
Discovery of potential biomarkers in exhaled breath for diagnosis of type 2 diabetes mellitus based on GC-MS with metabolomics†
Abstract
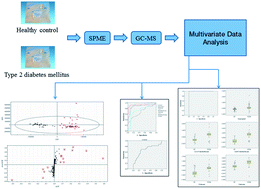
The aim of the study was to apply gas chromatography-mass spectrometry (GC-MS) combined with a metabolomics approach to identify distinct metabolic signatures of type 2 diabetes mellitus (T2DM) and healthy controls from exhaled breath, which are characterized by a number of differentially expressed breath metabolites. In this study, breath samples of patients with type 2 diabetes mellitus (T2DM, n = 48) and healthy subjects (n = 39) were analyzed by GC-MS. Multivariate data analysis including principal component analysis (PCA) and orthogonal partial least squares discriminant analysis (OPLS-DA) was successfully applied to discriminate the T2DM and healthy controls. Eight specific metabolites were identified and may be used as potential biomarkers for diagnosis of T2DM. Isopropanol and 2,3,4-trimethylhexane, 2,6,8-trimethyldecane, tridecane and undecane in combination might be the best biomarkers for the clinical diagnosis of T2DM with a sensitivity of 97.9% and a specificity of 100%. The study indicated that this breath metabolite profiling approach may be a promising non-invasive diagnostic tool for T2DM.
 Please wait while we load your content...
Please wait while we load your content...

