
The Monte Carlo validation framework for the discriminant partial least squares model extended with variable selection methods applied to authenticity studies of Viagra® based on chromatographic impurity profiles
Abstract
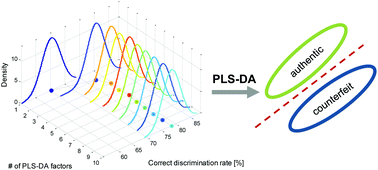
The aim of this work was to develop a general framework for the validation of discriminant models based on the Monte Carlo approach that is used in the context of authenticity studies based on chromatographic impurity profiles. The performance of the validation approach was applied to evaluate the usefulness of the diagnostic logic rule obtained from the partial least squares discriminant model (PLS-DA) that was built to discriminate authentic Viagra® samples from counterfeits (a two-class problem). The major advantage of the proposed validation framework stems from the possibility of obtaining distributions for different figures of merit that describe the PLS-DA model such as, e.g., sensitivity, specificity, correct classification rate and area under the curve in a function of model complexity. Therefore, one can quickly evaluate their uncertainty estimates. Moreover, the Monte Carlo model validation allows balanced sets of training samples to be designed, which is required at the stage of the construction of PLS-DA and is recommended in order to obtain fair estimates that are based on an independent set of samples. In this study, as an illustrative example, 46 authentic Viagra® samples and 97 counterfeit samples were analyzed and described by their impurity profiles that were determined using high performance liquid chromatography with photodiode array detection and further discriminated using the PLS-DA approach. In addition, we demonstrated how to extend the Monte Carlo validation framework with four different variable selection schemes: the elimination of uninformative variables, the importance of a variable in projections, selectivity ratio and significance multivariate correlation. The best PLS-DA model was based on a subset of variables that were selected using the variable importance in the projection approach. For an independent test set, average estimates with the corresponding standard deviation (based on 1000 Monte Carlo runs) of the correct classification rate, sensitivity, specificity and area under the curve were equal to 96.42% ± 2.04, 98.69% ± 1.38, 94.16% ± 3.52 and 0.982 ± 0.017, respectively.
 Please wait while we load your content...
Please wait while we load your content...

