
One-class classification based authentication of peanut oils by fatty acid profiles†
Liangxiao Zhang*adef,
Peiwu Li*acde,
Xiaoman Sunae,
Jin Maoae,
Fei Maabe,
Xiaoxia Dingade and
Qi Zhangabc
aOil Crops Research Institute, Chinese Academy of Agricultural Sciences, Wuhan 430062, China. E-mail: liangxiao_zhang@hotmail.com; peiwuli@oilcrops.cn; Fax: +86 27 86812862; Tel: +86 27 86812943
bKey Laboratory of Biology and Genetic Improvement of Oil Crops, Ministry of Agriculture, Wuhan 430062, China
cKey Laboratory of Detection for Mycotoxins, Ministry of Agriculture, Wuhan 430062, China
dLaboratory of Risk Assessment for Oilseeds Products (Wuhan), Ministry of Agriculture, Wuhan 430062, China
eQuality Inspection and Test Center for Oilseeds Products, Ministry of Agriculture, Wuhan 430062, China
fHubei Collaborative Innovation Center for Green Transformation of Bio-Resources, Wuhan 430062, China
First published on 2nd October 2015
Abstract
Developing a method of identifying oil authenticity is becoming critical for protecting customers' rights as adulteration of edible oils is a particular concern in food quality. Since adulterants in edible oils are usually unknown, the authenticity identification is a one-class classification problem in chemometrics. In this study, a one-class classification model was built to identify the authenticity of peanut oils by fatty acid profiles. Based on previous studies, 28 fatty acids were identified and quantified for peanut oils. The authenticity identification model was built by one-class partial least squares (OCPLS) classifier for peanut oils. Subsequently, the established model was validated by independent test sets. The results indicated that the OCPLS classifier could effectively detect adulterated oils and was therefore employed for authenticity assessment. Moreover, counterfeit oils adulterated with different levels of other edible oils were simulated by the Monte Carlo method and employed to test the lowest adulteration level of this one-class classifier. As a result, the model could identify peanut oils and sensitively detect adulteration of edible oils with other vegetable oils at adulteration level of more than 4%.
1. Introduction
Peanut oil has a pleasant flavor and is non-transgenic, experiencing a gradual increase in the market share in China and other Asian countries.1,2 Similar with adulteration of olive oil in western countries, adulteration of peanut oil is also a serious issue. Therefore, a reliable method to identify the authenticity of peanut oil is greatly in demand. Recently, different targets have been employed to identify the authenticity of edible oils including: (a) genetic markers of adulterants;3 (b) characteristic metabolites of adulterants;4 (c) spectra of entire edible oils detected by nuclear magnetic resonance (NMR),5 near-infrared spectroscopy (NIR),6 infrared spectroscopy (IR),7 fluorescence spectroscopy,8 Raman spectroscopy,9 electronic nose10 and ion mobility spectrometry;11,12 (d) metabolomics or metabolite profiles.13–16 With explicit chemical significance and advantages of multivariate analysis, the authentication methods based on metabolomics become the most promising for edible oils.14,17In the spectroscopy and metabolomics based authentication methods, chemometrics is a powerful tool to detect adulterated edible oils when used qualitatively for classifying unknown samples with similar characteristics and quantitatively for determining adulterant analytes in samples.18 Recently, chemometric methods, such as self-organizing maps based on chaotic parameters, cluster discriminant analysis (CDA), support vector machine (SVM) and random forests (RF), were used to distinguish edible oils from refined recycled cooking oils, identify edible oils from different regions, or detect adulteration of extra virgin olive oil with inferior edible oils, respectively.19–22 Generally, adulteration detection of edible oils is considered as a two- or multi-class classification problem to determine whether the target edible oil is adulterated with known oil. However, since the adulterants in edible oils are usually unknown, the authenticity identification of the target edible oil might be the best choice, which is a technique of one-class classification in chemometrics. Therefore, the key technologies of authenticity identification include stable markers or metabolite profiles and the effective one-class classification method. Among the four kinds of targets, genetic markers and some metabolite profiles are relatively stable. Since genetic markers of adulterants significantly decrease after refinement, it is further hard to detect them in adulterated edible oils. Fatty acids are the dominant components of edible oils, and their composition is relatively stable in the oilseeds from different producing areas and edible oils produced by different processing methods. Though these low-abundance fatty acids are not so attractive to nutritionists, our previous study indicates that they are highly sensitive in adulteration identification of edible oils.14 The fatty acid profiles are therefore taken as a key marker and quality parameter of different oilseeds and their products.17
Lately, partial least squares density modeling (PLS-DM) was proposed and employed in the identification of adulterated peanut oils by mid-infrared spectroscopy (MIR)23 and authentication of olives in brine by NIR,24 which could achieve a better balance between sensitivity and specificity than the typical SIMCA method.24 However, the IR and NIR spectra of edible oils reflect the whole chemical fingerprint instead of the detailed chemical compositions, and an effective one-class classification model therefore depends on a large number of training samples in practice. If not, many authentic edible oils out of the training set might be mistaken as adulterated edible oils, which is unacceptable in actual applications of quality supervision and inspection. Therefore, in this study, an authenticity identification model was built by the one-class partial least squares (OCPLS) classifier for peanut oil based on fatty acid profiles. Moreover, adulterated oils were simulated by adulterating peanut oil with different levels of other oils or mixtures thereof and employed to test the performance of the one-class classifier.
2. Experimental
2.1 Materials and reagents
To ensure that the oil samples could represent the actual edible oils, 80 peanut samples were collected from different production areas (see ESI Table S1†) and employed to prepare edible oils by TEN GUARD oil mill machinery (TZC-0502, China). Supelco 37 component fatty acid methyl esters (FAME) mix (no. 47885-U) was purchased from Sigma (St. Louis, MO, USA). 11-Octadecenoic acid (C18:1n-7, > 97.0 purity) and 7-hexadecenoic acid methyl ester were also purchased from Sigma (St. Louis, MO, USA).2.2 Fatty acid analysis
As descried in the previous study,14,25 fatty acids in edible oils were first derived to produce FAMEs and subsequently analyzed by GC–MS in selected ion monitoring (SIM) mode. The detailed procedure of fatty acid analysis was described in the ESI.†Identification of fatty acids in SIM mode was conducted according to the protocol in our previous study.25 The fatty acid percentage composition (percentage of the peak area) of edible oils was employed as quantitative results.
2.3 Multivariate analysis
Data matrix includes the relative contents of fatty acids of edible oils. Since the chemical properties of fatty acids are relatively stable, the weight of fatty acid composition in blended oil approximatively equals to the sum of the weights of fatty acid composition in individual oils. To establish a more accurate adulteration detection model, adulterated oils were simulated by the Monte Carlo method. In this study, the adulterated oils were simulated by adulterating with low proportions of one or more vegetable oils.14 For example, we could obtain an adulterated peanut oil by adding 5% of soybean, sesame, sunflower and rapeseed with random proportions to 95% of peanut oil.A one-class partial least squares (OCPLS) classifier was proposed based on partial least squares (PLS) using a distance-based sample density measurement as the response variable.26–29 In OCPLS, the potential function probability density is calculated on PLS scores and residual Q statistics to develop an efficient one-class classifier. The detailed algorithm of OCPLS modeling is described elsewhere.24,27–29 Initially, a PLS model was developed by analytical data and response vectors with all elements being 1 using the SIMPLS algorithm.30 The number of PLS components was estimated by cross validation (CV). Then, the PLS scores on the first several latent variables (LVs) were used to estimate the PFM probability density of the class to obtain the critical value. In addition, the PLS residuals were used to compute the critical value of Q statistics. The predicted residual sum of squares (PRESS) obtained by Monte Carlo cross validation (MCCV) or leave-one-out cross validation (LOOCV) can be used to estimate the number of significant LVs. Finally, the score distance (SD) of an object in the space spanned by the primary OCPLS components and the absolute centered residual (ACR) were calculated and plotted to screen for outliers. OCPLS outlier diagnosis depended on the ACR of response variables and the OCPLS scores of primary LVs. Four regions at the bottom left, bottom right, top left and top right denote the regular points, good leverage points, class outliers and bad leverage points, respectively. The samples falling in the top left and top right regions were determined as adulterated oils. In this study, the Gaussian radial basis function (GRBF) transformation was placed in the position of the training objects, and the number of RBFs equaled the number of training objects to conduct nonlinear GRBF–OCPLS.28
The programs of Monte Carlo simulation of adulterated oils were coded in Matlab 2011a for Windows (The Mathworks, Natick, MA), and the programs of OCPLS were kindly provided by Dr Xu.29
3. Results and discussion
3.1 Fatty acid profiles of peanut oils
In this study, fatty acid profiles of peanut oils were obtained by GC/MS. To build a robust authentication model, the SIM mode was used to detect more fatty acids in edible oils. FAMEs were identified by combining the selective ions with retention indices based on equivalent chain lengths (ECL).24 As a result, 28 fatty acids were identified and quantified (see ESI Table S2†), which were significantly more than in full scan mode (23 fatty acids).22 Fatty acid profiles of peanut oils were described by the percentage content and used in subsequent multivariate analysis.3.2 One-class partial least squares (OCPLS) classifier
After determination and quantification of fatty acids in 80 peanut samples, the data matrix of relative contents was used in one-class classification modeling. The Kennard and Stone (K–S) algorithm31,32 was employed to divide authentic edible oil samples into a training set and a test set at a ratio of 6![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) :4. The OCPLS model was developed based on the fatty acid profiles of peanut oils. MCCV with a sampling ratio of 0.8 was conducted to select significant OCPLS components and estimate the standard deviation of prediction residuals. The number of significant components was estimated by examining the PRESS values obtained by MCCV according to the previous study.28,29
:4. The OCPLS model was developed based on the fatty acid profiles of peanut oils. MCCV with a sampling ratio of 0.8 was conducted to select significant OCPLS components and estimate the standard deviation of prediction residuals. The number of significant components was estimated by examining the PRESS values obtained by MCCV according to the previous study.28,29
The OCPLS model was built using 80 peanut oils. According to MCCV with a sampling ratio of 0.8 (Fig. 1a), when the number of significant OCPLS components was set to 8 (δ2 = 10), the lowest standard deviation of residual of cross validation was obtained. According to the OCPLS score distance (SD) and ACR of the predicted responses, four regions at the bottom left, bottom right, top left and top right denote the regular points, good leverage points, class outliers and bad leverage points, respectively. Generally, the samples at the bottom left, bottom right regions were identified as pure peanut oils, while the samples at the top left and top right regions were identified as impure peanut oil or other oil. The prediction results of the samples in training and test sets by OCPLS with the fatty profiles of pure peanut oils are shown in Fig. 1b and c and Table 1. The samples in the training (Fig. 1b) and test sets (Fig. 1c) are predicted as regular points with a small SD and a small ACR or good leverage points with a large SD and a small ACR (3 samples in the training set). Meanwhile, the reference edible oils from our previous study14 including 62 sunflower seed oils, 63 rapeseed oils and 80 sesame oils were also used to test this model. The results in Fig. 1d show that this model could effectively predict these three kinds of edible oils as bad leverage points. The validation by the independent test sets of peanut oils and other three kinds of edible oils indicated that the OCPLS model with fatty acid profiles could effectively determine the authenticity of peanut oils.
 | ||
| Fig. 1 (a) Cross validation of robust GRBF–OCPLS for peanut oils; (b) training of robust GRBF–OCPLS for peanut oils; (c) prediction of robust GRBF–OCPLS for peanut oils; (d) prediction of robust GRBF–OCPLS for sunflower seed, rapeseed and sesame oils. | ||
| Test set | Sensitivity | Specificity | |
|---|---|---|---|
| 1 | Pure peanut oils | — | 100% (32/32) |
| 2 | Other edible oils | 100% (205/205) | — |
| 3 | Adulterated peanut oils (3%) | 92.5% (37/40) | — |
| 4 | Adulterated peanut oils (4%) | 100% (40/40) | — |
3.3 Adulteration detection of edible oils
In the OCPLS model for peanut oil, we found that the one-class model could completely differentiate peanut oils from other kinds of edible oils. However, the adulteration of edible oils with other cheap edible or inedible oils is more common in practice. Therefore, it is essential to detect these adulterated edible oils. Generally, adulteration detection of edible oils is taken as a two- or multi-class classification method to classify authentic edible oils from fake oils adulterated with one or more known oils. However, since the adulterants in edible oils are usually unknown, the adulteration detection falls into the one-class classification field in chemometrics. Meanwhile, the combination of multiple adulterants is usually ignored in the establishment and validation of adulteration detection methods. Recently, based on the fact that fatty acids are relatively stable and no chemical reaction happens in physical blends of vegetable oils, the Monte Carlo simulation of adulterated oils was proposed to test the adulteration detection model by blending a fixed proportion (Q%) of other adulterant oils with random proportions to (1 – Q%) of the current edible oils.14In this study, counterfeit oils with different adulteration levels (3–12%, mol mol−1) were simulated to check the lowest adulteration level of this model. As results, 40 adulterated oils were obtained at each adulteration level. At the beginning, 80 peanut oils were used to build the OCPLS model. Then, the simulated adulterated oils were predicted by this model. As shown in Fig. 2a, the OCPLS model could correctly identify all of 80 authentic peanut oils in the training set. From Fig. 2b and Table 1, we just misidentified three adulterated peanut oils as authentic peanut oils at the adulteration level of 3%, indicating that the accuracy rate of this model equals 92.5% (37/40) for the adulterated peanut oils with the adulteration level of 3%. When the adulteration level is higher than 3%, this OCPLS model could completely detect these adulterated peanut oils. Thus, the lowest adulteration level of this OCPLS model is 4%.
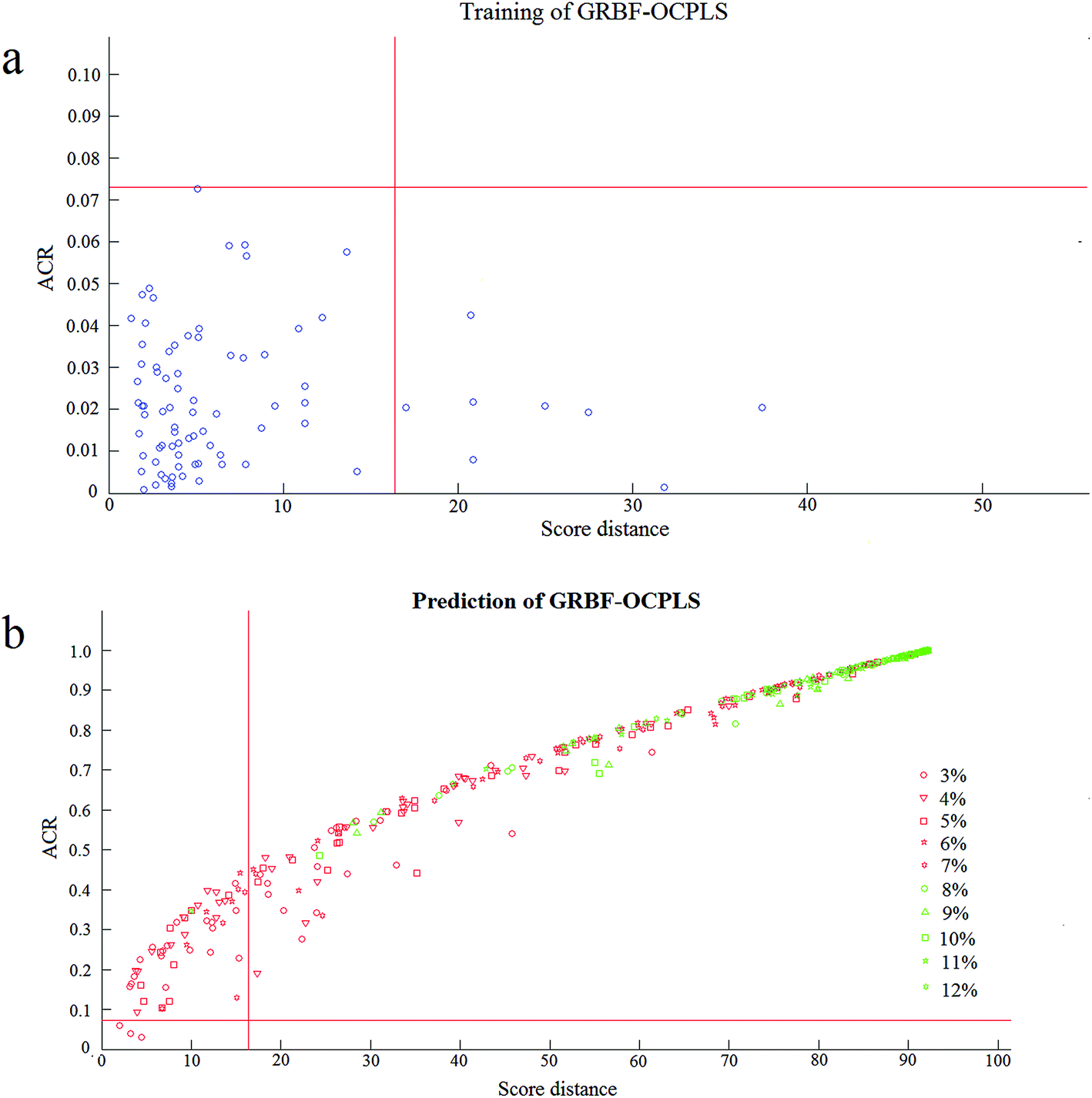 | ||
| Fig. 2 (a) Training of robust GRBF–OCPLS for peanut oils; (b) prediction of robust GRBF–OCPLS for fake peanut oils with the adulteration levels of 3–12%. | ||
The results in this work indicated that the OCPLS model with fatty acid profiles could be a good strategy to identify authenticity of peanut oils and other edible oils. Compared with the previous authentication methods, this method possesses the following advantages: (1) it can detect counterfeit oils adulterated with any unknown oils; (2) it can also detect the multivariate adulteration.
4. Conclusion
In this study, a one-class classification model was built to identify the authenticity of peanut oils. The authentication identification model was built by the one-class partial least squares (OCPLS) classifier for peanut oils. Subsequently, the established model was validated by independent test sets. The results indicated that the OCPLS classifier could completely detect adulterated oils and were therefore employed for authenticity assessment. Moreover, the oils adulterated with different levels of other edible oils were simulated by the Monte Carlo method and employed to test the lowest adulteration level of this one-class classifier. Compared with the studies in ref. 14, the OCPLS model for peanut oil is more robust in detecting all kinds of adulteration including known adulterants and multiple adulterants. As a result, this model could identify peanut oils and sensitively detect adulteration of edible oils with other vegetable oils at the adulteration level of more than 4%.Conflict of interest
No authors declared any potential conflicts of interest.Acknowledgements
This work was supported by the Project of National Science & Technology Pillar Plan (2012BAK08B03), the Special Fund for “Quality Inspection” Research in the Public Interest (2012104010-4), the National Major Project for Agro-product Quality & Safety Risk Assessment (GJFP2015006), the National Natural Science Foundation of China (21205118), and the earmarked fund for China Agriculture research system (CARS-13).References
- J. K. Kim, H. J. Lim, D. H. Shin and E. C. Shin, Comparison of nutritional quality and thermal stability between peanut oil and common frying oils, J. Korean Soc. Appl. Biol. Chem., 2015, 58, 527–532 CrossRef.
- F. Zhao, J. Liu, X. Wang, P. Li, W. Zhang and Q. Zhang, Detection of adulteration of sesame and peanut oils via volatiles by GC×GC–TOF/MS coupled with principal components analysis and cluster analysis, Eur. J. Lipid Sci. Technol., 2013, 115, 337–347 CrossRef CAS PubMed.
- H. Zhang, Y. Wu, Y. Li, B. Wang, J. Han, X. Ju and Y. Chen, PCR-CE-SSCP used to authenticate edible oils, Food Control, 2012, 27, 322–329 CrossRef CAS PubMed.
- X. Zhao, F. Ma, P. W. Li, G. M. Li, L. X. Zhang, Q. Zhang, W. Zhang and X. Q. Wang, Simultaneous determination of isoflavones and resveratrols for adulteration detection of soybean and peanut oils by mixed-mode SPE LC-MS/MS, Food Chem., 2015, 176, 465–471 CrossRef CAS PubMed.
- P. Daisa and E. Hatzakisb, Quality assessment and authentication of virgin olive oil by NMR spectroscopy: a critical review, Anal. Chim. Acta, 2013, 765, 1–27 CrossRef PubMed.
- O. Galtier, N. Dupuy, Y. le Dréau, D. Ollivier, C. Pinatel, J. Kister and J. Artaud, Geographic origins and compositions of virgin olive oils determinated by chemometric analysis of NIR spectra, Anal. Chim. Acta, 2007, 595, 136–144 CrossRef CAS PubMed.
- L. Xu, C. B. Cai and D. H. Deng, Multivariate quality control solved by one-class partial least squares regression: identification of adulterated peanut oils by mid-infrared spectroscopy, J. Chemom., 2011, 25, 568–574 CrossRef CAS PubMed.
- F. Ge, C. Y. Chen, D. Q. Liu and S. L. Zhao, Rapid Quantitative Determination of Walnut Oil Adulteration with Sunflower Oil Using Fluorescence Spectroscopy, Food Anal. Methods, 2014, 7, 146–150 CrossRef.
- D. Wei, Y. Q. Zhang, B. Zhang and X. P. Wang, Rapid prediction of fatty acid composition of vegetable oil by Raman spectroscopy coupled with least squares support vector machines, J. Raman Spectrosc., 2013, 44, 1739–1745 CrossRef PubMed.
- A. Guadarrama, M. L. Rodríguez-Méndez, C. Sanz, J. L. Ríos and J. A. de Saja, Electronic nose based on conducting polymers for the quality control of the olive oil aroma discrimination of quality, variety of olive and geographic origin, Anal. Chim. Acta, 2001, 432, 283–292 CrossRef CAS.
- L. X. Zhang, Q. Shuai, P. W. Li, Q. Zhang, F. Ma, W. Zhang, X. X. Ding and X. Ding, Ion mobility spectrometry fingerprints: a rapid detection technology for adulteration of sesame oil, Food Chem., 2016, 192, 60–66 CrossRef CAS PubMed.
- Q. Shuai, L. X. Zhang, P. W. Li, Q. Zhang, X. P. Wang, X. X. Ding and W. Zhang, Rapid adulteration detection for flaxseed oil using ion mobility spectrometry and chemometric methods, Anal. Methods, 2014, 6, 9575–9580 RSC.
- T. Řezanka and H. Řezanková, Characterization of fatty acids and triacylglycerols in vegetable oils by gas chromatography and statistical analysis, Anal. Chim. Acta, 1999, 398, 253–261 CrossRef.
- L. X. Zhang, P. W. Li, X. M. Sun, X. F. Wang, B. C. Xu, W. P. Wang, F. Ma, Q. Zhang and X. X. Ding, Classification and adulteration detection of vegetable oils based on fatty acid profiles, J. Agric. Food Chem., 2014, 62, 8745–8751 CrossRef CAS PubMed.
- B. C. Xu, L. X. Zhang, H. Wang, D. L. Luo and P. W. Li, Characterization and authentication of four important edible oils using free phytosterol profiles established by GC-GC-TOF/MS, Anal. Methods, 2014, 6, 6860–6870 RSC.
- W. Hu, L. X. Zhang, P. W. Li, X. P. Wang, Q. Zhang, B. C. Xu, X. M. Sun, F. Ma and X. X. Ding, Characterization of volatile components in four vegetable oils by head space two-dimensional comprehensive chromatography time-of-flight mass spectrometry, Talanta, 2014, 129, 629–635 CrossRef CAS PubMed.
- L. X. Zhang, X. Y. Ji, B. B. Tan, Y. Z. Liang, N. N. Liang, X. L. Wang and H. Dai, Identification of the composition of fatty acids in Eucommia ulmoides seed oil by fraction chain length and mass spectrometry, Food Chem., 2010, 121, 815–819 CrossRef CAS PubMed.
- J. C. Moore, M. Lipp and J. C. Griffiths, Preventing the adulteration of food protein, Food Technol., 2011, 62, 46–50 Search PubMed.
- F. Mümtaz, H. Dıraman and D. Özdemir, Classification of Turkish Monocultivar (Ayvalık and Memecik cv.) Virgin Olive Oils from north and south zones of Aegean region based on their triacyglycerol profiles, J. Am. Oil Chem. Soc., 2013, 90, 1661–1671 CrossRef.
- T. B. Liu, L. J. Zhou, Z. W. Chen, B. B. Li and Y. Shi, Authentication of edible vegetable oil and refined recycled cooking oil using a Micro-UV spectrophotometer based on chemometrics, J. Am. Oil Chem. Soc., 2013, 90, 1599–1606 CrossRef CAS.
- J. S. Torrecilla, J. C. Cancilla, G. Matute, P. Díaz-Rodríguez and A. I. Flores, Self-organizing maps based on chaotic parameters to detect adulterations of extra virgin olive oil with inferior edible oils, J. Food Eng., 2013, 118, 400–405 CrossRef CAS PubMed.
- F. F. Ai, J. Bin, Z. M. Zhang, J. H. Huang, J. B. Wang, Y. Z. Liang, L. Yu and Z. Y. Yang, Application of random forests to select premium quality vegetable oils by their fatty acid composition, Food Chem., 2014, 143, 472–478 CrossRef CAS PubMed.
- L. Xu, C. B. Cai and D. H. Deng, identification of adulterated peanut oils by mid-infrared spectroscopy, J. Chemom., 2011, 25, 568–574 CrossRef CAS PubMed.
- P. Oliveri, M. I. López, M. C. Casolino, I. Ruisánchez, M. P. Callao, L. Medini and S. Lanteri, Partial least squares density modeling (PLS-DM)-A new class-modeling strategy applied to the authentication of olives in brine by near-infrared spectroscopy, Anal. Chim. Acta, 2014, 851, 30–36 CrossRef CAS PubMed.
- L. X. Zhang, P. W. Li, X. M. Sun, W. Hu, X. P. Wang, Q. Zhang and X. X. Ding, Untargeted fatty acid profiles based on the selected ion monitoring mode, Anal. Chim. Acta, 2010, 839, 44–50 CrossRef PubMed.
- L. Xu, H. Y. Fu, N. Jiang and X. P. Yu, A new class model based on partial least square regression and its applications for identifying authenticity of bezoar samples, Chin. J. Anal. Chem., 2010, 38, 175–180 CrossRef CAS.
- L. Xu, C. B. Cai and D. H. Deng, identification of adulterated peanut oils by mid-infrared spectroscopy, J. Chemom., 2011, 25, 568–574 CrossRef CAS PubMed.
- L. Xu, S. M. Yan, C. B. Cai and X. P. Yu, One-class partial least squares (OCPLS) classifier, Chemom. Intell. Lab. Syst., 2013, 126, 1–5 CrossRef CAS PubMed.
- L. Xu, M. Goodarzi, W. Shi, C. B. Cai and J. H. Jiang, A MATLAB toolbox for class modeling using one-class partial least squares (OCPLS) classifiers, Chemom. Intell. Lab. Syst., 2014, 139, 58–63 CrossRef CAS PubMed.
- S. de Jong, SIMPLS: an alternative approach to partial least squares regression, Chemom. Intell. Lab. Syst., 1993, 18, 251–263 CrossRef CAS.
- R. W. Kemmrd and L. A. Stone, Technometrics, 1969, 11, 137–148 CrossRef PubMed.
- M. Daszykowski, S. Serneels, K. Kaczmarek, P. van Espen, C. Croux C and B. Walczak, TOMCAT: a MATLAB toolbox for multivariate calibration techniques, Chemom. Intell. Lab. Syst., 2007, 85, 269–277 CrossRef CAS PubMed.
Footnote |
| † Electronic supplementary information (ESI) available. See DOI: 10.1039/c5ra07329d |
| This journal is © The Royal Society of Chemistry 2015 |