
Partial least squares-discriminant analysis (PLS-DA) for classification of high-dimensional (HD) data: a review of contemporary practice strategies and knowledge gaps†

Abstract
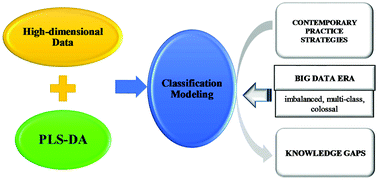
Partial least squares-discriminant analysis (PLS-DA) is a versatile algorithm that can be used for predictive and descriptive modelling as well as for discriminative variable selection. However, versatility is both a blessing and a curse and the user needs to optimize a wealth of parameters before reaching reliable and valid outcomes. Over the past two decades, PLS-DA has demonstrated great success in modelling high-dimensional datasets for diverse purposes, e.g. product authentication in food analysis, diseases classification in medical diagnosis, and evidence analysis in forensic science. Despite that, in practice, many users have yet to grasp the essence of constructing a valid and reliable PLS-DA model. As the technology progresses, across every discipline, datasets are evolving into a more complex form, i.e. multi-class, imbalanced and colossal. Indeed, the community is welcoming a new era called big data. In this context, the aim of the article is two-fold: (a) to review, outline and describe the contemporary PLS-DA modelling practice strategies, and (b) to critically discuss the respective knowledge gaps that have emerged in response to the present big data era. This work could complement other available reviews or tutorials on PLS-DA, to provide a timely and user-friendly guide to researchers, especially those working in applied research.
- This article is part of the themed collection: Recent Review Articles
 Please wait while we load your content...
Please wait while we load your content...

