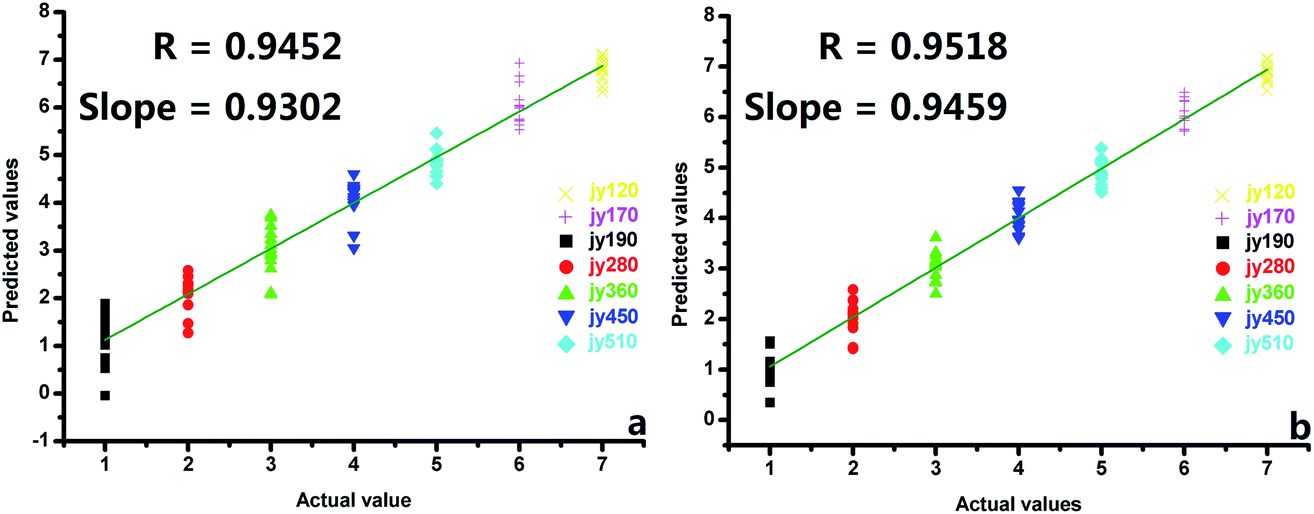
3.4.1. The PLSR results of tea quality grades. Leave-one-out cross-validation was applied to verify the PAFD and TAFD results. The cross-validation residual sum of squares (CVRss) and the correlation coefficient between the measured and predicted values (R2) on the basis of PAFD were 23.9824 and 0.9452, respectively (Fig. 8a). The results indicated that the combination of the e-nose and e-tongue was effective for forecasting the quality grade, and the volatility and flavor information contained in the fusion data could reflect the quality grades of green teas. The aftertaste values were included in the feature data for forecasting the quality grade, and the CVRss and R2 on the basis of TAFD were 18.7225 and 0.9518, respectively (Fig. 8b). The predicted results on the basis of TAFD were somewhat better. The characteristics of the green teas were obtained during the adsorption and desorption processes of the e-nose and e-tongue sensors. Taste and aftertaste detection could be interpreted as the effective ability of adsorption and desorption of those sensors, and the aftertaste values completed the information for the samples. The PLSR provided a clear indication of the ability of the combination of the e-nose and e-tongue, and the PLSR performed better in predicting he tea grade based on the TAFD.
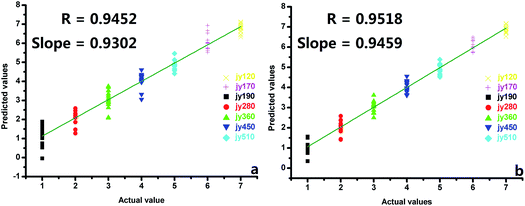 |
| | Fig. 8 The PLSR prediction results of the quality levels on the basis of PAFD and TAFD: (a) on the basis of PAFD, (b) on the basis of TAFD. | |
3.4.2. The PLSR results of the main volatile and flavor compounds. The main volatile and flavor compounds of the Longjing teas were predicted by PLSR using the solo e-nose (used for the prediction of geraniol and linalool oxide) or e-tongue data (used for the prediction of water extract and polyphenol)-PAFD and TAFD, respectively (Fig. 9 and 10). The sole usage of e-nose to predict geraniol was ineffective, and R2 = 0.6795 (Fig. 9a1). As discussed in the previous section, the information obtained by the e-nose was not enough to classify green teas with different quality grades. Therefore, the regression results based on the e-nose signals were bad. As showed in Fig. 9a2 and a3, the PLSR performed well in predicting geraniol on the basis of PAFD and TAFD, R2 = 0.9175 and R2 = 0.9252, respectively. The TAFD, which contained more useful information (the aftertaste values), worked better than the PAFD. All three types of feature data performed well for predicting linalool oxide. The prediction results obtained on the basis of the e-nose data alone (R2 = 0.8142) were much better than the prediction results of geraniol obtained on the basis of the same database (Fig. 9b1). Although the PAFD contained less information than the TAFD, the PAFD was more effective than the TAFD for predicting linalool oxide, R2 = 0.9520 for the PAFD and R2 = 0.9065 for the TAFD (Fig. 9b2 and b3). The results may be caused by some volatile compounds which have stronger influence than aftertaste on the responses.
 |
| | Fig. 9 The PLSR prediction results of geraniol and linalool oxide on the basis of e-nose data, PAFD and TAFD: (a1) and (b1), (a2) and (b2), (a3) and (b3) on the basis of e-nose data, PAFD and TAFD for the geraniol and linalool oxide prediction, respectively. | |
 |
| | Fig. 10 The PLSR prediction results of water extract and polyphenol on the basis of e-tongue data, PAFD and TAFD: (a1) and (b1), (a2) and (b2), (a3) and (b3) on the basis of e-tongue data, PAFD and TAFD for the water extract and polyphenol prediction, respectively. | |
The PLSR prediction results of the water extracts and polyphenol on the basis of the e-tongue data alone were not good, R2 = 0.7422 and R2 = 0.6480, respectively (Fig. 10a1 and b1). The PAFD exhibited good results for predicting the water extracts and polyphenol, and R2 = 0.9004 and R2 = 0.9086, respectively (Fig. 10a2 and b2). It was obvious that the performances based on fusion were much better than that based on the use of the e-tongue alone. Although the volatile compounds of the green teas could not be detected by the e-tongue sensors, the flavor compounds were influenced by the volatile compounds whose characteristics could be reflected by the detection of flavor compounds indirectly. This can be observed in Fig. 10a3 and b3, where the aftertaste values had a positive effect on the prediction. Furthermore, the TAFD exhibited the best results for predicting both water extracts and polyphenol, R2 = 0.9298 and R2 = 0.9202, respectively.
As discussed above, the combined usage of the e-nose and e-tongue worked more effectively than the use of the e-nose or e-tongue alone. With the exception of the prediction of linalool oxide, the TAFD exhibited the best results for predicting those volatile and flavor compounds. The desorption process of the sensors was not a simple inverse process of adsorption, which meant that the aftertaste values contained independent feature information of the green teas, thereby serving a crucial role in classification and prediction.
4. Conclusions
(1) Three feature extraction methods, the 80 s' datum method, the partial-area method, and the total-area method, were employed to extract the feature data from the original responses of the e-nose and e-tongue, and the areas under the aftertaste values were obtained by the total-area method. The PCA results showed that neither the e-nose nor e-tongue could classify the tea samples independently using the three methods, but the aftertaste values increased the efficiency of the total-area method. Using the total-area method, jy120, jy360, and jy450 can be separated from the other samples using the e-nose and jy120, jy280, jy360, and jy510 could be separated from the other samples using the e-tongue. All the samples could be separated on the basis of DFA with PAFD or TAFD. The position of each type of the rice wine samples were grouped much better in the DFA plots than in the PCA plots, moreover, the tea samples plucked before TSD could also be separated clearly with the tea samples plucked after TSD.
(2) The e-nose and e-tongue sensing systems were combined, and two fusion feature datasets were established: PAFD and TAFD. The tea samples could not be separated by the 2D-PCA on the basis of the PAFD or TAFD, the 3D-PCA exhibited a better result and all tea samples could be separated on the basis of the TAFD. The first seven PCs were used as the PLSR regression factors for the tea grade prediction, and PLSR gave a clear indication of the ability of the combination of e-nose and e-tongue. The correlation coefficient between the measured and predicted values of the PAFD and TAFD were 0.9452 and 0.9518, respectively. The combined usage of the e-nose and e-tongue was worked more effective than the use of the e-nose or e-tongue alone in predicting volatile and flavor compounds, and TAFD presented the best results in predicting geraniol (R2 = 0.9252), water extract (R2 = 0.9298), and polyphenol (R2 = 0.9202) contents.
In conclusion, the quality grades of teas can be detected by the combination of e-nose and e-tongue, and the addition of aftertaste values could enrich the tea sample's information and improve the classification and prediction results. Based on this study, it is evident that more effort should be directed into correlating fusion response data with human sensory data, and monitoring the production process of teas. Moreover, the feasibility to combine the hardware of e-tongue and e-nose should be performed in the future study.
Nomenclature
Chinese holiday
Detection instruments
| Electronic nose | e-nose |
| Electronic tongue | e-tongue |
| Gas chromatography-mass spectrometry | GC-MS |
| High-performance liquid chromatography | HPLC |
| Visible near infrared spectroscopy | Vis-NIRs |
Different types of sensors
| Electronic tongue | ZZ, BA, BB, CA, GA, HA, and JB |
| Electronic nose | W1C, W5S, W3C, W6S, W5C, W1S, W1W, W2S, W2W and W3S |
Pattern recognition technique
| Partial least squares regression | PLSR |
| Principal component analysis | PCA |
Statistical terms
| Cross-validation residual sum of squares | CVRss |
| Linear-retention-index | LRI |
Tea samples
The tea samples produced in Jiyun with different prices: jy120, jy170, jy190, jy280, jy360, jy450 and jy510 (the number is the price (¥)).
Two types of datasets
| Partial-area fusion dataset | PAFD |
| Total-area fusion dataset | TAFD |
Acknowledgements
The authors acknowledge the financial support of the Chinese National Foundation of Nature and Science through Project 31570005 and 31201368.
References
- C. Schneider and T. Segre, Am. Fam. Physician, 2009, 79, 591–594 Search PubMed.
- P. W. Wang, B. Wang, S. Y. Chung, Y. Y. Wu, S. M. Henning and J. V. Vadgama, RSC Adv., 2014, 4, 35242–35250 RSC.
- M. Krstic, M. Stojadinovic, K. Smiljanic, D. Stanic-Vucinic and T. C. Velickovic, RSC Adv., 2015, 5, 3260–3268 RSC.
- L. Y. Wang, K. Wei, H. Cheng, W. He, X. H. Li and W. Y. Gong, Food Chem., 2014, 146, 98–103 CrossRef CAS PubMed.
- U. J. Unachukwu, S. Ahamed, A. Kavalier, J. T. Lyles and E. J. Kennelly, J. Food Sci., 2010, 75, C541–C548 CrossRef CAS PubMed.
- V. R. Sinija and H. N. Mishra, Food Bioprocess Technol., 2011, 4, 408–416 CrossRef.
- S. R. Jaeger, D. Giacalone, C. M. Roigard, B. Pineau, L. Vidal, A. Giménez and G. Ares, Food Quality and Preference, 2013, 30, 242–249 CrossRef.
- H. Yu and J. Wang, Sens. Actuators, B, 2007, 122, 134–140 CrossRef CAS.
- Z. H. Qin, X. L. Pang, D. Chen, H. Cheng, X. S. Hu and J. H. Wu, Food Res. Int., 2013, 53, 864–874 CrossRef CAS.
- N. Cabaleiro, I. de la Calle, C. Bendicho and I. Lavilla, Anal. Methods, 2013, 5, 323–340 RSC.
- N. Glube, L. Moos and G. Duchateau, Results Pharma Sci., 2013, 3, 1–6 CrossRef PubMed.
- H. Sereshti, M. Khosraviani, S. Samadia and M. S. Amini-Fazlb, RSC Adv., 2014, 4, 47114–47120 RSC.
- J. W. Drynan, M. N. Clifford, J. Obuchowiczc and N. Kuhnert, Nat. Prod. Rep., 2010, 27, 417–462 RSC.
- L. Xu, P. T. Shi, X. S. Fu, H. F. Cui, Z. H. Ye and C. B. Cai, J. Raman Spectrosc., 2013, 501924, 1–8 Search PubMed.
- M. F. Abdullah, R. Zakaria and S. H. S. Zein, RSC Adv., 2014, 4, 34510–34518 RSC.
- L. Lu, S. Y. Tian, S. P. Deng, Z. W. Zhu and X. Q. Hu, RSC Adv., 2015, 5, 47900–47908 RSC.
- R. Consonni and L. R. Cagliani, RSC Adv., 2015, 5, 59696–59714 RSC.
- E. Gobbi, M. Falasconi, G. Zambotti, V. Sberveglieri, A. Pulvirenti and G. Sberveglieri, Sens. Actuators, B, 2015, 207, 1104–1113 CrossRef CAS.
- P. Ivarsson, Y. Kikkawa, F. Winquist, C. Krantz-Rulcker, N. E. Hojer and K. Hayashi, Anal. Chim. Acta, 2001, 449, 59–68 CrossRef CAS.
- X. Cetó, A. González-Calabuig, J. Capdevila, A. Puig-Pujol and M. Del Valle, Sens. Actuators, B, 2014, 207, 1053–1059 CrossRef.
- X. Cetó, M. Llobet, J. Marco and M. Del Valle, Anal. Methods, 2013, 5, 1120–1129 RSC.
- F. Longobardi, G. Casiello, A. Ventrella, V. Mazzilli, A. Nardelli and D. Sacco, Food Chem., 2015, 170, 90–96 CrossRef CAS PubMed.
- P. Ciosek and W. Wróblewski, Anal. Methods, 2015, 7, 3958–3966 RSC.
- F. K. Han, X. Y. Huang, E. Teye, F. F. Gu and H. Y. Gu, Anal. Methods, 2014, 6, 529–536 RSC.
- Z. Haddi, N. El Barbri, K. Tahri, M. Bougrini, N. El Bari, E. Llobet and B. Bouchikhi, Anal. Methods, 2015, 7, 5193–5203 RSC.
- Y. N. Zhang, J. F. Yin, J. X. Chen, F. Wang, Q. Z. Du, Y. W. Jiang and Y. Q. Xu, Food Chem., 2016, 192, 470–476 CrossRef CAS PubMed.
- G. Neely and G. Borg, Chem. Senses, 1999, 24, 19–21 CrossRef CAS PubMed.
- Chinese National Standards, GB/T., 23776–2009.
- J. D. Seo and S. Y. Gong, Journal of Tea Science, 2005, 31, 166–169 Search PubMed.
- R. Banerjee, B. Tudu, L. Shaw, A. Jana and N. Bhattacharyya, J. Food Eng., 2012, 110, 356–363 CrossRef.
- Z. B. Wei and J. Wang, J. Food Eng., 2013, 117, 158–164 CrossRef CAS.
Footnote |
| † Electronic supplementary information (ESI) available. See DOI: 10.1039/c5ra17978e |
|
| This journal is © The Royal Society of Chemistry 2015 |
Click here to see how this site uses Cookies. View our privacy policy here.