Hot off the Press
In the Hot off the Press section of Molecular BioSystems members of the Editorial Board and their research groups highlight recent literature for the benefit of the community. This month the highlighted topics include the way cells take up carbon nanotubes, sequence recognition in molecules that bind DNA and the use of elastin to produce precisely oriented antibody arrays.
Light shed on the intracellular uptake mechanism of carbon nanotubes
Carbon nanotubes have been attracting lots of attention in recent years. Because of their interesting properties, they are used in many different applications ranging from material design to intracellular transport. The latter is particularly interesting since it was shown that proteins and DNA could be shuttled into the living cell with the help of single walled carbon nanotubes (SWCNT). Additionally, SWCNT were found to be biocompatible and non-toxic to cells. However, the transport mechanism leading to the internalization of carbon nanotube–biomolecule constructs was not clear.Now a group of scientists from Stanford University have conducted a range of experiments in a first systematic study of SWCNT cellular uptake. Their aim was to check whether endocytosis is a possible transport mechanism. Firstly, short (50–200 nm) SWCNT conjugates were prepared containing non-covalently bound, fluorescently labeled protein or 15-mer DNA. The cellular uptake of such conjugates was monitored under a range of conditions. It is known that endocytosis is hindered when the temperature of incubation is decreased (to 4 °C as compared to the standard 37 °C) or in the absence of ATP. The production of ATP in cells is disturbed upon treatment with NaN3. To test whether SWCNT conjugates are transported via endocytosis, the fluorescence measurements of living cells were performed after incubation at 4 °C and after pretreatment with NaN3. In both cases the cellular uptake of protein- and DNA-SWCNT's was significantly lower than the uptake under standard conditions. To test which of possible endocytosis pathways was being used, additional experiments were preformed. One of the most common pathways includes clathrin coated vesicle formation. Treatment of cells with sucrose rich or K+ depleted medium disrupts clathrin dependent mediated pathways. When endocytosis of SWCNT protein conjugates was attempted under those conditions, low fluorescence detected inside the cell indicated that cellular uptake was blocked. Further tests to check if an endocytosis pathway that does not involve clathrin is responsible for the transport gave negative results. This last set of experiments proved that short SWCNT which transport protein or DNA into living cells do that through clathrin, energy dependent, endocytosis (Fig. 1). Understanding the entry mechanism will contribute further to the development of the carbon nanotube aided transport of biological compounds into living cells and possibly lead to the development of novel drug transport strategies.
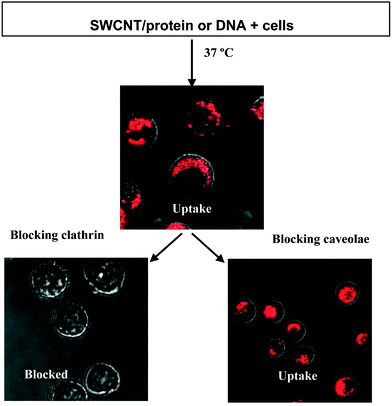 | ||
| Fig. 1 Determination of the internalization mechanism for SWCNT conjugates into mammalian cells by pre-treating cells to block various endocytosis pathways. Reprinted with permission from Angew. Chem. Int. Ed., 2006, 45(4), 577–581. Copyright 2006 Wiley-VCH. | ||
N. Wong, S. Kam, Z. Liu, H. Dai, Angew. Chem. Int. Ed., 2006, 45(4), 577–581.
Reviewed by: Ljiljana Fruk, Universität Dortmund, GermanyDefining the sequence-recognition profile of DNA-binding molecules
There is great interest in the design of sequence-specific DNA-binding molecules as potential reagents for the manipulation of gene expression. One of the most advanced classes of such molecules are the hairpin polyamides, developed by Dervan and co-workers at Caltech. These are composed of N-methylpyrrole and N-methylimidazole moieties strung together in a specific sequence. The nature of how these molecules bind to DNA is relatively well understood, such that one can predict, approximately, the preferred binding site of a given hairpin polyamide molecule. Or, put another way, it is generally possible to design a hairpin polyamide that will recognize a given DNA sequence, though some sequences are better targets than others. As research with hairpin polyamides and other DNA-binding molecules focuses increasingly on their use in cells, it is becoming increasingly important to understand the binding specificity. The human genome is comprised of approximately 3 × 109 base pairs, providing abundant opportunities for “off target” binding of designed DNA-binding molecules, with potentially undesirable biological effects. The problem addressed in this paper is how to assess binding specificity on a global scale, at least in vitro.To accomplish this goal, Ansari and collaborators took advantage of the recent availability of high density oligonucleotide arrays made by “maskless photolithography”. This process, commercialized by Nimblegen, allows the creation of “Affymetrix-style” high-density oligonucleotide arrays with any sets of sequences desired. While most oligonucleotide arrays are employed for gene expression profiling experiments, duplex probes are required to probe the binding specificity of hairpin polyamides. Therefore, the researchers created stem-loop structures in which a single 34 residue oligonucleotide folded upon itself to create a double helical region flanked by a linker connecting it to the array surface on one side and a four nucleotide loop on the other. The duplex region was comprised of a permuted region of eight base pairs flanked on both sides by a constant region of three base pairs to prevent “breathing” of the central duplex region (Fig. 2). When the array was incubated with a fluorescently labeled, well-characterized hairpin polyamide, the pattern of binding was consistent with the known solution binding preference of 5′-WWGWWCWN-3′ (W = A or T), thus validating the method. Careful analysis of the intensities at features that varied slightly from this consensus provided valuable quantitative information regarding the level of sequence preference for the desired target sites over closely related “off-target” sites. The authors also employed this technique to monitor the sequence preference of modified polyamides that bind cooperatively with native DNA-binding proteins.
Based on the results presented in this paper, it is clear that high-density arrays comprised of self-complimentary oligonucleotide probes are likely to be valuable tools in understanding the detailed sequence specificity of both synthetic DNA ligands, such as hairpin polyamides, as well as native transcription factors. While these arrays are expensive, they are commercially available, providing access to this technology to almost any laboratory (with sufficient funding).
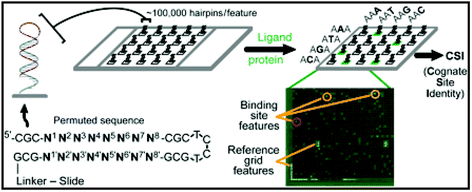 | ||
| Fig. 2 Illustration of a CSI microarray and the experimental approach. Each hairpin probe is composed of a permuted hairpin stem (N1–N8) with a 3 bp flanking sequence (CGC) on either side. N′ represents the exact complement to the permuted (N) forward sequence. A fluorescently tagged ligand is applied to the microarray to obtain a comprehensive ligand-binding profile. In addition to reference grid features, high intensity features are circled, indicating tight binding of the ligand to that specific probe sequence. Reprinted with permission from Proc. Natl. Acad. Sci. U. S. A., 2006, 103, 867–872. Copyright 2006 National Academy of Sciences, U. S. A. | ||
Christopher L. Warren, Natasha C. S. Kratochvil , Karl E. Hauschild , Shane Foister , Mary L. Brezinski , Peter B. Dervan , George N. Phillips, Jr., and Aseem Z. Ansari, Defining the sequence-recognition profile of DNA-binding molecules, Proc. Natl. Acad. Sci. U. S. A., 2006, 103, 867–872.
Reviewed by: Thomas Kodadek, University of Texas Southwestern Medical Center, USAElastin fusion proteins for fabrication of antibody arrays
Arrays based on spatially patterned antibodies have a growing importance in the area of medical and environmental diagnostics. However, problems often occur in the antibody immobilization step. Most of the immobilization techniques are based on covalent coupling or interaction with modified substrates. This can lead to the loss of antibody functionality or random orientation which can, in turn, cause the blockage of the binding sites. To overcome these problems, W. Chen and coworkers used a property of the smart biomolecule elastin (ELP) which adheres selectively to hydrophobic surfaces under controlled conditions to produce precisely oriented antibody arrays. Three different ELP fusion constructs containing Pro A, Pro G and Pro L proteins for selective binding of three different types of immunoglobulin were designed and expressed in E. coli in high yield. Purified ELP-Pro A, G and L fusion proteins were then mixed with different antibodies at 4 °C. At this temperature the ELP domain is hydrophilic and water soluble. At 37 °C with addition of 1 M NaCl, the ELP domain becomes hydrophobic and interacts with octadecyltrichlorosilane modified glass slides. A DNA microarrayer was used to spot hydrophobic ELP-Pro A, ELP-Pro G and ELP-Pro L containing rabbit, goat and mouse antibodies each, into a 96 well plate. To distinguish between different antibodies, three different fluorophores were used as labels. After immobilization strong fluorescence signals were obtained only in regions spotted with corresponding labeled antibodies. Control experiments confirmed that immobilization is based solely on the reversible hydrophobic interaction between the ELP domain and the solid surface. At the end, the sensor for liver tumor marker CA 19-9 based on the sandwich immunoassay principle was designed using ELP-Pro L-cancer marker antibody. The sensor showed wide dynamic range with a lower detection limit of 21 U ml−1 and had high specificity. This proved that there is a great promise in the use of relatively simple ELP-based immobilization in the fabrication of microarray sensors (Fig. 3).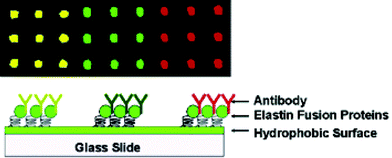 | ||
| Fig. 3 ELP-based immobilization of antibody arrays. Reprinted with permission from J. Am. Chem. Soc., January 25, 2006, volume 128, issue 3, pages 676–677 (DOI: 10.1021/ja056364e). Copyright 2006 American Chemical Society. | ||
D. Gao, N. McBean, J. S. Schultz, Y. Yan, A. Mulchandani, W. Chen, J. Am. Chem. Soc. 2006, 128, 676–677.
Reviewed by: Ljiljana Fruk, Universität Dortmund, GermanyChIP-PET detects p53 binding to genome
The ability to detect binding of transcription factors to DNA in cells on a genomic scale has become a powerful tool in functional genomics. Recently Wei, et al. have described using chromatin immunoprecipitation to enrich for DNA bound by the p53 tumor suppressor protein, followed by high-throughput sequencing of the enriched DNA using paired end ditag (PET) sequencing, a method developed by the authors.PET sequencing is preceded by cloning the ChIP-enriched DNA fragments into a vector containing MmeI recognition sites (MmeI enzyme cuts 18–20 bp downstream of the recognition site). The insert is then digested by MmeI, the 3′ overhangs removed, and the two ends of the insert ligated so that each plasmid contains the first and last 18 bp of the fragment fused together. The collection of plasmids at this step are called a “single ditag library” because there is a single copy of the 36 bp DNA fragment with a known sequence (tag) on both ends (ditag). The fragment and flanking sequences (50 bp) are then cut out, concatenated with other inserts, and the 1–2 kb fragments are cloned into a new vector to be sequenced. The tags allow for the separation of fragments during data analysis and the 36 bp fragment contains enough sequence information to pinpoint the size and location of the original ChIP-ed DNA fragment. Unlike ChIP-on-chip assays, ChIP-PET is not limited by what sequences one puts on an array. It is able to detect with high resolution the location of transcription factor binding by tiling ChIP-ed fragments and looking for regions of overlap (Fig. 4). It also has a lower false-positive rate than the SAGE method of sequencing.
 | ||
| Fig. 4 ChIP-PET analysis. Reprinted from Cell, volume 124, Chia-Lin Wei, Qiang Wu, Vinsensius B. Vega, Kuo Ping Chiu, Patrick Ng, Tao Zhang, Atif Shahab, How Choong Yong, YuTao Fu, Zhiping Weng, JianJun Liu, Xiao Dong Zhao, Joon-Lin Chew, Yen Ling Lee, Vladimir A. Kuznetsov, Wing-Kin Sung, Lance D. Miller, Bing Lim, Edison T. Liu, Qiang Yu, Huck-Hui Ng and Yijun Ruan, ‘A Global Map of p53 Transcription-Factor Binding Sites in the Human Genome’, pp. 207–219, issue number 1, Copyright 2006, with permission from Elsevier. | ||
Using this “ChIP-PET” technology, the authors performed the first whole-genome location analysis for p53 and identified 542 high-confidence p53 binding sites, many of which suggest novel roles for p53 and provide a plethora of interesting targets for further investigation. They treated human HCT116 colorectal cancer cells with 5-fluorouracil (which induces DNA damage and initiates a p53-mediated response) for 6 h prior to cross-linking and immunoprecipitation. Binding events were verified by randomly selecting 40 loci and performing ChIP-qPCR (all 40 were confirmed) and by showing that 41 of 66 well-known p53 targets were identified in their assay. The authors then used 39 random binding loci from their study to develop a new model for the p53 binding motif. Their “p53PET” model significantly outperformed the two other methods of motif prediction when tested against the rest of their data set. They further characterized direct p53 regulation of gene expression by showing that of 275 genes with expression data on a microarray, 112 were either up- or down-regulated in response to 5-fluorouracil in wild-type compared to p53 mutant cells. Finally, the authors looked at expression data from 251 primary breast tumors and found that several of their genes of interest were differentially regulated between tumors with and without p53 mutations and that specific expression levels correlated with metastasis. In addition to introducing the ChIP-PET technique and identifying p53 targets, this study provides specific examples of clinically relevant information, including evidence suggesting p53 plays an important role in tumor metastasis and invasion, as well as potential biomarkers to help assess patient prognosis.
Chia-Lin Wei, Qiang Wu, Vinsensius B. Vega, Kuo Ping Chiu, Patrick Ng, Tao Zhang, Atif Shahab, How Choong Yong, YuTao Fu, Zhiping Weng, JianJun Liu, Xiao Dong Zhao, Joon-Lin Chew, Yen Ling Lee, Vladimir A. Kuznetsov, Wing-Kin Sung, Lance D. Miller, Bing Lim, Edison T. Liu, Qiang Yu, Huck-Hui Ng and Yijun Ruan, Cell, 2006, 124(1), 207–219.
Reviewed by: John Astle, University of Texas Southwestern Medical Center, USA| This journal is © The Royal Society of Chemistry 2006 |